Biostatistics-Lecture 15 High-throughput sequencing and sequence alignment Ruibin Xi Peking University School of Mathematical Sciences

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Biostatistics-Lecture 15High-throughput sequencing and
sequence alignment
Ruibin XiPeking University
School of Mathematical Sciences

High-throughput sequencing
HTS platforms Roche 454 platforms Illumina/Solexa platforms (most widely used) Applied Biosystem (ABI) SOLiD Helicos HeliSopeTM sequencer(single molecular
sequencing) Life Technologies platforms
The throughput is increasing and the price is dropping
Short read but high throughput

High-throughput sequencing
HTS platforms Roche 454 platforms Illumina/Solexa platforms (most widely used) Applied Biosystem (ABI) SOLiD Helicos HeliSopeTM sequencer(single molecular
sequencing) Life Technologies platforms
The throughput is increasing and the price is dropping
Short read but high throughput

What sequencing data can do
Detection of genomic variations (Whole genome sequencing or targeted sequencing)Single nucleotide polymorphisms (SNP)Copy number variations (CNV)Structural variations (SV)
Analyze protein interactions with DNA (ChIP-seq) Whole Transcriptome study (RNA-seq) DNA methylation study and many more …..

5
Sequencing (Illunima)
Mardis Nature Reivew Genetics (2010)

6
What the data look like?
Fastq Format detail:1st line: the name of a short read2nd line: the read itself (a short sequence of A,C,G,T)3rd line: the name of the short read or plus (+) sign4th line: the quality score

General strategy for analyzing HTS data
• Alignment-based
• Assembly-based

Comparing two DNA sequences

How can we evaluate an alignment

How can we evaluate an alignment
• Scores:– Mutation (mismatch): 0– Match: 1– Gap: -1

Find a best alignment
• Exhaustively search all possible alignments– Computationally too expensive!!!
• Observation: for a pair (i,j)

Find a best alignment

Find a best alignment—Solution I

Find a best alignment—Solution II

Dynamical programming

Dynamical programming

Dynamical programming

Dynamical programming

Dynamical programming

Dynamical programming

Dynamical programming

Dynamical programming

Semiglobal alignment

Semiglobal alignment

Semiglobal alignment
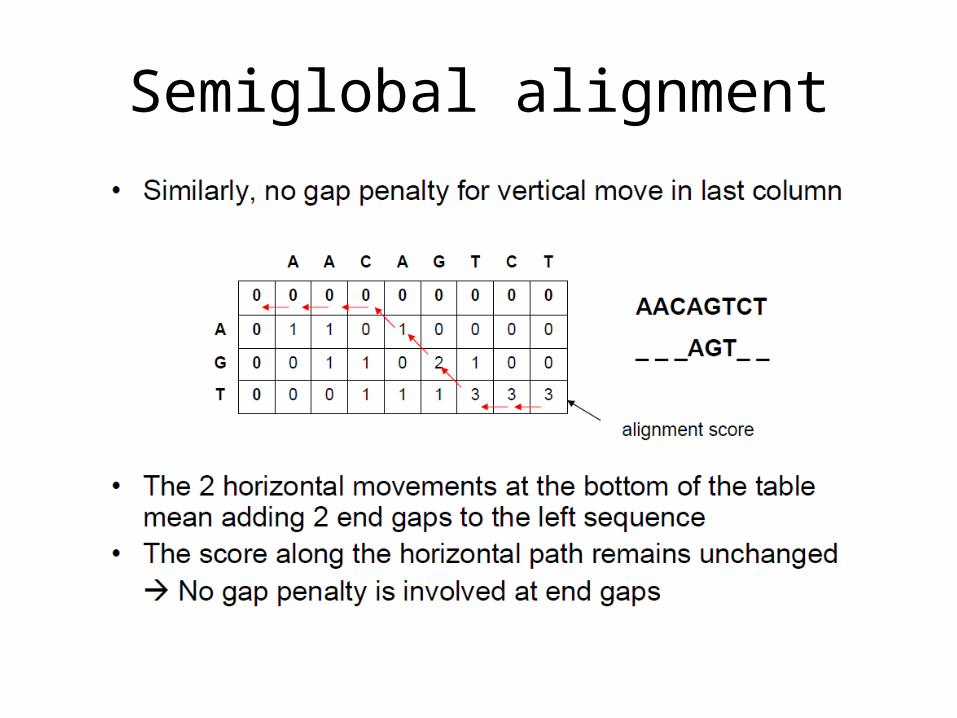
Semiglobal alignment

Local Alignment

Local Alignment

Local Alignment

Local Alignment

BLAST and BLAT
• BLAST: Basic Local Alignment Search Tool
• BLAT: BLAST Like Alignment Tool

BLAST
• BLAST:– A search algorithm for finding local alignments of
two sequences S and T– An associated theory for evaluating the statistical
significant• Terminology and notation– S(a,b): scoring system– High-scoring Segment Pair (HSP):
• Cannot be extended or shortened without dropping the score

BLAST
• The number of HSPs with a score ≥ S approximately follows a Poisson Distribution (under the null hypothesis) with parameter
– Assumptions
Some probability to take positive score– Based on extreme value theory– E-value– Bit score

BLAST
• Algorithm: seed and extend– Build an index for k-mers of the query sequence– Find the hits of the k-mers in the database
sequence in the query sequence– Extend the seeds with a score ≥ a threshold and
find the HSPs with a score ≥ S– Evaluate the statistical significance

BLAT
• Strategy: seed and extend– In the seed stage, detects regions of two
sequences that are likely to be homologous– In the extend stage, those regions are examined in
detail and alignments are produced.
• Index the non-overlapping K-mers of the database sequences instead of the query sequence

BLAT
• Strategy: seed and extend– In the seed stage, detects regions of two
sequences that are likely to be homologous– In the extend stage, those regions are examined in
detail and alignments are produced.
• Index the non-overlapping K-mers of the database sequences instead of the query sequence

BLAT
• Seeding strategy– Single perfect K-mer matches– Single near perfect K-mer matches– Multiple perfect K-mer matches

BLAT
• Some definitions

BLAT
• Single perfect match– the probability that a specific K-mer in a homologous
region of the database matches perfectly the corresponding K-mer in the query
– Sensitivity: the probability of a hit (at least one non-overlapping K-mers in the database matches perfectly with the corresponding K-mer in the query)
– Specificity: the expected number of non-overlapping K-mers that matches, assuming all letters are equally likely

BLAT
• Single perfect match– the probability that a specific K-mer in a homologous
region of the database matches perfectly the corresponding K-mer in the query
– Sensitivity: the probability of a hit (at least one non-overlapping K-mers in the database matches perfectly with the corresponding K-mer in the query)
– Specificity: the expected number of non-overlapping K-mers that matches, assuming all letters are equally likely

BLAT
• Single imperfect match– The probability
– The sensitivity
– The specificity

BLAT
• Single imperfect match– The probability
– The sensitivity
– The specificity

BLAT
• Multiple perfect Matches– Probability
– Sensitivity
– Specificity

BLAT
• Multiple perfect Matches– Probability
– Sensitivity
– Specificity

BLAT
• Clumping the hits– The hit list L is sorted by database coordinate.– The list L is split into buckets of size 64 kb each, based on the
database coordinate.– Each bucket is sorted along the diagonal, i.e. hits are sorted by
the value of database position minus query position.– Hits that are within the gap limit are grouped together into
proto-clumps.– Hits within proto-clumps are then sorted by their database
coordinate and put into real clumps– Clumps within 300 bp or 100 amino acids of each other in the
database are merged

BLAT
• Nucleotide alignment– A hit list is generated between the query sequence q and the
homologous region h in the database, looking for smaller, perfect K-mers.
– If a K-mer w in q matches multiple K-mers in h, then w is repeatedly extended by one until the match is unique or exceeds a certain size.
– The hits are extended as far as possible, without mismatches– Overlapping hits are merged.– Then extensions using indels followed by matches are
considered.
Related Documents











