IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 1 Benchmarking Data Exchange amongst Semantic-Web Ontologies Carlos R. Rivero, Inma Hernández, David Ruiz, and Rafael Corchuelo Abstract—The increasing popularity of the Web of Data is motivating the need to integrate semantic-web ontologies. Data exchange is one integration approach that aims to populate a target ontology using data that come from one or more source ontologies. Currently, there exist a variety of systems that are suitable to perform data exchange amongst these ontologies; unfortunately, they have uneven performance, which makes it appealing assessing and ranking them from an empirical point of view. In the bibliography, there exist a number of benchmarks, but they cannot be applied to this context because they are not suitable for testing semantic-web ontologies or they do not focus on data exchange problems. In this article, we present MostoBM, a benchmark for testing data exchange systems in the context of such ontologies. It provides a catalogue of three real-world and seven synthetic data exchange patterns, which can be instantiated into a variety of scenarios using some parameters. These scenarios help analyse how the performance of data exchange systems evolves as the exchanging ontologies are scaled in structured and/or data. Finally, we provide an evaluation methodology to compare data exchange systems side by side and to make informed and statistically-sound decisions regarding: 1) which data exchange system performs better; and 2) how the performance of a system is influenced by the parameters of our benchmark. Index Terms—Performance and scalability, data exchange, Web of Data. ✦ 1 I NTRODUCTION The goal of the Semantic Web is to endow the current Web with metadata, i.e., to evolve it into a Web of Data [27]. Currently, there is an increasing popularity of semantic-web ontologies, chiefly in the context of Linked Open Data, and they focus on a variety of do- mains, such as government, life sciences, geographic, media, or publications [17]. Semantic-web ontologies build on the so-called semantic-web technologies, i.e., RDF, RDFS and OWL ontology languages for mod- elling structure and data, and the SPARQL query language to query them [3]. For the sake of brevity, we refer to semantic-web ontologies as ontologies. Ideally, ontologies are shared data models that are developed with the consensus of one or more commu- nities; unfortunately, reaching an agreement in a com- munity is not a trivial task [4, 16]. Furthermore, new ontologies try to reuse existing ontologies as much as possible since it is considered a good practice; unfor- tunately, it is usual that existing ontologies cannot be completely reused, but require to be adapted [17]. Due to these facts, there exists a variety of heterogenous ontologies to publish data on the Web, and there is a need to integrate them [17]. In the bibliography, there are different approaches to address this problem, such as data exchange, data integration, model matching, or model evolution [6]. In this article, we focus on data exchange [10], which aims to populate a target ontology using data that C.R. Rivero, I. Hernández, D. Ruiz, and R. Corchuelo are with the Uni- versity of Sevilla, ETSI Informática, Avda. Reina Mercedes, s/n, Sevilla E-41012, Spain. {carlosrivero, inmahernandez, druiz, corchu}@us.es. come from one or more source ontologies. In the bibliography, there are proposals that use ad-hoc techniques, reasoners, or SPARQL query engines for performing data exchange. When using ad-hoc tech- niques, data exchange is based on handcrafted pieces of software that transform source data into target data. When using reasoners, data exchange consists of reclassifying source instances into target instances by means of rules. Finally, when using SPARQL queries, data exchange is performed by executing a number of CONSTRUCT queries that extract data from the source ontologies, transform them, and load the re- sults into the target ontology. Currently, there exists a variety of systems that implement semantic-web technologies and are, thus, suitable to perform data exchange, e.g., Sesame, OWLIM, Jena, TDB, Oracle, or Pellet to mention a few. Unfortunately, they have uneven performance [7, 14, 33, 36], which makes it appealing assessing and ranking them from an empirical point of view, since this helps make informed decisions about which the best system for a particular integration problem is. A data exchange system is a piece of software that allows to exchange data. In our context, such a system comprises an RDF store, a reasoner, and a query engine. The systems that implement semantic-web technologies provide different services, e.g., Pellet is a reasoner, ARQ is a query engine, Jena provides an RDF store and a reasoner, and Oracle or OWLIM provide an RDF store, a reasoner, and a query engine. In the bibliography, there is a benchmark that fo- cuses on data exchange systems for nested relational models [2]; however, it cannot be applied to our con-

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 1
Benchmarking Data Exchange amongstSemantic-Web Ontologies
Carlos R. Rivero, Inma Hernández, David Ruiz, and Rafael Corchuelo
Abstract—The increasing popularity of the Web of Data is motivating the need to integrate semantic-web ontologies. Dataexchange is one integration approach that aims to populate a target ontology using data that come from one or more sourceontologies. Currently, there exist a variety of systems that are suitable to perform data exchange amongst these ontologies;unfortunately, they have uneven performance, which makes it appealing assessing and ranking them from an empirical point ofview. In the bibliography, there exist a number of benchmarks, but they cannot be applied to this context because they are notsuitable for testing semantic-web ontologies or they do not focus on data exchange problems. In this article, we present MostoBM,a benchmark for testing data exchange systems in the context of such ontologies. It provides a catalogue of three real-world andseven synthetic data exchange patterns, which can be instantiated into a variety of scenarios using some parameters. Thesescenarios help analyse how the performance of data exchange systems evolves as the exchanging ontologies are scaled instructured and/or data. Finally, we provide an evaluation methodology to compare data exchange systems side by side and tomake informed and statistically-sound decisions regarding: 1) which data exchange system performs better; and 2) how theperformance of a system is influenced by the parameters of our benchmark.
Index Terms—Performance and scalability, data exchange, Web of Data.
F
1 INTRODUCTION
The goal of the Semantic Web is to endow the currentWeb with metadata, i.e., to evolve it into a Web ofData [27]. Currently, there is an increasing popularityof semantic-web ontologies, chiefly in the context ofLinked Open Data, and they focus on a variety of do-mains, such as government, life sciences, geographic,media, or publications [17]. Semantic-web ontologiesbuild on the so-called semantic-web technologies, i.e.,RDF, RDFS and OWL ontology languages for mod-elling structure and data, and the SPARQL querylanguage to query them [3]. For the sake of brevity,we refer to semantic-web ontologies as ontologies.
Ideally, ontologies are shared data models that aredeveloped with the consensus of one or more commu-nities; unfortunately, reaching an agreement in a com-munity is not a trivial task [4, 16]. Furthermore, newontologies try to reuse existing ontologies as much aspossible since it is considered a good practice; unfor-tunately, it is usual that existing ontologies cannot becompletely reused, but require to be adapted [17]. Dueto these facts, there exists a variety of heterogenousontologies to publish data on the Web, and there is aneed to integrate them [17].
In the bibliography, there are different approachesto address this problem, such as data exchange, dataintegration, model matching, or model evolution [6].In this article, we focus on data exchange [10], whichaims to populate a target ontology using data that
C.R. Rivero, I. Hernández, D. Ruiz, and R. Corchuelo are with the Uni-versity of Sevilla, ETSI Informática, Avda. Reina Mercedes, s/n, SevillaE-41012, Spain. {carlosrivero, inmahernandez, druiz, corchu}@us.es.
come from one or more source ontologies. In thebibliography, there are proposals that use ad-hoctechniques, reasoners, or SPARQL query engines forperforming data exchange. When using ad-hoc tech-niques, data exchange is based on handcrafted piecesof software that transform source data into targetdata. When using reasoners, data exchange consists ofreclassifying source instances into target instances bymeans of rules. Finally, when using SPARQL queries,data exchange is performed by executing a numberof CONSTRUCT queries that extract data from thesource ontologies, transform them, and load the re-sults into the target ontology.
Currently, there exists a variety of systems thatimplement semantic-web technologies and are, thus,suitable to perform data exchange, e.g., Sesame,OWLIM, Jena, TDB, Oracle, or Pellet to mention afew. Unfortunately, they have uneven performance [7,14, 33, 36], which makes it appealing assessing andranking them from an empirical point of view, sincethis helps make informed decisions about which thebest system for a particular integration problem is.
A data exchange system is a piece of software thatallows to exchange data. In our context, such a systemcomprises an RDF store, a reasoner, and a queryengine. The systems that implement semantic-webtechnologies provide different services, e.g., Pellet isa reasoner, ARQ is a query engine, Jena provides anRDF store and a reasoner, and Oracle or OWLIMprovide an RDF store, a reasoner, and a query engine.
In the bibliography, there is a benchmark that fo-cuses on data exchange systems for nested relationalmodels [2]; however, it cannot be applied to our con-

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 2
text due to a number of inherent differences betweenontologies and nested relational models [25, 29]. Inaddition, there are several benchmarks to test systemsthat implement semantic-web technologies [7, 12, 14,24, 31, 33, 36]. Unfortunately, these benchmarks haveone or more of the following drawbacks: 1) they donot focus on data exchange problems, i.e., they do notprovide source and target ontologies and mechanismsto exchange data; 2) they are domain-specific, i.e.,they provide ontologies with a fixed structure in aparticular domain, i.e., they only allow to tune theconstruction of synthetic data but not their structure;3) they focus on SELECT queries instead of the CON-STRUCT queries that are required to exchange data.
In this article, we present MostoBM, a benchmarkfor testing data exchange systems in the context of on-tologies and query engines. Our benchmark providesa catalogue of three real-world and seven syntheticdata exchange patterns; seven parameters to constructscenarios that are instantiations of the patterns; and apublicly available tool1 that facilitates the instantia-tion of the patterns and the gathering of data aboutthe performance of systems. In addition, we providean evaluation methodology that allows to comparedata exchange systems side by side. To the best ofour knowledge, this is the first such benchmark andevaluation methodology in the bibliography.
Regarding the catalogue, the three real-world pat-terns are relevant data exchange problems in the con-text of Linked Open Data, whereas the seven syntheticpatterns are common integration problems that arebased on current approaches in the ontology evolu-tion context, and our experience regarding real-worldinformation integration problems. This catalogue isnot meant to be exhaustive: the patterns described inthis article are the starting point to a community effortthat is expected to extend them.
Regarding the parameters, a benchmark should bescalable and the results that it produces should bedeterministic and reproducible [15]. To fulfil theseproperties, our benchmark provides a number of pa-rameters to construct scenarios, each of which is athree-element tuple (S,T,Q), where S is the sourceontology, T is the target ontology, and Q is a setof SPARQL queries to perform data exchange. Ourbenchmark is based on SPARQL 1.1 and quite acomplete subset of the OWL 2 Lite profile that leavesout only subproperty, zero-cardinality, general prop-erty, and intersection restrictions. The set of SPARQLqueries of each scenario allows to exchange data witha 100% of effectiveness.
The parameters allow to scale the data of the sourceontology for the real-world patterns, and to scale thestructure of source and target ontologies, the dataof the source ontology, and the SPARQL queries toperform data exchange for the synthetic patterns.
1. http://www.tdg-seville.info/carlosrivero/MostoBM
Thanks to them, we can automatically construct thestructure of a source and a target ontology with, forinstance, a thousand classes, a dozen specialisationlevels, or the data of a source ontology with a mil-lion triples. The scaling of the patterns helps analysethe performance of data exchange systems in future,when it is assumed that data exchange problems aregoing to increase their scale in structure and/or data.
Our evaluation methodology helps software engi-neers make informed and statistically-sound decisionsbased on rankings that focus on: 1) which data ex-change system performs better; and 2) how the per-formance of a system is influenced by the parametersof our benchmark.
We presented a preliminary version of our bench-mark in [28]; in this version, we extend our initialproposal with real-world patterns (see Section 3), withan evaluation methodology (see Section 6.1), and illus-trate how to use it to make informed and statistically-sound decisions (see Sections 6.2 and 6.3). An ex-tended technical report that illustrates our benchmarkand methodology extensively is also available at [30].
The rest of the article is organised as follows: Sec-tion 2 reports on preliminaries regarding semantic-web technologies and data exchange. In Section 3and Section 4, we present our catalogue of real-worldand synthetic data exchange patterns, respectively.Section 5 describes the parameters of our benchmark.In Section 6, we describe our evaluation methodologyand illustrate how to make informed and statistically-sound decisions regarding a number of systems. InSection 7, we present the related work. Finally, Sec-tion 8 recaps on our main conclusions.
2 PRELIMINARIES
The OWL ontology language allows to model boththe structure and the data of an ontology. Regardingmodelling structure, an OWL ontology comprises aset of entities identified by URIs, each of these entitiesmay be a class, a data property, or an object property.Figure 1a shows the structure of a sample ontologyusing a tree notation. In the figure, sch:Author is a classthat models an author, and we denote it as a circle.It is important to notice that, in this example, we usenamespace sch: as a prefix. A class can be specialisedinto other classes, e.g., sch:Author is a subclass ofsch:Person, and we denote it as sch:Author [sch:Person].An example of a data property is sch:name, whichmodels the name of a person, and we denote it as asquare. Data properties have a set of classes as domainand a basic XSD data type as range, e.g., the domain ofsch:name is {sch:Person}, and we denote it by nestingsch:name into sch:Person. The range of sch:name isxsd:string, and we denote it as sch:name<xsd:string>.An example of an object property is sch:writes, whichmodels “an author writes a paper”, and we denote itas a pentagon. Object properties have a set of classes

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 3sch:Personsch:name <xsd:string>sch:alias <xsd:string>sch:writes <sch:Paper>sch:Author [sch:Person]sch:Documentsch:Paper [sch:Document ]sch:year <xsd:gYear>
(a) Structure.
sch:CRRivero [sch:Author]sch:alias “Carlos R . Rivero”sch:name “Carlos Rivero”sch:writes [sch:CIKMPaper]sch:CIKMPaper [sch:Paper ]sch:year “2011”sch:alias “Carlos R . Osuna”sch:ERPaper [sch:Paper]sch:writes [sch:ERPaper]
(b) Data.Q1: CONSTRUCT {?p rdf:type sch:Person .} WHERE {?p rdf:type sch:Author . } Q2: CONSTRUCT {?p rdf:type sch:Person .?p sch:name ?n .} WHERE {?p rdf:type sch:Author .?p sch:alias ?a .BIND(toName(?a) AS ?n) }(c) Queries.
Figure 1: Examples of the structure and data of anontology, and two SPARQL queries.
Source (populated) Source(populated & explicit )Target(empty & explicit )Target(populated) Target(populated & explicit )
1. Loading 2. Reasoning(Optional) 3. Query Execution4. Reasoning(Optional) 5. Unloading
Source, Target and SPARQL Queries Target(populated)Target (empty)SPARQL Queries
Figure 2: Steps of data exchange.
as domain and range, e.g., the domain of sch:writes is{sch:Author} and the range is {sch:Paper}.
Regarding data modelling, a class instance is iden-tified by its own URI, and it may have a numberof types (see Figure 1b). We denote a class instanceas a diamond, e.g., sch:CRRivero is a class instanceof type sch:Author. sch:CRRivero is also, implicitly,an instance of sch:Person, since sch:Author is a sub-class of sch:Person; reasoners are used to make thisknowledge explicit [21]. In addition, it is possible tohave class instances of types that are not related byspecialisation, e.g., assume that sch:CRRivero is theURL of a web page that provides the biography of aperson, therefore, sch:CRRivero might have both typessch:Person and sch:Document.
A data property instance relates a class instancewith a literal, and we denote it as a square, e.g.,sch:name relates sch:CRRivero with “Carlos Rivero”. Anobject property instance relates two class instances,e.g., sch:writes relates sch:CRRivero and sch:CIKMPaper.By default, data and object property instances havea minimal cardinality of zero, e.g., there is no data
property instance of sch:year relating sch:ERPaper anda year; however, there is a data property instance ofsch:year relating sch:CIKMPaper and “2011”. By de-fault, data and object property instances may be mul-tiple, e.g., sch:CRRivero is related to “Carlos R.Rivero”and “Carlos R.Osuna” by data property sch:alias.
RDF, which is based on triples, is used to representboth the structure and data of an OWL ontology. Atriple comprises three elements: a subject, a predicate,and an object. Sample triples are the following:
(sch:Person, rdf :type, owl:Class)(sch:Author, rdf :type, owl:Class)(sch:Author, rdfs:subClassOf , sch:Person)(sch:CIKMPaper, rdf :type, sch:Document)(sch:CIKMPaper, rdf :type, sch:Paper)(sch:CIKMPaper, sch:year, “2011”)
SPARQL queries are used to retrieve and constructtriples from RDF stores. SPARQL provides four typesof queries, namely: SELECT, CONSTRUCT, ASK, andDESCRIBE. They are based on triple patterns thatare similar to triples, but allow to specify variablesin the subject, predicate, and/or object, which areprefixed with a ‘?’. In this article, we focus on theCONSTRUCT type, since this type of queries allowsto both retrieve and construct RDF data, which is re-quired to perform data exchange by means of queries.Figure 1c shows two examples of SPARQL queries: Q1
retrieves instances of sch:Author (the WHERE clause)and reclassifies them as sch:Person (the CONSTRUCTclause); Q2 is similar to Q1 but also transforms thevalue of sch:alias into sch:name by means of a toNamefunction using a BIND clause, which assigns the valueto variable ?n.
Performing data exchange between OWL ontolo-gies using a SPARQL query engine comprises fivesteps (see Figure 2), namely:
1) Loading: This step consists of loading the sourceand target ontologies and the set of SPARQLqueries from a persistent storage into the appro-priate internal data structures.
2) Reasoning over source: This step is optional anddeals with making it explicit the knowledge inthe source. This step is not required if the knowl-edge is already explicit in the source ontology,but it is a must in many cases since SPARQLdoes not deal with RDFS or OWL entailments.
3) Query execution: This step consists of executinga set of SPARQL queries over the source ontol-ogy to produce instances of the target ontology.The result of this step must be the same regard-less of the order in which queries are executed.
4) Reasoning over target: This step is also optionaland it deals with making it explicit the knowl-edge in the target ontology.
5) Unloading: This step deals with saving the targetontology to a persistent storage.

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 4
dbp32:imdbId <xsd:string>dbp36:Persondbp36:academyAward <dbp36:Award>
dbp32:starring <dbp32:Person>dbp32:director <dbp32:Person>dbp32:Actor [dbp32:Artist ]dbp32:Film [dbp32:Work]dbp32:Artist [dbp32:Person]dbp32:Persondbp32:awards <xsd:anyURI>dbp32:Work dbp36:Artist [dbp36:Person]dbp36:Awarddbp36:Actor [dbp36:Artist ]dbp36:Workdbp36:starring <dbp36:Person>dbp36:Film [dbp36:Work]dbp36:director <dbp36:Person>dbp36:imdbId <xsd:string>
(a) Evolving DBpedia.dbp37:Workpo:Programme dbp37:TelevisionShow [dbp37:Work]po:Brand [po:Programme] dbp37:TelevisionEpisode [dbp37:Work]po:Episode [po:Programme]po:title <xsd:string> dbp37:title <xsd:string>dbp37:series<dbp37:TelevisionEpisode >po:series <po:Series>po:Series [po:Programme]po:episode <po:Episode>po:Version [po:Programme]po:version <po:Version> dbp37:runtime <xsd:double>po:duration <xsd:int>
po:actor <po:Person> dbp37:starring <dbp37:Actor>po:director <po:Person> dbp37:director <dbp37:Director>(b) Adapting BBC Programmes to DBpedia.
prf:serviceName <xsd:string> msm:Servicemsm:hasOper <msm:Oper>srv:presents <srv:ServiceProfile >srv:Serviceprf:Profile [srv:ServiceProfile ]prf:textDescription <xsd :string> rdfs:label <rdf:Literal>rdfs:comment <rdf:Literal>msm:Opergd:WsdlAtomicProcessGroundinggd:wsdlOperation <gd:WsdlOpRef>gd:WsdlOpRefgd:operation <xsd:anyURI>(c) Publishing OWL-S services as Linked Open Data.
Figure 3: Real-world patterns of our benchmark.
3 REAL-WORLD PATTERNS
Our benchmark provides three real-world data ex-change patterns, each of which is instantiated into avariety of scenarios using a number of parameters (seeSection 5). These patterns are illustrated in Figure 3and presented below. The source ontology is on theleft side and the target is on the right side; the arrowsrepresent correspondences between the entities of theontologies. These correspondences are visual hints tohelp readers understand each real-world pattern [2].We selected these three patterns to be part of ourbenchmark because they represent integration prob-lems that are common in practice in the context ofLinked Open Data. We use some prefixes to denotedifferent ontologies, such as dbp32:, dbp36:, srv: or po:.
Evolution of an ontology Usually, ontologies changein response to a certain need [11], including that thedomain of interest has changed, the perspective under
which the domain is viewed needs to be changed, ordue to design flaws in the original ontology. In thiscontext, the source ontology is the ontology beforechanges are applied and the target ontology is theontology after changes are applied.
This pattern focuses on DBpedia [8], which is acommunity effort to annotate and make the datastored at Wikipedia accessible by means of an ontol-ogy. DBpedia comprises a number of different ver-sions due to a number of changes in its conceptuali-sation. When a new version of DBpedia is devised, thenew ontology may be populated by performing dataexchange from a previous version to the new one. Inthis pattern, we perform data exchange from a part ofDBpedia 3.2 that focuses on artists, actors, directors,and films to DBpedia 3.6 (see Figure 3a).
Vocabulary adaptation It is not uncommon that twoontologies offer the same data structured according todifferent vocabularies. In this context, it is necessaryto adapt the vocabulary of a source ontology to thevocabulary of a target ontology.
This pattern focuses on the BBC Programmes andDBpedia ontologies. The BBC [20] provides ontologiesthat adhere to the Linked Open Data principles topublicise the music and programmes they broadcaston both radio and television. In this pattern, whichis shown in Figure 3b, we perform data exchangefrom the Programmes Ontology 2009, which describesprogrammes including brands, series (seasons), andepisodes, to a part of DBpedia 3.7 that models televi-sion shows and episodes.
Publication of Linked Open Data Many existing on-tologies do not adhere to the principles of the LinkedOpen Data initiative, and there is usually a need totransform them to comply with such principles.
This pattern focuses on publishing semantic webservices as Linked Open Data. OWL-S [19] is oneof the main approaches for describing semantic webservices that defines an upper ontology in OWL.MSM (Minimal Service Model) [26] is a web ser-vice ontology that allows to publish web services asLinked Open Data. In this pattern, which is shown inFigure 3c, we publish OWL-S 1.1 services as LinkedOpen Data by means of MSM 1.0.
4 SYNTHETIC PATTERNS
A synthetic data exchange pattern represents a com-mon and relevant integration problem. Our bench-mark provides a catalogue of seven synthetic dataexchange patterns; to design them, we have lever-aged our experience on current approaches in theontology evolution context (see Section 7), and ourexperience regarding real-world information integra-tion problems. Each pattern represents an intentionof change [11], i.e., each pattern represents a numberof atomic changes that are applied to an ontology in

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 5src:Personsrc:name <xsd:string>src:Author [src:Person]src:birth <xsd:date> tgt:Persontgt:name <xsd:string>tgt:birth <xsd:date>tgt:Author [ tgt:Person](a) Lift Properties.tgt:Persontgt:name <xsd:string>tgt:Author [tgt:Person]tgt:birth <xsd :date>src:Personsrc:name <xsd:string>src:birth <xsd:date>src:Author [src:Person](b) Sink Properties.src:Personsrc:name <xsd:string> tgt:Persontgt:name <xsd:string>src:paper <xsd:string> tgt:Author [tgt:Person]tgt :paper <xsd:string>
(c) Extract Subclasses.src:Authorsrc:name <xsd:string> tgt:Persontgt:name <xsd:string>tgt:Author [tgt:Person]src:paper <xsd:string> tgt:paper <xsd:string>(d) Extract Superclasses.tgt:Papertgt:title <xsd:string>tgt:Authortgt:name <xsd:string>tgt:writtenBy <tgt:Author>src:Papersrc:title <xsd:string>src:author <xsd:string> f
(e) Extract Related Classes.tgt:name <xsd:string>tgt:Persontgt:totalPapers <xsd:int>src:Personsrc:name <xsd:string>src:Author [src:Person]src:totalPapers <xsd:int>(f) Simplify Specialisation.src:Authorsrc:name <xsd:string>src:Papersrc:writes <src:Paper> tgt:Publicationsrc:title <xsd:string> tgt:author <xsd:string>tgt: title <xsd:string>f
(g) Simplify Related Classes.
Figure 4: Synthetic patterns of our benchmark.
response to certain needs. In addition, each syntheticpattern is instantiated into a variety of scenarios usinga number of parameters (see Section 5). Below, wepresent our synthetic patterns, which are illustratedin Figure 4. Note that src: and tgt: prefixes are usedfor the source and target ontologies, respectively.
Lift Properties The intention of change is that theuser wishes to extract common properties to a super-class in a hierarchy. Therefore, the data properties of aset of subclasses are moved to a common superclass.In the example, the src:name and src:birth data prop-erties are lifted to tgt:name and tgt:birth, respectively.
Sink Properties The intention of change is that theuser wishes to narrow the domain of a number ofproperties. Therefore, the data properties of a super-class are moved to a number of subclasses. In theexample, the src:name and src:birth data properties aresunk to tgt:name and tgt:birth, respectively.
Extract Subclasses The intention of change is that theuser wishes to specialise a class. Therefore, a sourceclass is split into several subclasses and the domainof the target data properties is selected amongst thesubclasses. In the example, every instance of src:Personis transformed into an instance of tgt:Person.
Extract Superclasses The intention of change is thatthe user wishes to generalise a class. So, a class issplit into several superclasses, and data properties aredistributed amongst them. After exchanging data inthis example, all target instances are of type tgt:Author,which are implicitly instances of tgt:Person, too.
Extract Related Classes The intention of change isthat the user wishes to extract a number of classesbuilding on a single class. Therefore, the data proper-ties that have this single class as domain change theirdomains by the new classes, which are related to theoriginal one by a number of object properties. In theexample, the source class src:Paper is split into twotarget classes called tgt:Paper and tgt:Author that arerelated by object property tgt:writtenBy. Instances oftgt:Author are constructed by applying a user-definedfunction f to the instances of src:Paper.
Simplify Specialisation The intention of change isthat the user wishes to flat a hierarchy of classes. Thus,a set of specialised classes are flattened into a singleclass. In the example, src:Person and src:Author, whichspecialises src:Person, are simplified to tgt:Person.
Simplify Related Classes The intention of change isthat the user wishes to join a set of classes that arerelated by object properties. Therefore, several sourceclasses are transformed into one class that aggregatesthem all. In the example, for every two instances ofsrc:Author and src:Paper related by src:writes, a newinstance of tgt:Publication is constructed.
5 PARAMETERS
Our benchmark takes a number of input parametersthat allow to tune the data of the source ontologyin the real-world patterns, and both structure anddata of the source and/or the target ontologies inthe synthetic patterns. Thanks to them, a user caninstantiate multiple scenarios per pattern.
The structure parameters are the following:• Levels of classes (L ∈ N): number of relationships
(specialisations or object properties) amongst oneclass and the rest of the classes in the source ortarget ontologies. L allows to scale the structureof ontologies in depth.

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 6src:A0src:d0 <xsd:string>src:A1 [src:A0]src:A2 [src:A0]src:A3 [src:A0]src:d1 <xsd:string>src:d2 <xsd:string> tgt:A0tgt:d0 <xsd:string>tgt:A1 [tgt:A0]tgt:A2 [tgt:A0]tgt:A3 [tgt:A0]tgt:d1 <xsd:string>tgt:d2 <xsd:string>(a) Sample structure.Q1: CONSTRUCT {?a rdf:type tgt:A0.} WHERE {?a rdf:type src:A0. }Q2: CONSTRUCT {?a rdf:type tgt:A1.?a tgt:d0 ?d.} WHERE {?a rdf:type src:A0.?a src:d0 ?d. }
(b) Samplequeries.
I0 [src:A0]src:d0 Value0I1 [src:A0]src:d1 Value1I2 [src:A0]I3 [src:A0]src:d2 Value2src:d0 Value3I0 [tgt:A0, tgt:A1]tgt:d0 Value0I1 [tgt:A0, tgt:A2]tgt:d1 Value1I2 [tgt:A0, tgt:A3]I3 [tgt:A0, tgt:A1]tgt:d2 Value2tgt:d0 Value3
(c) Sample data.
Figure 5: Sample scenario.
• Number of related classes (C ∈ N): number ofclasses related to each class by specialisation orobject properties. C allows to scale the structureof ontologies in breadth.
• Number of data properties (D ∈ N): of the sourceand target ontologies.
L and C may be applied to both source and targetontologies, which is the case of the Lift Propertiesand Sink Properties patterns; to the target ontologyonly, i.e., the Extract Subclasses, Extract Superclassesand Extract Related Classes patterns; or to the sourceontology only, i.e., the Simplify Specialisation andSimplify Related Classes patterns.
Figure 5a shows a sample instantiation of the SinkProperties pattern in which L = 1, C = 3, D = 3.Structure parameters can be tuned to construct realis-tic ontologies, e.g., ontologies in the context of life sci-ences usually comprise a large set of classes that forma wide and/or deep taxonomy. For instance, the GeneOntology [5], which represents gene and gene productattributes, comprises roughly 32 000 classes with adozen specialisation levels. Therefore, to constructontologies that resemble the Gene Ontology, we needto specify the following parameters L = 14, C = 2.The total number of classes an ontology comprises iscomputed by the following formula:
∑Li=0 C i.
Structure parameters also have an effect on theSPARQL queries constructed by our benchmark, sincethey vary depending on the structure of the sourceand target ontologies. Figure 5b shows two samplequeries for the example scenario of the Sink Propertiespattern: Q1 is responsible for reclassifying A0 in thesource as A1 in the target, and Q2 is responsiblefor both reclassifying A0 as A1 in the target, andexchanging the value of src:d0 into tgt:d0.
Data parameters are used to scale the instances of
3.2. Sensitivity
Analysis
Scenario Results
2. Scenario
Execution
3.1. Performance
Analysis
4. Decision
Making
Informed Decisions
Rankings of Performance Analysis
Rankings of Sensitivity Analysis
1. Initial
Setup
Data Exchange Systems
Real-world /Synthetic Patterns
Parameters
Performance Variable
Figure 6: Workflow of the evaluation methodology.
the source ontology, which are the following:• Number of individuals (I ∈ N\{0}): number of
instances of owl:Thing in the source ontology.• Number of types (IT ∈ N): number of types that
each individual shall have.• Number of data properties (ID ∈ N): number
of data property instances for which a givenindividual is the subject.
• Number of object properties (IO ∈ N): numberof object property instances for which a givenindividual is the subject.
The actual types and instances may be randomlyselected from the whole set of classes, data propertiesand object properties of the ontology to be populated.In our tool, we provide 44 statistical distributions torandomly select them, including Uniform, Normal,Exponential, Zipf, Pareto and empirical distributions,to mention a few. As a result, it is possible to use sta-tistical distributions that model real-world ontologies.
Figure 5c shows an example of the data constructed(left side) to populate the source ontology in Figure 5a,in which the data parameters are the following: I =4, IT = 1, ID = 1, IO = 0. Furthermore, this figureshows the target instances (right side) that result fromperforming data exchange with the SPARQL queriesin Figure 5b. We may compute the number of datatriples that a populated ontology comprises by meansof the following formula: I(1 + IT + ID + IO).
Data parameters can be tuned to populate ontolo-gies that resemble realistic ones, e.g., the SwetoD-BLP [1] ontology models computer science publica-tions. It comprises roughly 2 million triples of individ-uals of a single type, 4 million triples of data propertyinstances, and 7 million triples of object propertyinstances. To simulate this ontology, we have to setthe following values: I = 2 106, IT = 1 (the individualsare of a single type), ID = 2 (4 million triples ofdata property instances divided by 2 million triplesof individuals), and IO = 4 (7 million triples of objectproperties divided by 2 million triples of individuals).
6 EVALUATION METHODOLOGYHaving a catalogue of data exchange patterns is notenough to evaluate a data exchange system in prac-tice. It is necessary to rely on a disciplined evalua-tion methodology if we wish to make informed and

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 7
statistically-sound decisions. We have devised such amethodology and present its workflow in Figure 6.
We refer to performing data exchange over a sce-nario as executing that scenario. In the Initial Setupstep, the user is responsible for selecting the dataexchange systems to test, the patterns to test thesesystems, the values of parameters, and a variable tomeasure the performance of these systems. The Sce-nario Execution step consists of executing scenariosof each pattern using each system. After executingthe scenarios, the results are used to compute whichsystem performs better (Performance Analysis step)and to analyse the influence of parameters in theirperformance (Sensitivity Analysis step). Finally, inthe Decision Making step, the user is responsible formaking decisions based on the previous analysis.
We describe the details of the methodology in Sec-tion 6.1, and illustrate it in Sections 6.2 and 6.3.
6.1 Steps
1. Initial Setup First, we need to select the studywe are going to conduct. In this initial setup we areresponsible for selecting the data exchange systemsto test: M = {m1, . . . ,ma}, a ≥ 2; the data exchangepatterns: P = {p1, . . . , pb}, b ≥ 1; the set of valuesfor the parameters, and a performance variable. Ourmethodology is devised to focus only on real-worldor synthetic patterns, but not both at the same time,since they entail the study of different sets of param-eters: in the real-world patterns, we only study dataparameters since the structure of the source and targetontologies is fixed; in the synthetic patterns, we studyboth the structure and data parameters. Regardingstructure parameters, we refer to their sets as PL, PC,and PD; regarding the data parameters, we refer totheir sets as PI, PIT, PID, and PIO; in both cases, thesubindex refers to the corresponding parameter.
A configuration is a tuple that comprises a valuefor each parameter; we denote the set of all possibleconfigurations as C. When dealing with real-worldpatterns, C = PI × PIT × PID × PIO; when dealing withsynthetic patterns, C = PL×PC×PD×PI×PIT×PID×PIO.The combination of a pattern and a configurationforms a scenario, we denote the set of all possiblescenarios as X = P × C. In addition, a setting is acombination of a system and a pattern, we denote theset of all possible settings as S = M×P. Consequently,the total number of scenarios for each pattern is |C|.
Regarding the performance variable, there are twotypes of variables that we can select to measure theperformance of systems: context-sensitive or context-insensitive. On the one hand, context-sensitive vari-ables are affected by other processes that are executedin parallel in the computer, such as antiviruses, auto-matic updates, or backup tasks. So it is mandatory toexecute the scenarios a number of times, usually 25-30 times, and compute the average of the performance
variable, removing possible outliers. Some examplesare the following: user time, I/O time, or memoryfaults. On the other hand, context-insensitive variablesare not (notoriously) affected by other processes, so itis not needed to execute the scenarios more than once;some examples are the following: CPU time, numberof target triples, or memory used.
2. Scenario Execution For each system m ∈ M andeach pattern p ∈ P, we need to execute the scenariosrelated to p using m, so we need to execute the scenar-ios of all possible settings. Typical setups may involvethe execution of a large number of scenarios, each ofwhich may take hours or even days to complete; thismakes it necessary to use the Monte Carlo method toselect a subset of scenarios to execute randomly. Theproblem that remains is to determine which the sizeof this subset must be.
Our evaluation methodology comprises a sensitiv-ity analysis for which we use a regression method.This imposes an additional constraint on the numberof scenarios to execute, since it is known that the ratioof scenarios to parameters must be at least 10 [22].As a conclusion, when dealing with real-world pat-terns, we should execute at least 40 scenarios, sincethey involve four data parameters, and when dealingwith synthetic patterns, we should execute at least 70scenarios, since they involve three structure and fourdata parameters. To provide a more precise figure onthe number of scenarios to execute, we use an iterativemethod that relies on Cochran’s formula [9], which isbased on the variance of the performance variable.
In this iterative method, we introduce a thresholdto limit the total number of scenarios to execute:µ ∈ R, 0 < µ ≤ 1, since, in the worst case, this numberis equal to |C|, which means that the variance beingstudied is so high that it is not possible to calculatean average at confidence level 95% with an estimatederror less than 3% (the standard values of Cochran’sformula). The same occurs with the number of itera-tions of this method, i.e., a large number of iterationsof this method means that the variance being studiedis high; therefore, we introduce another thresholdregarding the number of iterations: δ ∈ N, δ > 0. Wedescribe the iterative method below:
1) For each setting si, we select 40 or 70 scenariosto execute using the Monte Carlo method.
2) We execute the selected scenarios.3) We use Cochran’s formula to compute the new
number of scenarios to execute using the vari-ance of the performance variable, which is com-puted from the scenarios previously executed.
4) Let e be the new number of scenarios to beexecuted, let k be the current number of iter-ations, and w the number of scenarios alreadyexecuted; there are several alternatives: 1) e ≤ wand δ ≤ k: we stop executing more scenarios andcontinue with the next step of the methodology;

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 8
2) µ |C| ≥ e > w and δ ≤ k: we select e − wscenarios using the Monte Carlo method andreturn to the second step of this method; 3)e > µ |C| or δ > k: we discard si since it isnot possible to make informed and statistically-sound decisions about this setting.
At the end of this step, we have results of theperformance variable for each setting, i.e., a set oftuples of the form (s, c, v), where s is a setting, c isa configuration, and v the corresponding value of theperformance variable.
3.1. Performance Analysis To compute which systemperforms better, we need a method to compare thevalues of the performance variable we gathered in theprevious step. We can consider them as samples ofan unknown random variable, which implies that weneed to rely on statistical inference.
We apply Kruskal-Wallis’s H test [18] to the resultsof each pattern in isolation, and to all of the results.The goal of this test is to determine if there are statisti-cally significant differences amongst the performancevariable for the systems under test. If the result isthat there is no difference amongst the systems, itmeans that they all behave statistically identicallywith respect to the performance variable.
Otherwise, we use Wilcoxon’s Signed Rank [18]test; if more than two systems are compared thenwe use Bonferroni’s correction [23]. According to thecorrection, the p-value must not be compared with α,the confidence level, usually 0.05, but α/a, where adenotes the number of systems to be tested. In otherwords, given ten systems to test, if we compare m1
and m2 using Wilcoxon’s Signed Rank test and itreturns a p-value less than α/10, then the conclusionis that there is not enough evidence to reject thehypothesis that m1 performs better than m2.
As a conclusion, the results of this step are a numberof rankings of systems and patterns, i.e., a set of tuplesof the form (P, r), in which P ⊆ P is a subset ofpatterns and r is a ranking of systems.
3.2. Sensitivity Analysis In this step, we need amethod to analyse the influence of the parameters inthe performance of the systems. For each setting s, weuse ReliefF to rank the influence of the parameterson the performance variable [32]. ReliefF is a generalparameter estimator that is based on regression, whichdetects conditional dependencies amongst parametersand the performance variable. As a result, it outputsa number of numerical coefficients for each parame-ter; the lower a coefficient, the less influence of thecorresponding parameter.
Before using ReliefF, we need to normalise thevalues of the performance variable that we havemeasured in our scenarios, since ReliefF coefficientswould not be comparable otherwise. To perform thisnormalisation, we take the minimum and maximumvalues of the performance variable in the execution
of scenarios for each setting, vm and vM, respectively,and we use the following formula: v′
i = (vi − vm)/vM,where vi is the value of the performance variable ineach scenario and v′
i is the normalised value.After applying ReliefF to our results, we obtain a
ranking of the influence of parameters on the perfor-mance variable for each setting. Then, it is possibleto rank the influence of parameters by clusteringsystems and/or patterns. Both types of rankings arecomputed by means of the Majoritarian Compromisemethod [34], which clusters individual rankings into asingle global ranking. To rank the influence by system,we take the individual rankings of each system anduse the Majoritarian Compromise method to computethe global ranking. Similarly, to rank the influence bypattern, we compute the global ranking taking theindividual rankings of each pattern into account.
This step outputs a number of rankings on the in-fluence of parameters for each setting, for each systemand every pattern, and for each pattern and everysystem, i.e., tuples of the form (m, p, rx), (m,P, ry) and(M, p, rz), respectively, where m denotes a system, pdenotes a pattern, P ⊆ P denotes a subset of patterns,M ⊆ M denotes a subset of systems, and rx, ry and rzdenote rankings on the influence of parameters.
4. Decision Making In this step, the user use theprevious rankings to make informed and statistically-sound decisions on which the best system is regardingthe patterns and the analysed performance variable.
6.2 Example with real-world patternsTo perform this example of our evaluation method-ology, we used a tool implemented using Java thatallows to execute the scenarios on several data ex-change systems [30]. The tool was run on a virtualcomputer that was equipped with a four-threadedIntel Xeon 3.00 GHz CPU and 16 GB RAM, run-ning on Windows Server 2008 (64-bits), JRE 1.6.0,Oracle 11.2.0.1.0, Jena 2.6.4, ARQ 2.8.7, TDB 0.8.7,Pellet 2.2.2, and OWLIM 4.2. Regarding the executionof scenarios, we forced our benchmark to wait for tenseconds every two scenario execution to ensure thatthe Java garbage collector had finished collecting oldobjects from memory. Furthermore, we dropped andcreated the Oracle’s tablespace in which we stored theontologies in each scenario execution.
Note that, other benchmarks perform warm-upsof the systems under test before running their ex-periments, since they focus on query response orreasoning time, which may be improved by thesewarm-ups [7]. However, in our benchmark, we areinterested in real-world data exchange problems, inwhich the exchange of data is performed off-line, sowe avoid warm-ups to fill caches since it is not theusual behaviour in real-world problems.
1. Initial Setup For this example, we selected tendata exchange systems to test (recall that a system
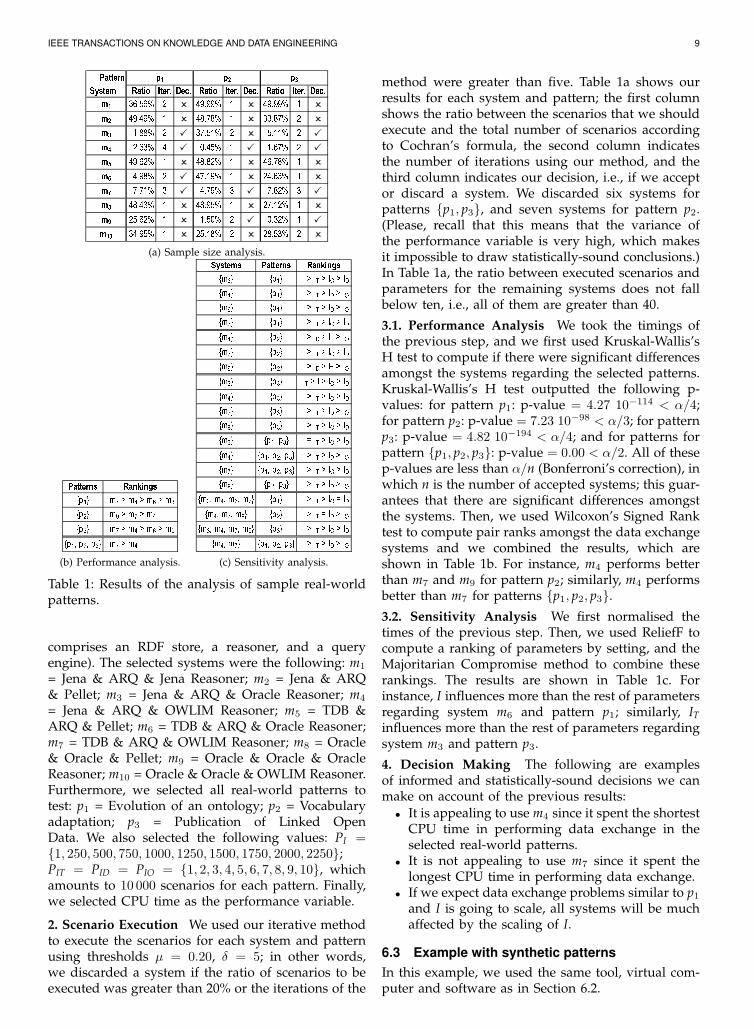
IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 9Pattern System Ratio Iter. Dec. Ratio Iter. Dec. Ratio Iter. Dec.m1 36.56% 2 � 49.99% 1 � 49.99% 1 �m2 49.49% 1 � 48.78% 1 � 33.87% 2 �m3 1.88% 2 � 37.51% 2 � 5.11% 2 �m4 2.63% 4 � 0.45% 1 � 1.67% 2 �m5 49.62% 1 � 48.82% 1 � 46.78% 1 �m6 4.98% 2 � 47.19% 1 � 24.63% 1 �m7 7.71% 3 � 4.79% 3 � 7.82% 3 �m8 48.43% 1 � 48.95% 1 � 27.12% 1 �m9 25.62% 1 � 1.50% 2 � 0.32% 1 �m10 34.95% 1 � 25.18% 2 � 28.53% 2 �
p1 p2 p3
(a) Sample size analysis.
Patterns Rankings{p1} m7 > m4 > m6 > m3{p2} m9 > m7 > m4{p3} m7 > m4 > m6 > m9{p1, p2, p3} m7 > m4(b) Performance analysis.
Systems Patterns Rankings{m3} {p1} I > IT > IO > ID{m4} {p1} I > IT > ID > IO{m6} {p1} I > IT > ID > IO{m7} {p1} I > IT > IO > ID{m4} {p2} I > ID > IT > IO{m7} {p2} I > IT > IO > ID{m9} {p2} I > ID > IT > IO{m3} {p3} IT > I > IO > ID{m4} {p3} I > IT > IO > ID{m7} {p3} I > IT > ID > IO{m9} {p3} I > IT > IO > ID{m3} {p1, p3} I = IT > IO > ID{m4} {p1, p2, p3} I > IT > ID > IO{m7} {p1, p2, p3} I > IT > IO > ID{m9} {p2, p3} I > IT > ID > IO{m3, m4, m6, m7} {p1} I > IT > IO = ID{m4, m7, m9} {p2} I > IT = ID > IO{m3, m4, m7, m9} {p3} I > IT > IO > ID{m4, m7} {p1, p2, p3} I > IT > ID > IO(c) Sensitivity analysis.
Table 1: Results of the analysis of sample real-worldpatterns.
comprises an RDF store, a reasoner, and a queryengine). The selected systems were the following: m1
= Jena & ARQ & Jena Reasoner; m2 = Jena & ARQ& Pellet; m3 = Jena & ARQ & Oracle Reasoner; m4
= Jena & ARQ & OWLIM Reasoner; m5 = TDB &ARQ & Pellet; m6 = TDB & ARQ & Oracle Reasoner;m7 = TDB & ARQ & OWLIM Reasoner; m8 = Oracle& Oracle & Pellet; m9 = Oracle & Oracle & OracleReasoner; m10 = Oracle & Oracle & OWLIM Reasoner.Furthermore, we selected all real-world patterns totest: p1 = Evolution of an ontology; p2 = Vocabularyadaptation; p3 = Publication of Linked OpenData. We also selected the following values: PI ={1, 250, 500, 750, 1000, 1250, 1500, 1750, 2000, 2250};PIT = PID = PIO = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}, whichamounts to 10 000 scenarios for each pattern. Finally,we selected CPU time as the performance variable.
2. Scenario Execution We used our iterative methodto execute the scenarios for each system and patternusing thresholds µ = 0.20, δ = 5; in other words,we discarded a system if the ratio of scenarios to beexecuted was greater than 20% or the iterations of the
method were greater than five. Table 1a shows ourresults for each system and pattern; the first columnshows the ratio between the scenarios that we shouldexecute and the total number of scenarios accordingto Cochran’s formula, the second column indicatesthe number of iterations using our method, and thethird column indicates our decision, i.e., if we acceptor discard a system. We discarded six systems forpatterns {p1, p3}, and seven systems for pattern p2.(Please, recall that this means that the variance ofthe performance variable is very high, which makesit impossible to draw statistically-sound conclusions.)In Table 1a, the ratio between executed scenarios andparameters for the remaining systems does not fallbelow ten, i.e., all of them are greater than 40.
3.1. Performance Analysis We took the timings ofthe previous step, and we first used Kruskal-Wallis’sH test to compute if there were significant differencesamongst the systems regarding the selected patterns.Kruskal-Wallis’s H test outputted the following p-values: for pattern p1: p-value = 4.27 10−114 < α/4;for pattern p2: p-value = 7.23 10−98 < α/3; for patternp3: p-value = 4.82 10−194 < α/4; and for patterns forpattern {p1, p2, p3}: p-value = 0.00 < α/2. All of thesep-values are less than α/n (Bonferroni’s correction), inwhich n is the number of accepted systems; this guar-antees that there are significant differences amongstthe systems. Then, we used Wilcoxon’s Signed Ranktest to compute pair ranks amongst the data exchangesystems and we combined the results, which areshown in Table 1b. For instance, m4 performs betterthan m7 and m9 for pattern p2; similarly, m4 performsbetter than m7 for patterns {p1, p2, p3}.
3.2. Sensitivity Analysis We first normalised thetimes of the previous step. Then, we used ReliefF tocompute a ranking of parameters by setting, and theMajoritarian Compromise method to combine theserankings. The results are shown in Table 1c. Forinstance, I influences more than the rest of parametersregarding system m6 and pattern p1; similarly, ITinfluences more than the rest of parameters regardingsystem m3 and pattern p3.
4. Decision Making The following are examplesof informed and statistically-sound decisions we canmake on account of the previous results:
• It is appealing to use m4 since it spent the shortestCPU time in performing data exchange in theselected real-world patterns.
• It is not appealing to use m7 since it spent thelongest CPU time in performing data exchange.
• If we expect data exchange problems similar to p1and I is going to scale, all systems will be muchaffected by the scaling of I.
6.3 Example with synthetic patternsIn this example, we used the same tool, virtual com-puter and software as in Section 6.2.
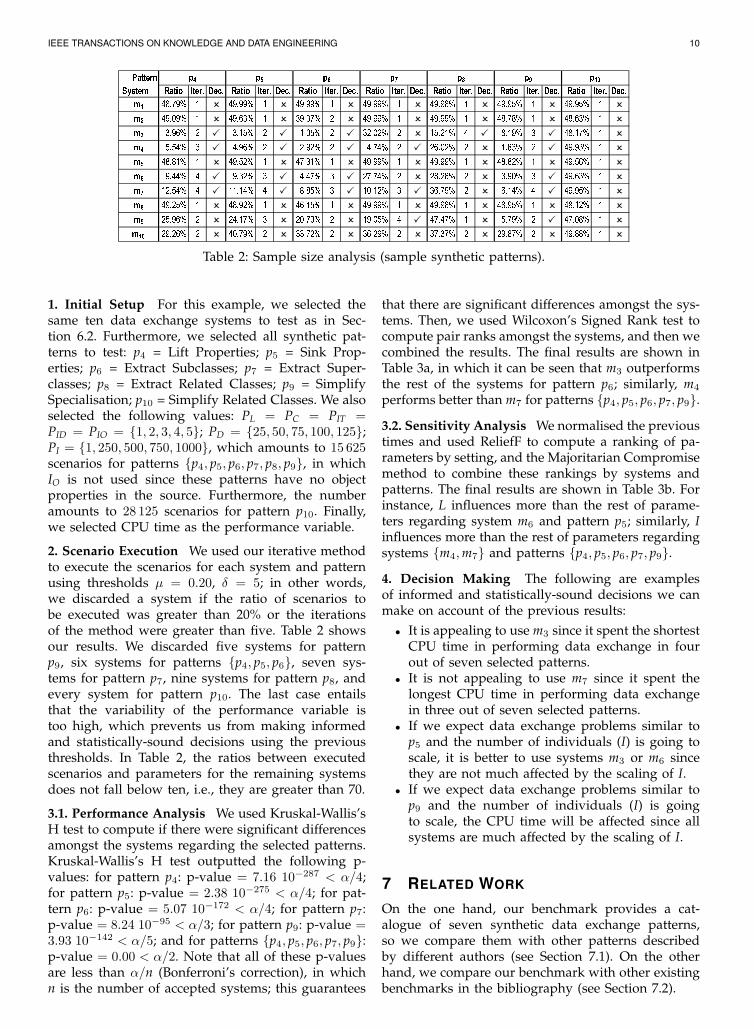
IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 10Pattern System Ratio Iter. Dec. Ratio Iter. Dec. Ratio Iter. Dec. Ratio Iter. Dec. Ratio Iter. Dec. Ratio Iter. Dec. Ratio Iter. Dec.m1 48.79% 1 � 49.99% 1 � 49.99% 1 � 49.99% 1 � 49.98% 1 � 49.95% 1 � 49.95% 1 �m2 49.09% 1 � 49.63% 1 � 39.37% 2 � 49.99% 1 � 49.99% 1 � 48.78% 1 � 48.63% 1 �m3 3.96% 2 � 3.15% 2 � 1.05% 2 � 32.02% 2 � 15.21% 4 � 8.19% 3 � 48.17% 1 �m4 5.54% 3 � 4.96% 2 � 2.92% 2 � 4.74% 2 � 26.02% 2 � 1.83% 2 � 49.93% 1 �m5 48.81% 1 � 49.52% 1 � 47.31% 1 � 49.99% 1 � 49.99% 1 � 48.82% 1 � 49.56% 1 �m6 9.44% 4 � 9.32% 3 � 4.47% 3 � 27.74% 2 � 28.26% 2 � 3.90% 3 � 49.63% 1 �m7 12.54% 4 � 11.14% 4 � 8.85% 3 � 10.12% 3 � 36.79% 2 � 6.14% 4 � 49.95% 1 �m8 49.25% 1 � 48.92% 1 � 46.15% 1 � 49.99% 1 � 49.98% 1 � 48.95% 1 � 48.12% 1 �m9 25.96% 2 � 24.17% 3 � 20.70% 2 � 19.05% 4 � 47.47% 1 � 5.79% 2 � 47.08% 1 �m10 29.26% 2 � 40.79% 2 � 33.72% 2 � 36.29% 2 � 37.37% 2 � 29.87% 2 � 49.88% 1 �
p7 p8 p9 p10p4 p5 p6
Table 2: Sample size analysis (sample synthetic patterns).
1. Initial Setup For this example, we selected thesame ten data exchange systems to test as in Sec-tion 6.2. Furthermore, we selected all synthetic pat-terns to test: p4 = Lift Properties; p5 = Sink Prop-erties; p6 = Extract Subclasses; p7 = Extract Super-classes; p8 = Extract Related Classes; p9 = SimplifySpecialisation; p10 = Simplify Related Classes. We alsoselected the following values: PL = PC = PIT =PID = PIO = {1, 2, 3, 4, 5}; PD = {25, 50, 75, 100, 125};PI = {1, 250, 500, 750, 1000}, which amounts to 15 625scenarios for patterns {p4, p5, p6, p7, p8, p9}, in whichIO is not used since these patterns have no objectproperties in the source. Furthermore, the numberamounts to 28 125 scenarios for pattern p10. Finally,we selected CPU time as the performance variable.
2. Scenario Execution We used our iterative methodto execute the scenarios for each system and patternusing thresholds µ = 0.20, δ = 5; in other words,we discarded a system if the ratio of scenarios tobe executed was greater than 20% or the iterationsof the method were greater than five. Table 2 showsour results. We discarded five systems for patternp9, six systems for patterns {p4, p5, p6}, seven sys-tems for pattern p7, nine systems for pattern p8, andevery system for pattern p10. The last case entailsthat the variability of the performance variable istoo high, which prevents us from making informedand statistically-sound decisions using the previousthresholds. In Table 2, the ratios between executedscenarios and parameters for the remaining systemsdoes not fall below ten, i.e., they are greater than 70.
3.1. Performance Analysis We used Kruskal-Wallis’sH test to compute if there were significant differencesamongst the systems regarding the selected patterns.Kruskal-Wallis’s H test outputted the following p-values: for pattern p4: p-value = 7.16 10−287 < α/4;for pattern p5: p-value = 2.38 10−275 < α/4; for pat-tern p6: p-value = 5.07 10−172 < α/4; for pattern p7:p-value = 8.24 10−95 < α/3; for pattern p9: p-value =3.93 10−142 < α/5; and for patterns {p4, p5, p6, p7, p9}:p-value = 0.00 < α/2. Note that all of these p-valuesare less than α/n (Bonferroni’s correction), in whichn is the number of accepted systems; this guarantees
that there are significant differences amongst the sys-tems. Then, we used Wilcoxon’s Signed Rank test tocompute pair ranks amongst the systems, and then wecombined the results. The final results are shown inTable 3a, in which it can be seen that m3 outperformsthe rest of the systems for pattern p6; similarly, m4
performs better than m7 for patterns {p4, p5, p6, p7, p9}.
3.2. Sensitivity Analysis We normalised the previoustimes and used ReliefF to compute a ranking of pa-rameters by setting, and the Majoritarian Compromisemethod to combine these rankings by systems andpatterns. The final results are shown in Table 3b. Forinstance, L influences more than the rest of parame-ters regarding system m6 and pattern p5; similarly, Iinfluences more than the rest of parameters regardingsystems {m4,m7} and patterns {p4, p5, p6, p7, p9}.
4. Decision Making The following are examplesof informed and statistically-sound decisions we canmake on account of the previous results:
• It is appealing to use m3 since it spent the shortestCPU time in performing data exchange in fourout of seven selected patterns.
• It is not appealing to use m7 since it spent thelongest CPU time in performing data exchangein three out of seven selected patterns.
• If we expect data exchange problems similar top5 and the number of individuals (I) is going toscale, it is better to use systems m3 or m6 sincethey are not much affected by the scaling of I.
• If we expect data exchange problems similar top9 and the number of individuals (I) is goingto scale, the CPU time will be affected since allsystems are much affected by the scaling of I.
7 RELATED WORK
On the one hand, our benchmark provides a cat-alogue of seven synthetic data exchange patterns,so we compare them with other patterns describedby different authors (see Section 7.1). On the otherhand, we compare our benchmark with other existingbenchmarks in the bibliography (see Section 7.2).
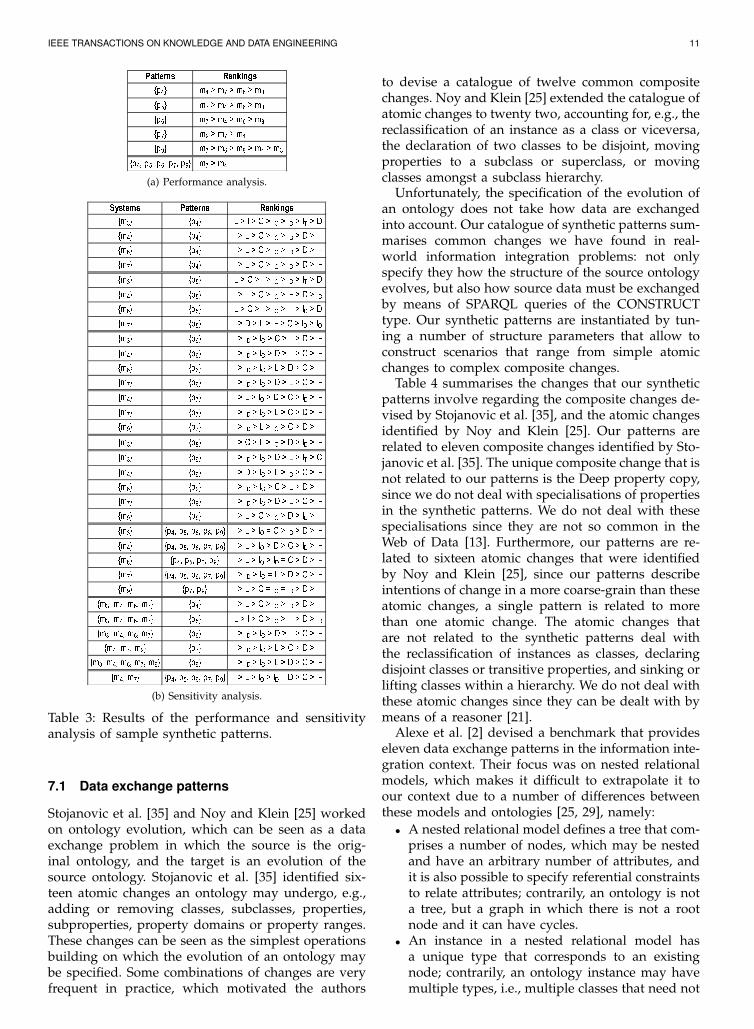
IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 11Patterns Rankings{p4} m4 > m7 > m6 > m3{p5} m7 > m4 > m6 > m3{p6} m7 > m4 > m6 > m3{p7} m9 > m7 > m4{p9} m7 > m6 > m9 > m4 > m3 {p4, p5, p6, p7, p9} m7 > m4(a) Performance analysis.Systems Patterns Rankings{m3} {p4} L > I > C > IO > ID > IT > D{m4} {p4} I > L > C > IO > ID > D > IT{m6} {p4} I > L > C > IO > ID > D > IT{m7} {p4} I > L > C > IO > ID > D > IT{m3} {p5} L > C > I > IO > ID > IT > D{m4} {p5} I > L > C > IO > IT > D > ID{m6} {p5} L > C > I > IO > IT > ID > D{m7} {p5} I > D > L > IT > C > ID > IO {m3} {p6} I > ID > IO > C > L > D > IT{m4} {p6} I > ID > IO > D > L > C > IT{m6} {p6} I > ID > IO > L > D > C > IT{m7} {p6} I > ID > IO > D > L > C > IT{m4} {p7} I > L > IO > D > C > ID > IT{m7} {p7} I > ID > IO > L > C > D > IT{m9} {p7} I > ID > L > IO > C > D > IT{m3} {p8} I > C > L > IO > D > ID > IT{m3} {p9} I > ID > IO > D > L > IT > C{m4} {p9} I > D > IO > L > ID > C > IT{m6} {p9} I > ID > IO > C > L > D > IT{m7} {p9} I > ID > IO > D > L > C > IT{m9} {p9} I > L > C > IO > D > ID > IT{m3} {p4, p5, p6, p8, p9} I > L > IO = C > ID > D > IT{m4} {p4, p5, p6, p7, p9} I > L > IO > D > C > ID > IT{m6} {p4, p5, p6, p9} I > L > IO > ID = C > D > IT{m7} {p4, p5, p6, p7, p9} I > ID > IO = L > D > C > IT{m9} {p7, p9} I > L > C = IO = ID > D > IT{m3, m4, m6, m7} {p4} I > L > C > IO > ID > D > IT{m3, m4, m6, m7} {p5} L > I > C > IO > IT > D > ID{m3, m4, m6, m7} {p6} I > ID > IO > D > L > C > IT{m4, m7, m9} {p7} I > ID > IO > L > C > D > IT{m3, m4, m6, m7, m9} {p9} I > ID > IO > L > D > C > IT{m4, m7} {p4, p5, p6, p7, p9} I > L > IO > ID = D > C > IT(b) Sensitivity analysis.
Table 3: Results of the performance and sensitivityanalysis of sample synthetic patterns.
7.1 Data exchange patterns
Stojanovic et al. [35] and Noy and Klein [25] workedon ontology evolution, which can be seen as a dataexchange problem in which the source is the orig-inal ontology, and the target is an evolution of thesource ontology. Stojanovic et al. [35] identified six-teen atomic changes an ontology may undergo, e.g.,adding or removing classes, subclasses, properties,subproperties, property domains or property ranges.These changes can be seen as the simplest operationsbuilding on which the evolution of an ontology maybe specified. Some combinations of changes are veryfrequent in practice, which motivated the authors
to devise a catalogue of twelve common compositechanges. Noy and Klein [25] extended the catalogue ofatomic changes to twenty two, accounting for, e.g., thereclassification of an instance as a class or viceversa,the declaration of two classes to be disjoint, movingproperties to a subclass or superclass, or movingclasses amongst a subclass hierarchy.
Unfortunately, the specification of the evolution ofan ontology does not take how data are exchangedinto account. Our catalogue of synthetic patterns sum-marises common changes we have found in real-world information integration problems: not onlyspecify they how the structure of the source ontologyevolves, but also how source data must be exchangedby means of SPARQL queries of the CONSTRUCTtype. Our synthetic patterns are instantiated by tun-ing a number of structure parameters that allow toconstruct scenarios that range from simple atomicchanges to complex composite changes.
Table 4 summarises the changes that our syntheticpatterns involve regarding the composite changes de-vised by Stojanovic et al. [35], and the atomic changesidentified by Noy and Klein [25]. Our patterns arerelated to eleven composite changes identified by Sto-janovic et al. [35]. The unique composite change that isnot related to our patterns is the Deep property copy,since we do not deal with specialisations of propertiesin the synthetic patterns. We do not deal with thesespecialisations since they are not so common in theWeb of Data [13]. Furthermore, our patterns are re-lated to sixteen atomic changes that were identifiedby Noy and Klein [25], since our patterns describeintentions of change in a more coarse-grain than theseatomic changes, a single pattern is related to morethan one atomic change. The atomic changes thatare not related to the synthetic patterns deal withthe reclassification of instances as classes, declaringdisjoint classes or transitive properties, and sinking orlifting classes within a hierarchy. We do not deal withthese atomic changes since they can be dealt with bymeans of a reasoner [21].
Alexe et al. [2] devised a benchmark that provideseleven data exchange patterns in the information inte-gration context. Their focus was on nested relationalmodels, which makes it difficult to extrapolate it toour context due to a number of differences betweenthese models and ontologies [25, 29], namely:
• A nested relational model defines a tree that com-prises a number of nodes, which may be nestedand have an arbitrary number of attributes, andit is also possible to specify referential constraintsto relate attributes; contrarily, an ontology is nota tree, but a graph in which there is not a rootnode and it can have cycles.
• An instance in a nested relational model hasa unique type that corresponds to an existingnode; contrarily, an ontology instance may havemultiple types, i.e., multiple classes that need not

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 12Data Exchange Patterns Stojanovic et al. Noy and KleinLift Properties Pull up properties, Move properties, Deep concept copy Create slot, Delete slot, Attach slot to class, Remove slot from class, Move slot from sub to superclass, Widen a restriction for a slot, Encapsulate slots into a new classSink Properties Pull down properties, Move properties, Deep concept copy Create slot, Delete slot, Attach slot to class, Move slot from sub to superclass, Narrow a restriction for a slot, Encapsulate slots into a new classExtract Subclasses Extract subconcepts, Move properties, Shallow concept copy Create class, Attach slot to class, Remove slot from class, Add subclass link, Move slot from super to subclass, Encapsulate slots into a new class, Narrow a restriction for a slot, Split a class into several classesExtract Superclasses Extract superconcept, Move properties, Shallow concept copy Create class, Create slot, Attach slot to class, Remove slot from class, Add subclass link, Move slot from sub to superclass, Widen a restriction for a slot, Encapsulate slots into a new classExtract Related Classes Extract related concept, Move properties, Shallow concept copy, Move instance Create class, Attach slot to class, Create slot, Remove slot from class, Move slots to referenced class, Encapsulate slots into a new class, Split a class into several classesSimplify Specialisation Pull up properties, Move properties, Shallow concept copy Delete class, Attach slot to class, Remove slot from class, Remove subclass link, Merge classes, Move slot from sub to superclass, Encapsulate slots into a new class, Widen a restriction for a slotSimplify Related Classes Merge concepts, Move properties, Move instance Delete class, Delete slot, Attach slot to class, Remove slot from class, Merge classes, Encapsulate slots into a new classTable 4: Changes involved in our synthetic patterns.
be related by specialisation.• In nested relational models, queries to exchange
data are encoded using XQuery or XSLT, whichbuild on the structure of the XML documentson which they are executed; contrarily, in anontology, these queries must be encoded in alanguage that is independent from the structureof the documents used to represent an ontology,since the same ontology may be serialised tomultiple languages, e.g., XML, N3, or Turtle.
7.2 Benchmarks
The most-related benchmark is LODIB [31], whichwas devised to test the performance of data exchangesystems in the context of Linked Data. LODIB fo-cuses on three e-commerce data exchange patterns,each of which comprises a different source ontologyand the same target ontology. This benchmark allowsto automatically populate and scale the data of thesource ontologies. Unfortunately, LODIB uses fourfixed ontologies (three sources and one target), so it isnot possible to test the performance of data exchangesystems when the structure of the ontologies scale.
Guo et al. [14] presented LUBM, a benchmark tocompare systems that support ontologies. This bench-mark provides a single university ontology, a dataconstructor algorithm that allows to create scalablesynthetic data, and fourteen SPARQL queries of theSELECT type. This benchmark is similar to ours;however, it has a number of crucial differences:
• LUBM focuses on a single ontology. Contrarily,our benchmark focuses on data exchange prob-lems that comprise source and target ontologiesand a set of queries.
• LUBM provides a data constructor to populate anontology in the university context with syntheticdata. On the contrary, our benchmark allows totune the structure and/or data of source andtarget ontologies for each pattern instantiation.
• LUBM provides fourteen SPARQL queries of theSELECT type. Our benchmark provides a queryconstructor that allows to automatically construct
SPARQL queries of the CONSTRUCT type toperform data exchange for the synthetic patterns.
Wu et al. [36] presented the conclusions regardingan implementation of an inference engine for Oracle,which implements the RDFS and OWL entailments,i.e., it performs reasoning over OWL and RDFS on-tologies. They described a performance study basedon two examples: LUBM, which comprises data thatrange from 6.7 to 133.7 million triples, and UniProt,which comprises roughly 5 million triples.
Bizer and Schultz [7] presented BSBM, a benchmarkto compare the performance of SPARQL queries usingnative RDF stores and SPARQL-to-SQL query rewrit-ers. It focuses on an e-commerce pattern, and theyprovide a data constructor and a test driver: the for-mer allows to create large ontologies and offers RDFand relational outputs to compare the approaches;the latter emulates a realistic workload by simulatingmultiple clients that concurrently execute queries. Thebenchmark consists of twelve SPARQL queries thatare divided into ten SELECT queries, one DESCRIBEquery, and one CONSTRUCT query.
Schmidt et al. [33] presented a benchmark to testSPARQL query engines that is based on DBLP, andcomprises both a data constructor and a set of bench-mark queries in SPARQL. They study the DBLPdataset to construct a realistic set of synthetic data bymeasuring probability distributions for certain prop-erties, e.g., authors or cites in papers. The benchmarkcomprises seventeen queries that are divided intofourteen SELECT queries and three ASK queries.
Garcia-Castro and Gómez-Pérez [12] described abenchmark to test the interoperability amongst differ-ent systems that implement semantic-web technolo-gies, which represent ontologies in different ontologylanguages, such as RDFS or OWL. They claim thatit is necessary to be aware of these interoperabil-ity problems when combining such systems. Morseyet al. [24] presented DBPSB, a benchmark to testthe performance of RDF stores and SPARQL queryengines using RDF data that do not resemble a re-lational schema. It automatically generates RDF dataof multiple sizes by duplicating the original data and

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 13
changing their namespaces. The authors selected 25representative SPARQL queries of the SELECT typethat were extracted by analysing real-world queriesissued to the official DBpedia SPARQL endpoint.
Finally, Alexe et al. [2] devised a benchmark that isused to test data exchange systems in the context ofnested relational models. Unfortunately, this bench-mark is not suitable in our context since ontologieshave a number of inherent differences with respect tonested relational models (see Section 7.1).
8 CONCLUSIONS
In this article, we present a benchmark to test data ex-change systems in the context of ontologies that buildon SPARQL query engines. Existing benchmarks inthe bibliography are not suitable to test such systemssince: 1) they focus on nested relational models, whichare not applicable to ontologies due to a number ofinherent differences between them; 2) they do notfocus on data exchange problems, which implies thatthey do not provide source and target ontologies andqueries to exchange data; 3) they provide ontologieswith a fixed structure in a particular domain and donot allow to tune their structure; or 4) they focus onSELECT queries instead of CONSTRUCT queries thatare required to exchange data.
Our benchmark provides a catalogue of three real-world and seven synthetic data exchange patterns.The former are relevant data exchange problems in thecontext of Linked Open Data. The latter are commonintegration problems based on current approachesin the context of ontology evolution, and on ourexperience in information integration. This catalogueof patterns is not meant to be exhaustive: we expecta community effort to extend them.
These patterns can be instantiated into syntheticscenarios by means of seven parameters that al-low to control the construction of both the structureand/or data of ontologies. The scaling of the patternshelps analyse the performance of systems when dataexchange problems increase their scale in structureand/or data. Finally, our benchmark provides an eval-uation methodology that allows to compare systemsside by side, and to make informed and statistically-sound decisions about their performance. It is appliedto a number of patterns and systems, and allows torank which system performs better or how the perfor-mance of a system is influenced by the parameters.
ACKNOWLEDGEMENTS
We would like to thank Christian Bizer, AndreasSchultz, and José C. Riquelme for their helpful sug-gestions on an earlier draft of this article. The vir-tual computer to test the systems was provided bythe Communications and Computing Service of theUniversity of Sevilla. The work was supported bythe European Commission (FEDER), the Spanish and
the Andalusian R&D&I programmes (grants TIN2007-64119, P07-TIC-2602, P08-TIC-4100, TIN2008-04718-E, TIN2010-21744, TIN2010-09809-E, TIN2010-10811-E, TIN2010-09988-E, and TIN2011-15497-E).
REFERENCES
[1] B. Aleman-Meza, F. Hakimpour, I. B. Arpinar,and A. P. Sheth. SwetoDblp ontology of com-puter science publications. J. Web Sem., 5(3):151–155, 2007.
[2] B. Alexe, W. C. Tan, and Y. Velegrakis. STBench-mark: Towards a benchmark for mapping sys-tems. PVLDB, 1(1):230–244, 2008.
[3] G. Antoniou and F. van Harmelen. A SemanticWeb Primer. The MIT Press, 2008.
[4] J. L. Arjona, R. Corchuelo, D. Ruiz, and M. Toro.From wrapping to knowledge. IEEE Trans. Knowl.Data Eng., 19(2):310–323, 2007.
[5] M. Bada, R. Stevens, C. A. Goble, Y. Gil, M. Ash-burner, J. M. Cherry, J. A. Blake, M. A. Harris,and S. Lewis. A short study on the success of theGene Ontology. J. Web Sem., 1(2):235–240, 2004.
[6] Z. Bellahsene, A. Bonifati, and E. Rahm, editors.Schema Matching and Mapping. Springer, 2011.
[7] C. Bizer and A. Schultz. The Berlin SPARQLbenchmark. Int. J. Semantic Web Inf. Syst., 5(2):1–24, 2009.
[8] C. Bizer, J. Lehmann, G. Kobilarov, S. Auer,C. Becker, R. Cyganiak, and S. Hellmann. DBpe-dia: A crystallization point for the Web of Data.J. Web Sem., 7(3):154–165, 2009.
[9] W. G. Cochran. Sampling techniques. John Wiley& Sons, 1977.
[10] R. Fagin, P. G. Kolaitis, R. J. Miller, and L. Popa.Data exchange: Semantics and query answering.Theor. Comput. Sci., 336(1):89–124, 2005.
[11] G. Flouris, D. Manakanatas, H. Kondylakis,D. Plexousakis, and G. Antoniou. Ontologychange: Classification and survey. Knowledge Eng.Review, 23(2):117–152, 2008.
[12] R. Garcia-Castro and A. Gómez-Pérez. Interop-erability results for semantic-web technologiesusing OWL as the interchange language. J. WebSem., 8(4):278–291, 2010.
[13] B. Glimm, A. Hogan, M. Krötzsch, andA. Polleres. OWL: Yet to arrive on the Web ofData? In LDOW, 2012.
[14] Y. Guo, Z. Pan, and J. Heflin. LUBM: A bench-mark for OWL knowledge base systems. J. WebSem., 3(2-3):158–182, 2005.
[15] Y. Guo, A. Qasem, Z. Pan, and J. Heflin. A re-quirements driven framework for benchmarkingsemantic web knowledge base systems. IEEETrans. Knowl. Data Eng., 19(2):297–309, 2007.
[16] A. Y. Halevy, Z. G. Ives, J. Madhavan, P. Mork,D. Suciu, and I. Tatarinov. The Piazza peer datamanagement system. IEEE Trans. Knowl. DataEng., 16(7):787–798, 2004.

IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 14
[17] T. Heath and C. Bizer. Linked Data: Evolving theWeb into a Global Data Space. Morgan & Claypool,2011.
[18] M. Hollander and D. A. Wolfe. NonparametricStatistical Methods. Wiley-Interscience, 1999.
[19] M. Klusch, B. Fries, and K. P. Sycara. OWLS-MX:A hybrid semantic web service matchmaker forOWL-S services. J. Web Sem., 7(2):121–133, 2009.
[20] G. Kobilarov, T. Scott, Y. Raimond, S. Oliver,C. Sizemore, M. Smethurst, C. Bizer, and R. Lee.Media meets Semantic Web: How the BBC usesDBpedia and Linked Data to make connections.In ESWC, pages 723–737, 2009.
[21] G. Meditskos and N. Bassiliades. A rule-basedobject-oriented OWL reasoner. IEEE Trans. Knowl.Data Eng., 20(3):397–410, 2008.
[22] D. E. Miller and J. T. Kunce. Prediction andstatistical overkill revisited. Measurement andEvaluation in Guidance, 6(3):157–163, 1973.
[23] R. G. Miller. Simultaneous statistical inference.Springer, 1981.
[24] M. Morsey, J. Lehmann, S. Auer, and A.-C. N.Ngomo. DBpedia SPARQL benchmark: Perfor-mance assessment with real queries on real data.In ISWC, pages 454–469, 2011.
[25] N. F. Noy and M. C. A. Klein. Ontology evolu-tion: Not the same as schema evolution. Knowl.Inf. Syst., 6(4):428–440, 2004.
[26] C. Pedrinaci and J. Domingue. Toward the nextwave of services: Linked services for the Web ofData. J. UCS, 16(13):1694–1719, 2010.
[27] A. Polleres and D. Huynh. Special issue: TheWeb of Data. J. Web Sem., 7(3):135, 2009.
[28] C. R. Rivero, I. Hernández, D. Ruiz, andR. Corchuelo. On benchmarking data translationsystems for semantic-web ontologies. In CIKM,pages 1613–1618, 2011.
[29] C. R. Rivero, I. Hernández, D. Ruiz, andR. Corchuelo. Generating SPARQL executablemappings to integrate ontologies. In ER, pages118–131, 2011.
[30] C. R. Rivero, D. Ruiz, and R. Corchuelo.On benchmarking data translation systems forsemantic-web ontologies. Technical report, Uni-versity of Sevilla, 2012. URL http://tdg-seville.info/Download.ashx?id=205.
[31] C. R. Rivero, A. Schultz, C. Bizer, and D. Ruiz.Benchmarking the performance of linked-datatranslation systems. In LDOW, 2012.
[32] M. Robnik-Sikonja and I. Kononenko. Theoreticaland empirical analysis of ReliefF and RReliefF.Machine Learning, 53(1-2):23–69, 2003.
[33] M. Schmidt, T. Hornung, G. Lausen, andC. Pinkel. SP2Bench: A SPARQL performancebenchmark. In ICDE, pages 222–233, 2009.
[34] M. R. Sertel and B. Yilmaz. The majoritarian com-promise is majoritarian-optimal and subgame-perfect implementable. Social Choice and Welfare,
16:615–627, 1999.[35] L. Stojanovic, A. Maedche, B. Motik, and N. Sto-
janovic. User-driven ontology evolution manage-ment. In EKAW, pages 285–300, 2002.
[36] Z. Wu, G. Eadon, S. Das, E. I. Chong, V. Kolovski,J. Srinivasan, and M. Annamalai. Implementingan inference engine for RDFS/OWL constructsand user-defined rules in Oracle. In ICDE, pages1239–1248, 2008.
Carlos R. Rivero is an Assistant Professorof Software Engineering who is with the De-partment of Computer Languages and Sys-tems of the University of Sevilla, Spain. Hereceived his PhD degree from this Universityand he works as a researcher for the Re-search Group on Distributed Systems (TDG).His research interests focus on integratingand benchmarking of semantic-web tech-nologies and web page classification.
Inma Hernández is a Lecturer who is withthe Department of Computer Languages andSystems of the University of Sevilla, Spain.She received her MSc degree from the sameUniversity in 2008. She has been a re-searcher for the Research Group on Dis-tributed Systems (TDG) since 2009, andher research interests include Semantic Weband Linked Data, web page classification,URL patterns and web crawling.
David Ruiz is a Reader of Software En-gineering who is with the Department ofComputer Languages and Systems of theUniversity of Sevilla, Spain. He received hisPhD degree in 2003. Previously, he workedas a software engineer for IBM in a speechrecognition project. His current research in-terests focus on semantic web services, inte-gration and benchmarking of semantic-webtechnologies, and web page classification.
Rafael Corchuelo is a Reader of SoftwareEngineering who is with the Department ofComputer Languages and Systems of theUniversity of Sevilla, Spain. He received hisPhD degree from this University, and heleads its Research Group on Distributed Sys-tems (TDG) since 1997. His current researchinterests focus on the integration of web dataislands; previously, he worked on multipartyinteraction and fairness issues.
Related Documents











