System Effec+veness, User Models, and User U+lity A Conceptual Framework for Inves+ga+on Ben CartereBe University of Delaware [email protected]

Ben Carterette "Advances in Information Retrieval Evaluation"
Jul 27, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

System Effec+veness, User Models, and User U+lity
A Conceptual Framework for Inves+ga+on
Ben CartereBe University of Delaware

Effec+veness Evalua+on
• Determine how good the system is at finding and ranking relevant documents
• An effec+veness measure should be correlated to the user’s experience – Value increases when user experience gets beBer; decreases when it gets worse
• Thus interest in effec+veness measures based on explicit models of user interac+on – RBP [Moffat & Zobel], DCG [Järvelin & Kekäläinen], ERR [Chapelle et al.], EBU [Yilmaz et al.], sessions [Kanoulas et al.], etc.

Discounted Gain Model
• Simple model of user interac+on: – User steps down ranked results one-‐by-‐one – Gains something from relevant documents – Increasingly less likely to see documents deeper in the ranking
• Implementa+on of model: – Gain is a func+on of relevance at rank k – Ranks k are increasingly discounted – Effec+veness = sum over ranks of gain +mes discount
• Most measures can be made to fit this framework

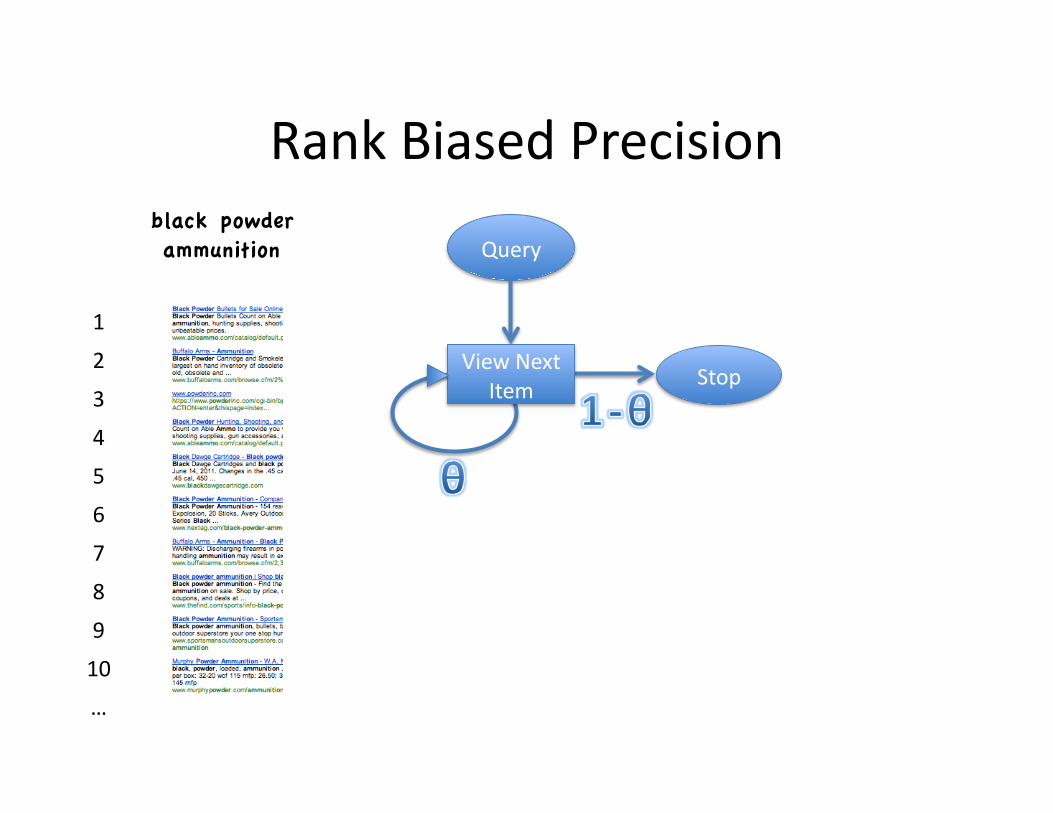
Rank Biased Precision [Moffat and Zobel, TOIS08]
black powder ammunition
1
2
3
4
5
6
7
8
9
10
…
Toss a biased coin (θ)
If HEADS, observe next document
IF TAILS, stop

Rank Biased Precision black powder ammunition
1
2
3
4
5
6
7
8
9
10
…
Let θ=0.8
0.532<θ
0.933≥θ
Rank Biased Precision black powder ammunition
1
2
3
4
5
6
7
8
9
10
…
Query
Stop View Next
Item

Rank Biased Precision black powder ammunition
1
2
3
4
5
6
7
8
9
10
…
RBP = (1− θ)∞�
k=1
relkθk−1
=∞�
k=1
relkθk−1(1− θ)
Relevance discounted by geometric distribu+on
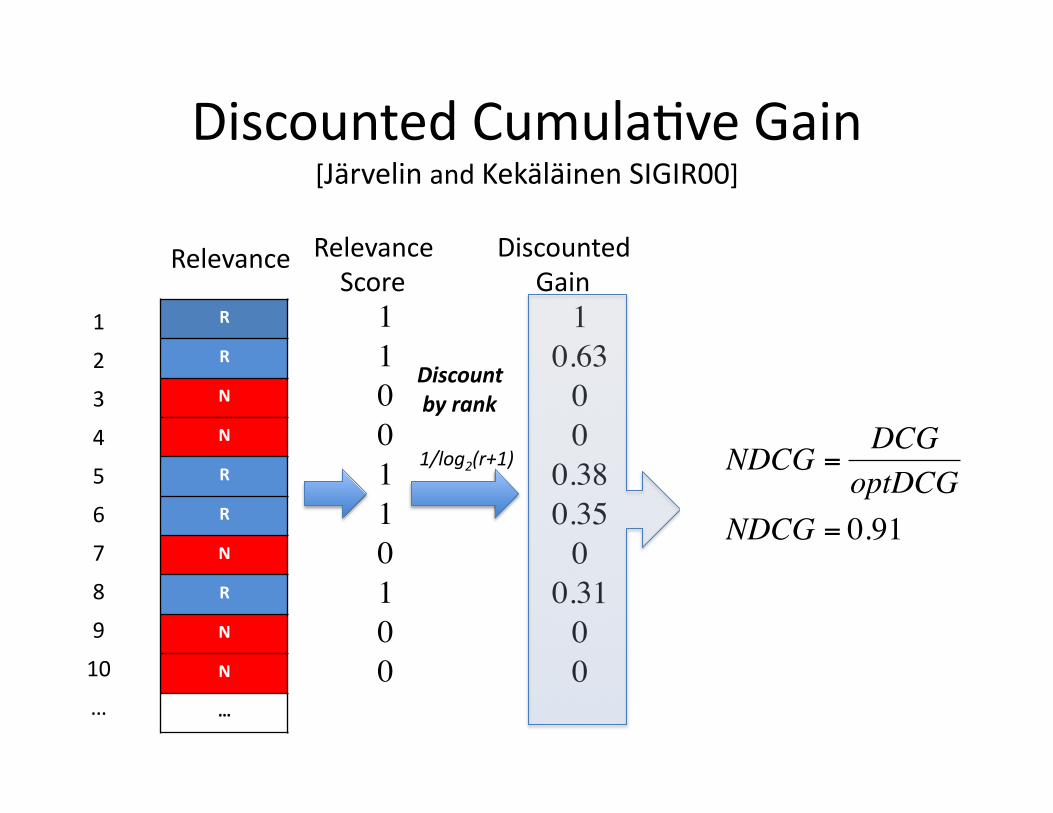
Discounted Cumula+ve Gain [Järvelin and Kekäläinen SIGIR00]
black powder ammunition
1
2
3
4
5
6
7
8
9
10
…
R
R
N
N
R
R
N
R
N
N
…
Discounted Gain 1 0.63 0 0 0.38 0.35 0 0.31 0 0
DCG = 2.689 1/log2(r+1)
Relevance Score 1 1 0 0 1 1 0 1 0 0
Discount by rank
Relevance
€
NDCG =DCG
optDCGNDCG = 0.91
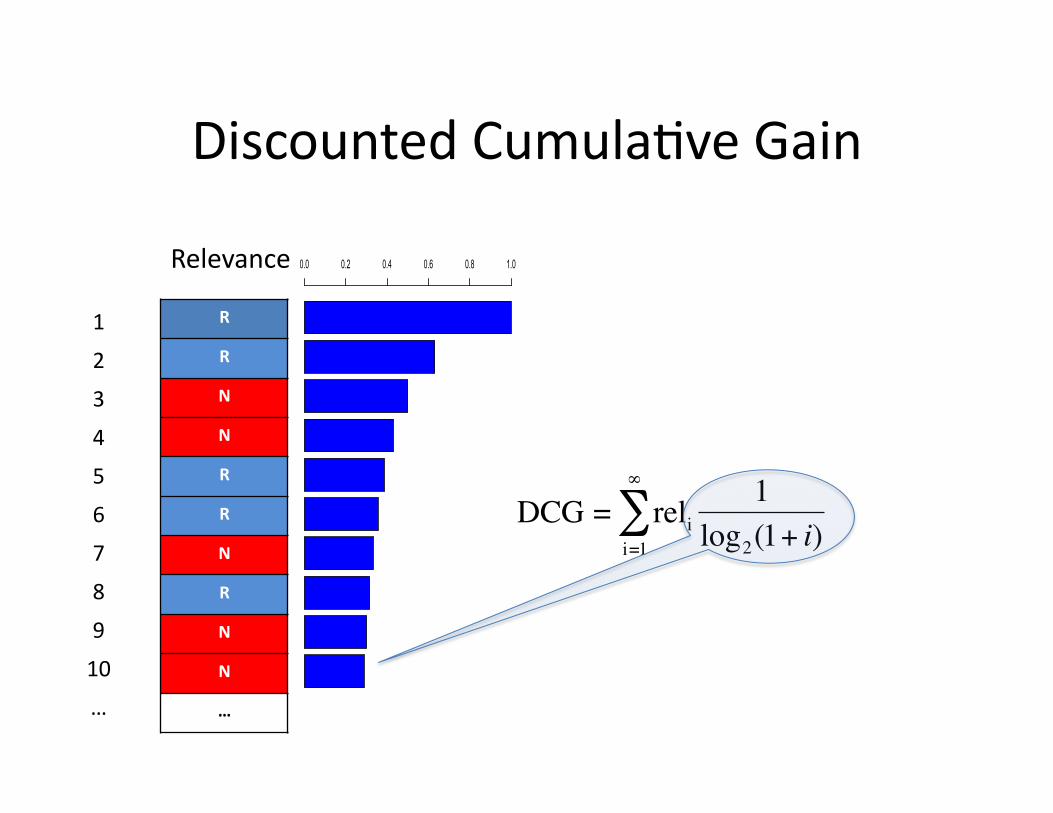
Discounted Cumula+ve Gain
1
2
3
4
5
6
7
8
9
10
…
R
R
N
N
R
R
N
R
N
N
…
Relevance
€
DCG = reli1
log2(1+ i)i=1
∞
∑
0.0 0.2 0.4 0.6 0.8 1.0
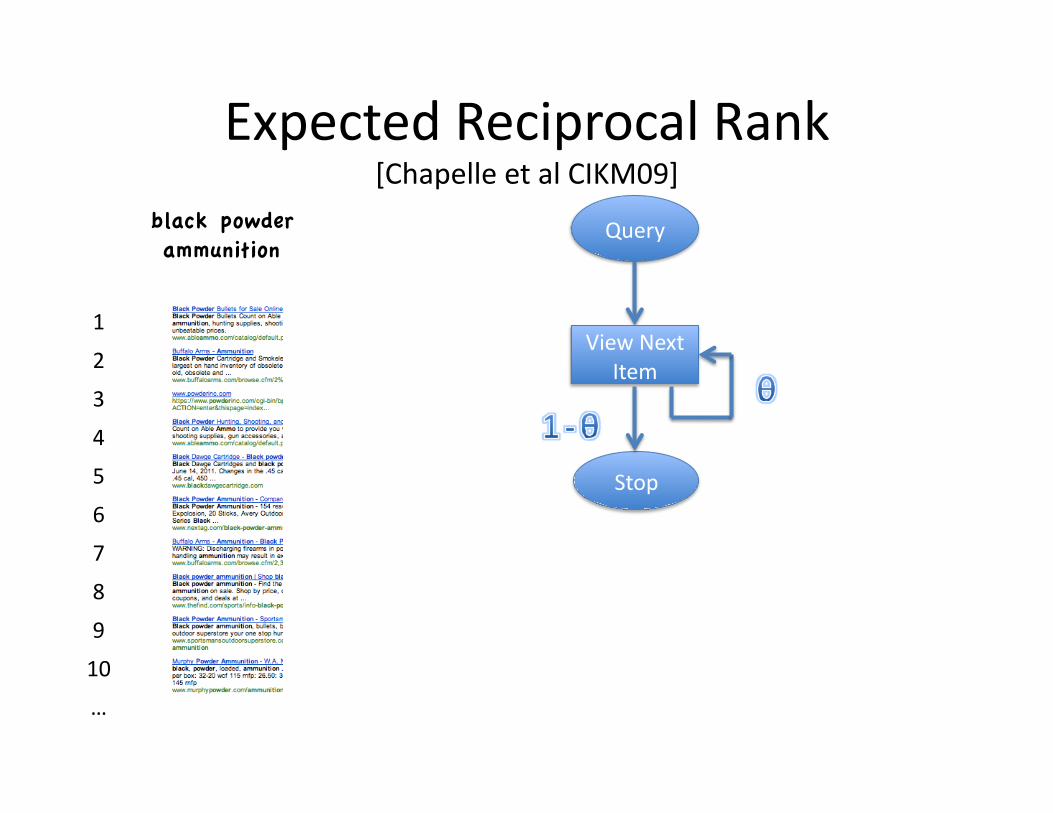
Expected Reciprocal Rank [Chapelle et al CIKM09]
Query
Stop
View Next Item
black powder ammunition
1
2
3
4
5
6
7
8
9
10
…
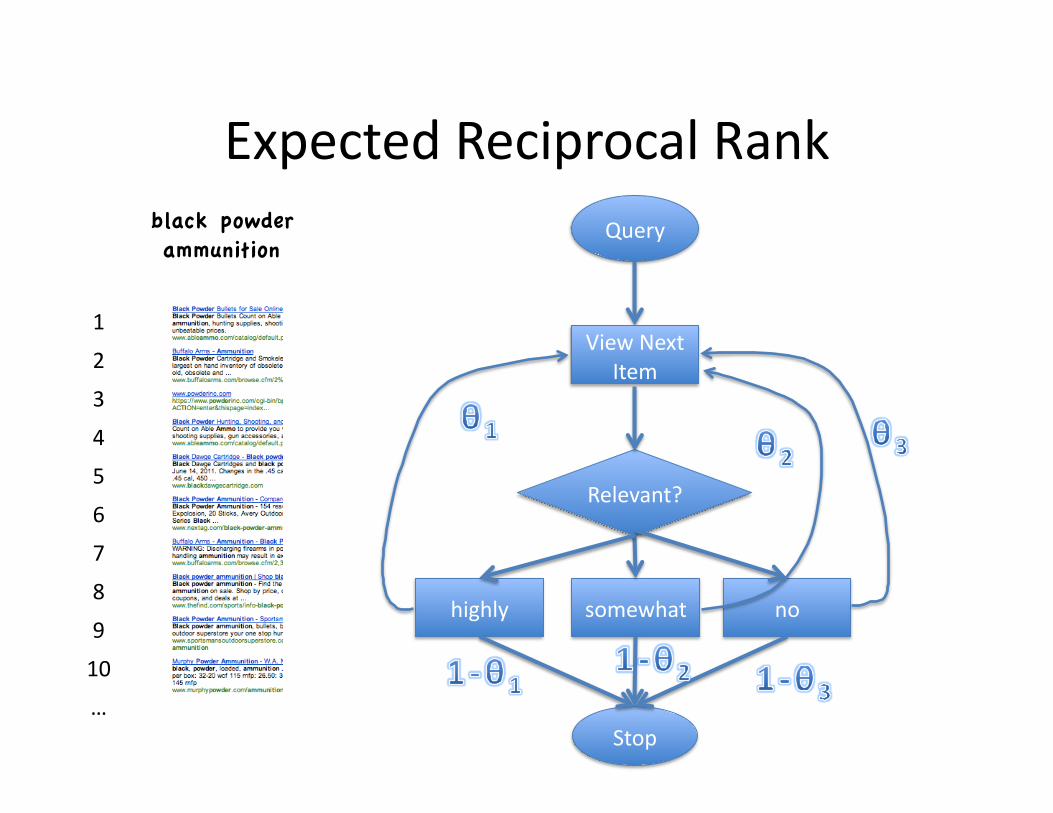
Expected Reciprocal Rank Query
Stop
Relevant?
View Next Item
no somewhat highly
black powder ammunition
1
2
3
4
5
6
7
8
9
10
…

Models of Browsing Behavior
Posi+on-‐based models The chance of observing a
document depends on the posi+on of the document in the ranked list.
black powder ammunition
1
2
3
4
5
6
7
8
9
10
…
Cascade models The chance of observing a
document depends on its posi+on as well as the relevance of documents ranked above it.

A More Formal Model
• My claim: this implementa+on conflates at least four dis+nct models of user interac+on
• Formalize it a bit: – Change rank discount to stopping probability density P(k) – Change gain func+on to either a u+lity func+on or a cost func+on
• Then effec+veness = expected u+lity or cost over stopping points
M =∞�
k=1
f(k)P (k)

Our Framework
• The components of a measure are: – stopping rank probability P(k)
• posi+on-‐based vs cascade is a feature of this distribu+on – document u+lity model (binary relevance) – u+lity accumula+on model or cost model
• We can test hypotheses about general proper+es of stopping distribu+on, u+lity/cost model – Instead of trying to evaluate every possible measure on its own, evaluate proper+es of the measure
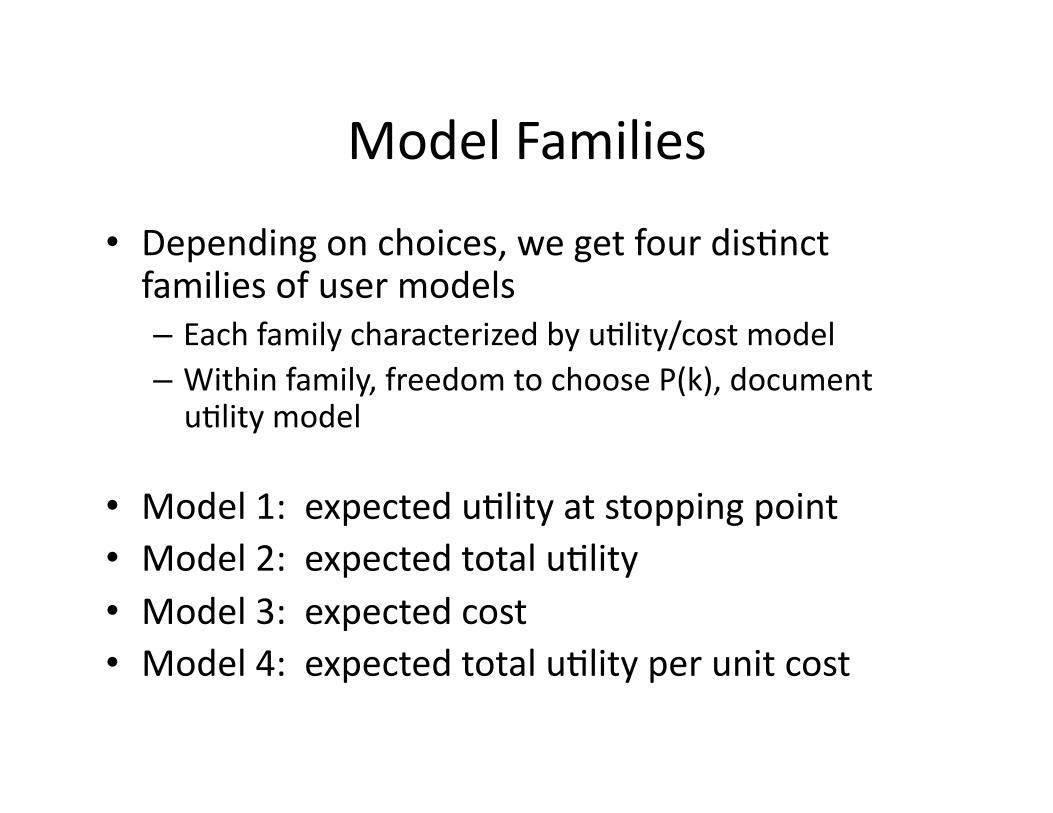
Model Families
• Depending on choices, we get four dis+nct families of user models – Each family characterized by u+lity/cost model – Within family, freedom to choose P(k), document u+lity model
• Model 1: expected u+lity at stopping point • Model 2: expected total u+lity • Model 3: expected cost • Model 4: expected total u+lity per unit cost

Model 1: Expected U+lity at Stopping Point
• Exemplar: Rank-‐Biased Precision (RBP)
• Interpreta+on: – P(k) = geometric density func+on – f(k) = relevance of document at stopping rank – Effec+veness = expected relevance at stopping rank
RBP = (1− θ)∞�
k=1
relkθk−1
=∞�
k=1
relkθk−1(1− θ)

Model 2: Expected Total U+lity
• Instead of stopping probability, think about viewing probability
• This fits in discounted gain model framework:
• Does it fit in expected u+lity framework? – Yes, and Discounted Cumula+ve Gain (DCG; Jarvelin et al.) is exemplar for this class
P (view doc at k) =∞�
i=k
P (k) = F (k)
M =∞�
k=1
relkF (k)

Model 2: Expected Total U+lity
• f(k) = Rk (total summed relevance)
• Let FDCG(k) = 1/log2(k+1) – Then PDCG(k) = FDCG(k) – FDCG(k+1) – PDCG(k) = 1/log2(k+1) – 1/log2(k+2)
• Work algebra backwards to show that you get binary-‐relevance DCG (if summing to infinity)
M =∞�
k=1
relkF (k) =∞�
k=1
relk
∞�
i=k
P (i)
=∞�
k=1
P (k)k�
i=1
reli =∞�
k=1
RkP (k)

Model 3: Expected Cost
• User stops with probability based on accumulated u+lity rather than rank alone – P(k) = P(Rk) if document at rank k is relevant, 0 otherwise
• Then use f(k) to model cost of going to rank k
• Exemplar measure: Expected Reciprocal Rank (ERR; Chapelle et al.) (with binary relevance) – P(k) = – 1/cost = f(k) = 1/k
relk · θRk−1(1− θ)

Model 4: Expected U+lity per Unit Cost
• User considers expected effort of further browsing axer each relevant document
• Similar to M2 family, manipulate algebraically
M =∞�
k=1
relk
∞�
i=k
f(k)P (k)
∞�
k=1
relk
∞�
i=k
f(i)P (i) =∞�
k=1
f(k)P (k)k�
i=1
reli
=∞�
k=1
f(k)RkP (k)

Model 4: Expected U+lity per Unit Cost
• When f(k) = 1/k, we get:
• Average Precision (AP) is exemplar for this class – P(k) = relk/R – u+lity/cost = f(k) = prec@k
M =∞�
k=1
prec@k · P (k)

Summary So Far
• Four ways to turn a sum over gain +mes discounts into an expecta+on over stopping ranks – M1, M2, M3, M4
• Four exemplar measures from IR literature – RBP, DCG, ERR, AP
• Four stopping probability distribu+ons – PRBP, PDCG, PERR, PAP – Add two more:
• PRR(k) = 1/(k(k+1)), PRRR(k) = 1/(Rk(Rk+1))
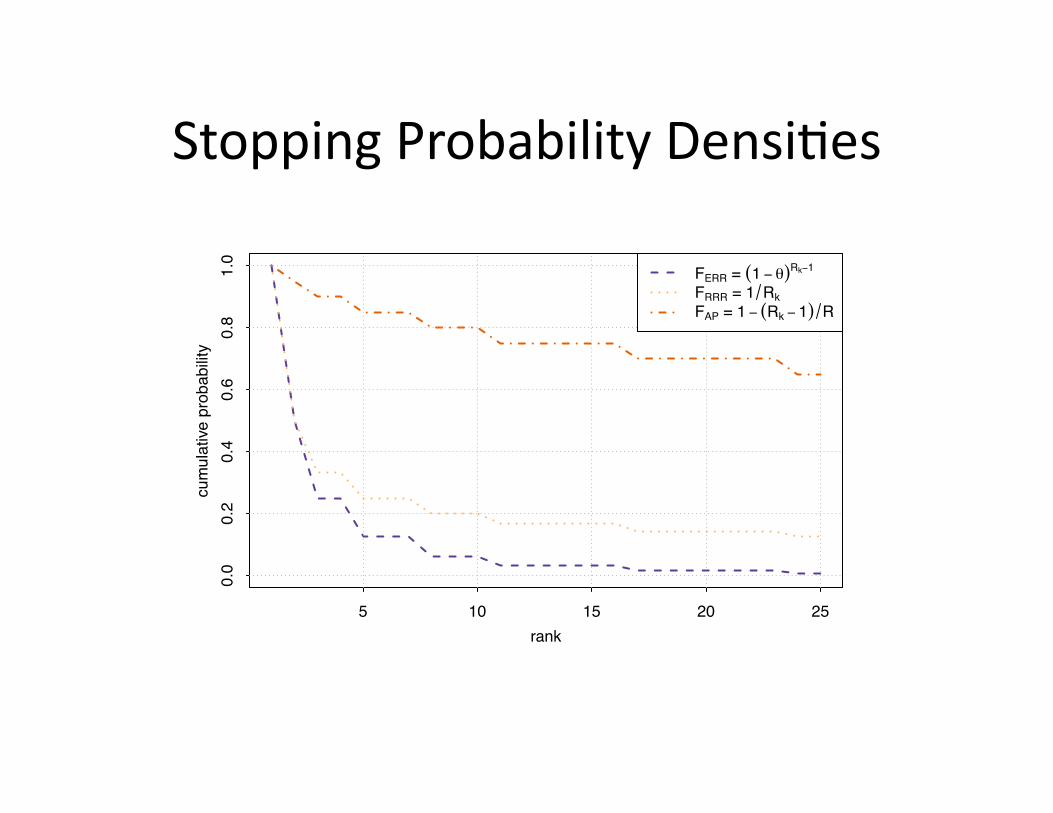
Stopping Probability Densi+es
5 10 15 20 25
0.0
0.1
0.2
0.3
0.4
0.5
rank
prob
abilit
y
PRBP = (1 ! ")k!1"PRR = 1 (k(k + 1))PDCG = 1 log2(k + 1) ! 1 log2(k + 2)
5 10 15 20 25
0.0
0.2
0.4
0.6
0.8
1.0
rank
cum
ulat
ive p
roba
bilit
y
FRBP = (1 ! ")k!1
FRR = 1 kFDCG = 1 log2(k + 1)
5 10 15 20 25
0.0
0.1
0.2
0.3
0.4
0.5
rank
prob
abilit
y
PERR = relk(1 ! ")Rk!1"PRRR = relk (Rk(Rk + 1))PAP = relk R
5 10 15 20 25
0.0
0.2
0.4
0.6
0.8
1.0
rank
cum
ulat
ive p
roba
bilit
y
FERR = (1 ! ")Rk!1
FRRR = 1 RkFAP = 1 ! (Rk ! 1) R

From Models to Measures
• Six stopping probability distribu+ons, four model families
• Mix and match to create up to 24 new measures – Many of these are uninteres+ng: isomorphic to precision/recall, or constant-‐valued
– 15 turn out to be interes+ng
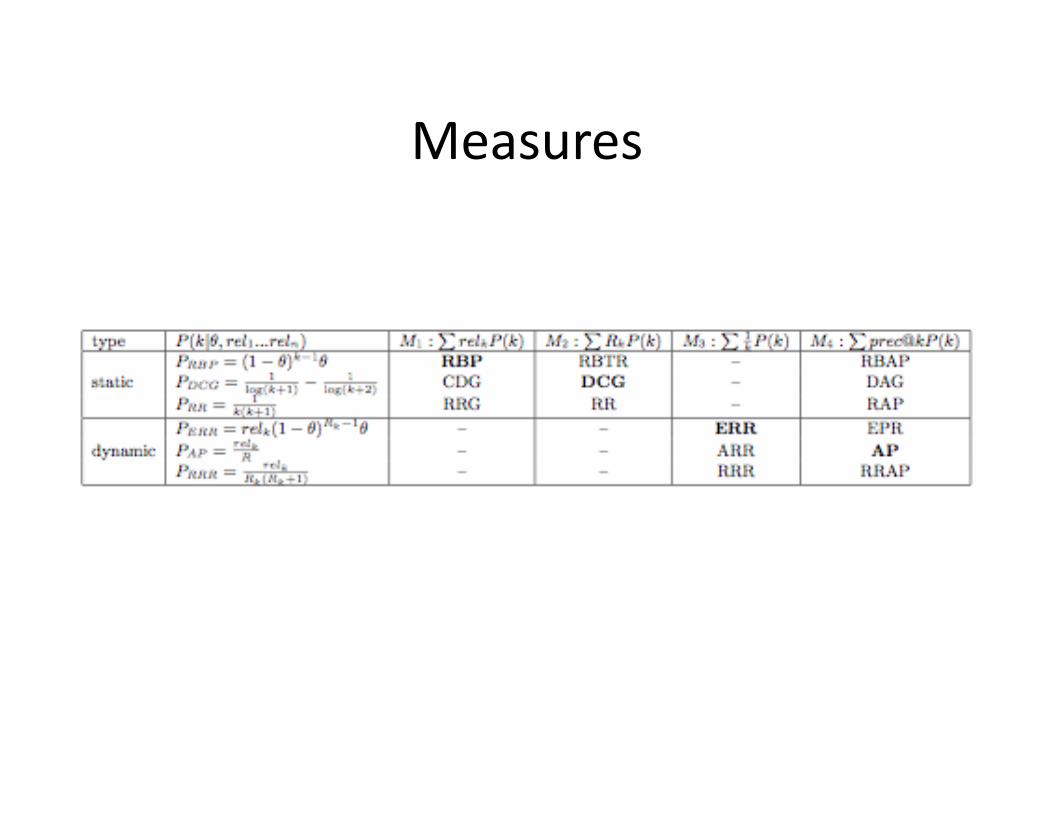
Measures

Some Brief Asides
• From geometric to reciprocal rank – Integrate geometric w.r.t. parameter theta – Result is 1/(k(k+1)) – Cumula+ve form is approximately 1/k
• Normaliza+on – Every measure in M2 family must be normalized by max possible value
– Other measures may not fall between 0 and 1

Some Brief Asides
• Rank cut-‐offs – DCG formula+on only works for n going to infinity
– In reality we usually calculate DCG@K for small K – This fits our user model if we make worst-‐case assump+on about relevance of documents below rank K

Analyzing Measures
• Some ques+ons raised: – Are models based on u+lity beBer than models based on effort? (Hypothesis: no difference)
– Are measures based on stopping probabili+es beBer than measures based on viewing probabili+es? (Hypothesis: laBer more robust)
– What proper+es should the stopping distribu+on have? (Hypothesis: faBer tail, sta+c more robust)

How to Analyze Measures
• Many possible ways, no one widely-‐accepted – How well they correlate with user sa+sfac+on – How robust they are to changes in underlying data – How good they are for op+mizing systems – How informa+ve they are

Fit to Click Logs
• How well does a stopping distribu+on fit to empirical click probabili+es? – A click does not mean the end of a search – But we need some model of the stopping point, and a click is a decent proxy
• Good fit may indicate a good stopping model
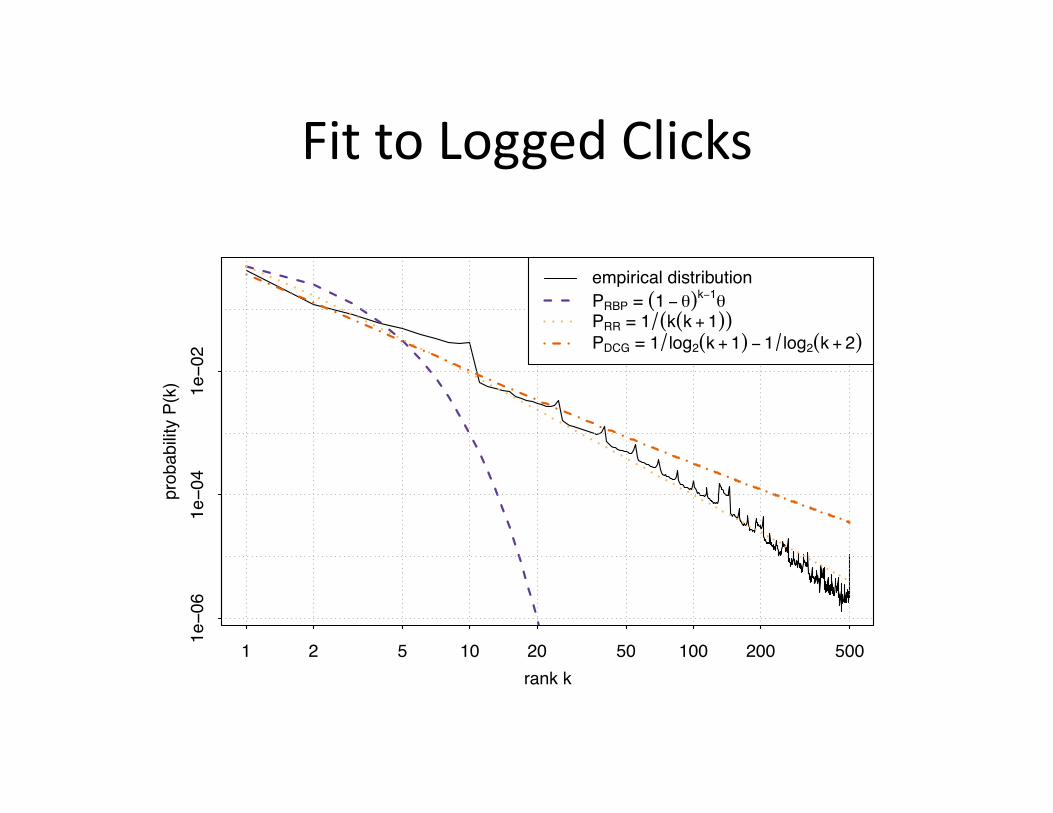
Fit to Logged Clicks
1 2 5 10 20 50 100 200 500
1e−0
61e−0
41e−0
2
rank k
prob
abilit
y P(
k)
empirical distributionPRBP = (1 ! ")k!1"PRR = 1 (k(k + 1))PDCG = 1 log2(k + 1) ! 1 log2(k + 2)

Robustness and Stability
• How robust is the measure to changes in underlying test collec+on data? – If one of the following changes: • topic sample
• relevance judgments • pool depth of judgments
– how different are the decisions about rela+ve system effec+veness?

Data
• Three test collec+ons + evalua+on data: – TREC-‐6 ad hoc: 50 topics, 72,270 judgments, 550,000-‐document corpus; 74 runs submiBed to TREC • Second set of judgments from Waterloo
– TREC 2006 Terabyte named page: 180 topics, 2361 judgments, 25M-‐doc corpus; 43 runs submiBed to TREC
– TREC 2009 Web ad hoc: 50 topics, 18,666 judgments, 500M-‐doc corpus; 37 runs submiBed to TREC

Experimental Methodology
• Pick some part of the collec+on to vary – e.g. judgments, topic sample size, pool depth
• Evaluate all submiBed systems with TREC’s gold standard data
• Evaluate all submiBed systems with the modified data
• Compare first evalua+on to second using Kendall’s tau rank correla+on
• Determine which proper+es are most robust – Model family, tail fatness, sta+c/dynamic distribu+on
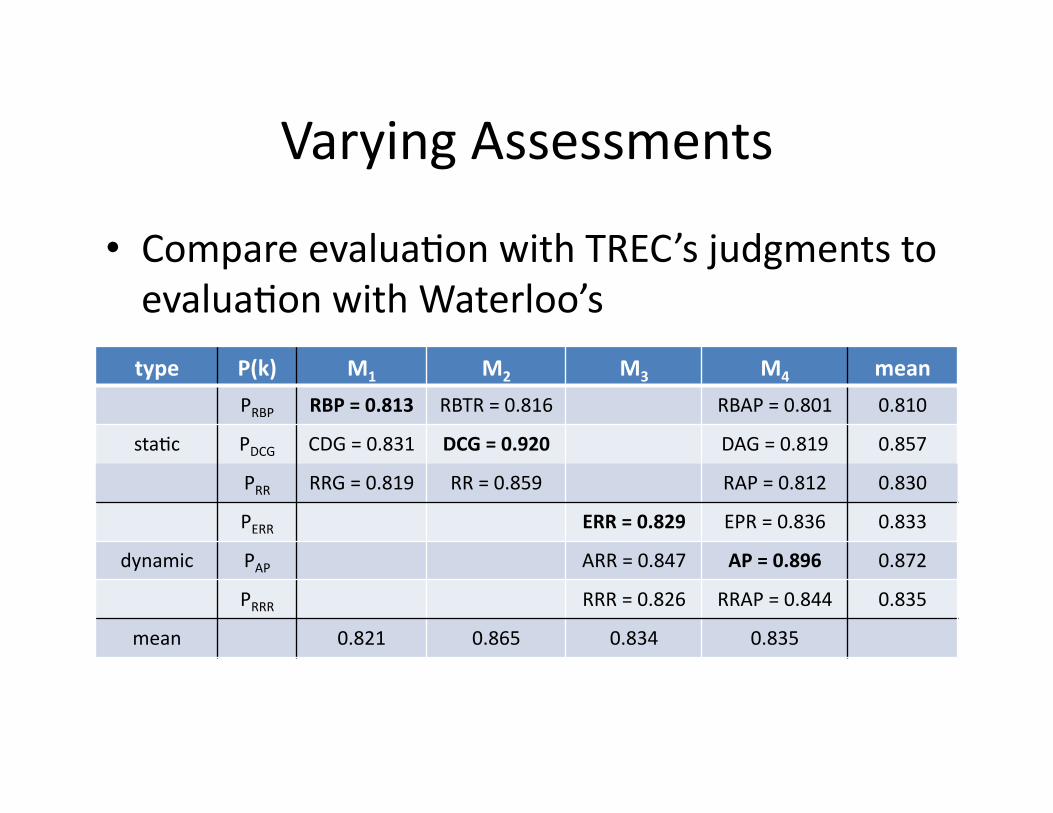
Varying Assessments
• Compare evalua+on with TREC’s judgments to evalua+on with Waterloo’s
• Tenta+ve conclusions: – M2 most robust, followed by M3 (axer removing AP outlier)
– FaBer-‐tail distribu+ons more robust – Dynamic a bit more robust than sta+c
type P(k) M1 M2 M3 M4 mean
PRBP RBP = 0.813 RBTR = 0.816 RBAP = 0.801 0.810
sta+c PDCG CDG = 0.831 DCG = 0.920 DAG = 0.819 0.857
PRR RRG = 0.819 RR = 0.859 RAP = 0.812 0.830
PERR ERR = 0.829 EPR = 0.836 0.833
dynamic PAP ARR = 0.847 AP = 0.896 0.872
PRRR RRR = 0.826 RRAP = 0.844 0.835
mean 0.821 0.865 0.834 0.835
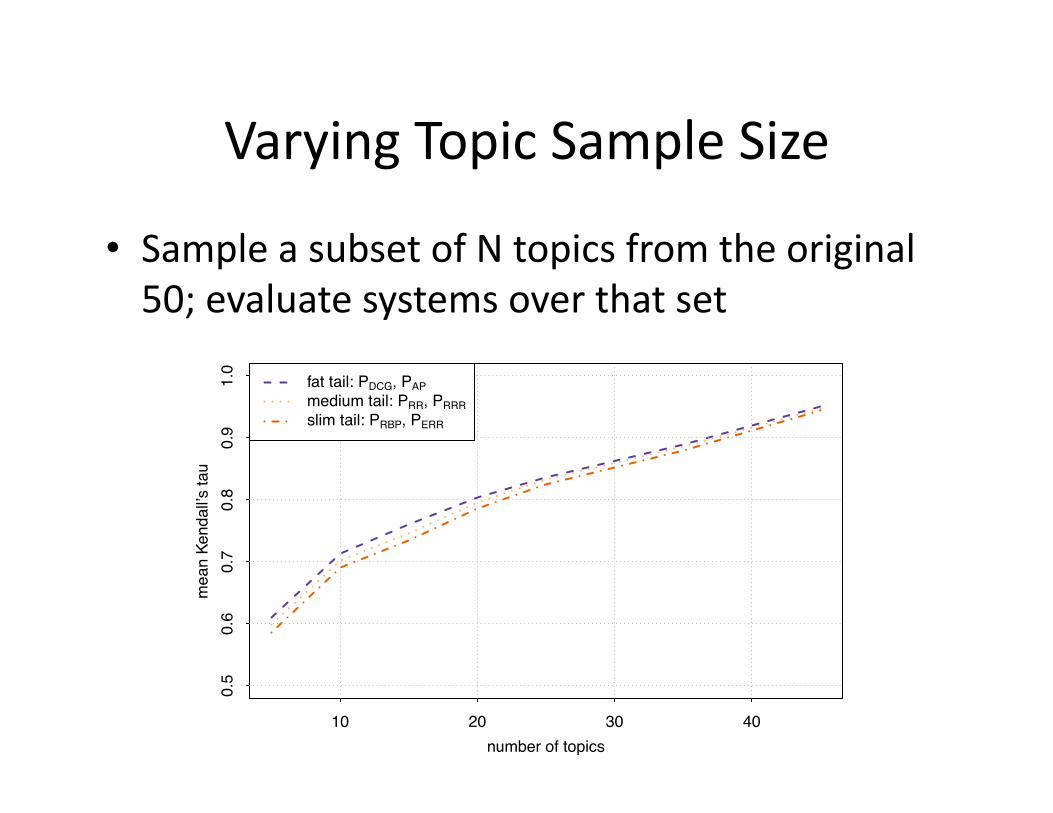
Varying Topic Sample Size
• Sample a subset of N topics from the original 50; evaluate systems over that set
10 20 30 40
0.5
0.6
0.7
0.8
0.9
1.0
number of topics
mea
n Ke
ndal
l’s ta
u
M1M2M3M4
10 20 30 40
0.5
0.6
0.7
0.8
0.9
1.0
number of topics
mea
n Ke
ndal
l’s ta
u
fat tail: PDCG, PAPmedium tail: PRR, PRRRslim tail: PRBP, PERR
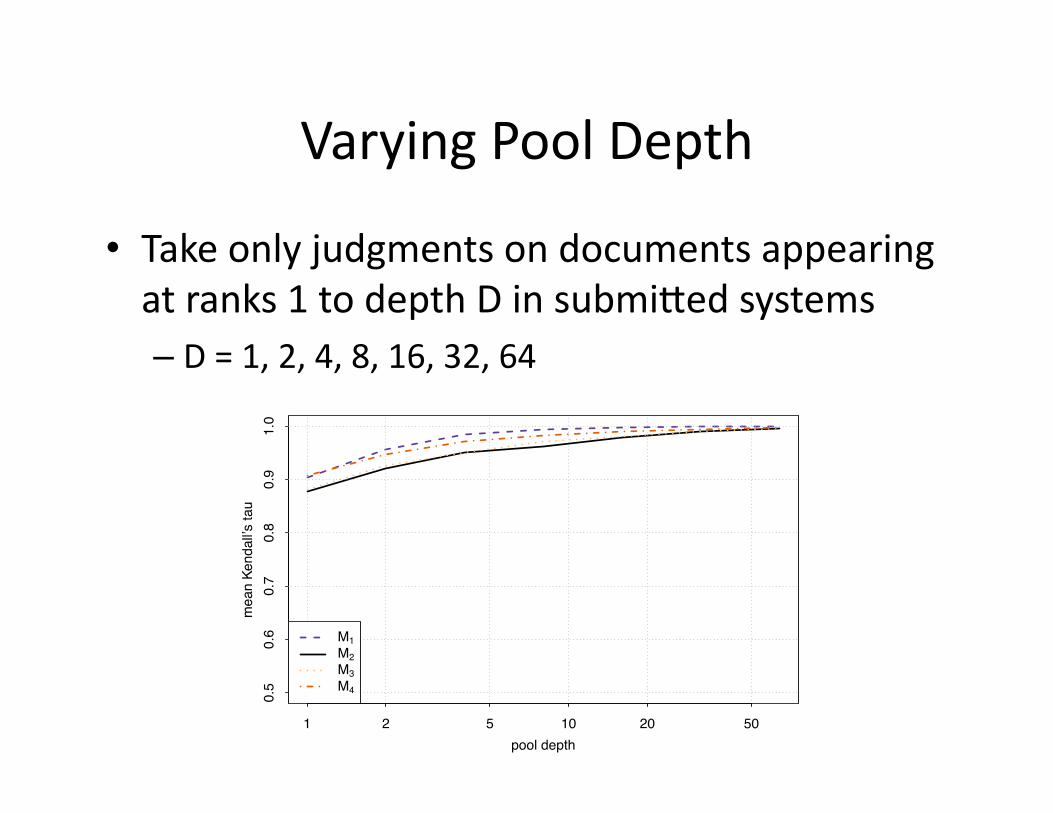
Varying Pool Depth
• Take only judgments on documents appearing at ranks 1 to depth D in submiBed systems – D = 1, 2, 4, 8, 16, 32, 64
1 2 5 10 20 50
0.5
0.6
0.7
0.8
0.9
1.0
pool depth
mea
n Ke
ndal
l’s ta
u
M1M2M3M4

Conclusions
• FaBer-‐tailed distribu+ons generally more robust – Maybe beBer for mi+ga+ng risk of not sa+sfying tail users
• M2 (expected total u+lity; DCG) generally more robust – But does it model users beBer?
• M3 (expected cost; ERR) more robust than expected
• M4 (expected u+lity per cost; AP) not as robust as expected – AP is an outlier with a very fat tail
• DCG may be based on a more realis+c user model than commonly thought

Conclusions
• The gain +mes discount formula+on conflates four dis+nct models of user behavior
• Teasing these apart allows us to test hypotheses about general proper+es of measures
• This is a conceptual framework: it organizes and describes measures in order to provide structure for reasoning about general proper+es
• Hopefully will provide direc+ons for future research on evalua+on measures
Related Documents











