
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


Outline• Bayes’ Theorem• MAP Learners• Bayes optimal classifier• Naïve Bayes classifier• Example – text classification• Bayesian networks• EM algorithm
Bayesian Learning CSL465/603 - Machine Learning 2

Features Bayesian Learning• Practical learning algorithms• Naïve Bayes learning• Bayesian network learning• Combine prior knowledge with observations
• Require prior probabilities
• Useful conceptual framework• “gold standard” for evaluating other classifiers• Tools for analysis
Bayesian Learning CSL465/603 - Machine Learning 3

Bayes Theorem• If 𝐴 and 𝐵 are two random variables
• In the context of classifier hypothesis h and training data 𝐼
• 𝑃(h) – prior probability of hypothesis h• 𝑃(𝐼) – prior probability of training data 𝐼• 𝑃 h|𝐼 – probability of h given 𝐼• 𝑃 𝐼|h – probability of 𝐼 given h
Bayesian Learning CSL465/603 - Machine Learning 4
𝑃 𝐴 𝐵 =𝑃 𝐵 𝐴 𝑃(𝐴)
𝑃(𝐵)
𝑃 h 𝐼 =𝑃 𝐼 h 𝑃(h)
𝑃(𝐼)

Choosing the Hypotheses• Given the training data, we are interested in the
most probable hypothesis• Maximum a posteriori hypothesis - h+,-
h+,- ≡ argmax4∈6𝑃 h 𝐼 ≡ argmax4∈6
𝑃 𝐼 h 𝑃(h) 𝑃(𝐼)
≡ argmax4∈6𝑃 𝐼 h 𝑃 h • If every hypothesis is equally probable, 𝑃 h7 =𝑃 h8 , ∀h7, h8 ∈ 𝐻, then we can simplify it to Maximum likelihood (ML) hypothesis - h+<
h+< = argmax4=∈6𝑃 𝐼|h7
Bayesian Learning CSL465/603 - Machine Learning 5

Example• Does the patient have cancer or not?• A patient takes a lab test and the result comes back
positive. The test returns a correct positive result in only 98% of the cases in which the disease is actually present, and a correct negative result in only 97% of the cases in which the disease is no present. Furthermore, 0.008 of the entire population have this cancer.
Bayesian Learning CSL465/603 - Machine Learning 6

Bayesian Learning CSL465/603 - Machine Learning 7
𝑃 𝑐𝑎𝑛𝑐𝑒𝑟 = 𝑃 ¬𝑐𝑎𝑛𝑐𝑒𝑟 =
𝑃 +|𝑐𝑎𝑛𝑐𝑒𝑟 = 𝑃 −|𝑐𝑎𝑛𝑐𝑒𝑟 =
𝑃 +|¬𝑐𝑎𝑛𝑐𝑒𝑟 = 𝑃 −|¬𝑐𝑎𝑛𝑐𝑒𝑟 =
𝑃 𝑐𝑎𝑛𝑐𝑒𝑟| + =

Brute-Force MAP Hypothesis Learner (1)• If we are given 𝐼 =< 𝑥H, 𝑦H , … , 𝑥K, 𝑦K >,
examples and the class labels, • For each hypothesis h ∈ 𝐻 , calculate the posterior
probability
• Output the hypothesis ℎ+,- that has the highest posterior probability
Bayesian Learning CSL465/603 - Machine Learning 8
𝑃 h 𝐼 =𝑃 𝐼 h 𝑃(h)
𝑃(𝐼)
h+,- = argmax4∈6𝑃 h 𝐼

Brute-Force MAP Hypothesis Learner (2)• If we are given 𝐼 =< 𝑥H, 𝑦H , … , 𝑥K, 𝑦K >,
examples and the class labels, choose 𝑃(𝐼|h)• 𝑃(𝐼|h) = 1 if h is consistent with 𝐼• 𝑃(𝐼|h) = 0 otherwise
• Choose 𝑃(h) to be uniform distribution• 𝑃 h = H
6 ∀h ∈ 𝐻
• Then 𝑃 h 𝐼 = - 𝐼 h -(4) -(P)
Bayesian Learning CSL465/603 - Machine Learning 9

Bayesian Learning CSL465/603 - Machine Learning 10

Brute-Force MAP Hypothesis Learner (3)• If we are given 𝐼 =< 𝑥H, 𝑦H , … , 𝑥K, 𝑦K >,
examples and the class labels, choose 𝑃(𝐼|h)• 𝑃(𝐼|h) = 1 if h is consistent with 𝐼• 𝑃(𝐼|h) = 0 otherwise
• Choose 𝑃(h) to be uniform distribution• 𝑃 h = H
6
• Then
𝑃 h 𝐼 = QH
RS,T, ifhisconsistentwith𝐼
0, otherwise
Bayesian Learning CSL465/603 - Machine Learning 11

Evolution of Posterior Probabilities
Bayesian Learning CSL465/603 - Machine Learning 12
𝑃h
h
Ph|𝐼 H
h
Ph|𝐼 H,𝐼_
h

Classifying new instances• Given a new instance x, what is the most probable
classification?• One solution – h+,-(x)
• But can we do better?• Consider the following example containing three
hypotheses:𝑃 hH 𝐼 = 0.4, 𝑃 h_ 𝐼 = 0.3, 𝑃 hc 𝐼 = 0.3
• Given a new instance x,hH x = +, h_ x = −, hc x = −
• What is the most probable classification for x
Bayesian Learning CSL465/603 - Machine Learning 13

Bayes Optimal Classifier (1)• Combine the prediction of all hypotheses weighted
by their posterior probabilities• Bayes optimal classification
argmaxd∈𝒴 f 𝑃 y h7 𝑃(h7|𝐼)�
4=∈6
• Example𝑃 hH 𝐼 = .4, 𝑃 − hH = 0, 𝑃 + hH = 1𝑃 h_ 𝐼 = .3, 𝑃 − h_ = 1, 𝑃 + h_ = 0𝑃 hc 𝐼 = .3, 𝑃 − hc = 1, 𝑃 + hc = 0
Bayesian Learning CSL465/603 - Machine Learning 14
f 𝑃 + h7 𝑃(h7|𝐼)�
4=∈6
= f 𝑃 − h7 𝑃(h7|𝐼)�
4=∈6
=

Bayes Optimal Classifier (2)• Optimal in the sense• No other classification method using the same hypothesis
space and same prior knowledge can outperform this method on average.
• Method maximizes the probability that the new instance is classified correctly, given the available data, hypothesis space and prior probabilities over the hypothesis.• But it is inefficient• Compute posterior probability for every hypothesis and
combine the predictions of each hypothesis.
Bayesian Learning CSL465/603 - Machine Learning 15

Gibbs Classifier• Gibbs Algorithm• Choose a hypothesis h ∈ H at random, according to the
posterior probability distribution over 𝐻• Use h to classify the new instance x.
• Observation – Assume target concepts are drawn at random from 𝐻 according to the priors on 𝐻, Then
Bayesian Learning CSL465/603 - Machine Learning 16
E 𝐸l7mmn ≤ 2E 𝐸qrstnuvw7xry
Haussler et al., ML 1994

Naïve Bayes Classifier (1)• Bayes rule, slightly different application• Let 𝒴 = {𝑐H, 𝑐_, … 𝑐{} be the different class labels. • The label for 𝑖~� instance 𝑦� ∈ 𝒴
• 𝑃 𝑐� x - posterior probability that instance x belongs to class 𝑐�
• 𝑃 x 𝑐� - probability that an instance drawn from class 𝑐�would be x (likelihood)
• 𝑃(𝑐�) – probability of class 𝑐� (prior)• 𝑃(x) – probability of instance x (evidence)
Bayesian Learning CSL465/603 - Machine Learning 17
𝑃 𝑐� x =𝑃 x 𝑐� 𝑃(𝑐�)
𝑃(x)

Naïve Bayes Classifier (2)• Classify instance x as class 𝑦 with maximum
posterior probability
• Ignore the denominator (since we are only interested in the maximum)
• If the prior is uniform
Bayesian Learning CSL465/603 - Machine Learning 18
𝑦 = argmax�𝑃(𝑐�|x)
𝑦 = argmax�𝑃 x 𝑐� 𝑃(𝑐�)
𝑦 = argmax�𝑃 x 𝑐�

Naïve Bayes Classifier (3)• Look at the classifier
• What is each instance x?• A 𝐷 dimensional tuple – (𝑥H, … , 𝑥�)
• Estimate the joint probability distribution𝑃 𝑥H, … 𝑥� 𝑐�• Practical issue- need to know the probability of every
possible instance given every possible class.• With 𝐷 Boolean features and 𝐾 classes – K2� probability
values!!!
Bayesian Learning CSL465/603 - Machine Learning 19
𝑦 = argmax�𝑃 x 𝑐�

Naïve Bayes Classifier (4)• Make the naïve Bayes assumption –
features/attributes are conditionally independent given the target attribute (class label)
𝑃 𝑥H, … 𝑥� 𝑐� = �𝑃 𝑥� 𝑐�
�
��H
• This results in the naïve Bayes classifier (NBC)!
Bayesian Learning CSL465/603 - Machine Learning 20
𝑦 = argmax��𝑃 𝑥� 𝑐�
�
��H
𝑃(𝑐�)

NBC – Practical Issues (1)• Estimating probabilities from I• Prior probabilities
𝑃 𝑐� = | x7, 𝑦� : 𝑦� = 𝑐�|
|𝐼|• If the features are discrete
𝑃 𝑥� = 𝑣 𝑐� =| x7, 𝑦� : 𝑥�� = 𝑣 ∧ 𝑦�= 𝑐�|
| x7, 𝑦� : 𝑦� = 𝑐�|
Bayesian Learning CSL465/603 - Machine Learning 21

NBC – Practical Issues (2)• If the features are continuous?• Assume some parameterized distribution for 𝑥�, e.g.,
Normal• Learn parameters of distribution from data, e.g., mean and
variance of 𝑥� values• Determine the parameters that maximize the likelihood.• 𝑃 𝑥� 𝑐� ~𝑁(𝜇, 𝜎_), 𝜇 and 𝜎_ are unknown
Bayesian Learning CSL465/603 - Machine Learning 22

Maximum Likelihood Estimate
Bayesian Learning CSL465/603 - Machine Learning 23

Bayesian Learning CSL465/603 - Machine Learning 24

NBC – Practical Issues (3)• If the features are continuous?• Assume some parameterized distribution for 𝑥�, e.g.,
Normal• Learn parameters of distribution from data, e.g., mean and
variance of 𝑥� values• Determine the parameters that maximize the likelihood.
• Discretize the feature• E.g., price ∈ ℛ to price ∈ 𝑙𝑜𝑤,𝑚𝑒𝑑𝑖𝑢𝑚, ℎ𝑖𝑔ℎ
Bayesian Learning CSL465/603 - Machine Learning 25

NBC – Practical Issues (4)• If there are no examples in class 𝑐� for which 𝑥� = 𝑣
𝑃 𝑥� = 𝑣 𝑐� = 0
�𝑃 𝑥� 𝑐�
�
��H
𝑃 𝑐� = 0
• Use m-estimate defined as follows
𝑃 𝑥� = 𝑣 𝑐� =x7, 𝑦� : 𝑥�� = 𝑣 ∧ 𝑦�= 𝑐� + 𝑚𝑝
x7, 𝑦� : 𝑦� = 𝑐� + 𝑚• Prior estimate of the probability – 𝑝• Equivalent sample size – 𝑚 (how heavily to weight 𝑝
relative to the observed data)
Bayesian Learning CSL465/603 - Machine Learning 26

Example – Learn to Classify Text• Problem Definition• Given a set of news articles that are of interest, we would
to like to learn to classify the articles by topic.• Naïve Bayes is among the most effective algorithms
to perform this task.• What will be attributes to represent the documents?• Vector of words – one attribute per word position in the
document• What is the Target concept• Is the document interesting?• Topic of the document
Bayesian Learning CSL465/603 - Machine Learning 27

Algorithm – Learn Naïve Bayes• Collect all words and tokens that occur in the
Examples (𝐼)• Vocabulary – all distinct words and tokens in 𝐼
• Compute probabilities 𝑃 𝑐� and 𝑃 𝑥� 𝑐�• 𝐼� – Examples for which the target label is 𝑐�• 𝑃 𝑐� = |P�||P|• 𝑛 – total number of words in 𝐼� (counting duplicates
multiple times)• For each work 𝑥� in Vocabulary
• 𝑛� = number of times word 𝑥� occurs in 𝐼�• 𝑃 𝑥�|𝑐� = ���H
��|R�� ¡¢£ ¤d|
Bayesian Learning CSL465/603 - Machine Learning 28

Algorithm – Classify Naïve Bayes• Given a test instance• Compute the frequency of occurrence in the test instance
of each term in the vocabulary• Apply naïve Bayes classification rule!
Bayesian Learning CSL465/603 - Machine Learning 29

Example: 20 Newsgroup• Given 1000 training documents from each group• Learn to classify new documents according to the
newsgroup it came from• NBC – 89% accuracy
Bayesian Learning CSL465/603 - Machine Learning 30

Bayesian Network (1)• Naïve Bayes assumption of conditional
independence is too restrictive.• The problem is intractable without some conditional
independent assumption• Bayesian networks describe conditional
independence among subsets of variables.• Allows for combining prior knowledge about (in)
dependencies among variables with training data• Recollect – Conditional Independence
Bayesian Learning CSL465/603 - Machine Learning 31
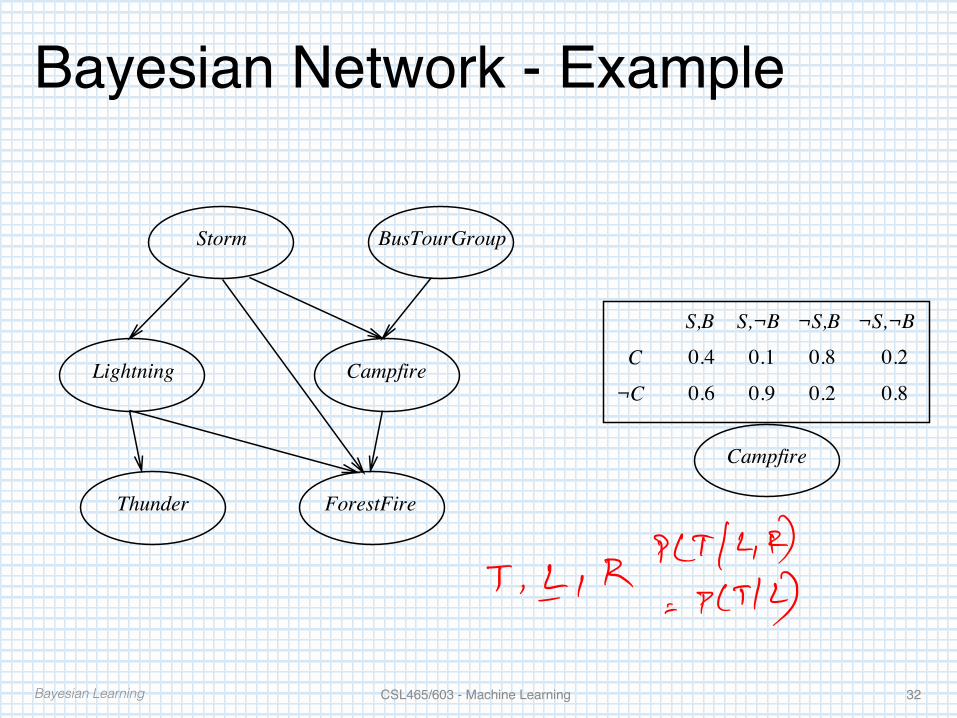
Bayesian Network - Example
Storm
CampfireLightning
Thunder ForestFire
Campfire
C
¬C
¬S,B ¬S,¬B
0.4
0.6
0.1
0.9
0.8
0.2
0.2
0.8
S,¬B
BusTourGroup
S,B
Bayesian Learning CSL465/603 - Machine Learning 32

Bayes Network (2)• Network represents the joint probability distribution
over all variables• 𝑃(𝑆𝑡𝑜𝑟𝑚, 𝐵𝑢𝑠𝑇𝑜𝑢𝑟𝐺𝑟𝑜𝑢𝑝,… 𝐹𝑜𝑟𝑒𝑠𝑡𝐹𝑖𝑟𝑒)• In general,
𝑃 𝑥H, 𝑥_, … , 𝑥� =�𝑃 𝑥�|𝑃𝑎𝑟𝑒𝑛𝑡𝑠 𝑥�
�
��H• Where 𝑃𝑎𝑟𝑒𝑛𝑡𝑠 𝑥� denotes immediate predecessors of 𝑥� in the graph.
• What is the Bayes Network corresponding to the Naive Bayes Classifier?
Bayesian Learning CSL465/603 - Machine Learning 33

Bayes Network (3)• Inference• Bayes network encodes all the information required for
inference.• Exact inference methods
• Work well for some structures• Monte Carlo methods
• Simulate the network randomly to calculate approximate solutions.
• Learning• If the structure is known and there are no missing values,
it is easy to learn a Bayes network• If the network structure is known and there are some
missing values, expectation – maximization algorithm• If the structure is unknown, the problem is very difficult.
Bayesian Learning CSL465/603 - Machine Learning 34

Summary• Bayes rule• Bayes Optimal Classifier• Practical Naïve Bayes Classifier• Example – text classification task
• Maximum-likelihood estimates• Bayesian networks
Bayesian Learning CSL465/603 - Machine Learning 35
Related Documents











