Bayesian Inference and Bayesian Inference and Posterior Probability Posterior Probability Maps Maps Guillaume Flandin Guillaume Flandin Wellcome Department of Imaging Wellcome Department of Imaging Neuroscience, Neuroscience, University College London, UK University College London, UK SPM Course, London, May 2005 SPM Course, London, May 2005

Bayesian Inference and Posterior Probability Maps Guillaume Flandin Wellcome Department of Imaging Neuroscience, University College London, UK SPM Course,
Jan 03, 2016
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Bayesian Inference and Bayesian Inference and Posterior Probability Maps Posterior Probability Maps
Bayesian Inference and Bayesian Inference and Posterior Probability Maps Posterior Probability Maps
Guillaume FlandinGuillaume Flandin
Wellcome Department of Imaging Neuroscience,Wellcome Department of Imaging Neuroscience,University College London, UKUniversity College London, UK
SPM Course, London, May 2005SPM Course, London, May 2005

Overview
Introduction Bayesian inference
Segmentation and Normalisation Gaussian Prior and Likelihood Posterior Probability Maps (PPMs)
Global shrinkage prior (2nd level) Spatial prior (1st level)
Bayesian Model Comparison Comparing Dynamic Causal Models (DCMs)
Summary
SPM5

In SPM, the p-value reflects the probability of getting the observed data in the effect’s absence. If sufficiently small, this p-value can be used to reject the null hypothesis that the effect is negligible.
Classical approach shortcomings
)|)(( 0HYfp
Shortcomings of this approach:
Solution: using the probability distribution of the activation given the data.
Probability of the data, given no activation
)|( Yp
One can never accept the null hypothesis
Correction for multiple comparisons
Given enough data, one can always demonstrate a significant effect at every voxel

)(
)()|()|(
Yp
pYpYp
Baye’s Rule
YY
Given p(Y), p() and p(Y,) Conditional densities are given by
)(
),()|(
Yp
YpYp
)(
),()|(
p
YpYp
Eliminating p(Y,) gives Baye’s rule
Likelihood Prior
Evidence
Posterior

Bayesian Inference
Three steps:
Observation of data
Y
Formulation of a generative model
likelihood p(Y|)
prior distribution p()
Update of beliefs based upon observations, given a prior state of knowledge
)(
)()|()|(
Yp
pYpYP

Overview
Introduction Bayesian inference
Segmentation and Normalisation Gaussian Prior and Likelihood Posterior Probability Maps (PPMs)
Global shrinkage prior (2nd level) Spatial prior (1st level)
Bayesian Model Comparison Comparing Dynamic Causal Models (DCMs)
Summary
SPM5

Bayes and Spatial Preprocessing
NormalisationNormalisation
)(log)|(log)|(log pypyp
Mean square difference between template and source image
(goodness of fit)
Mean square difference between template and source image
(goodness of fit)
Squared distance between parameters and their expected values
(regularisation)
Squared distance between parameters and their expected values
(regularisation)
MAP:MAP:
Deformation parametersDeformation parameters
Unlikely deformationUnlikely deformation
Bayes and Spatial Preprocessing
SegmentationSegmentation
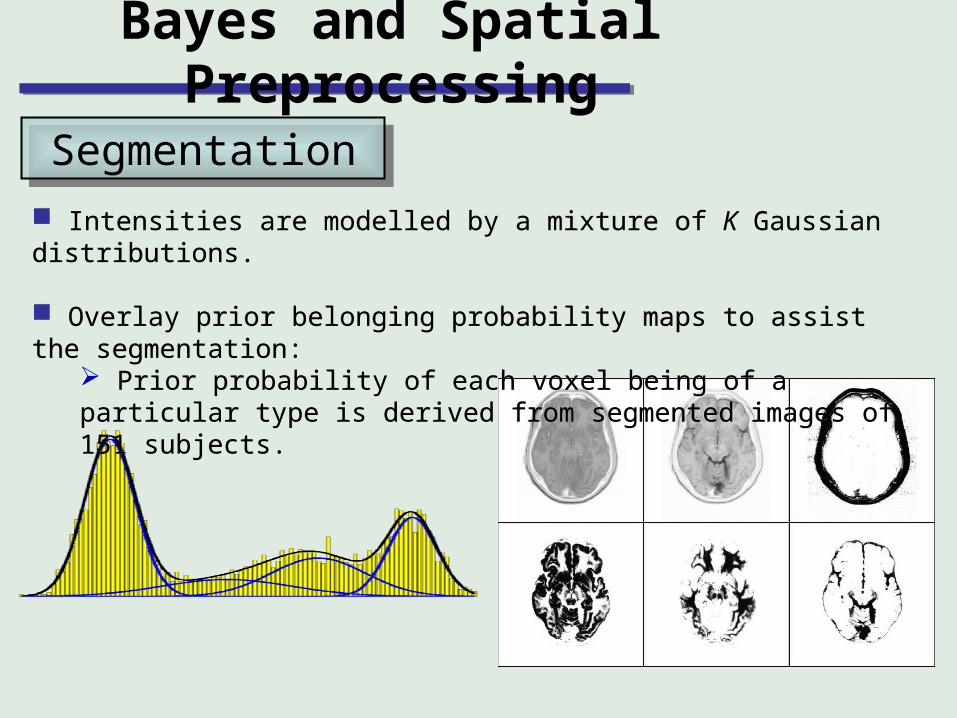
Intensities are modelled by a mixture of K Gaussian distributions.
Overlay prior belonging probability maps to assist the segmentation: Prior probability of each voxel being of a particular type is derived from segmented images of 151 subjects.
Intensities are modelled by a mixture of K Gaussian distributions.
Overlay prior belonging probability maps to assist the segmentation: Prior probability of each voxel being of a particular type is derived from segmented images of 151 subjects.

Overview
Introduction Bayesian inference
Segmentation and Normalisation Gaussian Prior and Likelihood Posterior Probability Maps (PPMs)
Global shrinkage prior (2nd level) Spatial prior (1st level)
Bayesian Model Comparison Comparing Dynamic Causal Models (DCMs)
Summary
SPM5
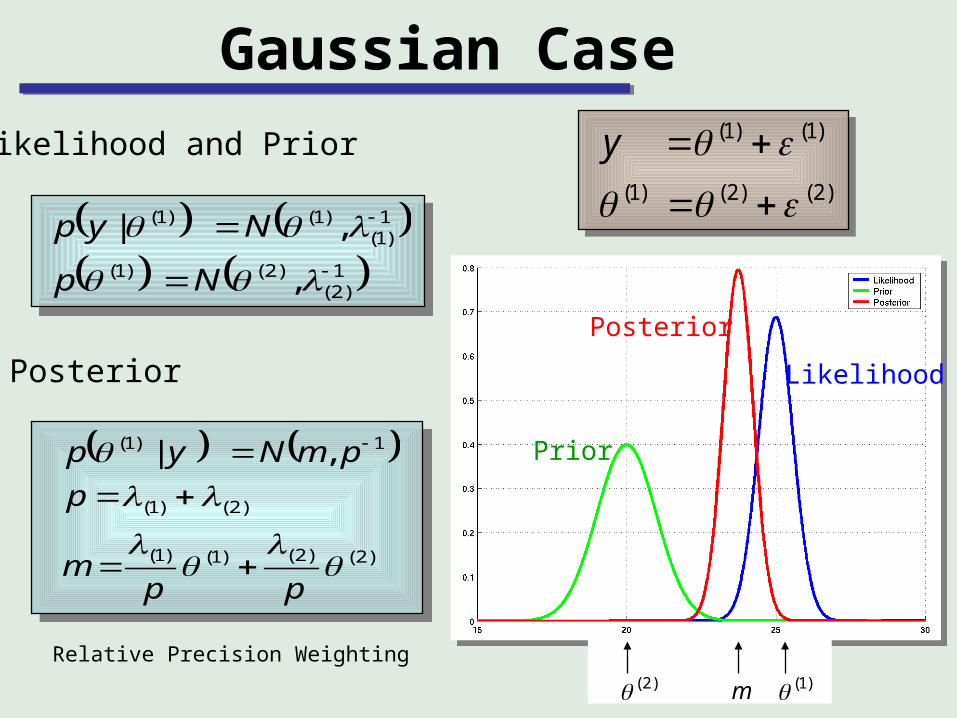
Gaussian Case
Likelihood and Prior
Posterior
)2( m )1(
Relative Precision Weighting
Prior
Likelihood
Posterior
)2()2()1(
)1()1(
y
1
)2()2()1(
1)1(
)1()1(
,
, |
Np
Nyp
)2()2()1()1(
)2()1(
1)1( , |
ppm
p
pmNyp

Overview
Introduction Bayesian inference
Segmentation and Normalisation Gaussian Prior and Likelihood Posterior Probability Maps (PPMs)
Global shrinkage prior (2nd level) Spatial prior (1st level)
Bayesian Model Comparison Comparing Dynamic Causal Models (DCMs)
Summary
SPM5
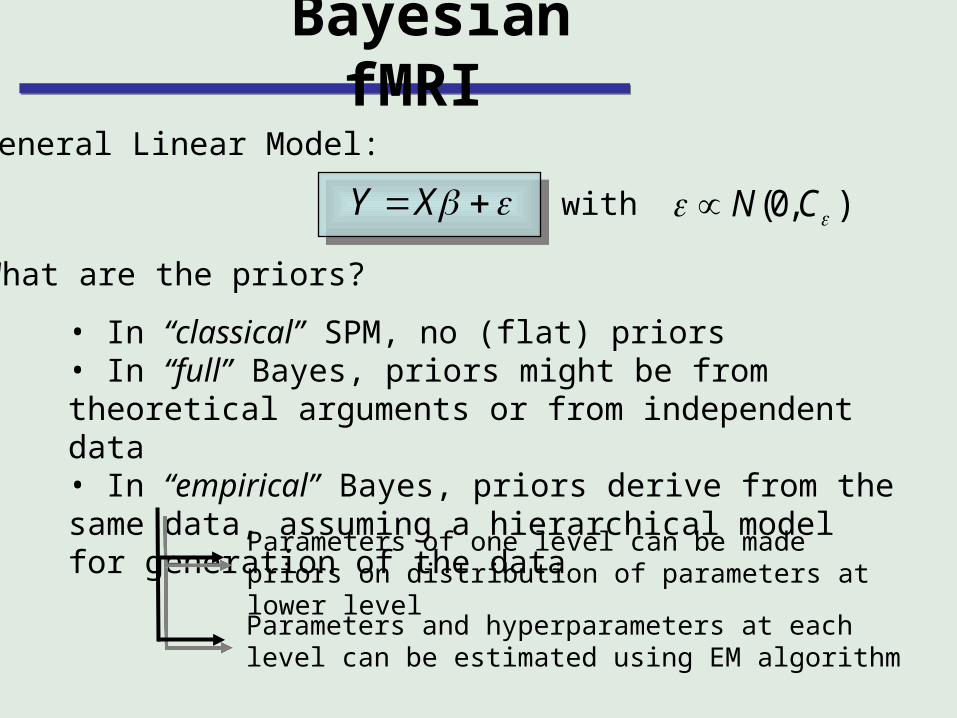
Bayesian fMRI
XY
General Linear Model:
What are the priors?
),0( CNwith
• In “classical” SPM, no (flat) priors• In “full” Bayes, priors might be from theoretical arguments or from independent data• In “empirical” Bayes, priors derive from the same data, assuming a hierarchical model for generation of the data
Parameters of one level can be made priors on distribution of parameters at lower level
Parameters and hyperparameters at each level can be estimated using EM algorithm

Bayesian fMRI: what prior?
)1( XY
General Linear Model:
Shrinkage prior:
),0()( )1( CNp
)2(0 ),0()( CNp
)(p
0
In the absence of evidenceto the contrary, parameters
will shrink to zero
If Cε and Cβ are known, then the posterior is:
YCXCm
CXCXCT
YY
TY
1||
111|
We are looking for the same effect over multiple voxels
Pooled estimation of Cβ over voxels via EM

Bayesian Inference
LikelihoodLikelihood PriorPriorPosteriorPosterior
SPMsSPMsSPMsSPMs
PPMsPPMsPPMsPPMs
u
)(yft
)0|( tp)|( yp
)()|()|( pypyp
Bayesian testBayesian test Classical T-testClassical T-test

Posterior Probability Maps
)|( yp )|( yp
Posterior distribution: probability of getting an effect, given the dataPosterior distribution: probability of getting an effect, given the data
Posterior probability map: images of the probability or confidence that an activation exceeds some specified threshold, given the dataPosterior probability map: images of the probability or confidence that an activation exceeds some specified threshold, given the data
)|( yp
Two thresholds:• activation threshold : percentage of whole brain mean signal (physiologically relevant size of effect)• probability that voxels must exceed to be displayed (e.g. 95%)
Two thresholds:• activation threshold : percentage of whole brain mean signal (physiologically relevant size of effect)• probability that voxels must exceed to be displayed (e.g. 95%)
mean: size of effectprecision: variabilitymean: size of effectprecision: variability
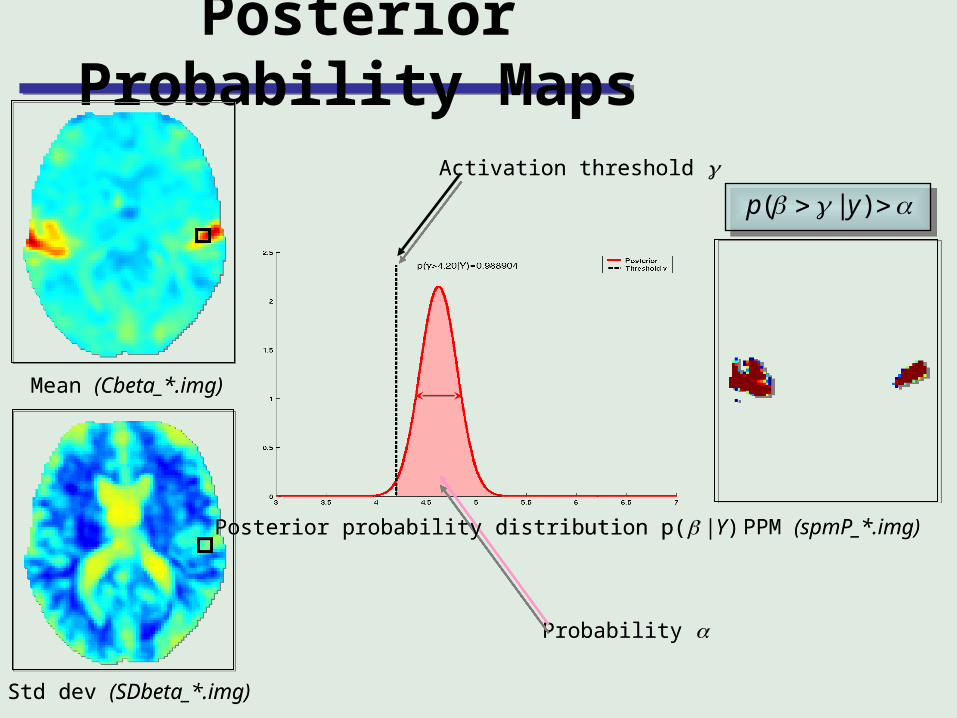
Posterior Probability Maps
Mean (Cbeta_*.img)Mean (Cbeta_*.img)
Std dev (SDbeta_*.img)Std dev (SDbeta_*.img)
PPM (spmP_*.img)PPM (spmP_*.img)
Activation threshold Activation threshold
Probability Probability
Posterior probability distribution p( |Y)Posterior probability distribution p( |Y)
)|( yp
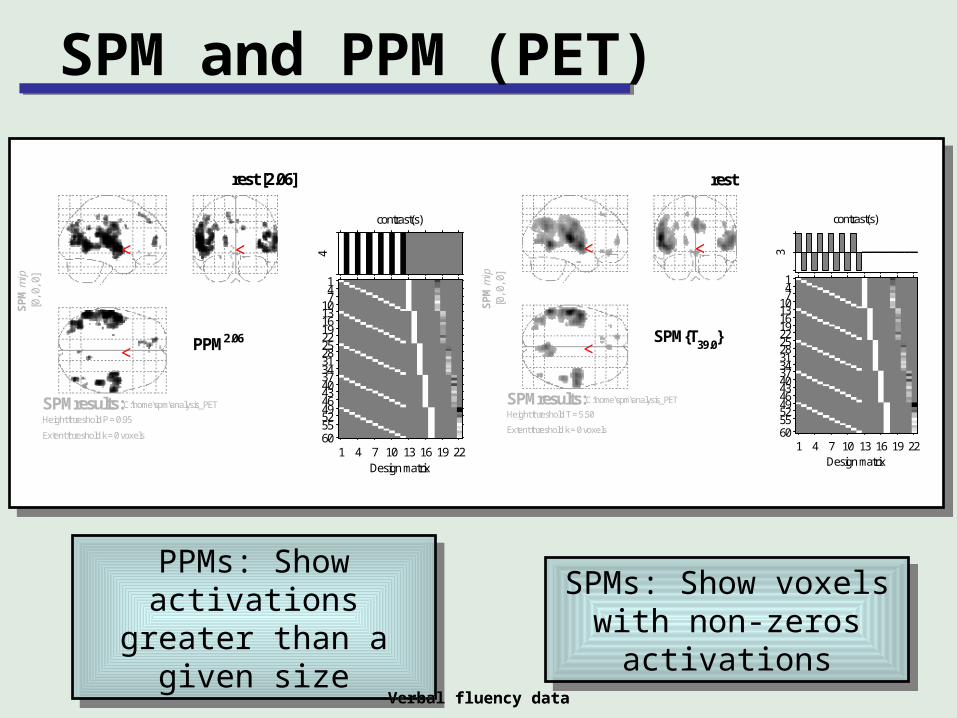
SPM and PPM (PET)S
PM
mip
[0, 0
, 0]
<
< <
PPM2.06
rest [2.06]
SPMresults:C:\home\spm\analysis_PET
Height threshold P = 0.95
Extent threshold k = 0 voxels
Design matrix1 4 7 10 13 16 19 22
147
1013161922252831343740434649525560
contrast(s)
4
SP
Mm
ip[0
, 0, 0
]
<
< <
SPM{T39.0
}
rest
SPMresults:C:\home\spm\analysis_PET
Height threshold T = 5.50
Extent threshold k = 0 voxels
Design matrix1 4 7 10 13 16 19 22
147
1013161922252831343740434649525560
contrast(s)
3
PPMs: Show activations greater than a given size
PPMs: Show activations greater than a given size
SPMs: Show voxels with non-zeros activations
SPMs: Show voxels with non-zeros activations
Verbal fluency dataVerbal fluency data
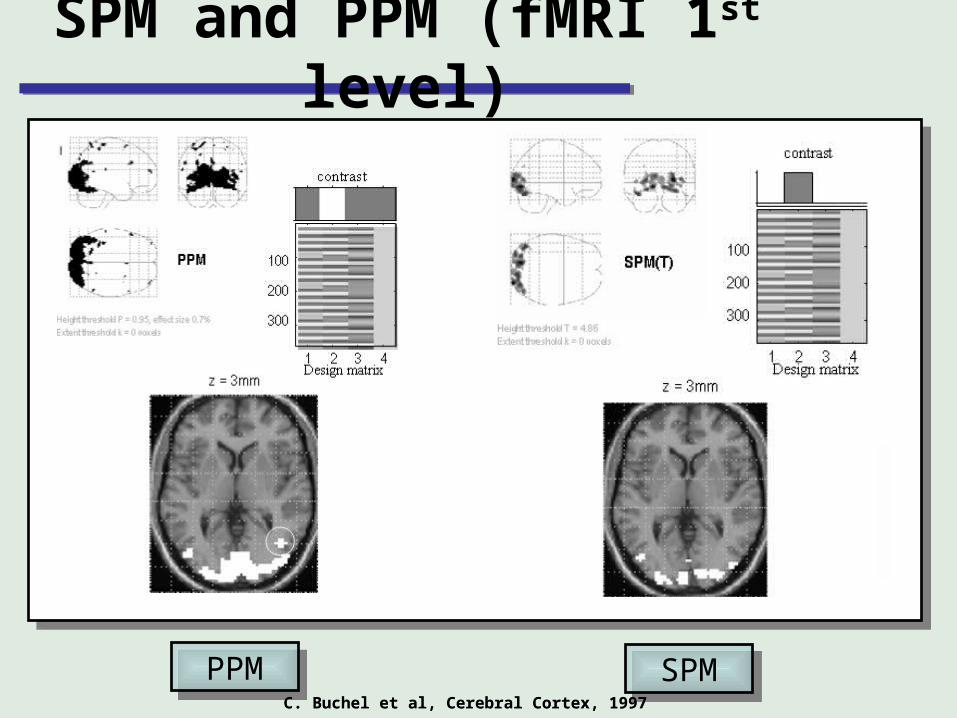
SPM and PPM (fMRI 1st level)
SPMSPMPPMPPMC. Buchel et al, Cerebral Cortex, 1997C. Buchel et al, Cerebral Cortex, 1997
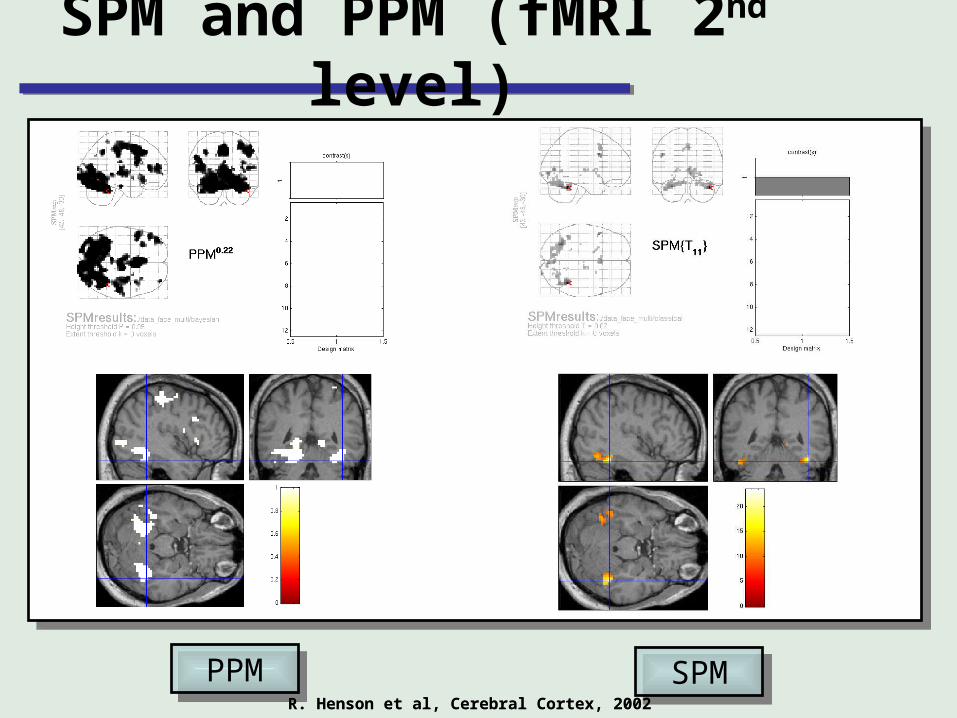
SPM and PPM (fMRI 2nd level)
SPMSPMPPMPPMR. Henson et al, Cerebral Cortex, 2002R. Henson et al, Cerebral Cortex, 2002

PPMs: Pros and Cons
■ One can infer a cause DID NOT elicit a response
■ Inference independent of search volume
■ SPMs conflate effect-size and effect-variability
■ One can infer a cause DID NOT elicit a response
■ Inference independent of search volume
■ SPMs conflate effect-size and effect-variability
DisadvantagesDisadvantagesAdvantagesAdvantages
■ Use of priors over voxels is computationally demanding
■ Utility of Bayesian approach is yet to be established
■ Use of priors over voxels is computationally demanding
■ Utility of Bayesian approach is yet to be established

Bayesian fMRI with spatial priors
Even without applied spatial smoothing, activation maps (and maps of eg. AR coefficients) have spatial structure.
AR(1)Contrast
Definition of a spatial prior via Gaussian Markov Random Field Automatically spatially regularisation of Regression coefficients and AR coefficients
11stst level level11stst level level

The Generative Model
A
Y
Y=X β +E where E is an AR(p)
),0()( 11 DNp kk ),0()( 11 DNap pp
General Linear Model with Auto-Regressive error terms (GLM-AR):
t
p
iititt eaXy
1

Spatial prior
11,0 DNp kk
Over the regression coefficients:
Shrinkage prior
Same prior on the AR coefficients.
Spatial kernel matrix
Spatial precison: determines the amount of smoothness
Gaussian Markov Random Field priors D
1
1
1
1
ji
ij
d
dD 1 on diagonal elements dii
dij > 0 if voxels i and j are neighbors. 0 elsewhere

Prior, Likelihood and Posterior
The prior:
The likelihood:
The posterior?
The posterior over doesn’t factorise over k or n. Exact inference is intractable.
p( |Y) ?
nn
ppppk
kkk
uup
rrpapqqppAp
),|(
),|()|(),|()|(),,,,(
21
2121
n
nnnn aypAYp ),,|(),,|(

Variational Bayes
Approximate posteriors that allows for factorisation
nnnn
pp
kk YqYaqYqYqYqAq )|()|()|()|()|(),,,,(
InitialisationWhile (ΔF > tol) Update Suff. Stats. for β Update Suff. Stats. for A Update Suff. Stats. for λ Update Suff. Stats. for α Update Suff. Stats. for γEnd
InitialisationWhile (ΔF > tol) Update Suff. Stats. for β Update Suff. Stats. for A Update Suff. Stats. for λ Update Suff. Stats. for α Update Suff. Stats. for γEnd
Variational Bayes AlgorithmVariational Bayes Algorithm

Event related fMRI: familiar versus unfamiliar faces
Global priorGlobal prior Spatial PriorSpatial Prior
Smoothing
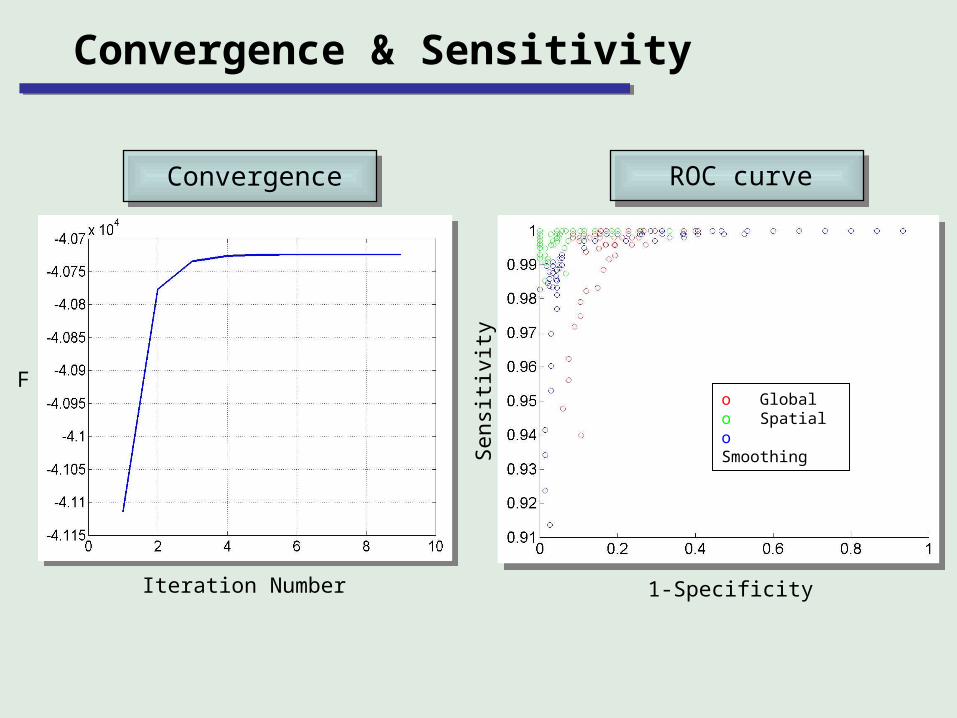
Convergence & Sensitivity
o Global o Spatialo SmoothingS
ensi
tivity
Iteration Number
F
1-Specificity
ROC curveConvergence

SPM5 Interface

Overview
Introduction Bayesian inference
Segmentation and Normalisation Gaussian Prior and Likelihood Posterior Probability Maps (PPMs)
Global shrinkage prior (2nd level) Spatial prior (1st level)
Bayesian Model Comparison Comparing Dynamic Causal Models (DCMs)
Summary
SPM5

Bayesian Model Comparison
)(
)()|()|(
Yp
mpmYPYmp
Select the model m with the highest probability given the data:
Model comparison and Baye’s factor:
)|(
)|(
2
112 mYp
mYpB
mmm dmpmYpmYp )|(),|()|(
Model evidence (marginal likelihood):
AccuracyAccuracy ComplexityComplexity
B12 p(m1|Y) Evidence
1 to 3 50-75 Weak
3 to 20 75-95 Positive
20 to 150 95-99 Strong
150 99 Very strong
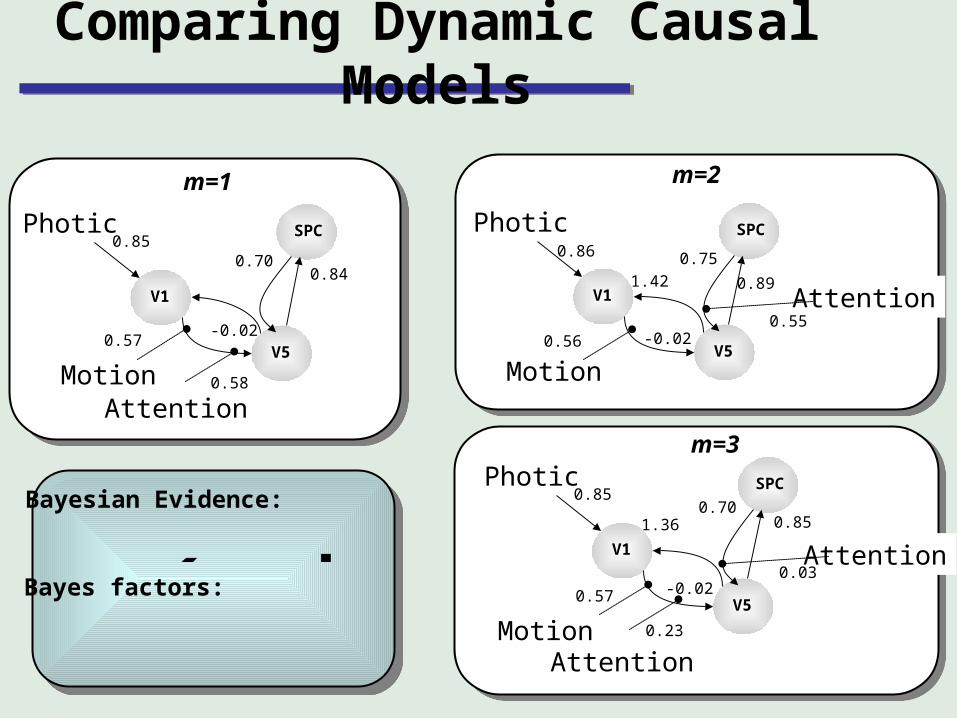
Comparing Dynamic Causal Models
V1
V5
SPC
Motion
Photic
Attention
0.85
0.57-0.02
0.84
0.58
V1
V5
SPC
Motion
Photic
Attention
0.85
0.57 -0.02
1.360.70
0.85
0.23
V1
V5
SPC
Motion
Photic
Attention
0.86
0.56 -0.02
1.42
0.55
0.75
0.89
12
( | 1)
( | 2)
p y mB
p y m
( | ) ( | , ) ( | )p y m p y m p m d Bayesian Evidence:
Bayes factors:
m=1
m=3
m=2
0.70
Attention0.03

Summary
■ Bayesian inference:– There is no null hypothesis
– Allows to incorporate some prior belief
■ Posterior Probability MapsEmpirical Bayes for 2nd level analyses:
Global shrinkage priorVariational Bayes for single-subject analyses:
Spatial prior on regression and AR coefficients
■ Bayesian framework also allows:– Bayesian Model Comparison

References
■ Classical and Bayesian Inference, Penny and Friston, Human Brain Function (2nd edition), 2003.
■ Classical and Bayesian Inference in Neuroimaging: Theory/Applications, Friston et al., NeuroImage, 2002.
■ Posterior Probability Maps and SPMs, Friston and Penny, NeuroImage, 2003.
■ Variational Bayesian Inference for fMRI time series, Penny et al., NeuroImage, 2003.
■ Bayesian fMRI time series analysis with spatial priors, Penny et al., NeuroImage, 2005.
■ Comparing Dynamic Causal Models, Penny et al, NeuroImage, 2004.
Related Documents











