Πανεπιστήμιο Κύπρου – Τμήμα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD Κώστας Νεοκλέους, PhD Τηλέφωνο Γραφείου: 22406391 Email: [email protected] ΕΠΛ 604 Τεχνητή Νοημοσύνη ***************** Πανεπιστήμιο Κύπρου – Τμήμα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD Adaline, Madaline, MLP Αλγόριθμος Ελαχίστων Μέσων Τετραγώνων Least Mean Square Algorithm (LMS) Αλγόριθμος Backpropagation ΤΕΧΝΗΤΑ ΝΕΥΡΩΝΙΚΑ ∆ΙΚΤΥΑ

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Κώστας Νεοκλέους, PhDΤηλέφωνο Γραφείου: 22406391
Email: [email protected]
ΕΠΛ 604Τεχνητή Νοηµοσύνη*****************
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Adaline, Madaline, MLP
Αλγόριθµος Ελαχίστων Μέσων ΤετραγώνωνLeast Mean Square Algorithm (LMS)
Αλγόριθµος Backpropagation
ΤΕΧΝΗΤΑ ΝΕΥΡΩΝΙΚΑ ∆ΙΚΤΥΑ

2
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Γενικά
Στη σειρά αυτή θα δούµε µερικές από τις πιο βασικές αρχιτεκτονικές (ή τοπολογίες) τεχνητών νευρωνικών δικτύων που µπορούν να χρησιµοποιηθούν για τη δηµιουργία άλλων, πιο σύνθετων δοµών.
Αυτές είναι τα Adaline, Madaline, Perceptrons και σταδιακά τα MLP.
Τέτοιες αρχιτεκτονικές έχουν πολλές εφαρµογές όπως θα δούµε στη συνέχεια.
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Είναι µια βασική δοµή ενός γραµµικού νευρώνα.
Είναι προσαρµοζόµενος (adaptive) γραµµικός συνδυαστής (simple adaptive linear combiner).
Οι πληροφορίες εισόδου και εξόδου είναι συνήθως σε ψηφιακή (δυαδική) µορφή.
ADALINE

3
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
∆οµή ενός απλού Adaline
x1(κ)
x2(κ)
.
.
.
xN(κ)
Στοιχείαεισόδου
x
w1(κ)
w2(κ)
wN(κ)
ΣυναπτικάΒάρη
Σ
w u = xTw
N
1 i i
iu x w
=
= ∑
όπου,
x ∈ ℜNx1
w ∈ ℜNx1
u ∈ ℜ
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Το απλό µοντέλο Adaline µοιάζει µε το Finite Impulse Response Filter – FIR που χρησιµοποιείται στη ψηφιακή επεξεργασία σήµατος.
Μετά από κατάλληλη µάθηση – που γίνεται συνήθως µε αλγόριθµο LMS που θα δούµε αργότερα – το adaline µπορεί να χρησιµοποιηθεί για να αναγνωρίζει τα αρχικά σήµατα έστω και αν αυτά έχουν αλλοιωθεί ελαφρά.
ADALINE

4
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Παράδειγµα εφαρµογής φίλτρου που προσαρµόστηκε µε µάθηση LMS:
ΦΙΛΤΡΟ 1 Καλό φιλτράρισµα
κ.ο.κ
ΦΙΛΤΡΟ 0.5 Ικανοποιητικό
φιλτράρισµα
ΦΙΛΤΡΟ 0 Απορριπτέο
φιλτράρισµα
Το σήµα εισόδου Η κατηγοριοποίηση
ΒΑΣΙΚΑ ΣΤΟΙΧΕΙΑ ΓΙΑ ΦΙΛΤΡΑ
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
ΒΑΣΙΚΑ ΣΤΟΙΧΕΙΑ ΓΙΑ ΦΙΛΤΡΑ
Τα φίλτρα µπορεί να είναι υλισµικά (physical hardware) ή υπολογιστικά (computer software).
Οι εργασίες που συνήθως κάνουν είναι:
Φιλτράρισµα (filtering) υπό την έννοια της απάλειψης θορύβου (noise) και άλλων µη-επιθυµητών παρεµβολών.
Βελτίωση (smoothening) που γίνεται συνήθως όταν έχουµε καλή γνώση των σχετικών διαδικασιών.
Χρονική πρόβλεψη (prediction).

5
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
1. Σε συστήµατα εντοπισµού στόχων µε ραντάρ (pulse radar tracking systems), το φίλτρο θα µπορούσε να κάνει, καθάρισµασήµατος (filtering), βελτίωση(smoothening) και πρόγνωση (prediction).
Τα φίλτρα µπορούν να κατηγοριοποιηθούν ως γραµµικά ή µη-γραµµικά.
2. ∆ιαχωρισµός ηλεκτροκαρδιογραφήµατος (ΗΚΓ, ΕCG) εγκύου από το ΗΚΓ του εµβρύου
ΜΕΡΙΚΑ ΠΑΡΑ∆ΕΙΓΜΑΤΑ ΕΦΑΡΜΟΓΗΣ ΦΙΛΤΡΩΝ
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Παράδειγµα 3:Καθαρισµός ECG σήµατος από παρεµβολές Η/Μ πεδίου 50 Hz
Ηλεκτροκαρδιογράφος Ηλεκτροκαρδιογράφηµα µε παρεµβολές από το Η/Μ πεδίο των 50 Ηz
Παράδειγµα ΕΚΓ
6
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
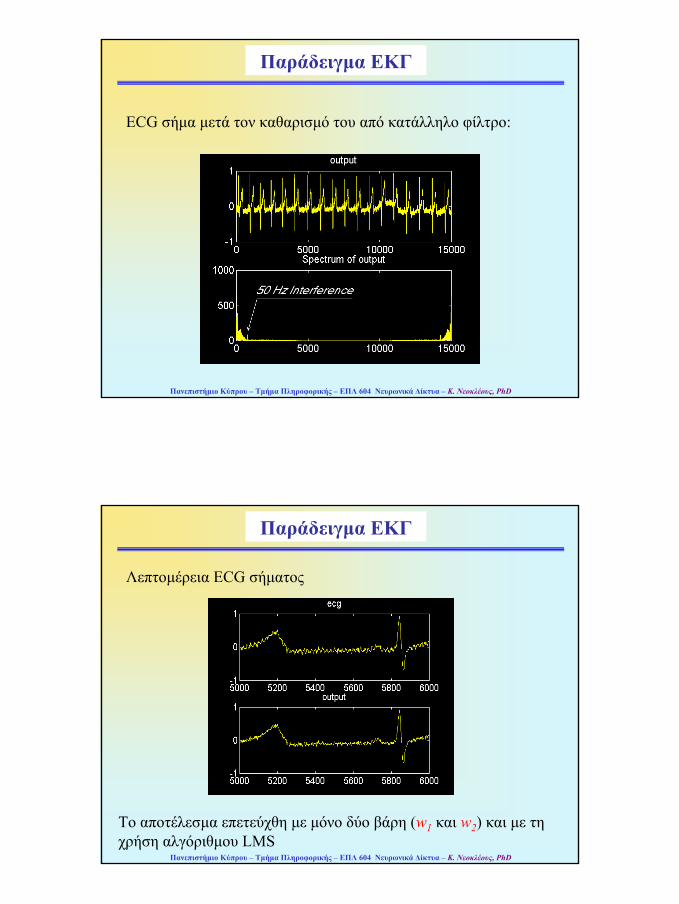
ECG σήµα µετά τον καθαρισµό του από κατάλληλο φίλτρο:
Παράδειγµα ΕΚΓ
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Λεπτοµέρεια ECG σήµατος
Το αποτέλεσµα επετεύχθη µε µόνο δύο βάρη (w1 και w2) και µε τη χρήση αλγόριθµου LMS
Παράδειγµα ΕΚΓ

7
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Adaline
x1(κ)
x2(κ)
.
.
.
xN(κ)
w1(κ)
w2(κ)
wN(κ)
Σ
N
1 i i
iu x w
=
= ∑
Για επεξεργασία µε ψηφιακά σήµατα, συχνά χρησιµοποιούµε στην έξοδο περιοριστή (ή κβαντιστή, ή ψαλιδιστή, ή στοιχείο κατωφλίου) (threshold, quantizer, signum, hard limiter, Heavyside,) όπως πιο κάτω:
y = +1 ή -1
Κβαντιστής
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
AdalineΓενικά το Adaline - όπως και τα περισσότερα µονοκατευθυντικάτεχνητά νευρωνικά δίκτυα (feedforward neural networks) –πραγµατοποιούν µιαν αντιστοίχηση (mapping) από N στοιχεία εισόδου σε 1 στοιχείο εξόδου.
ℜΝ ℜ
Μετά που θα µάθει τα παραδείγµατα που το δόθηκαν, θα πρέπει να ελεγχθεί µε άγνωστες περιπτώσεις.
Εάν διακριβώνει σωστά µε ικανοποιητική πιθανότητα, τότε λέµε ότι έµαθε να γενικεύει (generalization).

8
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Λίγη ξεκούραση !
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Adalines σαν λογικές πύλεςΤα Adalines – µπορούν να χρησιµοποιηθούν σαν λογικές πύλες AND, OR, MAJ, NOT
Μαθηµατικά:
1 2
N
1 ( ) 1 - N , , ... ,
Ni
iy x x x x
=
= + = =
∑ AND( )sgn( )
+1 Εάν όλα τα xi = +1
-1 Εάν όχι
1 2
N
1 ( ) N - 1 , , ... ,
Ni
iy x x x x
=
= + = =
∑ OR( )sgn( )
+1 Εάν µερικά xi = +1
-1 Εάν όχι

9
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Adalines σαν λογικές πύλες
1 2
N
1 , , ... ,
Ni
iy x x x x
=
= = =
∑ MAJ(sgn( ) )
+1 Εάν τα πλείστα xi = +1
-1 Εάν όχι
y x x = − = − =
NOn T(s ) )g (
+1 Εάν x = -1
-1 Εάν x = +1
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Adalines σαν λογικές πύλεςΟι πύλες AND, OR, MAJ δείχνονται γραφικά µε adalines πιο κάτω:
x1(κ)
x2(κ)
.
.
.
xN(κ)
1
1
1
Σ
1 - Νx0(κ)=1
y = πύλη AND
AND

10
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Adalines σαν λογικές πύλες
x1(κ)
x2(κ)
.
.
.
xN(κ)
1
1
1
Σ
Ν -1x0(κ)=1
y = πύλη OR
OR
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Adalines σαν λογικές πύλες
x1(κ)
x2(κ)
.
.
.
xN(κ)
1
1
1
Σ
0x0(κ)=1
y = πύλη MAJ
MAJ

11
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Adaline µε µη-γραµµικά στοιχεία εισόδου(Polynomial Discriminant Function – Specht, 1967)
w1
Σy
x1
x2
w2
w3
w4
w5[•]2
X
[•]2x1x2w3
Χρησιµοποιήθηκε για ανάλυση δεδοµένων ECG
Περιοριστής
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Στις περιπτώσεις που τα σήµατα εισόδου δεν µπορούν να διαχωριστούν γραµµικά, τα απλά adaline αποτυγχάνουν να τα διαχωρίσουν.
Σε τέτοιες περιπτώσεις θα µπορούσαµε να χρησιµοποιήσουµε MADALINES (από το Multiple ADALINE) όπου πολλά adalines συνδέονται σε σειρά.
MADALINE

12
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
x1
x2
.
.
.
xN
Σ
Σ
Σ
…
Σ
Σ
y1 = sgn(u1)
y2 = sgn(u2)
Όπου για ευκρίνεια τα βάρη δεν δείχνονται
MADALINE
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Τo απλό µονοεπίπεδο (single-layer) PERCEPTRON(Rosenblatt, 1950) είχε εξαιρετικά µεγάλη επίδραση στην ανάπτυξη των τεχνητών νευρωνικών δικτύων.
Μοιάζει πολύ µε το Adaline που είδαµε.
Ο Rosenblatt χρησιµοποίησε το απλό µοντέλο νευρώνων των McCuloch - Pitts (1947).
PERCEPTRON

13
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ο Rosenblatt χρησιµοποίησε το µοντέλο που ονόµασε Perceptron, στη προσπάθεια του να µελετήσει τη λειτουργία του οφθαλµού.
Απλό µονοεπίπεδο PERCEPTRON
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Τo απλό µονοεπίπεδο PERCEPTRON έχει πολλές οµοιότητες µε αυτό που ονοµάζεται Maximum- likelihood Gaussian Classifier.
Παρόλο που ήταν µια νέα νέα και πρωτοποριακή µοντελοποίηση νευρωνικού δικτύου, υποβλήθηκε σε πολλή κριτική, κυρίως από τους Minsky και Papert* γιατί, µεταξύ άλλων, δεν µπορούσε να επιλύσει το κλασσικό πρόβληµα ΧOR.
Φαίνεται ότι ο κάπως υπερβολικός όρος “Perceptron”, προδιάθεσε µερικούς επιστήµονες αρνητικά.
Σήµερα, το ενδιαφέρον εστιάζεται στα πολυεπίπεδα perceptrons που θα δούµε λίγο µετά._______________________________________________________________________________________* M. Minsky and S. A. Papert. Perceptrons: An Introduction to Computational Geometry. MIT Press, Cambridge, MA, expanded edition, 1988/1969.
Απλό µονοεπίπεδο PERCEPTRON

14
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Τυπικά ένα τέτοιο δίκτυο αποτελείται από:
Πολυεπίπεδα PERCEPTRONSMultiLayer Perceptrons (MLP)
Ένα σύνολο αισθητήρων ή πληροφοριών εισόδου (πηγαίοι κόµβοι), που αποτελούν το επίπεδο εισόδου (input layer).
Ένα ή περισσότερα κρυµµένα επίπεδα (hidden layers)υπολογιστικών κόµβων.
και ένα επίπεδο υπολογιστικών κόµβων εξόδου.
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πολυεπίπεδα PERCEPTRONS
ΕΙΣΟ∆ΟΣ
ΕΞΟ∆ΟΣ
κρυµµέναεπίπεδα

15
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πολυεπίπεδα PERCEPTRONS - MLP
Τα MLP εφαρµόστηκαν µε επιτυχία στην επίλυση ποικίλων και δύσκολων προβληµάτων, όπως δείχνεται παρακάτω για “ηλεκτρονική µύτη”
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD

16
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Μάθηση στα
ADALINESMADALINES
PERCEPTRONSκαι
MLP
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Μάθηση στο απλό Adaline
x1(κ)
x2(κ)
.
.
.
xN(κ)
w1(κ)
w2(κ)
wN(κ)
Σ
N
1) i i
iu(κ x w
=
= ∑Σ
Επιθυµητή έξοδος
d(κ)
+
-
Αλγόριθµος µάθησης
Σύγκριση
e(κ) = d(κ) – u(κ)Σφάλµα
Ο αλγόριθµος µάθησης καθορίζει πως να προσαρµοστούν τα βάρη ώστε το σφάλµα να γίνει ικανοποιητικά µικρό.

17
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Αλγόριθµος Ελαχίστων Μέσων Τετραγώνων(ΕΜΤ, LMS)
Τα Adalines συνήθως εκπαιδεύονται µε τον αλγόριθµο των Ελαχίστων Μέσων Τετραγώνων, που είναι επίσης γνωστός ως “Widrow-Hoff” ή “Κανόνας ∆έλτα” (Delta Rule) ή “Error Correction Rule”.
Είναι ένας απλός κανόνας.
Εφαρµόζεται συνήθως σε γραµµικάστοιχεία.
Θα εξηγηθεί για ένα απλό νευρώνα.
Bernard Widrow
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Είναι προϊόν πρωτοποριακής εργασίας που έγινε στο Πανεπιστήµιο Stanford από τους Widrow και Hoff τη δεκαετία του 1960.
Βοηθά στη κατανόηση της θεωρίας των γραµµικών προσαρµοζόµενων φίλτρων που χρησιµοποιούν απλό γραµµικό νευρώνα.
Βοηθά επίσης στη θεωρητική ανάπτυξη των µη-γραµµικών πολυεπίπεδων perceptron (Multi Layer Perceptrons, MLP).
Αλγόριθµος Ελαχίστων Μέσων Τετραγώνων
Η µέθοδος είναι σηµαντική γιατί:

18
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Οι Widrow και Hoff προσπάθησαν να βρουν µια διαδικασία που να προσαρµόζει τα συναπτικά βάρη w έτσι ώστε ο νευρώνας να αναγνωρίζει (ξεχωρίζει, καθορίζει) κάποια πρότυπα εισόδου, µε όσο το δυνατό λιγότερο γενικό σφάλµα.
Σαν µέτρο αποδοτικότητας (performance), χρησιµοποίησαν το κριτήριο Ελάχιστου Μέσου Τετραγωνικού Σφάλµατος (LMS).
Βασίστηκαν στην εργασία του Rosenblatt που έγινε στα Perceptrons.
Αλγόριθµος Ελαχίστων Μέσων Τετραγώνων
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Προσαρµοζόµενα κυκλώµατα [Adaptive Switching Circuits (Widrow και Hoff, 1960)]
Προσαρµοζόµενες τηλεφωνικές γραµµές για γρήγορη µεταφορά πληροφοριών [Adaptive equalization of telephone channels (Lucky 1965, 1966)]
Προσαρµοζόµενες αντένες για τη µείωση των παρεµβολών [Adaptive antennas (Widrow et al., 1967)]
Προσαρµοζόµενη ακύρωση ηχούς που έρχεται από µακρινές αποστάσεις[Adaptive echo cancellation (Sondhi και Berkley, 1980)]
Προσαρµοζόµενη κωδικοποίηση οµιλίας [Adaptive differential pulse code modulation (Jayant και Noll, 1984)]
O αλγόριθµος LMS έχει πολλές εφαρµογές όπως σε:
(ήταν η πρώτη εφαρµογή που έγινε)
Αλγόριθµος Ελαχίστων Μέσων Τετραγώνων

19
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Έστωx = [x1, x2, … , xN]T
τα σήµατα εισόδου που παράγονται από κάποιους αισθητήρες.
w1
wN
w2
Σ...
.
.
.
x1
x2
xN
Αισθητήρες(Sensors)
ΒάρηWeights (multipliers)
Αθροιστής(Adder)
y
x1w1
N
1i i
iy x w
=
= =∑ Tw x
Ανάπτυξη Αλγόριθµου Ελαχίστων Μέσων Τετραγώνων
Έντασηφωτός
Θέση
αισθητήρα
Tα σήµατα εφαρµόζονται σε αντίστοιχο σύνολο βαρών:w = [ w1, w2 ,..., wN]T
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
όπου, y είναι η έξοδος (εξαρτηµένη µεταβλητή) του δικτύου d είναι η επιθυµητή έξοδος (desired output)
[είναι επίσης γνωστή ως target ή observation]
Το ζητούµενο είναι να υπολογιστούν οι βέλτιστες τιµές του w, έτσι ώστε να ελαχιστοποιείται κάποιο κατάλληλο συνολικό σφάλµα, J.
Αυτό είναι συνήθως µια συνάρτηση του σφάλµατος e
όπου e ≡ d – y
Όταν το συνολικό σφάλµα εκφράζεται ως µέσο τετραγωνικό, η λύση θα µπορούσε να βρεθεί από ένα σύστηµα εξισώσεων που είναι γνωστές ως Wiener-Hopf.
Την απόδειξη αυτών των εξισώσεων θα δούµε αµέσως µετά.
Ανάπτυξη Αλγόριθµου Ελαχίστων Μέσων Τετραγώνων

20
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
H σχέση εισόδου-εξόδου είναι:
Το σήµα σφάλµατος για ένα πρότυπο µάθησης και για ένα νευρώνα εξόδου είναι:
e = d – y
N
1i i
iy x w
=
= =∑ Tw x (4.1)
Ανάπτυξη Εξισώσεων Wiener-Hopfµε χρήση Αλγόριθµου Ελαχίστων Μέσων Τετραγώνων
(4.2)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ένα κατάλληλο µέτρο απόδοσης (performance criterion ή measure), ή συνάρτηση κόστους (cost function) J, για όλα τα πρότυπα, είναι το µέσο τετραγωνικό σφάλµα (mean square error - MSE), που ορίζεται από τη σχέση:
N2 2 2
1
1 1 1( ) ( )2 2 2 i i
iJ E e E d y E d w x
=
= = − = − ∑
Όπου Ε είναι ο τελεστής της «αναµενόµενης τιµής» ή στατιστική µέση τιµή (expectation, mean, ensemble average).
Αλγόριθµος Ελαχίστων Μέσων Τετραγώνων
(4.3)

21
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ορισµός και ιδιότητες του Ε[.]
Για τυχαία συνεχή µεταβλητή x, που παρουσιάζεται µε πιθανότητα Px:
Νοουµένου βέβαια ότι το ολοκλήρωµα έχει απόλυτη σύγκλιση.
Ορισµός:
Για τυχαία διακριτή µεταβλητή, x:
[ ] ( )xE x x xP x dx+∞
−∞
= ≡ ∫
[ ] i i i ii i
E x x x Px x x P= ≡ = =∑ ∑
(4.4)
(4.5)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ορισµός και ιδιότητες του Ε[.]
Ε[c1x + c2] = c1Ε[x] + c2
Χρήσιµες ιδιότητες του Ε[.] :
Εάν c1 και c2 είναι σταθερές που παίρνουν πραγµατικές τιµές,
Ε[x1x2x3 …] = Ε[x1] Ε[x2] Ε[x3]…
|Ε[x]| ≤ Ε[|x|]
(4.6)
(4.7)
(4.8)

22
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Το πρόβληµα αυτό µπορεί να θεωρηθεί και ως γραµµικό πρόβληµα βέλτιστου φιλτραρίσµατος(linear optimum filtering problem) που συνοπτικά ορίζεται ως εξής:
Γραµµικό πρόβληµα βέλτιστου φιλτραρίσµατος
Ζητείται να καθοριστεί το βέλτιστο σύνολο βαρών w*
1,w*2 ,..., w*
Ν, για το οποίο το µέσο τετραγωνικό λάθος J είναι ελάχιστο.
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
N N N2
1 1 1
1 1[ ]2 2i i i j i j
i j iJ E d E w x d E w w x x
= = =
= − +
∑ ∑∑
Λύση: (γνωστή σαν φίλτρο Wiener)
Από την (4.3) και τις ιδιότητες του τελεστή E[•]:
Εξισώσεις Wiener-Hopf
(4.9)
όπου Ν είναι ο αριθµός των στοιχείων εισόδου.

23
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Επειδή ο τελεστής Ε[.] είναι γραµµικός, µπορούµε να αλλάξουµε τη σειρά του Ε µε το Σ, οπόταν η (4.9) γίνεται:
όπου τα συναπτικά βάρη w θεωρούνται σταθερά, και βγαίνουν έξω από τα Ε[.]
N N N2
1 1 1
1 1[ ] [ ] [ ]2 2i i i j i j
i j iJ E d w E x d ww E x x
= = =
= − +∑ ∑∑
Εξισώσεις Wiener-Hopf
(4.10)
21 1[ ] [ ] [ ]2 2
J E d E d E= − +T T Tx w w xx w (4.11)
ή σε διανυσµατική µορφή:
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Τη συνάρτηση ετεροσυσχέτισης (cross-correlation):
E[d2] ≡ rd = Μέση τετραγωνική τιµή
E[xid] ≡ Rxd (i) όπου i = 1, 2, … ,Ν
Εξισώσεις Wiener-Hopf
Για ευκολία στη χρήση, και χρησιµοποιώντας τους γνωστούς στατιστικούς ορισµούς:
και τη συνάρτηση αυτοσυσχέτισης (auto-correlation):
( ), [ , ] , 1, 2, ... , Nxx i jR i j E x x i j≡ =
Η (4.10) γράφεται:
(4.12)
(4.13)
(4.14)

24
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
N N N
1 1 1
1 1( ) ( , )2 2d i xd i j xx
i j iJ r wR i ww R i j
= = =
= − +
∑ ∑∑
Εξισώσεις Wiener-Hopf
Η εξίσωση αυτή είναι θετική για όλα τα βάρη, και εποµένως έχει ολικό ελάχιστο (global minimum).
Για τη περίπτωση δύο βαρών µόνο, η επιφάνεια δείχνεται παρακάτω.
(4.15)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Επιφάνεια σφάλµατος για Adaline

25
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Επιφάνεια σφάλµατος
Γενικότερα, η σχεδίαση του κόστους J σαν συνάρτηση δύο παραµέτρων w1, w2δείχνει µιαν επιφάνεια σφάλµατος, µε πολλά ελάχιστα.
J
w1w2
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ανάλογα, η σχεδίαση κόστους J σε πολυδιάστατο χώρο είναι µια νοητή επιφάνεια σφάλµατος.
Στο γραµµικό adaline, η επιφάνεια έχει κοίλο σχήµα (convex), µε πολύ καλά καθορισµένα τοπικά ελάχιστα και ολικό ελάχιστο (global minimum).
Αυτό το σηµείο, είναι το βέλτιστο για το φίλτρο, µε την έννοια ότι το µέσο τετραγωνικό λάθος δίνει την ελάχιστη τιµή στο J.
Επιφάνεια σφάλµατος

26
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Όπως για να βρούµε το ελάχιστο µιας µονοδιάστατης συνάρτησης, εξισώνουµε τη παράγωγο µε µηδέν και λύνουµε την εξίσωση, έτσι και εδώ, για το προσδιορισµό του βέλτιστου, διαφορίζουµε τη συνάρτηση κόστους J ως προς τα βάρη wi και εξισώνουµε µε µηδέν.
Η µερική παράγωγος του J ως προς wi, είναι η κλίση(gradient) της επιφάνειας σφάλµατος ως προς το συγκεκριµένο wi. Παραγωγίζοντας την (4.15) ως προς wi και εξισώνοντας µε µηδέν, έχουµε:
Ελάχιστο της επιφάνειας σφάλµατος
N
1( ) ( , ) 0xd j xxi
ji
JJ R i w R i jw w =
∂∇ = = − + =
∂ ∑ (4.16)

27
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
N*
1( , ) ( ) 1, 2, ... , Nj xx dx
jw R i j R i i
=
= =∑
Εξισώσεις Wiener-Hopf
Όπου το w*i δηλώνει τη βέλτιστη τιµή του wi.
Έτσι παίρνουµε τις εξισώσεις Wiener-Hoff για βέλτιστο φίλτρο τύπου Adaline:
Tο νευρωνικό δίκτυο που έχει βάρη που ικανοποιούν τις πιο πάνω εξισώσεις, είναι γνωστό ως φίλτρο Wiener.
(4.17)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Εφαρµογή φίλτρου Wiener
Lena µε θόρυβο Lena µετά από φίλτρο Wiener

28
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Συνήθως δεν είναι εύκολο (ή είναι αδύνατο) να βρεθούν αναλυτικές λύσεις του συστήµατος Wiener-Hopf.
Χρειάζεται να βρεθεί το αντίστροφο ενός µεγάλου πίνακα [ΝxΝ], που είναι δύσκολη και χρονοβόρος εργασία.
Μπορούν όµως να να βρεθούν µε διερεύνηση (search), ψάχνοντας στο χώρο της επιφάνειας σφάλµατος, εφαρµόζοντας τη µέθοδο ταχυτέρας καθόδου που είδαµε προηγουµένως.
Η µέθοδος που προκύπτει λέγεται “Μέθοδος Ελαχίστων Τετραγώνων” (LMS) ή “Κανόνας ∆ιορθώµατος Σφάλµατος” (Error Correction Learning), ή “Κανόνας ∆έλτα” (Delta Rule) (Widrow –Hoff, 1960).
Λύση εξισώσεων Wiener-Hopf
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Μέθοδος ταχυτέρας καθόδου στη λύση των εξισώσεων Wiener-Hoff
Χρησιµοποιώντας τη µέθοδο όπως εξηγήθηκε προηγουµένως, έχουµε:
(4.19)
όπου η παράµετρος η είναι γνωστή ως Ρυθµός Μάθησης(Learning Rate ή Learning Coefficient).
∆wi = - η∇wiJ i = 1, …, N
ή σε διαφορική µορφή για τη περίπτωση συνεχούς χρονικής µεταβολής των βαρών:
Jdtdw
iw∇= η -
(4.18)

29
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Χρησιµοποιώντας τον δείκτη κ, να αναφέρεται στον αριθµό επανάληψης (ή δοκιµής, ή προσπάθειας), ο συνδυασµός των εξισώσεων (4.15) και (4.18) δίνουν:
wi[κ+1] = wi[κ] + ηRxd(i) - i = 1, …, Ν1
[ ] ( , )N
j xxj
w R i jκ=∑ (4.20)
Θα µπορούσαµε να καταλήξουµε σε ανάλογα συµπεράσµατα χρησιµοποιώντας ένα συνολικό άθροισµα των σφαλµάτων αντί της αναµενόµενης ή µέσης τιµής J.
Μέθοδος ταχυτέρας καθόδου στη λύση των εξισώσεων Wiener-Hoff
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Σε τέτοια περίπτωση το κόστος που προσπαθούµε να ελαχιστοποιήσουµε συµβολίζεται συνήθως µε Ε (από το Energy) ή C, και δίνεται όπως πιο κάτω:
(4.21)P
2
1
1 2
iολικόi
E e=
= ∑
Στη βιβλιογραφία θα το βρείτε επίσης µε το όνοµα SSE από το Sum Square Error.
Μέθοδος ταχυτέρας καθόδου στη λύση των εξισώσεων Wiener-Hoff

30
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ο συνδυασµός της έκφρασης του κόστους ως συνάρτηση των µέσων τετραγώνων του σφάλµατος, και της µεθόδου της ταχυτέρας καθόδου, είναι γνωστός ως:
Αλγόριθµος Ελαχίστου Μέσου Τετραγώνουή Κανόνας ∆έλτα ή Κανόνας Widrow-Hoff
Επειδή δεν γνωρίζουµε τη τελική µορφή της επιφάνειας σφάλµατος, σε πρακτική αλγοριθµική µορφή χρησιµοποιούµε τα στιγµιαία βάρη και τη στιγµιαία επιφάνεια.
Μέθοδος ταχυτέρας καθόδου στη λύση των εξισώσεων Wiener-Hoff
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Αλγόριθµος Ελαχίστου Μέσου ΤετραγώνουLeast Mean Square Algorithm (LMS)
Αρχικοποίηση (initialization):
Για χρόνους κ = 1, 2, ... Υπολόγισε:
0[1]ˆ =iw για i = 1, … , N
Φιλτράρισµα (filtering):
N
1
ˆ[ ] [ ] [ ] i ii
y x wκ κ κ=
=∑και
e[κ] = d[κ] – y[κ]
Το καπελάκι υποδηλώνει καθ’ υπολογισµό βάρη, για τη στιγµιαία επιφάνεια
(4.22)
(4.23)
(4.24)

31
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Αναθεώρηση βαρών w (weight updating):
][][ ][1][ˆ κκκκ iii xηeww +=+
για i = 1, … , Ν
Για την αρχικοποίηση, συνήθως βάζουµε τα βάρη να έχουν αρχικές τιµές ίσες µε µηδέν. Θα µπορούσαµε όµως να χρησιµοποιήσουµε άλλες τιµές.
Αλγόριθµος Ελαχίστου Μέσου ΤετραγώνουLeast Mean Square Algorithm (LMS)
(4.24)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Όπως είπαµε, µεγάλες τιµές του η θα µπορούσαν να οδηγήσουν σε αστάθειες, ενώ πολύ µικρές θα έκαναν το ρυθµό µάθησης πολύ αργό.
Σηµαντική θεωρητική εργασία που έγινε, δίνει καθοδήγηση για µεταβαλλόµενο η όπως δείχνετε στον παρακάτω αλγόριθµο.
Αλγόριθµος Ελαχίστου Μέσου ΤετραγώνουLeast Mean Square Algorithm (LMS)

32
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Αλγόριθµος Ελαχίστου Μέσου Τετραγώνου µε µεταβαλλόµενο ρυθµό µάθησης, η
N
1
ˆ[ ] ( ) - [ ] [ ] i ii
e d w xκ κ κ κ=
= ∑
∆ώσε αρχικά βάρη w[1] και διάλεξε τιµές για το ηο και το τ.Βήµα 1 Για χρόνο κ = 1
τκ
o
1 ][
+=
ηκη
Βήµα 2 Υπολόγισε το ρυθµό µάθησης από:
Βήµα 3 Βρές το σφάλµα:
(4.25)
(4.25)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Βήµα 4 Αναθεώρησε τα βάρη:
][][][ ][1][ˆ κκκκκ iii xeηww +=+
για i = 1, … , Ν
Εάν ναι, σταµάτα.
Εάν όχι, θέσε: κ κ +1
Πίσω στο βήµα 2.
Βήµα 5 Έλεγχος για σύγκλιση:
(4.24)
Αλγόριθµος Ελαχίστου Μέσου Τετραγώνου µε µεταβαλλόµενο ρυθµό µάθησης, η

33
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Τα MADALINES µπορούν να εκπαιδευτούν µε τον κανόνα LMS ή από άλλους κατάλληλους που θα δούµε αργότερα.
Μάθηση στα MADALINES
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Λίγη ξεκούραση !

34
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Μάθηση σε Πολυεπίπεδα PERCEPTRONS
Συνήθως εκπαιδεύονται µε επιβλεπόµενο τρόπο (supervised learning), χρησιµοποιώντας τον πολύ δηµοφιλή αλγόριθµο ανατροφοδότησης σφάλµατος (ΑΣ) (Error Backpropagation - BP) που είναι επίσης γνωστός ως Γενικευµένος Κανόνας ∆έλτα (Generalized Delta Rule).
Ο αλγόριθµος βασίζεται σε κανόνα µάθησης που χρησιµοποιεί το σφάλµα στην έξοδο για να οδηγήσει το δίκτυο σε σταδιακά καλύτερη απόδοση (Error Correction Learning Rule).
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Η µάθηση που συνήθως χρησιµοποιείται είναι βασισµένη σε µέσο τετραγωνικό σφάλµα (MSE) και σε κανόνα ταχυτέρας καθόδου.
Μάθηση σε Μη-Γραµµικά PERCEPTRONS κατωφλίου
Ο αρχικός αλγόριθµος όπως προτάθηκε από τον Rosenblatt ήταν:
wij[κ+1] = wij[κ] + ηej[κ]xi[κ]
και ej[κ] = dj[κ] – yj [κ] = dj [κ] – sgn(uj [κ])
(4.25)

35
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Μάθηση σε Μη-Γραµµικά PERCEPTRONS
Στη περίπτωση που η συνάρτηση δραστηριοποίησης είναι σιγµοειδής, η εφαρµογή του πιο πάνω κανόνα οδηγά στον κλασσικό αλγόριθµο Backpropagation (BP) για µονοεπίπεδο, µη-γραµµικό perceptron.Στη περίπτωση που η συνάρτηση δραστηριοποίησης είναι για παράδειγµα η:
)( tanh )( jjj uufy γ==
Ο αλγόριθµος µάθησης γίνετε:wij[κ+1] = wij[κ] + ηej[κ]1- (yj[κ])2xi[κ] Που είναι ο BP για µονοεπίπεδο perceptron.
(4.26)
(4.27)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
MLP και BP
Βασικά η διαδικασία της ΑΣ αποτελείται από δυο περάσµατα διαµέσου των επιπέδων του δικτύου:
Ένα πέρασµα προς τα εµπρός (ενεργοποίηση) (forward pass) και ένα πέρασµα προς τα πίσω (ανάδραση) (backward pass).
Στην την ενεργοποίηση τα βάρη στο δίκτυο διατηρούνται σταθερά.
Κατά τη διάρκεια της ανατροφοδότησης τα βάρη προσαρµόζονται σύµφωνα µε τον κανόνα διόρθωσης σφάλµατος, ώστε σταδιακά να µειωθεί το συνολικό σφάλµα.

36
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
MLP και BPΗ παρουσία της µη-γραµµικότητας είναι σηµαντική, διότι διαφορετικά η σχέση εισόδου-εξόδου θα µπορούσε να απλοποιηθεί σε αυτή ενός µονοεπίπεδου perceptron.
Η χρήση της λογιστικής συνάρτησης στη δραστηριοποίηση έχει και βιολογικά κίνητρα, µιας και προσοµοιάζει την επίµονη φάση (refractory phase) των πραγµατικών νευρώνων.
Σηµειώνεται επίσης το σηµαντικό χαρακτηριστικό των πραγµατικών βιολογικών νευρώνων, ότι δεν έχουν ψηφιακές (δυαδικές) εξόδους, αλλά η έξοδος τους έχει συνεχώς κάποια τιµή (συρµός από ώσεις).
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
MLP και BP
Η κατανεµηµένη µορφή της µη-γραµµικότητας και η υψηλή διασύνδεση του δικτύου κάνουν την θεωρητική ανάλυση ενός MLP εξαιρετικά δύσκολη.
Επίσης, η χρήση κρυµµένων νευρώνων κάνει την διαδικασία µάθησης δύσκολη, και δυσνόητη.
O αλγόριθµος BP είναι ένας γρήγορος τρόπος για τη µάθηση τέτοιων νευρωνικών δικτύων, όπου βοηθά στη κατανοµή της αναγκαίας διόρθωσης στους κρυµµένους νευρώνες, ώστε το συνολικό σφάλµα να µειώνεται σταδιακά.

37
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
MLP και BP
O κλασσικός αλγόριθµος BP εφαρµόζεται σε πολυεπίπεδα δίκτυα που έχουν ένα ή περισσότερα κρυµµένα επίπεδα, που είναι πλήρως συνδεδεµένα.
Οι υπολογισµοί από την είσοδο προς την έξοδο, λέγονται συνήθως σήµατα ενεργοποίησης ή συναρτησιακά σήµατα (function signals), ή σήµατα δραστηριοποίησης, ενώ τα σήµατα που στέλλονται πίσω για να διορθώσουν τα βάρη λέγονται σήµατα διόρθωσης βαρών (error correction signals) ή ανατροφοδότησης (feedback signals).
Έρευνες έδειξαν ότι δύο κρυµµένα επίπεδα µε λογιστική-σιγµοειδή δραστηριοποίηση, είναι αρκετό για να επιλύσει τα πλείστα µη- γραµµικά προβλήµατα απεικόνισης εισόδου-εξόδου (Kolmogorov, White, Hecht- Nielsen).
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ο Αλγόριθµος BPΗ πρώτη εργασία έγινε από τον Paul Werbos* το 1974 στο διδακτορικό του. Ακολούθως ξανα-ανακαλύφθηκε από τον Parker το 1982, και από τον LeCun σε παρόµοια µορφή το 1985.
Ο όρος BACKPROPAGATIONκαθιερώθηκε µε τη σηµαντικότατη εργασία των Rumelhart, Hinton και McClelland** το 1986.
Paul Werbos
** Rumelhart D. E., Hinton G. E. and McClelland J. L. (1986). In McClelland J. L., Rumelhart D. E. and the PDP Research Group (Eds.). Parallel Dis-tributed Processing: Explorations in the Microstructure of Cognition. Vol. 1. Foundations. Cambridge, MA: MIT Press.
_____________________________________________________________________________________________*Werbos P. (1974). Beyond regression: New tools for prediction and analysis in the behavioral sciences. Ph. D. Dissertation. Harvard University.

38
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ο Αλγόριθµος BPΟυσιαστικά ο αλγόριθµος ψάχνει και βρίσκει ένα καλό σύνολο από βάρη w ώστε το δίκτυο να κάνει ικανοποιητικά την αντιστοίχηση (mapping) ℜNx1 ℜMx1.
Είναι µια µορφή βελτιστοποίησης χωρίς περιορισµούς (unconstrained optimization).
Συνήθως οργανώνονται δύο περάσµατα. H ενεργοποίηση από την είσοδο στην έξοδο, και η ανατροφοδότηση (πισωδιάδοση) από το σφάλµα στις διορθώσεις των βαρών.
Μετά τη µάθηση, τα βάρη «παγώνουν» και το δίκτυο εφαρµόζει τηναντιστοίχηση για διάγνωση, κατηγοριοποίηση, αναγνώριση προτύπων, κ.α.
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ο Αλγόριθµος BP
Το συνολικό (global ή total) σφάλµα εκφράζεται ως:
Για ευκολία, θα αποφύγουµε τον αυτονόητο δείκτη κ, έχοντας υπόψη ότι ∆w = w[κ+1] - w[κ]
Η διαδικασία βασίζεται στη µέθοδο ταχυτέρας καθόδου εφαρµοζόµενησε σφάλµα Εp για το δείγµα p (τοπικό σφάλµα): (p = 1,…,P)
2 2,
1 1
1 1( )2 2
p jp jp out jpj j
E d y eΝ Ν
= =
= − =∑ ∑o o
P P P2 2
,1 1
1 1 1( )2 2 2p jp jp out jp
p p j p jE E d y e
Ν Ν
= =
= = − =∑ ∑∑ ∑∑o o
(4.29)
(4.28)
Στα αγγλικά είναι γνωστό σαν Sum Square Error (SSE).

39
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ο Αλγόριθµος BP
Θα παρουσιασθεί για αρχιτεκτονική 3 επιπέδων και ακολούθως θα γίνει γενίκευση σε πολλαπλά επίπεδα.
Ας δούµε πρώτα τους σχετικούς συµβολισµούς για το στάδιο της ενεργοποίησης (εµπρός-περάσµατος) (feedforward pass ή function signal pass)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
x1
x2
.
.
.
xN
Σ
…
Σ
Σ
ΕπίπεδοΕισόδου
1οΚρυ
µµένο
Επίπεδο
Σ
…
Σ
Σ
2οΚρυ
µµένο
Επίπεδο
y1
y2
.
.
.
yNo
ΕπίπεδοΕξόδου

40
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
x1
x2
.
.
.
xN
Σ
…
Σ
Σ
ΕπίπεδοΕισόδου
Σ
…
Σ
Σ
y1
y2
.
.
.
yNo
ΕπίπεδοΕξόδου
Συναπτικάβάρη
u
a
S(.)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
x1
x2
.
.
.
xN
Σ
…
Σ
Σ
ΕπίπεδοΕισόδου
Σ
…
Σ
Σ
y1
y2.
.
.
yNo
ΕπίπεδοΕξόδου
u[1]1
u[1]2
u[1]n1
Σ
…Σ
Σ
Κρυµµένο επίπεδο 1,µε n1 νευρώνες
Κρυµµένο επίπεδο 2, µε n2 νευρώνες
Κρυµµένο επίπεδο 3, µε No νευρώνες
2 2 2 1
2 1
n n n n[ ] [3] [3] [3] [3] [2] [3] [3] [2] [2] [3] [3] [2] [1] [2] [3]
1 1 1 1
n n[3] [2] [1] [1] [2] [3] [3] [2]
1 1
outl l l l l k kl l k k kl l k j jk kl
k k k j
l k j j jk kl l kk j
y y f u f a w f f u w f f a w w
f f f u w w f f
= = = =
= =
= = ∑ ∑ ∑ ∑
∑ ∑
( ) = ( ) = ( ( ) ) = ( ( ) ) =
= ( ( ( ) ) ) = ( (2 1n n N
[1] [1] [2] [3]o
1 1 1= 1, ..., Nj i ij jk kl
k j if x w w w l
= = =∑ ∑ ∑( ) ) )
a[1]1
a[1]2
a[1]n1
a[2]1
a[2]2
a[2]n2
u[2]1
u[2]2
u[2]n2
u[3]1
u[3]2
u[3]n0
f(.)[3]1
f(.)[3]n0
f(.)[2]1

41
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
2 2
2 1
2 1
[ ] [3] [3] [3]
n n[3] [2] [3] [3] [2] [2] [3]
1 1n n
[3] [2] [1] [2] [3]
1 1
n n[3] [2] [1] [1] [2] [3]
1 1
[3] [2
outl l l l
l k kl l k k klk k
l k j jk klk j
l k j j jk klk j
l k
y y f u
f a w f f u w
f f a w w
f f f u w w
f f
= =
= =
= =
= =
∑ ∑
∑ ∑
∑ ∑
( ) =
= ( ) = ( ( ) ) =
= ( ( ) ) =
= ( ( ( ) ) ) =
= (2 1n n N
] [1] [1] [2] [3]
1 1 1
o΄Οπου, l = 1, ..., N
j i ij jk klk j i
f x w w w= = =∑ ∑ ∑( ( ) ) )
Ο Αλγόριθµος BP: Υπολογισµοί ενεργοποίησης
κ. ο. κ. για MLP περισσότερων επιπέδων.
(4.30)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Ο Αλγόριθµος BPΥπολογισµοί Ενεργοποίησης - Γενική µορφή
L-1n[L] [L-1] [L]
1j i ij
iu a w
=∑ =
L-1n[L] [L] [L-1] [L]
1j j i ij
iy f a w
=∑ = ( ) (4.32)
(4.31)

42
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
“Ότι δεν θέλεις να σου κάνουν, µην κάνεις στους άλλους”, Κονφούκιος
“Είσαι αυτά που γνωρίζεις”, Albert Einstein
“ΟΠΟΥ ΑΣΤΟΧΗΣΕΙΣ ΓΥΡΙΣΕ, ΚΙ' ΟΠΟΥ ΠΕΤΥΧΕΙΣ ΦΥΓΕ”, Λαϊκή ρήση από τη Κρήτη
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πισωδιάδοση σφάλµατος
Συνήθως ακολουθείται µια από τις πιο κάτω εναλλακτικές τακτικές:
α) Μάθηση ανά δείγµα (online learning)Η διόρθωση γίνεται µετά από κάθε δείγµα
β) Μάθηση ανά οµάδα ή εποχή (batch ή epoch learning)Η διόρθωση συσσωρεύεται και γίνεται µετά που περνούν όλα τα δείγµατα
[ ]ij∆w L

43
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πισωδιάδοση σφάλµατος
[3] [3] [2][3]
[3] [3][3]
[3] [3]
και
( )
pij j i
ij
j jj jp jp jp
j j
E∆w a
w
f fe d y
u u
η ηδ
δ
∂= − =
∂
∂ ∂= = −
∂ ∂
Μάθηση ανά δείγµα (online learning)
Η µάθηση βασίζεται στο τοπικό σφάλµα, Ep
Ας δούµε αναλυτικά τον αλγόριθµο για σύστηµα τριών επιπέδων:
(4.33)
(4.34)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πισωδιάδοση σφάλµατος
[2] [2] [1][2]
[2][2] [3] [3]
[2]1
και
pij j i
ij
jj i ij
ij
E∆w a
w
fw
u
η ηδ
δ δ=
∂= − =
∂
∂=∂ ∑
3n
Μάθηση ανά δείγµα (online learning)
(4.35)
(4.36)

44
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πισωδιάδοση σφάλµατος
[1] [1]
[1][1] [2] [2]
[1]1
και
ij j i
jj i ij
ij
∆w x
fw
u
ηδ
δ δ=
=
∂=∂ ∑
2n
Μάθηση ανά δείγµα (online learning)
(4.37)
(4.38)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πισωδιάδοση σφάλµατος
Βήµατα στη µάθηση ανά δείγµα:
1. Αρχικοποίησε τα συναπτικά βάρη w δίνοντας τους µικρές τυχαίες τιµές.
2. Εφάρµοσε ένα δείγµα µάθησης x στην είσοδο, από το ζεύγος δείγµατος µάθησης (x, d), και υπολόγισε την έξοδο y µε βάση την τρέχουσα τιµή των w, χρησιµοποιώντας τις εξισώσεις (4.31) και (4.32).
3. Χρησιµοποιώντας τις τιµές της επιθυµητής εξόδου d, υπολόγισε τα τοπικά σφάλµατα δj
[L] από τις (4.34), (4.36) και (4.38).4. ∆ιόρθωσε τα βάρη wij
[L] για L=1,2,3 σύµφωνα µε την εξίσωση:wij
[L] = ηδj[L] xi
[L]
5. Επανάλαβε από το βήµα 2, εφαρµόζωντας νέο δείγµα, µέχρι το σφάλµα να πάρει ικανοποιητική τιµή, και τα βάρη να σταθεροποιηθούν.

45
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
BP µε συντελεστή ορµής
Για να έχουµε ευσταθή µάθηση χρειάζεται να χρησιµοποιήσουµε µικρή τιµή του συντελεστή µάθησης η. Αυτό οδηγεί σε αργό ρυθµό µάθησης.
Επίσης, εάν υπάρχουν τοπικά ελάχιστα, τα βάρη θα µπορούσαν να περιοριστούν γύρω από τέτοιο ελάχιστο.
Ένας τρόπος που χρησιµοποιείται για αποφυγή αυτών των προβληµάτων είναι η χρήση ενός συντελεστή ορµής µ (momentum fficient) όπως πιο κάτω:
[ ] [ ] [ ] [ ][ ] [ 1]ij j i ijw a wκ ηδ µ κ∆ = + ∆ −L L L-1 L
Όπου η > 0 και 0 ≤ µ < 1
(4.39)
[ ] [ ] [ ][ 1] [ ] [ ]ij ij ijw w wκ κ κ+ = + ∆L L Lή (4.40)

46
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
BP - Γενικό σχόλιο
Με τα προηγούµενα, φαίνεται ότι η µέθοδος αυτή, όπως και οι πλείστες παρόµοιες, δουλεύουν όπως και οι στατιστικές πολυπαραµετρικές µέθοδοι για παλινδροµική προσέγγιση ενός υπερεπιπέδου στον πολυδιάστατο χώρο, όπου η προσέγγιση γίνεται µε παραδείγµατα.
(Multidimensional curve fitting)
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Πισωδιάδοση σφάλµατος
Μάθηση ανά οµάδα (Batch processing)Σε αυτή τη τακτική, το τοπικό σφάλµα Epσυσσωρεύεται για µερικά δείγµατα (συνήθως για όλα) και ακολούθως γίνεται η διόρθωση των σφαλµάτων. Ο απλός αλγόριθµος σε αυτή τη περίπτωση γίνεται:
Μια πιο περίπλοκη µορφή αλλά πιο διαδεδοµένη είναι:
[ ] [ ] [ ] [ ][ ]ij p ij jp ip
p pij
Ew w aw
η η δ∂∆ = ∆ = − =
∂∑ ∑L L L L-1L (4.41)
[L] [L] [L-1] [L] [L]
L-1
[ ] [ 1] [ ]nij jp ip ij ij
pw a w wηκ δ µ κ γ κ∆ = + ∆ − −∑ (4.42)
Όπου γ είναι ένας συντελεστής απόσβεσης (decay factor)

47
Πανεπιστήµιο Κύπρου – Τµήµα Πληροφορικής – ΕΠΛ 604 Νευρωνικά ∆ίκτυα – Κ. Νεοκλέους, PhD
Κώστας Νεοκλέους, PhDΤηλέφωνο Γραφείου: 22406391
Email: [email protected]
ΕΠΛ 604Τεχνητή Νοηµοσύνη*****************
Τέλος στα MLP και BP
Related Documents







![Introdução e Principais Conceitos - feis.unesp.br · A rede neural MADALINE (Multi-ADALINE) ([9]) é constituída por vários elementos ADALINE. Contudo, o processo de treinamento](https://static.cupdf.com/doc/110x72/5b5051d47f8b9a206e8e4bdf/introducao-e-principais-conceitos-feisunespbr-a-rede-neural-madaline-multi-adaline.jpg)



