CPGS First Year Report Listening to Your Health: Automatic and Reliable Respiratory Disease Detection through Sounds Tong Xia Supervisor: Professor Cecilia Mascolo University of Cambridge Computer Laboratory Queens’ College Email: [email protected] June 2021

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CPGS First Year Report
Listening to Your Health:Automatic and Reliable RespiratoryDisease Detection through Sounds
Tong Xia
Supervisor: Professor Cecilia Mascolo
University of CambridgeComputer Laboratory
Queens’ College
Email: [email protected]
June 2021


Contents
1 Introduction 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Research Statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 Report Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Related Work 82.1 Acoustic Machine Learning for Health . . . . . . . . . . . . . . . . . . . . 82.2 Techniques to Improve Audio Utilisation . . . . . . . . . . . . . . . . . . . 10
2.2.1 Transfer learning for Audio Signals . . . . . . . . . . . . . . . . . . 102.2.2 Self-supervised Learning for Audio Signals . . . . . . . . . . . . . . 11
2.3 Fusion of Audio Signals and Other Data for Diagnosis . . . . . . . . . . . . 122.3.1 Identifying helpful modalities . . . . . . . . . . . . . . . . . . . . . 122.3.2 Fusion techniques . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4 Uncertainty Estimation and Application . . . . . . . . . . . . . . . . . . . 132.4.1 Bayesian Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4.2 Ensemble Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.4.3 Uncertainty-aware Applications . . . . . . . . . . . . . . . . . . . . 16
2.5 Trustworthy Deep Learning for Health . . . . . . . . . . . . . . . . . . . . 16
3 First Year Contributions 18
4 Thesis Proposal 21
A Uncertainty-Aware COVID-19 Detection from Imbalanced Sound Data 24A.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24A.2 Related Works . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25A.3 Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
A.3.1 COVID-19 Detection Model . . . . . . . . . . . . . . . . . . . . . . 26A.3.2 Ensemble Training and Inference . . . . . . . . . . . . . . . . . . . 27A.3.3 Uncertainty Estimation . . . . . . . . . . . . . . . . . . . . . . . . . 28
A.4 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28A.4.1 Dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
i

A.4.2 Experimental setup . . . . . . . . . . . . . . . . . . . . . . . . . . . 29A.4.3 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
A.5 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
ii

Chapter 1
Introduction
1.1 Motivation
The respiratory system is one of the major components of the human body, with theprimary and very important function of gas exchange to supply oxygen to the blood [1].It consists of two respiratory tracts: 1) the upper tract including the nose, nasal cavities,sinuses, pharynx and the part of the larynx above the vocal folds, and 2) the lower tractincluding the lower part of the larynx, the trachea, bronchi, bronchioles and the lung,as shown in Fig. 1.1.1 [2]. The upper track also works for pronunciation: generatingsounds and speech. Inflammation, bacterial infection or viral infection of the respiratorytracts can lead to respiratory diseases [3, 4]. Illnesses caused by inflammation includechronic conditions such as asthma, cystic fibrosis and chronic obstructive pulmonary disease(COPD), etc. Acute conditions, caused by either bacterial or viral infection, can affecteither the upper or lower respiratory tract like pneumonia, influenza, and the COVID-19.As reported, respiratory disease affects one in five people and it is the third biggest causeof death in England1.
Because the nature and location of the underlying irritant of various diseases in the res-piratory system are quite different, leading to audibly distinct changes, sounds have beenused for centuries by doctors as diagnostic signals. For example, auscultation of the lungis an important examination to distinguish normal respiratory sounds from abnormal oneslike crackles, wheezes, and pleural rub to make correct diagnosis [5]. However, trainingrespiratory physicians who expert in auscultation is costly in both time and money. More-over, to be diagnosed, patients need to go to the hospital or clinical venues, which raisesmore clinical expense and increases the risk of virus exposure.
Thanks to the advance of smartphones, the high-quality built-in microphones provide aunique opportunity to achieve sound-based automatic respiratory health diagnosis and
1https://www.england.nhs.uk/ourwork/clinical-policy/respiratory-disease/
1
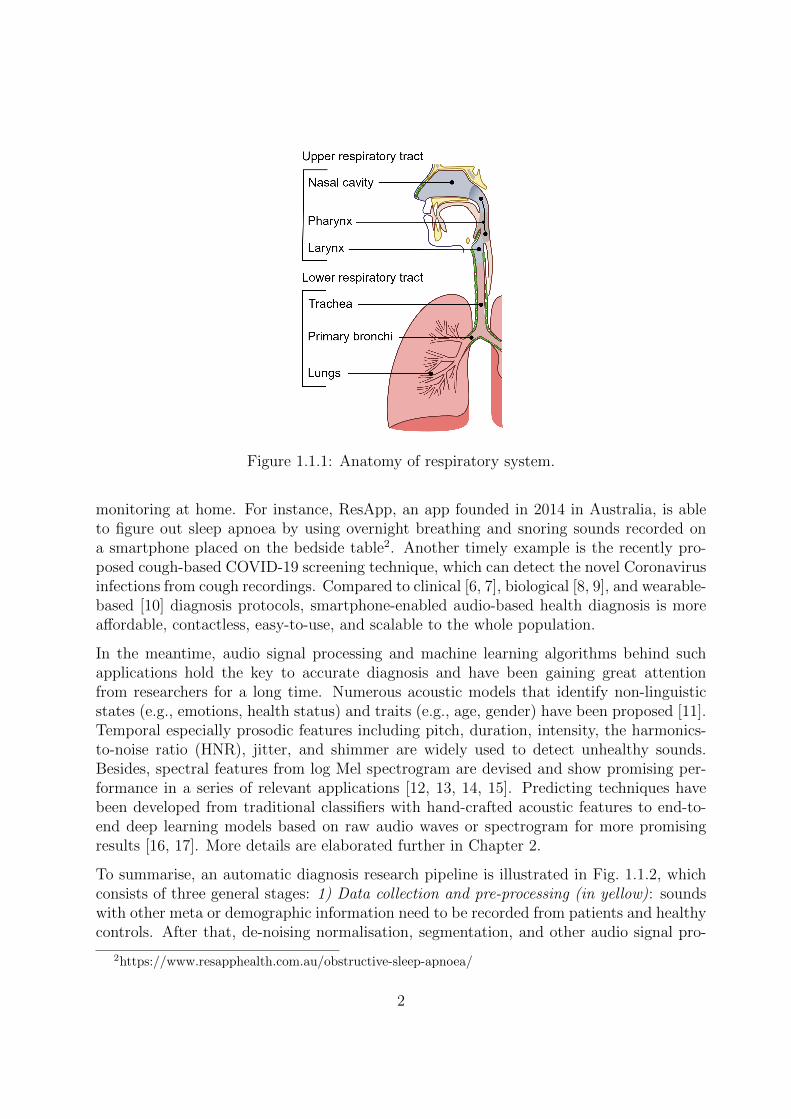
Figure 1.1.1: Anatomy of respiratory system.
monitoring at home. For instance, ResApp, an app founded in 2014 in Australia, is ableto figure out sleep apnoea by using overnight breathing and snoring sounds recorded ona smartphone placed on the bedside table2. Another timely example is the recently pro-posed cough-based COVID-19 screening technique, which can detect the novel Coronavirusinfections from cough recordings. Compared to clinical [6, 7], biological [8, 9], and wearable-based [10] diagnosis protocols, smartphone-enabled audio-based health diagnosis is moreaffordable, contactless, easy-to-use, and scalable to the whole population.
In the meantime, audio signal processing and machine learning algorithms behind suchapplications hold the key to accurate diagnosis and have been gaining great attentionfrom researchers for a long time. Numerous acoustic models that identify non-linguisticstates (e.g., emotions, health status) and traits (e.g., age, gender) have been proposed [11].Temporal especially prosodic features including pitch, duration, intensity, the harmonics-to-noise ratio (HNR), jitter, and shimmer are widely used to detect unhealthy sounds.Besides, spectral features from log Mel spectrogram are devised and show promising per-formance in a series of relevant applications [12, 13, 14, 15]. Predicting techniques havebeen developed from traditional classifiers with hand-crafted acoustic features to end-to-end deep learning models based on raw audio waves or spectrogram for more promisingresults [16, 17]. More details are elaborated further in Chapter 2.
To summarise, an automatic diagnosis research pipeline is illustrated in Fig. 1.1.2, whichconsists of three general stages: 1) Data collection and pre-processing (in yellow): soundswith other meta or demographic information need to be recorded from patients and healthycontrols. After that, de-noising normalisation, segmentation, and other audio signal pro-
2https://www.resapphealth.com.au/obstructive-sleep-apnoea/
2

Figure 1.1.2: Sound-based machine learning research pipeline for health diagnosis.
cessing steps will be conducted as the pre-processing. 2) Experiment setting up and modeltraining (in green): data will be split into training/testing sets, and acoustic feature-basedclassifiers or end-to-end deep neural models will be developed and optimised based on thetraining set. 3) Model evaluation and deployment (in blue): the developed model will beevaluated on the held testing data and will be future packaged into a tool like an app forreal deployment.
However, exploring machine learning for respiratory disease detection imposes unique chal-lenges for computer scientists:
1. Insufficient and imbalanced labelled respiratory sound data. Although itis not difficult to collect audio data, disease and other meta information are moreintractable to be massively obtained due to the clinical diagnosis expense, user privacyand ethic issues. Hence, labelled data are usually scarce with much fewer illnesssamples collected compared to the healthy controls. Consequently, such insufficiencyand imbalance characters sophisticate the deep neural network optimisation.
2. Finding helpful and fusing heterogeneous modalities for respiratory dis-eases. Various types of audio sounds can be exploited for respiratory diseases, suchas breathing, cough, and speech. However, the best sound type is unclear and need tobe explored. For instance, existing studies of audio-based COVID-19 detection focuson cough while others on voice data or breathing. While a fusion of varied modal-ities might improve. Moreover, other modalities like symptoms and demographicinformation may also help, thus an effective fusion approach is required.
3. Reliability and risk management for respiratory disease prediction. As isknown, any incorrect automatic diagnosis without any warning from an automaticmodel will raise the massive clinical cost. However, most if not all of the current
3

deep models are very sensitive to the data through which they are trained and tested.To address this issue and to develop reliable and trustworthy models for respiratoryillness prediction, two questions should be seriously answered before any model beingdeployed in the real: 1) Does the model have any bias or perform fairly across allsubgroups? 2) How confident the model is for each prediction? For the first question,confounding factors of the studied disease and used data must be figured out for a fairevaluation and causal explanation. For the second question, in addition to predictinga probability of a respiratory problem, the confidence, or in another word, uncertaintyneeds to be precisely estimated, so that doctors can be included timely in the loopfor a more reliable outcome.
All these unsolved problems motivate me to investigate variants of existing techniques anddevelop some novel techniques in the audio domain for respiratory disease detection. Tosupport my study, the main data to exploit is the one collected from our COVID-19 SoundsProject3, which consists of crowd-sourced audios, demographics, onset symptoms, medicalhistory and other health statuses. Clinically validated data are continual under collectionthrough our collaborators, and the proposed system is likely to be tested in the real. Thereare also several public respiratory sound data sets like Virufy [18] and ICBHI [19], whichare summarised in Table 1.2.1 and will be utilised in my research.
1.2 Research Statement
Inspired by the great potential of audio for respiratory disease prediction, the main ob-jective of my thesis is the exploration and development of audio-based data-efficient, high-performance, and risk-aware automatic diagnosis systems, in order to achieve ubiquitous,affordable, portable daily respiratory disease pre-screening, diagnosis, monitoring throughmobile-phones. Specifically, the following directions will be the main tasks in my research tospecifically tackle the aforementioned three research challenges in sound-based respiratorydisease detection.
Developing data-efficient acoustic models for COVID-19 and other respiratorycondition prediction.
1. Firstly, to solve the imbalance issues of the labelled audio recordings, I have validatedthe effectiveness of applying ensemble learning [20] in the COVID-19 prediction task.Ensembles can yield better results when there is significant diversity among themodels trained from different data or with various structures. For implementation,I proposed a data sampling approach to generate balanced subsets to learn multiplemodel units. The final prediction of each given input is defined as the majority votingof all predictions across all units. (More discussion can refer to Chapter 3).
2. Albeit the limited well-labelled and high-quality data, there are a large amount ofunlabelled (or even out of domain) audio data that could be valuable and leveraged for
3https://www.covid-19-sounds.org/en/
4
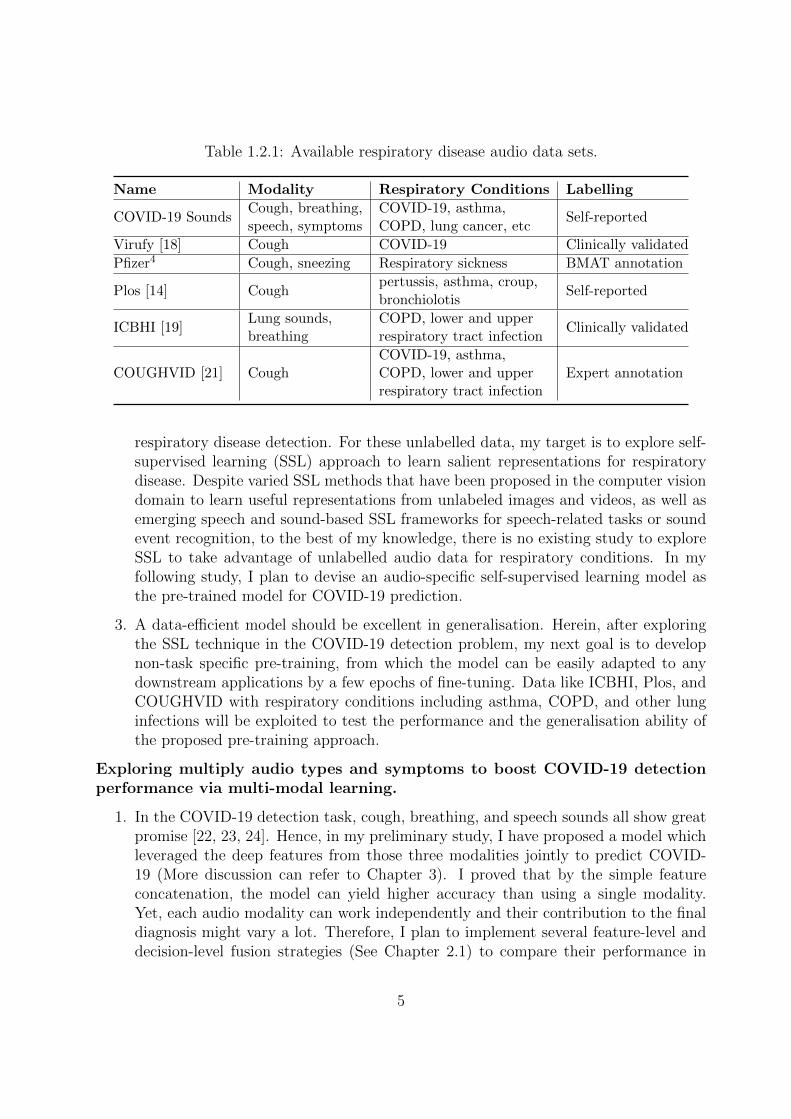
Table 1.2.1: Available respiratory disease audio data sets.
Name Modality Respiratory Conditions Labelling
COVID-19 SoundsCough, breathing,speech, symptoms
COVID-19, asthma,COPD, lung cancer, etc
Self-reported
Virufy [18] Cough COVID-19 Clinically validated
Pfizer4 Cough, sneezing Respiratory sickness BMAT annotation
Plos [14] Coughpertussis, asthma, croup,bronchiolotis
Self-reported
ICBHI [19]Lung sounds,breathing
COPD, lower and upperrespiratory tract infection
Clinically validated
COUGHVID [21] CoughCOVID-19, asthma,COPD, lower and upperrespiratory tract infection
Expert annotation
respiratory disease detection. For these unlabelled data, my target is to explore self-supervised learning (SSL) approach to learn salient representations for respiratorydisease. Despite varied SSL methods that have been proposed in the computer visiondomain to learn useful representations from unlabeled images and videos, as well asemerging speech and sound-based SSL frameworks for speech-related tasks or soundevent recognition, to the best of my knowledge, there is no existing study to exploreSSL to take advantage of unlabelled audio data for respiratory conditions. In myfollowing study, I plan to devise an audio-specific self-supervised learning model asthe pre-trained model for COVID-19 prediction.
3. A data-efficient model should be excellent in generalisation. Herein, after exploringthe SSL technique in the COVID-19 detection problem, my next goal is to developnon-task specific pre-training, from which the model can be easily adapted to anydownstream applications by a few epochs of fine-tuning. Data like ICBHI, Plos, andCOUGHVID with respiratory conditions including asthma, COPD, and other lunginfections will be exploited to test the performance and the generalisation ability ofthe proposed pre-training approach.
Exploring multiply audio types and symptoms to boost COVID-19 detectionperformance via multi-modal learning.
1. In the COVID-19 detection task, cough, breathing, and speech sounds all show greatpromise [22, 23, 24]. Hence, in my preliminary study, I have proposed a model whichleveraged the deep features from those three modalities jointly to predict COVID-19 (More discussion can refer to Chapter 3). I proved that by the simple featureconcatenation, the model can yield higher accuracy than using a single modality.Yet, each audio modality can work independently and their contribution to the finaldiagnosis might vary a lot. Therefore, I plan to implement several feature-level anddecision-level fusion strategies (See Chapter 2.1) to compare their performance in
5

this task and further improve the prediction accuracy.
2. Based on the above findings, I will further extend the framework to include non-audio features, e.g., symptoms. This can be more challenging as symptoms areheterogeneous from audio and need to be well encoded before fusion. Compare torecent works which extract acoustic features and obtain symptom embedding via twomodel structures and fuse the predictions by majority voting [25, 26], my target isto develop more explainable models by exploring attention mechanism to fill in theblank: the fusion of deep-acoustic features and symptoms.
3. For a more user-friendly diagnosis tool, it is required that the detection is passive withless user interaction involved. Inspired by this, I will propose the audio-based modelthat leverages other modalities only in the training phase as supervised labels. Toachieve this, a multi-task learning strategy will be deployed with disease detection andauxiliary task(s) to learn more representative features. As the non-audio informationis only utilised in the output side for training, the model purely requires audio asinput for deployment with closed performance compared to the multi-modality inputmodel.
Removing potential bias for experiments and incorporating uncertainty esti-mation for real deployment.
1. Apart from overall performance comparison against the state-of-the-arts, for diagno-sis decision-making, disease prediction models should be rigorously evaluated and betransparent to any potential bias. Causal explanations are necessary to avoid usingany unfair features, which has yet gained sufficient attention in the machine learningfield. As in previous studies, many biases have been identified in the COVID-19Sounds data like the uneven distribution of various languages and demographics. Toavoid biased performance, I target to establish a fair data selection and evaluationprotocol to guarantee the reliability of my research.
2. With ensemble learning, apart from dealing with the data imbalance issue, an es-timation of uncertainty can be obtained from the model disagreement level amongmultiple predictions of the subunits. For this aim, I plan to understand the capabilityand limitations of the digital prediction model, by exploring varied uncertainty esti-mation methods in respiratory disease prediction tasks (as discussed in Chapter 2.4).The outcome of this research will be a more reliable prediction model for respiratorydisease detection, and thus might be more acceptable in real applications.
Revolving around respiratory health diagnosis, particularly the detection of COVID-19, theabove techniques will be developed during my PhD, consequently forming a reliable systemwith the goal of ubiquitous, affordable, portable daily respiratory illness pre-screening,diagnosis, monitoring from home.
6

1.3 Report Structure
The motivation and research target of my thesis have been introduced in this chapter,followed by an overview of existing related works with state-of-the-art techniques discussedin Chapter 2. My first-year contribution is summarised in Chapter 3 with details providedin the appendix (Uncertainty-Aware COVID-19 Detection from Imbalanced Sound Data).In the final Chapter 4, I give my work plan for the following years with some researchmilestones that I aim to achieve.
7

Chapter 2
Related Work
2.1 Acoustic Machine Learning for Health
Vocal behaviour analysis and audio signal processing have a long history, research findingsfrom which enable a variety of real applications ranging from automatic speech recognition(ASR) and machine translation to emotion recognition and music synthesis [27, 16]. Inbrief, vocal modelling can be divided into linguistics and acoustics. The former refersto understanding the context of voice such as speech recognition tasks, while the latteraims to identify non-linguistic states (e.g., emotions, health status) and traits (e.g., age,gender) [11]. Acoustic modelling is closely relevant to my research. In the followingsections, the progress of acoustic modelling with some distinguished works will be discussed.
At the very beginning, temporal especially prosodic features including pitch, durationand cross-zero-rate (CZR) were used. With the knowledge of sounds extended to the fre-quency domain, harmonics-to-noise ratio (HNR), jitter, shimmer, Mel-frequency cepstralcoefficients (MFCC) and other spectral features were proposed from the frequency view.Through Fast Fourier Transform (FFT), a one-dimensional audio wave is converted into atwo-dimensional temporal-frequency array. The unique energy distribution in the spectro-gram makes it the fingerprint of the audio. In the health domain, a lesion or inflammationof the respiratory system might change the vocal behaviour, leading to different spectro-gram characters. Fig. 2.1.1 represents an example of the comparison between a pneumoniacough and an asthma cough, from which we can observe that the asthma cough has lessenergy in 15KHz to 20KHz [28]. This intuitive difference allows distinguishing respiratorydiseases via spectrograms.
However, these differences in spectrograms cannot be simply and explicitly formulated byrules as they are complex, subtle and in-explicit. To this end, a number of statisticalfunctions have been proposed to extract massive but low-dimensional representation fromspectrograms, such as the mean, peak, and percentiles of HNR, jitter, shimmer, and MFCCacross all frames of audio. OpenSmile [29], GeMAPS [30], and other tools were developed to
8
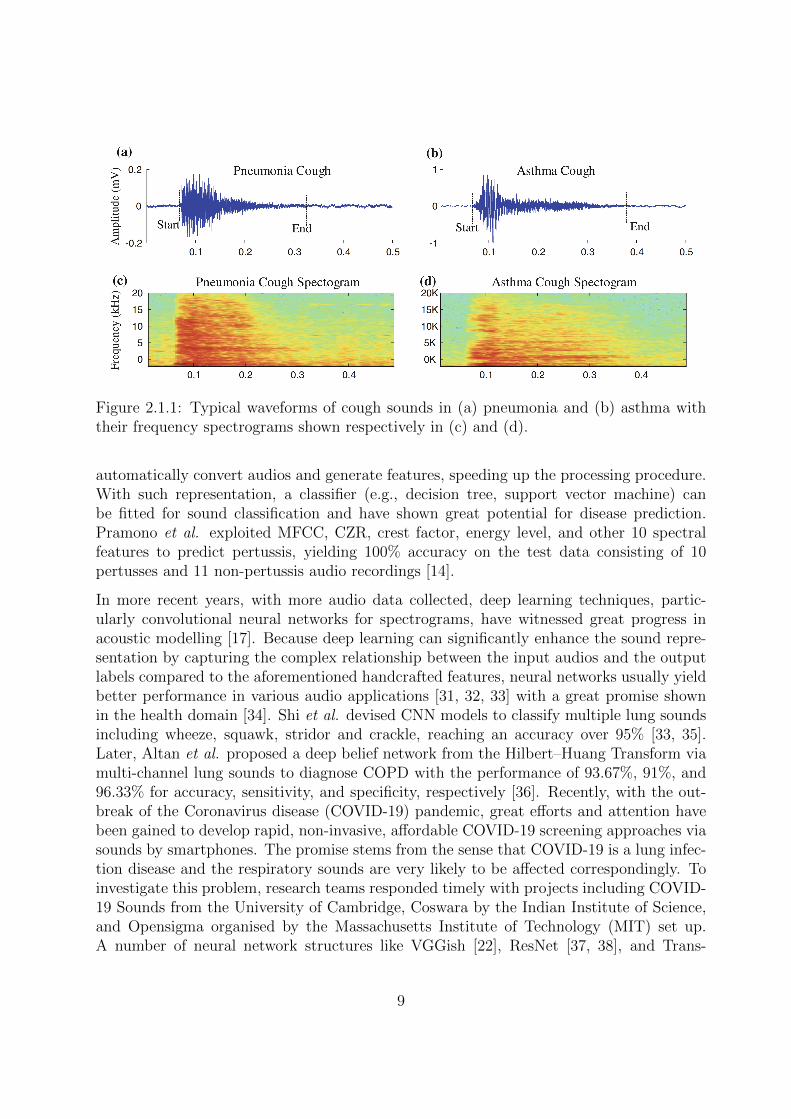
Figure 2.1.1: Typical waveforms of cough sounds in (a) pneumonia and (b) asthma withtheir frequency spectrograms shown respectively in (c) and (d).
automatically convert audios and generate features, speeding up the processing procedure.With such representation, a classifier (e.g., decision tree, support vector machine) canbe fitted for sound classification and have shown great potential for disease prediction.Pramono et al. exploited MFCC, CZR, crest factor, energy level, and other 10 spectralfeatures to predict pertussis, yielding 100% accuracy on the test data consisting of 10pertusses and 11 non-pertussis audio recordings [14].
In more recent years, with more audio data collected, deep learning techniques, partic-ularly convolutional neural networks for spectrograms, have witnessed great progress inacoustic modelling [17]. Because deep learning can significantly enhance the sound repre-sentation by capturing the complex relationship between the input audios and the outputlabels compared to the aforementioned handcrafted features, neural networks usually yieldbetter performance in various audio applications [31, 32, 33] with a great promise shownin the health domain [34]. Shi et al. devised CNN models to classify multiple lung soundsincluding wheeze, squawk, stridor and crackle, reaching an accuracy over 95% [33, 35].Later, Altan et al. proposed a deep belief network from the Hilbert–Huang Transform viamulti-channel lung sounds to diagnose COPD with the performance of 93.67%, 91%, and96.33% for accuracy, sensitivity, and specificity, respectively [36]. Recently, with the out-break of the Coronavirus disease (COVID-19) pandemic, great efforts and attention havebeen gained to develop rapid, non-invasive, affordable COVID-19 screening approaches viasounds by smartphones. The promise stems from the sense that COVID-19 is a lung infec-tion disease and the respiratory sounds are very likely to be affected correspondingly. Toinvestigate this problem, research teams responded timely with projects including COVID-19 Sounds from the University of Cambridge, Coswara by the Indian Institute of Science,and Opensigma organised by the Massachusetts Institute of Technology (MIT) set up.A number of neural network structures like VGGish [22], ResNet [37, 38], and Trans-
9

former [39] based on the spectrograms of breathing, cough, and speech have been explored,yielding 80%-90% accuracy on the crowd-sourced or clinically-validated data.
In spite of these huge signs of progress, there are still many limitations in previous works:1) Data collected for model training and valuation are small-scale, raising the doubt thatthe deep models are heavily over-fitting and the testing data are not representative for arealistic evaluation. Hence, data-efficient frameworks and holistic evaluation protocols areunder-explored. 2) It is not enough to inspect the model through the performance presentingby numerical metrics. For a reliable deployment, understanding how models make decisionsand to what degree the model is confident in its prediction are crucial for health applications.Yet, few works have been done in this direction. My research will target to fill in these gaps.
2.2 Techniques to Improve Audio Utilisation
The success of deep learning relies on leveraging massive data to fit numerous modelparameters for representative feature extraction. However, data collection and labellingtake enormous time, effort and money. Particularly, in the health domain, disease labelsare associated with a medical history and other personal information, inevitably raisingprivacy concerns. Consequently, labelled data for health research are generally scarce.
2.2.1 Transfer learning for Audio Signals
Transfer learning provides the opportunities to learn from small data with the assumptionthat some common knowledge can be shared from one domain with another. More specifi-cally, if the training data in the target domain is scarce, transfer the alike knowledge fromthe source domain with more data available is an effective way to boost model performance.Transfer learning has been extensively studied in computer vision. Tan et al. [40] cate-gorised it into four classes: 1) Instance-based methods, which utilise instances in sourcedomain by appropriate weight. 2) Mapping-based methods, which map instances from twodomains into a new data space with better similarity. 3) Network-based methods, whichreuse the partial of network pre-trained in the source domain. 4) Adversarial-based meth-ods, which use adversarial technology to find transferable features that both suitable fortwo domains. In the audio research field, finding a proper source domain such as a relevanttask or a similar data set is the key for a successful transferring.
In my study, I am interested in the network-based method, i.e., seeking some pre-trainingmodels for audio classification so that some model parameters can be reused or fine-tunedto the health domain with limited labelled data. Up to now, the largest labelled audiodata is AudioSet, a dataset of over 2 million human-labelled 10-second YouTube videosoundtracks, with labels taken from an ontology of more than 600 audio event classes [41].AlexNet, VGG, Inception, and ResNet models were pre-trained on the data set by thegoogle research team with a large amount of computing resources [42], imposing the chanceto adapt the network to health problems. Hershey et al. [42] compared the performance of
10

COVID-19 detection from coughs among a pre-trained VGG, a fine-tuned VGG and a fully-trained VGG. They found that only by using the pre-trained VGG as a feature extractor,good performance can be achieved, and after a few epochs of fine-tuning, the accuracycan be further boosted. On the contrary, the fully-trained VGG is over-fitted: the highperformance on the training set cannot be generated to the testing set. This demonstratesthe promise of transfer learning when the data in the target domain is insufficient.
2.2.2 Self-supervised Learning for Audio Signals
However, a successful transfer learning still needs sufficient data in the source domain andnegative transfer is common due to the domain shifts [43]. Recently, a new machine learningdiagram, namely self-supervised learning, gains extensive attention due to its capabilityof learning without external labels. The key idea behind this is to leverage the intrinsicstructure of the data to generate pseudo labels to pre-train the model through the definedauxiliary task. This learning paradigm was studied in the computer vision domain firstlyand has been widely applied in many image applications [44].
An important application of self-supervised learning is data generation including bothimage generation and video generation. Generative Adversarial Network (GAN) is com-monly used in this direction due to its inherent structure. Variants such as DCGAN [45],BiGAN [46], and SensoryGAN [47] were proposed for different types of data. Another ideais to leverage GAN to learn representations while generation is just an auxiliary task. Thepart of the input data will be masked and the model needs to fill in the blanks throughunderstanding the structure of the data. Inpating [48] is a classical example to recoverythe hidden pixels from images and BERT (bidirectional encoder representation from trans-formers) is a famous pre-trained model to predict the missing words in sentences. Despitethe success of applying generation-based self-supervised learning in computer vision andnatural language processing, few works have been done in the field of audio and acoustics,particularly for respiratory sounds. Approaches to mask the raw audio wave or mask thespectrograms for effective audio representations needs to be further explored and validated.
The third branch of self-supervised learning is to exploit the structure that is intrinsicin the data thereof to learn representations, with the principle that the instances withinthe group are more similar to each other compared to the instances outside the group.Contrastive learning is an approach to train a model based on such ideas, where positive(very similar) and negative (relatively different) instance pairs will be generated from theraw data and the model is trained by the positive/negative labels. SimCLR, proposed byChen et al. in 2020 [49], is a simple but effective dual-network to learn representationthrough maximising the similarity of instances generated from the same raw picture withvarious data augmentations (in other words, positive pairs). Each time, a pair of instanceswill be fed into the model with two systematic branches, and the similarity between themwill be calculated to update the parameters of the model. Following SimCLR, Wu et al. [50]adapted this ideas into machine translation, Nandan et al. [51] explored it in emotiondetection, and Wu et al. [52] validated its effectiveness in speech recognition. Yet, up to
11

now, to the best of my knowledge, only one work [39], leveraged the contrastive learningin cough audio data, and they pre-trained the model by only applying masking strategy togenerate positive/negative pairs on a very small data set. Sound-specific pair generationand contrastive loss function for digital diagnosis purposes are under-explored.
Briefly, in my study, I target to find a technical combination of model-based transfer learn-ing and sound-specific self-supervised learning to maximise the data utility for respiratoryhealth research.
2.3 Fusion of Audio Signals and Other Data for Di-
agnosis
Identify the proper modalities and efficiently fusing them are of great importance to im-prove the diagnosis accuracy when developing machine learning models. In the followingsection, I will reflect on existing works under this direction.
2.3.1 Identifying helpful modalities
For respiratory diagnosis in the clinical trial, it is common to see that doctors will collectmultiply types of signals, such as coughing sounds, breathing sounds, lung sounds, com-puterised tomography (CT) scan, symptoms and medical history questionnaire to makecomprehensive evaluations and give reliable decisions [53]. For automatic diagnosis onsmartphones, apart from respiratory sounds and speech, I now reflect on a couple of modal-ities that are easy to collect and are helpful for respiratory disease diagnosis.
As audio-based COVID-19 detection is widely studied recently, the discussions will mainlyrotate around it. As shown in existing studies, users’ self-reported symptoms are usefulto diagnose COVID-19, as some symptoms like the loss of smell&taste are unique forCOVID-19 compared to other respiratory diseases [23]. Han et al. [24, 25] fused audio-basedprediction and symptom-based prediction for the final decision, yielding better performancecompared to only by using audio or only using symptoms. Heart rate, number of daily stepsand time asleep, such activity signals collected from smartwatch were also proved usefulfor COVID-19 monitoring [54]. A combination of sensor data and self-reported symptomsshowed an accuracy of over 80% through a simple logistic regression model [55]. Overall,activity trackers from wearable, self-reported symptoms, electronic health record data,as well as audios are promising modalities for COVID-19 and other respiratory diseasedetection [56]. Yet, currently, most works focused on the validation of the effectiveness ofa single modality. My target is to adapt the advance of dynamic fusion developed in otheraudio-based applications to the respiratory disease domain.
12

2.3.2 Fusion techniques
Leveraging multiple modalities together can usually boost the model performance whenthose modalities complement each other and are well fused [57]. In brief, multi-modalfusion can be divided into two categories: decision-level fusion and feature-level fusion.
For decision-level fusion, models are trained separately for every single modality and thefinal decision is a weighted/unweighted combination of the output of each model. Majorityvoting and average voting are commonly used [24, 25]. This approach generally requiresevery single modality can yield relatively good performance and hence, through voting, theaccuracy and robustness can be further boosted.
Feature-level fusion aims to leverage the potential of all modalities through an earlier datainteraction [58, 59, 60, 61]. Multi-signals can be treated as different channels of the input asan input fusion. For example, in [32] where audio-based COVID-19 prediction is explored,breathing audio and cough audio are transferred into spectrograms and are merged intoa 2-channel image, based on which CNN is applied to extract features. Another methodis to extract deep representations of different signals and take the concatenation of thoserepresentations as a feature vector, which is fed into the final classification layers [22].This approach allows different network strictures to obtain features from various signals,which is more flexible than the input-level fusion. yet, all the above works fuse features forinstances following the same rule, but the importance of modalities might be different acrossinstances due to the signal quality and other issues. Compared to input concatenation andfeature concatenation, attention-based fusion is more adaptive, which exploits dynamicinteraction from multiple modalities [58, 59, 62, 60]. In [58], both acoustic features fromaudios and linguistic features from texts are leveraged to predict users’ emotion, and thesetwo types of features are combined by the self-attention mechanism proposed for machinetranslation [63]. To be more specific, the audio feature of the input instance is definedas the query vector, to calculate the attention score with the linguistic feature, and viceversa. After that, the acoustic and linguistic features are combined to the scores. Sincethose features are different across users, the attention scores vary and dynamic fusion isachieved. Such techniques will be further explored in my study based on respiratory sounddata.
2.4 Uncertainty Estimation and Application
Deep neural networks are state-of-the-art approaches for audio-based applications such asemotion recognition, depression detection, and lung disease prediction [34]. As discussedbefore, the key to their promise depends on their non-linear modelling capability whichmakes the feature very expressive in capturing the complex relationship between the inputaudio and the output prediction. However, in spite of the high accuracy of applying deeplearning for health, difficult diagnosis cases (e. g., out of training data distribution, noise,sound distortion) are unavoidable, which makes irrational decisions or suggestions leading
13

to serve healthcare consequence [64, 65]. In this respect, information about the reliabilityof the automated diagnosis is essential to be integrated into diagnostic systems for betterrisk management.
For the classification task, the Softmax probability at hand may indicate the confidence ofthe prediction, but it tends to overestimate confidence and requires further calibration [66].Only well-calibrated uncertainty would be very useful to tell to what degree the model iscertain about its prediction. In machine learning, there two types of uncertainties thatcan be quantified separately given a probabilistic model [67]. Aleatoric certainty stemsfrom noise, perturbation, and bias in data. Noisy or unrepresentative data can introducevariability in the input and output. Yet, to reduce this kind of uncertainty, instead ofimproving the model, seeking multiple reliable data sources is more crucial. The othertype is known as epistemic uncertainty, which is caused by the incapability of themodel itself. A model that is under-fitted because of the lack of training data to constrainthe parameters or a model with improper network structure may raise high epistemicuncertainty, which is reducible via adjusting the model or supplementing data. Those twotypes of uncertainties are usually coupled and quantified together. Quantification methodscan be broadly classified into two categories.
2.4.1 Bayesian Methods
Bayesian methods explicitly define a combination of infinite plausible models accordingto a learnable prior distribution estimated from the observed data. Given the observeddata set D = {y, x}, a conditional likelihood p(y|x, θ) tells how each model θ explains therelation of input x and target y. With the posterior distribution p(θ|D), for a new testdata point x′, the predictive posterior distribution can be derived as,
p(y|x′) =
∫p(y|x′, θ)p(θ|D)dθ, (2.1)
p(θ|D) =p(y|x, θ)p(θ)∫p(y|x, θ)p(θ)dθ
. (2.2)
p(y|x′) captures both epistemic and aleatory uncertainty. However, deep neural networksusually have millions of parameters, making it intractable to compute the exact posteriorp(θ|D) and predictive p(y|x′). To this ends, a number of approximation approaches havebeen proposed,
Markov chain Monte Carlo (MCMC): Hamiltonian Monte Carlo (HMC) sampling wasthe state-of-the-art uncertainty estimation approach when full gradients are computablein a small model [68]. While in modern machine learning, stochastic gradients are morecommonly leveraged for backpropagation. Hence, stochastic gradient HMC (SGHMC) [69]and stochastic gradient Langevin dynamics (SGLD) [70] were introduced as alternatives,which sample from the posterior in the limit of infinitely small step sizes. However, thismakes the posterior estimation extremely slow and inefficient.
14

Variational Inference: As discussed, getting the exact posterior p(θ|D) is computation-ally intractable. The key idea of applying variational inference for uncertainty qualificationis to seek a predefined and easy-to-estimated distribution q(θ;w) parameterized by w toapproximate p(θ|D) [71]. Kullback-Leibler divergence (KLD) is exploited to minimise thedifference between p(θ|D) and q(θ;w). Graves [72] introduced Monte Carlo sampling andGaussian Posterior to optimise KLD. However, q(θ;w) contains the non-differentiable ele-ments, which cannot be solved by sampling. To this end, Kingma and Welling [73] proposedthe reparameterization trick for training deep latent variable models. This improved thegeneralisation and scability of variational inference for uncertainty qualification.
Monte Carlo Dropout (MCDrop): The above two methods, although can estimateuncertainty, will raise additional and expensive computations. Considering that in moderndeep learning, Dropout is widely used to avoid over-fitting [74, 75], Gal et al. [76, 77]leveraged variational distribution to view dropout in the forward phrase as approximateBayesian inference. To keep the model capability, Dropout is generally closed, however,if it remains open, the predictive probability is calibrated through the randomly sampledmodel weights, and thus can be treated as an estimation of uncertainty. More importantly,involves minimum computational cost.
2.4.2 Ensemble Methods
Ensemble also named frequentist methods, do not specify a prior distribution over data.Instead of learning infinite models, ensemble approaches only require a limited number ofmodels, which is computationally tractable [78]. Herein, uncertainty stems from how theprediction is expected to change with different network structures or training data. Anensemble consists of multiple models with the same network structure but trained fromdifferent instances re-sampled from the dataset [79, 80]. One of the popular strategies isbagging (a.k.a. bootstrapping), where ensemble members are trained on different bootstrapsamples of the original training set. Ensemble methods can capture both aleatoric andepistemic uncertainty, with the predictive probability formulated by a uniformly-weightedcombination of the outputs from N units, denoted as,
p(y|x′) =1
N
N∑i=1
p(y|x′, θi). (2.3)
Through extensive experiments on synthetic and real-world data, Lakshminarayanan et al.proved a simple ensemble can produce well-calibrated uncertainty estimates which areas good or better than approximate Bayesian neural networks [81]. In addition, with theestimated uncertainty, the model is able to detect out-of-data-distribution for more reliableprediction [82]. Overall, the ensemble is a comprehensive, robust, and accurate method forposterior inference, although obtaining a bootstrap ensemble of size N is computationallyintense as N times as training a single model.
15

2.4.3 Uncertainty-aware Applications
In application wise, uncertainty qualification is crucial for automatic clinical decision mak-ing to minimise the false prediction [67]. Informed with uncertainty, doctors can be involvedtimely to handle the difficult cases, leading to a more reliable and safe system [83]. Severalworks show that a well-calibrated uncertainty is helpful to identify the cases that the ma-chine learning model that is unconfined, and the system performance can be further boostedby referring to these cases to experts [84, 85, 86, 64]. For example, Leibig et al. [64] lever-aged the MCDrop based Bayesian uncertainty measures for a deep convolutional neuralnetwork in diagnosing diabetic retinopathy (RD) from fundus images. Experiments showedthat incorrect model predictions yielded higher uncertainty on average compared to thetrue predictions. As such, by setting an uncertainty threshold to refer 20% of the datafor further inspection, diagnosis accuracy on the retained data can be improved to above90% (87% before referring). Recently, Ghoshal et al. [87] investigated how Dropweightsbased Bayesian Convolutional Neural Networks can estimate uncertainty COVID-19 fromchest X-rays. Similar conclusions have been observed with the RD diagnosis. This workvalidated that the uncertainty in weight space captured by the posterior is incorporatedinto the predictive uncertainty, giving the model a way to say “I don’t know”. However,all the existing uncertainty-aware diagnosis works are image-based. The performance ofapplying these approaches to audios for uncertainty-informed respiratory disease detectionis unclear and needs to further explore.
As a preparation, a couple of audio-based uncertainty estimation and understanding papersfor other applications have been reviewed. Wu et al. [88] applied ensemble approachesin spoken language evaluation problem and the estimated uncertainty measured by thevariance of the predicted distributions were used for detecting outliers. Daubener et al. [89,90] compared the acoustic uncertainty obtained by a Bayesian neural network, Monte Carlodropout, and a deep ensemble in the task of detecting adversarial examples for speechrecognition. Audio-specific attacks including adding noise, fusing music, implementingperturbation, masking spectrogram were applied to inspect how the qualified uncertaintyis sensitive to these adversaries. All those works pave the way for the evaluation of audio-based uncertainty estimation. In my study, these acoustic attacks will be adapted and newdisease-related attacks will be developed to validate the robustness of the system and theeffectiveness of the estimated uncertainty.
2.5 Trustworthy Deep Learning for Health
Despite the high performance, deep learning lacks explainability and transparency whichdisable a proper understanding of how the model works, limiting its application in manycritical decision-making scenarios such as health care1. Building a trustworthy deep learn-ing model requires resisting attacks, reporting uncertainty, and disclosing biases, which im-posing extra challenges to the terminology, design choices, and evaluation strategies when
1https://aiforgood.itu.int/events/trustworthy-ai-bayesian-deep-learning/
16

developing the model [91]. Uncertainty qualification has been discussed before, hence inthe following, I will mainly focus on developing unbiased deep learning for health diagnosismodels [92].
Demographics bias. A study investigated the gender and age bias in a smoking historysurvey released in one of the largest biomedical data repositories, namely UK Biobank,showing that self-reported health status distributed unevenly in different age and gendersubgroups and thus the data is not representative of the general population, raising thedoubts that studies based on this dataset reported biased results by underestimating thedemographic distribution [92]. Audio is the modality that is very sensitive to demographics,with the evidence showing that a simple machine learning model can precisely predict ageand gender [93, 94]. As such, when leveraging audio for healthcare, the demographicsshould be carefully controlled to avoid introducing bias to the model. Another way is todevelop models separately for each demographic subgroup. In [95], acoustic features wereanalysed and compared within the female group and male group respectively for smokingstatus evaluation. However, it is computationally expensive and poor in generalisation. Inmy study, balancing and audio-specific de-biasing approaches will be explored.
Collection Bias. Commonly, the data used for the study are collected in a crowdsourcedmanner [96]. This means data are collected through diverse spots, environments, peri-ods and devices, increasing the variance and potential bias recorded by the audio. Anaudio-based COVDI-19 detection work [26], Sharma et al. investigated the impact of datasplitting based on collecting place or time or randomly, showing a performance fluctuationcaused by label shift. This kind of performance bias can be even serious when audiosfrom patients are collected in hospitals while health controls are recorded at home, withbackground sounds captured. Yet, other audio-based COVID-19 prediction works seldomreflected on such impact [97].
There might be some other audio-specific biases such as language, accent, recording sam-pling rate, etc., depending on the data used for a specific study. With the importanceof measuring the influence of potential confounding factors, removing all observed biases,selecting data that are representative of the general population in mind, in my study, Iwill carefully design the experiments and evaluations to report trustworthy and realisticperformance.
17

Chapter 3
First Year Contributions
The recent outbreak of the novel Coronavirus (COVID-19) has caused hundreds of millionsof infections and millions of deaths worldwide. The rapid, contactless, inexpensive COVID-19 screening method is in urgent need to help manage the pandemic. As the virus mainlyattacks the human respiratory system and rises symptoms including fever and cough whichare very likely to change the voice, an audio-based COVID-19 pre-screening approachhas been proposed and gained increasing attention [98]. From previous works, acousticfeature analysis on small but real-world data has primarily validated the promise of thisidea [37, 22]. With more and more data collected and available for further study, greatinterests are seen in exploring deep learning frameworks to achieve more accurate COVID-19 screening results from sounds.
To classify sounds, audios are generally first converted into spectrograms, from which deepfeatures can be extracted through convolutional neural networks (CNN). Before COVID-19, researchers have explored CNN in other audio-based disease detection studies. In [99],a CNN model with an auto-encoder structure has been proposed to predict asthma coughfrom health sounds. Another study also validated the promise of utilising CNN for ChronicObstructive Pulmonary Disease (COPD) detection from respiratory sounds, yielding anaccuracy above 90%. These prior studies inspire a CNN-based deep method to distinguishCOVID-19 sounds.
Deep learning can achieve promising performance due to the superior feature representationability when there are sufficient data to fit the large-scale parameters of neural networks.However, in the urgent pandemic era and for a prompt response, human sounds withCOVID-19 test results are not easy to collect. We launched an app in April 2020 tocrowdsourced data1. As of February 26th 2021, 68 324 data samples from 36 675 users havebeen collected, but only less than 10% of the users provided COVID-19 test results, whichcan be used as ground-truth in this study. Moreover, the data is imbalanced, with a smallproportion of COVID-19 positive users, which poses a great challenge for deep learning.
1https://www.covid-19-sounds.org/en/
18

On the other hand, another important concern about the robustness of deep learning hasbeen raised. The deep model is sensitive to the input data and is usually overconfident withits output probability. When deploying deep learning to healthcare, any wrong predictionwithout warnings will cause detrimental costs. In other words, a digital diagnosis systemrequires risk management, which is to report the confidence apart from the prediction. Inthe field of machine learning, uncertainty estimation provides the opportunity to under-stand a model’s confidence. Although for the classification problem, predicted probabilitycan be obtained from the softmax function, it is not a good indicator for confidence andneeds further calibration [66]. More advanced uncertainty estimation techniques need tobe explored in the study of audio-based COVID-19 screening.
Those aforementioned issues motivated me to develop a data-efficient and uncertainty-aware deep learning model. As the first attempt, I adapted transfer learning to this prob-lem by introducing a pre-trained VGGish model from the audio classification task. Byfine-tuning this model through the COVID-19 data, the learned features are more mean-ingful compared to the learning model from random initialisation. Based on this, I thenproposed an ensemble learning framework to tackle the training data imbalance and uncer-tainty estimation challenges, simultaneously. Briefly, when training deep learning modelsfor COVID-19 detection, several balanced training sets were generated from the imbalanceddata to learn multiple ensemble units. During inference, decisions were fused to maximisedata utilisation and improve generalisation ability. More importantly, disagreement acrossthe learned deep learning models was leveraged as a measure of uncertainty. With un-certainty, predictions with low confidence can be identified and these samples could beexcluded from digital screening. The users who produced these samples could be asked torepeat smartphone testing or referred to for different types of testing. As a consequence,this method improves the system performance and patient safety at the same time [83].
I used the data collected from our COVID-19 sound app, with 330 COVID-19 positiveand 920 negative users after a quality check. Each sample consisted of breathing, coughand voice three audio recordings. The basic deep learning unit is based on a multi-layerCNN structure, named VGGish, using spectrograms of the three sounds as input. 10 unitsare learned and aggregated into an ensemble model. Consequently, data are utilised moreeffectively compared to traditional up-sampling and down-sampling approaches: an AUCof 0.74 with a sensitivity of 0.68 and a specificity of 0.69 is achieved. Simultaneously, theuncertainty is estimated from the disagreement across multiple units. It is shown that falsepredictions often yield higher uncertainty, enabling us to suggest the users with certaintyhigher than a threshold repeat the audio test on their phones or take clinical tests if digitaldiagnosis still fails. This study paves the way for a more robust sound-based COVID-19automated screening system. More details of this work can be found in the appendix.
A major part of my first year is to understand the audio-based health diagnosis field. Vastliterature overview and acoustic model re-productivity have deepened my understandingand sharpened my skill towards this interdisciplinary subject, and lead to a clear picture ofmy PhD thesis. The first year’s work initially explored developing a deep health diagnosis
19

model from insufficient data and estimating uncertainty from ensembles, but there areseveral limitations in algorithm design. In the following years, more extensive research willbe conducted.
20

Chapter 4
Thesis Proposal
My research target is to pursue high-performance and reliable audio-based respiratorydisease detection systems that do not rely on large-scale labelled data sets. Correspondingto the research statements discussed in Chapter 1, the following is a detailed plannedtimetable that outlines the targets and milestones during my PhD.
1. Literature review and preliminary acoustic feature analysis: October 2020- December 2021 (Completed)
• Understanding traditional and typical audio signal processing and acoustic fea-ture extraction methods.
• Getting access to COVID-19 Sound project data and setting up data pre-processing pipeline.
• Implementing preliminary COVID-19 feature analysis and developing acousticfeatures based SVM classification model.
• Co-authoring a KDD paper submission for the above study (Paper accepted).
2. Early research on audio-based COVID-19 screening via deep neural net-works: January 2021 - May 2021 (Completed)
• Reviewing and understanding deep acoustic model for the audio classificationtask. Identifying a proper pre-trained state-of-the-art model for transfer learn-ing.
• Uncover potential bias and confounding factors in the COVID-19 sound data andpreparing a balanced, high-quality, and well-controlled data set for experiments.
• Adapting the pre-trained model to solve the COVID-19 detection problem andconducting in-depth result analysis (Co-author paper submitted).
21

3. Uncertainty-Aware COVID-19 Detection from Imbalanced Sound Data:March 2021 - April 2021 (Completed)
• Based on the previous study, an ensemble learning strategy has been exploredin this stage to utilise the COVID-19 data more efficiently and improve perfor-mance.
• Different uncertainty estimation techniques have been implemented and com-pared to achieve risk-management and doctor-in-the-loop diagnosis system.
• Summarizing the research findings to INTERSPEECH 2021 and submittingan uncertainty-aware audio-based healthcare abstract paper to MobiUK 2021(Papers accepted).
4. Self-supervised learning for robust audio-based for respiratory disease de-tection: June 2021 - September 2021 (In progress)
• Surveying the latest semi-supervised and self-supervised algorithms to under-stand their advantages.
• In particularly, implementing contrastive learning, the state-of-the-art self-surprisedlearning approach, to pre-train a cough-based sound representation model, fol-lowed by applying it COVID-19, asthma, COPD and other diseases.
• Evaluating the model performance and validating the superiority against fullysupervised learning with a small proportion of labelled data that are publiclyavailable. Submitting a paper to ICLR 2022.
5. Attention-wise multi-channel and multi-type sound fusion for COVID-19diagnosis: October 2021 - February 2022
• Rotating around COVID-19 detection, reviewing signal fusion papers and se-lecting helpful sound types for use.
• Implementing and comparing several fusion baseline models, from which inves-tigating the limitation of existing methods.
• Devising new attention-based audio fusion models for more accurate health di-agnosis, conducting experiments and preparing a paper submission.
6. Symptom and audio signal fusion for superior COVID-19 prediction: March2022 - May 2022
• Based on previous research, extending the signal fusion to include symptoms tofurther improve diagnostic accuracy.
• Comparing the results with/without external data like symptoms and demo-graphics to explain the prediction.
22

• Using symptoms and other data as supervised labels, which are only availablein the training phase to free users from reporting the information manually.
• Summarising findings and preparing a paper submission.
7. Potential industrial-research internship in the intelligent healthcare sys-tem: June 2022 - September 2022
8. Audio-based uncertainty estimation towards automatic diagnosis risk man-agement: October 2022 - April 2023
• Based on the previous ensemble learning framework in the COVID-19 study,extending uncertainty research to various sound types to achieve uncertainty-aware fusion.
• Investigating the method to disentangle model uncertainty and data uncertaintyfor risk explanation.
• Building an automatic system with actions responding to different uncertaintyfor a more robust diagnosis.
• Evaluating the system in the real deployment scenario and preparing to submita paper.
9. Thesis writing-up: May 2023 - September 2023
23

Appendix A
Uncertainty-Aware COVID-19Detection from Imbalanced SoundData
A.1 Introduction
Since the outbreak of the Coronavirus Disease 2019 (COVID-19) in March 2020, over100 million confirmed cases and 2 million deaths have been identified globally. Frequentand massive screening with targeted interventions is of vital need to mitigate the epi-demic [100, 101]. Currently, the most common screening tool for COVID-19 is the ReverseTranscription Polymerase Chain Reaction (RT-PCR), which is limited by cost, time, andresources [102, 103]. To fight against the virus, researchers’ effort has gone into exploringmachine learning for fast, contactless, and affordable COVID-19 detection from soundson smartphones [98]: COVID-19 is an infectious disease, and most infected people ex-perience mild to moderate respiratory illness [104]. To validate the effectiveness of theseapproaches, sound data are normally collected with self-reported COVID-19 testing resultsor more trustworthy COVID-19 clinical testing codes.
Although recently great progress have been witnessed on cough [105, 106, 107, 22, 38]and speech-based [37, 108, 109] COVID-19 detection, there are still unsolved issues whichhinder the rollout of this technology to the masses. First, the collected sound data aregenerally imbalanced, with a small proportion of COVID-19 infected or tested positiveparticipants [38, 37, 106]. Such imbalance in training makes the classifier biased to themajority class for a relatively small loss, but it does not mean distinguishable COVID-19features can be learned from human sounds [110, 111]. This issue is even more detrimentalin deep learning as the data are limited and thus balancing solutions are insufficient [112].In addition, even if machine learning can achieve high precision, difficult diagnosis cases(e. g., out of training data distribution, noise, sound distortion) are unavoidable [64, 65]. In
24

this respect, information about the reliability of the automated COVID-19 screening is akey requirement to be integrated into diagnostic systems for better risk management. Yet,none of the existing works on sound-based COVID-19 detection takes into considerationthe uncertainty in the machine learning prediction.
In this paper, we propose an ensemble learning-based framework to tackle the training dataimbalance and uncertainty estimation challenges, simultaneously. Briefly, when trainingdeep learning models for COVID-19 detection, a number of balanced training sets aregenerated from the imbalanced data to learn multiple ensemble units. During inference,decisions are fused to maximize data utilization and improve generalization ability. Moreimportantly, we make use of the disagreement across the learned deep learning models asa measure of uncertainty. Softmax probability may indicate the confidence of the predic-tion, but it tends to overestimate confidence and requires further calibration [66]. Instead,disagreement from deep ensembles as the uncertainty estimation was proven to better rep-resent the overall model confidence [81]. With uncertainty, predictions with low confidencecan be identified and these samples could be excluded from digital screening. The userswho produced these samples could be asked to repeat smartphone testing or referred on fordifferent types of testing. As a consequence, this method improves the system performanceand patient safety at the same time [83].
To help with this research, we launched a mobile app in April 2020 to crowdsource sounddata including breathing, cough, and speech with self-reported COVID-19 testing results1.In conclusion, our contributions in this paper are summarised as follows,
• To handle the limited and imbalanced training data problem, we propose an deepensemble learning-based framework for COVID-19 sounds analysis, yielding higherAUC and sensitivity compared to other balancing approaches.
• To the best of our knowledge, we are the first to investigate the uncertainty of deeplearning for sound-based COVID-19 detection, leading to a more reliable and robustautomated diagnosis system.
• We perform experiments on our collected data with 469 tested positive and 1 526healthy control samples, achieving an AUC of 0.74 against 0.62 from an SVM baseline.With the estimated uncertainty, the AUC is further improved up to 0.85.
A.2 Related Works
In [105, 106, 22, 38, 113], respiratory sounds, especially coughs, have been analysed and de-tectable features have been discovered from spectrograms to distinguish COVID-19 coughsfrom healthy or other disease coughs. At the same time, researchers have exploited speechsignals [37, 108, 109, 114], which are more natural and informative. All those studies
1www.covid-19-sounds.org
25

demonstrate the promise of detecting COVID-19 form sounds, in a non-invasive, inex-pensive, and largely available manner. However, all the above works have suffered fromimbalanced data problem. For instance, 92 COVID-19 tested positive and 1079 healthysubjects were included in [106, 115]. The imbalance was either dealt with down-sampling,up-sampling or generally not yet tackled in the research [22, 24, 113, 38, 116]. How-ever, down-sampling, by discarding samples from the majority class, results in an evensmaller size of training data and might lose important discriminative information, whileup-sampling, by repeating samples from minority class, might change the original distri-bution of the data and lead to model overfitting. Moreover, although Synthetic MinorityOversampling Technique (SMOTE) is a more advanced up-sampling method [117], it isinherently dangerous as it violates the independence assumption and blindly generalizesthe minority area without regard to the majority class.
There has been a consensus in the literature that uncertainty estimation could be used toaid automated clinical diagnosis, for example for clinical imaging analysis [64]. In termsof COVID-19 diagnosis, one work has obtained uncertainty from CT images to achieveinterpretable COVID-19 detection [87]. Though softmax probability may indicate the con-fidence of the prediction, to some extent, it only captures the relative probability that aninstance is from a particular class, compared to the other classes, instead of the overallmodel confidence. Furthermore, it tends to overestimate confidence and thus requires fur-ther calibration [66]. In general, Bayesian Convolutional Neural Network [118] and MonteCarlo Dropout (MCDrop) [76] have been exploited to estimate uncertainty. However,Bayesian estimation is computationally expensive, which is not an optimal solution for ourtask with limited training data, while MCDrop, deployed in [87], keeps dropout on duringinference, reducing the model capacity and may leading to lower accuracy [81]. With evi-dence suggesting that uncertainty from deep ensembles outperforms MCDrop [81, 119, 88],this paper proposed the ensemble learning framework which tackles the data imbalanceand uncertainty estimation simultaneously within a unified framework.
A.3 Methodology
In this paper, we focus on developing an uncertainty-aware audio-based covid-19 predictionmodel. In particular, the basic unit integrates information from three different sound types,i. e., breathing, cough, and speech. Then, ensemble learning is exploited to handle thehighly unbalanced data. Furthermore, an uncertainty estimation can be obtained from theensemble framework. The proposed framework is illustrated in Figure A.3.1.
A.3.1 COVID-19 Detection Model
Three different modalities are adopted to develop the deep learning-based COVID-19 de-tection model - the basic unit of ensemble learning. Following previous work [22], the CNNmodel named Vggish [42] is applied and adapted as the feature extractor, which is trainedon a large-scale audio dataset for audio event classification. In particular, Mel-spectrums
26

Figure A.3.1: Uncertainty-aware deep ensemble learning-based COVID-19 detection frame-work. Balanced training sets are generated to train multiple CNN-based models, andprobabilities for a testing sample are fused to form the final decision. Simultaneously, thedisagreement level across these models as a measure of uncertainty is obtained and usedto indicate the reliability of digital diagnose.
are extracted from each modality and fed into Vggish, which yield a 128-dimensional em-bedding for each 0.96-second audio segment. It is followed with average pooling alongthe time-axis to obtain a fixed-sized feature vector from length-varying inputs. The fea-ture vectors of three modalities are then concatenated as the combined features. Finally,another two dense layers with a softmax function are utilized as a binary classifier, theoutputs of which can be interpreted as the probability of COVID-19 infection.
A.3.2 Ensemble Training and Inference
Many machine learning approaches struggle to deal with real-world health data because itis common to have imbalanced datasets where the healthy users are a significant majorityof the whole set. This is also the case for COVID-19 sound-based detection, where theusers who tested positive are the minority class. To tackle this problem, as described inFigure A.3.1, we generate a series of training bags {(X1, Y1), (X2, Y2), ..., (XN , YN)} with anequal number of positive and healthy users by re-sampling from the majority healthy class,where Xi denotes the input audio samples within the i-th bag and Yi are the correspondinglabels. Note that since some healthy users can be re-used, we can generate numerous bags.Consequently, based on a fixed and shared validation set, we train N neural networks, asintroduced in Sec. A.3.1, via cross-entropy loss, independently. During inference, we passthe testing sample x into the ensemble suite and obtain probability-based fusion [120] asthe final output, formulated as follows,
p(y) =1
N
N∑i=1
P (y = 1|x,Xi, Yi, θi), (A.1)
where P (y|x,Xi, Yi, θi) is the predicted softmax probability of i-th model. If p(y) is higherthan 0.5, the given testing sample will be predicted as COVID-19 positive.
27

A.3.3 Uncertainty Estimation
No matter how good the deep learning model is, difficult cases to diagnose are unavoidable:this could be due to many reasons, including very noisy samples. This highlights theimportance of uncertainty estimation for the digital screening. Considering the incapabilityof softmax probability to capture model confidence, we define the disagreement level acrossmodels within the ensemble suite as the measure of uncertainty. Uncertainty from deepensembles has also been shown to be more effective than other estimation approaches [81].To be specific, we use the standard deviation across the N models as the measurement ofuncertainty as follows,
σ(y) =
√√√√ 1
N
N∑i=1
(P (y = 1|x,Xi, Yi, θi)− µ)2, (A.2)
where µ is the averaged probability, as p(y) in Eq. (A.1).
If the uncertainty σ(y) is higher than a predefined threshold, it implies that the model isconfident enough with its prediction during digital pre-screening. Under this circumstance,the system can first request a second or even more repeated audio testing on smartphones.If the uncertainty is still high, this particular sample could be then referred for furtherclinical or another testing. As a consequence, both system performance and patient safetycan be improved.
A.4 Evaluation
A.4.1 Dataset
Given the great potential of audio-based COVID-19 digital screening, we launched an app,namely COVID-19 Sounds App, to crowdsource data for research. In the initial registra-tion, users’ basic demographic and medical history information are required. Then, usersare guided to record and submit breathing, coughing, and short speech audios, togetherwith the latest coronavirus testing results and associated symptoms, if any, every otherday. As of February 26th 2021, 68 324 data samples from 36 675 users have been collected.
In this study, we focus on the group consisting of users who declared to have tested positiveand ones who declared they have tested negative and declared no symptoms: we call theseusers “healthy”. To avoid any language confounders in the voice recordings, only Englishspeakers were retained. After a manual quality check, 330 positive users with 469 samplesand 688 healthy users with 1 526 samples were selected. Overall, 58% of the users aremale and more than 60% are aged between 20 to 49. Demographic and medical historydistributions are similar in the two classes. As for pre-processing, we resample all therecordings to 16 kHz mono audios, and then we crop them by removing the silence periodat the beginning and the end of the recording as in [24]. Finally, audio normalisation isapplied to eliminate the discrepancy across recording devices.
28

Table A.4.1: Basic statistics of COVID-19 sound data.
Positive Healthy
#Users #Samples #Users #Samples
Train 231 327 589+231 1376+405Validation 33 44 33 56Test 66 98 66 94
A.4.2 Experimental setup
To evaluate the proposed framework, for the positive group, we hold out 10% and 20% ofusers as validation and testing sets, and then use the remaining data for training. Corre-spondingly, we select the same of healthy users for validation and testing (see Table A.4.1).Furthermore, to generate a balanced training set for each ensemble unit (Xi, Yi), 231 usersare randomly selected from 589 negative tested users. The number of hidden units of denselayers in our model is set to 64 and 2, respectively. When training, our batch size is 1,the learning rate is 0.0001 with a decay factor of 0.99 and we use cross-entropy loss andAdam optimiser. Early stopping is applied on the validation set to avoid over-fitting. Allexperiments are implemented in Python and TensorFlow. Feature extractor is initialledby pre-trained VGGish model and then updated with the following dense layers jointly.
Moreover, baselines from the latest literature are conducted for performance comparison.In addition to deep models, acoustic feature-driven SVM achieved state-of-the-art perfor-mance in sound-based COVID-19 detection due to its effectiveness and robustness in smalldata learning [22, 37, 24]. Therefore, we repeat the experiments in [24] by using the openS-MILE toolkit to extract 384 acoustic features and SVM with linear kernel and complexconstant C = 0.01 as the classifier. For both SVM and deep models, to test the superiorperformance of ensemble learning, we compare training one single model with all samples,with balanced samples by down or up-sampling, against training N = 10 models in an en-semble learning manner. For down-sampling balancing, we randomly discard some healthyusers, while for up-sampling, synthetic minority oversampling techniques (SMOTE) [117]is performed to generate synthetic observations of the minority class. This is the mostcommonly adopted technique for imbalanced data.
To justify the performance of the proposed framework for COVID-19 screening and diagno-sis, we calculate the following metrics: Sensitivity , also named true positive rate or recalldefined by TP/(TP +FN), Specificity , also referred to as true negative rate formulatedby TN/(TN + FP ), and ROC-AUC , the area under receiver operating characteristicscurve. which measures the overall sensitivity and specificity at various probability thresh-olds. Besides, for both the baseline and our proposed methods, the mean and standarddeviation of the aforementioned metrics across 10 runs are reported.
29
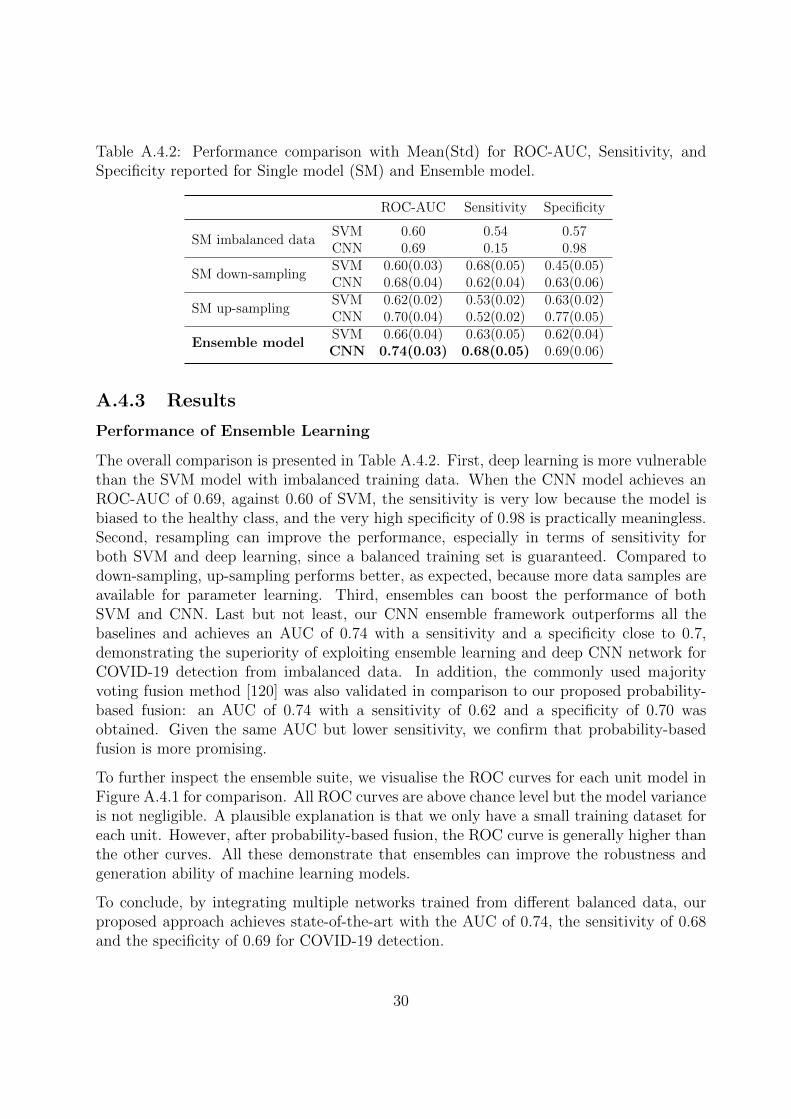
Table A.4.2: Performance comparison with Mean(Std) for ROC-AUC, Sensitivity, andSpecificity reported for Single model (SM) and Ensemble model.
ROC-AUC Sensitivity Specificity
SM imbalanced dataSVM 0.60 0.54 0.57CNN 0.69 0.15 0.98
SM down-samplingSVM 0.60(0.03) 0.68(0.05) 0.45(0.05)CNN 0.68(0.04) 0.62(0.04) 0.63(0.06)
SM up-samplingSVM 0.62(0.02) 0.53(0.02) 0.63(0.02)CNN 0.70(0.04) 0.52(0.02) 0.77(0.05)
Ensemble modelSVM 0.66(0.04) 0.63(0.05) 0.62(0.04)CNN 0.74(0.03) 0.68(0.05) 0.69(0.06)
A.4.3 Results
Performance of Ensemble Learning
The overall comparison is presented in Table A.4.2. First, deep learning is more vulnerablethan the SVM model with imbalanced training data. When the CNN model achieves anROC-AUC of 0.69, against 0.60 of SVM, the sensitivity is very low because the model isbiased to the healthy class, and the very high specificity of 0.98 is practically meaningless.Second, resampling can improve the performance, especially in terms of sensitivity forboth SVM and deep learning, since a balanced training set is guaranteed. Compared todown-sampling, up-sampling performs better, as expected, because more data samples areavailable for parameter learning. Third, ensembles can boost the performance of bothSVM and CNN. Last but not least, our CNN ensemble framework outperforms all thebaselines and achieves an AUC of 0.74 with a sensitivity and a specificity close to 0.7,demonstrating the superiority of exploiting ensemble learning and deep CNN network forCOVID-19 detection from imbalanced data. In addition, the commonly used majorityvoting fusion method [120] was also validated in comparison to our proposed probability-based fusion: an AUC of 0.74 with a sensitivity of 0.62 and a specificity of 0.70 wasobtained. Given the same AUC but lower sensitivity, we confirm that probability-basedfusion is more promising.
To further inspect the ensemble suite, we visualise the ROC curves for each unit model inFigure A.4.1 for comparison. All ROC curves are above chance level but the model varianceis not negligible. A plausible explanation is that we only have a small training dataset foreach unit. However, after probability-based fusion, the ROC curve is generally higher thanthe other curves. All these demonstrate that ensembles can improve the robustness andgeneration ability of machine learning models.
To conclude, by integrating multiple networks trained from different balanced data, ourproposed approach achieves state-of-the-art with the AUC of 0.74, the sensitivity of 0.68and the specificity of 0.69 for COVID-19 detection.
30
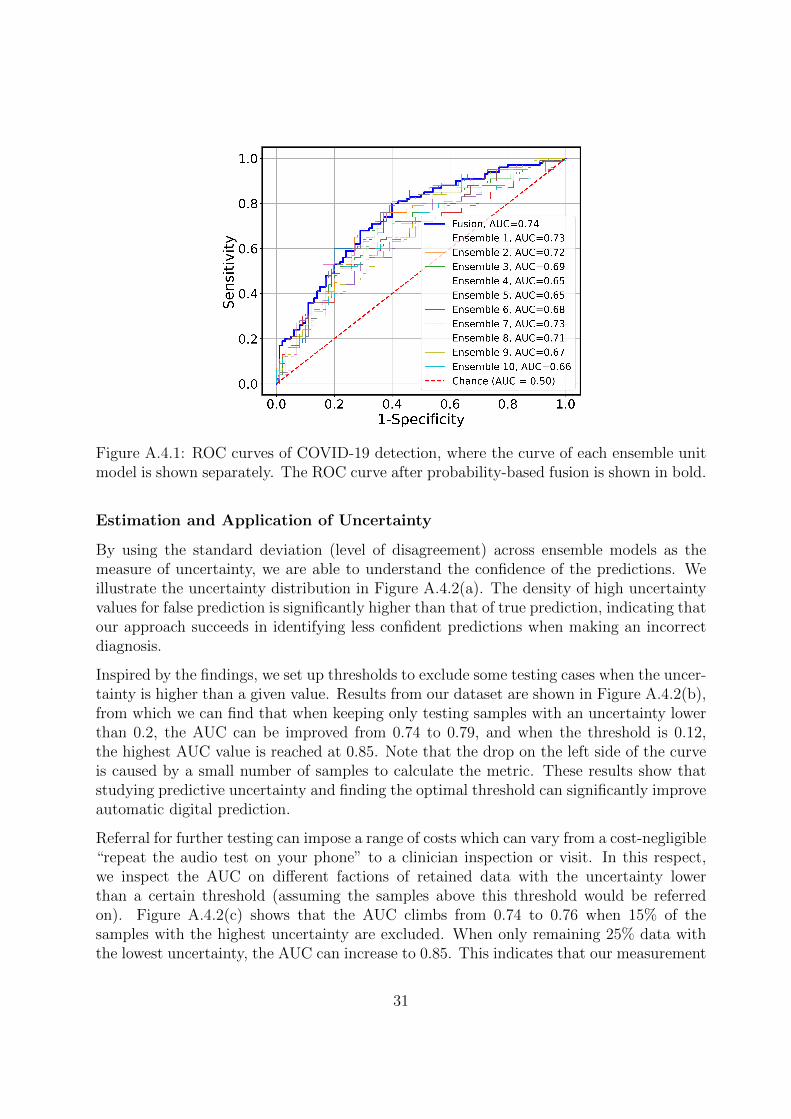
Figure A.4.1: ROC curves of COVID-19 detection, where the curve of each ensemble unitmodel is shown separately. The ROC curve after probability-based fusion is shown in bold.
Estimation and Application of Uncertainty
By using the standard deviation (level of disagreement) across ensemble models as themeasure of uncertainty, we are able to understand the confidence of the predictions. Weillustrate the uncertainty distribution in Figure A.4.2(a). The density of high uncertaintyvalues for false prediction is significantly higher than that of true prediction, indicating thatour approach succeeds in identifying less confident predictions when making an incorrectdiagnosis.
Inspired by the findings, we set up thresholds to exclude some testing cases when the uncer-tainty is higher than a given value. Results from our dataset are shown in Figure A.4.2(b),from which we can find that when keeping only testing samples with an uncertainty lowerthan 0.2, the AUC can be improved from 0.74 to 0.79, and when the threshold is 0.12,the highest AUC value is reached at 0.85. Note that the drop on the left side of the curveis caused by a small number of samples to calculate the metric. These results show thatstudying predictive uncertainty and finding the optimal threshold can significantly improveautomatic digital prediction.
Referral for further testing can impose a range of costs which can vary from a cost-negligible“repeat the audio test on your phone” to a clinician inspection or visit. In this respect,we inspect the AUC on different factions of retained data with the uncertainty lowerthan a certain threshold (assuming the samples above this threshold would be referredon). Figure A.4.2(c) shows that the AUC climbs from 0.74 to 0.76 when 15% of thesamples with the highest uncertainty are excluded. When only remaining 25% data withthe lowest uncertainty, the AUC can increase to 0.85. This indicates that our measurement
31
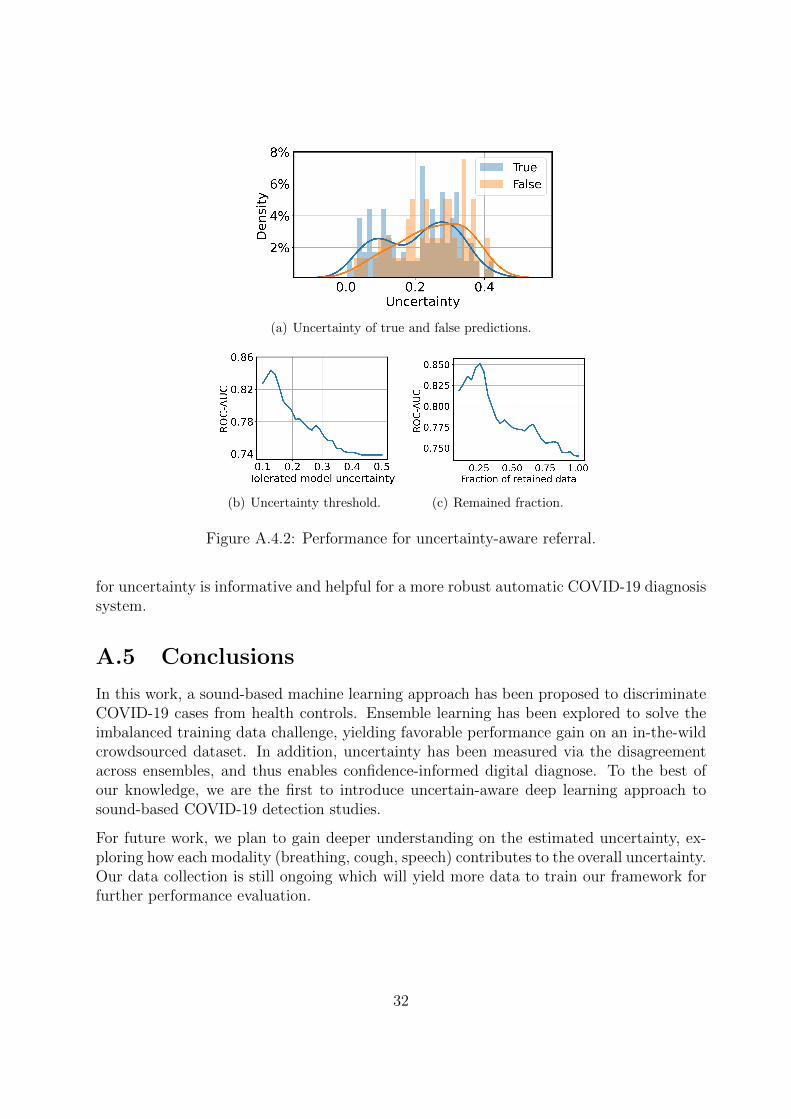
(a) Uncertainty of true and false predictions.
(b) Uncertainty threshold. (c) Remained fraction.
Figure A.4.2: Performance for uncertainty-aware referral.
for uncertainty is informative and helpful for a more robust automatic COVID-19 diagnosissystem.
A.5 Conclusions
In this work, a sound-based machine learning approach has been proposed to discriminateCOVID-19 cases from health controls. Ensemble learning has been explored to solve theimbalanced training data challenge, yielding favorable performance gain on an in-the-wildcrowdsourced dataset. In addition, uncertainty has been measured via the disagreementacross ensembles, and thus enables confidence-informed digital diagnose. To the best ofour knowledge, we are the first to introduce uncertain-aware deep learning approach tosound-based COVID-19 detection studies.
For future work, we plan to gain deeper understanding on the estimated uncertainty, ex-ploring how each modality (breathing, cough, speech) contributes to the overall uncertainty.Our data collection is still ongoing which will yield more data to train our framework forfurther performance evaluation.
32

Bibliography
[1] Clara Mihaela Ionescu. The human respiratory system: an analysis of the interplaybetween anatomy, structure, breathing and fractal dynamics. Springer Science &Business Media, 2013.
[2] Gustavo Xavier Andrade Miranda. Analyzing of the vocal fold dynamics using laryn-geal videos. PhD thesis, Universidad Politecnica de Madrid, 2017.
[3] Stephen A Martin, Brandt D Pence, and Jeffrey A Woods. Exercise and respiratorytract viral infections. Exercise and sport sciences reviews, 37(4):157, 2009.
[4] Diane Cappelletty. Microbiology of bacterial respiratory infections. The Pediatricinfectious disease journal, 17(8):S55–S61, 1998.
[5] Malay Sarkar, Irappa Madabhavi, Narasimhalu Niranjan, and Megha Dogra. Aus-cultation of the respiratory system. Annals of thoracic medicine, 10(3):158, 2015.
[6] Shuang Leng, Ru San Tan, Kevin Tshun Chuan Chai, Chao Wang, Dhanjoo Ghista,and Liang Zhong. The electronic stethoscope. Biomedical engineering online, 14(1):1–37, 2015.
[7] Rainer K Rienmuller, Jurgen Behr, Willi A Kalender, Manfred Schatzl, Irene Alt-mann, Manfred Merin, and Thomas Beinert. Standardized quantitative high reso-lution ct in lung diseases. Journal of computer assisted tomography, 15(5):742–749,1991.
[8] Victoria J Chalker, Wanda MA Owen, Caren Paterson, Emily Barker, HarrietBrooks, Andrew N Rycroft, and Joe Brownlie. Mycoplasmas associated with ca-nine infectious respiratory disease. Microbiology, 150(10):3491–3497, 2004.
[9] Laura E Lamb, Sarah N Bartolone, Elijah Ward, and Michael B Chancellor. Rapiddetection of novel coronavirus (covid19) by reverse transcription-loop-mediatedisothermal amplification. Available at SSRN 3539654, 2020.
[10] Asma Channa, Nirvana Popescu, et al. Managing covid-19 global pandemic withhigh-tech consumer wearables: A comprehensive review. In 2020 12th InternationalCongress on Ultra Modern Telecommunications and Control Systems and Workshops(ICUMT), pages 222–228. IEEE, 2020.
33

[11] Magdalena Igras-Cybulska. Analysis of non-linguistic content of speech signals. PhDthesis, 03 2017.
[12] Himadri Mukherjee, Priyanka Sreerama, Ankita Dhar, Sk Md Obaidullah, KaushikRoy, Mufti Mahmud, and KC Santosh. Automatic lung health screening using res-piratory sounds. Journal of Medical Systems, 45(2):1–9, 2021.
[13] Arpan Srivastava, Sonakshi Jain, Ryan Miranda, Shruti Patil, Sharnil Pandya, andKetan Kotecha. Deep learning based respiratory sound analysis for detection ofchronic obstructive pulmonary disease. PeerJ Computer Science, 7, 2021.
[14] Renard Xaviero Adhi Pramono, Syed Anas Imtiaz, and Esther Rodriguez-Villegas. A cough-based algorithm for automatic diagnosis of pertussis. PloS one,11(9):e0162128, 2016.
[15] Tian Hao, Guoliang Xing, and Gang Zhou. isleep: Unobtrusive sleep quality moni-toring using smartphones. In Proceedings of the 11th ACM Conference on EmbeddedNetworked Sensor Systems, pages 1–14, 2013.
[16] Bjorn Schuller. Chain of audio processing. In Intelligent Audio Analysis, pages 17–22.Springer, 2013.
[17] Dong Yu and Jinyu Li. Recent progresses in deep learning based acoustic models.IEEE/CAA Journal of automatica sinica, 4(3):396–409, 2017.
[18] Gunvant Chaudhari, Xinyi Jiang, Ahmed Fakhry, Asriel Han, Jaclyn Xiao, SabrinaShen, and Amil Khanzada. Virufy: Global applicability of crowdsourced and clinicaldatasets for ai detection of COVID-19 from cough. arXiv:2011.13320, 2020.
[19] Yi Ma, Xinzi Xu, Qing Yu, Yuhang Zhang, Yongfu Li, Jian Zhao, and GuoxingWang. Lungbrn: A smart digital stethoscope for detecting respiratory disease usingbi-resnet deep learning algorithm. In 2019 IEEE Biomedical Circuits and SystemsConference (BioCAS), pages 1–4. IEEE, 2019.
[20] Ludmila I Kuncheva and Christopher J Whitaker. Measures of diversity in classifierensembles and their relationship with the ensemble accuracy. Machine learning,51(2):181–207, 2003.
[21] Lara Orlandic, Tomas Teijeiro, and David Atienza. The coughvid crowdsourcingdataset: A corpus for the study of large-scale cough analysis algorithms. arXivpreprint arXiv:2009.11644, 2020.
[22] Chloe Brown, Jagmohan Chauhan, Andreas Grammenos, Jing Han, ApinanHasthanasombat, Dimitris Spathis, Tong Xia, Pietro Cicuta, and Cecilia Mascolo.Exploring automatic diagnosis of COVID-19 from crowdsourced respiratory sounddata. In Proceedings of the 26th ACM SIGKDD International Conference on Knowl-edge Discovery & Data Mining (KDD), pages 3474–3484, 2020.
34

[23] Cristina Menni, Ana M Valdes, Maxim B Freidin, Carole H Sudre, Long H Nguyen,David A Drew, Sajaysurya Ganesh, Thomas Varsavsky, M Jorge Cardoso, Julia SEl-Sayed Moustafa, et al. Real-time tracking of self-reported symptoms to predictpotential covid-19. Nature medicine, 26(7):1037–1040, 2020.
[24] Jing Han, Chloe Brown, Jagmohan Chauhan, Andreas Grammenos, ApinanHasthanasombat, Dimitris Spathis, Tong Xia, Pietro Cicuta, and Cecilia Mascolo.Exploring automatic COVID-19 diagnosis via voice and symptoms from crowd-sourced data. In Proceedings of the International Conference on Acoustics, Speech,and Signal Processing (ICASSP), pages 1–5, 2021.
[25] Srikanth Raj Chetupalli, Prashant Krishnan, Neeraj Sharma, Ananya Muguli, RohitKumar, Viral Nanda, Lancelot Mark Pinto, Prasanta Kumar Ghosh, and SriramGanapathy. Multi-modal point-of-care diagnostics for covid-19 based on acousticsand symptoms. arXiv preprint arXiv:2106.00639, 2021.
[26] Makkunda Sharma, Nikhil Shenoy, Jigar Doshi, Piyush Bagad, Aman Dalmia, ParagBhamare, Amrita Mahale, Saurabh Rane, Neeraj Agrawal, and Rahul Panicker. Im-pact of data-splits on generalization: Identifying covid-19 from cough and context.arXiv preprint arXiv:2106.03851, 2021.
[27] Bjorn Schuller. Voice and speech analysis in search of states and traits. In ComputerAnalysis of Human Behavior, pages 227–253. Springer, 2011.
[28] Udantha R Abeyratne, Vinayak Swarnkar, Amalia Setyati, and Rina Triasih. Coughsound analysis can rapidly diagnose childhood pneumonia. Annals of biomedicalengineering, 41(11):2448–2462, 2013.
[29] Florian Eyben, Martin Wollmer, and Bjorn Schuller. Opensmile: the munich versa-tile and fast open-source audio feature extractor. In Proceedings of the 18th ACMinternational conference on Multimedia, pages 1459–1462, 2010.
[30] Florian Eyben, Klaus R Scherer, Bjorn W Schuller, Johan Sundberg, ElisabethAndre, Carlos Busso, Laurence Y Devillers, Julien Epps, Petri Laukka, Shrikanth SNarayanan, et al. The geneva minimalistic acoustic parameter set (gemaps) forvoice research and affective computing. IEEE transactions on affective computing,7(2):190–202, 2015.
[31] Joel Shor, Aren Jansen, Ronnie Maor, Oran Lang, Omry Tuval, Felix de Chau-mont Quitry, Marco Tagliasacchi, Ira Shavitt, Dotan Emanuel, and Yinnon Haviv.Towards learning a universal non-semantic representation of speech.
[32] Harry Coppock, Alex Gaskell, Panagiotis Tzirakis, Alice Baird, Lyn Jones, and BjornSchuller. End-to-end convolutional neural network enables covid-19 detection frombreath and cough audio: a pilot study. BMJ Innovations, 7(2):356–362, 2021.
[33] Lukui Shi, Kang Du, Chaozong Zhang, Hongqi Ma, and Wenjie Yan. Lung soundrecognition algorithm based on vggish-bigru. IEEE Access, 7:139438–139449, 2019.
35

[34] Nicholas Cummins, Alice Baird, and Bjorn W Schuller. Speech analysis for health:Current state-of-the-art and the increasing impact of deep learning. Methods, 151:41–54, 2018.
[35] Dalal Bardou, Kun Zhang, and Sayed Mohammad Ahmad. Lung sounds classificationusing convolutional neural networks. Artificial intelligence in medicine, 88:58–69,2018.
[36] Gokhan Altan, Yakup Kutlu, and Novruz Allahverdi. Deep learning on computerizedanalysis of chronic obstructive pulmonary disease. IEEE journal of biomedical andhealth informatics, 24(5):1344–1350, 2019.
[37] Jing Han, Kun Qian, Meishu Song, Zijiang Yang, Zhao Ren, Shuo Liu, Juan Liu,Huaiyuan Zheng, Wei Ji, Tomoya Koike, and Bjorn W Schuller. An early study onintelligent analysis of speech under COVID-19: Severity, sleep quality, fatigue, andanxiety. In Proceedings of INTERSPEECH, pages 4946–4950, 2020.
[38] Jordi Laguarta, Ferran Hueto, and Brian Subirana. COVID-19 artificial intelli-gence diagnosis using only cough recordings. IEEE Open Journal of Engineeringin Medicine and Biology, 1:275–281, 2020.
[39] Hao Xue and Flora D Salim. Exploring self-supervised representation ensembles forcovid-19 cough classification. arXiv preprint arXiv:2105.07566, 2021.
[40] Chuanqi Tan, Fuchun Sun, Tao Kong, Wenchang Zhang, Chao Yang, and ChunfangLiu. A survey on deep transfer learning. In International conference on artificialneural networks, pages 270–279. Springer, 2018.
[41] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence,R Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology andhuman-labeled dataset for audio events. In 2017 IEEE International Conference onAcoustics, Speech and Signal Processing (ICASSP), pages 776–780. IEEE, 2017.
[42] Shawn Hershey, Sourish Chaudhuri, Daniel PW Ellis, Jort F Gemmeke, Aren Jansen,R Channing Moore, Manoj Plakal, Devin Platt, Rif A Saurous, Bryan Seybold,et al. CNN architectures for large-scale audio classification. In Proceedings of theInternational Conference on Acoustics, Speech, and Signal Processing (ICASSP),pages 131–135, 2017.
[43] Sinno Jialin Pan and Qiang Yang. A survey on transfer learning. IEEE Transactionson knowledge and data engineering, 22(10):1345–1359, 2009.
[44] Longlong Jing and Yingli Tian. Self-supervised visual feature learning with deepneural networks: A survey. IEEE Transactions on Pattern Analysis and MachineIntelligence, 2020.
36

[45] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representationlearning with deep convolutional generative adversarial networks. arXiv preprintarXiv:1511.06434, 2015.
[46] Jeff Donahue, Philipp Krahenbuhl, and Trevor Darrell. Adversarial feature learning.ICLR, 2016.
[47] Jiwei Wang, Yiqiang Chen, Yang Gu, Yunlong Xiao, and Haonan Pan. Sensorygans:An effective generative adversarial framework for sensor-based human activity recog-nition. In 2018 International Joint Conference on Neural Networks (IJCNN), pages1–8. IEEE, 2018.
[48] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei AEfros. Context encoders: Feature learning by inpainting. In Proceedings of the IEEEconference on computer vision and pattern recognition, pages 2536–2544, 2016.
[49] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A sim-ple framework for contrastive learning of visual representations. In Internationalconference on machine learning, pages 1597–1607. PMLR, 2020.
[50] Anne Wu, Changhan Wang, Juan Pino, and Jiatao Gu. Self-supervised representa-tions improve end-to-end speech translation. arXiv preprint arXiv:2006.12124, 2020.
[51] Apoorv Nandan and Jithendra Vepa. Language agnostic speech embeddings foremotion classification. 2020.
[52] Lidan Wu, Daoming Zong, Shiliang Sun, and Jing Zhao. A sequential contrastivelearning framework for robust dysarthric speech recognition. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), pages 7303–7307. IEEE, 2021.
[53] PM Dixon, DI Railton, and BC McGorum. Equine pulmonary disease: a case controlstudy of 300 referred cases. part 1: Examination techniques, diagnostic criteria anddiagnoses. Equine veterinary journal, 27(6):416–421, 1995.
[54] Tejaswini Mishra, Meng Wang, Ahmed A Metwally, Gireesh K Bogu, Andrew WBrooks, Amir Bahmani, Arash Alavi, Alessandra Celli, Emily Higgs, Orit Dagan-Rosenfeld, et al. Pre-symptomatic detection of covid-19 from smartwatch data. Na-ture Biomedical Engineering, 4(12):1208–1220, 2020.
[55] Giorgio Quer, Jennifer M Radin, Matteo Gadaleta, Katie Baca-Motes, LaurenAriniello, Edward Ramos, Vik Kheterpal, Eric J Topol, and Steven R Steinhubl.Wearable sensor data and self-reported symptoms for covid-19 detection. NatureMedicine, 27(1):73–77, 2021.
[56] Elena-Anca Paraschiv and Catalina-Maria Rotaru. Machine learning approachesbased on wearable devices for respiratory diseases diagnosis. In 2020 InternationalConference on e-Health and Bioengineering (EHB), pages 1–4. IEEE, 2020.
37

[57] Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, and An-drew Y Ng. Multimodal deep learning. In ICML, 2011.
[58] DN Krishna and Ankita Patil. Multimodal emotion recognition using cross-modalattention and 1d convolutional neural networks. Proc. Interspeech 2020, pages 4243–4247, 2020.
[59] Darshana Priyasad, Tharindu Fernando, Simon Denman, Sridha Sridharan, and Clin-ton Fookes. Attention driven fusion for multi-modal emotion recognition. In ICASSP2020-2020 IEEE International Conference on Acoustics, Speech and Signal Process-ing (ICASSP), pages 3227–3231. IEEE, 2020.
[60] Zexu Pan, Zhaojie Luo, Jichen Yang, and Haizhou Li. Multi-modal attention forspeech emotion recognition. Proc. Interspeech 2020, pages 4235–4257, 2020.
[61] Junghyun Koo, Jie Hwan Lee, Jaewoo Pyo, Yujin Jo, and Kyogu Lee. Exploitingmulti-modal features from pre-trained networks for alzheimer’s dementia recognition.Proc. Interspeech 2020, pages 2217–2221, 2020.
[62] Morteza Rohanian, Julian Hough, and Matthew Purver. Multi-modal fusion withgating using audio, lexical and disfluency features for alzheimer’s dementia recogni-tion from spontaneous speech. Proc. Interspeech 2021, pages 1126–1130, 2021.
[63] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan NGomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proceed-ings of the 31st International Conference on Neural Information Processing Systems,pages 6000–6010, 2017.
[64] Christian Leibig, Vaneeda Allken, Murat Seckin Ayhan, Philipp Berens, and SiegfriedWahl. Leveraging uncertainty information from deep neural networks for diseasedetection. Scientific Reports, 7(1):1–14, 2017.
[65] Lorena Qendro, Jagmohan Chauhan, Alberto Gil CP Ramos, and Cecilia Mascolo.The benefit of the doubt: Uncertainty aware sensing for edge computing platforms.arXiv:2102.05956, 2021.
[66] Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration ofmodern neural networks. In Proceedings of the International Conference on MachineLearning (ICML), pages 1321–1330, 2017.
[67] Umang Bhatt, Javier Antoran, Yunfeng Zhang, Q Vera Liao, Prasanna Sattigeri, Ric-cardo Fogliato, Gabrielle Gauthier Melancon, Ranganath Krishnan, Jason Stanley,Omesh Tickoo, et al. Uncertainty as a form of transparency: Measuring, communi-cating, and using uncertainty. arXiv preprint arXiv:2011.07586, 2020.
[68] Radford M Neal. Bayesian learning for neural networks, volume 118. Springer Science& Business Media, 2012.
38

[69] Tianqi Chen, Emily Fox, and Carlos Guestrin. Stochastic gradient hamiltonian montecarlo. In International conference on machine learning, pages 1683–1691. PMLR,2014.
[70] Max Welling and Yee W Teh. Bayesian learning via stochastic gradient langevindynamics. In Proceedings of the 28th international conference on machine learning(ICML-11), pages 681–688. Citeseer, 2011.
[71] David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A reviewfor statisticians. Journal of the American statistical Association, 112(518):859–877,2017.
[72] Alex Graves. Practical variational inference for neural networks. In Advances inneural information processing systems, pages 2348–2356. Citeseer, 2011.
[73] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXivpreprint arXiv:1312.6114, 2013.
[74] Pierre Baldi and Peter J Sadowski. Understanding dropout. Advances in neuralinformation processing systems, 26:2814–2822, 2013.
[75] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and RuslanSalakhutdinov. Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research, 15(1):1929–1958, 2014.
[76] Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Rep-resenting model uncertainty in deep learning. In Proceedings of the InternationalConference on Machine Learning (ICML), pages 1050–1059, 2016.
[77] Yarin Gal and Zoubin Ghahramani. A theoretically grounded application of dropoutin recurrent neural networks. Advances in neural information processing systems,29:1019–1027, 2016.
[78] MA Ganaie, Minghui Hu, et al. Ensemble deep learning: A review. arXiv preprintarXiv:2104.02395, 2021.
[79] Thomas G Dietterich. Ensemble methods in machine learning. In Internationalworkshop on multiple classifier systems, pages 1–15. Springer, 2000.
[80] Zhi-Hua Zhou. Ensemble methods: foundations and algorithms. CRC press, 2012.
[81] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple andscalable predictive uncertainty estimation using deep ensembles. In Proceedings of the31st International Conference on Neural Information Processing Systems (NeurIPS),pages 6405–6416, 2017.
[82] Kimin Lee, Honglak Lee, Kibok Lee, and Jinwoo Shin. Training confidence-calibratedclassifiers for detecting out-of-distribution samples. In International Conference onLearning Representations, 2018.
39

[83] Max-Heinrich Laves, Sontje Ihler, Tobias Ortmaier, and Luder A Kahrs. Quantifyingthe uncertainty of deep learning-based computer-aided diagnosis for patient safety.Current Directions in Biomedical Engineering, 5(1):223–226, 2019.
[84] Yongchan Kwon, Joong-Ho Won, Beom Joon Kim, and Myunghee Cho Paik. Un-certainty quantification using bayesian neural networks in classification: Applica-tion to biomedical image segmentation. Computational Statistics & Data Analysis,142:106816, 2020.
[85] Aryan Mobiny, Aditi Singh, and Hien Van Nguyen. Risk-aware machine learningclassifier for skin lesion diagnosis. Journal of clinical medicine, 8(8):1241, 2019.
[86] Angelos Filos, Sebastian Farquhar, Aidan N Gomez, Tim GJ Rudner, Zachary Ken-ton, Lewis Smith, Milad Alizadeh, Arnoud de Kroon, and Yarin Gal. A systematiccomparison of bayesian deep learning robustness in diabetic retinopathy tasks. arXivpreprint arXiv:1912.10481, 2019.
[87] Biraja Ghoshal and Allan Tucker. Estimating uncertainty and interpretability indeep learning for coronavirus (COVID-19) detection. arXiv:2003.10769, 2020.
[88] Xixin Wu, Kate M Knill, Mark JF Gales, and Andrey Malinin. Ensemble approachesfor uncertainty in spoken language assessment. In Proceedings of INTERSPEECH,pages 3860–3864, 2020.
[89] Sina Daubener, Lea Schonherr, Asja Fischer, and Dorothea Kolossa. Detecting adver-sarial examples for speech recognition via uncertainty quantification. arXiv preprintarXiv:2005.14611, 2020.
[90] Tejas Jayashankar, Jonathan Le Roux, and Pierre Moulin. Detecting audio attackson asr systems with dropout uncertainty. arXiv preprint arXiv:2006.01906, 2020.
[91] Aniek F Markus, Jan A Kors, and Peter R Rijnbeek. The role of explainability increating trustworthy artificial intelligence for health care: a comprehensive surveyof the terminology, design choices, and evaluation strategies. Journal of BiomedicalInformatics, page 103655, 2020.
[92] Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and AramGalstyan. A survey on bias and fairness in machine learning. arXiv preprintarXiv:1908.09635, 2019.
[93] Nidaa F Hassan and Sarah Qusay Selah Alden. Gender classification based on audiofeatures. Journal of Al-Ma’moon College, (31), 2018.
[94] Onno Kampman, Elham J Barezi, Dario Bertero, and Pascale Fung. Investigating au-dio, visual, and text fusion methods for end-to-end automatic personality prediction.arXiv preprint arXiv:1805.00705, 2018.
40

[95] Zhizhong Ma, Chris Bullen, Joanna Ting Wai Chu, Ruili Wang, Yingchun Wang,and Satwinder Singh. Towards the objective speech assessment of smoking statusbased on voice features: A review of the literature. Journal of Voice, 2021.
[96] Kun Qian, Bjorn W Schuller, and Yoshiharu Yamamoto. Recent advances in com-puter audition for diagnosing covid-19: An overview. In 2021 IEEE 3rd Global Con-ference on Life Sciences and Technologies (LifeTech), pages 181–182. IEEE, 2021.
[97] D Trejo Pizzo, Santiago Esteban, and M Scetta. Iatos: Ai-powered pre-screeningtool for covid-19 from cough audio samples. arXiv preprint arXiv:2104.13247, 2021.
[98] Bjorn W. Schuller, Dagmar M. Schuller, Kun Qian, Juan Liu, Huaiyuan Zheng, andXiao Li. COVID-19 and computer audition: An overview on what speech & soundanalysis could contribute in the sars-cov-2 corona crisis. Frontiers in Digital Health,3:1–10, 2021.
[99] Marıa Teresa Garcıa-Ordas, Jose Alberto Benıtez-Andrades, Isaıas Garcıa-Rodrıguez, Carmen Benavides, and Hector Alaiz-Moreton. Detecting respiratorypathologies using convolutional neural networks and variational autoencoders forunbalancing data. Sensors, 20(4):1214, 2020.
[100] Ewan Hunter, David A Price, Elizabeth Murphy, Ina Schim van der Loeff, Kenneth FBaker, Dennis Lendrem, Clare Lendrem, Matthias L Schmid, Lucia Pareja-Cebrian,Andrew Welch, et al. First experience of COVID-19 screening of health-care workersin england. The Lancet, 395(10234):e77–e78, 2020.
[101] Andrew Atkeson, Michael C Droste, Michael Mina, and James H Stock. Economicbenefits of COVID-19 screening tests. National Bureau of Economic Research, 2020.
[102] Muge Cevik, Krutika Kuppalli, Jason Kindrachuk, and Malik Peiris. Virology, trans-mission, and pathogenesis of SARS-CoV-2. British Medical Journal, 371:1–6, 2020.
[103] Chantal BF Vogels, Anderson F Brito, Anne L Wyllie, Joseph R Fauver, Isabel MOtt, Chaney C Kalinich, Mary E Petrone, Arnau Casanovas-Massana, M CatherineMuenker, Adam J Moore, et al. Analytical sensitivity and efficiency comparisons ofSARS-CoV-2 RT–qPCR primer–probe sets. Nature Microbiology, 5(10):1299–1305,2020.
[104] Wei-jie Guan, Zheng-yi Ni, Yu Hu, Wen-hua Liang, Chun-quan Ou, Jian-xing He,Lei Liu, Hong Shan, Chun-liang Lei, David SC Hui, et al. Clinical characteristics ofcoronavirus disease 2019 in china. New England Journal of Medicine, 382(18):1708–1720, 2020.
[105] Wenqi Wei, Jianzong Wang, Jiteng Ma, Ning Cheng, and Jing Xiao. A real-timerobot-based auxiliary system for risk evaluation of COVID-19 infection. In Proceed-ings of INTERSPEECH, pages 701–705, 2020.
41

[106] Ali Imran, Iryna Posokhova, Haneya N Qureshi, Usama Masood, Muhammad SajidRiaz, Kamran Ali, Charles N John, MD Iftikhar Hussain, and Muhammad Nabeel.Ai4COVID-19: Ai enabled preliminary diagnosis for COVID-19 from cough samplesvia an app. Informatics in Medicine Unlocked, 20:100378, 2020.
[107] Piyush Bagad, Aman Dalmia, Jigar Doshi, Arsha Nagrani, Parag Bhamare, AmritaMahale, Saurabh Rane, Neeraj Agarwal, and Rahul Panicker. Cough against covid:Evidence of COVID-19 signature in cough sounds. arXiv:2009.08790, 2020.
[108] Gadi Pinkas, Yarden Karny, Aviad Malachi, Galia Barkai, Gideon Bachar, and VeredAharonson. Sars-cov-2 detection from voice. IEEE Open Journal of Engineering inMedicine and Biology, 1:268–274, 2020.
[109] Maral Asiaee, Amir Vahedian-Azimi, Seyed Shahab Atashi, Abdalsamad Keramatfar,and Mandana Nourbakhsh. Voice quality evaluation in patients with COVID-19: Anacoustic analysis. Journal of Voice, pages 1–7, 2020.
[110] Xinjian Guo, Yilong Yin, Cailing Dong, Gongping Yang, and Guangtong Zhou. Onthe class imbalance problem. In Proceedings of the International Conference onNatural Computation (ICNC), volume 4, pages 192–201, 2008.
[111] Max Schubach, Matteo Re, Peter N Robinson, and Giorgio Valentini. Imbalance-aware machine learning for predicting rare and common disease-associated non-coding variants. Scientific Reports, 7(1):1–12, 2017.
[112] Nathalie Japkowicz and Shaju Stephen. The class imbalance problem: A systematicstudy. Intelligent Data Analysis, 6(5):429–449, 2002.
[113] Madhurananda Pahar, Marisa Klopper, Robin Warren, and Thomas Niesler. COVID-19 cough classification using machine learning and global smartphone recordings.arXiv:2012.01926, 2020.
[114] Bjorn W Schuller, Anton Batliner, Christian Bergler, Cecilia Mascolo, Jing Han, IuliaLefter, Heysem Kaya, Shahin Amiriparian, Alice Baird, Lukas Stappen, et al. TheINTERSPEECH 2021 computational paralinguistics challenge: COVID-19 cough,COVID-19 speech, escalation & primates. arXiv:2102.13468, 2021.
[115] Neeraj Sharma, Prashant Krishnan, Rohit Kumar, Shreyas Ramoji, Srikanth RajChetupalli, Prasanta Kumar Ghosh, Sriram Ganapathy, et al. Coswara–a databaseof breathing, cough, and voice sounds for COVID-19 diagnosis. In Proceedings ofINTERSPEECH, pages 4811–4815, 2020.
[116] Bjorn W Schuller, Harry Coppock, and Alexander Gaskell. Detecting COVID-19from breathing and coughing sounds using deep neural networks. arXiv:2012.14553,2020.
42

[117] Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer.SMOTE: synthetic minority over-sampling technique. Journal of Artificial Intelli-gence Research, 16:321–357, 2002.
[118] Mattias Teye, Hossein Azizpour, and Kevin Smith. Bayesian uncertainty estimationfor batch normalized deep networks. In Proceedings of the International Conferenceon Machine Learning (ICML), pages 4907–4916, 2018.
[119] Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, David Sculley, SebastianNowozin, Joshua V Dillon, Balaji Lakshminarayanan, and Jasper Snoek. Can youtrust your model’s uncertainty? Evaluating predictive uncertainty under datasetshift. arXiv:1906.02530, 2019.
[120] Bjorn W Schuller, Stefan Steidl, Anton Batliner, Peter B Marschik, Harald Baumeis-ter, Fengquan Dong, Simone Hantke, Florian B Pokorny, Eva-Maria Rathner, Ka-trin D Bartl-Pokorny, et al. The 2018 computational paralinguistics challenge: Atyp-ical self-assessed affect, crying & heart beats. In Proceedings of the INTERSPEECH,pages 122–126, 2018.
43
Related Documents











