P A R A L L E L C O M P U T I N G L A B O R A T O R Y EECS Electrical Engineering and Computer Sciences BERKELEY PAR LAB Autotuning Memory-Intensive Kernels for Multicore Sam Williams and Kaushik Datta PMPP Workshop July 10, 2008 [email protected]

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

P A R A L L E L C O M P U T I N G L A B O R A T O R Y
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Autotuning Memory-IntensiveKernels for Multicore
Sam Williams and Kaushik DattaPMPP Workshop
July 10, [email protected]

2
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Motivation
Multicore processors are now ubiquitous Current architectures are extremely diverse Compilers alone do not fully exploit system resources
How do we get good performance across architectures?
Our answer: Autotuning Provides a portable and effective solution
We autotuned 3 scientific kernels on 4 different architectures toexamine: Performance Productivity Portability
3
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
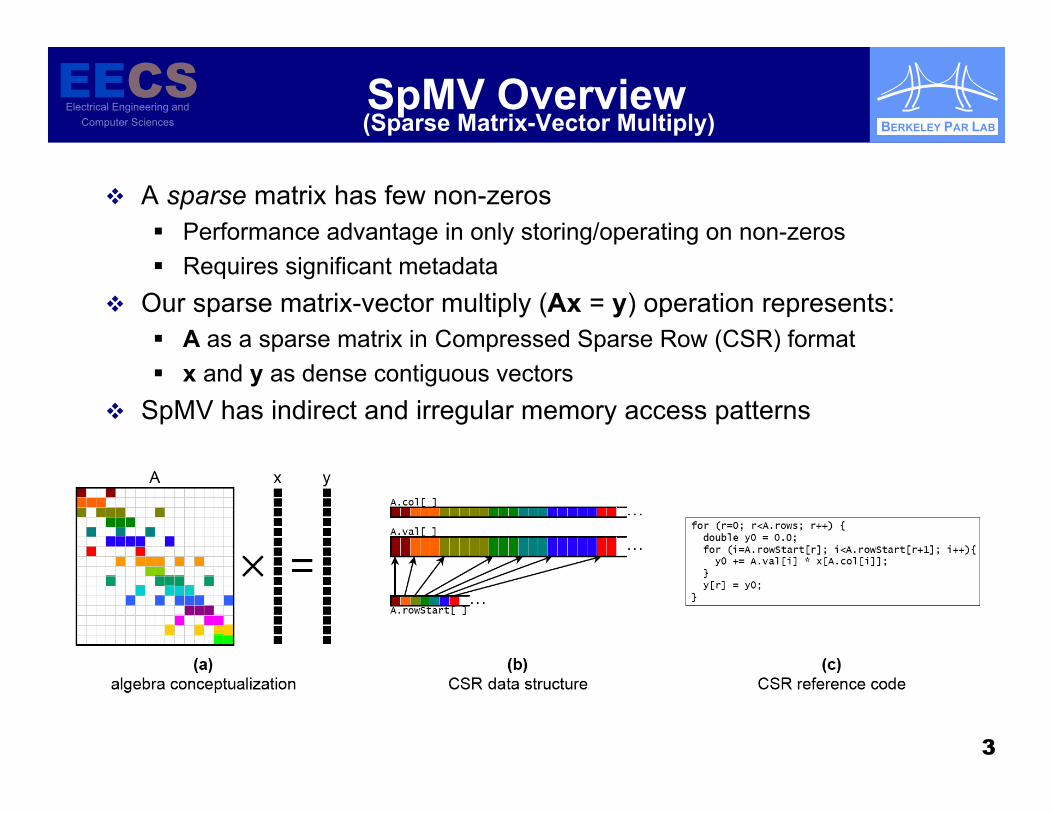
SpMV Overview
A sparse matrix has few non-zeros Performance advantage in only storing/operating on non-zeros Requires significant metadata
Our sparse matrix-vector multiply (Ax = y) operation represents: A as a sparse matrix in Compressed Sparse Row (CSR) format x and y as dense contiguous vectors
SpMV has indirect and irregular memory access patterns
(Sparse Matrix-Vector Multiply)
4
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
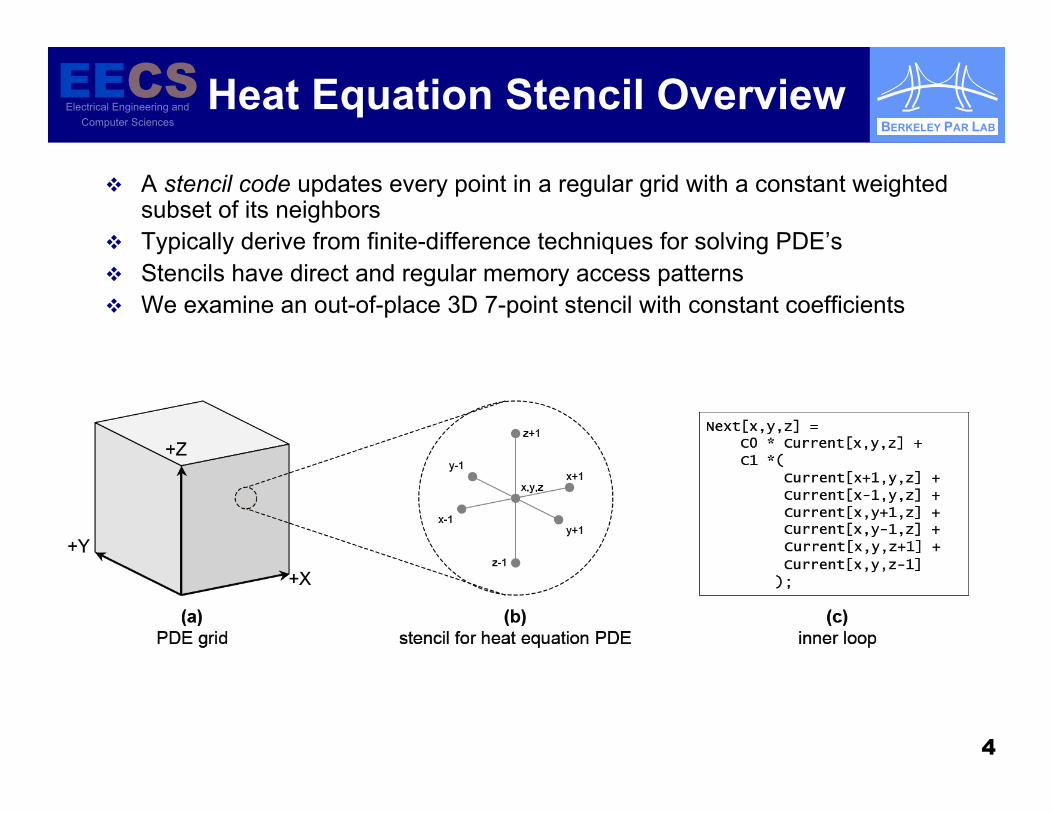
Heat Equation Stencil Overview
A stencil code updates every point in a regular grid with a constant weightedsubset of its neighbors
Typically derive from finite-difference techniques for solving PDE’s Stencils have direct and regular memory access patterns We examine an out-of-place 3D 7-point stencil with constant coefficients
5
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
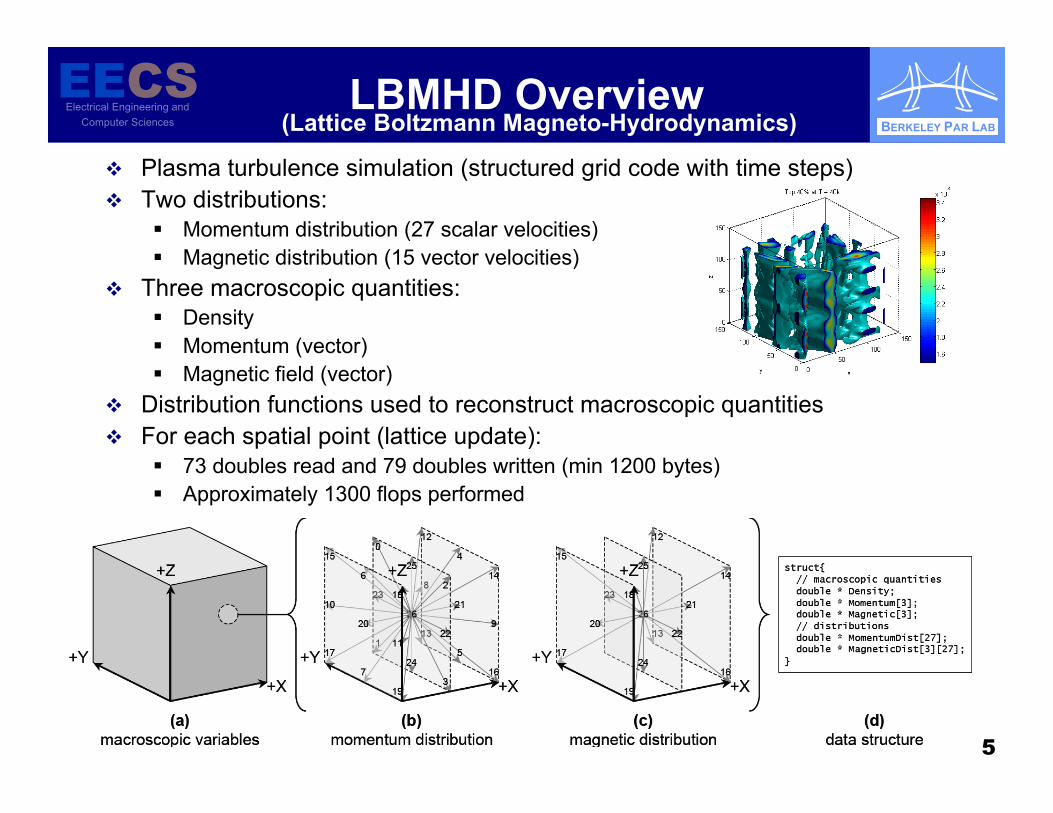
LBMHD Overview Plasma turbulence simulation (structured grid code with time steps) Two distributions:
Momentum distribution (27 scalar velocities) Magnetic distribution (15 vector velocities)
Three macroscopic quantities: Density Momentum (vector) Magnetic field (vector)
Distribution functions used to reconstruct macroscopic quantities For each spatial point (lattice update):
73 doubles read and 79 doubles written (min 1200 bytes) Approximately 1300 flops performed
(Lattice Boltzmann Magneto-Hydrodynamics)

6
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Common Kernel Optimizations
Threading and Parallelization Thread blocking
Maximizing in-core performance Loop unrolling/reordering SIMDization
Maximizing memory bandwidth NUMA-Aware (collocating data with processing threads) Software prefetching Limiting number of memory streams
Minimizing memory traffic (Addressing 3 C’s model) Cache blocking (reduce capacity misses) Padding (reduce conflict misses) Cache bypass (via intrinsic for x86)
7
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
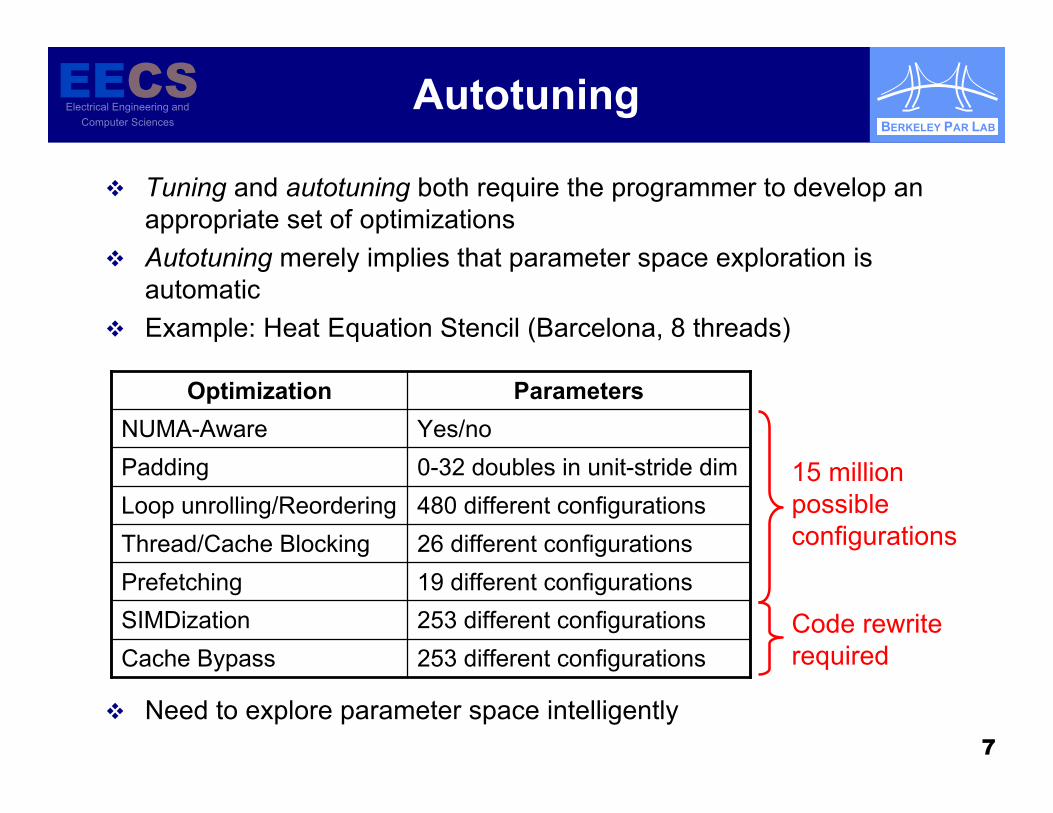
Autotuning
Tuning and autotuning both require the programmer to develop anappropriate set of optimizations
Autotuning merely implies that parameter space exploration isautomatic
Example: Heat Equation Stencil (Barcelona, 8 threads)
Need to explore parameter space intelligently
253 different configurationsCache Bypass253 different configurationsSIMDization19 different configurationsPrefetching26 different configurationsThread/Cache Blocking480 different configurationsLoop unrolling/Reordering0-32 doubles in unit-stride dimPaddingYes/noNUMA-Aware
ParametersOptimization
15 millionpossibleconfigurations
Code rewriterequired

8
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Autotuning Strategies
All three kernels used Perl scripts to generate code variants SpMV: Heuristic search
Chose best parameter values via heuristics Example: Selected best matrix compression parameters by finding
minimum matrix size Stencil: “Greedy” exhaustive search
Large search space, so applied each optimization individually Performed exhaustive search using power-of-two values within each
optimization’s parameter space Chose the best value before proceeding
LBMHD: Full exhaustive search Relatively small search space allowed full exhaustive search using
power-of-two values
9
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
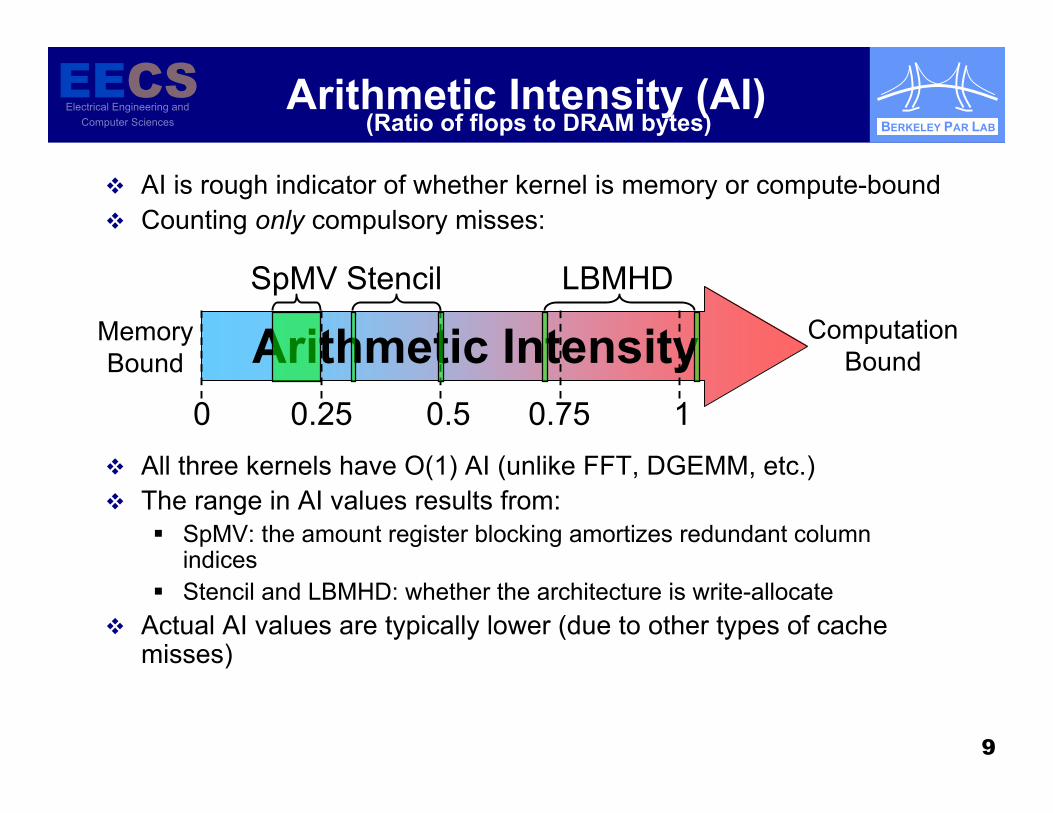
Arithmetic Intensity (AI)
AI is rough indicator of whether kernel is memory or compute-bound Counting only compulsory misses:
All three kernels have O(1) AI (unlike FFT, DGEMM, etc.) The range in AI values results from:
SpMV: the amount register blocking amortizes redundant columnindices
Stencil and LBMHD: whether the architecture is write-allocate Actual AI values are typically lower (due to other types of cache
misses)
(Ratio of flops to DRAM bytes)
Arithmetic Intensity0 10.50.25 0.75
SpMV Stencil LBMHDComputation
BoundMemoryBound
10
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
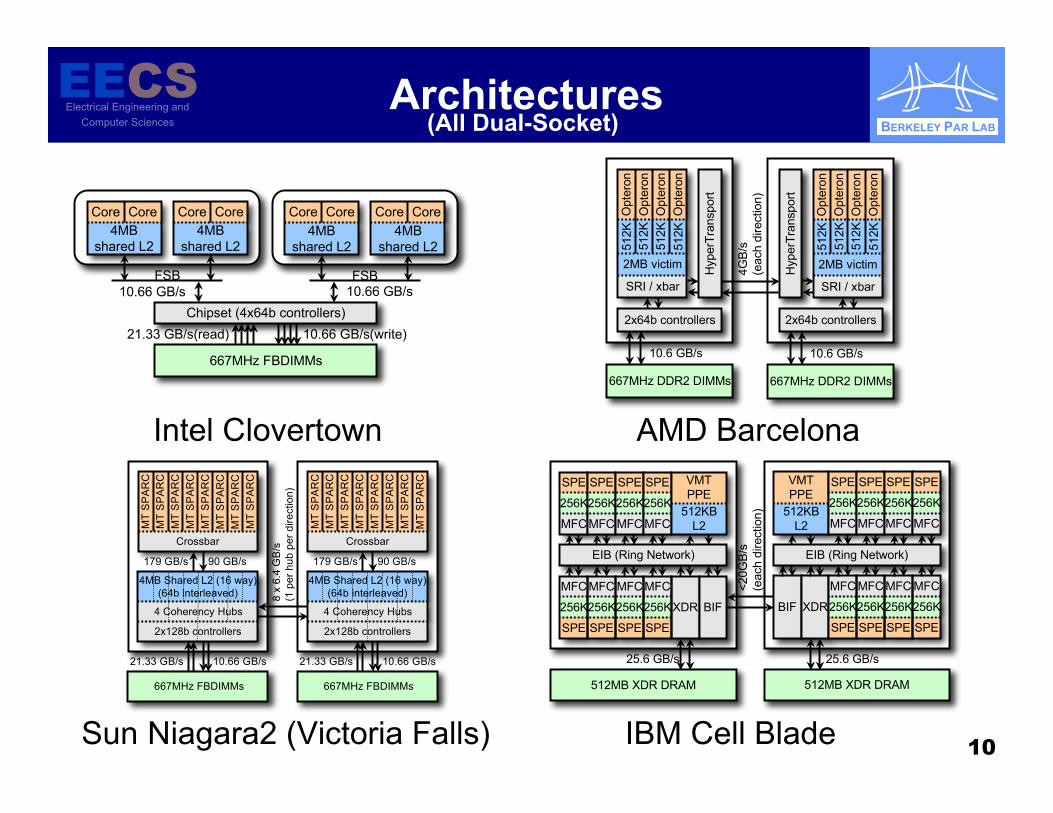
Architectures
Intel Clovertown AMD Barcelona
667MHz FBDIMMs
Chipset (4x64b controllers)10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core4MB
shared L24MB
shared L24MB
shared L24MB
shared L2
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
4GB/
s(e
ach
dire
ctio
n)
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
8 x
6.4
GB
/s(1
per
hub
per
dire
ctio
n)
Sun Niagara2 (Victoria Falls) IBM Cell Blade
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
XDR BIF
VMTPPE
512KBL2
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
BIF XDR
VMTPPE
512KBL2
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
<20G
B/s
(eac
h di
rect
ion)
(All Dual-Socket)
11
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Architectures
Intel Clovertown AMD Barcelona
667MHz FBDIMMs
Chipset (4x64b controllers)10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core4MB
shared L24MB
shared L24MB
shared L24MB
shared L2
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
4GB/
s(e
ach
dire
ctio
n)
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
8 x
6.4
GB
/s(1
per
hub
per
dire
ctio
n)
Sun Niagara2 (Victoria Falls) IBM Cell Blade
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
XDR BIF
VMTPPE
512KBL2
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
BIF XDR
VMTPPE
512KBL2
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
<20G
B/s
(eac
h di
rect
ion)
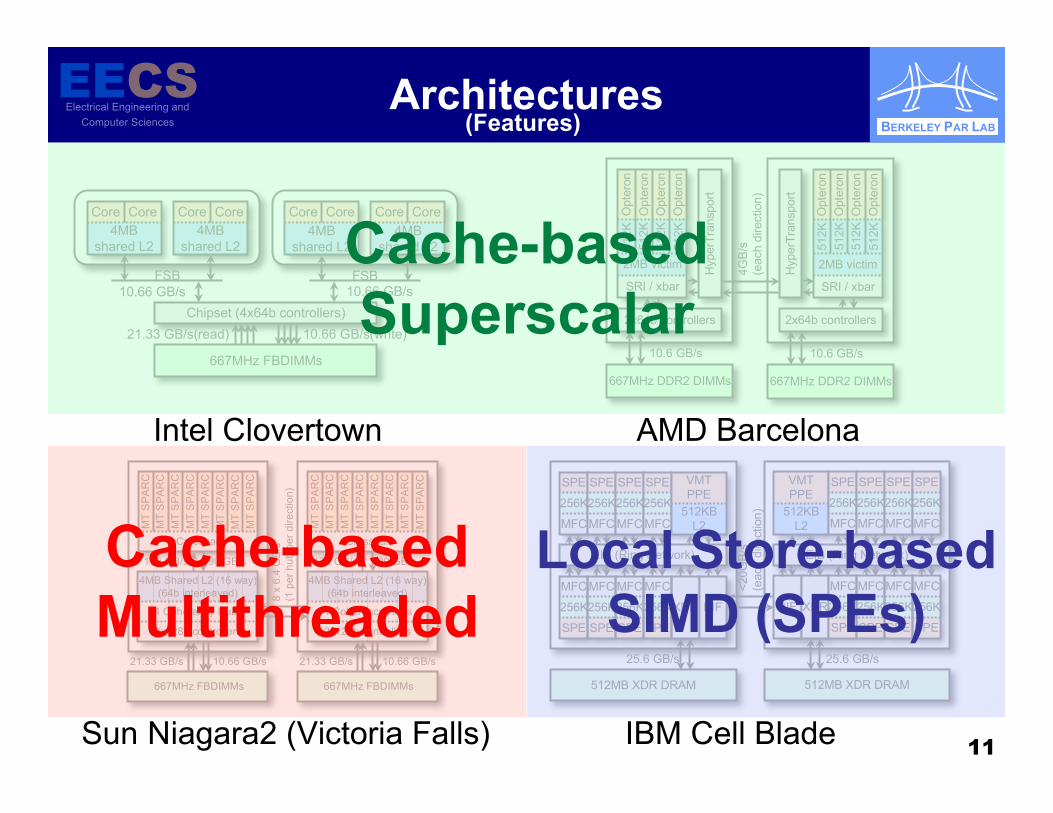
Cache-basedSuperscalar
Cache-basedMultithreaded
Local Store-basedSIMD (SPEs)
(Features)

12
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Architectures
Intel Clovertown AMD Barcelona
667MHz FBDIMMs
Chipset (4x64b controllers)10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core4MB
shared L24MB
shared L24MB
shared L24MB
shared L2
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
4GB/
s(e
ach
dire
ctio
n)
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
8 x
6.4
GB
/s(1
per
hub
per
dire
ctio
n)
Sun Niagara2 (Victoria Falls) IBM Cell Blade
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
XDR BIF
VMTPPE
512KBL2
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
BIF XDR
VMTPPE
512KBL2
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
<20G
B/s
(eac
h di
rect
ion)
75 GFlops/s 74 GFlops/s
18.7 GFlops/s 29 GFlops/s(SPEs only)
(Double Precision Peak Flops)

13
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Architectures
Intel Clovertown AMD Barcelona
667MHz FBDIMMs
Chipset (4x64b controllers)10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core4MB
shared L24MB
shared L24MB
shared L24MB
shared L2
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
4GB/
s(e
ach
dire
ctio
n)
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
8 x
6.4
GB
/s(1
per
hub
per
dire
ctio
n)
Sun Niagara2 (Victoria Falls) IBM Cell Blade
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
XDR BIF
VMTPPE
512KBL2
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
BIF XDR
VMTPPE
512KBL2
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
<20G
B/s
(eac
h di
rect
ion)
21.33 GB/s (read)10.66 GB/s (write) 21.33 GB/s
42.66 GB/s (read)21.33 GB/s (write) 51.2 GB/s
(Raw DRAM Bandwidth)

14
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Architectures
Intel Clovertown AMD Barcelona
667MHz FBDIMMs
Chipset (4x64b controllers)10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core4MB
shared L24MB
shared L24MB
shared L24MB
shared L2
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
667MHz DDR2 DIMMs
10.6 GB/s
2x64b controllers
Hyp
erTr
ansp
ort
Opt
eron
Opt
eron
Opt
eron
Opt
eron
512K
512K
512K
512K
2MB victim
SRI / xbar
4GB/
s(e
ach
dire
ctio
n)
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
667MHz FBDIMMs
21.33 GB/s 10.66 GB/s
4MB Shared L2 (16 way)(64b interleaved)
4 Coherency Hubs
2x128b controllers
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
MT
SP
AR
CM
T S
PA
RC
Crossbar
179 GB/s 90 GB/s
8 x
6.4
GB
/s(1
per
hub
per
dire
ctio
n)
Sun Niagara2 (Victoria Falls) IBM Cell Blade
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
XDR BIF
VMTPPE
512KBL2
512MB XDR DRAM
25.6 GB/s
EIB (Ring Network)
BIF XDR
VMTPPE
512KBL2
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
SPE
256K
MFC
MFC MFC MFC MFC
256K256K256K256K
SPE SPE SPE SPE
<20G
B/s
(eac
h di
rect
ion)
7.2 GB/s(23% of Raw BW)
17.6 GB/s(83% of Raw BW)
22.4 GB/s(35% of Raw BW)
46.0 GB/s(90% of Raw BW)
(Stream Bandwidth)
15
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
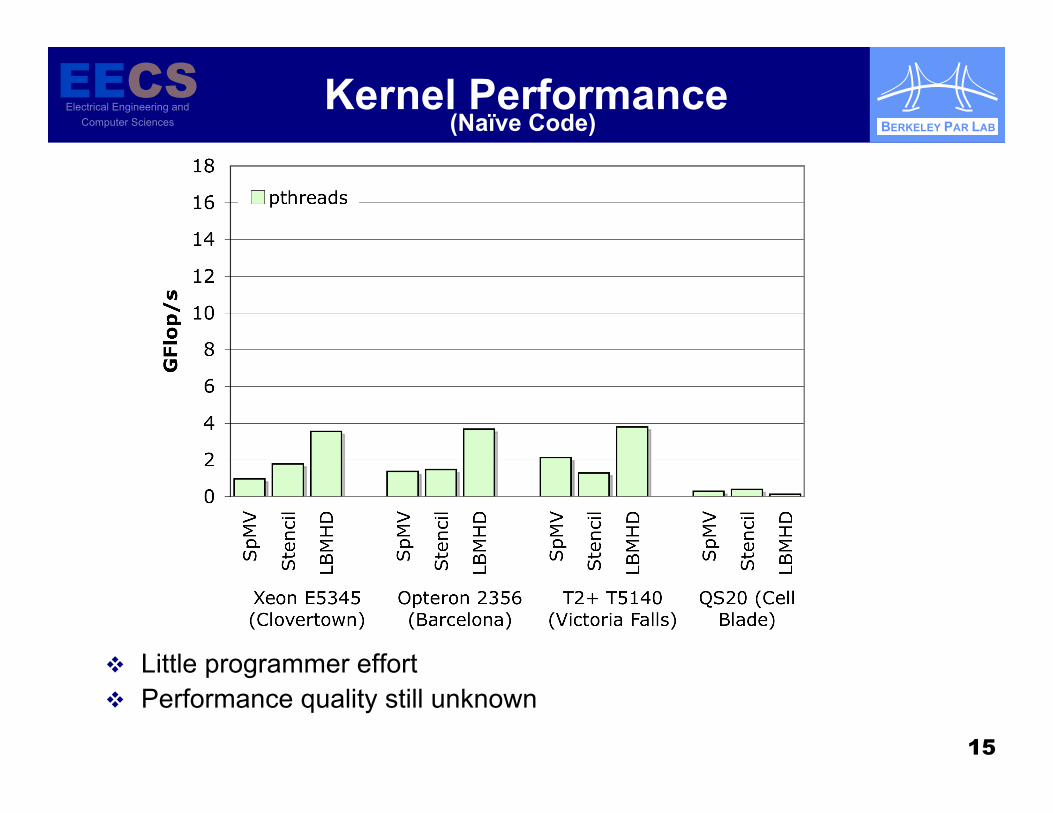
Kernel Performance
Little programmer effort Performance quality still unknown
(Naïve Code)
16
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
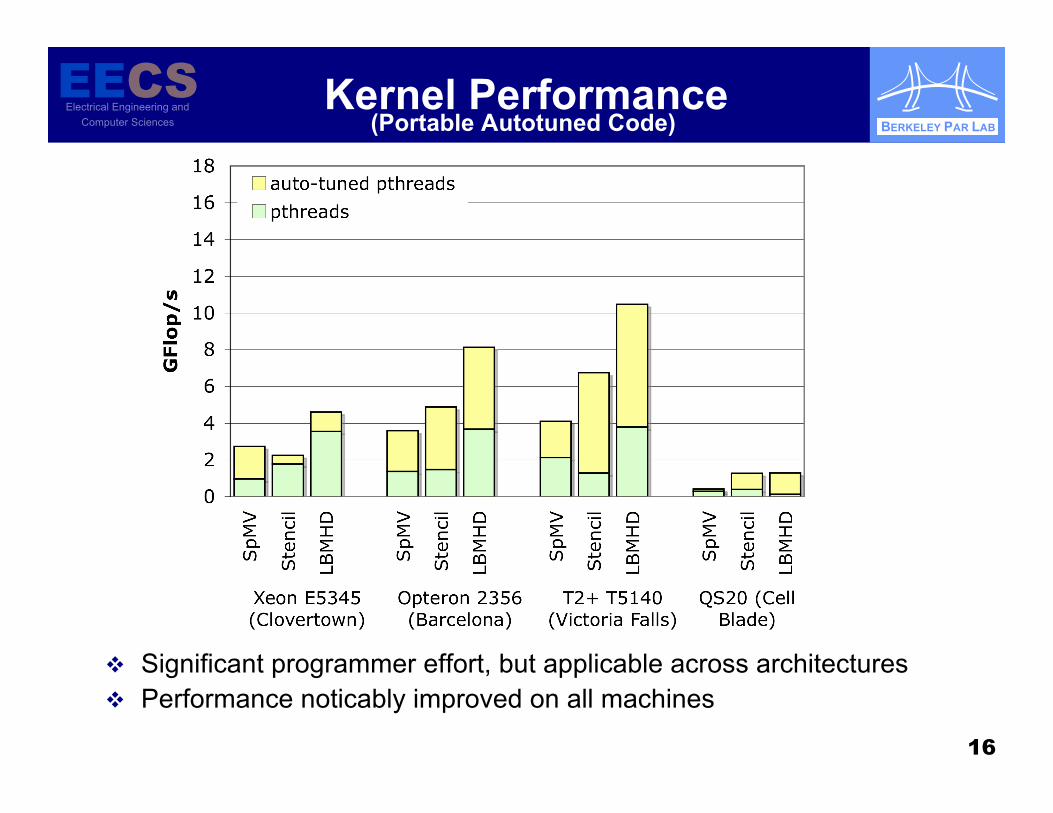
Kernel Performance
Significant programmer effort, but applicable across architectures Performance noticably improved on all machines
(Portable Autotuned Code)
17
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
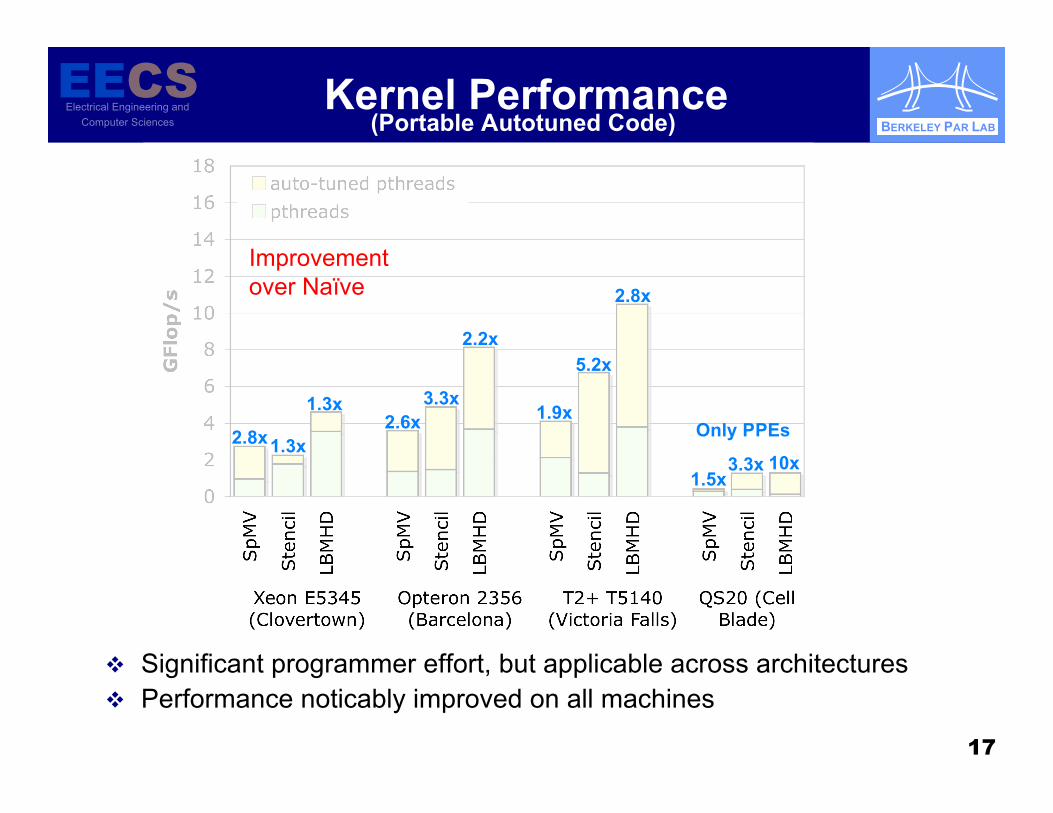
Kernel Performance
Significant programmer effort, but applicable across architectures Performance noticably improved on all machines
(Portable Autotuned Code)
2.8x1.3x
1.3x2.6x
3.3x
2.2x
1.9x
5.2x
2.8x
1.5x3.3x 10x
Improvementover Naïve
Only PPEs
18
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
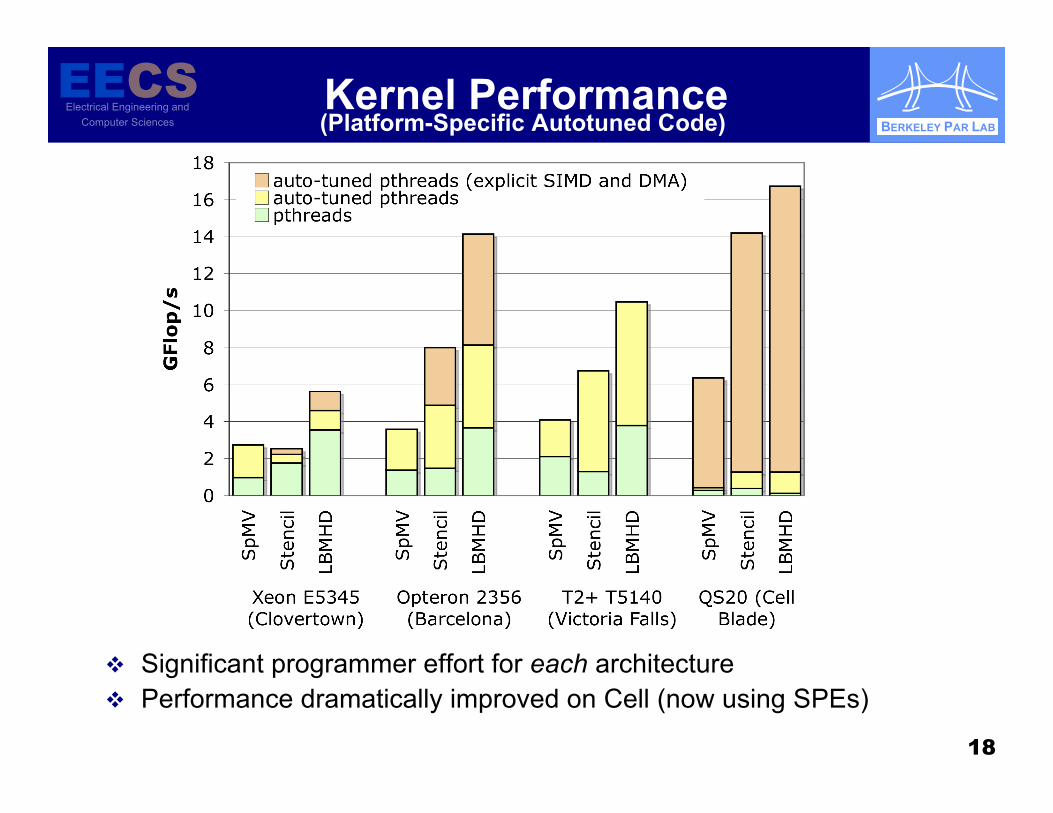
Kernel Performance
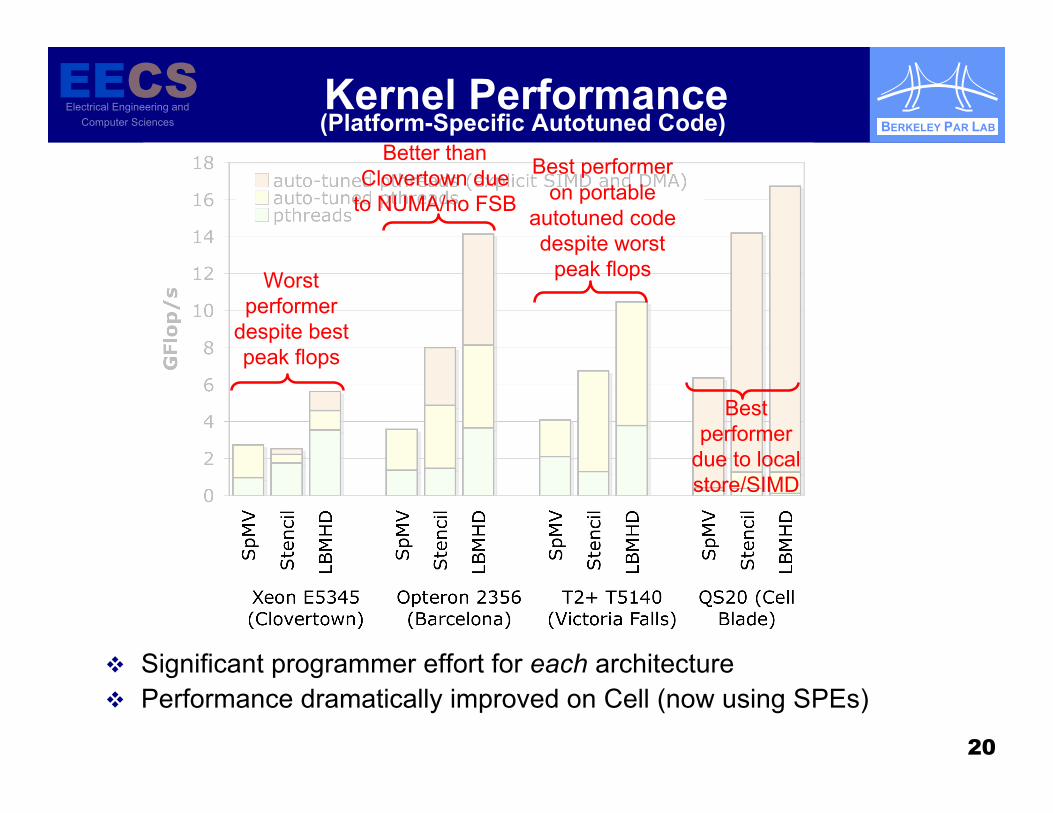
Significant programmer effort for each architecture Performance dramatically improved on Cell (now using SPEs)
(Platform-Specific Autotuned Code)
19
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
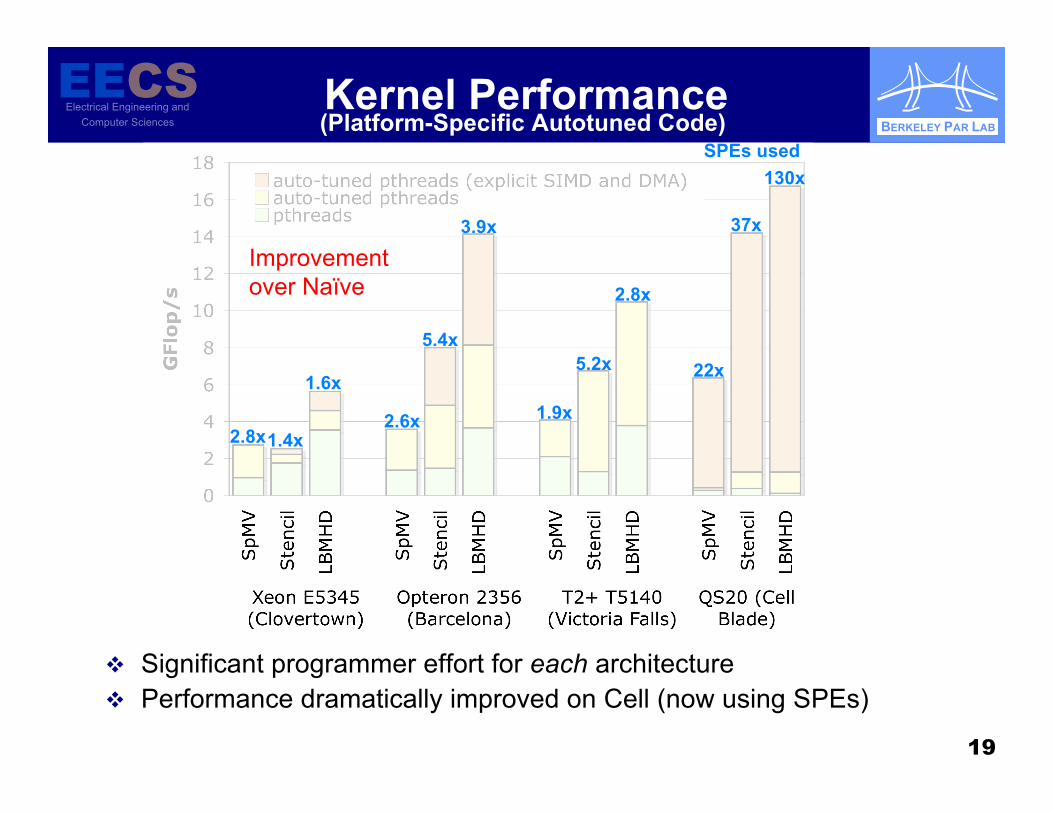
Kernel Performance
Significant programmer effort for each architecture Performance dramatically improved on Cell (now using SPEs)
(Platform-Specific Autotuned Code)
2.8x1.4x
1.6x
2.6x
5.4x
3.9x
1.9x
5.2x
2.8x
22x
37x
130x
Improvementover Naïve
SPEs used
20
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Kernel Performance
Significant programmer effort for each architecture Performance dramatically improved on Cell (now using SPEs)
(Platform-Specific Autotuned Code)
Worstperformer
despite bestpeak flops
Bestperformer
due to localstore/SIMD
Better thanClovertown due
to NUMA/no FSB
Best performeron portable
autotuned codedespite worst
peak flops
21
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
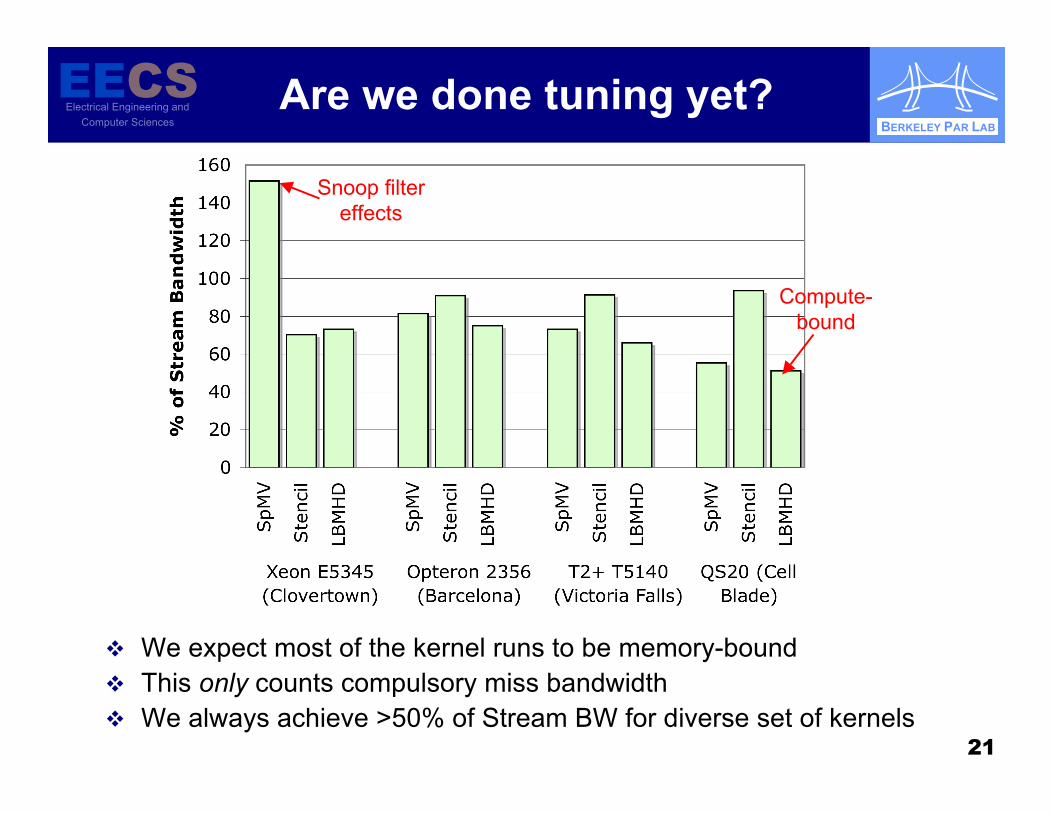
Are we done tuning yet?
We expect most of the kernel runs to be memory-bound This only counts compulsory miss bandwidth We always achieve >50% of Stream BW for diverse set of kernels
Snoop filtereffects
Compute-bound

22
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Roofline Model
Naively, performance upper bound would be:Min(peak GFlops/s, AI * peak GB/s)
However, this assumes fully exploiting every architectural feature: Common computational features:
• Achieving a balance between multiplies and adds• Sufficient loop unrolling to cover functional unit latency• SSE register usage
Common memory bandwidth features:• Long, direct, unit-stride accesses• NUMA-aware memory allocation• Properly-tuned software prefetching
Not exploiting any of these will cause a performance dropoff Based on this, Sam Williams developed a Roofline model:
Indicates the best optimization order for a given kernel and architecture Displays the expected performance after each optimization Indicates when further tuning is fruitless
See paper reference listed at end of presentation

23
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Autotuning Concerns
Limiting the time to search Which optimizations:
• can be performed offline?• can be chosen via heuristics?• are mutually independent?• can be modeled?
Can we perform guided search at runtime? How good is good enough?
Improving performance What if we have a poor compiler? Can we add compiler hooks (to avoid replication, gain transparency)?
Improving code generation How hard is it to build and extend the code generator? How portable is the generator (for evolutionary/revolutionary
architectures)? Can it do dependency analysis or correctness checking?
These topics are currently being explored
24
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
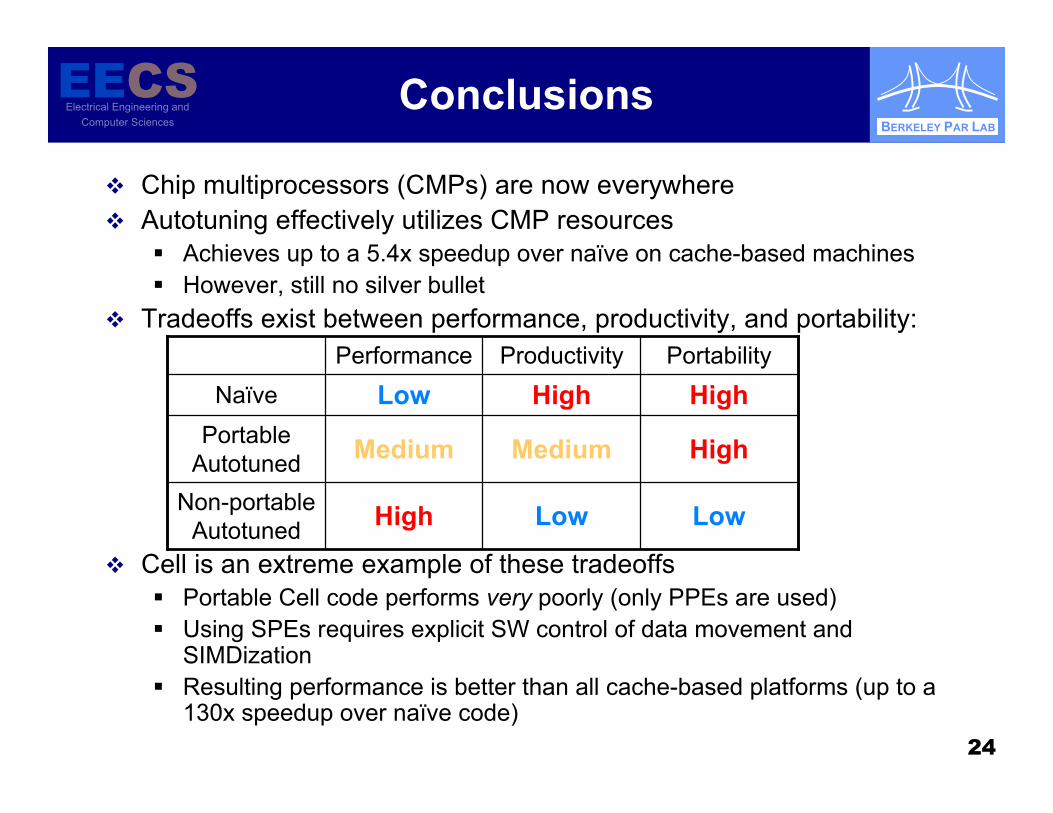
Conclusions
Chip multiprocessors (CMPs) are now everywhere Autotuning effectively utilizes CMP resources
Achieves up to a 5.4x speedup over naïve on cache-based machines However, still no silver bullet
Tradeoffs exist between performance, productivity, and portability:
Cell is an extreme example of these tradeoffs Portable Cell code performs very poorly (only PPEs are used) Using SPEs requires explicit SW control of data movement and
SIMDization Resulting performance is better than all cache-based platforms (up to a
130x speedup over naïve code)
LowLowHighNon-portableAutotuned
HighMediumMediumPortableAutotuned
HighHighLowNaïvePortabilityProductivityPerformance

25
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
Acknowledgements
Research supported by: Microsoft and Intel funding (Award #20080469) DOE Office of Science under contract number DE-AC02-05CH11231 NSF contract CNS-0325873 Sun Microsystems - Niagara2 / Victoria Falls machines AMD - access to Quad-core Opteron (Barcelona) access Forschungszentrum Jülich - access to QS20 Cell blades IBM - virtual loaner program to QS20 Cell blades

26
EECSElectrical Engineering and
Computer Sciences BERKELEY PAR LAB
References
http://www.cs.berkeley.edu/~samw S. Williams, L. Oliker, R. Vuduc, J. Shalf, K. Yelick, J. Demmel,
“Optimization of Sparse Matrix-Vector Multiplication on EmergingMulticore Platforms”, Supercomputing (SC), 2007.
S. Williams, J. Carter, L. Oliker, J. Shalf, K. Yelick, “LatticeBoltzmann Simulation Optimization on Leading MulticorePlatforms”, International Parallel & Distributed ProcessingSymposium (IPDPS), 2008.
K. Datta, M. Murphy, V. Volkov, S. Williams, J. Carter, L. Oliker, D.Patterson, J. Shalf, K. Yelick, “Stencil Computation Optimizationand Autotuning on State-of-the-Art Multicore Architectures”,Supercomputing (SC) 2008 (to appear).
S. Williams, K. Datta, J. Carter, L. Oliker, J. Shalf, K. Yelick, D. Bailey,“PERI: Auto-tuning Memory Intensive Kernels for Multicore”,SciDAC PI conference, Journal of Physics: Conference Series, 2008(to appear). Includes Roofline Model
Related Documents











