Apprenticeship Learning Pieter Abbeel Stanford University In collaboration with: Andrew Y. Ng, Adam Coates, J. Zico Kolter, Morgan Quigley, Dmitri Dolgov, Sebastian Thrun.

Apprenticeship Learning Pieter Abbeel Stanford University
Dec 30, 2015
Apprenticeship Learning Pieter Abbeel Stanford University In collaboration with: Andrew Y. Ng, Adam Coates, J. Zico Kolter, Morgan Quigley, Dmitri Dolgov , Sebastian Thrun. Machine Learning. Large number of success stories: Handwritten digit recognition Face detection Disease diagnosis - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Apprenticeship LearningPieter Abbeel
Stanford University
In collaboration with: Andrew Y. Ng, Adam Coates, J. Zico Kolter, Morgan Quigley, Dmitri Dolgov, Sebastian Thrun.

Large number of success stories: Handwritten digit recognition Face detection Disease diagnosis …
All learn from examples a direct mapping from inputs to outputs.
Reinforcement learning / Sequential decision making: Humans still greatly outperform
machines.
Machine Learning
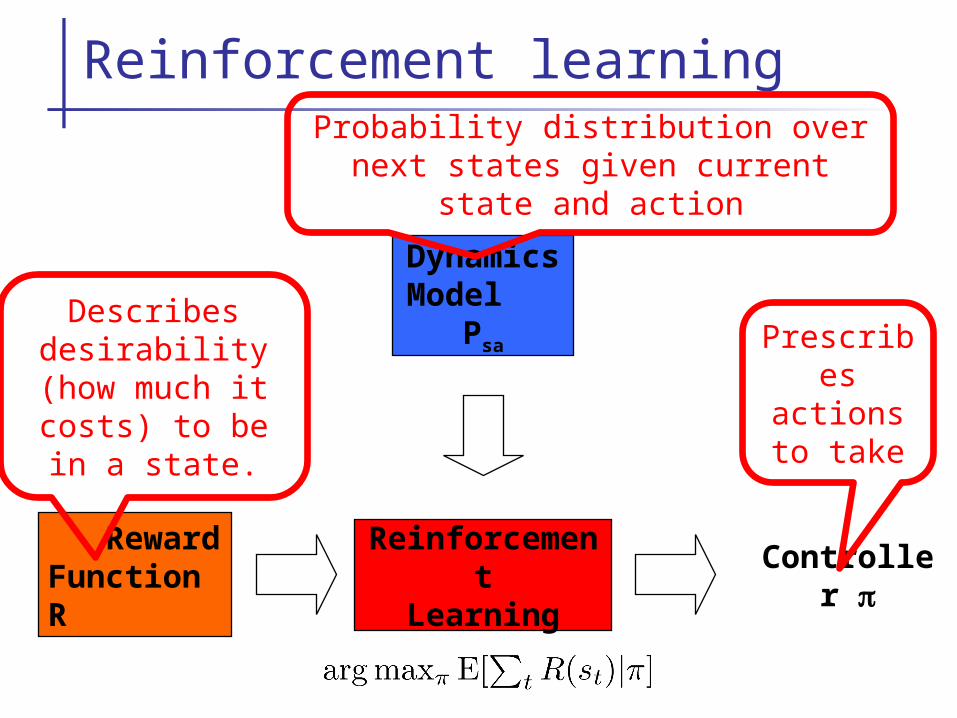
Reinforcement learning
Dynamics Model
Psa
Reward Function R
ReinforcementLearning
Controller p
Prescribes actions to take
Probability distribution over next states given current state and
action
Describes desirability (how much it costs) to
be in a state.

Apprenticeship learning
Dynamics Model
Psa
Reward Function R
ReinforcementLearning
Controller p
Teacher Demonstration
(s0, a0, s1, a1, ….)

Example task: driving

Learning from demonstrations
Learn direct mapping from states to actions Assumes controller simplicity. E.g., Pomerleau, 1989; Sammut et al., 1992; Kuniyoshi et
al., 1994; Demiris & Hayes, 1994; Amit & Mataric, 2002;
Inverse reinforcement learning [Ng & Russell, 2000]
Tries to recover the reward function from demonstrations. Inherent ambiguity makes reward function impossible to
recover.
Apprenticeship learning [Abbeel & Ng, 2004]
Exploits reward function structure + provides strong guarantees.
Related work since: Ratliff et al., 2006, 2007; Neu & Szepesvari, 2007; Syed & Schapire, 2008.

Apprenticeship learning
Key desirable properties:
Returns controller with performance guarantee:
Short running time.
Small number of demonstrations required.

Apprenticeship learning algorithm
Assume
Initialize: pick some controller 0.
Iterate for i = 1, 2, … :
Make the current best guess for the reward function. Concretely, find the reward function such that the teacher maximally outperforms all previously found controllers.
Find optimal optimal controller i for the current guess of the
reward function Rw.
If , exit the algorithm.

Theoretical guarantees

Highway drivingInput: Driving demonstration Output: Learned behavior
The only input to the learning algorithm was the driving demonstration (left panel). No reward function was provided.

Parking lot navigation
Reward function trades off: curvature, smoothness,distance to obstacles, alignment with principal directions.

Reward function trades off 25 features.
Learn on training terrain.
Test on previously unseen terrain.
Quadruped
[NIPS 2008]

Quadruped on test-board

LearnR
Apprenticeship learning
Dynamics Model
Psa
Reward Function R
ReinforcementLearning
Controller p
Teacher’s flight
(s0, a0, s1, a1, ….)

LearnR
Apprenticeship learning
Dynamics Model
Psa
Reward Function R
ReinforcementLearning
Controller p
Teacher’s flight
(s0, a0, s1, a1, ….)

Accurate dynamics model Psa
Motivating example
• Textbook model• Specification
Accurate dynamics model Psa
Collect flight data.
• Textbook model• Specification
Learn model from data.
How to fly helicopter for data collection? How to ensure that entire flight envelope is covered by the data collection process?

Learning the dynamics model
State-of-the-art: E3 algorithm, Kearns and Singh (1998,2002). (And its variants/extensions: Kearns and Koller, 1999; Kakade, Kearns and Langford, 2003; Brafman and Tennenholtz, 2002.)
Have goodmodel of dynamics?
NO
“Explore”
YES
“Exploit”

Learning the dynamics model
State-of-the-art: E3 algorithm, Kearns and Singh (2002). (And its variants/extensions: Kearns and Koller, 1999; Kakade, Kearns and Langford, 2003; Brafman and Tennenholtz, 2002.)
Have goodmodel of dynamics?
NO
“Explore”
YES
“Exploit”
Exploration policies are impractical: they do not even try
to perform well.Can we avoid explicit exploration and just
exploit?

Learn P sa
Learn Psa
Apprenticeship learning of the model
Dynamics Model
Psa
Reward Function R
ReinforcementLearning
Controller p
Autonomous flight
(s0, a0, s1, a1, ….)
Teacher’s flight
(s0, a0, s1, a1, ….)

Here, polynomial is with respect to
1/, 1/(failure probability), the horizon T, the maximum reward R,
the size of the state space.
Theoretical guarantees

From initial pilot demonstrations, our model/simulator Psa will be accurate for the part of the state space (s,a) visited by the pilot.
Our model/simulator will correctly predict the helicopter’s behavior under the pilot’s controller *.
Consequently, there is at least one controller (namely *) that looks capable of flying the helicopter well in our simulation.
Thus, each time we solve for the optimal controller using the current model/simulator Psa, we will find a controller that successfully flies the helicopter according to Psa.
If, on the actual helicopter, this controller fails to fly the helicopter---despite the model Psa predicting that it should---then it must be visiting parts of the state space that are inaccurately modeled.
Hence, we get useful training data to improve the model. This can happen only a small number of times.
Model Learning: Proof Idea

Learning the dynamics model Exploiting structure from physics
Explicitly encode gravity, inertia. Estimate remaining dynamics from data.
Lagged learning criterion Maximize prediction accuracy of the simulator
over time scales relevant for control (vs. digital integration time scale).
Similar to machine learning: discriminative vs. generative.
[Abbeel et al. {NIPS 2005, NIPS 2006}]

Autonomous nose-in funnel

Related work Bagnell & Schneider, 2001; LaCivita et al., 2006;
Ng et al., 2004a; Roberts et al., 2003; Saripalli et al., 2003.; Ng et al., 2004b; Gavrilets, Martinos, Mettler and Feron, 2002.
Maneuvers presented here are significantly more difficult than those flown by any other autonomous helicopter.

Learn P sa
Learn Psa
Apprenticeship learning
Dynamics Model
Psa
Reward Function R
ReinforcementLearning
Controller p
Autonomous flight
(s0, a0, s1, a1, ….)
Teacher’s flight
(s0, a0, s1, a1, ….)
Model predictive control
Receding horizon differential dynamic programming
LearnR

Learn P sa
Learn Psa
Learn Psa
Learn P sa
LearnR
LearnR
Dynamics Model
Psa
Reward Function R
ReinforcementLearning
Controller p
Autonomous flight
(s0, a0, s1, a1, ….)
Teacher’s flight
(s0, a0, s1, a1, ….)
Applications:
Apprenticeship learning: summary

Demonstrations

Learned reward (trajectory)


Applications:
Autonomous helicopters to assist in wildland fire fighting.
Fixed-wing formation flight: Estimated fuel savings for three aircraft formation: 20%.
Learning from demonstrations only scratches the surface of how humans learn (and teach).
Safe autonomous learning.
More general advice taking.
Current and future work

Thank you.

Apprenticeship Learning via Inverse Reinforcement Learning, Pieter Abbeel and Andrew Y. Ng. In Proc. ICML, 2004.
Learning First Order Markov Models for Control, Pieter Abbeel and Andrew Y. Ng. In NIPS 17, 2005.
Exploration and Apprenticeship Learning in Reinforcement Learning, Pieter Abbeel and Andrew Y. Ng. In Proc. ICML, 2005.
Modeling Vehicular Dynamics, with Application to Modeling Helicopters, Pieter Abbeel, Varun Ganapathi and Andrew Y. Ng. In NIPS 18, 2006.
Using Inaccurate Models in Reinforcement Learning, Pieter Abbeel, Morgan Quigley and Andrew Y. Ng. In Proc. ICML, 2006.
An Application of Reinforcement Learning to Aerobatic Helicopter Flight, Pieter Abbeel, Adam Coates, Morgan Quigley and Andrew Y. Ng. In NIPS 19, 2007.
Hierarchical Apprenticeship Learning with Application to Quadruped Locomotion, J. Zico Kolter, Pieter Abbeel and Andrew Y. Ng. In NIPS 20, 2008.

Airshow accuracy

Chaos

Tic-toc

Applications:
Autonomous helicopters to assist in wildland fire fighting.
Fixed-wing formation flight: Estimated fuel savings for three aircraft formation: 20%.
Learning from demonstrations only scratches the surface of how humans learn (and teach).
Safe autonomous learning.
More general advice taking.
Current and future work

Full Inverse RL Algorithm
Initialize: pick some arbitrary reward weights w.
For i = 1, 2, …
RL step:
Compute optimal controller i for the current estimate of the
reward function Rw.
Inverse RL step:
Re-estimate the reward function Rw:
If , exit the algorithm.

Helicopter dynamics model in auto

Parking lot navigation---experiments

Helicopter inverse RL: experiments


Auto-rotation descent

Learn P sa
Learn Psa
Apprenticeship learning
Dynamics Model
Psa
Reward Function R
ReinforcementLearning
Controller p
Autonomous flight
(s0, a0, s1, a1, ….)
Teacher’s flight
(s0, a0, s1, a1, ….)
LearnR

Input to algorithm: approximate model. Start by computing the optimal controller
according to the model.
Algorithm Idea
Real-life trajectory
Target trajectory

Algorithm Idea (2) Update the model such that it becomes exact for
the current controller.

Algorithm Idea (2) Update the model such that it becomes exact for
the current controller.

Algorithm Idea (2)

Performance Guarantees


First trial.(Model-based controller.)
After learning. (10 iterations)

Performance guarantee intuition
Intuition by example:
Let
If the returned controller satisfies
Then no matter what the values of and are, the controller performs as well as the teacher’s controller *.

SummaryTeacher: human pilot flight
(a1, s1, a2, s2, a3, s3, ….)
Learn P sa
(a1, s1, a2, s2, a3, s3, ….)
Autonomous flight
Learn Psa
Dynamics Model
Psa
Reward Function R
ReinforcementLearning )(...)(Emax 0 TsRsR
Controller p
LearnR Im
prov
e
When given a demonstration:
Automatically learn reward function, rather than (time-consumingly) hand-engineer it.
Unlike exploration methods, our algorithm concentrates on the task of interest, and always tries to fly as well as possible.
High performance control with crude model + small number of trials.

Perfect demonstrations are extremely hard to obtain.
Multiple trajectory demonstrations: Every demonstration is a noisy instantiation of
the intended trajectory. Noise model captures (among others):
Position drift. Time warping.
If different demonstrations are suboptimal in different ways, they can capture the “intended” trajectory implicitly.
[Related work: Atkeson & Schaal, 1997.]
Reward: Intended trajectory

Preliminaries: reinforcement learning.
Apprenticeship learning algorithms.
Experimental results on various robotic platforms.
Outline

Reinforcement learning (RL)
System
Dynamics
Psa
state s0
s1
System
dynamics
Psa
…
System
Dynamics
PsasT-1
sT
s2
a0 a1 aT-1
reward R(s0) R(s2) R(sT-1)R(s1) R(sT)+ ++…++
Goal: Pick actions over time so as to maximize the expected score: E[R(s0) + R(s1) + … + R(sT)]
Solution: controller which specifies an action for each possible state for all times t= 0, 1, … , T-1.

Model-based reinforcement learning
Run reinforcement
learning algorithm in simulator.
controller

Probabilistic graphical model for multiple demonstrations

Algorithms such as E3 (Kearns and Singh, 2002) learn the dynamics by using exploration policies, which are dangerous/impractical for many systems.
Our algorithm Initializes model from a demonstration.
Repeatedly executes “exploitation policies'' that try to maximize rewards.
Provably achieves near-optimal performance (compared to teacher).
Machine learning theory: Complicated non-IID sample generating process. Standard learning theory bounds not applicable. Proof uses martingale construction over relative losses.
Apprenticeship learning for the dynamics model
[ICML 2005]

Accuracy

Modeling extremely complex: Our dynamics model state:
Position, orientation, velocity, angular rate.
True state: Air (!), head-speed, servos, deformation, etc.
Key observation: In the vicinity of a specific point along a
specific trajectory, these unknown state variables tend to take on similar values.
Non-stationary maneuvers
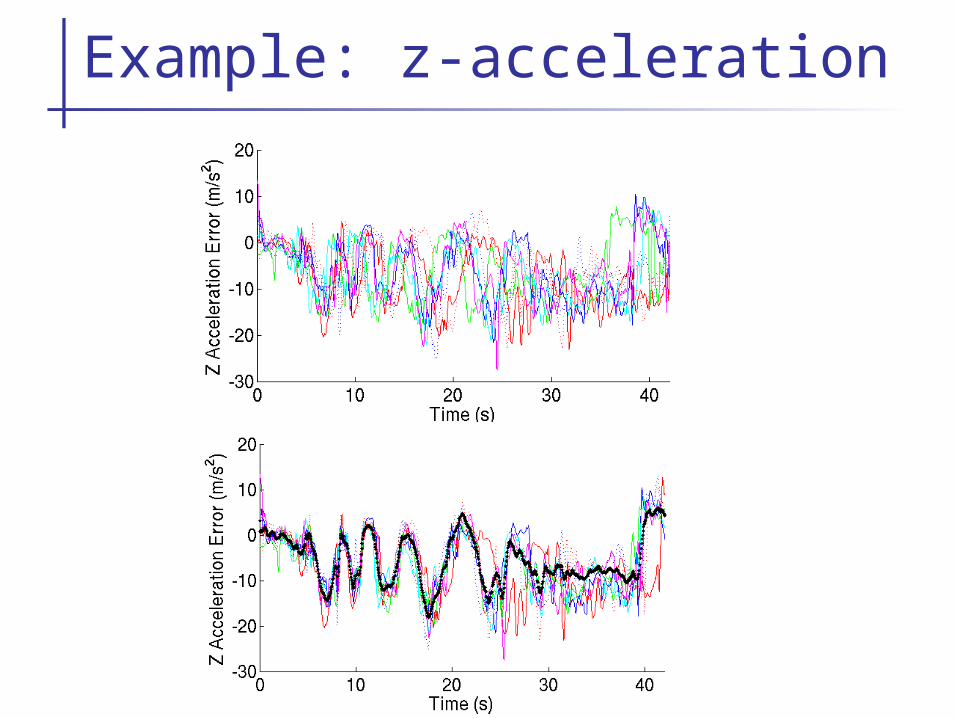
Example: z-acceleration

1. Time align trajectories.
2. Learn locally weighted models in the vicinity of the trajectory.
W(t’) = exp(- (t – t’)2 /2 )
Local model learning algorithm

Input to algorithm: Teacher demonstration. Approximate model.
Algorithm Idea w/Teacher
Teacher trajectory
Trajectory predicted by simulator/model
for same inputs
[ICML 2006]

Algorithm Idea w/Teacher (2)
Update the model such that it becomes exact for the demonstration.

Algorithm Idea w/Teacher (2)
Update the model such that it becomes exact for the demonstration.

Algorithm Idea w/Teacher (2)
The updated model perfectly predicts the state sequence obtained during the demonstration.
We can use the updated model to find a feedback Controller.

1. Record teacher’s demonstration s0, s1, …
2. Update the (crude) model/simulator to be exact for the teacher’s demonstration by adding appropriate time biases for each time step.
3. Return the policy that is optimal according to the updated model/simulator.
Algorithm w/Teacher

Theorem.
Performance guarantees w/Teacher

Algorithm [iterative]
1. Record teacher’s demonstration s0, s1, …
2. Update the (crude) model/simulator to be exact for the teacher’s demonstration by adding appropriate time biases for each time step.
3. Find the policy that is optimal according to the updated model/simulator.
4. Execute the policy and record the state trajectory.
5. Update the (crude) model/simulator to be exact along the trajectory obtained with the policy .
6. Go to step 3.
Related work: iterative learning control (ILC).

Algorithm
1. Find the (locally) optimal policy for the model.2. Execute the current policy and record the state
trajectory.3. Update the model such that the new model is exact
for the current policy .4. Use the new model to compute the policy gradient
and update the policy: := + . 5. Go back to Step 2.
Notes: The step-size parameter is determined by a line search. Instead of the policy gradient, any algorithm that provides
a local policy improvement direction can be used. In our experiments we used differential dynamic programming.

Algorithm
1. Find the (locally) optimal policy for the model.
2. Execute the current policy and record the state trajectory.
3. Update the model such that the new model is exact for the current policy .
4. Use the new model to compute the policy gradient and update the policy: := + .
5. Go back to Step 2.
Related work: Iterative learning control.

Future work

Acknowledgments
J. Zico Kolter, Andrew Y. Ng
Morgan Quigley, Andrew Y. Ng
Andrew Y. Ng
Adam Coates, Morgan Quigley, Andrew Y. Ng

RC Car: Circle

RC Car: Figure-8 Maneuver

Teacher demonstration for quadruped
Full teacher demonstration = sequence of footsteps.
Much simpler to “teach hierarchically”: Specify a body path. Specify best footstep in a small area.

Hierarchical inverse RL
Quadratic programming problem (QP): quadratic objective, linear constraints.
Constraint generation for path constraints.

Training: Have quadruped walk straight across a fairly
simple board with fixed-spaced foot placements.
Around each foot placement: label the best foot placement. (about 20 labels)
Label the best body-path for the training board.
Use our hierarchical inverse RL algorithm to learn a reward function from the footstep and path labels.
Test on hold-out terrains: Plan a path across the test-board.
Experimental setup

Task: Hover at a specific point. Initial state: tens of meters away from target.
Reward function trades off: Position accuracy, Orientation accuracy, Zero velocity, Zero angular rate, … (11 features total)
Helicopter Flight

Learned from “careful” pilot

Learned from “aggressive” pilot
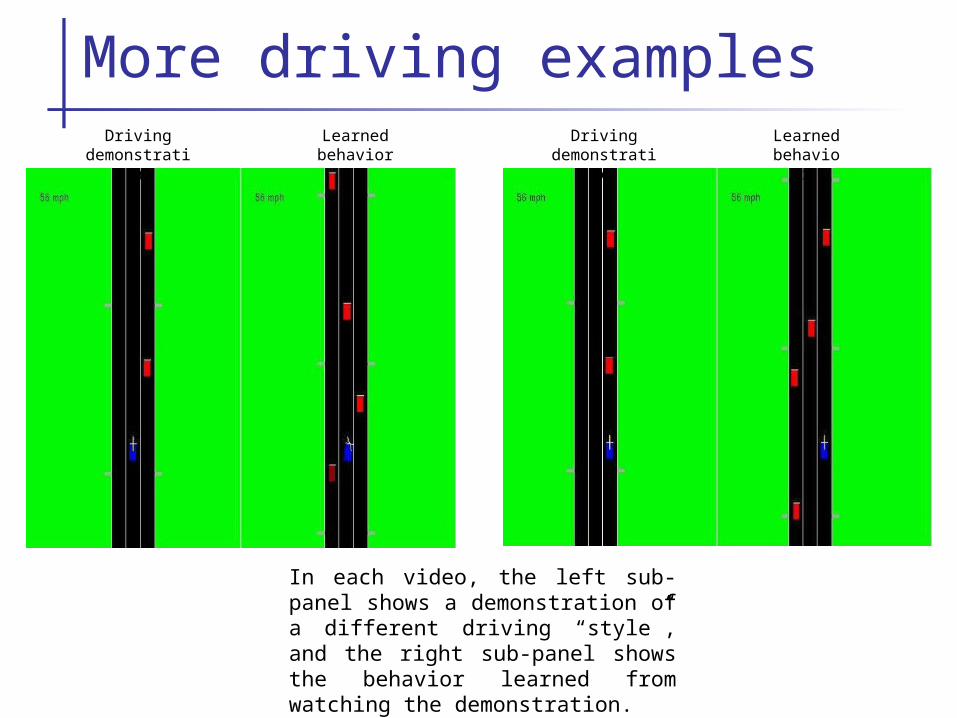
More driving examples
In each video, the left sub-panel shows a demonstration of a different driving “style”, and the right sub-panel shows the behavior learned from watching the demonstration.
Driving demonstratio
n
Driving demonstrati
on
Learned behavior
Learned behavior
Related Documents




![Nonlinear Optimization for Optimal Control Pieter Abbeel UC Berkeley EECS Many slides and figures adapted from Stephen Boyd [optional] Boyd and Vandenberghe,](https://static.cupdf.com/doc/110x72/56649d3f5503460f94a18efb/nonlinear-optimization-for-optimal-control-pieter-abbeel-uc-berkeley-eecs-many.jpg)






