Applications in GIS (Kriging Interpolation) Dr. S.M. Malaek Assistant: M. Younesi

Applications in GIS (Kriging Interpolation) Dr. S.M. Malaek Assistant: M. Younesi.
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Applications in GIS(Kriging Interpolation)
Dr. S.M. MalaekAssistant: M. Younesi

Interpolating a Surface From
Sampled Point Data

Interpolating a Surface From Sampled Point Data
Assumes a continuous surface that is sampled
Interpolation
Estimating the attribute values of locations that are within the range of available data using known data values
Extrapolation
Estimating the attribute values of locations outside the range of available data using known data values

Interpolating a Surface From Sampled Point Data
Estimating a point here: interpolation
Sample data
Interpolation

Interpolating a Surface From Sampled Point Data
Estimating a point here: extrapolation
Sample data
Extrapolation

Sampling Strategies for Interpolation
Regular Sampling Random Sampling
Interpolating a Surface From Sampled Point Data

Interpolating a Surface From Sampled Point Data
Elevation profile
Sample elevation data
A
B
If
A = 8 feet and
B = 4 feet
then
C = (8 + 4) / 2 = 6 feetC
Linear Interpolation

Interpolating a Surface From Sampled Point Data
Non-Linear Interpolation
Elevation profile
Sample elevation data
A
B
C
Often results in a more realistic interpolation but estimating missing data values is more complex

Interpolating a Surface From Sampled Point Data
Global InterpolationUses allall known sample points to estimate a value at an unsampled location
Sample data

Interpolating a Surface From Sampled Point Data
Local InterpolationUses a neighborhood of sample points to estimate a value at an unsampled location
Sample data
Uses a local neighborhood to estimate value, i.e. closest n number of points, or within a given search radius

Trend Surface

Trend Surface
Global method
Inexact
Can be linear or non-linear
predicting a z elevation value [dependent variable] with x and y location values [independent variables]

Trend Surface
1st Order Trend Surface
In one dimension: z varies as a linear function of x
x
zz = b0 + b1x + e

Trend Surface
1st Order Trend Surface
In two dimensions: z varies as a linear function of x and y
z = b0 + b1x + b2y + e
x
yz

Trend Surface

Inverse Distance Weighted (IDW)

Inverse Distance Weighted
Local method
Exact
Can be linear or non-linear
The weight (influence) of a sampled data value is inversely proportional to its distance from the estimated value

Inverse Distance Weighted(Example)
4
3
2
100
160
IDW: Closest 3 neighbors, r = 2
200
1),(1
),(
1
1
i
with
iin
ip
i
n
ip
i
i
zyxzor
d
dz
yxz

Inverse Distance Weighted(Example)
4
3
2
A = 100
B = 160
C = 200
1 / (42) = .0625 1 / (32) = .1111 1 / (22) = .2500
Weights
A BC

Inverse Distance Weighted(Example)
1 / (42) = .0625 1 / (32) = .1111 1 / (22) = .2500
.0625 * 100 = 6.25 .1111 * 160 = 17.76 .2500 * 200 = 50.00
Weights Weights * Value
A BC
74.01 / .4236 = 175
Total = .4236
6.25 +17.76 + 50.00 = 74.01 4
3
2
A = 100
B = 160
C = 200

Geostatistics

Geostatistics Geostatistics:The original purpose of geostatistics
centered on estimating changes in ore grade within a mine.
The principles have been applied to a variety of areas in geology and other scientific disciplines.
A unique aspect of geostatistics is the use of regionalized variables which are variables that fall between random variables and completely deterministic variables.

Geostatistics Regionalized variables describe phenomena
with geographical distribution (e.g. elevation of ground surface).
The phenomenon exhibit spatial continuity.

Geostatistics It is notalways possible to sample every location. Therefore, unknown values must be estimated
from data taken at specific locations that can be sampled.
The size, shape, orientation, and spatial
arrangement of the sample locations are termed the support and influence the capability to predict the unknown samples.

Semivariance

Semivariance Regionalized variable theory uses a related
property called the semivariancesemivariance to express the degree of relationship between points on a surface.
The semivariance is simply half the
variance of the differences between all possible points spaced a constant distance apart.
Semivariance is a measure of the degree of spatial dependence between samples (elevation(

Semivariance semivariance :The magnitude of the
semivariance between points depends on the distance between the points. A smaller distance yields a smaller semivariance and a larger distance results in a larger semivariance.

Calculating the Semivariance (Regularly Spaced PointsRegularly Spaced Points(
Consider regularly spaced points distance (d) apart, the semivariance can be estimated for distances that are multiple of (d) (Simple form):
hN
ihii
h
zzN
h1
2)(2
1)(

Semivariance
Zi is the measurement of a regionalized variable taken at location i ,
Zi+h is another measurement taken h intervals away d
Nh is number of separating distance = number of points –Lag (if the points are located in a single profile)
hN
ihii
h
zzN
h1
2)(2
1)(

Calculating the Semivariance
(Irregularly Spaced PointsRegularly Spaced Points( Here we are going to explore directional variograms. Directional variograms is defines the spatial variation among points separated by space lag h. The difference from the omnidirectional variograms is that h is a vector rather than a scalar.
For example, if d={d1,d2}, then each pair of compared samples should be separated in E-W direction and in S-N direction.
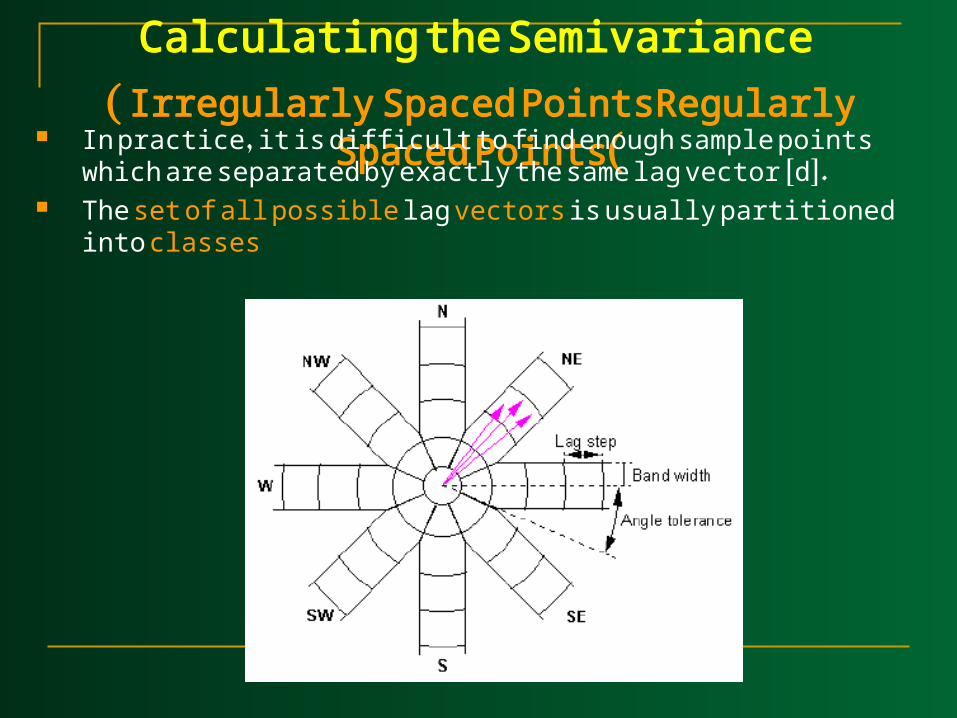
Calculating the Semivariance
(Irregularly Spaced PointsRegularly Spaced Points( In practice, it is difficult to find enough sample points which are
separated by exactly the same lag vector [d]. The set of all possible lag vectors is usually partitioned into
classes

Variogram
Variogram
The plot of the semivariances as a function of distance from a point is referred to as a semivariogram or variogram.

Variogram The semivariance at a distance d = 0 should be zero, because there
are no differences between points that are compared to themselves. However, as points are compared to increasingly distant points, the
semivariance increases.

Variogram The range is the greatest distance over which the value at a point
on the surface is related to the value at another point. The range defines the maximum neighborhood over which
control points should be selected to estimate a grid node.

Variogram (Models(
It is a ‘model’ semi-variogram and is usually called the spherical model. a is called the range of influence of a sample.
C is called the sill of the semi-variogram.
ahC
ahah
ah
Ch
where
where3
3
21
23
)(

Variogram (Models(Exponential Model
aheCh 1)(γ
spherical and exponential with the
same range and sill spherical and exponential with the same
sill and the same initial slope

Kriging
Interpolation

Kriging Interpolation
Kriging is named after the South African engineer, D. G. Krige, who first developed the method.
Kriging uses the semivariogram, in calculating estimates of the surface at the grid nodes.

Kriging Interpolation The procedures involved in kriging incorporate measures of error and uncertainty
when determining estimations. In the kriging method, every known data value and every missing data value has
an associated variance. If ‘C’ is constant (i.e. known value exactly), its variance is zero.
Based on the semivariogram used, optimal weights are assigned to known values in order to calculate unknown ones. Since the variogram changes with distance, the weights depend on the known sample distribution.

Ordinary Kriging

Ordinary Kriging Ordinary kriging is the simplest form of kriging.
It uses dimensionless points to estimate other dimensionless points, e.g. elevation contour plots.
In Ordinary kriging, the regionalized variable is assumed to be stationary.

Punctual (Ordinary) Kriging In our case Z, at point p, Ze (p) to be calculated
using a weighted average of the known values or control points:
)()(iie
pzwpz This estimated value will most likely differ from the actual
value at point p, Za(p), and this difference is called the
estimation errorestimation error:
)()( pzpzaep

Punctual (Ordinary) Kriging If no drift exists and the weights used in the estimation sum to
one, then the estimated value is said to be unbiased. The scatter of the estimates about the true value is termed the error or estimation variance,
n
pzpzn
iiiaie
z
1
2
2
)]()([σ

Punctual (Ordinary) Kriging kriging tries to choose the optimal weights that produce the minimum
estimation error . Optimal weights, those that produce unbiased estimates and have a minimum
estimation variance, are obtained by solving a set of simultaneous equations .
)(γ)(γ)(γ)(γ
)(γ)(γ)(γ)(γ
)(γ)(γ)(γ)(γ
3333322311
2233222211
1133122111
p
p
p
hhwhwhw
hhwhwhw
hhwhwhw
1321 www

Punctual (Ordinary) Kriging A fourth variable is introduced called the Lagrange
multiplier
1
)()()()(
)()()()(
)()()()(
321
3333322311
2233222211
1133122111
www
hhwhwhw
hhwhwhw
hhwhwhw
p
p
p
1
)(
)(
)(
0111
1)()()(
1)()()(
1)()()(
3
2
1
3
2
1
333231
232121
131211
p
p
p
h
h
h
w
w
w
hhh
hhh
hhh

Punctual (Ordinary) Kriging Once the individual weights are known, an estimation
can be made by
332211)( zwzwzwpze
And an estimation variance can be calculated by
λ)(γ)(γ)(γσ 313212112 pppz hwhwhw


Related Documents











