
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


The Team
Renato Marroquín
● PhD student at:● Interested in:
○ Stream processing○ Distributed data management
● Apache contributor○ Apache Gora, Giraph, Nutch, Samza
● rmarroquin [at] apache [dot] org

The Team
Yan Fang
● Software engineer at:● Interested in:
○ Stream processing○ Information retrieval○ Natural language processing
● Committer and PMC for Apache Samza ● yfang [at] apache [dot] org

Background● Messaging systems
Shared message queue
SendersReceivers

Background● Messaging systems
SendersReceivers
Twitter’s Kestrel

Background● Stream processing
○ Message producers and consumers are not so trivial○ Partitioning○ State○ Failure semantics○ Reprocessing○ Joins to services or databases

Apache Samza
● Distributed stream processing framework● Developed @ LinkedIn● Open sourced ~ 2013● Used by
○ LinkedIn○ Uber○ Tivo○ Nextel○ Metamarkers○ ...
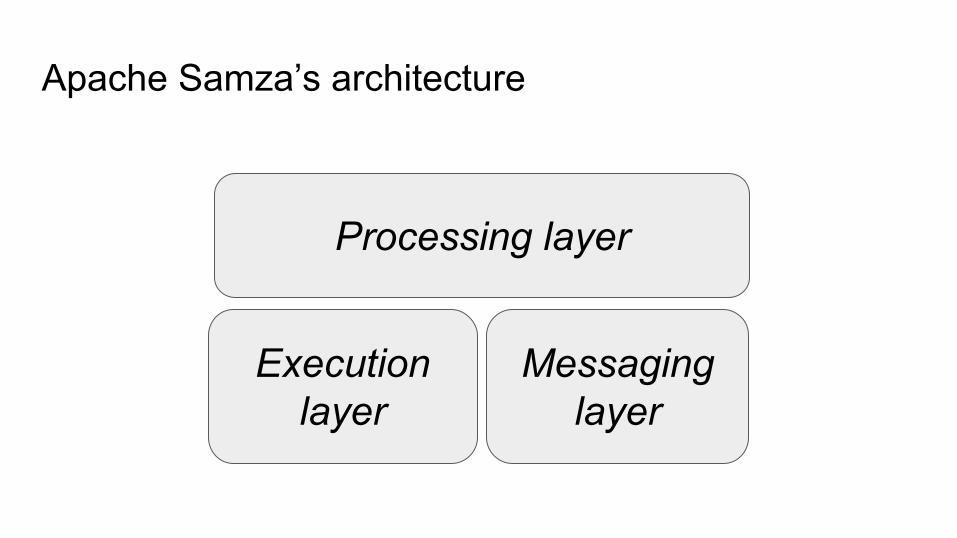
Apache Samza’s architecture
Execution layer
Messaging layer
Processing layer

Apache Samza’s architecture
YARN
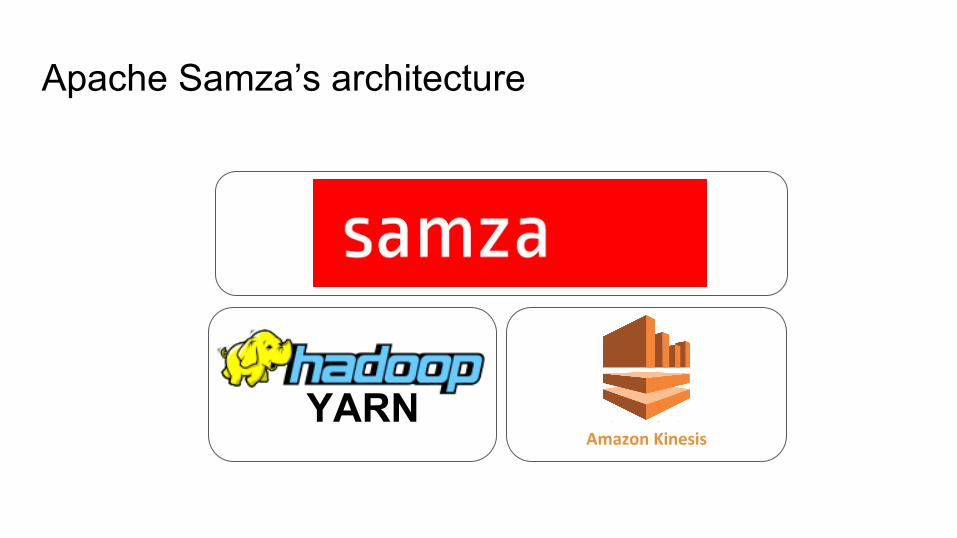
Apache Samza’s architecture
YARNAmazon Kinesis

Apache Samza
How it works?
● Streams● Tasks● Execution
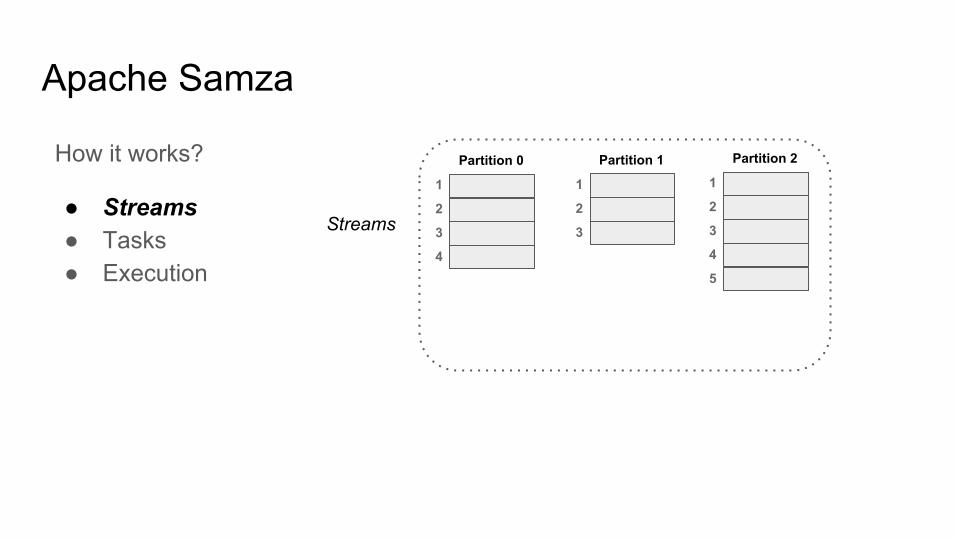
Apache Samza
1
Partition 0
2
3
4
1
Partition 1
2
3
1
Partition 2
2
3
4
5
Streams
How it works?
● Streams● Tasks● Execution

Apache Samza
1
Partition 0
2
3
4
1
Partition 1
2
3
1
Partition 2
2
3
4
5
Streams
5
How it works?
● Streams● Tasks● Execution

Apache Samza
1
Partition 0
2
3
4
1
Partition 1
2
3
1
Partition 2
2
3
4
5
Streams
5
4
6
How it works?
● Streams● Tasks● Execution

Apache Samza
How it works?
● Streams● Tasks● Execution
1
Partition 0
2
3
4
1
Partition 1
2
3
1
Partition 2
2
3
4
5
Streams
5
4
66
5
7
to be appended

Apache Samza
Streams
Tasks
How it works?
● Streams● Tasks● Execution
Stream A Stream B
Task 1 Task 2 Task 3
Stream C
input

Apache Samza
Streams
Tasks
How it works?
● Streams● Tasks● Execution
Stream A Stream B
Task 1 Task 2 Task 3
Stream C
output
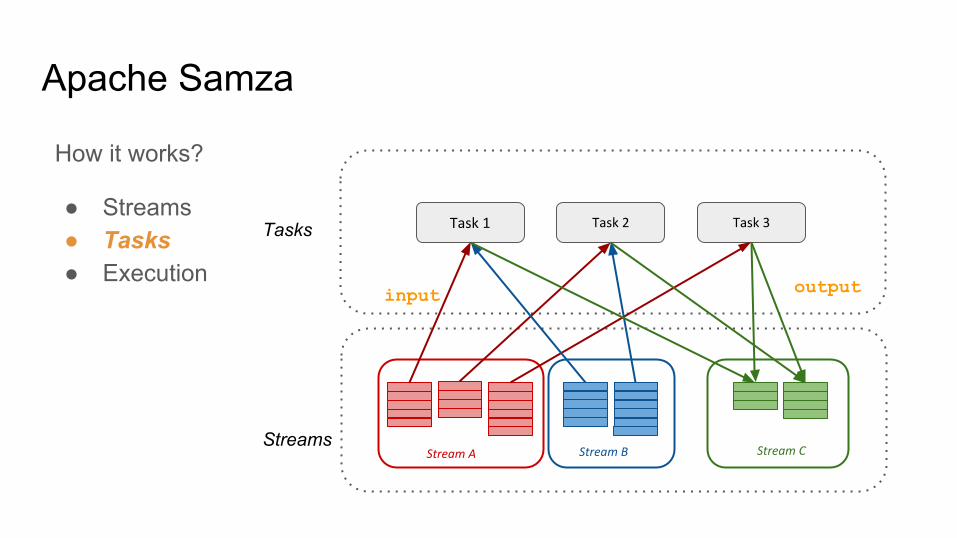
Apache Samza
Streams
Tasks
How it works?
● Streams● Tasks● Execution
Stream A Stream B
Task 1 Task 2 Task 3
Stream C
input output
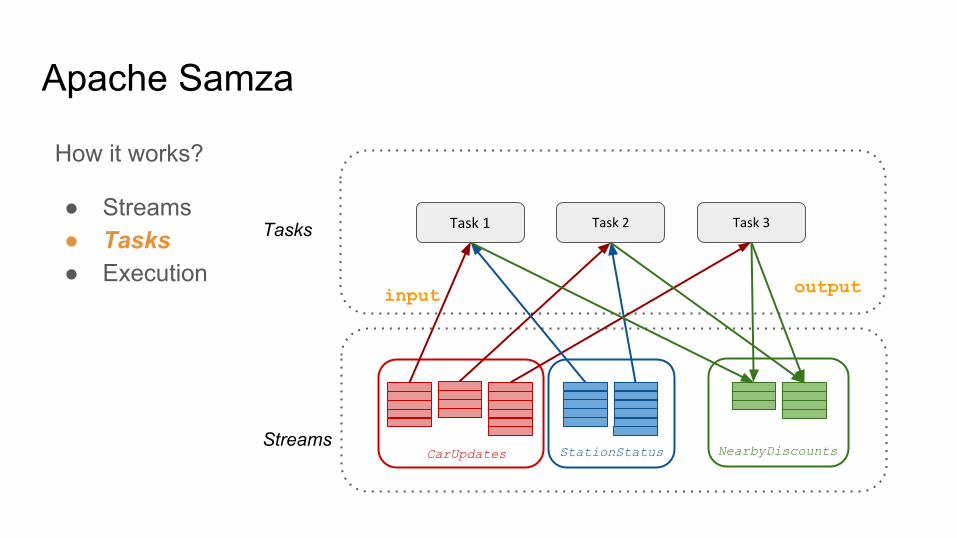
Apache Samza
Streams
Tasks
How it works?
● Streams● Tasks● Execution
CarUpdates StationStatus
Task 1 Task 2 Task 3
NearbyDiscounts
input output

Apache Samza
How it works?
● Streams● Tasks● Execution
Class MyExampleTask implements StreamTask {
public void process (IncomingMessageEnvelope env,
MessageCollector col,
TaskCoordinator coord) {
final TextMessage msg = (TextMessage) envelope.getMessage();
Map<String, Object> outMap = new HashMap<>(){{
put(msg.getMessageID(), msg.getText());
}};
collector.send(new OutgoingMessageEnvelope(outStream, outMap));
}}
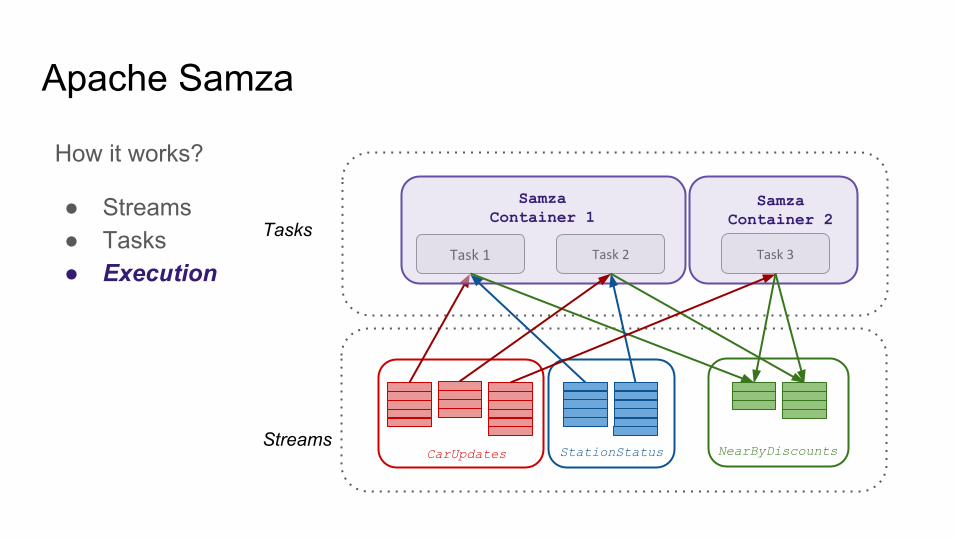
Apache Samza
Streams
Tasks
How it works?
● Streams● Tasks● Execution
CarUpdates StationStatus
Task 1 Task 2 Task 3
NearByDiscounts
Samza Container 2
SamzaContainer 1

Apache Samza
How it works?
● Streams● Tasks● Execution
Task 1 Task 2 Task 3
Samza Container 2
SamzaContainer 1
Host 1 Host 2

Apache Samza
How it works?
● Streams● Tasks● Execution
Task 1 Task 2 Task 3
Samza Container 2
SamzaContainer 1
NodeManager NodeManager
Host 1 Host 2

Apache Samza
How it works?
● Streams● Tasks● Execution
Task 1 Task 2 Task 3
Samza Container 2
SamzaContainer 1
NodeManager NodeManager
Host 1 Host 2
Samza YARN AM

Kafka Broker
Apache Samza
How it works?
● Streams● Tasks● Execution
Task 1 Task 2 Task 3
Samza Container 2
SamzaContainer 1
NodeManager NodeManager
Host 1 Host 2
Samza YARN AM
Kafka Broker
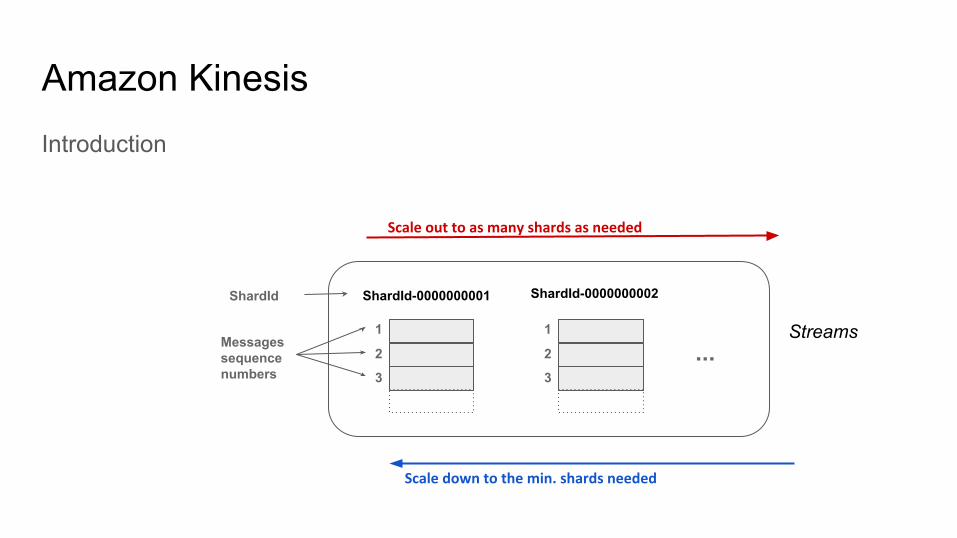
Amazon KinesisIntroduction
1
ShardId-0000000001
2
3
Messages sequence numbers
1
ShardId-0000000002
2
3...
Scale out to as many shards as needed
Scale down to the min. shards needed
ShardId
Streams

Amazon Kinesis● Two types of API
○ Amazon KCL○ Amazon Kinesis API

Amazon Kinesis● Two types of API
○ Amazon KCL■ Specification for handling records: IRecordProcessor interface■ Assigns a shard to an IRecordProcessor■ Create a KCL Worker to consumer data■ If many workers, they coordinate through Amazon Dynamo
KinesisClientLibConfiguration config = new KinesisClientLibConfiguration(...)
IRecordProcessorFactory recordProcessorFactory = new RecordProcessorFactory();
Worker worker = new Worker.Builder()
.recordProcessorFactory(recordProcessorFactory)
.config(config)
.build();
○ Amazon Kinesis API

Amazon Kinesis● Two types of API
○ Amazon KCL■ Specification for handling records: IRecordProcessor interface■ Assigns a shard to an IRecordProcessor■ Create a KCL Worker to consumer data■ If many workers, they coordinate through Amazon Dynamo
KinesisClientLibConfiguration config = new KinesisClientLibConfiguration(...)
IRecordProcessorFactory recordProcessorFactory = new RecordProcessorFactory();
Worker worker = new Worker.Builder()
.recordProcessorFactory(recordProcessorFactory)
.config(config)
.build();
○ Amazon Kinesis API
Record processor

Amazon Kinesis● Two types of API
○ Amazon KCL■ Specification for handling records: IRecordProcessor interface■ Assigns a shard to an IRecordProcessor■ Create a KCL Worker to consumer data■ If many workers, they coordinate through Amazon Dynamo
KinesisClientLibConfiguration config = new KinesisClientLibConfiguration(...)
IRecordProcessorFactory recordProcessorFactory = new RecordProcessorFactory();
Worker worker = new Worker.Builder()
.recordProcessorFactory(recordProcessorFactory)
.config(config)
.build();
○ Amazon Kinesis API
KCL worker

Amazon Kinesis● Two types of API
○ Amazon KCL○ Amazon Kinesis API

Amazon Kinesis● Two types of API
○ Amazon KCL○ Amazon Kinesis API
■ Get data from Kinesis shards ■ To iterate over shards: getNextShardIterator■ To get shard iterator: getShardIterator
GetRecordsRequest getRecordsRequest = new GetRecordsRequest();getRecordsRequest.setShardIterator(shardIterator);getRecordsRequest.setLimit(25);
GetRecordsResult getRecordsResult = client.getRecords(getRecordsRequest);List<Record> records = getRecordsResult.getRecords();
Configure Kinesis request

Amazon Kinesis● Two types of API
○ Amazon KCL○ Amazon Kinesis API
■ Get data from Kinesis shards ■ To iterate over shards: getNextShardIterator■ To get shard iterator: getShardIterator
GetRecordsRequest getRecordsRequest = new GetRecordsRequest();getRecordsRequest.setShardIterator(shardIterator);getRecordsRequest.setLimit(25);
GetRecordsResult getRecordsResult = client.getRecords(getRecordsRequest);List<Record> records = getRecordsResult.getRecords();
Executing the request

Integration storypublic interface SystemConsumer {
void start();
void stop();
void register( SystemStreamPartition systemStreamPartition, String lastReadOffset);
List<IncomingMessageEnvelope> poll(
Map<SystemStreamPartition, Integer> systemStreamPartitions,
long timeout) throws InterruptedException;
}

Integration storypublic interface SystemProducer {
void start();
void stop();
void register(String source);
void send(String source, OutgoingMessageEnvelope envelope);
void flush(String source);
}

Integration story● Map each Kinesis shard → Samza’s logical partition ● Remember → Messages coming from a specific partition go to:
○ Particular task ○ Inside a specific container
● Approach 1:○ Auto-scaling○ Load balancing
● Approach 2:○ Correctness○ At-least once guarantees

Integration storyAttempt 1: KCL
● Every task uses its own KCL
Stream A Stream B
KCL KCLKCL
Stream C
Samza Container 2
SamzaContainer 1
Task 2Task 1 Task 3
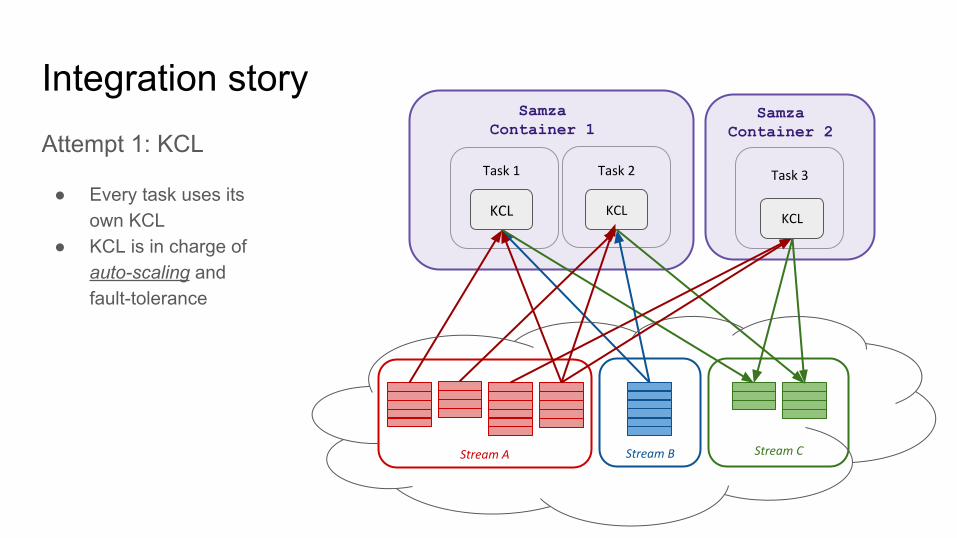
Integration storyAttempt 1: KCL
● Every task uses its own KCL
● KCL is in charge of auto-scaling and fault-tolerance
Stream A Stream B
KCL
Stream C
Samza Container 2
SamzaContainer 1
Task 2Task 1 Task 3
KCLKCL

Integration story
Stream A Stream B
KCL
Stream C
Samza Container 2
SamzaContainer 1
Task 2Task 1 Task 3
KCLKCL
Attempt 1: KCL
● Every task uses its own KCL
● KCL is in charge of auto-scaling and fault-tolerance

Integration story
Stream A Stream B
KCL
Stream C
Samza Container 2
SamzaContainer 1
Task 2Task 1 Task 3
KCLKCL
Attempt 1: KCL
● Every task uses its own KCL● KCL is in charge of auto-scaling
and fault-tolerance● But
○ Fix mapping between streams partitions and containers
○ Msgs should go to a specific container
● Messages could be lost!

Integration storyAttempt 2:
Amazon Kinesis API
● Assuring correctness
● Letting Samza deal with fault-tolerance and load balancing
Stream A Stream B Stream C
Samza Container 2
SamzaContainer 1
Task 1+
Kinesis API
Task 2+
Kinesis API
Task 3+
Kinesis API

Integration storyAttempt 2: Amazon Kinesis API
● Register each Kinesis shard as Samza’s partitions.○ Involves creating a shardIterator per partition
● Create a GetShardIteratorRequest per partition to fetch data○ From the beginning of the stream○ From a specific sequence number
● Keep track of each record received from Kinesis● Checkpoint in Samza

Integration story // Create a new getRecordsRequest with an existing shardIterator
GetRecordsRequest getRecordsRequest = new GetRecordsRequest();
getRecordsRequest.setShardIterator(shardIterator);
GetRecordsResult result = kClient.getRecords(getRecordsRequest);
// Put the result into record list.
for (Record record : result.getRecords()) {
IncomingMessageEnvelope envelope = new IncomingMessageEnvelope(ssp,
record.getSequenceNumber(),
record.getPartitionKey(),
record.getData());
put(ssp, envelope);
trackDeliveries(ssp.getName(), envelope);
}

Integration story // Create a new getRecordsRequest with an existing shardIterator
GetRecordsRequest getRecordsRequest = new GetRecordsRequest();
getRecordsRequest.setShardIterator(shardIterator);
GetRecordsResult result = kClient.getRecords(getRecordsRequest);
// Put the result into record list.
for (Record record : result.getRecords()) {
IncomingMessageEnvelope envelope = new IncomingMessageEnvelope(ssp,
record.getSequenceNumber(),
record.getPartitionKey(),
record.getData());
put(ssp, envelope);
trackDeliveries(ssp.getName(), envelope);
}
Creating a handle toKinesis shards

Integration story // Create a new getRecordsRequest with an existing shardIterator
GetRecordsRequest getRecordsRequest = new GetRecordsRequest();
getRecordsRequest.setShardIterator(shardIterator);
GetRecordsResult result = kClient.getRecords(getRecordsRequest);
// Put the result into record list.
for (Record record : result.getRecords()) {
IncomingMessageEnvelope envelope = new IncomingMessageEnvelope(ssp,
record.getSequenceNumber(),
record.getPartitionKey(),
record.getData());
put(ssp, envelope);
trackDeliveries(ssp.getName(), envelope);
}
Executing the request

Integration story // Create a new getRecordsRequest with an existing shardIterator
GetRecordsRequest getRecordsRequest = new GetRecordsRequest();
getRecordsRequest.setShardIterator(shardIterator);
GetRecordsResult result = kClient.getRecords(getRecordsRequest);
// Put the result into record list.
for (Record record : result.getRecords()) {
IncomingMessageEnvelope envelope = new IncomingMessageEnvelope(ssp,
record.getSequenceNumber(),
record.getPartitionKey(),
record.getData());
put(ssp, envelope);
trackDeliveries(ssp.getName(), envelope);
}
Passing messages to Samza

Integration story // Create a new getRecordsRequest with an existing shardIterator
GetRecordsRequest getRecordsRequest = new GetRecordsRequest();
getRecordsRequest.setShardIterator(shardIterator);
GetRecordsResult result = kClient.getRecords(getRecordsRequest);
// Put the result into record list.
for (Record record : result.getRecords()) {
IncomingMessageEnvelope envelope = new IncomingMessageEnvelope(ssp,
record.getSequenceNumber(),
record.getPartitionKey(),
record.getData());
put(ssp, envelope);
trackDeliveries(ssp.getName(), envelope);
}
Keeping track of messages received

Task 1+
Kinesis API
Task 2+
Kinesis API
Task 3+
Kinesis API
Integration story: Samza’s fault tolerance
Stream A Stream B Stream C
Samza Container 2
SamzaContainer 1

Local
Task 1+
Kinesis API
Task 2+
Kinesis API
Task 3+
Kinesis API
Integration story: Samza’s fault tolerance
Stream A Stream B Stream C
Samza Container 2
SamzaContainer 1
Local Local
Durable change log

Local
Task 1+
Kinesis API
Task 2+
Kinesis API
Task 3+
Kinesis API
Integration story: Samza’s fault tolerance
Stream A Stream B Stream C
Samza Container 2
SamzaContainer 1
Local Local
Durable change log

Local
Task 1+
Kinesis API
Task 2+
Kinesis API
Task 3+
Kinesis API
Integration story: Samza’s fault tolerance
Stream A Stream B Stream C
Samza Container 2
SamzaContainer 1
Local Local
Durable change log

Local
Task 1+
Kinesis API
Task 2+
Kinesis API
Task 3+
Kinesis API
Integration story: Samza’s fault tolerance
Stream A Stream B Stream C
Samza Container 2
SamzaContainer 1
Local Local
Durable change log

Local
Task 1+
Kinesis API
Task 2+
Kinesis API
Task 3+
Kinesis API
Integration story: Samza’s fault tolerance
Stream A Stream B Stream C
Samza Container 2
SamzaContainer 1
Local Local
Durable change log
->Restart container->Replay log from durable change log

Local
Task 1+
Kinesis API
Task 2+
Kinesis API
Task 3+
Kinesis API
Integration story: Samza’s fault tolerance
Stream A Stream B Stream C
Samza Container 2
SamzaContainer 1
Local Local
Durable change log
->Restart container->Replay log from durable change log

Apache Samza next moves● Tighter integration with Apache Kafka● Samza as
○ a stream processing as a service○ the transformation layer for many services
● Pluggable mapping from streams/tasks/containers● Different execution layers
○ Yarn is not always needed○ Standalone mode
● Integrate with other systems

Thanks!
@renatomarroquinrmarroquin [at] apache [dot] org
Related Documents











