Go DataDriven PROUDLY PART OF THE XEBIA GROUP @fzk [email protected] Apache Spark Friso van Vollenhoven for applied machine learning

Apache Spark Talk for Applied machine learning
Aug 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

GoDataDrivenPROUDLY PART OF THE XEBIA GROUP
@fzk [email protected]
Apache Spark
Friso van Vollenhoven
for applied machine learning

GoDataDriven

GoDataDriven

GoDataDriven
This talk is about tools.

GoDataDriven


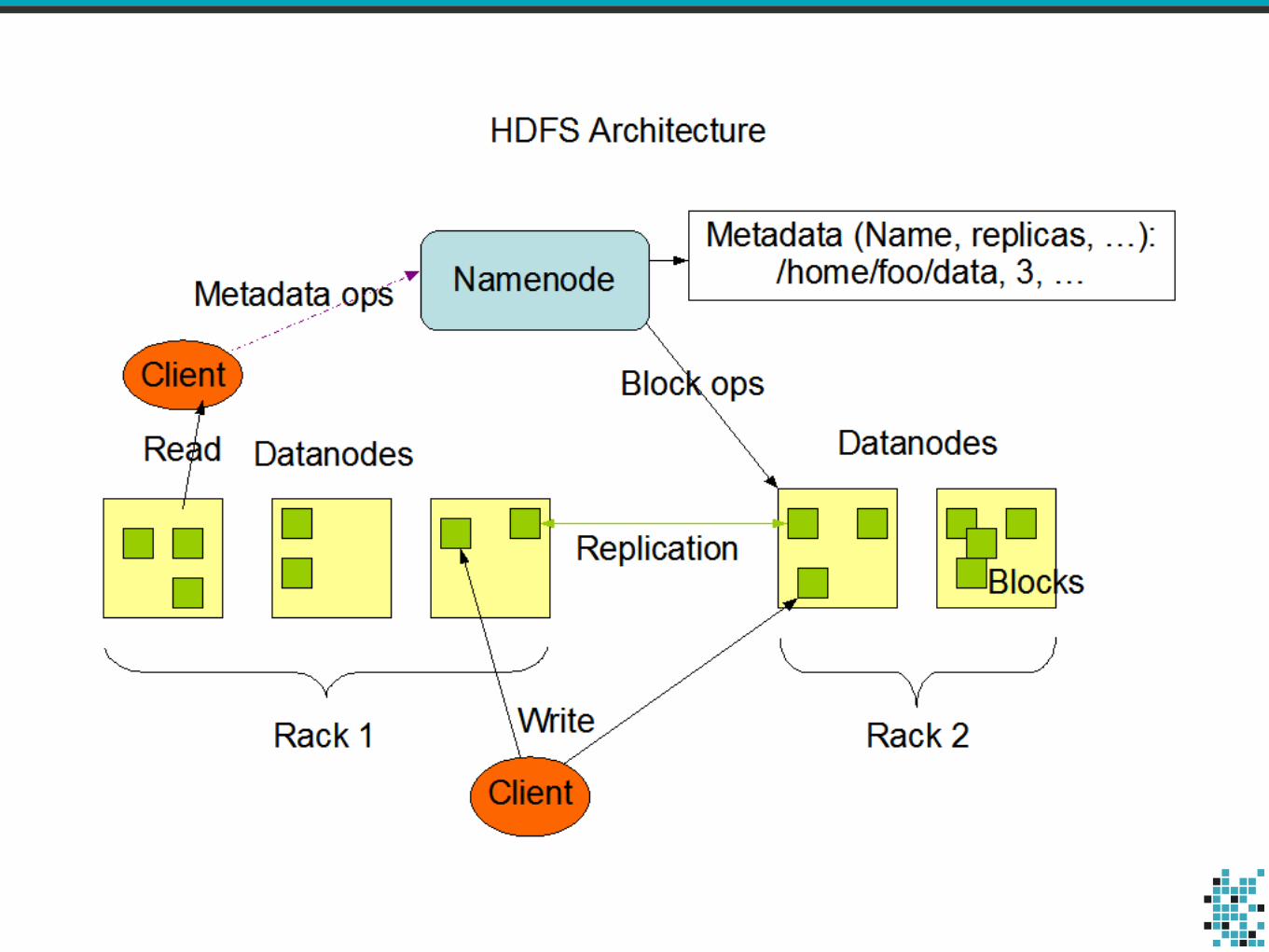
GoDataDriven

GoDataDriven
GoDataDriven

GoDataDriven



GoDataDriven
Resilient Distributed Dataset
• Immutable set of records (e.g. tuples)
• Distributed across a cluster of workers
• Stored in RAM or on disk (partially)
• Built through transformations
• Automatically rebuilt on failure
• Possibly replicated

GoDataDriven
Operations
• Operate on RDD’s
• Create a new RDD
• Or materialise RDD and return data
• Transformations: map, filter, groupBy, etc.
• Actions: count, collect, reduce, save, etc.



GoDataDriven
The good parts
• Language bindings for Java, Scala and Python
• Works interactively from a shell:
• Scala + IPython (notebook)
• Plays nice with Hadoop
• Deploy on top of YARN cluster manager
• Read data from HDFS
• Hadoop-like fault tolerance

The better part?https://github.com/Bridgewater/scala-notebook



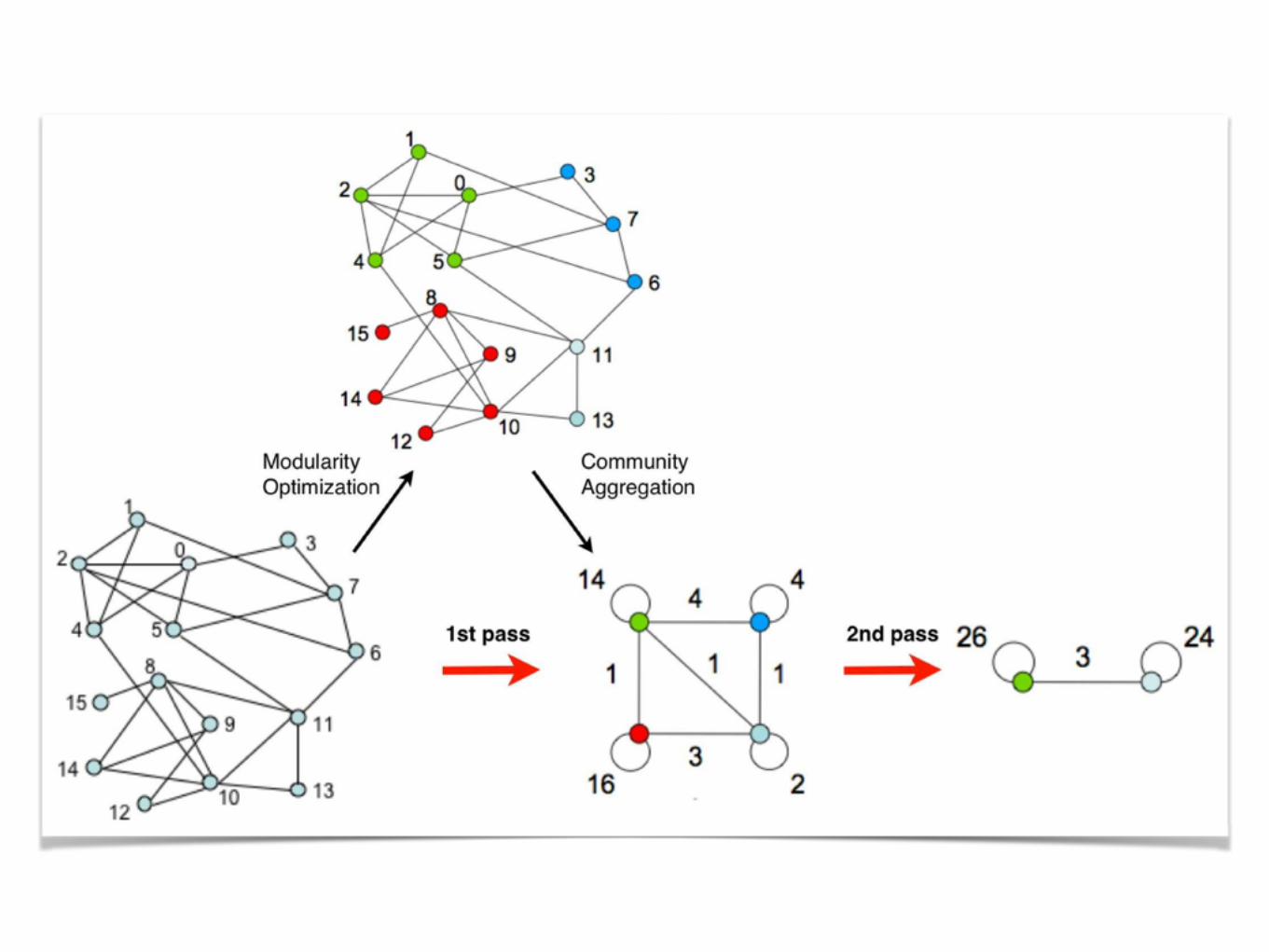



https://github.com/Sotera/spark-distributed-louvain-modularity

Related Documents










![[@NaukriEngineering] Apache Spark](https://static.cupdf.com/doc/110x72/588304451a28abe70d8b6157/naukriengineering-apache-spark.jpg)
