Apache Spark ile Twitter’ı izlemek Mehmet Uluer @Tübitak-Uzay Özgür Web Teknolojileri Günleri 23 Ekim 2016 [email protected]

Apache Spark ile Twitter’ı izlemekApache Spark ile Twitter’ı izlemek Mehmet Uluer @Tübitak-Uzay Özgür Web Teknolojileri Günleri 23 Ekim 2016 [email protected]
Feb 03, 2020
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Apache Spark ile Twitter’ı izlemek
Mehmet Uluer @Tübitak-UzayÖzgür Web Teknolojileri Günleri
23 Ekim 2016

Apache Spark
● Açık kaynak kodlu bir “Küme Hesaplama” altyapısı
● Matei Zaharia, (Mart 30, 2014)– Tathagata Das (Streaming)
● AMPLAB – Algorithms, Machines and People Lab.
– Univ. of California, Berkeley
● Apache Yazılım Vakfı himayesinde
● Kararlı son sürümü:– v.2.0.1
● http://spark.apache.org
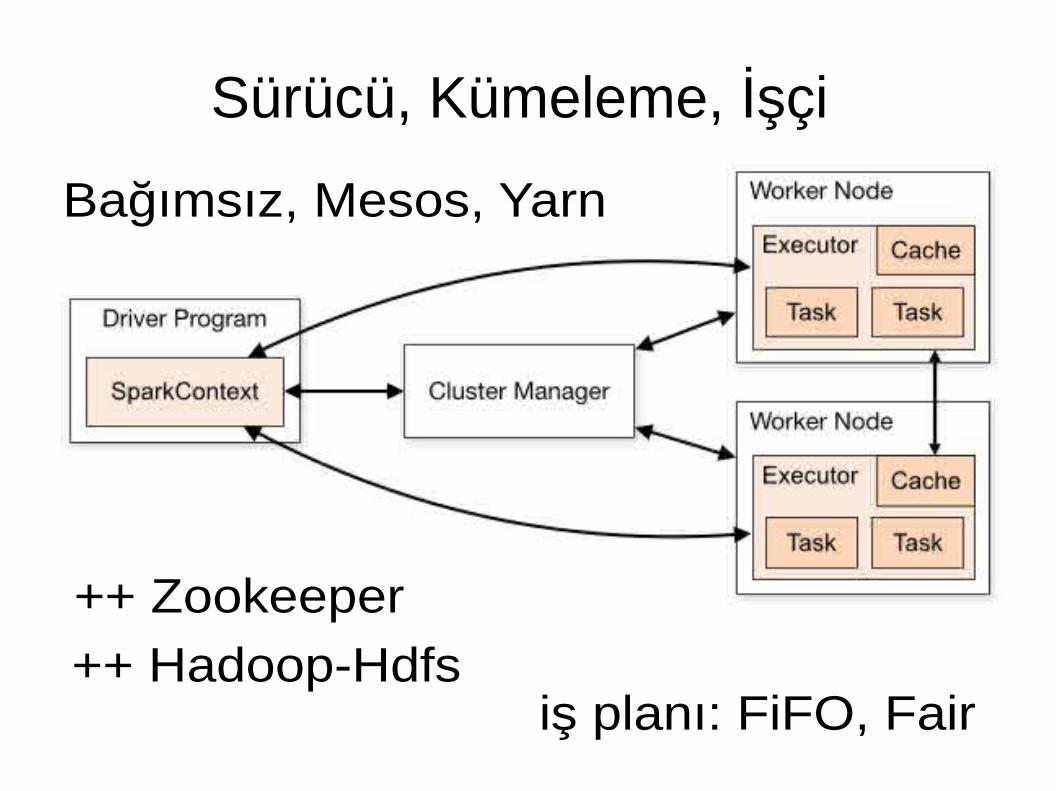
Sürücü, Kümeleme, İşçi
iş planı: FiFO, Fair
Bağımsız, Mesos, Yarn
++ Zookeeper
++ Hadoop-Hdfs

Veri Yapısı
● RDD– Resilient Distributed Datasets
● böl, parçala, ye..● Immutable : oluştumu değişmez● Dağıtık● lazily evaluated : tembel işler
– 10 yaş ve üzeri binek araçlar
● Cachelenebilir
● Partition : mantıksal veri bölümü
● Chunk : fiziksel parça @hdfs
+ Fault-Tolerant Stream Processing

Veri → Transformasyon
● Tekli/Çiftli Transformasyon– filter : filtrele
– map : her eleman için bir dönüşüm
– flatmap : böl parçala ye -> böl, parçala, ye
– distinct: mükerrer temizle..
● Çoklu Transformasyon– Union, intersection, subtract
● 2 data set > birleştir, ortak olanı al, farklı olanları al..

Veri → İşlem (Aksiyon)
● Hesapla, Cachele, HDFS 'e yaz– count
– collect
– take(n)
– reduce(fonksiyon)

Shared Variables : Ortaklık
● Accumulators– Merkezi sayaç
● Broadcast Variables– sözlük, şehir zipkodları,..
SQL, Streaming, MLlib, GraphX

Bilgi Gereksinimleri
● Linux– Terminal, Ssh, syslog, man..
● Eclipse, SVN, Maven, Jmeter..
● Java ( > 8 ) ( → Scala ? )– Lambda Expressions
● System.out.println(kostur.kos(a -> a+1));
– Multithreading● Senkronizasyon, deadlock, semaphore..
– Runnable vs. Callable● Dönmek yada dönmemek● public interface Runnable { void run();}● public interface Callable<V> { V call() throws Exception;}
● Map - Reduce

Bir Küme Kurulumu : Külüstür
● 3 Node– 2 Centos + 1 Ubuntu
– 10.1.10.1 kulustur1– 10.1.10.2 kulustur2– 10.1.10.3 kulustur3
● 20 Core, 70GB Ram ve 2.5TB Depolama
● Hadoop, Yarn, Zookeeper, Mesos, Spark,Ganglia..

ZOOKEEPER
[root@kulustur1 zookeeper]# cat conf/zoo.cfg
ckTime=2000
dataDir=/usr/local/zookeeper/var
clientPort=2181
initLimit=5
SyncLimit=2
server.1=kulustur1:2888:3888
server.2=kulustur2:2888:3888
server.3=kulustur13:2888:3888
root@kulustur1:/usr/local/zookeeper# rm -rf /usr/local/zookeeper/var/*
[root@kulustur1 zookeeper]# bin/zkServer-initialize.sh --force --myid=1
[root@kulustur1 mesos]# /usr/local/zookeeper/bin/zkServer.sh start

MESOS
● [root@kulustur1 mesos]# nohup mesos-master--hostname=kulustur1 --ip=10.1.10.177 --port=5050--cluster=kulustur --quorum=1--zk=zk://kulustur1:2181,kulustur2:2181,kulustur3:2181/mesos--work_dir=/usr/local/mesos/var/ --authenticate--authenticate_slaves --credentials=credentials &
● [root@kulustur mesos]# nohup mesos-slave--hostname=kulustur1 --ip=10.1.10.177--master=zk://kulustur1:2181,kulustur2:2181,kulustur3:2181/mesos --work_dir=/usr/local/mesos/var/ --credential=slave_credential&

HADOOP
● [root@kulustur1 hadoop]# bin/hdfs namenode -format kulus
● [root@kulustur1 hadoop]# sbin/hadoop-daemon.sh --config etc/hadoop --script hdfsstart namenode
● [root@kulustur1 hadoop]# sbin/hadoop-daemon.sh --config etc/hadoop --script hdfsstart datanode
core-site.xml
<property><name>fs.defaultFS</name>
<value>hdfs://kulustur4:9000</value></property><property> <name>hadoop.tmp.dir</name> <value>/hdfs/tmp</value></property>
hdfs-site.xml
<property><name>dfs.namenode.name.dir</name> <value>/hdfs/nn1</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/hdfs/dn1</value> </property>

SPARK
● [root@kulustur1 spark]# sbin/start-mesos-dispatcher.sh --host kulustur1 --port 7077--webui-port 8083 --name kulustur --mastermesos://zk://kulustur1:2181,kulustur2:2181,kulustur3:2181/mesos
● [root@kulustur1 spark-1.6.0-bin-hadoop2.6]#bin/spark-submit --mastermesos://zk://kulustur1:2181/mesos --classorg.apache.spark.examples.JavaSparkPilib/spark-examples-1.6.0-hadoop2.6.0.jar 10

GANGLiA
● [root@kulustur1 ~]# vim /etc/ganglia/gmond.conf– cluster {
– name = "kulustur"
– owner = "k1" }
– udp_send_channel {
– host = kulustur1
– bind_hostname = yes
– port = 8649
– ttl = 1}
● Client → – udp_recv_channel {
– port = 8649 }
– tcp_accept_channel {
– port = 8649 }

Önemli Portlar
● Spark4mesos java 8220 root 16u IPv6 1514861 0t0 TCP *:8083 (LISTEN)
● Spark java 8220 root 34u IPv6 1511230 0t0 TCP kulustur1:7077 (LISTEN)
● Zookeeper java 11830 root 30u IPv6 1280213 0t0 TCP *:2181 (LISTEN)
● Zookeeper java 11830 root 37u IPv6 1280216 0t0 TCP *:8080 (LISTEN)
● Namenode java 17122 root 183u IPv4 1357929 0t0 TCP *:50070 (LISTEN)
● Namenode java 17122 root 200u IPv4 1357936 0t0 TCP kulustur1:9000 (LISTEN)
● Datanode java 17217 root 183u IPv4 1359068 0t0 TCP *:50010 (LISTEN)
● Mesos-master mms 20433 root 5u IPv4 1368804 0t0 TCP kulustur1:5050 (LISTEN)
● Mesos-slave msl 6111 root 5u IPv4 1506301 0t0 TCP kulustur1:5051 (LISTEN)
● Resourcemngr java 2456 root 224u IPv6 2034210 0t0 TCP kulustur1:8088 (LISTEN)
● Nodemanager java 32568 root 241u IPv6 2035354 0t0 TCP *:8040 (LISTEN)

Map-Reduce

Kelime Sayıcı
bash #: cat uzunTekerleme.file
| tr '[A-Z]' '[a-z]'
| tr '[:punct:]' ' '
| tr '\t' ' '
| tr ' ' '\n'
| sed '/^$/d'
| sort -d
| uniq -c
| sort -nr

@Apache-Spark
SparkConf conf = new SparkConf()
.setAppName("test1")
.setMaster("local[*]");
JavaSparkContext sc =
new JavaSparkContext(conf);

List<Tuple2<Integer, String>> liste = sc.textFile("data/uzunTekerleme.file",1000).cache().filter(satir -> !(satir.isEmpty())).map(satir -> satir.toLowerCase()).map(satir -> satir.replaceAll("[^\\p{L}\\s]", " ")).flatMap(satir -> Arrays.asList(satir.split(" "))).mapToPair(kelime -> new Tuple2<>(kelime, 1)).reduceByKey((i1, i2) -> i1 + i2).mapToPair(s1 -> new Tuple2<Integer, String>(s1._2(), s1._1())).sortByKey(false).collect();
Transformasyon - Aksiyon

Lambda 'sız
.map(
new Function<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public String call(String satir) throws Exception {
return satir.toLowerCase();
}
});

Yazdır - Kapat
for (Tuple2<Integer, String> l : liste)
System.out.printf("%4d %s\n",l._1(),l._2());
sc.close();

Örnek İşletme : Girdi - Çıktı
17855120 boz
12498584 tarlaya
12498584 kekere
12498584 şinik
8927560 pis
8927560 dadanan
8927560 başlıklı
3571024 mekere
3571024 bi
3571024 ben
3571024 ekmişler
3571024 porsuğum
3571024 şu
1785512 da
8927560 bir
8927560 mekereye
8927560 ala
8927560 ekilen
7142048 bu
5356536 demiş
1785512 de
1785512 öteki
1785512 ki
1785512 porsuğa
1785512 porsuk
1785512 porsukta
tekerleme..Şu tarlaya bi şinik kekere mekere ekmişler.
Bu tarlaya da bi şinik kekere mekere ekmişler.
Şu tarlaya ekilen bir şinik kekere mekereye dadanan boz ala boz başlıklı pis porsuk,bu tarlaya ekilen bir şinik kekere mekereye dadanan boz ala boz başlıklı pis porsuğa demiş ki;"ben bu tarlaya ekilen bir şinik kekere mekereye dadanan boz ala boz başlıklı pis porsuğum" demiş.Öteki tarlaya ekilen bir şinik kekere mekereye dadanan boz ala boz başlıklı pis porsukta;ben de; "bu tarlaya ekilen bir şinik kekere mekereye dadanan boz ala boz başlıklı pis porsuğum" demiş...
Örnek veriyi çoğaltmak için (yeterince büyüdüğünde CTRL+D);bash # cat tekerleme >> tekerleme
1GB →→→→→→→ < 1dk 10GB →→→→→→→ < 4dk
https://databricks.com/blog/2014/10/10/spark-petabyte-sort.html
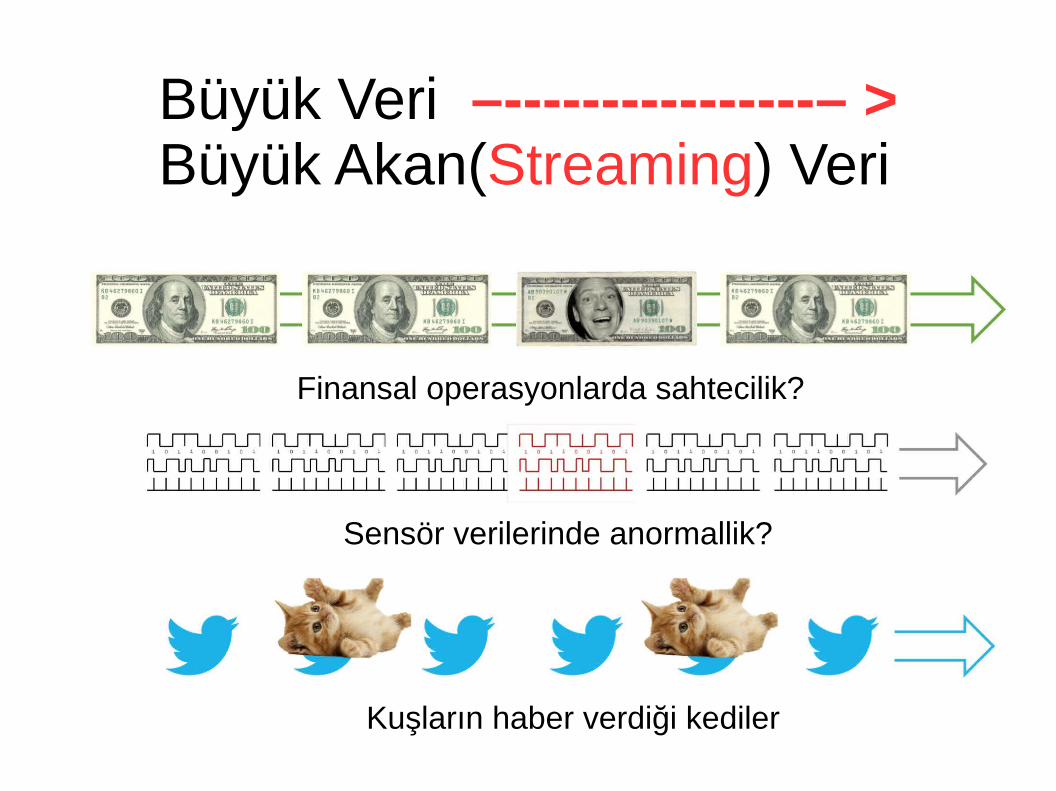
Büyük Veri –----------------– > Büyük Akan(Streaming) Veri
Finansal operasyonlarda sahtecilik?
Sensör verilerinde anormallik?
Kuşların haber verdiği kediler
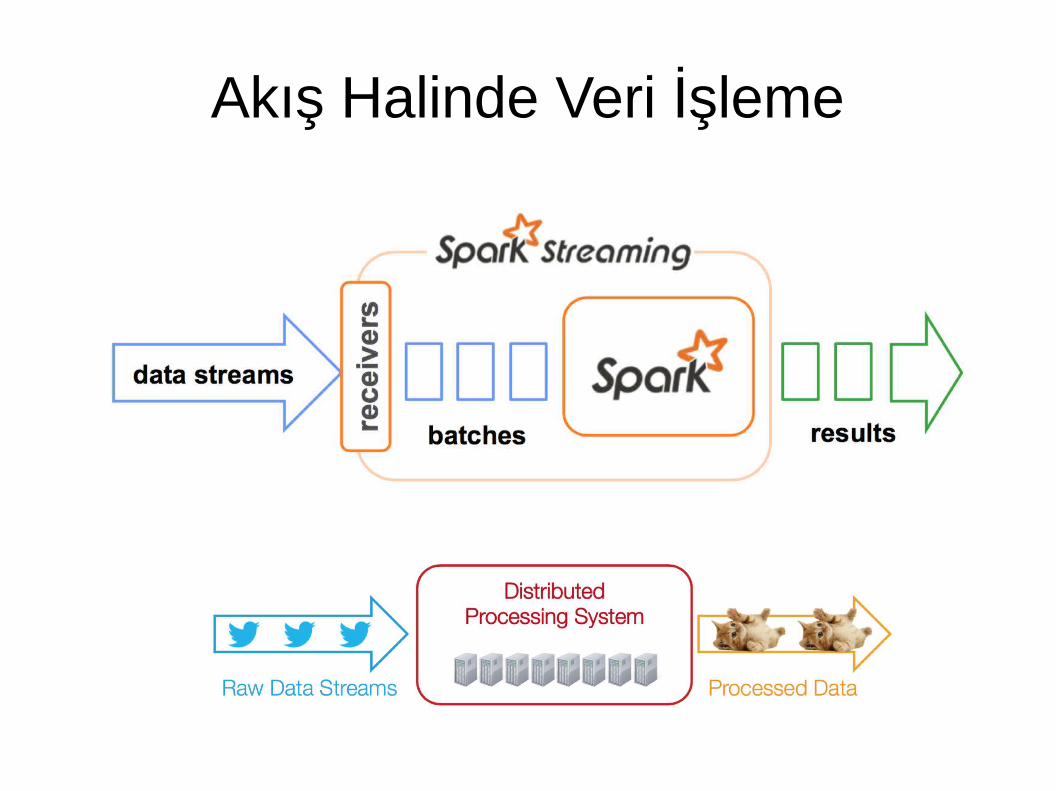
Akış Halinde Veri İşleme

Maven Bağımlılıkları <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-twitter_2.11</artifactId>
<version>1.6.2</version>
</dependency>

Twitter4j : OAuth hazırlık
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] filtreler = Arrays.copyOfRange(args, 4, args.length);
System.setProperty("twitter4j.oauth.consumerKey", consumerKey);
System.setProperty("twitter4j.oauth.consumerSecret", consumerSecret);
System.setProperty("twitter4j.oauth.accessToken", accessToken);
System.setProperty("twitter4j.oauth.accessTokenSecret", accessTokenSecret);

Twitter : Veri Çekme / İşleme
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf,
new Duration(60000));
JavaReceiverInputDStream<Status> stream = TwitterUtils.createStream(jssc, filtreler);
JavaDStream<String> kelimeler = stream
.flatMap(status -> Arrays.asList(status.getText().split(" ")));
JavaDStream<String> hashTags = kelimeler
.filter(kelime -> kelime.startsWith("#"));
hashTags.print();
SparkConf sparkConf = new SparkConf()
.setAppName("Twitterizle")
.setMaster("local[4]");
jssc.start();
jssc.awaitTermination();

Kelime Filtresi : Türkiye
●
● -------------------------------------------
● #CANLI
● #Istanbul
● #hava
● #Türkiye
● #Ankara/Esenboğa
● #hava
● #Türkiye
● #Istanbul
● #hava
● #Türkiye
●

İzleme ( Monitoring )
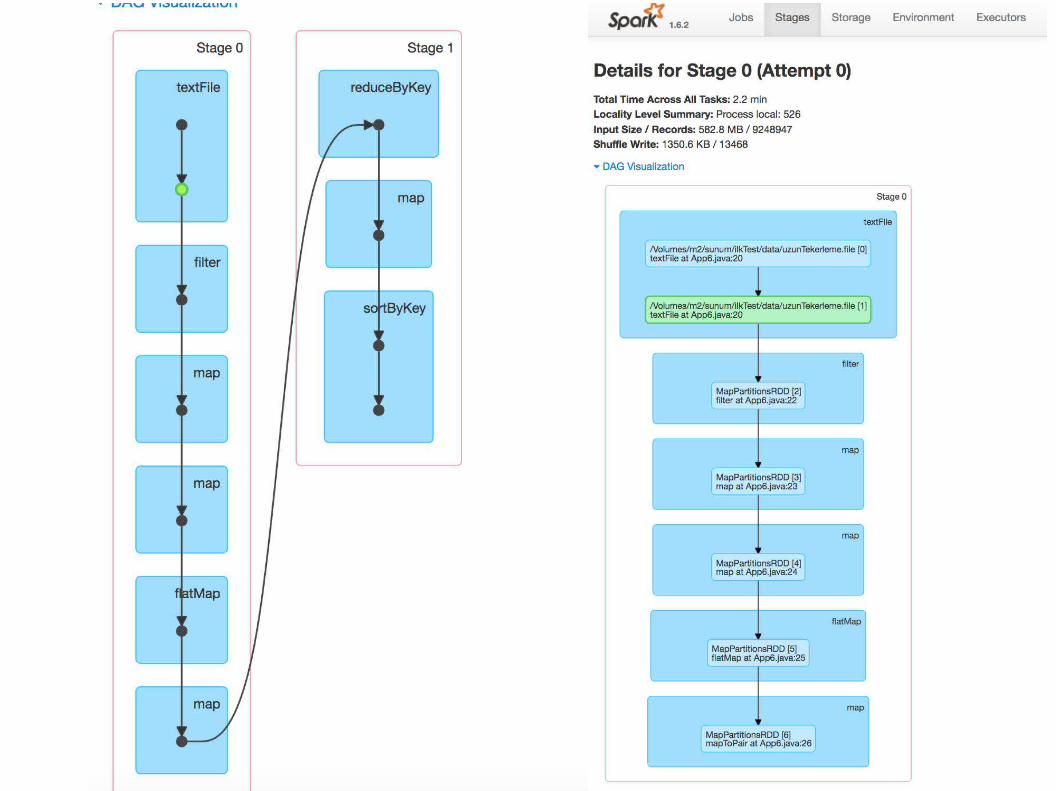


HDFS 'e okuma / yazma
● Java API
oku = sc.textFile("hdfs://kulustur1:9000/data/tekerleme.file")
...
JavaDStream<Status> twitler =
ssc.twitterStream()
JavaDstream<String> hashTags = twitler.flatMap(new Function<...>{ })
hashTags.saveAsHadoopFiles("hdfs://…")
…
.saveAsTextFile("hdfs://kulustur1:9000/data/sonuc.txt");

Spark 'a İş Ver (:7077)
root@kulustur1:/opt/kulustur/submit#/opt/kulustur/spark/spark-1.6.1-bin-hadoop2.6/bin/spark-submit --masterspark://kulustur1:7077 –classtest2.owg.tw2.Twitterizle target/test2.owg.tw2-0.0.1-SNAPSHOT-jar-with-dependencies.jar
● Remote – → API (:6066)
– → İzleme (:4040)

Öküzün Boynuzlarındamıyız yoksaHorton sadece bir ses mi duydu ??
Teşekkürler,
Related Documents











![[Spark meetup] Spark Streaming Overview](https://static.cupdf.com/doc/110x72/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)