Stephan Ewen Flink committer co-founder @ data Artisans @StephanEwen Apache Flink

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Stephan Ewen
Flink committer
co-founder @ data Artisans
@StephanEwen
ApacheFlink
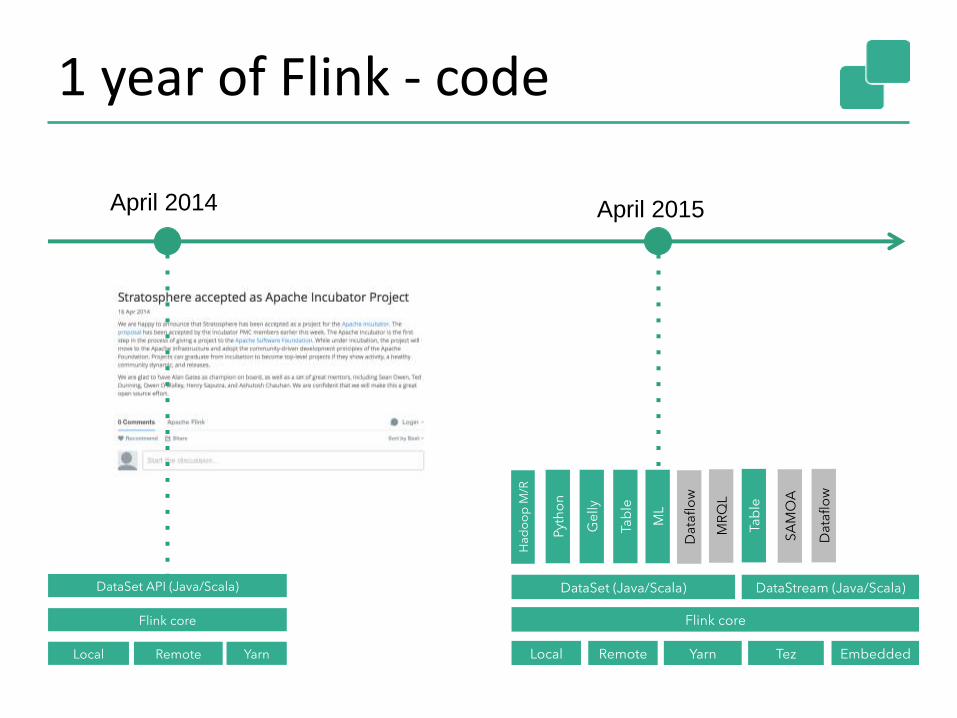
1 year of Flink - code
April 2014 April 2015
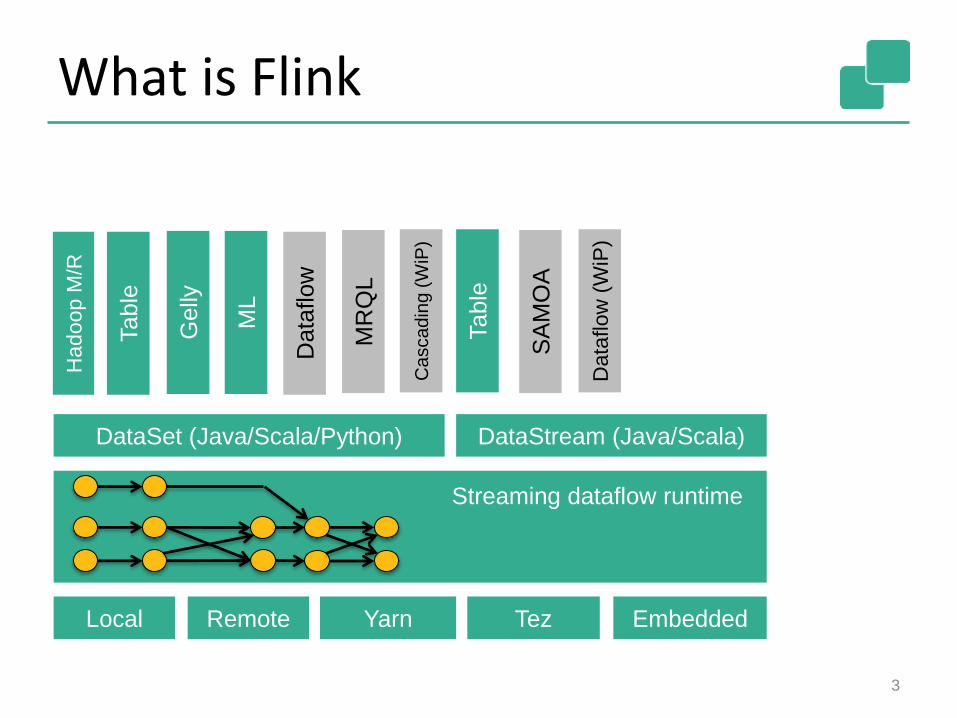
What is Flink
3
Gelly
Table
ML
SA
MO
A
DataSet (Java/Scala/Python) DataStream (Java/Scala)
Hadoop M
/R
Local Remote Yarn Tez Embedded
Data
flow
Data
flow
(W
iP)
MR
QL
Table
Ca
sca
din
g (
WiP
)
Streaming dataflow runtime

Native workload support
5
Flink
Streaming
topologies
Long batch
pipelinesMachine Learning at scale
How can an engine natively support all these workloads?
And what does "native" mean?
Graph Analysis
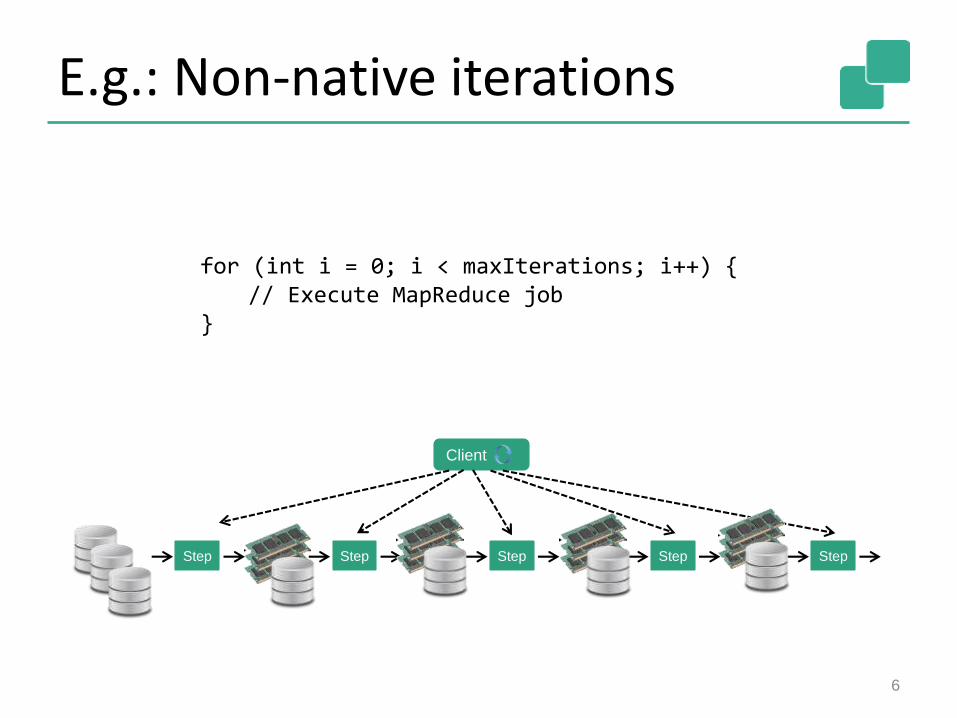
E.g.: Non-native iterations
6
Step Step Step Step Step
Client
for (int i = 0; i < maxIterations; i++) {// Execute MapReduce job
}

E.g.: Non-native streaming
7
stream
discretizer
Job Job Job Jobwhile (true) {// get next few records// issue batch job
}

Native workload support
8
Flink
Streaming
topologies
Heavy
batch jobsMachine Learning at scale
How can an engine natively support all these workloads?
And what does native mean?

Flink Engine
1. Execute everything as streams
2. Allow some iterative (cyclic) dataflows
3. Allow some mutable state
4. Operate on managed memory
9

Program compilation
10
case class Path (from: Long, to:Long)val tc = edges.iterate(10) {
paths: DataSet[Path] =>val next = paths
.join(edges)
.where("to")
.equalTo("from") {(path, edge) =>
Path(path.from, edge.to)}.union(paths).distinct()
next}
Optimizer
Type extraction
stack
Task
scheduling
Dataflow
metadata
Pre-flight (Client)
MasterWorkers
Data
Sourceorders.tbl
Filter
MapDataSourc
elineitem.tbl
JoinHybrid Hash
build
HTprobe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
Dataflow
Graph
deploy
operators
track
intermediate
results

Flink by Use Case
11

Data Streaming Analysis
streaming dataflows
12

3 Parts of a Streaming Infrastructure
13
Gathering Broker Analysis
Sensors
Transaction
logs …
Server Logs

3 Parts of a Streaming Infrastructure
14
Gathering Broker Analysis
Sensors
Transaction
logs …
Server Logs
Result may be fed back to the broker

Cornerstones of Flink Streaming
Pipelined stream processor (low latency)
Expressive APIs
Flexible operator state, streaming windows
Efficient fault tolerance for streams and state.
15

Pipelined stream processor
16
StreamingShuffle!

Expressive APIs
17
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):

Windows
18More at: http://flink.apache.org/news/2015/02/09/streaming-example.html
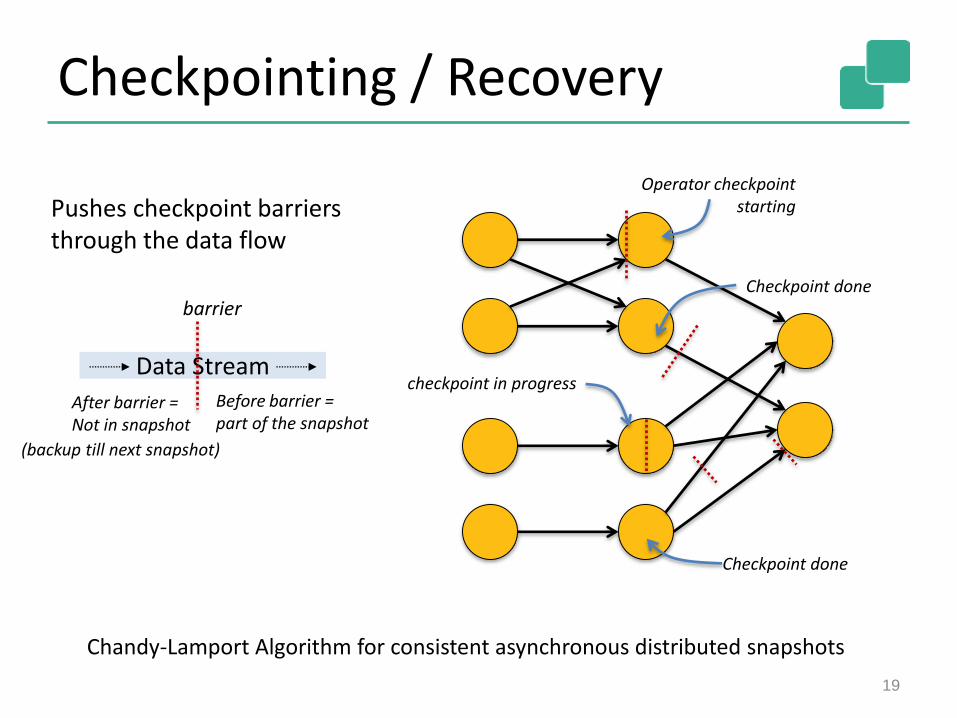
Checkpointing / Recovery
19
Chandy-Lamport Algorithm for consistent asynchronous distributed snapshots
Pushes checkpoint barriersthrough the data flow
Operator checkpointstarting
Checkpoint done
Data Stream
barrier
Before barrier =part of the snapshot
After barrier =Not in snapshot
Checkpoint done
checkpoint in progress
(backup till next snapshot)

Long batch pipelines
Batch on Streaming
20

Batch Pipelines
21

Batch on Streaming
Batch programs are a special kind of streaming program
22
Infinite Streams Finite Streams
Stream Windows Global View
PipelinedData Exchange
Pipelined or Blocking Exchange
Streaming Programs Batch Programs

Batch Pipelines
23
Data exchange (shuffle / broadcast)is mostly streamed
Some operators block (e.g. sorts / hash tables)

Operators Execution Overlaps
24
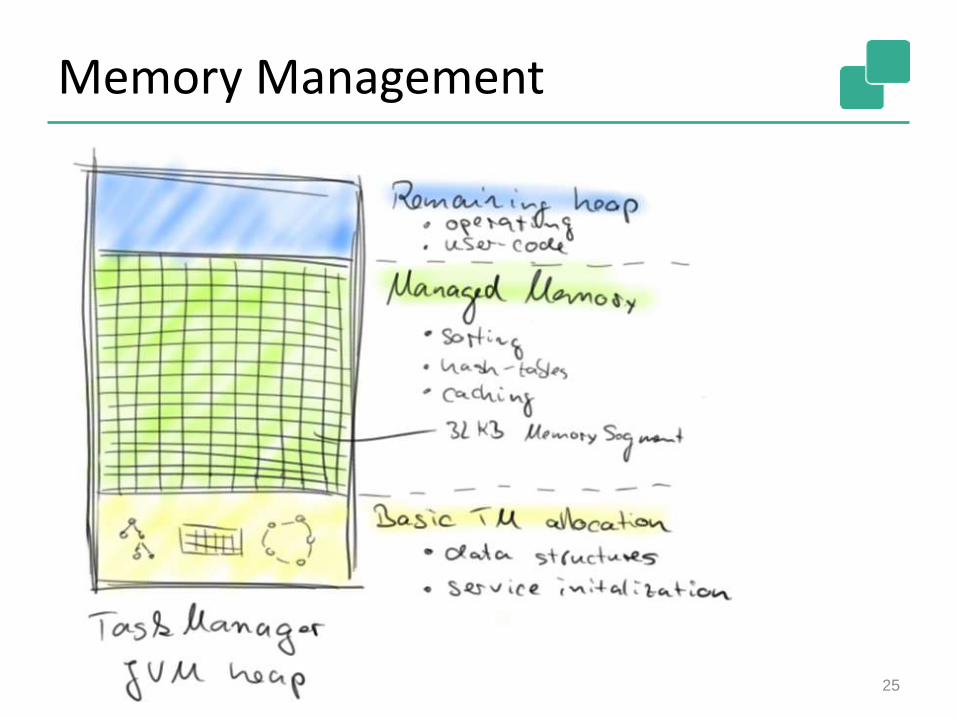
Memory Management
25
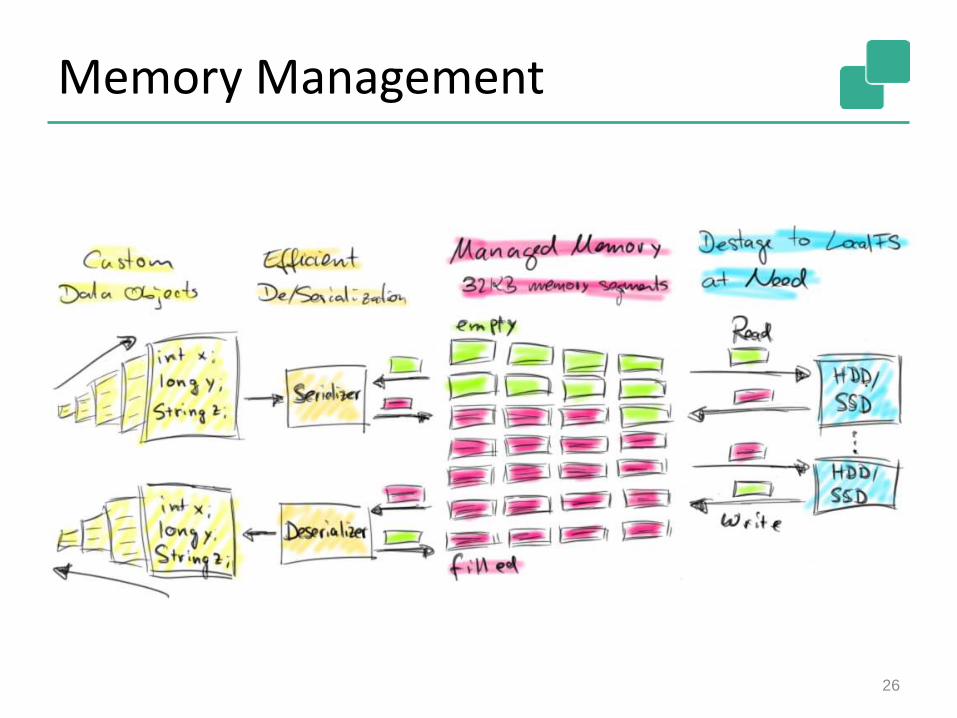
Memory Management
26

Smooth out-of-core performance
27More at: http://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html
Blue bars are in-memory, orange bars (partially) out-of-core

Table API
28
val customers = envreadCsvFile(…).as('id, 'mktSegment).filter("mktSegment = AUTOMOBILE")
val orders = env.readCsvFile(…).filter( o => dateFormat.parse(o.orderDate).before(date) ).as("orderId, custId, orderDate, shipPrio")
val items = orders.join(customers).where("custId = id").join(lineitems).where("orderId = id").select("orderId, orderDate, shipPrio,
extdPrice * (Literal(1.0f) – discount) as revenue")
val result = items.groupBy("orderId, orderDate, shipPrio").select('orderId, revenue.sum, orderDate, shipPrio")

Machine Learning Algorithms
Iterative data flows
29
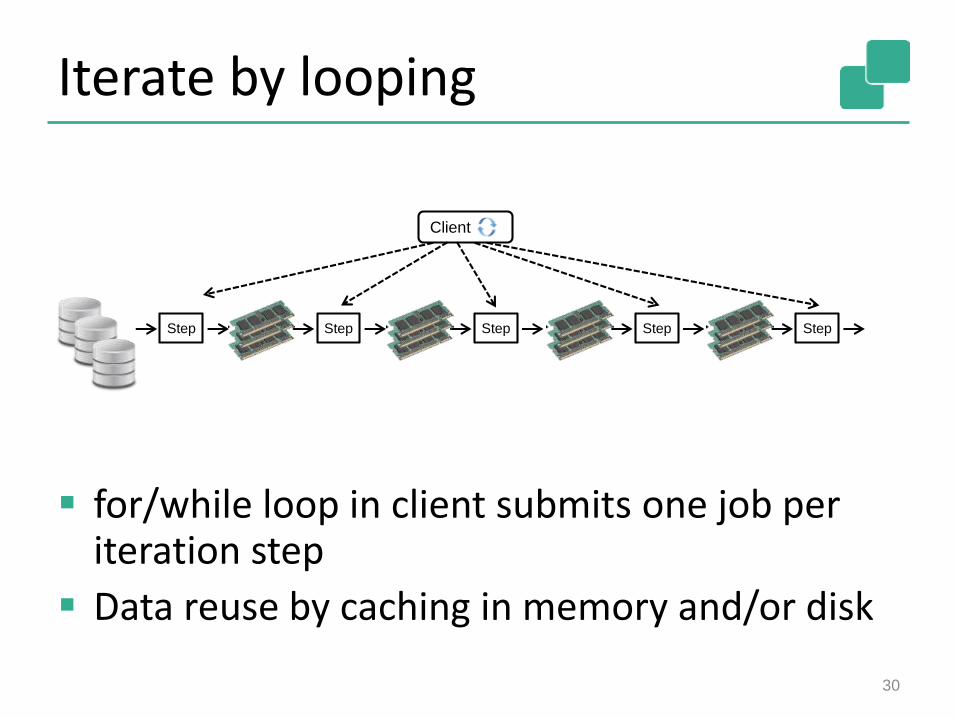
Iterate by looping
for/while loop in client submits one job per iteration step
Data reuse by caching in memory and/or disk
Step Step Step Step Step
Client
30
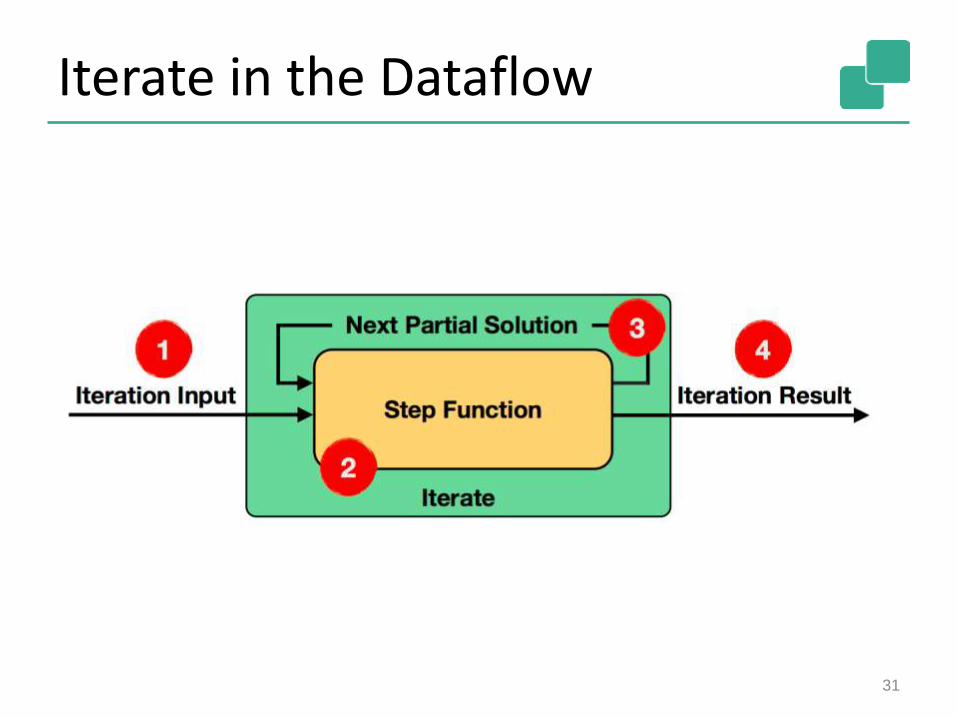
Iterate in the Dataflow
31
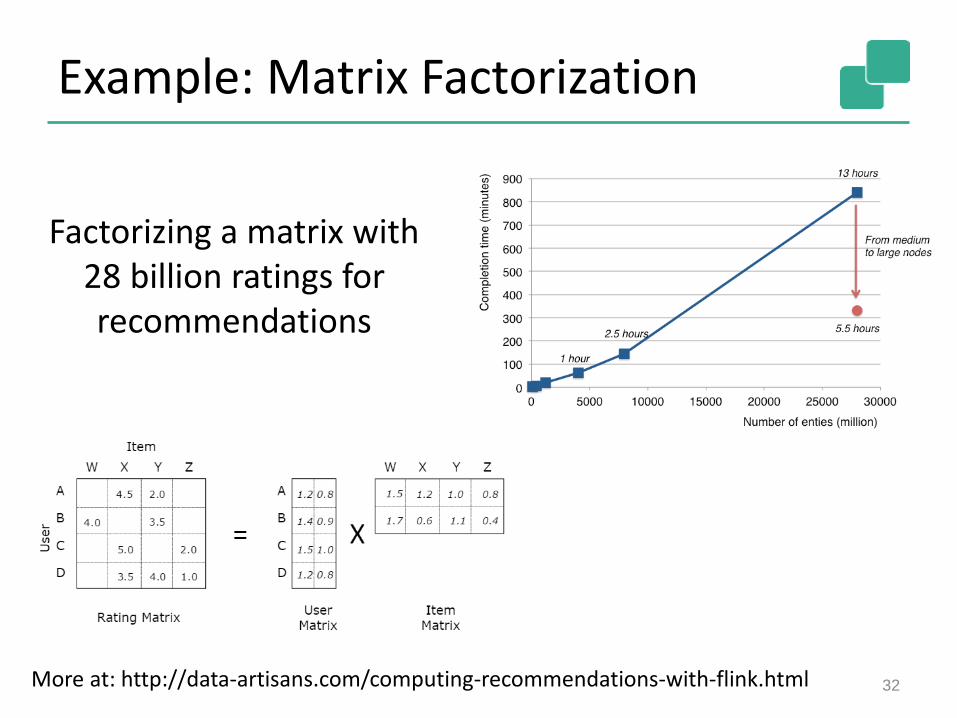
Example: Matrix Factorization
32
Factorizing a matrix with28 billion ratings forrecommendations
More at: http://data-artisans.com/computing-recommendations-with-flink.html

Graph Analysis
Stateful Iterations
33
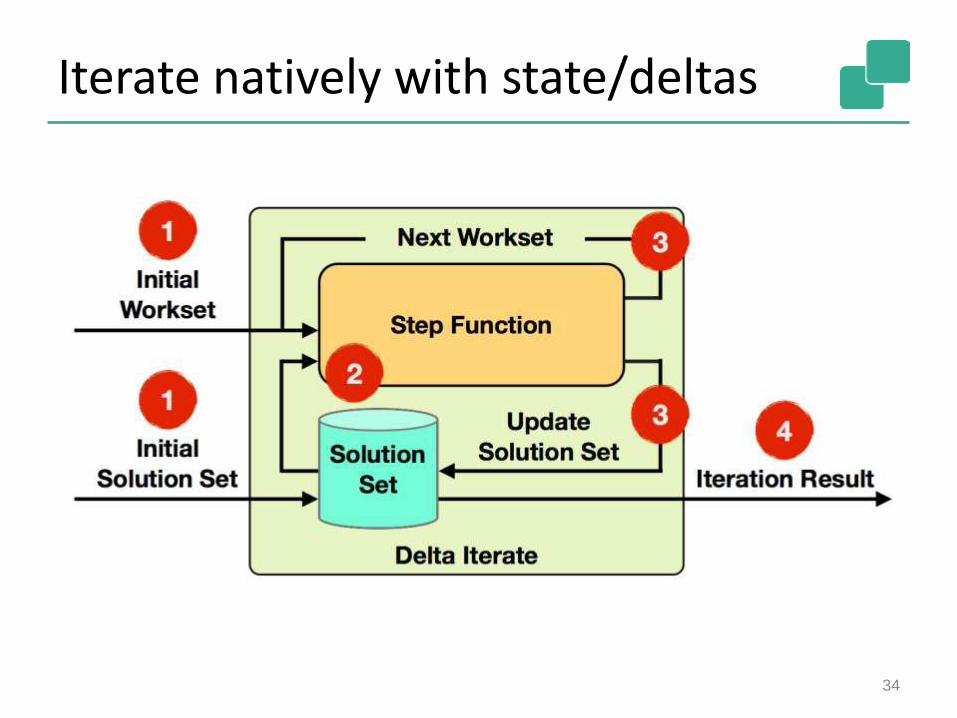
Iterate natively with state/deltas
34

Effect of delta iterations…
0
5000000
10000000
15000000
20000000
25000000
30000000
35000000
40000000
45000000
1 6 11 16 21 26 31 36 41 46 51 56 61
# o
f e
lem
en
ts u
pd
ate
d
iteration

… fast graph analysis
36More at: http://data-artisans.com/data-analysis-with-flink.html

Closing
37

Flink Roadmap for 2015
Some highlights that we are working on
More flexible state and state backends in streaming
Master Failover
Improved monitoring
Integration with other Apache projects
• SAMOA, Zeppelin, Ignite
More additions to the libraries
38

39

flink.apache.org
@ApacheFlink
Related Documents











