Answering Defini tion Questions U sing Multiple Kn owledge Sources Wesley Hildebrandt, Boris Katz, and Jimm y Lin MIT Computer Science and Artificial Inte lligence Laboratory 32 Vassar Street, Cambridge, MA 02139 {wes,boris,jimmylin}@csail.mit.edu

Answering Definition Questions Using Multiple Knowledge Sources Wesley Hildebrandt, Boris Katz, and Jimmy Lin MIT Computer Science and Artificial Intelligence.
Jan 02, 2016
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Answering Definition Questions Using Multiple Knowledge Sources
Wesley Hildebrandt, Boris Katz, and Jimmy LinMIT Computer Science and Artificial Intelligence Labor
atory32 Vassar Street, Cambridge, MA 02139
{wes,boris,jimmylin}@csail.mit.edu

Abstract
Definition questions represent a largely unexplored area of question answering.
Multi-strategy approach: a database constructed offline with surface patterns a Web-based dictionary an off-the-shelf document retriever
Results are from: component-level evaluation end-to-end evaluation of the system at the TREC 200
3 Question Answering Track

Answering Definition Questions
1: extract the target term (target) 2: lookup in a database created from the
AQUAINT corpus 3: lookup in a Web dictionary followed by answer
projection *4: lookup directly in the AQUAINT corpus with
an IR engine 5: answers from 2~4 are then merged to
produce the final system output

Target Extraction
A simple pattern-based parser to extract the target term using regular expressions
The extractor was tested on all definition questions from the TREC-9 and TREC-10 QA Track testsets and performed with 100% accuracy
But, several instances were not correctly extracted from the definition questions in TREC 2003

Database Lookup
Surface patterns for answer extraction An effective strategy for factoid question but often suffers from low recall
To boost recall applying the set of surface patterns offline “precompile” from the AQUAINT corpus a list of nuggets about e
very entity construct an immense relational database containing nuggets di
stilled from every article in the corpus. The task then becomes a simple lookup for the relevant t
erm

Database Lookup
Surface patterns operated both at the word and part-of-speech level. Rudimentary chunking, such as marking the
boundaries of noun phrases, was performed by grouping words based on their part-of-speech tags.
Contextual information results in higher-quality answers
11 surface patterns in Table1, with examples in Table2

11 Surface Patterns

Surface Patterns with examples

Dictionary Lookup
TREC evaluations requires pairs of (ans, doc) Answer projection techniques to (Brill, 2001)
Dictionary-Lookup Approach: Keywords from the target term’s dictionary definition and the tar
get itself used as the query to Lucene Top 100 documents returned and tokenized into individual sente
nces, discarding sentences without target term remaining sentences are scored by keyword overlap with the dic
tionary definition, weighted by the idf of each keyword non-zero-score sentences are retained and shortened to 100 ch
aracters centered around the target term, if necessary.

Document Lookup
This approach is adopted If no answers were found by the previous two techniques (Database & Dictionary Lookup)
Using traditional IR technique

Answer Merging
Redundancy removal this problem is especially severe since every entity in
the entire AQUAINT corpus was precompiled Simple heuristic: if two responses share more than
60% of their keywords, one of them is randomly discarded
Expected accuracy all responses are ordered by EA to extract nugget
# of responses to be returned Given n total responses, the number is

Component Evaluation
160 definition questions from the TREC-9 and TREC-10 QA Track testsets Database lookup: 8 nuggets per question at accuracy 38.37 Dictionary lookup: 1.5 nuggets per question at accuracy 45.23
Recall of the techniques is extremely hard to measure directly
The results: represent baseline for the performance of each technique
The focus: not on perfecting each individual pattern and the dictionary matching algorithm, but on building a complete working system

Component Evaluation

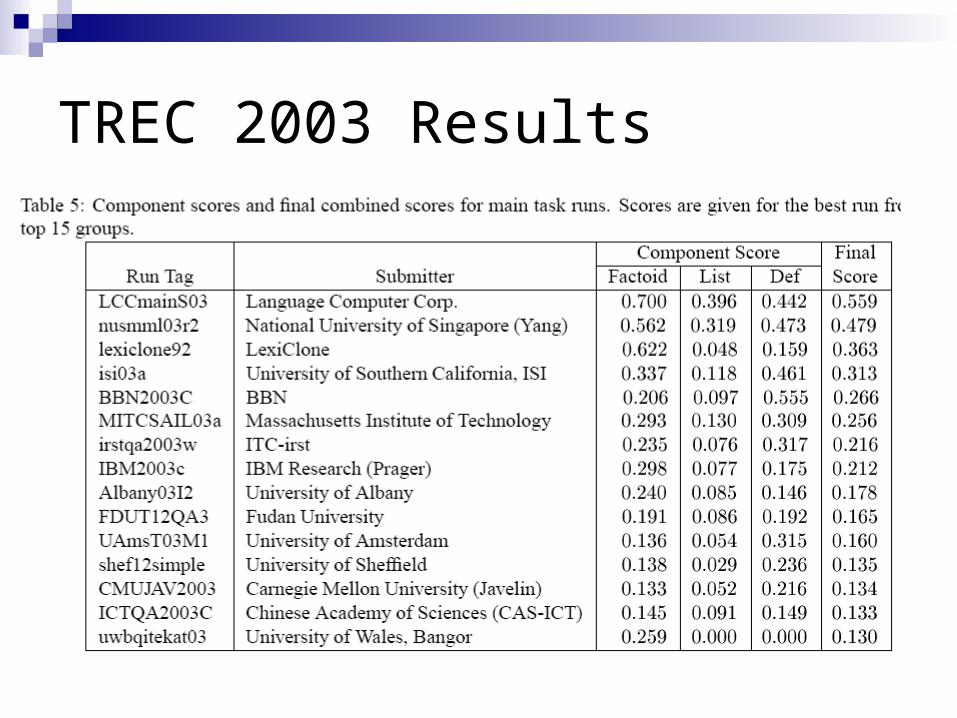
TREC 2003 Results
This system performed well, ranking 8th out of 25 groups that participated in TREC 2003 QA Track
Official results for the definition sub-task are shown in Table 4
The formula used to calculate the F-measure is given in Figure 1

TREC 2003 Results

TREC 2003 Results
BBN (Xu et al., 2003) The best run, with an F-measure of 0.555 use many of the same techniques described here one important exception—they did not precompile nuggets into a
database they also cited recall as a major cause of bad performance IR baseline achieved an F-measure of 0.493 which beat all other
runs Because the F-measure heavily favored recall over preci
sion, simple IR techniques worked extremely well
TREC 2003 Results

Evaluation Reconsidered
The Scoring Metric Variations in Judgment

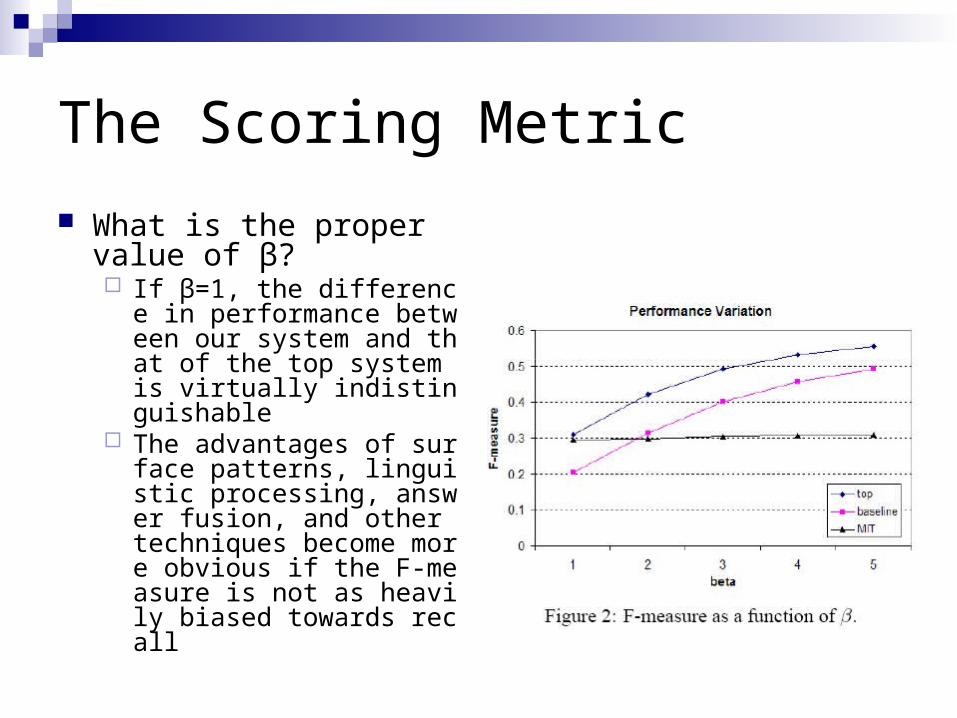
The Scoring Metric
Recall(R) = r/R a system that returned every non-vital nugget but no v
ital nuggets would receive a score of zero The distinction between vital and non-vital nugge
ts is itself somewhat arbitrary. For example, “What is Bausch & Lomb?”
world’s largest eye care company -> vital about 12000 employees -> vital in 50 countries -> vital approx. $1.8 billion annual revenue -> vital based in Rochester, New York -> non-vital
The Scoring Metric
What is the proper value of β? If β=1, the difference in perf
ormance between our system and that of the top system is virtually indistinguishable
The advantages of surface patterns, linguistic processing, answer fusion, and other techniques become more obvious if the F-measure is not as heavily biased towards recall

Variations in Judgment
Human naturally have differing opinions
These differences of opinion are not mistakes, but legitimate variations in what assessors consider to be acceptable
Different assessors may judge nuggets differently, contributing to detectable variations in score

Variations in Judgment
For the assessors’ nugget list, it should satisfy: Atomic — each nugget should ideally represent an atomic
concept Uniqueness — nuggets should be unique, not only in their text
but also in their meaning Completeness — many relevant items of information returned
did not make it onto the assessors’ nugget list (even as non-vital nuggets)
Evaluating answers to definition questions is a challenging task. Consistent, repeatable, and meaningful scoring guidelines are critical to the field

Examples of Atomic & Unique
AtomicHarlem civil rights leader:
provide one factAlexander Pope is “English
poet”: two separate facts Uniqueness

Future Work
Robust named-entity extractor forTarget extraction: key, non-trivial capability cri
tical to the success of a systemDatabase lookup: works only if the relevant ta
rget terms are identified and indexed while preprocessing the corpus
For example, able to identify specialized names (e.g., “Bausch & Lomb”, “Destiny’s Child”, “Akbar the Great”)

Future Work
More accurate surface patterns expanding the context on which these patterns operate to
reduce false matches As an example, consider e1_is pattern:
over 60% of irrelevant nuggets were cases where the target is the object of a preposition and not the subject of
the copular verb immediately following it For example, Question “What is mold?” to Sentence “tools you
need to look for mold are . . .”
Good-nugget Predictor separate “good” from “bad” nuggets using machine learning techniques

Conclusion
A novel set of strategies from multiple sources Database, Dictionary & Documents
Smoothly integrate the derived answers to produce a final set of answers
The analyses show: Difficulty of evaluating definition questions Inability of present metrics to accurately capture the
information needs of real-world users
Related Documents











