Analyzing the Change-Proneness of APIs and web APIs

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Analyzing the Change-Pronenessof APIs and web APIs


Analyzing the Change-Pronenessof APIs and web APIs
PROEFSCHRIFT
ter verkrijging van de graad van doctoraan de Technische Universiteit Delft,
op gezag van de Rector Magnificus prof. ir. K.C.A.M. Luyben,voorzitter van het College voor Promoties,
in het openbaar te verdedigen op woensdag 7 januari 2015 om 12.30uur door
Daniele ROMANO
Master of Science in Computer Science - University Of Sanniogeboren te Benevento, Italy.

Dit proefschrift is goedgekeurd door de promotors:
Prof. dr. A. van Deursen
Prof. dr. M. Pinzger
Samenstelling promotiecomissie:
Rector Magnificus voorzitterProf. Dr. A. van Deursen Delft University of Technology, The Netherlands, promotorProf. Dr. M. Pinzger University of Klagenfurt, Austria, promotorProf. Dr. G. Antoniol École Polytechnique de Montréal, CanadaDr. Alexander Serebrenik Eindhoven University of Technology, The NetherlandsDr. Cesare Pautasso University of Lugano, SwitzerlandProf. Dr. Ir. D.M. van Solingen Delft University of Technology, The NetherlandsProf. Dr. Frances Brazier Delft University of Technology, The Netherlands
This work was carried out as part of the Re-Engineering Service-Oriented Systems(ReSOS) project. This project was partially funded by the NWO-Jacquard programand supported by Software Improvement Group and KPMG.
SERG
Copyright c© 2014 by Daniele Romano
Cover image by Craig S. Kaplan, University of Waterloo.

”Pain is inevitable. Suffering is optional.”Haruki Murakami


Acknowledgments
The 10th of October, 2010 I had my job interview at the Software EngineeringResearch Group (SERG) of the Technology University of Delft. It was an unbe-lievably sunny and warm day and I immediately fell in love with the researchperformed at the SERG group, the people, the city of Delft, and the Dutch sun.After 4 amazing years I can say that the only thing I was wrong was when Ithought "Dutch weather is not that bad". When I started my research in Novem-ber 2010 all other expectations became reality. I am really happy to have spentthe last 4 year in such a competitive research group with amazing people. Iwish to thank all those who have supported me on this journey starting fromMartin Pinzger and Arie van Deursen who gave me the opportunity to pursuethis PhD.
First of all, I would like to thank my supervisor Martin Pinzger whoseguidance went far beyond my expectations. He always gave me his honestand professional guidance in performing scientific research. I am very thank-ful for his enthusiastic and human approach that made him not only a goodsupervisor but also a great friend. Thanks a lot Martin! All the time we spenttogether discussing about research or simply enjoying leisure time has beenimportant for my professional and private life and now it is part of me. I willnever forget it. Also, I will never forget the only time when you were not ableto guide me (on the top of an Austrian hill). That was funny!
Furthermore, I would like to thank all my colleagues who have alwaysprovided me with valuable feedback that has been important to improve thequality of my research. Especially, I would like to thank Andy Zaidman for hisunending willingness in helping me as well as anyone in the group. ThanksAndy! You are in my list of best people I have met in my entire life.
Finally, I would like to thank all my friends and my family who alwaysdistracted me from my dedication in performing my research activities. Thishas been really important even though I have not always been able to discon-
vii

nect my mind from my research. Especially, I want to thank my family whoaccepted my willingness to move abroad and all its consequences. Claudio,Grazia, Maria Elena, Guido, nonna Elena, zio Tonino I love you all a lot! I amsure one day I will regret to have spent part of my life abroad to pursue myprofessional goals and not with you. Thanks a lot for accepting it. We are agreat family and the geographical distance will never change anything.
Delft,November 2014
Daniele Romano
viii

Contents
Acknowledgements vii
1 Introduction 1
1.1 Services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Approach and Research Questions . . . . . . . . . . . . . . . . . . 8
1.3 Research Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.4 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.5 Origin of Chapters . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2 Change-Prone Java Interfaces 17
2.1 Interface Metrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2 The Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.3 Empirical Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.5 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.6 Conclusions and Future Work . . . . . . . . . . . . . . . . . . . . . 36
3 Change-Prone Java APIs 41
3.1 Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.2 Empirical Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.3 Threats to Validity . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.4 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
ix

3.5 Conclusion and Future Work . . . . . . . . . . . . . . . . . . . . . . 60
4 Fine-Grained WSDL Changes 63
4.1 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.2 WSDLDiff . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.3 Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.4 Conclusion & Future Work . . . . . . . . . . . . . . . . . . . . . . . 78
5 Dependencies among Web APIs 81
5.1 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.3 Study Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
5.4 Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
5.5 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
5.6 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
5.7 Conclusion & Future Work . . . . . . . . . . . . . . . . . . . . . . . 98
6 Change-Prone Web APIs 99
6.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.2 Research Questions and Approach . . . . . . . . . . . . . . . . . . 103
6.3 Online Survey . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
6.4 Quantitative Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . 115
6.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
6.6 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
6.7 Concluding remarks . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
7 Refactoring Fat APIs 125
7.1 Problem Statement and Solution . . . . . . . . . . . . . . . . . . . 127
7.2 Genetic Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
7.3 Random and Local Search . . . . . . . . . . . . . . . . . . . . . . . 135
7.4 Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
7.5 Threats to Validity . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
7.6 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
7.7 Conclusions and Future Work . . . . . . . . . . . . . . . . . . . . . 148
x

8 Refactoring Chatty web APIs 149
8.1 Problem Statement and Solution . . . . . . . . . . . . . . . . . . . 151
8.2 The Genetic Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . 156
8.3 Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
8.4 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
8.5 Conclusion & Future Work . . . . . . . . . . . . . . . . . . . . . . . 166
9 Conclusion 167
9.1 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
9.2 The Research Questions Revisited . . . . . . . . . . . . . . . . . . . 170
9.3 Recommendations for Future Work . . . . . . . . . . . . . . . . . . 175
9.4 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
Bibliography 179
Summary 197
Samenvatting 201
Curriculum Vitae 205
xi


1.Introduction
Several years of research on software maintenance have produced numerousapproaches to identify and predict change-prone components in a softwaresystem. Among others, source code metrics and heuristics to detect antipat-terns and code smells have been widely validated as indicators of changes.However, these indicators have been mainly proposed and validated for object-oriented systems. There is still the need to define and validate indicators ofchanges for systems implemented in other programming paradigms such asthe service-oriented one.
In recent years there has been a tendency to adopt Service-Oriented Archi-tectures (SOAs) [Josuttis, 2007] in companies and government organizationsfor two main reasons. First, SOAs allow companies to organize and use dis-tributed capabilities (i.e., services) that may be under the control of differentorganizations or different departments within the same organization [Brownand Hamilton, 2006]. Second, organizations benefit from the loose couplingbetween clients and services. However, clients and services are still coupledand changes in the services can impact negatively their clients and entire sys-tems. The dependencies removed in SOAs are the dependencies betweenclients and the underlying technologies used to implement services. Clientsand services are still coupled through function coupling and data structure cou-pling [Daigneau, 2011]. In fact, clients depend 1) on the functionalities imple-mented by services (i.e., function coupling) and 2) on the data structures thata service’s instance receives and returns (i.e., data structure coupling). Bothare specified in its interface, that we refer to as web API throughout this thesis.For this reason web APIs are considered contracts between clients and ser-vice providers and they should remain as stable as possible [Daigneau, 2011;Murer et al., 2010]. However, like any other software component, servicesevolve to satisfy changing or new functional and non functional requirements.
In this PhD research we investigate quality indicators that can highlightchange-prone web APIs. Web APIs can be split into two main categories
1

2 Chapter 1. Introduction
SOAP/WSDL (WS-*) APIs and REST APIs [Pautasso et al., 2008]. In this dis-sertation we focus on SOAP/WSDL APIs [Alonso et al., 2010]. First, we inves-tigate which indicators can highlight change-prone APIs. Changes in the im-plementation logic can cause changes in the web APIs, especially when legacyAPIs are made available through web APIs. Then, we analyze indicators thathighlight change-prone web APIs. Finally, based on design practices that cancause changes in APIs and web APIs we propose techniques to automaticallyrefactor them.
In this introductory chapter, first, we present services, their history, and theimportance of designing and implementing stable web APIs (Section 1.1). InSection 1.2 we present the research approach, the research questions, and thecontributions of this PhD thesis. In Section 1.3 we show the research methodused to answer our research questions. Section 1.4 discusses the related work.Finally, we present the outline of this thesis and we present the peer reviewedpublications on which the chapters of this thesis are based (Section 1.5).
1.1 ServicesThe term service has been introduced to refer to software functions that carryout business tasks. Business tasks include tasks such as providing access to filesand databases, performing functions like authentication or logging, bridgingtechnological gaps, etc. Services can be implemented using many technolo-gies that range from the older CORBA and DCOM to the newer REST andSOAP/WSDL technologies. Services have become popular and are widely usedto ease the integration of heterogeneous systems. In fact, the main goal ofservices is to share business tasks across systems that run on different hard-ware platforms (e.g., Linux, Windows, Mac OS, Android, iOS) and are imple-mented through different software frameworks and programming languages(e.g., Java, .NET, Objective-C).
1.1.1 Software Integration with Web ServicesThe benefits of using services instead of other software components to easeintegration is well discussed in the book Service Design Patterns by Daigneau[Daigneau, 2011].
Objects have been the first components used for integrating business tasksacross different software systems [Daigneau, 2011]. An object (e.g., a Javaclass) can encapsulate business functions or data and it can be reused in dif-ferent software systems. To reuse an object developers instantiate it and accesstheir business tasks invoking their methods. The main problem of objects is

1.1. Services 3
Figure 1.1: Components are reused through platform specific interfaces.Taken from [Daigneau, 2011].
that it is challenging to reuse them in software systems implemented withdifferent programming languages.
To overcome this problem component technologies have been proposed.Components are deployable binary software units that can be easily integratedinto software systems implemented in different programming languages. Thebusiness tasks encapsulated into them are accessible through binary interfacesthat describe their methods, attributes, and events as shown in Figure 1.1.Unlike with objects, developers do not have access to the internals of the com-ponents but only to their interfaces. The interfaces, however, are describedthrough platform-specific languages (e.g., Microsoft Interface Definition Lan-guage). While reusing components within systems implemented in differentprogramming languages is easy, developers are now constrained to reuse com-ponents in specific platforms (e.g., Microsoft computing platforms).
To address this problem objects have been deployed on servers allowingclients to access their business tasks invoking their methods remotely (Fig-ure 1.2). Distributed objects can be reused by different software systems in-dependently of the platforms on which clients and objects are deployed. Themost popular technologies to invoke distributed objects are CORBA, DCOM,Java Remote Method Invocation (RMI), and .NET Remoting. As shown inFigure 1.2 a client invokes the remote object through a proxy. The proxyforwards the invocation to a stub that is deployed on the distributed object’sserver. Then, the stub is responsible of invoking the distributed object.
This design pattern has its drawbacks as well. First, the implementation is

4 Chapter 1. Introduction
Figure 1.2: Distributed objects invoked over a network by their clients. Takenfrom [Daigneau, 2011].
not easy for developers. The serialization and deserialization of the messagesexchanged is not standardized. As a consequence, the design pattern workswell if both client and server use the same technologies to create the chan-nel. Otherwise, technical problems can arise frequently. Other problems aredue to the fact that servers maintain states between client calls that can beextremely expensive. Maintaining states requires to implement proper tech-niques to perform effectively load-balancing and it can cause a degradation ofthe server memory utilization with an increasing number of clients.
Web services have been conceived to solve the aforementioned problemsof the local objects, components, and distributed objects. They provide a stan-dard means of interoperating between different software applications, running ona variety of platforms and/or frameworks and based on "stateless" interactionsin the sense that the meaning of a message does not depend on the state of theconversation [W3C, 2004]. The W3C has defined a web service as a softwaresystem designed to support interoperable machine-to-machine interaction over anetwork. It has an interface described in a machine-processable format (specifi-cally WSDL). Other systems interact with the web service in a manner prescribedby its description using SOAP messages, typically conveyed using HTTP with anXML serialization in conjunction with other Web-related standards.
To reach a high portability between different platforms the W3C defined aWeb Services Architecture Stack based on XML languages that offers standard,flexible and inherently extensible data formats. Among these languages SOAP(Simple Object Access Protocol) and WSDL (Web Services Description Language)are the core languages to invoke a web service and to describe its interface.SOAP is a protocol that specifies the data structures of the messages exchangedwith the web services and auxiliary data structures to represent other infor-mation such as header information or error information occurred while pro-cessing the message. WSDL describes the web services’ interface in terms of1) operations exposed in web services, 2) addresses or connection endpoints

1.1. Services 5
to web services, 3) protocols to bind web services, 4) operations and messagesto invoke web services. Note that WSDL interfaces can be mapped to any im-plementation language, platform, object model, or messaging system. As aconsequence a WSDL interface is a contract between web services providersand its clients that hides the implementation behind the web services.
The architectural styles of the SOAP/WSDL web services is also knownas RPC (Remote Procedure Call) API highlighting the fact that clients invokeprocedures over a network. However, the W3C defined another architecturalstyle for web services called Resource API. According to this style, web servicesexposes resources (e.g., text files, media files) and not actions like in the RPCAPI style. Clients have access and can manipulate these resources throughrepresentations (e.g., XHTML, XML, JSON). When a client receives a resourcerepresentation from a web service it receives the current state of the resource.If it sends a representation of the resource to a web service it possibly altersthe state of the resource. For this reason this architectural style is also knownas Representational State Transfer or REST APIs [Fielding, 2000]. ResourceAPIs use HTTP as application protocol. Specifically, PUT is used to createor update resources, GET is used to retrieve a resource representation, andDELETE removes a resource. For a detailed comparison between SOAP/WSDLweb services and REST APIs we refer the reader to the work by [Pautassoet al., 2008]
1.1.2 Change-Proneness of Web APIsUsing web services allows software engineers to reduce coupling between dis-tributed components and, hence, eases the integration among such compo-nents. Web services eliminate the dependencies between the clients and theunderlying technologies used by a web service. Eliminating dependencies ontechnologies reduces the coupling but it does not decouple completely clientsand web services. There are still four different levels of coupling, namely, thefunction coupling, the data structure coupling, the temporal coupling, and theURI coupling [Daigneau, 2011]. For more details on coupling in service ori-ented system we refer the reader to the work by [Pautasso and Wilde, 2009].
First of all, clients invoke web services to execute a business task (i.e., RPCAPI) or to retrieve, update, create, or delete a resource (i.e., Resource API).Clients depend indirectly on the business logic implemented by web services.This coupling is called function coupling. Second, the clients depend on thedata structures used to invoke a web service and to receive the results of theinvocations. These data structures are defined in the API of web services thatwe refer to as web API throughout this book. This dependency is also known as

6 Chapter 1. Introduction
data structure coupling. Third, clients and web services are coupled throughtemporal coupling. This level of coupling indicates that the web service shouldbe operational when a client invokes it. Finally, clients are coupled to the webservices URIs (i.e., URI coupling). As a consequence, clients depend on theimplementations, the web APIs, the reliability, and the URIs of web services.Changes to these four factors are problematic for clients and they can breakthem.
In this PhD thesis we investigate the change-proneness of APIs and webAPIs, focusing on SOAP/WSDL APIs [Alonso et al., 2010]. We decided tofocus on web APIs, and hence on data structure coupling, because they areconsidered contracts between clients and web services specifying how theyshould interact. One of the key factors for deploying successful web APIs isassuring an adequate level of stability. Changes in a web API might breakthe clients’ systems forcing them to continuously adapt them to new versionsof the web API. For this reason, assessing the stability of web APIs is key toreduce the likelihood of continuous updates.
1.1.3 Performance of Web APIsDuring the frequent discussions with industry, practitioners kept repeating thatperformance issues are one of the causes that lead web APIs to be changed.Web APIs are invoked over a network and, hence, the latency can be signifi-cantly higher than calling a similar web API when it is deployed on the samemachine than the client. When a client invokes a method of a web API therequest should be serialized in a stream of bytes, transmitted over a network,deserialized on the server side, and dispatched to the web services. The samesteps should be executed when the web service returns the results back tothe client. As a consequence designers should pay attention in designing aweb API that can execute a use case with the lowest number of messages ex-changed between clients and web services. To reduce the latency designersshould usually prefer web APIs that exchange few chunky messages instead ofmany smaller messages [Daigneau, 2011]. In this way they can avoid chattyconversations that increase the latency.
To better understand this problem consider the redesign of web APIs adoptedat Netflix [Jacobson, 2012] and shown in Figure 1.3. At the beginning of itshistory Netflix had adopted an one-size-fit-all (OSFA) Rest API approach toprovide its services to its clients. This approach is shown in Figure 1.3a. Ac-cording to this approach there is a unique Rest API invoked by all the differentclients. To satisfy the requirements of all clients this API requires a large num-ber of interactions with clients that should invoke multiple times the API to

1.1. Services 7
AUTH SIMILAR MOVIES RATINGS MEMBER
DATA MOVE DATA
REST API
Network Border Network Border
(a) One-size-fit-all (OSFA) Rest API approach at Netflix. Each clientshould invoke multiple times the single Rest API. Taken from [Jacob-son, 2012].
AUTH SIMILAR MOVIES RATINGS MEMBER
DATA MOVE DATA
JAVA API
Network Border Network Border
(b) Each client invokes once its specifically designed Rest API reduc-ing the chattiness and improving the latency. Taken from [Jacobson,2012].
Figure 1.3: Web APIs redesign at Netflix [Jacobson, 2012].

8 Chapter 1. Introduction
execute a use case, as shown by the colored arrows in Figure 1.3a. Amongother issues, this approach degrades the performance since network calls areexpensive. To overcome this problem engineers at Netflix have adopted a newapproach (shown in Figure 1.3b) reducing the latency in some cases by severalseconds. In this new approach, the clients make a single chunky request (blackarrow in Figure 1.3b) to their specific endpoint designed to handle the requestof a specific client. As of consequence each different client has its own webAPI with which it interacts with a single request per use case. These ad hocweb APIs communicate locally with a fine-grained Java API. The functionalityof this API is similar to the original Rest APIs. However, its fine-grained meth-ods are invoked locally while the clients perform only a single remote request.Thanks to this new approach engineers at Netflix have reduced the chattinessof their web API and improved considerably the latency. This story showsthe relevance to design web APIs with an adequate granularity. Inadequategranularity can cause performance issues that force web APIs to be changed.
1.2 Approach and Research QuestionsThe work presented in this PhD thesis is part of the work performed withinthe ReSOS (Re-enegineering Service-Oriented Systems) project. ReSOS beganin November 2010 and it is aimed at improving the quality of service-orientedsystems. However, the term quality is generic and it includes many differentquality attributes (e.g., reliability, efficiency, security, maintainability). Basedon the literature (e.g., [Daigneau, 2011]) and on the frequent discussions withour industrial partners (KPMG1 and SIG2) and collaborators we found that thestability of web APIs is crucial for designing and maintaining service-orientedsystems. As discussed in the previous section, web services became a popularmeans to integrate software systems that may belong to different organiza-tions. As a consequence, web APIs are considered contracts [Daigneau, 2011;Murer et al., 2010] for integrating systems and they should stay as stable aspossible.
Based on these discussions with our industrial partners and collaborators,we set up a research approach consisting of the following research tracks:
• Track 1: Analysis of change-prone APIs
• Track 2: Analysis of change-prone web APIs
• Track 3: Refactoring of change-prone web APIs
1http://www.kpmg.com/2http://www.sig.eu/en/

1.2. Approach and Research Questions 9
1.2.1 Track 1: Change-Prone APIsEach web service is implemented by an implementation logic that is hiddento its clients through its web API. Changes to the implementation logic canbe propagated and affect the web API. Among all the software units compos-ing the implementation logic, APIs are likely to be mapped directly into webAPIs. This scenario happens especially when a legacy API is made availablethrough a web service. For this reason, in the first track we analyze the change-proneness of APIs, where we refer to API as the set of public methods declaredin a software unit. To perform this study we use existing techniques to minesoftware repositories and to extract changes performed in the APIs. We thenanalyze whether there is a correlation between the amount of changes an APIundergoes and the values of source code metrics and/or the presence of an-tipatterns. The outcome of this track will consist in a set of quality indicators(e.g., heuristics and software metrics) that can highlight change-prone APIsand assist software engineers to design stable APIs. In our context, these in-dicators are particularly useful to check the stability of APIs when they aremapped directly to web APIs.
To investigate change-prone APIs, we first focus on the following researchquestion:
Research Question 1: Which software metrics do indicate change-prone APIs?
We investigate this research question in Chapter 2 by empirically investi-gating the correlation between source code metrics and the number of fine-grained source code changes performed in the interfaces of ten Java open-source systems. Moreover, we use the metrics to train prediction models usedto predict change-prone Java interfaces.
In Chapter 3 we answer our second research question:
Research Question 2: What is the impact of antipatterns on thechange-proneness of APIs?
Previous studies showed that classes with antipatterns change more frequentlythan classes without antipatterns. In Chapter 3 we answer this research ques-tions by extending these studies and taking into account fine-grained sourcecode changes extracted from 16 Java open-source systems. In particular weinvestigate: (1) whether classes with antipatterns are more change-pronethan classes without; (2) whether the type of antipattern impacts the change-proneness of Java classes; and (3) whether certain types of changes are per-

10 Chapter 1. Introduction
formed more frequently in classes affected by a certain antipattern. Perform-ing this analysis we retrieve the set of antipatterns that are more correlatedwith changes performed in APIs.
1.2.2 Track 2: Change-Prone Web APIsThe second track consists of investigating the change-proneness of web APIsthrough the analysis of their evolution. This analysis can help us in identifyingbad design practices that can increase the probability that a web API will bechanged in the future.
To perform this study we detect and extract changes performed in webAPIs. This task is performed by a tool that compares two subsequent versionsof a web API and extracts changes taking into account the syntax of the webAPI specification. In this way we can extract the type of a change performedin the interface as they have been classified in [Leitner et al., 2008]. Knowingthe type of a change is particularly useful for two reasons. First, we can seewhich element is affected by the change and how it changes. Second, we canclassify the changes depending on the impact they can have on the clients. Infact, changes can be divided into breaking changes and non-breaking changesdepending on whether web service client developers need to update their codeor not [Daigneau, 2011].
Once we are able to extract and classify changes we investigate heuristicsand software metrics that can be used as indicators of change-prone web APIs.Similar to Track 1, we then investigate the correlation between them and thechanges performed in the web API.
To perform such analysis, we first need a tool to extract fine-grained changesamong different version of a web API. Then, such analysis might require atool to track the dependencies among web APIs. As already described in Sec-tion 1.1.2, even though services are loosely coupled they are still coupledthrough function and data structure coupling. Coupling can be a good qual-ity indicator in service-oriented systems like it has been already proved forsystems implemented in other programming paradigms. We expect that a ser-vice with a higher incoming and outgoing coupling can show a higher responsetime. However, measuring coupling in service-oriented systems is more chal-lenging than for systems implemented in other paradigms. This is mainly dueto the dynamic and distributed nature of service-oriented systems.
Besides coupling, we analyze other attributes that can affect change-pronenesssuch as cohesion. We argue that a web API should be cohesive to preventchanges in the future. A low cohesive web API can affect the comprehensionof the web API resulting in a lower reusability. Moreover, a web API with

1.2. Approach and Research Questions 11
different responsibilities can be a bottleneck that can affect response time be-cause of the different clients invoking it.
To analyze the impact of these quality attributes on change-proneness weanalyze existing antipatterns defined in literature and described in Section 1.4.The outcome of this study consists of a set of heuristics and metrics that canassist software engineers in designing web APIs that are less change-prone.
To perform this track, first we implement a tool to extract fine-grainedchanges between different versions of web APIs and we answer the followingresearch question:
Research Question 3: How can we extract fine-grained changes amongsubsequent versions of web APIs?
We answer this research question in Chapter 4 by proposing a tool calledWSDLDiff able to extract fine-grained changes from subsequent versions of aweb API defined in WSDL. In contrast to existing approaches, WSDLDiff takesinto account the syntax of WSDL and extracts the WSDL elements affected bychanges and the types of changes. We show a first study aimed at analyzingthe evolution of web APIs using the fine-grained changes extracted from thesubsequent versions of four real world WSDL APIs. Based on the results of thisstudy web service subscribers can highlight the most frequent types of changesaffecting a WSDL API. This information is relevant to assess the risk associatedto the usage of web services and to subscribe to the most stable ones.
As second step in Track 2 we propose a portable approach to infer the dy-namic dependencies among web services at run time answering the followingresearch question:
Research Question 4: How can we mine the full chain of dynamicdependencies among web services?
We answer this research question in Chapter 5 by proposing an approachable to extract dynamic dependencies among web services. The approach isbased on vector clocks, originally conceived and used to order events in dis-tributed environments. We use vector clocks to order web service executionsand to infer causal dependencies among web services. We show the feasi-bility of the approach by implementing it into the Apache CXF framework3
and instrumenting SOAP messages. Moreover, we show two experiments toinvestigate the impact of the approach on the response time.
3http://cxf.apache.org

12 Chapter 1. Introduction
Finally, we conclude Track 2 and investigate the change-proneness of webAPIs answering the following research question:
Research Question 5: What are the scenarios in which developers change webAPIs with low internal and external cohesion?
We address this research question in Chapter 6. We present a qualitativeand quantitative study of the change-proneness of web APIs with low exter-nal and internal cohesion. The internal cohesion measures the cohesion ofthe operations (also referred as methods) declared in a web API. The externalcohesion measures the extent to which the operations of a web API are usedby external consumers (also called clients). First, we report on an online sur-vey to investigate the maintenance scenarios that cause changes to web APIs.Then, we define an internal cohesion metric and analyze its correlation withthe changes performed in ten well known WSDL APIs. The goal of the study isto provide several insights into the interface, method, and data-type change-proneness of web APIs with low internal and external cohesion. The choiceof focusing on internal and external cohesion, instead of other attributes, isbased on our previous and related work and discussed in Chapter 6.
1.2.3 Track 3: Refactoring Web APIsTrack 1 and Track 2 give useful insights into the change-proneness of APIsand web APIs. Based on the findings of these tracks in Track 3 we investigatetechniques to assist software engineers in refactoring change-prone web APIs.Among all change-prone indicators found in Track 1 and Track 2 we focus onexternal cohesion and we define techniques to refactor web APIs with low ex-ternal cohesion. We focus on this attribute because it highlights both change-prone APIs (Track 1) and change-prone web APIs (Track 2). Web APIs, andin general APIs, with low external cohesion can be refactored through the In-terface Segregation Principle [Martin, 2002]. As a consequence, as first stepin this track, we use search based software engineering techniques to refactorAPIs with low external cohesion answering the following research question:
Research Question 6: Which search based techniques can be used to apply theInterface Segregation Principle?
We answer this research question in Chapter 7. We formulate the problemof applying the Interface Segregation Principle as a multi-objective clusteringproblem and we propose a genetic algorithm to solve it. We evaluate thecapability of the proposed genetic algorithm with 42,318 public Java APIs

1.2. Approach and Research Questions 13
whose clients’ usage has been mined from the Maven repository. The capabilityof the genetic algorithm is then compared with the capability of other searchbased approaches (i.e.,, random and simulated annealing approaches).
The last part of this track consists in refactoring fine-grained web APIs (i.e.,chatty APIs). As discussed in Section 1.1.3 fine-grained APIs can be changedover time to improve the performance and to reduce the number of remoteinvocations. In this part we answer the following research question:
Research Question 7: Which search based techniques can transform afine-grained APIs into multiple coarse-grained APIs reducing the total number of
remote invocations?
In Chapter 8 we answer this research question by proposing a genetic al-gorithm that mines the clients’ usage of web service operations and suggestsFaçade web services whose granularity reflects the usage of each different typeof clients. These Façade web services can be deployed on top of the originalweb service and they become contracts for the different types of clients sat-isfying the Consumer-Driven Contracts pattern [Daigneau, 2011]. Accordingto this pattern the granularity of a web API, in terms of exposed operations,should reflect the clients’ usage.
1.2.4 ContributionsThe contributions of this PhD research can be summarized as follows:
• A set of validated quality indicators, comprising metrics and heuristics,to highlight change-prone APIs;
• A set of validated quality indicators, comprising metrics, heuristics, tech-niques, and tools to highlight change-prone web APIs;
• A tool to mine fine-grained changes between different versions of a webAPI;
• An approach to infer the dynamic dependencies among web service atrun time;
• An approach to refactor web APIs, and in general APIs, with low externalcohesion applying the Interface Segregation Principle;
• An approach to refactor fine-grained web APIs into coarse-grained webAPIs with a lower number of required remote invocations.

14 Chapter 1. Introduction
1.3 Research Method
Our research has been done in close collaboration with our industrial partnersand collaborators following an industry-as-laboratory approach [Potts, 1993].The involvement of the industry in our research is crucial to address challengesfaced by practitioners and develop techniques and tools capable of assistingthem in solving real world problems. Frequent discussions allowed us to focuson their main problems and agree on sustainable solutions. As a consequence,all the problems addressed in this thesis have arisen from these discussionswith the industrial parties. This step has been particularly useful to definethe aforementioned research questions and the directions of our research (i.e.,change-proneness of APIs and web APIs).
To answer our research questions we used different research methods.Research questions 1, 2, and 5 are aimed at validating indicators that high-light change-prone APIs and web APIs. They have been mainly answered per-forming quantitative studies based on mining software repositories techniques[Kagdi et al., 2007] and using statistics [Sheskin, 2007] and machine learningtechniques [Witten and Frank, 2005]. We performed these studies analyzingopen source systems from different domains. The reason behind the choice ofthese systems is two-fold. First, industrial parties are reluctant to release theirsystems’ repositories and to allow public discussions about them. Second, us-ing open source systems allows other researchers to compare our findings withtheirs and also to verify and extend our work. Whenever the available datawas not enough to draw statistical conclusions (i.e., Research Question 5) wefollowed a mixed-methods approach [Creswell and Clark, 2010] which is acombination of quantitative and qualitative methods. In this case the resultsof statistical tests are complemented with an online survey [Floyd J. Fowler,2009].
The remaining research questions are aimed at validating approaches toanalyze service oriented systems (i.e., research question 3 and 4) and to refac-tor APIs and web APIs (i.e., research questions 6 and 7). Whenever the avail-able data was not enough to validate these approaches (i.e., Research ques-tion 4 and 7) we use synthetic data and performed controlled experiments[Wohlin et al., 2000]. The approaches used to refactor APIs and web APIshave been implemented and evaluated with state of the art search-based tech-niques [Harman et al., 2012].

1.4. Related Work 15
1.4 Related WorkIn this section we present an overview of related work while the main chaptersof this PhD thesis provide more details.
Many studies (e.g., [Perepletchikov et al., 2010; Moha et al., 2012; Rotem-Gal-Oz, 2012; Král and Zemlicka, 2007]) propose quality indicators for service-oriented systems. However, these indicators have been poorly validated mainlybecause of the lack of availability of such systems.
Perepletchikov et al. [2010, 2006] defined a set of cohesion and couplingmetrics for service-oriented systems. They analyzed cohesion in the context ofweb services and proposed four different types of cohesion metrics for measur-ing analyzability [Perepletchikov et al., 2010]. Furthermore, they proposedthree different coupling measures for web services and they showed their im-pact on maintainability [Perepletchikov et al., 2006].
The most recent work on web services antipatterns has been proposed byMoha et al. [2012]. They proposed an approach to specify and detect an ex-tensive set of antipatterns that encompass concepts like granularity, cohesionand duplication. Their tool is capable of detecting the most popular web ser-vices antipatterns defined in literature. Besides these antipatterns, they speci-fied three more antipatterns, namely: bottleneck service, service chain and dataservice. Bottleneck service is a web service used by many web services and itis affected by a high incoming and outgoing coupling that can affect responsetime. Service chain appears when a business task is achieved by a long chainof consecutive web services invocations. Data service is a web service that per-forms simple information retrieval or data access operations that can affectthe cohesion.
Rotem-Gal-Oz [2012] defined the knot antipattern as a set of low cohe-sive web services which are tightly coupled. This antipattern can cause lowusability and high response time.
The sand pile defined by Král and Zemlicka [2007] appears when manyfine-grained web services share common data that may be available through aweb service affected by the data service antipattern.
Cherbakov et al. [2006] proposed the duplicate service antipattern that af-fect services sharing similar methods and that can cause maintainability issues.
Dudney et al. [2002] defined a set of antipatterns for J2EE applications.Among these we investigate the multi service, tiny service and chatty service an-tipatterns. The multi service is a service that provides different business opera-tions that are low cohesive and can affect availability and response time. Tinyservices are small web services with few methods that are used together. This

16 Chapter 1. Introduction
antipattern can affect the reusability of such services. Finally the chatty serviceantipattern affects services that communicate with each other with small data.This antipattern can affect the response time.
All the aforementioned studies suggest and detect antipatterns for design-ing web APIs but they do not investigate the effects of these antipatterns onthe change-proneness and do not suggest techniques to refactor web APIs.
1.5 Origin of ChaptersThe chapters of this thesis have been published before as peer-reviewed pub-lications or are under review. As a consequence they are self-contained and,hence, they might contain some redundancy in the background, motivation,and implication sections.
The author of this thesis is the main contributor of all chapters and all pub-lications have been co-authored by Martin Pinzger. The following list providesan overview of these publications:
Chapter 2 was published in the 27th International Conference on SoftwareMaintenance (ICSM 2011) [Romano and Pinzger, 2011a].
Chapter 3 was published in the 19th Working Conference on Reverse Engineer-ing (WCRE 2012) [Romano et al., 2012].
Chapter 4 was published in the 19th International Conference on Web Services(ICWS 2012) [Romano and Pinzger, 2012].
Chapter 5 was published in the 4th International Conference on Service Ori-ented Computing and Application (SOCA 2011) [Romano et al., 2011].
Chapter 6 is currently under review and published as technical report [Ro-mano et al., 2013].
Chapter 7 was published in the 30th International Conference on SoftwareMaintenance and Evolution (ICSME 2014) [Romano et al., 2014].
Chapter 8 was published in the 10th World Congress on Services (Services2014) [Romano and Pinzger, 2014].

2.Change-Prone Java Interfaces
Recent empirical studies have investigated the use of source code metrics topredict the change- and defect-proneness of source code files and classes. Whileresults showed strong correlations and good predictive power of these metrics,they do not distinguish between interface, abstract or concrete classes. In par-ticular, interfaces declare contracts that are meant to remain stable during theevolution of a software system while the implementation in concrete classes ismore likely to change.
This chapter aims at investigating to which extent the existing source codemetrics can be used for predicting change-prone Java interfaces. We empiri-cally investigate the correlation between metrics and the number of fine-grainedsource code changes in interfaces of ten Java open-source systems. Then, weevaluate the metrics to calculate models for predicting change-prone Java inter-faces.
Our results show that the external interface cohesion metric exhibits thestrongest correlation with the number of source code changes. This metric alsoimproves the performance of prediction models to classify Java interfaces intochange-prone and not change-prone.1
2.1 Interface Metrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2 The Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.3 Empirical Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.5 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.6 Conclusions and Future Work . . . . . . . . . . . . . . . . . . . . . . . . 36
Software systems are continuously subjected to changes. Those changesare necessary to add new features, to adapt to a new environment, to fix bugs
1This chapter was published in the 27th International Conference on Software Maintenance(ICSM 2011) [Romano and Pinzger, 2011a]
17

18 Chapter 2. Change-Prone Java Interfaces
or to refactor the source code. However, the maintenance of software systemsis also risky and costly.
Several approaches have been developed to optimize the maintenance ac-tivities and reduce the costs. They range from automated reverse engineeringtechniques to ease program comprehension to prediction models that can helpidentifying the change- and defect-prone parts in the source code. Develop-ers should focus on understanding these change- and defect prone parts inorder to take appropriate counter measures to minimize the number of futurechanges [Girba et al., 2004].
Many of these prediction models have been developed using source codemetrics, such as by Briand et al. [2002], Subramanyam and Krishnan [2003],and Menzies et al. [2007]. While those prediction models showed good per-formance, they work on file and class level. None of them takes the kindof class into account, whether it is a concrete class, abstract class, or interfacethat is change- or defect-prone. We believe that changes in interfaces can havea stronger impact than changes in concrete and abstract classes, and shouldtherefore be treated separately. Interfaces are meant to represent contractsamong modules and logic units in a software system. For this reason, theyare supposed to be more stable to avoid contract violations and to reduce theeffort to maintain a software system.
In this chapter, we focus on Java interfaces and investigate the predictivepower of various source code metrics to classify Java interfaces into change-prone and not change-prone. Concerning the source code metrics, we take intoaccount (1) the set of metrics defined by Chidamber and Kemerer [1994];(2) a set of metrics to measure the complexity and the usage of interfaces;and (3) two metrics to measure the external cohesion of Java interfaces. Thenumber of fine-grained source code changes (#SCC), as introduced by Fluriet al. [2007], is used to distinguish between change-prone and not change-prone interfaces.
We selected the Chidamber and Kemerer (C&K) metrics suite because it iswidely used and it has been validated by several approaches, such as [Rom-bach, 1987], [Li and Henry, 1993], [Basili et al., 1996]. The two externalcohesion metrics are Interface Usage Cohesion (IUC) and a clustering metric.These metrics are meant as heuristics to indicate violations of the InterfaceSegregation Principle (ISP) as described by Martin [2002]. We believe thatthe violation of the ISP can impact the maintenance of interfaces and the soft-ware system as a whole. The complexity and usage metrics for interfaces havebeen added to provide a broader set of interface metrics for our study.
To investigate our claim, we perform an empirical study with the source

2.1. Interface Metrics 19
code and versioning data of ten Java open source systems, namely: eight plug-in projects from the Eclipse platform, Hibernate2 and Hibernate3. In the study,we address the following two research hypotheses:
• H1: IUC has a stronger correlation with the #SCC of interfaces than theC&K metrics
• H2: IUC can improve the performance of prediction models to classifyJava interfaces into change- and not change-prone
The results show that most of the C&K perform well for predicting change-prone concrete and abstract classes but are limited in predicting change-proneJava interfaces, therefore confirming our claim that interfaces need to betreated separately. The IUC metric exhibits the strongest correlation with#SCC of Java interfaces and proves to be an adequate metric to computeprediction models for classifying Java interfaces.
The remainder of this chapter is organized as follows. Section 2.1 discussesthe C&K metrics and their effectiveness when used for measuring the sizeand complexity of interfaces. We furthermore introduce the IUC metric andseveral other interface complexity and usage metrics. Section 2.2 describesthe approach used to measure the metrics and to mine the fine-grained sourcecode changes from versioning repositories. The empirical study and resultsare presented in Section 2.3. Section 2.4 discusses the results and threats tovalidity. Related work is presented in Section 2.5. We draw our conclusionsand outline directions for future work in Section 2.6.
2.1 Interface MetricsIn this section, we present the set of source code metrics used in our empiricalstudy. We furthermore discuss their applicability to measure the size, com-plexity, and cohesion of Java interfaces. We then present the IUC metric andmotivate its application to predict change-prone interfaces. At the end of thesection, we list additional metrics to measure the complexity and the usageof interfaces. Those metrics are meant to provide further validation of thepredictive power of the IUC metric.
2.1.1 Object-Oriented Metrics & InterfacesAmong the existing product metrics [Henderson-Sellers, 1996], we focus onthe object-oriented metrics introduced by Chidamber and Kemerer [1994].They have been widely used as quality indicators of object-oriented softwaresystems. These metrics are:

20 Chapter 2. Change-Prone Java Interfaces
• Coupling Between Objects (CBO)
• Lack of Cohesion Of Methods (LCOM)
• Number Of Children (NOC)
• Depth of Inheritance Tree (DIT)
• Response For Classes (RFC)
• Weighted Methods per Class (WMC)
We selected the C&K metrics mainly because prior work demonstratedtheir usefulness for building models for change prediction, e.g., [Li and Henry,1993] [Zhou and Leung, 2007], as well as defect prediction, e.g., [Basili et al.,1996]. In the following, we briefly describe each metric and discuss its appli-cation to interfaces.
Coupling Between Objects (CBO)The CBO metric represents the number of data types a class is coupled with.More specifically, it counts the unique number of reference types that occurthrough method calls, method parameters, return types, exceptions, and fieldaccesses. If applied to interfaces, this metric is limited to method parameters,return types and exceptions leaving out method calls and field accesses.
Lack of Cohesion Of Methods (LCOM)The LCOM metric counts the number of pairwise methods without any sharedinstance variable, minus the number of pairwise methods that share at leastone instance variable. More precisely, the LCOM metric revised in [Henderson-Sellers et al., 1996] is defined as:
LCOM =
�
1a
∑aj=1µ
�
A j
�
�
−m
1−m
where a represents the number of attributes of a class, m the number of meth-ods, and µ(A j) the number of methods which access each attribute A j of aclass. Perfect cohesion is defined as all methods accessing all variables, inthat case the value of LCOM is 0. In contrast, if all methods do not share anyinstance variable, the value of LCOM is 1.
The LCOM metric is not applicable to interfaces since interfaces do notcontain logic and consequently attribute accesses. For instance, the commer-cial metric tool Understand2 outputs either 0 or 1 as values for LCOM for an
2http://www.scitools.com/

2.1. Interface Metrics 21
interface. The value 1 denotes that the interface also contains the definitionof constant attributes, otherwise the value for LCOM is 0. This limits the useof LCOM for computing prediction models.
Weighted Methods per Class (WMC)WMC is the sum of the cyclomatic complexities of all methods declared by aclass. Formally, the metric is defined as:
W MC =n∑
i=1
ci
where ci is the cyclomatic complexity of the ith method of a class. In case ofUnderstand, this metric corresponds to the Number Of Methods (NOM), sincethe complexity of each method declared in an interface is 1. In case of theMetrics tool3 this metric is always 0 for interfaces. This limits the predictivepower of this metric for predicting change-prone interfaces.
Number Of Children (NOC)The NOC metric counts the number of directly derived classes of a class orinterface. Even though this metric is sound for interfaces, we argue that itsapplication for predicting change prone interfaces is limited. The main reasonbeing that interfaces inherit only the type definition (i.e., sub-typing) whileabstract classes and concrete classes also inherit the business logic.
Depth of Inheritance Tree (DIT)The DIT metric denotes the length of the longest path from a sub-class toits base class in an inheritance structure. The idea behind the usage of DITas change-proneness indicator is that classes contained in a deep inheritancestructure are more likely to change (e.g., changes in a super-class cause changesin its sub-classes). Similar to NOC, we believe that this metric is more usefulfor abstract and concrete classes than for interfaces.
Response For Classes (RFC)The RFC metric counts the number of local methods (including inherited meth-ods) of a class. This metric remains valid for interfaces, but it is close to theWMC metric since the only added information is the count of the inheritedmethod.
In summary, while most of the C&K metrics are adequate metrics for ab-stract and concrete classes they are not as powerful for interfaces. Moreover,
3http://metrics.sourceforge.net/

22 Chapter 2. Change-Prone Java Interfaces
these metrics fall short in expressing the cohesion of interfaces, therefore weintroduce the two external cohesion metrics as presented in the following sec-tion.
2.1.2 External Cohesion Metrics of InterfacesDevelopers should not design fat interfaces that are interfaces whose clients in-voke different methods. This problem has been formalized in the Interface Seg-regation Principle (ISP) described by Martin [2002]. The ISP principle statesthat fat interfaces need to be split into smaller interfaces according to theclients of an interface. Any client should only know about the set of meth-ods provided by an interface that are used by the client. In literature the lackof conformance to the ISP principle is mainly associated to a higher risk forclients to change when an interface is changed. To the best of our knowledgethere exists no empirical evidence that underlines this association.
In order to measure the violation of the ISP principle, we use two cohesionmetrics: the external cohesion metric for services called Service Interface UsageCohesion (SIUC) taken from Perepletchikov et al. [Perepletchikov et al., 2007,2010] and a clustering metric.
In the following, we refer to the SIUC metric as Interface Usage Cohesion(IUC) because we apply it in the context of object-oriented systems. The metricis defined as:
IUC(i) =
∑nj=1
used_methods( j,i)num_methods(i)
n
where j denotes a client of the interface i; used_methods (j,i) is the functionwhich computes the number of methods defined in i and used by the clientj; num _methods(i) returns the total number of methods defined in i; and ndenotes the number of clients of the interface i. The external cohesion definedby Perepletchikov et al., and hence the IUC metric, states that there is a strongexternal cohesion if every client uses all methods of an interface. We arguethat interfaces with strong external cohesion (the value of IUC is close to one)are less likely to change. On the other hand, when there is a high lack ofexternal cohesion (the value of IUC is close to zero) the interface is morelikely to change due to the larger number of clients.
Consider the example in Figure 2.1a that shows an interface for providingbank services. The service is used by two different clients, namely the Profes-sional Client and the Student Client. The two clients share only one interfacemethod, namely the method accountBalance(). Since this method is shared bytwo different clients, it is more likely to change to satisfy the requirements of
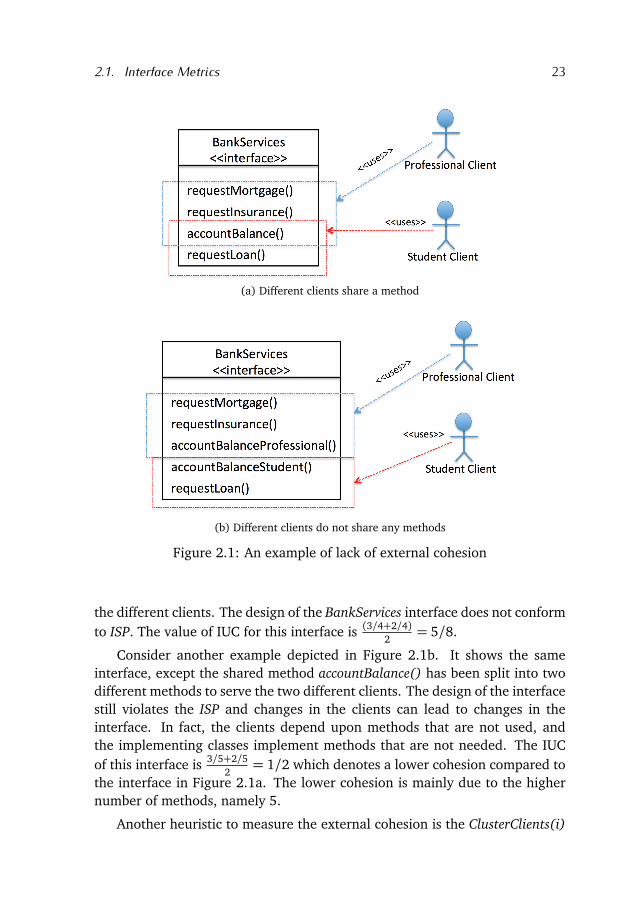
2.1. Interface Metrics 23
(a) Different clients share a method
(b) Different clients do not share any methods
Figure 2.1: An example of lack of external cohesion
the different clients. The design of the BankServices interface does not conformto ISP. The value of IUC for this interface is (3/4+2/4)
2= 5/8.
Consider another example depicted in Figure 2.1b. It shows the sameinterface, except the shared method accountBalance() has been split into twodifferent methods to serve the two different clients. The design of the interfacestill violates the ISP and changes in the clients can lead to changes in theinterface. In fact, the clients depend upon methods that are not used, andthe implementing classes implement methods that are not needed. The IUCof this interface is 3/5+2/5
2= 1/2 which denotes a lower cohesion compared to
the interface in Figure 2.1a. The lower cohesion is mainly due to the highernumber of methods, namely 5.
Another heuristic to measure the external cohesion is the ClusterClients(i)

24 Chapter 2. Change-Prone Java Interfaces
metric. This metric counts the number of clients of an interface i that do notshare any method. Higher values for this metric indicate lower cohesion. Forthe interface in Figure 2.1a the value of ClusterClients is 0 and for the interfacein Figure 2.1b the value is 2. We use this metric to investigate whether thecontribution of the shared methods, as computed by the IUC metric, is relevantto predict change-prone interfaces.
2.1.3 Complexity and Usage Metrics for InterfacesIn addition to the object-oriented metrics we validate the IUC metric againstseveral other metrics defined to measure the complexity and usage of an in-terface. The complexity metrics are:
• NOM(i): counts the number of methods declared in the interface i;
• Arguments(i): counts the total number of arguments of the declaredmethods in the interface i;
• APP(i): measures the mean size of method declarations of an interfacei and is equal to Arguments(i) divided by NOM(i), as defined by Boxalland Araban [2004];
The usage metrics are:
• Clients(i): counts the number of distinct classes that invoke the interfacei;
• Invocations(i): counts the number of static invocations of the methodsdeclared in the interface i;
• Implementing_Classes(i): counts the number of direct classes that imple-ment the interface i.
2.2 The ApproachIn this section, we illustrate the approach used to extract the fine-grainedsource code changes, to measure the metrics and to perform the experimentsaimed at addressing our research hypotheses. Figure 2.2 shows an overviewof our approach that consists of three stages: (A) in the first stage we checkoutthe source code of the projects from their versioning repositories and we mea-sure the source code metrics; (B) we then compute the number of SCC fromthe versioning data for each class and interface; (C) finally we use the metrics

2.2. The Approach 25
and the number of SCC to perform our experiments with the PASWStatistics4
and RapidMiner5 toolkits.
2.2.1 Source Code Metrics ComputationThe first step of the process consists of checking out the source code of eachproject from the versioning repositories. The source code of each project thenis parsed with the Evolizer Famix Importer, belonging to the Evolizer6 tool set.The parser extracts a FAMIX model that represents the source code entities andtheir relationships [Tichelaar et al., 2000]. Figure 2.3 shows the core of theFAMIX meta model. The model represents inheritance relationships amongclasses, the methods belonging to a class, the attribute accessed by a methodand the invocations among methods. For more details we refer the reader to[Tichelaar et al., 2000].
After obtaining the FAMIX model, the next step consists of measuring thesource code metrics of classes and interfaces. We use the Understand tool tomeasure the C&K metrics. We decided to use the Understand tool because inour view it provides the most precise measurement of these metrics for inter-faces. We use the FAMIX model to measure the external cohesion, complexityand usage metrics of interfaces. For example, to measure the Invocations(i)metric we count the number of invocation objects in the FAMIX model thatpoint to a method of the interface i.
2.2.2 SCC ExtractionThe first step of the SCC extraction stage consists of retrieving the version-ing data from the repositories (e.g., CVS, SVN, or GIT) for which we use theEvolizer Version Control Connector [Gall et al., 2009]. The versioning reposi-tories provide log entries that contain information about revisions of files thatbelong to the system under analysis. For each log entry, it extracts the revisionnumber, the revision timestamp, the name of the developer who checked-inthe revision, the commit message, the total number of lines modified (LM),and the source code.
In the second step, we use ChangeDistiller [Gall et al., 2009] to extract thefine-grained source code changes (SCC) from the various source code revisionsof each file. ChangeDistiller implements a tree differencing algorithm, thatcompares the Abstract Syntax Trees (ASTs) between all direct subsequent re-visions of a file. Each change represents a tree edit operation that is required
4http://www.spss.com/software/statistics/5http://rapid-i.com/content/view/181/196/6http://www.evolizer.org/

26 Chapter 2. Change-Prone Java Interfaces
to transform one version of the AST into the other. In this way we can trackfine-grained source changes down to the statement level. Based on this infor-mation we count the number of fine-grained source code changes (#SCC) foreach class and interface over the selected observation period.
2.2.3 Correlation and Prediction AnalysisWe use the collection of metric values and #SCC of each class and interface asinput to our experiments. First, we use the PASWStatistics tool to perform acorrelation analysis between the source code metrics and the #SCC. Then, weuse the RapidMiner tool to analyze the predictive power of the source codemetrics to discriminate between change- and not change-prone interfaces. Weperform a series of classification experiments with different machine learningalgorithms, namely: Support Vector Machine, Naive Bayes Network and NeuralNets. The next section details the empirical study.
2.3 Empirical StudyThe goal of this empirical study is to evaluate the possibility of using the IUCmetric for predicting the change-prone interfaces and to highlight the limitedpredictive power of the C&K metrics. The perspective is that of a researcher,interested in investigating whether the traditional object-oriented metrics areuseful to predict change-prone interfaces. The results of our study are alsointeresting for quality engineers who want to monitor the quality of their soft-ware systems, using an external cohesion metric for interfaces.
The context of this study consists of ten open-source systems, widely usedin both, the academic and industrial community. These systems are eight plu-gins from the Eclipse7 platform and the Hibernate2 and Hibernate3 systems.8
Eclipse is a popular open source system that has been studied extensively bythe research community (e.g., [Businge et al., 2010], [Businge et al., 2013],[Businge, 2013] [Bernstein et al., 2007], [Nagappan et al., 2010], [Zimmer-mann et al., 2007], and [Zimmermann et al., 2009]). Hibernate is an object-relational mapping (ORM) library for the Java language.
Table 2.1 shows an overview of the dataset used in our empirical study.The #Files is the number of unique Java files, #Interfaces is the number ofunique Java interfaces, #Rev is the total number of Java file revisions, #SCCis the number of fine-grained source code changes performed within the giventime period (Time).
7http://www.eclipse.org/8http://www.hibernate.org/

2.3. Empirical Study 27
Table 2.1: Dataset used in the empirical study
Project #Files #Interfaces #Rev #SCC Time[M,Y]
Hibernate3 970 165(17%) 30774 34960 Jun04-Mar11Hibernate2 494 69(14%) 13584 22960 Jan03-Mar11eclipse.debug.core 188 97(52%) 8295 11670 May01-Mar11eclipse.debug.ui 793 129(16%) 41860 55259 May01-Mar11eclipse.jface 381 105(28%) 22136 27041 Sep02-Mar11eclipse.jdt.debug 469 140(30%) 11711 33895 Jun01-Mar11eclipse.team.core 172 44(26%) 3726 4551 Nov01-Mar11eclipse.team.cvs.core 189 25(13%) 12343 23311 Nov01-Mar11eclipse.team.ui 293 45(15%) 20183 32267 Nov01- Mar11eclipse.update.core 274 71(26%) 7425 25617 Oct01-Mar11
In this study, we address the following two research hypotheses:
• H1: IUC has a stronger correlation with the #SCC of interfaces than theC&K metrics
• H2: IUC can improve the performance of prediction models to classifyJava interfaces into change- and not change-prone
We first perform an initial analysis of the extracted information, in termsof number of changes and in terms of metric values. Figure 2.4 shows the boxplots of the #SCC of Java classes and interfaces mined from the versioningrepositories of each project.
The results show that on average the number of changes involving Javaclasses are at least one order of magnitude higher than the ones involvingJava interfaces. This result is not surprising since interfaces can be consideredcontracts among modules, and in general among logic units of a system.
Figure 2.5 shows the values of the C&K metrics for classes and interfacesover all ten projects. The values of the CBO metric are in general lower for in-terfaces, since it counts only the number of reference types in the parameters,return types and thrown exceptions in the method signatures. The values ofthe RFC metric are higher for classes than for interfaces. Also the values of theDIT metric are in general higher for classes than for interfaces.
Analyzing the LCOM we can notice that Java classes have a low medianLCOM and hence a high cohesion. On the other hand, interpreting the LCOMof interfaces we can state that most of them do not expose any attributes intheir body. In fact, the Understand tool registers a 0 LCOM when there are noattribute declarations, and 1 if there are some. The values of WMC confirm
28 Chapter 2. Change-Prone Java Interfaces
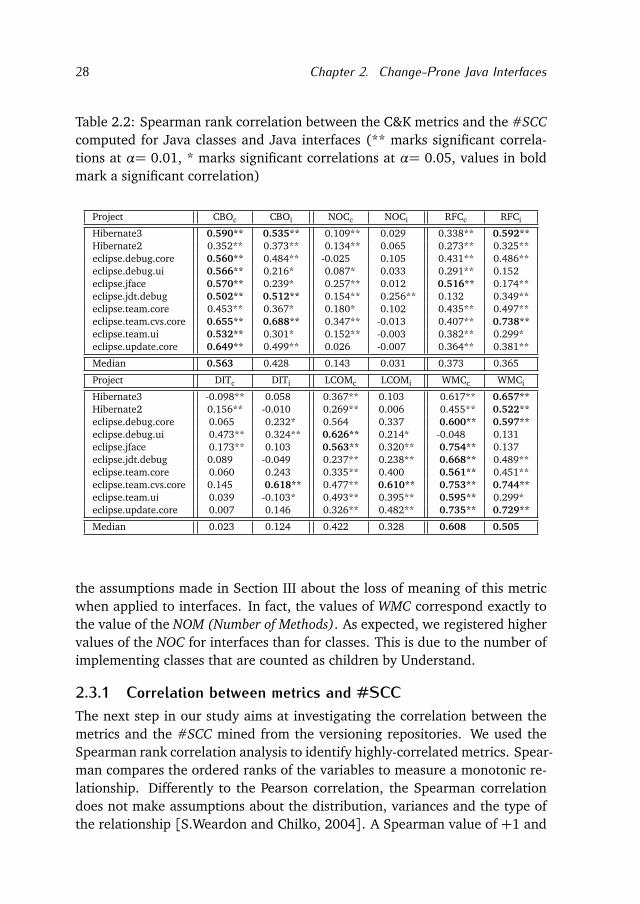
Table 2.2: Spearman rank correlation between the C&K metrics and the #SCCcomputed for Java classes and Java interfaces (** marks significant correla-tions at α= 0.01, * marks significant correlations at α= 0.05, values in boldmark a significant correlation)
Project CBOc CBOi NOCc NOCi RFCc RFCi
Hibernate3 0.590** 0.535** 0.109** 0.029 0.338** 0.592**Hibernate2 0.352** 0.373** 0.134** 0.065 0.273** 0.325**eclipse.debug.core 0.560** 0.484** -0.025 0.105 0.431** 0.486**eclipse.debug.ui 0.566** 0.216* 0.087* 0.033 0.291** 0.152eclipse.jface 0.570** 0.239* 0.257** 0.012 0.516** 0.174**eclipse.jdt.debug 0.502** 0.512** 0.154** 0.256** 0.132 0.349**eclipse.team.core 0.453** 0.367* 0.180* 0.102 0.435** 0.497**eclipse.team.cvs.core 0.655** 0.688** 0.347** -0.013 0.407** 0.738**eclipse.team.ui 0.532** 0.301* 0.152** -0.003 0.382** 0.299*eclipse.update.core 0.649** 0.499** 0.026 -0.007 0.364** 0.381**
Median 0.563 0.428 0.143 0.031 0.373 0.365
Project DITc DITi LCOMc LCOMi WMCc WMCi
Hibernate3 -0.098** 0.058 0.367** 0.103 0.617** 0.657**Hibernate2 0.156** -0.010 0.269** 0.006 0.455** 0.522**eclipse.debug.core 0.065 0.232* 0.564 0.337 0.600** 0.597**eclipse.debug.ui 0.473** 0.324** 0.626** 0.214* -0.048 0.131eclipse.jface 0.173** 0.103 0.563** 0.320** 0.754** 0.137eclipse.jdt.debug 0.089 -0.049 0.237** 0.238** 0.668** 0.489**eclipse.team.core 0.060 0.243 0.335** 0.400 0.561** 0.451**eclipse.team.cvs.core 0.145 0.618** 0.477** 0.610** 0.753** 0.744**eclipse.team.ui 0.039 -0.103* 0.493** 0.395** 0.595** 0.299*eclipse.update.core 0.007 0.146 0.326** 0.482** 0.735** 0.729**
Median 0.023 0.124 0.422 0.328 0.608 0.505
the assumptions made in Section III about the loss of meaning of this metricwhen applied to interfaces. In fact, the values of WMC correspond exactly tothe value of the NOM (Number of Methods). As expected, we registered highervalues of the NOC for interfaces than for classes. This is due to the number ofimplementing classes that are counted as children by Understand.
2.3.1 Correlation between metrics and #SCCThe next step in our study aims at investigating the correlation between themetrics and the #SCC mined from the versioning repositories. We used theSpearman rank correlation analysis to identify highly-correlated metrics. Spear-man compares the ordered ranks of the variables to measure a monotonic re-lationship. Differently to the Pearson correlation, the Spearman correlationdoes not make assumptions about the distribution, variances and the type ofthe relationship [S.Weardon and Chilko, 2004]. A Spearman value of +1 and

2.3. Empirical Study 29
-1 indicates high positive or high negative correlation, whereas 0 indicatesthat the variables under analysis do not correlate at all. Values greater than+0.5 and lower than -0.5 are considered to be substantial; values greater than+0.7 and lower than -0.7 are considered to be strong correlations.
To test the hypothesis H1, we performed two correlation analyses: (1)we analyze the correlation among the C&K metrics and the #SCC in Javaclasses and Java interfaces. An insignificant correlation of the C&K metrics forinterfaces is a precondition for any further analysis of the interface complexityand usage metrics. (2) We explore the extent to which the interface cohesion,complexity and usage metrics correlate with #SCC.
Table 2.2 lists the results of the correlation analysis between the C&K met-rics and #SCC for classes and interfaces in each project. The heading Xc in-dicates the correlation of the metric X with the #SCC of classes, and Xi thecorrelation with the #SCC of interfaces.
The first important result is that only the metrics CBOc and WMCc havea substantial correlation with the #SCC of Java classes, since their mediancorrelation is greater than 0.5. In five projects out of ten WMCc exhibits asubstantial correlation and in three cases the correlation is strong. Similarly,the CBOc metric shows a substantial correlation in eight cases but no strongcorrelations. The other metrics do not show a significant correlation with the#SCC.
The median correlation values of the C&K metrics applied to interfacesare significantly lower. Among the six metrics WMCi exhibits the strongestcorrelation with #SCC. It shows three substantial and two strong correlations.CBOi shows a substantial correlation for three projects.
We applied the same correlation analysis to the interface complexity andusage metrics defined in Section III. We report the result in Table 2.3. IUCi isthe only metric that exposes a substantial correlation with the #SCC of inter-faces. This metric shows a median correlation value of -0.605, having a sub-stantial correlation in six projects and a strong correlation in one project. Thenegative correlation is due to the nature of the metric and it means that theIUCi value is inversely proportional to the #SCC. More precisely, the strongerthe external cohesion is (values of IUCi close to one) the less frequently aninterface changes.
Concerning the other metrics, the NOMi shows the strongest correlationwith the #SCC. This result is not surprising since the more methods are de-clared in the interface the more likely the interface changes. Surprisingly,neither the number of clients nor the number of invocations result in a sub-
30 Chapter 2. Change-Prone Java Interfaces
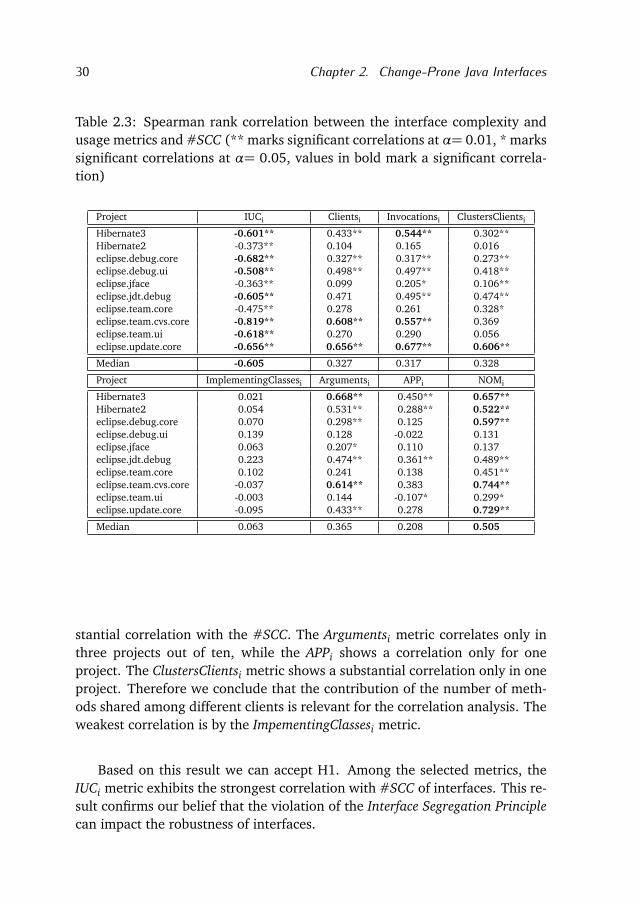
Table 2.3: Spearman rank correlation between the interface complexity andusage metrics and #SCC (** marks significant correlations at α= 0.01, * markssignificant correlations at α= 0.05, values in bold mark a significant correla-tion)
Project IUCi Clientsi Invocationsi ClustersClientsi
Hibernate3 -0.601** 0.433** 0.544** 0.302**Hibernate2 -0.373** 0.104 0.165 0.016eclipse.debug.core -0.682** 0.327** 0.317** 0.273**eclipse.debug.ui -0.508** 0.498** 0.497** 0.418**eclipse.jface -0.363** 0.099 0.205* 0.106**eclipse.jdt.debug -0.605** 0.471 0.495** 0.474**eclipse.team.core -0.475** 0.278 0.261 0.328*eclipse.team.cvs.core -0.819** 0.608** 0.557** 0.369eclipse.team.ui -0.618** 0.270 0.290 0.056eclipse.update.core -0.656** 0.656** 0.677** 0.606**
Median -0.605 0.327 0.317 0.328
Project ImplementingClassesi Argumentsi APPi NOMi
Hibernate3 0.021 0.668** 0.450** 0.657**Hibernate2 0.054 0.531** 0.288** 0.522**eclipse.debug.core 0.070 0.298** 0.125 0.597**eclipse.debug.ui 0.139 0.128 -0.022 0.131eclipse.jface 0.063 0.207* 0.110 0.137eclipse.jdt.debug 0.223 0.474** 0.361** 0.489**eclipse.team.core 0.102 0.241 0.138 0.451**eclipse.team.cvs.core -0.037 0.614** 0.383 0.744**eclipse.team.ui -0.003 0.144 -0.107* 0.299*eclipse.update.core -0.095 0.433** 0.278 0.729**
Median 0.063 0.365 0.208 0.505
stantial correlation with the #SCC. The Argumentsi metric correlates only inthree projects out of ten, while the APPi shows a correlation only for oneproject. The ClustersClientsi metric shows a substantial correlation only in oneproject. Therefore we conclude that the contribution of the number of meth-ods shared among different clients is relevant for the correlation analysis. Theweakest correlation is by the ImpementingClassesi metric.
Based on this result we can accept H1. Among the selected metrics, theIUCi metric exhibits the strongest correlation with #SCC of interfaces. This re-sult confirms our belief that the violation of the Interface Segregation Principlecan impact the robustness of interfaces.

2.3. Empirical Study 31
2.3.2 Prediction analysisTo test the research hypothesis H2, we analyzed whether the IUC metric canimprove prediction models to classify interfaces into change-prone and notchange-prone. We performed a series of classification experiments with threedifferent machine learning algorithms. Prior work [Lessmann et al., 2008]showed that some machine learning techniques perform better than others,even though they state that performance differences among classifiers aremarginal and not necessarily significant. For that reason we used the followingclassifiers: Support Vector Machine (LibSVM), Naive Bayes Network (NBayes)and Neural Nets (NN) provided by the RapidMiner toolkit.
For each project, we binned the interfaces into change-prone and not change-prone using the median of the #SCC per project:
interface=
¨
change-prone if # SCC>mediannot change-prone otherwise
First, we trained the machine learning algorithms using the following objectoriented metrics: CBO, RFC, LCOM, WMC. We selected these metrics becausethey showed the strongest correlation with the #SCC. We refer to this set ofmetrics as OO. Next, the training is performed using the OO metrics plus theIUC metric. We refer to this set of metrics as IUC.
In order to evaluate the classifications models, we use the area under thecurve statistic (AUC). In addition we report the precision (P) and recall (R)of each model. AUC represents the probability, that, when choosing randomlya change-prone and a not change-prone interface, the trained model assignsa higher score to the change-prone interface [Green and Swets, 1966]. Wetrained the models using 10 fold cross-validation and we considered modelswith an AUC value greater than 0.7 to have adequate classification perfor-mance [Lessmann et al., 2008].
Table 2.4 reports the results obtained with the NBayes learner. The resultsshow that the median AUC is higher when we include the IUC metric. More-over, for each project we obtained an adequate performance (AUC>0.7) withthe IUC. Only for two projects (JDT Debug and Team UI) out of ten we regis-tered a better performance for the OO metrics. Using the LibSVN (see Table2.5) and the NN (see Table 2.6) classifiers we obtained similar results. WithLibSVN, in eight projects the IUC metrics outperformed the OO metrics. UsingNN, in seven projects out of ten the IUC metrics outperformed the OO metrics.
The median values of the Precision and Recall show similar results for mostof the projects. In several projects, however, the Precision and Recall is af-fected by the lack of information about interfaces (i.e., a high percentage of
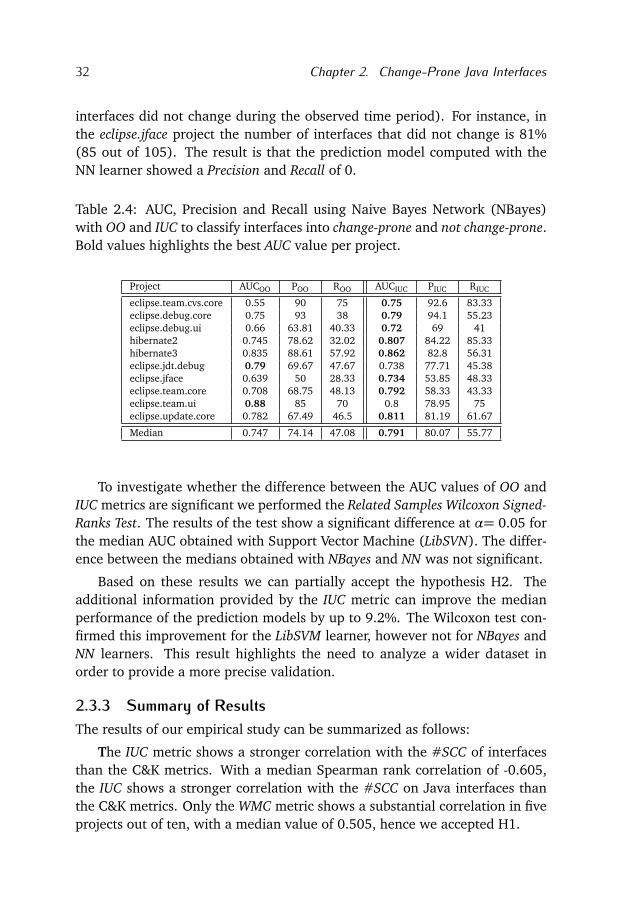
32 Chapter 2. Change-Prone Java Interfaces
interfaces did not change during the observed time period). For instance, inthe eclipse.jface project the number of interfaces that did not change is 81%(85 out of 105). The result is that the prediction model computed with theNN learner showed a Precision and Recall of 0.
Table 2.4: AUC, Precision and Recall using Naive Bayes Network (NBayes)with OO and IUC to classify interfaces into change-prone and not change-prone.Bold values highlights the best AUC value per project.
Project AUCOO POO ROO AUCIUC PIUC RIUC
eclipse.team.cvs.core 0.55 90 75 0.75 92.6 83.33eclipse.debug.core 0.75 93 38 0.79 94.1 55.23eclipse.debug.ui 0.66 63.81 40.33 0.72 69 41hibernate2 0.745 78.62 32.02 0.807 84.22 85.33hibernate3 0.835 88.61 57.92 0.862 82.8 56.31eclipse.jdt.debug 0.79 69.67 47.67 0.738 77.71 45.38eclipse.jface 0.639 50 28.33 0.734 53.85 48.33eclipse.team.core 0.708 68.75 48.13 0.792 58.33 43.33eclipse.team.ui 0.88 85 70 0.8 78.95 75eclipse.update.core 0.782 67.49 46.5 0.811 81.19 61.67
Median 0.747 74.14 47.08 0.791 80.07 55.77
To investigate whether the difference between the AUC values of OO andIUC metrics are significant we performed the Related Samples Wilcoxon Signed-Ranks Test. The results of the test show a significant difference at α= 0.05 forthe median AUC obtained with Support Vector Machine (LibSVN). The differ-ence between the medians obtained with NBayes and NN was not significant.
Based on these results we can partially accept the hypothesis H2. Theadditional information provided by the IUC metric can improve the medianperformance of the prediction models by up to 9.2%. The Wilcoxon test con-firmed this improvement for the LibSVM learner, however not for NBayes andNN learners. This result highlights the need to analyze a wider dataset inorder to provide a more precise validation.
2.3.3 Summary of ResultsThe results of our empirical study can be summarized as follows:
The IUC metric shows a stronger correlation with the #SCC of interfacesthan the C&K metrics. With a median Spearman rank correlation of -0.605,the IUC shows a stronger correlation with the #SCC on Java interfaces thanthe C&K metrics. Only the WMC metric shows a substantial correlation in fiveprojects out of ten, with a median value of 0.505, hence we accepted H1.
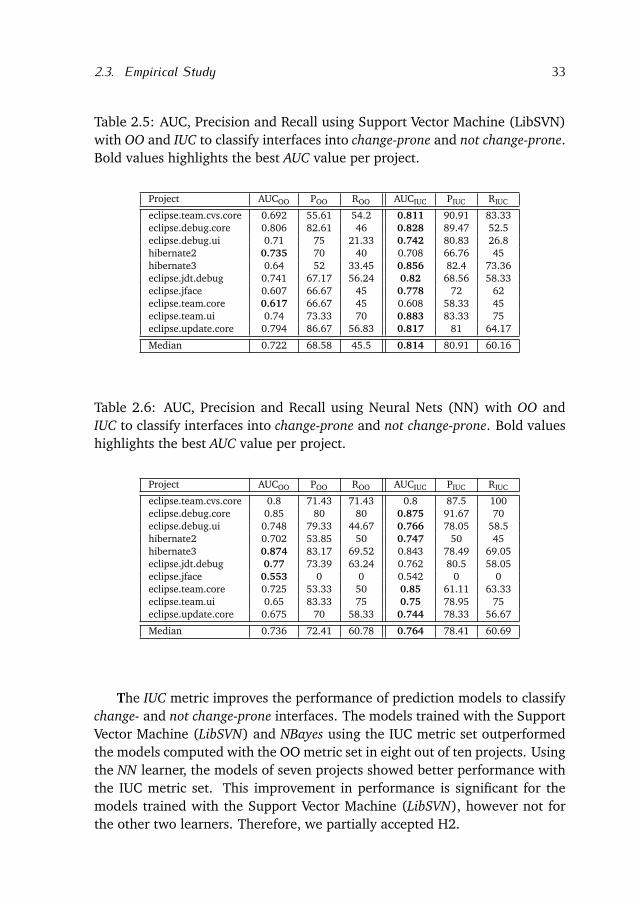
2.3. Empirical Study 33
Table 2.5: AUC, Precision and Recall using Support Vector Machine (LibSVN)with OO and IUC to classify interfaces into change-prone and not change-prone.Bold values highlights the best AUC value per project.
Project AUCOO POO ROO AUCIUC PIUC RIUC
eclipse.team.cvs.core 0.692 55.61 54.2 0.811 90.91 83.33eclipse.debug.core 0.806 82.61 46 0.828 89.47 52.5eclipse.debug.ui 0.71 75 21.33 0.742 80.83 26.8hibernate2 0.735 70 40 0.708 66.76 45hibernate3 0.64 52 33.45 0.856 82.4 73.36eclipse.jdt.debug 0.741 67.17 56.24 0.82 68.56 58.33eclipse.jface 0.607 66.67 45 0.778 72 62eclipse.team.core 0.617 66.67 45 0.608 58.33 45eclipse.team.ui 0.74 73.33 70 0.883 83.33 75eclipse.update.core 0.794 86.67 56.83 0.817 81 64.17
Median 0.722 68.58 45.5 0.814 80.91 60.16
Table 2.6: AUC, Precision and Recall using Neural Nets (NN) with OO andIUC to classify interfaces into change-prone and not change-prone. Bold valueshighlights the best AUC value per project.
Project AUCOO POO ROO AUCIUC PIUC RIUC
eclipse.team.cvs.core 0.8 71.43 71.43 0.8 87.5 100eclipse.debug.core 0.85 80 80 0.875 91.67 70eclipse.debug.ui 0.748 79.33 44.67 0.766 78.05 58.5hibernate2 0.702 53.85 50 0.747 50 45hibernate3 0.874 83.17 69.52 0.843 78.49 69.05eclipse.jdt.debug 0.77 73.39 63.24 0.762 80.5 58.05eclipse.jface 0.553 0 0 0.542 0 0eclipse.team.core 0.725 53.33 50 0.85 61.11 63.33eclipse.team.ui 0.65 83.33 75 0.75 78.95 75eclipse.update.core 0.675 70 58.33 0.744 78.33 56.67
Median 0.736 72.41 60.78 0.764 78.41 60.69
The IUC metric improves the performance of prediction models to classifychange- and not change-prone interfaces. The models trained with the SupportVector Machine (LibSVN) and NBayes using the IUC metric set outperformedthe models computed with the OO metric set in eight out of ten projects. Usingthe NN learner, the models of seven projects showed better performance withthe IUC metric set. This improvement in performance is significant for themodels trained with the Support Vector Machine (LibSVN), however not forthe other two learners. Therefore, we partially accepted H2.

34 Chapter 2. Change-Prone Java Interfaces
2.4 DiscussionThis section discusses the implications of our results and the threats to validity.
2.4.1 Implications of ResultsThe implications of the results of our study are interesting for researchers,quality engineers and, in general, for developers and software architects.
The results of our study can be used by researchers interested in investi-gating software systems through the analysis of source code metrics. Studiesbased on source code metrics should take into account the nature of the enti-ties that are measured. This can help to obtain more accurate results.
Quality engineers should consider the possibility to enlarge their metricsuite. In particular, the set of metrics should include specific metrics for mea-suring the cohesion of interfaces, such as the IUC metric. The C&K metrics arelimited in measuring this cohesion of interfaces.
Finally, developers and software architects should use the IUC metric tomeasure the conformance to the ISP. Our results showed that low IUC values,indicating a violation of the ISP, can increase the effort needed to maintainsoftware systems.
2.4.2 Threats to ValidityWe consider the following threats to validity: construct, internal, conclusion,external and reliability validity. Threats to construct validity concern the re-lationship between theory and observation. In our study, this threat can bedue to the fact that we measured the metrics on the last version of the sourcecode. Previous studies in literature also used metrics collected from a singlerelease (e.g., [Mauczka A., 2009] [Alshayeb and Li, 2003]). We mitigated thisthreat by collecting the metrics from the last release, since this release reflectsthe history of a system. Nevertheless, we believe that further validation withmetrics measured over time (i.e., from different releases) is desirable.
Threats to internal validity concern factors that may affect an independentvariable. In our study, the independent variables (values of the metrics and#SCC) are computed using deterministic algorithms (provided by the Under-stand and Evolizer tools) that always deliver the same results.
Threats to conclusion validity concern the relationship between the treat-ment and the outcome. Wherever possible, we used proper statistical tests tosupport our conclusions for the two research questions. We used the Spear-man correlation, which does not make any assumption on the underlying datadistribution to test H1. To address H2 we selected a set of three machine learn-

2.5. Related Work 35
ing techniques. Further techniques can be applied to build predictive models,even though previous work [Lessmann et al., 2008] states that performancedifferences among classifiers are not significant.
Threats to external validity concern the generalization of our findings. Inour study, this threat can be due to the fact that eight out of ten projects stemfrom the Eclipse platform. Therefore, the generalizability of our findings andconclusions should be verified for other projects. Nevertheless, we consideredsystems of different size and different roles in the Eclipse platform. Eclipse hasbeen widely used by the scientific community and we can compare our find-ings with previous work. Moreover, we added two projects from Hibernate.As a matter of fact, any result from empirical work is in general threatened bythe bias of their datasets [Menzies et al., 2007].
Threats to reliability validity concern the possibility of replicating our studyand obtaining consistent results. The analyzed systems are open source sys-tems and hence publicly available; the tools used to implement our approach(Evolizer and ChangeDistiller) are available from the reported web sites.
2.5 Related WorkIn this section, we discuss previous work related to the usage of change pre-diction models to guide and understand maintenance of software systems.
Rombach was among the first researchers to investigate the impact ofsoftware structure on maintainability aspects [Rombach, 1987], [Rombach,1990]. He focused on comprehensibility, locality, modifiability, and reusabilityin a distributed system environment, highligthing the impact of the intercon-nectivity between components.
In literature several approaches used source code metrics to predict thechange-prone classes. Khoshgoftaar and Szabo [1994] presented an approachto predict maintenance measured as lines changed. They trained a regressionmodel and a neural network using size and complexity metrics. Li and Henryused the C&K metrics to predict maintenance in terms of lines changed [Liand Henry, 1993]. The results show that these metrics can significantly im-prove a prediction model compared to traditional metrics. In 2009, Mauczkaet al. measured the relationship of code changes with source-level softwaremetrics [Mauczka A., 2009]. This work focuses on evaluating the C&K met-rics suite against failure data. Zhou et al. [2009] used three size metrics toexamine the potentially confounding effect of class size on the associationsbetween object-oriented metrics and change-proneness. A further validationof the object-oriented metrics was provided by Alshayeb and Li [2003]. This

36 Chapter 2. Change-Prone Java Interfaces
work highlights the capability of those metrics in two different iterative pro-cesses. The results show that the object-oriented metrics are effective in pre-dicting design efforts and source lines modified in the short-cycled agile pro-cess. On the other hand they are ineffective in predicting the same aspects inthe long-cycled framework process.
Object-oriented metrics were not only successfully applied for mainte-nance but als for defect prediction. Basili et al. [1996] empirically investi-gated the suite of object-oriented design metrics as predictors of fault-proneclasses. Subramanyam and Krishnan [2003] validated the C&K metrics suitein determining software defects. Their findings show that the effects of thosemetrics on defects vary across the data set from two different programminglanguages, C++ and Java.
Besides the correlation between metrics and change proneness, other de-sign practices have been investigated in correlation with the number of changes.Khomh et al. [2009] investigated the impact of classes with code smells onchange-proneness. They showed that classes with code smells are more change-prone than classes without and that specific smells are more correlated thanothers. Penta et al. [2008] developed an exploratory study to analyze thechange-proneness of design patterns and the kinds of changes occurring toclasses involved in design patterns.
A complementary branch of change prediction is the detection of changecouplings. Shirabad et al. [2003] used a decision tree to identify files thatare change coupled. Zimmermann et al. [2004] developed the ROSE tool thatsuggests change coupled source code entities to developers. They are ableto detect coupled entities on a fine-grained level. Robbes et al. [2008] usedfine-grained source changes to detect several kinds of distinct logical couplingsbetween files. Canfora et al. [2010] use the multivariate time series analysisand forecasting to determine whether a change occurred on a software artifactwas consequentially related to changes on other artifacts.
Our work is complementary to the existing work since (1) we explore lim-itations of the C&K metrics in predicting the change-prone Java interfaces; (2)we investigate the impact of the ISP violation as measured by the IUC metricon the change-proneness of interfaces.
2.6 Conclusions and Future WorkInterfaces declare contracts that are meant to remain stable during the evolu-tion of a software system while the implementation in concrete classes is morelikely to change. This leads to a different evolutionary behavior of interfaces

2.6. Conclusions and Future Work 37
compared to concrete classes.
In this chapter, we empirically investigated this behavior with the C&Kmetrics that are widely used to evaluate the quality of the implementation ofclasses and interfaces. The results of our study with eight Eclipse plug-in andtwo Hibernate projects showed that:
• The IUC metric shows a stronger correlation with #SCC than the C&Kmetrics when applied to interfaces (we accepted H1)
• The IUC metric can improve the performance of prediction models inclassifying Java interfaces into change-prone and not change-prone (wepartially accepted H2)
Our findings provide a starting point for studying the quality of interfacesand the impact of design violations, such as the ISP, on the maintenance ofsoftware systems. In particular, the acceptance of the hypothesis H1 implicatesengineers should measure the quality of interfaces with specific interface co-hesion metrics. Software designers and architects should follow the interfacedesign principles, in particular the ISP. Furthermore, researchers should con-sider distinguishing between classes and interfaces when investigating modelsto estimate and predict the change-prone interfaces.
In future work, we plan to evaluate the IUC metric with more open sourceand also commercial software systems. Furthermore, we plan to analyze theperformance of our models taking into account releases (train the model witha previous release to predict the change-prone interfaces of the next release).Another direction of future work is to apply our models to other types of sys-tems, such as Component Based Systems (CBS) and Service Oriented Systems(SOS), in which interfaces play a fundamental role.
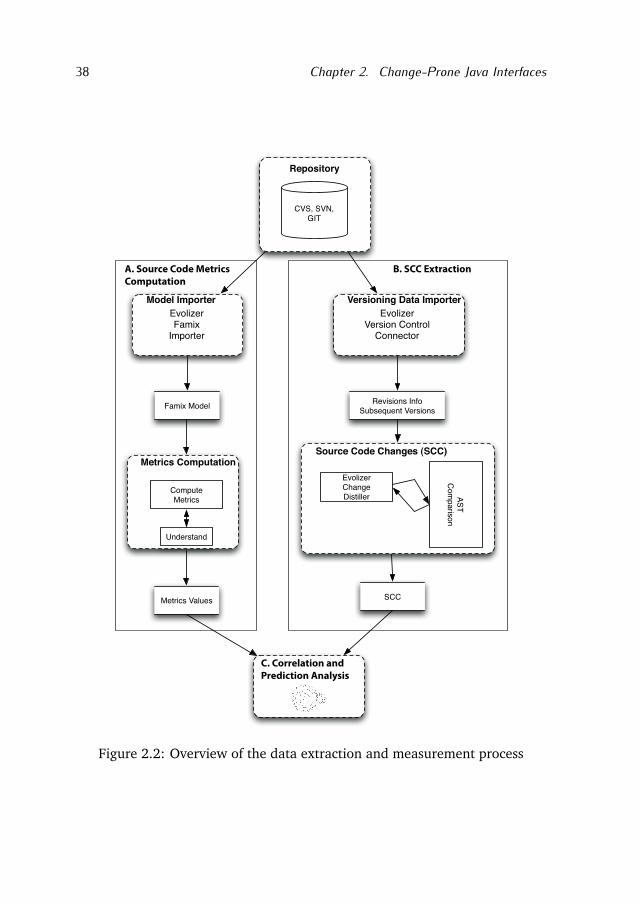
38 Chapter 2. Change-Prone Java Interfaces
C. Correlation and Prediction Analysis
A. Source Code MetricsComputation
B. SCC Extraction
Figure 2.2: Overview of the data extraction and measurement process
2.6. Conclusions and Future Work 39
Class
Method
Inheritance
InvocationAccess
Attribute
Superclass
SubclassBelongsToClass
BelongsToClass
InvokedBy
InvokesAccessedIn
Accesses
Figure 2.3: Core of the FAMIX meta model [Tichelaar et al., 2000]
#SCC
160
150
140
130
120
110
100
90
80
70
60
50
40
30
20
10
0
Project
eclipse.update.core
eclipse.team.ui
eclipse.team.cvs.core
eclipse.team.core
eclipse.jface
eclipse.jdt.debug
eclipse.debug.ui
eclipse.debug.core
hibernate3
Hibernate2
interfaceclassType
Figure 2.4: Box plots of the #SCC of interfaces and classes per project
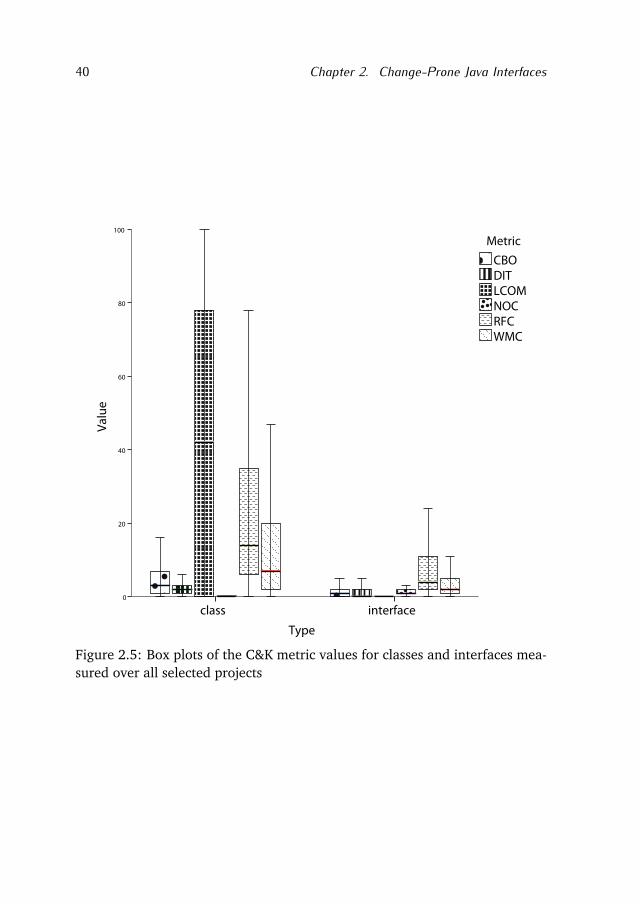
40 Chapter 2. Change-Prone Java Interfaces
Typeinterfaceclass
Value
100
80
60
40
20
0
WMCRFCNOCLCOMDITCBO
Metric
Figure 2.5: Box plots of the C&K metric values for classes and interfaces mea-sured over all selected projects

3..Change-Prone Java APIs
Antipatterns are poor solutions to design and implementation problems whichare claimed to make object oriented systems hard to maintain. Recent studiesshowed that classes with antipatterns change more frequently than classes with-out antipatterns. In this chapter, we detail these analyses by taking into accountfine-grained source code changes (SCC) extracted from 16 Java open source sys-tems. In particular we investigate: whether classes with antipatterns are morechange-prone (in terms of SCC) than classes without; (2) whether the type of an-tipattern impacts the change-proneness of Java classes; and (3) whether certaintypes of changes are performed more frequently in classes affected by a certainantipattern.
Our results show that: 1) the number of SCC performed in classes affectedby antipatterns is statistically greater than the number of SCC performed inclasses with no antipattern; 2) classes participating in the three antipatternsComplexClass, SpaghettiCode, and SwissArmyKnife are more change-prone thanclasses affected by other antipatterns; and 3) certain types of changes are morelikely to be performed in classes affected by certain antipatterns, such as APIchanges are likely to be performed in classes affected by the ComplexClass,SpaghettiCode, and SwissArmyKnife antipatterns.1
3.1 Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.2 Empirical Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.3 Threats to Validity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.4 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.5 Conclusion and Future Work . . . . . . . . . . . . . . . . . . . . . . . . 60
Over the past two decades, maintenance costs have grown to more than50% and up to 90% of the overall costs of software systems [Erlikh, 2000].To help reduce the cost of maintenance, researchers have proposed several
1This chapter was published in the 19th Working Conference on Reverse Engineering (WCRE2012) [Romano et al., 2012].
41

42 Chapter 3. Change-Prone Java APIs
approaches to ease program comprehension, and identify change- and bug-prone parts of the source code of software systems. These approaches includesource code metrics (e.g., [Mauczka A., 2009]) and heuristics to assess thedesign of a software system (e.g., [Posnett et al., 2011; Khomh et al., 2012;Thummalapenta et al., 2010]).
Recently, Khomh et al. analyzing the impact of antipatterns on the change-proneness of software units [Khomh et al., 2012]. Antipatterns [Brown et al.,1998] are “poor” solutions to design and implementation problems. In con-trast to design patterns [Gamma et al., 1995] which are “good" solutions torecurring design problems. Antipatterns are typically introduced in softwaresystems by developers lacking the adequate knowledge or experience in solv-ing a particular problem or having misapplied some design patterns. Coplienand Harrison [2005] described an antipattern as “something that looks like agood idea, but which back-fires badly when applied”. Previous studies, such asours [Khomh et al., 2012], support this description by showing that softwareunits, i.e., classes, affected by antipatterns are more likely to undergo changesthan other units.
Existing literature proposes many different antipatterns, such as the 40 an-tipatterns described by Brown et al. [1998]. Furthermore, antipatterns occurin large numbers and affect large portions of some software systems. For in-stance, we found that more than 45% of the classes in the systems studied in[Khomh et al., 2012] contained at least one antipattern. Because of the diver-sity and the large number of antipatterns, support is needed, for instance bysoftware engineers, to identify the risky classes affected by antipatterns thatlead to errors and increase development and maintenance costs. For this, weneed to obtain a deeper understanding of the change-proneness of differentantipatterns and the types of changes occurring in classes affected by them.Providing this deeper understanding is the main objective of this chapter.
In this chapter we investigate the extent to which antipatterns can be usedas indicators of changes in Java classes. The goal of this study is to investigatewhich antipattern is more likely to lead to changes and which types of changesare likely to appear in classes affected by certain antipatterns. Differently toexisting studies (i.e., [Khomh et al., 2009, 2012]), the approach of our studyis based on the analysis of fine-grained source code changes (SCC) minedfrom version control systems [Fluri et al., 2007; Gall et al., 2009]. This ap-proach allows us to analyze the types of changes performed in classes affectedby a particular antipattern which was not possible with previous approaches.Moreover, we take into account the significance of the change types [Fluri andGall, 2006] and we filter out irrelevant change types (e.g., changes to com-

43
ments and copyrights), that account for more than 10% of all changes in ourdataset.
Using the data of fine-grained source code changes and antipatterns, weaim at providing answers to the following three research questions:
• RQ1: Are Java classes affected by antipatterns more change-prone thanJava classes not affected by any antipattern?This research question is aimed at replicating the previous study [Khomhet al., 2012] with fine-grained source code changes (SCC).
• RQ2: Are Java classes affected by certain types of antipatterns morechange-prone than Java classes affected by other antipatterns – i.e., doesthe type of antipattern impact change-proneness?The results from this research question can assist software engineers inidentifying the risky classes affected by antipatterns.
• RQ3: Are particular types of changes more likely to be performed inJava classes affected by certain types of antipatterns?The results of this question will assist software engineers in prioritizingantipatterns that need to be resolved to prevent certain types of changesin a system. For example changes in the method declarations of a classexposing a public API.
To answer our research questions, we perform an empirical study with dataextracted from 16 Java open-source software systems. Our main outcomesare:
• The number of SCC performed in classes affected by antipatterns is sta-tistically greater than the number of SCC performed in other classes.
• Classes affected by ComplexClass, SpaghettiCode, and SwissArmyKnifeare more change-prone than classes affected by other antipatterns.
• Changes in APIs are more likely to appear in classes affected by the Com-plexClass, SpaghettiCode, and SwissArmyKnife; methods are more likelyto be added/deleted in classes affected by ComplexClass and Spaghetti-Code; changes in executable statements are likely in AntiSingleton, Com-plexClass, SpaghettiCode, and SwissArmyKnife; changes in conditionalstatements and else-parts are more likely in classes affected by Spaghet-tiCode.

44 Chapter 3. Change-Prone Java APIs
These findings suggest that software engineers should consider detect-ing and resolving instances of certain antipatterns to prevent certain typesof changes. For instance, they should resolve instances of the ComplexClass,SpaghettiCode, and SwissArmyKnife to prevent frequent changes in the APIs.
The remainder of this chapter is organized as follows. Section 3.1 de-scribes the approach used to mine fine-grained source code changes and todetect Java classes participating in antipatterns. The study design and ourfindings are presented in Section 3.2. Section 3.3 discusses threats to the va-lidity of the results of our study. Section 3.4 presents related work. We drawour conclusions and outline directions for future work in Section 3.5.
3.1 Data CollectionIn this section, we describe the approach used to gather the data needed toperform our study. The data consist of the fine-grained source code changes(SCC), performed in each Java class along the history of the systems underanalysis, and the type and number of antipatterns in which a class participatesduring its evolution. Figure 3.1 shows an overview of our approach consistingof 4 steps. In the following we describe each step in details.
3.1.1 Importing Versioning DataThe first step concerns retrieving the versioning data for the Java classes fromthe version control systems (e.g., CVS, SVN or GIT). To perform this step weuse the Evolizer Version Control Connector (EVCC) [Gall et al., 2009], belong-ing to the Evolizer2 tool set. For each class EVCC fetches and parses the logentries from the versioning repository. Per log entry, EVCC extracts the revisionnumbers, the revision timestamps, the name of the developers who checked-inthe revision, the commit messages, the total number of lines modified, and thesource code. This information plus the source code of each revision of Javaclass is stored into the Evolizer repository.
3.1.2 Fine-Grained Source Code Changes ExtractionIn the second step, ChangeDistiller is used [Fluri et al., 2007] to extract thefine-grained source code changes (SCC) between the subsequent versions of aJava class. ChangeDistiller first parses the source code from the two subse-quent versions of a Java class and creates the corresponding Abstract SyntaxTrees (ASTs). Second, the two ASTs are compared using a tree differencingalgorithm that outputs the differences in form of the tree-edit operations add,
2http://www.evolizer.org/

3.1. Data Collection 45
1. Versioning Data Importer
Source CodeRepository
Revision InfoSubsequent Versions Classes affected
by antipatterns
3. AntipatternsDetector
2. Fine-Grained Source Code
Changes Extractor
4. Data Preparation
Fine-grained source code changes (SCCs)
Figure 3.1: Overview of the approach to extract fine-grained source codechanges and antipatterns for Java classes.
delete, update, and move. Next, each edit operation for a given node in theAST is annotated with the semantic information of the source code entity itrepresents and is classified as a specific change type based on a taxonomy ofcode changes [Fluri and Gall, 2006]. For instance, the insertion of a noderepresenting an else-part in the AST is classified as else-part insertchange type. The result is a list of change types between two subsequentversions of each Java class which is stored into the Evolizer repository.
3.1.3 Antipatterns DetectionThe third step of our approach is detecting the antipatterns that occur in Javaclasses. This is achieved by DECOR (Defect dEtection for CORrection) [Mohaet al., 2008a,b, 2010]. DECOR provides a domain-specific language to de-scribe antipatterns through a set of rules (e.g., lexical, structural, internal,etc.) and an algorithm to detect antipatterns’ in Java classes.
We use the predefined specifications of antipatterns and run DECOR on

46 Chapter 3. Change-Prone Java APIs
the different source code releases of our systems under analysis. Among theantipatterns detectable with DECOR we select the following twelve antipat-terns:
• AntiSingleton: A class that provides mutable class variables, which con-sequently could be used as global variables.
• Blob: A class that is too large and not cohesive enough, that monopolisesmost of the processing, takes most of the decisions, and is associated todata classes.
• ClassDataShouldBePrivate (CDSBP): A class that exposes its fields, thusviolating the principle of encapsulation.
• ComplexClass (ComplexC): A class that has (at least) one large and com-plex method, in terms of cyclomatic complexity and LOCs.
• LazyClass (LazyC): A class that has few fields and methods (with littlecomplexity).
• LongMethod (LongM): A class that has a method that is overly long, interm of LOCs.
• LongParameterList (LPL): A class that has (at least) one method with atoo long list of parameters with respect to the average number of pa-rameters per methods in the system.
• MessageChain (MsgC): A class that uses a long chain of method invoca-tions to realise (at least) one of its functionality.
• RefusedParentBequest (RPB): A class that redefines inherited methodusing empty bodies, thus breaking polymorphism.
• SpaghettiCode (Spaghetti): A class declaring long methods with no pa-rameters and using global variables. These methods interact too muchusing complex decision algorithms. This class does not exploit and pre-vents the use of polymorphism and inheritance.
• SpeculativeGenerality (SG): A class that is defined as abstract but thathas very few children, which do not make use of its methods.
• SwissArmyKnife (Swiss): A class whose methods can be divided in dis-junct set of many methods, thus providing many different unrelatedfunctionalities.

3.1. Data Collection 47
Per release, we obtain a list of detected antipatterns for each Java class.We choose this subset of antipatterns because (1) they are well-described byBrown et al. [1998], (2) they appear frequently in the different releases of thesystems under analysis and (3) they are representative of design and imple-mentation problems with data, complexity, size, and the features provided byJava classes. Moreover they allow us to compare our findings with those of aprevious study [Khomh et al., 2012].
3.1.4 Data PreparationIn this step, the fine-grained source code changes are grouped and linked withthe antipatterns. ChangeDistiller currently supports more than 40 types ofsource code changes that cover the majority of modifications to entities ofobject oriented programming languages [Fluri and Gall, 2006]. We groupthese change types into five categories. Grouping them facilitates the analysisof the contingency between different types of changes and the interpretationof the results.
Table 3.1: Categories of source code changes [Giger et al., 2011].
Category Description
API
Changes that involve the declaration ofclasses (e.g., class renaming and class APIchanges) and the signature of methods(e.g., modifier changes, method renaming,return type changes, changes of the param-eter list).
oStateChanges that affect object states of classes(e.g., fields addition and deletion).
funcChanges that affect the functionality of aclass (e.g., methods addition and deletion)
stmtChanges that modify executable state-ments (e.g., statements insertion and dele-tion)
condChanges that alter condition expressions incontrol structures and the modification ofelse-parts
The different categories are shown in Table 3.1 together with a short de-scription of each category. Per Java class revision we count the number ofchanges for each category. Per Java class we compute the sum for each changetype category over the Java class revisions between two subsequent releasesk and k+1. Finally, for each Java class we add the number of antipatternsdetected in the Java class at release k. We did not normalize the number of

48 Chapter 3. Change-Prone Java APIs
changes in classes by the number of lines of code, because we wanted ourresults to be comparable to previous studies. Furthermore, one of previousstudies [Khomh et al., 2012] has shown that size alone is not the dominatingfactor affecting the change proneness of classes with antipatterns.
The resulting list contains for each release k a list of Java classes withthe number of detected instances of the twelve antipatterns at release k plusthe number of fine-grained changes per change type category that occurredbetween the two subsequent releases k and k+1. The analyses performed onthese data will be described in the next section.
3.2 Empirical StudyThe goal of this empirical study is to investigate the association between an-tipatterns and the change proneness of Java classes. We performed the empir-ical study with 16 open-source systems from different domains, implementedin Java and widely used in academic and industrial communities. Table 3.2shows an overview of the dataset. #Files denotes the number of Java files inthe last release, #Releases denotes the number of releases analyzed, #SCC de-notes the number of fine-grained source code changes in the given time period(Time) and #SCC’ denotes the number of fine-grained source code changeswithout counting changes performed in the comments and copyrights. In to-tal, changes due to comments and copyrights modifications account for ap-proximately 11% of all the changes (i.e., 64021 out of 585614). This highpercentage highlights the necessity to filter out changes related to commentsand copyrights, in order to avoid biasing the results.
Table 3.3 shows the number of antipatterns detected by DECOR in thefirst and last release of the analyzed systems. Basically, all systems containinstances of most of the 12 antipatterns. In particular, rapid miner and vuzecontain the largest number of antipatterns which is not surprising since theyalso are the largest systems in our sample set. According to our numbers, theantipatterns LongMethod (LongM), MessageChain (MsgC), and RefusedParent-Bequest (RPB) occur most frequently while SpaghettiCode (Spaghetti), Specu-latigeGenerality (SG), and SwissAmryKnife (Swiss) occur less frequently. Over-all, the frequency of antipatterns and changes allows us to investigate thethree research questions stated at the beginning of this chapter.
The raw data used to perform our analysis are available on our web site.3
In the following, we state the hypotheses, explain the analysis methods, and
3http://swerl.tudelft.nl/twiki/pub/DanieleRomano/WebHome/WCRE12rawData.zip

3.2. Empirical Study 49
Table 3.2: Dataset used in our empirical study.
System #Files #Releases #SCC #SCC’ Time [M,Y]argo 1716 9 97767 79414 Oct02-Mar09hibernate2 494 10 26099 23638 Jan03-Mar11hibernate3 970 20 37271 34440 Jun04-Mar11eclipse.debug.core 188 12 7600 6555 May01-Mar11eclipse.debug.ui 793 22 40551 37306 May01-Mar11eclipse.jface 381 17 14072 11789 Sep02-Mar11eclipse.jdt.debug 469 16 14983 13647 Jun01-Mar11eclipse.team.core 172 6 2318 1790 Nov01-Mar11eclipse.team.cvs.core 189 11 13070 11544 Nov01-Mar11eclipse.team.ui 293 13 9787 8948 Nov01- Mar11jabref 1996 30 41665 37983 Dec03-Oct11mylyn 1288 17 67050 63601 Dec06-Jun09rhino 184 8 14795 13693 May99-Aug07rapidminer 2061 4 9899 9277 Oct09-Aug10vuze 3265 29 119138 113570 Dec06-Apr10xerces 710 20 69549 54398 Dec00-Dec12
report on the results for each research question.
3.2.1 Investigation of RQ1The goal of RQ1 is to analyze the change-proneness of Java classes affectedby antipatterns, compared to the change-proneness of classes not affected byantipatterns. We address RQ1 by testing the following two null hypotheses:
• H1a: The proportion of classes changed at least once between two re-leases is not different between classes that are affected by antipatternsand classes not affected by antipatterns.
• H1b: The distribution of SCC performed in classes between two releasesis not different for classes affected by antipatterns and classes not af-fected by antipatterns.
Analysis MethodFor investigating H1a we classify the Java classes of each system and releasek into change-prone if there was at least one change in between two subse-quent releases (k and k+1). Otherwise they are classified as not change-prone.This binary variable (we refer to it as change-proneness(k,k+1)) denotes thedependent variable. As independent variable we also use a binary variable thatdenotes whether a Java class is affected by at least one antipattern in a givenrelease k. We refer to this variable as antipatterns(k).
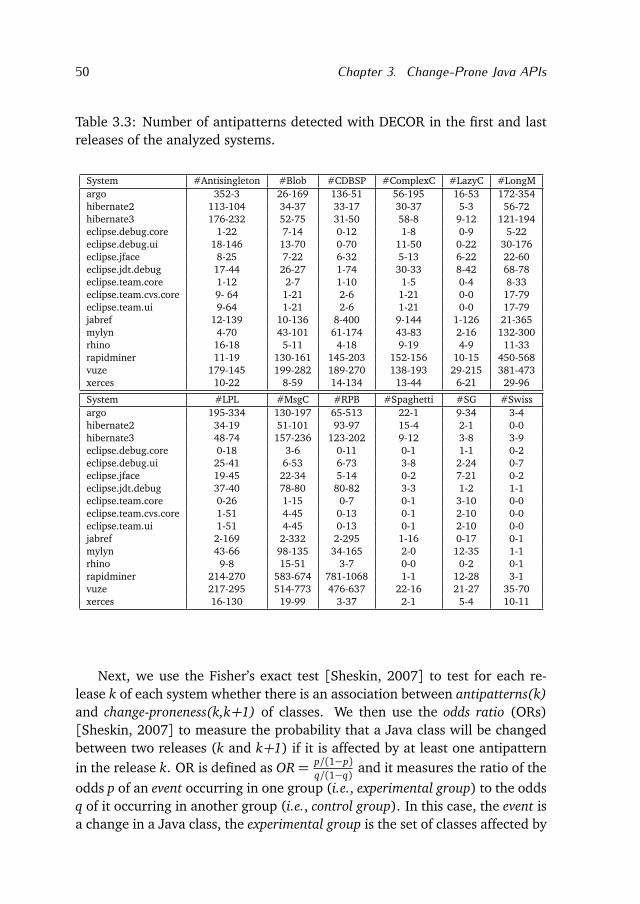
50 Chapter 3. Change-Prone Java APIs
Table 3.3: Number of antipatterns detected with DECOR in the first and lastreleases of the analyzed systems.
System #Antisingleton #Blob #CDBSP #ComplexC #LazyC #LongMargo 352-3 26-169 136-51 56-195 16-53 172-354hibernate2 113-104 34-37 33-17 30-37 5-3 56-72hibernate3 176-232 52-75 31-50 58-8 9-12 121-194eclipse.debug.core 1-22 7-14 0-12 1-8 0-9 5-22eclipse.debug.ui 18-146 13-70 0-70 11-50 0-22 30-176eclipse.jface 8-25 7-22 6-32 5-13 6-22 22-60eclipse.jdt.debug 17-44 26-27 1-74 30-33 8-42 68-78eclipse.team.core 1-12 2-7 1-10 1-5 0-4 8-33eclipse.team.cvs.core 9- 64 1-21 2-6 1-21 0-0 17-79eclipse.team.ui 9-64 1-21 2-6 1-21 0-0 17-79jabref 12-139 10-136 8-400 9-144 1-126 21-365mylyn 4-70 43-101 61-174 43-83 2-16 132-300rhino 16-18 5-11 4-18 9-19 4-9 11-33rapidminer 11-19 130-161 145-203 152-156 10-15 450-568vuze 179-145 199-282 189-270 138-193 29-215 381-473xerces 10-22 8-59 14-134 13-44 6-21 29-96
System #LPL #MsgC #RPB #Spaghetti #SG #Swissargo 195-334 130-197 65-513 22-1 9-34 3-4hibernate2 34-19 51-101 93-97 15-4 2-1 0-0hibernate3 48-74 157-236 123-202 9-12 3-8 3-9eclipse.debug.core 0-18 3-6 0-11 0-1 1-1 0-2eclipse.debug.ui 25-41 6-53 6-73 3-8 2-24 0-7eclipse.jface 19-45 22-34 5-14 0-2 7-21 0-2eclipse.jdt.debug 37-40 78-80 80-82 3-3 1-2 1-1eclipse.team.core 0-26 1-15 0-7 0-1 3-10 0-0eclipse.team.cvs.core 1-51 4-45 0-13 0-1 2-10 0-0eclipse.team.ui 1-51 4-45 0-13 0-1 2-10 0-0jabref 2-169 2-332 2-295 1-16 0-17 0-1mylyn 43-66 98-135 34-165 2-0 12-35 1-1rhino 9-8 15-51 3-7 0-0 0-2 0-1rapidminer 214-270 583-674 781-1068 1-1 12-28 3-1vuze 217-295 514-773 476-637 22-16 21-27 35-70xerces 16-130 19-99 3-37 2-1 5-4 10-11
Next, we use the Fisher’s exact test [Sheskin, 2007] to test for each re-lease k of each system whether there is an association between antipatterns(k)and change-proneness(k,k+1) of classes. We then use the odds ratio (ORs)[Sheskin, 2007] to measure the probability that a Java class will be changedbetween two releases (k and k+1) if it is affected by at least one antipatternin the release k. OR is defined as OR= p/(1−p)
q/(1−q) and it measures the ratio of theodds p of an event occurring in one group (i.e., experimental group) to the oddsq of it occurring in another group (i.e., control group). In this case, the event isa change in a Java class, the experimental group is the set of classes affected by

3.2. Empirical Study 51
at least one antipattern and the control group is the set of classes not affectedby any antipattern. ORs equal to 1 indicate that a change can appear with thesame probability in both groups. ORs greater than 1 indicate that the changeis more likely to appear in a class affected by at least one antipattern. ORs lessthan 1 indicate that classes not affected by antipatterns are more likely to bechanged.
Concerning H1b we use the Mann-Whitney test to analyze for each re-lease k whether there is a significant difference in the distributions of#SCC(k,k+1) performed in Java classes affected by antipatterns and in Javaclasses not affected by any antipattern. We apply the Cliff’s Delta d effect size[Grissom and Kim, 2005] to measure the magnitude of the difference. Cliff’sDelta estimates the probability that a value selected from one group is greaterthan a value selected from the other group. Cliff’s Delta ranges between +1if all selected values from one group are higher than the selected values inthe other group and -1 if the reverse is true. 0 expresses two overlappingdistributions. The effect size is considered negligible for d < 0.147, small for0.147 ≤ d < 0.33, medium for 0.33 ≤ d < 0.47 and large for d ≥ 0.47 [Gris-som and Kim, 2005]. We chose the Mann-Whitney test and Cliff’s Delta effectsize because the values of the SCC per class are non-normally distributed.Furthermore, our different levels (small, medium, and large) facilitate the in-terpretation of the results. The Cliff’s Delta effect size has been computed withthe orddom package4 available for the R environment.5
ResultsThe odds ratios computed to test H1a are summarized in Table 3.4. Table 3.4shows for each system the total number of releases (#Releases) and the num-ber of releases that showed a p-value for the Fisher’s exact test smaller than0.01 and odds ratios greater than 1 (ORs>1). The results show that, except forthree systems (eclipse.team.cvs.core, jabref and rhino), in most of the analyzedreleases, Java classes affected by at least one antipattern are more change-prone than other classes. In total, for 190 out of 244 releases (≈82%), classesaffected by at least one antipattern are more change-prone. These resultsallow us to reject H1a and accept the alternative hypothesis that Java classesaffected by antipatterns are more likely to be changed than classes not affectedby them.
Table 3.5 shows the p-values of the Mann-Whitney tests and values of theCliff’s Delta d effect size for testing H1b. Only in 18 releases (≈7%) there is
4http://cran.r-project.org/web/packages/orddom/index.html5http://www.r-project.org/

52 Chapter 3. Change-Prone Java APIs
Table 3.4: Total number of releases (#Releases) and number of releasesfor which Fisher’s exact test and OR show a significant association betweenchange-proneness and antipatterns in Java classes.
System #Releases Fisher p-value < 0.01 & OR >1argo 9 9hibernate2 10 10hibernate3 20 19eclipse.debug.core 12 8eclipse.debug.ui 22 20eclipse.jface 17 16eclipse.jdt.debug 16 16eclipse.team.core 6 4eclipse.team.cvs.core 11 5eclipse.team.ui 13 9jabref 30 3mylyn 17 17rhino 8 2rapidminer 4 4vuze 29 29xerces 20 19Total 244 190
no significant difference (Mann-Whitney p-value≥0.01) between the distribu-tions of SCC performed in classes affected by antipatterns and in other classes.In the other 226 releases (≈93%) the difference is significant (Mann-Whitneyp-value<0.01). Concerning the effect size we found that this difference issmall (0.147≤d<0.33) in 102 releases (≈42%), medium (0.33≤d<0.47) in26 releases (≈11%), large (0.47≤d) in 9 releases (≈4%) and negligible (d <0.147) in 89 releases (≈36%). Based on these results we reject H1b and ac-cept the alternative hypothesis that in most cases Java classes with antipat-terns undergo more changes during the next release than classes that are freeof antipatterns.
Based on these findings we can answer RQ1: Java classes affected by an-tipatterns are more change-prone than other classes. The results confirm thefindings of the previous study [Khomh et al., 2012], this time taking into ac-count the type of changes, and filtering out non source code changes such aschanges to indentations and comments.
3.2.2 Investigation of RQ2The goal of RQ2 is to test whether certain antipatterns lead to more changesin Java classes than other antipatterns. The basic idea is to assist software en-gineers in identifying the most change-prone classes affected by antipatterns.

3.2. Empirical Study 53
Table 3.5: p-values of the Mann-Whitney (M-W) tests and Cliff’s Delta d show-ing the magnitude of the difference between the distribution of SCC in classesaffected and not affected by antipatterns.
M-W<0.01 ≥0.01System #Releases 0.47≤d 0.33≤d<0.47 0.147≤d<0.33 d≤0.147argo 9 0 1 6 2 0hibernate2 10 0 1 6 3 0hibernate3 20 0 3 7 10 0eclipse.debug.core 12 4 2 4 1 1eclipse.debug.ui 22 0 0 14 8 0eclipse.jface 17 0 0 12 4 1eclipse.jdt.debug 16 0 1 8 5 2eclipse.team.core 6 0 1 3 0 2eclipse.team.cvs.core 11 1 3 4 3 0eclipse.team.ui 13 1 4 3 1 4jabref 30 0 3 11 16 0mylyn 17 0 2 9 6 0rhino 8 2 0 0 0 6rapidminer 4 0 0 0 4 0vuze 29 0 2 7 20 0xerces 20 1 3 8 6 2total 244 9 26 102 89 18
They should be resolved first. We address RQ2 by testing the following nullhypotheses:
• H2: The distribution of SCC is not different for classes affected by dif-ferent antipatterns.
Analysis MethodAs dependent variable we use the number of SCC performed in a class betweentwo releases #SCC(k,k+1). As independent variable we use a binary variablefor each antipattern that denotes whether a class is affected by a particularantipattern. To test H2 we use the Mann-Whitney test and Cliff’s Delta deffect size over all releases for a system. We selected all releases per systemsince some releases had too few data points (e.g., there have been only 6 SCCbetween releases 1.6R3 and 1.6R4 of Rhino). The orddom package used tocompute Cliff’s Delta d is not optimized for very big data sets. Therefore, incases of systems with more than 5000 data points (i.e., more than 5000 classesexperiencing changes over the revision history), we randomly sampled 5000data points 30 times and computed the average of the obtained Cliff’s Deltavalues. This sampling allows us to compute Cliff’s Delta values for each system
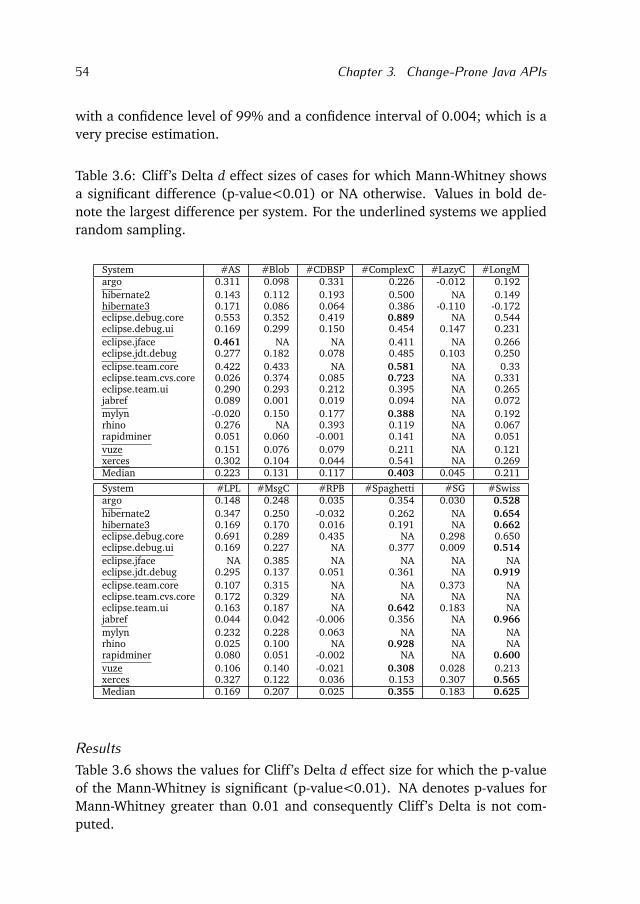
54 Chapter 3. Change-Prone Java APIs
with a confidence level of 99% and a confidence interval of 0.004; which is avery precise estimation.
Table 3.6: Cliff’s Delta d effect sizes of cases for which Mann-Whitney showsa significant difference (p-value<0.01) or NA otherwise. Values in bold de-note the largest difference per system. For the underlined systems we appliedrandom sampling.
System #AS #Blob #CDBSP #ComplexC #LazyC #LongMargo 0.311 0.098 0.331 0.226 -0.012 0.192hibernate2 0.143 0.112 0.193 0.500 NA 0.149hibernate3 0.171 0.086 0.064 0.386 -0.110 -0.172eclipse.debug.core 0.553 0.352 0.419 0.889 NA 0.544eclipse.debug.ui 0.169 0.299 0.150 0.454 0.147 0.231eclipse.jface 0.461 NA NA 0.411 NA 0.266eclipse.jdt.debug 0.277 0.182 0.078 0.485 0.103 0.250eclipse.team.core 0.422 0.433 NA 0.581 NA 0.33eclipse.team.cvs.core 0.026 0.374 0.085 0.723 NA 0.331eclipse.team.ui 0.290 0.293 0.212 0.395 NA 0.265jabref 0.089 0.001 0.019 0.094 NA 0.072mylyn -0.020 0.150 0.177 0.388 NA 0.192rhino 0.276 NA 0.393 0.119 NA 0.067rapidminer 0.051 0.060 -0.001 0.141 NA 0.051vuze 0.151 0.076 0.079 0.211 NA 0.121xerces 0.302 0.104 0.044 0.541 NA 0.269Median 0.223 0.131 0.117 0.403 0.045 0.211
System #LPL #MsgC #RPB #Spaghetti #SG #Swissargo 0.148 0.248 0.035 0.354 0.030 0.528hibernate2 0.347 0.250 -0.032 0.262 NA 0.654hibernate3 0.169 0.170 0.016 0.191 NA 0.662eclipse.debug.core 0.691 0.289 0.435 NA 0.298 0.650eclipse.debug.ui 0.169 0.227 NA 0.377 0.009 0.514eclipse.jface NA 0.385 NA NA NA NAeclipse.jdt.debug 0.295 0.137 0.051 0.361 NA 0.919eclipse.team.core 0.107 0.315 NA NA 0.373 NAeclipse.team.cvs.core 0.172 0.329 NA NA NA NAeclipse.team.ui 0.163 0.187 NA 0.642 0.183 NAjabref 0.044 0.042 -0.006 0.356 NA 0.966mylyn 0.232 0.228 0.063 NA NA NArhino 0.025 0.100 NA 0.928 NA NArapidminer 0.080 0.051 -0.002 NA NA 0.600vuze 0.106 0.140 -0.021 0.308 0.028 0.213xerces 0.327 0.122 0.036 0.153 0.307 0.565Median 0.169 0.207 0.025 0.355 0.183 0.625
ResultsTable 3.6 shows the values for Cliff’s Delta d effect size for which the p-valueof the Mann-Whitney is significant (p-value<0.01). NA denotes p-values forMann-Whitney greater than 0.01 and consequently Cliff’s Delta is not com-puted.

3.2. Empirical Study 55
The results of the Mann-Whitney tests show that, except for the LazyClassand SpeculativeGenerality (SG), the distributions of SCC performed in classesaffected by a specific antipattern are different from the distribution of SCCperformed in classes not affected by that antipattern. According to the medianvalues for Cliff’s Delta shown in the last row of Table 3.6, this difference islarge for SwissArmyKnife (Swiss), medium for 2 antipatterns (0.33≤d<0.47),small for 5 antipatterns (0.147≤d<0.33) and negligible for 4 antipatterns.Note, that for classes affected by LazyClass and SG the Mann-Whitney test wassignificant only in 4 and respectively 7 systems.
Looking at the values in bold we can see that classes affected by the Com-plexClass (ComplexC), SpaghettiCode (Spaghetti) and SwissArmyKnife (Swiss)antipatterns are more change-prone than classes affected by any other an-tipattern. More specifically, in 8 systems out of 16 the Cliff’s Delta effect sizeis highest for classes affected by SwissArmyKnife. In 4 systems the Cliff’s Deltaeffect size is higher for classes affected by ComplexClass. In the other 3 systemsthe highest effect size is for classes affected by SpaghettiCode. Only in one sys-tem, namely eclipse.jface, the Antisingleton antipattern shows the highest valuefor Cliff’s Delta.
Based on these results we reject H2 and we conclude that among allclasses the classes affected by the ComplexClass, SpaghettiCode, and Swis-sArmyKnife antipatterns are more change-prone. These results detail the find-ings in [Khomh et al., 2012] by highlighting three antipatterns that are morechange-prone than the other antipatterns. Moreover, the new findings allowus to advice software engineers to focus on detecting instances of these threechange-prone antipatterns and fix them first.
3.2.3 Investigation of RQ3To address RQ3, we analyze the relationship between different antipatternsand different types of changes. The goal is to further assist software engineersby verifying whether a particular type of changes is more likely to be per-formed in classes affected by a specific antipattern. This knowledge can helpengineers to avoid or fix certain antipatterns leading to changes that impactlarge parts of the rest of a software system, such as changes in the methoddeclarations of a class that exposes a public API. We answer RQ3 by testingthe following null hypothesis:
• H3: The distributions of different types of SCC performed in classesaffected by different antipatterns are not different.

56 Chapter 3. Change-Prone Java APIs
Analysis MethodTo test H3 we categorize the changes mined with ChangeDistiller in five differ-ent categories as listed in Table 3.1. As dependent variables we use the changetype categories representing the number of SCC that fall in each category. Asfor H2, the independent variables are the set of binary variables that denotewhether a class is affected by a specific antipattern or not. We test the differ-ence in the distributions of SCC per category using the Mann-Whitney test andcompute the magnitude of the difference with the Cliff’s Delta d effect size. Inorder to have enough data about each change type category we use the datafrom all systems as input for this analysis. Similar to H2, we use the randomsampling approach for computing Cliff’s Delta and we report the mean effectsize of the 30 random samples.
ResultsTable 3.7 lists the results of this analysis. Values in bold denotes differencesthat are at least small according to Cliff’s Delta. They show that changes inthe class and methods declaration (API) are more likely to appear in classesaffected by the ComplexClass, SpaghettiCode and SwissArmKnife antipatterns.Changes in the functionalities (func) are likely in classes affected by the Com-plexClass and SpaghettiCode antipatterns. Changes in the execution statements(stmt) are likely to appear in classes affected by the Antisingleton, Complex-Class, SpaghettiCode and SwissArmyKnife antipatterns. Finally, changes in thecondition expressions and else-parts (cond) are more frequent in classes af-fected by the SpaghettiCode antipattern. Based on these results we reject H3and conclude that classes affected by different antipatterns undergo differenttypes of changes.
3.2.4 Manual InspectionTo further highlight the relationship between antipatterns and change prone-ness we manually inspected several classes affected by antipatterns that havebeen resolved. For these classes we analyzed the number of changes beforeand after the removal of the antipatterns. The analysis clearly shows that whenclasses are affected by an antipattern they undergo a considerably higher num-ber of changes.For instance, the class org.apache.xerces.StandardParserConfiguration from theXerces system. This class was affected by the ComplexClass antipattern untilthe release 2.0.2. Before release 2.0.2, the class underwent on average 64.5changes per release. The average number of changes decreased to 5.2 after theantipattern was removed. Furthermore, the average number of API changesdecreased from 2 to 0.07.
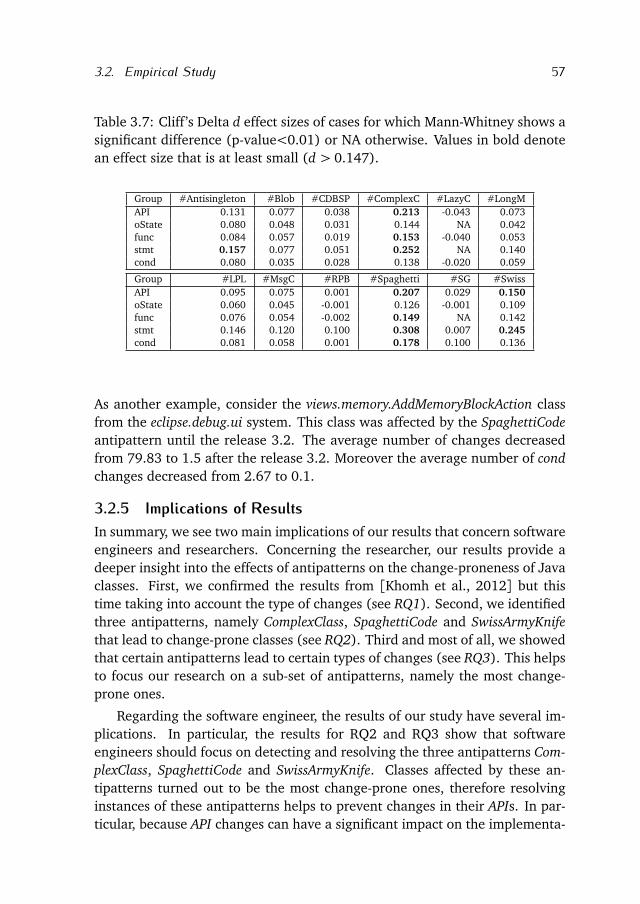
3.2. Empirical Study 57
Table 3.7: Cliff’s Delta d effect sizes of cases for which Mann-Whitney shows asignificant difference (p-value<0.01) or NA otherwise. Values in bold denotean effect size that is at least small (d > 0.147).
Group #Antisingleton #Blob #CDBSP #ComplexC #LazyC #LongMAPI 0.131 0.077 0.038 0.213 -0.043 0.073oState 0.080 0.048 0.031 0.144 NA 0.042func 0.084 0.057 0.019 0.153 -0.040 0.053stmt 0.157 0.077 0.051 0.252 NA 0.140cond 0.080 0.035 0.028 0.138 -0.020 0.059
Group #LPL #MsgC #RPB #Spaghetti #SG #SwissAPI 0.095 0.075 0.001 0.207 0.029 0.150oState 0.060 0.045 -0.001 0.126 -0.001 0.109func 0.076 0.054 -0.002 0.149 NA 0.142stmt 0.146 0.120 0.100 0.308 0.007 0.245cond 0.081 0.058 0.001 0.178 0.100 0.136
As another example, consider the views.memory.AddMemoryBlockAction classfrom the eclipse.debug.ui system. This class was affected by the SpaghettiCodeantipattern until the release 3.2. The average number of changes decreasedfrom 79.83 to 1.5 after the release 3.2. Moreover the average number of condchanges decreased from 2.67 to 0.1.
3.2.5 Implications of ResultsIn summary, we see two main implications of our results that concern softwareengineers and researchers. Concerning the researcher, our results provide adeeper insight into the effects of antipatterns on the change-proneness of Javaclasses. First, we confirmed the results from [Khomh et al., 2012] but thistime taking into account the type of changes (see RQ1). Second, we identifiedthree antipatterns, namely ComplexClass, SpaghettiCode and SwissArmyKnifethat lead to change-prone classes (see RQ2). Third and most of all, we showedthat certain antipatterns lead to certain types of changes (see RQ3). This helpsto focus our research on a sub-set of antipatterns, namely the most change-prone ones.
Regarding the software engineer, the results of our study have several im-plications. In particular, the results for RQ2 and RQ3 show that softwareengineers should focus on detecting and resolving the three antipatterns Com-plexClass, SpaghettiCode and SwissArmyKnife. Classes affected by these an-tipatterns turned out to be the most change-prone ones, therefore resolvinginstances of these antipatterns helps to prevent changes in their APIs. In par-ticular, because API changes can have a significant impact on the implementa-

58 Chapter 3. Change-Prone Java APIs
tion of the other parts of a software system therefore should be prevented.
For instance, consider the scenario in which APIs are made available throughweb services. The responsible software engineers want to assure the robust-ness of these classes to minimize the possibility of breaking the clients of theweb services. Based on the results of our study they can use DECOR to detectinstances of the ComplexClass, SpaghettiCode and SwissArmyKnife antipatternsin the set of API classes. These are the antipatterns they should resolve first inorder to reduce the probability that APIs are changed and, hence, that clientsare broken.
3.3 Threats to ValidityThis section discusses the threats to validity that can affect the results of ourempirical study.
Threats to construct validity concern the relationship between theory andobservation. In our study, this threat can be due to the fact that we consideredSCC performed in between two subsequent releases. However, the effects ofantipatterns can manifest themselves after the next immediate release when-ever the class affected by antipatterns needs to be changed. We mitigated thisthreat by testing all the hypotheses taking into account all the SCC performedafter a release for which we obtained similar results.
Threats to internal validity concern factors that may affect an indepen-dent variable. In our study, both the independent and dependent variablesare computed using deterministic algorithms (implemented in ChangeDistillerand DECOR) delivering always the same results.
Threats to conclusion validity concern the relationship between the treat-ment and the outcome. To mitigate these threats our conclusions have beensupported by proper statistical tests, in particular by non-parametric tests thatdo not require any assumption on the underlying data distribution.
Threats to external validity concern the generalization of our findings. Ev-ery result obtained through empirical studies is threatened by the bias of theirdatasets [Menzies et al., 2007]. To mitigate these threats we tested our hy-potheses over 16 open-source systems of different size and from different do-mains.
Threats to reliability validity concern the possibility of replicating our studyand obtaining consistent results. We mitigated these threats by providing allthe details necessary to replicate our empirical study. The systems under anal-ysis are open-source and the source code repositories are publicly available.

3.4. Related Work 59
Moreover, we published on-line the raw data to allow other researches to repli-cate our study and to test other hypotheses on our dataset.
3.4 Related WorkIn this section, we discuss the related literature on antipatterns in relation tosoftware evolution.
Code Smells/Antipatterns Detection Techniques. The first book on an-tipatterns in object-oriented development was written in Webster [1995]. Thebook made several contributions on conceptual, political, coding, and quality-assurance problems. Fowler [1999] defined 22 code smells, suggesting wheredevelopers should apply refactorings. Mantyla [2003] and Wake [2003] pro-posed classifications for code smells. Brown et al. [1998] described 40 antipat-terns, including the Blob, the Spaghetti Code, and the MessageChain. Thesebooks provide in-depth views on heuristics, code smells, and antipatterns, andare the basis of all approaches to detect (semi-)automatically code smells andantipatterns, such as DECOR [Moha et al., 2010] used in this study.
Several approaches to specify and detect code smells and antipatterns ex-ist in the literature. They range from manual approaches, based on inspec-tion techniques [Travassos et al., 1999], to metric-based heuristics [Mari-nescu, 2004; Munro, 2005; Oliveto et al., 2010], using rules and thresh-olds on various metrics or Bayesian belief networks [Khomh et al., 2011].Some approaches for complex software analysis use visualization [Dhambriet al., 2008; Simon et al., 2001]. Although visualization is sometimes con-sidered as an interesting compromise between fully automatic detection tech-niques, which are efficient but loose track of the context, and manual inspec-tions, which are slow and subjective [Langelier et al., 2005], visualization re-quires human expertise and is thus time-consuming. Sometimes, visualizationtechniques are used to present the results of automatic detection approaches[Lanza and Marinescu, 2006; van Emden and Moonen, 2002]. This previouswork significantly contributed to the specification and detection of antipat-terns. The approach used in this study, DECOR, builds on this previous work.
Code Smells/Antipatterns and Software Evolution. Deligiannis et al. [Ig-natios et al., 2003, 2004] proposed the first quantitative study of the relationbetween antipatterns and software quality. They performed a controlled ex-periments with 20 students on two software systems to understand the impactof Blobs on the understandability and maintainability of software systems. Theresults of their study suggested that Blob classes considerably affect the evolu-

60 Chapter 3. Change-Prone Java APIs
tion of design structures, in particular the use of inheritance. Bois et al. [2006]showed that the decomposition of Blob classes into a number of collaboratingclasses using refactorings can improve comprehension. Abbes et al. [2011]conducted three experiments, with 24 subjects each, to investigate whetherthe occurrence of antipatterns does affect the understandability of systemsby developers during comprehension and maintenance tasks. They concludedthat although the occurrence of one antipattern does not significantly decreasedevelopers’ performance, a combination of two antipatterns impedes signifi-cantly developers’ performance during comprehension and maintenance tasks.
Li and Shatnawi [2007] investigated the relationship between the prob-ability of a class to be faulty and some antipatterns based on three versionsof Eclipse and showed that classes with antipatterns Blob, Shotgun Surgery,and Long Method have a higher probability to be faulty than other classes.Olbrich et al. [2009], analyzed the historical data of Lucene and Xerces overseveral years and concluded that classes with the antipatterns Blob and Shot-gun Surgery have a higher change frequency than other classes; with Blobclasses featuring more changes. However, they did not investigated the kindsof changes performed on the antipatterns.
Using Azureus and Eclipse, we investigated the impact of code smells onthe change-proneness of classes and showed that in general, the likelihoodfor classes with code smells to change is very high [Khomh et al., 2009]. In[Khomh et al., 2012] we also investigated the relation between the presenceof antipatterns and the change- and fault-proneness of classes. We found thatclasses participating in antipatterns are significantly more likely to be subjectto changes and to be involved in fault-fixing changes than other classes. Fur-thermore, we also investigated the kind of changes, namely structural andnon-structural changes, experienced by classes with antipatterns. Structuralchanges are changes that alter a class interface while non-structural changesare changes to method bodies. We found that in general structural changesare more likely to occur in classes participating in antipatterns. The main dif-ference with this work is that we detailed the changes into 40 types of sourcecode changes classified in 5 change type categories. This detailed informationabout changes allowed us to analyze which antipatterns lead to which types ofsource code changes. Also, this work is performed with more systems, namely16, compared to previous work which was done with only 4 systems.
3.5 Conclusion and Future WorkAntipatterns have been defined to denote poor solutions to design and im-plementation problems. Previous studies have shown that classes affected by

3.5. Conclusion and Future Work 61
antipatterns are more change-prone than other classes. In this chapter we pro-vide a deeper insight into which antipatterns lead to which types of changesin Java classes. We analyzed the change-proneness of these classes taking intoaccount 40 types of fine-grained source code changes (SCC) extracted fromthe version control repositories of 16 Java open-source systems. Our resultsshow that:
• Classes affected by antipatterns change more frequently along the evo-lution of a system, confirming previous findings (see RQ1).
• Classes affected by the ComplexClass, SpaghettiCode and SwissArmyKnifeantipatterns are more likely to be changed than classes affected by otherantipatterns (see RQ2).
• Certain antipatterns lead to certain types of source code changes, suchas API changes are more likely to appear in classes affected by the Com-plexClass, SpaghettiCode and SwissArmyKnife antipatterns (see RQ3).
Our results have several implications on software engineers and researchers.Regarding researchers our results suggest to focus our efforts on understand-ing a subset of antipatterns that lead to change-prone classes or changes witha high impact on the other parts of a software system. Concerning softwareengineers, our results provide strong evidence to use antipatterns detectiontools, such as DECOR, to detect and resolve ComplexClass, SpaghettiCode andSwissArmyKnife antipatterns. Resolving them shows to be beneficial in termsof preventing source code changes, such as API changes, that impact otherparts of a system.
In future work, we plan to perform a more extended qualitative analysisof antipatterns. We also plan to enlarge our data set and analyze industrialsoftware systems. Another direction of future work is to analyze the typesof changes performed when antipatterns are introduced and when they areresolved. These analysis are needed to further estimate the development andmaintenance costs caused by antipatterns.


4.Fine-Grained WSDL Changes
In the service-oriented paradigm web service interfaces are considered contractsbetween web service consumers and providers. However, these interfaces arecontinuously evolving over time to satisfy changes in the requirements and tofix bugs. Changes in a web service interface typically affect the systems of itsconsumers. Therefore, it is essential for consumers to recognize which typesof changes occur in a web service interface in order to analyze the impact onhis/her systems.
In this chapter we propose a tool called WSDLDiff to extract fine-grainedchanges from subsequent versions of a web service interface defined in WSDL.In contrast to existing approaches, WSDLDiff takes into account the syntax ofWSDL and extracts the WSDL elements affected by changes and the types ofchanges. With WSDLDiff we performed a study aimed at analyzing the evolutionof web services using the fine-grained changes extracted from the subsequentversions of four real world WSDL interfaces.
The results of our study show that the analysis of the fine-grained changeshelps web service consumers to highlight the most frequent types of changesaffecting a WSDL interface. This information can be relevant for web serviceconsumers who want to assess the risk associated to the usage of web servicesand to subscribe to the most stable ones.1
4.1 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.2 WSDLDiff . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.3 Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.4 Conclusion & Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . 78
Over the last decades, the evolution of software systems has been studiedin order to analyze and enhance the software development and maintenanceprocesses. Among other applications, the information mined from the evolu-
1This chapter was published in the 19th International Conference on Web Services (ICWS2012) [Romano and Pinzger, 2012].
63

64 Chapter 4. Fine-Grained WSDL Changes
tion of software systems has been applied to investigate the causes of changesin software components [Khomh et al., 2009; Penta et al., 2008]. Softwareengineering researchers have developed several tools to extract informationabout changes from software artifacts [Fluri et al., 2007] [Tsantalis et al.,2011] [Xing and Stroulia, 2005a] and to analyze their evolution.
In service-oriented systems understanding and coping with changes is evenmore critical and challenging because of the distributed and dynamic natureof services [Papazoglou, 2008]. In fact, service providers do not necessar-ily know the service consumers and how changes on a service can impactthe existing service clients. For this reason service interfaces are consideredcontracts between providers and consumers and they should be as stable aspossible [Erl, 2007]. On the other hand, services are continuously evolvingto satisfy changes in the requirements and to fix bugs. Recognizing the typesof changes is fundamental for understanding how a service interface evolvesover time. This can help service consumers to quantify the risk associatedto the usage of a particular service and to compare the evolution of differentservices with similar features. Moreover, detailed information about changesallow software engineering researchers to analyze the causes of changes in aservice interface.
In order to analyze the evolution of WSDL2 interfaces, Fokaefs et al. [2011]propose a tool called VTracker. This tool is based on the Zhang-Shasha’s tree-edit distance [Zhang and Shasha, 1989] comparing WSDL interfaces as XML3
documents. However, VTracker does not take into account the syntax of WSDLinterfaces. As consequence, their approach outputs only the percentage ofadded, changed and removed XML elements. We argue that this informationis inadequate to analyze the evolution of WSDL interfaces without manuallychecking the types of changes and the WSDL elements affected by changes.Moreover, their approach of transforming a WSDL interface into a simplifiedrepresentation can lead to the detection of multiple changes while there hasbeen only one change.
In this chapter we propose a tool called WSDLDiff that compares subse-quent versions of WSDL interfaces to automatically extract the changes. Incontrast to VTracker, WSDLDiff takes into account the syntax of WSDL andXSD,4 used to define data types in a WSDL interface. In particular, WSDLDiffextracts the types of the elements affected by changes (e.g., Operation, Mes-sage, XSDType) and the types of changes (e.g., removal, addition, move, at-
2http://www.w3.org/TR/wsdl3http://www.w3.org/XML/4http://www.w3.org/XML/Schema

4.1. Related Work 65
tribute value update). We refer to these changes as fine-grained changes. Thefine-grained changes extraction process of WSDLDiff is based on the UMLDiffalgorithm [Xing and Stroulia, 2005a] and has been implemented on top of theEclipse Modeling Framework (EMF).5
With WSDLDiff we performed a study aimed at analyzing the evolution ofweb services using the fine-grained changes extracted from subsequent ver-sions of four real world WSDL interfaces. We address the following two re-search questions:
• RQ1: What is the percentage of added, changed and removed elementsof a WSDL interface?
• RQ2: Which types of changes are made to the elements of a WSDLinterface?
The study shows that different WSDL interfaces are affected by different typesof changes highlighting how they are maintained with different strategies.While in one case mainly Operations were added continuously, in the otherthree cases the data type specifications were the most affected by changes.Moreover, we found that in all four WSDL interfaces under analysis there is atype of change that is predominant. From this information web service con-sumers can be aware of the frequent types of changes when subscribing to aweb service and they can compare the evolution of web services that providesimilar features in order to subscribe to the most stable web service.
The remainder of this chapter is organized as follows. In Section 4.1 wereport the related work and we discuss the main differences with our work.Section 4.2 describes the WSDLDiff tool and the process to extract fine-grainedchanges implemented into it. The study and results are presented in Sec-tion 4.3. We draw our conclusions and outline directions for future work inSection 4.4.
4.1 Related WorkFokaefs et al. [2011] analyzed the evolution of web services using a tool calledVTracker. This tool is based on the Zhang-Shasha’s tree edit distance algorithm[Zhang and Shasha, 1989], which calculates the minimum edit distance be-tween two trees. In this study the WSDL interfaces are compared as XML files.Specifically the authors created an intermediate XML representation to reduce
5http://www.eclipse.org/modeling/emf/

66 Chapter 4. Fine-Grained WSDL Changes
the verbosity of the WSDL specification. In this simplified XML representa-tion, among other transformations, the authors trace the references betweenmessages parameters (Parts) and data types (XSDTypes) and they replace thereferences with the data types themselves. The output of their analysis con-sists of the percentage of added, changed and removed elements among theXML models of two WSDL interfaces. There are two main differences betweenour work and the approach proposed by Fokaefs et al. First, we compute thechanges between WSDL models taking into account the syntax of WSDL andXSD and, hence, extracting the type of the elements affected by changes (e.g.,Operation, Message, XSDType) and the types of changes (e.g., removal, addi-tion, move, attribute value update). For example, WSDLDiff extracts differ-ences in the order of the elements only if it is relevant, such as changes in theorder of Parts defined in a Message. Our approach is aware of irrelevant orderchanges, such as changes in the order of XSDTypes defined in the WSDL typesdefinition. This allows us to analyze the evolution of a WSDL interface onlylooking at the changes without manually inspecting the XML coarse-grainedchanges. Second, WSDLDiff does not replace the references to data types withthe data types themselves. This transformation can lead to the detection of achange in a data type multiple times while there has been only one change.
Wang and Capretz [2009] proposed an impact analysis model based onservice dependency. The authors analyze the service dependencies graphmodel, service dependencies and the relation matrix. Based on this infor-mation they infer the impact of the service evolution. However, they do notpropose any technique to analyze the evolution of web services. Aversanoet al. [2005] proposed an approach to understand how relationships betweensets of services change across service evolution. Their approach is based onformal concept analysis. They used the concept lattice to highlight hierarchyrelationships and to identify commonalities and differences between services.While the work proposed by Aversano et al. consists in extracting relationshipsamong services, our work focuses on the evolution of single web services usingfine-grained changes. As future work the two approaches can be integrated tocorrelate different types of changes with the different relationships.
In literature several approaches have been proposed to measure the sim-ilarity of web services (e.g., [Liu et al., 2010] [Plebani and Pernici, 2009]).However, these approaches compute the similarity amongst WSDL interfacesto assist the search and classification of web services and not to analyze theirevolution.
Concerning the model differencing techniques, the approach proposed byXing et al. [Xing and Stroulia, 2005a] [Xing and Stroulia, 2005b] is most

4.2. WSDLDiff 67
relevant for our work. In fact, their algorithm to infer differences amongUML6 diagrams has been implemented by the EMF Compare7 that we used toimplement our tool WSDLDiff. The authors proposed the UMLDiff algorithmfor detecting structural changes between the designs of subsequent versions ofobject oriented systems, represented through UML diagrams. This algorithmhas been later adapted in the EMF Compare to compare models conformingto any arbitrary metamodel and not only UML models [Brun and Pierantonio,2008].
Several approaches have been proposed to classify changes in service inter-faces. For instance Feng et al. [2011] and Treiber et al. [2008] have proposedapproaches to classify the changes of web services taking into account theirimpact to different stakeholders. These classifications can be easily integratedin our tool to classify the different fine-grained changes extracted along theevolution of a web service.
As can be deduced from the overview of related work there currently doesnot exist any tool for extracting fine-grained changes amongst web services.In this chapter, we present such a tool based on the UMLDiff algorithm [Xingand Stroulia, 2005a].
4.2 WSDLDiffIn this section, we illustrate the WSDLDiff tool used to extract the fine-grainedchanges between two versions of a WSDL interface. Since the tool is basedon the Eclipse Modeling Framework, we first present an overview of this frame-work and then we describe the fine-grained changes extraction process imple-mented by WSDLDiff. A first prototype of WSDLDiff is available on our website.8
4.2.1 Eclipse Modeling FrameworkThe Eclipse Modeling Framework (EMF) is a modeling framework that lets de-velopers build tools and other applications based on a structured data model.This framework provides tools to produce a set of Java classes from a modelspecification and a set of adapter classes that enable viewing and editing ofthe models. The models are described by meta models called Ecore.
As part of the EMF project, there is the EMF Compare plug-in. It providescomparison and merge facilities for any kind of EMF Models through a frame-
6http://www.uml.org/7http://www.eclipse.org/emf/compare/8http://swerl.tudelft.nl/twiki/pub/DanieleRomano/WebHome/
WSDLDiff.zip

68 Chapter 4. Fine-Grained WSDL Changes
Matching Engine org.eclipse.compare.match
Match Model
Diff Model
Differencing Engine org.eclipse.compare.diff
XSD Transformer XSD Transformer
WSDL Model1’ WSDL Model2’
WSDL Model1 WSDL Model2
WSDL Version1 WSDL Version2
WSDL Parser org.eclipse.wst.wsdl
org.eclipse.xsd
WSDL Parser org.eclipse.wst.wsdl
org.eclipse.xsd A
B
C
D
Figure 4.1: The process implemented by WSDLDiff to extract fine-grainedchanges between two versions of a WSDL interface.
work easy to be used and extended to compare instances of EMF Models. TheEclipse community provides already an Ecore meta model for WSDL interfaces,including a meta model for XSD, and tools to parse them into EMF Models. Weuse these features to parse and extract changes between WSDL interfaces asdescribed in the following.
4.2.2 Fine-Grained Changes Extraction ProcessFigure 4.1 shows the process implemented by WSDLDiff to extract fine-grainedchanges between two versions of a WSDL interface. The process consists offour stages:
• Stage A: in the first stage we parse the WSDL interfaces using the APIsprovided by the org.eclipse.wst.wsdl and org.eclipse.xsd projects. The out-put of this stage consists of the two EMF Models (WSDL Model1 and

4.2. WSDLDiff 69
WSDL Model2) corresponding to the two WSDL interfaces taken as in-put (WSDL Version1 and WSDL Version2).
• Stage B: in this stage we transform the EMF Models corresponding to theXSD (contained by the WSDL models) in order to improve the accuracyof the fine-grained changes extraction process as it will be shown in theSubsection 4.2.4. The output of this stage consist of the transformedmodels (WSDL Model1’ and WSDL Model2’).
• Stage C: in the third stage we use the Matching Engine provided bythe EMF Compare framework to detect the nodes that match in the twomodels.
• Stage D: the Match Model produced by the Matching Engine is then usedto detect the differences among the two WSDL models under analysis.This task is accomplished by the Differencing Engine provided also byEMF Compare. The output of this stage is a tree of structural changesthat reports the differences between the two WSDL models. The differ-ences are reported in terms of additions, removals, moves and modifica-tions of each element specified in the WSDL and in the XSD.
In the next subsection we first illustrate the strategies behind EMF Comparedescribing the matching (Stage C) and differencing (Stage D) stages and thenwe describe the XSD transformation (Stage B).
4.2.3 Eclipse EMF CompareThe comparison facility provided by EMF Compare is based on the work devel-oped by Xing and Stroulia [2005a]. This work has been adapted to comparegeneric EMF Models instead of UML models as initially developed by Xing.The comparison consists of two phases: (1) the matching phase (Stage C inour approach) and (2) the differencing phase (Stage D in our approach). Thematching phase is performed computing a set of similarity metrics. Thesemetrics are computed for two nodes while traversing the two models underanalysis with a top-down approach. In the generic Matching Engine, providedin org.eclipse.compare.match and used in our approach, the set of metrics con-sists of four similarity metrics:
• type similarity: to compute the match of the types of two nodes;
• name similarity: to compute the similarity between the values of theattribute name of two nodes;

70 Chapter 4. Fine-Grained WSDL Changes
• value similarity: to compute the similarity between the values of otherattributes declared in the nodes;
• relations similarity: to compute the similarity of two nodes based onthe relationships they have with other nodes (e.g., children and parentsin the model).
Once the matching phase has been completed, it produces a matchingmodel consisting of all the entities that are matched in the two models. Thematching model is then used in the differencing phase to extract all the differ-ences between the two models. Specifically, the matching model is browsed bya Differencing Engine that computes the tree edit operations. These operationsrepresent the minimum set of operations to transform a model into an othermodel. They are classified in added, changed, removed and moved operations.For more details about the matching and differencing phases implemented byEMF Compare we refer the reader to [Brun and Pierantonio, 2008].
4.2.4 XSD TransformationIn an initial manual validation of EMF Compare on WSDL models we foundthat in a particular case the set of differences produced did not correspond tothe minimum set of tree edit operations. The problem was due to the EMFModel used to represent the XSDs. For this reason we decided to add the XSDTransformer. To better understand the problem behind the original EMF Modeland the solution adopted, consider the example shown in Figure 4.2. Fig-ure 4.2a shows an XSDElement book that consists of an XSDModelGroup (theelement sequence) that contains two XSDElements (the elements author andtitle). Figure 4.2b shows the original EMF Model parsed by the WSDL Parser(Stage A in Figure 4.1). The EMF Model contains the nodes XSDParticle. Thesenodes are necessary to represent the attributes minOccurs, maxOccurs and reffor each XSDElement declared in an XSDModelGroup and for the XSDModel-Group itself.
The XSDParticles in the original model are parents of the elements to whichthey are associated. This structure can lead to mistakes when the order of XS-DElements within an XSDModelGroup changes. In this case, when the MatchingEngine traverses the models, it can detect a match between XSDParticles thatare associated to different XSDElements (e.g., a match between the XSDParticleof the element author and the XSDParticle of the element title). This matchis likely because the values of the attributes minOccurs, maxOccurs and refare set to their default values. When this match occurs the Matching Enginekeeps traversing the model and it detects a mismatch when it traverses the

4.2. WSDLDiff 71
<xs:element name=”book"> <xs:complexType> <xs:sequence> <xs:element name=”author” type="xs:string"/> <xs:element name=”>tle" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element>
(a) Definition of an XSD element
XSDElement
book
XSDPar.cle
XSDComplexType
XSDModelGroup
XSDPar.cle XSDPar.cle
XSDElement
%tle XSDElement
author
(b) Original EMF Model
XSDElement
book
XSDPar.cle
XSDComplexType
XSDModelGroup
XSDPar.cle XSDPar.cle
XSDElement
%tle XSDElement
author
(c) Transformed EMF Model
Figure 4.2: An example that shows the XSD transformation performed by theXSD Transformer in the Stage B of the fine-grained changes extraction process.
children of the previously matched XSDParticles (e.g., a mismatch between theelements author and title). As consequence, even if there are no differencesamong the models the Differencing Engine can produce the added XSDelementtitle, the added XSDelement author, the removed XSDelement title and the re-moved XSDelement author as changes.
To overcome this problem, we decided to transform the EMF Model in-verting the parent-child relationship in presence of XSDParticles as shown inFigure 4.2c. In the transformed models, the Matching Engine traverses the XS-DParticles only when a match is detected between the XSDElements to whichthey are associated.
Besides this problem, in one case, WSDLDiff reported the removed Partand added Part changes instead of the changed Part change when a Part wasrenamed. However for this study the two set of changes are equivalent. For

72 Chapter 4. Fine-Grained WSDL Changes
this reason we have not considered it as a problem. Clearly, as part of ourfuture work we plan to validate the fine-grained changes extraction processwith a benchmark.
4.3 StudyThe goal of this study is to analyze the evolution of web services throughthe analysis of fine-grained changes extracted from subsequent versions of aWSDL interface. The perspective is that of web services consumers interestedin extracting the types of changes that appear along the evolution of a webservice. They can analyze the most frequent changes in a WSDL interfaceestimating the risk related to the usage of a specific element. The contextof this study consists of all the publicly available WSDL versions of four realworld web services, namely:
• Amazon EC2: Amazon Elastic Compute Cloud is a web service thatprovides resizable compute capacity in the cloud. In this study we haveanalyzed 22 versions.
• FedEx Rate Service: the Rate Service provides the shipping rate quotefor a specific service combination depending on the origin and desti-nation information supplied in the request. We analyzed 10 differentversions.
• FedEx Ship Service: the Ship Service provides functionalities for man-aging package shipments and their options. 7 versions out of 10 havebeen analyzed in this study.
• FedEx Package Movement Information Service: the Package Move-ment Information Service provides operations to check service availabil-ity, route and postal codes between origin and destination. We analyzed3 versions out of 4. For the sake of simplicity we refer to this service asFedEx Pkg.
We chose these web services because they were previously used by Fokaefset al. [2011]. The other web services analyzed by Fokaefs et al. [2011] (PayPalSOAP API9 and Bing Search10) have not been considered because the previousversions of the WSDL interfaces are not publicly available. For the same rea-sons not every version of the web services has been considered in our analysis.
9https://www.paypalobjects.com/enUS/ebook/PPAPIReference/architecture.html
10http://www.bing.com/developers
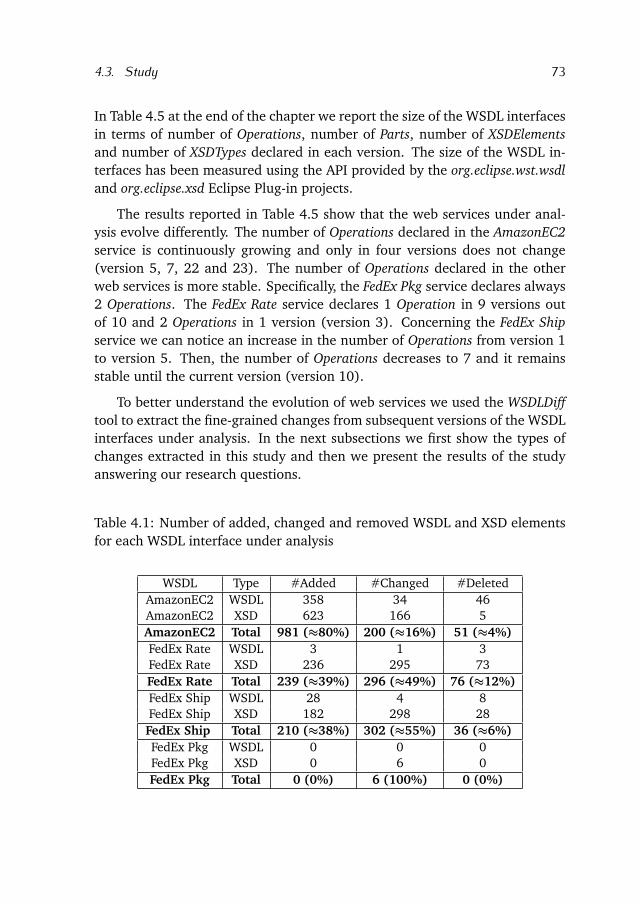
4.3. Study 73
In Table 4.5 at the end of the chapter we report the size of the WSDL interfacesin terms of number of Operations, number of Parts, number of XSDElementsand number of XSDTypes declared in each version. The size of the WSDL in-terfaces has been measured using the API provided by the org.eclipse.wst.wsdland org.eclipse.xsd Eclipse Plug-in projects.
The results reported in Table 4.5 show that the web services under anal-ysis evolve differently. The number of Operations declared in the AmazonEC2service is continuously growing and only in four versions does not change(version 5, 7, 22 and 23). The number of Operations declared in the otherweb services is more stable. Specifically, the FedEx Pkg service declares always2 Operations. The FedEx Rate service declares 1 Operation in 9 versions outof 10 and 2 Operations in 1 version (version 3). Concerning the FedEx Shipservice we can notice an increase in the number of Operations from version 1to version 5. Then, the number of Operations decreases to 7 and it remainsstable until the current version (version 10).
To better understand the evolution of web services we used the WSDLDifftool to extract the fine-grained changes from subsequent versions of the WSDLinterfaces under analysis. In the next subsections we first show the types ofchanges extracted in this study and then we present the results of the studyanswering our research questions.
Table 4.1: Number of added, changed and removed WSDL and XSD elementsfor each WSDL interface under analysis
WSDL Type #Added #Changed #DeletedAmazonEC2 WSDL 358 34 46AmazonEC2 XSD 623 166 5AmazonEC2 Total 981 (≈80%) 200 (≈16%) 51 (≈4%)FedEx Rate WSDL 3 1 3FedEx Rate XSD 236 295 73FedEx Rate Total 239 (≈39%) 296 (≈49%) 76 (≈12%)FedEx Ship WSDL 28 4 8FedEx Ship XSD 182 298 28FedEx Ship Total 210 (≈38%) 302 (≈55%) 36 (≈6%)FedEx Pkg WSDL 0 0 0FedEx Pkg XSD 0 6 0FedEx Pkg Total 0 (0%) 6 (100%) 0 (0%)

74 Chapter 4. Fine-Grained WSDL Changes
4.3.1 Fine-Grained ChangesThe output of WSDLDiff consists of the set of edit operations. These operationsare associated with the elements declared in the WSDL and XSD specifications.Among all the elements the following WSDL elements have been detected asaffected by changes: BindingOperation, Operation, Message and Part. The XSDelements detected as affected by changes are: XSDType, XSDElement, XSDAt-tributeGroup and XSDAnnotation. These elements were affected by the follow-ing fine-grained changes:
• XSD Element changes: consist of added XSDElements (XSDElementA),removed XSDElements (XSDElementR) and moved XSDElements (XSDEle-mentM) within a declaration of an XSDType or an XSDElement.
• Attribute changes: changes due to the update of an attribute value.Specifically we detected changes to the values of the attributes name(NameUpdate), minOccurs (MinOccursUpdate), maxOccurs (MaxOccur-sUpdate) and fixed (FixedUpdate).
• Reference Changes: consists of changes to a referenced value (RefUp-date).
• Enumeration Changes: changes of elements declared within an XSDE-numeration element. We detected added enumeration values (Enumer-ationA) and removed enumeration values (EnumerationR).
For the sake of simplicity we have presented only the changes detected in ourstudy. However WSDLDiff is able to detect changes to every element declaredin the WSDL and XSD specifications.
4.3.2 Research Question 1 (RQ1)The first research question (RQ1) is:
What is the percentage of added, changed and removed elements of a WSDLinterface?
To answer RQ1, for each type of element declared in the WSDL and XSD spec-ifications, we counted the number of times they have been added, changed,or removed between every pair of subsequent versions of the WSDL interfacesunder analysis. We present the results in three different tables. In Table 4.2we report the number of added, changed and deleted WSDL elements whilethe added, changed and removed XSD elements are shown in Table 4.3. Ta-ble 4.1 summarizes the results showing the total number and the percentage
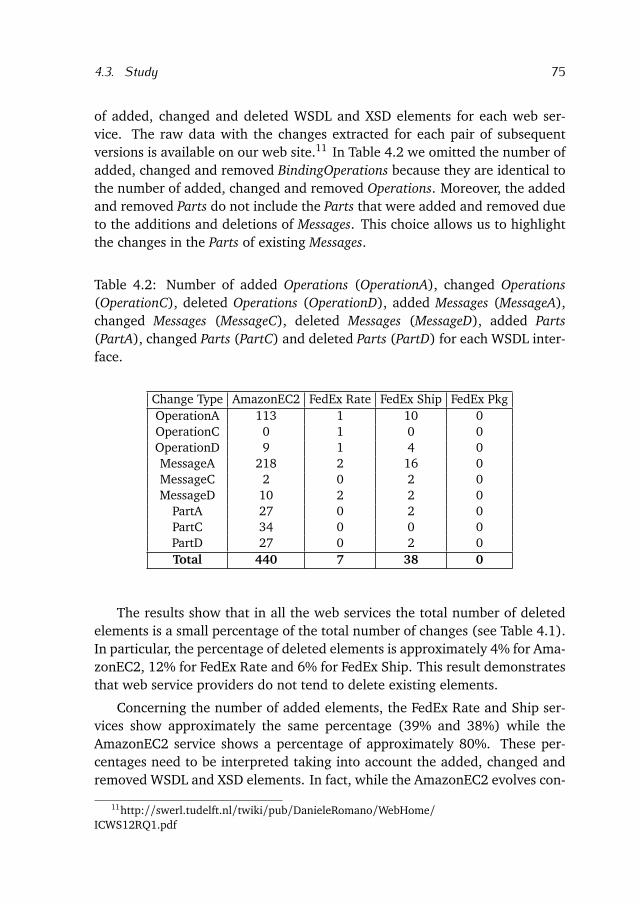
4.3. Study 75
of added, changed and deleted WSDL and XSD elements for each web ser-vice. The raw data with the changes extracted for each pair of subsequentversions is available on our web site.11 In Table 4.2 we omitted the number ofadded, changed and removed BindingOperations because they are identical tothe number of added, changed and removed Operations. Moreover, the addedand removed Parts do not include the Parts that were added and removed dueto the additions and deletions of Messages. This choice allows us to highlightthe changes in the Parts of existing Messages.
Table 4.2: Number of added Operations (OperationA), changed Operations(OperationC), deleted Operations (OperationD), added Messages (MessageA),changed Messages (MessageC), deleted Messages (MessageD), added Parts(PartA), changed Parts (PartC) and deleted Parts (PartD) for each WSDL inter-face.
Change Type AmazonEC2 FedEx Rate FedEx Ship FedEx PkgOperationA 113 1 10 0OperationC 0 1 0 0OperationD 9 1 4 0MessageA 218 2 16 0MessageC 2 0 2 0MessageD 10 2 2 0
PartA 27 0 2 0PartC 34 0 0 0PartD 27 0 2 0Total 440 7 38 0
The results show that in all the web services the total number of deletedelements is a small percentage of the total number of changes (see Table 4.1).In particular, the percentage of deleted elements is approximately 4% for Ama-zonEC2, 12% for FedEx Rate and 6% for FedEx Ship. This result demonstratesthat web service providers do not tend to delete existing elements.
Concerning the number of added elements, the FedEx Rate and Ship ser-vices show approximately the same percentage (39% and 38%) while theAmazonEC2 service shows a percentage of approximately 80%. These per-centages need to be interpreted taking into account the added, changed andremoved WSDL and XSD elements. In fact, while the AmazonEC2 evolves con-
11http://swerl.tudelft.nl/twiki/pub/DanieleRomano/WebHome/ICWS12RQ1.pdf
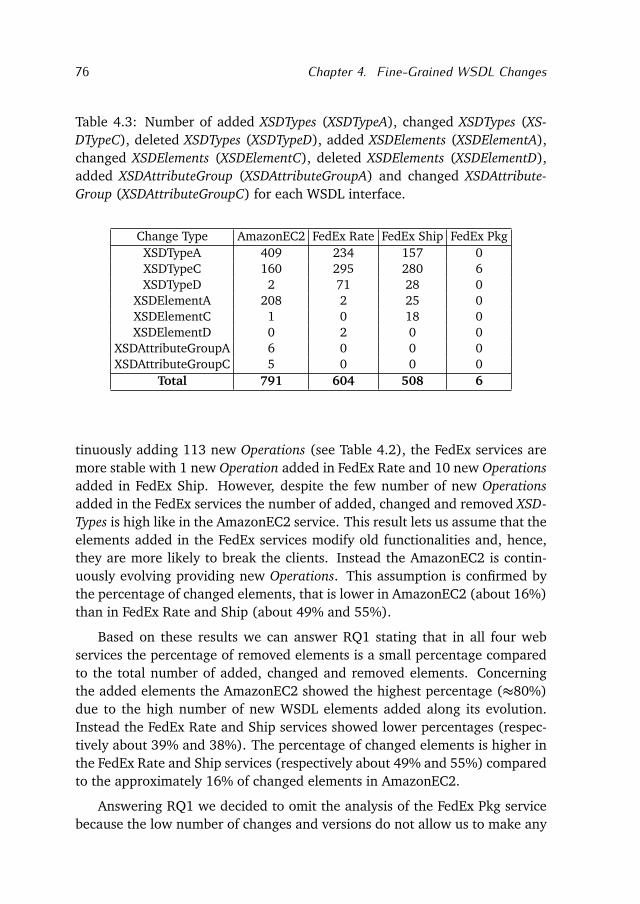
76 Chapter 4. Fine-Grained WSDL Changes
Table 4.3: Number of added XSDTypes (XSDTypeA), changed XSDTypes (XS-DTypeC), deleted XSDTypes (XSDTypeD), added XSDElements (XSDElementA),changed XSDElements (XSDElementC), deleted XSDElements (XSDElementD),added XSDAttributeGroup (XSDAttributeGroupA) and changed XSDAttribute-Group (XSDAttributeGroupC) for each WSDL interface.
Change Type AmazonEC2 FedEx Rate FedEx Ship FedEx PkgXSDTypeA 409 234 157 0XSDTypeC 160 295 280 6XSDTypeD 2 71 28 0
XSDElementA 208 2 25 0XSDElementC 1 0 18 0XSDElementD 0 2 0 0
XSDAttributeGroupA 6 0 0 0XSDAttributeGroupC 5 0 0 0
Total 791 604 508 6
tinuously adding 113 new Operations (see Table 4.2), the FedEx services aremore stable with 1 new Operation added in FedEx Rate and 10 new Operationsadded in FedEx Ship. However, despite the few number of new Operationsadded in the FedEx services the number of added, changed and removed XSD-Types is high like in the AmazonEC2 service. This result lets us assume that theelements added in the FedEx services modify old functionalities and, hence,they are more likely to break the clients. Instead the AmazonEC2 is contin-uously evolving providing new Operations. This assumption is confirmed bythe percentage of changed elements, that is lower in AmazonEC2 (about 16%)than in FedEx Rate and Ship (about 49% and 55%).
Based on these results we can answer RQ1 stating that in all four webservices the percentage of removed elements is a small percentage comparedto the total number of added, changed and removed elements. Concerningthe added elements the AmazonEC2 showed the highest percentage (≈80%)due to the high number of new WSDL elements added along its evolution.Instead the FedEx Rate and Ship services showed lower percentages (respec-tively about 39% and 38%). The percentage of changed elements is higher inthe FedEx Rate and Ship services (respectively about 49% and 55%) comparedto the approximately 16% of changed elements in AmazonEC2.
Answering RQ1 we decided to omit the analysis of the FedEx Pkg servicebecause the low number of changes and versions do not allow us to make any
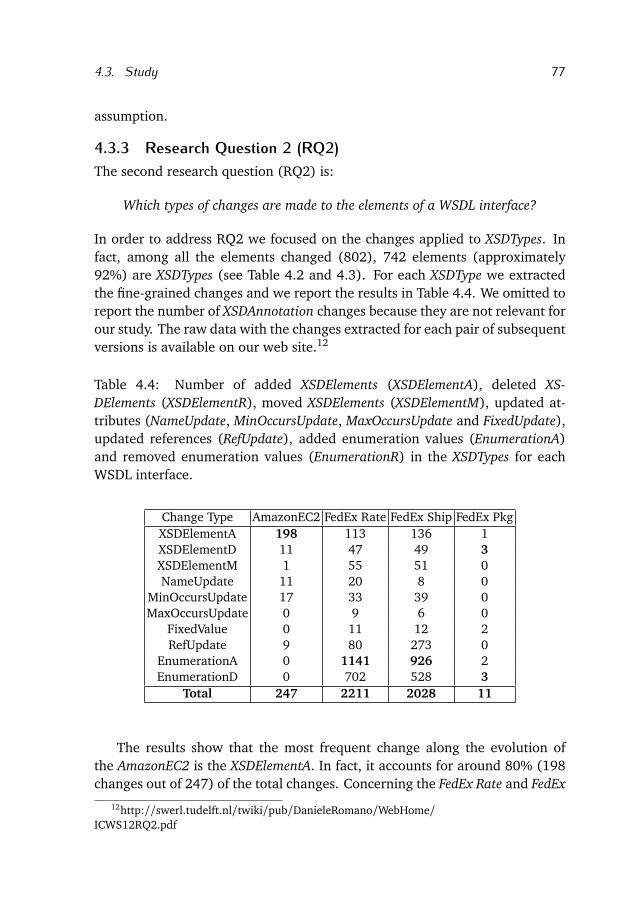
4.3. Study 77
assumption.
4.3.3 Research Question 2 (RQ2)The second research question (RQ2) is:
Which types of changes are made to the elements of a WSDL interface?
In order to address RQ2 we focused on the changes applied to XSDTypes. Infact, among all the elements changed (802), 742 elements (approximately92%) are XSDTypes (see Table 4.2 and 4.3). For each XSDType we extractedthe fine-grained changes and we report the results in Table 4.4. We omitted toreport the number of XSDAnnotation changes because they are not relevant forour study. The raw data with the changes extracted for each pair of subsequentversions is available on our web site.12
Table 4.4: Number of added XSDElements (XSDElementA), deleted XS-DElements (XSDElementR), moved XSDElements (XSDElementM), updated at-tributes (NameUpdate, MinOccursUpdate, MaxOccursUpdate and FixedUpdate),updated references (RefUpdate), added enumeration values (EnumerationA)and removed enumeration values (EnumerationR) in the XSDTypes for eachWSDL interface.
Change Type AmazonEC2 FedEx Rate FedEx Ship FedEx PkgXSDElementA 198 113 136 1XSDElementD 11 47 49 3XSDElementM 1 55 51 0NameUpdate 11 20 8 0
MinOccursUpdate 17 33 39 0MaxOccursUpdate 0 9 6 0
FixedValue 0 11 12 2RefUpdate 9 80 273 0
EnumerationA 0 1141 926 2EnumerationD 0 702 528 3
Total 247 2211 2028 11
The results show that the most frequent change along the evolution ofthe AmazonEC2 is the XSDElementA. In fact, it accounts for around 80% (198changes out of 247) of the total changes. Concerning the FedEx Rate and FedEx
12http://swerl.tudelft.nl/twiki/pub/DanieleRomano/WebHome/ICWS12RQ2.pdf

78 Chapter 4. Fine-Grained WSDL Changes
Ship services, the EnumerationA changes are the most frequent, accounting forapproximately 51% (1141 changes out of 2211) and for 45% (926 changesout of 2028) of all changes. Adding the EnumerationD changes, we obtainapproximately 83% (1843 changes out of 2211) and 71% (1454 changes outof 2028) of changes occurring in the enumeration elements. The results showthat in 3 web services out of 4 there is a type of change that is predominant.Based on this result web services consumers can become aware of the mostfrequent types of changes affecting a WSDL interface. Like for RQ1, the smallnumber of changes in the FedEx Pkg does not allow any valid conclusion.
4.3.4 Summary and implications of the resultsThe changes collected in this study highlight how different WSDL interfacesevolve differently. This study with the WSDLDiff tool can help services con-sumers to analyze which elements are frequently added, changed and re-moved and which types of changes are performed more frequently. For ex-ample, a developer who wants to integrate a FedEx service into his/her appli-cation can learn that the specification of data types changes most frequentlywhile Operations change only rarely (RQ1). In particular, the enumerationvalues are the most unstable elements (RQ2). Instead, an AmazonEC2 con-sumer can be aware that new Operations are continuously added (RQ1) andthat data types are continuously modified adding new elements (RQ2).
4.4 Conclusion & Future WorkIn this chapter we proposed a tool called WSDLDiff to extract fine-grainedchanges between two WSDL interfaces. With WSDLDiff we performed a studyaimed at understanding the evolution of web services looking at the changesdetected by our tool. The results of our study showed that the fine-grainedchanges are a useful means to understand how a particular web service evolvesover time. This information is relevant for web services consumers who want1) to analyze the most frequent changes affecting a WSDL interface and 2) tocompare the evolution of different web services with similar features. Fromthis information they can estimate the risk associated to the usage of a webservice.
The study presented in this chapter is the first study on the evolution ofweb services and we believe that our tool provides an essential starting point.
As future work, first we plan to investigate metrics that can be used asindicators of changes in WSDL elements. For instance in our work shown inChapter 2, we found an interesting correlation between the number of changesin Java interfaces and the external cohesion metric defined for services by

4.4. Conclusion & Future Work 79
Perepletchikov et al. [2010]. With our tool to extract fine-grained changeswe performed a similar study with WSDL interfaces that will be shown inChapter 6.
Next, we plan to classify the changes retrievable with WSDLDiff, integrat-ing and possibly extending the works proposed by Feng et al. [2011] andTreiber et al. [2008].
Finally, we plan to investigate the co-evolution of the different web servicescomposing a service oriented system. With WSDLDiff we can highlight webservices that evolve together, hence, violating the loosely coupling property.This analysis can help us to investigate the causes of web services co-evolutionand techniques to keep their evolution independent.
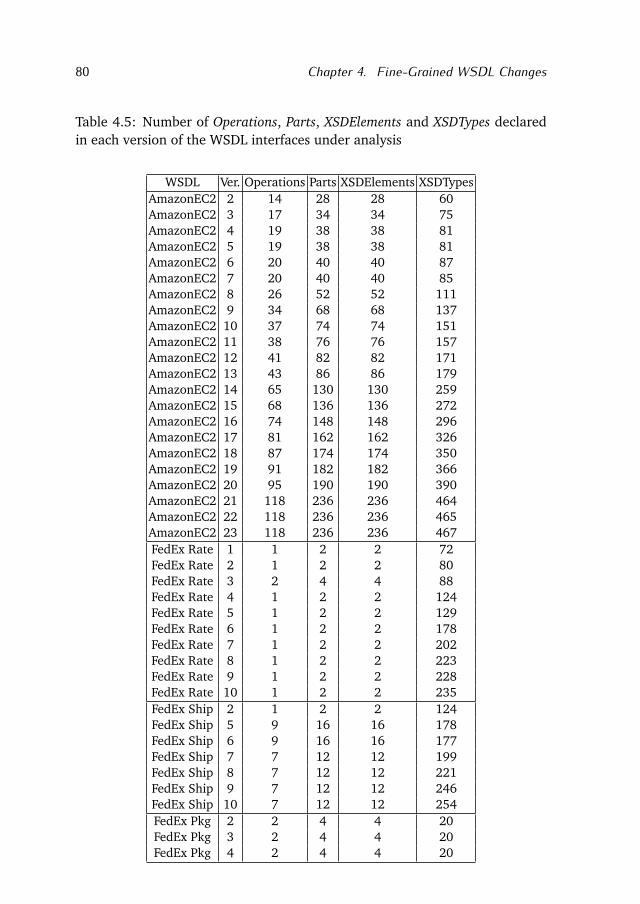
80 Chapter 4. Fine-Grained WSDL Changes
Table 4.5: Number of Operations, Parts, XSDElements and XSDTypes declaredin each version of the WSDL interfaces under analysis
WSDL Ver. Operations Parts XSDElements XSDTypesAmazonEC2 2 14 28 28 60AmazonEC2 3 17 34 34 75AmazonEC2 4 19 38 38 81AmazonEC2 5 19 38 38 81AmazonEC2 6 20 40 40 87AmazonEC2 7 20 40 40 85AmazonEC2 8 26 52 52 111AmazonEC2 9 34 68 68 137AmazonEC2 10 37 74 74 151AmazonEC2 11 38 76 76 157AmazonEC2 12 41 82 82 171AmazonEC2 13 43 86 86 179AmazonEC2 14 65 130 130 259AmazonEC2 15 68 136 136 272AmazonEC2 16 74 148 148 296AmazonEC2 17 81 162 162 326AmazonEC2 18 87 174 174 350AmazonEC2 19 91 182 182 366AmazonEC2 20 95 190 190 390AmazonEC2 21 118 236 236 464AmazonEC2 22 118 236 236 465AmazonEC2 23 118 236 236 467FedEx Rate 1 1 2 2 72FedEx Rate 2 1 2 2 80FedEx Rate 3 2 4 4 88FedEx Rate 4 1 2 2 124FedEx Rate 5 1 2 2 129FedEx Rate 6 1 2 2 178FedEx Rate 7 1 2 2 202FedEx Rate 8 1 2 2 223FedEx Rate 9 1 2 2 228FedEx Rate 10 1 2 2 235FedEx Ship 2 1 2 2 124FedEx Ship 5 9 16 16 178FedEx Ship 6 9 16 16 177FedEx Ship 7 7 12 12 199FedEx Ship 8 7 12 12 221FedEx Ship 9 7 12 12 246FedEx Ship 10 7 12 12 254FedEx Pkg 2 2 4 4 20FedEx Pkg 3 2 4 4 20FedEx Pkg 4 2 4 4 20

5..Dependencies among Web APIs
Service Oriented Architecture (SOA) enables organizations to react to require-ment changes in an agile manner and to foster the reuse of existing services.However, the dynamic nature of service oriented systems and their agility bearthe challenge of properly understanding such systems. In particular, under-standing the dependencies among services is a non trivial task, especially if ser-vice oriented systems are distributed over several hosts belonging to differentdepartments of an organization.
In this chapter, we propose an approach to extract dynamic dependenciesamong web services. The approach is based on the vector clocks, originally con-ceived and used to order events in a distributed environment. We use the vectorclocks to order service executions and to infer causal dependencies among ser-vices.
We show the feasibility of the approach by implementing it into the ApacheCXF framework and instrumenting the SOAP messages. We designed and exe-cuted two experiments to investigate the impact of the approach on the responsetime. The results show a slight increase that is deemed to be low in typical in-dustrial service oriented systems.1
5.1 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.3 Study Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
5.4 Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
5.5 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
5.6 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
5.7 Conclusion & Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . 98
IT organizations need to be agile to react to changes in the market. As aconsequence they started to develop their software systems as Software as a
1This chapter was published in the 4th International Conference on Service Oriented Comput-ing and Application (SOCA 2011) [Romano et al., 2011].
81

82 Chapter 5. Dependencies among Web APIs
Service (SaaS), overcoming the poor inclination of monolithically architectedsystems towards agility. Hence, the adoption of Service Oriented Architectures(SOAs) has become popular. In addition, SOA-based application developmentalso aims at reducing development costs through service reuse.
On the other hand, mining dependencies between services in a SOA isrelevant to understand the entire system and its evolution over time. The dis-tributed and dynamic nature of those architectures makes this task particularlychallenging.
In order to get an accurate picture of the dependencies within a SOA sys-tem a dynamic analysis is required. Using static analyses simply fails to coverimportant features of a SOA architecture, for example the ability to performdynamic binding. To the best of our knowledge, existing technologies usedto deploy a service oriented system do not provide tool to accurately detectthe entire chain of dependencies among services. For instance, open sourceEnterprise Service Bus systems (e.g., MuleESB2 and ServiceMix3) are limitedto detect only direct dependencies (i.e., invocation between pair of services).Such monitoring facilities are widely implemented through the wire tap andthe message store patterns described by Hohpe and Woolf [2003]. Other tools,such as HP OpenView SOA Manager4, allow the exploration of the dependen-cies, but they must explicitly be specified by the user [Basu et al., 2008].
In this chapter, we propose (1) an adaptation of our approach based onvector clocks [Romano and Pinzger, 2011b] to extract dynamic dependenciesamong web services deployed in an enterprise; (2) a non-intrusive, easy-to-implement and portable implementation and (3) an analysis of the impact ofour approach on the performance.
Vector clocks have originally been conceived and used to order events ina distributed environment [Mattern, 1989; Fidge, 1988]. We bring this tech-nique to the domain of service oriented systems by attaching the vector clocksto SOAP messages and use them to order service executions and to infer causaldependencies.
The approach has been implemented into the Apache CXF5 frameworktaking advantage of the Pipes and Filters pattern [Hohpe and Woolf, 2003].Since this pattern is widely used in the most popular web service frameworksand Enterprise Service Buses, the approach can be implemented on other SOA
2http://www.mulesoft.org/3http://servicemix.apache.org/4http://h20229.www2.hp.com/products/soa/5http://cxf.apache.org/

5.1. Applications 83
platforms (e.g., Apache Axis26 and Mule ESB) in a similar manner.
To analyze the impact of the approach on the performance of a systemwe investigate how the approach affects the response time of services. Theresults show a slight increase due to the increasing message size and the in-strumented Apache CXF framework. To determine the impact on real systemsa repository of 41 industrial systems is examined. Given the amount of ser-vices typically deployed within these industrial systems we do not expect asignificant increase of the response time when using our approach.
This chapter is structured as follows. In Section 5.1 we present the mainapplications of the proposed approach. In Section 5.2 we report the relatedwork. In Section 5.3 we describe the context in which we plan to apply ourstudy. In Section 5.4 we describe our approach to extract dynamic depen-dencies among web services. In Section 5.5 we propose an implementationof our approach. In Section 5.6 we report the first experiments and the ob-tained results. Finally, we conclude the chapter and present the future workin Section 5.7.
5.1 ApplicationsIn this section we discuss the main applications of our approach that we planto perform in future work.
5.1.1 Quality attributes measurementOur approach can be used to build up dynamic dependency graphs. Thesegraphs are commonly weighted, where the weights indicate the number oftimes a particular service is invoked or a particular execution path is traversed.The information contained in these graphs can help software engineers tomeasure important quality attributes (e.g., analyzability and changeability)for measuring maintainability of the system under analysis.
For instance Perepletchikov et al. defined several cohesion and couplingmetrics to estimate the maintainability and analyzability of service orientedsystems [Perepletchikov et al., 2006, 2007, 2010]. In our work shown in Chap-ter 2, we found an interesting correlation between the number of changes inJava interfaces and the external cohesion metric defined by Perepletchikov etal. With our approach to extract dynamic dependencies among services weplan to perform similar studies to validate and improve those metrics by an-alyzing service oriented systems. More in general, our dynamic dependencyanalysis is a starting point to study the interactions among services in indus-
6http://axis.apache.org/

84 Chapter 5. Dependencies among Web APIs
trial service oriented systems and to define anti-patterns that can affect thequality attributes required by a SOA.
5.1.2 Change Impact AnalysisBesides the measurement of quality attributes our approach can be used toperform Change Impact Analyses (IA) on service oriented systems. Bohner etal. [Shawn A. Bohner, 1996; Bohner, 2002] defined the IA as the identificationof potential consequences of a change, or the assessment of what needs to bemodified to accomplish a change. They defined two techniques to perform IA,namely Traceability and Dependency.
Wang and Capretz [2009] defined an IA approach for service orientedsystems based on a service dependency graph. Our approach fits in with theirwork by adding a dynamic dependency graph.
5.2 Related WorkThe most recent work on mining dynamic dependencies in service orientedsystems has been developed by Basu et al. [2008]. Basu et al. infer the causaldependencies through three dependencies identification algorithms, respec-tively based on the analysis of 1) occurrence frequency of logged messagepairs, 2) distribution of service execution time and 3) histogram of executiontime differences. This approach does not require the instrumentation of thesystem infrastructure. However, it is based on probabilities and there is stillthe need for properly setting the parameters of their algorithms to reach agood accuracy.
Briand et al. [2006] proposed a methodology and an instrumentation in-frastructure aimed at reverse engineering of UML sequence diagrams fromdynamic analysis of distributed Java systems. Their approach is based on acomplete instrumentation of the systems under analysis which in turn requiresa complete knowledge of the system.
Hrischuk and Woodside [2002] provided a series of requirements to re-verse engineer scenarios from traces in a distributed system. However, be-sides the requirements, this work does not provide any approach to extractdependencies in a service oriented system.
As can be deduced from the overview of related work there currently doesnot exist any accurate approach for inferring the dependencies amongst ser-vices. In this chapter, we present such an approach based on the concept ofvector clocks.

5.3. Study Context 85
Figure 5.1: A sample enterprise with web services deployed in two depart-ments
5.3 Study ContextIn this section we describe the context in which we plan to apply our study.The perspective is that of a quality engineer who wants to extract the dynamicdependencies among services within the boundaries of an enterprise. We referto dependencies as message dependencies, according to which two services aredependent if they exchange messages. We furthemore refer to web services asservices which are compliant to the following XML-standards:
• WSDL7 (Web Services Description Language) which describes the ser-vice interfaces.
• SOAP8 (Simple Object Access Protocol) widely adopted as a simple, ro-bust and extensible XML-based protocol for the exchange of messagesamong web services.
7http://www.w3.org/TR/wsdl8http://www.w3.org/TR/soap/

86 Chapter 5. Dependencies among Web APIs
Finally, we assume that the enterprise provides a UDDI9 (Universal Descrip-tion, Discovery, and Integration) registry to allow for the publication of ser-vices and the search for services that meet particular requirements.
Our sample enterprise is composed of several departments (a sample en-terprise with two departments is shown in Figure 5.1). Each departmentexposes some functionality as web services that can be invoked by web ser-vices deployed in other departments. Services deployed within the bound-aries of the enterprise are called internal services. Services deployed outsidethe boundaries of the enterprise are called external services.
We assume that hosts within the departments publish web services throughan application server (e.g., JBoss AS10 or Apache Tomcat11) and web serviceengines (e.g., Apache Axis2 or Apache CXF).
5.4 ApproachOur approach to extract dynamic dependencies among web services is basedon the concept of vector clocks. In this section, we first provide a backgroundon vector clocks after which we present our approach to order service execu-tions and to infer dynamic dependencies among web services.
5.4.1 Vector ClocksOrdering events in a distributed system, such as a service oriented system,is challenging since the physical clock of different hosts may not be perfectlysynchronized. The logical clocks were introduced to deal with this problem.The first algorithm relying on logical clocks was proposed by Lamport [1978].This algorithm is used to provide a partial ordering of events, where the termpartial reflects the fact that not every pair of events needs to be related. Lam-port formulated the happens-before relation as a binary relation over a set ofevents which is reflexive, antisymmetric and transitive.
Lamport’s work is a starting point for the more advanced vector clocks de-fined by Fidge and Mattern in 1988 [Fidge, 1988; Mattern, 1989]. Like thelogical clocks, they have been widely used for generating a partial orderingof events in a distributed system. Given a system composed by N processes,a vector clock is defined as a vector of N logical clocks, where the ith clock isassociated to the ith process. Initially all the clocks are set to zero. Every timea process sends a message, it increments its own logical clock, and it attaches
9http://uddi.xml.org/10http://www.jboss.org/jbossas/11http://tomcat.apache.org/

5.4. Approach 87
the vector clock to the message. When a process receives a message, first it in-crements its own logical clock and then it updates the entire vector clock. Theupdating is achieved by setting the value of each logical clock in the vectorto the maximum of the current value and the values contained by the vectorreceived with the message.
5.4.2 Inferring dependencies among web servicesWe conceive a vector clock (VC) as a vector/array of pairs (s,n), where s isthe service id and n is number of times the service s is invoked. When an in-stance of the service s receives an execution request the vector clock is updatedaccording to the following rules:
• if the request does not contain a vector clock (e.g., a request from outsidethe system), the vector clock is created, and the pair (s,1) is added to it;
• if the request contains a vector clock and a pair with service id s is alreadycontained in the vector clock, the value of n is incremented by one; if not,the pair (s,1) is added to the vector.
Once the vector clock is updated, its value is associated to the execution ofservice s and we label it VC(s). The vector clock is then stored in a database.
Whenever an instance of the service s sends an execution request to an-other service x, then the following actions are performed:
• if the service x is an internal service, then the vector clock is attached tothe outgoing message;
• if the service x is an external service, the pair (x,1) is added to the vectorclock and the vector clock is stored in the database but not attached tothe outgoing message.
From the set of vector clocks stored in the database, we can infer the causalorder of the service executions. Given the vector clocks associated to the ex-ecution of the service i and the service j, VC(i) and VC(j), we can state thatthe execution of service i causes the execution of service j, if VC(i) <VC(j),according to the following equation:
V C(i)< V C( j)⇔∀x�
V C(i)x ≤ V C( j)x�
∧∃x ′�
V C(i)x ′ < V C( j)x ′�
(5.1)

88 Chapter 5. Dependencies among Web APIs
Figure 5.2: Example of a service oriented system to open a bank account
where VC(i)x denotes the value for n in the pair (x,n) of the vector clockVC(i). In other words, the execution of a service i causes the execution of aservice j, if and only if all the pairs contained in the vector VC(i) have valuesfor n that are less or equal to the corresponding values for n in VC(j), and atleast one value for n is smaller.
If all the corresponding pairs of the two vector clocks VC(i) and VC(j) con-tain the same values for n except one corresponding pair whose values for ndiffer exactly by 1, we state that there is a direct dependency (i.e., a directcall) between service i and service j.
If a pair with id s is missing in the vector the value for n is considered tobe 0.
Finally, to infer the dynamic dependencies among services, it is necessaryto apply the binary relation in (5.1) among each pair of vector clocks whosevalues are stored in the database.

5.4. Approach 89
5.4.3 Working ExampleConsider the example system from Figure 5.2 composed by six services insidethe enterprise boundary, one external service and one client which triggers theexecution. The system provides the services to open an account in a bankingsystem.
In this example, the client interested in creating an account needs to in-voke the service OpenAccount. This service invokes the services GetUserInfo,Deposit and RequestCreditCard. These services invoke the service WriteDB toaccess a database. WriteDB first writes in a database and then, if its invocationhas been triggered by RequestCreditCard, invokes NotifyUser which performsactions to notify the user. The external service TaxAuthority is invoked byGetUserInfo to inquire fiscal information about the user.
The execution flow resulting from the invocation of the service OpenAc-count is shown as a UML sequence diagram in Figure 5.3. The arrows in thediagram are labeled with the vector clocks associated to the execution of theinvoked service. Vector clocks with superscripts mark vector clocks associated todifferent instances of the same service. When the OpenAccount (OA) service isinvoked, there is no vector clock attached to the message, since the invocationrequest comes from outside (i.e., Client). Hence, a new vector clock (VC(OA))is created with the single pair (OA,1) and it is stored in the database. Thenthe execution of the service OpenAccount triggers the execution of the serviceGetUserInfo (GUI). When this service is invoked, a new pair (GUI,1) is addedto the vector clock, obtaining the new clock VC(GUI)=[(OA,1),(GUI,1)] that isstored in the database.
When the service GetUserInfo (GUI) invokes the external service TaxAu-thority (TA) the vector clock is set to VC(TA)=[(OA,1),(GUI,1),(TA,1)] and isstored in the database. In this way we can infer dependencies to externalservices. Since TaxAuthority (TA) is an external service and we do not havecontrol of external services the vector clock is not attached to this message.
Consider the execution of the service WriteDB (WDB), and assume we wantto infer all the services that depend on it. Since we have multiple invocationsof the service WriteDB in the execution flow, the dependent services are all theservices x whose vector clocks VC(x) satisfy the following boolean expression:
V C(x)< V C(W DB)′ ∨ V C(x)< V C(W DB)′′∨∨V C(x)< V C(W DB)′′′
These services are OpenAccount, GetUserInfo, Deposit and RequestCreditCard(see Figure 5.3).

90 Chapter 5. Dependencies among Web APIs
/Ope
nAcc
ount
(OA
)<
<in
tern
al>
>/G
etU
serI
nfo
(GU
I)<
<in
tern
al>
>/T
axA
utho
rity
(TA
)<
<ex
tern
al>
>/D
epos
it (D
)<
<in
tern
al>
>/R
eque
stCr
edit
Card
(RCC
)<
<in
tern
al>
>/W
rite
DB
(WD
B)<
<in
tern
al>
>/N
otif
yUse
r (N
U)
<<
inte
rnal
>>
/Clie
nt<
<ex
tern
al>
>
VC(O
A)=
[(O
A,1
)]VC
(GU
I)=[(
OA
,1),(
GU
I,1)]
VC(T
A)=
[(O
A,1
),(G
UI,1
),(TA
,1)]
VC(WDB)ʼ=[(OA,1),(GUI,1),(WDB,1)]
VC(D
)=[(
OA
,1),(
D,1
)]
VC(R
CC)=
[(O
A,1
),(RC
C,1)
]
VC(WDB)ʼʼ=[(OA,1),(D,1),(WDB,1)]
VC(WDB)ʼʼʼ=[(OA,1),(RCC,1),(WDB,1)]
VC(N
U)=
[(O
A,1
),(RC
C,1)
,
(
WD
B,1)
,(NU
,1)]
Figure 5.3: Sequence diagram for opening a bank account. The arrows in thediagram are labeled with the vector clocks associated to the execution of theinvoked service.

5.5. Implementation 91
If we want to infer all the services that WriteDB depends on, we look for allthe services x whose vector clock VC(x) satisfy the following boolean expres-sion:
V C(x)> V C(W DB)′ ∨ V C(x)> V C(W DB)′′∨∨V C(x)> V C(W DB)′′′
The sole service which WriteDB depends on is NotifyUser.
Consider the execution of the service OpenAccount (OA), and assume wewant to infer the services that OpenAccount depends on directly. Those servicesare the services GetUserInfo(GUI), Deposit(D) and RequestCreditCard(RCC). Theirvector clocks (VC(GUI), VC(D) and VC(RCC)) contain only one pair (respec-tively (GUI,1), (D,1) and (RCC,1)) with a value for n that is larger exactly by 1than the corresponding values in the vector clock VC(OA). Among the servicesOA and WDB there are no direct dependencies because the vector clocks corre-sponding to the execution of WDB contain two pairs with different values forn.
The values for n from the example in Figure 5.3 are all equal to 1. How-ever, they are needed to detect the presence of cycles along the executionflows. Assume that the NotifyUser service invokes the WriteDB service intro-ducing a cycle. In this case the vector clock associated to the second invocationof the service WriteDB is VC(WDB)=[(OA,1),(RCC,1),(WDB,2),(NU,1)].
5.5 ImplementationThe implementation of the proposed approach should be non-intrusive, easy-to-implement and portable to different SOA platforms. Only if these propertieshold we can be sure that the approach can be adapted in an industry setting.In this section we propose an implementation that meets these requirements.
The implementation requires three steps. First, the messages need to beinstrumented to attach the vector clock data structure. Next, we need a tech-nique to capture the incoming messages in order to retrieve the vector clock,update it and store its value in the database. Finally the outgoing messageshave to be captured to attach the updated vector clock to them.
To instrument the messages we use the SOAP header element. This ele-ment is meant to contain additional information (e.g., authentication informa-tion) not directly related to the particular message.
For example, after attaching the vector clock to the message sent from theservice GetUserInfo to the service WriteDB (see Figure 5.3), the message con-tains the following header:

92 Chapter 5. Dependencies among Web APIs
<soap:Envelope><soap:Header><vc :Vec torC lock><v c : p a i r>
<v c : s>OpenAccount</ v c : s><vc:n>1</ vc:n>
</ v c : p a i r><v c : p a i r>
<v c : s>GetUserInfo</ v c : s><vc:n>1</ vc:n>
</ v c : p a i r></ vc :Vec torC lock>
</ soap:Header>. . .</ soap:Envelope>
Concerning the interception of the incoming and outgoing messages, we adopteda technique that relies on the Pipes and Filters [Hohpe and Woolf, 2003] ar-chitectural pattern. The Pipes and Filters pattern allows to divide a larger pro-cessing task into a sequence of smaller, independent processing steps, calledFilters, that are connected by channels, called Pipes. This pattern is widelyadopted to process incoming and outgoing messages in web service enginesand frameworks such as Apache Axis2 and Apache CXF.
Those frameworks use Filters to implement the message processing tasks(e.g., messages marshaling and unmarshaling) and they allow the developersto easily extend the chains of Filters to further process messages. Since thispattern is widely used, even by the Enterprise Service Bus platforms (e.g.,MuleESB), we decided to use this pattern to implement the logic needed toretrieve, update, store and forward the vector clocks.
Instrumenting the services would be an alternative implementation ap-proach. However, instrumentation is risky since it modifies the implementa-tion and can introduce bugs. To implement our approach we use the ApacheCXF service framework. In Apache CXF the filters are called interceptors. Fig-ure 5.4 shows the chains of interceptors between an Apache CXF DeployedService and an Apache CXF Developed Consumer.
When the consumer invokes a remote service, the Apache CXF runtimecreates an outbound chain (Out Chain) to process the request. If the invo-cation starts a two-way message exchange, the runtime creates an inboundchain to process the response (omitted in Figure 5.4).
When a service receives a request from a consumer, a similar process takesplace. The Apache CXF runtime creates an inbound interceptor chain (In

5.5. Implementation 93
Figure 5.4: The chains containing our vector clock interceptors between aApache CXF Deployed Service and a Apache CXF Developed Consumer
Chain) to process the request. If the request is part of a two-way messageexchange, the runtime also creates an outbound interceptor chain (omitted inFigure 5.4).
In this implementation we add two interceptors. We add VectorClockInIn-terceptor in the In Chain to update/create the vector clock value and store itin the database. In the Out Chain we added the VectorClockOutInterceptor toattach the vector clock to the outgoing message, or to update and store thevector clock in the case of invocations to external services.
Those interceptors can be added dynamically to the chain of interceptors.This feature allows us to use our approach without re-deploying the systemunder analysis.

94 Chapter 5. Dependencies among Web APIs
5.6 ExperimentsTo investigate the impact of our approach on the service response time wedesigned and executed two experiments. The response time of a system canincrease because the approach introduces two variables. First, we introducedtwo new filters in the Pipes and Filters pattern and the Apache CXF runtimeis loaded with additional message processing tasks. Secondly, we introduceda new header element in the SOAP messages to attach the vector clock whichincreases the size of the messages passed between services.
We performed two experiments in which we measure the impact of theinstrumented Apache CXF framework (Experiment 1) and the impact of theincreasing size of the messages (Experiment 2) on the response time.
To perform our experiments the Apache CXF framework 2.4.1 is instru-mented as described in the previous section. Tomcat 7.0.19 is used as anapplication server and Hibernate 3 as Java persistence framework. On thehardware part two platforms are connected through a 100 Mbit/s Ethernetconnection:
• Platform 1: MacBook pro 6.2 , processor 2.66 GHz Intel Core i7, mem-ory 4 GB DDR3, Mac OS 10.6.5.
• Platform 2: MacBook pro 7.1 , processor 2.4 GHz Intel Core 2 Duo,memory 4 GB DDR3, Mac OS 10.6.4.
Each platform uses a MySQL 5.1.53 (Community Edition) database to storethe vector clocks values for subsequent dependencies extraction. Executiontimes are measured using the Java timer method, System.currentTime(). Thismethod returns the current value of the most precise available system timer,in milliseconds (ms).
5.6.1 Experiment 1In the first experiment we investigate the impact of the instrumented versionof the Apache CXF framework on the response time. We implemented the ex-ample shown in Figure 5.2 deploying the services within the boundary on Plat-form 1 and the external service on Platform 2. We deployed the services withinthe system in one platform to achieve more accurate timing and eliminate thenetwork overhead, which is not relevant for this experiment. Moreover theimplementation of each service contains only the logic needed to invoke otherservices. We measured the response time of the service OpenAccount in threedifferent scenarios:
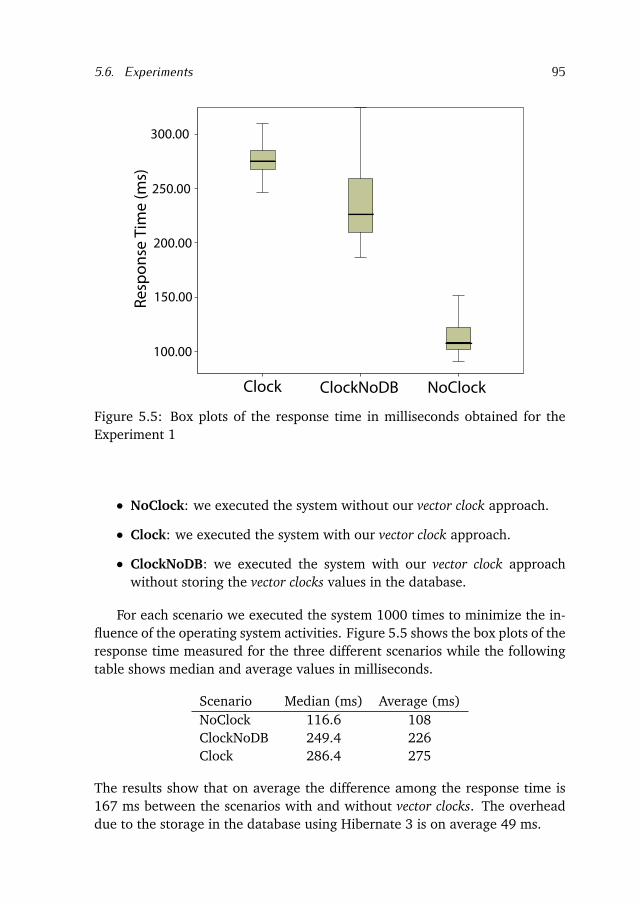
5.6. Experiments 95
NoClockClockNoDBClock
Resp
onse
Tim
e (m
s)300.00
250.00
200.00
150.00
100.00
Figure 5.5: Box plots of the response time in milliseconds obtained for theExperiment 1
• NoClock: we executed the system without our vector clock approach.
• Clock: we executed the system with our vector clock approach.
• ClockNoDB: we executed the system with our vector clock approachwithout storing the vector clocks values in the database.
For each scenario we executed the system 1000 times to minimize the in-fluence of the operating system activities. Figure 5.5 shows the box plots of theresponse time measured for the three different scenarios while the followingtable shows median and average values in milliseconds.
Scenario Median (ms) Average (ms)NoClock 116.6 108ClockNoDB 249.4 226Clock 286.4 275
The results show that on average the difference among the response time is167 ms between the scenarios with and without vector clocks. The overheaddue to the storage in the database using Hibernate 3 is on average 49 ms.

96 Chapter 5. Dependencies among Web APIs
The difference measured is relevant, but it is relative to a system whichinvolves the execution of 7 services without any business logic. The impactof our approach can be lower in real systems since the increase in millisec-onds introduced by the instrumented Apache CXF framework is expected tobe a small percentage of the total response time when additional logic is alsoexecuted.
5.6.2 Experiment 2In the second experiment we investigate the impact of the increasing messagesize on the response time. We implemented the system shown in Figure 5.6.The system is composed of 12 web services that we labeled from 1 to 12. Eachweb service Servicei invokes the Servicei+1, except the last service Service12.The invocations among services are synchronous. To take into account thenetwork overhead we deployed the Servicei on the Platform 1 if i is an oddnumber and on Platform 2 if it is even. Similarly to Experiment 1 the services’implementations do not contain any business logic except the logic needed toinvoke the other service.
Figure 5.6: System deployed to perform the Experiment 2
We measure the response time of the service Service1 while increasing thevector clock size from 1 to 2000 pairs. The vector clock is added to the messagesent to Service1 that forwards the message to Service2 until the last serviceof the execution flow is reached. For each vector clock size, this scenario isexecuted 1000 times to minimize the influence of the operating system activi-ties. The vector clocks are not stored to the database in order to achieve moreaccurate time measures.
Figure 5.7 shows the median and average of the measured response timesfor each vector clock size. As shown by the plot the increasing size of themessages has a relevant impact on the response time. Basically, the more
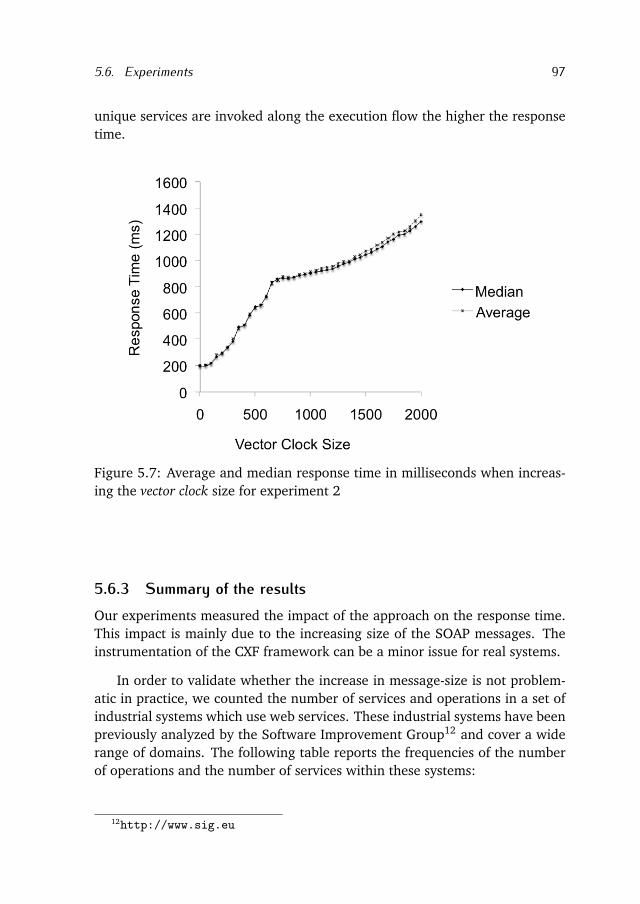
5.6. Experiments 97
unique services are invoked along the execution flow the higher the responsetime.
Figure 5.7: Average and median response time in milliseconds when increas-ing the vector clock size for experiment 2
5.6.3 Summary of the resultsOur experiments measured the impact of the approach on the response time.This impact is mainly due to the increasing size of the SOAP messages. Theinstrumentation of the CXF framework can be a minor issue for real systems.
In order to validate whether the increase in message-size is not problem-atic in practice, we counted the number of services and operations in a set ofindustrial systems which use web services. These industrial systems have beenpreviously analyzed by the Software Improvement Group12 and cover a widerange of domains. The following table reports the frequencies of the numberof operations and the number of services within these systems:
12http://www.sig.eu

98 Chapter 5. Dependencies among Web APIs
#Services #Systems #Operations #Systems1-10 31 1-10 13
11-100 6 11-100 17101-201 4 101-500 9
> 501 2
According to these results, applying our approach to extract dependenciesin the biggest system (composed of 201 services) in our repository would leadto an increase of the response time of 140 ms in the worst case. This differenceis significant for a system without any business logic, but we believe it is onlya small percentage of the response time in real systems. In our future work weplan to investigate the impact of our approach in a subset of those systems.
5.7 Conclusion & Future WorkIn this chapter, we presented a novel approach to extract dynamic dependen-cies among services using the concept of vector clocks. They allow the recon-struction of an accurate dynamic dependency graph from the execution of aservice oriented system.
We implemented our approach into the Apache CXF framework using thePipes and Filters pattern. This pattern makes our approach portable to a widerange of SOA platforms, such as Mule ESB and Apache Axis2.
The information retrievable with our approach is of great interest for bothresearchers and developers of service-oriented systems. Amongst others, thedependencies can be used to study service usage patterns and anti-patterns. Inaddition, the information can be used to identify the potential consequencesof a change or a failure in a service, also known in literature as change andfailure impact analysis.
As future work, we plan to apply our approach to extract dependencies inboth open-source and industrial systems. The extracted graphs allows us tomeasure important quality attributes of the systems under analysis, such aschangeability, maintainability and analyzability.
Moreover, we plan to further investigate the impact of our approach onthe response time of industrial systems. If the impact is significant, we plan toimprove our approach to minimize the introduced overhead.

6..Change-Prone Web APIs
Several metrics have been proposed in literature to highlight change-prone soft-ware components in order to ease their maintainability. However, to the bestof our knowledge, no such studies exist for web APIs (i.e., APIs exposed andaccessible via networks) whose popularity has grown considerably over the lastyears. Web APIs are considered contracts between providers and consumers andstability is a key quality attribute of them.
We present a qualitative and quantitative study of the change-proneness ofweb APIs with low external and internal cohesion. First, we report on an onlinesurvey to investigate the maintenance scenarios that cause changes to web APIs.Then, we define an internal cohesion metric and analyze its correlation with thechanges performed in ten well known WSDL APIs.
Our results provide several insights into the interface, method, and data-type change-proneness of web APIs with low internal and external cohesion.The results assist both providers and consumers in assessing the stability of webAPIs, and provide directions for future research.1
6.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.2 Research Questions and Approach . . . . . . . . . . . . . . . . . . . . . 103
6.3 Online Survey . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
6.4 Quantitative Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
6.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
6.6 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
6.7 Concluding remarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
Over the last years software systems have grown significantly from iso-lated software systems to distributed software systems (e.g., service-orientedsystems) [Neukom, 2004; Murer et al., 2010]. These systems consist of in-terconnected, distributed components that are implemented and deployed by
1This chapter has been published as technical report [Romano et al., 2013].
99

100 Chapter 6. Change-Prone Web APIs
different organizations or different departments within the same organiza-tion. In these systems the distributed component’s API, referred to as web APIthroughout this chapter, is considered a contract between the component’sprovider and its consumers [Erl, 2007].
One of the key factors for deploying successful web APIs, and in generalAPIs, is assuring an adequate level of stability [Erl, 2007; Daigneau, 2011;Vásquez et al., 2013]. Changes in a web API might break the consumers’systems forcing them to continuously adapt to new versions of the web API[Papazoglou, 2008; Daigneau, 2011]. For this reason, assessing the stabilityof web APIs is key to reduce the likelihood of continuous updates.
To reduce the effort and the costs to maintain software systems severalapproaches have been defined to identify change-prone software components[Girba et al., 2004; Khomh et al., 2009; Posnett et al., 2011; Penta et al.,2008]. Based on these studies software engineers can use quality indicators(e.g., software metrics, heuristics to measure antipatterns) that can estimatethe components’ change frequency and can assist them in taking appropriatecountermeasures. However, to the best of our knowledge, none of these stud-ies investigates change indicators for web APIs. We believe that this is mainlydue to the lack of publicly available web APIs with long histories which makesperforming such studies challenging for reasearchers.
Change-proneness indicators would bring relevant benefits for bothproviders and consumers. On the one hand, consumers can estimate thechange-proneness of suitable web APIs available on the market and subscribeto the most stable one. On the other hand, providers want to publish stableweb APIs to reduce the maintenance effort and to attract more consumers and,consequently, increase their profits.
Among all the structural properties of web APIs (e.g., complexity and size),we believe that the cohesion can affect their change-proneness. Our intuitionis based on our work shown in Chapter 2 and existing work [Perepletchikovet al., 2007, 2010]. In Chapter 2, we showed that, among the existing sourcecode metrics, the external cohesion has the strongest correlation with the num-ber of changes performed in Java interfaces. Moreover, Perepletchikov et al.[Perepletchikov et al., 2007, 2010] showed that the cohesion can affect theunderstandability and, consequently, the maintainability of web APIs.
In this chapter, to assist both providers and consumers, we use a mixedmethod approach [Creswell and Clark, 2010] to analyze the impact of the in-ternal and external cohesion on the change-proneness of web APIs. Internalcohesion measures the cohesion of the operations (also referred to as meth-ods) of a web API. External cohesion measures the extent to which the oper-

6.1. Background 101
ations of a web API are used together by external consumers (also referred toas clients).
In the first part of our study, we use an online survey to investigate 1) theinterface and method level change-proneness of web APIs with low externalcohesion and 2) the interface and data-type level change-proneness of webAPIs with low internal cohesion. The results show the likelihood with whichmaintenance scenarios can cause changes in web APIs affected by low internaland external cohesion.
The second part of our study consists of a quantitative analysis of thechange-proneness of web APIs with low internal cohesion. We first introducethe Data Type Cohesion (DTC) metric to overcome the problem of the existinginternal cohesion metrics. Based on frequent discussions with industrial part-ners and colleagues, we believe that the existing metrics should be improvedbecause they do not take into account the cohesion among data types. Wethen analyze the change-proneness of ten public WSDL2 (Web Service Descrip-tion Language) APIs investigating the correlation between our DTC metric andthe number of changes performed in the WSDL APIs. The results show thatthe values for the DTC metric are correlated with the number of changes theWSDL APIs undergo to.
The contributions of this chapter are:
• insights into the likelihood of maintenance scenarios to cause changesin web APIs with low internal and external cohesion.
• a new internal cohesion metric that takes into account the cohesionamong data types to highlight change-prone WSDL APIs.
• guidelines for researchers to investigate the method level of web APIswith low external cohesion and the data-type level of web APIs with lowinternal cohesion.
6.1 BackgroundThe concept of software cohesion has been widely investigated in the con-text of different programming paradigms [Briand et al., 1998; Counsell et al.,2006; Perepletchikov et al., 2007; Kumar et al., 2011; Zhao and Xu, 2004].In this chapter we adhere to the classification defined by Perepletchikov etal. [Perepletchikov et al., 2007, 2010] who investigated the cohesion of webAPIs. According to their classification there are 8 different levels of cohesion
2http://www.w3.org/TR/wsdl

102 Chapter 6. Change-Prone Web APIs
involving web APIs: coincidental, logical, temporal, communicational, external,implementation, sequential, and conceptual. In this chapter we focus on the ex-ternal and communicational cohesion to which we refer as internal cohesion.The internal cohesion measures the cohesion of the operations (also referredas methods throughout the chapter) declared in a web API. Similar to themethod cohesion (i.e., LCOM) defined by Chidamber et al. [Chidamber andKemerer, 1991, 1994], the internal cohesion expresses the extent to which theoperations belong together counting their common parameters. The externalcohesion measures the extent to which the operations of a web API are usedby external consumers (also called clients). In the next subsections, first, wepresent existing metrics proposed in literature to measure the external andinternal cohesion. Then, we present the existing antipatterns in web APIs thatresult from low internal and external cohesion.
6.1.1 Cohesion MetricsTo compute the external cohesion of a web API, Perepletchikov et al. [Pere-pletchikov et al., 2007, 2010] proposed the SIUC (Service Interface Usage Co-hesion) metric. This metric computes the sum of operations invoked by eachclient normalized by the number of clients and operations declared in the webAPI. To the best of our knowledge there are no further studies proposing othermetrics for measuring the external cohesion.
Existing studies propose different metrics to measure the internal cohe-sion of web APIs. Perepletchikov et al. [Perepletchikov et al., 2007, 2010]proposed the SIDC (Service Interface Data Cohesion) metric, Sindhgatta et al.[Sindhgatta et al., 2009] proposed the LCOS (Lack of COhesion in Service)and the SFCI (Service Functional Cohesion Index). Even though their formulasdiffer, these metrics have in common that they only measure the degree towhich operations use common messages without considering the cohesion ofmessages. For this reason, in this paper, we refer to these existing metrics asmessage-level metrics.
6.1.2 AntipatternsIn literature different antipatterns for web APIs, and more in general forAPIs, have been proposed [Moha et al., 2012; Rotem-Gal-Oz, 2012; Král andZemlicka, 2007; Cherbakov et al., 2006; Dudney et al., 2002; Martin, 2002].Among the proposed antipatterns two antipatterns in web APIs are symptomsof low internal and external cohesion: the Multiservice [Dudney et al., 2002]and the Fat [Martin, 2002] antipatterns.
The Multiservice antipattern was originally conceived by Dudney et al.

6.2. Research Questions and Approach 103
<<webAPI>> CommerceAPI
placeOrder() reserveInventory() generateInvoice() acceptPayment() validateCredit() getOrderStatus() cancelOrder() getPaymentStatus()
Figure 6.1: Example of a Multiservice web API (symptom of low internal co-hesion). It exposes operations related to five different business entities (i.e.,Order, Inventory, Invoice, Payment, and Credit).
[Dudney et al., 2002] and it is also known as God Object in literature [Mohaet al., 2012]. A Multiservice web API exposes many operations that are re-lated to different business entities. The CommerceAPI shown in Figure 6.1is an example of a Multiservice API. This API exposes operations related tofive different business entities: Order, Inventory, Invoice, Payment, and Credit.Such a web API ends up to be low internally cohesive because of the differ-ent entities encapsulated by it. As a consequence, many clients can invokesimultaneously its operations causing performance bottlenecks [Moha et al.,2012].
The Fat antipattern was proposed by Martin in [Martin, 2002]. This an-tipattern occurs in web APIs and other types of APIs, such as Java interfaces.A Fat web API is an API with disjoint sets of operations that are invoked bydifferent clients and, hence, they show low external cohesion. The BankAPIshown in Figure 6.2 is an example of a Fat API. The Student and Professionalclients invoke two disjoint sets of operations. Martin proposed the InterfaceSegregation Principle (ISP) to refactor such APIs. The ISP states that Fat APIsneed to be split into smaller APIs according to its clients’ usage. Each smallerAPI should be specific to a client and each client should only know about theset of operations it is interested in.
6.2 Research Questions and ApproachThe change-proneness of web APIs is relevant to design and maintain largedistributed information systems [Murer, 2011; Murer et al., 2010]. To better
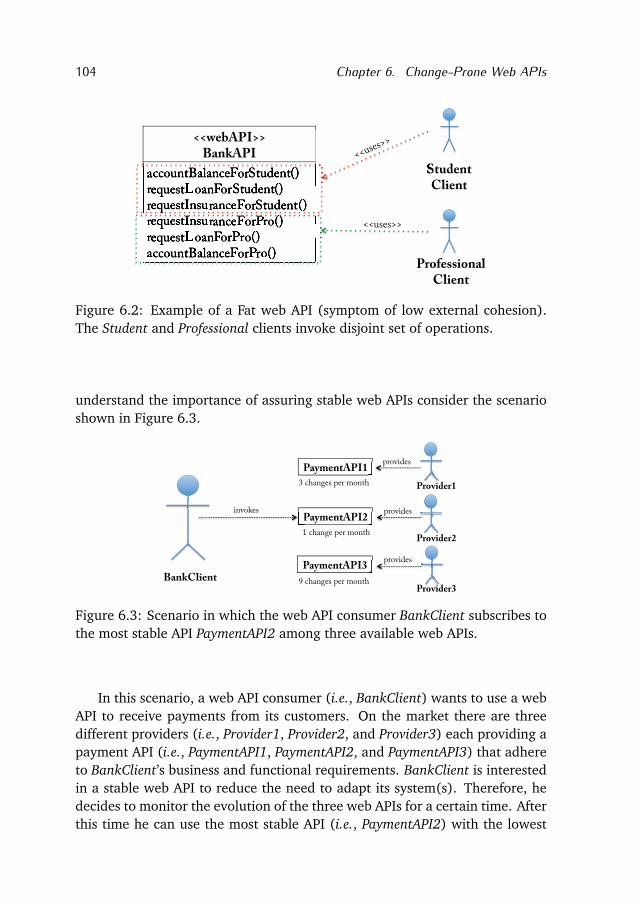
104 Chapter 6. Change-Prone Web APIs
<<webAPI>> BankAPI
accountBalanceForStudent() requestLoanForStudent() requestInsuranceForStudent() requestInsuranceForPro() requestLoanForPro() accountBalanceForPro()
Student Client
Professional Client
<<uses>>
Figure 6.2: Example of a Fat web API (symptom of low external cohesion).The Student and Professional clients invoke disjoint set of operations.
understand the importance of assuring stable web APIs consider the scenarioshown in Figure 6.3.
BankClient
Provider1
Provider2
Provider3
PaymentAPI1
PaymentAPI2
PaymentAPI3
provides
provides
provides
Pinvokes
3 changes per month
1 change per month
9 changes per month
Figure 6.3: Scenario in which the web API consumer BankClient subscribes tothe most stable API PaymentAPI2 among three available web APIs.
In this scenario, a web API consumer (i.e., BankClient) wants to use a webAPI to receive payments from its customers. On the market there are threedifferent providers (i.e., Provider1, Provider2, and Provider3) each providing apayment API (i.e., PaymentAPI1, PaymentAPI2, and PaymentAPI3) that adhereto BankClient’s business and functional requirements. BankClient is interestedin a stable web API to reduce the need to adapt its system(s). Therefore, hedecides to monitor the evolution of the three web APIs for a certain time. Afterthis time he can use the most stable API (i.e., PaymentAPI2) with the lowest

6.2. Research Questions and Approach 105
change frequency (i.e., 1 change per month).
In a real world scenario, where time-to-market is important for gainingcompetitive advantage, BankClient typically does not have the time to moni-tor the stability of different web APIs. Moreover, the number of past changesmight not be available and they might not be a good indicator for futurechanges. For instance, an API might have been refactored to improve itschange-proneness. Furthermore, from the perspective of providers, they areinterested in providing stable web APIs to increase the likelihood with whichclients subscribe to their APIs and, consequently, increasing their profits.
In this chapter, we investigate the relationship between internal and ex-ternal cohesion and the change-proneness of web APIs. The results can assistweb APIs consumers and providers in estimating the stability of web APIs. Inthe following, we motivate and state our research questions, as well as, outlineour research approach.
6.2.1 External Cohesion and Change-PronenessConcerning web APIs with low external cohesion we want to investigate whichscenarios are more likely to cause future changes in Fat web APIs. Moreover,we want to analyze the change-proneness of methods exposed in such webAPIs. APIs with low external cohesion can have two different types of methods.Shared methods are methods invoked by all different clients. In Figure 6.4requestInsurance() is a shared method since both the Student and Professionalclients invoke it. Non-shared methods are methods invoked only by a specificclient (e.g., the requestLoanForStudent() method in Figure 6.4). We believethat these two classes of methods can be changed for different reasons andknowing these reasons can give further insights into the change-proneness ofweb APIs with low external cohesion. To assist providers in evaluating thechange-proneness of their web APIs with low external cohesion, we answerthe following research question:
• RQ1: What are the scenarios in which developers change web APIs withlow external cohesion? In which cases do they change the shared andnon-shared methods?
We investigate the change-proneness on two different levels: interfacelevel (i.e., change-proneness of a web API as a whole) and method level (i.e.,change-proneness of the methods exposed by a web API). The results fromthis research question assist only providers because consumers typically donot have access to the information needed to measure the external cohesion(i.e., how other consumers invoke the API).

106 Chapter 6. Change-Prone Web APIs
<<webAPI>> BankAPI
accountBalanceForStudent() requestLoanForStudent() requestInsurance() requestLoanForPro() accountBalanceForPro()
Student Client
Professional Client
<<uses>>
Figure 6.4: Web API with low external cohesion where only the method re-questInsurance() is shared by the two different clients Student Client and Pro-fessional Client.
6.2.2 Internal Cohesion and Change-PronenessSimilar to external cohesion we investigate which scenarios are more likelyto cause changes in Multiservice web APIs (i.e., web APIs with low internalcohesion). Furthermore, we analyze the change-proneness of the data typesdeclared within a web API. This allows to highlight the differences betweenthe change-proneness of shared data types (i.e., data types referenced multipletimes within a web API) and non-shared data types (i.e., data types referencedonly once). To evaluate the change-proneness of web APIs with low internalcohesion, we answer the following research question:
• RQ2: What are the scenarios in which developers change web APIs withlow internal cohesion? In which cases do they change the shared andnon-shared data types?
We investigate the change-proneness on two different levels: interfacelevel (i.e., change-proneness of a web API as a whole) and data-type level(i.e., change-proneness of the data types declared in a web API). Differently toRQ1, the results from RQ2 assist both, providers and consumers. Both haveaccess to the web API to measure the internal cohesion.
6.2.3 Internal Cohesion Metrics as Change IndicatorsTo make the results from RQ2 actionable in an industrial environment [Bouw-ers et al., 2013] a metric should be used to measure the internal cohesion.

6.2. Research Questions and Approach 107
However, as shown in Section 6.1, the existing metrics are message-level met-rics that do not consider the usage of data types to compose messages. Tounderstand this drawback consider the two examples in Figure 6.5.
operation1
operation2
message1 type1
type2
type3
(a) Two operations operation1 and operation2 that use thesame message message1.
operation1
operation2
message1 type1 type2
type3 message2 type4
(b) Two operations operation1 and operation2 that use differ-ent messages message1 and message2 referencing indirectly thesame data types type2 and type3.
Figure 6.5: Example that shows the drawback of existing message-level inter-nal cohesion metrics SIDC, LCOS, and SFCI.
The web API shown in Figure 6.5a exposes two operations operation1 andoperation2 that use the same message message1. The message-level metrics arecapable to detect the cohesion of this web API, however, fail when measuringthe cohesion of the web API shown in Figure 6.5b. This API has two operationsoperation1 and operation2 that use different messages, namely message1 andmessage2. In this case the message-level metrics result in a low value of co-hesion. However, message1 and message2 reference the same data types type2and type3. We argue that the web API is cohesive because both, type1 andtype4 (referenced by respectively message1 and message2), are complex datatypes composed of type2 and type3.
To overcome this problem Bansiya et al. [Bansiya and Davis, 2002] de-fined the CAMC (Cohesion Among Methods of Class) metric that measures thecohesion of object oriented classes. In this chapter we adapt the CAMC metricfor web APIs proposing the Data Type Cohesion (DTC) metric. For a web API

108 Chapter 6. Change-Prone Web APIs
s, DTC is computed as follows:
DT C(s) =
∑
x ,yεOp(s) Co(x , y)
|Op(s)|(6.1)
where Op(s) represents the set of operations exposed in s. Co(x , y) is thecohesion between two operations x and y, and it is defined as:
Co(x , y) =
∑
m,nεM P(s) Cd t(m, n)
|M P(s)|(6.2)
where MP(s) is the set of all message pairs used by x and y; Cd t(m, n) is thecohesion between the messages m and n computed as:
Cd t(m, n) =Com(m, n)
Com(m, n) + Uncom(m, n)(6.3)
where Com(m, n) represents the number of data types referenced by bothmessages m and n; and Uncom(m, n) is the number of data types referencedonly in one message.
To investigate quantitatively the change-proneness of web APIs with lowinternal cohesion we answer the following research question:
• RQ3: To which extent does the DTC metric highlight change-proneWSDL APIs? Which data types declared in a WSDL API are more change-prone?
Similar to RQ2 we investigate the change-proneness on two different levels:interface level and data-type level. The results from RQ3 are useful for both,providers and consumers, interested in measuring the internal cohesion in or-der to highlight change-prone web APIs and change-prone data types declaredby them.
6.2.4 Research ApproachTo answer our research questions we adopt a mixed method approach [Creswelland Clark, 2010]. First, we answer RQ1 and RQ2 with a qualitative analysisconsisting of an online survey. Then, following an exploratory sequential ap-proach [Creswell and Clark, 2010], we refine the results from RQ2 with aquantitative analysis aimed at answering RQ3. Note, we do not quantitativelyrefine the results from RQ1 because the needed information ( i.e., how con-sumers invoke web APIs) are not available. We present the study, the analysismethods and the results of the qualitative and quantitative analyses respec-tively in Section 6.3 and Section 6.4.

6.3. Online Survey 109
6.3 Online SurveyTo answer the first two research questions RQ1 and RQ2, we performed anonline survey consisting of three different parts. The first part of the surveyintroduces the terminology that might be used differently in academia andin industry. The next questions are on the background of participants. Inparticular, we asked information about their current position within their in-stitutions/companies and their background in the areas involving web APIs(i.e., service-oriented, cloud computing, WSDL APIs, and RESTful APIs).
In the second part, the questions are aimed at investigating the change-proneness of four SOA antipatterns (i.e., Fat, Multiservice, Tiny, and SandPileantipatterns). In this chapter, we focus on and report the results about the Fatantipattern (RQ1) and the Multiservice antipattern (RQ2). We do not reportthe results about the Tiny and the SandPile antipatterns because they are notsymptoms of web APIs with low external and/or internal cohesion. In fact,they are symptoms of inadequate granularity [Moha et al., 2012] and subjectof our future work.
In the third and final part of the survey, we asked participants to share theirexperiences with other design practices that can affect the change-pronenessof web APIs and have not been covered by the survey. They are meant to drawdirections for future work on this subject. Then, we asked questions to assesstheir prior knowledge about the antipatterns presented in the survey.
Before publishing our survey, we conducted three rounds of pilots withfive software engineering researchers with a strong background in qualitativeanalyses. In each round we refined the survey questions and its structurebased on their feedback. This step was necessary to attract participants incompleting the survey. The complete survey is available on our website.3
In the following subsections, we first present information about the partic-ipants and their background and, then, we answer our research questions RQ1and RQ2. For each research question we present the data used, the analysismethod, and the results to answer it.
6.3.1 ParticipationOur survey was opened on July 1st, 2013 and closed on July 31st. We for-warded the survey to our industrial partners and academics working on re-search topics related to web API development. Moreover, we advertised it ingoogle groups related to web APIs. During this time we collected responsesfrom 79 participants among which 47 (59.5%) completed the entire survey an-
3http://goo.gl/f0gi17

110 Chapter 6. Change-Prone Web APIs
swering all questions. Given that participants needed to answer 36 questions,investing on average approximately 40 minutes of their time, we consider ita good number of participants and a high rate of completion [Smith et al.,2013].
Among the 79 participants 44 work in industry, 30 in academia, and 5 inboth academia and industry. Participants rated their background on a 5-pointLikert scale ranging from absent, weak, medium, good, to strong. Participants,who answered the questions of the second and third part, have at least agood background in at least one of the following areas: service-oriented, cloudcomputing, WSDL APIs, and RESTful APIs. Few participants have an absentor weak background in any of these topics and quit the survey just after thebackground questions.
Interestingly, 72.7% of the participants answered that they do not knowany metric/quality indicators to estimate the change-proneness of web APIs.The most common indicators used by the remaining 27.3% are the responsetime and information about the changes (e.g., number of changes between twoversions, number of operations changed, etc.).
6.3.2 External Cohesion and Change-PronenessTo investigate the answer to RQ1, we analyzed the change-proneness of webAPIs with low external cohesion on two different levels: interface level andmethod level.
Interface Level Change-PronenessFocusing on the interface level, we asked the participants to rank six scenariosthat can lead a Fat web API to be changed. As discussed in Section 6.2, thisantipattern is a symptom of web APIs with low external cohesion. Table 6.1shows the list of scenarios. We derived them from our frequent discussionswith our industrial and academic partners and colleagues. Furthermore, weasked the participants to state additional scenarios in a text box. For eachscenario, 53 participants ranked the likelihood on a 5-point Likert scale: 0(Won’t change), 1 (Might change), 2 (Likely to change), 3 (Very likely to change),and 4 (Sure will change).
We first used the non-parametric Kruskal-Wallis rank sum test [Kruskaland Wallis, 1952] to analyze whether there is a difference between the sce-narios to cause changes. Kruskal-Wallis tests whether samples originate fromthe same distribution comparing three or more sets of scores (i.e., the valuesof the 5-point Likert scale) that come from different groups (i.e., the differ-ent scenarios). We used the non-parametric Kruskal-Wallis test because the

6.3. Online Survey 111
Table 6.1: Scenarios that cause changes in Fat web APIs (i.e., web APIs withdisjoint sets of operations that are invoked by different clients indicating lowexternal cohesion).
Id A Fat API is changed because ...Fat1 its clients have troubles in understanding it.Fat2 having a specific method for each client would
introduce clones and the API would becomehard to be maintained
Fat3 it is a bottleneck for the performance of the sys-tem. It should be split into APIs specific for eachdifferent client (i.e., Interface Segregation Prin-ciple [Martin, 2002]).
Fat4 different developers work on the specific func-tionalities for the different clients.
Fat5 if the functional requirements of a clientchange, the other clients will be affected as well.
Fat6 test cases for all clients should pass before theAPI can be deployed.
distributions of scores given by the participants are ordinal and non-normallydistributed. Moreover, this test has been designed to compare three or moredistributions in contrast to the non-parametric Mann-Whitney test [Lehmannand D’Abrera, 1975] that compares two distributions. Performing the Kruskal-Wallis rank sum test among the scores given to the different scenarios resultedin a p-value < 0.01. This shows that the given scenarios cause changes to Fatweb APIs with different probabilities.
The distributions of the scores given to the different scenarios are reportedin Figure 6.6. To analyze these probabilities, we ranked the scenarios by themedian and mean values. According to this ranking the Fat2 is the most likelyscenario with a median value of 3. This means that a Fat web API is verylikely to be changed to reduce the amount of clones and ease maintainability.The second most likely scenario is Fat1. According to its median score of 2,a Fat web API is likely to be changed to improve its understandability for theclients. The other 4 scenarios have median values equal to 1 indicating thatthey might force a Fat web API to be changed.
To conclude and answer the first part of RQ1, we can state that: 1) Fat webAPIs are very likely to be changed to ease maintainability and reduce clones;2) they are also likely to be changed for improving understandability.
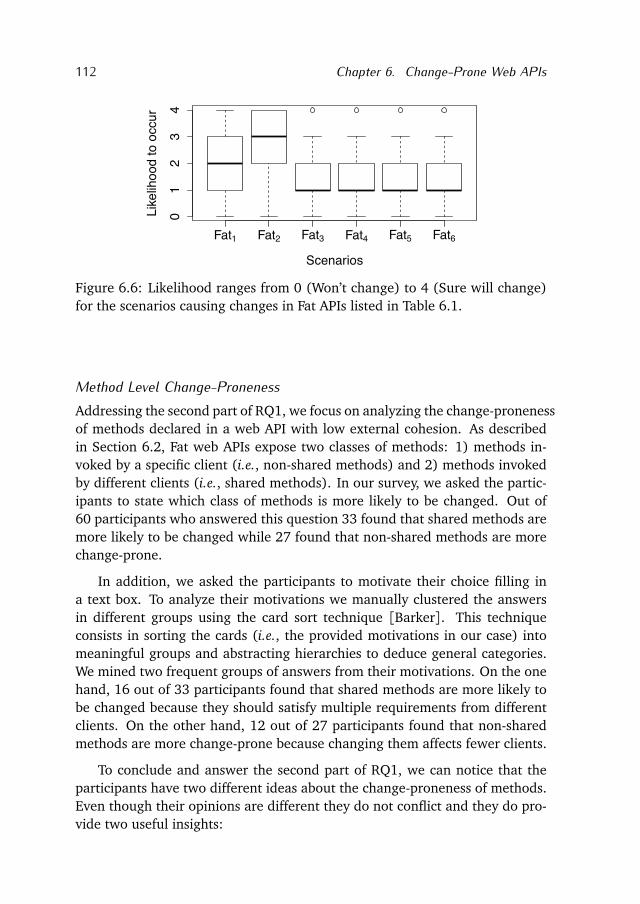
112 Chapter 6. Change-Prone Web APIs
Fat1 Fat2 Fat3 Fat4 Fat5 Fat6
01
23
4
Scenarios
Likeli
hood
to o
ccur
Figure 6.6: Likelihood ranges from 0 (Won’t change) to 4 (Sure will change)for the scenarios causing changes in Fat APIs listed in Table 6.1.
Method Level Change-PronenessAddressing the second part of RQ1, we focus on analyzing the change-pronenessof methods declared in a web API with low external cohesion. As describedin Section 6.2, Fat web APIs expose two classes of methods: 1) methods in-voked by a specific client (i.e., non-shared methods) and 2) methods invokedby different clients (i.e., shared methods). In our survey, we asked the partic-ipants to state which class of methods is more likely to be changed. Out of60 participants who answered this question 33 found that shared methods aremore likely to be changed while 27 found that non-shared methods are morechange-prone.
In addition, we asked the participants to motivate their choice filling ina text box. To analyze their motivations we manually clustered the answersin different groups using the card sort technique [Barker]. This techniqueconsists in sorting the cards (i.e., the provided motivations in our case) intomeaningful groups and abstracting hierarchies to deduce general categories.We mined two frequent groups of answers from their motivations. On the onehand, 16 out of 33 participants found that shared methods are more likely tobe changed because they should satisfy multiple requirements from differentclients. On the other hand, 12 out of 27 participants found that non-sharedmethods are more change-prone because changing them affects fewer clients.
To conclude and answer the second part of RQ1, we can notice that theparticipants have two different ideas about the change-proneness of methods.Even though their opinions are different they do not conflict and they do pro-vide two useful insights:

6.3. Online Survey 113
• shared methods are changed when the requirements of their differentclients evolve differently.
• otherwise developers tend to change non-shared methods because theimpact of a change is lower.
6.3.3 Internal Cohesion and Change-PronenessSimilar to RQ1, we answer RQ2 analyzing the change-proneness of web APIswith low internal cohesion on two different levels: interface level and data-type level.
Interface Level Change-PronenessThe first part of RQ2 aims at investigating scenarios that can cause changes inMultiservice web APIs. As discussed in Section 6.1, this antipattern is a symp-tom of web APIs with low internal cohesion. Similar to before, we providedthe participants with seven scenarios to be ranked on the same 5-point Lik-ert scale. Table 6.2 lists the seven scenarios stemming from discussions withour industrial and academic partners. Furthermore, we asked them to stateadditional scenarios in a text box. 51 participants ranked these scenarios.
To analyze the results we followed the same approach used for analyzingthe Fat web APIs’ results before. First, we used the Kruskal-Wallis rank sumtest to verify whether there is a statistical difference between the distributionsof scores given to the different scenarios. The test resulted in a p-value<0.01indicating that these scenarios cause changes to Multiservice web APIs withdifferent probabilities.
Then, we ranked the scenarios based on the median and mean values oftheir scores. The distributions of the scores given to the different scenarios arereported in Figure 6.7. The ranking shows that a Multiservice web API is verylikely to be changed because of the different entities encapsulated by theseweb APIs (MS1). These changes can affect different clients even though theyare not interested in the changed entity (MS2). Multiservice web APIs are alsovery likely to be changed to improve their understandability (MS7). Further-more, the scenarios MS3, MS4, MS5 and MS6 are likely to cause changes.
To conclude and answer the first part of RQ2, we can state that Multiser-vice web APIs are very likely to be changed because: 1) every time it changesmany clients are affected (MS2); 2) the web API can change for different rea-sons caused by the different entities (MS1); and 3) understanding the web APIis complicated for its clients (MS7).

114 Chapter 6. Change-Prone Web APIs
Table 6.2: Scenarios that cause changes in Multiservice web APIs (i.e., APIsthat expose many operations that are related to different business entities).
Id A Multiservice API is changed because ...MS1 every business entity can change for different
reasons (e.g., different evolving requirements).A new version should be published every timeone of these entities changes.
MS2 changes to the API affect many clients (eventhough they do not use the changed businessentity).
MS3 all the tests involving the different entitiesshould pass before the entire web API is de-ployed.
MS4 the number of invocations to the Multiserviceweb API is high due to the different businessentities.
MS5 proper pool tuning techniques are needed toachieve adequate performance due to the nu-merous clients.
MS6 different developers work on different businessentities.
MS7 many business entities are exposed complicat-ing the understanding of the API.
Data-Type Level Change-PronenessAddressing the second part of RQ2, we focus on analyzing the change-pronenessof data types declared in Multiservice web APIs with low internal cohesion. Inour survey, we asked participants to select which of the two classes of datatypes is more change-prone: shared data types (referenced more than oncein a web API) and non-shared data types (referenced only once). Out of 48participants who answered this question 30 (62.5%) found that non-shareddata types are more likely to be changed, while 18 (37.5%) found that shareddata types are more change-prone.
In addition, participants motivated their answers filling in a text box. Ap-plying the card sort technique we manually clustered their motivations intotwo common groups of answers. On the one hand, 12 out of 18 participantsstated that shared data types are likely to be changed because they are used bydifferent messages and/or data types that can force them to change. In otherwords, they have multiple causes to change. On the other hand, 8 out of 30participants stated that non-shared data types are more change-prone because

6.4. Quantitative Analysis 115
MS1 MS2 MS3 MS4 MS5 MS6 MS7
01
23
4
Scenarios
Likeli
hood
to o
ccur
Figure 6.7: Likelihood ranges from 0 (Won’t change) to 4 (Sure will change)for the scenarios causing changes in Multiservice APIs listed in Table 6.2.
developers prefer to share stable data types that represent generic businessabstractions.
Similarly to the change-proneness of methods, the participants have twodifferent opinions. However, they do not conflict and give two relevant in-sights into the change-proneness of data types:
• shared data types are changed when their operations evolve differently.
• otherwise developers tend to change non-shared data types because theimpact of a change is lower.
6.4 Quantitative AnalysisThe goal of the quantitative analysis is to provide an answer to RQ3, and con-sequently refine the results from RQ2. To reach this goal, we analyzed thecorrelation between the DTC cohesion metric and the number of changes per-formed in the different versions of ten public WSDL APIs. Table 6.3 lists theselected WSDL APIs from Amazon,4 eBay,5 and FedEx6 with their basic char-acteristics. WSDL is a standard interface description language used by manyservice-oriented systems to describe the functionality offered by a web API.We selected these WSDL APIs because they have sufficiently long histories asindicated by the increase in number of operations and data types. Further-more, they have been used and discussed for similar studies in prior research
4http://aws.amazon.com5http://developer.ebay.com6http://www.fedex.com/us/web-services

116 Chapter 6. Change-Prone Web APIs
Table 6.3: WSDL APIs selected for the quantitative analysis showing the name(WSDL_API), the number of versions (Vers), the number of operations in thefirst and last versions (Ops), and the number of data types in the first and lastversion (Types).
WSDL_API Vers Ops TypesAmazonEC2 22 14-118 60-463AmazonFPS 3 29-27 19-18AmazonQueueService 4 8-15 26-51AWSECommerceService 5 23-23 35-35AWSMechanicalTurkRequester 6 40-44 86-102eBay 5 156-156 897-902FedExPackageMovement 4 2-2 15-15FedExRateService 11 1-1 43-140FedExShipService 8 1-7 74-166FedExTrackService 5 3-4 29-33
[Fokaefs et al., 2011]. Even though a bigger data set is desirable, having ac-cess to WSDL APIs with long histories is not a trivial task. Most of them areused in a closed environment allowing access only to registered customers.
6.4.1 Interface Level Change-Proneness ofWSDL APIs
For analyzing the change-proneness of the selected WSDL APIs we first com-puted the values for the DTC metric for each version of each WSDL API. Next,we extracted the changes between each pair of subsequent versions of a WSDLAPI. The changes were extracted using our WSDLDiff tool (presented in Chap-ter 4) that loads the specification of two versions of a WSDL API and com-pares them by using the differencing algorithm provided by the Eclipse EMFCompare plugin.7 In particular, WSDLDiff extracts the types of the elementsaffected by changes (e.g., Operation, Message, Data Type) and the types ofchanges (e.g., removal, addition, move, attribute value update). With this, WS-DLDiff is capable of extracting changes, such as "a message has been added toan operation" or "the name of an attribute in a data type has been modified".We refer to these changes as fine-grained changes. Using WSDLDiff for eachversion of a WSDL API we counted the number of fine-grained changes thatoccurred between the current and previous version.
7http://www.eclipse.org/modeling/emf/

6.4. Quantitative Analysis 117
We used the Spearman rank correlation for computing the correlation be-tween the values of the DTC metric and the number of changes. Spearmancompares the ordered ranks of two variables to measure a monotonic rela-tionship. We chose the Spearman correlation because it does not make as-sumptions about the distribution, variances and the type of the relationship[S.Weardon and Chilko, 2004]. A Spearman value (i.e., rho) of +1 and -1indicates high positive or high negative correlation, whereas 0 indicates thatthe variables under analysis do not correlate at all. Values greater than +0.3and lower than-0.3 indicate a moderate correlation; values greater than +0.5 and lower than-0.5 are considered to be strong correlations [Hopkins, 2000].
The result of the Spearman correlation analysis shows that the DTC metrichas a significant and moderate negative correlation with a rho value equal to-0.361 (i.e., rho<-0.3) and with a p-value equal to 0.007.
Moreover, we computed the values of the existing message-level metrics(i.e., LCOS, SFCI, and SIDC) on the same WSDL APIs. We found out thattheir values are always 0 or 1. For instance, the value for LCOS is 1 in 62 outof 73 versions and 0 in 11 versions. Manually analyzing the WSDL APIs wenoticed that this is due to their design. As shown by the example in Figure 6.5bmessages reference different data types that are used as wrappers to isolate thedata type declarations from the declaration of the operations and messages.For the WSDL APIs under analysis, this result confirms that existing metricssuffer from the problem explained in Section 6.2 and discussed in previouswork [Bansiya and Davis, 2002].
We can conclude that DTC shows a moderate correlation, indicating that inincrease in the internal cohesion is associated with a decrease in the numberof changes.
6.4.2 Data-Type Level Change-Proneness ofWSDL APIs
To detail these results, we investigated the change-proneness of shared andnon-shared data types. For each data type in each version, we computed thenumber of times they are referenced in the WSDL API and the number ofchanges as extracted by our WSDLDiff tool. Next, we used Spearman to com-pute the correlation between these two metrics. Table 6.4 presents the resultsof this analysis.
Looking at the p-values of the correlation analysis, we note that significantresults were obtained for 5 WSDL APIs (i.e., p-value< 0.01). Among them thevalues for three WSDL APIs show a strong correlation (i.e., rho<-0.5) and for

118 Chapter 6. Change-Prone Web APIs
Table 6.4: Results of the Spearman correlation analysis between the numberof references and number of changes of data types. Bold values highlightsignificant correlations.
WSDL p-value rhoAmazonEC2 0.248 -0.048AmazonFPS 0.612 -0.104AmazonQueueService 0.301 -0.130AWSECommerceService 0.089 0.291AWSMechanicalTurkRequester 0.000 -0.502eBay 0.638 -0.015FedExPackageMovement 0.005 -0.512FedExRateService 0.000 -0.418FedExShipService 0.000 0.193FedExTrackService 0.000 -0.559
one WSDL API they show a moderate correlation (i.e., rho<-0.3). These corre-lations indicate that the more a data type is referenced the less change-proneit is. Manually analyzing a sample set of shared data types, we found thatthey represent generic business entities or satellite data used by operations ofthe same domain. Hence, we assume that their requirements do not evolvedifferently. For instance, the ClientDetail in FedexShipService is a shared datatype referenced directly and indirectly on average 9 times by shipment oper-ations that require information about the client. This data type encapsulatesdescriptive data about clients and it did not change across the releases. Thisresult partially confirms the results of our survey namely: shared data typesare change-prone if referenced by operations with different requirements, oth-erwise developers tend to change non-shared data types.
Based on these results, we can answer RQ3 stating that the DTC metric isable to highlight change-prone WSDL APIs. Moreover, we can partially confirmthe insights of our participants about change-prone data types. However, tofully validate this result a bigger data set is needed. An ideal data set wouldconsist of several WSDL APIs with long histories and from different domainsor companies. This is needed to avoid that the results might be WSDL orcompany specific. Unfortunately, as already discussed, getting access to theseartifacts is challenging.

6.5. Discussion 119
6.5 DiscussionIn this section we summarize the results of our study, discuss the implicationsof the results and the threats to validity.
6.5.1 Summary of the ResultsSummarizing the findings of our study, we found that Fat web APIs are verylikely to be improved to reduce clones and ease maintainability and they arelikely to be changed to improve understandability (RQ1). Multiservice APIsare very likely to be improved because such a web API declares different busi-ness entities and a change in one entity typically affects all the clients. Similarto Fat web APIs, Multiservice APIs are also affected by understandability issues(RQ2).
Analyzing the change-proneness of methods and data types we found thatboth shared messages and shared data types are likely to be changed if theyare shared by clients and operations with different requirements (RQ1 andRQ2). For instance, if two clients with different requirements invoke the sameoperations, these operations change every time one of the two clients’ require-ments change. Hence, they are more change-prone.
If modification tasks are not driven by clients’ or operations’ requirementsthen developers tend to modify non-shared operations and non-shared datatypes to keep the impact of a change low (RQ1 and RQ2).
To compute the internal cohesion and making the results of RQ2 action-able, useful metrics are needed [Bouwers et al., 2013]. This led us to intro-duce the DTC metric and to investigate its ability to highlight change-proneWSDL APIs. The quantitative study showed that DTC is able to highlightchange-prone WSDL APIs. Moreover, we partially confirmed our survey par-ticipants’ insight: shared data types are change prone if they are referenced byoperations with different requirements, otherwise non-shared data types aremore likely to be changed (RQ3).
6.5.2 Implications of the ResultsThe results of this study are useful for web API providers, web API consumers,and software engineering researchers.
Providers & Consumers. Both, web API providers and consumers, canbenefit from a new internal cohesion metric (DTC) that overcomes the prob-lem of the message-level metrics. Using DTC they can measure the internal co-hesion to estimate the interface level change-proneness of WSDL APIs (RQ3).Based on the metric values, consumers can select and subscribe to the moststable web API that shows the best internal cohesion, thereby reducing the risk

120 Chapter 6. Change-Prone Web APIs
to continuously update their clients to new web API versions. Providers canuse DTC to identify the set of most change-prone web APIs (with low valuesfor DTC) that should undergo a refactoring. For example, in case of a Multi-service API, the provider should consider splitting the API into different webAPIs each one encapsulating a different business entity.
Providers. Furthermore, based on the values of the external cohesionmetric they can estimate the change-proneness considering the maintenancescenarios likely to cause changes as suggested by our study. For instance, theycan measure the SIUC metric as proposed by Perepletchikov [Perepletchikovet al., 2007, 2010] and refactor the web APIs with low values for externalcohesion potentially affected by the Fat antipattern. They should refactor theseAPIs applying the Interface Segregation Principle described by Martin [2002].According to this principle, Fat APIs should be split into different APIs so thatclients only have to know about the methods they are interested in.
Researchers. The results of this study are also valuable input to softwareengineering researchers. In this study we showed the impact of low exter-nal and internal cohesion on change-proneness of web APIs. As next step,researchers should investigate techniques for refactoring these kinds of webAPIs. For instance, to the best of our knowledge there are no approaches ableto apply the Interface Segregation Principle to refactor Fat APIs. Such an ap-proach should mine the usage of a web API’ clients and, based on it, outputthe ideal sub APIs. This task is particularly challenging if a web API is invokeddifferently by many different clients.
In general, the results of this study are a precious input for researchersinterested in investigating the change-proneness of web APIs. Each mainte-nance scenario that causes changes in web APIs should be further investigatedto further assist web API providers.
6.5.3 Threats to ValidityIn this study threats to construct validity concern the set of selected scenariosthat we used to investigate changes in web APIs. This set is not complete. Tomitigate this threat, we asked the participants of the survey to provide addi-tional scenarios. Only three participants provided further scenarios. Hence,we cannot draw any statistical conclusion. Based on this result, we believethat we provided a good first set of scenarios that can be extended in futurestudies.
With respect to internal validity, the main threat is the possibility that thestructure of the survey could have affected the answers of participants. Wemitigated this threat by randomly changing the order of the scenarios for each

6.6. Related Work 121
participant. While this randomization worked for the scenarios, the threatstemming from the order of the questions in our survey remains - participantscould have gained knowledge from answering the earlier questions that couldhave affected the answers to latter questions.
The threats to external validity have been mitigated thanks to our partic-ipants who work on software systems from different domains (e.g., bankingsystems, mobile applications, telecommunication systems, financial systems).Moreover, 18 participants are employed in international consulting companieswith expertise in a wide range of software systems. Moreover, with regardsto the quantitative analysis the set of WSDLs APIs should be enlarged in ourfuture work to improve the generalization of the results. However, accessingWSDLs APIs with a long history is not an easy task. In fact, most of them areused in a closed environment and allowing access only to registered clients.
6.6 Related WorkWe identify three areas of related work: change-proneness, stability of APIs,and analysis of web APIs.
Change-proneness. Khoshgoftaar and Szabo [1994] and Li and Henry[1993] were among the first researchers to investigate the impact of soft-ware structures on change-proneness. Khoshgoftaar et al. trained a regres-sion model and a neural network using size and complexity metrics to predictchange-prone components. The results show that the neural network is astronger predictive model compared to the multiple regression model. Li etal. used the C&K metrics to predict maintenance effort improving the per-formance of prediction models. Girba et al. [2004] defined the Yesterday’sweather approach to predict change-prone classes based on values of metricsand the analysis of their evolution. Di Penta et al. [2008] showed that classesparticipating in antipatterns are more or less change-prone depending on therole they play in the antipattern. Khomh et al. [2009] investigated the im-pact of code smells on the change-proneness of Java classes. Their resultsshow that classes affected by code smells are more change-prone and spe-cific smells are more correlated than others to change-proneness. Zhou et al.[2009] examined the confounding effect of class size on the associations be-tween metrics and change-proneness. They show that the size of a class isa relevant confounding variable to take into account to estimate its change-proneness. These studies represent a subset of existing work (e.g., [Tsantaliset al., 2005; Elish and Al-Khiaty, 2013]) that underlines the importance ofour research on providing indicators for highlighting change-prone softwarecomponents. However, no study exists that investigates such indicators for

122 Chapter 6. Change-Prone Web APIs
highlighting change-prone web APIs.
Stability of APIs. The stability of APIs is a well known problem in the re-search community. A recent study by Vásquez et al. [2013] shows that change-prone APIs negatively impact the success of Android apps. This work does notprovide indicators for change-prone APIs but it shows the relevance of assuringan adequate stability of APIs. Recently, Raemaekers et al. [2012] analyzed thestability of third parties libraries using four metrics to show how third partieslibraries evolve. Hou and Yao [2011] analyzed the evolution of AWT/SwingAPIs and their findings show that the majority of the changes is performed inthe early versions. Dig and Johnson [2006] analyzed four frameworks andone library finding that on average 80% of the API breaking changes are dueto refactoring. Even though these studies show the relevance of investigatingthe stability of APIs there are few studies proposing metrics as indicators ofchange-prone APIs. In our previous work presented in Chapter 2, we investi-gated such indicators for interfaces. In Chapter 3 we analyzed the impact ofantipatterns on the change-proneness of Java APIs. The results show that APIsare more change-prone if they participate in ComplexClass, SpaghettiCode, andSwissArmyKnife antipatterns. In Chapter 2 we showed that the external cohe-sion is the best performing metric to highlight and predict change-prone Javainterfaces in the analyzed systems. Those studies were on Java APIs whilethe focus of this chapter is on web APIs analyzing metrics and antipatternsspecifically defined for web APIs.
Analyses of web APIs. In Chapter 4 we analyzed the evolution of fourWSDL APIs. We proposed the WSDLDiff tool to extract automatically fine-grained changes and we showed that it helps consumers in highlighting themost frequent changes in WSDL APIs. A similar analysis was performed byFokaefs et al. [2011] in 2011. They manually extracted the changes from thedifferent versions of the WSDL APIs. Several antipatterns for web APIs havebeen proposed in literature, however, none of them has been investigated toindicate change-prone web APIs. Moha et al. [2012] proposed an approachfor specifying and detecting web API antipatterns. In their work they providea complete and concise description of the most popular antipatterns.
Perepletchikov et al. [2007] proposed five cohesion metrics, but an empir-ical evaluation of them for indicating change-prone APIs is missing. In theirlater study [Perepletchikov et al., 2010] they proposed three additional cohe-sion metrics and a controlled study. The results from this study show that theproposed metrics can help in predicting the analyzability of web APIs earlyin the software development life cycle, but not their stability. Our work iscomplementary to this existing work. Starting from the external and internal

6.7. Concluding remarks 123
cohesion defined by Perepletchikov et al. and the antipatterns described inSection 6.1, we present a qualitative and quantitative study of using cohesionmetrics to indicate the change-proneness of web APIs.
6.7 Concluding remarksAssuring an adequate level of stability of web APIs is one of the key factors fordeploying successful distributed systems [Erl, 2007; Daigneau, 2011; Vásquezet al., 2013]. While consumers want to rely on stable web APIs in order toprevent continuous updates of their systems, providers want to publish highquality web APIs in order to prevent such updates and to stay successful onthe market. Previous work has shown that the cohesion of an API is an indi-cator for understandability and stability [Perepletchikov et al., 2007, 2010].In this chapter, we extended this research to web APIs and investigated therelationship between internal and external cohesion and stability, measured aschange-proneness.
We first presented an online survey to rank a number of typical main-tenance scenarios to improve web APIs affected by the Multiservice and Fatantipatterns, both symptoms of web APIs with low internal and external cohe-sion. The results narrow down the many possible scenarios to two scenariosfor Fat APIs and three scenarios for Multiservice APIs in which changes arevery likely to occur. Focusing on internal cohesion, we detailed these resultsin a quantitative study with ten public available web APIs specified in WSDL.Results showed that the DTC metric is able to highlight change-prone WSDLAPIs.
The results of our studies also open several directions for future work.Specifically, the method level and the data-type level change-proneness needsto be further investigated to better classify change-prone methods and datatypes. Furthermore, we plan to analyze the impact of granularity on thechange-proneness of web APIs, for instance with the SandPile and Tiny an-tipatterns (both symptoms of APIs with inadequate granularity) [Moha et al.,2012].


7...Refactoring Fat APIs
Recent studies have shown that the violation of the Interface Segregation Prin-ciple (ISP) is critical for maintaining and evolving software systems. Fat inter-faces (i.e., interfaces violating the ISP) change more frequently and degrade thequality of the components coupled to them. According to the ISP the interfaces’design should force no client to depend on methods it does not invoke. Fat inter-faces should be split into smaller interfaces exposing only the methods invokedby groups of clients. However, applying the ISP is a challenging task when fatinterfaces are invoked differently by many clients.
In this chapter, we formulate the problem of applying the ISP as a multi-objective clustering problem and we propose a genetic algorithm to solve it. Weevaluate the capability of the proposed genetic algorithm with 42,318 publicJava APIs whose clients’ usage has been mined from the Maven repository. Theresults of this study show that the genetic algorithm outperforms other searchbased approaches (i.e., random and simulated annealing approaches) in split-ting the APIs according to the ISP.1
7.1 Problem Statement and Solution . . . . . . . . . . . . . . . . . . . . . . 1277.2 Genetic Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1317.3 Random and Local Search . . . . . . . . . . . . . . . . . . . . . . . . . . 1357.4 Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1377.5 Threats to Validity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1467.6 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1477.7 Conclusions and Future Work . . . . . . . . . . . . . . . . . . . . . . . . 148
When designing interfaces developers should refactor fat interfaces [Mar-tin, 2002]. Fat interfaces are interfaces whose clients invoke different subsetsof their methods. Such interfaces should be split into smaller interfaces eachone specific for a different client (or a group of clients). This principle has
1This chapter was published in the in the 30th International Conference on Software Main-tenance and Evolution (ICSME 2014) [Romano et al., 2014].
125

126 Chapter 7. Refactoring Fat APIs
been formalized by Martin [Martin, 2002] in 2002 and is also known as theInterface Segregation Principle (ISP). The rationale behind this principle is thatchanges to an interface break its clients. As a consequence, clients should notbe forced to depend upon interface methods that they do not actually invoke[Martin, 2002]. This guarantees that clients are affected by changes only ifthey involve the methods they invoke.
Recent studies have shown that violation of the ISP and, hence, fat inter-faces can be problematic for the maintenance of software systems. First, inChapter 2 we showed that such interfaces are more change-prone than non-fat interfaces. Next, Abdeen et al. [Abdeen et al., 2013] proved that violationsof the ISP lead to degraded cohesion of the components coupled to fat inter-faces. Finally, Yamashita et al. [Yamashita and Moonen, 2013] showed thatchanges to fat interfaces result in a larger ripple effect. The results of thesestudies, together with Martin’s insights [Martin, 2002], show the relevance ofdesigning and implementing interfaces according to the ISP.
However, to the best of our knowledge, there are no studies that proposeapproaches to apply the ISP. This task is challenging when fat interfaces exposemany methods and have many clients that invoke differently their methods,as shown in [Mendez et al., 2013]. In this case trying to manually infer theinterfaces into which a fat interface should be split is unpractical and expen-sive.
In this chapter, we define the problem of splitting fat interfaces accord-ing to the ISP as a multi-objective clustering optimization problem [Pradit-wong et al., 2011]. We measure the compliance with the ISP of an interfacethrough the Interface Cohesion Metric (IUC). To apply the ISP we propose amulti-objective genetic algorithm that, based on the clients’ usage of a fat in-terface, infers the interfaces into which it should be split to conform to the ISPand, hence, with higher IUC values. To validate the capability of the proposedgenetic algorithm we mine the clients’ usage of 42,318 public Java APIs fromthe Maven repository. For each API, we run the genetic algorithm to split theAPI into sub-APIs according to the ISP. We compare the capability of the ge-netic algorithm with the capability of other search-based approaches, namelya random algorithm and a multi-objective simulated annealing algorithm. Thegoal of this study is to answer the following research questions:
Is the genetic algorithm able to split APIs into sub-APIs with higher IUC values?Does it outperform the random and simulated annealing approaches?
The results show that the proposed genetic algorithm generates sub-APIswith higher IUC values and it outperforms the other search-based approaches.

7.1. Problem Statement and Solution 127
These results are relevant for software practitioners interested in applying theISP. They can monitor how clients invoke their APIs (i.e., which methods areinvoked by each client) and they can use this information to run the geneticalgorithm and split their APIs so that they comply with the ISP.
The remainder of this chapter is organized as follows. Section 7.1 intro-duces fat APIs, the main problems they suffer, and formulates the problem ofapplying the ISP as a multi-objective clustering problem. Section 7.2 presentsthe genetic algorithm to solve the multi-objective clustering problem. Sec-tion 7.3 presents the random and local search (i.e., simulated annealing) ap-proaches implemented to evaluate the capability of the genetic algorithm. Thestudy and its results are shown and discussed in Section 7.4 while threats tovalidity are discussed in Section 7.5. Related work is presented in Section 7.6.We draw our conclusions and outline directions for future work in Section 7.7.
7.1 Problem Statement and SolutionIn this section, first, we introduce fat APIs, their drawbacks, and the InterfaceSegregation Principle to refactor them. Then, we discuss the challenges ofapplying the Interface Segregation Principle for real world APIs. Finally, wepresent our solution to automatically apply the principle.
7.1.1 Fat APIs and Interface Segregation PrincipleThe Iterface Segregation Principle (ISP) has been originally described by Mar-tin in [Martin, 2002] and it copes with fat APIs. Fat APIs are APIs whose clientsinvoke different sets of their methods. As a consequence clients depend on in-terface methods that they do not invoke. These APIs are problematic and theyshould be refactored because their clients can be broken by changes to meth-ods which they do not invoke. To refactor fat APIs Martin [Martin, 2002]introduced the ISP.
The ISP states that fat APIs need to be split into smaller APIs (referredto as sub-APIs throughout this chapter) according to their clients’ usage. Anyclient should only know about the set of methods that it invokes. Hence, eachsub-API should reflect the usage of a specific client (or of a class of clients thatinvoke the same set of methods). To better understand the ISP consider theexample shown in Figure 7.1. The API shown in Figure 7.1a is considered afat API because the different clients (i.e., Client1, Client2, and Client3) invokedifferent methods (e.g., Client1 invokes only method1, method2, and method3out of the 10 methods declared in the API). According to the ISP, this APIshould be split into three sub-APIs as shown in Figure 7.1b. These sub-APIsare specific to the different clients (i.e., Client1, Client2, and Client3) and, as

128 Chapter 7. Refactoring Fat APIs
a consequence, clients do not depend anymore on interface methods they donot invoke.
FatAPI
1-method1()
2-method2()
3-method3()
5-method5()
4-method4()
6-method6()7-method7()8-method8()
9-method9()10-method10()
Client1
Client2
Client3
(a) A fat API with different clients (i.e.,Client1, Client2, and Client3) invoking differ-ent sets of methods (denoted by rectangles).Clients depend on methods which they do notinvoke.
Client1
Client2
Client3
SubAPI1
1-method1()2-method2()3-method3()
SubAPI2
4-method4()5-method5()6-method6()
SubAPI3
7-method7()8-method8()9-method9()10-method10()
(b) The fat API is split into sub-APIs each onespecific for a client. Clients depend only onmethods which they invoke.
Figure 7.1: An example of applying the Interface Segregation Principle.
7.1.2 Fat APIs and Change-PronenessFat APIs are also problematic because they change frequently. In Chapter 2we showed empirically that fat APIs are more change-prone compared to non-fat APIs. In this work we used external cohesion as a heuristic to detect fatAPIs. The external cohesion was originally defined by Perepletchikov et al.[Perepletchikov et al., 2007, 2010] for web APIs and it measures the extentto which the methods declared in an API are used by their clients. An APIis considered externally cohesive if all clients invoke all methods of the API.It is not externally cohesive and considered a fat API if they invoke differentsubsets of its methods.
To measure the external cohesion we used the Interface Usage Cohesionmetric (IUC) defined by Perepletchikov et al. [Perepletchikov et al., 2007,2010]. This metric is defined as:
IUC(i) =
∑nj=1
used_methods( j,i)num_methods(i)
n

7.1. Problem Statement and Solution 129
where j denotes a client of the API i; used_methods (j,i) is the function whichcomputes the number of methods defined in i and used by the client j; num_methods(i) returns the total number of methods defined in i; and n denotesthe number of clients of the API i. Note that the IUC values range between 0and 1.
Consider the example shown in Figure 7.1. The FatAPI in Figure 7.1ashows a value of IUCFatAPI= (
310+ 3
10+ 4
10)/3 = 0.366 indicating low external
cohesion that is a symptom of a fat API. The sub-APIs generated after applyingthe ISP (shown in Figure 7.1b) show higher external cohesion. They have thefollowing values for IUC: IUCSubAPI1= (
33)/1 = 1, IUCSubAPI2= (
33)/1 = 1, and
IUCSubAPI3= (44)/1= 1.
In Chapter 2 we investigated to which extent the IUC metric can be usedto highlight change-prone Java interface classes. The results showed that theIUC metric exhibits the strongest correlation with the number of source codechanges performed in Java interface classes compared to other software met-rics (e.g., C&K metrics [Chidamber and Kemerer, 1994]). The IUC metric alsoimproved the performance of prediction models in predicting change-proneJava interface classes.
These results, together with Martin’s insights [Martin, 2002] and resultsof previous studies [Abdeen et al., 2013; Yamashita and Moonen, 2013], mo-tivated us to investigate and develop an approach to refactor fat APIs usingthe ISP.
7.1.3 ProblemThe problem an engineer can face in splitting a fat API is coping with APIusage diversity. In 2013, Mendez et al. [Mendez et al., 2013] investigatedhow differently the APIs are invoked by their clients. They provided empiricalevidence that there is a significant usage diversity. For instance, they showedthat Java’s String API is used in 2,460 different ways by their clients. Clientsdo not invoke disjoint sets of methods (as shown in Figure 7.1a) but the set ofmethods can overlap and can be significantly different. As a consequence, weargue that manually splitting fat APIs can be time consuming and error prone.
A first approach to find the sub-APIs consists in adopting brute-force searchtechniques. These techniques enumerate all possible sub-APIs and check whetherthey maximize the external cohesion and, hence, the value for the IUC metric.The problem with these approaches is that the number of possible sub-APIscan be prohibitively large causing a combinatorial explosion. Imagine for in-stance to adopt this approach for finding the sub-APIs for the AmazonEC2 webAPI. This web API exposes 118 methods in version 23. The number of 20-

130 Chapter 7. Refactoring Fat APIs
combinations of the 118 methods in AmazonEC2 are equal to:
�
11820
�
=118!
20!98!≈ 2 ∗ 1021
This means that for evaluating all the sub-APIs with 20 methods the searchrequires to analyze at least 2 ∗ 1021 possible combinations, which can takeseveral days on a standard PC.
As a consequence, brute-force search techniques are not an adequate solu-tion for this problem.
7.1.4 SolutionTo overcome the aforementioned problems we formulate the problem of find-ing sub-APIs (i.e., applying the ISP) as a clustering optimization problem de-fined as follows. Given the set of n methods X={X1,X2...,Xn} declared in afat API, find the set of non-overlapping clusters of methods C={C1,C2...,Ck}that maximize IUC(C) and minimize clusters(C); where IUC(C) computes thelowest IUC value of the clusters in C and clusters(C) computes the number ofclusters. In other words, we want to cluster the methods declared in a fat APIinto sub-APIs that show high external cohesion, measured through the IUCmetric.
This problem is an optimization problem with two objective functions, alsoknown as multi-objective optimization problem. The first objective consists inmaximizing the external cohesion of the clusters in C. Each cluster in C (i.e.,a sub-API in our case) will have its own IUC value (like for the sub-APIs inFigure 7.1b). To maximize their IUC values we maximize the lowest IUC valuemeasured through the objective function IUC(C).
The second objective consists in minimizing the number of clusters (i.e.,sub-APIs). This objective is necessary to avoid solutions containing as manyclusters as there are methods declared in the fat API. If we assign each methodto a different sub-API, all the sub-APIs would have an IUC value of 1, showingthe highest external cohesion. However, such sub-APIs do not group togetherthe methods invoked by the different groups of clients. Hence, the clientswould depend on many sub-APIs each one exposing a single method.
To solve this multi-objective clustering optimization problem we imple-mented a multi-objective genetic algorithm (presented in next section) thatsearches for the Pareto optimal solutions, namely solutions whose objectivefunction values (i.e., IUC(C) and clusters(C) in our case) cannot be improvedwithout degrading the other objective function values.

7.2. Genetic Algorithm 131
Moreover, to compare the performance of the genetic algorithm with ran-dom and local search approaches we implemented a random approach anda multi-objective simulated annealing approach that are presented in Sec-tion 7.3.
7.2 Genetic AlgorithmTo solve multi-objective optimization problems different algorithms have beenproposed in literature (e.g., [Deb et al., 2000; Rudolph, 1998; Zitzler andThiele, 1999]). In this chapter, we use the multi-objective genetic algorithmNSGA-II proposed by Deb et al. [Deb et al., 2000] to solve the problem offinding sub-APIs for fat APIs according to the ISP, as described in the previoussection. We chose this algorithm because 1) it has been proved to be fast, 2)to provide better convergence for most multi-objective optimization problems,and 3) it has been widely used in solving search based software engineeringproblems, such as presented in [Deb et al., 2000; Yoo and Harman, 2007;Zhang et al., 2013; Li et al., 2013]. In the following, we first introduce thegenetic algorithms. Then, we show our implementation of the NSGA-II usedto solve our problem. For further details about the NSGA-II we refer to thework by Deb et al. [Deb et al., 2000].
Genetic Algorithms (GAs) have been used in a wide range of applicationswhere optimization is required. Among all the applications, GAs have beenwidely studied to solve clustering problems [Hruschka et al., 2009]. The keyidea of GAs is to mimic the process of natural selection providing a searchheuristic to find solutions to optimization problems. A generic GA is shown inFigure 8.4.
Different to other heuristics (e.g., Random Search, Brute-Force Search, andLocal search) that consider one solution at a time, a GA starts with a set ofcandidate solutions, also known as population (step 1 in Figure 8.4). Thesesolutions are randomly generated and they are referred to as chromosomes.Since the search is based upon many starting points, the likelihood to explorea wider area of the search space is higher than other searches. This featurereduces the likelihood to get stuck in a local optimum. Each solution is eval-uated through a fitness function (or objective function) that measures howgood a candidate solution is relatively to other candidate solutions (step 2).Solutions from the population are used to form new populations, also knownas generations. This is achieved using the evolutionary operators. Specifically,first a pair of solutions (parents) is selected from the population through aselection operator (step 4). From these parents two offspring solutions aregenerated through the crossover operator (step 5). The crossover operator

132 Chapter 7. Refactoring Fat APIs
Create initial population of chromosomes
Evaluate !tness of each chromosome
Select next generation(Selection Operator)
Perform reproduction(Crossover operator)
Perform mutation(Mutation operators)
MaxIterations
Outputbest chromosomes
1
2
4
5
6
3
7
Figure 7.2: Different steps of a genetic algorithm.
is responsible to generate offspring solutions that combine features from thetwo parents. To preserve the diversity, the mutation operators (step 6) mutatethe offspring. These mutated solutions are added to the population replacingsolutions with the worst fitness function values. This process of evolving thepopulation is repeated until some condition (e.g., reaching the max numberof iterations in step 3 or achieving the goal). Finally, the GA outputs the bestsolutions when the evolution process terminates (step 7).
To implement the GA and adapt it to find the set of sub-APIs into whicha fat API should be split we next define the fitness function, the chromosome(or solution) representation, and the evolutionary operators (i.e., selection,crossover, and mutation).
7.2.1 Chromosome representationTo represent the chromosomes we use a label-based integer encoding widelyadopted in literature [Hruschka et al., 2009] and shown in Figure 8.5. Ac-cording to this encoding, a solution is an integer array of n positions, where nis the number of methods exposed in a fat API. Each position corresponds to aspecific method (e.g., position 1 corresponds to the method method1() in Fig-

7.2. Genetic Algorithm 133
ure 7.1a). The integer values in the array represent the clusters (i.e., sub-APIsin our case) to which the methods belong. For instance in Figure 8.5, the meth-ods 1,2, and 10 belong to the same cluster labeled with 1. Note that two chro-mosomes can be equivalent even though the clusters are labeled differently.For instance the chromosomes [1,1,1,1,2,2,2,2,3,3] and [2,2,2,2,3,3,3,3,1,1]are equivalent. To solve this problem we apply the renumbering procedure asshown in [Falkenauer, 1998] that transforms different labelings of equivalentchromosomes into a unique labeling.
1 1 2 3 2 4 5 3 6 1
1 2 3 4 5 6 7 8 9 10
Figure 7.3: Chromosome representation of our candidate solutions.
7.2.2 Fitness FunctionsThe fitness function is a function that measures how good a solution is. Forour problem we have two fitness functions corresponding to the two objectivefunctions discussed in Section 7.1, namely IUC(C)) and clusters(C). IUC(C)returns the lowest IUC value of the clusters in C and clusters(C) returns thenumber of clusters in C. Hence, the two fitness functions are f1=IUC(C) andf2=clusters(C). While the value of f1 should be maximized the value of f2should be minimized.
Since we have two fitness functions, we need a comparator operator that,given two chromosomes (i.e., candidate solutions), returns the best one basedon their fitness values. As comparator operator we use the dominance com-parator as defined in NSGA-II. This comparator utilizes the idea of Pareto opti-mality and the concept of dominance for the comparison. Precisely, given twochromosomes A and B, the chromosome A dominates chromosome B (i.e., Ais better than B) if 1) every fitness function value for chromosome A is equalor better than the corresponding fitness function value of the chromosome B,and 2) chromosome A has at least one fitness function value that is better thanthe corresponding fitness function value of the chromosome B.
7.2.3 The Selection OperatorThe selection operator selects two parents from a population according to theirfitness function values. We use the Ranked Based Roulette Wheel (RBRW) thatis a modified roulette wheel selection operator as proposed by Al Jadaan andRajamani [2008]. RBRW ranks the chromosomes in the population by thefitness values: the highest rank is assigned to the chromosome with the best

134 Chapter 7. Refactoring Fat APIs
fitness values. Hence, the best chromosomes have the highest probabilities tobe selected as parents.
7.2.4 The Crossover OperatorOnce the GA has selected two parents (ParentA and ParentB) to generate theoffspring, the crossover operator is applied to them with a probability Pc. Ascrossover operator we use the operator defined specifically for clustering prob-lems by Hruschka et al. [2009]. In order to illustrate how this operator worksconsider the example shown in Figure 8.6 from [Hruschka et al., 2009]. Theoperator first selects randomly k (1≤k≤n) clusters from ParentA, where n isthe number of clusters in ParentA. In our example assume that the clusterslabeled 2 (consisting of methods 3, 5, and 10) and 3 (consisting of method 4)are selected from ParentA (marked red in Figure 8.6). The first child (ChildC)originally is created as copy of the second parent ParentB (step 1). As secondstep, the selected clusters (i.e., 2 and 3) are copied into ChildC. Copying theseclusters changes the clusters 1, 2, and 3 in ChildC. These changed clusters areremoved from ChildC (step 3) leaving the corresponding methods unallocated(labeled with 0). In the fourth step (not shown in Figure 8.6) the unallocatedmethods are allocated to an existing cluster that is randomly selected.
The same procedure is followed to generate the second child ChildD. How-ever, instead of selecting randomly k clusters from ParentB, the changed clus-ters of ChildC (i.e., 1,2, and 3) are copied into ChildD that is originally a copyof ParentA.
7.2.5 The Mutation OperatorsAfter obtaining the offspring population through the crossover operator, theoffspring is mutated through the mutation operator with a probability Pm. Thisstep is necessary to ensure genetic diversity from one generation to the nextones. The mutation is performed by randomly selecting one of the follow-ing cluster-oriented mutation operators [Falkenauer, 1998; Hruschka et al.,2009]:
• split: a randomly selected cluster is split into two different clusters. Themethods of the original cluster are randomly assigned to the generatedclusters.
• merge: moves all methods of a randomly selected cluster to anotherrandomly selected cluster.
• move: moves methods from one cluster to another. Both methods andclusters are randomly selected.

7.3. Random and Local Search 135
1 1 2 3 2 4 5 1 2 5 4 2 1 2 3 3 2 1 2 4
4 2 1 2 3 3 2 1 2 4
ParentA ParentB
ChildC
1: copy ParentB into ChildC
4 2 2 3 2 3 2 1 2 4ChildC
2: copy clusters 2 and 3 from ParentA to ChildC
4 0 2 3 2 0 0 0 2 4ChildC
3: remove changed methods from B (i.e., 1,2,3)
4: unallocated objects are allocated to randomly selected clusters
1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10
Figure 7.4: Example of crossover operator for clustering problems [Hruschkaet al., 2009].
We implemented the proposed genetic algorithm on top of the JMetal2
framework that is a Java framework that provides state-of-the-art algorithmsfor optimization problems, including the NSGA-II algorithm.
7.3 Random and Local SearchTo better evaluate the performance of our proposed genetic algorithm we im-plemented a random algorithm and a local search algorithm (i.e., a multi-objective simulated annealing algorithm) that are presented in the followingsub-sections.
7.3.1 Random AlgorithmThe random algorithm tries to find an optimal solution by generating randomsolutions. To implement the random algorithm we use the same solution rep-resentation (i.e., chromosome representation) used in the genetic algorithmdescribed in Section 7.2. The algorithm iteratively generates a random solu-tion and evaluates it using the same fitness functions defined for the geneticalgorithm. When the maximum number of iterations is reached the best so-
2http://jmetal.sourceforge.net

136 Chapter 7. Refactoring Fat APIs
lution is output. This algorithm explores the search space randomly relyingon the likelihood to find a good solution after a certain number of iterations.We use a random search as baseline because this comparison is considered thefirst step to evaluate a genetic algorithm [Sivanandam and Deepa, 2007].
7.3.2 Multi-Objective Simulated AnnealingAs second step to evaluate the performance of our proposed genetic algorithmwe implemented a local search approach.
A local search algorithm (e.g., hill-climbing) starts from a candidate solu-tion and then iteratively tries to improve it. Starting from a random gener-ated solution the solution is mutated obtaining the neighbor solution. If theneighbor solution is better than the current solution (i.e., it has higher fitnessfunction values) it is taken as current solution to generate a new neighborsolution. This process is repeated until the best solution is obtained or themaximum number of iterations is reached. The main problem of such localsearch approaches is that they can get stuck in a local optimum. In this casethe local search approach cannot further improve the current solution.
To mitigate this problem advanced local search approaches have been pro-posed like simulated annealing. The simulated annealing algorithm was in-spired from the process of annealing in metallurgy. This process consists inheating and cooling a metal. Heating the metal alters its internal structureand, hence, its physical properties. On the other hand, when the metal coolsdown its new internal structure becomes fixed.
The simulated annealing algorithm simulates this process. Initially thetemperature is set high and then it is decreased slowly as the algorithm runs.While the temperature is high the algorithm is more likely to accept a neighborsolution that is worse than the current solution, reducing the likelihood to getstuck in a local optimum. At each iteration the temperature is slowly decreasedby multiplying it by a cooling factor α where 0 < α < 1. When the temperatureis reduced, worse neighbor solutions are accepted with a lower probability.
Hence, at each iteration a neighbor solution is generated mutating the cur-rent solution. If this solution has better fitness function values it is taken ascurrent solution. Otherwise it is accepted with a certain probability called ac-ceptance probability. This acceptance probability is computed by a functionbased on 1) the difference between the fitness function values of the currentand neighbor solution and 2) the current temperature value.
To adapt this algorithm for solving our multi-objective optimization prob-lem we implemented a Multi-Objective Simulated Annealing algorithm follow-ing the approach used by Shelburg et al. [2013]. To represent the solutions

7.4. Study 137
we use the same solution representation used in the genetic algorithm (i.e.,label-based integer encoding). We generate the neighbor solutions using themutation operators used in our genetic algorithm. We compare two solutionsusing the same fitness functions and dominance comparator of our genetic al-gorithm. The acceptance probability is computed as in [Shelburg et al., 2013]with the following function:
AcceptProb(i, j, temp) = e−abs(c(i, j))
temp
where i and j are the current and neighbor solutions; temp is the currenttemperature; and c(i,j) is a function that computes the difference between thefitness function values of the two solutions i and j. This difference is computedas the average of the differences of each fitness function values of the twosolutions according to the following equation:
c(i, j) =
∑|D|k=1(ck( j)− ck(i))
|D|
where D is the set of fitness functions and ck( j) is the value of the fitnessfunction k of the solution j. In our case the fitness functions are the IUC(C)and clusters(c) functions used in the genetic algorithm. Note that since thisdifference is computed as average it is relevant that the fitness function valuesare measured on the same scale. For this reason the values of the fitnessfunction clusters(C) are normalized to the range between 0 and 1. For furtherdetails about the multi-objective simulated annealing we refer to the work in[Nam and Park, 2000; Shelburg et al., 2013].
7.4 StudyThe goal of this empirical study is to evaluate the effectiveness of our proposedgenetic algorithm in applying the ISP to Java APIs. The quality focus is theability of the genetic algorithm to split APIs in sub-APIs with higher externalcohesion that is measured through the IUC metric. The perspective is that ofAPI providers interested in applying the ISP and in deploying APIs with highexternal cohesion. The context of this study consists of 42,318 public Java APIsmined from the Maven repository.
In this study we answer the following research questions:
Is the genetic algorithm able to split APIs into sub-APIs with higher IUC values?Does it outperform the random and simulated annealing approaches?

138 Chapter 7. Refactoring Fat APIs
In the following, first, we show the process we used to extract the APIs andtheir clients’ usage from the Maven repository. Then, we show the procedurewe followed to calibrate the genetic algorithm and the simulated annealingalgorithms. Finally, we present and discuss the results of our study.
7.4.1 Data ExtractionThe public APIs under analysis and their clients’ usage have been retrievedfrom the Maven repository.3 The Maven repository is a publicly available dataset containing 144,934 binary jar files of 22,205 different open-source Javalibraries, which is described in more detail in [Raemaekers et al., 2013]. Eachbinary jar file has been scanned to mine method calls using the ASM4 Javabytecode manipulation and analysis framework. The dataset was processedusing the DAS-3 Supercomputer5 consisting of 100 computing nodes.
To extract method calls we scanned all .class files of all jar files. Classfiles contain fully qualified references to the methods they call, meaning thatthe complete package name, class name and method name of the called methodis available in each .class file. For each binary file, we use an ASM bytecodevisitor to extract the package, class and method name of the callee.
Once we extracted all calls from all .class files, we grouped togethercalls to the same API. As clients of an API we considered all classes declaredin other jar files from the Maven repository that invoke public methods of thatAPI. Note that different versions of the same class are considered different forboth clients and APIs. Hence, if there are two classes with the same namebelonging to two different versions of a jar file they are considered different.To infer which version of the jar file a method call belongs to we scanned theMaven build file (pom.xml) for dependency declarations.
In total we extracted the clients’ usage for 110,195 public APIs stored inthe Maven repository. We filtered out APIs not relevant for our analysis byapplying the following filters:
• APIs should declare at least two methods.
• APIs should have more than one client.
• IUC value of the APIs should be less than one.
After filtering out non relevant APIs we ended up with a data set of 42,318public APIs whose number of clients, methods, and invocations are shown by
3http://search.maven.org4http://asm.ow2.org5http://www.cs.vu.nl/das3/
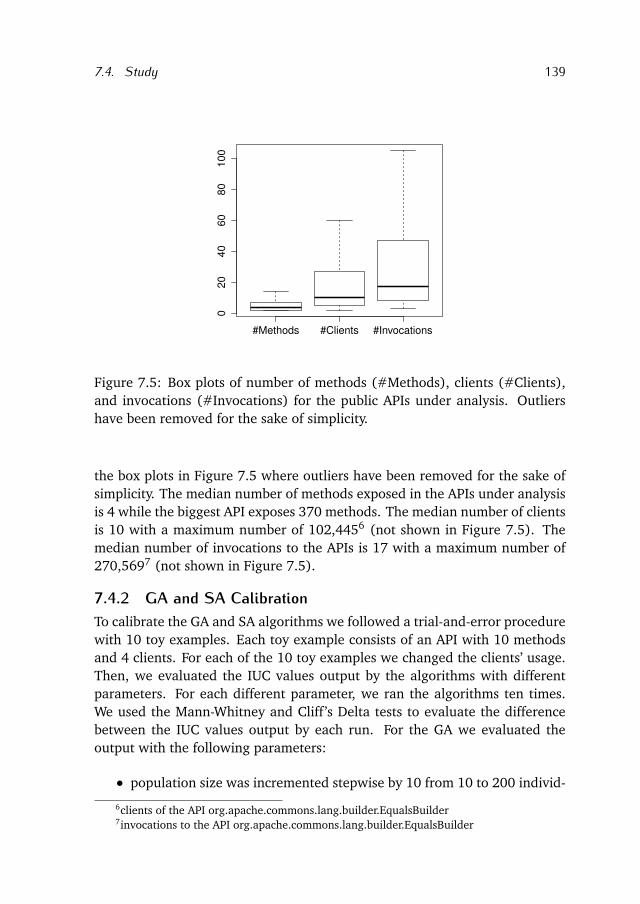
7.4. Study 139
#Methods #Clients #Invocations
020
40
60
80
100
Figure 7.5: Box plots of number of methods (#Methods), clients (#Clients),and invocations (#Invocations) for the public APIs under analysis. Outliershave been removed for the sake of simplicity.
the box plots in Figure 7.5 where outliers have been removed for the sake ofsimplicity. The median number of methods exposed in the APIs under analysisis 4 while the biggest API exposes 370 methods. The median number of clientsis 10 with a maximum number of 102,4456 (not shown in Figure 7.5). Themedian number of invocations to the APIs is 17 with a maximum number of270,5697 (not shown in Figure 7.5).
7.4.2 GA and SA CalibrationTo calibrate the GA and SA algorithms we followed a trial-and-error procedurewith 10 toy examples. Each toy example consists of an API with 10 methodsand 4 clients. For each of the 10 toy examples we changed the clients’ usage.Then, we evaluated the IUC values output by the algorithms with differentparameters. For each different parameter, we ran the algorithms ten times.We used the Mann-Whitney and Cliff’s Delta tests to evaluate the differencebetween the IUC values output by each run. For the GA we evaluated theoutput with the following parameters:
• population size was incremented stepwise by 10 from 10 to 200 individ-
6clients of the API org.apache.commons.lang.builder.EqualsBuilder7invocations to the API org.apache.commons.lang.builder.EqualsBuilder

140 Chapter 7. Refactoring Fat APIs
uals.
• numbers of iterations was incremented stepwise by 1,000 from 1,000 to10,000.
• crossover and mutation probability were increased stepwise by 0.1 from0.0 to 1.0.
We noticed a slower convergence of the GA only when the population size wasless than 50, the number of iterations was less than 1,000, and the crossoverand mutation probability was less than 0.7. Hence, we decided to use thedefault values specified in JMetal (i.e., population of 100 individuals, 10,000iterations, crossover and mutation probability of 0.9).
Similarly, the output of the SA algorithm was evaluated with different val-ues for the cooling factor. The cooling factor was incremented stepwise by 0.1from 0.1 to 1.0. We did not register any statistically significant difference andwe chose a starting temperature of 0.0003 and a cooling factor of 0.99965 asproposed in [Shelburg et al., 2013]. The number of iterations for the SA andRND algorithms is 10,000 to have a fair comparison with the GA.
7.4.3 ResultsTo answer our research questions, first, we compute the IUC value for eachpublic API using the extracted invocations. We refer to this value as IUCbefore.Then, we run the genetic algorithm (GA), the simulated annealing algorithm(SA), and random algorithm (RND) with the same number of iterations (i.e.,10,000). For each API under analysis, these algorithms output the set of sub-APIs into which the API should be split. Each sub-API will show a different IUCvalue. Among these sub-APIs we take the sub-API with the lowest IUC value towhich we refer as IUCafter. We chose the lowest IUC value because this givesus the lower boundary for the IUC values of the resulting sub-APIs.
Figure 7.6 shows the distributions of IUCafter values and number of sub-APIs output by the different algorithms. The box plots in Figure 7.6a show thatall the search-based algorithms produced sub-APIs with higher IUCafter valuescompared to the original APIs (ORI). The genetic algorithm (GA) producedsub-APIs that have higher IUCafter values than the original APIs (ORI) and thesub-APIs generated by the simulated annealing algorithm (SA) and by therandom algorithm (RND). The second best algorithm is the random algorithmthat outperforms the simulated annealing.
The higher IUCafter values of the genetic algorithm are associated with ahigher number of sub-APIs as shown in Figure 7.6b. These box plots show that
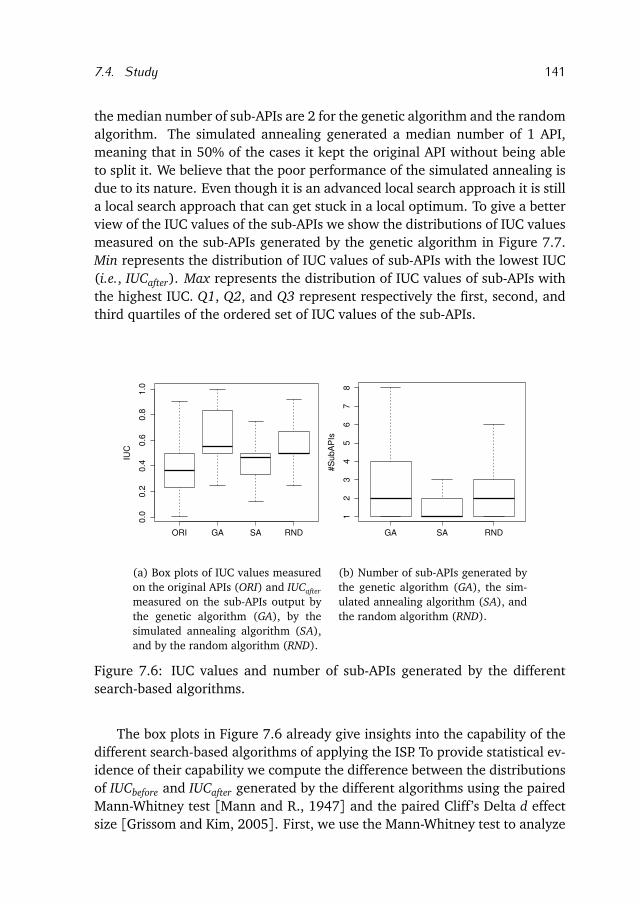
7.4. Study 141
the median number of sub-APIs are 2 for the genetic algorithm and the randomalgorithm. The simulated annealing generated a median number of 1 API,meaning that in 50% of the cases it kept the original API without being ableto split it. We believe that the poor performance of the simulated annealing isdue to its nature. Even though it is an advanced local search approach it is stilla local search approach that can get stuck in a local optimum. To give a betterview of the IUC values of the sub-APIs we show the distributions of IUC valuesmeasured on the sub-APIs generated by the genetic algorithm in Figure 7.7.Min represents the distribution of IUC values of sub-APIs with the lowest IUC(i.e., IUCafter). Max represents the distribution of IUC values of sub-APIs withthe highest IUC. Q1, Q2, and Q3 represent respectively the first, second, andthird quartiles of the ordered set of IUC values of the sub-APIs.
ORI GA SA RND
0.0
0.2
0.4
0.6
0.8
1.0
IUC
(a) Box plots of IUC values measuredon the original APIs (ORI) and IUCafter
measured on the sub-APIs output bythe genetic algorithm (GA), by thesimulated annealing algorithm (SA),and by the random algorithm (RND).
GA SA RND
12
34
56
78
#S
ub
AP
Is
(b) Number of sub-APIs generated bythe genetic algorithm (GA), the sim-ulated annealing algorithm (SA), andthe random algorithm (RND).
Figure 7.6: IUC values and number of sub-APIs generated by the differentsearch-based algorithms.
The box plots in Figure 7.6 already give insights into the capability of thedifferent search-based algorithms of applying the ISP. To provide statistical ev-idence of their capability we compute the difference between the distributionsof IUCbefore and IUCafter generated by the different algorithms using the pairedMann-Whitney test [Mann and R., 1947] and the paired Cliff’s Delta d effectsize [Grissom and Kim, 2005]. First, we use the Mann-Whitney test to analyze
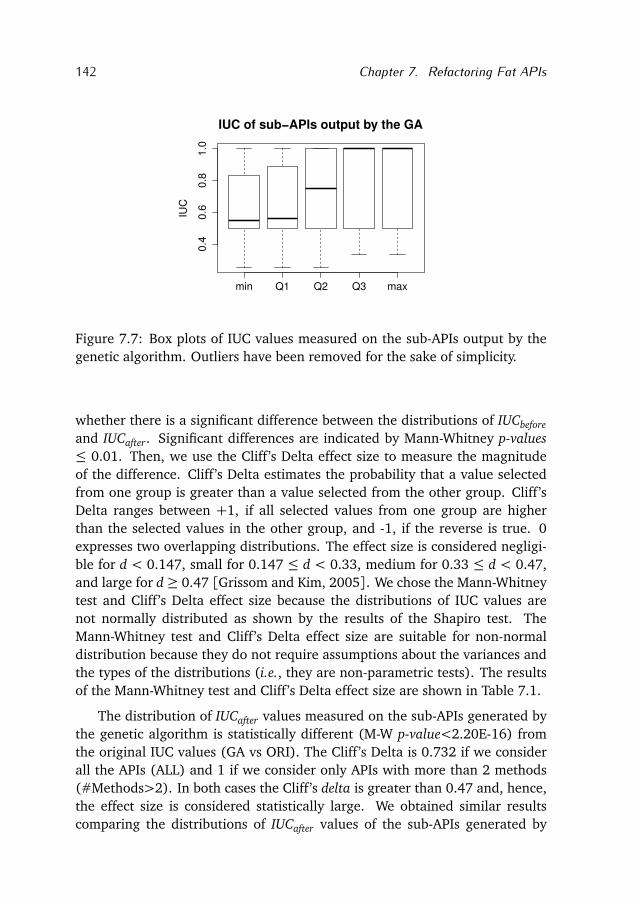
142 Chapter 7. Refactoring Fat APIs
min Q1 Q2 Q3 max
0.4
0.6
0.8
1.0
IUC of sub−APIs output by the GA
IUC
Figure 7.7: Box plots of IUC values measured on the sub-APIs output by thegenetic algorithm. Outliers have been removed for the sake of simplicity.
whether there is a significant difference between the distributions of IUCbeforeand IUCafter. Significant differences are indicated by Mann-Whitney p-values≤ 0.01. Then, we use the Cliff’s Delta effect size to measure the magnitudeof the difference. Cliff’s Delta estimates the probability that a value selectedfrom one group is greater than a value selected from the other group. Cliff’sDelta ranges between +1, if all selected values from one group are higherthan the selected values in the other group, and -1, if the reverse is true. 0expresses two overlapping distributions. The effect size is considered negligi-ble for d < 0.147, small for 0.147 ≤ d < 0.33, medium for 0.33 ≤ d < 0.47,and large for d ≥ 0.47 [Grissom and Kim, 2005]. We chose the Mann-Whitneytest and Cliff’s Delta effect size because the distributions of IUC values arenot normally distributed as shown by the results of the Shapiro test. TheMann-Whitney test and Cliff’s Delta effect size are suitable for non-normaldistribution because they do not require assumptions about the variances andthe types of the distributions (i.e., they are non-parametric tests). The resultsof the Mann-Whitney test and Cliff’s Delta effect size are shown in Table 7.1.
The distribution of IUCafter values measured on the sub-APIs generated bythe genetic algorithm is statistically different (M-W p-value<2.20E-16) fromthe original IUC values (GA vs ORI). The Cliff’s Delta is 0.732 if we considerall the APIs (ALL) and 1 if we consider only APIs with more than 2 methods(#Methods>2). In both cases the Cliff’s delta is greater than 0.47 and, hence,the effect size is considered statistically large. We obtained similar resultscomparing the distributions of IUCafter values of the sub-APIs generated by

7.4. Study 143
GA vs ORIAPIs M-W p-value Cliff’s delta MagnitudeALL <2.20E-16 0.732 large
#Methods>2 <2.20E-16 1 largeGA vs SA
APIs M-W p-value Cliff’s delta MagnitudeALL <2.20E-16 0.705 large
#Methods>2 <2.20E-16 0.962 largeGA vs RND
APIs M-W p-value Cliff’s delta MagnitudeALL <2.20E-16 0.339 medium
#Methods>2 <2.20E-16 0.463 medium
Table 7.1: Mann-Whitney p-value (M-W p-value) and Cliff’s delta between thedistributions of IUCafter values measured on the sub-APIs generated by thegenetic algorithm and measured on the original APIs (i.e., GA vs ORI) andon the sub-APIs generated by the simulated annealing (i.e., GA vs SA) andrandom algorithm (i.e., GA vs RND). The table reports the results for all theAPIs under analysis (i.e., ALL) and for APIs with more than 2 methods (i.e.,#Methods>2).
the genetic algorithm and the simulated annealing algorithm (GA vs SA). TheMann-Whitney p-value is<2.20E-16 and the Cliff’s delta is large (i.e., 0.705 forALL and 0.962 for #Methods>2). The distributions of IUCafter values of thegenetic algorithms and random algorithm (GA vs RND) are also statisticallydifferent (M-W p-value<2.20E-16). Its effect size is medium (i.e., 0.339 forALL and 0.463 for #Methods>2).
Moreover, from the results shown in Table 7.1 we notice that the Cliff’sdelta effect size is always greater when we consider only APIs with more thantwo methods. This result shows that the effectiveness of the genetic algorithm,random algorithm, and simulated annealing algorithm might depend on thenumber of methods declared in the APIs, number of clients, and number ofinvocations. To investigate whether these variables have any impact on theeffectiveness of the algorithms, we analyze the Cliff’s Delta for APIs with in-creasing numbers of methods, clients, and invocations. First, we partition thedata set grouping together APIs with the same number of methods. Then, wecompute the Cliff’s Delta between the distributions of IUCbefore and IUCafter foreach different group. Finally, we use the paired Spearman correlation test toinvestigate the correlation between the Cliff’s Delta measured on the different
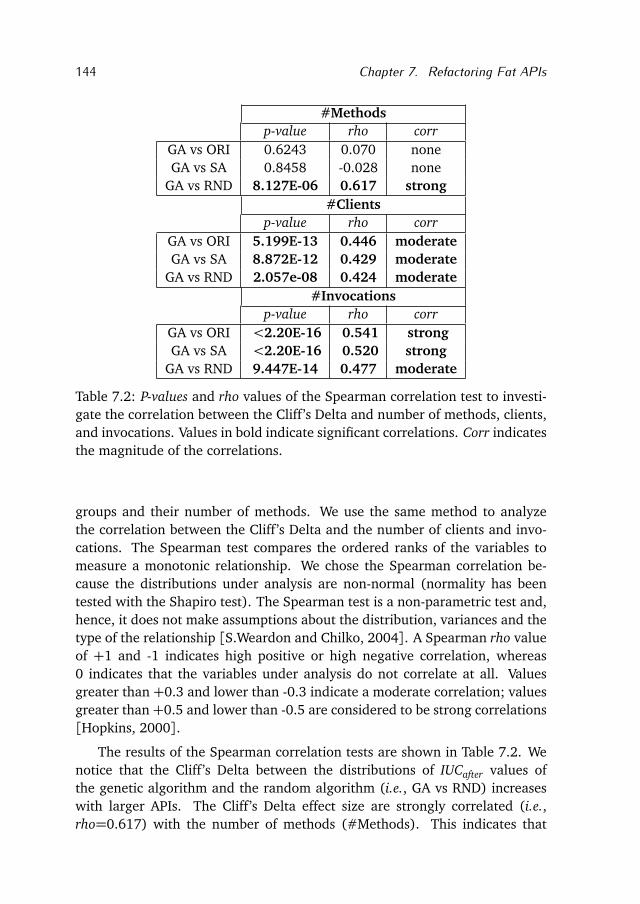
144 Chapter 7. Refactoring Fat APIs
#Methodsp-value rho corr
GA vs ORI 0.6243 0.070 noneGA vs SA 0.8458 -0.028 none
GA vs RND 8.127E-06 0.617 strong#Clients
p-value rho corrGA vs ORI 5.199E-13 0.446 moderateGA vs SA 8.872E-12 0.429 moderate
GA vs RND 2.057e-08 0.424 moderate#Invocations
p-value rho corrGA vs ORI <2.20E-16 0.541 strongGA vs SA <2.20E-16 0.520 strong
GA vs RND 9.447E-14 0.477 moderate
Table 7.2: P-values and rho values of the Spearman correlation test to investi-gate the correlation between the Cliff’s Delta and number of methods, clients,and invocations. Values in bold indicate significant correlations. Corr indicatesthe magnitude of the correlations.
groups and their number of methods. We use the same method to analyzethe correlation between the Cliff’s Delta and the number of clients and invo-cations. The Spearman test compares the ordered ranks of the variables tomeasure a monotonic relationship. We chose the Spearman correlation be-cause the distributions under analysis are non-normal (normality has beentested with the Shapiro test). The Spearman test is a non-parametric test and,hence, it does not make assumptions about the distribution, variances and thetype of the relationship [S.Weardon and Chilko, 2004]. A Spearman rho valueof +1 and -1 indicates high positive or high negative correlation, whereas0 indicates that the variables under analysis do not correlate at all. Valuesgreater than +0.3 and lower than -0.3 indicate a moderate correlation; valuesgreater than +0.5 and lower than -0.5 are considered to be strong correlations[Hopkins, 2000].
The results of the Spearman correlation tests are shown in Table 7.2. Wenotice that the Cliff’s Delta between the distributions of IUCafter values ofthe genetic algorithm and the random algorithm (i.e., GA vs RND) increaseswith larger APIs. The Cliff’s Delta effect size are strongly correlated (i.e.,rho=0.617) with the number of methods (#Methods). This indicates that

7.4. Study 145
the more methods an API exposes the more the genetic algorithm outperformsthe random algorithm generating APIs with higher IUC. Moreover, with in-creasing number of clients (i.e., #Clients) and invocations (i.e., #Invocations)the Cliff’s Delta between the distributions of IUCafter values of the genetic al-gorithm and the other search algorithms increases as well. This is indicatedby rho values that are greater than 0.3.
Based on these results we can answer our research questions stating that1) the genetic algorithm is able to split APIs into sub-APIs with higher IUC val-ues and 2) it outperforms the other search-based algorithms. The difference inperformance between the genetic algorithm and random algorithm increaseswith an increasing number of methods declared in the APIs. The difference inperformance between the genetic algorithm and the other search-based tech-niques increases with an increasing number of clients and invocations.
7.4.4 Discussions of the ResultsThe results of our study are relevant for API providers. Publishing stable APIsis one of their main concerns, especially if they publish APIs on the web. APIsare considered contracts between providers and clients and they should stayas stable as possible to not break clients’ systems. In Chapter 2 we showed em-pirically that fat APIs (i.e., APIs with low external cohesion) are more change-prone than non-fat APIs. To refactor such APIs Martin [2002] proposed theInterface Segregation Principle (ISP). However, applying this principle is nottrivial because of the large API usage diversity [Mendez et al., 2013].
Our proposed genetic algorithm assists API providers in applying the ISP.To use our genetic algorithm providers should monitor how their clients invoketheir API. For each client they should record the methods invoked in order tocompute the IUC metric. This data is used by the genetic algorithm to evaluatethe candidate solutions through fitness functions as described in Section 7.2.The genetic algorithm is then capable to suggest the sub-APIs into which anAPI should be split in order to apply the ISP.
This approach is particularly useful to deploy stable web APIs. One of thekey factors for deploying successful web APIs is assuring an adequate levelof stability. Changes in a web API might break the consumers’ systems forc-ing them to continuously adapt them to new versions of the web API. Usingour approach providers can deploy web APIs that are more externally cohe-sive and, hence, less change-prone as shown in Chapter 2. Moreover, sinceour approach is automated, it can be integrated into development and con-tinuous integration environments to continuously monitor the conformance ofAPIs to the ISP. Providers regularly get informed when and how to refactor

146 Chapter 7. Refactoring Fat APIs
an API. However, note that the ISP takes into account only the clients’ usageand, hence, the external cohesion. As a consequence, while our approach as-sures that APIs are external cohesive, it currently does not guarantee otherquality attributes (e.g., internal cohesion). As part of our future work we planto extend our approach in order to take into account other relevant qualityattributes.
7.5 Threats to ValidityThis section discusses the threats to validity that can affect the empirical studypresented in the previous section.
Threats to construct validity concern the relationship between theory andobservation. In our study this threat can be due to the fact that we mined theAPIs usage through a binary analysis. In our analysis we have used binary jarfiles to extract method calls. The method calls that are extracted from com-piled .class files are, however, not necessarily identical to the method callsthat can be found in the source code. This is due to compiler optimizations.For instance, when the compiler detects that a certain call is never executed, itcan be excluded. However, we believe that the high number of analyzed APIsmitigates this threat.
With respect to internal validity, the main threat is the possibility that thetuning of the genetic algorithm and the simulated annealing algorithm can af-fect the results. We mitigated this threat by calibrating the algorithms with 10toys examples and evaluating statistically their performance while changingtheir parameters.
Threats to conclusion validity concern the relationship between the treat-ment and the outcome. Wherever possible, we used proper statistical tests tosupport our conclusions. In particular we used non-parametric tests which donot make any assumption on the underlying data distribution that was testedagainst normality using the Shapiro test. Note that, although we performedmultiple Mann-Whitney and Spearman tests, p-value adjustment (e.g., Bonfer-roni) is not needed as we performed the tests on independent and disjointdata sets.
Threats to external validity concern the generalization of our findings. Wemitigated this threat evaluating the proposed genetic algorithm on 42,318public APIs coming from different Java systems. The invocations to the APIshave been mined from the Maven repository. These invocations are not acomplete set of invocations to the APIs because they do not include invocationsfrom software systems not stored in Maven. However, we are confident that

7.6. Related Work 147
the data set used in this chapter is a representative sample set.
7.6 Related WorkInterface Segregation Principle. After the introduction of the ISP by Martin[2002] in 2002 several studies have investigated the impact of fat interfaceson the quality of software systems.
In 2013, Abdeen et al. [2013] investigated empirically the impact of inter-faces’ quality on the quality of implementing classes. Their results show thatviolations of the ISP lead to degraded cohesion of the classes that implementfat interfaces.
In 2013, Yamashita and Moonen [2013] investigated the impact of inter-smell relations on software maintainability. They analyzed the interactions of12 code smells and their relationships with maintenance problems. Amongother results, they show that classes violating the ISP manifest higher afferentcoupling. As a consequence changes to these classes result in a larger rippleeffect.
In Chapter 2, we showed that violations of the ISP can be used to pre-dict change-prone interfaces. Among different source code metrics (e.g., C&Kmetrics [Chidamber and Kemerer, 1994]) we demonstrated that fat interfaces(i.e., interfaces showing a low external cohesion measured through the IUCmetric) are more change-prone than non-fat interfaces. Moreover, our resultsproved that the IUC metric can improve the performance of prediction modelsin predicting change-prone interfaces.
The results of this related work show the relevance of applying the ISP andmotivated us in defining the approach presented in this chapter.
Search Based Software Engineering. Over the last years genetic algo-rithms, and in general search based algorithms, have become popular to per-form refactorings of software systems. The approach closest to ours has beenpresented by Praditwong et al. [2011] in 2011. The authors formulated theproblem of designing software modules that adhere to quality attributes (e.g.,coupling and cohesion) as multi-objective clustering search problem. Similarlyto our work, they defined a multi-objective genetic algorithm that clusters soft-ware components into modules. Moreover, they show that multi-objective ap-proaches produce better solutions than existing single-objective approaches.This work influenced us in defining the problem as multi-objective probleminstead of a single-objective problem. However, the problem we solve is dif-ferent from theirs. Our approach splits fat API accordingly to the ISP and usesdifferent fitness functions.

148 Chapter 7. Refactoring Fat APIs
Prior to this work [Praditwong et al., 2011], many other studies proposedapproaches to cluster software components into modules (e.g., [Mitchell andMancoridis, 2006; Mancoridis et al., 1999, 1998; Mitchell and Mancoridis,2002; Mahdavi et al., 2003; Harman et al., 2005]). These studies proposesingle-objective approaches that have been proven to produce worse solutionsby Praditwong et al. [2011].
To the best of our knowledge there are no studies that propose approachesto split fat APIs accordingly to the ISP as proposed in this chapter.
7.7 Conclusions and Future WorkIn this chapter we proposed a genetic algorithm that automatically obtainsthe sub-APIs into which a fat API should be split according to the ISP. Miningthe clients’ usage of 42,318 Java APIs from the Maven repository we showedthat the genetic algorithm is able to split APIs into sub-APIs. Comparing theresulting sub-APIs, based on the IUC values, we showed that the genetic al-gorithms outperforms the random and simulated annealing algorithms. Thedifference in performance between the genetic algorithm and the other search-based techniques increases with APIs with an increasing number of methods,clients, and invocations. Based on these results API providers can automati-cally obtain and refactor the set of sub-APIs based on how clients invoke thefat APIs.
While this approach is already actionable and useful for API providers,we plan to further improve it in our future work. First, we plan to evaluatequalitatively the sub-APIs generated by the genetic algorithm. The higherIUC values guarantee that sub-APIs are more external cohesive and, hence,they better conform to the ISP. However, we have not investigated yet whatdevelopers think about the sub-APIs. Hence, we plan to contact developersand perform interviews to investigate the quality of these sub-APIs. Next, weplan to extend our approach taking into account other quality attributes, suchas internal cohesion. Finally, we plan to slightly modify the genetic algorithmto generate overlapping sub-APIs (i.e., sub-APIs that share common methods).

8.Refactoring Chatty web APIs
The relevance of the service interfaces’ granularity and its architectural impacthave been widely investigated in literature. Existing studies show that the gran-ularity of a service interface, in terms of exposed operations, should reflect theirclients’ usage. This idea has been formalized in the Consumer-Driven Contractspattern (CDC). However, to the best of our knowledge, no studies propose tech-niques to assist providers in finding the right granularity and in easing the adop-tion of the CDC pattern.
In this chapter, we propose a genetic algorithm that mines the clients’ usageof service operations and suggests Façade services whose granularity reflect theusage of each different type of clients. These services can be deployed on top ofthe original service and they become contracts for the different types of clientssatisfying the CDC pattern. A first study shows that the genetic algorithm iscapable of finding Façade services and outperforms a random search approach.1
8.1 Problem Statement and Solution . . . . . . . . . . . . . . . . . . . . . . 1518.2 The Genetic Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1568.3 Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1618.4 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1658.5 Conclusion & Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . 166
One of the key factors for deploying successful services is assuring an ad-equate level of granularity [Hohpe and Woolf, 2003; Daigneau, 2011; Mureret al., 2010; Haesen et al., 2008; Kulkarni and Dwivedi, 2008]. The choiceof how operations should be exposed through a service interface can have animpact on both performance and reusability [Hohpe and Woolf, 2003; Mureret al., 2010]. This level of granularity is also know in literature as functional-ity granularity [Haesen et al., 2008]. For the sake of simplicity we refer to itsimply as granularity throughout this chapter. Choosing the right granularity
1This chapter was published in the 10th World Congress on Services (Services 2014) [Romanoand Pinzger, 2014].
149

150 Chapter 8. Refactoring Chatty web APIs
is not a trivial task. On the one hand, fine-grained services lead their clients toinvoke their interfaces multiple times worsening the performance [Hohpe andWoolf, 2003; Daigneau, 2011]. On the other hand, coarse-grained services canreduce reusability because their use is limited to very specific contexts [Hohpeand Woolf, 2003; Daigneau, 2011]. To find a trade-off between fine-grainedand coarse-grained services the Consumer-Driven Contracts (CDC) pattern hasbeen proposed [Daigneau, 2011]. This pattern states that the granularity ofa service interface should reflect their clients’ usage satisfying their require-ments and becoming a contract between clients and providers.
In literature several studies have investigated the impact of granularity(e.g., [Hohpe and Woolf, 2003; Daigneau, 2011; Murer et al., 2010; Haesenet al., 2008; Kulkarni and Dwivedi, 2008]), have classified the different levelsof granularity (e.g., [Haesen et al., 2008]), and have proposed metrics to mea-sure them (e.g., [Khoshkbarforoushha et al., 2010; Alahmari et al., 2011]).However, to the best of our knowledge, there are no studies proposing tech-niques to assist service providers in finding the right granularity and adoptingthe CDC pattern. This task can be expensive because many clients invoke a ser-vice interface in different ways. Providers should, first, analyze the usage ofmany clients and, then, design a service interface that satisfies all the clients’requirements.
In this chapter, we propose a genetic algorithm to assist service providersin finding the adequate granularity and adopting the CDC pattern. This al-gorithm mines the clients’ usage of a service interface and it retrieves Façadeservices [Krafzig et al., 2004] whose interfaces have an adequate granular-ity for each different type of clients. These Façade services become contractsthat reflect clients’ usage easing the adoption of the CDC pattern. Moreover,providers can deploy them on top of the existing service making this approachactionable without modifying it.
The contributions of this chapter are as follows:
• a genetic algorithm designed to infer Façade services from clients’ usagethat represent contracts with the different types of clients.
• a study to evaluate the capability of the genetic algorithm compared tothe capability of a random search approach.
The results show that the genetic algorithm is capable of finding Façadeservices and it outperforms the random search.
The remainder of this chapter is organized as follows. Section 8.1 presentsthe problem and the proposed solution. Section 8.2 shows the proposed ge-

8.1. Problem Statement and Solution 151
netic algorithm. Section 8.3 presents the study, its results, and discusses them.Related work is presented in Section 8.4 while in Section 8.5 we draw ourconclusions and outline directions for future work.
8.1 Problem Statement and SolutionIn this section, first, we introduce the problem of finding the adequate granu-larity of service interfaces presenting the Consumer-Driven Contracts pattern.Then, we present our solution to address this problem.
8.1.1 Problem StatementChoosing the adequate granularity of a service is a relevant task and a widelydiscussed topic [Hohpe and Woolf, 2003; Daigneau, 2011; Murer et al., 2010;Haesen et al., 2008; Kulkarni and Dwivedi, 2008].
On the one hand, fine-grained services can lead to service-oriented sys-tems with inadequate performance due to an excessive number of remote calls[Hohpe and Woolf, 2003]. Consider for instance the fragment of a service in-terface to order an item shown in Figure 8.1. Figure 8.1a shows a fine-graineddesign for this service that exposes methods to set shipment and billing in-formation for ordering an item. This design is efficient if the methods’ invo-cation happens in a local environment (e.g., in a software system deployedon a single machine) [Hohpe and Woolf, 2003]. In a distributed environment(e.g., in a service-oriented system) a client needs to invoke three methods (i.e.,setBillingAddress(), setShippingAdress(), and addPriorityShipment()) to set theneeded information. This causes a significant communication overhead sincethree methods needs to be invoked over a network.
On the other hand, the coarse-grained OrderItem (shown in Figure 8.1b)exposes only one method (i.e., setShipmentInfo()) to set all the informationrelated to the shipment and the billing. In this way clients invoke the serviceonly once reducing the communication overhead. However, if the servicesare too coarse-grained they can limit the reusability because their use will belimited to very specific contexts [Hohpe and Woolf, 2003; Murer et al., 2010;Daigneau, 2011]. In our example in Figure 8.1, the clients of the coarse-grained service (Figure 8.1b) are constrained to set the billing address, theshipping address, and to add the priority shipment details. The service is notsuitable for contexts where, for instance, priority shipments are not allowed.Maintenance tasks are needed to adapt coarse-grained services to differentcontexts. Hence, finding the adequate granularity of a service requires findinga trade-off between having a too fine-grained or a too coarse-grained service.

152 Chapter 8. Refactoring Chatty web APIs
This allows to publish a service with an acceptable communication overheadand an adequate level of reusability.
OrderItem<<FineGrained>>
-setBillingAddress()
-setShippingAddress()
-addPriorityShipment()
(a) Fine-grained version exposing dif-ferent methods for setting each differ-ent needed information.
OrderItem<<CoarseGrained>>
-setShipmentInfo()
(b) Coarse-grained version exposing amethod to set all the needed informa-tion.
Figure 8.1: An example of fine-grained and coarse-grained service interfacesto set the shipping and the billing data for ordering an item.
To find such an adequate level of granularity the Consumer-Driven Con-tracts (CDC) has been defined for service interfaces [Daigneau, 2011]. TheCDC pattern states that a service interface should reflect their clients needsthrough its granularity. In this way the service interface is considered a con-tract that satisfies the clients’ requirements.
Applying the CDC pattern is not a trivial task. A service has usually severalclients with different requirements invoking its interface differently. To de-ploy a service with an adequate granularity (using the CDC pattern) providersshould know all these requirements. Within an enterprise or a corporate en-vironment providers know their clients and they can understand how clientsexpect to use a service. However, clients are usually not known a priori andthey bind a service only after it has been published and advertised. Moreoverthe number of clients and their different requirements can be huge and changeover time.
8.1.2 SolutionOur solution to the aforementioned problem consists in applying a clusteranalysis. This analysis consists in clustering the set of methods in such a waythat methods in the same cluster are invoked together by the clients. The goalof our cluster analysis is to find clusters that minimize the number of remoteinvocations to a service.
To better understand the cluster analysis for the granularity problem con-sider the example in Figure 8.2. The OrderItem extends the service shown

8.1. Problem Statement and Solution 153
OrderItem<<FineGrained>>
1-setBillingAddress()2-setShippingAddress()3-setPriorityShipment()
5-addWishCardType()4-addPaymentDetails()
6-addWishCardMsg()7-trackShipmentByApp()8-trackShipmentByEmail()9-trackShipmentBySMS()10-notifyArrivalTime()
Client1
Client2
Client3
Client4
Figure 8.2: An example of a service interface to order an item for an e-commerce system. The rectangles represent independent methods that areinvoked by a client.
in Figure 8.1a exposing further methods to 1) add payment details (addPay-mentDetails()), 2) add a wish card to an order (addWishCardType() and ad-dWishCardMsg()), and 3) to track the shipment (trackShipmentByApp(), track-ShipmentByEmail(), trackShipmentBySMS(), and notifyArrivalTime()). Imag-ine this service has four clients (Client1, Client2, Client3, and Client4). Theseclients invoke different sets of independent methods denoted in Figure 8.2 byrectangles (e.g., Client1 invokes setBillingAddress(), setShippingAddress(), andsetPriorityShipment()). These methods are considered independent becausethe invocation of one method does not require the invocation of the otherones [Wu et al., 2013]. In total there are 13 remote invocations: 3 performedby Client1, 3 by Client2, 3 by Client3, and 4 by Client4.
In this example we can retrieve three clusters (shown in Figure 8.3a) thatminimize the number of remote invocations:
• Cluster1 (i.e., Shipment): consists of setBillingAddress(), setShippin-gAddress(), and setPriorityShipments().
• Cluster2 (i.e., WishCard): consists of addWishCardType() and addWish-CardMsg().
• Cluster3 (i.e., TrackShipment): consists of trackShipmentByApp() track-ShipmentByEmail(), trackShipmentBySMS() and notifyArrivalTime().
Once we know the clusters we can combine the fine-grained methods be-longing to a cluster into a single coarse-grained method. These coarse-grainedmethods can be exposed through Façade services [Krafzig et al., 2004] as

154 Chapter 8. Refactoring Chatty web APIs
OrderItem<<FineGrained>>
1-setBillingAddress()2-setShippingAddress()3-setPriorityShipment()
5-addWishCardType()4-addPaymentDetails()
6-addWishCardMsg()7-trackShipmentByApp()8-trackShipmentByEmail()9-trackShipmentBySMS()10-notifyArrivalTime()
Client1
Client2
Client3Client4
Shipment
-setShipmentInfo()
WishCard
-setWishCard()
TrackShipment
-setTrackingShip()
<<Cluster1>>
<<Cluster2>>
<<Cluster3>>
(a) The Shipment, WishCard, and TrackShipment havebeen introduced. This design has 9 local invocationsand 6 remote invocations.
OrderItem<<FineGrained>>
1-setBillingAddress()2-setShippingAddress()3-setPriorityShipment()
5-addWishCardType()4-addPaymentDetails()
6-addWishCardMsg()7-trackShipmentByApp()8-trackShipmentByEmail()9-trackShipmentBySMS()10-notifyArrivalTime()
Client1
Client2
Client3Client4
Shipment
-setShipmentInfo()
Client2
-setClient2Details()
TrackShipment
-setTrackingShip()
<<Cluster1>>
<<Cluster2>>
<<Cluster3>>
(b) The Shipment, Client2, and TrackShipment havebeen introduced. This design has 10 local invocationsand 6 remote invocations.
Figure 8.3: Two possible refactorings of the service interface shown in Fig-ure 8.2 using the proposed cluster analysis and using the Façade pattern. Blackarrows indicate local invocations while non-black arrows indicate remote in-vocations.

8.1. Problem Statement and Solution 155
shown in Figure 8.3a. Façade services (i.e., Shipment, WishCard, and Track-Shipment in our example) have been defined to provide different views oflower level services (i.e., OrderItem in our example). Since the invocationsfrom Façade services to lower-level services are local invocations (shown withblack arrows in Figure 8.3), the total number of remote invocations (shownwith non-black arrows in Figure 8.3) has been reduced from 9 to 6. Moreover,adopting this design choice allows to keep public the fine-grained OrderItemthat can be still invoked by current clients without breaking their behavior.
Choosing the clusters that minimize the number of remote invocationscan lead to multiple solutions. Imagine for instance that we change Cluster2adding the method addPaymentDetails() as shown in Figure 8.3b. This clus-ter is optimal for Client2 that should perform only one remote invocation.However, Client3 cannot invoke anymore the Façade service associated to theCluster2 because it contains a method (i.e., addPaymentDetails()) in which itis not interested. The number of remote invocations is still equal to 6. At thispoint an engineer should decide which architectural design is more suitablefor her specific domain. The decision might be influenced by three differentfactors:
• Cohesion of Façade services: the design in Figure 8.3a might be pre-ferred because the WishCard service is more cohesive than the Client2service since it exposes related methods (methods related to the wishcard concern).
• Number of local invocations: the design in Figure 8.3a might be pre-ferred because it has 9 local invocations while the design in Figure 8.3bhas 10 local invocations.
• Relevance of different clients: the service provider might want to givea better service (e.g., upon a higher registration fee) to Client2 and,hence, adopt the design in Figure 8.3b.
8.1.3 ContributionsIn this chapter we propose a search-based approach to retrieve the clustersof methods that minimize the number of remote invocations. As explainedpreviously, the methods belonging to the same cluster can be exposed througha Façade service whose granularity reflects clients’ usage and, hence, satisfiesthe CDC pattern.
A first approach to find these clusters consists in adopting brute-forcesearch techniques. These techniques consist of enumerating all possible clus-ters and checking whether they minimize the number of invocations. The

156 Chapter 8. Refactoring Chatty web APIs
problem of these approaches is that the number of possible clusters can beprohibitively large causing a combinatorial explosion. Imagine for instance toadopt this approach for finding the right granularity of the AmazonEC2 webservice. This web service exposes 118 methods in the version 23. The numberof 20-combinations of the 118 methods in AmazonEC2 are equal to:
�
11820
�
=118!
20!98!≈ 2 ∗ 1021
This means that for only evaluating all the clusters with 20 methods thesearch will require executing at least 2 ∗ 1021 computer instructions, whichwill take several days on a typical PC. Moreover, we should evaluate clusterswith size ranging from 2 to 118 causing the number of computer instructionsto further increase.
To solve this issue we propose a genetic algorithm (shown in Section 8.2)that mimicking the process of natural selection finds optimal solutions (i.e.,cluster that minimize the number of remote invocations) in acceptable timewithout requiring special hardware configurations (e.g., the use of supercom-puters).
Moreover, we perform a first study aimed at investigating the capabilityof the proposed approach in finding Façade services that is presented in Sec-tion 8.3.
In this chapter we do not cover the problem of mining independent meth-ods because it has already been subject of related work [Wu et al., 2013] thatcan be integrated in our approach. Furthermore, related work [Wu et al.,2013] shows that 78.1% of the methods in their analyzed web services are in-dependent. This percentage shows that most of the methods can be clusteredinto coarse-grained methods,further motivating the need of performing thistask with a proper approach.
8.2 The Genetic AlgorithmGenetic Algorithms (GAs) have been used in a wide range of applicationswhere optimization is required. Among all the applications GAs have beenwidely studied to solve clustering problems [Hruschka et al., 2009].
GAs mimic the process of natural selection to provide a search heuristicable to solve optimization problems. A generic GA is shown in Figure 8.4 andconsists of seven different steps.
In the fist step, the GA creates a set of randomly generated candidate solu-tions (also known as chromosomes) called population (step 1 in Figure 8.4).

8.2. The Genetic Algorithm 157
Create initial population of chromosomes
Evaluate !tness of each chromosome
Select next generation(Selection Operator)
Perform reproduction(Crossover operator)
Perform mutation(Mutation operators)
MaxEvaluations
Outputbest chromosomes
1
2
4
5
6
3
7
Figure 8.4: Different steps of a genetic algorithm.
In the second step, the candidate solutions are evaluated through a fitnessfunction (step 2). This function measures the goodness of a candidate solu-tion. Then, the population is evolved iteratively through evolutionary oper-ators (steps 4, 5, and 6) until some conditions are satisfied (e.g., reachingthe max number of fitness evaluations in step 3 or achievement of the goal).Each evolution iteration is performed through a selection operator (step 4), acrossover operator (step 5), and a mutation operator (step 6). The selectionoperators selects a pair of solutions (parents) from the population. The par-ents are used by the crossover operator to generate two offspring solutions(step 5). The offspring solutions are generated in such a way that combinefeatures from the two parents. The mutation operators (step 6) mutate theoffspring in order to preserve the diversity. The mutated solutions are addedto the population replacing solutions with the worst fitness scores. Finally, theGA outputs the best solutions when the evolution process terminates (step 7).
To implement the GA and adapt it to find the set of clusters that mini-mize the number of remote invocations we have to define the fitness function,the chromosome (or solution) representation, and the evolutionary operators(i.e., selection, crossover, and mutation) that are shown in the following sub-sections.

158 Chapter 8. Refactoring Chatty web APIs
ClientID InvokedMethodsClient1 1;2;3Client2 4;5;6Client3 5;6;7Client4 7;8;9;10
Table 8.1: Data set containing independent methods invoked by each differentclient in Figure 8.2.
8.2.1 Chromosome representationThe chromosomes are represented with a label-based integer encoding widelyadopted in literature [Hruschka et al., 2009] and shown in Figure 8.5. Ac-cording to this encoding, a solution is represented by an integer array of n po-sitions, where n is the number of methods exposed in a service. Each positioncorresponds to a specific method (e.g., position 1 corresponds to the methodsetBillingAddress() in Figure 8.2). The integer values in the array represent thecluster to which the methods belong. For instance in Figure 8.5, the methods1,2, and 10 belong to the same cluster labeled with 1. Note that two chro-mosomes can be equivalent even though the clusters are labeled differently.For instance the chromosomes [1,1,1,1,2,2,2,2,3,3] and [2,2,2,2,3,3,3,3,1,1]represent the same clusters. To solve this problem we apply the renumberingprocedure as shown in [Falkenauer, 1998] that transforms different labelingsof equivalent clusterings into a unique labeling.
1 1 2 3 2 4 5 3 6 1
1 2 3 4 5 6 7 8 9 10
Figure 8.5: Chromosome representation of our candidate solutions.
8.2.2 FitnessThe fitness function is a function that measures how "good" a solution is. Ourfitness function counts for each chromosome the number of remote invoca-tions needed by the clients. Imagine that the clients’ usage information ofFigure 8.2 are saved in the data set shown in Table 8.1.
In this data set, each row contains the id of the client (i.e., ClientID) andthe set of independent methods invoked by it (i.e., InvokedMethods). The In-vokedMethods are sets of methods where each integer value corresponds to adifferent method in the service. We label the methods in the OrderItem (shownin Figure 8.2) from 1 to 10 depending on the order they appear in the service

8.2. The Genetic Algorithm 159
(e.g., setBillingAddress() is labeled with 1, setShippingAddress() is labeled with2, etc.).
Once we have this data set, we compute the fitness function as the sum ofthe number of remote invocations required to invoke each InvokedMethods setin the data set. If the methods (or a subset of methods) in an InvokedMeth-ods set belong to a cluster containing no other methods, the methods in thiscluster account for 1 invocation in total. Otherwise each different method ac-counts for 1. Consider for instance the chromosome [1,1,1,1,2,2,2,2,3,3]. Thischromosome clusters together the methods 1, 2, 3, and 4 (i.e., cluster 1), themethods 5, 6, 7, and 8 (i.e., cluster 2), and the methods 9 and 10 (i.e., cluster3). In this case the number of remote invocations to execute the Invoked-Methods of Client1 (i.e., 1;2;3) is 3 because the cluster 1 contains the method4 that is not needed by it. Hence, Client1 cannot invoke the Façade servicerepresented by the cluster labeled 1 and invokes the methods of the originalservice OrderItem. If we change the chromosome into [1,1,1,2,2,2,2,2,3,3],the total number of invocations is equal to 1 because Client1 can execute thesingle operation declared in the Façade service represented by the cluster 1.If the chromosome becomes [1,1,2,2,2,2,2,2,3,3] then the total number of re-mote invocations is equal to 2. The client invokes once the method of cluster1 to invoke the methods 1 and 2. Then it invokes method 3 in the originalservice.
8.2.3 The Selection OperatorTo select the parents we use the Ranked Based Roulette Wheel (RBRW) opera-tor. This operator is a modified roulette wheel selection operator that has beenproposed by Al Jadaan and Rajamani [2008]. RBRW ranks the chromosomesin the population by the fitness value: the highest rank is assigned to the chro-mosome with the best fitness value. Hence, the best chromosomes have thehighest probabilities to be selected as parents.
8.2.4 The Crossover OperatorThe two parents (ParentA and ParentB) are then used to generate the off-spring. The crossover operator is applied with a probability Pc. To performthe crossover we use the operator defined for clustering problems byHruschkaet al. [2009]. Consider the example shown in Figure 8.6 from [Hruschkaet al., 2009]. The operator first selects randomly k (1≤k≤n) clusters fromParentA, where n is the number of clusters in ParentA. Assume that the clus-ters 2 and 3 are selected from ParentA (marked in red in Figure 8.6). Thefirst child (ChildC) originally is created as copy of the second parent ParentB(step 1). As second step, the selected clusters (i.e., 2 and 3) are copied into

160 Chapter 8. Refactoring Chatty web APIs
ChildC. Copying these clusters changes the clusters 1, 2, and 3 in ChildC. Thesechanged clusters are removed from ChildC (step 3) leaving the correspondingmethods unallocated (labeled with 0). In the forth step the unallocated meth-ods are allocated to the cluster with the nearest centroid.
The same procedure is followed to generate the second child ChildD. How-ever, instead of selecting randomly k clusters from ParentB, the changed clus-ters of ChildC (i.e., 1,2, and 3) are copied into ChildD that is originally a copyof ParentA.
1 1 2 3 2 4 5 1 2 5 4 2 1 2 3 3 2 1 2 4
4 2 1 2 3 3 2 1 2 4
ParentA ParentB
ChildC
1: copy ParentB into ChildC
4 2 2 3 2 3 2 1 2 4ChildC
2: copy clusters 2 and 3 from ParentA to ChildC
4 0 2 3 2 0 0 0 2 4ChildC
3: remove changed methods from B (i.e., 1,2,3)
4: unallocated objects are allocated to randomly selected clusters
Figure 8.6: Example of crossover operator for clustering problems [Hruschkaet al., 2009].
8.2.5 The Mutation OperatorsFinally, the offspring is mutated through the mutation operator with a proba-bility Pm. This step ensures genetic diversity from one generation to the nextones. We perform the mutation selecting one of the following cluster-orientedmutation operators (randomly selected) [Falkenauer, 1998; Hruschka et al.,2009]:
• split: a randomly selected cluster is split into two different clusters. Themethods of the original cluster are randomly assigned to the generatedclusters.

8.3. Study 161
• merge: moves all methods of a randomly selected cluster to anotherrandomly selected cluster.
• move: moves methods between clusters. Both methods and clusters arerandomly selected.
8.2.6 ImplementationWe implemented the proposed genetic algorithm on top of the JMetal2 frame-work. JMetal is a Java framework that provides state-of-the-art algorithms foroptimization problems. We calibrated the genetic algorithm as follows:
• the population is composed by 100 chromosomes. The initial populationis randomly generated;
• the crossover and mutation probability is 0.9;
• the maximum number of fitness evaluation (step 3 in Figure 8.4) is100,000.
8.3 StudyThe goal of this study is to evaluate the capability of our approach in findingFaçade services that minimize the number of remote invocations and reflectclients’ usage. The perspective is that of service providers interested in applyingthe Consumer-Driven Contracts pattern using Façade services with adequategranularity. In this study we answer the following research question:
To which extent is the propose GA capable of identifying Façade services thatminimize the number of remote invocations and reflect clients’ usage?
In the following subsections, first, we present the analysis we performedto answer our research question. Then, we show the results and answer theresearch question. Finally, we discuss the results and the threats to validity ofour study.
8.3.1 AnalysisTo answer our research question we run the genetic algorithm (GA) definedin Section 8.2 to find the Façade services for the working example shown inFigure 8.2. To measure the performance of our GA we register the number
2http://jmetal.sourceforge.net

162 Chapter 8. Refactoring Chatty web APIs
of GA fitness evaluations needed to find the Façade services shown in Fig-ure 8.3a and Figure 8.3b. Also, we compare the GA with a random search(RS), in which the solutions are randomly generated but no genetic evolutionis applied. Both the GA and RS are executed 100 times and the number offitness evaluations required to find the Façade services are compared throughstatistical tests. We use a random search as baseline because this comparisonis considered the first step to evaluate a genetic algorithm [Sivanandam andDeepa, 2007]. Comparisons with other search-based approaches (e.g., localsearch algorithms) will be subject of our future work.
First, we use the Mann-Whitney test to analyze whether there is a signif-icant difference between the number of fitness evaluations required by theGA and the ones required by the RS. Significant differences are indicated byMann-Whitney p-values ≤ 0.01. Then, we use the Cliff’s Delta d effect size tomeasure the magnitude of the difference. Cliff’s Delta estimates the probabil-ity that a value selected from one group is greater than a value selected fromthe other group. Cliff’s Delta ranges between +1 if all selected values fromone group are higher than the selected values in the other group and -1 if thereverse is true. 0 expresses two overlapping distributions. The effect size isconsidered negligible for d < 0.147, small for 0.147≤ d < 0.33, medium for0.33≤ d < 0.47, and large for d ≥ 0.47. We chose the Mann-Whitney testand Cliff’s Delta effect size because they do not require assumptions aboutthe variances and the types of the distributions (i.e., they are non-parametrictests).
Moreover, to analyze the capability of the GA in finding Façade services forbigger services, we increase stepwise the number of methods declared in Or-derItem keeping unchanged the original methods (i.e., 1-10), their clients, andthe clients’ usage (as shown in Figure 8.2). In this way we enlarge the searchspace and we analyze whether the GA is able to find the same Façade services.For each different size of the OrderItem we perform the same analysis: 1) weexecute 100 times the GA and RS, 2) we register the number of fitness eval-uations needed for finding the Façade services shown in Figure 8.3, and 3)we perform the Mann-Withney and Cliff’s Delta test to analyze statistically thedifferences between the distributions. We increment the size of the service upto 118 methods, that is the size of the biggest WSDL interface (AmazonEC2)analyzed in our previous work shown in Chapter 4.
8.3.2 ResultsTable 8.2 shows the percentage of executions in which GA and RS find theright Façade services shown in Figure 8.3. The results show that, while the

8.3. Study 163
#Methods GA RS10 100% 82%11 100% 70%12 100% 65%13 100% 35%14 100% 20%15 100% 10%16 100% 0%
118 100% 0%
Table 8.2: Percentage of successful executions in which GA and RS find theFaçade services shown in Figure 8.3.
GA is always capable of finding the Façade services, the capability of the RSdecreases with an increasing number of methods. For services with 16 or moremethods the RS is not capable to find the Façade services.
The number of fitness evaluations required by the GA and RS are shownin the form of box plots in Figure 8.7. The median number of fitness evalua-tions for the OrderItem with 118 methods required by the GA (not shown inFigure 8.7) is equal to 5754 (with a median execution time of 295 seconds3).Comparing it to the median number of fitness evaluations for the service with10 methods (i.e., 1049 fitness evaluations with a median execution time of34.5 seconds) shows that GA scales well with an increasing number of meth-ods.
Moreover, the distributions of the number of fitness evaluations requiredby the GA and the RS is statistically different as shown by the Mann-Whitneyp-values (<0.01) in Table 8.3. The magnitude of these differences is alwayslarge as shown by Cliff’s Deltas d (=1) in Table 8.3. All the distributions,except RS12 in Figure 8.7, are not normally distributed (normality has beentested with the Shapiro test and a confidence level of 0.05). As a consequencethe non-parametric tests used in our analysis are the most suitable for thesedistributions.
Based on these results, we can answer our research question stating thatthe GA is capable to find Façade services and outperforms the RS approach.
3Execution times has been evaluated on a MacBook Pro Mid 2010, processor 2.66 GHzIntel Core i7, memory 4 GB 1067 MHz DDR3, OS 10.8.5.
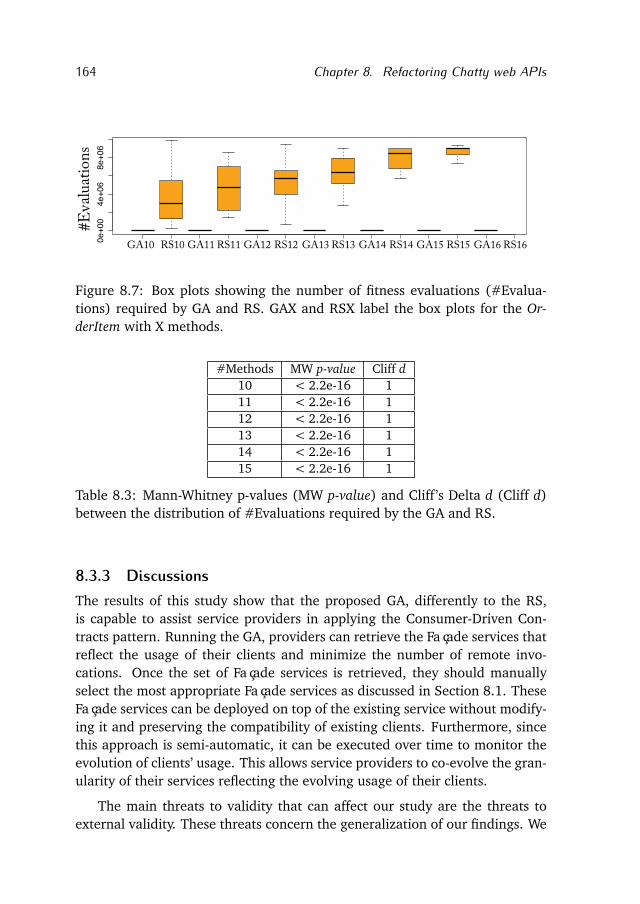
164 Chapter 8. Refactoring Chatty web APIs
GA10 RS10 GA11 RS11 GA12 RS12 GA13 RS13 GA14 RS14 GA15 RS15 GA16 RS16
0e+00
4e+06
8e+06
#Evaluations
Figure 8.7: Box plots showing the number of fitness evaluations (#Evalua-tions) required by GA and RS. GAX and RSX label the box plots for the Or-derItem with X methods.
#Methods MW p-value Cliff d10 < 2.2e-16 111 < 2.2e-16 112 < 2.2e-16 113 < 2.2e-16 114 < 2.2e-16 115 < 2.2e-16 1
Table 8.3: Mann-Whitney p-values (MW p-value) and Cliff’s Delta d (Cliff d)between the distribution of #Evaluations required by the GA and RS.
8.3.3 DiscussionsThe results of this study show that the proposed GA, differently to the RS,is capable to assist service providers in applying the Consumer-Driven Con-tracts pattern. Running the GA, providers can retrieve the Façade services thatreflect the usage of their clients and minimize the number of remote invo-cations. Once the set of Façade services is retrieved, they should manuallyselect the most appropriate Façade services as discussed in Section 8.1. TheseFaçade services can be deployed on top of the existing service without modify-ing it and preserving the compatibility of existing clients. Furthermore, sincethis approach is semi-automatic, it can be executed over time to monitor theevolution of clients’ usage. This allows service providers to co-evolve the gran-ularity of their services reflecting the evolving usage of their clients.
The main threats to validity that can affect our study are the threats toexternal validity. These threats concern the generalization of our findings. We

8.4. Related Work 165
evaluated our approach with a small working example. However, to best ofour knowledge, there are no available data sets that contain service usageinformation suitable for our analysis. In literature different data sets are avail-able for research on QoS (e.g., [Al-Masri and Mahmoud, 2008; Zhang et al.,2010]). However, these data sets do not contain information about the opera-tions invoked but only the service names and their url. As a consequence theyare not suitable for our analysis.
8.4 Related WorkGranularity of services. The closest work to ours is the study developed byJiang et al. [2011]. In this study the authors propose an approach to inferthe granularity of services by mining the activities of business processes. Themain idea consists of using frequent pattern mining algorithms to analyzethe invocations to service interfaces. Our approach differs to theirs becauseit can mine the granularity of every kind of services and not only servicesinvolved in business processes. Furthermore, we have not used the proposedfrequent pattern mining algorithm because they require a special tuning of thesupport and confidence parameters that are problem specific. Moreover, theseparameters, together with other relevant details, are not reported in [Jianget al., 2011] making the replication of this study not possible. To the best ofour knowledge we are not aware of further studies aimed a inferring the rightgranularity of service interfaces.
Related work have mostly proposed classifications for different levels ofgranularity and have investigated metrics for measuring the granularity. Hae-sen et al. [2008] have proposed a classification of three service granularitytypes (i.e., functionality, data, and business value granularity). For each ofthese types they have discussed the impact on a set of architectural attributes(e.g., performance, reusability and flexibility). In this chapter we adhered totheir functionality granularity that has been referred to as granularity for thesake of simplicity. Haesen et al. confirm that the functionality granularitycan have an impact on both performance and reusability as stated in [Hohpeand Woolf, 2003; Murer et al., 2010; Daigneau, 2011] and already discussedin Section 8.1. Many other studies have investigated metrics to measure thegranularity (e.g., [Khoshkbarforoushha et al., 2010; Alahmari et al., 2011]).For instance, Khoshkbarforoushha et al. [2010] measure the granularity ap-propriateness with a model that integrates four different metrics that measure:1) the business value of a service, 2) the service reusability, 3) the servicecontext-independency, and 4) the service complexity. Alahmari et al. [2011]proposed a set of metrics to measure the granularity based on internal struc-

166 Chapter 8. Refactoring Chatty web APIs
tural attributes (e.g., number of operations, number of messages, complexityof data types). However, these studies are limited to measure the granularityand do not provide suggestions on inferring the right granularity.
Refactoring through genetic algorithms. Over the last years genetic al-gorithms, and in general search based algorithms, have become popular toperform refactorings of software artifacts. For instance, Ghannem et al. [2013]found appropriate refactoring suggestions using a set of refactoring examples.Their approach is based on an Interactive Genetic Algorithm which enablesto interact with users and integrate their feedbacks into a classic GA. Ghaithand Cinnéide [2012] presented an approach to automate improvements ofsoftware security based on search-based refactoring. O’Keeffe and í Cinnéide[2008] have constructed a software tool capable of refactoring object-orientedsystems. This tool uses search-based techniques to conform the design of asystem to a given design quality model. These studies confirm that geneticalgorithms are a useful technique to solve refactoring problems and satisfyingdesired quality attributes.
8.5 Conclusion & Future WorkIn this chapter we have proposed a genetic algorithm to mine the adequategranularity of a service interface. According to the Consumer-Driven Contractspattern, the granularity of a service should reflect its clients’ usage. To adoptthis pattern our genetic algorithm suggests Façade services whose granularityreflect the clients’ usage. These services can be deployed on top of existing ser-vices allowing an easy adaptation of the Consumer-Driven Contracts patternthat does not require any modifications to existing services.
Our approach is semi-automatic as discussed in Section 8.1. The geneticalgorithm outputs different sets of Façade services that should be reviewed byproviders. In our future work, first, we plan to further improve this approachto minimize the effort required from the user. Specifically, we plan to add pa-rameters that can guide the search algorithm towards more detailed goals:giving more relevance to certain clients, satisfying other quality attributes(e.g., high cohesion of Façade services, low number of local invocations), etc.Then, we plan to compare our genetic algorithm with other search-based tech-niques (e.g., local search algorithms). Finally, we plan to improve the geneticalgorithm suggesting overlapping Façade services that allow a method to be-long to different Façade services. However, an ad-hoc study is needed to inves-tigate to which extent the methods can be exposed through different Façadeservices because it can be problematic for the maintenance of service-orientedsystems.

9..Conclusion
The need of reusing existing software components has caused the emergenceof a new programming paradigm called service-oriented. According to serviceorientation, existing software systems (e.g., legacy systems) can be integratedwith web services. The main goal of web services is to provide a standardizedAPI that hide the technologies used to implement the legacy system. Othersystems can reuse the business logic of legacy systems without knowing theirimplementation details and only binding these APIs. As a consequence thecoupling between integrated systems is reduced as discussed in Chapter 1.However, such systems are still coupled through web APIs that specify theoperations exposed by web services and the data structures needed to invokethem. These web APIs are considered contracts between web service providersand their clients and they should stay as stable as possible. Changes in theweb APIs can lead the client systems to be broken and their business can bedamaged.
In this dissertation we have focused on better understanding the change-proneness of APIs and web APIs. Specifically to that end, this work has inves-tigated which indicators can be used to highlight change-prone APIs and webAPIs providing approaches to assist practitioners in refactoring them.
9.1 ContributionsThe main contributions of this thesis can be summarized as follows:
• An external cohesion metric (i.e., IUC) capable of highlighting change-prone Java interfaces. We performed an empirical study aimed at inves-tigating which software metrics can be used to highlight change-proneJava interfaces. We compared the capability of existing software met-rics defined for object oriented and service oriented systems. Softwaremetrics have been measured along the history of a software system andthey have been correlated through statistical tests with the changes per-
167

168 Chapter 9. Conclusion
formed in the analyzed systems. These metrics have also been used totrain prediction models aimed at predicting change-prone Java inter-faces. The results of this study are useful for software engineers andsoftware researchers. Software engineers can better measure the sta-bility of their interfaces. This helps them in highlighting change-proneinterfaces before they are bound to web APIs. Software researchers canuse this first study to further investigate the change-proneness of Javainterfaces and more in general of APIs.
• A set of antipatterns (i.e., ComplexClass, SpaghettiCode, and SwissArmyKnife)that highlight change-prone Java APIs. We performed an empirical studyaimed at investigating which antipatterns can be used as indicators ofchanges in Java classes. We investigated which antipatterns are morelikely to lead to changes and which types of changes are likely to appearin Java classes affected by certain types of antipatterns. Among othertypes of changes, we investigated changes that APIs undergo along theirhistory and which antipatterns are more likely to cause these changes.As in the previous contribution, we measured the presence of antipat-terns along the history of software systems and we statistically corre-lated them with the number and type of changes performed in the soft-ware systems. The perspective of this study is that of software engineerswho want to estimate the stability of Java classes that participate in cer-tain antipatterns. Among thess antipatterns, they might be interested inantipatterns that cause changes to APIs. This is particularly relevant ifAPIs are bound to web APIs.
• An approach to mine dynamic dependencies among web services de-ployed in an enterprise. To that end, we used the vector clocks tech-nique originally conceived to order events in a distributed environment.We used this technique in the domain of web service systems by attach-ing the vector clocks to the header of SOAP messages. We modified thevector clocks’ value along the execution of a service oriented system andwe used them to order service executions and to infer causal depen-dencies among the executions. The implementation of this approach isportable and it relies on well known integration patterns. Moreover, weanalyzed the impact of the attached vector clocks on the performanceof a service oriented systems. This approach is useful for software engi-neers who want to monitor the dynamic chain of dependencies amongweb services that might be useful for debugging and reverse engineeringtasks.

9.1. Contributions 169
• A tool called WSDLDiff that extracts fine-grained changes between dif-ferent versions of WSDL APIs. Differently to existing approaches, ourtool takes into account the syntax of WSDL and XSD that are used todefine operations and data structures in a WSDL API. This tool is usefulfor web service subscribers and researchers. WSDLDiff can be used bysubscribers who want to analyze which elements are frequently added,changed, and removed in a WSDL API and which types of changes aWSDL API undergoes more frequently. Based on this information theycan subscribe to the most stable WSDL APIs reducing the likelihood thatunstable APIs might break their systems. Researchers can use our toolto further investigate the change-proneness of WSDL APIs retrieving au-tomatically the fine-grained changes performed along their history.
• A set of maintenance scenarios that can affect web APIs with low inter-nal end external cohesion. We performed an empirical study aimed at in-vestigating the impact of internal and external cohesion on the change-proneness of web APIs. This analysis is performed using a mixed-methodapproach. First, we used an online survey to investigate the interface,method, and data-type level change-proneness of web APIs with lowexternal and internal cohesion. The survey reports on maintenance sce-narios that are likely to cause changes in such web APIs. Then, we ana-lyzed the history of ten well known WSDL APIs to investigate the impactof internal cohesion on the change-proneness. Specifically, we intro-duced a new internal cohesion metric (DTC) and we correlated statis-tically the values of this metric with the fine-grained changes extractedwith WSDLDiff from the WSDL APIs under analysis. The perspective ofthis study is that of web service providers, subscribers, and software re-searchers. Both, web service providers and subscribers, can benefit fromthe new metric to estimate the interface change-proneness of a WSDLAPI. Based on the values of the DTC metric, subscribers can subscribeto the most internally cohesive WSDL API to avoid that changes canbreak their systems. Providers can highlight WSDL APIs that should berefactored to avoid frequent changes. Moreover, they can estimate thechange-proneness based on the value of external cohesion metrics (e.g.,SIUC). Based on the internal and external cohesion, they can estimatethe likelihood that certain maintenance scenario can cause changes totheir APIs. Software researchers can also benefit from this first study onchange-prone web APIs to further investigate the change-proneness ofweb APIs.
• An approach to automatically refactor APIs with low external cohesion,

170 Chapter 9. Conclusion
also knows as fat APIs. We propose an approach to split fat APIs accord-ing to the Interface Segregation Principle (ISP). We defined the problemof splitting fat APIs as a multi-objective clustering optimization problemand we proposed a genetic algorithm to solve it. Based on the clientusage of a fat API, the genetic algorithm infers the APIs into which itshould be split to conform to the ISP and, hence, showing a higher ex-ternal cohesion. To validate the genetic algorithm we mined the clients’usage of 42,318 public Java APIs from the Maven repositories. We com-pared the capability of the genetic algorithm with the capabilities ofother search-based techniques, namely a random approach and a multi-objective simulated annealing approach. The genetic algorithm is usefulfor software engineers who want to refactor APIs and web APIs with lowexternal cohesion that is symptomatic of change-prone APIs.
• An approach to refactor chatty web APIs. We proposed a genetic algo-rithm that assists web service providers in finding the right granularityfor their web APIs. Based on the clients’ usage of a web API, the geneticalgorithm mines the Façade APIs that reflect the usage of the differ-ent clients according to the Consumer-Driven Contracts (CDC) patterns.These Façade APIs cluster together methods that are invoked together bythe different clients reducing the number of remote invocations. FaçadeAPIs can be deployed on top of the original APIs with which they com-municate locally. As a consequence, the remote chattiness is reduced.
9.2 The Research Questions RevisitedIn Chapter 1 we have formulated a set of high level research questions whoseanswers can be found in the studies presented in the chapters of this disser-tation. In this section we answer these high level research questions basedon the findings of our studies and we discuss them in the context of this PhDthesis.
9.2.1 Track 1: Change-Prone APIsThe first track of this PhD research was aimed at investigating indicators ofchanges for APIs that might be bound to web APIs.
Research Question 1: Which software metrics do indicate change-prone APIs?
This research question can be answered from the results of the study pre-sented in Chapter 2. In this chapter we investigated the change-proneness

9.2. The Research Questions Revisited 171
of Java interfaces correlating the values of software metrics with the num-ber of fine-grained changes performed in Java interfaces. As software metricswe selected the popular C&K metrics, already used to highlight change-proneJava classes, and a set of complexity and usage metrics defined for interfaces.The fine-grained changes have been extracted with ChangeDistiller mining thesoftware repositories of 10 well known open source Java projects. The re-sults have shown that the Interface Usage Cohesion (IUC) metric exhibits thestrongest correlation with the number of changes performed in Java interfaces.As a consequence, software engineers should design interfaces with high ex-ternal cohesion (measured with the IUC metric) to avoid frequent changes.Low external cohesion is also known as symptom of the violation of the Inter-face Segregation Principle (ISP). This principle was already popular amongstsoftware practitioners before our study. However, our study provides a firstempirical evidence of the effects of the ISP on the stability of interfaces.
In the second part of this study we used prediction models (i.e., SupportVector Machine, Naive Bayes Network, and Neural Nets) to predict change-proneJava interfaces. First, we trained these models with object oriented metricsthat showed the highest correlation with the number of fine-grained changesnamely, CB0, RFC, LCOM, and WMC. Then, we added the IUC metric to thesemetrics. The results showed that when adding the IUC metric the precisionand recall increased.
Based on these results, we can answer Research Question 1 stating that theIUC metric is the best metric in highlighting change-prone Java interfaces asfar as our research showed. This indicates that external cohesion is a requiredquality attribute to design stable interfaces. Interestingly low external cohe-sion highlights also change-prone web APIs as it has been found in the studyshown in Chapter 6. This result suggests that the clients usage should be takeninto account when we expose operations through an API.
Research Question 2: What is the impact of antipatterns on thechange-proneness of APIs?
Previous studies have already shown the impact of antipatterns on thechange-proneness of software artifacts. In the context of this PhD research wewanted to investigate whether antipatterns impact also the change-pronenessof APIs. We can answer Research Question 2 with the results of the studyreported in Chapter 3. In Chapter 3 we performed an empirical study to in-vestigate 1) the impact of certain antipatterns on change-proneness and 2) thefrequency of appearance of certain type of fine-grained changes in Java classesaffected by certain antipatterns.

172 Chapter 9. Conclusion
The fine-grained changes have been extracted with ChangeDistiller fromthe repositories of 16 Java open source projects. These changes have beenclustered in 5 different categories depending on the entity of the change.Among these categories we defined a category that includes all changes per-formed on APIs (e.g., method renaming, changes of parameters, changes ofreturn types). Besides extracting the changes performed in each class, we de-tected the list of antipatterns affecting each class with the DECOR tool [Mohaet al., 2008a,b, 2010].
Based on this extracted data, we correlated the presence of certain antipat-terns with the frequency of certain types of changes. We showed empiricallythat changes to APIs are more likely to appear if APIs are affected by the Com-plexClass, SpaghettiCode, and SwissArmyKnife antipatterns. These results allowus to answer Research Question 2 stating that these antipatterns have a greaterimpact on the change-proneness of APIs in the analyzed systems. Togetherwith the results of the study showed in Chapter 2, they provide heuristics todetect change-prone APIs. If these APIs are made available through web ser-vices, engineers should resolve these antipatterns, and assure high externalcohesion, to avoid frequent changes in the future.
9.2.2 Track 2: Change-Prone Web APIsIn the second track of this PhD research we focused on change-proneness ofweb APIs. First, we defined two approaches to analyze service oriented sys-tems. Then, we analyzed the change-proneness answering the research ques-tions reported below.
Research Question 3: How can we extract fine-grained changes amongsubsequent versions of web APIs?
In Chapter 4 we have proposed the WSDLDiff tool to extract fine-grainedchanges from the history of WSDL APIs. The tool has been implemented ontop of the Eclipse Modeling Framework (EMF). This framework allows to parseWSDL APIs into standardized models (i.e., ecore models) that can be com-pared through the Matching and Differencing engines. Differently to previouswork, our tool takes into account the syntax of WSDL and XSD languages andoutputs the elements affected by a change (e.g., XSDElement, WSDLMessage)and the type of change (i.e., addition, deletion, and modification).
In our first study (shown in Chapter 4) we used WSDLDiff to analyze theevolution of four well known public WSDL APIs. The changes extracted inthis study showed that WSDL APIs evolve differently and they do change fre-quently. This result further motivated us to investigate the change-proneness

9.2. The Research Questions Revisited 173
of web APIs. WSDLDiff is a useful tool that can help web service subscribersin analyzing which elements are frequently added, removed, and changed ina WSDL API. Based on this information they can subscribe to the most stableWSDL API to avoid to continuously adapt their clients to new versions of aWSDL API. Researchers can benefit from this tool to further investigate theevolution of WSDL APIs.
We can answer Research Question 3 stating that EMF provides a frameworksuitable to extract changes between different versions of a WSDL API.
Research Question 4: How can we mine the full chain of dynamicdependencies among web services?
We can answer Research Question 4 based on the study presented in Chap-ter 5. We have reported on an approach to extract dynamic dependenciesamong web services based on the vector clocks. We provided a non-intrusive,easy-to-implement, and portable implementation that relies on the well knownPipes and Filters integration pattern. As a consequence this approach can beimplemented in many enterprise service buses and web service frameworkssuch as Apache Axis2, Apache CXF, and MuleESB.
This approach consists in attaching vector clocks to the header of SOAPmessages. When a web service is invoked, the vector clock is captured and up-dated storing information about the invoked web service. Along the executionof a service oriented system the vector clock stores the chains of invocationsthat can be viewed at run-time or at a later time. This approach is particularlyuseful to reverse engineering and debugging service oriented systems. A firstanalysis of the overhead due to this approach showed that extra overhead isnegligible.
To summarize we can answer Research Question 4 stating that the existingtechnique of vector clocks can be used to retrieve dependencies among webservices and its overhead is negligible.
Research Question 5: What are the scenarios in which developers change webAPIs with low internal and external cohesion?
In Chapter 6 we have presented a mixed-method approach to investigatethe change-proneness of web APIs with low internal and low external cohe-sion. The survey we performed gives insights into the maintenance scenariosthat can lead such web APIs to change. Specifically, we can state that low ex-ternally cohesive web APIs change frequently to 1) improve understandability

174 Chapter 9. Conclusion
and 2) ease maintainability and reduce clones in the APIs. Low internallycohesive web APIs change frequently to 1) reduce the impact of changes onthe many clients they have, 2) avoid that all the clients lead the APIs to bechanged frequently, and 3) improve understandability.
We complemented the finding of our survey performing a quantitativeanalysis of low internally cohesive web APIs. First, we defined a new inter-nal cohesion metric (DTC) to measure properly the internal cohesion. Then,we correlated the values of DTC with the number of changes performed in tenwell known WSDL APIs. The changes have been extracted with our WSDLD-iff tool presented in Chapter 4. The results confirm that web APIs with lowinternal cohesion are more change-prone than internally cohesive web APIs.
9.2.3 Track 3: Refactoring Web APIsThe last track of this dissertation is dedicated to approaches to refactor change-prone web APIs.
Research Question 6: Which search based techniques can be used to apply theInterface Segregation Principle?
Both studies presented in Chapter 2 and Chapter 6 showed that low in-ternally cohesive APIs and web APIs are more change-prone. To refactor suchAPIs we presented an approach to apply the Interface Segregation Principle(ISP) in Chapter 7. We defined the problem of splitting fat APIs into smallerAPIs specific for each client (i.e., ISP) as a multi-objective clustering optimiza-tion problem. To solve this problem we used two state-of-the art search basedapproaches namely, a genetic algorithm and a simulated annealing algorithm.The results of this study showed that the genetic algorithm is able to infermore externally cohesive APIs for 42,318 public APIs whose usage has beenmined from the Maven repositories.
This approach is useful for API and web API providers. To use our geneticalgorithm API providers should monitor how their clients invoke their API.This data is then used by the genetic algorithm to split the API into smallerAPIs accordingly to the ISP.
Research Question 7: Which search based techniques can transform afine-grained APIs into multiple coarse-grained APIs reducing the total number of
remote invocations?
As discussed in Section 1.1.3 fine-grained web APIs should be refactoredinto coarse-grained web APIs to avoid performance problems. In Chapter 8

9.3. Recommendations for Future Work 175
we defined a genetic algorithm to infer coarse-grained Façade APIs from theclients usage of a fine-grained API. The genetic algorithm looks for FaçadeAPIs that cluster together the fine-grained methods of the original API. Fine-grained methods are clustered into a single coarse-grained method if they areinvoked consecutively by the clients. In this way the clients can invoke thecoarse-grained methods in the Façade APIs reducing the number of remoteinvocations. A first study showed that the genetic algorithm outperforms therandom search technique and is always able to suggest the right Façade APIsfor the working example shown in Chapter 8. The capability of the randomapproach decreases with larger fine-grained APIs.
This approach can be used every time there is the need to reduce thechattiness of web APIs. In such cases the Façade APIs retrieved by the geneticalgorithm can be deployed on top of the original APIs. This allows the clientsto interact with the APIs with less invocations while keeping the original APIs.
9.3 Recommendations for Future WorkThe work presented in this dissertation provides relevant insights into thechange-proneness of web APIs. However, this is only a first step in this areaof research that certainly needs to be incrementally enriched and revised. Inthis section we present the recommendations for future work for each of thedifferent tracks of this PhD project.
To investigate the change-proneness of APIs we have performed quantita-tive studies. These studies provide statistical evidence of heuristics to high-light change-prone APIs. This track should be enriched performing qualitativeanalyses. These qualitative analyses should include questionnaires, surveys,interviews allowing developers and engineers to further refine our findings.Moreover, it is desirable to perform a more extended quantitative analysis thatanalyzes software systems implemented in different programming languagesand paradigms also including commercial software systems.
The recommendations for the future work of Track 2 are threefold. First,a quantitative analysis of the change-prone externally cohesive web APIs isdesirable. This analysis should refine and revise the insights we collected inour survey. However, performing this analysis requires access to the clientsusage of web APIs that might not be publicly available. As a consequence, thisanalysis should be performed in an industrial environment where this data isavailable.
A second important step to understand why web APIs change over time isunderstanding their purpose. Track 2 should be extended taking into account

176 Chapter 9. Conclusion
the web service typologies. Heuristics to classify web services into differenttypologies, as suggested by Krafzig et al. [Krafzig et al., 2004], should bedefined. We expect that some web service typologies change less frequentlyand for different reasons than others. For instance, the web API of a webservice that is meant to bridge a technological gap would change only whenthe bridged technologies change. On the other hand, the interface of a webservice that provides search functionalities can change every time that thesearch criterion changes.
To automatically classify web services we can analyze two sources of infor-mation. First, we can analyze the documentations that are usually available innatural language and published on websites. For instance, Google Maps webservices are documented on their website.1 The second source of informationconsists of the web API that is composed of: 1) method declarations, 2) datatypes needed to invoke the methods and to retrieve the results, and 3) com-ments to ease the comprehension of a service interface. To obtain relevantinformation from these two sources future work should be based on informa-tion retrieval techniques, widely used in the software engineering communityfor similar purposes.
Finally, future work should investigate the change-proneness of REST APIsseparately. In this dissertation we have focused on RPC APIs such as WSDLAPIs. As discussed in Chapter 1 REST APIs are different because they areResource APIs that expose resources through HTTP as application protocol. Asconsequence, the operations they expose are fixed but the resource itself canchange. Dedicated studies to investigate the change-proneness of resources isdesirable to understand why REST APIs change.
As future work of Track 3 both the genetic algorithms presented in Chap-ter 7 and Chapter 8 can be further improved. For instance, the sub-APIs gen-erated by the genetic algorithm Chapter 7 exposes disjoint sets of methods.These sub-APIs might expose overlapping sets of methods to show higher val-ues of external cohesion. However, this causes the introduction of clones andfurther studies are needed to investigate how they impact other quality at-tributes such as maintainability.
9.4 Concluding RemarksThe work presented in this dissertation was aimed at investigating the change-proneness of APIs and web APIs. This work by no means covers all the aspectsof change-prone APIs and web APIs nor provides a complete guideline on de-
1https://developers.google.com/maps/documentation/webservices/

9.4. Concluding Remarks 177
signing stable APIs and web APIs. However, we advanced the state-of-the-artin 1) validating software metrics (i.e., internal and external cohesion) thathighlight change-prone APIs and web APIs, 2) analyzing service oriented sys-tems, and 3) refactoring fine-grained and low externally cohesive APIs andweb APIs. Our contributions are aimed at giving new insights into the change-proneness of APIs and web APIs that allow the research community to furtheradvance and refine our findings.


Bibliography
Marwen Abbes, Foutse Khomh, Yann-Gaël Guéhéneuc, and Giuliano Antoniol.An empirical study of the impact of two antipatterns, blob and spaghetticode, on program comprehension. In Tom Mens, Yiannis Kanellopoulos, andAndreas Winter, editors, CSMR, 15th European Conference on Software Main-tenance and Reengineering, pages 181–190. IEEE Computer Society, 2011.
Hani Abdeen, Houari A. Sahraoui, and Osama Shata. How we design inter-faces, and how to assess it. In ICSM, pages 80–89, 2013.
Omar Al Jadaan and Lakishmi Rajamani. Improved selection operator for ga.Journal of Theoretical and Applied Information Technology, 4(4), 2008.
Eyhab Al-Masri and Qusay H. Mahmoud. Investigating web services on theworld wide web. WWW, pages 795–804, New York, NY, USA, 2008. ACM.ISBN 978-1-60558-085-2.
Saad Alahmari, Ed Zaluska, and David C. De Roure. A metrics framework forevaluating soa service granularity. SCC, pages 512–519, Washington, DC,USA, 2011. ISBN 978-0-7695-4462-5.
Gustavo Alonso, Fabio Casati, Harumi Kuno, and Vijay Machiraju. Web Ser-vices: Concepts, Architectures and Applications. Springer Publishing Com-pany, Incorporated, 1st edition, 2010. ISBN 3642078885, 9783642078880.
Mohammad Alshayeb and Wei Li. An empirical validation of object-orientedmetrics in two different iterative software processes. Transactions on Soft-ware Engineering, 29:1043–1049, November 2003.
179

180 BIBLIOGRAPHY
Lerina Aversano, Marcello Bruno, Massimiliano Di Penta, Amedeo Falanga,and Rita Scognamiglio. Visualizing the evolution of web services using for-mal concept analysis. In IWPSE, pages 57–60, 2005.
Jagdish Bansiya and Carl G. Davis. A hierarchical model for object-orienteddesign quality assessment. IEEE Trans. Softw. Eng., 28(1):4–17, January2002. ISSN 0098-5589.
I. Barker. What is information architecture? URL http://www.steptwo.com.au.
Victor R. Basili, Lionel C. Briand, and Walcélio L. Melo. A validation of object-oriented design metrics as quality indicators. IEEE Trans. Software Eng., 22(10):751–761, 1996.
Sujoy Basu, Fabio Casati, and Florian Daniel. Toward web service dependencydiscovery for soa management. In Proceedings of the 2008 IEEE InternationalConference on Services Computing - Volume 2, pages 422–429, Washington,DC, USA, 2008. IEEE Computer Society. ISBN 978-0-7695-3283-7-02.
Abraham Bernstein, Jayalath Ekanayake, and Martin Pinzger. Improving de-fect prediction using temporal features and non linear models. In Ninth in-ternational workshop on Principles of software evolution: in conjunction withthe 6th ESEC/FSE joint meeting, IWPSE ’07, pages 11–18, New York, NY,USA, 2007. ACM. ISBN 978-1-59593-722-3.
Shawn A. Bohner. Software change impacts - an evolving perspective. In ICSM,pages 263–272, 2002.
Bart Du Bois, Serge Demeyer, Jan Verelst, Tom Mens, and Marijn Temmerman.Does god class decomposition affect comprehensibility? In Proceedings of theIASTED International Conference on Software Engineering, pages 346–355.IASTED/ACTA Press, 2006.
Eric Bouwers, Arie van Deursen, and Joost Visser. Evaluating usefulness ofsoftware metrics: an industrial experience report. In Proceedings of the In-ternational Conference on Software Engineering, pages 921–930, 2013.
Marcus A. S. Boxall and Saeed Araban. Interface metrics for reusability analy-sis of components. In Proceedings of the 2004 Australian Software Engineer-ing Conference, ASWEC ’04, pages 40–, Washington, DC, USA, 2004. IEEEComputer Society. ISBN 0-7695-2089-8.

BIBLIOGRAPHY 181
Lionel Briand, Walcelio Melo, and Juergen Wuest. Assessing the applicabilityof fault-proneness models across object-oriented software projects. IEEETrans. Softw. Eng., 28:706–720, July 2002.
Lionel C. Briand, John W. Daly, and Jürgen Wüst. A unified framework forcohesion measurement in object-oriented systems. Empirical Software Engi-neering, 3(1):65–117, July 1998. ISSN 1382-3256.
Lionel C. Briand, Yvan Labiche, and Johanne Leduc. Toward the reverse engi-neering of uml sequence diagrams for distributed java software. IEEE Trans.Softw. Eng., 32:642–663, September 2006. ISSN 0098-5589.
Peter F Brown and Rebekah Metz Booz Allen Hamilton. Reference model forservice oriented architecture 1.0, 2006.
William J. Brown, Raphael C. Malveau, Hays W. McCormikk III, and T.J. Mow-bray. Anti Patterns: Refactoring Software, Architectures, and Projects in Crisis.Wiley, 1998.
Cedric Brun and Alfonso Pierantonio. Model differences in the eclipse mod-elling framework. UPGRADE The European Journal for the Informatics Pro-fessional, IX:29–34, 2008.
John Businge. Co-evolution of the eclipse SDK framework and its third-partyplug-ins. In 17th European Conference on Software Maintenance and Reengi-neering, CSMR 2013, Genova, Italy, March 5-8, 2013, pages 427–430, 2013.
John Businge, Alexander Serebrenik, and Mark van den Brand. An empir-ical study of the evolution of eclipse third-party plug-ins. In Proceedingsof the Joint ERCIM Workshop on Software Evolution (EVOL) and Interna-tional Workshop on Principles of Software Evolution (IWPSE), IWPSE-EVOL’10, pages 63–72, New York, NY, USA, 2010. ACM. ISBN 978-1-4503-0128-2.
John Businge, Alexander Serebrenik, and Mark van den Brand. Analyzingthe eclipse API usage: Putting the developer in the loop. In 17th EuropeanConference on Software Maintenance and Reengineering, CSMR 2013, Genova,Italy, March 5-8, 2013, pages 37–46, 2013.
Gerardo Canfora, Michele Ceccarelli, Luigi Cerulo, and Massimiliano Di Penta.Using multivariate time series and association rules to detect logical changecoupling: An empirical study. In Proceedings of the 2010 IEEE InternationalConference on Software Maintenance, ICSM ’10, pages 1–10, Washington,DC, USA, 2010. IEEE Computer Society. ISBN 978-1-4244-8630-4.

182 BIBLIOGRAPHY
Luba Cherbakov, Mamdouh Ibrahim, and Jenny Ang. Soa antipatterns: theobstacles to the adoption and successful realization of service-orientedarchitecture, 2006. URL http://www.ibm.com/developerworks/webservices/library/ws-antipatterns/.
Shyam R. Chidamber and Chris F. Kemerer. Towards a metrics suite for objectoriented design. In Proceedings of the Conference on Object-Oriented Pro-gramming Systems, Languages, and Applications, pages 197–211, 1991.
Shyam R. Chidamber and Chris F. Kemerer. A metrics suite for object orienteddesign. Transactions on Software Engineering, 20(6):476–493, June 1994.ISSN 0098-5589.
James O. Coplien and Neil B. Harrison. Organizational Patterns of Agile Soft-ware Development. Prentice-Hall, Upper Saddle River, NJ (2005), 1st edi-tion, 2005.
Steve Counsell, Stephen Swift, and Jason Crampton. The interpretation andutility of three cohesion metrics for object-oriented design. Transactions onSoftware Engineering and Methodology, 15(2):123–149, April 2006. ISSN1049-331X.
John W. Creswell and Vicki L.P. Clark. Designing and Conducting Mixed MethodsResearch. SAGE Publications, 2010. ISBN 9781412975179.
Robert Daigneau. Service Design Patterns: Fundamental Design Solutions forSOAP/WSDL and RESTful Web Services. Pearson Education, 2011. ISBN032154420X.
Kalyanmoy Deb, Samir Agrawal, Amrit Pratap, and T. Meyarivan. A fast elitistnon-dominated sorting genetic algorithm for multi-objective optimisation:Nsga-ii. In PPSN, volume 1917, pages 849–858, 2000. ISBN 3-540-41056-2.
Karim Dhambri, Houari Sahraoui, and Pierre Poulin. Visual detection of de-sign anomalies. In Proceedings of the 12th European Conference on SoftwareMaintenance and Reengineering, Tampere, Finland, pages 279–283. IEEE CSPress, April 2008.
Danny Dig and Ralph E. Johnson. How do apis evolve? a story of refactoring.Journal of Software Maintenance, 18(2):83–107, 2006.

BIBLIOGRAPHY 183
Bill Dudney, Joseph Krozak, Kevin Wittkopf, Stephen Asbury, and David Os-borne. J2EE Antipatterns. John Wiley & Sons, Inc., New York, NY, USA, 1edition, 2002. ISBN 0471146153.
Mahmoud O. Elish and Mojeeb-Al-Rahman Al-Khiaty. A suite of metrics forquantifying historical changes to predict future change-prone classes inobject-oriented software. Journal of Software: Evolution and Process, 25(5):407–437, 2013.
Thomas Erl. SOA Principles of Service Design (The Prentice Hall Service-OrientedComputing Series from Thomas Erl). Prentice Hall PTR, Upper Saddle River,NJ, USA, 2007.
Len Erlikh. Leveraging legacy system dollars for e-business. IT Professional, 2(3):17 –23, may/jun 2000. ISSN 1520-9202.
Emanuel Falkenauer. Genetic Algorithms and Grouping Problems. John Wiley& Sons, Inc., New York, NY, USA, 1998. ISBN 0471971502.
Zaiwen Feng, Keqing He, Rong Peng, and Yutao Ma. Taxonomy for evolutionof service-based system. In SERVICES, pages 331–338, 2011.
Colin J. Fidge. Timestamps in message-passing systems that preserve partialordering. In Proceedings of the 11th Australian Computer Science Conference,pages 56–66, 1988.
Roy Thomas Fielding. Architectural Styles and the Design of Network-basedSoftware Architectures. PhD thesis, 2000. AAI9980887.
Jr. Floyd J. Fowler. Survey Research Methods (4th ed.). SAGE Publications, Inc.,0 edition, 2009.
Beat Fluri and Harald C. Gall. Classifying change types for qualifying changecouplings. In Proceedings of the 14th IEEE International Conference on Pro-gram Comprehension, ICPC ’06, pages 35–45, Washington, DC, USA, 2006.IEEE Computer Society. ISBN 0-7695-2601-2.
Beat Fluri, Michael Wuersch, Martin PInzger, and Harald Gall. Change distill-ing: Tree differencing for fine-grained source code change extraction. IEEETrans. Softw. Eng., 33:725–743, November 2007.
Marios Fokaefs, Rimon Mikhaiel, Nikolaos Tsantalis, Eleni Stroulia, and AlexLau. An empirical study on web service evolution. In Proceedings of theInternational Conference on Web Services, pages 49–56, 2011.

184 BIBLIOGRAPHY
Martin Fowler. Refactoring – Improving the Design of Existing Code. Addison-Wesley, 1st edition, June 1999. ISBN 0-201-48567-2.
Harald C. Gall, Beat Fluri, and Martin Pinzger. Change analysis with evolizerand changedistiller. IEEE Softw., 26:26–33, January 2009. ISSN 0740-7459.
Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. Design pat-terns: elements of reusable object-oriented software. Addison-Wesley Long-man Publishing Co., Inc., Boston, MA, USA, 1995. ISBN 0-201-63361-2.
Shadi Ghaith and Mel Ó Cinnéide. Improving software security using search-based refactoring. In SSBSE, pages 121–135, 2012.
Adnane Ghannem, Ghizlane El-Boussaidi, and Marouane Kessentini. Modelrefactoring using interactive genetic algorithm. In SSBSE, pages 96–110,2013.
Emanuel Giger, Martin Pinzger, and Harald C. Gall. Comparing fine-grainedsource code changes and code churn for bug prediction. In Proceedings ofthe 8th Working Conference on Mining Software Repositories, MSR ’11, pages83–92, New York, NY, USA, 2011. ACM. ISBN 978-1-4503-0574-7.
Tudor Girba, Stéphane Ducasse, and Michele Lanza. Yesterday’s weather:Guiding early reverse engineering efforts by summarizing the evolution ofchanges. In Proceedings of the International Conference on Software Mainte-nance, pages 40–49, 2004.
David M. Green and John A. Swets. Signal detection theory and psychophysics,volume 1. Wiley, 1966.
Robert J. Grissom and John J. Kim. Effect sizes for research: A broad practicalapproach. Lawrence Earlbaum Associates, 2nd edition edition, 2005.
Raf Haesen, Monique Snoeck, Wilfried Lemahieu, and Stephan Poelmans. Onthe definition of service granularity and its architectural impact. CAiSE,pages 375–389, Berlin, Heidelberg, 2008. ISBN 978-3-540-69533-2.
Mark Harman, Stephen Swift, and Kiarash Mahdavi. An empirical study ofthe robustness of two module clustering fitness functions. In GECCO, pages1029–1036, 2005. ISBN 1-59593-010-8.
Mark Harman, S. Afshin Mansouri, and Yuanyuan Zhang. Search-based soft-ware engineering: Trends, techniques and applications. ACM Comput. Surv.,45(1):11:1–11:61, December 2012. ISSN 0360-0300.

BIBLIOGRAPHY 185
Brian Henderson-Sellers. Object-oriented metrics: measures of complexity.Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 1996. ISBN 0-13-239872-9.
Brian Henderson-Sellers, Larry L. Constantine, and Ian M. Graham. Couplingand cohesion (towards a valid metrics suite for object-oriented analysis anddesign). Object Oriented Systems, 3:143–158, 1996.
Gregor Hohpe and Bobby Woolf. Enterprise Integration Patterns: Designing,Building, and Deploying Messaging Solutions. Addison-Wesley Longman Pub-lishing Co., Inc., Boston, MA, USA, 2003. ISBN 0321200683.
Will G. Hopkins. A new view of statistics. Internet Society for Sport Science,2000.
Daqing Hou and Xiaojia Yao. Exploring the intent behind api evolution: Acase study. In Proceedings of the Working Conference on Reverse Engineering,pages 131–140, 2011.
Curtis E. Hrischuk and Murray C. Woodside. Logical clock requirements forreverse engineering scenarios from a distributed system. IEEE Trans. Softw.Eng., 28:321–339, April 2002. ISSN 0098-5589.
Eduardo Raul Hruschka, Ricardo J. G. B. Campello, Alex A. Freitas, and An-dré C. Ponce Leon F. De Carvalho. A survey of evolutionary algorithms forclustering. Trans. Sys. Man Cyber Part C, 39(2):133–155, March 2009. ISSN1094-6977.
Deligiannis Ignatios, Stamelos Ioannis, Angelis Lefteris, Roumeliotis Manos,and Shepperd Martin. A controlled experiment investigation of an objectoriented design heuristic for maintainability. Journal of Systems and Soft-ware, 65(2), February 2003.
Deligiannis Ignatios, Shepperd Martin, Roumeliotis Manos, and StamelosIoannis. An empirical investigation of an object-oriented design heuristicfor maintainability. Journal of Systems and Software, 72(2), 2004.
Daniel Jacobson. Embracing the differences : Inside the netflixapi redesign. http://techblog.netflix.com/2012/07/embracing-differences-inside-netflix.html, 2012. [Online; accessed May-2014].

186 BIBLIOGRAPHY
Jinlei Jiang, Yongwei Wu, and Guangwen Yang. Making service granularityright: An assistant approach based on business process analysis. CHINA-GRID, pages 204–210, Washington, DC, USA, 2011. ISBN 978-0-7695-4472-4.
Nicolai Josuttis. Soa in Practice: The Art of Distributed System Design. O’ReillyMedia, Inc., 2007. ISBN 0596529554.
Huzefa Kagdi, Michael L. Collard, and Jonathan I. Maletic. A survey andtaxonomy of approaches for mining software repositories in the context ofsoftware evolution. J. Softw. Maint. Evol., 19(2):77–131, March 2007. ISSN1532-060X.
Foutse Khomh, Massimiliano Di Penta, and Yann-Gael Gueheneuc. An ex-ploratory study of the impact of code smells on software change-proneness.In Proceedings of the Working Conference on Reverse Engineering, pages 75–84, 2009.
Foutse Khomh, Stephane Vaucher, Yann-Gaël Guéhéneuc, and HouariSahraoui. Bdtex: A gqm-based bayesian approach for the detection of an-tipatterns. Journal of Systems and Software, 84(4):559 – 572, 2011. ISSN0164-1212. <ce:title>The Ninth International Conference on Quality Soft-ware</ce:title>.
Foutse Khomh, Massimiliano Di Penta, Yann-Gaël Guéhéneuc, and GiulianoAntoniol. An exploratory study of the impact of antipatterns on classchange- and fault-proneness. Empirical Software Engineering, 17(3):243–275, 2012.
Taghi M. Khoshgoftaar and Robert M. Szabo. Improving code churn predic-tions during the system test and maintenance phases. In Proceedings of theInternational Conference on Software Maintenance, pages 58–67, 1994.
Alireza Khoshkbarforoushha, R. Tabein, Pooyan Jamshidi, and Ferei-doon Shams Aliee. Towards a metrics suite for measuring composite servicegranularity level appropriateness. In SERVICES, pages 245–252, 2010. ISBN978-0-7695-4129-7.
Dirk Krafzig, Karl Banke, and Dirk Slama. Enterprise SOA: Service-Oriented Ar-chitecture Best Practices (The Coad Series). Prentice Hall PTR, Upper SaddleRiver, NJ, USA, 2004. ISBN 0131465759.

BIBLIOGRAPHY 187
Jaroslav Král and Michal Zemlicka. The most important service-oriented an-tipatterns. In Proceedings of the International Conference on Software Engi-neering Advances, page 29, 2007.
WH Kruskal and WA Wallis. Use of ranks in one-criterion variance analysis.Journal of the American Statistical Association, 47(260):583–621, 1952.
Naveen N. Kulkarni and Vishal Dwivedi. The role of service granularity in asuccessful soa realization - a case study. In SERVICES I, pages 423–430. IEEEComputer Society, 2008. ISBN 978-0-7695-3286-8.
Avadhesh Kumar, Rajesh Kumar, and P. S. Grover. Unified cohesion measuresfor aspect-oriented systems. International Journal of Software Engineeringand Knowledge Engineering, 21(1):143–163, 2011.
Leslie Lamport. Time, clocks, and the ordering of events in a distributed sys-tem. Commun. ACM, 21(7):558–565, 1978.
Guillaume Langelier, Houari A. Sahraoui, and Pierre Poulin. Visualization-based analysis of quality for large-scale software systems. In proceedings ofthe 20th international conference on Automated Software Engineering. ACMPress, Nov 2005.
Michele Lanza and Radu Marinescu. Object-Oriented Metrics in Practice.Springer-Verlag, 2006. ISBN 3-540-24429-8.
Erich Leo Lehmann and H.J.M D’Abrera. Nonparametrics : Statistical MethodsBased on Ranks. Holden-Day Series in Probability and Statistics. Holden-DayNew York Dusseldorf Johannesbourg, 1975. ISBN 0-07-037073-7.
Philipp Leitner, Anton Michlmayr, Florian Rosenberg, and Schahram Dustdar.End-to-end versioning support for web services. In 2008 IEEE InternationalConference on Services Computing (SCC), pages 59–66, 2008.
Stefan Lessmann, Bart Baesens, Christophe Mues, and Swantje Pietsch. Bench-marking classification models for software defect prediction: A proposedframework and novel findings. IEEE Trans. Softw. Eng., 34:485–496, July2008. ISSN 0098-5589.
Wei Li and Sallie M. Henry. Object-oriented metrics which predict maintain-ability. Technical report, Virginia Polytechnic Institute & State University,Blacksburg, VA, USA, 1993.

188 BIBLIOGRAPHY
Wei Li and Raed Shatnawi. An empirical study of the bad smells and class errorprobability in the post-release object-oriented system evolution. Journal ofSystems and Software, 80(7), 2007.
Zheng Li, Yi Bian, Ruilian Zhao, and Jun Cheng. A fine-grained parallel multi-objective test case prioritization on gpu. In SSBSE, pages 111–125, 2013.
Fangfang Liu, Yuliang Shi, Jie Yu, Tianhong Wang, and Jingzhe Wu. Measuringsimilarity of web services based on wsdl. In ICWS, pages 155–162, 2010.
Kiarash Mahdavi, Mark Harman, and Robert M. Hierons. A multiple hill climb-ing approach to software module clustering. In ICSM, pages 315–324, 2003.ISBN 0-7695-1905-9.
Spiros Mancoridis, Brian S. Mitchell, Chris Rorres, Yih-Farn Chen, and Em-den R. Gansner. Using automatic clustering to produce high-level systemorganizations of source code. In IWPC, pages 45–52, 1998. ISBN 0-8186-8560-3.
Spiros Mancoridis, Brian S. Mitchell, Yih-Farn Chen, and Emden R. Gansner.Bunch: A clustering tool for the recovery and maintenance of software sys-tem structures. In ICSM, pages 50–59, 1999.
Henry B. Mann and Whitney D. R. On a test of whether one of two ran-dom variables is stochastically larger than the other. Annals of MathematicalStatistics, 18(1):50–60, 1947.
Mika Mantyla. Bad Smells in Software - a Taxonomy and an Empirical Study.PhD thesis, Helsinki University of Technology, 2003.
Radu Marinescu. Detection strategies: Metrics-based rules for detecting de-sign flaws. In Proceedings of the 20th International Conference on SoftwareMaintenance, pages 350–359. IEEE CS Press, 2004.
Robert C. Martin. Agile Software Development, Principles, Patterns, and Prac-tices. Prentice-Hall, Inc, 2002.
Friedemann Mattern. Virtual time and global states of distributed systems. InParallel and Distributed Algorithms, pages 215–226. North-Holland, 1989.
Bernhart M. Mauczka A., Grechenig T. Predicting code change by using staticmetrics. In Software Engineering Research, Management and Applications,pages 64–71, 2009.

BIBLIOGRAPHY 189
Diego Mendez, Benoit Baudry, and Martin Monperrus. Empirical evidenceof large-scale diversity in api usage of object-oriented software. In SCAM,pages 43–52, 2013.
Tim Menzies, Jeremy Greenwald, and Art Frank. Data mining static code at-tributes to learn defect predictors. IEEE Trans. Softw. Eng., 33:2–13, January2007. ISSN 0098-5589.
Brian S. Mitchell and Spiros Mancoridis. Using heuristic search techniques toextract design abstractions from source code. In GECCO, pages 1375–1382,2002. ISBN 1-55860-878-8.
Brian S. Mitchell and Spiros Mancoridis. On the automatic modularization ofsoftware systems using the bunch tool. IEEE Trans. Software Eng., 32(3):193–208, 2006.
Naouel Moha, Yann-Gaël Guéhéneuc, Anne-Françoise Le Meur, and LaurenceDuchien. A domain analysis to specify design defects and generate detec-tion algorithms. In Proceedings of the Theory and practice of software, 11thinternational conference on Fundamental approaches to software engineering,FASE’08/ETAPS’08, pages 276–291, Berlin, Heidelberg, 2008a. Springer-Verlag. ISBN 3-540-78742-9, 978-3-540-78742-6.
Naouel Moha, Amine Mohamed Rouane Hacene, Petko Valtchev, and Yann-Gaël Guéhéneuc. Refactorings of design defects using relational conceptanalysis. In Proceedings of the 6th international conference on Formal conceptanalysis, ICFCA’08, pages 289–304, Berlin, Heidelberg, 2008b. Springer-Verlag. ISBN 3-540-78136-6, 978-3-540-78136-3.
Naouel Moha, Yann-Gael Gueheneuc, Laurence Duchien, and Anne-FrancoiseLe Meur. Decor: A method for the specification and detection of code anddesign smells. IEEE Trans. Softw. Eng., 36(1):20–36, January 2010. ISSN0098-5589.
Naouel Moha, Francis Palma, Mathieu Nayrolles, Benjamin Joyen Conseil,[email protected] Yann-Gael, Guéhéneuc, Benoit Baudry,and Jean-Marc Jézéquel. Specification and detection of soa antipatterns. InProceedings of the International Conference on Service Oriented Computing,pages 1–16, Shanghai, China, 2012.
Matthew James Munro. Product metrics for automatic identification of “badsmell" design problems in java source-code. In Proceedings of the 11th Inter-national Software Metrics Symposium. IEEE Computer Society Press, Septem-ber 2005.

190 BIBLIOGRAPHY
Stephan Murer. 13 years of soa at credit suisse: Lessons learned-remainingchallenges. In Proceedings of the European Conference on Web Services,page 12, Sept 2011.
Stephan Murer, Bruno Bonati, and Frank Furrer. Managed Evolution - A Strat-egy for Very Large Information Systems. Springer, 2010. ISBN 3-642-01632-4.
Nachiappan Nagappan, Andreas Zeller, Thomas Zimmermann, Kim Herzig,and Brendan Murphy. Change bursts as defect predictors. In ISSRE, pages309–318, 2010.
Dongkyung Nam and Cheol Hoon Park. Multiobjective simulated snnealing:a comparative study to evolutionary algorithms. International Journal ofFuzzy Systems, 2(2):87–97, 2000.
Hans Neukom. Early use of computers in swiss banks. IEEE Annals of theHistory of Computing, 26(3):50–59, 2004.
Mark O’Keeffe and Mel í Cinnéide. Search-based refactoring for software main-tenance. J. Syst. Softw., 81(4):502–516, April 2008. ISSN 0164-1212.
Steffen Olbrich, Daniela S. Cruzes, Victor Basili, and Nico Zazworka. Theevolution and impact of code smells: A case study of two open source sys-tems. In Third International Symposium on Empirical Software Engineeringand Measurement, 2009.
Rocco Oliveto, Foutse Khomh, Giuliano Antoniol, and Yann-Gaël Guéhéneuc.Numerical signatures of antipatterns: An approach based on b-splines. InRafael Capilla, Rudolf Ferenc, and Juan Carlos Dueas, editors, Proceedings ofthe 14th Conference on Software Maintenance and Reengineering. IEEE Com-puter Society Press, March 2010.
Mike P. Papazoglou. The challenges of service evolution. In Proceedings ofthe international Conference on Advanced Information Systems Engineering,pages 1–15, 2008.
Cesare Pautasso and Erik Wilde. Why is the web loosely coupled?: A multi-faceted metric for service design. In Proceedings of the 18th InternationalConference on World Wide Web, WWW ’09, pages 911–920, New York, NY,USA, 2009. ACM. ISBN 978-1-60558-487-4.
Cesare Pautasso, Olaf Zimmermann, and Frank Leymann. Restful web servicesvs. "big"’ web services: Making the right architectural decision. In Proceed-ings of the 17th International Conference on World Wide Web, WWW ’08,pages 805–814, New York, NY, USA, 2008. ACM. ISBN 978-1-60558-085-2.

BIBLIOGRAPHY 191
Massimiliano Di Penta, Luigi Cerulo, Yann-Gaël Guéhéneuc, and Giuliano An-toniol. An empirical study of the relationships between design pattern rolesand class change proneness. In Proceedings of the International Conferenceon Software Maintenance, pages 217–226, 2008.
Mikhail Perepletchikov, Caspar Ryan, and Keith Frampton. Towards the def-inition and validation of coupling metrics for predicting maintainability inservice-oriented designs. In OTM Workshops (1), pages 34–35, 2006.
Mikhail Perepletchikov, Caspar Ryan, and Keith Frampton. Cohesion metricsfor predicting maintainability of service-oriented software. In Proceedingsof the International Conference on Quality Software, pages 328–335, 2007.ISBN 0-7695-3035-4.
Mikhail Perepletchikov, Caspar Ryan, and Zahir Tari. The impact of servicecohesion on the analyzability of service-oriented software. Transactions onServices Computing, 3(2):89–103, April 2010. ISSN 1939-1374.
Pierluigi Plebani and Barbara Pernici. Urbe: Web service retrieval based onsimilarity evaluation. IEEE Trans. on Knowl. and Data Eng., 21:1629–1642,November 2009. ISSN 1041-4347.
Daryl Posnett, Christian Bird, and Prem Dévanbu. An empirical study on theinfluence of pattern roles on change-proneness. Empirical Software Engi-neering, 16(3):396–423, June 2011. ISSN 1382-3256.
Colin Potts. Software-engineering research revisited. IEEE Softw., 10(5):19–28, September 1993. ISSN 0740-7459.
Kata Praditwong, Mark Harman, and Xin Yao. Software module clustering as amulti-objective search problem. IEEE Trans. Software Eng., 37(2):264–282,2011.
Steven Raemaekers, Arie van Deursen, and Joost Visser. Measuring softwarelibrary stability through historical version analysis. In Proceedings of theInternational Conference on Software Maintenance, pages 378–387, 2012.
Steven Raemaekers, Arie van Deursen, and Joost Visser. The maven repositorydataset of metrics, changes, and dependencies. In MSR, pages 221–224,2013.
Romain Robbes, Damien Pollet, and Michele Lanza. Logical coupling basedon fine-grained change information. In Proceedings of the 2008 15th Work-ing Conference on Reverse Engineering, pages 42–46, Washington, DC, USA,2008. IEEE Computer Society. ISBN 978-0-7695-3429-9.

192 BIBLIOGRAPHY
Daniele Romano and Martin Pinzger. Using source code metrics to predictchange-prone java interfaces. In ICSM, pages 303–312, 2011a. ISBN 978-1-4577-0663-9.
Daniele Romano and Martin Pinzger. Using vector clocks to monitor depen-dencies among services at runtime. In Proceedings of the International Work-shop on Quality Assurance for Service-Based Applications, QASBA ’11, pages1–4, 2011b. ISBN 978-1-4503-0826-7.
Daniele Romano and Martin Pinzger. Analyzing the evolution of web servicesusing fine-grained changes. In ICWS, pages 392–399, 2012. ISBN 978-1-4673-2131-0.
Daniele Romano and Martin Pinzger. A genetic algorithm to find the adequategranularity for service interfaces. In 2014 IEEE World Congress on Services,Anchorage, AK, USA, June 27 - July 2, 2014, pages 478–485, 2014.
Daniele Romano, Martin Pinzger, and Eric Bouwers. Extracting dynamic de-pendencies between web services using vector clocks. In SOCA, pages 1–8,2011.
Daniele Romano, Paulius Raila, Martin Pinzger, and Foutse Khomh. Analyzingthe impact of antipatterns on change-proneness using fine-grained sourcecode changes. In Proceedings of the Working Conference on Reverse Engineer-ing, pages 437–446, 2012.
Daniele Romano, Maria Kalouda, and Martin Pinzger. Analyzing the impact ofexternal and internal cohesion on the change-proneness of web apis. Tech-nical Report TUD-SERG-2013-018, Software Engineering Research Group,Delft University of Technology, 2013. URL http://swerl.tudelft.nl/twiki/pub/Main/TechnicalReports/TUD-SERG-2013-018.pdf.
Daniele Romano, Steven Raemaekers, and Martin Pinzger. Refactoringfat interfaces using a genetic algorithm. Technical Report TUD-SERG-2014-007, Software Engineering Research Group, Delft University of Tech-nology, 2014. URL http://swerl.tudelft.nl/twiki/pub/Main/TechnicalReports/TUD-SERG-2014-007.pdf.
Dieter H. Rombach. A controlled expeniment on the impact of software struc-ture on maintainability. IEEE Trans. Softw. Eng., 13:344–354, March 1987.ISSN 0098-5589.
Dieter H. Rombach. Design measurement: Some lessons learned. IEEE Softw.,7:17–25, March 1990. ISSN 0740-7459.

BIBLIOGRAPHY 193
Arnon Rotem-Gal-Oz. SOA Patterns. Manning Pubblications, 1 edition, 2012.ISBN 9781933988269.
Günter Rudolph. Evolutionary search for minimal elements in partially or-dered finite sets. In Evolutionary Programming, volume 1447 of LectureNotes in Computer Science, pages 345–353, 1998. ISBN 3-540-64891-7.
R.S. Arnold Shawn A. Bohner. Software change impact analysis. IEEE Com-puter Society Press, 1996.
Jeffery Shelburg, Marouane Kessentini, and Daniel R. Tauritz. Regression test-ing for model transformations: A multi-objective approach. In SSBSE, vol-ume 8084 of Lecture Notes in Computer Science, pages 209–223, 2013. ISBN978-3-642-39741-7.
David J. Sheskin. Handbook of Parametric and Nonparametric Statistical Pro-cedures. Chapman & Hall/CRC, 4 edition, 2007. ISBN 1584888148,9781584888147.
Jelber Sayyad Shirabad, Timothy C. Lethbridge, and Stan Matwin. Mining themaintenance history of a legacy software system. In Proceedings of the Inter-national Conference on Software Maintenance, ICSM ’03, pages 95–, Wash-ington, DC, USA, 2003. IEEE Computer Society. ISBN 0-7695-1905-9.
Frank Simon, Frank Steinbrückner, and Claus Lewerentz. Metrics based refac-toring. In Proceedings of the Fifth European Conference on Software Mainte-nance and Reengineering (CSMR’01), page 30. IEEE CS Press, 2001. ISBN0-7695-1028-0.
Renuka Sindhgatta, Bikram Sengupta, and Karthikeyan Ponnalagu. Measur-ing the quality of service oriented design. In Proceedings of the InternationalJoint Conference on Service-Oriented Computing, pages 485–499, Berlin, Hei-delberg, 2009. Springer-Verlag.
S. N. Sivanandam and S. N. Deepa. Introduction to Genetic Algorithms.Springer Publishing Company, Incorporated, 1st edition, 2007. ISBN354073189X, 9783540731894.
Edward Smith, Robert Loftin, Emerson Murphy-Hill, Christian Bird, andThomas Zimmermann. Improving developer participation rates in surveys.In Proceedings of the International Workshop on Cooperative and Human As-pects of Software Engineering, pages 89–92, 2013.

194 BIBLIOGRAPHY
Ramanath Subramanyam and M. S. Krishnan. Empirical analysis of ck met-rics for object-oriented design complexity: Implications for software defects.IEEE Trans. Softw. Eng., 29:297–310, April 2003. ISSN 0098-5589.
S. Dowdy S.Weardon and D. Chilko. Statistics for Research. Probability andStatistics. John Wiley and Sons, 2004.
Suresh Thummalapenta, Luigi Cerulo, Lerina Aversano, and Massimiliano DiPenta. An empirical study on the maintenance of source code clones. Em-pirical Software Engineering, 15(1):1–34, 2010.
Sander Tichelaar, Stéphane Ducasse, and Serge Demeyer. Famix and xmi.In Proceedings of the Seventh Working Conference on Reverse Engineering(WCRE’00), WCRE ’00, pages 296–, Washington, DC, USA, 2000. IEEE Com-puter Society. ISBN 0-7695-0881-2.
Guilherme Travassos, Forrest Shull, Michael Fredericks, and Victor R. Basili.Detecting defects in object-oriented designs: using reading techniques toincrease software quality. In Proceedings of the 14th Conference on Object-Oriented Programming, Systems, Languages, and Applications, pages 47–56.ACM Press, 1999.
Martin Treiber, Hong Linh Truong, and Schahram Dustdar. On analyzing evo-lutionary changes of web services. In ICSOC Workshops, pages 284–297,2008.
Nikolaos Tsantalis, Alexander Chatzigeorgiou, and George Stephanides. Pre-dicting the probability of change in object-oriented systems. IEEE Transac-tions on Software Engineering, 31(7):601–614, 2005. ISSN 0098-5589.
Nikolaos Tsantalis, Natalia Negara, and Eleni Stroulia. Webdiff: A genericdifferencing service for software artifacts. In ICSM, pages 586–589, 2011.
Eva van Emden and Leon Moonen. Java quality assurance by detecting codesmells. In Proceedings of the 9th Working Conference on Reverse Engineering(WCRE’02). IEEE CS Press, October 2002.
Mario Linares Vásquez, Gabriele Bavota, Carlos Bernal-Cárdenas, Massimil-iano Di Penta, Rocco Oliveto, and Denys Poshyvanyk. Api change and faultproneness: a threat to the success of android apps. In Proceedings of theESEC/SIGSOFT Foundations of Software Engineering, pages 477–487, 2013.
W3C. Web services architecture. http://www.w3.org/TR/ws-arch/,2004. [Online; accessed May-2014].

BIBLIOGRAPHY 195
William C. Wake. Refactoring Workbook. Addison-Wesley Longman PublishingCo., Inc., Boston, MA, USA, 2003. ISBN 0321109295.
Shuying Wang and Miriam A. M. Capretz. A dependency impact analysismodel for web services evolution. In ICWS, pages 359–365, 2009.
Bruce F. Webster. Pitfalls of Object Oriented Development. M & T Books, 1st
edition, February 1995. ISBN 1558513973.
Ian H. Witten and Eibe Frank. Data Mining: Practical Machine Learning Toolsand Techniques, Second Edition (Morgan Kaufmann Series in Data Manage-ment Systems). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA,2005. ISBN 0120884070.
Claes Wohlin, Per Runeson, Martin Höst, Magnus C. Ohlsson, Bjöorn Regnell,and Anders Wesslén. Experimentation in Software Engineering: An Introduc-tion. Kluwer Academic Publishers, Norwell, MA, USA, 2000. ISBN 0-7923-8682-5.
Qian Wu, Ling Wu, Guangtai Liang, Qianxiang Wang, Tao Xie, and Hong Mei.Inferring dependency constraints on parameters for web services. In WWW,pages 1421–1432, 2013.
Zhenchang Xing and Eleni Stroulia. Umldiff: an algorithm for object-orienteddesign differencing. In Proceedings of the 20th IEEE/ACM international Con-ference on Automated software engineering, ASE ’05, pages 54–65, 2005a.
Zhenchang Xing and Eleni Stroulia. Analyzing the evolutionary history of thelogical design of object-oriented software. IEEE Trans. Software Eng., 31(10):850–868, 2005b.
Aiko Fallas Yamashita and Leon Moonen. Exploring the impact of inter-smellrelations on software maintainability: an empirical study. In ICSE, pages682–691, 2013. ISBN 978-1-4673-3076-3.
Shin Yoo and Mark Harman. Pareto efficient multi-objective test case selection.In ISSTA, pages 140–150, 2007. ISBN 978-1-59593-734-6.
Kaizhong Zhang and Dennis Shasha. Simple fast algorithms for the editingdistance between trees and related problems. SIAM J. Comput., 18:1245–1262, December 1989.
Yilei Zhang, Zibin Zheng, and Michael R. Lyu. Wsexpress: A qos-aware searchengine for web services. In ICWS, pages 91–98. IEEE Computer Society,2010. ISBN 978-0-7695-4128-0.

196 BIBLIOGRAPHY
Yuanyuan Zhang, Mark Harman, and Soo Ling Lim. Empirical evaluation ofsearch based requirements interaction management. Information & SoftwareTechnology, 55(1):126–152, 2013.
Jianjun Zhao and Baowen Xu. Measuring aspect cohesion. In Proceedings ofthe Fundamental Approaches to Software Engineering, pages 54–68, 2004.
Yuming Zhou and Hareton Leung. Predicting object-oriented software main-tainability using multivariate adaptive regression splines. J. Syst. Softw., 80:1349–1361, August 2007. ISSN 0164-1212.
Yuming Zhou, Hareton Leung, and Baowen Xu. Examining the potentiallyconfounding effect of class size on the associations between object-orientedmetrics and change-proneness. Transactions on Software Engineering, 35(5):607–623, 2009.
Thomas Zimmermann, Peter Weisgerber, Stephan Diehl, and Andreas Zeller.Mining version histories to guide software changes. In Proceedings of the26th International Conference on Software Engineering, ICSE ’04, pages 563–572, Washington, DC, USA, 2004. IEEE Computer Society. ISBN 0-7695-2163-0.
Thomas Zimmermann, Rahul Premraj, and Andreas Zeller. Predicting defectsfor eclipse. In Proceedings of the Third International Workshop on PredictorModels in Software Engineering, PROMISE ’07, pages 9–, Washington, DC,USA, 2007. IEEE Computer Society. ISBN 0-7695-2954-2.
Thomas Zimmermann, Nachiappan Nagappan, Harald Gall, Emanuel Giger,and Brendan Murphy. Cross-project defect prediction: a large scale exper-iment on data vs. domain vs. process. In Proceedings of the the 7th jointmeeting of the European software engineering conference and the ACM SIG-SOFT symposium on The foundations of software engineering, ESEC/FSE ’09,pages 91–100, New York, NY, USA, 2009. ACM. ISBN 978-1-60558-001-2.
Eckart Zitzler and Lothar Thiele. Multiobjective evolutionary algorithms: acomparative case study and the strength pareto approach. IEEE Trans. Evo-lutionary Computation, 3(4):257–271, 1999.

Summary
Analyzing the Change-Proneness of APIs and web APIsAPIs and web APIs are used to expose existing business logic and, hence, toease the reuse of functionalities across multiple software systems. Softwaresystems can use the business logic of legacy systems by binding their APIsand web APIs. With the emergence of a new programming paradigm calledservice-oriented, APIs are exposed as web APIs hiding the technologies usedto implement legacy systems. As a consequence, web APIs establish contractsbetween legacy systems and their consumers and they should stay as stable aspossible to not break consumers’ systems.
This dissertation aims at better understanding the change-proneness ofAPIs and web APIs. Specifically to that end, we investigated which indicatorscan be used to highlight change-prone APIs and web APIs and we providedapproaches to assist practitioners in refactoring them. To perform this analysiswe adopted a research approach consisting of three different tracks: analysisof change-prone APIs, analysis of change-prone web APIs, and refactoring ofchange-prone APIs and web APIs.
Change-Prone APIsService-oriented systems are composed by web services. Each web service isimplemented by an implementation logic that is hidden to its clients throughits web APIs. Along the history of a software system the implementationlogic can be changed and its changes can be propagated and affect web APIs.Among all the software units composing the implementation logic, APIs arelikely to be mapped directly into web APIs. This scenario is likely to happenespecially if a legacy API is made available through a web service.
197

198 Summary
In this first track we focused on analyzing the change-proneness of APIs(i.e., the set of public methods declared in a software unit). Among all themetrics we analyzed, we have shown that the Interface Usage Cohesion (IUC)metric is the most suitable metric to highlight change-prone Java interfaces.This result suggests that software engineers should design interfaces with highexternal cohesion (measured with the IUC metric) to avoid frequent changes.Moreover, we analyzed the impact of specific antipatterns on the change-proneness of APIs. We showed empirically that changes to APIs are morelikely to appear if APIs are affected by the ComplexClass, SpaghettiCode, andSwissArmyKnife antipatterns. As a consequence software engineers shouldrefactor APIs affected by these antipatterns.
Change-Prone Web APIsIn the second track we analyzed the change-proneness of web APIs. First,we developed two tools to analyze software systems composed of web APIs.The first tool is called WSDLDiff and extracts fine-grained changes betweensubsequent versions of WSDL APIs. The second tool extracts the full chains ofdependencies among web APIs at run time.
Second, we performed an empirical study to investigate which scenarioscan cause changes to web APIs. We showed that low externally cohesive APIschange frequently to 1) improve understandability and 2) ease maintainabilityand reduce clones in the APIs. Low internally cohesive APIs change frequentlyto 1) reduce the impact of changes on the many clients they have, 2) avoidthat all the clients lead the APIs to be changed frequently, and 3) improve un-derstandability. Moreover, we proposed a new internal cohesion metric (DTC)to measure the internal cohesion of WSDL APIs.
Refactoring APIs and Web APIsBased on the results of the studies performed in the first and second track, wedefined two approaches to refactor APIs and web APIs.
The first approach assists software engineers in refactoring APIs with lowexternal cohesion based on the Interface Segregation Principle (ISP). We de-fined the problem of splitting low externally cohesive APIs into smaller APIsspecific for each client (i.e., ISP) as a multi-objective clustering optimizationproblem. To solve this problem we proposed a genetic algorithm that outper-forms other search based approaches.
The second approach assists software engineers in refactoring fine-grainedweb APIs. These APIs should be refactored into coarse-grained web APIs toreduce the number of remote invocations and avoid performance problems.

199
To achieve this goal we proposed a genetic algorithm that looks for FaçadeAPIs that cluster together the fine-grained methods of the original API.
ConclusionWe believe that these results advance the state-of-the-art in designing, ana-lyzing, and refactoring software systems composed of web APIs (i.e., service-oriented systems) and provide to the research community new insights intothe change-proneness of APIs and web APIs.
Daniele Romano


Samenvatting
Analyse van Veranderlijke Web APIs en APIsAPIs en web APIs helpen om bestaande business-logica aan te bieden en vereen-voudigen het hergebruik van functionaliteit in meerdere software systemen.Software systemen kunnen de business-logica van legacy systemen gebruikendoor elkaars APIs en web APIs te verbinden. Met de opkomst van het ser-vice georiënteerde programmeerparadigma worden APIs geëxposeerd als webAPIs die de technologie waarmee de legacy systemen geïmplementeerd zijnverbergen. Als gevolg hiervan sluiten web APIs contracten af tussen legacysystemen en hun gebruikers en dienen ze zo stabiel mogelijk te zijn zodat zede systemen van deze gebruikers niet kapot maken.
Het doel van dit proefschrift is om een beter begrip te krijgen van de veran-derlijkheid van APIs en web APIs. Hiervoor hebben we onderzocht welke indi-catoren gebruikt kunnen worden om APIs en web APIs met een hoge verander-lijkheid te identificeren en we hebben ontwikkelaars van methodes voorzienom deze APIs te herschrijven. Om deze analyse uit te voeren hebben we eenonderzoeksmethode gehanteerd die is opgedeeld in drie delen: analyse vanveranderlijke APIs, analyse van veranderlijke web APIs en het herschrijvenvan veranderlijke APIs en web APIs.
Veranderlijke APIsService-georiënteerde systemen zijn opgebouwd uit web services. Elke webservice is geïmplementeerd met behulp van een logica die verborgen is voorzijn gebruikers door middel van web APIs. Gedurende de geschiedenis vaneen software systeem, kunnen veranderingen in deze logica doorwerken naarweb APIs. Van alle software componenten waaruit de implementatie logicabestaat, is de API de meest waarschijnlijke om direct gekoppeld te worden
201

202 Samenvatting
aan web APIs. Dit scenario komt vaak voor als een legacy API beschikbaarwordt gemaakt als web service.
In dit eerste deel van het onderzoek focusten wij op het analyseren van deveranderlijkheid van APIs (i.e., de set publieke methoden in een software com-ponent). We hebben aangetoond dat de Interface Usage Cohesion (IUC) me-triek de meest geschikte metriek is om veranderlijke Java-interfaces te identifi-ceren. Dit resultaat suggereert dat software engineers interfaces met een hogemate van externe cohesie (gemeten met de IUC metriek) zouden moeten on-twerpen om frequente veranderingen te vermijden. Ook hebben we de impactop de veranderlijkheid van APIs van specifieke antipatronen geanalyseerd. Wehebben empirisch aangetoond dat veranderingen van APIs waarschijnlijkerzijn wanneer ze slachtoffer zijn van het ComplexClass, SpaghettiCode of Swis-sArmyKnife antipatroon. Daarom dienen software engineers APIs die geraaktworden door deze antipatronen te herschrijven.
Veranderlijke web APIsIn het tweede deel van het onderzoek hebben we de veranderlijkheid vanweb APIs geanalyseerd. Ten eerste hebben we twee tools ontwikkeld om soft-ware systemen die opgebouwd zijn uit web APIs te analyseren. De eerste tool,WSDLDiff, extraheert zeer kleine veranderingen tussen opeenvolgende versiesvan WSDL APIs. De tweede tool extraheert de volledige reeks van afhankeli-jkheden tussen web APIs tijdens run-time.
Daarnaast hebben we een empirische studie uitgevoerd om te onderzoekenwelke scenarios veranderingen in web APIs kunnen veroorzaken. We hebbenaangetoond dat APIs met een lage externe cohesie vaak veranderen om 1)de begrijpelijkheid te verbeteren en 2) onderhoud te vereenvoudigen en hetaantal clones binnen de API te verkleinen. APIs met een lage interne cohe-sie veranderen vaak om 1) de impact van veranderingen op het grote aantalklanten dat ze hebben te verkleinen, 2) te vermijden dat veranderende eisenvan klanten leiden tot veranderingen in de APIs en 3) om de begrijpelijkheid teverbeteren. Daarnaast hebben we een nieuwe interne cohesie metriek (DTC)voorgesteld voor het meten van interne cohesie van WSDL APIs.
Het herschrijven van APIs en Web APIsGebaseerd op de resultaten van de studies uit het eerste en tweede deel vandit onderzoek hebben we twee methodes voor het herschrijven van APIs enweb APIs gepresenteerd.
De eerste methode assisteert software engineers met het herschrijven vanAPIs met een lage externe cohesie en is gebaseerd op het Interface Segrega-

203
tion Principle (ISP). We hebben het probleem van het opdelen van APIs meteen lage externe cohesie in kleinere APIs specifiek voor elke klant (i.e., ISP)gedefinieerd als een multi-objective clustering optimalisatie probleem. Omdit probleem op te lossen hebben we een genetisch algoritme voorgesteld datbeter presteert dan andere search-based methodes.
De tweede methode assisteert software engineers met het herschrijven vanfine-grained web APIs. Deze APIs dienen herschreven te worden als coarse-grained APIs om het aantal aanroepen van buitenaf te verkleinen en hiermeeperformance problemen te vermijden. Om dit te bereiken hebben we eengenetisch algoritme voorgesteld dat zoekt naar Façade APIs die de fine-grainedmethodes van de originele API samenvoegen.
ConclusieWe geloven dat deze resultaten de state-of-the-art in het ontwerpen, analy-seren en herschrijven van software systemen die bestaan uit web APIs (i.e.,service- georiënteerde systemen) vooruit helpen. Daarnaast bieden ze de on-derzoeksgemeenschap nieuwe inzichten in de veranderlijkheid van APIs enweb APIs.
Daniele Romano


Curriculum VitaeEducation2010 – 2014: Ph.D., Computer Science
Delft University of Technology, Delft, The Netherlands. Under the super-vision of prof. dr. M. Pinzger.
2007 – 2010: M.Sc., Computer ScienceUniversity of Sannio, Benenvento, Italy.Master’s thesis title: An Approach for Search Based Testing of Null PointerExceptions.
2001 – 2006: B.Sc., Computer ScienceUniversity of Sannio, Benevento, Italy. Bachelor’s thesis title: Develop-ment and testing of a GUI tool for the creation and modification of nomadicapplications.
Work Experience2014 – present: Advisory IT Specialist/Continuous Delivery Product Owner
ING Nederland, Amsterdam, The Netherlands.
2010: Software Engineering ResearcherInternship at École Polytechnique de Montréeal, Canada.
2005 – 2007 : Java and SOA Software Developer as Freelancer.Benevento, Italy.
2006: Software Engineering ResearcherRCOST (Research Centre On Software Technology), Benevento, Italy.
205

206 Curriculum Vitae
Related Documents











