Analytical Performance Evaluation of Data Replication Based Shared Memory Model SiniSa SrbljiC and Leo Budin University of Zagreb, Faculty of Electrical Engineering Avenija Vukovar 39, 41000 Zagreb, Croatia Abstract The proposed distributed shared memoy model is based on a data replication scheme that provides an environmmt for a collection of processes that interact to solve a parallel programming problem. In the implementation of the scheme we suppose that the replicas of the shared data are present at each node and that an appropriate coherence protocol for maintaining the consistency among the replicas is applied. The p$ormance of the distributed computation is v e y sensitive to the data-access behavior of the application and to the applied coherence protocol. Communication cost is regarded as an appropriate pet$onnance measure. Therefore, we first introduce a model characterizing the computation behavior with $ve workload parameters. Second, we formally describe the coherence protocols as cooperating state machines in order to evaluate their communication costs as functions of workload parameters. 1 : Introduction In a distributed shared memory environment the inherently present message passing mechanism together with underlying hardware and s o h a r e is hidden from the application [ 11. [2], but they heavily influence the performance of the distributed computation. Therefore, to improve the performance of such systems, appropriate models for the performance analysis and prediction are needed. The models have to take into consideration enough subtle details, in order to accomplish eventual fine tuning of the computation behavior. In this paper we describe a methodology for performance evaluation of distributed shared memory system based on data replication. In this scheme data are replicated at every node of the distributed system and suitable coherence protocols for maintaining the consistency among replica are applied. A substantial number of data replication coherence protocols have been designed and analyzed [3]-[5]. We analyze eight protocols obtained by modification of seven well-known decentralized cache coherence protocols designed for the bus-based multiprocessors (Write-Once, Write-Through, Synapse, Illinois, Berkeley, Dragon, and Firefly [6], [7]). The Write-Through protocol is modified into two distributed versions. Message passing is the only used mechanism in these modified protocols. For the sake of simplicity, in this paper we analyze in details the Write-Through protocol. The detailed description of all the protocols is given in [SI, [SI. 0-8186-3900-8193 $3.00 0 1993 IEEE In Section 2 we describe the structure of the distributed system. In order to simplify the presentation we concentrate only on the features needed for the application of the Write- Through coherence protocol. The formal model of a coherence protocol based on the Mealy state-machine is given in Section 3. In section 4 we first define the workload parameters and develop an analytic method for performance evaluation. Performance is expressed as steady-state average communication cost per read and write operation. Finally, in Section 5, the eight modified coherence protocols are mutually compared and some simulation results are discussed. 2: The distributed system model In this section, we present the essential features of the distributed system under consideration. We describe the distributed system structure, the structure of nodes in the model, and the mechanism of the shared memory operation execution. The description is restricted to the Write-Through protocol to simplify the discussion, but can be easily modified for other coherence protocols. In the system there is a set of N+1 nodes. Each node has a local memory and a processing element. We assume fault free communication between nodes and the implementation of the message passing mechanism through channels that behave like first-inlfirst-out queues. Thus, every message sent is delivered and not cormpted. We suppose that in each node only one application process accesses the memory. The global address space is decomposed into M disjoint shared data blocks that can be identified by unique indexj (j=l, ...W. A data block is collection of data that does not necessarily have to be stored consecutively in memory. For the sake of simplicity, we deal with the full-replication scheme, i.e., we assume that the shared data blocks are replicated at each node. Every copy of a data block at each node is controlled by its protocol process. The application process at one of the nodes can access an arbitrary data block j issuing a read or write request to the corresponding local protocol process. Further on, we concentrate our analysis on only one data block, sayjth, and only on the protocol processes associated with the copies of that particular data block. The protocol processes are implemented as Mealy state machines, as described in Section 3, that produce sequences of atomic actions for the fulfillment of a particular request. Some requests are executed locally and produce only one action. Others have to be executed network wide producing sequences 326 ~. 7

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Analytical Performance Evaluation of Data Replication Based Shared Memory Model
SiniSa SrbljiC and Leo Budin
University of Zagreb, Faculty of Electrical Engineering Avenija Vukovar 39, 41000 Zagreb, Croatia
Abstract The proposed distributed shared memoy model is based on a data replication scheme that provides an environmmt for a collection of processes that interact to solve a parallel programming problem. In the implementation of the scheme we suppose that the replicas of the shared data are present at each node and that an appropriate coherence protocol for maintaining the consistency among the replicas is applied. The p$ormance of the distributed computation is v e y sensitive to the data-access behavior of the application and to the applied coherence protocol. Communication cost is regarded as an appropriate pet$onnance measure. Therefore, we first introduce a model characterizing the computation behavior with $ve workload parameters. Second, we formally describe the coherence protocols as cooperating state machines in order to evaluate their communication costs as functions of workload parameters.
1 : Introduction
In a distributed shared memory environment the inherently present message passing mechanism together with underlying hardware and s o h a r e is hidden from the application [ 11. [2], but they heavily influence the performance of the distributed computation. Therefore, to improve the performance of such systems, appropriate models for the performance analysis and prediction are needed. The models have to take into consideration enough subtle details, in order to accomplish eventual fine tuning of the computation behavior.
In this paper we describe a methodology for performance evaluation of distributed shared memory system based on data replication. In this scheme data are replicated at every node of the distributed system and suitable coherence protocols for maintaining the consistency among replica are applied. A substantial number of data replication coherence protocols have been designed and analyzed [3]-[5]. We analyze eight protocols obtained by modification of seven well-known decentralized cache coherence protocols designed for the bus-based multiprocessors (Write-Once, Write-Through, Synapse, Illinois, Berkeley, Dragon, and Firefly [6] , [7]). The Write-Through protocol is modified into two distributed versions. Message passing is the only used mechanism in these modified protocols. For the sake of simplicity, in this paper we analyze in details the Write-Through protocol. The detailed description of all the protocols is given in [SI, [SI.
0-8186-3900-8193 $3.00 0 1993 IEEE
In Section 2 we describe the structure of the distributed system. In order to simplify the presentation we concentrate only on the features needed for the application of the Write- Through coherence protocol. The formal model of a coherence protocol based on the Mealy state-machine is given in Section 3. In section 4 we first define the workload parameters and develop an analytic method for performance evaluation. Performance is expressed as steady-state average communication cost per read and write operation. Finally, in Section 5 , the eight modified coherence protocols are mutually compared and some simulation results are discussed.
2: The distributed system model
In this section, we present the essential features of the distributed system under consideration. We describe the distributed system structure, the structure of nodes in the model, and the mechanism of the shared memory operation execution. The description is restricted to the Write-Through protocol to simplify the discussion, but can be easily modified for other coherence protocols.
In the system there is a set of N+1 nodes. Each node has a local memory and a processing element. We assume fault free communication between nodes and the implementation of the message passing mechanism through channels that behave like first-inlfirst-out queues. Thus, every message sent is delivered and not cormpted. We suppose that in each node only one application process accesses the memory.
The global address space is decomposed into M disjoint shared data blocks that can be identified by unique indexj (j=l, ...W. A data block is collection of data that does not necessarily have to be stored consecutively in memory. For the sake of simplicity, we deal with the full-replication scheme, i.e., we assume that the shared data blocks are replicated at each node. Every copy of a data block at each node is controlled by its protocol process. The application process at one of the nodes can access an arbitrary data block j issuing a read or write request to the corresponding local protocol process. Further on, we concentrate our analysis on only one data block, sayjth, and only on the protocol processes associated with the copies of that particular data block.
The protocol processes are implemented as Mealy state machines, as described in Section 3, that produce sequences of atomic actions for the fulfillment of a particular request. Some requests are executed locally and produce only one action. Others have to be executed network wide producing sequences
326
~. 7

of actions in more then one node. In such distributed opemtions, protocol processes communicate by message passing hidden to the application processes.
The protocol processes associated with the copies of the same data block in all nodes, except one of them which we distinguish by index N+I, are identical. These protocol processes have two input queues: a local queue. where the requests from a local application process are enqueued, and a distributed queue for enqueuing the messages from other protocol processes. The protocol process at node N+I has only a dishibuted queue, where both the requests from its local application process and messages sent from other nodes are enqueued. The Mealy machine at this node is also slightly different from the Mealy machines in other nodes with indices i= 1 ,. . . ,N.
Protocol process at node N+l is responsible for global sequential filtering of concurrent distributed operations and is therefore named a sequencer. The other protocol processes are later on referred to as clients [ I ] . Since we are analyzing the protocol processes associated with the copies of only one data block, the node whose protocol process is the sequencer may also be called the sequencer. Analogously, those nodes whose protocol processes are clients may also be referred to as clients. It will be clear from the context whether we are talking about the sequencer and the clients as protocol processes or as nodes. The brief description of interactions between clients and the sequencer is as follows:
The sequencer can communicate with all the clients, but clients communicate only with the sequencer, and not among themselves. The application process in the sequencer starts the execution of the read or write operation by sending a request message into its distributed queue. The application process in one of the clients initiates the execution of the operations by putting the request message into the local queue of its protocol process. Tlus message starts the execution of the first action of the operation. If the operation is executed locally, then this action is the only one that is executed. If one of the clients initiates the execution of a distributed operation, then the first action of the protocol process in the client sends a permission-asking message into the distributed queue of the sequencer. The sequencer's distributed queue sequences the clients' distributed operations together with its own operations. The actions initiated from the sequencer's distributed queue may send invalidation or grant messages into the distributed queues of the clients. In that case, the executions of the distributed operations terminate in the clients by the execution of the actions initiated from their distributed queues. When the execution of the client's distributed operation requires a response from the sequencer, the pending requests in the local queue are temporarily disabled until the response from the sequencer is obtained. Therefore, the first action of a distributed operation initiated from the local queue disables M e r requests from the Same queue, whereas an action initiated by the response message from client's distributed queue enables further requests.
To keep the copies of the same shared data block consistent, we globally sequence the actions of the different operations. Three assumed features which preserve the sequence order of the operations started from one of the nodes, and insure the same sequence of the action executions of the different operations at all nodes are: first infirst out communication channels, first inlfirst out queues and disable/enable mechanisms associated with local queues.
3: The formal model of a data replication coherence protocol
To enable detailed analysis of different coherence protocols, we introduce the formal model described by Mealy machines. First, we introduce the formalized notation and describe the general outlook of the machine and later on we use them for modeling the distributed WriteThrough coherence protocol. This model Serves as a modeling paradigm for other coherence protocols [8], 191.
A particular operation is initiated by the first message taken out of the local queue of the client or by dequeuing a message from the distributed queue of the sequmcer.
A message consists of two parts: a message token and additional parameters. A message token is represented by a five-tuple (type, operation-initiator, objed-name, queue, parametergresence), where: 0 type is the type of the message (in the WriteThrough
protocol there are six message types: R-REQ and W-REQ for read and write request messages, R-PER and W-PER for permission-asking messages, R-GNT for the grant message and W-INV for the invalidation message);
0 operation-initiator is the index of the node which starts the execution of the operation (i=l, ...A+ 1); object-nme selects one of the shared memory blocks that is later on named as shared object (j=l, ... J4);
0 queue points to the queue from which the message came ( I - for local queue, d - for distributed quae); parmeterpresence marks the presence of additional parameters in the queue beside the message token (0 - additional parameters are not present, r - read operation parameters are present, w - write operation parameters are present, ui - complete new user information part of a copy is present). For every replica of the shared object in each node one
Mealy machine is introduced. In each of the clients, the Mealy machines are the same. A Mealy machine is a finite automaton with output defined as a six-tuple MM=(Q, Z, f2, 6, k, qo). The finite set of states Q is equal to the set of states of a shared object copy (for the protocol in consideration the set consists of the VALID and the INVALID state for the client's machine, and contains only the VALID state for the sequencer's machine). The finite input alphabet Z consists of all message tokens. The tmnsition ]unction 6 maps QxZ to Q. The output alphabet R is determined by a set of output routines. The output function k maps QxC to f2 (this fimction determines which of the output routines will be executed on a particular input and the present state). The starting state Q is INVALID in the client's machine and VALID in the sequencer's machine.
327

Table 1: Mealy machine transition table for a copy of jth v=1, ..., M) shared object at ith client (i=l, ..., N) for Write-
Through protocol
1 - a message token as input symbol 2 - a state of a copy of shared ohjct as a state of Mealy
machine, the first row is labeled with the starting state 3 - a new state defined by function 6 4 - an output routine as output symbol defined byfunction 1 5 - error (errors are not analyzed by the given protocol) 6 - kd, k=l, ...,N+ 1
10 1
102
103 I04
I client i read operation w ' t e operation
pop @arametm-r(i)); retum(parameters a), user infonnation(i))
change @arameters-w(i), user-infmation(j)); push (except (N+l), (W INV. N+l, j, d, 0)) push (k (R GNT, k. j. 4 ui), user infmationfi)) pop @arameters-w(i)); change (parametem-w(i). user-infmation(i)), push (except (k N+I), (W MV, k, j. d. 0))
pop (Parameta-wfj));
.- I shared object
Table 2: Set of Mealy machine output routines for a copy of f l (i=l, ..., M) shared object at ith client (i=l, ..., N ) for Write-
Through protocol
The output routines are described as concatenation of simple functions. The implementation of the considered model requires the following seven simple functions:
Function pop(wriabIe) updates the contents of a specified variable. The content of variable is popped from a queue from which the message token came. There are three variables in this model. The user information part of a copy of thejth shared object is defined by the content of tlie variable user-informdion6). Variables parameters-ro') and parameters-*> temporarily store additional parameters of read and write operations. respectively. The structure of the last two variables depends on the organization of the user information part of a copy. Function push(destination, message-token, add2ionalgarameter.v) sends the message-token and add2ionaljarameters to the destination nodes. The message is sent to a queue specified by the parameter queue in the message-token. Function except(&ess-list) determines that the message has to be sent to all nodes excluding those listed in
Function change@arameters-w6), urer-information(i)) updates the content of the variable user-information03 according to the write operation parameters defined in the parameters-n$J) variable. Function [email protected](j, urer-information(i)) returns the data to the application ymcess according to the
wess- l is t .
Table 3: Mealy machine transition table for a copy of f l (,i=l,...,M) shared object ai the sequencer for Write-Through
protocol 1 - k=l, ...,A'
INVALID
.. >.U Figure 1: The state of the copy at ith client for Write-Through
protocol.
The described formal model for the Write-Through protocol serves as a paradigm for the formal description of different protocols. hi Appendix A, we only illustrate the transition state diagrams for other seven well-known cache coherence protocols which we have modified for use in a distributed environment. Detailed descriptions of the adapted protocols can be found in VI and 191.
328

4: Performance evaluation
In this section we use the formal model for performance analysis of a distributed shared memory system. We assume that the cost of accessing locally available data is negligible and that the communication cost due to message exchanges between clients and the sequencer can be considered as a performance measure. Therefore, we first estimate the communication costs associated with different modes of operation executions and second, we introduce a model for the data access behavior of the application. We characterize the workload as a specific deviation from an ideal one that consists of application processes accessing disjoint data objects. We introduce some deviation parameters and compare the performance of different coherence protocols for some of their typical values.
4.1: Traces of actions and their communication costs
Every access to the shared memory is initiated by one of the application processes of the distributed computation. Application processes put the read or write requests into the appropriate queues of their protocol process. These messages initiate sequences of actions that we call traces of actions, or shortly tmces.
It can be shown that for a given coherence protocol the set of all traces TR is finite [8] and that every operation execution results in exactly one trace from the set TR. The set of traces has to be determined by a thorough analysis of the applied coherence protocol [SI. 191. Every trace tr,,eTR depends on: the type of operation, the state of the copies of the shared object, and on the interaction of operations that are executed concurrently on the same object.
With each trace trh we associate the corresponding trace communication cost cch which is established by summing up the communication costs of all actions in the trace. We distinguish four different action communication costs:
the communication cost is zero if the action is executed inside a node; the unit communication cost is associated to the action sending an inter-node message that contains only the message token (i.e., withpmumeterjresence = 0); the communication cost of S+1 units is associated to the action sending an inter-node message (with parumeterjresence = ui) that contains the message token and the updating user information; the communication cost of P+l units is associated to the action sending an inter-node message (with pmumermjresence = w ) that contains the message token and the write operation parameters. The set of traces for the Write-Through protocol, that we
use in this paper to demonstrate the proposed methodology, consists of six traces. We describe each trace and its communication cost for one of the shared objects, sayjth.
The client's mad operation of the copy in VALID state generates trace trl with only an action executed locally with the communication cost cc,?). If the copy is in INVALID state, trace tr2 is generated with communication cost cc2=S+2. First, the read permission-asking message token is sent to the sequencer which responds with a read grant message token joined with user information (Fig. 2.).
Figure 2: The messages in trace fr2
Traces tr3 and tr4 are initiated by the client's write operation to the shared object in VALID and INVALID state% respectively. The messages emerging in traces are illustrated in Fig. 3. Both traces have the same communication cost cc3=cc4=P+N. Namely, the write permission-asking message token together with write parameters are passed from the client to the sequencer with cost P+l, and after that the sequencer sends invalidation message tokens to the remaining N-l clients.
Figure 3: The messages in traces tr3 and tr4
Traces tr5 and tr6 are generated by sequencer's operations. A read operation executes locally on the copy that is always VALID with the zero cost, i.e., ccs 4, whereas the write operation initiates trace tr6 sending N invalidation message tokens to all clients with communication cost cc6 =N. (Fig. 4)
The defined trace communication costs will be used to evaluate the cost of the distributed computation.
Figure 4: The messages in trace tr6
4.2: Workload characterization
The performance of the distributed shared memory system is very sensitive to data-access behavior of the distributed computation. Therefore, a generalized characterization of workload is usehl so that different coherence schemes can be compared with respect to only few workload parameters.
We assume that the workload consists of a collection of processes that behave in a stochastic steady-state manner.
329

Concerning the communication cost, we denote as an ideal workload the computation in which every object is accessed in one and only one node. That is, an ideal workload is a computation without shared data.
If, in an ideal workload, node i issues the read and write requests to objectj, we call node i the activity centerfor object j . Further on. we concentrate our analysis only on clients associated with the copies of one object. The activity center read operation (Ar) and write operation (Aw) may be considered as the only two random events of the sample space that are mutually exclusively exhaustive. Also, their occurrences are statistically independent in time. Therefore, the sum of the probabilities of the read operation y(Ar) and the write operation HAW) is equal to one. If we introduce the parameter P=Y(Aw) for the write operation in the activity center, then the probability of the read operation is y(Ar)= I -p.
We analyze three deviations/rom an ideal workload and call them: read disturbance, write disturbance and multiple activity centers disturbance. For each deviation we determine the event sample space and introduce the corresponding parameters, as follows:
In the workload with reud disturbance only activity center i can start a read operation (Ar) and a write operation (Aw), whereas some number a (a<N) of other clients can start only a read operation (Or&i). The sample space consists of a+2 events: Ar, Aw, and a events Ork If the probabilities are expressed as y(Aw)=p and p(Ork)=uk, the probability for an activity center read operation p(Ar) can be determined. To simplify the presentation of performance evaluation we assume the homogeneous case where &Ork) are all equal, i.e., y(Ork)=ak=u. In that case, p(Ar)=l-
In the workload with write disturbance only activity center i can start a read operation (Ar) and a write operation (Aw), whereas some number a (a<N ) of other clients can start only write operation (Ow+i). The sample space consists of a+2 events: Ar, Aw, and a events Owk If the probabilities are expressed as p(Aw)=p and p(Owk)=&, the probability for an activity center read operation AAr) can be determined. To simplify the presentation of performance evaluation we again assume the homogeneous case where &Owk) are all equal, i.e., y(Owk)'5k~, . In that case,
In the workload with multiple activity centers disturbance more than one client can behave as activity center. If there are p clients declared as activity centers then the sample space consists of 28 events. To simplify the analytic performance comparison we consider only the homogeneous case with equal read and write probabilities at all activity centers. In that case, if the total write probability is p, the probabilities of wn'te and read operations at a particular node k are y(AwkFplp and y(Ark)=( I-p)/p, respectively. The five parameters p. cr, 5. a and p describe an assumed
synthetic workload, although they may be obtained by estimating the relative frequencies of events in some real distributed computation. Parameters and the communication costs per trace are input to the performance comparison model. All model parameters are summarized in Table 5.
d A w + & = I,...,a@kFl-Fu.
p(Ar)=l-y(Aw+~~1,...,aOwk)=l-pa5.
Table 5: Parameters of the model
N -number of clients (Section 2) a -number of clients that start read or write operations
-number of clients declared as activity centers (Section 4.2)
(Section 4.2) p steady-state probability of the activity center write
operation (Section 4.2) B - steady-state probability of read operation of one of a
clients (Section 4.2) 5 - steady-state probability of write operation of one of a
clients (Section 4.2) S -communication cost of user mformation part of copy
transmission (Section 4.1) P -communication cost of write operation parameters
transmission (Section 4.1) llcc - steady-state average communication cost per operation
4.3: Steady-state average communication cost as a performance measure
We define as a performance measure the average communication cost, denoted by acc, of an operation accessing a shared object in the stochastic steady-state computation. The average communication cost can be expressed as:
where CC,, is the communication cost for trace rrk X h is the steady-state probability that operation execution wll result in trace trh, and TR is the set of all traces for a given coherence protocol (xrrhC#h=l 1.
The Probabilities xh are functions of the parameters p, U, 5, a and p. These functions can be determined for the steady-state behavior of the interacting Mealy machines for a particular coherence protocol.
We analyze in detail the derivation of the expression for the average communication cost of the workload with read disturbance deviation for the Write-Trough protocol, and give only the final formulae for the other two deviations. The same methodology can be used to express the average communication costs for other coherence protocols [8]. [SI.
We recall from Section 4.2 that the read and write operations are treated as random events from sample space and that they are mutually exhaustive and their occurrences are statistically independent in time. Therefore, a specific sequence of operations can be treated as a sequence of repeated independent trials. We denote the events by symbols Ar, Aw and Ork for activity center read operation, activity center write operation and other client's read operation, respectively. The probability of a specific sequence of operations is equal to the product of probabilities of the individual items. To obtain the probability of a specific outcome, the probabilities of all sequences giving this outcome have to be summed up. We symbolize the sequence of trials by a string of event symbols,
multiple consecutive appearance of the same symbol, e.g., A1f0r~)~ArAw.
e.g., &(kkfik(%#Aw, with exponent denoting the
330

In read disturbance deviation h m ideal workload at an activity center read and write operations are allowed, whereas in a other clients only read operations can be executed. Therefore, in an activity center four traces can emerge: trl or tr2 for read operation, and tr3 or tr4 for write operation. The other a clients produce only traces trl and tr2
In the activity center, the execution of the read operation will result in trace trl if at least one read operation of the activity center has been executed previously. The read operations of the other a clients do not change the state of the activity center copy. Therefore, an arbitrary number of Or
Ork) events from other clients can be interpolated E2ghdaconsecu t ive Ar events giving as the outcome trace tr l . So, the probability of trace trl is dl=p(trl)= p(<c,, ... &OrYcAr)= ( l-paa)2/(1-aa). With d are denoted the ste'ady-state probabilities of the activity center traces, whereas with 1c" are denoted the probabilities of the traces of the one of other a clients. The probability of trace tr2 is the probability that the read operation event Ar follows the write operation event Aw. Again, between these two events an arbitrary number of Or events can emerge, and we have:
A write operation execution of activity center can result in one of two traces: tr3 or tr4. The execution will result in trace tr3 if at least one read operation of the activity center has been executed previously, and in trace tr4 if at least one write operation of the activity center has been executed previously. With the same reasoning as before, we have the probability for trace tr3: ~ ' ~ = y ( t r ~ ) = y ( ~ , . . . , ~ O r Y A w ) = p ( 1 -pas)/( 1 - aa) and probability for trace tr4: b4=y(tr4)=
A read operation execution of one of the a clients can result in one of two traces: trl or tr2. The execution will result in trl if at least one read operation of the same client has been executed previously. The other read operations have no influence on the state of that copy. Let Z, be a random event denoting a read operation which is executed outside that client. The steady-state probability of that event is p(Zi)=l- y(Aw+Ori)=l-po. Now, the steady-state probability of trace tr can be expressed as: ~"l=y(trl)=y(~O,....ooOr,(Zi~OriCori)=
write operation of activity center has been executed previously
The total steady-state probabilities for the traces of tlie same type trh can be calculated by expression "h='F'h+aX"h. They are:
A'2=Y(tr2)=14Zr=,...,Aw(~Y~CAr)=p( 1 - P - m lac).
v(c,o,...,&w(~Y~w)=pz/( la@.
a 1 /(p+a). The execution will result in trace tr2 if at least one
giving: " '~~v(~~) 'v (~~,~~, ,~w(~~ycor i )=ap l (p t~~
"13 I-pacr)2/( laa)+ao2/(p+a), 'c2=p( I-paa)/( 1 aa)+aap/( *),
5 = p ( I -paa)/( I aa), rr4=p2/( lac).
Using ( I ) with appropriate communication costs CCh for traces, introduced in Section 4. I , the communication cost per operation can be expressed as:
acc=z1(0)+n2(S+2)+x3(P+N)+lc4(P+N). (2)
Putting the derived probabilities in (2), we obtain the following average communication costs per operation and per shared object for read disturbance deviation: acc"(p( I -paa)l( 1 -aa)+aupl(p+o))(S+2)+p(P+N). (3)
Putting d or a=O into eqn. (3). the communication cost for ideal workload amID can be obtained.
accID=p(( 1 -p)(S+2)+P+N), and if, additionally, there are no write operations at the activity center, i.e., if p=O, the communication cost is equal to zero.
Similar reasoning for write disturbance deviation gives the following total steady-state trace probabilities:
xl=x~l=y(ArAr)=(I-p-ac$)2, ~2=~ '2=y( (Aw+Ow)ArHm)( 1 -&),
~3=~'3=p(ArA~)=p( I-&), ~ ~ ~ ~ ' ~ + o r Z ~ ~ p ( ( A ~ ~ ~ ~ ) + a p ( ~ ~ ) = p ( ~ + o C r ) + a 5 ,
where 0w=Zk1 .. ,Owk Putting these probabilities into (2), the average conmitihication cost per operation is:
a c ~ w D = ( m X I - w 5 X S + 2 ) Y m x P + N ) . (4) Finally, for multiple activib cmters dmiation the total
steady-state trace probabilities are:
~ l = P Y ( Z ~ , . . . , a ~ X j Y A r j H I-P)'/( IYP-I )P), ~ 2 = C l v ( ~ - o , . . . , A w ( X j ~ A r j ) = P ( I-PM 1YP-I )PX K 3 = P Y ( ~ , o , , , . , a , ( x j ~ A w j ~ p ( l-p)/( I+(P-I >P), x4=Pu(~,,,,,,&w(x,ycAwj~~~2~(IYP-1 >P),
where Xi=Zki k=l Ark, and AWEkcl... AWk Ushg (2). the average coniiiitkcation cost per ofifhion can be expressed as:
( 5 ) accM(+P( I-P)P/( 1YP- 1 )P)XS+2)+P(P+N).
5: Analytical performance comparison of coherence protocols with respect to read disturbance
We used the proposed methodology to analyze the performance of distributed computation in the distributed shared memory system implemented by eight coherence protocols. Here, we compare the performances only for read disturbance deviation from ideal workload. The obtained analytical results are compared with the results of simulation.
5.1: Analytical performance comparison of coherence protocols
The steady-state average communication costs per operation and per shared object for read disturbance deviation fkom ideal workload for eight coherence protocols IS] are given in Table 6. These expressions were obtained by a thorough analysis of the protocols. To give an impression of the outlook of the protocols, we have added in Appendix A the state transition diagrams for these protocols. It should be pointed out that in these diagrams emerge some states not mentioned in the description of the Write-Through protocol.
331
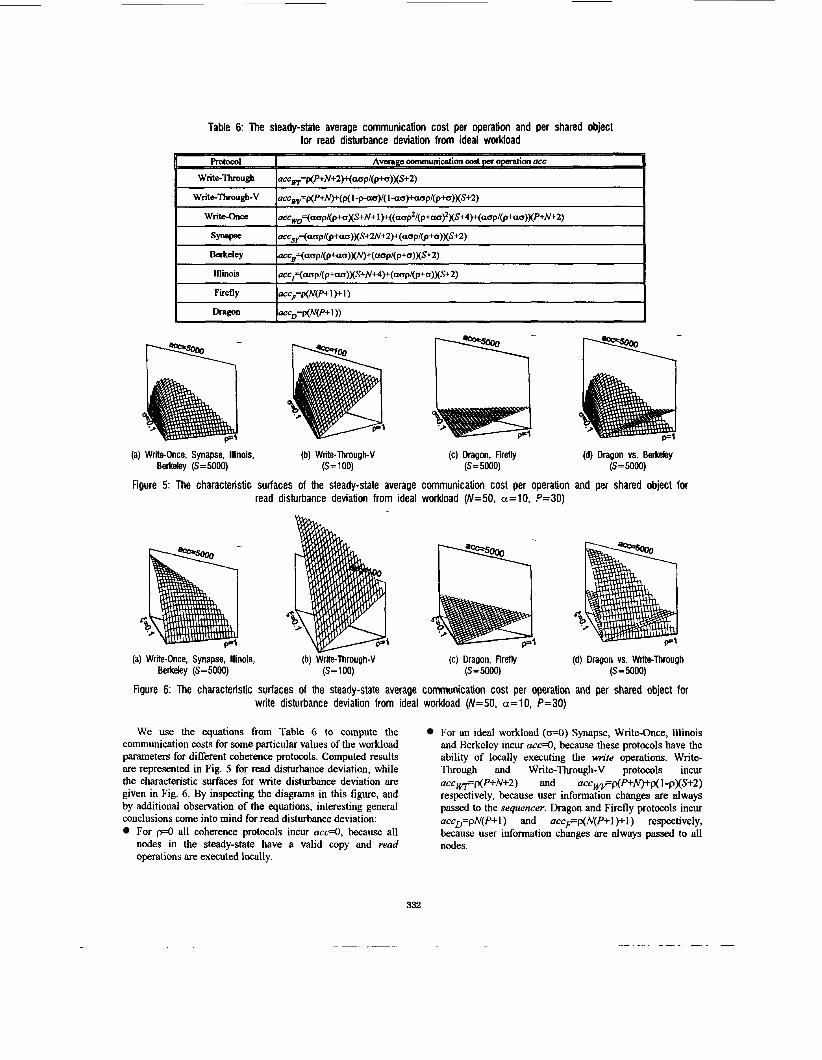
Table 6: The steady-state average communication cost per operation and per shared object for read disturbance deviation from ideal workload
I
(a) Write-Once, Synapse, Illinois, (b) Write-Through-V (c) Dragon, Firefly (d) Dragon vs. Berkeley Berkeley (S=5000) (S=lOO) (S= 5000) (S=5000)
Figure 5: The characteristic surfaces of the steady-state average communication cost per operation and per shared object for read disturbance deviation from ideal workload (N=50, a=10, P=30)
-
(a) Write-Once, Synapse, Illinois, (b) Write-Through4 (c) Dragon, Firefly (d) Dragon vs. Write-Through
Figure 6: The characteristic surfaces of the steady-state average communication cost per operation and per shared object for write disturbance deviation from ideal workload (N=50, a=10, P=30)
Berkeley (S=5000) (S=lOO) (S=5000) (S= 5000)
We use the equations from Table 6 to compute the communication costs for some particular values of the workload parameters for different coherence protocols. Computed results are represented in Fig. 5 for read disturbance deviation, while the characteristic surfaces for write disturbance deviation are given in Fig. 6. By inspecting the diagrams in this figure, and by additional observation of the equations, interesting general conclusions come into mind for read disturbance deviation:
For p=O all coherence protocols incur acc=0, because all nodes in the steady-state have a valid copy and read operations are executed locally.
Far an ideal workload (cFO) Synapse, Write-Once, Illinois and Berkeley incur acc=0, because these protocols have the ability of locally executing the write operations. Write- Through and Write-Through-V protocols incur
respectively, because user information changes are always passed to the sequencer. Dragon and Firefly protocols incur accD=pN(P+l) and acc~p(N(P+I)+l) respectively, because user information changes are always passed to all nodes.
U C C ~ - ~ ( P + N + ~ ) and a ~ c ~ p ( P + N ) + p ( 1 -pXS+2)
332

Table 7: A comparison of analytical and simulation results for Write-Once and Write-Through4 protocol
N=3, a=2, P=30, S=100
Write-Once Rotocol
Simulation Results acts II II 100 x (acca-acc$/acca (Yo) Analytical ~esults ama
Inl Inl
1 write-Through-v Protocol 1 Inl Inl
I 0.0 1 0 . 2 I 0.4 1 0 . 6 1 0 . 8 I 1.0 11 0.0 I 0.2 1 0 . 4 1 0 . 6 1 0 . 8 I 1.0 11 0.0 1 0 . 2 1 0 . 4 1 0 . 6 1 0 . 8 I 1.0
Protocol Berkeley incurs the minimum communication cost in comparison with Write-Through, Write-Through-V, Write-Once, Illinois and Synapse, because in the steady- state, an activity center becomes the sequencer. Protocol Illinois incurs acc lower than the Synapse scheme, because Illinois dynamically updates the address of the client which has the only valid copy. The Synapse incurs acc lower then Write-Thlrough-V if b S + N . If Pd+N, a line p=au(S+N-P)/(P+N+2) separates two regions where Synapse or Write-Through-V protocol incur minimum acc. A line p= -uu(S/(S+2))+S/(S+2) separates two regions where Write-Through-V or Write-Through protocol incur minimum QCC.
In Fig. 5d Dragon vs. Berkeley are compared. The perfonnance comparison of Dragon and Berkeley protocols shows that for Np>S+2 the Berkeley protocol incurs acc lower then the Dragon protocol. For NPCr+2 and a= I , the line p=a(S+2-NP)/(P+N+2) separates two regions where the Dragon or the Berkeley protocol incur minimum acc. Additionally, the numerical performance comparison
between the Write-Once and the Wnte-Through-V prot&ols is presented in Table 7. The values are double-bordered if the communication costs are lower, single-bordered if the costs are higher for the corresponding protocol, and thick-bordered if the costs are equal. In the same table the simulation results, discussed in the next section, are also given.
5.2: Comparison between analytical and simulation results
We simulated the behavior of coherence protocols by executing the protocols implemented in a multitasking Ada environment [ IO]. The implementation allows the simulation with real or synthetic workloads. For synthetic workloads, the application processes at each node randomly generate the read or write operations in concordance to specified stochastic steady-state workload parameters.
The comparison between the simulation and analytical results is given in Table 7 for the Write-Once and the Write- Through-V protocol. In this example, there are N-3 clients. One of them is the activity center, whereas two other nodes (a=2) start only the read operations. The data structure is decomposed into M=20 shared objects. The probabilities of the accesses to all of the shared objects are the same. If only one shared object is considered, then the probability of the write operation at the activity center, the probability of the read operation at the activity center and the probability of the read operations at one of the other clients for that object are p, 1-p 2 a and U, respectively. These probabilities are assumed to be the same for all shared objects.
To eliminate the influence of the transient period, the first 500 operations are neglected. Approximately 1500 operations from the steady-state period are taken into consideration for each pair of parameters p and 6. From the data given in Table 7 it is visible that the maximum discrepancy between analysis and simulation is less than f8%.
6: Conclusion
In this paper, we have described the methodology for the performance evaluation of data replication based distributed shared memory systems implemented with various coherence protocols. We used the proposed methodology to compare different coherence protocols. For comparison purposes, we applied a synthetic workload characterized by five parameters which can be also used to estimate the behavior of real distributed computation. The obtained results indicate that the choice of a coherence protocol is a significant design decision problem since the performance differences for a given workload can be quite large. We applied our analytical comparison model for a class of coherence protocols that we have constructed by the modification of well-known cache coherence protocols, but the methodology is convenient for general use. We feel that the model can be applied to implement a classifier for the development of adaptive data replication coherence protocols
333
with self-tuning capability based on run-time information. The model is also a sound basis for further research. We consider its modifications in order to include other types of operations (eject operation, synchronization operation) and the influence of some distributed system parameters, such as the size of the free memory pool.
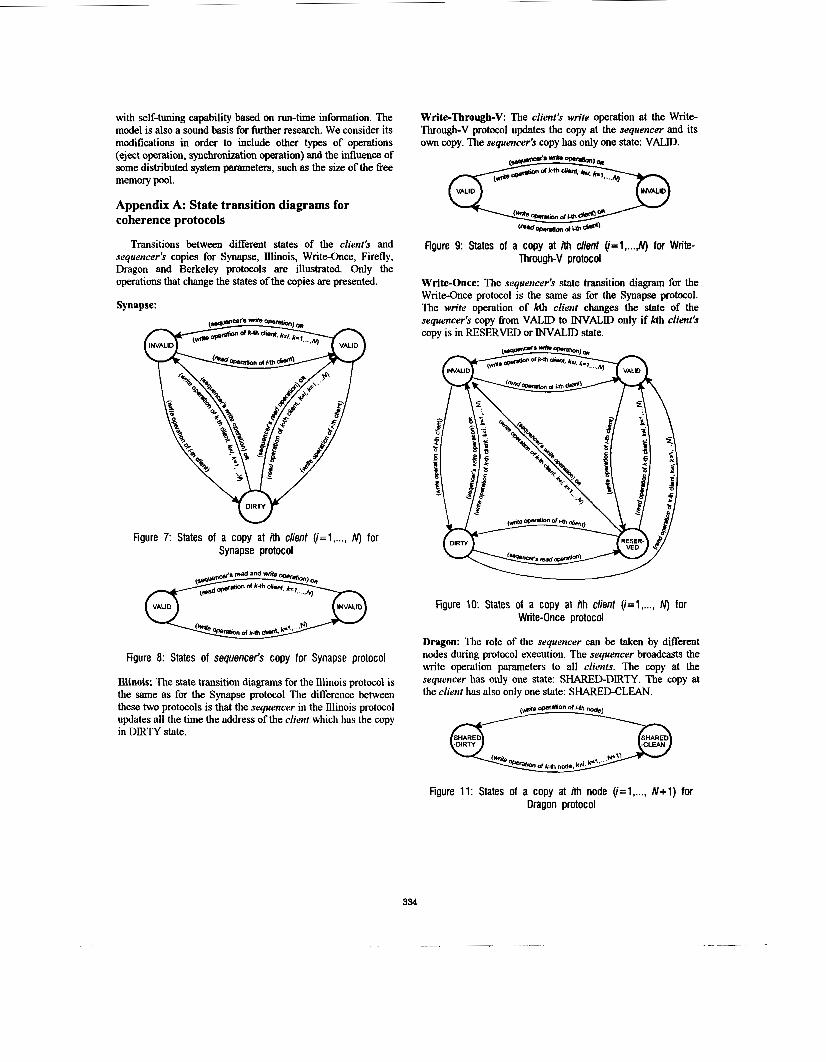
Appendix A: State transition diagrams for coherence protocols
Transitions between different states of the client's and sequencer's copies for Synapse, Illinois, Write-Once, Firefly, Dragon and Berkeley protocols are illustrated. Only the operations that change the states of the copies are presented.
Synapse:
W Figure 7: States of a copy at ith client (i=l, ..., N) for
Synapse protocol
Figure 8: States of sequencer's copy for Synapse protocol
Illinois: The state transition diagrams for the Illinois protocol is the same as for the Synapse protocol Tlie difference between these two protocols is that the sequencer in the Illinois protocol updates all the time the address of the client which has the copy in DIRTY state.
Write-Through-V: The client's write operation at the Write Through-V protocol updates the copy at the sequencer and its own copy. The sequencer's copy has only one state: VALID.
Figure 9: States of a copy at ith client (i=1, ...,N) for Write- Through-V protocol
Write-Once: The sequencer's state transition diagram for the Write-Once protocol is the same as for the Synapse protocol. The write operation of kth client changes the state of the sequencer's copy from VALD to INVALID only if kth client's copy is in RESERVED or INVALID state.
Figure 10: States of a copy at ith client (i=l, ..., N) for Write-Once protocol
Dragon: The role of the sequencer can be taken by different nodes during protocol execution. The sequencer broadcasts the write operation parameters to all clients. The copy at the sequencer has only one state: S€WRED-DIRTY. The copy at the client has also only one state: SHARED-CLEAN.
Figure 11: States of a copy at ith node (i=l, ..., N+1) for Dragon protocol

Firefly: The copy at the sequencer has only one state: VALID. The copy at the client has also only one state: SHARED. The client always passes the write operation parameters to the sequencer. The sequencer braadcasts the write operation parameters to all clients.
Berkeley: The role of the sequencer can be taken by different nodes during protocol execution. The copy at the sequencer can be in one of two states: DIRTY or SHARED-DIRTY. The copy at the client can be in one of two states: VALID or INVALID.
Figure 12: States of a copy at ith node (i=l, ..., N+1) for Berkeley protocol
Acknowledgments
This research has advanced through valuable discussions with Dalibor VrsaloviC (Ready Systems Corporation, Califomia) and Zvonko VraneSiC (University of Toronto). The authors are grateful to mado Sruk (University of Zagreb, Faculty of Electrical Engineering) who implemented the coherence protocols into the multitasking Ada simulator and prepared the results of the simulation. The authors also thank Neven ElezoviC, Hrvoje Bunjevac, Andrea Budin, Tomislav GrEanac, JoSko Radej, Goran OmrEen-Ceko (University of Zagreb, Faculty of Electrical Engineering) and Zoran IvkoviC (University of Delaware) for many fruitful discussions and suggestions.
References
M. Stumm and S . Zhou, "Algorithms Implementing Distributed Shared Memory", IEEE Computer, Vol. 23 , No. 5, May 1990, pp. 54-64. P. Stenstrom, D. Vrsalovic, and 2. Segall, "Shared Data Structures in a Distributed System - Performance Evaluation and Practical Considerations", in. Proc. Int. Seminar on PerJormance of Distributed and Pamllel Systems, Kyoto, Japan, December 1988. B. Ciciani, D.M. Dias, and P.S. Yu, "Analysis of Replication in Distributed Database Systems", IEEE Transactions on Knowledge and Data Engineering, Vol. 2, No. 2, June 1990, pp. 247-26 1. M. Thapar and B. Delagi, "Cache Coherence for Large Scale Shared Memory Multiprocessors", ACM Computer Architecture NLWS, Vol. 19, No. 1, March 199 1, pp. 1 14- 119. D. Chaiken, J. Kubiatowicz, and A. Agarwal, "LimitLESS Directories: A Scalable Cache coherence Scheme", ASPLOS-IV Proceedings, San& Clam, California, April 8-
Q. Yang, L.N. Bhuyan, and B . 4 . Liu, "Analysis and Comparison of Cache Coherence Protocols for a Packet- Switched Multiprocessor", IEEE Tmnsaction on Computers, Vol. 38, No. 8, August 1989, pp. 1143-1 153. J. Archibald and J.-L. Baer, "Cache Coherence Protocols: Evaluation thing a Multiprocessor Simulation Model", ACM Transactions on Computer System, Vol. 4, No. 4, November 1986, pp. 273-298. S . SrbljiC, "Model of Distributed Processing in Flexible Manufacturing Systems", Ph.D. dissertation, Institute for Electronics, Faculty of Electrical Engineering, University of Zagreb, Croatia, November 1990. (Work published in Croatian, original title: "Model distribuirane obrade U prilagodljivim proizvodnim sustavima" ) S.SrbljiC and L.Budin, "A Fonnal Model of Data Replication Coherence Protocols", Technical Report, Institute for Electronics, Faculty of Electrical Engineering, University of Zagreb, Croatia, November I99 1.
1 I , 199 1, pp. 224-234.
[ I O ] V.Sruk and S.SrbljiC, "Comparison of Data Replication Coherence Protocols for Distributed Systems", Technical Report, Institute for Electronics, Faculty of Electrical Engineering, IJniversity of Zagreb, Croatia, January 1993.
335
-. .
Related Documents











