ANÁLISIS DE DATOS INFERENCIAL PARAMÉTRICO Y NO PARAMÉTRICO Autor: Fernando Martínez Abad ([email protected] ), Universidad de Salamanca. ÍNDICE INTRODUCCIÓN AL ANÁLISIS INFERENCIAL DE DATOS EN CCSS ...................................................... 2 FUNDAMENTOS DE LA ESTIMACIÓN DE PARÁMETROS .................................................................. 5 DISTRIBUCIONES TEÓRICAS: LA DISTRIBUCIÓN NORMAL ................................................................... 5 LA DISTRIBUCIÓN MUESTRAL y DISTRIBUCIÓN MUESTRAL DE LA MEDIA .......................................... 9 ESTIMACIÓN DE PARÁMETROS y CONTRASTE DE HIPÓTESIS ........................................................ 15 ESTIMACIÓN DE PARÁMETROS ......................................................................................................... 15 CONTRASTE DE HIPÓTESIS ................................................................................................................ 21 CONTRASTES DE HIPÓTESIS CON SOFTWARE INFORMÁTICO (SPSS) ................................................ 30 COMPROBACIÓN DEL SUPUESTO DE NORMALIDAD..................................................................... 32 1. EXPLORACIÓN INICIAL GRÁFICA .................................................................................................... 32 2. ESTUDIO DE LOS ÍNDICES DE ASIMETRÍA Y CURTOSIS .................................................................. 34 3. CONTRASTE DE HIPÓTESIS ACERCA DE LA NORMALIDAD DE LA VARIABLE.................................. 34 DOS MUESTRAS INDEPENDIENTES .............................................................................................. 36 1. EXPLORACIÓN DESCRIPTIVA INICIAL ............................................................................................. 36 2. SUPUESTOS PREVIOS ..................................................................................................................... 37 3. CONTRASTE PARAMÉTRICO: PRUEBA DE T PARA GRUPOS O MUESTRAS INDEPENDIENTES ....... 38 4. CONTRASTE NO PARAMÉTRICO: PRUEBA DE LA U DE MANN-WHITNEY ...................................... 40 4.1 Una variable de agrupación y otra cuantitativa ....................................................................................................... 40 4.2 Una variable de agrupación y otra ordinal ............................................................................................................... 42 DOS MUESTRAS RELACIONADAS ................................................................................................. 45 1. EXPLORACIÓN DESCRIPTIVA INICIAL ............................................................................................. 45 2. SUPUESTOS PREVIOS ..................................................................................................................... 46 3. CONTRASTE PARAMÉTRICO: PRUEBA DE T PARA GRUPOS O MUESTRAS RELACIONADAS .......... 46 4. CONTRASTE NO PARAMÉTRICO: TEST O PRUEBA DE WILCOXON................................................. 48 K MUESTRAS INDEPENDIENTES ................................................................................................... 50 1. EXPLORACIÓN DESCRIPTIVA INICIAL ............................................................................................. 50 2. SUPUESTOS PREVIOS ..................................................................................................................... 51 3. CONTRASTE NO PARAMÉTRICO: PRUEBA DE KRUSKAL-WALLIS ................................................... 52 4. CONTRASTE PARAMÉTRICO: ANOVA DE 1 FACTOR ...................................................................... 55 5. EXPLICACIÓN TEÓRICA: ANOVA DE 1 FACTOR .............................................................................. 58

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

ANÁLISIS DE DATOS INFERENCIAL PARAMÉTRICO Y NO PARAMÉTRICO Autor: Fernando Martínez Abad ([email protected]), Universidad de Salamanca.
ÍNDICE
INTRODUCCIÓN AL ANÁLISIS INFERENCIAL DE DATOS EN CCSS ...................................................... 2
FUNDAMENTOS DE LA ESTIMACIÓN DE PARÁMETROS .................................................................. 5
DISTRIBUCIONES TEÓRICAS: LA DISTRIBUCIÓN NORMAL ................................................................... 5
LA DISTRIBUCIÓN MUESTRAL y DISTRIBUCIÓN MUESTRAL DE LA MEDIA .......................................... 9
ESTIMACIÓN DE PARÁMETROS y CONTRASTE DE HIPÓTESIS ........................................................ 15
ESTIMACIÓN DE PARÁMETROS ......................................................................................................... 15
CONTRASTE DE HIPÓTESIS ................................................................................................................ 21
CONTRASTES DE HIPÓTESIS CON SOFTWARE INFORMÁTICO (SPSS) ................................................ 30
COMPROBACIÓN DEL SUPUESTO DE NORMALIDAD ..................................................................... 32
1. EXPLORACIÓN INICIAL GRÁFICA .................................................................................................... 32
2. ESTUDIO DE LOS ÍNDICES DE ASIMETRÍA Y CURTOSIS .................................................................. 34
3. CONTRASTE DE HIPÓTESIS ACERCA DE LA NORMALIDAD DE LA VARIABLE .................................. 34
DOS MUESTRAS INDEPENDIENTES .............................................................................................. 36
1. EXPLORACIÓN DESCRIPTIVA INICIAL ............................................................................................. 36
2. SUPUESTOS PREVIOS ..................................................................................................................... 37
3. CONTRASTE PARAMÉTRICO: PRUEBA DE T PARA GRUPOS O MUESTRAS INDEPENDIENTES ....... 38
4. CONTRASTE NO PARAMÉTRICO: PRUEBA DE LA U DE MANN-WHITNEY ...................................... 40
4.1 Una variable de agrupación y otra cuantitativa ....................................................................................................... 40
4.2 Una variable de agrupación y otra ordinal ............................................................................................................... 42
DOS MUESTRAS RELACIONADAS ................................................................................................. 45
1. EXPLORACIÓN DESCRIPTIVA INICIAL ............................................................................................. 45
2. SUPUESTOS PREVIOS ..................................................................................................................... 46
3. CONTRASTE PARAMÉTRICO: PRUEBA DE T PARA GRUPOS O MUESTRAS RELACIONADAS .......... 46
4. CONTRASTE NO PARAMÉTRICO: TEST O PRUEBA DE WILCOXON ................................................. 48
K MUESTRAS INDEPENDIENTES ................................................................................................... 50
1. EXPLORACIÓN DESCRIPTIVA INICIAL ............................................................................................. 50
2. SUPUESTOS PREVIOS ..................................................................................................................... 51
3. CONTRASTE NO PARAMÉTRICO: PRUEBA DE KRUSKAL-WALLIS ................................................... 52
4. CONTRASTE PARAMÉTRICO: ANOVA DE 1 FACTOR ...................................................................... 55
5. EXPLICACIÓN TEÓRICA: ANOVA DE 1 FACTOR .............................................................................. 58

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
2
INTRODUCCIÓN AL ANÁLISIS INFERENCIAL DE DATOS EN CCSS
Tal y como hemos estudiado el curso pasado (paradigmas de la investigación educativa, T1
‘Metodología de Investigación’), cuando se lleva a cabo un proceso de investigación empírica en el
ámbito de las Ciencias de la Educación desde la perspectiva del paradigma positivista o cuantitativo,
se posee el objetivo primordial de extraer, a partir de los datos obtenidos en la muestra (n) recogida,
conclusiones que sean generalizables a toda la población (N) de la que proviene dicha muestra.
Dicho de manera más formal, podemos definir la inferencia estadística como el “conjunto de
técnicas para llegar a inducciones (o inferencias) acerca de una población completa basándose en
datos de una muestra integrante de la misma” (Welkowitz, Ewen & Cohen, 1981, p.106).
Ocurre, como ya vimos, que para que fuera posible extraer estas generalizaciones las características
de la muestra obtenida debían ser similares a las de la población, es decir, la muestra debía de ser
representativa. Si esto no fuera así, la muestra podría estar sesgada, y nos encontraríamos con
muchas posibilidades de que los resultados obtenidos distasen mucho de los parámetros reales en
los que se mueve la población. En este caso, el estudio resulta erróneo y queda invalidado
simplemente por esta falta de representatividad de la muestra elegida.
Figura 1. Población y muestra
Cabe recordar también, que para obtener una muestra representativa se consideraba como lo más
importante que las características socio-demográficas de interés en la muestra (distribución por sexo,
edad, curso, provincia, nivel socio-económico, localidad rural-urbana, estado civil, etc.) debían estar
repartidas de manera similar a las características de la población, y que para conseguir esto existían
diversas técnicas de muestreo probabilísticas (aleatoria simple y sistemática, estratificada y por
conglomerados) y no probabilísticas (accidental, intencional y por cuotas).
Podríamos preguntarnos en este punto que, dado que se puede cometer un sesgo (error) importante
al seleccionar una muestra inapropiada, por qué no trabajar directamente con la población completa
para evitarlo, asegurando de este modo la representatividad y posibilidad de generalización de los
POBLACIÓN N
n
MUESTRA

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
3
resultados obtenidos. Realmente, una situación en la que se trabaja con la población completa es la
ideal en el marco de la investigación cuantitativa en Ciencias Sociales. No obstante, en contadas
ocasiones se puede trabajar en la práctica de la Investigación Educativa con una población completa,
por diversos factores:
En muchas ocasiones, el tamaño de la población es infinito, es decir ni siquiera está
claramente definido el alcance de la población, ni se tiene un listado completo de todos los
sujetos que la componen, por lo que el acceso a todos ellos es una labor imposible. Si, por
ejemplo, queremos realizar un estudio a partir de la población de educadores en Castilla y
León, independientemente de si se trata de educadores en el ámbito formal, no formal o
informal, o en cualquier nivel educativo, nos va a ser muy difícil delimitar el tamaño y
características de la población de referencia. En este ejemplo, el acceso a la población
completa será imposible, ya que no es posible conocer con exactitud (sí de manera
aproximada) la distribución completa de la población. Por tanto, será imposible disponer de
un listado completo con todas las personas que desarrollan su labor profesional en el ámbito
de la educación en Castilla y León y, en última instancia, acceder a ellas.
Existen otras ocasiones en las que, a pesar de que sí es viable obtener un listado íntegro
acerca de todos los sujetos y/o grupos que componen la población, no es recomendable o
posible acceder a la población completa por varios motivos. Estos motivos pueden estar
relacionados con varias cuestiones:
o Los recursos (económicos, humanos y/o materiales) de los que dispone el grupo que
está implementando la investigación son demasiado limitados como para poder
establecer un contacto con todos los miembros de la población.
o El tamaño de la población es tan elevado y/o parte de la población de tan difícil
acceso que el tiempo y esfuerzo necesarios para obtener información de todos los
sujetos no lo posibilita (por la planificación temporal o cronograma, por falta de
recursos, por rápida obsolescencia de los temas tratados, etc.).
Se desean estudiar las competencias digitales del profesorado de educación básica
(Educación Infantil, Primaria y Secundaria) de centros educativos de Castilla y León. La
Consejería de Educación tiene un registro de todo el profesorado, por lo que podemos
obtener un listado completo del mismo. No obstante, tanto el tamaño de la población como
la extensión de la propia comunidad autónoma y las posibilidades de acceso a profesores
dificultan poder realizar la prueba de competencias digitales a todos los profesores:
Conforme al cronograma disponemos de 2 meses para el trabajo de campo, 2 investigadores
que disponibles para desplazarse a las localidades de cada profesor y 3000€ para gastos de
dietas y desplazamiento. Así, dadas las limitaciones, se estima necesario llevar a cabo un
muestreo a partir de ese listado completo de profesores.
Dicho esto, queda clara la importancia capital de establecer técnicas de muestreo apropiadas y lo
que es más importante, una vez obtenida la muestra representativa, implementar técnicas
estadísticas concretas para obtener información precisa acerca de la población de referencia a partir

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
4
de la información muestral disponible en el estudio. A este conjunto de técnicas, que tratan de
ofrecer la información poblacional con la mayor precisión a partir de la información aportada por la
muestra obtenida, se les denomina como técnicas inferenciales, o estadística inferencial. Todo el
procedimiento de la estadística inferencial, al menos a nivel conceptual, se puede resumir en el
gráfico mostrado a continuación.
Figura 2. Procedimiento de la estadística inferencial
Resulta que, dadas las cuestiones anteriormente señaladas, en las investigaciones cuantitativas
desarrolladas en el ámbito de las Ciencias de la Educación se emplea de manera generalizada
información de muestras de sujetos procedentes de una población para tratar de establecer
conclusiones o generalizaciones acerca de la población completa.
Desde un punto de vista formal, cabe destacar que todos los índices que se pueden calcular a partir
de una muestra (media, desviación típica, mediana, varianza, asimetría, curtosis, coeficiente de
correlación, etc.) se denominan estadísticos. Estos estadísticos simplemente aportan una
información acerca de los sujetos disponibles en nuestra muestra, nunca sobre la población
completa. Por eso surgen las técnicas de estadística inferencial, que se emplean para estimar los
parámetros poblacionales de los que provienen esos estadísticos muestrales.
Así, partiendo de los datos de una muestra que se supone que es representativa de la población,
podemos estimar, con unos supuestos previos y unos niveles de error previamente asumidos, que
el valor poblacional (parámetro) de un estadístico obtenido en la muestra se encuentra en un
intervalo o rango de puntuaciones. Por ejemplo, si he evaluado el nivel de competencia lingüística en
lengua inglesa de una muestra representativa de profesores de Educación Primaria de Castilla y León,
conocida la puntuación media ( ) en esta variable (estadístico), puedo aplicar las técnicas
inferenciales para estimar entre qué valores se encontrará la competencia lingüística media () en
toda la población (parámetro) asumiendo un error en esta estimación de, por ejemplo, el 5% (el
asumido comúnmente).

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
5
FUNDAMENTOS DE LA ESTIMACIÓN DE PARÁMETROS
Siempre que tengamos el interés de generalizar los datos obtenidos en una muestra a la población
de referencia, va a ser necesaria la estimación de los parámetros poblacionales a partir de los
estadísticos descriptivos obtenidos en nuestra muestra. Para poder estimar estos parámetros, las
técnicas estadísticas parten de unas bases teóricas fundamentales relacionadas con la existencia de
distribuciones teóricas y con las distribuciones muestrales de los datos. En este apartado se
estudiarán de manera superficial estas dos cuestiones.
DISTRIBUCIONES TEÓRICAS: LA DISTRIBUCIÓN NORMAL
La mayor parte de las medidas cuantitativas de rendimiento, actitudes, percepciones, etc. tomadas
en el marco de la investigación cuantitativa en Ciencias de la Educación (y en las Ciencias Sociales en
general) suelen tener un comportamiento similar en cuanto a la forma de su distribución: La medida
de la altura de la población, del peso de los bebés recién nacidos, el cociente intelectual, el nivel socio-
económico, el rendimiento académico, etc., poseen distribuciones muy parecidas.
Las características de estas distribuciones tienen que ver con varias cuestiones:
La mayor parte de los sujetos de la población se encuentran alrededor o cerca de los niveles
medios de altura, peso, cociente intelectual, rendimiento o nivel, mientras que son pocos los
que se alejan mucho del punto central, ya sea por la parte inferior o por la parte superior de
la distribución.
Aproximadamente, los sujetos se distribuyen de manera simétrica en torno a las
puntuaciones superiores e inferiores a la media.
En suma, la distribución de puntuaciones en estas variables tiene forma acampanada y simétrica, o
dicho de otra forma, la distribución de este tipo de variables se ajusta habitualmente de una manera
muy importante a la distribución normal, también conocida como la campana de Gauss.
Figura 3. Distribución normal o campana de Gauss (Fuente: www.wikipedia.org)

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
6
La fórmula para la obtención de la función de densidad de esta distribución teórica es muy compleja,
ya que estamos hablando de una distribución continua:
(x,)
A esta distribución teórica la llamaremos a partir de ahora distribución normal o Z, con una media y
una desviación típica , y su notación habitual será del siguiente modo: Z(). Así, una variable
observada en una muestra tendrá una distribución similar a la normal siempre y cuando la forma de
la distribución sea similar a esta distribución teórica. Esta cuestión es independiente de la media y
desviación típica de la variable1, de hecho, lo más habitual es estandarizar la media y desviación
típica de la distribución normal a una =0 y =1, o lo que es lo mismo, Z(0,1). Cabe destacar también
que el valor mínimo y máximo de esta distribución, dado que es asintótica, está entre (-∞, +∞)
Por tanto, la propiedad fundamental de esta distribución es que es simétrica y posee curtosis
mesocúrtica. Gracias a esta propiedad a la que generalmente se ajustan las distribuciones de las
variables estudiadas, es posible simplificar el conjunto de técnicas estadísticas empleadas para
estimar los parámetros poblacionales, o lo que es lo mismo, calcular entre qué valores se encontrará
un parámetro poblacional partiendo de unos datos y unos estadísticos muestrales y asumiendo un
nivel de error concreto.
Pero en muchos casos en la investigación práctica ocurre que a partir de las variables originales
disponibles se realizan una serie de cálculos que impiden utilizar directamente la distribución teórica
Z como distribución de referencia para la estimación de parámetros, y es necesario emplear otras
distribuciones. Las otras distribuciones empleadas habitualmente son la T de student, la distribución
2 y la F de Snedecor.
En lo que respecta a la distribución 2, cabe señalar que es una distribución teórica conformada por
un sumatorio de variables independientes que siguen una distribución normal Z(0,1) al cuadrado2.
2n
Así, como se puede observar en la figura 4, en este caso no se obtiene una distribución teórica
simétrica, sino que, al estar conformada por un sumatorio de cuadrados, la distribución tiene origen
en el 0, estando su rango de puntuaciones entre (0, +∞), dado que se trata de una curva asintótica
por el lado derecho. El apuntamiento de la curva de esta distribución y la intensidad de su caída hacia
el eje x está determinado por el número de grados de libertad (n) de la distribución, es decir, el
número de sumas de Z2 del que provenga. Si una variable que sigue esta distribución proviene de una
suma de 10 variables que provienen de una distribución normal (Z) al cuadrado, entonces los grados
1 Cabe recordar que, gracias a las propiedades de la media y la varianza/desviación típica, podemos modificar la
media o la desviación típica de una variable sin modificar su forma. Por lo tanto, podemos encontrarnos variables con distribuciones muy similares o iguales a la normal con medias y desviaciones típicas muy diferentes. 2 La mayor parte de las veces que tratamos de estimar parámetros a partir de distribuciones teóricas,
estandarizamos los valores de la media y la desviación típica de la variable que entendemos que se distribuye
como una Z a una =0 y =1.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
7
de libertad serán 10, lo cual implica que esa curva asociada a la distribución teórica 2 sea de una
manera y no de otra.
Figura 4. Función de densidad 2 (Fuente: adaptado de www.wikipedia.org)
En cuanto a la T de student, es la distribución que se emplea en la estimación de parámetros como
alternativa a la distribución normal cuando las varianzas o desviaciones típicas poblacionales () son
desconocidas. Así, la distribución T posee propiedades similares a la Z, ya que es una distribución
simétrica asintótica por ambos lados, con puntuaciones por tanto entre (-∞, +∞). De hecho, a
medida que los tamaños de las muestras a partir de las que se emplea para la estimación de los
parámetros son mayores, la distribución T se aproximará más a la Z, siendo ambas distribuciones
iguales cuando el tamaño o tamaños de muestra tienden a infinito. La formulación de la distribución
t es algo más compleja, ya que procede de una combinación entre la distribución Z y la 2:
en donde Z sigue una distribución normal Z(0,1) y X sigue una distribución 2 con n grados de
libertad.
Esta distribución, por tanto, es simétrica, con media 0 y n grados de libertad. Esto quiere decir que en
función del número de grados de libertad de la distribución, su forma variará ligeramente. A nivel
general, la distribución T se representa como una normal. En la figura 5 se puede observar cómo
cambia el apuntamiento de la curva en función de los grados de libertad encontrados en la
distribución teórica.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
8
Figura 5. Función de densidad T (Fuente: adaptado de www.wikipedia.org)
Por último, estudiaremos la distribución F de Snedecor, basada también en la distribución normal
Z(0, 1), como una distribución teórica proveniente de una división entre dos variables que siguen una
distribución 2:
en donde X es una variable con distribución 2 con n grados de libertad e Y es otra variable con
distribución 2 con m grados de libertad. Así, en este caso, en lugar de trabajar con un indicador de
grados de libertad, como ocurría en las distribuciones 2 y T, en este caso trabajamos con 2
indicadores n y m. Así, se suele notar esta distribución como Fn,m. La función de densidad de esta
distribución la podemos observar en la figura 6. Nótese que, al igual que la distribución 2, la
distribución F tiene el mínimo en el valor 0 y es asintótica por la cola derecha. Así, su rango de
puntuaciones es (0, +∞), como se puede observar en la figura 6.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
9
Figura 5. Función de densidad F (Fuente: adaptado de www.wikipedia.org)
LA DISTRIBUCIÓN MUESTRAL y DISTRIBUCIÓN MUESTRAL DE LA MEDIA
Cuando se extrae una muestra de n sujetos a partir de una población de N sujetos, la muestra
obtenida es una de las otras muchas muestras que se habrían podido obtener en base a esa
población. Para poder extraer conclusiones o inferencias acerca de toda la población con respecto a
la variable o variables estudiadas a partir de los sujetos obtenidos en la muestras, es necesario tener
en cuenta que los valores, por ejemplo, de la media o medias de las variables medidas ( ) en la
muestra obtenida pueden no coincidir exactamente con el valor de la media poblacional ().
Analicemos más en profundidad este aspecto: Sabemos que el cálculo del número de muestras
posibles de tamaño n a partir de una población de tamaño N se calcula de la siguiente manera:

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
10
EJEMPLO 1
Por ejemplo, si tenemos una población de 5 sujetos y queremos obtener una muestra de 2 sujetos,
la cantidad de muestras posibles a obtener son 10. Imaginemos en este mismo ejemplo que
evaluamos el rendimiento en matemáticas de los 5 sujetos de la población, obteniendo los
siguientes resultados:
Tabla 1. Distribución poblacional. Variable rendimiento en matemáticas (N=5)
PUNTUACIÓN (xi)
María 6
Pedro 6
Juan 8
Sonia 4
Laura 6
Si calculamos la puntuación media de la población =(6+6+7+5+6)/5=6.
Podemos tratar de obtener todas las muestras posibles de tamaño 2 para esta población.
Tabla 2. Distribución muestral de la media. Variable rendimiento en matemáticas (N=5; n=2)
xi
María y Pedro 6; 6 6
María y Juan 6; 7 6.5
María y Sonia 6; 5 5.5
María y Laura 6; 6 6
Pedro y Juan 6; 7 6.5
Pedro y Sonia 6; 5 5.5
Pedro y Laura 6; 6 6
Juan y Sonia 7; 5 6
Juan y Laura 8; 6 7
Sonia y Laura 4; 6 5
Así, se puede observar que, por ejemplo, la probabilidad de obtener una muestra con una media de 7
puntos (si se elige en la muestra a Juan y a Laura) es de 1 entre 10 muestras posibles (si
consideramos que todas las muestras posibles han tenido las mismas probabilidades de ser elegidas,
es decir, si el muestreo se ha realizado de manera probabilística), es decir, existe un 10% de

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
11
probabilidades o 1/10 de que sea elegida. Por su parte, la probabilidad de obtener una muestra con
una media de 6 puntos es de 4 (María y Pedro; María y Laura; Pedro y Laura; Juan y Sonia) entre 10
muestras posibles, es decir, de 4/10, o lo que es lo mismo, 2/5 o un 40% de probabilidad.
O visto en una tabla con los datos acumulados:
Tabla 3. Frecuencias distribución muestral de la media rendimiento en matemáticas (N=5; n=2)
ni Pi Pa
5 1 10% 10%
5.5 2 20% 30%
6 4 40% 70%
6.5 2 20% 90%
7 1 10% 100%
Así, se puede definir el siguiente gráfico de la distribución muestral de la media en la variable
‘rendimiento en matemáticas’ para la población definida de N=5 y n=2:
Gráfico 1. Distribución muestral de la media. Variable rendimiento en matemáticas (n=2)
Nótese que de todas las muestras posibles (10), la mayor parte tienen una puntuación media de 6, es
más probable obtener una muestra con una puntuación media igual a la puntuación media de la
población que una muestra con una puntuación media de 5 (una muestra de las 10, un 10% de
probabilidades de que salga elegida) o con una puntuación media de 7 (una muestra de las 10, un
10% de probabilidades de que salga elegida).
EJEMPLO 2
Pensemos ahora en un ejemplo un poco más complejo, imaginemos que tenemos una población de
10 sujetos (N=10) y que queremos medir el rendimiento en matemáticas a una muestra de 5 sujetos
(n=5) de los 10 que componen la población. En este caso, el número de muestras posibles que se
pueden extraer aumenta considerablemente:
0
1
2
3
4
5
5 5,5 6 6,5 7
Frecuencia

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
12
Tenemos las siguientes puntuaciones de los sujetos de la población:
Tabla 4. Distribución poblacional. Variable rendimiento en matemáticas (N=10)
PUNTUACIÓN (xi)
María 3
Julio 8
Claudia 5
Marta 6
Elena 6
Fernando 7
Carmen 4
Álvaro 6
Rodrigo 7
Andrés 8
En este caso, la puntuación media de la población es =(3+8+5+6+6+7+4+6+7+8)/10=6.Todas las
muestras posibles que se pueden extraer de este conjunto de sujetos de la población tienen la
siguiente distribución:
Tabla 5. Frecuencias distribución muestral media rendimiento en matemáticas (N=10; n=5)
ni Pi Pa
4.8 3 1.2% 1.2%
5.0 7 2.8% 4.0%
5.2 15 6.0% 9.9%
5.4 20 7.9% 17.9%
5.6 28 11.1% 29.0%
5.8 32 12.7% 41.7%
6.0 42 16.7% 58.3%
6.2 32 12.7% 71.0%
6.4 30 11.9% 82.9%
6.6 20 7.9% 90.9%
6.8 13 5.2% 96.0%
7.0 7 2.8% 98.8%
7.2 3 1.2% 100.0%
TOTAL 252 100.0%
Y esta distribución muestral de la media se puede representar en el siguiente diagrama de densidad:

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
13
Gráfico 2. Distribución muestral de la media. Variable rendimiento en matemáticas (n=5)
Pensemos, en primer lugar, en el porcentaje de las muestras que está en un rango de puntuaciones
determinado; por ejemplo, el 97.6% de todas las muestras posibles obtiene una media en la variable
rendimiento en matemáticas de entre 5 y 7 puntos, por lo que es muy poco probable que se obtenga
una muestra de n=5 a partir de una población de N=10 en la que la puntuación media sea de 4.8 o de
7.2 puntos.
En la estadística inferencial se juega con esta probabilidad, asumiendo un error (nivel de
significación) o una confianza (nivel de confianza) en todas las estimaciones de parámetros. En el
caso de este ejemplo anterior, lo más probable (un 97.6% de probabilidad, o un nivel de confianza
del 97.6%) es que yo obtenga una muestra con un rendimiento medio en matemáticas de entre 5 y 7
puntos. Así, el error que se asume si se estima que la media poblacional está entre 5 y 7 puntos es
del 2.4% (100%-97.6%). Igualmente, existen un 73% de probabilidades de que obtenga una muestra
cuya puntuación media esté entre 5.4 y 6.6 puntos. Así, si yo estimo que la media poblacional
(parámetro) en esta variable está entre 5.4 y 6.6 puntos estoy asumiendo un nivel de significación del
27% o un nivel de confianza del 73%, un error demasiado grande (hay un 27% de posibilidades de
que la media de la muestra obtenida finalmente no esté dentro del intervalo del parámetro
poblacional).
De todos modos, el problema no es tan sencillo como lo planteado en el ejemplo anterior por dos
cuestiones básicas:
En primer lugar, en los estudios que se implementan en el ámbito de las Ciencias de la
Educación rara vez se tiene un conocimiento exacto de las puntuaciones de toda la población
en la variable, por lo que no se puede calcular directamente la distribución muestral de la
media a partir de la distribución poblacional empírica. De hecho, si se conocieran las
puntuaciones de todos los sujetos de la población en la variable o variables medidas no
tendría sentido estimar el intervalo en el que se encontraría el parámetro poblacional (ya lo
conoceríamos exactamente) y, por ende, la distribución muestral de la media.
Por otro lado, normalmente ni los tamaños de la población ni los tamaños de la muestra con
los que contamos en nuestras investigaciones en Ciencias Sociales son tan reducidos como
en el ejemplo, por lo que el número posible de muestras a seleccionar es excesivamente
3
7
15
20
28
32
42
32 30
20
13
7
3
0
5
10
15
20
25
30
35
40
45
4,80 5,00 5,20 5,40 5,60 5,80 6,00 6,20 6,40 6,60 6,80 7,00 7,20
Frecuencia

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
14
grande, y la obtención empírica de la distribución muestral de la media en la mayor parte de
los casos es una cuestión muy compleja o imposible si la población es infinita/desconocida.
Así, para simplificar y posibilitar la obtención de la distribución muestral de la media, la estadística
inferencial aprovecha las propiedades de las distribuciones teóricas (Z, T, 2, F). Antes de continuar,
es necesario añadir dos definiciones básicas al respecto:
Si una variable se distribuye normalmente, entonces la distribución muestral de la media
de esa variable también tendrá una distribución normal.
En la distribución muestral de la media, el valor puntual de la media poblacional ()
coincide con el valor puntual de la media muestral ( ).
Así, en el caso de que se cumpla el supuesto de normalidad de una variable (que la variable sea
normal), entonces la distribución muestral de la media de esa variable será también normal.
Podemos ir más allá de esta simple definición y apoyarnos en el teorema central del límite para
afirmar que “a medida que el tamaño muestral crece, la distribución de la media muestral se
aproxima cada vez más a la normal, independientemente de la distribución de la variable que se esté
mididendo” (Tejedor Tejedor & Etxeberría Murgiondo, 2006, p.52). En este caso, podemos afirmar
que, si una muestra tiende al infinito, su distribución muestral de la media tenderá a una distribución
normal.
Nótese además que la distribución de la distribución muestral de la media en la variable del anterior
ejemplo tiene una forma acampanada (distribución normal). De hecho, se entiende que la gran
mayoría de las variables cuantitativas que se miden en Ciencias Sociales tienen una forma similar a la
distribución normal, o lo que es lo mismo, las variables de escala que medimos en Ciencias de la
Educación (rendimiento, actitud, percepción, etc.) provienen en la mayor parte de los casos de una
distribución normal. Cuando se cumple este supuesto de normalidad de la variable (o la
fundamentación del teorema central del límite), se entiende que la distribución muestral de la media
de esa variable es normal, y se puede partir de esta distribución (Z) para estimar el intervalo en el
que se encontrará el parámetro poblacional de la media () a partir del estadístico de la media ( )
obtenido en la muestra. Basadas en la distribución normal o Z se encuentran otras distribuciones que
(T, 2, F), una vez identificada la distribución muestral de la media como normal, permiten llevar a
cabo estimaciones de parámetros en diversas situaciones prácticas, como veremos en los siguientes
temas.
Por tanto, como conclusión práctica de este apartado se puede señalar que, si las variables medidas
en nuestra muestra siguen una distribución normal, es posible aprovechar el potencial de las
distribuciones teóricas para estimar los parámetros poblacionales de los que provienen los
estadísticos de interés calculados. Este conjunto de técnicas de análisis de datos es el que
aplicaremos cuando llevemos a cabo algún procedimiento estadístico inferencial o de contraste de
hipótesis paramétrico.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
15
ESTIMACIÓN DE PARÁMETROS y CONTRASTE DE HIPÓTESIS
Es a partir de las bases teóricas estudiadas desde donde es posible extraer inferencias poblacionales
habiendo simplemente obtenido información en una muestra (al menos desde una perspectiva
paramétrica). En estos 2 apartados siguientes estudiaremos cómo extraer esta inferencia partiendo
del supuesto de que las variables obtenidas en la muestra proceden de la distribución normal,
planteada a nivel teórico.
ESTIMACIÓN DE PARÁMETROS
Ya hemos señalado que, gracias a la inferencia estadística, es posible estimar con un margen de error
determinado entre qué valores se encontrará en la población (parámetro) un estadístico obtenido en
la muestra. Lo cierto es que, mientras que es posible estimar el intervalo poblacional sobre cualquier
estadístico descriptivo (media, mediana, desviación típica, varianza, asimetría, etc.), lo más habitual
es emplear la media como estadístico sobre el que extraer inferencias3. De hecho, en este curso
estudiaremos a nivel teórico simplemente la estimación paramétrica de la media, aunque a nivel
práctico también estudiaremos las técnicas estadísticas alternativas cuando las distribuciones de las
variables no se ajustan a la distribución normal.
Decíamos que para estimar un parámetro debemos asumir un error en esa estimación, y que la
estimación consiste (generalmente) en el cálculo de un intervalo en el que tenemos cierta seguridad
de que se encuentra el valor del estadístico que estamos estimando en la población (normalmente la
media). Así, en términos generales, si en una estimación queremos asumir un error más pequeño, el
intervalo de confianza será más grande. ¿Por qué ocurre esto?, pues lo vemos sencillamente con un
ejemplo:
Imaginemos que me apuesto con un amigo una cena: si soy capaz de calcular correctamente la altura
de un edificio, con un margen de error de 2 metros, mi amigo me pagará la cena, si no, se la pago yo.
En el ejemplo, me está permitido alejarme de la altura real del edificio como máximo 2 metros. Así, si
el edificio mide realmente 23 metros, mi estimación tiene que ser de entre 21 y 25 metros, o lo que
es lo mismo, debe estar dentro del intervalo (21, 25). Dicho de otro modo, tengo un margen de error
de 23 ±2 (este margen de error de 4 metros como máximo, 2 m por encima y 2 m por debajo, podría
ser considerado como mi nivel de confianza en la estimación).
Imaginemos ahora que realizo la misma apuesta, pero que en este caso el margen de error en mi
estimación es de 4 metros.
En este caso, para ganar la apuesta, considerando que el edificio mide 23 metros, debo dar una
estimación de 23 ±4, es decir de entre 19 y 27 metros. Quiere decir esto que, al aumentar el tamaño
del intervalo de confianza, esto es, al aumentar el nivel de confianza de la estimación, es menos
probable que yo pierda la apuesta, es decir, que cometa un error en la estimación.
3 Cuando no es posible considerar que la distribución muestral de la media de una variable posee la
distribución normal porque la variable de origen tiene una forma de su distribución muy diferente a la normal, se suele utilizar la mediana como estadístico para realizar la estimación poblacional de la tendencia central de la distribución.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
16
En el segundo ejemplo, por tanto, mientras que al aumentar el intervalo en el que puede entrar mi
estimación de la altura del edificio aumenta mi confianza en ganar la apuesta, también se reduce la
posibilidad de error.
En la estimación de parámetros estadística ocurre exactamente lo mismo que en este ejemplo:
Mientras que en el ejemplo trato de estimar cuál es la altura real del edificio a partir de la
información obtenida a través de mis sentidos, permitiendo un margen de error más o menos
amplio, en la estimación de parámetros trato de estimar cuál es el valor real (poblacional) de un
estadístico a partir de la información obtenida en la muestra, permitiendo un margen de error
concreto (intervalo de confianza).
Y, ¿cómo se realiza la estimación del intervalo de confianza exactamente? Pues bien, para realizar la
estimación llevamos a cabo varios pasos:
1. Aceptación del supuesto previo de que la distribución de la variable a partir de la que quiero
realizar la estimación es similar a la distribución normal Z(, ).
2. Establecimiento del nivel de error y de confianza asumidos en la estimación.
3. Estimación del parámetro a partir de la distribución muestral de la media de la variable, bajo
el supuesto previo de que es normal.
1. Supuesto previo de normalidad de la variable observada
La aceptación de este supuesto previo se puede llevar a cabo mediante la aplicación de varias
técnicas estadísticas, que nos van a dar una seguridad suficiente como para aceptar que la
distribución de la variable y, por ende, de la distribución muestral de la media, es normal Z(, ). En
el caso más habitual de que la varianza de la variable estudiada en la población de referencia sea
desconocida, la distribución empleada para la estimación será la T, y la media y desviación típica de
la distribución serán = y =
.
Las técnicas que se emplean de modo más habitual son las siguientes:
Exploración gráfica de la variable original obtenida en la muestra. Se puede obtener el
histograma y/o el diagrama de cajas de la variable y comprobar de manera visual si la
distribución es simétrica y si el apuntamiento (curtosis) es muy elevado o muy poco.
Mientras que su empleo puede bastar para asumir la falta de normalidad de una variable
cuando tenemos distribuciones claramente asimétricas, cuando parece que la distribución es
simétrica y con curtosis mesocúrtica esta técnica suele acompañarse de otro análisis
numérico que confirme la normalidad de la variable o variables.
Análisis de los valores de asimetría y curtosis de la variable o variables. Como ya se ha
estudiado el curso pasado, la distribución normal posee un valor de asimetría=0 y un valor
de curtosis=0, es decir, es una distribución simétrica y con curtosis mesocúrtica. Así, se
podrían analizar los valores de asimetría y curtosis de las variables directamente para
comprobar si éstos son o no son cercanos al 0, como prueba confirmatoria de la exploración
visual llevada a cabo previamente. Si con este análisis aún tenemos dudas sobre la
normalidad de las variables, podemos aplicar alguna prueba concreta o contraste de
hipótesis, técnica señalada a continuación.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
17
El contraste de hipótesis comúmente empleado para comprobar la hipótesis de normalidad
de una variable es la prueba de Kolmogorov-Smirnov. Esta prueba simplemente plantea la
hipótesis nula de que la distribución de la variable es normal, hipótesis que se rechaza o no
se rechaza. Esta prueba se estudiará en los siguientes temas.
2. Establecimiento del nivel de error y de confianza asumidos
El nivel de error asumido generalmente se denomina nivel o nivel de significación, y en Ciencias
Sociales se suele emplear de manera generalizada un 5% de error, aunque en ocasiones en las que
interesa mantener errores más pequeños a la hora de plantear las estimaciones e hipótesis se
emplea el 1% de error. Un término íntimamente relacionado con el nivel o nivel de significación es
el nivel de confianza. El nivel de confianza es igual al valor inverso del nivel de significación. Así, por
ejemplo, si establecemos un nivel de significación del 5%, el nivel de confianza será del 95% (100%-
5%). Por otro lado, si el nivel a es del 1%, el nivel de confianza será del 99%.
Como ya se ha indicado previamente, si el nivel de significación o de error es del 5%, el intervalo de
confianza de la estimación de un parámetro será más pequeño que si el nivel de error asumido para
la estimación de ese mismo parámetro es del 1%. Recordemos que esto es así porque, si quiero tener
una mayor seguridad en que no me estoy equivocando en mi estimación (si quiero asumir un error
menor en mi estimación), necesariamente deberé incluir un rango superior, un intervalo más grande,
de puntuaciones en las que posiblemente se encuentre el parámetro poblacional (normalmente de la
media). Por lo tanto, si decido asumir un error muy pequeño, es muy probable que el intervalo
resultante en la estimación del parámetro sea demasiado amplio, y que no me aporte por tanto
demasiada información. Por otro lado, si asumo un error muy grande, mi estimación estará dada en
un intervalo muy pequeño, por lo que mientras que voy a tener una información más clara también
va a ser mucho más probable que mi estimación esté equivocada. El consenso científico más común
acerca del nivel de error, como hemos señalado, es del 5%, y si no se indica lo contrario, ese será el
nivel de significación empleado en adelante.
3. Estimación del parámetro deseado
Una vez tomadas las decisiones y asunciones previas, llega el momento de calcular el intervalo de
confianza del parámetro. En el caso (más habitual) de que el parámetro a estimar sea la media,
partiremos, como ya hemos señalado, de la distribución muestral de la media para llevar a cabo la
estimación, considerando que la forma de esta distribución es como la distribución normal teórica ya
estudiada.
Imaginemos que hemos obtenido una muestra de tamaño n y queremos estimar el intervalo del
parámetro media en una variable. El objetivo ahora es calcular un intervalo a partir de la media de
esa variable que incluya la mayor cantidad posible de muestras que hubieran podido extraerse de la
población inicial (cada una de ellas con una puntuación media que puede ser distinta), hasta llegar al
error máximo definido en el paso 2. Por eso debemos volver a la distribución muestral de la media
para calcular esto. Entendemos en primer lugar que la distribución muestral de la media de nuestra
variable a partir de la que queremos estimar el parámetro de la media es normal Z(, ). Como
hemos visto antes, a partir de la distribución muestral de la media de una variable, podemos calcular
en qué porcentaje de todas las muestras posibles su media se encuentra dentro de un intervalo dado
(ver ejemplo 2 página 12). O dicho de otro modo, podemos calcular un intervalo alrededor del punto

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
18
central de la distribución muestral de la media que incluya un porcentaje determinado de todas las
muestras posibles de tamaño n que se podrían obtener a partir de la población de referencia.
En la mayor parte de los casos, en los que es imposible obtener la distribución muestral de la media
empírica porque no se tiene información sobre todos los sujetos de la población, si se cumple el
supuesto de normalidad de la variable, se entiende que la distribución de la media es normal y se
genera el intervalo de confianza alrededor de la media de la variable (estimación puntual de la media
poblacional) a partir de esta distribución normal (Z o T, en función de si se conoce o desconoce la
varianza poblacional). Aquí, como se puede ver en la figura 6, se puede generar un intervalo
alrededor de la media (por definición, la media de la distribución muestral de la media se entiende
que es igual a la media poblacional, que se estima puntualmente a partir de la media muestral) que
incluya un porcentaje concreto de todas las muestras posibles. Este porcentaje debe coincidir
exactamente con el nivel de confianza asumido en el paso anterior.
Figura 6. Distribución muestral de la media normal (Fuente: adaptado de www.sac.org.ar)
Por definición, en una distribución normal Z(0, ), exactamente el 95% de los sujetos de la
distribución está entre ±1.96*. Por tanto, si la distribución se estandariza a una Z(0, 1), el 95% de los
sujetos y, por ende, el 95% de las todas las muestras posibles en una distribución muestral de la
media normal, se encontrará en el intervalo (-1.96, 1.96). Así, si asumo la normalidad de la variable
original y un error del 5%, tendré un 95% de confianza si afirmo que el intervalo del parámetro media
para una =0 y Sx=1 se encontrará entre -1.96 y 1.96. Si se mantiene todo igual excepto el nivel de
error, que pasa del 5% al 1%, podría afirmar con un 99% de confianza que la media poblacional se
encuentra en el intervalo (-2.58, 2.58). Claro, siempre puedo haber elegido por pura mala suerte o
por errores/problemas en el muestreo una muestra tan extrema que esté equivocándome en la
estimación, este es el error asumido.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
19
Ocurre, no obstante, que las variables que obtenemos en nuestros estudios no tienen =0 y Sx=1,
sino puntuaciones totalmente diferentes. En este caso, simplemente aplicando las propiedades de la
media y de la varianza, se puede estimar el intervalo del parámetro ajustado a los valores exactos de
la media y la desviación típica de la variable original. La fórmula general para el cálculo de la amplitud
del intervalo de confianza si se conoce la varianza poblacional es la siguiente:
Donde 1-/2 se refiere al percentil correspondiente a la puntuación Z que hay que seleccionar,
siendo el nivel de error asumido; y el ET se refiere al error típico, un valor obtenido directamente a
partir de la varianza de la variable, en este caso:
En el caso de desconocer la varianza poblacional, cuestión que ocurre en la práctica totalidad de los
casos, no podemos emplear la distribución Z, sino que tenemos que recurrir a la T, y por eso cambia
mínimamente la fórmula:
Donde n-1 se refiere al número de grados de libertad (igual al tamaño de la muestra menos 1) y al
nivel de error asumido. En este caso, el
Cabe destacar que las fórmulas anteriores son válidas para todos los casos en los que se realiza un
contraste de hipótesis basado en las distribuciones teóricas Z o T. Lo único que cambia en el cálculo
de la fórmula es el cálculo del Error Típico, que es diferente en función del tipo de contraste
realizado.
Nosotros trabajaremos en todo caso con esta segunda fórmula para la estimación de la amplitud del
intervalo de las medias poblacionales, ya que los ejemplos que veremos en clase consideran
desconocida la varianza poblacional. Así, la fórmula que emplearemos definitivamente para el cálculo
de un intervalo de confianza para la media poblacional será la siguiente:
EJEMPLO 3. Cálculo de un intervalo para la media
Imaginemos que obtenemos una muestra representativa de n=61 maestros de Educación Primaria en
formación en la que medimos mediante una escala el nivel de actitudes hacia el empleo de la Pizarra
Digital Interactiva (PDI) en la docencia. Esta escala tiene un valor máximo posible de 10 puntos y
mínimo de 50, y en la muestra se obtienen los siguientes descriptivos para la variable:
=35.6 Sx=8.3
Tras comprobar que la variable actitudes hacia el empleo de la PDI en la docencia se distribuye
conforme a la distribución normal, se nos pide que calculemos el intervalo de confianza para el
parámetro media (media poblacional) a partir de los datos de la muestra, tanto para el caso de que el
error sea de =5% como que sea de =1%.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
20
Para el caso en el que el error es del 5%, debemos calcular el valor de la T para 60 (n-1) grados de
libertad y un error de 0.025 (por cada lado de la distribución). Si consultamos las tablas de la
distribución teórica T, resulta que el valor para un nivel del 5% y 60 grados de libertad es de
2.0003.
Podemos observar esto mismo de manera visual. Como se muestra en la figura 7, en una distribución
muestral de la media con forma T y 60 grados de libertad, el 95% de las muestras posibles están en el
intervalo (-2.003, 2.003).
Figura 7. Intervalo para un nivel =0.05 en la distribución t60;0.025 (Fuente: elaboración propia)
Así, ya disponemos de toda la información para poder calcular el intervalo del parámetro media:
En conclusión, si establezco una seguridad del 95% en mi estimación, puedo afirmar que la media
poblacional de la variable actitudes hacia el empleo de la PDI en la docencia se encuentra dentro del
intervalo (33.46, 36.74).
Para el caso en el que el error es del 1%, debemos calcular el valor de la T para 60 (n-1) grados de
libertad y un error de 0.005 (por cada lado de la distribución). Si consultamos las tablas de la
distribución teórica T, resulta que el valor para un nivel del 1% y 60 grados de libertad es de
2.6603, como se puede observar en la figura 8.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
21
Figura 8. Intervalo para un nivel =0.01 en la distribución t60;0.025 (Fuente: elaboración propia)
Así, ya disponemos de toda la información para poder calcular el intervalo del parámetro media:
Nótese que la amplitud del intervalo, en este caso, es mayor que en el anterior, porque estamos
asumiendo un error menor, es decir, que tenemos una confianza mayor (del 99% en este caso) sobre
la estimación realizada.
CONTRASTE DE HIPÓTESIS
Todo este artefacto matemático tiene mucho más potencial que la simple estimación del valor o
valores entre los que con mucha seguridad se va a encontrar el estadístico en la población. Las bases
teóricas y matemáticas de la estimación de parámetros se emplean de manera generalizada para
tratar de contrastar hipótesis de todo tipo:
Hipótesis sobre un solo estadístico en un grupo o una muestra: Comprobar si es plausible o si
se puede aceptar que una determinada población posee una puntuación media ()
determinada en una variable estudiada a partir de una muestra. Esto nos puede servir para
determinar el comportamiento de una población, en comparación con algún fundamento
teórico (por ejemplo, si planteo la hipótesis teórica de que la población de Finlandia posee un
cociente intelectual superior a 100 puntos, valor medio en toda la población general, puedo
obtener una muestra representativa de ciudadanos finlandeses a la que mido el cociente
intelectual con algún instrumento y estimar posteriormente el intervalo de la media en esa
población. Si toda la amplitud o rango del intervalo calculado está por encima de 100, o lo

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
22
que es lo mismo, si el límite inferior del intervalo obtenido es superior a 100 puntos, entonces
puedo aceptar la hipótesis planteada. En caso contrario, no puedo aceptar la hipótesis).
Hipótesis sobre un estadístico en dos o más grupos o muestras: En muchas ocasiones nos
ocurre que queremos conocer si se puede concluir que una población posee una puntuación
media más elevada que otro en alguna variable. Esto nos puede servir, por ejemplo, para
determinar si una población tiene un grado de conocimientos superior a otra, si posee unas
actitudes más elevadas que otra, etc. (por ejemplo, puedo querer comparar, a partir de la
muestra obtenida en las pruebas PISA, el rendimiento en comprensión lectora de las
poblaciones de estudiantes de algunas comunidades autónomas de España. Para ello,
estimaré el intervalo para la media en cada una de las poblaciones por separado y compararé
dichos intervalos en cada pareja. Si los dos intervalos obtenidos en dos de las comunidades no
se solapan en ningún momento, es decir, si los rangos de ambos intervalos no tienen valores
conjuntos, podré afirmar con el nivel de confianza establecido que existen diferencias
significativas en ambas poblaciones. En el caso contrario de que exista alguna parte conjunta
en la amplitud o rango de ambos intervalos, no podré afirmar que existan diferencias
significativas en cuanto a la media de ambas poblaciones).
Hipótesis sobre dos o más estadísticos en un grupo o muestra: Principalmente en los
estudios de corte experimental en los que existe al menos una medida pretest y una postest,
nos interesa conocer si existen diferencias significativas entre el nivel alcanzado en la
medición de la variable en el pretest y la medición en el postest. Así, determinaremos si una
población ha alcanzado, por ejemplo, aprendizajes significativos (por ejemplo, si he diseñado
un programa para la mejora de la convivencia en centros de Educación Secundaria y quiero
evaluar su eficacia, puedo tomar como medida pretest el número de conductas disruptivas de
la convivencia generadas por la muestra de estudiantes de institutos las semanas previas a la
implementación del programa y como medida postest el número de conductas disruptivas
generadas las semanas posteriores. En este caso, la técnica procede calculando el intervalo
para la media poblacional de la diferencia entre las conductas disruptivas generadas en el
postest y en el pretest (postest-pretest), y comprobando si el valor 0 está incluido en ese
intervalo. En este caso, podré concluir que el programa no genera efecto alguno sobre la
población de estudiantes de educación secundaria en cuanto al número de conductas
disruptivas generadas antes y después del programa. En el caso contrario podré concluir que
el programa genera un efecto significativo en la población de estudiantes de educación
secundaria).
Antes de entrar a estudiar en profundidad el funcionamiento de los contrastes de hipótesis para
resolver problemas, conjeturas o hipótesis como las planteadas encima, es necesario reparar
brevemente en los aspectos o elementos clave que posee todo contraste de hipótesis:
Hipótesis nula (H0): Se refiere a la conjetura que se pone a prueba en el contraste, es decir,
la hipótesis que plantea para su rechazo o no rechazo. La hipótesis nula siempre es la
hipótesis de igualdad.
Hipótesis alternativa (H1): Es la hipótesis opuesta o complementaria a la hipótesis nula. Si se
rechaza la hipótesis nula, entonces la hipótesis alternativa no se puede rechazar (se puede
aceptar como válida). Sin embargo, si no se rechaza la hipótesis nula, entonces deberemos

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
23
rechazar la hipótesis alternativa planteada. En todo caso, la hipótesis alternativa es la
hipótesis de desigualdad.
Región de rechazo (RR): Se refiere al conjunto de valores para los que se rechaza la H0, y por
tanto se acepta como válida la hipótesis alternativa. Al igual que existe una Región de
Rechazo de la hipótesis nula, existe una región de aceptación o no rechazo de la misma, que
denominaremos RA. Por último, el punto o valor exacto que separa la región de rechazo de la
región de aceptación lo denominaremos región crítica (RC).
Nivel de significación o error tipo I (): Ya hemos hablado del error, nivel o nivel de
significación. Se refiere a la probabilidad de rechazar la H0 cuando realmente es verdadera
(normalmente se asume un error del 5%). Se podría llamar algo así como falso positivo.
Hemos dicho que cuando realizamos la estimación de un parámetro, si asumimos un error
del 5%, resulta que puede nos puede haber ocurrido (por mala suerte o errores de muestreo)
que la muestra obtenida sea una muestra con una puntuación media extrema, y que el
intervalo estimado no incluya el valor real del parámetro en la población. Asumiendo ese
nivel de error, la probabilidad de que eso ocurra es del 5%. Cuando realizamos un contraste
de hipótesis nos ocurre lo mismo, podemos haber tenido mala suerte en la obtención de la
muestra y que este problema nos lleve a rechazar hipótesis que en realidad en la población
son ciertas.
Error tipo II (): Al igual que se puede rechazar la H0 cuando realmente esta hipótesis es
verdadera, también nos puede ocurrir lo contrario, que no rechacemos la H0 cuando en la
realidad esta hipótesis es falsa. A este error, que en realidad es un falso negativo, se le llama
error tipo II, o , y es mucho más difícil de controlar que el error tipo I en un contraste de
hipótesis.
En realidad, se puede pensar el procedimiento del contraste de hipótesis como un juicio. Pensemos
en que somos miembros de un tribunal que debe juzgar y decidir sobre si un acusado es condenado o
queda en libertad. Evidentemente, al igual que en un contraste de hipótesis, deberemos tomar la
decisión a partir de las pruebas o evidencias que se tengan disponibles. Antes de iniciar el juicio y
durante el mismo se mantiene la propia presunción de inocencia del acusado (hipótesis nula, el
acusado es inocente) hasta que las evidencias no demuestren claramente lo contrario (hipótesis
alternativa, de culpabilidad). Podríamos resumir todas las posibles conclusiones del juicio en una
simple tabla.
EN REALIDAD
Es inocente Es culpable
SENTENCIA
Queda en libertad
El acusado es inocente y queda en libertad
ACEPTO H0
El acusado es culpable y queda en libertad
ERROR II (Ac. H0)
Es condenado
El acusado es inocente y es condenado
ERROR I (Rech. H0)
El acusado es culpable y es condenado
RECHAZO H0

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
24
En estos 4 escenarios existen dos situaciones acertadas y otras dos erróneas. Sin embargo, el lector
estará de acuerdo con que no es lo mismo el error de condenar a un inocente que el error de que un
culpable quede en libertad. Al igual que ocurre con un juicio, lo más importante en un contraste de
hipótesis es evitar el error tipo I, ya que se considera más grave que el error tipo II. No obstante, si
nos ponemos muy estrictos (asumimos un error muy pequeño) para evitar el error tipo I, es decir,
para evitar condenar a un inocente, va a ser más fácil acabar cayendo en el error tipo II, dejar en
libertad a una persona que realmente es culpable. Si un tribunal o juez nunca condena a nadie,
evidentemente no caerá en el error tipo I, pero no pensaremos por ello que está realizando su labor
encomendada correctamente. Al respecto, se ha convenido en la comunidad científica que el mejor
equilibrio entre el error tipo I y el II está en considerar como tolerable un erro tipo I del 5% o del 1%,
según el caso, como hemos visto hasta ahora.
“En realidad este procedimiento corresponde al espíritu de un juicio en el que la presunción de
inocencia (hipótesis nula) se mantiene mientras no se demuestre claramente lo contrario
(hipótesis alternativa). El juez ha de tomar la decisión a partir de las pruebas que se presenten.
En estadística las pruebas son los datos, los resultados del experimento, las observaciones o las
respuestas de una encuesta. La pregunta que nos hacemos es: ¿desmienten los hechos
claramente la hipótesis nula? […] Resulta evidente que si nos ponemos muy estrictos en el
control del Error I podríamos caer fácilmente en el Error II lo que tampoco es muy deseable. [...]
Un equilibrio entre las probabilidades de ambos errores es muy deseable […]. No es más que un
reflejo de la vida misma, en la que tomamos las decisiones asumiendo siempre un cierto riesgo”
(López Fidalgo, 2015, p.86-88).
Partiendo de estas ideas, podemos plantear el esquema general o los pasos que deben ser seguidos
en el contraste de hipótesis:
0. Planteamiento inicial del problema: Hipótesis o cuestiones de investigación.
1. Determinación de la normalidad de la variable o variables implicadas en el análisis y del nivel
de error asumido.
2. Planteamiento de la hipótesis nula (H0) y la hipótesis alternativa (H1).
3. Cálculo del intervalo o intervalos de los parámetros intervinientes en las hipótesis.
4. Toma de una decisión con respecto a las hipótesis planteadas
Normalmente, las cuestiones o hipótesis iniciales de la investigación, vienen formuladas
previamente, ya que es lo que nos suele llevar a realizar todo el proceso investigador. Veamos a
continuación algunos ejemplos de contrastes de hipótesis para los 3 casos generales abordados al
inicio de este apartado.
EJEMPLO 4. Contraste de hipótesis para una media en un grupo
Un investigador plantea que la clave de que los estudiantes de Educación Secundaria de Finlandia
alcancen rendimientos tan altos en relación a estudiantes de otros países de la OCDE tiene que ver
con que el cociente intelectual medio de los jóvenes Finlandeses es superior al del resto de estudiantes
de estos países. Por los estudios demográficos previos que existen al respecto, se sabe que el cociente
intelectual medio de los jóvenes de estos países es de 100 puntos (no se posee información acerca de

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
25
la varianza en la población). Tras obtener una muestra representativa de n=105 estudiantes de
Finlandia, resulta que poseen un CI medio de =102.2 y una varianza de Sx2=164. La exploración
previa de datos muestra que la distribución de la variable CI es normal, y el investigador decide
asumir un nivel de significación o error del 5%.
Así, podemos plantear como hipótesis de investigación (paso 0):
El cociente intelectual alcanzado por la población estudiantes finlandeses de Educación Secundaria
será más elevado que el cociente intelectual general del resto de estudiantes de Educación
Secundaria de países miembros de la OCDE
En cuanto al paso 1, ya hemos señalado que la variable CI en la muestra de estudiantes finlandeses
obtenida se distribuye normalmente y que el nivel de confianza marcado es del 95%.
En este ejemplo deberemos calcular el intervalo del parámetro poblacional media en la población de
estudiantes finlandeses para comprobar si es plausible considerar que el CI medio de esta muestra es
de 100 puntos (H0) o no (H1). En este caso, como el valor del CI medio obtenido en la muestra es
superior a 100 puntos, en caso de rechazar la hipótesis nula podremos concluir que los estudiantes
finlandeses tienen un CI superior a 100 puntos. De este modo, las hipótesis estadísticas planteadas
son, por tanto, las siguientes (paso 2):
H0: finl=100
H1: finl≠100
Nótese que la hipótesis nula es la de igualdad y la alternativa la de desigualdad, y que lo que plantea
es, o bien que el CI medio poblacional de los estudiantes finlandeses se puede considerar de 100
puntos, o que no puede realizarse esta consideración.
Una vez planteadas las hipótesis estadísticas, ya estamos en disposición de generar el intervalo de
confianza para la media de la muestra, apoyándonos en la fórmula descrita en la página 18. En este
caso, dado que no se posee información sobre la varianza poblacional, sólo sabemos la muestral, la
distribución a emplear es la distribución t con 104 (n-1) grados de libertad. Cabe destacar que los
valores disponibles son los del tamaño de la muestra, la media y la varianza. La varianza debe ser
previamente transformada en el valor de la desviación típica, ya que este es el valor necesario para
realizar los cálculos.
Recordemos que la desviación típica es la raíz cuadrada de la varianza: Sx2=164 Sx=12.81.
Se observa que el intervalo (99.71, 104.69), aunque por unas pocas décimas, incluye el valor 100
dentro de los valores poblacionales de la media plausibles, por lo que no se puede rechazar la
hipótesis nula. Así, la decisión tomada por el investigador (paso 4), o la conclusión final, es que los
estudiantes de educación secundaria finlandeses no poseen un cociente intelectual diferente (ni por

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
26
supuesto superior) al del resto de estudiantes de este nivel educativo de países pertenecientes a la
OCDE.
Podemos ver este intervalo mejor en una imagen (figura 9). Resulta que, como hemos entendido que
la distribución muestral de la media en la variable CI tiene una forma normal, y que la estimación
puntual de la m coincide con el valor de la media muestral obtenido, podemos calcular el intervalo
de puntuaciones entre el que se encuentran, en esta distribución muestral, el 95% de todas las
muestras posibles obtenidas a partir de la población de estudiantes de educación secundaria en
Finlandia:
Figura 8. Intervalo para un nivel =0.05. EJEMPLO 4 (Fuente: elaboración propia)
Se puede observar cómo ahora tenemos en este gráfico una región de aceptación (si el valor
hipotético 100 entra en esta región se acepta la hipótesis nula) y una región de rechazo (sin el valor
hipotético 100 se encuentra fuera del intervalo, esto es, dentro de la región de rechazo, se rechaza la
hipótesis nula), que nos aportan una indicación precisa acerca de la decisión a tomar.
EJEMPLO 5. Contraste de hipótesis para comparar la media de una variable en varios grupos
Un grupo de investigadores de la Universidad de Salamanca tiene indicios de que existen diferencias
significativas en cuanto al nivel de comprensión lectora de los estudiantes de Educación Secundaria
de algunas comunidades autónomas en España. Por eso, quiere comparar, a partir de la muestra
obtenida en las pruebas PISA 2012, el rendimiento en comprensión lectora de las poblaciones de
estudiantes de Madrid, Andalucía y Castilla y León. Para ello, extrae los resultados obtenidos por los
estudiantes de estas 3 comunidades autónomas, comprobando previamente que se cumple el
supuesto previo de normalidad en cada una de las 3 poblaciones (se desea trabajar con un 5% de
error):

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
27
nMad= 536 =87.9 32.3
nAnd= 883 =83.6 15.2
nCyL= 345 =90.1 19.8
Podemos plantear como hipótesis de investigación (paso 0):
Los niveles de comprensión lectora de los estudiantes de último curso de educación secundaria en
España serán diferentes en función de la comunidad autónoma en la que cursen sus estudios
Ya sabemos que las distribuciones son normales y que el nivel de confianza deseado en este caso es
del 99% (paso 1), así que directamente vamos a plantear las hipótesis estadísticas. En este caso no
planteo que si los valores medios en la muestra se ajustan o no a un valor teórico exacto, sino que
me estoy planteando si existen diferencias entre varios grupos, por eso ahora no debo estimar
solamente el intervalo de un parámetro, sino de 3. Por lo tanto, estos 3 parámetros deben estar
presentes en la hipótesis, y mantenerse el criterio general de que la hipótesis nula es de igualdad y la
alternativa de desigualdad (paso 2):
H0: Mad =And= CyL
H1: Mad ≠And≠ CyL
Vemos que simplemente planteo en un caso que las medias entre los grupos son iguales y en el otro
que no son iguales. Podría generar a partir de esta hipótesis general algunas hipótesis subordinadas,
una por cada pareja de comunidades autónomas (Madrid con Andalucía; Madrid con Castilla y León;
Andalucía con Castilla y León), pero esta formulación puede ser suficiente en este caso (lo
importante en el planteamiento de las hipótesis es que se entienda lo que se contrasta, en este caso
vamos a contrastar la igualdad o desigualdad de las medias poblacionales de 3 poblaciones distintas).
Ahora, pues, debemos calcular los parámetros poblacionales en los 3 grupos a partir de una T con n-1
grados de libertad en todo caso (paso 3). A pesar de que existe un procedimiento estadístico más
ajustado para el contraste de estas diferencias entre grupos (que es el que emplea el software SPSS),
el procedimiento estudiado puede ser considerado como válido:
En este caso, vemos que la media poblacional con un intervalo de puntuaciones más bajo es el de los
estudiantes de Andalucía, pero que su intervalo se solapa con el de los estudiantes de Madrid. Por
otro lado, el intervalo de los estudiantes de Castilla y León, que poseen los valores más elevados, se
solapa con el de los de Madrid, pero con el de los de Andalucía. Veamos estos resultados incluyendo
las 3 distribuciones muestrales de la media en un hipotético eje x conjunto en la figura 9:

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
28
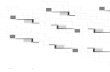
Figura 9. Intervalos distribuciones muestrales EJEMPLO 5 (Fuente: elaboración propia)
Claramente se muestra cómo, mientras que existe un intervalo común en las estimaciones
poblacionales de Andalucía y Madrid y de Madrid y Castilla y León, los intervalos entre Andalucía y
Castilla y León están separados. Entonces, puedo acabar tomando las siguientes decisiones a partir
de este contraste (paso 4):
- A nivel general, puedo rechazar H0, ya que los niveles de comprensión lectora de los
estudiantes en España son diferentes en función de la comunidad autónoma, al menos en
algún caso. Así, existen diferencias significativas en función de la comunidad autónoma de
procedencia en cuanto al nivel de comprensión lectora de los estudiantes españoles.
- A nivel específico, puedo establecer 3 conclusiones:
o No rechazo la H0 en el caso de las diferencias entre los estudiantes de Andalucía y de
Madrid. No se poseen evidencias suficientes para afirmar que las poblaciones de
estudiantes de estas dos comunidades autónomas posean unos rendimientos en
comprensión lectora diferentes (recordemos que esto es un juicio, y que no
debemos juzgar al acusado como culpable hasta que no tengamos evidencias
irrefutables, en este caso parece que los estudiantes de la muestra de Madrid tienen
un rendimiento ligeramente superior, pero con el nivel de error asumido no
podemos afirmar que estas diferencias puedan ser reales en la población). Así, no
existen diferencias significativas entre ambos grupos en cuanto a su nivel de
comprensión lectora.
o No rechazo la H0 en el caso de las diferencias entre los estudiantes de Madrid y
Castilla y León por las mismas circunstancias. Además, en este caso, las puntuaciones
son mucho más cercanas entre ambos grupos, y el área común de los intervalos
estimados es mucho más grande, por lo que tenemos mucha más seguridad en
nuestra afirmación de no rechazar la H0. Por tanto, no existen diferencias
significativas entre ambos grupos.
o Rechazo la H0 en el caso de las diferencias entre los estudiantes de Andalucía y
Castilla y León. Parece que la población de estudiantes de Castilla y León posee un
rendimiento en comprensión lectora superior a la población de estudiantes de
Andalucía, alcanzándose diferencias significativas entre ambos grupos.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
29
EJEMPLO 6. Contraste de hipótesis para comparar varias variables en un grupo
Un equipo de investigadores quiere comprobar la eficacia de un programa integral para la mejora de
la convivencia en el aula de Educación Primaria. Para ello, tras medir el número de conductas
disruptivas de cada uno de los 15 estudiantes de 6º curso participantes en el programa durante el
mes anterior a la aplicación del programa (pretest), procede a la implementación de las actividades
del mismo, con una duración de tres meses. Finalmente, durante el mes posterior a la aplicación del
programa, se vuelve a registrar la cantidad de conductas disruptivas de cada estudiante,
obteniéndose los siguientes resultados:
Pretest Postest
Estudiante 1 6 3
Estudiante 2 0 1
Estudiante 3 2 3
Estudiante 4 11 2
Estudiante 5 15 10
Estudiante 6 27 12
Estudiante 7 4 2
Estudiante 8 7 1
Estudiante 9 8 0
Estudiante 10 20 3
Estudiante 11 4 2
Estudiante 12 6 5
Estudiante 13 8 1
Estudiante 14 7 3
Estudiante 15 2 0
Para tomar una mayor seguridad de los resultados obtenidos, se desea trabajar con un nivel del
1%.
En este caso, debemos trabajar con los datos de la diferencia entre el postest y el pretest, así que el
primer paso es generar una nueva variable que resulte de esta resta (diferencia=postest-pretest).
Pretest Postest Diferencia
Estudiante 1 6 3 3
Estudiante 2 0 1 -1
Estudiante 3 2 2 0
Estudiante 4 11 2 9
Estudiante 5 15 10 5
Estudiante 6 27 12 15
Estudiante 7 4 2 2
Estudiante 8 7 1 6
Estudiante 9 8 0 8
Estudiante 10 20 3 17
Estudiante 11 4 2 2
Estudiante 12 6 5 1
Estudiante 13 8 1 7
Estudiante 14 7 3 4
Estudiante 15 2 0 2

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
30
8.47 3.13 5.33
Sx 7.26 3.46 5.21
Ya vemos, en primer lugar, cómo, mientras que inicialmente la cantidad media de conductas
disruptivas de la muestra de estudiantes fue de 8.47 puntos, tras la aplicación del programa se
reduce a 3.13 conductas disruptivas de media por estudiante. Así, se han reducido de media 5.33
conductas disruptivas por estudiante. Ahora la duda es si estas diferencias son suficientes como para
poder considerarse significativas. Aunque los programas estadísticos emplean un cálculo estadístico
específico más ajustado para realizar esta estimación, realizaremos los cálculos a partir de la fórmula
estudiada inicialmente, que realiza un ajuste razonablemente similar.
La hipótesis de investigación planteada en este caso podría ser la siguiente (paso 0):
El número de conductas disruptivas de la convivencia escolar de estudiantes de 6º de educación
primaria se reducirá tras la aplicación de un programa de mejora de la convivencia escolar en el aula.
En cuanto al paso 1, ya se ha señalado que se posee un nivel de significación del 1%, y tras el estudio
de la distribución de la variable, resulta que se acepta la normalidad de la misma.
Así, se pueden generar las siguientes hipótesis estadísticas con respecto a los grupos (paso 2):
H0: pretest =postest postest -pretest = 0
H1: pretest ≠postest postest -pretest ≠ 0
Vamos a calcular ahora el intervalo de confianza de la variable diferencia (paso 3). Dado que esta
variable nos muestra la diferencia de conductas disruptivas entre el postest y el pretest, en este
orden, en este caso nos interesa que exista un intervalo con un rango de puntuaciones negativo
(indicando que en el postest existen menos conductas disruptivas que en el pretest) y que no incluya
el valor 0 como plausible (que nos indicaría que se podría aceptar que en la población no existe
ningún tipo de reducción de las conductas disruptivas). Recordemos que en este caso trabajamos con
una distribución T con 14 grados de libertad y un nivel /2 de 0.005 (existe un error de 0.01, el 1%):
En conclusión (paso 4), resulta que tengo evidencias suficientes para rechazar la H0, ya que resulta
que postest-pretest≠0 para un nivel de confianza del 99%. Así, el programa de mejora de la convivencia
es efectivo, ya que parece que ejerce un efecto significativo sobre la reducción de conductas
disruptivas en el aula.
CONTRASTES DE HIPÓTESIS CON SOFTWARE INFORMÁTICO (SPSS)
Aunque en realidad cuando realizamos un contraste de hipótesis estamos empleando todo este
artefacto estadístico/matemático, el software estadístico empleado para el análisis de datos
descriptivo e inferencial de manera más generalizada, SPSS, no nos suele aportar la información de
los contrastes de hipótesis de este modo, incorporando las hipótesis estadísticas, los intervalos de
confianza para los parámetros que se deben estimar y la decisión tomada. En su lugar, simplemente
nos aporta información en todo contraste de hipótesis acerca del valor de la significación exacta de
ese contraste (SPSS llama a este valor ‘Sig.’, aunque también lo podemos denominar como p-valor).

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
31
¿Qué quiere decir esto exactamente? Pues el valor devuelto por el programa informático es una
probabilidad, es decir, un valor entre 0 y 1. Lo que nos está indicando exactamente en cada uno de
los 3 casos estudiados es lo siguiente:
Contraste de hipótesis para una media en un grupo: El valor de la significación (sig.)
devuelto por el programa estadístico en este caso nos indica la probabilidad que existe de
que la muestra a partir de la que se ha generado la estimación provenga de una población
con la media con el valor señalado en la hipótesis nula (en el ejemplo 3, =100).
Contraste de hipótesis para comparar la media de una variable en varios grupos: En este
caso, el valor de la significación devuelto por SPSS nos indica la probabilidad exacta de que
las muestras que se comparan provengan de la misma población o de poblaciones con la
misma media (en el ejemplo 4, Mad =And= CyL). En el caso de que el contraste sea no
paramétrico, la comparación se hace entre las medianas de los grupos (MdnMad = Mdn And =
MdnCyL)
Contraste de hipótesis para comparar varias variables en un grupo: Lo que indica este valor
Sig. o p-valor es la probabilidad de que la muestra obtenida en el estudio provenga de una
población en la que la diferencia entre las puntuaciones de las variables es 0 (En el caso del
ejemplo 5, las variables pretest y postest, o sea, postest-pretest=0). En el caso de que el
contraste sea no paramétrico, la comparación se hace entre las medianas de las variables
(Mdnpret = Mdnpost).
Nótese que en realidad, este valor de la significación o p-valor se está refiriendo en todos los casos a
la probabilidad de que H0 sea cierta o, dicho en términos del ejemplo del juicio, la probabilidad de
que el acusado sea inocente (si la probabilidad de que sea inocente no es suficientemente baja, tan
baja como el nivel de significación planteado inicialmente, no deberíamos acusarle). Así, la
interpretación de este nivel Sig. o p-valor siempre es la misma, en función del nivel de error o que
hayamos prefijado:
En el caso de que p-valor < , entonces tendré evidencias suficientes como para rechazar la
H0, ya que la probabilidad de cometer un error tipo I es menor al nivel de error establecido
previamente (normalmente del 5%). En este caso rechazaré la hipótesis nula y podré afirmar
que existen diferencias significativas bien entre varios grupos, o entre varias medidas en un
mismo grupo, o entre la media de un grupo y la de una población hipotética.
En el caso de que p-valor ≥ , entonces no tendré evidencias suficientes como para rechazar
la H0, ya que la probabilidad de cometer un error tipo I es menor al nivel de error establecido
previamente. En este caso no rechazaré la hipótesis nula y no podré afirmar que existan
diferencias significativas entre las puntuaciones en una variable de varias muestras, o entre
la puntuación en varias variables en una muestra, o entre la puntuación de una muestra y la
de una población hipotética.
A lo largo de los siguientes temas abordaremos desde un punto de vista práctico una por una las
técnicas estadísticas inferenciales más habituales, por lo que profundizaremos en las implicaciones
de este p-valor.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
32
COMPROBACIÓN DEL SUPUESTO DE NORMALIDAD
En todo caso, para poder proceder a la estimación de parámetros conforme a las técnicas
paramétricas estudiadas en el apartado previo, es necesario comprobar previamente la normalidad
de la variable o variables intervinientes en el análisis. Para ello, se planteaban 3 grupos de técnicas
complementarias entre sí, que vamos a desglosar en este capítulo.
1. EXPLORACIÓN INICIAL GRÁFICA
El objetivo principal de la exploración gráfica es la comprobación inicial de si la forma de la
distribución se podría ajustar a una distribución normal, esto es, de forma simétrica y con un
apuntamiento ni exageradamente alto ni bajo.
Para ello, se pueden emplear varios gráficos, como son, principalmente, el histograma y el diagrama
de cajas.
En primer lugar, el histograma, como ya hemos estudiado, presenta la información en forma de
diagrama de barras en el que no existe separación entre cada una de las barras del gráfico al
considerarse que la variable representada es una variable continua o de intervalo. Así, la anchura de
cada una de las barras presenta un intervalo de puntuaciones concreto de la variable, y la altura la
proporción o frecuencia de sujetos que han obtenido una puntuación comprendida en ese intervalo.
Imaginemos que hemos evaluado el rendimiento en matemáticas (entre 0 y 10 puntos) en una
muestra de 260 estudiantes de 4º de educación secundaria, habiendo obtenido una puntuación
mínima de 3.85 puntos y máxima de 10). Podríamos calcular el histograma mostrado en el gráfico 1.
Este gráfico se obtiene en SPSS en menú gráficos generador de gráficos histograma.
Gráfico 1. Histograma rendimiento en matemáticas, intervalos de 0.4 puntos
En este primer histograma se observa cómo se presentan los resultados con intervalos de 0.4 puntos,
empezando el intervalo en la puntuación más baja hasta el primer corte [3.85, 4.25), el segundo
desde 4.25 hasta 4.65, y así sucesivamente.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
33
El tamaño del intervalo podemos prefijarlo nosotros como nos venga en gana, por ejemplo, el gráfico
2 muestra el histograma de la misma distribución con los intervalos de 1 punto de tamaño y no de
0.4 puntos.
Gráfico 2. Histograma rendimiento en matemáticas, intervalos de 1 punto
En este ejemplo el tamaño del intervalo elegido nos permite observar la distribución general de la
variable de manera un poco más clara.
Podemos también elegir, como se puede observar en el gráfico 3, como gráfico para observar la
distribución el diagrama de cajas, que nos muestra esta distribución pero en lugar de en un eje
horizontal, en un eje vertical. En SPSS este gráfico se obtiene en menú gráficos generador de
gráficos diagramas de caja.
Gráfico 3. Diagrama de cajas rendimiento en matemáticas.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
34
En este caso recordemos que el diagrama de cajas representa los 3 cuartiles (Q1 o P25, Q2 o P50 o
mediana y Q3 o P75).
En el ejemplo, tanto en el gráfico de cajas, como en el histograma, se observa cómo de manera muy
ligera la distribución posee una asimetría negativa, esto es, la cola más larga de la distribución desde
la posición más elevada o la posición de la mediana se encuentra en las puntuaciones bajas. O lo que
es lo mismo, hay una mayor acumulación de sujetos en las puntuaciones altas que en las bajas de la
variable.
2. ESTUDIO DE LOS ÍNDICES DE ASIMETRÍA Y CURTOSIS
El análisis gráfico inicial simplemente nos aporta información exploratoria acerca de la distribución
de la variable en la que ya veamos algunas cuestiones de falta de normalidad más o menos claras.
Mientras que la observación gráfica de una clara falta de normalidad puede ser suficiente para
considerar que una variable no se distribuye normalmente, no se puede tomar la decisión de que una
variable es normal simplemente con el análisis gráfico. Es necesario realizar un análisis posterior al
menos de los índices de asimetría y curtosis.
Recordemos que una distribución de datos se considera normal cuando la asimetría y la curtosis
tienen exactamente el valor 0. En la práctica esto no nos va a ocurrir nunca, pero sí es importante
que los valores de asimetría y curtosis estén cercanos a esta puntuación central.
Esta información la pedimos en SPSS en menú analizar Estadísticos descriptivos Descriptivos,
obeniendo la siguiente tabla:
Estadísticos descriptivos
N Asimetría Curtosis
Estadístico Estadístico Error típico Estadístico Error típico
REND_MATEM 260 -,342 ,151 -,459 ,301
N válido (según lista) 260
A partir de la tabla anterior, podríamos extraer la siguiente información esencial:
ASIMETRÍA CURTOSIS
RENDIMIENTO MATEMÁTICAS -0.342 -0.459
En este caso, a pesar de que los valores muestran que la variable posee una ligera asimetría negativa
y curtosis platicúrtica, los valores son cercanos a 0, por lo que se podría aceptar la hipótesis de
normalidad de la variable. No obstante, dado que aún existen algunas dudas, puede ser preferible
establecer los contrastes de normalidad que nos saquen de dudas al respecto.
3. CONTRASTE DE HIPÓTESIS ACERCA DE LA NORMALIDAD DE LA VARIABLE
Como ya hemos indicado, existe una prueba básica para el contraste del ajuste a la distribución
normal de una variable, que se llama generalmente prueba o test de Kolmogorov-Smirnov. Esta
prueba realizará un contraste de hipótesis en el que planteará la hipótesis nula de que la variable se
distribuye conforme a una distribución normal o que no lo hace. Por lo tanto, si se obtiene un p-
valor, o Sig., inferior al nivel , o de significación, preestablecido se deberá rechazar la H0, y si este
valor es superior se deberá aceptar la hipótesis de que la distribución de la variable medida proviene
de una distribución normal.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
35
Así, las hipótesis planteadas son:
H0: La distribución de los datos proviene de una distribución normal
H1: La distribución de los datos no proviene de una distribución normal
En menú SPSS analizar pruebas no paramétricas cuadros de diálogo antiguos K-S de una
muestra se obtiene la siguiente tabla:
Prueba de Kolmogorov-Smirnov para una muestra
REND_MATEM
N 260
Parámetros normalesa,b
Media 7,0769
Desviación típica 1,27851
Diferencias más extremas Absoluta ,087
Positiva ,051
Negativa -,087
Z de Kolmogorov-Smirnov 1,403
Sig. asintót. (bilateral) ,039
a. La distribución de contraste es la Normal.
b. Se han calculado a partir de los datos.
La información básica que se debe extraer de esta tabla generalmente para informar del resultado de
la prueba es simplemente la de la Z y la de la Sig.:
Zk-s P-VALOR
RENDIMIENTO MATEMÁTICAS 1.403 0.039
Nótese que el p-valor es de 0.39, es decir, resulta que hay una probabilidad de 0.039 de que la
variable rendimiento en matemáticas obtenida a partir de la muestra provenga de una variable con
distribución normal en la población. Esto quiere decir que el nivel de error tipo I exacto que puedo
cometer si rechazo H0 es del 3.9%. Dependerá, por tanto, la decisión final que yo tome en este
contraste del nivel o de error que yo haya preestablecido (del 5% o del 1%):
Si he establecido un a=0.05 Rechazo H0, la distribución de los datos no proviene de una
distribución normal.
Si a=0.01 No rechazo H0, la distribución de los datos proviene de una distribución normal.
A nivel general, en este caso, en base a los 3 análisis realizados, se podría asumir que la distribución
proviene de una distribución normal, ya que parece que no existen grandes problemas de asimetría y
normalidad y que las gráficas de la distribución parecen ser cercanas a una distribución normal.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
36
DOS MUESTRAS INDEPENDIENTES
Ya hemos comentado que cuando queremos comparar la media de dos grupos en una variable, y se
cumplen las condiciones de normalidad de la variable objeto de estudio, estamos en condiciones de
aplicar un contraste de hipótesis paramétrico, la prueba de t para dos muestras independientes,
basada en el estadístico de contraste t. En este caso, la variable que establece los dos grupos será
una variable cualitativa (normalmente dicotómica) y la variable sobre la que se quieren comparar las
puntuaciones medias será una variable cuantitativa (recordemos que no se puede calcular la media
en variables no cuantitativas). En el caso de que no se cumpla el supuesto de normalidad, o que la
variable sobre la que se quieren comparar las puntuaciones medias no sea cuantitativa, o sea, que
sea ordinal, el contraste a realizar será el contraste no paramétrico de la U de Mann-Whitney.
Así, como en todo proceso de contraste de hipótesis, lo primero que tendremos que hacer será una
exploración descriptiva inicial de las variables y la comprobación del supuesto previo de normalidad.
En este ejemplo, vamos a comparar las puntuaciones obtenidas en el pretest de nuestra base de
datos entre los estudiantes de Castilla y León y de Andalucía
1. EXPLORACIÓN DESCRIPTIVA INICIAL
Parece que la distribución por comunidad autónoma no está repartida de modo muy equilibrado,
tenemos 200 estudiantes en Castilla y León por 60 en Andalucía.
No obstante, esto no es problemático, ya que la técnica estadística ajusta automáticamente estas
diferencias (en caso de que existieran diferencias mucho más marcadas deberíamos plantearnos de
nuevo la aplicación del contraste de hipótesis). Sí que queda patente que tenemos más de 30 sujetos
por grupo, cuestión esencial para poder realizar el contraste con mínimas garantías.
En cuanto a la variable cuantitativa, veamos algunas de sus características para todo el grupo y
separando por comunidad autónoma (en SPSS menú datos Segmentar archivo). Se observa cómo
la puntuación media de la muestra de Castilla y León en el pretest es más alta, y cómo tenemos
200
60
Comunidad autónoma
Castilla y León
Andalucía

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
37
niveles de dispersión similares en ambos grupos, asimetría prácticamente nula y curtosis platicúrtica
moderada de manera generalizada.
Mdn CV As Curt
Castilla y León 37.43 37 7.44 19.88% 0.06 -0.61
Andalucía 34.97 34 6.84 19.56% -0.08 -0.74
Total 36.86 36 7.36 19.97% 0.06 -0.58
2. SUPUESTOS PREVIOS
En este caso sólo será necesario comprobar el supuesto previo de normalidad. Posteriormente,
deberemos comprobar la homocedasticidad (igualdad de varianzas) cuando realicemos la prueba.
En primer lugar, vimos que las distribuciones parecían simétricas y con leve curtosis platicúrtica.
Veremos si este pequeño desajuste con respecto a la curva normal es suficiente para que exista falta
de normalidad. Recordemos que la prueba de dos muestras independientes compara las medias de
las dos distribuciones de los dos grupos (en este caso estudiantes de Castilla y León y de Andalucía),
por lo que deberemos comprobar la normalidad de los dos grupos por separado. Veamos en primer
lugar, por tanto, el histograma para ambos grupos en la variable ‘puntuación en el pretest’ (vamos
forzar 10 intervalos y el eje X con puntuaciones entre 20 y 55 puntos).
Vemos distribuciones aproximadamente normales, al menos a priori. En todo caso, veamos lo que
ocurre cuando aplicamos la prueba de normalidad. Recordemos antes las hipótesis planteadas en
este contraste:
H0: La distribución de los datos proviene de una distribución normal
H1: La distribución de los datos no proviene de una distribución normal

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
38
Zk-s P-VALOR
Castilla y León 1.024 0.245
Andalucía 0.689 0.729
Recordemos que partíamos, si no se decía lo contrario, de un nivel de significación del 5%, es decir,
aceptaremos la hipótesis nula cuando el p-valor sea superior o igual a 0.05 y la rechazaremos cuando
sea inferior a este valor. En este caso, ambos contrastes indican un p-valor superior a 0.05, por lo que
aceptamos H0, es decir, podemos afirmar que ambas distribuciones provienen de la distribución
normal. Así, puedo continuar con el contraste de hipótesis.
3. CONTRASTE PARAMÉTRICO: PRUEBA DE T PARA GRUPOS O MUESTRAS
INDEPENDIENTES
Bien, una vez hecho todo lo anterior, vamos a completar la prueba. Para ello debemos, inicialmente,
quitar la segmentación del archivo. Para ello, vamos a menú datos Segmentar archivo y
seleccionamos ‘analizar todos los casos…’.
Una vez estamos seguros de que el archivo no está segmentado, seleccionarmos menú analizar
Comparar medias Prueba T para muestras independientes. En la ventana emergente, debemos
añadir como variable de agrupación la variable cualitativa que establece los dos grupos (comunidad
autónoma en este caso) y en el botón ‘definir grupos’ indicar los dos grupos que se quieren
comparar4. En grupo 1 y grupo 2 deberemos añadir el número con el que se han codificado ambos
grupos (recordemos que esto lo podemos ver en la vista de variables, en ‘valores’). Por otra parte, en
la ventana ‘variables para contrastar’ se debe añadir la variable cuantitativa (en este caso la
puntuación en el pretest).
Obtenemos las siguientes tablas:
Estadísticos de grupo
Comunidad autónoma N Media Desviación típ.
Error típ. de la
media
Puntuación
en el pretest
Castilla y León 200 37,4250 7,43781 ,52593
Andalucía 60 34,9667 6,83948 ,88297
Prueba de muestras independientes
Prueba de Levene
para la igualdad de
varianzas Prueba T para la igualdad de medias
F Sig. t gl
Sig.
(bilateral)
Diferencia
de medias
Error típ.
diferencia
95% Int. de conf.
Inf Sup.
Puntuación
en el pretest
Se han asumido
varianzas iguales
,646 ,422 2,286 258 ,023 2,45833 1,07531 ,34083 4,5758
No se han asumido
varianzas iguales
2,392 104,4 ,019 2,45833 1,02774 ,42038 4,4962
4 ¿Por qué crees que el SPSS requiere que definas qué grupos comparar?

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
39
La información de la primera tabla (a excepción del error típico en la variable puntuación en el
pretest para cada grupo) ya la habíamos obtenido en las fases previas, por lo que no cabe analizarla.
En cuanto a la información obtenida en la segunda tabla, es la que me interesa. Se observa, en
primer lugar, que nos aparece una prueba llamada Prueba de Levene. Esta es la prueba de
homocedasticidad a la que hacíamos referencia previamente. En función de esta prueba,
asumiremos varianzas iguales o no las asumiremos, y deberemos coger la información de arriba o la
información de abajo. Veamos las hipótesis de esta prueba:
H0: Se asumen varianzas iguales
H1: No se asumen varianzas iguales
Como el p-valor asociado (en SPSS siempre se llama sig.) a esta prueba es de 0.422, superior al valor
0.05, aceptamos la hipótesis nula, y asumimos varianzas iguales. Así, en este caso debo interpretar
los datos superiores de la prueba de t y desechar los de la fila inferior. En todo caso, las hipótesis
planteadas en esta prueba de t para grupos independientes se mantienen inalterables:
H0: And= CyL
H1: And≠ CyL
Por lo tanto, estamos planteando si es plausible aceptar que la población de estudiantes andaluces y
castellanoleoneses poseen niveles de desempeño en el pretest diferentes (H1) o si los niveles
mostrados en la prueba del pretest se pueden considerar iguales (H0).
En cuanto a la información que aparece, además del valor del estadístico de contraste (t) y el de la
significación de la prueba (p-valor), nos encontramos con los grados de libertad de la prueba (gl), la
diferencia de medias (media en la variable cuantitativa, punt. en el pretest, de los estudiantes de
Castilla y León, menos la media de los estudiantes de Andalucía, 37.4250-34.9667), el error típico,
que ya lo hemos explicado como un indicador para calcular los intervalos de confianza, y el intervalo
de confianza de la diferencia de medias, es decir, de 2.45833. En este caso, ese intervalo (0.34083,
4.5758) se puede calcular a partir de la siguiente fórmula:
En todo caso, normalmente, es suficiente con informar del valor del estadístico de contraste t y el p-
valor. Podríamos resumir todo el proceso de la siguiente manera:
Tras la exploración inicial del comportamiento de la variable puntuación en el pretest y
la comprobación del supuesto de normalidad de la misma tanto para los estudiantes
andaluces (Zk-s=0.689; p.=0.729) como para los de Castilla y León (Zk-s=1.024; p.=0.245),
se aplica el contraste de hipótesis paramétrico. Asumiendo un nivel de confianza del
95%, el resultado de la prueba de t para grupos independientes muestra diferencias
significativas entre ambos grupos (t=2.286; p.=0.023). Por lo tanto, se rechaza la
hipótesis nula, y se puede afirmar que los niveles medios de desempeño en el pretest
de los estudiantes andaluces y castellanoleoneses son diferentes. En concreto, los
estudiantes de Castilla y León poseen un nivel de desempeño en la prueba superior a
los estudiantes de Andalucía.

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
40
4. CONTRASTE NO PARAMÉTRICO: PRUEBA DE LA U DE MANN-WHITNEY
4.1 Una variable de agrupación y otra cuantitativa
Imaginemos que, en el mismo contraste anterior (comparar el rendimiento en el pretest de
estudiantes de Castilla y León y Andalucía), tras realizar las pruebas de normalidad, las evidencias nos
indican que las distribuciones de la variable cuantitativa en los dos grupos o en alguno de los dos
grupos no se ajustan a la distribución normal. En ese caso no sería lo más correcto implementar
técnicas paramétricas de análisis de datos; deberíamos plantear la aplicación de una prueba no
paramétrica, en concreto la prueba de la U de Mann-Whitney.
Las pruebas no paramétricas tienen la peculiaridad, con respecto a las pruebas paramétricas, de que
emplean la mediana como estadístico de contraste en lugar de emplear la media. Así, en el caso de
la prueba de la U de Mann-Whitney, las hipótesis planteadas son las siguientes:
H0: Mdn1= Mdn2
H1: Mdn1 ≠ Mdn2
Así, comprobaremos la hipótesis de si las medianas de los grupos son iguales o diferentes. Antes de
plantear el contraste, como nos interesa comparar medianas, es interesante generar los diagramas
de cajas para la variable objeto de contraste (puntuación en el pretest) para cada uno de los grupos
de estudiantes:
A priori se observa que la mediana (raya central) de la variable puntuación en el pretest es
ligeramente superior en los estudiantes de la muestra Castilla y León (si solicitamos la información
exacta sobre la mediana para esta variable en ambos grupos, resulta que es de 37 puntos en Castilla
y León y de 34 en Andalucía). Ahora la duda es ¿serán estas diferencias en la muestra
suficientemente grandes para considerar que en la población se encuentran diferencias
significativas? Para resolver esta cuestión es para lo que vamos a aplicar la prueba inferencial no
paramétrica de la U de Mann-Whitney. Para realizar la prueba, simplemente accedemos a menú
analizar Pruebas no paramétricas Cuadros de diálogo antiguos Muestras independientes.
La ventana emergente es muy similar a la de la prueba de t para grupos independientes: Debemos
señalar la variable de agrupación, en este caso comunidad autónoma, y los valores de las categorías

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
41
Castilla y León y Andalucía, y añadir la variable cuantitativa u ordinal que se va a contrastar, en este
caso puntuación en el pretest. Las hipótesis concretas planteadas son:
H0: MdnAnd= MdnCyL
H1: MdnAnd ≠ MdnCyL
Así, en SPSS Se obtienen las siguientes tablas:
Rangos
Comunidad autónoma N
Rango
promedio
Suma de
rangos
Puntuación en el pretest
(competencias digitales)
Castilla y León 200 135,74 27147,50
Andalucía 60 113,04 6782,50
Total 260
Estadísticos de contrastea
Puntuación en
el pretest
(competencias
digitales)
U de Mann-Whitney 4952,500
W de Wilcoxon 6782,500
Z -2,053
Sig. asintót. (bilateral) ,040
a. Variable de agrupación: Comunidad
autónoma
La primera de las tablas indica los rangos de los sujetos de cada muestra, es decir, la posición media
de los sujetos de cada grupo después de ordenar a todos los sujetos de menor a mayor puntuación
en función de la variable de contraste (en este caso, puntuación en el pretest). Resulta, como ya
veíamos en el diagrama de cajas, que los estudiantes de Castilla y León ocupan posiciones más altas
en esta ‘clasificación de puntuaciones en el pretest’, o lo que es lo mismo, en términos promedios los
estudiantes de Castilla y León tienen puntuaciones más elevadas en el pretest que los de Andalucía.
Esto ya lo sabíamos por la información analizada previamente, tanto en los diagramas de cajas, como
en los estadísticos descriptivos, por lo que esta primera tabla no es de gran interés, simplemente
confirma esas observaciones previas.
La tabla que más interesa es la siguiente, que tiene 4 datos. Los 3 primeros datos indican
puntuaciones de los estadísticos a partir de los que se realiza el contraste de hipótesis. De éstos, al
ser la distribución teórica más conocida, se suele informar del valor de la Z junto con la significación o
p-valor. Vemos cómo, al igual que ocurría en el contraste paramétrico, los resultados informan de
que existen diferencias significativas entre las medianas de los dos grupos, esto es, que se puede
afirmar que existen diferencias significativas entre los dos grupos de estudiantes. Podríamos
informar de esto en un artículo o informe de investigación de la siguiente manera:

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
42
Tras la decisión sobre el empleo de contrastes no paramétricos, se procede a la
aplicación de la prueba de la U de Mann-Whitney. Los resultados indican que existen
diferencias significativas entre ambos grupos de estudiantes (Z=-2.053; p.=0.040),
siendo los estudiantes castellanoleoneses los que alcanzan un nivel de desempeño
superior en la variable puntuación en el pretest (MdnCyL=37; MdnA=34).
Véase que las conclusiones que se pueden extraer del contraste paramétrico y del no paramétrico
son muy similares. Realmente, ante una variable cuantitativa con distribución exactamente normal,
los resultados de aplicar el contraste paramétrico o el no paramétrico son prácticamente
coincidentes (recordemos que en una distribución normal la media y la mediana coinciden en el
mismo valor de la variable).
4.2 Una variable de agrupación y otra ordinal
Nos puede ocurrir que deseemos comparar el desempeño en una variable ordinal entre dos grupos.
Partiendo de la base de datos anterior, puede interesarnos saber si los estudiantes de Andalucía y de
Castilla y León poseen niveles de actitudes diferentes en la variable ‘Creo que el manejo de
herramientas informáticas es esencial para los ciudadanos del siglo XXI’. Dicha variable consiste en
una escala tipo Likert con valores de 1 a 5 puntos, correspondiendo 1 con ‘Totalmente en
desacuerdo’ y 5 con ‘Totalmente de acuerdo’.
Veamos primero brevemente la distribución de puntuaciones de esa variable en los dos grupos:
Se ha generado el diagrama de barras conjunto por las puntuaciones relativas porque recordemos
que los tamaños de muestra de ambos grupos eran diferentes, y por lo tanto, no directamente
comparables. Parece que las distribuciones de las variables en ambas muestras es similar, teniendo
los estudiantes de Castilla y León unas actitudes ligeramente superiores (más de un 36% de los
estudiantes de Castilla y León están totalmente de acuerdo con la afirmación, mientras que esto
ocurre con un 30% de los estudiantes andaluces).
También podríamos obtener el diagrama de cajas para cada grupo, para hacer una primera
comparación de ambos grupos:
2,50% 4,50%
18,00%
38,50% 36,50%
0,00%
6,70%
18,30%
45,00%
30,00%
0%
5%
10%
15%
20%
25%
30%
35%
40%
45%
50%
Totalmente en desacuerdo
En desacuerdo Ni de acuerdo ni en
desacuerdo
De acuerdo Totalmente de acuerdo
Castilla y León
Andalucía

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
43
Vemos en ambos casos distribuciones con una asimetría negativa muy importante (los estudiantes
tienden a valorar con puntuaciones muy altas esta variable) y con una puntuación mediana igual en
ambos casos (Mdn=’De acuerdo’). En todo caso, parecen distribuciones muy semejantes…
¿Serán estas diferencias obtenidas en la muestra suficientes como para poder afirmar que en las
poblaciones también existen? Veamos, en primer lugar, que la formulación de las hipótesis se
mantiene, ya que los grupos son los mismos que en el contraste previo:
H0: MdnAnd= MdnCyL
H1: MdnAnd ≠ MdnCyL
Por otro lado, podemos realizar el contraste del mismo modo que señalamos antes, accediendo a
menú analizar Pruebas no paramétricas Cuadros de diálogo antiguos Muestras
independientes. Veamos las tablas resultantes:
Rangos
Comunidad autónoma N
Rango
promedio
Suma de
rangos
Creo que el manejo de
herramientas informáticas
es esencial para los
ciudadanos del siglo XXI
Castilla y León 200 131,89 26377,50
Andalucía 60 125,88 7552,50
Total 260
Estadísticos de contrastea
El manejo de herramientas inf. es esencial para los ciudadanos del siglo XXI
U de Mann-Whitney 5722,500
W de Wilcoxon 7552,500
Z -,577
Sig. asintót. (bilateral) ,564
a. Variable de agrupación: Comunidad autónoma

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
44
Vemos, en primer lugar, que el rango promedio de los estudiantes de Castilla y León (131.89) es
ligeramente superior al de los estudiantes de Andalucía (125.88), observación coincidente con lo
señalado en el diagrama de barras conjunto.
En cuanto al contraste de hipótesis propiamente dicho, se observa que no existen diferencias
significativas entre las medianas de los grupos en la variable actitudes hacia las competencias
digitales (Z=-0.577; p.=0.564). Así, acepto la hipótesis nula y concluyo que los dos grupos poseen
actitudes similares en lo que tiene que ver con las actitudes hacia las competencias digitales (no
existen diferencias significativas entre ambos grupos).

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
45
DOS MUESTRAS RELACIONADAS
Los contrastes para dos muestras relacionadas se emplean habitualmente cuando disponemos de
dos variables cuantitativas diferentes que queremos comparar en una sola muestra (también
podemos emplear este contraste, en la modalidad no paramétrica, en el caso de que queramos
comparar dos variables ordinales en una muestra). El caso más prototípico en el que se aplica esta
prueba es cuando hemos desarrollado un diseño experimental con pretest y postest y queremos
comprobar si los sujetos muestran un nivel de desempeño diferente5 en el postest.
Al igual que en todo proceso de contraste de hipótesis, lo primero que tendremos que hacer será una
exploración descriptiva inicial de las variables y la comprobación del supuesto previo de normalidad.
En este ejemplo, vamos a comparar las puntuaciones obtenidas por los estudiantes en el pretest y en
el postest en nuestra base de datos de trabajo, sin tener en cuenta ninguna variable de agrupación.
1. EXPLORACIÓN DESCRIPTIVA INICIAL
Del total de 260 estudiantes de la muestra, resulta que la totalidad han completado tanto el pretest
como el postest, por lo que realizaremos el contraste incluyendo a todos los sujetos disponibles en la
base de datos. En el caso de que, por ejemplo, solamente 20 sujetos hubieran contestado tanto el
pretest como el postest, sería problemático, ya que el contraste sólo se podría realizar con esos 20
sujetos (independientemente de que, por ejemplo, hubieran completado el pretest 125 personas y el
postest 156).
En el caso de la prueba de t para grupos relacionados, si recordamos el primer bloque de contenido,
el cálculo se realiza a partir de una nueva variable que podemos denominar diferencia (Xpostest-
Xpretest). Así, la comprobación de la normalidad se debe realizar sobre la nueva variable resultante de
restar la puntuación en el postest menos la puntuación en el pretest. En SPSS realizamos esa
operación en menú transformarCalcular variable, y en la ventana emergente, en el cuadro
variable de destino añadimos el nombre de la nueva variable, y en el cuadro expresión numérica
añadimos la resta (Puntuación en el pretest-Puntuación en el postest) seleccionando las variables de
la columna inferior izquierda.
Veamos los estadísticos descriptivos básicos tanto para las variables pretest y postest como para la
variable diferencia. Dado que en este caso la homogeneidad de varianzas no es una cuestión
esencial, no es necesario aportar la información sobre el coeficiente de variación:
n Mdn As Curt
Pretest 260 36.86 36 7.36 0.06 -0.58
Postest 260 36.73 38 6.59 -0.33 -0.46
Diferencia 260 -0.13 -1 9.48 0.23 -0.22
Parece que los estudiantes mostraron un nivel de desempeño prácticamente igual (ligeramente
superior en el pretest) en el pretest y en el postest67. Los niveles de asimetría en el pretest son
5 ¿Cuándo buscaremos que las puntuaciones en el postest sean más altas? ¿Y más bajas?
6 ¿Es deseable en este caso, en base al diseño, que los sujetos obtengan una puntuación más alta en el pretest?
7 ¿Por qué en la mediana sí se localizan esas diferencias? (piensa en las distribuciones de las variables)

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
46
prácticamente nulos y de ligera asimetría negativa en el postest, mientras que la variable diferencia
muestra una ligera asimetría positiva. En cuanto a la curtosis, tenemos una ligera curtosis platicúrtica
en todos los casos.
2. SUPUESTOS PREVIOS
Veamos si estos ligeros desvíos en cuanto a la asimetría y la curtosis son suficientes para rechazar la
normalidad de las variables o no. En primer lugar, podemos observar el histograma de la variable
diferencia.
A priori parece que la distribución tiene una variación muy ligera sobre la distribución normal teórica.
En todo caso, aunque podríamos considerar la distribución normal a partir de este gráfico, siempre
es mejor realizar el contraste, la prueba de Kolmogorov-Smirnov, que recordemos que tiene las
siguientes hipótesis:
H0: La distribución de los datos proviene de una distribución normal
H1: La distribución de los datos no proviene de una distribución normal
Zk-s P-VALOR
Diferencia 1.201 0.112
Recordemos que el nivel de significación es del 5%, es decir, aceptaremos la hipótesis nula cuando el
p-valor sea superior o igual a 0.05 y la rechazaremos cuando sea inferior a este valor. En este caso, el
contraste indica un p-valor superior a 0.05, por lo que aceptamos H0, es decir, podemos afirmar que
la distribución de la variable diferencia proviene de la distribución normal. Así, puedo continuar con
el contraste de hipótesis.
3. CONTRASTE PARAMÉTRICO: PRUEBA DE T PARA GRUPOS O MUESTRAS RELACIONADAS
Una vez hemos hecho un análisis descriptivo de las variables que vamos a contrastar y hemos
comprobado el supuesto de normalidad de la nueva variable generada denominada diferencia,

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
47
seleccionarmos menú analizar Comparar medias Prueba T para muestras relacionadas. En este
caso, en la ventana emergente, debemos añadir como variable 1 la puntuación en el postest y como
variable 2 la puntuación en el pretest89 de agrupación la variable cualitativa que establece los dos
grupos (comunidad autónoma en este caso) y en el botón ‘definir grupos’ indicar los dos grupos que
se quieren comparar10. En grupo 1 y grupo 2 deberemos añadir el número con el que se han
codificado ambos grupos (recordemos que esto lo podemos ver en la vista de variables, en ‘valores’).
Por otra parte, en la ventana ‘variables para contrastar’ se debe añadir la variable cuantitativa (en
este caso la puntuación en el pretest).
Obtenemos las siguientes tablas:
Estadísticos de muestras relacionadas
Media N Desviación típ.
Error típ. de la
media
Par 1 Puntuación en el postest
(competencias digitales)
36,7308 260 6,59330 ,40890
Puntuación en el pretest
(competencias digitales)
36,8577 260 7,36467 ,45674
Correlaciones de muestras relacionadas
N Correlación Sig.
Par 1 Puntuación en el postest
(competencias digitales) y
Puntuación en el pretest
(competencias digitales)
260 ,082 ,190
Prueba de muestras relacionadas
Diferencias relacionadas
t gl
Sig.
(bilateral) Media Desv.Tip. E.T. media
95% Int. conf. dif.
Inferior Superior
Par 1 Punt. post-Punt. pret -,12692 9,47600 ,58768 -1,28416 1,03031 -,216 259 ,829
En este caso no hay comprobación de la igualdad de varianzas porque el procedimiento sólo trabaja
con una variable, la variable diferencia. Recordemos la hipótesis planteada en esta prueba de t para
grupos relacionados:
H0: Postest= Pretest
H1: Postest≠ Pretest
8 ¿En qué casos podría ser más interesante poner el pretest como variable 1 y el postest como variable 2?
9 ¿Qué crees que ocurrirá si ponemos las variables al revés?
10 ¿Por qué crees que el SPSS requiere que definas qué grupos comparar?

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
48
Por lo tanto, estamos planteando si es plausible aceptar que el grupo de estudiantes ha demostrado
niveles de desempeño diferentes en el pretest y el postest (H1) o si los niveles mostrados en ambas
pruebas se pueden considerar iguales (H0).
En este caso, nos encontramos con información complementaria similar al caso de la prueba de t
para grupos independientes. Además del valor del estadístico de contraste (t) y el de la significación
de la prueba (p-valor), nos encontramos con los grados de libertad de la prueba (gl), la diferencia de
medias (postest – pretest, en la tabla llamada ‘Media’), el error típico, y el intervalo de confianza de
la diferencia de medias. En este caso, ese intervalo (-1.28416, 1.03031) se puede calcular a partir de
la siguiente fórmula:
Podríamos interpretar directamente el contraste a partir de ese intervalo de confianza11, pero en
todo caso, es suficiente con informar del valor del estadístico de contraste t y el p-valor. Podríamos
resumir todo el proceso de la siguiente manera:
Tras la exploración inicial del comportamiento de la variables puntuación en el pretest
y en el postest, y la comprobación del supuesto de normalidad de la variable diferencia
(Zk-s=1.201; p.=0.112), se aplica el contraste de hipótesis paramétrico. Asumiendo un
nivel de significación del 5%, el resultado de la prueba de t para grupos relacionados
muestra que no existen diferencias significativas entre las puntuaciones del pretest y el
postest (t=-0.216; p.=0.829). Por lo tanto, no se rechaza la hipótesis nula, y se puede
afirmar que los estudiantes han alcanzado niveles similares de desempeño en el
pretest y en el postest.
4. CONTRASTE NO PARAMÉTRICO: TEST O PRUEBA DE WILCOXON
El contraste no paramétrico equivalente a la prueba de t paramétrica para grupos relacionados se
denomina test de Wilcoxon. Simplemente realiza el contraste de la igualdad de medianas de dos
variables en un mismo grupo cuando no se asegura el supuesto de normalidad de la variable
diferencia o cuando se quieren comparar dos variables ordinales. Las hipótesis planteadas son las
siguientes:
H0: MdnPost = MdnPret
H1: MdnPost ≠ MdnPret
Imaginemos que, en el ejemplo anterior, hubiéramos determinado en las pruebas de normalidad que
la variable diferencia (postest-prestest) no se distribuye normalmente. En ese caso deberíamos haber
aplicado la prueba de Wilcoxon de la manera que se expone a continuación. En primer lugar, para
solicitar la prueba debemos acceder en SPSS a menú analizar contrastes no paramétricos
Cuadros de diálogo antiguos 2 muestras relacionadas. La ventana emergente que aparece es
prácticamente igual a la que utilizamos en la prueba de t para muestras relacionadas, simplemente
deberemos insertar la variable postest en la columna 1 y la pretest en la columna 2. Las tablas
resultantes de solicitar el contraste en SPSS son las siguientes:
11
¿Cómo podríamos hacerlo?

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
49
Rangos
N
Rango
promedio Suma de rangos
Puntuación en el pretest
(competencias digitales) -
Puntuación en el postest
(competencias digitales)
Rangos negativos 112a 136,06 15238,50
Rangos positivos 139b 117,90 16387,50
Empates 9c
Total 260
a. Puntuación en el pretest (competencias digitales) < Puntuación en el postest (competencias digitales)
b. Puntuación en el pretest (competencias digitales) > Puntuación en el postest (competencias digitales)
c. Puntuación en el pretest (competencias digitales) = Puntuación en el postest (competencias digitales)
Estadísticos de contrasteb
Puntuación en el pretest (competencias
digitales) - Puntuación en el postest
(competencias digitales)
Z -,499a
Sig. asintót. (bilateral) ,618
a. Basado en los rangos negativos.
b. Prueba de los rangos con signo de Wilcoxon
En la primera tabla se observan los rangos. Esta prueba va comparando cada pareja de valores en las
dos variables para cada sujeto, y comprueba si un sujeto posee una puntuación mayor, menor o igual
en la primera variable que en la segunda. Como indica bajo la tabla, los rangos positivos se referirán a
aquellas veces en las que el sujeto ha obtenido una puntuación mayor en el pretest que en el
postest, los rangos negativos cuando el sujeto ha obtenido una puntuación mayor en el postest que
en el pretest y los empates cuando la puntuación ha sido exactamente la misma. Se observa que, de
los 260 estudiantes de la muestra, 139 obtuvieron una nota superior en el pretest, 112 en el postest
y 9 obtuvieron puntuaciones iguales. No es necesario interpretar el rango promedio ni la suma de
rangos haciendo una interpretación correcta de esta N.
Una vez visto que hay más sujetos en la muestra que obtienen mejor puntuación en el pretest que en
el postest, podemos comprobar si esas diferencias son significativas a partir del contraste de
hipótesis no paramétrico de la prueba de la W de Wilcoxon. Resulta que estas diferencias no son
significativas (Z=0.499; p.=0.618), por lo que aceptamos H0 y no podemos afirmar que los sujetos
obtienen puntuaciones más altas en el pretest que en el postest (y evidentemente, tampoco
podemos realizar la afirmación contraria).

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
50
K MUESTRAS INDEPENDIENTES
En ocasiones nos ocurre que queremos comparar las puntuaciones en una variable de más de dos
grupos al mismo tiempo. Imaginemos, por ejemplo, que nos interesa comparar el rendimiento
académico en matemáticas de los estudiantes de las distintas provincias de Castilla y León; en este
caso, debemos aplicar una técnica que permita comparar a varios grupos a la vez (estudiantes de
Ávila, Burgos, León, Palencia, Valladolid, etc.). El conjunto de técnicas que vamos a exponer aquí
permiten realizar estos cálculos de manera conjunta, sin tener que separar los grupos en cada una de
las parejas posibles y realizar varias pruebas para 2 muestras independientes.
En este ejemplo, vamos a comparar el rendimiento alcanzado en Lengua Castellana por los
estudiantes de las distintas provincias de Castilla y León representadas en la Base de Datos. Así, lo
primero que debemos hacer es seleccionar los datos de los estudiantes de Castilla y León. Para ello
vamos a menú datos Seleccionar casos. En la ventana emergente debemos seleccionar ‘si se
satisface la condición’, y en el cuadro en blanco de la ventana ‘si la opción’, añadir en el cuadro
blanco la variable Comunidad autónoma y poner ‘=1’ (en la ventana debe aparecer el texto
‘CCAA=1’).
1. EXPLORACIÓN DESCRIPTIVA INICIAL
Parece que la distribución por provincia está repartida de modo razonablemente equilibrado y que
tenemos más de 30 sujetos por grupo, por lo que estaríamos en condiciones de aplicar un contraste
de hipótesis. Tenemos 200 estudiantes en Castilla y León que se reparten del siguiente modo:
En cuanto al rendimiento en Lengua, la puntuación media de los estudiantes de la muestra de
Salamanca es más alta, y cómo tenemos niveles de dispersión superiores en Valladolid y variaciones
generales muy altas. La asimetría es claramente negativa y la curtosis mesocúrtica en Salamanca,
mientras que tenemos curtosis platicúrticas y ligera asimetría positiva en las otras provincias.
Mdn CV As Curt
Valladolid 5.06 4.6 2.66 52.57% 0.25 -1.14
León 5.27 5.6 2.19 41.56% 0.10 -0.61
Total 6.80 7.15 2.14 31.48% -0.75 0.02
49
69
82
0
10
20
30
40
50
60
70
80
90
Valladolid León Salamanca
Provincia

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
51
A priori, parece que las distribuciones de alguna de las variables pueden alejarse de la distribución
normal, tanto por los estadísticos de forma como por la gran variación de las mismas. Veamos para
confirmar estas observaciones el análisis de los supuestos previos.
2. SUPUESTOS PREVIOS
En este caso será necesario comprobar tanto el supuesto previo de normalidad como el de
homocedasticidad.
Veremos en primer lugar la prueba de normalidad, tras el análisis de los histogramas de las
distribuciones de las variables (forzando a 10 intervalos y el eje X con puntuaciones entre 0 y 10).
Vemos distribuciones alejadas de la normalidad por varias cuestiones tanto en Valladolid (curtosis
platicúrtica) como en Salamanca (asimetría negativa). En todo caso, veamos lo que ocurre cuando
aplicamos la prueba de normalidad. Recordemos antes las hipótesis planteadas en este contraste:

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
52
H0: La distribución de los datos proviene de una distribución normal
H1: La distribución de los datos no proviene de una distribución normal
Zk-s P-VALOR
Valladolid 0.844 0.475
León 0.567 0.905
Salamanca 1.231 0.097
En base a estos resultados no tenemos evidencias suficientes para afirmar que existen diferencias
significativas entre la distribución normal y las distribuciones de la variable rendimiento en lengua en
los grupos. No obstante, aún tenemos que comprobar la hipótesis de igualdad de varianzas. Para ello,
tras quitar la segmentación del archivo, accedemos a menú analizar Comparar medias ANOVA
de un factor. En la ventana emergente debemos añadir en la ‘lista de dependientes la variable
continua que queremos contrastar (rendimiento en lengua) y en el factor la variable de agrupación
(provincia). En el botón ‘opciones’ debemos seleccionar la opción ‘prueba de homogeneidad de las
varianzas’. Recordemos las hipótesis asociadas a la prueba de homogeneidad de varianzas:
H0: Las varianzas en la variable de los 3 grupos son iguales
H1: Las varianzas en la variable de los 3 grupos no son iguales
La primera tabla que nos aparece es la que debemos interpretar:
Prueba de homogeneidad de varianzas
Rendimiento en Lengua Castellana
Estadístico de
Levene gl1 gl2 Sig.
3,825 2 197 ,023
Se observa un p-valor de 0.023<0.05. Por lo tanto, rechazo H0, y puedo afirmar que las varianzas
entre los grupos no son iguales, es decir, que no existe homocedasticidad. Este resultado imposibilita
la aplicación de las técnicas paramétricas, por lo que vamos a aplicar en este caso el contraste no
paramétrico.
3. CONTRASTE NO PARAMÉTRICO: PRUEBA DE KRUSKAL-WALLIS
Bien, una vez hecho todo lo anterior, vamos a completar la prueba. Para ello, vamos a menú datos
Segmentar archivo y seleccionamos ‘analizar todos los casos…’.
Una vez estamos seguros de que el archivo no está segmentado, seleccionarmos menú analizar
Pruebas no paramétricas Muestras independientes. En la pestaña ‘objetivo’ de la ventana
emergente, debemos seleccionar ‘personalizar análisis’. Tras esto, accedemos a la pestaña ‘campos’,
donde añadimos en el cuadro ‘campos de prueba’ la variable de contraste (en este caso, rendimiento
en Lengua), y en el cuadro ‘grupos’ la variable de agrupación (en este caso, provincia). Una vez hecho
eso, accedemos a la pestaña ‘Configuración’, hacemos clic en ‘personalizar pruebas’, y seleccionamos
ANOVA de 1 vía de Kruskal-Wallis. Seleccionamos ‘ejecutar’ y nos aparecerá en la ventana de

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
53
resultados la información del contraste. Recordemos antes de nada las hipótesis asociadas a este
contraste no paramétrico:
H0: MdnVallad= MdnLeón = MdnSalam
H1: MdnVallad≠ MdnLeón ≠ MdnSalam
Por tanto, el contraste principal simplemente indica si existen o no existen diferencias significativas
entre alguno de los 3 grupos, independientemente de entre qué grupos se obtengan las diferencias.
La tabla mostrada inicialmente es la siguiente:
La información mostrada es muy simple y nos dice directamente que existen diferencias significativas
entre las medianas de alguno de los tres grupos. Veamos la información un poco más detallada
haciendo doble clic encima del cuadro en SPSS:
En este caso ya vemos la información un poco más desarrollada: en los 200 sujetos que compone la
muestra de estudiantes de Castilla y León, parece que la división por Provincia devuelve diferencias

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
54
significativas (2=22.902; p.<0.001). El diagrama de cajas ya nos muestra que parece que, mientras
que Valladolid y León poseen distribuciones de puntuaciones similares, los estudiantes de Salamanca
tienden a unas puntuaciones superiores. Si recordamos los estadísticos descriptivos obtenidos más
arriba, la mediana del rendimiento en Lengua de los estudiantes de Valladolid era de 4.6, de los de
León 5.6 y de los de Salamanca 7.15.
Pero en este punto surge una duda, ¿es esta información suficiente para poder hacer una
interpretación clara de las diferencias entre los grupos? Evidentemente, esta información global no
es suficiente, ya que no nos permite saber entre qué parejas de grupos en concreto (en este caso
entre qué provincias) se establecen estas diferencias. Para realizar esta comprobación, SPSS incluye
las pruebas post-hoc, es decir, las pruebas por parejas asociadas al contraste de Kruskal-Wallis. Para
acceder a ellas, en la misma ventana en la que hemos localizado la información de los diagramas de
cajas, el N, el valor del estadístico de contraste Chi-Cuadrado, los grados de libertad y el p-valor,
buscamos en la ventana de la derecha la opción ‘ver’, hacemos clic en el desplegable, y
seleccionamos la categoría ‘Comparaciones por parejas’. Se nos abrirá la siguiente información:

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
55
Cada uno de los puntos del gráfico nos indica cada uno de los grupos y las líneas los contrastes. Las
líneas amarillas se corresponden con los contrastes que han resultado significativos en las
comparaciones por parejas. La información concreta está desplegada en la tabla inferior. En esta
tabla tenemos tanto la información del estadístico de contraste (Prueba estadística), como la
información sobre la desviación y error típico en cada contraste y la significación de la prueba. De las
dos columnas de la significación siempre hay que interpretar como p-valor la que dice ‘sig. ady.’.
En este caso, se puede concluir que la muestra de estudiantes de Salamanca ha obtenido
puntuaciones medianas significativamente superiores (rechazo H0) tanto con respecto a los
estudiantes de León (2=-38.695; p.<0.001), como en relación a los estudiantes de Valladolid (2=-
41.280; p.<0.001). Sin embargo, no existen diferencias significativas (acepto H0) entre el rendimiento
demostrado por los estudiantes de León y de Valladolid (2=-2.584; p.>0.999).
Así pues, la prueba de Kruskal-Wallis me permite comparar el desempeño en una variable
cuantitativa (cuando no se cumplen las condiciones de normalidad o homocedasticidad) u ordinal en
varios grupos al mismo tiempo (variable cualitativa politómica), y comprobar entre qué grupos
exactamente se generan las diferencias significativas, en el caso de existir.
4. CONTRASTE PARAMÉTRICO: ANOVA DE 1 FACTOR
Nos puede ocurrir que se cumplan las condiciones de normalidad y homocedasticidad, caso en el que
podremos realizar el contraste de hipótesis paramétrico denominado ANOVA (Análisis de Varianza)
de 1 factor. Imaginemos, en el ejemplo anterior, que se cumplen las condiciones de normalidad y
homocedasticidad, por lo que estaríamos en condiciones de realizar este contraste.
Recordemos que para poder aplicar el ANOVA de 1 factor es necesario disponer en SPSS de una
variable cuantitativa (variable de contraste) y otra cualitativa politómica (variable de agrupación).
En el ejemplo anterior, para realizar este contraste de hipótesis, debemos acceder a menú analizar
Comparar medias Anova de un factor. En la ventana emergente debemos añadir en la ‘lista de
dependientes la variable continua que queremos contrastar (rendimiento en lengua) y en el factor la
variable de agrupación (provincia). Por otro lado, es recomendable que seleccionemos en el botón
‘opciones’ la opción ‘descriptivos’ (si no hemos comprobado la homocedasticidad, recordemos en
esta misma opción debemos seleccionar ‘prueba de homogeneidad de las varianzas’). Para que, en
caso de localizarse diferencias significativas en el contraste general, se realicen las pruebas post hoc
para cada pareja de grupos, debemos seleccionar el botón ‘Post hoc…’, y seleccionar la opción
‘Scheffé’. Estas pruebas post-hoc realizan una prueba de t para 2 grupos independientes en cada
pareja.
Recordemos las hipótesis del contraste principal:
H0: Vallad= León = Salam
H1: Vallad≠ León ≠ Salam
Las tablas principales que devuelve SPSS en este contraste se muestran a continuación:

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
56
Descriptivos
Rendimiento en Lengua Castellana
N Media Desviación
típica
Error
típico
I.C. para la media al 95% Mínimo Máximo
Lím inferior Lím. superior
Valladolid 49 5,0627 2,65983 ,37998 4,2987 5,8266 ,90 9,98
León 69 5,2732 2,19392 ,26412 4,7462 5,8002 1,20 10,00
Salamanca 82 6,8041 2,13677 ,23597 6,3346 7,2736 1,30 10,00
Total 200 5,8493 2,41925 ,17107 5,5120 6,1866 ,90 10,00
ANOVA de un factor
Rendimiento en Lengua Castellana
Suma de
cuadrados
gl Media cuadrática F Sig.
Inter-grupos 127,985 2 63,993 12,160 ,000
Intra-grupos 1036,719 197 5,263
Total 1164,704 199
Pruebas post hoc
Comparaciones múltiples
Variable dependiente: Rendimiento en Lengua Castellana
Scheffé
(I) Provincia (J) Provincia Diferencia de
medias (I-J)
Error
típico
Sig. Intervalo de confianza al 95%
Límite inferior Límite superior
Valladolid León -,21054 ,42856 ,886 -1,2676 ,8465
Salamanca -1,74149* ,41422 ,000 -2,7632 -,7198
León Valladolid ,21054 ,42856 ,886 -,8465 1,2676
Salamanca -1,53096* ,37476 ,000 -2,4553 -,6066
Salamanca Valladolid 1,74149
* ,41422 ,000 ,7198 2,7632
León 1,53096* ,37476 ,000 ,6066 2,4553
*. La diferencia de medias es significativa al nivel 0.05.
En primer lugar, se muestra la tabla de los estadísticos descriptivos para los 3 grupos de estudiantes.
Vemos inicialmente la N, media, desviación típica y error típico para cada grupo en la variable
rendimiento en lengua, y en las últimas columnas la puntuación mínima y máxima registrada en la
variable. El intervalo de confianza mostrado es el resultante del cálculo del intervalo para la media,
que ya vimos en el primer tema. Por ejemplo, en el caso de los estudiantes de Valladolid:
Realmente, podríamos comparar estos intervalos de confianza de la media para anticiparnos al
resultado del contraste:

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
57
Se observa en el gráfico anterior cómo, mientras que los intervalos de confianza de León y Valladolid
tienen una parte en la que se superponen (no existen diferencias significativas en la media de estos
dos grupos), el intervalo de confianza del rendimiento medio en Lengua en el caso de los estudiantes
de Salamanca no se solapa en ningún caso con los otros dos grupos. Así, podríamos concluir
simplemente con esta información que existen diferencias significativas globales entre los grupos y
que las diferencias existen entre los estudiantes de Salamanca y los de León-Valladolid, teniendo los
estudiantes de Salamanca un rendimiento medio superior a los otros dos grupos.
En todo caso, vamos a analizar el resto de datos para confirmar estas afirmaciones. La segunda tabla
(ANOVA de un factor), muestra los resultados del contraste de hipótesis principal, el que determina si
existen diferencias globales entre los grupos. La información que interesa interpretar de esa tabla es
la puntuación del estadístico de contraste, en este caso F, y el p-valor (Sig.). Los valores de la Suma
de Cuadrados, grados de libertad y Media Cuadrática serán explicados a nivel teórico en el siguiente
apartado. En este ejemplo, los resultados obtenidos en el contraste de hipótesis del ANOVA de 1
factor indican que existen diferencias significativas entre los grupos en cuanto al rendimiento en
lengua (F=12.16; p.<0.001), es decir, que rechazo la hipótesis nula de que no existen diferencias
entre los grupos.
En lo que respecta a las pruebas post-hoc, que determinan entre qué grupos en concreto se localizan
las diferencias, vemos información sobre la diferencia concreta de medias de cada pareja
contrastada, el error típico del contraste, el p-valor asociado al contraste y el intervalo de confianza
de la diferencia de medias, calculado a partir de la obtención de la amplitud del intervalo (t*E.T.). Se
observa que los contrastes significativos resultan de la comparación SALAMANCA-LEÓN (p.<0.001) y
SALAMANCA-VALLADOLID (p.<0.001), mientras que la comparación de la diferencia de medias LEÓN-
VALLADOLID no resulta significativa (p.=0.886). Así, se confirman las observaciones realizadas a partir
del gráfico y los intervalos de confianza iniciales:
Los resultados de la prueba de ANOVA de un factor para comprobar si los estudiantes
de las distintas provincias de Castilla y León obtienen rendimientos medios en Lengua
5,06
5,27
6,80
4,30
4,75
6,33
5,83 5,80
7,27
4,0
4,5
5,0
5,5
6,0
6,5
7,0
7,5
Media
Lím. Inf
Lím. Sup.
Valladolid León Salamanca

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
58
Castellana diferentes resultan significativos (F=12.16; p.<0.001). Así, se rechaza la
hipótesis nula de que no existen diferencias en las medias de los grupos de
estudiantes, y es necesario aplicar las pruebas post-hoc para determinar entre qué
grupos en concreto se obtienen las diferencias. En estas pruebas post-hoc se confirma
que el grupo de estudiantes de Salamanca alcanza rendimientos medios más altos
tanto con respecto a los estudiantes de Valladolid como a los estudiantes leoneses
(p<.001), y que no existen diferencias significativas entre los estudiantes de Valladolid
y León (p=0.886).
5. EXPLICACIÓN TEÓRICA: ANOVA DE 1 FACTOR
Cabe realizar una breve explicación de los valores de la tabla de ANOVA que no se han interpretado
(Suma de cuadrados, grados de libertad y Cuadrados medios). Veamos la siguiente tabla-resumen:
Suma de cuadrados gl Media
cuadrática F Sig.
Efectos principales
I-1
p-valor
Error
n-I
Total n-1
Se observa el cálculo de todas las celdas. Veamos un pequeño ejemplo para hacernos una idea.
Imaginemos que tenemos un grupo de 12 estudiantes en un aula de educación infantil y queremos
comprobar si el nivel de comprensión lectora (medido en una escala de 0 a 100 puntos) cambia en
función del método de enseñanza de la lectura aplicado a los estudiantes (método alfabético, mixto y
global). Así, dividimos a los 12 estudiantes en 3 grupos de 4 estudiantes y a cada grupo le enseñamos
durante todo el curso con uno de los 3 métodos. Al final del curso medimos el nivel de comprensión
lectora, obteniendo los siguientes resultados:
Alfabético Mixto Global
60 39 60
30 66 75
50 80 62
45 58 88
Si quisiéramos preparar los datos para utilizar en SPSS, la información debería aparecer del siguiente
modo:

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
59
Comprensión lectora Método*
1 60 1
2 30 1
3 50 1
4 45 1
5 39 2
6 66 2
7 80 2
8 58 2
9 60 3
10 75 3
11 62 3
12 88 3
1=Método alfabético; 2= Método mixto; 3=Método global
Pues bien, primero debemos calcular algunas cuestiones básicas:
I= 3 (existen 3 grupos de sujetos, uno por método de enseñanza de la lectura).
A partir de aquí puedo calcular las sumas de cuadrados:
Nótese que
A partir de aquí ya sólo me queda calcular las medias cuadráticas, el valor de F y el p-valor asociado:
Veamos pues la tabla de ANOVA completa que se obtiene de estos cálculos:
Suma de cuadrados gl Media
cuadrática F Sig.
Ef. Ppales 1260.67 2 630.33 30.59 0.097
Error 1854.25 9 206.03
Total 3114.92 11

Análisis de datos inferencial paramétrico y no paramétrico en Ciencias Sociales Fernando Martínez Abad
60
Por tanto, en este caso, dado que el p-valor es superior al nivel alfa (0.05), podemos determinar que
no existen diferencias significativas en cuanto al nivel de comprensión lectora alcanzado en función
del método de enseñanza aplicado a los estudiantes. No es necesario, pues, aplicar los contrastes de
hipótesis post-hoc para comprobar las diferencias entre cada pareja, ya que este contraste nos indica
que no existen diferencias entre ninguna de las parejas.
Related Documents