Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici 1 Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici (tra teoria e realtà) 2010 Cristiano Fragassa Alma Mater Studiorum Università di Bologna ISBN 978-88-906500-7-9 Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici 2 PREMESSA Il rapido progresso della tecnologia, lo sviluppo di prodotti altamente sofisticati, la forte competizione globale, e l’aumento delle aspettative dei clienti hanno messo nuove pressioni sui produttori per garantire sempre più prodotti di alta qualità. I clienti si aspettano che i prodotti acquistati siano affidabili e sicuri. Tutti siamo consapevoli della necessità per un prodotto di essere affidabile; quando invece cerchiamo di quantificare questa caratteristica o vogliamo calcolare i benefici che produce, ci possono essere delle discordanze. Secondo la visione del produttore, l’affidabilità si ha quando, a seguito di un certo numero di controlli (effettuati su determinati attributi o specifiche del prodotto) con esito favorevole, il prodotto è consegnato al cliente. Questi, al momento dell’acquisto, accetta anche la possibilità di rottura. Spesso questo semplice approccio è associato ad una garanzia, che costituisce una sorta di protezione in caso di rottura, entro un certo periodo di tempo. Quando si verifica un rottura all’interno del periodo di garanzia il disagio è sia del cliente, che non ha la possibilità di utilizzare il prodotto, che del produttore, dovendo sostenere i costi dovuti alla riparazione od alla sostituzione. Fuori dal periodo di garanzia i problemi saranno apparentemente solo del cliente ma solo apparentemente perché vi saranno dei costi indiretti quali quelli collegati all’immagine del prodotto stesso. Diventa quindi sempre più importante acquisire un concetto di qualità che si sviluppa nel tempo, lungo tutto l’arco di vita del prodotto, non limitandosi al semplice controllo prima della consegna, ma che investe gli aspetti di affidabilità e soddisfacimento delle aspettative del cliente. In genere l’affidabilità viene definita in ingegneria come la probabilità che un prodotto svolga la funzione richiesta senza guasti, nel rispetto delle condizioni definito e per un periodo di tempo definito, il tempo di missione. Ed è attraverso l’opportuna analisi delle informazioni di guasto provenienti dai servizi di assistenza alla clientela che è possibile effettuare una valutazione di affidabilità del prodotto. Realizzare uno studio affidabilistico e previsionale di prodotti industriali a partire dall’osservazione dei dati di rottura ( Reliability Data Analysis) di un insieme di questi manufatti, soggetti alle reali condizioni d’utilizzo consiste in: raccogliere e registrare le informazioni sulle rotture e sui difetti riscontrati filtrare, interpretare ed analizzare tutte queste informazioni ricavare le curve di probabilità che rappresentano il comportamento affidabilistico del prodotto prevedere l’andamento nel tempo delle future rotture. La Reliability Data Analysis (RDA) interessa tutti i campi produttivi, ma si presta con particolare efficacia in quei settori dove coesistono elevate produzioni e fortissime esigenze qualitative dei prodotti Per la definizione del modello matematico da impiegare nel calcolo dell’affidabilità si farà riferimento a quanto comunemente disponibile nella letteratura specialistica (ad esempio attraverso l’utilizzo di “stimatori non parametrici” quali Keplan-Mayer, Herald-Jonsohn, etc.), che attraverso formulazioni semiempiriche consentono di realizzare valide stime di qualità. Ma la difficoltà dell’analisi arriverà dalla complessità intrinseca della realtà che si intende analizzare, ricca di parametri e quantità non deterministici, di cui, l’unica possibile conoscenza risiede nelle forme delle distribuzioni di probabilità che le caratterizzano. Al fine di superare le enormi complessità di modellazione teorica della realtà, si renderà quindi necessario l’impiego di un codice di montecarlo, appositamente realizzato, che attraverso la

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
1
Analisi dei dati di
guasto per la stima di
affidabilità di
componenti
automobilistici (tra teoria e realtà)
2010
Cristiano Fragassa
Alma Mater Studiorum Università di Bologna
ISBN 978-88-906500-7-9
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
2
PREMESSA Il rapido progresso della tecnologia, lo sviluppo di prodotti altamente sofisticati, la forte competizione globale, e l’aumento delle aspettative dei clienti hanno messo nuove pressioni sui produttori per garantire sempre più prodotti di alta qualità. I clienti si aspettano che i prodotti acquistati siano affidabili e sicuri. Tutti siamo consapevoli della necessità per un prodotto di essere affidabile; quando invece cerchiamo di quantificare questa caratteristica o vogliamo calcolare i benefici che produce, ci possono essere delle discordanze. Secondo la visione del produttore, l’affidabilità si ha quando, a seguito di un certo numero di controlli (effettuati su determinati attributi o specifiche del prodotto) con esito favorevole, il prodotto è consegnato al cliente. Questi, al momento dell’acquisto, accetta anche la possibilità di rottura. Spesso questo semplice approccio è associato ad una garanzia, che costituisce una sorta di protezione in caso di rottura, entro un certo periodo di tempo. Quando si verifica un rottura all’interno del periodo di garanzia il disagio è sia del cliente, che non ha la possibilità di utilizzare il prodotto, che del produttore, dovendo sostenere i costi dovuti alla riparazione od alla sostituzione. Fuori dal periodo di garanzia i problemi saranno apparentemente solo del cliente ma solo apparentemente perché vi saranno dei costi indiretti quali quelli collegati all’immagine del prodotto stesso. Diventa quindi sempre più importante acquisire un concetto di qualità che si sviluppa nel tempo, lungo tutto l’arco di vita del prodotto, non limitandosi al semplice controllo prima della consegna, ma che investe gli aspetti di affidabilità e soddisfacimento delle aspettative del cliente. In genere l’affidabilità viene definita in ingegneria come la probabilità che un prodotto svolga la funzione richiesta senza guasti, nel rispetto delle condizioni definito e per un periodo di tempo definito, il tempo di missione. Ed è attraverso l’opportuna analisi delle informazioni di guasto provenienti dai servizi di assistenza alla clientela che è possibile effettuare una valutazione di affidabilità del prodotto. Realizzare uno studio affidabilistico e previsionale di prodotti industriali a partire dall’osservazione dei dati di rottura (Reliability Data Analysis) di un insieme di questi manufatti, soggetti alle reali condizioni d’utilizzo consiste in:
� raccogliere e registrare le informazioni sulle rotture e sui difetti riscontrati � filtrare, interpretare ed analizzare tutte queste informazioni � ricavare le curve di probabilità che rappresentano il comportamento affidabilistico del
prodotto � prevedere l’andamento nel tempo delle future rotture.
La Reliability Data Analysis (RDA) interessa tutti i campi produttivi, ma si presta con particolare efficacia in quei settori dove coesistono elevate produzioni e fortissime esigenze qualitative dei prodotti Per la definizione del modello matematico da impiegare nel calcolo dell’affidabilità si farà riferimento a quanto comunemente disponibile nella letteratura specialistica (ad esempio attraverso l’utilizzo di “stimatori non parametrici” quali Keplan-Mayer, Herald-Jonsohn, etc.), che attraverso formulazioni semiempiriche consentono di realizzare valide stime di qualità. Ma la difficoltà dell’analisi arriverà dalla complessità intrinseca della realtà che si intende analizzare, ricca di parametri e quantità non deterministici, di cui, l’unica possibile conoscenza risiede nelle forme delle distribuzioni di probabilità che le caratterizzano. Al fine di superare le enormi complessità di modellazione teorica della realtà, si renderà quindi necessario l’impiego di un codice di montecarlo, appositamente realizzato, che attraverso la

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
3
simulazione di storie ed eventi si pone l’obbiettivo di calcolare quelle quantità di interesse affidabilistico altrimenti indeterminate. Grandissimi sforzi saranno portati avanti per realizzare una efficace schematizzazione del modello con standardizzazione delle variabili di input e output del codice. Inoltre, pur rivestendo la RDA un notevole interesse in vari settori applicativi, tanto gli esempi di validazione delle metodologia e del codice, quanto le successive applicazioni saranno tratti da casi reali provenienti dal settore “automotive”. Per motivi di riservatezza industriale, i risultati previsionali saranno presentati in forma anonima oppure adimensionalizzata, ma sono tutti riconducibili a studi di affidabilità condotti su autovetture delle Aziende del Gruppo FIAT (Fiat Auto, Magneti Marelli, Lancia, Alfa Romeo). Si ringrazia i responsabili qualità delle relative aziende per il supporto allo sviluppo della presente metodologia di analisi.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
4
INTRODUZIONE ALLA QUALITÀ La qualità di un prodotto è un elemento fondamentale e prioritario per rimanere sul mercato in un mondo fortemente competitivo. Lo sviluppo tecnologico, l'allargamento del sistema produttivo e le conseguenti modifiche nelle aspettative del cliente hanno fortemente cambiato nel tempo il significato di questo termine. Sino a pochi anni fa, la buona corrispondenza fra le specifiche richieste e le caratteristiche di funzionamento verificate attraverso un controllo finale erano condizione sufficiente a garantire la “buona qualità” di un prodotto. L’accresciuta complessità dei componenti con il rapido aumento dei costi conseguenti ad una perdita di operatività e alla necessaria manutenzione hanno portato ad una più articolata e complessa valutazione della qualità di un prodotto che investe tutti i settori aziendali così da assicurare uno sforzo comune ed indirizzato a raggiungere i desideri del consumatore. La determinazione della integrità e la necessaria manutenzione nel tempo di un prodotto è senza dubbio un elemento base per soddisfare le esigenze del mercato. Di conseguenza esiste una grande esigenza di metodologie e strumenti in grado di valutare l’affidabilità di un componente o di un sistema e di ottimizzare il meccanismo di manutenzione così da prevenire costi elevati dovuti a soste non previste dell’impianto o ad improvvise rotture di un componente. L’affidabilità è una misura del comportamento nel tempo di un prodotto che influenza non solo la funzionalità del componente ma anche i costi operativi e di riparazione e le condizioni di sicurezza.
Che cos’è la qualità? La qualità di un prodotto può essere valutata secondo diversi aspetti. Garvin (1987) propone un elenco di otto componenti della qualità,che vengono sintetizzate di seguito:
1. Prestazione 2. Affidabilità 3. Durata 4. Manutenibilità 5. Aspetti formali 6. Funzionalità 7. Livello di qualità percepito 8. Conformità alle normative
L’affidabilità è la componente sulla quale ci concentreremo nei prossimi capitoli analizzandone le principali problematiche e i possibili metodi di analisi. La definizione tradizionale del termine qualità si basa sul presupposto che beni e servizi devono soddisfare le richieste di coloro che li utilizzano. Ci sono due aspetti generali della qualità: la qualità di progetto e la conformità alle normative. Tutti i beni e i servizi vengono progettati con vari gradi o livelli di qualità: queste diversità sono intenzionali; il termine tecnico appropriato è qualità di progetto. Ad esempio tutte le automobili hanno come obiettivo basilare quello di essere un mezzo di trasporto sicuro per le acquista, tuttavia esse differiscono per dimensioni equipaggiamento modello e prestazioni. Queste differenze sono il risultato di progettazioni intenzionali, che comprendono anche i tipi di materiali usati nella costruzione, le specifiche caratteristiche dei componenti, l’affidabilità ottenuta mediante lo sviluppo ingegneristico dei motori e di altri accessori ed equipaggiamenti. La conformità alle normative è invece relativa a quanto il prodotto risulta coerente alle specifiche che sono richieste al progetto.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
5
Sfortunatamente la definizione di qualità è stata associata più agli aspetti della conformità alle normative che a quelli della qualità di progetto. Ciò è dovuto, in parte, alla scarsa educazione formale che progettisti e tecnici ricevono in merito alla metodologia della qualità. Vi è inoltre una convinzione diffusa che la qualità sia un problema che riguarda unicamente la fabbricazione, o che l’unico modo con cui si può migliorare la qualità sia quello di “indorare” il prodotto.
Introduzione alla Qualità Totale In un contesto di competitività sempre più esasperata, in cui la sfida tra aziende si gioca sul piano della soddisfazione del cliente, le problematiche relative alla qualità acquistano un rilievo sempre maggiore. Lo stesso concetto di qualità si è evoluto nel tempo da quello di conformità ad una specifica tecnica a quello di adeguatezza alle esigenze del cliente. Questa nuova definizione enfatizza la voce del cliente che, tramite la definizione degli obiettivi di affidabilità, deve essere tradotta in caratteristiche tecniche del prodotto, ovvero in obiettivi tecnici di progetto. Il miglioramento della qualità è emerso dunque come nuova, fondamentale strategia aziendale, e questo per diversi motivi, tra cui:
� aumento di consapevolezza da parte della clientela nel giudicare la qualità di un prodotto; � aumento della affidabilità richiesta ai prodotti; � aumento dei costi del lavoro, dell’energia e delle materie prime; � concorrenza più agguerrita; � aumento della produttività attraverso efficaci programmi di miglioramento della qualità e
dei metodi di produzione. Parte di questa strategia aziendale consiste nella pianificazione della qualità, nell’analisi e nel controllo indirizzati a fare della qualità uno strumento di miglioramento della situazione finanziaria,in termini di bilancio e profitti. Il miglioramento della qualità può produrre crescita di fatturato e di posizione competitiva aziendale e riduzione dei costi di produzione. È dunque importante dedicare nella fase iniziale della progettazione un grande sforzo nel capire i bisogni del cliente e a scomporli in elementi misurabili e correlabili alle caratteristiche del prodotto e dei suoi componenti.
Gli strumenti di ricerca della qualità Molto utilizzate sono a tal proposito tecniche di progettazione dell’affidabilità di un prodotto come la FMEA (Failure Mode Effect and Analysis) e la FMECA, utili per analizzare un progetto identificandone i punti deboli e le criticità, oppure la FTA (Fault Tree Analysis), una metodologia di analisi previsionale utilizzata per stimare la probabilità di un evento critico basandosi sulla individuazione delle cause di avaria e sulle loro possibili interconnessioni, rappresentate tramite l’albero dei guasti, oppure infine tecniche avanzate che si inseriscono nel concetto più generale di “Design for Reliability” (Progettazione Orientata all’Affidabilità). Gli strumenti finora descritti sono indispensabili per un reale miglioramento di qualità, ma sono tali da agire solo a livello di progettazione del sistema e presentano i seguenti inconvenienti:
� non tengono conto del rischio di realizzare un prodotto difettoso � difficilmente riescono a prevedere le reali condizioni di utilizzo
Per superare il primo dei due problemi, si realizzano analisi FMEA indirizzandoli alla comprensione e correzione del processo di produzione, mentre ulteriori strumenti di controllo statistico (Statistic Process Control) si occupano di verificare come il processo produttivo conservi la propria qualità e stabilità nel tempo. Ma le tecniche di analisi statistica assumono una importanza fondamentale in relazione al secondo aspetto, quando si tratta di stimare le concrete condizioni di utilizzo del prodotto e prevedere il modo in cui tali condizioni agiscano sull’affidabilità del sistema. Osservando le informazioni sui guasti provenienti dai sistemi di assistenza alla clientela ed utilizzando opportuni
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
6
metodi di elaborazione dei dati è possibile effettuare delle previsioni di affidabilità molto più attinenti alla realtà perché eseguite su un campione di prodotti sottoposti alle reali condizioni di utilizzo e deterioramento: questa tipologia di analisi prende il nome di Analisi Dati di Guasto (Reliability Data Analisys). Tutti questi strumenti rappresentano degli strumenti critici per il controllo e il miglioramento della qualità ma, affinché il loro utilizzo risulti più efficace, è necessario che queste siano considerate parte integrante di un sistema di gestione orientato alla qualità. Questa filosofia manageriale viene indicata usualmente con l’acronimo TQM (Total Quality Management).
Evoluzione del concetto di qualità Si può far risalire a poco prima degli anni ’50 il periodo in cui con una certa diffusione, dapprima nei paesi anglosassoni e successivamente in Europa, le aziende di media e grande dimensione iniziarono ad occuparsi del problema della qualità. I contenuti del problema e il concetto stesso della parola “qualità” erano diretta conseguenza dei nuovi mezzi e delle moderne tecniche per una produzione di massa a bassi costi. Le aziende si rendevano conto che qualsiasi processo di grande serie comportava delle caratteristiche non uniformi sugli elementi prodotti e verificavano che non sempre un sistema produttivo era in grado di conferire le caratteristiche prescritte. Tutto ciò dava luogo ad una serie molto vasta di problemi che investivano le aziende sia per la messa a punto delle loro tecniche di produzione sia per la variabilità del prodotto consegnato al consumatore. Nei riguardi del consumatore i produttori si ritrovavano invece a distribuire un prodotto con caratteristiche di funzionamento e di utilizzazione variabili da un’unità all’altra o addirittura mancanti. In quel momento ciò non rappresentava una catastrofe in quanto il mercato era in forte espansione, i consumatori non si trovavano (come ai giorni nostri) a dover scegliere tra molti prodotti simili, ma si preoccupavano principalmente di acquistare e possedere un determinato bene e non si lamentavano eccessivamente se le loro esigenze erano soddisfatte parzialmente. Da allora ad oggi le condizioni in cui si sono ritrovate a operare le aziende produttrici si sono notevolmente modificate e le caratteristiche dei mercati sono profondamente mutate. Si è assistito pertanto ad una parallela evoluzione dl concetto di “qualità” e all’ampliarsi della relativa problematica. Questo sviluppo dovuto essenzialmente alle mutate abitudini del consumatore, ha comportato la radicale modifica delle caratteristiche prescritte per il prodotto e la ristrutturazione degli organismi atte ad assicurarle. Ciò perché il consumatore o l’utente riesce oggi a discernere i suoi effettivi bisogni, a confrontarli con quello che il nostro prodotto offre, e nel momento in cui una società concorrente gli offrisse qualcosa che risponda meglio alle sue esigenze non tarderà di certo a cambiare le sue preferenze.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
7
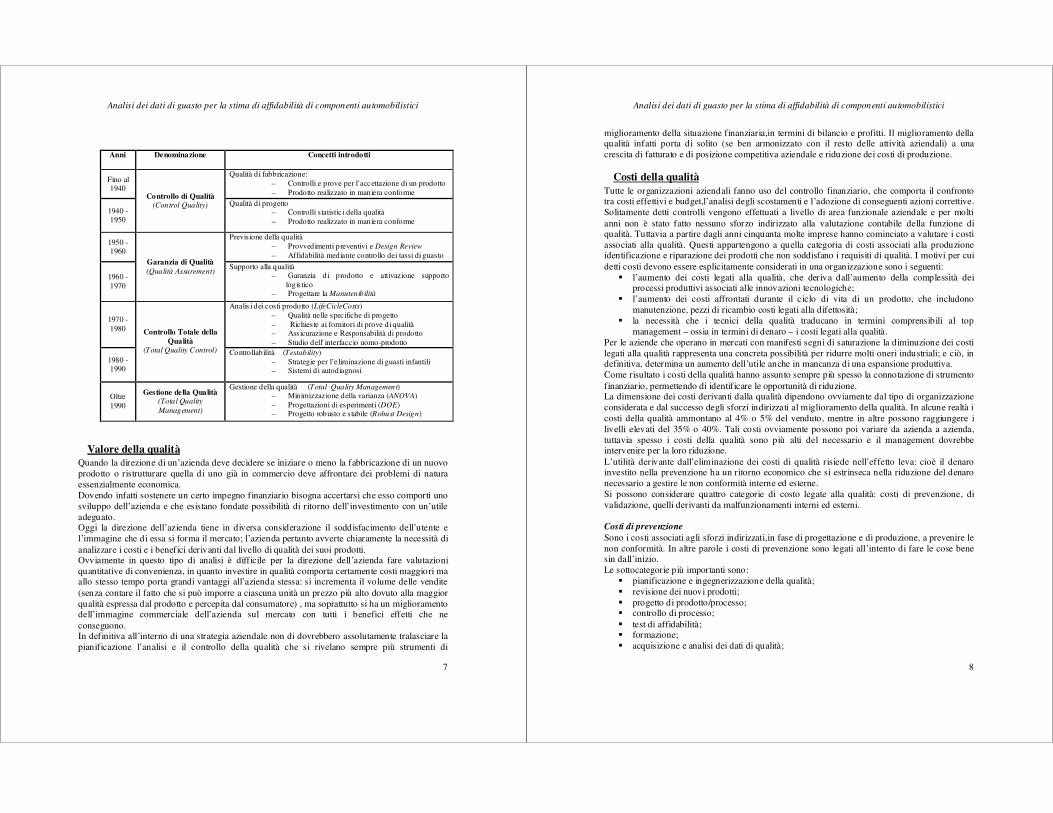
Anni Denominazione Concetti introdotti
Fino al 1940
Controllo di Qualità (Control Quality)
Qualità di fabbricazione: – Controlli e prove per l’accettazione di un prodotto – Prodotto realizzato in maniera conforme
1940 - 1950
Qualità di progetto – Controlli statistici della qualità – Prodotto realizzato in maniera conforme
1950 - 1960
Garanzia di Qualità (Qualità Assurement)
Previsione della qualità
– Provvedimenti preventivi e Design Review – Affidabilità mediante controllo dei tassi di guasto
1960 - 1970
Supporto alla qualità – Garanzia di prodotto e attivazione supporto
logistico – Progettare la Manutenibilità
1970 - 1980 Controllo Totale della
Qualità (Total Quality Control)
Analis i dei costi prodotto (LifeCicleCosts) – Qualità nelle specifiche di progetto – Richieste ai fornitori di prove di qualità – Assicurazione e Responsabilità di prodotto – Studio dell’ interfaccio uomo-prodotto
1980 - 1990
Controllabilità (Testability) – Strategie per l’eliminazione di guasti infantili – Sistemi di autodiagnosi
Oltre 1990
Gestione della Qualità (Total Quality
Management)
Gestione della qualità (Total Quality Management) – Minimizzazione della varianza (ANOVA) – Progettazioni di esperimenti (DOE) – Progetto robusto e stabile (Robust Design)
Valore della qualità Quando la direzione di un’azienda deve decidere se iniziare o meno la fabbricazione di un nuovo prodotto o ristrutturare quella di uno già in commercio deve affrontare dei problemi di natura essenzialmente economica. Dovendo infatti sostenere un certo impegno finanziario bisogna accertarsi che esso comporti uno sviluppo dell’azienda e che esistano fondate possibilità di ritorno dell’investimento con un’utile adeguato. Oggi la direzione dell’azienda tiene in diversa considerazione il soddisfacimento dell’utente e l’immagine che di essa si forma il mercato; l’azienda pertanto avverte chiaramente la necessità di analizzare i costi e i benefici derivanti dal livello di qualità dei suoi prodotti. Ovviamente in questo tipo di analisi è difficile per la direzione dell’azienda fare valutazioni quantitative di convenienza, in quanto investire in qualità comporta certamente costi maggiori ma allo stesso tempo porta grandi vantaggi all’azienda stessa: si incrementa il volume delle vendite (senza contare il fatto che si può imporre a ciascuna unità un prezzo più alto dovuto alla maggior qualità espressa dal prodotto e percepita dal consumatore) , ma soprattutto si ha un miglioramento dell’immagine commerciale dell’azienda sul mercato con tutti i benefici effetti che ne conseguono. In definitiva all’interno di una strategia aziendale non di dovrebbero assolutamente tralasciare la pianificazione l’analisi e il controllo della qualità che si rivelano sempre più strumenti di
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
8
miglioramento della situazione finanziaria,in termini di bilancio e profitti. Il miglioramento della qualità infatti porta di solito (se ben armonizzato con il resto delle attività aziendali) a una crescita di fatturato e di posizione competitiva aziendale e riduzione dei costi di produzione.
Costi della qualità Tutte le organizzazioni aziendali fanno uso del controllo finanziario, che comporta il confronto tra costi effettivi e budget,l’analisi degli scostamenti e l’adozione di conseguenti azioni correttive. Solitamente detti controlli vengono effettuati a livello di area funzionale aziendale e per molti anni non è stato fatto nessuno sforzo indirizzato alla valutazione contabile della funzione di qualità. Tuttavia a partire dagli anni cinquanta molte imprese hanno cominciato a valutare i costi associati alla qualità. Questi appartengono a quella categoria di costi associati alla produzione identificazione e riparazione dei prodotti che non soddisfano i requisiti di qualità. I motivi per cui detti costi devono essere esplicitamente considerati in una organizzazione sono i seguenti:
� l’aumento dei costi legati alla qualità, che deriva dall’aumento della complessità dei processi produttivi associati alle innovazioni tecnologiche;
� l’aumento dei costi affrontati durante il ciclo di vita di un prodotto, che includono manutenzione, pezzi di ricambio costi legati alla difettosità;
� la necessità che i tecnici della qualità traducano in termini comprensibili al top management – ossia in termini di denaro – i costi legati alla qualità.
Per le aziende che operano in mercati con manifesti segni di saturazione la diminuzione dei costi legati alla qualità rappresenta una concreta possibilità per ridurre molti oneri industriali; e ciò, in definitiva, determina un aumento dell’utile anche in mancanza di una espansione produttiva. Come risultato i costi della qualità hanno assunto sempre più spesso la connotazione di strumento finanziario, permettendo di identificare le opportunità di riduzione. La dimensione dei costi derivanti dalla qualità dipendono ovviamente dal tipo di organizzazione considerata e dal successo degli sforzi indirizzati al miglioramento della qualità. In alcune realtà i costi della qualità ammontano al 4% o 5% del venduto, mentre in altre possono raggiungere i livelli elevati del 35% o 40%. Tali costi ovviamente possono poi variare da azienda a azienda, tuttavia spesso i costi della qualità sono più alti del necessario e il management dovrebbe intervenire per la loro riduzione. L’utilità derivante dall’eliminazione dei costi di qualità risiede nell’effetto leva: cioè il denaro investito nella prevenzione ha un ritorno economico che si estrinseca nella riduzione del denaro necessario a gestire le non conformità interne ed esterne. Si possono considerare quattro categorie di costo legate alla qualità: costi di prevenzione, di validazione, quelli derivanti da malfunzionamenti interni ed esterni. Costi di prevenzione Sono i costi associati agli sforzi indirizzati,in fase di progettazione e di produzione, a prevenire le non conformità. In altre parole i costi di prevenzione sono legati all’intento di fare le cose bene sin dall’inizio. Le sottocategorie più importanti sono:
� pianificazione e ingegnerizzazione della qualità; � revisione dei nuovi prodotti; � progetto di prodotto/processo; � controllo di processo; � test di affidabilità; � formazione; � acquisizione e analisi dei dati di qualità;

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
9
Costi di validazione
Sono quei costi associati alla misurazione,valutazione e controllo interno del sistema dei prodotti, componenti e materie prime, per assicurare la conformità degli standard fissati. Questi costi si presentano quindi quando si deve valutare un prodotto dal punto di vista della qualità. Le sottocategorie sono le seguenti:
� ispezione e valutazione del materiale in arrivo � ispezione e valutazione di prodotto � materiali e servizi consumati � manutenzione della sicurezza delle attrezzature di prova
Costi di malfunzionamento Questi costi derivano da tutte le deficienze qualitative rilevate sul prodotto all’interno dell’azienda o che si manifestano durante l’utilizzazione da parte del cliente. Di solito vengono separati gli insuccessi interni da quelli esterni in quanto questi ultimi comportano, per uno stesso difetto, degli oneri economici notevolmente diversi.
Costi di malfunzionamento interno I malfunzionamenti interni intervengono quando i prodotti, i materiali e i servizi non soddisfano il livello di qualità richiesto e il difetto viene scoperto prima che il prodotto sia inviato alla clientela. Questi sono costi nulli in caso di assenza di pezzi difettosi. Le maggiori sottocategorie sono le seguenti:
� scarto � ripetizione delle lavorazioni � ripetizione dei test � analisi da malfunzionamento � fermo macchina � perdite di produzione � declassamento
Costi di malfunzionamento esterno I costi di malfunzionamento esterno insorgono quando un prodotto non soddisfacente è inviato al consumatore. Anche questi sono costi nulli se la produzione non presenta difettosità. Alcune sottocategorie sono le seguenti:
� gestione dei reclami � costi di assicurazione � costo dei resi di materiale, di eventuali bonifici o indennizzi; � costo delle sostituzioni di particolari o dei difetti riparati sui prodotti in garanzia
(includendo lavoro e materiale aggiunto); � costo delle modifiche di assistenza clienti dovute a errori di progettazione o di
fabbricazione. � costi per responsabilità di prodotto � costi indiretti
Questi costi sono quelli che ci riguardano più da vicino perché grazie all’analisi affidabilistica dei dati (RDA) - di cui ci occuperemo nei prossimi capitoli – sarà possibile per l’azienda avere un idea concreta sull’entità degli insuccessi esterni che il prodotto presenta una volta messo sul mercato e rilevare le anomalie commercialmente ed economicamente importanti che la rete di controllo lascia arrivare alla clientela; è possibile in tal modo conoscere i punti ove le ispezioni devono essere irrigidite.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
10
Perché e importante fare un analisi affidabilistica dei dati ? Secondo la visione del produttore l’affidabilità si ha quando, a seguito di un certo numero di controlli (effettuati su determinati attributi o specifiche del prodotto) con esito favorevole, il prodotto è consegnato al cliente. Ciò non significa che per il produttore non sia importante avere notizie su quanto accada ai suoi prodotti dal momento della consegna in poi: abbiamo visto che eventuali rotture, problemi non dipendenti dal consumatore e richieste di assistenza nel periodo di garanzia gravano sui costi di una azienda in modo non troppo trascurabile;anche i problemi e i cali di prestazioni presentati dal prodotto al di fuori del periodo di garanzia rappresentano per il produttore dei costi magari non diretti come i precedenti ma a livello di futuri cali nelle vendite a causa di cattiva reputazione presso i clienti. Si capisce allora perché sia importante per un’azienda raccogliere monitorare e analizzare i dati provenienti dal mercato, magari facendo uso di metodi statistici, in modo da poter rendersi conto e intervenire tempestivamente nel caso si avverassero situazioni non previste. Oltre a consentire le necessarie migliorie al prodotto già distribuito,ciò comporta la formazione di una esperienza utile nello studio dei nuovi prodotti, evitando soluzioni che hanno comportato difetti nei modelli precedenti e viceversa.
Ragioni per raccogliere informazioni e dati sull’affidabilità Riepilogando ci sono diverse ragioni per cui è importante raccogliere dati affidabilistici:
� accertarsi delle caratteristiche di un prodotto dopo un determinato periodo di vita o alla fine del periodo di garanzia;
� predire l’affidabilità del prodotto; � predire i costi di garanzia del prodotto; � procurarsi gli input necessari per la previsione dei rischi di guasto del sistema; � accertarsi degli effetti di eventuali cambiamenti apportati; � accertarsi che sia le aspettative dell’utente che le normative siano soddisfatte; � monitorare il prodotto sul campo in modo da avere informazioni sulle cause di rottura ed
eventualmente sui possibili metodi per porvi rimedio; � mettere a confronto prodotti dello stesso tipo ma usciti da due stabilimenti diversi o che
differiscono solo per un materiale, per periodo di produzione, per condizioni di funzionamento o per una determinata caratteristica;
� controllare la veridicità delle proprie promesse promozionali In precedenza si è accennato alla necessità di conoscere le prestazioni di un prodotto durante la fase di garanzia e lungo tutto il periodo di vita utile allo scopo di valutare il decadimento delle prestazioni e gli inconvenienti verso la clientela che non sono segnalati in azienda. Ciò consente di predisporre meglio i controlli, di modificare le specifiche o, eventualmente, di variare le operazioni di fabbricazione. Nei casi in cui ragioni di economia o una produzione di grande serie impediscono un’indagine estesa a tutte le unità prodotte, il gruppo “analisi statistiche” determina periodicamente la composizione e la numerosità del campione necessario per poter disporre di dati significativi e trarre delle conclusioni attendibili dalla loro analisi. La presenza di un settore specializzato nell’utilizzazione delle tecniche statistiche si rivela indispensabile in una direzione che voglia impostare un controllo basato su metodi moderni e scientificamente validi. Dal momento che raramente i responsabili dei servizi tecnici sono anche degli esperti di statistica, vi è la necessità di un gruppo di specialisti che si occupi di tali attività. Rientra tra le funzioni di questi esperti il progetto dei piani di esperimenti necessari a conoscere le caratteristiche di un prodotto con sufficiente attendibilità, cosi come la scelta della numerosità

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
11
del campione da sottoporre a prove per una valutazione significativa dell’affidabilità di un componente. Le tecniche di analisi statistica rappresentano degli strumenti fondamentali per il controllo e il miglioramento della qualità ma è necessario che queste siano considerate parte integrante di un sistema di gestione orientato alla qualità.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
12
CONCETTI E DEFINIZIONI IN RDA
Concetto di affidabilità Fino agli anni ’50, e per molti settori industriali anche più tardi, per qualità di un dispositivo si intendeva la conformità dei suoi parametri funzionali a certi valori prestabiliti senza alcuna implicazione della quantità tempo. Ciò non vuol dire che non ci si è preoccupato di assicurare il corretto funzionamento in esercizio del dispositivo per un congruo periodo di tempo. Anzi questo concetto è contemporaneo di quello di prodotto industriale ed è sottinteso in varie espressioni quali bontà del prodotto o più in generale qualità del dispositivo. Inoltre si sono sempre più sviluppate le procedure di assistenza tecnica al cliente, creando una corretta struttura logistica che va sotto il nome di manutenzione, avente appunto lo scopo di ripristinare il buon funzionamento del dispositivo ogni qualvolta esso manifesti un’interruzione, o quantomeno una degradazione insopportabile delle sue prestazioni. Tuttavia, sono proprio stati gli elevati costi di manutenzione, soprattutto in quegli impieghi in cui la disponibilità continuativa delle apparecchiature era particolarmente importante, a far sorgere la necessità di prevedere con sufficiente anticipo gli interventi di manutenzione e le azioni necessarie per ridurle a livelli economicamente convenienti. L’ambiente che per primo ha espresso questa esigenza è stato quello militare, soprattutto negli U.S.A. Sono stati pertanto gli enti di ricerca militari e quelli delle industrie fornitrici delle Forze Armate ad intraprendere per primi gli studi tendenti a prevedere in termini quantitativi e non più qualitativi il comportamento in esercizio di un dispositivo. E’ del 1952 la prima definizione, formulata da R. Lusser (S. Diego California), di questa nuova quantità, ormai universalmente conosciuta con il nome di affidabilità (in inglese Reliability): essa è la probabilità che un dispositivo adempi alla sua specifica funzione fino ad un determinato istante, in prefissate condizioni di impiego. Il 20 giugno 1958 esce la prima norma (military standard) sull’affidabilità e nel 1962 si pubblica il primo manuale sui parametri affidabilistici dei componenti elettronici di uso più comune. Nel frattempo anche le industrie elettroniche operanti nel settore civile manifestano una sempre maggiore sensibilità all’esigenza di assicurare e certificare determinati livelli di affidabilità, soprattutto per motivi di natura economica. Di conseguenza, tra il 1968 ed il 1969, vengono pubblicate le prime Raccomandazioni in materia in ambito civile. Ai nostri giorni, il vocabolo affidabilità è ormai entrato nel linguaggio corrente, sia tecnico che commerciale. Anzi esso è da tempo affiancato da altri termini esprimenti concetti direttamente collegati ad esso, quali la disponibilità, la manutenibilità e la prontezza.
Concetto di guasto Il periodo di regolare funzionamento di una unità si conclude quando un qualsiasi fenomeno fisico-chimico prodottosi in una o più delle sue parti componenti determina variazioni delle prestazioni nominali che l’utente ritiene insopportabili per l’uso che egli fa del dispositivo. Questa situazione va genericamente sotto il nome di guasto. L’istante in cui si determina il guasto, valutato a partire dal momento in cui l’unità è messa in esercizio, è detto tempo di guasto ed assume un’importanza fondamentale per la verifica del valore presunto dell’affidabilità e quindi della qualità globale dell’apparecchio. E’ il parametro fondamentale su cui vengono calcolate o misurate, sia direttamente che implicitamente, le proprietà affidabilistiche di un sistema. E’ essenziale quindi stabilire senza possibilità di equivoco il valore temporale nel quale sopravviene detto guasto. Purtroppo le modalità di guasto possono essere molteplici e manifestarsi in varia maniera con la conseguenza di non essere facilmente ed immediatamente rilevabili, presentando lente modificazioni ed andamenti irregolari nel tempo. I guasti sono

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
13
classificabili secondo vari criteri. La classificazione più importante può essere ritenuta quella secondo le cause che li provocano, ed in tal caso si distinguono: Guasti per impiego improprio, attribuibili all’applicazione di sollecitazioni superiori ai valori massimi ammissibili; Guasti dovuti a deficienza intrinseca, attribuibili a debolezze costruttive; Guasti primari, non provocati in alcun modo da mancanze di altri dispositivi; Guasti indotti, provocati da deficienze di altre unità; Guasti per usura, provocati da fenomeni di degradazione caratteristici dei materiali costituenti e la cui probabilità di occorrenza aumenta direttamente col tempo. Un secondo criterio di classificazione dei guasti si basa sulle loro conseguenze ed in tal caso si definiscono: Guasti critici, quando possono causare con alta probabilità danni alle persone o danni gravissimi ad altre parti del sistema; Guasti di primaria importanza, quando riducono sensibilmente la funzionalità del sistema; Guasti di secondaria importanza, quando non riducono la funzionalità del sistema. Un terzo criterio si basa sull’entità del guasto ed in tal caso distinguiamo: Guasti parziali, consistenti nella variazione di una o più prestazioni dei dispositivi ma tali da non impedire completamente il funzionamento dell’unità; Guasti totali, quando le prestazioni sono talmente diminuite da impedire il corretto funzionamento dell’unità; Guasti intermittenti, costituiti dalla successione generalmente casuale di periodi di funzionamento e non, senza che si intervenga con operazioni di manutenzione. Prendendo in considerazione la modalità temporale di manifestazione dei guasti distinguiamo: Guasti progressivi, quelli che sarebbe stato possibile prevedere con una rilevazione continuativa o periodica delle prestazioni dei dispositivi; Guasti improvvisi, quelli impossibili da prevedere. Combinando le ultime due classificazioni definiamo: Guasti per degradazione, quelli contemporaneamente progressivi e parziali; Guasti catastrofici, quelli improvvisi e totali.
Teoria e funzioni dell’affidabilità Il fine ultimo di uno studio affidabilistico è quello di prevedere la funzione temporale dell’affidabilità, o il valore di qualche parametro atto a rappresentarla in forma sintetica. Questo studio si avvale di due procedure che si integrano vicendevolmente. Una consiste nella determinazione per via sperimentale dei parametri dei componenti elementari impiegati nel settore tecnologico considerato; l’altra analizza il comportamento funzionale del sistema, applicando le teorie probabilistiche note o sviluppate ad hoc per tale disciplina. Come per qualsiasi grandezza fisica, quello che vorremmo conoscere è il vero valore del parametro affidabilistico relativo all’intera popolazione dell’unità considerata. Il metodo sperimentale deve pertanto fare ricorso a procedure statistiche. In molti casi esso viene attuato in laboratorio mediante prove simulanti le reali condizioni di impiego, eseguite su di un campione rappresentativo della popolazione dei dispositivi in esame oppure su un prototipo di un’apparecchiatura: si parla in tal caso di grandezze osservate. Per motivi economici risulta vantaggioso utilizzare anche i dati rilevabili durante l’impiego effettivo dei dispositivi: essi vengono raccolti in banche dati e sono detti grandezze di utilizzazione . Se i dati ottenuti per via sperimentale soddisfano a certe condizioni statistiche, al valore osservato è possibile associare un intervallo di variabilità relativo ad un prestabilito livello di confidenza: in tal caso si parla di grandezza valutata. Quando questi valori vengono utilizzati nelle leggi del calcolo combinatorio
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
14
per un sistema complesso, la caratteristica di affidabilità è detta grandezza di previs ione. Va infine indicato un ultimo criterio di specificazione, consistente nel valutare una grandezza affidabilistica in un certo periodo di tempo o in certe condizioni di sollecitazioni attraverso i dati sperimentali ottenuti in differenti periodi di tempo o per diversi valori di carico. Questa procedura, valida per determinate ipotesi tecniche e statistiche, definisce le grandezze estrapolate. Il comportamento di una unità durante il suo funzionamento è esprimibile quantitativamente mediante diverse funzioni temporali. Procedure matematiche e leggi statistiche stabiliscono relazioni analitiche tra queste funzioni in modo che la conoscenza di una permetta di ottenere tutte le altre. Le funzioni non possono essere valutate per l’intera popolazione, per motivi di rigore matematico si considereranno le grandezze osservate, rilevate sperimentalmente su un campione omogeneo e rappresentativo. Trattandosi di grandezze statistiche queste funzioni possono essere definite a priori attraverso le corrispondenti grandezze probabilistiche o di previsione, dando così origine a modelli matematici che trovano larghissimo impiego nella trattazione analitica dell’affidabilità. E’ importante rilevare che la grandezza osservata (nella maggioranza dei casi il tempo di guasto t) è una variabile aleatoria discontinua, essendo tale la sua modalità di rilevazione; la corrispondente grandezza di previsione è invece una variabile aleatoria continua (trattandosi di una generica popolazione di unità). Prendendo pertanto in esame un campione di componenti elementari, di grandezza No , sottoposta ad una o più sollecitazioni costanti, misuriamo i parametri funzionali di tutti gli elementi del campione fino ad individuare, per ognuno di essi, l’istante nel quale si verifica la condizione di guasto. Ad un generico tempo t saranno stati rilevati ng(t) elementi guasti mentre ns(t) elementi ancora funzionanti. La grandezza statistica fondamentale che rappresenta la distribuzione temporale dei guasti è la densità di frequenza dei guasti f*(t) individuata dal rapporto incrementale riferito all’intervallo di tempo finito δt :
tN
tnttntf
gg
δ
δ
*
)()()(*
0
−+= (1)
La corrispondente funzione teorica, o di previsione, è la funzione di densità di probabilità di guasto, deducibile dalla precedente facendo tendere δt a zero:
)()(
*)/1()(* 0lim0
tfdt
tdnNtf
g
t==
→δ (2)
L’andamento dei guasti nel tempo può essere descritto anche dalla funzione cumulativa, definita dal rapporto:
0
)()(*
N
tntF
g= (3)
La corrispondente funzione di previsione è fornita dall’integrale della (2.2):

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
15
∫=t
dttftF0
')'()( (4)
In campo affidabilistico la funzione F(t) esprime la probabilità P(t ≤ t’) che la variabile aleatoria tempo di guasto t di un elemento non superi t’. La F(t) è anche detta comunemente funzione di inaffidabilità. La probabilità complementare P(t > t’) è proprio l’affidabilità R(t) di quell’elemento e, poiché la probabilità totale dei due eventi è la certezza, dovrà valere in generale:
)
)()(*
)(1)(
1)()(
0N
tntR
tFtR
tFtR
s=
−=
=+
(5)
Una funzione particolarmente importante per il calcolo di R(t) è la funzione di azzardo, definita sperimentalmente dal rapporto incrementale:
ttn
ttntntz
s
ss
δ
δ
*)(
)()()(*
+−= (6)
La corrispondente funzione di previsione z(t) è definita come la probabilità che un elemento si guasti nell’intervallo ( t , t + δt ), condizionata all’ipotesi che esso risulti funzionante al tempo t, divisa per l’intervallo temporale considerato:
( ) ( )[ ]t
ttttttPtttz
δ
δδ
>+≤<=+
/),( (7)
Il soprassegno della funzione sta ad indicare che si tratta di un valore medio relativo all’intervallo δt. Tra la funzione di azzardo e le altre funzioni di previsione già definite sussistono precise relazioni analitiche che ora andremo ad esplicitare. Il numeratore della (7) è esprimibile nella forma:
( ) ( )[ ] ( )( )ttP
ttttPttttttP
>
+≤<=>+≤<
δδ /
ovvero la probabilità condizionata è il rapporto tra i casi favorevoli (guasti in δt) e i casi possibili (guasti dopo l’is tante t). Dalla (2.4) si deduce che la probabilità assoluta è calcolabile con l’integrale:
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
16
∫+
+−=−+==+≤<tt
t
ttRtRtFttFdttfttttP
δ
δδδ )()()()(')'()(
Vale inoltre:
)()( tRttP => La (2.7) diviene pertanto:
ttR
ttRtRtttz
δ
δδ
*)(
)()(),(
+−=+
Il valore istantaneo della funzione di azzardo, detto tasso di guasto z(t) sarà dato dal limite:
dt
tdR
tRt
ttRtR
tRtz
t
)(*
)(
1)()(
)(
1)( lim
0−=
+−=
→ δ
δ
δ
Riscrivendo questa relazione nella forma
dttztR
tdR)(
)(
)(−=
si ottiene un’equazione differenziale che, integrata per parti, fornisce la soluzione generale:
−= ∫
t
dttztR0
')'(exp)(
(8) Questa espressione costituisce la legge fondamentale e generale che consente di calcolare la funzione di affidabilità partendo dalla conoscenza, o quanto meno da un’ipotesi, sulla funzione di azzardo. Dalle relazioni (4) e (5) discende:
dt
tdRtR
dt
d
dt
tdFtf
)())(1(
)()( −=−==
Ricordando la formula di z(t) si ottiene il risultato:
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
17
)(
)()(
)(*)()(
tR
tftz
tRtztf
=
=
(9)
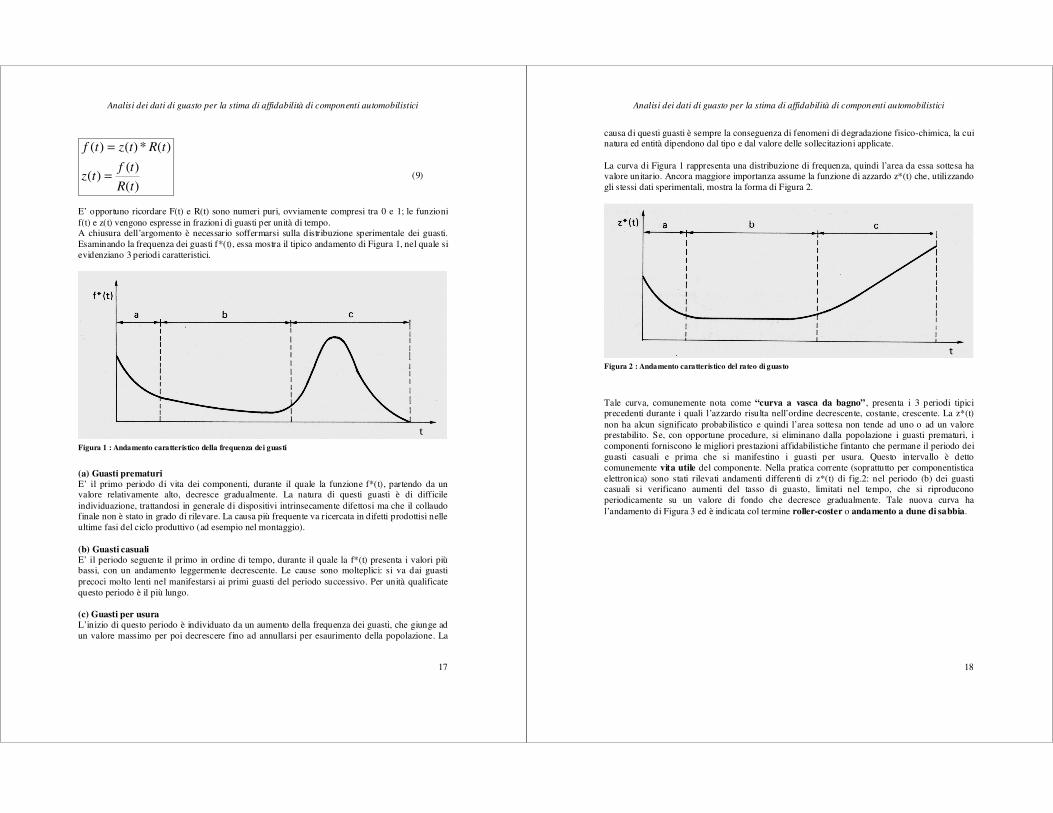
E’ opportuno ricordare F(t) e R(t) sono numeri puri, ovviamente compresi tra 0 e 1; le funzioni f(t) e z(t) vengono espresse in frazioni di guasti per unità di tempo. A chiusura dell’argomento è necessario soffermarsi sulla distribuzione sperimentale dei guasti. Esaminando la frequenza dei guasti f*(t), essa mostra il tipico andamento di Figura 1, nel quale si evidenziano 3 periodi caratteristici.
Figura 1 : Andamento caratteristico della frequenza dei guasti
(a) Guasti prematuri E’ il primo periodo di vita dei componenti, durante il quale la funzione f*(t), partendo da un valore relativamente alto, decresce gradualmente. La natura di questi guasti è di difficile individuazione, trattandosi in generale di dispositivi intrinsecamente difettosi ma che il collaudo finale non è stato in grado di rilevare. La causa più frequente va ricercata in difetti prodottisi nelle ultime fasi del ciclo produttivo (ad esempio nel montaggio). (b) Guasti casuali E’ il periodo seguente il primo in ordine di tempo, durante il quale la f*(t) presenta i valori più bassi, con un andamento leggermente decrescente. Le cause sono molteplici: si va dai guasti precoci molto lenti nel manifestarsi ai primi guasti del periodo successivo. Per unità qualificate questo periodo è il più lungo. (c) Guasti per usura L’inizio di questo periodo è individuato da un aumento della frequenza dei guasti, che giunge ad un valore massimo per poi decrescere fino ad annullarsi per esaurimento della popolazione. La
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
18
causa di questi guasti è sempre la conseguenza di fenomeni di degradazione fisico-chimica, la cui natura ed entità dipendono dal tipo e dal valore delle sollecitazioni applicate. La curva di Figura 1 rappresenta una distribuzione di frequenza, quindi l’area da essa sottesa ha valore unitario. Ancora maggiore importanza assume la funzione di azzardo z*(t) che, utilizzando gli stessi dati sperimentali, mostra la forma di Figura 2.
Figura 2 : Andamento caratteristico del rateo di guasto
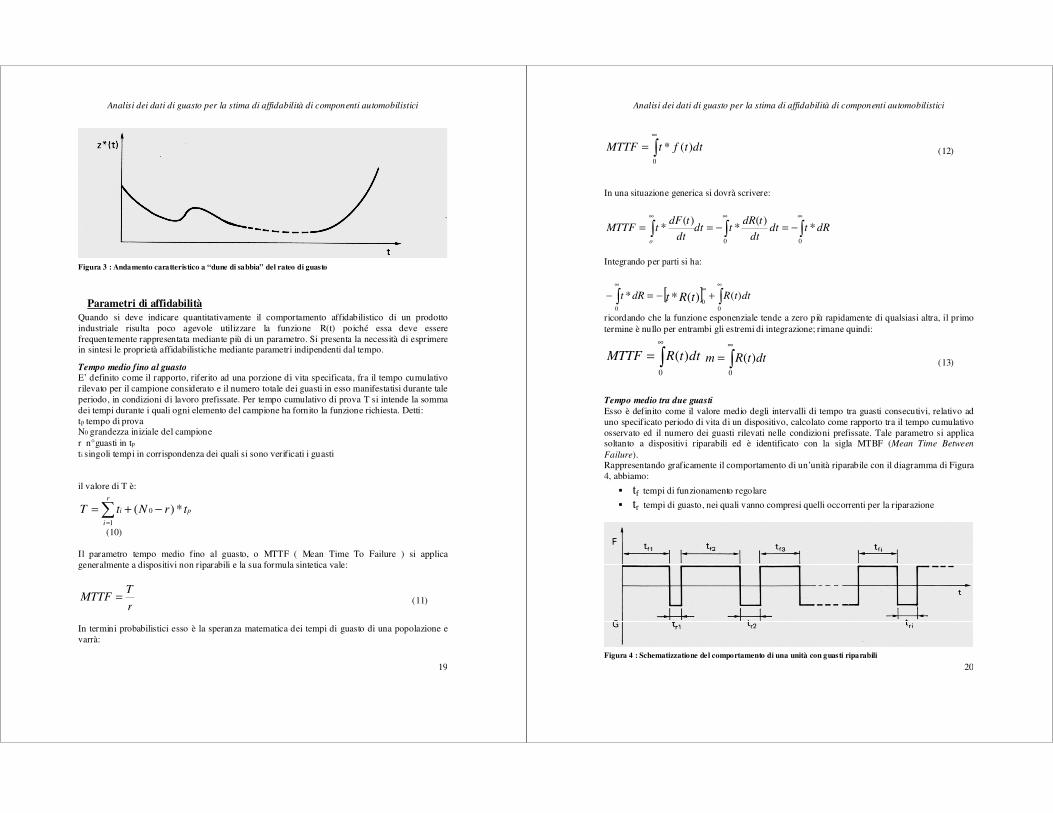
Tale curva, comunemente nota come “curva a vasca da bagno” , presenta i 3 periodi tipici precedenti durante i quali l’azzardo risulta nell’ordine decrescente, costante, crescente. La z*(t) non ha alcun significato probabilistico e quindi l’area sottesa non tende ad uno o ad un valore prestabilito. Se, con opportune procedure, si eliminano dalla popolazione i guasti prematuri, i componenti forniscono le migliori prestazioni affidabilistiche fintanto che permane il periodo dei guasti casuali e prima che si manifestino i guasti per usura. Questo intervallo è detto comunemente vita utile del componente. Nella pratica corrente (soprattutto per componentistica elettronica) sono stati rilevati andamenti differenti di z*(t) di fig.2: nel periodo (b) dei guasti casuali si verificano aumenti del tasso di guasto, limitati nel tempo, che si riproducono periodicamente su un valore di fondo che decresce gradualmente. Tale nuova curva ha l’andamento di Figura 3 ed è indicata col termine roller-coster o andamento a dune di sabbia.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
19
Figura 3 : Andamento caratteristico a “dune di sabbia” del rateo di guasto
Parametri di affidabilità Quando si deve indicare quantitativamente il comportamento affidabilistico di un prodotto industriale risulta poco agevole utilizzare la funzione R(t) poiché essa deve essere frequentemente rappresentata mediante più di un parametro. Si presenta la necessità di esprimere in sintesi le proprietà affidabilistiche mediante parametri indipendenti dal tempo.
Tempo medio fino al guasto E’ definito come il rapporto, riferito ad una porzione di vita specificata, fra il tempo cumulativo rilevato per il campione considerato e il numero totale dei guasti in esso manifestatisi durante tale periodo, in condizioni di lavoro prefissate. Per tempo cumulativo di prova T si intende la somma dei tempi durante i quali ogni elemento del campione ha fornito la funzione richiesta. Detti: tp tempo di prova N0 grandezza iniziale del campione r n°guasti in tp ti singoli tempi in corrispondenza dei quali si sono verificati i guasti il valore di T è:
∑=
−+=r
i
pi trNtT1
0 *)(
(10) Il parametro tempo medio fino al guasto, o MTTF ( Mean Time To Failure ) si applica generalmente a dispositivi non riparabili e la sua formula sintetica vale:
r
TMTTF = (11)
In termini probabilistici esso è la speranza matematica dei tempi di guasto di una popolazione e varrà:
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
20
∫∞
=0
)(* dttftMTTF (12)
In una situazione generica si dovrà scrivere:
∫ ∫∫∞ ∞∞
−=−==0 0
*)(
*)(
* dRtdtdt
tdRtdt
dt
tdFtMTTF
o
Integrando per parti si ha:
[ ] ∫∫∞∞
∞
+−=−00
0)(* )(* dttRdRt tRt
ricordando che la funzione esponenziale tende a zero più rapidamente di qualsiasi altra, il primo termine è nullo per entrambi gli estremi di integrazione; rimane quindi:
∫∞
=0
)( dttRMTTF ∫∞
=0
)( dttRm (13)
Tempo medio tra due guasti
Esso è definito come il valore medio degli intervalli di tempo tra guasti consecutivi, relativo ad uno specificato periodo di vita di un dispositivo, calcolato come rapporto tra il tempo cumulativo osservato ed il numero dei guasti rilevati nelle condizioni prefissate. Tale parametro si applica soltanto a dispositivi riparabili ed è identificato con la sigla MTBF (Mean Time Between
Failure). Rappresentando graficamente il comportamento di un’unità riparabile con il diagramma di Figura 4, abbiamo:
� tf tempi di funzionamento regolare
� tr tempi di guasto, nei quali vanno compresi quelli occorrenti per la riparazione
Figura 4 : Schematizzatione del comportamento di una unità con guasti riparabili

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
21
Con questo simbolismo si otterrà un’espressione del tipo:
∑=
=r
i
fitr
MTBF1
*1
(14)
Tempo medio di riparazione e disponibilità
Osservando la fig. 4 si può rilavare che ogni intervallo di tempo tr include tutte quelle operazioni logistiche e amministrative che concorrono a ripristinare la funzionalità dell’unità danneggiata. L’insieme di tali azioni è indicato col termine manutenzione e l’attitudine di un dispositivo a facilitare tale operazione è detta manutenibilità. Si può stabilire un valore medio degli intervalli di riparazione, detto appunto tempo medio di riparazione o MTTR ( Mean Time To Repair ); esso è dato dalla formula:
∑=
=r
i
ritr
MTTR1
*1
(15)
Esso rappresenta un indice della manutenibilità del dispositivo ed è conveniente che tale parametro risulti molto minore del corrispondente valore del MTBF. Per esprimere quantitativamente questo concetto si fa ricorso ad un valore probabilistico: la disponibilità, una funzione del tempo definita come probabilità che una unità sia funzionante al tempo t, in determinate condizioni di impiego. Come si può notare, manca la condizione di funzionamento fino al tempo t contenuto nel concesso di affidabilità, e pertanto è ammesso che tale dispositivo possa risultare guasto in certi periodi della sua vita. Questa nuova funzione è indicata con il simbolo A(t) (Availability), parte da un valore unitario per tendere, per tempi molto grandi, ad un valore minimo costante fornito dal rapporto:
MTTRMTBF
MTBFA
+=∞)( (16)
Problemi statistici in affidabilità Poiché i dati relativi alle durate di vita di un componente si esprimono nella loro generalità come valori del tempo sino al momento di guasto, ciò crea un ordinamento dei dati che pone condizioni alla completa casualità del campionamento e impone alla teoria statistica di scegliere particolari strade nella ricerca delle soluzioni ai problemi stessi. Se, infatti, si vuol conoscere qualche aspetto della distribuzione (forma e valore dei parametri) che regola la durata di vita di una determinata unità, si ha naturalmente che i tempi di guasto, raccolti osservando una collettività di elementi in prova di funzionamento, costituiscono una sequenza ordinata di valori t1≤t2≤t3≤…≤tn dove t1 è il tempo di guasto del primo elemento e tn quello dell’n-esimo. Ciò mette in luce la particolare situazione dei problemi statistici in affidabilità: gli insiemi dei dati rilevati sono ordinati poiché il successivo valore nella rilevazione è certamente più grande del precedente. Un aspetto che particolarizza i problemi statistici in affidabilità è quello che, succedendosi nel tempo la rilevazione dei dati, il tempo necessario alla rilevazione stessa rappresenta un fattore di
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
22
costo delle informazioni di importanza fondamentale. Per la metodologia statistica ciò significa dover sviluppare procedure di stima e controllo delle ipotesi che si basano su informazioni relative soltanto ad una parte dei risultati che si potrebbero avere aspettando che tutte le unità di un campione di n elementi siano giunte al momento del guasto. Il problema che normalmente si pone è di esprimere una valutazione sulla probabilità che l’elemento del tipo considerato operi senza guasti, per un numero di ore maggiore di quello per le quali si è tenuto in osservazione e si sono ottenute informazioni. Esistono 2 tipi di approcci per condurre alla soluzione di tali problematiche. Il primo è quello di assumere che esiste una relazione conosciuta fra i tempi di guasto dell’elemento sotto accelerate condizioni di prova e i tempi di guasto nelle condizioni operative normali dell’elemento stesso. In termini semplicistici si potrebbe assumere che, se le normali condizioni operative danno luogo ad un certo numero di guasti in un certo tempo, portando tali condizioni ad un livello di sforzo doppio del normale, se la relazione che lega i tempi di guasto è lineare, si dovrebbe avere un numero doppio di guasti nel medesimo tempo. Purtroppo in realtà non è sempre facile ricavare dette relazioni e, elemento forse ancora più importante, tali espressioni funzionali sono limitate a ristretti casi di utilizzo sperimentali, impedendo così il formarsi di una metodologia generale. L’altro tipo di approccio è quello di presupporre come nota la forma della distribuzione della durata di vita dell’elemento e su questa assunzione basare l’analisi e le induzioni che dai dati campionari si possono trarre. Il processo logico è quello di scegliere, in base ad un giudizio tecnico o ad una verifica campionaria di ipotesi (test di adattamento), il modello probabilistico che meglio rappresenta la distribuzione di probabilità delle durate di vita dell’elemento e, poi, adottare procedure di stima e di controllo di ipotesi sui diversi parametri che possono esprimere l’affidabilità nel tempo dell’unità in esame.
Rilevazione e rappresentazione dei dati I dati empirici che si possono trarre da una prova sperimentale permettono di individuare il tempo esatto del guasto dei diversi elementi guastatisi in una popolazione di individui; oppure il numero di elementi che si sono guastati entro certi intervalli di tempo al termine dei quali si effettua la verifica di funzionamento degli stessi. E’ molto importante la scelta del campione: esso deve essere prelevato a caso dalla popolazione che interessa per lo studio specifico (se così non è occorre sapere in quale misura esso rappresenta la popolazione in esame e quanto ci si possa fidare delle informazioni ottenibili); deve essere significativo nel numero degli elementi da osservare; deve essere stocastico, cioè deve esistere la stessa probabilità di trovare tutti gli attributi in questione nella popolazione dal quale viene prelevato. Prescindendo per il momento dal considerare le modalità di rilevazione, se si prendono in considerazione N elementi, posti in condizioni di prova al tempo t=0, ed all’avanzare della variabile tempo si registrano i valori di n(t), numero dei sopravviventi al tempo t, è possibile definire la funzione di densità empirica di guasto relativamente ad un intervallo di tempo (ti, ti+∆ti), data dal rapporto tra il numero dei guasti che avvengono nell’intervallo e il numero N degli elementi sottoposti alla prova, espresso in termini della lunghezza dell’intervallo considerato:
i
iii
tN
ttntntf
∆
∆+−=
*
)()()( (17)
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
23
Inoltre si può definire la funzione tasso di guasto empirica nell’intervallo (ti,ti+∆ti) come rapporto tra il numero dei guasti nell’intervallo e il numero degli elementi funzionanti all’inizio dell’intervallo stesso, espresso in termini di lunghezza dell’intervallo:
ii
iii
ttn
ttntnt
∆
∆+−=
*)(
)()()(λ (18)
Analogamente si possono definire le funzioni di inaffidabilità e affidabilità empiriche:
N
tntFtR
N
tnNdssftF
t
)()(1)(
)()()(
0
=−=
−== ∫
(19)
La funzione che rappresenta il numero dei guasti sino al tempo t è:
)()( tnNtd −=
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
24
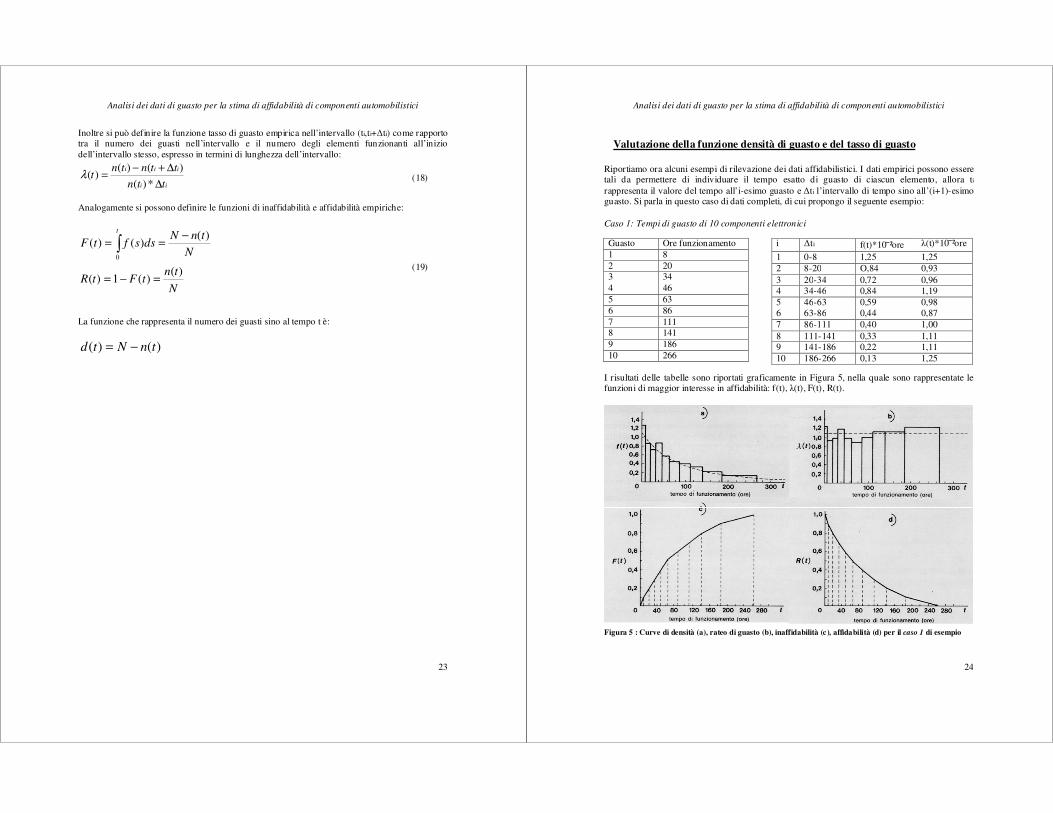
Valutazione della funzione densità di guasto e del tasso di guasto Riportiamo ora alcuni esempi di rilevazione dei dati affidabilistici. I dati empirici possono essere tali da permettere di individuare il tempo esatto di guasto di ciascun elemento, allora ti rappresenta il valore del tempo all’i-esimo guasto e ∆ti l’intervallo di tempo sino all’(i+1)-esimo guasto. Si parla in questo caso di dati completi, di cui propongo il seguente esempio: Caso 1: Tempi di guasto di 10 componenti elettronici
I risultati delle tabelle sono riportati graficamente in Figura 5, nella quale sono rappresentate le funzioni di maggior interesse in affidabilità: f(t), λ(t), F(t), R(t).
Figura 5 : Curve di densità (a), rateo di guasto (b), inaffidabilità (c), affidabilità (d) per il caso 1 di esempio
Guasto Ore funzionamento 1 8 2 20 3 34 4 46 5 63 6 86 7 111 8 141 9 186 10 266
i ∆ti f(t)*10²ore λ(t)*10²ore
1 0-8 1,25 1,25 2 8-20 O,84 0,93 3 20-34 0,72 0,96 4 34-46 0,84 1,19 5 46-63 0,59 0,98 6 63-86 0,44 0,87 7 86-111 0,40 1,00 8 111-141 0,33 1,11 9 141-186 0,22 1,11 10 186-266 0,13 1,25
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
25
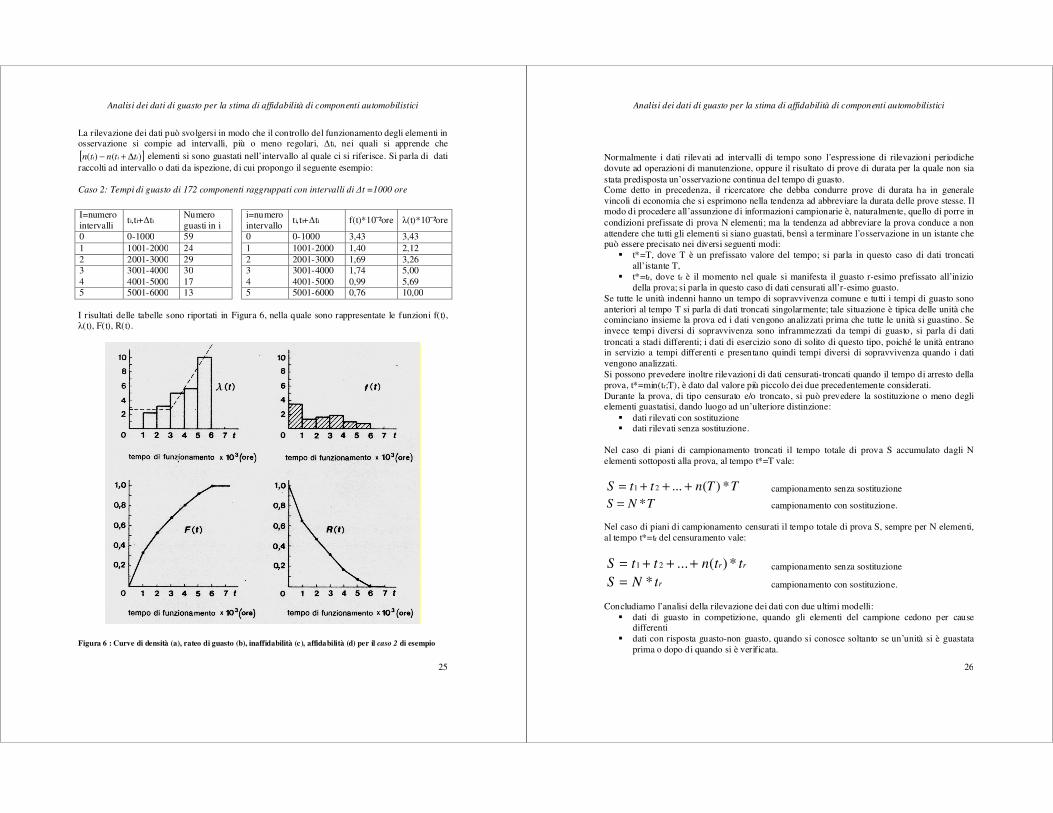
La rilevazione dei dati può svolgersi in modo che il controllo del funzionamento degli elementi in osservazione si compie ad intervalli, più o meno regolari, ∆ti, nei quali si apprende che [ ])()( iii ttntn ∆+− elementi si sono guastati nell’intervallo al quale ci si riferisce. Si parla di dati raccolti ad intervallo o dati da ispezione, di cui propongo il seguente esempio: Caso 2: Tempi di guasto di 172 componenti raggruppati con intervalli di ∆t =1000 ore
I risultati delle tabelle sono riportati in Figura 6, nella quale sono rappresentate le funzioni f(t), λ(t), F(t), R(t).
Figura 6 : Curve di densità (a), rateo di guasto (b), inaffidabilità (c), affidabilità (d) per il caso 2 di esempio
I=numero intervalli
ti,ti+∆ti Numero guasti in i
0 0-1000 59 1 1001-2000 24 2 2001-3000 29 3 3001-4000 30 4 4001-5000 17 5 5001-6000 13
i=numero intervallo
ti,ti+∆ti f(t)*10²ore λ(t)*10²ore
0 0-1000 3,43 3,43 1 1001-2000 1,40 2,12 2 2001-3000 1,69 3,26 3 3001-4000 1,74 5,00 4 4001-5000 0,99 5,69 5 5001-6000 0,76 10,00
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
26
Normalmente i dati rilevati ad intervalli di tempo sono l’espressione di rilevazioni periodiche dovute ad operazioni di manutenzione, oppure il risultato di prove di durata per la quale non sia stata predisposta un’osservazione continua del tempo di guasto. Come detto in precedenza, il ricercatore che debba condurre prove di durata ha in generale vincoli di economia che si esprimono nella tendenza ad abbreviare la durata delle prove stesse. Il modo di procedere all’assunzione di informazioni campionarie è, naturalmente, quello di porre in condizioni prefissate di prova N elementi; ma la tendenza ad abbreviare la prova conduce a non attendere che tutti gli elementi si siano guastati, bensì a terminare l’osservazione in un istante che può essere precisato nei diversi seguenti modi:
� t*=T, dove T è un prefissato valore del tempo; si parla in questo caso di dati troncati all’istante T,
� t*=tr, dove tr è il momento nel quale si manifesta il guasto r-esimo prefissato all’inizio della prova; si parla in questo caso di dati censurati all’r-esimo guasto.
Se tutte le unità indenni hanno un tempo di sopravvivenza comune e tutti i tempi di guasto sono anteriori al tempo T si parla di dati troncati singolarmente; tale situazione è tipica delle unità che cominciano insieme la prova ed i dati vengono analizzati prima che tutte le unità si guastino. Se invece tempi diversi di sopravvivenza sono inframmezzati da tempi di guasto, si parla di dati troncati a stadi differenti; i dati di esercizio sono di solito di questo tipo, poiché le unità entrano in servizio a tempi differenti e presentano quindi tempi diversi di sopravvivenza quando i dati vengono analizzati. Si possono prevedere inoltre rilevazioni di dati censurati-troncati quando il tempo di arresto della prova, t*=min(tr;T), è dato dal valore più piccolo dei due precedentemente considerati. Durante la prova, di tipo censurato e/o troncato, si può prevedere la sostituzione o meno degli elementi guastatisi, dando luogo ad un’ulteriore distinzione:
� dati rilevati con sostituzione � dati rilevati senza sostituzione.
Nel caso di piani di campionamento troncati il tempo totale di prova S accumulato dagli N elementi sottoposti alla prova, al tempo t*=T vale:
TTnttS *)(...21 +++= campionamento senza sostituzione
TNS *= campionamento con sostituzione. Nel caso di piani di campionamento censurati il tempo totale di prova S, sempre per N elementi, al tempo t*=tr del censuramento vale:
rr ttnttS *)(...21 +++= campionamento senza sostituzione
rtNS *= campionamento con sostituzione. Concludiamo l’analisi della rilevazione dei dati con due ultimi modelli:
� dati di guasto in competizione, quando gli elementi del campione cedono per cause differenti
� dati con risposta guasto-non guasto, quando si conosce soltanto se un’unità si è guastata prima o dopo di quando si è verificata.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
27
A corredo di quanto illustrato raccogliamo tutte le informazioni citate nei grafici di Figura 7.
Figura 7 : Esempi di piani di campionamento troncati
Ricordiamo infine che l’analisi dei dati non fornisce decisioni; essa dà soltanto informazioni numeriche a coloro che dovranno prendere tali decisioni. Se questi ultimi sono in difficoltà nello specificare le informazioni numeriche di cui hanno bisogno, essi dovrebbero immaginare di avere a disposizione tutti i dati della popolazione e quindi decidere quali valori calcolati dei dati sarebbero utili. L’analisi dei dati porta a stime di questi valori della popolazione partendo da piccoli campioni.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
28
ANALISI NON PARAMETRICA
Cos’è un’analisi non parametrica. Volendo dare una semplice definizione potremmo dire che un analisi non parametrica è una procedura statistica che riesce ad ottenere risultati di una certa accuratezza pur basandosi su assunzioni non troppo forti relativamente alla popolazione da cui sono stati ottenuti i dati. Ciò permette alle informazioni di passare attraverso le analisi senza subire le inevitabili distorsioni che si avrebbero facendo ipotesi errate o troppo restrittive sui modelli che si assumono possano descrivere la popolazione oggetto di studio. In alcuni casi un analisi non parametrica può fornirci tutte le informazioni che ci servono con la giusta approssimazione, mentre altre volte l’analisi non parametrica rappresenta solo un primo passo in un’analisi che porterà a inferenze più estese e precise sfruttando ipotesi e modelli più complessi. Il rapido e continuo sviluppo di procedure statistiche non parametriche è dovuto ai seguenti vantaggi ottenibili da tecniche non parametriche:
� come detto esse richiedono poche e poco vincolanti assunzioni sulla popolazione oggetto di studio: in particolare tali procedure non contemplano la tradizionale ipotesi che la popolazione da studiare sia normale;
� i metodi non parametrici permettono di ottenere valori esatti per le grandezze da stimare e per i relativi intervalli di confidenza, sempre tralasciando l’ipotesi di normalità della popolazione;
� le tecniche non parametriche sono spesso (anche se non sempre) più facili da usare rispetto alle tecniche che richiedono l’assunzione di modelli;
� inoltre esse sono spesso più intuitive e semplici da capire; � studi teorici hanno dimostrato che analisi non parametriche sono leggermente meno
efficienti delle parametriche quando le popolazioni analizzate sono di tipo normale ma possono arrivare ad essere notevolmente più precise quando le popolazioni sottostanti la statistica non sono normali;
� i metodi non parametrici sono relativamente insensibili alle osservazioni esterne; � le procedure non parametriche possono essere utilizzate in molte situazioni dove le
procedure basate sulle teorie normali non sono applicabili; � lo sviluppo di software ha facilitato l’aspetto computazionale di molti tests non
parametrici facendo in modo che i risultati ottenuti siano molto precisi e non gravati da intervalli di incertezza troppo elevati.
Definizioni preliminari La maggior parte dei processi di guasto nel tempo sono modellati su scala continua ma a causa delle limitazioni nell’accuratezza delle misure i tempi di rottura sono sempre discreti. Conviene allora suddividere l’intero arco di tempo in m+1 intervalli di osservazione che possono essere espressi nella maniera seguente:
(t0,t1], (t1,t2], …, (tm-1,tm], (tm,tm+1]

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
29
dove t0 = 0 e tm+1 = ∞. In generale, questi intervalli non hanno bisogno di essere di uguale lunghezza, e l’ultimo è di lunghezza infinita. Sull’asse dei tempi è anche indicata per ciascun intervallo la grandezza πi = Pr ( ti-1 < T ≤ ti ) = F(ti) – F(ti-1) che indica la probabilità che un’unità fallisca nell’intervallo i. Con T si indica la variabile continua non negativa e casuale che descrive il tempo di rottura di un unità o di un sistema.
Nota che π i ≥ 0 e ∑+
==
1
11
m
j jπ . La funzione di sopravvivenza valutata al tempo ti è
S(ti) = Pr(T>ti) = 1-F(ti) =∑+
+=
1
1
m
ij jπ .
Definiamo anche
pi = Pr ( ti-1 < T ≤ ti T > ti-1) = )()(1
)()(
11
1
−−
− =−
−
i
i
i
ii
tStF
tFtF π
come la probabilità condizionata che un’unità si rompa nell’intervallo i, ovvero la probabilità che l’unità si rompa nell’intervallo i condizionata al fatto che essa sia arrivata all’inizio dell’intervallo i stesso. Allora sarà pm+1= 1 e solo per una restrizione pi su p1, …, pm si avrà 0≤pi≤1. Data questa definizione di pi si può dimostrare che
( ) [ ]∏=
−=i
j
ji ptS1
1 i = 1, 2, …, m+1
La funzione di distribuzione cumulativa dei tempi di guasto, valutata al tempo ti, può essere espressa come:
[ ]∏=
−−=i
j
jiptF
1
11)( i = 1, 2, …, m+1
o come:
( ) ∑=
=i
j
jitF1
π i = 1, 2, …, m+1
Così π = (π1, …, πm+1) o p = (p1, …,pm+1) sono insiemi di parametri di base equivalenti del modello discreto dei dati relativi ai tempi di guasto.
Concetti di base sulla statistica inferenziale
Una stima, come può essere la ( )itF , ricavata da un certo numero di dati può essere interpretata in due diversi modi:
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
30
� come una semplice descrizione di quel particolare gruppo di dati (statistica descrittiva); � più comunemente la stima viene usata per fare inferenze su un processo o sulla
popolazione più grande da cui il campione è estratto in maniera casuale (inferenza statistica).
Nell’inferenza statistica una stima differirà dal valore reale della popolazione oggetto di studio per una certa quantità. I metodi standard per studiare l’entità di questa differenza consistono nel considerare cosa succederebbe se la stessa procedura inferenziale fosse ripetuta per un gran numero di volte,prendendo campioni diversi e ottenendo ogni volta dei valori differenti per la grandezza da stimare. La stima di un valore puntuale da sola può risultare fuorviante in quanto può essere più o meno vicina alla reale quantità che stiamo stimando. Gli intervalli di confidenza sono uno degli strumenti più utili per quantificare l’incertezza dovuta a errori di campionamento che nascono di solito a causa della presenza di campioni di grandezza troppo limitata. Comunque generalmente gli intervalli di confidenza non quantificano gli errori che derivano da un modello inadeguato o da errate ipotesi su di esso. Tali intervalli hanno uno specifico “livello di confidenza”, di solito 90-95%, che esprime appunto il grado di accuratezza con cui l’intervallo considerato stima il valore che ci interessa. Cosa diversa è invece la probabilità che tale intervallo di confidenza possa contenere il vero valore che ci interessa.
Stime non parametriche per dati non censurati Molti studi richiedono ispezioni in un determinato istante t di un iniziale campione di unità a tempo zero. L’informazione su queste unità è disponibile solo allo stato finale di un intervallo di tempo,non possiamo quindi risalire all’istante preciso in cui viene a verificarsi la rottura. Sia n è il numero iniziale di unità (taglia del campione) e d i il numero di unità guaste nell’i-esimo
intervallo (ti-1,ti]. Lo stimatore non parametrico ( )itF basato sulla semplice distribuzione binomiale, è:
( )n
dtF
i
j j
i
∑ ==
1ˆ
dove ∑ =
i
j jd
1 è il numero di guasti al tempo ti.
Il corrispondente stimatore non parametrico di S(t) è:
( ) ( )ii tFtS ˆ1ˆ −=
Limiti di confidenza per dati binomiali
I limiti di confidenza bilaterali al 100(1-α)% per F(ti ) basata su dati binomiali saranno:
( )itF =
1
ˆƒ)1ˆ(
1)ˆ2,2ˆ22;2/1(
−
+−
++−−
Fn
Fnn FnFnnα

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
31
( )itF = 1
)ˆ22,2ˆ2;2/1(ƒ)1ˆ(
ˆ1
−
+
−+
−+− FnnFnFn
Fnn
α
dove F = ( )itF e 2;1;(ƒ vvp è il p-quantile della distribuzione F (binomiale) con ( 21,vv ) gradi di
libertà (queste informazioni possono essere agevolmente trovate sui testi di statistica).
Dati poissoniani Nel caso ci trovassimo ad operare con dati poissoniani (ad esempio il numero di eventi Y in un dato periodo t di osservazione) e volessimo provare a stimare la densità degli eventi,λ, avremo:
λ = Y/t e Var( λ ) = λ/t I limiti di confidenza al 100γ% bilaterali per il valore vero di λ sono:
( )[ ] tY /2;2/15.0 2 γχλ −=
( )[ ] tY /22;2/15.0 2 ++= γχλ
dove 2χ [ ]νσ ; è il σ percentile del 2χ con ν gradi di libertà.
Stime non parametriche per dati censurati Molto spesso,come visto nel precedente capitolo, ci troviamo di fronte a dati censurati o troncati e diventa quindi importante saper gestire anche situazione di questo genere,riuscendo ad elaborare una stima non parametrica di una funzione di distribuzione cumulativa proveniente da dati con censura. Supponiamo che un iniziale campione di n unità inizia a operare a tempo zero. Se un’unità non si guasta nell’intervallo i, è censurata alla fine dell’intervallo i oppure continua ad operare nell’intervallo i+1. Le informazioni sullo stato delle unità sono disponibili alla fine di ogni intervallo. Questi intervalli possono essere ampi o stretti e non è necessario che siano tutti della stessa lunghezza, purché non si sovrappongano. Denotiamo con di il numero di unità che si rompono nell’intervallo i-esimo (ti-1,ti] e con ri il numero di unità che sopravvivono all’intervallo i. Le unità che sono vive all’inizio dell’intervallo i sono chiamate risk-set per l’intervallo i e la grandezza di questo risk-set all’inizio di un dato i è:
∑∑−
=
−
=
−−=1
0
1
0
i
j
j
i
j
jirdnn i = 1, 2, …, m
dove m è il numero di intervalli ed è inteso che d0=0 e r0=0. Uno stimatore della probabilità condizionata di fallire nell’intervallo i, dato che un unità fa parte di questo intervallo, è la percentuale del campione che si guasta, cioè:
i
i
in
dp =ˆ i = 1, 2, …, m
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
32
Sostituendo questa espressione in quella che definisce S(ti) si ottiene uno stimatore della funzione di sopravvivenza, cioè:
( ) [ ]∏=
−=i
j
ji ptS1
ˆ1ˆ i = 1, 2, …, m
e di conseguenza si può ricavare il corrispondente stimatore non parametrico di F(t) :
( ) ( )ii tStF ˆ1ˆ −= i = 1, 2, …, m
Lo stimatore ( )itF è definito per tutti i valori ti (punti finali di tutti gli intervalli di osservazione).
Si avrà quindi che se l’intervallo i non contiene guasti, allora ( )itF = ( )1ˆ
−itF per ti-1 ≤ t ≤ ti; se
invece l’intervallo i contiene uno o più guasti, ( )tF cresce da ( )1ˆ
−itF a ( )itF nell’intervallo (ti-1,ti]. Per determinare questi intervalli di confidenza è necessario definire alcune grandezze. Dato che
( ) ( )ii tStF ˆ1ˆ −= Allora avremo che
Var[ ( )itF ] = Var[ ( )itS ].
un’approssimazione in serie di Taylor del primo ordine di ( )itS usando il metodo delta:
( )itS ( ) ( )jjq
i
j j
iqq
q
StS
j−
∂
∂+≈ ∑
=
ˆ1
dove qj= 1-p j.
Poiché i valori jq sono approssimativamente percentuali binomiali non correlate, segue che:
( )[ ] ( )[ ] ( )[ ] ( )∑= −
≈=i
j jj
j
iiipn
ptStSVartFVar
1
2
1ˆˆ .
Sostituendo jp con pj e ( )itS con ( )itS si ha il seguente stimatore di varianza:
( )[ ] ( )[ ] ( )[ ] ( )∑= −
==i
j jj
j
iiipn
ptStSarVtFarV
1
2
ˆ1
ˆˆˆˆˆˆ
Questa è conosciuta come formula di Greenwood.
Uno stimatore dell’errore standard di ( )itF è:
)](ˆ[ˆˆ ˆ iFtFarVes =

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
33
Poiché ( )tF è definita solamente nel punto massimo dell’intervallo che contiene guasti, ( )tF è
generalmente stimata su qualche punto (se in un intervallo non ci sono guasti ( )tF rimane costante su tutto l’intervallo). Per il punto massimo ti di (ti-1,ti] al quale una stima è desiderata, un’approssimazione normale al 100(1-α)% dell’intervallo di confidenza per ( )itF è:
( ) ( )[ ] ( ) ( ) Fiii esztFtFtF ˆ21 ˆˆ, α−±=
dove z(p) è il p-quartile della distribuzione normale standard. In generale, un limite di confidenza unilaterale al 100(1-α)% approssimato può essere ottenuto sostituendo ( )21 α−z con ( )α−1z e usando l’appropriato punto finale dell’intervallo di confidenza
bilaterale (per α= 0.05 z(0.975)= 1.960). L’intervallo di confidenza approssimato precedentemente calcolato è basato sull’assunzione che la distribuzione di:
( ) ( )
F
ii
F es
tFtFZ
ˆˆ ˆ
ˆ −=
può essere approssimata adeguatamente da NOR(0,1) (distribuzione normale standard). Quindi:
( ) ( )[ ] ααα −≈≤< − 1Pr 21ˆ2 zZzF
implica che :
( ) ( ) ( ) ( ) ( )[ ] ααα −≈−≤<− − 1ˆˆˆˆPr ˆ2ˆ21 FiiFiesztFtFesztF
Questo è l’intervallo zona di probabilità approssimata per l’intervallo calcolato. L’approssimazione di quest’ultima espressione è valida per un campione ampio e migliora con l’aumentare della taglia del campione stesso. Quando la taglia del campione non è grande, comunque, la distribuzione di
FZ ˆ può essere gravemente deviata e la distribuzione normale può
non fornire un’adeguata approssimazione, particolarmente negli estremi della distribuzione.
Per esempio è possibile che dalla (3.4.2) risulti ( ) 0<tF e ( ) 1>tF , un risultato che è fuori dal possibile range per F(t). Generalmente, una migliore approssimazione può essere ottenuta usando la trasformazione logit (logit-transformation) (logit(p) = log[p/(1-p)]) e basando l’intervallo di confidenza sulla distribuzione di:
( )( )( ) ( )( )
( )Fit
ii
Fit es
tFittFitZ
ˆlog
ˆlog ˆ
logˆlog −=
Questo conduce all’intervallo di confidenza bilaterale al 100(1-α)% approssimato:
( ) ( )[ ]( ) ( )
−+×−+=
wFF
F
wFF
FtFtF
ii/ˆ1ˆ
ˆ,
ˆ1ˆ
ˆ,
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
34
dove ( ) ( )[ ]{ }FFeszwF
ˆ1ˆˆexp ˆ2/1 −= −α . Il punto finale di questo intervallo potrà sempre essere
posizionato tra 0 e 1. Un limite di confidenza unilaterale al 100(1-α)% approssimato può essere ottenuto sostituendo ( )21 α−z con ( )α−1z e usando l’appropriato punto finale dell’intervallo di confidenza bilaterale.
Stime per dati censurati con tempi di guasto esatti I guasti sono spesso riportati al tempo di guasto esatto. I tempi di guasto esatti sorgono da un processo di ispezione continuo e generalmente, sono denotati da ti. Al limite, quando il numero delle ispezioni aumenta e la distanza tra un’ispezione e un’altra si avvicina a zero, i guasti sono concentrati in un relativo piccolo numero di intervalli. La maggior parte di questi intervalli non
conterrà nessun guasto ed è qui che la ( )tF rimane costante.
In questo modo, ( )tF diventerà una funzione a tratti con spazi vuoti sugli intervalli dove non ci sono guasti, e con salti al punto superiore di questi intervalli. Al limite, quando la distanza tra un’ispezione e un’altra tende a zero, l’ampiezza degli spazi vuoti tende a zero e il tratto della funzione aumenta. Questo caso limite di intervalli basati su stimatori non parametrici è generalmente conosciuto come stimatore di prodotto-limite o di Kaplan-Meier. Il metodo ordina i dati, come nello studio empirico, in ordine crescente dei tempi di sopravvivenza e definisce un nuovo intervallo ogni volta che si ha almeno un guasto. Se ci sono dati censurati li si considera come presenti all’inizio dell’intervallo in cui è avvenuta la censura ma assente alla fine dello stesso in modo che i dati di riferimento per l’intervallo successivo sono esclusivamente i pezzi rimasti in funzione. In questo modo se fino al tempo ti si avevano ni elementi nel campione e all’istante ti si rompono di elementi mentre ci elementi sono usciti dallo studio fra ti e ti+1 si ha la seguente stima per la probabilità di sopravvivenza nell’intervallo tra ti e ti+1 : pi = (ni + d i )/ ni Il numero ni+1 cui riferire i dati del prossimo intervallo coincide con il numero di soggetti presenti nello studio (e attivi) all’istante ti+1 . Quindi sarà ni+1 = ni - di - ci Di conseguenza sarà:
[ ]∏=
=
−=kj
j
tS1
jjj n)/ d (n)(
Questo tipo di stima immagina che l’evento guasto si presenti all’istante ti in modo che un eventuale censura che intervenga allo stesso istante si collochi immediatamente dopo ti .In pratica se 10 elementi sono arrivati all’istante 3, che marca l’inizio di un nuovo intervallo, e a quell’istante 2 elementi si rompono e 1 viene censurato, la stima di sopravvivenza detrae dai 10 elementi solo i 2 rotti, ma aggiorna la base per la prossima stima detraendo anche l’elemento censurato. Se l’ultima osservazione è censurata la stima è indefinita sulla destra. Un ipotesi implicita ma fondamentale in tutte queste stime è che i guasti avvengano in modo indipendente tra gli elementi dello studio. La stima dell’errore standard per lo studio di Kaplan-Meier viene di solito fatta ricorrendo alla già vista formula di Greenwood.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
35
Stime per dati censurati con tempi di guasto incerti I metodi sino ad ora trattati assumono che tutte le osservazioni censurate accadono al punto superiore dell’intervallo. Se tutti i tempi di censura fossero conosciuti, questa non sarebbe una seria restrizione perché gli intervalli di dati potrebbero essere definiti per accogliere tutti i dati. Se, comunque, i tempi di censura fossero conosciuti solamente per essere all’interno di specifici intervalli, il risk-set (insieme delle unità vive all’inizio dell’intervallo) sarebbe decrescente su tutto l’intervallo in un modo che non potrebbe essere specificato precisamente. Senza qualche conoscenza, è necessario un altro approccio. I due metodi estremi di manipolare i dati censurati negli intervalli sono:
� assumere che tutte le osservazioni siano riportate al tempo ti, cioè al punto superiore dell’intervallo. Questo vuol dire che
iiindp =ˆ . In questo modo la stima di pi è deviata
verso l’alto. � assumere che tutte le osservazioni censurate siano riportate al tempo ti-1, cioè al punto
inferiore dell’intervallo. Questo vuol dire che ( )iiii rndp −=ˆ . Questa stima è deviata verso il basso.
Un compromesso usato comunemente è quello di porre )2(ˆiiii rndp −= , la media armonica
delle due stime più estreme.
Questo compromesso stima ip che può essere sostituito nella ( ) [ ]∏
=
−=i
j
jiptS
1
ˆ1ˆ e nella
( )[ ] ( )[ ] ( )[ ] ( )∑= −
==i
j jj
j
iiipn
ptStSarVtFarV
1
2
ˆ1
ˆˆˆˆˆˆ che conducono all’attuariale
stima non parametrica di ( )tF e al corrispondente errore standard F
es ˆˆ .
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
36
DEFINIZIONI E CONCETTI DELLA SIMULAZIONE
Il metodo Montecarlo
Generalità I metodi di simulazione numerica hanno ricevuto un notevole interesse poiché consentono di studiare problemi per i quali non è possibile fornire una soluzione analitica in forma chiusa o non è pensabile eseguire una sperimentazione diretta perché troppo complessa o costosa. In un procedimento di simulazione occorre individuare un modello del sistema in esame che ne rappresenti il comportamento in base alla descrizione degli eventi relativi ai singoli componenti del sistema e delle interrelazioni tra questi, dando una visione dinamica e realistica dell’intero processo. Al modello di simulazione vengono forniti gli stessi dati di ingresso del sistema effettivo, del quale il modello simula il comportamento tramite la costruzione di possibili evoluzioni basate sulle conoscenze statistiche dei fenomeni elementari che le determinano, Di conseguenza, ci si aspetta che, se correttamente modellato e portato a termine un “esperimento” di simulazione sia in grado di fornire risultati analoghi a quelli ottenibili con esperimenti fisici, e che possono essere interpretati nello stesso modo. In metodo Montecarlo, applicato al caso dell’affidabilità, consiste nella simulazione su calcolatore dell’evoluzione di un sistema fisico, e consente di ricavare quelle stesse grandezze di affidabilità ottenibili dall’esame di un elevato numero di sistemi fisici identici e funzionanti in identiche condizioni. Le fasi successive della simulazione del comportamento di un sistema fisico, dal punto di vista dell’affidabilità, possono essere così riassunte:
1. individuazione del modello matematico che rapprenda il comportamento del sistema dal punto di vista che interessa e determinazione delle variabili che presentano un particolare significato nello studio del problema in esame;
2. impostazione di una procedura di evoluzione del modello aderente alla realtà fisica e realizzazione del relativo programma di calcolo;
3. validazione del modello di simulazione, cioè verifica, se possibile, in base all’osservazione di sistemi fisici effettivamente realizzati, della validità del modello, delle variabili significative del fenomeno e delle modalità di evoluzione;
4. esecuzione di nuovi esperimenti di simulazione 5. analisi ed interpretazione dei dati ottenuti con la determinazione delle statistiche di
interesse
Vantaggi e svantaggi Questo processo di simulazione è di elevata complessità realizzativa e validativa sebbene presenti numerosi vantaggi quali:
� consente di risolvere sistemi complessi con approssimazioni normalmente adeguata ai casi pratici;
� permette di ricavare qualsiasi parametro di affidabilità partendo da un solo modello evolutivo scelto come descrittivo del sistema e da un solo insieme di “storie campione”;
� permette di valutare direttamente e in modo rapido l’influenza di strategie di intervento (es. manutenzioni preventive e/o correttive) ai fini di una maggiore affidabilità oppure economia del sistema;
� consente di tenere in considerazione casi di componenti con caratteristiche di affidabilità complesse
Per contro, la simulazione presenta svantaggi quali:

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
37
� richiede programmi di calcolo spesso complessi; � non fornisce espressioni analitiche per le grandezze di interesse e quindi non consente di
rendersi conto direttamente delle interrelazioni tra i vari parametri che determinano il funzionamento del sistema e di definire i valori ottimali di un insieme di parametri che influenzano il sistema;
� l’accuratezza delle stime fornite dipende essenzialmente dal numero di prove che tende a crescere rapidamente, in maniera non lineare, all’aumentare dell’accuratezza richiesta per i risultati, ingigantendo i tempi di calcolo.
Costruzione del simulatore La costruzione dell’opportuno modello di simulazione rappresenta una fase delicata. Il problema che ci si pone è quello di generare una lista di eventi (detta anche storia campione) in cui siano riportati gli eventi che si verificano (es. guasti, riparazione, etc.) dando una visione dinamica del comportamento del sistema, e cioè della sua evoluzione tra i vari stati unitamente alle probabilità di transizione di essi. Per far ciò, occorre generare delle opportune distribuzione di tempi di evento, che rappresentino nella maniera più fedele possibile i fenomeni sotto esame. Il nucleo di tutto ciò è la generazione di variabili aleatorie che rappresentino le distribuzione di probabilità volute. Si suppongo che il sistema sia pervenuto in un certo istante in un generico stato. Il tempo di permanenza in questo stato è una variabile aleatoria e la transizione da uno stato ad un altro è definibile in termini di probabilità. Ad ogni transizione di stato, cioè al verificarsi di un qualsiasi evento, il simulatore prende nota di ciò che si è verificato, ed aggiorna i contatori interni così come le statistiche relative alle grandezze di affidabilità sotto studio. Il procedimento di simulazione viene ripetuto n volte fino ad ottenere un insieme di n storie indipendenti.
Generazione di variabili aleatorie con distribuzione preassegnata
Il problema di generare variabili aleatorie con preassegnata distribuzione si reduce a generare una variabile aleatoria con distribuzione uniforme e ad effettuare opportune trasformazioni di variabili. Ciascun linguaggio di programmazione ha la possibilità di accedere a subroutines che generano variabili aleatorie con distribuzione uniforme. Le routine di generazione di numeri casuali sono pseudoperiodiche, con periodo elevato, e necessitano di un numero di innesco (o seme). Ad uno stesso numero di innesco corrisponde la stessa sequenza. A rigore, dato il carattere di aleatorietà delle routines di calcolo, la ripetizione di una stessa simulazione montecarlo a partire dai medesimi dati di input condurrà ad insiemi di storie differenti e risultati leggermente diversi tra loro. Solo la scelta di uno stesso numero di innesco può garantire la ripetibilità forzata dei risultati ottenuti. Quantunque alcuni risultati possano apparire più esatti (nel senso di più probabili) di altri, nel caso in cui la struttura di calcolo sia stata realizzata in modo corretto e le simulazioni vengano condotte con dati di input esatti, non esiste nessuna motivazione aprioristica per considerare più validi i risultati di una singola simulazioni rispetto alle altre. Inoltre la variabilità dei risultati può rappresentare sia un indice sulla stabilità del sistema simulato (e del convergere di alcune grandezze che lo definiscono) come una prima valutazione dell’errore statistico del processo di simulazione.
La simulazione Montecarlo per l’analisi dei dati di rottura
I codici di simulazione di tipo montecarlo applicate allo studio affidabilistico e previsionale dei dati di rottura riscontrati consentono di superare numerose problematiche quali, come principali:
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
38
� la simulazione di curve di produzione reali � la simulazione delle reali condizioni di utilizzo del prodotto, spesso complesse o non
chiaramente definibili in modo esplicito dimostrandosi così uno strumento indispensabile per simulare e prevedere con accuratezza il progressivo invecchiamento dell’intero insieme di prodotti industriali (sistema) durante il loro normale impiego. Senza la conoscenza del grado di invecchiamento non si disporrebbe del giusto metro per pesare opportunamente le informazione di rottura riscontrate.
Le caratteristiche peculiare dei sistemi produttivi “automotive” L’analisi e la simulazione di sistemi automobilistic i non si discosta come principio dallo studio di sistemi produttivi di altro tipo (es. impiego di macchine utensili, rotture di elettrodomestici, etc.), ma presenta, raggruppate, alcune caratteristiche peculiari che rendono estremamente interessante la possibilità di calibrare qualsiasi metodologia sviluppata proprio su esempi estratti da questo settore. In particolare si segnala come:
1. si è spesso in presenza di un elevato numero di veicoli circolanti (o sottocomponenti prodotti); di conseguenza
� i guasti riscontrati sono di solito un numero abbastanza alto, tale da rendere statisticamente significativi i risultati probabilistici ottenuti dai calcoli;
� i costi di disservizio procurati al singolo automezzo sono amplificati dal numero di veicoli circolanti rendendo concretamente interessante uno studio di riduzione del problema;
� in particolare, tutte le Aziende sono fortemente interessate a stimare da subito con cura i costi di garanzia in modo da poter meglio prevedere i margini di guadagno.
2. la richiesta di qualità è molto forte essendo realmente divenuta un parametro di successo
del prodotto; di conseguenza � molti sforzi sono stati fatti per migliorare l’affidabilità del prodotto in particolare
realizzando database di guasti aggiornati, rendendo disponibili informazioni di utilizzo, effettuando previsioni sulle rotture, verificandone i consunti, etc.
� esiste una forte sensibilità per l’introduzione e la sperimentazione di nuove metodologie di analisi
Al modello di simulazione vengono forniti gli stessi dati di ingresso del sistema effettivo che, nel caso specifico di una produzione automobilistica, si concretizza nella necessità di fornire informazioni su:
� dati di produzione (necessari a dimensionare e a temporizzare la produzione e la vendita) � dati di utilizzo (necessari a definire i parametri di utilizzo e di invecchiamento del
sistema) � dati di rottura (collegati al comportamento affidabilistico del sistema e delle rotture
riscontrate) Al termine della simulazione saranno valutati e resi disponibili, quali risultati:
� una stima dell’invecchiamento del sistema ad ogni istante di interesse � le curve di affidabilità (densità, inaffidabilità, rateo e loro derivate) � una previsioni nel tempo delle rotture e degli interventi di riparazione
Tipologie dei dati di rottura e sistemi a censure multiple
Le metodologie di analisi dei dati di rottura dipendono dal tipo di dati che si ha a disposizione.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
39
Si parla di dati completi se, per ciascuna delle unità campione sotto osservazione, se ne conosce con esattezza il tempo al rottura (TTF, time to failure); in tal caso, il sistema di dati prende il nome di sistema completo. Questa situazione, molto particolare, è quella che si verifica quando l’analisi viene condotta in una fase successiva rispetto alla rottura di tutte le unità e nell’ipotesi di unità non riparabili (come ad esempio nel caso di prove distruttive di affidabilità con analisi condotta dopo la rottura dell’ultimo campione). Tuttavia, nella realtà dell’analisi di dati di rottura provenienti da un parco di autovetture circolanti, qualsiasi sia il momento scelto per l’analisi, molti dati di rottura risulteranno non disponibili o incompleti per le seguenti ragioni:
� non tutte le autovetture si sono rotte, anzi, di solito le rotture sono una percentuale molto limitata
� le vetture rotte sono state riparate e messe di nuovo in circolazione � alcune delle rotture non sono inerenti rispetto alla causa di rottura di interesse
Quando al momento dell’analisi, alcune unità non risultano guastate, dalla loro storia si può riconoscere solo che il proprio TTF è di certo maggiore rispetto al tempo di sopravvivenza senza rottura (di censura). In questo caso le unità non guaste sono chiamate, indifferentemente, run-out (fuori corsa), survivors (sopravvissute), remuvals (rimosse) oppure suspended units (unità sospese) ad indicare come fuoriescano dal sistema in esame senza apportare contributi di rottura. Al contrario la propria esistenza è una informazione che innalza la curva di affidabilità con una indicazione positiva del tipo “quella unità è vissuta almeno TTF” Siamo in questo caso in presenza di sistema dati con censure. Se tutte le unità hanno un comune tempo di esercizio, i dati sono detti singolarmente censurati (singly censored data). Questo tipo di dati si presenta quando le unità iniziano insieme un test e i dati sono analizzati prima che tutte le unità falliscano. Tuttavia è molto comune nella pratica che i dati di rottura presentino diversi tempi di rottura e di censura dal momento che, di solito, le unità entrano in servizio in tempi diversi ed hanno, quindi, tempi di esercizio differenti. Siamo in presenza di un sistema dati a censura multipla (multiply
censored data)
Figura 8 : Sistema completi (a) e a censura multipla rispetto al tempo (b)
Riepilogando possiamo affermare come nel caso dell’analisi dei dati di rottura di un parco circolante di autovetture ci troviamo di fronte ad un sistema di dati a censura multipla dove, a fronte di informazioni sostanzialmente complete riguardo ai pochi dati di rottura riscontrati, si dovrà stimare la percorrenza di un elevatissimo numero di elementi censurati, le autovetture che non presenteranno rotture. A questo fine diventa insostituibile l’impiego di codici di montecarlo in grado di simulare il parco circolante e mettere a disposizione un campione stocastico di elementi censurati analogo a quanto si presenta nella realtà.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
40
Asse temporale ed scala di utilizzo La vita di molti prodotti può essere misurata su di più di una scala. Per esempio la durata della vita di molti componenti di automobili è misurata in termini di “distanza percorsa” (chilometri); in altri casi invece si misura in termini di “età di calendario” (anzianità); altri infine sono tipicamente misurate in termini di ore reale utilizzo, ma anche di numero di cicli on-off quando questi potrebbero influire sulla durata. La scelta di un tempo per la misurazione della vita di un prodotto è spesso suggerita dalle conoscenze fisiche del processo di degradazione che porta alla rottura, anche se può verificarsi che tale processo non risulta essere direttamente osservabile. Qualsiasi sia la variabile indipendente impiegata come scala di utilizzo per le funzioni affidabilistiche (spesso denominata come “running time”), nel momento in cui si effettuano delle predizioni di rotture si rivela necessario esprimere i risultati in termini di numero di rotture verificate in un certo istante storico e quindi utilizzare una ulteriore scala, un asse temporale (“calendar time”). Nella maggior parte delle cause di rottura relative ad un autovettura, la variabile indipendente che meglio descrivere l’evolversi del comportamento affidabilistico è rappresentato dal chilometraggio di percorrenza effettuata dal veicolo. Di conseguenza le curve di affidabilità saranno espresse con in ordinata il valore assunto da ratei, affidabilità, inaffidabilità e densità di rottura, mentre in ascissa, come variabile indipendente, avremo il chilometraggio percorso dall’autovettura (running time) Tuttavia la simulazione del sistema avverrà tenendo conto di informazioni storicizzate (quali la data di produzione, data di rottura, etc.). Per il calcolo delle curve di rottura si rende necessario, quindi, disporre di informazioni in grado di collegare i due differenti assi di simulazione. Queste informazioni, che indicheremo come profilo di utilizzo, sono fornite nel caso “automotive” sotto forma di curva di distribuzione della percorrenza chilometrica annua media e rappresenta appunto la frazione di utenti che percorrono in un anno un certo chilometraggio. Questa curva è ottenuta dalle Aziende attraverso le informazioni acquisite in occasione del primo tagliando.
Le informazioni di input della simulazione
Ogni applicazione di un modello previsionale alla complessità propria della realtà porta con sé la necessità di schematizzare e semplificare il sistema di variabili di ingresso per il modello in un approccio del tipo “step by step” dopo solo dopo aver verificato la validità delle previsioni con quel sistema di variabili, è possibile estenderlo procedendo con successivi raffinamenti. Anche nel caso di analisi affidabilistica relativo ad una produzione automobilistica, qualora si desiderasse modellare, in modo diretto e nel dettaglio, l’intero sistema ci troveremo di fronte ad una complessità tale da rendere i la modellazione laboriosa a fronte di risultati incerti e di difficile interpretazione. Si è reso, quindi, necessario provvedere ad effettuare delle semplificazioni che hanno condotto ad un modello di input delle informazione al simulatore come di seguito descritto.
� dati di produzione: contiene informazioni relative al momento di produzione di un veicolo (o di un suo sottosistema), al momento di vendita ed indicazioni di tutti i ritardi relativi;
� dati di utilizzo: contiene informazioni relative al modo di impiego del veicolo con, in particolare, indicazioni sulla frazione di popolazione che effettuata un certo chilometraggio medio annuo;
� dati di affidabilità: contiene tutte le informazioni registrate sulle casistiche di rottura e le operazioni di intervento effettuate dal sistema di assistenza alla clientela con particolari indicazioni sul tempo medio al guasto del veicolo (o componente), la causa di guasto e altro ancora.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
41
A questo sistema di dati di ingresso vanno affiancate informazioni relative al metodo di calcolo che si intende utilizzare, attraverso la definizione di opportuni parametri di calcolo, simulazione e convergenza. Descriviamo con maggiore dettaglio le varie voci di input del modello utilizzato per la simulazione.
Dati di produzione Contengono informazioni relative al momento di produzione dei veicoli (o di loro sottosistemi), al momento di vendita e all’eventuale indicazione di tutti i relativi ritardi. I dati di produzione devono obbligatoriamente riferirsi ad un insieme di veicoli o componenti omogenei tra loro e che quindi possono essere contraddistinti come appartenenti ad un unico lotto produttivo. In particolare non devono esserci ragioni specifiche che spingano a ritenere, all’interno del lotto produttivo, un autoveicolo differente da un altro, almeno da un punto di vista affidabilistico. Questo presuppone, come condizioni necessarie ma non sufficienti, che all’interno del lotto produttivo, le condizioni di produzione siano rimaste sostanzialmente identiche (p.e. stessa qualità dei componenti installati, stesse lavorazioni di riferimento, nessun errore del processo produttivo, etc.)
Andamento della messa in servizio
Rappresenta il momento in cui il cliente riceve il veicolo e inizia ad utilizzarlo secondo i propri specifici criteri di impiego. L’andamento di messa in servizio è una informazione obbligatoria ed assume la forma di una curva con in ascissa una data di calendario e in ordinata il numero (o la percentuale) di unità messe in servizio in quello specifico periodo storico e nell’intervallo di tempo di discretizzazione utilizzato (es. mese). Nei problemi analizzati la cadenza delle informazioni è tipicamente mensile oppure, in alternativa, per produzioni dell’ordine del milione, settimanale. Cadenze giornaliere risultano inappropriate perché troppo esatte rispetto alla precisione delle restanti procedure di calcolo, mentre con cadenze trimestrali, semestrali o annuali i dati sono troppo raggruppati per consentire una precisione accettabile. Può accadere che la fase di messa in servizio non sia conclusa al momento dell’analisi, e che, per una corretta stima dei ricambi, si debba tener conto delle previsioni di messa in servizio in istanti successivi. Di solito accade che le Aziende sono in grado di fornire direttamente tali curve di messa in servizio, specie quando la loro struttura fa sì che conservino un diretto controllo sulle fasi di vendita (es. concessionarie che comunicano alla Casa Madre la data di immatricolazione dell’autovettura). In tali casi la curva di messa in servizio è assunta equivalente all’andamento delle vendite al cliente finale. Il discorso può essere diverso in presenza, ad esempio, di Aziende che producono componentistica. In tal caso le loro curve di vendita si riferiscono alla consegna del componente alla Casa Automobilistica che provvederà a montarlo sull’autoveicolo, stoccarlo e poi venderlo al cliente ultimo. Per superare questi e ulteriori problemi è stata introdotto il concetto di scomporre l’andamento di messa in servizio, nel caso non fosse disponibile, in opportune grandezze e ritardi elementari che verranno poi combinate tra loro (tramite procedure di simulazione montecarlo) per ricostruire la curva di messa in servizio. Di seguito sono riportate e descritte le grandezze di interesse per
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
42
definire implicitamente la data di messa in servizio qualora questa ultima non fosse disponibile in modo esplicito.
0
1
2
3
4
5
6
7
8
0
1
2
3
4
5
6
7
8
Mese
Figura 9 : Esempio di un andamento di messa in servizio
Andamento della produzione
Rappresenta il momento in cui l’Azienda produttrice completa la realizzazione e i controlli di qualità del veicolo o, più spesso, del componente posizionandolo all’uscita della propria linea produttiva. Questa informazione assume la forma di una curva con in ascissa una data di calendario e in ordinata il numero (o la percentuale) di unità prodotte in quello specifico periodo storico e nell’intervallo di tempo di discretizzazione scelto (tipicamente mensile).
Ritardo di messa in opera Il componente è ora consegnato alla Casa Automobilistica che lo installa su una vettura della propria linea produttiva. Si può tener conto di questo ritardo tra la produzione del componente e la produzione della vettura attraverso una curva di distribuzione probabilistica dei ritardi di
messa in opera. Questa curva presenta in ascissa il ritardo (in settimane oppure mesi) e in ordinata la frazione di componenti che risultano mediamente soggetti a tale ritardo.
Ritardo di consegna al cliente
Nonostante i tentativi di realizzare una politica di vendita just-in-time con la produzione, una autovettura disponibile a fine della linea produttiva può presentare tutta una serie di ritardi aggiuntivi di tipo logistico e di marketing che spostano il momento di messa in strada anche di vari mesi. Tra questi ricordiamo:
� tempo di distribuzione e consegna presso i concessionari � tempo caratteristico necessario al concessionario per effettuare la vendita � ritardi di immatricolazione � politiche di immatricolazione anticipata da parte delle concessionari � etc.
Di queste informazione si può tener conto attraverso una curva di distribuzione complessiva dei ritardo di consegna al cliente e che presente in ascissa il valore del ritardo (in settimane o mesi) e in ordinata la frazione di autovetture che risultano mediamente soggette a tale ritardo.
Ritardo di ingresso del prodotto nel mercato
Una forma di ulteriore ritardo di cui si è reso necessario tener conto è quello relativo alla risposta
dell’acquirente rispetto all’ingresso di un nuovo prodotto. Spesso una nuova linea ha bisogno di un periodo iniziale prima di decollare nelle vendite; alcune volte, le Case Automobilistiche, sono
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
43
anche in grado di prevede questo particolare andamento nella richiesta e al fine di ottimizzare l’utilizzo degli impianti e la propria risposta di disponibilità alla futura richiesta di prodotto, realizzano una sovrapproduzione iniziale che sarà assorbita da un ampio “magazzino” intermedio. Di questo ritardo si può tener conto attraverso una curva di probabilità con in ascissa una data di calendario e in ordinata il ritardo medio (in mesi o settimane) che un lotto prodotto in quel momento storico ha dovuto subire per rispondere alle descritte esigenze di marketing. Nel differente asse di ascissa risiede la fondamentale differenza tra le due forme di ritardo descritte.
Dati di utilizzo Contiene informazioni relative al particolare modo di impiego del veicolo di ciascun utente. Quale fondamentale criterio di impiego si farà riferimento al chilometraggio annuo medio percorso e ai limiti chilometrici di utilizzo (sia di tipo deterministico che statistico), ma potrebbe rivelarsi necessario estendere l’analisi introducendo indicazioni di altro tipo (p.e. area geografica di impiego, velocità di crociera, etc.)
Profilo chilometrico di utilizzo
Rappresenta una indicazione dell’utilizzo chilometrico dell’autovettura ed è fornita sotto forma di curva di distribuzione della percorrenza chilometrica annua media con in ascissa il chilometraggio suddiviso per classi crescenti (es. 5000 km) e in ordinata la frazione di autovetture che risultano aver percorso quel chilometraggio annuo. Queste informazioni sono disponibili in Azienda con elevata accuratezza e vengono ottenute rielaborando i dati acquisiti in occasione del primo tagliando.
0
5
10
15
20
0
5
10
15
20
Figura 10 : Esempio di profilo di percorrenza chilometrica media (km/anno)
Limiti di utilizzo
Come limiti di utilizzo si intende il chilometraggio massimo e il numero di mesi massimi di utilizzo previsti per una autovettura. Tali limiti sono inseriti in forma deterministica attraverso un singolo valore di chilometraggio massimo e di età massima. Una volta raggiunto almeno uno di detti limiti il veicolo è considerato uscito dal sistema (rottamato per raggiunti limiti di anzianità temporale o chilometrica). La presenza di vincoli deterministici consente, inoltre, di impostare simulazioni per periodi di utilizzo ben definiti quali, ad esempio, il periodo di garanzia.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
44
Curva di rottamazione Rappresenta una indicazione della quota di autovetture che sono state tolte dalla circolazione ad un certo chilometraggio ed è fornita sotto forma di curva di probabilità con in ordinata la frazione di autovetture che risultano essere state rottamate e in ascissa il chilometraggio. Questa curva consente di tener in conto della progressiva rottamazione e diminuzione del parco di veicoli anche qualora questi non abbiano raggiunto i fissati limiti di età (p.es. incidenti, sostituzione anticipata). Questo genere di informazioni non sono di solito disponibili in Azienda, perché risulta di poco interesse tener traccia delle vetture che, essendo ben lontane dal periodo di garanzia, non incideranno sui costi riconosciuti. Al contrario, queste informazioni diventano indispensabili quando si desidera effettuare delle stime accurate sui pezzi di ricambio da produrre e rendere disponibili per supportare un parco circolante di autovetture per lunghi periodi dopo la fine della produzione (tipicamente 15 anni), come prevedono i contratti di fornitura tra Casa Automobilistiche e fornitori di componenti.
0
20
40
60
80
100
0
20
40
60
80
100
km
Figura 11 : Esempio di curva di rottamazione (motorizzazione benzina)
Condizioni specifiche di utilizzo In caso di particolari simulazioni potrebbe aver senso introdurre condizioni di utilizzo a maggiore specificità. L’esempio più comune è quello di avere la necessità di distingue i mercati di vendita delle autovetture per valutare i parametri di affidabilità rispetto a particolare condizioni di impiego (es. utilizzo di modelli con cambio automatico, temperature normali più basse oppure più alte rispetto alle condizioni di riferimento previste, etc.). Un’altra ragione per suddividere i mercati potrebbe essere quella di verificare su un solo mercato il rispetto dei limiti affidabilistici previsti dalle specifiche normative nazionali.
Europa
Usa&Canada
Sud America
Oriente
Altro
Figura 12 : Esempio di ripartizione per condizioni geografica di utilizzo

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
45
Dati di affidabilità Contiene tutte le informazioni registrate sulle casistiche di rottura e le operazioni di intervento effettuate dal sistema di assistenza alla clientela con particolari indicazioni sul tempo medio al guasto del veicolo (o componente), la causa di guasto e altro ancora.
Momento temporale di analisi
Non rappresenta l’istante in cui viene effettuata l’analisi affidabilistica, quanto piuttosto, se diverso, il momento di consuntivo dei dati di rottura. Ossia, se il sistema di rilevamento delle rotture cessa di registrare gli interventi di riparazione ad una certa data, è quella da considerarsi come il momento temporale di analisi indipendentemente da quanto tempo passerà prima della realizzazione concreta della simulazione.
Numero di rotture complessivamente rilevate
Deve essere pari a tutte le rotture che si sono manifestate relativamente alla produzione oggetto di esame, dall’istante di messa in circolazione del primo veicolo (o componente) fino al momento temporale di analisi. Non è necessario che di tutte queste rotture si abbiano informazioni aggiuntive, ma è obbligatorio che queste, come numero complessivo, rappresentino tutte e sole le rotture che si sono manifestate (o che risulta possibile prevedere come manifestate) relativamente all’isola produttiva in esame.
Rotture di cui si hanno informazioni complete Rappresentano tutte le rotture che si sono manifestate e di cui si dispongono di informazioni complete di rottura. Sono di numero necessariamente minore (o al limite uguale) al numero di rotture complessivamente rilevate e devono poter rappresentare l’intero lotto produttivo oggetto di studio. E’ necessario fare l’assunzione che le rotture di cui si hanno informazioni complete sono:
1. un campione stocastico di tutte le rotture rilevate e che, quindi, queste ultime, con informazioni incognite, presentino caratteristiche affidabilistiche sostanzialmente equivalenti a quelle rotture di cui si hanno informazioni;
2. un campione stocastico di tutto il lotto produttivo in esame che quindi rotture di cui si hanno informazioni sono in grado di descrivere in modo soddisfacente il comportamento affidabilistico dell’intera popolazione
Queste rotture non possono
� appartenere a differenti lotti produttivi � rappresentare solo parti dello stesso qualora queste parti non siano completamente
equivalenti da un punto di vista affidabilistico (es. per qualità dei sistemi, condizioni di impiego, metodo di acquisizione e filtro dei dati, etc.) al restante parte del lotto
Le informazioni a disposizione attraverso i dati di guasto sono riconducibili a:
Data di segnalazione dell’intervento
Rappresenta il momento in cui è stata segnalata la rottura ai servizi di assistenza per poi procedere, eventualmente, con la riparazione Data la scarsa importanza ai fini dei risultati della simulazione, non si terrà conto dei tempi di fuori servizio legati alla fase di riparazione. Di conseguenza l’instante di rilevamento delle rottura e l’istante di messa in servizio del sistema riparato sono fatti coincidere con la data di segnalazione dell’intervento, valore registrato nella scheda di intervento e disponibile in Azienda. Il sistema dopo la riparazione è considerato completamente rinnovato relativamente a quella causa di guasto.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
46
Data di inizio servizio Rappresenta l’istante storico in cui il veicolo risultato difettoso (oppure un suo sottosistema) era entrato in servizio.
Intervallo di utilizzo prima del rottura Rappresenta il valore di percorrenza chilometrica raggiunto nel momento in cui si è verificata la rottura (tempo al guasto, TTF). La correttezza di queste informazioni risulta fondamentale in quanto i valori dei tempi a guasto incidono in modo diretto sulla forma della curva di affidabilità, sulle successive predizioni di rottura.
Causa di rottura Rappresenta la particolare causa di rottura riscontrata (ed eventualmente riparata). Le successive analisi possono essere condotte cercando l’affidabilità complessiva oppure separando per causa di rottura. Le assunzioni di calcolo sono tali da necessitare cause di rottura indipendenti tra loro.
Codice di riconoscimento del componente
Di solito si dispone di un codice di riconoscimento del sistema (autovettura o componente) che consente la tracciabilità completa all’interno del processo produttivo ma che non viene utilizzato in modo diretto dalla simulazione.
Figura 13 : Esempio di database dei dati di rottura
Parametri di calcolo
Stimatori di affidabilità non parametrici Rappresentano dei metodi numerici per la stima delle curve di inaffidabilità (o di rateo) a partire dai dati di rottura. Tra i più noti troviamo gli stimatori di Keplan-Majer, Herald-Jonson, Metodo
Attuariale. Presentano la caratteristica di essere stimatori empirici non parametrici, ossia non hanno la necessità di ipotizzare a priori il modello di rottura (es. Weibull) rappresentativo del problema per poi valutare i parametri che ne ottimizzano la soluzione (ad es. con tecniche di Maximum
Likelihood) come avviene nel caso dell’utilizzo di stimatori parametrici.
Stimatori per tempi esatti e per tempi incerti
Gli stimatori parametrici comunemente rintracciabili in letteratura specialistica sono in grado di valutare le curve empiriche di inaffidabilità oppure di rateo a partire dai tempi di rottura, sia nel caso che tali dati siano forniti come tempi esatti (T1, T2, etc.), sia nel caso siano disponibili raggruppati in intervalli dentro i quali risultano tempi incerti (Ti < T1 < Ti+1). Una stima per tempi esatti consente di avere delle curve affidabilistiche con un punto di definizione per ciascun dei tempi di rottura riscontrati, mentre nella stima per tempi incerti si disporrà alla fine di un punto per ciascun intervallo di raggruppamento. Di contro, i punti calcolati utilizzando la stima per tempi incerti, risultando generalmente dal unione di più tempi al guasto, si riveleranno più corretti e meno soggetti a fluttuazione statistiche legate alla stocasticità dello specifico campione.
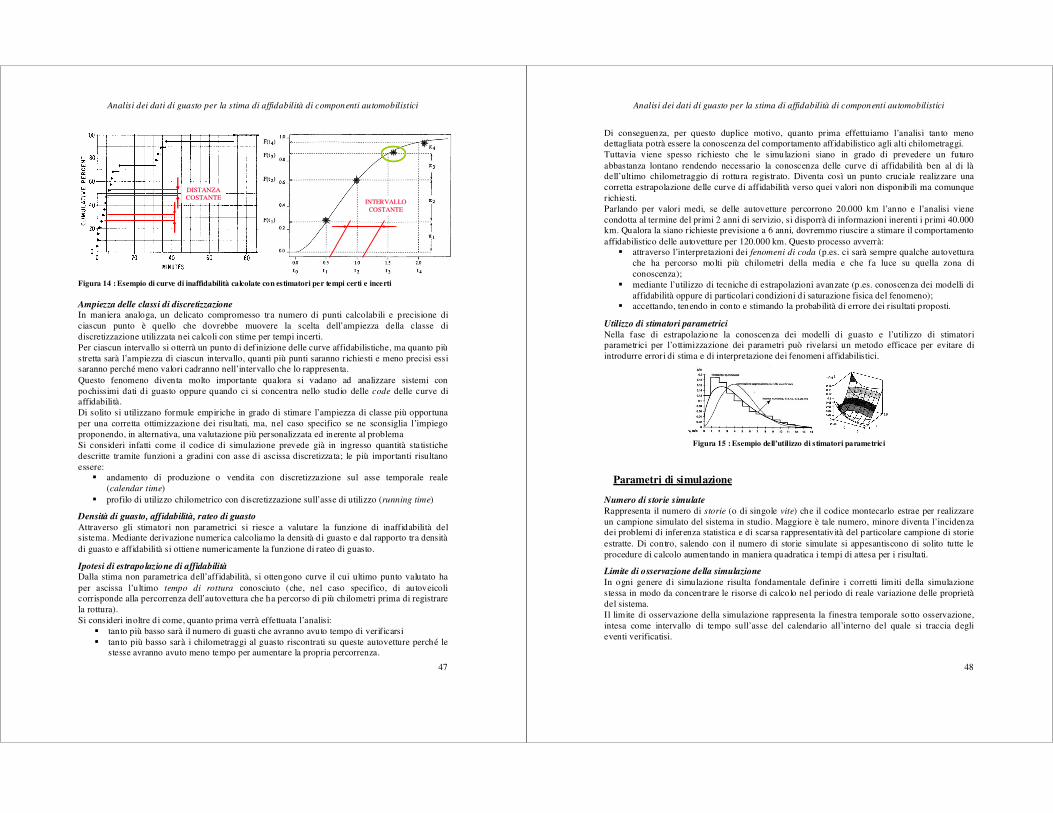
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
47
Figura 14 : Esempio di curve di inaffidabilità calcolate con estimatori per tempi certi e incerti
Ampiezza delle classi di discretizzazione In maniera analoga, un delicato compromesso tra numero di punti calcolabili e precisione di ciascun punto è quello che dovrebbe muovere la scelta dell’ampiezza della classe di discretizzazione utilizzata nei calcoli con stime per tempi incerti. Per ciascun intervallo si otterrà un punto di definizione delle curve affidabilistiche, ma quanto più stretta sarà l’ampiezza di ciascun intervallo, quanti più punti saranno richiesti e meno precisi essi saranno perché meno valori cadranno nell’intervallo che lo rappresenta. Questo fenomeno diventa molto importante qualora si vadano ad analizzare sistemi con pochissimi dati di guasto oppure quando ci si concentra nello studio delle code delle curve di affidabilità. Di solito si utilizzano formule empiriche in grado di stimare l’ampiezza di classe più opportuna per una corretta ottimizzazione dei risultati, ma, nel caso specifico se ne sconsiglia l’impiego proponendo, in alternativa, una valutazione più personalizzata ed inerente al problema Si consideri infatti come il codice di simulazione prevede già in ingresso quantità sta tistiche descritte tramite funzioni a gradini con asse di ascissa discretizzata; le più importanti risultano essere:
� andamento di produzione o vendita con discretizzazione sul asse temporale reale (calendar time)
� profilo di utilizzo chilometrico con discretizzazione sull’asse di utilizzo (running time)
Densità di guasto, affidabilità, rateo di guasto
Attraverso gli stimatori non parametrici si riesce a valutare la funzione di inaffidabilità del sistema. Mediante derivazione numerica calcoliamo la densità di guasto e dal rapporto tra densità di guasto e affidabilità si ottiene numericamente la funzione di rateo di guasto.
Ipotesi di estrapolazione di affidabilità Dalla stima non parametrica dell’affidabilità, si ottengono curve il cui ultimo punto valutato ha per ascissa l’ultimo tempo di rottura conosciuto (che, nel caso specifico, di autoveicoli corrisponde alla percorrenza dell’autovettura che ha percorso di più chilometri prima di registrare la rottura). Si consideri inoltre di come, quanto prima verrà effettuata l’analisi:
� tanto più basso sarà il numero di guasti che avranno avuto tempo di verificarsi � tanto più basso sarà i chilometraggi al guasto riscontrati su queste autovetture perché le
stesse avranno avuto meno tempo per aumentare la propria percorrenza.
INTERVALLOINTERVALLOCOSTANTECOSTANTE
INTERVALLOINTERVALLOCOSTANTECOSTANTE
DISTANZA DISTANZA COSTANTECOSTANTEDISTANZA DISTANZA COSTANTECOSTANTE
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
48
Di conseguenza, per questo duplice motivo, quanto prima effettuiamo l’analisi tanto meno dettagliata potrà essere la conoscenza del comportamento affidabilistico agli alti chilometraggi. Tuttavia viene spesso richiesto che le simulazioni siano in grado di prevedere un futuro abbastanza lontano rendendo necessario la conoscenza delle curve di affidabilità ben al di là dell’ultimo chilometraggio di rottura registrato. Diventa così un punto cruciale realizzare una corretta estrapolazione delle curve di affidabilità verso quei valori non disponibili ma comunque richiesti. Parlando per valori medi, se delle autovetture percorrono 20.000 km l’anno e l’analisi viene condotta al termine del primi 2 anni di servizio, si disporrà di informazioni inerenti i primi 40.000 km. Qualora la siano richieste previsione a 6 anni, dovremmo riuscire a stimare il comportamento affidabilistico delle autovetture per 120.000 km. Questo processo avverrà:
� attraverso l’interpretazioni dei fenomeni di coda (p.es. ci sarà sempre qualche autovettura che ha percorso molti più chilometri della media e che fa luce su quella zona di conoscenza);
� mediante l’utilizzo di tecniche di estrapolazioni avanzate (p.es. conoscenza dei modelli di affidabilità oppure di particolari condizioni di saturazione fisica del fenomeno);
� accettando, tenendo in conto e stimando la probabilità di errore dei risultati proposti.
Utilizzo di stimatori parametrici
Nella fase di estrapolazione la conoscenza dei modelli di guasto e l’utilizzo di stimatori parametrici per l’ottimizzazione dei parametri può rivelarsi un metodo efficace per evitare di introdurre errori di stima e di interpretazione dei fenomeni affidabilistici.
Figura 15 : Esempio dell’utilizzo di stimatori parametrici
Parametri di simulazione
Numero di storie simulate
Rappresenta il numero di storie (o di singole vite) che il codice montecarlo estrae per realizzare un campione simulato del sistema in studio. Maggiore è tale numero, minore diventa l’incidenza dei problemi di inferenza statistica e di scarsa rappresentatività del particolare campione di storie estratte. Di contro, salendo con il numero di storie simulate si appesantiscono di solito tutte le procedure di calcolo aumentando in maniera quadratica i tempi di attesa per i risultati.
Limite di osservazione della simulazione
In ogni genere di simulazione risulta fondamentale definire i corretti limiti della simulazione stessa in modo da concentrare le risorse di calcolo nel periodo di reale variazione delle proprietà del sistema. Il limite di osservazione della simulazione rappresenta la finestra temporale sotto osservazione, intesa come intervallo di tempo sull’asse del calendario all’interno del quale si traccia degli eventi verificatisi.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
49
Estendere il limite di simulazione al di là di quei particolari valori che definiscono il campo di variabilità del sistema (ad esempio, far stimare come continuare a variare il numero di ricambi anche dopo la rottamazione di ogni autovettura presente) condurrebbe ad inutili perdite di tempo.
Parametri di convergenza
Ripetitività dei risultati
In presenza di codici di simulazione montecarlo che utilizzano variabili aleatorie pseudocasuali, data la stocasticità degli eventi, i risultati di differenti simulazioni saranno in genere differenti tra loro. Anzi, qualora si pervenga in maniera ripetuta allo stesso risultato potrebbe voler indicare, non tanto la stabilità dei risultati globali al variare del campione estratto, ma solo che la precisione di visualizzazione dei risultati oppure le approssimazioni introdotte nella fase finale dell’elaborazione sono molto marcate e tali da inficiare la precisione utilizzata nelle routine parziali di calcolo. Inoltre la mancanza di ripetitività dei risultati può essere considerato un vantaggio in quanto consente di verificare se il processo di calcolo porti, nelle differenti simulazioni, a risultati grosso modo equivalenti. In tal caso il sistema è sotto controllo e queste oscillazioni possono essere utilizzate come stima della variabilità stessa dei risultati. Comunque, a volte, la non ripetitività stocastica dei risultati può rivelarsi fastidiosa come ad esempio avviene quando si desideri possedere un unico valore di risultato come riferimento fisso, in modo da verificare agilmente come eventuali variazioni delle variabili di input del sistema possano incidere sul risultato conclusivo. Per consentire questa operazione è sufficiente impostare le procedure di estrazione pseudocasuale sempre sullo stesso valore del numero di innesco.
Criterio di convergenza
Qualora si ripetano le simulazioni senza fissare il valore iniziale, la presenza di differenti risultati rende necessaria la definizione di criteri di convergenza degli stessi. Nella scelta della soluzione più giusta, intesa come quella unica soluzione fornita quale risultato della combinazione delle diverse simulazioni condotte a termine, possono essere scelti criteri di tipo puntuali oppure di tipo combinato. Un criterio puntuale è quello dove è scelto come il risultato quello ottenuto attraverso un unico insieme di storie; ad esempio, tra le m differenti simulazioni si definisce come criterio di convergenza quello di proporre i risultati ottenuti da quel particolare insieme di storie che ha condotto ai risultati migliori (best case), peggiori (worst case) oppure alla massima precisione di taratura su un valore di consuntivo (best fit). Altri criteri possono essere di tipo combinato, dove la soluzione proposta è ottenuta quale combinazione dei risultati ottenuti delle differenti simulazioni; il tipico esempio è quello di scegliere come risultato la media dei risultati delle singole soluzioni.
Tipologia di errore Esistono molte tipologie di errori presenti in un processo di simulazione del tipo descritto. Per maggiori dettagli si faccia riferimento a testi specialistici.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
50
METODOLOGIA DI ANALISI La metodologia di simulazione e di analisi prevede i seguenti passi:
� combinando i dati di vendita con i dati di utilizzo, attraverso una prima fase di simulazione, si stima l’invecchiamento del parco circolante al momento dell’analisi (che coincide con il momento di consuntivo dei dati di guasto) e si crea così un insieme da cui attingere per i tempi di censure;
� combinando i dati di guasto realmente riscontrati con i tempi di censura simulati, attraverso uno stimatore non parametrico, si ottiene la curva di affidabilità del sistema relativamente alla particolare causa di guasto presa in considerazione;
� combinando i dati di vendita, di utilizzo con le curve di affidabilità ed i limiti di impiego, attraverso una seconda fase di simulazione, si stimano le percorrenze e i momenti di rottura di ciascuno di ciascuna storia;
� raggruppando gli eventi di rottura e posizionandoli sull’asse temporale si ottengono i risultati di previsione.
Descriviamo la metodologia di simulazione con maggior dettaglio.
Simulazione degli elementi censurati Non essendo possibile conoscere con esattezza le proprietà (soprattutto i chilometri percorsi) di tutti i veicoli prodotti ed in circolazione, la prima fase di elaborazione si propone di simularli, simulandone il momento di produzione, di messa in servizio, la percorrenza presunta, l’eventuale rottamazione e così via. Questa prima fase mira quindi all’estrazione di un insieme di vite simulate che potranno essere utilizzati come database da cui attingere per ottenere gli elementi di censura che servono a definire correttamente l’ampiezza e l’invecchiamento del parco circolante da cui provengono i dati di rottura riscontrati. Di conseguenza, interessa simulare l’invecchiamento, non in un generico istante, ma proprio nel momento temporale di analisi, data del calendario di cui si hanno i consuntivi dei dati di rottura.
Nascita della singola vita La simulazione avviene attraverso la nascita di un singola vita, con caratteristiche individuali proprie (es. un istante di messa in vendita, una percorrenza chilometrica media, etc.), ma globalmente approssimanti la realtà (es. le curve date di messa in vendita, il profilo di percorrenza, etc.), per poi ripetere il processo mediante nascite successive fino a creare un campione statisticamente significativo su cui effettuare le elaborazioni necessarie.
Estrazione di una informazione di produzione.
Un primo generatore di numeri casuali e la successiva trasformazione di variabili consente di creare una variabile aleatoria che ha per distribuzione l’andamento della messa in servizio fornito come input al simulatore. Il risultato concreto di questa operazione è quindi l’estrazione di una data di calendario che può essere presa come riferimento per simulare la consegna al cliente di una prima, singola, autovettura. Il procedimento di estrazione di una data sarà ripetuto per le varie storie simulate. Ciascuna data estratta ha, come vincolo, la caratteristica che, se studiata
SCHEMA SEMPLIFICATO DI
METODOLOGIA DI SIMULAZIONEDATI DI PRODUZIONE
e VENDITA
DATI DI PRODUZIONE
e VENDITA
DATI DI AFFIDABILITA’
DATI DI AFFIDABILITA’
PREVISIONI DI ROTTURE
PREVISIONI DI ROTTURE
SIMULAZIONE
CURVE DI AFFIDABILITA’
REALI
CURVE DI AFFIDABILITA’
REALI
DATI DI UTILIZZO
DATI DI UTILIZZO
INVECCHIAMENTO PARCO CIRCOLANTE
INVECCHIAMENTO PARCO CIRCOLANTE

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
51
statisticamente insieme alle altre, ricostruirà (a meno di errori stocastici) la curva di distribuzione della messa in servizio di partenza. Nel caso non si disponga della curva di messa in servizio, ma della curva di produzione e dei vari ritardi, l’estrazione dei valori dalle curve a disposizione e la loro successiva combinazione consentirà di ricavare l’andamento di messa in servizio per poter procedere nei successivi calcoli.
Estrazione di una informazione di utilizzo
In modo analogo un secondo generatore estrae un chilometraggio medio annuo in modo che sia rispettato l’andamento del profilo di percorrenza proprio di quel tipo di autoveicolo. Se necessario, opportuni generatori ausiliari possono definire ulteriori informazioni caratteristiche quali l’appartenenza ad un particolare mercato geografico di utilizzo, la motorizzazione diesel o benzina, etc.
Applicazione dei criteri di limitazione
Viene infine estratto un chilometraggio di rottamazione nel rispetto della curva prevista per la rottamazione di quel modello di autoveicolo. Questo valore unito ai limiti deterministici di utilizzo (chilometrici e temporali) realizzano un sistema di filtri in grado di eliminare i veicoli quando fuoriescono dai termini di una corretta simulazione.
Simulazione di invecchiamento del sistema al momento dell’analisi
A seguito delle precedenti operazioni possiamo si giunge alla nascita di una singola vita, intesa come l’affiancamento di varie informazioni che collaborano nel definirla, di cui le più importanti restano un
momento di messa in servizio con la vendita dell’autovettura all’utente e l’indicazione del chilometraggio medio annuo che quello specifico utente percorrerà con il veicolo. Dalla conoscenza del momento di messa in servizio e di quanti chilometri percorre in un anno, una semplice operazione algebrica conduce a stimare l’invecchiamento, inteso come chilometri percorsi, di quello specifico veicolo rispetto al momento dell’analisi La simulazione viene ripetuta per un numero elevato di storie e si dispone così di tutte le informazioni necessarie a imporre delle censure al sistema di dati di guasto.
Stima non parametrica dell’inaffidabilità reale In questa fase, attraverso l’applicazione di stimatori non parametrici, si giunge alla definizione delle curve di inaffidabilità reali per sistemi con censure multiple.
Il sistema dati a disposizione Ricapitolando, in questa fase dell’analisi di affidabilità si dispone di:
� l’estensione della popolazione � un valore rappresentante il numero di rotture complessivamente riscontrate � un valore rappresentante il numero di rotture di cui si hanno informazioni complete � le informazioni e, in particolar modo, i tempi al gusto (ossia i chilometri) � un database da cui acquisire dati di invecchiamento (percorrenza) relativi alla
popolazione
m ag-0 1ago -01
no v-0 1feb -02
mag -02
0
500
1000
1500
2000
2500
3000
3500
4000
Andamento Mensi le Produz ione
Mercato ITALIA
2001 2002
Driver Pr ofile Distribu tion
mileage per year
M omento di Messa in Servizio
+ =Singola vita
simulata
Profilo di Percorrenza estratto (km/anni)
Simulazione della nascita di una
SINGOLA VITAEsempio
Generatore di numeri casual i
Andamento della Consegna al Cliente Finale
Andamento delProfilo di Percorrenza
Generatore di numeri casual i
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
52
Tutte queste quantità si riferiscono al medesimo lotto produttivo e sono consentivate allo stesso momento scelto per l’analisi.
Proporzionare e completare i dati di guasto con i dati di censura L’assunzione che le rotture di cui si hanno informazioni sono rappresentative, come fenomenologia, di tutte le rotture riscontrate che a loro volta sono le tutte e sole quelle verificate sulla popolazione rende molto semplice stimare proporzionalmente l’ampiezza che deve aver l’insieme degli elementi di censura. Il numero di rotture complessive sta alla popolazione come il numero di rotture di cui si hanno informazioni sta all’estensione della sottopopolazione da cui queste cause sono state generate. In questo modo si stima in modo proporzionale la parte di popolazione che condurrebbe al numero di rotture pari a quelle rotture di cui si hanno informazioni complete. Inoltre questa parte di popolazioni sarà necessariamente composta dai componenti rotti e di cui si hanno informazioni complete ai quali vanno aggiunti i restanti componenti, non rotti, di numero conosciuto e che possono essere acquisiti dal database di elementi censurati.
L’utilizzo di stimatori non parametrici
Una volta ben definito il sistema di dati a censura multipla, attraverso semplici operazioni di riordinamento e di calcolo numerico, risulta possibile stimare inaffidabilità e rateo di guasto mediante l’utilizzo dei più conosciuti stimatori non parametrici. Queste curve, pure se calcolate utilizzando una sottopopolazione, sono rappresentative dell’intero lotto produttivo e valgono per la particolare causa di guasto a cui i tempi di guasto facevano da riferimento.
Estrapolazioni La curva di inaffidabilità risulta costruita per punti dove, a seconda del tipo di stimatore, a tempi esatti o incerti, risulterà un punto di definizione per, rispettivamente, ciascun tempo (chilometro) al guasto o ciascun intervallo di discretizzazione dell’asse temporale (ossia dei chilometri). In ogni caso l’ultimo punto disponibile coincide grosso modo con il massimo chilometraggio registrato tra i veicoli che hanno presentato rottura, ma la curva di inaffidabilità dovrà essere è estrapolata fino al limite deterministico di utilizzo. Il simulatore non potrà interpretare correttamente le informazioni se non troverà la coincidenza tra questi due valori di margine: se si chiede di simulare la vita di un veicolo o di un componente fino a 200.000 km bisogna in ogni caso avvertire il codice di quale affidabilità associare a tale chilometraggio anche se i dati di guasto a disposizione non consentono di avere curve così estese. I criteri di estrapolazione sono diversi e devono essere scelti via via in base alle specifiche situazioni, con particolare riguardo a creare bande di massimo e di minimo nei risultati.
Calcolo AFFIDABILITA’ REALE
Curva di INAFFIDABILITA’
INVECCHIAMENTOINVECCHIAMENTO ELEMENTI ROTTIELEMENTI ROTTI
12345
6
Dati Censurati a Più Tempi
t
Esempio

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
53
Simulazione completa dell’evoluzione del sistema In questa fase ci si propone di simulare l’evoluzione completa dell’insieme di veicoli, dalla iniziale produzione e vendita attraverso il “passaggio” lungo tutta la curva di affidabilità, fino al momento della rottamazione o fuoriuscita dai limiti di calcolo.
Estrazione di una singole vite tra quelle precedentemente generate Da un punto di vista esecutivo, le procedure di creazione di una singola vita sono identiche a quanto realizzato e descritto in occasione della prima simulazione, quella condotta per la creazione di una lista di elementi censurati. In tal caso, si passava attraverso l’estrazione di informazioni sulla produzione (es. momento di vendita) e di informazioni sull’utilizzo (es. percorrenza chilometrica) che abbinate definivano la singola vita generata. La seconda simulazione parte ora direttamente dalla scelta casuale di una delle vite a partire dal campione di vite precedentemente generato.
Estrazione di un tempo di rottura Un ulteriore generatore di numeri casuali estrae un tempo medio al guasto tale da rispettare la curva di affidabilità calcolata. Per ciascuna storia estratta si dispone ora di:
� data di messa in servizio (in calendar time) � percorrenza media (in running time/calendar
time) � percorrenza a cui è prevista la rottura (in
running time) Combinando queste informazioni, risulta immediato valutare il momento storico in cui avviene la rottura riconducono le indicazioni di guasto sull’asse temporale reale.
Convergenza sull’asse temporale dei risultati
Le estrazioni ed i calcoli vengono ripetuti per un numero di volte pari al numero di storie previste. Come effettuato in precedenza, opportuni filtri verificano la validità delle informazioni apportate da ciascuna storia, scartandole qualora non rispettino i criteri di limitazione definiti sul sistema. Procedure di conteggio, normalizzando e sommando i contributi forniti dalle singole vite, sono in grado di calcolare tutti i principali risultati previsionali di interesse.
2000 5000 10000 20000 50000 100000. 200000.
0.01
0.02
0.05
0.1
0.2
0.5
1
Generatore di numeri casuali
Singola vita simulata
Istante temporale di guasto
Km a rottura
• Data di messa in servizioData di messa in servizio
•• Percorrenza media Percorrenza media (Km/anno)(Km/anno)
+ =
Simulazione di una ROTTURAEsem
pio
Curva di INAFFIDABILITA’
Registrazione di intervento
futuro
Istante di produzione
Istante di inizio servizio
Limite di dismissione dell’automezzo
Fine del periodo di osservazione
Inizio periodo di osservazione
Tempo al guasto
(MTTF)
Istante temporale di guasto
Convergenza sull’ASSE TEMPORALE REALEEsempio
Momento di analisi
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
54
Risultati delle simulazioni Dalle procedure di simulazione si ottengono risultati ed informazioni che possono dimostrarsi utili in differenti ambiti del miglioramento qualitativo del prodotto
Previsioni sul circolante
La simulazione consente di effettuare previsioni sull’invecchiamento chilometrico del parco circolante in qualsiasi istante di interesse. Questa informazione diventa particolarmente utile quando riveste un interesse economico valutare con accuratezza la quota di autoveicoli che sono, dal punto di vista della percorrenza chilometrica, al di fuori di specifici limiti di interesse, quali, ad esempio, quelli imposti dalla condizioni di garanzia. Ma la previsione di invecchiamento e di rottamazione può assumere una sua importanza anche per ricavare indicazione di marketing quando, ad esempio, si desidera lanciare un modello nuovo (oppure rinnovato) che si presume debba andare a sostituire un modello in fase di fuoriuscita dal mercato. I risultati di previsione sul circolante sono riportati come istogrammi di frequenze, in forma di densità o cumulata, con in ascissa il chilometraggio percorso e ordinata la frazione di autovetture che hanno effettuato o superato quei chilometraggi di riferimento.
Figura 16 : Esempio di invecchiamento del parco circolante: a) % di veicoli in circolazione, b) profilo di anzianità
Comportamento affidabilistico
Attraverso la simulazione delle condizioni di invecchiamento chilometrico effettuate scegliendo proprio l’istante temporale di consuntivo delle rotture manifestate, si riesce a ricostruire in modo completo lo stato del parco circolante. Si può così disporre di indicazioni accurate sul comportamento affidabilistico del veicolo nel suo insieme oppure per ciascuna causa di guasto. Questo consente di realizzare estrapolazioni di affidabilità e validazione dei modelli analitici interpretativi che conducono ad una migliore conoscenza e valutazione dei livelli qualitativi raggiunti. I risultati di affidabilità sono riportati come curva empirica con in ascissa il chilometraggio di riferimento e in ordinata una delle grandezze di interesse affidabilistico quali inaffidabilità, rateo di guasto, densità di guasto o loro cumulate. Queste informazioni si dimostrano indispensabili per supportare e verificare il rispetto dei target di qualità previsti in azienda, delle clausole contratti di fornitura tra aziende e delle normative nazionali di salvaguardia del consumatore.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
55
Previsioni di rotture e di interventi Dalla conoscenza del comportamento affidabilistico dei sistemi, la simulazione, condotta sull’intero intervallo di osservazione utile, consente di prevedere l’andamento nel tempo delle rotture (o degli interventi manutentivi) sia nel suo insieme che per le differenti cause di guasto. I risultati di previsione sono riportati come curva empirica con in ascissa una data del calendario e in ordinata il numero di rotture previsto in quel particolare periodo (forma di densità) oppure complessivo da inizio produzione (forma cumulata) In particolare queste informazioni risultano indispensabili per effettuare una stima corretta degli interventi previsti in garanzia e per valutarne i costi, ma possono dimostrarsi utili anche in condizioni particolari quali la necessità di dimensionare un magazzino di componenti da fornire per sostituzioni di rotture prima di chiudere o convertire i propri impianti produttivi. Ma queste previsioni assumono una loro particolare e notevole importanza quando si è di fronte al caso di incidenti ad elevata rischio e criticità, dove l’esigenza primaria sia quella di capire rapidamente l’ampiezza del problema e la reale possibilità di intervento.
Figura 17 : Esempio dei risultati delle simulazioni: a) curva di inaffidabilità - b) curva di rotture
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
56
IL CODICE Il codice di calcolo LifePrev è stato sviluppato in piattaforma di programma Visual Basic 5.0 E’ un codice di calcolo di tipo montecarlo con la simulazione diretta delle reali condizioni di utilizzo del sistema.
Routine VB di calcolo Si riportano e si descrivono di seguito le procedure Visual Basic fondamentali per le fasi di calcolo e simulazione.
Generazione di variabili aleatorie con distribuzione assegnata
Consente di generare una vettore (Dice) contenente un certo numero (Drivers) di valori stocastici che rispettano una densità di distribuzione assegnata e immessa tramite un vettore di densità (Density), il numero di intervalli di discretizzazione (Nsteps) e l’ampiezza di ciascun intervallo (Interval). Il processo di generazione avviene tramite:
� il calcolo della funzione cumulata della funzione attraverso la sua integrazione numerica � la sua inversione numerica � la re-discretizzazione della funzione inversa � l’estrazione di un intervallino equiprobabile sull’asse delle ordinate � il calcolo del corrispondente valore sull’asse delle ascisse � un aggiustamento per rendere continuo il processo discretizzato
Public Sub MonteCarloEstimation(NSteps, Interval, Density, Dice) 'estrae DRIVERS valori stocastici che rispettano curva di DENSITY ' Density As Single 'funzione di densità generica da rappresentare nelle finestre provvisorie ' NSteps As Integer 'numero di intervalli ' Interval As Single 'ampiezza di ogni intervallo ‘nint as Integer ‘precisione di calcolo ReDim Dice(Drivers) ‘definisce la matrice che conterrà i valori estratti ‘definizione delle variabili di discretizzazione ReDim Yi(nint) 'ordinata della funz. cumulata discretizzata Range = (NSteps + 0.5) * Interval 'lunghezza complessiva dell'intervallo di valori X DeltaX = Range / nint 'lunghezza intervallino discretizzante Area = 0 'calcolo cumulata funz distribuzione For i = 0 To nint X = DeltaX * i ' (0 --> Range) j = Int(X / Range * NSteps + 0.5) ' (0 --> NSteps) Y = Density(j) 'DENSITA' DI DISTRIBUZIONE ASSEGNATA Area = Area + Y * DeltaX / Interval Yi(i) = Area Next i If Area = 0 Then Exit Sub ‘impedisce di invertire una eventuale funzione nulla 'funzione discretizzata ha per vettori: ' X = i * DeltaX ‘ con valori (0 --> Range) ' Y = Yi(i) ‘ con valori (0 --> 1) 'inverto numericamente la funzione discretizzata ReDim Xi(nint) 'ascissa della funz. cumulata discretizzata (per intervallini di ordinate prefissate) k = 1 Xi(0) = 0 Xi(nint) = Range For j = 1 To nint - 1

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
57
Y = j / nint '(Y con valori compresi tra 0 --> 1) For i = k To nint If Y i(i) > Y Then k = i - 1 'si sposta al punto precedente X = k * DeltaX 'X associato a Yi(i) DeltaY = (Yi(k + 1) - Yi(k)) DY = Y - Yi(k) Xi(j) = DeltaX / DeltaY * DY + X '(0 --> Range) Exit For End If Next i Next j 'nuova funzione discretizzata invertita ha per vettori ' X = Xi(i) ‘ con valori (0 --> Range) ' Y = i / nint ‘ con valori (0 --> 1) 'selezione probabilistica dei valori (valori compresi tra 0 --> Range) For i = 1 To Drivers P = Int(R nd * (nint + 1)) 'scelta casuale di un intervallo tra 0 e nint Dice(i) = Xi(P) 'valore sull'asse (0 --> Range) Next i End Sub
Calcolo di media e varianza per funzione di densità e per variabile aleatoria
Consente di calcolare numericamente e in modo estremamente convenzionale i momenti di primo e secondo ordine (media e varianza) sia della distribuzione assegnata (Density), tanto dei valori stocastici estratti da questa funzione. Dal confronto tra le due medie arriva una prima stima degli errori introdotti in questa fase a causa del processo di discretizzazione delle funzioni e della campionamento statistico. Gli errori comunemente riscontrati restano al di sotto del 1% rendendo il processo di estrazione montecarlo estremamente preciso ed affidabile.
'calcola valore medio sulla densità Sum = 0 For i = 0 To NSteps X = i * Interval Sum = Sum + X * Density(i) Next i MeanDensity = Sum 'calcola valore medio sui valori estratti Sum = 0 For i = 0 To Drivers Sum = Sum + Dice(i) Next i MeanDice = Sum / Drivers ‘errore relativo di discretizzazione e campionamento statistico err_p = (MeanProfile - MeanDice) / MeanProfile * 100
Stima di invecchiamento del circolante
Attraverso la procedura generica sopra descritta per la generazione di variabili aleatorie con distribuzione conosciuta, modificando la funzione di densità assegnata, si ottengono dei campioni stocastici (di Drivers valori estratti) che conservano informazioni quali:
� istante di produzione (nel vettore DiceProduction) � ritardi tra produzione e messa in servizio (nel vettore DiceDelay) � profilo di guida come chilometri percorsi in un anno (nel vettore DiceProfile) � chilometraggio di rottamazione (nel vettore DiceDeath)
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
58
Combinando queste informazioni si può ricavare l’invecchiamento chilometrico di ciascuna vita estratta in un generico istante di analisi (TimeForAge). Unendo i dati di invecchiamento individuale si ottiene l’invecchiamento dell’intero parco circolante.
Public Sub Circulation(TimeForA ge) 'calcola l' invecchiamento parco circolante all' istante TimeForAge, ‘ DiceProduction, DiceDelay, DiceProfile, DiceDeath ‘sono vettori create attraverso la routine di generazione di v.a. con preassegnata distribuzione e contengono ‘rispettivamente: PRODUZIONE, RITARDI, PROFILO DI GUIDA, MOMENTO DI ROTTAMAZIONE ‘estratti per DRIVERS vite differenti 'invecchiamento estratto per ciascun Drivers ReDim DiceTravels(Drivers) ‘invecchiamento in “running units” (km) ReDim DiceLifeTime(Drivers) ‘invecchiamento in “calendar units“ (mesi) For i = 1 To Drivers 'per tutti i componenti simulati 'estrae parametri dei vari Drivers (tutte variabili locali) DriverNumber = Int(Drivers * Rnd) + 1 '= 1.... Drivers DriverProduction = D iceProduction(DriverNumber) 'singolo istante di produzione DriverNumber = Int(Drivers * Rnd) + 1 '= 1.... Drivers DriverDelay = D iceDelay(DriverNumber) 'singolo ritardo di messa in servizio (mesi) DriverNumber = Int(Drivers * Rnd) + 1 '= 1.... Drivers DriverProfile = Int(DiceProfile(DriverNumber) / 12) 'singolo profilo = (km/mese) DriverNumber = Int(Drivers * Rnd) + 1 '= 1.... Drivers DriverDeath = D iceDeath(DriverNumber) ' singola rottamazione = (km) DiceLifeTime(i) = TimeForAge - DriverProduction - DriverDelay + 0.5 'singola età vissuta (mesi) DiceTravels(i) = DiceLifeTime(i) * DriverProfile 'singolo percorso effettuato (km) Next i 'calcolo invecchiamento medio del sistema (in km) (solo per controllo) Sum = 0 For i = 1 To Drivers 'per tutti i componenti simulati Sum = Sum + DiceTravels(i) 'sistema simulato Next i DiceMeanAge = Sum / Drivers 'invecchiamento medio simulato (compresi i rottamati) End Sub
Creazione di un insieme di dati di censura Crea un insieme di tempi di censura che sia conforme e congruo con i dati di guasto disponibili. La procedure agisce nel seguente modo:
� nel caso di più cause di guasto seleziona quelle relative alla causa di interesse e sposta i loro tempi al guasto nel database (DB) dei tempi di rottura, muovendo i restanti tempi nel DB dei tempi di censura;
� dimensiona il DB dei tempi di censura tenendo conto, in forma proporzionale, del numero di vetture circolanti, dei guasti complessivamente registrati e dei guasti di cui si hanno i tempi al guasto;
� riempie la restante parte del DB dei tempi di censura con le indicazioni di percorrenza delle vetture simulate.
Public Sub CensoredTimeInsertinDB() 'Crea un DB di tempi censurati conforme al DB dei guasti ReDim UnReliabilityTime(NFailures) 'tempi di rottura (matrice inizialmente sovradimensionata) ReDim CensoredFailureTime(NFailures) 'tempi di censura (matrice inizialmente sovradimensionata) 'considera dati di rottura disponibili come rotture o censure a secondo della causa di guasto selezionata j = 0 For i = 1 To NFailures

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
59
If FailureMode(i) = FailureCode Or FailureCode = -1 Then 'copia da DB dati di rottura (se -1 prende tutti i guasti) j = j + 1 UnReliabilityTime(j) = FailureTime(i) Else 'copia da DB dati di censura CensoredFailureTime(i - j) = FailureTime(i) End If Next i 'n° rotture effettive del modo di guasto specificato NFailureSingleMode = j 'numero di censure previste per quel dato DB di rotture TotCensuredComponents = (TotC omponents - TotFailures) 'n° totale componenti previsti censurati NCensoredComponents = Int(TotCensuredComponents * NFailures / TotFailures + 0.5) 'n° componenti equival. nel DB 'ripristina dimensioni reali delli matrici ReDim Preserve UnReliabilityTime(NFailureSingleMode + NExtrapolationTime) ' tempi certi di rottura ReDim Preserve CensoredFailureTime(NCensoredComponents) 'censure equivalenti 'completa tempi di censura tra quelli simulati For i = NFailures - NFailureSingleMode To NCensoredComponents DriverUser = Int(R nd * Drivers) + 1 CensoredFailureTime(i) = DiceTravels(DriverUser) Next i End Sub
Calcolo dell’inaffidabilità per tempi esatti
Grazie alla conoscenza di un opportuno DB di tempi censurati con cui riscalare i tempi di guasto, è possibile applicare uno dei due estimatori per tempi esatti più comunemente impiegati in questo genere di analisi (Kaplan-Mayer oppure Median Ranking). Si faccia riferimento alla teoria relativa per l’esame di tali procedure.
Public Sub ExactTimeU nReliabilityCalculus() ReDim UnReliabilityExact(NFailureSingleMode) Select Case ReliabilityEstimator 'tecnica di stima di affidabilità Case 0 'Estimatore di Kaplan-Mayer Entered = NFailureSingleMode + NCensoredComponents + 1 Si = 1 UnReliabilityTime(0) = 0 For i = 1 To NFailureSingleMode 'punti di rottura Tmin = UnReliabilityTime(i - 1) Tmax = UnReliabilityTime(i) 'tempo di rottura 'conta quanti censurati nell'intervallo Censured = 0 For j = 1 To NCensoredComponents Censured = Censured - (CensoredFailureTime(j) >= Tmin And CensoredFailureTime(j) < Tmax) Next j pi = 1 / (Entered - Censured / 2) '<---- Entered = Entered - Censured - 1 Si = Si * (1 - pi) 'S i come produttoria dei pi UnReliabilityExact(i) = 1 - S i Next i Case 1 'Median Ranking Items = NFailureSingleMode
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
60
Entered = NFailureSingleMode + NCensoredComponents + 1 It0 = 1 For i = 1 To Items 'punti di rottura Tmin = UnReliabilityTime(i - 1) Tmax = UnReliabilityTime(i) 'tempo di rottura 'conta quanti censurati nell'intervallo Censured = 0 For j = 1 To NCensoredComponents Censured = Censured - (CensoredFailureTime(j) >= Tmin And CensoredFailureTime(j) < Tmax) Next j Entered = Entered - Censured - 1 Nti = ((Items + 1) - It0) / (1 + Entered) Iti = It0 + Nti UnReliabilityExact(i) = (Iti - 0.3) / (Items + 0.4) It0 = Iti Next i End Select End Sub

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
61
PREVISIONI E VALIDAZIONE La fase più delicata di ogni modellazione complessa resta sempre quella della verifica del modello e dei sui risultati previsionali.
Brevi cenni sulla validazione dei modelli Nel caso specifico, la validazione del modello e dei codici di simulazione avviene su due livelli differenti:
1. controllo di congruità e di esattezza matematica delle procedure 2. confronto tra previsioni e casi reali
Verifica di congruità delle elaborazioni
Questa tipologia di controllo interno del modello e delle procedure avviene attraverso test di verifica del tipo
� prove di convergenza delle procedure di calcolo e dei valori limite � verifica di conformità degli andamenti delle funzioni e delle evoluzioni temporali � semplici verifiche previsionale con casi ideali
ed ha lo scopo di � mettere alla prova la robustezza e flessibilità del modello analitico; � scovare errori di programmazione software nelle procedure di discretizzazione, calcolo
infinitesimale, inversione di matrici, convergenza, etc. � cercare i limiti di applicabilità del modello e delle procedure di calcolo da esso derivate. � verificare che gli errori associati alle singole procedure matematiche consentano
comunque di giungere a risultati complessivamente validi;
Verifica di validità predittiva dei risultati
Si passa di seguito alla validazione per confronto diretto, attraverso la verifica di coerenza e corrispondenza tra i risultati ottenuti dalla simulazione e quelli provenienti dalla osservazione dei sistemi fisici effettivamente realizzati. La corrispondenza dovrà verificarsi su tutte le variabili significative del fenomeno e sulla loro modalità di evoluzione.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
62
Descrizioni dei sistemi di validazione Per la validazione del modello affidabilistico e del codice di simulazione sono stati scelti sistemi reali forniti dalla Divisione Qualità del Gruppo FIAT Auto che si riferiscono a 6 differenti famiglie di autovetture prodotte a partire dalla fine degli anni ‘80. L’esigenza di tornare così indietro nel tempo per la scelta dei casi di test è spiegata dalla necessità di avere dei dati di consuntivo definitivi che si rendono disponibili solo dopo questi lunghi intervalli di tempo. Si riporta un riepilogo dei casi analizzati1:
Sig
la
SISTEMA
Vendite Inconvenienti rilevati (nel momento di analisi)
inizio fine veicoli totale ana lizza ti % sui ve icoli km max momento di
ana lisi
Caso 1 nov-93 apr-94 40.995 23 23 0.06% 20.000 lug-94
Caso 2 dic-91 giu-93 42.345 194 194 0.46% 57.000 gen-94
Caso 3 mar-88 mar-90 27.345 2427 1234 4.51% 175.000 lug-91
Caso 4 nov-89 mag-90 3.955 1709 580 14.66% 70.000 giu-91
Caso 5 ott-87 ott-88 203.568 19 19 0.01% 67.911 giu-89
Caso 6 mag-83 ago-83 23.869 30 30 0.13% 8.151 ott-83
1 Per motivi di riservatezza industriale le informazioni dei sistemi in studio verranno riportate modificando opportunamente i reali valori numeric i attraverso idonei fattori di scala. Di conseguenza, si considerino tali valori come indicazioni generiche volte al solo fine di meglio definire e descrivere le potenzialità del metodo.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
63
Criteri di confronto e di validazione La verifica di validità delle previsioni della simulazione possono essere condotte su differenti livelli e prendendo come riferimento le diverse informazioni di cui si ha disponibilità. Questi dati sono:
1. consuntivo di tutte le rotture registrate al momento dell’analisi (1° punto di consuntivo) 2. previsioni di rotture effettuate con altri metodi di validità ben riconosciuta (Metodo FIAT) 3. consuntivo delle rotture in un istante successivo al momento di analisi (2° punto di
consuntivo) I risultati delle simulazioni (Metodo LifePrev) dovranno coincidere, per quanto statisticamente accettabile, con le informazioni sopra descritte, ma tenendo sempre presente i limiti stessi di tali informazioni. In particolare si deve notare come:
� le previsioni effettuate con diverse ipotesi di modelli affidabilistici interpretative (specie per quanto riguarda le ipotesi di estrapolazione assunte come valide) portano a risultati molto differenti tra loro. Di conseguenza la congruenza dei risultati ottenuti dal Metodo
LifePrev con le previsioni del Metodo FIAT deve avvenire a fronte di analoghe condizioni di simulazione.
� il corretto consuntivo definitivo delle rotture spesso è di difficile quantificazione per le seguenti motivazioni:
o i risultati delle previsioni (Metodo FIAT) sono stati utilizzati per realizzare delle campagne di risanamento che hanno pregiudicato l’evoluzione prevista per il sistema;
o le previsioni realizzate su un lotto di autovetture è estesa ad altri lotti della stessa autovettura tanto da non aver corrispondenza tra lotto di analisi e lotto di consuntivo;
o le previsioni realizzate su alcuni modelli di autovetture sono automaticamente estese ad altri modelli analoghi (o con componenti difettosi analoghi) tanto da non aver corrispondenza tra sistema di analisi e sistema di consuntivo;
o a volte non si dispongono di dati accurati relativi ad un periodo così lungo. Si discuteranno, caso per caso, i risultati raggiunti.2
Risultati di validazione I risultati sono esposti sotto forma di curve con in ordinata il numero totale di guasti segnalati (quantità cumulata) a partire dal momento di messa in servizio della prima autovettura, mentre in ascissa è riportato l’istante del calendario a cui tali rotture fanno riferimento. Sui grafici sono riportate spesso differenti curve, una per ciascuna delle condizioni di simulazione scelte. I criteri fondamentali per il calcolo di tali curve sono stati:
� criteri di estrapolazione della curva di affidabilità o condizioni di saturazione sull’ultimo chilometro disponibile; o condizioni di saturazione su un altro chilometraggio a scelta; o rampa di salita fino ad arrivare ad un valore di saturazione a scelta per un
chilometraggio a scelta (generalizzazione dei casi precedenti);
2 Per riservatezza industriale non esiste una corrispondenza diretta tra le informazioni riportate in tabella e le considerazione esposte nelle sezioni relative ai “Risultati della Validazione”; ossia, ad esempio, i risultati esposti nella sezione “Corrispondenza delle Previs ioni” e il grafico relativo non riguardano il “caso 1” di tabella, ma uno dei restanti.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
64
� criteri di convergenza sulle storie o “worst case” e “best case” per definire il range di variazione possibile per i
risultati; o “minimo errore”, ossia i risultati di quella particolare storia che ha condotto alla
migliore corrispondenza tra le previsioni e il numero di rotture registrate al momento di analisi.
In particolare, la scelta di opportuni criteri di estrapolazione ha permesso di impostare condizioni di simulazione analoghe a quelle utilizzate da altri metodi di calcolo consentendo il confronto dei risultati. Sugli stessi grafici sono inoltre riportati i valori stimati attraverso l’impiego del Metodo FIAT (con simboli bianchi) e il consuntivo delle rotture realmente riscontrate (con simboli gialli) nel 1° punto e, quando disponibile e coerente con il modello previsionale, nel 2° punto di consuntivo.
Corrispondenza tra le previsioni
La previsione, per questo caso, è stata condotta scegliendo una ipotesi di estrapolazione della curva di inaffidabilità tale da saturare le rotture ai 300.000 km momento nel quale si è imposto di considerare rotti il 20% dei autoveicoli che arrivano a questa percorrenza. Questa scelta è state effettuata interpretando opportunamente le curva di inaffidabilità, disponibile fino ad elevatissimi chilometraggi, ed applicando particolari criteri conservativi. Dall’esame dei risultati (riportati in Figura 18), in relazione alla validazione del metodo e del codice, si ricavano le seguenti utili indicazioni:
���� tutti gli andamenti proposti dal Metodo LifePrev convergono sul 1° punto di consuntivo, in modo sostanzialmente indipendente dai particolari criteri di simulazione adottati;
���� esiste una corrispondenza marcata e prolungata di oltre 8 anni (pari a 100 punti di calcolo)tra i risultati della simulazione ottenuti mediante il Metodo LifePrev e quelli ottenuti dal precedente tecnica, il Metodo FIAT, da sempre considerati coerenti con la realtà.
Figura 18 : Convergenza dei risultati per lunghi periodi
Precisione assoluta
Dalla Figura 19, si osserva come: ���� i risultati proposti con il Metodo LifePrev sono in grado di prevedere il 2° punto di
consuntivo (posto in questo caso ad oltre 6 anni da inizio produzione, oltre 3 anni dopo il momento di analisi);

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
65
���� la curve di minimo errore proposta dal Metodo LifePrev è in grado di predire il 2° punto di consuntivo in modo molto più accurato del precedente Metodo Fiat (un errore ridotto al 1.72% rispetto al 9.50%).
Queste considerazioni diventano molto più interessanti se si considera come i risultati sono stati ottenuti con un caso dove la popolazione in circolazione era più di 2000 volte maggiore del campione di rotture analizzate.
Figura 19 : Elevata esattezza delle previsioni
Ridotto rischio di errore In un ulteriore caso analizzato, quello i cui risultati sono riportati in Figura 20, le condizioni di simulazioni erano particolarmente delicate in relazione alla corretta definizione della curva di inaffidabilità. Infatti il momento di consuntivo delle rotture (e di analisi previsionale) era posizionato a meno di 3 mesi dalla fine delle vendite. Di conseguenza le segnalazioni di rotture si erano rivelate meno di una parte per mille mentre il chilometraggio massimo di rotture restava all’interno del periodo di manifestazione dei guasti infantili e quindi non in grado di rivelare la presenza di eventuali fenomeni di usura. Di conseguenza, era necessario definire con cura le condizioni di estrapolazione della curva di affidabilità prima di procede alle stime. Le stime di previsione secondo il Metodo FIAT sono state condotte sotto le due ipotesi di
� guasti infantili completamente definiti dalle rotture finora rilevate, con conseguente curva di inaffidabilità che satura al valore raggiunto a circa 20.000 (simbolo bianco con bordo
rosso) � guasti casuali mischiati ai quelli infantili con una curva di inaffidabilità risultante che
continua a salire secondo il modello di Weibull definito dalle rotture finora rilevate per poi saturare al raggiungere dei 50.000 km (simbolo bianco con bordo verde)
Le due ipotesi hanno portato ad andamenti e risultati molto diversi tra loro (linee tratteggiate
verdi) con la conseguente necessità di ricercare informazioni aggiuntive che servissero a definire correttamente il tipo di rottura fisica riscontrata e definire quale fosse il modello di guasto più conforme e quella previsione più convalidata dalla realtà. Delle due ipotesi solo la prima appariva confortata dalle osservazioni sul modo di guasto fisico e anche la relativa previsione FIAT si è dimostrata corretta a fronte nel successivo controllo dei valori di consuntivo. Tuttavia, si lascia notare come non sempre potranno essere disponibili tali informazioni aggiuntive e, inoltre, anche in presenza di informazioni corrette, potrà accadere che le stesse vengano interpretate in forma errata.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
66
Utilizzando il software è stato possibile effettuare con rapidità differenti simulazioni, modificando le condizioni di calcolo e definendo in modo semplice le curve di variazione delle previsioni. Si dimostra di nuovo come, scegliendo le stesse condizioni impiegate nella simulazione FIAT, si ottengono praticamente gli stessi risultati nel caso queste condizioni siano fisicamente corrette (curva blu), mentre si ottengono risultati limitatamente inesatti qualora le assunzioni siano completamente errate (curva viola). Si osservi infatti come la seconda ipotesi, quella di curva di affidabilità che sale fino ai 50.000 km, avrebbe portato le stime FIAT verso una costante rampa di salita dei guasti previsti, mentre ogni simulazione condotta secondo il Metodo LifePrev (curva viola e gialla) è tale da indicare una saturazione su valori non corretti, ma di errore grosso modo accettabile. Di conseguenza, in relazione alla validazione del metodo e del codice, si può affermare come
���� in presenza di modelli interpretativi complessi e di assunzioni incerte, il metodo consente di ottenere risultati previsionali con un rischio di errore ridotto rispetto ad altri metodi.
Figura 20 : Riduce il rischi di accettare come valide previsioni errate
Supera le incertezze dei dati di input
Nel successivo caso analizzato si è presentata una discordanza tra i risultati della simulazione dei due differenti metodi (come riportato in Figura 21), ma questa differenza è giustificata dalla diversa precisione delle informazioni utilizzati come dati di ingresso. Infatti mentre l’analisi effettuata con il Metodo FIAT poteva utilizzare i dati di guasto espressi come tempi esatti, lo studio con il Metodo LifePrev ha ricevuto come input tempi al guasto espressi in forma raggruppata e in classi di discretizzazione di 10.000 km ciascuno. Di conseguenza, la curva di affidabilità è ottenuta con circa 10-12 punti, mentre quella originale vantava più di 1500 punti, una differente risoluzione che necessariamente si ripercuote sulle previsioni di rottura. Tuttavia, si può osservare come, benché non precisa sul 1° punto di consuntivo, sovrastimandole, le previsioni LifePrev appaiono confermare l’ultimo punto disponibile delle previsioni FIAT, prevedendo inoltre un curva di saturazione poco più oltre. Purtroppo non si dispongono di ulteriori punti di previsione FIAT o di consuntivo che confermino la validità dell’andamento di saturazione previsto. Un’altra indicazione di indubbio interesse risiede nel fatto che tutte le previsioni effettuate con i più disparati criteri sono concordi nel prevedere come esista realmente tale andamento di saturazione.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
67
Di conseguenza, in relazione alla validazione del metodo e del codice, possiamo ritenere come ���� il metodo consente di superare alcune delle incertezze e imprecisioni dei dati di input
senza peggiorare i risultati forniti e garantendo almeno una valutazione delle condizioni di saturazione dei fenomeni
Figura 21 : Riduce il rischio di errori nel caso di dati imprecisi
Velocità e flessibilità
Nel successivo caso analizzato ci si trova di fronte alle condizioni più estreme di analisi: una popolazione enorme a fronte di un limitatissimo numero di rotture, dell’ordine dell’uno su diecimila, con pochissimi punti di rottura ad alti chilometraggi e la necessità di estendere le previsioni di molto nel futuro. La previsione secondo Metodo FIAT ha superato questi problemi limitando la previsione a un anno dopo il momento dell’analisi e riservando delle ipotesi pessimistiche sulla curva di affidabilità. Con il Metodo LifePrev, grazie alla possibilità di effettuare previsione in modo rapido e flessibile, sono state condotte numerose analisi nel rispetto dei differenti profili di simulazione. Tutte le curve dei risultati convergono sul 1° punto di consuntivo e forniscono una previsione concorde (tra loro ma leggermente discorde rispetto al Metodo FIAT) per circa 2 anni rispetto al momento dell’analisi. Passato questo periodo i valori risultano differenti in base alle diverse condizioni di simulazione. In relazione alla validazione del metodo e del codice, si è dimostrato di come
���� il metodo consente di mettere a disposizione velocità e flessibilità di calcolo offrendo uno strumento in grado di studiare comodamente il sistema anche in casi estremamente complessi.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
68
Figura 22 : flessibile e veloce per le simulazioni più complesse
Supera le incertezze sul tempo di previsione
Nell’ultimo caso ci si poneva la domanda di verificare rapidamente se un fenomeno di rottura poteva considerarsi esaurito, o, in caso contrario, dopo quanto tempo potesse ritenersi sostanzialmente concluso. Attraverso la visualizzazione delle bande di soluzioni definite dal best case e dal worst case si dispone di un comodo strumento per verificare l’inizio della zona di saturazione. Di conseguenza, metodo e codice sono in grado di:
���� superare le incertezze e i dubbi relativi al momento di conclusione di un fenomeno di rottura, specie se caratterizzato da leggi di guasto infantile.
Figura 23 : Fornisce chiare indicazioni temporali

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
69
UNA PREVISIONE COMPLETA Finita la fase di validazione del modello e del codice di simulazione, si è passato ad analizzare casi più recenti nel tempo e di maggiore interesse strategico. Si descrivono di seguito i risultati previsionali raggiunti dal primo degli studi completi effettuati attraverso una analisi LifePrev. 3
Le motivazioni
La necessità di un continuo sviluppo di prodotti nuovi e sempre più perfezionati, porta le Aziende fornitrici di componentistica avanzata ad una politica di perenne ricerca di maggiori prestazioni e di miglioramento della qualità. Questo può avvenire solo attraverso lo sforzo costante volto a creare una fortissima simbiosi tra le differenti realtà aziendali dediti alla progettazione, alla produzione e al miglioramento di qualità. E così, mentre la linea produttiva sta rendendo disponibili i suoi prodotti, spesso a decine di migliaia di esemplari al mese, un numero elevato progettisti e tecnici specializzati si occupa di mettere a punto soluzioni nuove, migliorative tanto delle prestazioni quanto della qualità. Alcune modifiche si concentreranno sul progetto altre toccheranno prevalentemente il processo produttivo, ma tutte saranno finalizzate a realizzare un prodotto migliore di quello commercializzato in precedenza, finché ad un certo istante, differenti esigenze di marketing oppure lo sviluppo di nuove tecnologie renderanno indispensabile passare a ripensamento completo del componente. Qualsiasi siano le ragioni che spingono allo sviluppo di componenti più performanti, quando la soluzione proposta si dimostra molto migliore rispetto alle precedenti, può essere interessate valutare i vantaggi e gli svantaggi di una eventuale politica di sostituzione del dispositivo anche sulle precedenti autovetture. Potrebbe venire da pensare che questa scelta così estrema sia riservata solo a casi dove le nuove soluzioni andrebbero a risolvere malfunzionamenti di elevata criticità del precedente dispositivo quando, ad esempio, queste disfunzioni sono tali da poter incidere sulla sicurezza personale dell’utilizzatore. In realtà, la corsa estrema al soddisfacimento del cliente come chiave fondamentale del successo commerciale, appiattisce di molto la scala di critic ità delle differenti cause di guasto rendendole, in sostanza, tutte molto sconvenienti. Vale un concetto del tipo: “il cliente non deve restare a piedi e questo indipendentemente dalla causa di guasto, sia essa la fusione della testata, sia un problema elettrico secondario al motorino di avviamento”. Di conseguenza il parametro davvero fondamentale che contraddistingue le cause di guasto tra loro resta il costo di intervento, importante almeno nell’ottica del fornitore di componenti, specie quando, appositi contratti di garanzia della qualità, lo obbligano a rispettare fissati parametri qualitativi. Capita spesso, quindi, che le analisi di affidabilità vengano condotte anche semplicemente per verificare il livello qualita tivo del prodotto attualmente in distribuzione, riuscendo in questo modo ad avere, con un anticipo, delle valide indicazioni per poter scegliere la più opportuna politica di miglioramento del prodotto. Le azioni conseguenti potranno essere tanto quelle estreme di una campagna di risanamento, quanto semplicemente la definizione dei nuovi futuri target produttivi e qualitativi. Tutta questa premessa per rendere chiaro come non sempre ad una analisi di affidabilità è associato un reale rischio sul prodotto, anzi, molto spesso gli studi sono condotti solo per stimare il livello qualitativo raggiunto e verificare il rispetto dei parametri contrattuali definiti tra l’Azienda Madre e l’Azienda Fornitrice di componentistica.
3 Per motivi di riservatezza industriale alcune delle informazioni saranno riportate in forma adimensionalizzata.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
70
Inoltre, buona parte delle azioni correttive che prendono avvio dai risultati di questo genere di analisi, sono talmente trasparenti per l’utente finale che spesso neppure se ne accorgerse. Si immagini, ad esempio, tutte le cause di guasto interni al motore (calo di prestazioni, combustione imperfetta, gas di scarico non conformi) dove molte volte è sufficiente riprogrammare la centralina elettronica per risolvere oppure aggirare il problema. Ma questa soluzione avverrà in modo generalizzato e senza neppure informare il proprietario dell’autoveicolo, quando, presso le officine autorizzate, sarà istallato una nuova versione del software di controllo della centralina. Qualsiasi siano le criticità delle cause di guasto oppure la gravosità dei rimedi, solo attraverso l’analisi dei dati di guasto è possibile effettuare correttamente le opportune valutazioni.
Le informazioni a disposizione
Il sistema fisico
Il primo studio affidabilistico realizzato per scopi non validativi della metodologia, ma previsionali ed interpretativi della realtà è stato condotto su un particolare dispositivo di controllo motore installato su alcuni modelli della FIAT Stilo. La FIAT Stilo desidera porsi come punto di riferimento nella fascia delle autovetture medie
compatte giocando le carte di una tecnologia particolarmente avanzata, di proposte molto innovative e di alti standard qualitativi. La sfida è ambiziosa poiché va ad inserirsi nel contesto di in un segmento che è il più importante del mercato europeo. Sia per le dimensioni (vale poco meno di quattro milioni di vetture l'anno) sia perché presidiato da tutti i principali costruttori. La Stilo è nata seguendo un concetto realizzativo del tutto nuovo e di aggressione senza compromessi del mercato, dove a fronte di una apparente semplicità e convenzionalità delle linee, la nuova vettura è in grado di offrire dotazioni che fino a due anni fa non erano disponibili, tutte insieme, nemmeno sulle ammiraglie. Ne consegue una massiccia introduzione di elettronica e di tecnologie innovative che si affiancano per offrire una idea di avanguardia e di efficienza, una immagine che può resistere solo se supportata dal reale raggiungimento di elevati standard di qualità. Una sfida non da poco se si considera come, la necessità di bruciare sul tempo la concorrenza, ha spinto verso l’introduzione di dispositivi giovani, non ancora messi alla prova perché installati su altri modelli già circolanti, proprio in una autovettura su cui l’Azienda puntava per il rilancio della propria immagine.
In una delle sue motorizzazioni più avanzata la FIAT “Stilo” dispone di un dispositivo meccatronico di controllo motore denominato “Drive-by-Wire” (DBW) e realizzato dalla Magneti
Marelli PowerTrain. Il sistema consente di svincolare la posizione dell’acceleratore da quella
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
71
della farfalla, potendo scegliere per quest’ultima l’apertura ottimale per le condizioni fluidodinamiche istantanee. Questo dispositivo va a realizzare una completa integrazione con il sistema di controllo della trazione tale da permettere di ottenere livelli di emissione estremamente contenuti pur garantendo delle prestazioni in linea con una impostazione sportiva della vettura.
Figura 24 : Unità di Controllo Motore con dispositivo DBW (Marelli ECU 4/4N)
La produzione
Lo studio è rivolto ad uno specifico lotto produttivo di alcune decine di migliaia di dispositivi DBW, lotto che può essere definito come quello realizzato in un anno a partire dal luglio ’01. Inoltre, per esigenza di disporre di informazioni di guasto certe e rintracciabili, lo studio previsionale è limitato alla produzione effettuata per il Mercato Italia: eventuali generalizzazioni agli altri mercati saranno effettuate in modo proporzionale al numero di veicoli circolanti in ciascuno di questi mercati. La produzione di sistemi meccatronici DBW da installare sulla FIAT “Stilo” con motorizzazione con DBW è stata caratterizzata da una rapida ascesa nel numero di unità prodotte fino al mese di ottobre, novembre ’01, momento nel quale si è ridotta la produzione mantenendo un andamento costante, in leggera decrescita nei successivi 4/5 mesi. Un picco a maggio ’02 ha consentito di mettere a pari la produzione di dispositivi con l’andamento delle vendite e proseguire l’andamento costante di uscita dal mercato. A partire da luglio ’02, questo dispositivo è stato sostituito da un modello più perfezionato, di caratteristiche affidabilistiche differenti dal precedente e quindi al di fuori del lotto produttivo oggetto di studio.
Figura 25 : Andamento della produzione FIAT "Stilo" con DBW, Mercato Italia
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
72
Ritardo di consegna al cliente Per definire il corretto momento di messa in servizio, necessario alla successiva simulazione, all’andamento nel tempo della produzione realizzata presso l’Azienda Fornitrice, dovranno sommarsi i ritardi di:
���� consegna alla Casa Madre produttrice dei veicoli; ���� tempo di installazione e completa realizzazione del veicolo; ���� consegna ai distributori; ���� ritardo di vendita al cliente.
Dalle informazioni in nostro possesso si è verificata un andamento complessiva dei ritardo tra produzione e messa in servizio che lasciano intravedere una marcata situazione di just in time, dove i magazzini sono praticamente inesistenti e il ritardo medio resta sotto al mese e mezzo.
Figura 26 : Curva del ritardo tra produzione e vendita (del DBW)
Il profilo di utilizzo Attraverso i dati provenienti dal Servizio di Assistenza alla Cliente con particolare riferimento alla elaborazione delle informazioni acquisite al momento di primo tagliando, è possibile disporre di una curva di distribuzione dell’utilizzo chilometrico annuo delle autovetture. In particolare si osserva una funzione di densità grosso modo simmetrica rispetto ai 21.000 km valore che può essere assunto indicativamente pari al chilometraggio medio annuo effettuato da questa tipologia di autovetture.
Figura 27 : Profilo di utilizzo chilometrico annuo FIAT “Stilo”
La ripartizione dei guasti
La percentuale di dispositivi che hanno manifestato complessivamente un problema di guasto è relativamente basso, nel pieno rispetto del target previsto di soddisfacimento del Cliente ed in linea con le specifiche contrattuali di fornitura. La necessità imprescindibile di continuare nella strada del migliorare di prodotto porta comunque a realizzare una analisi per la stima dell’affidabilità e per la previsione degli interventi coperti o non coperti da garanzia.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
73
Quando una autovettura mostra dei problemi e le Officine di Riparazione collegano il problema al non corretto funzionamento di un componente complesso e di difficile intervento quale il DBW, allora il manutentore provvederà a sostituirlo con uno nuovo dispositivo segnalando l’evento alla Casa Madre che lo comunica al Fornitore. Per alcuni componenti, il Fornitore attraverso la Casa Madre richiede di esaminare il dispositivo in modo da definire la cause di rottura e procedere ad implementare i miglioramenti del caso. Dall’esame in laboratorio delle cause ricorrenti di rottura si riesce ad ottenere un diagramma di
Pareto dei difetti.
Figura 28 : Incidenza dei difetti (a circa un anno da fine produzione)
Si nota immediatamente come quasi un difetto su tre è del tipo Not Trouble Found, ossia il componente segnalato come guasto, quando provato in laboratorio risultava perfettamente funzionante ed il componente è stato sostituito senza nessuna ragione. Questo può avvenire o per errore umano manutentore oppure perché il dispositivo appariva non funzionare correttamente a causa del non funzionamento di qualcos’altro di esterno. Gli NTF sono componenti funzionanti, ma comunque sostituiti di cui quindi non tener conto nella stima dell’affidabilità reale del dispositivo, ma di grande interesse nella stima dei componenti che complessivamente devono essere prodotti per sostituire quelli segnalati come difettosi (che siano o meno realmente difettosi). Tra le altre cause di guasto risultano prevalenti le due tipologie:
� problemi di isolamento elettrico che si comportano essenzialmente come cause di guasto infantili, ossia problemi costruttivi e del processo realizzativo, che se presenti, si rivelano prestissimo, a bassi chilometraggi (39%):
� problemi di imbrattamento o di difettosità ad alti chilometraggi, che si presentano con modalità tipiche dei fenomeni di usura (23+3%) e che, per la soluzione, richiedono interventi sul progetto.
E’ da notare come tutte le indicazioni desunte dal diagramma di Pareto vadano prese con le dovute precauzioni. Infatti, si consideri come, qualsiasi sia la tipologia di guasto in esame, ci si deve attendere una incidenza dipendente dal grado di utilizzo della vettura che rende la curva di affidabilità relativa funzione del chilometraggio percorso. Quindi, ogni ripartizione sarà fortemente soggetta al grado di invecchiamento del parco circolante che alla fin fine dipende dal momento in cui si realizza l’analisi. Nel caso specifico, poiché l’analisi è stata condotta dopo poco più di un anno dalla fine della produzione, le autovetture hanno circolato per mediamente 2 anni percorrendo mediamente circa 40.000 km. Di conseguenza la ripartizione rappresentata nel Pareto dei Difetti sovrastimerà i problemi infantili a danno di quelli che avvengono a chilometraggio maggiore.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
74
Distribuzione chilometrica dei guasti rilevati Il fenomeno del concentrarsi di particolari tipologie di difetti intorno alcune specifiche fasce chilometriche può essere direttamente rilevato osservando la distribuzione chilometrica dei guasti Dalla Figura 29 si vede chiaramente come il difetto del non corretto isolamento elettrico risulta manifestarsi, immediatamente, prima dei 15.000-20.000 chilometri che equivalgono ai primi 9-12 mesi di utilizzo. Nessuno dispositivo ha sopravvissuto più di tale limite ed il problema rimane confinato, risolto entro un anno da fine produzione mentre i costi relativi sono a carico dell’azienda perché il problema resta all’interno del periodo di garanzia. Inoltre sembra sostanzialmente esaurito al momento dell’analisi Al contrario, il fenomeno dell’imbrattamento è praticamente inesistente al di sotto dei 10.000 km, momento in cui le prime rotture comincia a manifestarsi. Nei successivi chilometri il difetto si intensifica in modo marcato rendendo chiaro come potrebbe venire a rappresentare un chiaro problema. Tuttavia, senza la stima dell’invecchiamento del parco circolante, non risulta possibile pesare le rotture e non siamo in grado di capire se il rarefarsi dei difetti sopra i 50.000 km sia legato all’esaurirsi del fenomeno oppure al semplice diminuire delle autovetture che hanno percorso questi chilometraggi.
Figura 29 : Distribuzione chilometrica dei difetti segnalati
Si intuisce come le corrette indicazioni per interpretare i fenomeni di guasto non siano, quindi, da ricercare nei Diagrammi di Pareto oppure in grafici di distribuzione chilometrica dei difetti, ma negli andamenti delle curve di inaffidabilità.
Le informazioni acquisite
Studio non parametrico delle curve di affidabilità
Tutte le considerazioni sopra esposte assumono una forma più definita e chiara una volta calcolate le curve di affidabilità (densità di guasto, inaffidabilità e rateo di guasto) . Nel caso specifico, osservando la curva di inaffidabilità, si intuisce come 1. per la causa di guasto di mancato isolamento elettrico
� resta latente per le prime migliaia di chilometri � si manifesta in modo sempre più marcato tra i 5.000 e i 10.000 km, � ai 10.00 km si inverte la tendenza di crescita fino a saturare intorno ai 20.000 km. � nei primi 10.000 km il fenomeno ha già investito i 4/5 delle vetture che saranno coinvolte � tutti i costi di manutenzione saranno coperti dalla garanzia.
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
75
2. per la causa di guasto di imbrattamento (o le altre cause equivalenti)
� è praticamente inesistente fino ai 15.000 km; � cresce in modo progressivo e via via più marcato � a partire da 20.000 km diventa la prima causa di guasto � non sono evidenti effetti di saturazione della curva entro i 50.000 km � è necessario effettuare uno studio parametrico per vedere la saturazione � i costi di manutenzione sono preponderatamente a carico dell’utente � gli interventi di manutenzione a carico dell’Azienda (entro i 20.000 km) sono dello stesso
ordine di quelli legati alla mancanza di idoneo isolamento elettrico.
Figura 30 : Stima non parametrica di inaffidabilità del DBW
Studio parametrico delle curve di affidabilità
Dalla conoscenza della curva di inaffidabilità calcolata con il Metodo LifePrev, mediante l’utilizzo della Carta di Weibull, si è effettuato lo studio parametrico con la definizione di due andamenti caratteristici, per difetti a basso e alto chilometraggio (rappresentate sulla Carta da due rette) e la determinazione dei parametri delle Weibull approssimanti.
Figura 31 : Studio parametrico della curva di inaffidabilità
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
76
Le previsioni in garanzia La simulazione è stata condotta per conoscere la curva della richiesta di ricambi sia quelli complessivamente previsti, sia quella collegata agli interventi in garanzia. Nel caso delle curve in condizioni di garanzia, la simulazione ha presentato i limiti di utilizzo dei 20.000 km oppure 24 mesi di servizio, Dalla Figura 32 si osserva come: 3. per la causa di guasto di mancato isolamento elettrico
� gli interventi di garanzia avranno termino poco dopo il ventesimo mese dall’inizio della produzione, anticipando di poco la scadenza dei limiti temporali dei 18 mesi di garanzia;
� al termine del periodo, i difetti di isolamento avranno inciso per circa il 15% del totale 4. per la causa di guasto di imbrattamento (o le altre cause equivalenti)
� gli interventi di garanzia per l’imbrattamento si concluderanno invece solo con la fuoriuscita di tutti le vetture dal limite temporale di garanzia;
� al termine del periodo, i difetti di isolamento avranno inciso per circa il 46% del totale
5. per le segnalazioni non collegate a nessun guasto (NTF) � il numero di segnalazioni resta sempre molto elevato, pari a più di 38% delle rotture
complessive e sempre non molto inferiore alla causa principale di guasto.
Figura 32 : Previsione di richiesta di ricambi DBW in garanzia
I ritorni complessivi
Nel caso del calcolo dell’andamento degli interventi complessivi, la simulazione ha presentato i limiti di utilizzo dei 200.000 km oppure 180 mesi di servizio. I risultati sono fortemente legati alle ipotesi di estrapolazioni che vengono scelte per definire la curva di affidabilità tra i 50.000 km, pari all’ultimo chilometraggio di rottura conosciuto per la causa di guasto di imbrattamento, e i 200.000 km, pari al limite di simulazione. Di seguito si riportano i risultati relativi ad una particolare ipotesi di curva di inaffidabilità, tra le varie utilizzate per le analisi previsionali. In Figura 33 si deduce come 6. per la causa di guasto di mancato isolamento elettrico

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
77
� gli interventi complessivi avranno lo stesso andamento degli interventi in garanzia � tra il 2002 e il 2003 cesserà completamente il verificarsi questi problemi � globalmente, i difetti di isolamento saranno circa il 1/8 di quelli per imbrattamento
7. per la causa di guasto di imbrattamento (o le altre cause equivalenti)
� a partire dal 2002 saranno i soli interventi di riparazione significativi � solo tra il 2004 e il 2005 si raggiungerà un plateau di interventi � anche dopo il 2005 gli interventi continueranno con costanza, ma in forma non marcata.
Figura 33 : Previsione della richiesta complessiva di ricambi DBW
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
78
CONCLUSIONI Il lavoro di tesi si propone di fornire una metodologia avanzata per lo studio del comportamento affidabilistico e manutentivo di impianti industriali, sistemi complessi oppure singoli componenti meccanici attraverso la simulazione dell’intero ciclo di vita, dal momento di produzione e messa in funzione, attraverso l’applicazione delle condizioni di utilizzo, fino all’evento di rottura.
Per effettuare l’analisi statistica delle informazioni di rottura, dopo una attenta valutazione dei modelli teorici e delle metodologie di esami affidabilistic i comunemente riscontrabili in letteratura, è stato fondamentale sviluppare delle tecniche ad hoc per le analisi che consentissero di superare le numerose problematiche presenti nell’analisi dei casi specifici. Attraverso l’introduzione nei modelli classici di assunzioni semiempiriche e attraverso il massiccio impiego di codici di calcolo di simulazione, appositamente sviluppati, è stato possibile fornire un metodo di soluzione rapido e accurato per risolvere problemi di difficilissima modellazione.
L’attività di modellazione si è concentrata nell’approfondimento dei seguenti aspetti
� Processi stocastici nell’analisi di affidabilità � Limiti e condizioni di impiego di strumenti statistici nei processi stocastici � Metodi matematici per l’elaborazione statistica di dati sperimentali � Trattazione di dati provenienti da sottoinsiemi non completamente rappresentativi � Problematiche inerenti ad un basso numero di dati disponibili � Problematiche inerenti a sistemi complessi con più cause concorrenti � Concetti e condizioni di applicabilità dei codici di simulazione � Previsione di informazioni su rotture � Gestione e ottimizzazione delle scorte
La fase di definizione della metodologia previsionale è stata affiancata dallo sviluppo di un software user-friendly opportunamente validato mediate l’applicazioni di criteri di congruità e di convergenza verso i risultati corretti per quelle procedure del codice di maggiore interesse computazionale. Successivamente si è effettuata la completa validazione scientifica della metodologia mediante il confronto tra i risultati forniti dal modello e quanto riscontrato nella realtà, verificando, le previsioni su casi complessi provenienti dalla realtà di elevato interesse industriale e relativi al settore automobilistico. In questo modo si è messo a punto uno strumento di ricerca di qualità estremamente avanzato e raffinato che, affiancando alla semplicità di utilizzo una elevata flessibilità e precisione, si propone come una soluzione idonea per essere applicata con successo in svariate realtà produttive.

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
79
APPENDICI Seguono alcune appendici di interesse generale e specifico.
Checklist di realizzazione dei requisiti di qualità ed affidabilità
Nella tabella successiva è riportata l’elenco completo delle attività necessarie al miglioramento di qualità nell’ottica di un approccio TQM (assicurazione di qualità e di affidabilità di equipaggiamenti/attrezzature/macchinari e sistemi complessi con elevati requisiti funzionali) e le assegnazione di competenze delle diverse attività ai differenti settori aziendali. Sono inoltre evidenziate le fasi in cui effettuare una corretta analisi RDA potrà condurre al miglioramento dei risultati qualitativi raggiunti. Note esplicative: Settori interessati M – Marketing R&S – Ricerca e Sviluppo P – Produzione Q&A – Assicurazione di qualità Attività
R: responsabilità, C: cooperazione (deve cooperare), I: informazione (può cooperare)
Checklist per la preparazione di un programma di assicurazione della qualità e l’affidabilità
Mar
ketin
g (M
)
Svilu
ppo
(R&
S)
Prod
uzio
ne (
P)
Ass
icur
azio
ne
(Q&
A)
Influ
enza
R
DA
A Requisit i del cliente e del mercato 1 Valutazione di sistemi e attrezzature e macchinari venduti R I I C �
2 Identificazione richieste di cliente e mercato e delle loro solvibilità R I I C 3 Supporto al cliente R C B Analis i preliminare
1
Definizione degli obiettivi qualitativi previsionali per affidabilità, manutenibilità, disponibilità, sicurezza C C C R �
2
Sviluppo di analisi semplificate, rapide ed economiche, per l’identificazione dei problemi potenziali I C R
3 Ricerche comparative I C R � C Aspetti di qualità ed affidabilità nelle definizione di specifiche,
preventivi, contratti…ecc 1 Definizione delle funzioni richieste I R C 2 Identificazione dei fattori di rischio nelle condizioni del contesto C R C � 3 Definizione degli obiettivi quantitativi “realistici” di affidabilità,
manutenibilità, disponibilità, sicurezza e livello di qualità C C C R � 4 Specificazione di test e di criteri di accettazione C C C R 5 Identificazione delle possibilità di ottenere informazioni dal campo R C � 6 Costo stimato delle attività di assicurazione della qualità e
l’affidabilità C C C R � D Programma di assicurazione della qualità e l’affidabilità 1 Preparazione C C C R
2 Progettazione e valutazione I R I C
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
80
3 Produzione I I R C E Analis i di affidabilità e manutenibilità 1 Specificazione della funzione richiesta per ogni elemento R C 2 Identificazione dei fattori di rischio nelle condizioni nel contesto
operativo: condizioni ambientali, tempo di uso, modo di uso (con analisi nel dettaglio delle condizioni operative) R C �
3 Riassetto dei fattori di rischio (assessment of derating factors) C R � 4 Gestione e allocazione delle risorse di affidabilità e mantenibilità
(reliability and maintainability allocation) C R � 5 Preparazione dei diagrammi di blocco di affidabilità
- A livello delle attività di assemblaggio R C - A livello del sistema C R
6
Identificazione ed analisi dei punti di debolezza sull’affidabilità (FMEA/FMECA,FTA, caso peggiore,, stress-strength-analyses)
- A livello delle attività di assemblaggio R C - A livello del sistema C R 7 Sviluppo di studi comparativi - A livello delle attività di assemblaggio R C - A livello del sistema C R 8 Miglioramento dell’affidabilità attraverso la ridondanza - A livello delle attività di assemblaggio R C - A livello del sistema C R 9 Identificazione dei componenti con ciclo di vita limitato I R C � 10 Elaborazione del concetto di manutenzione I R I C � 11 Definizione di strategie di test C C C R 12 Analisi della manutenibilità R C � 13 Elaborazione di modelli matematici C R � 14 Calcolo dell’affidabilità e la manutenibilità prevedibile � - A livello delle attività di assemblaggio I R C - A livello del sistema I C R 15 Calcolo dell’affidabilità e la disponibilità a livello del Sistema I I R � F Analisi della sicurezza e del fattore umano 1 Analisi della sicurezza (evitabilità dei problemi legali) - Prevenzione di incidenti C R C C � - Sicurezza tecnica Identificazione ed analisi dei guasti critici e delle situazioni rischiose
(FMEA/FMECA/,FTA,ecc) - A livello delle attività di assemblaggio R C - A livello del sistema I C R Ricerche teoriche C R 2 Analisi dei fattori umani (interfaccia uomo-macchina) C R C C G Selezione e qualificazione dei componenti ed i materiali 1 Aggiornamento dell’elenco dei componenti ed i materiali preferiti I C I R 2 Selezione dei componenti ed i materiali non preferiti R C C 3 Qualificazione dei componenti ed i materiali non preferiti - Pianificazione C I R - Realizzazione C R

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
81
- Analisi dei risultati del Test I I R 4 Analisi dei componenti ed i materiali (Screening) I C R H Selezione e qualificazione del Fornitore 1 Selezione del fornitore - Componenti e materiali acquistati R C C - Produzione all’esterno C R C 2 Qualificazione del fornitore (qualità ed affidabilità) - Componenti e materiali acquistati I I R - Produzione all’esterno I I R 3 Controllo di ingresso - Pianificazione C C R - Realizzazione C R - Analisi dei risultati del Test C R - Definizione delle azioni correttive Componenti e materiali acquistati C C R Produzione all’esterno R C C
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
82
Bibliografia essenziale
Libri e testi 1. Antonio Zanini, “Elementi di affidabilità”, Progetto Leonardo, Bologna, 1991 2. T. D’Alessio, G. Meucci, R. Somma “Metodi dell’affidabilità: teorie…”, F. Angeli, Milano, 1987
3. Igor Bazovski, “Principi e metodi dell’affidabilità”, Etas Kompass, Milano, 1969 4. Fausto Galetto, “Affidabilità, Volume primo: teoria e metodi di calcolo”, CLEUP, Padova 5. U. Santarelli, “Affidabilità e sopravvivenza nella pratica aziendale”, F.Angeli, Milano, 1995 6. Pierluigi Piccari, “Manuale di controllo di qualità e affidabilità”, (1974) 7. P. Citti, G. Arcidiacono, G. Campatelli, “Fondamenti di affidabilità”, McGrawHill, Milano, 2003 8. Douglas C. Montgomery, “Controllo statistico della qualità”, Mc Graw-Hill, Milano, 2000 9. Waine Nelson, “Come analizzare i dati di affidabilità”, Editoriale Itaca, Milano, 1991 10. W. Q. Meeker, L. A. Escobar, “Statistical Methods for Reliability Data”, J. Wiley, NY, 1998 11. Myles Hollander, Douglas A. Wolfe, “Non parametric statistical methods”, J. Wiley, NY, 1999 12. Alessandro Birolini, “Reliability Engineering – 3rd Edition”, Springer, 2003 13. K.C. Kapur, L.R. Lamberson, “Reliability in Engineering Design”, Wiley, NY, 1977 14. A. Dui, “Montecarlo applications in System Engineering”, Wiley, England, 2000 15. K. Bathe, D. Owen, “Reliability of Methods for Engineering Analysis”, Pineridge Press, 1986 16. Karl Bury, “Statistical Distributions in Engineering”, Cambridge University Press, 1999 17. W. Press, B. Flannery, S. Teukolsky, W. Vetterling, “Numerical Recips”, Cambridge Un. P., 1986 18. R. Michelini, R. Razzoli, “Affidabilità Sicurezza Manufatto Industriale”, Tecniche Nuove, 2000 19. A.M. Law, W.D. Kelton, “Simulation Modelling & Analysis”, McGraw-Hill, 1991 Articoli e pubblicazioni 20. D. D’Ercoli, C. Fragassa, “Reliability prediction for a CNC woodworking machine”, YSESM
2003 – Milano Marittima (Italy) 21. D. D’Ercoli, C. Fragassa, “Analisi di affidabilità per una fresatrice CNC”, AIAS 2003 – Salerno 22. P. Morelli, C. Fragassa, , “Failure data analysis of defective populations”, YSESM 2002 –
Bertinoro (Italy) 23. C. Fragassa, P. Morelli, “DoE for Numerical simulation of maintenance”, Euromaintenance 2002,
Helsinki (Finland) 24. C. Fragassa, P. Morelli, A. Zucchelli, S. Massimo, “Studio affidabilistico e previsionale per un
sistema elettromeccanico di utilizzo automobilistico”, AIAS 2002 – Parma 25. C. Fragassa, G. Minak, R. Righini, “A Montecarlo Software Method for the Maintenance
Improvement ", ESREL 2000 – Edimburgh (UK) 26. G. Minak, R. Righini, C. Fragassa, “Scientific Validation of a New System Reliability Analysis
Code by means of an Existing Software", PSAM5 2000 – Osaka (Japan) 27. R. Righini, G. Minak, C. Fragassa, “An Innovative Processing Method for the Direct Calculation
of a Bathtub Failure Rate Distribution", PSAM5 2000 – Osaka (Japan) 28. P.Morelli, G. Minak, “Failure Data Uncertainties in RCM Approach”, Euromaintenance 2000 29. T.C. Sharma e I. Bazovsky, “Reliability Analysis of Large System by Markov Techniques”, 1993,
IEEE Prams
Manuali e Norme 30. RAC, “Nonelectronic parts Reliability Data”, American Department of Defense, 1995 31. BSC, “Formal-FTA Manual”, 2002 32. Relex, “Relex Software Manual”, 2003 33. Allison Trasmission, “FMEA, Quality at the sources”, 1990 34. H. Pham, “Handbook of Reliability Engineering”, 2003 35. Y. Ronen, “Handbook of Nuclear Reactors Calculations”, CRC Press, 1986

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
83
Indice
Premessa .......................................................................................................................................... 1
Introduzione alla Qualità ................................................................................................................ 4
Che cos’è la qualità? ............................................................................................................................................. 4
Introduzione alla Qualità Totale ....................................................................................................................... 5
Evoluzione del concetto di qualità .................................................................................................................... 6
Valore della qualità............................................................................................................................................... 7
Costi della qualità.................................................................................................................................................. 8
Perché e importante fare un analisi affidabilistica dei dati ? .................................................................. 10
Concetti e definizioni in RDA ....................................................................................................... 12
Concetto di affidabilità ...................................................................................................................................... 12
Concetto di guasto ............................................................................................................................................... 12
Teoria e funzioni dell’affidabilità.................................................................................................................... 13
Parametri di affidabilità .................................................................................................................................... 19
Problemi statistici in affidabilità ..................................................................................................................... 21
Rilevazione e rappresentazione dei dati ........................................................................................................ 22
Valutazione della funzione densità di guasto e del tasso di guasto ......................................................... 24
Analisi non parametrica................................................................................................................ 28
Cos’è un’analisi non parametrica. .................................................................................................................. 28
Definizioni preliminari....................................................................................................................................... 28
Concetti di base sulla statistica inferenziale ................................................................................................. 29
Stime non parametriche per dati non censurati .......................................................................................... 30
Stime non parametriche per dati censurati .................................................................................................. 31
Stime per dati censurati con tempi di guasto esatti .................................................................................... 34
Stime per dati censurati con tempi di guasto incerti .................................................................................. 35
Definizioni e concetti della simulazione ....................................................................................... 36
Il metodo Montecarlo ......................................................................................................................................... 36
Dati di produzione............................................................................................................................................... 41
Dati di utilizzo ...................................................................................................................................................... 43
Dati di affidabilità ............................................................................................................................................... 45
Parametri di calcolo............................................................................................................................................ 46
Parametri di simulazione .................................................................................................................................. 48
Parametri di convergenza ................................................................................................................................. 49
Metodologia di analisi ................................................................................................................... 50
Simulazione degli elementi censurati ............................................................................................................. 50
Stima non parametrica dell’inaffidabilità reale .......................................................................................... 51
Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
84
Simulazione completa dell’evoluzione del s istema...................................................................................... 53
Risultati delle simulazioni ................................................................................................................................. 54
Il codice.......................................................................................................................................... 56
Routine VB di calcolo ......................................................................................................................................... 56
Previsioni e validazione................................................................................................................. 61
Brevi cenni sulla validazione dei modelli ...................................................................................................... 61
Descrizioni dei sistemi di validazione ............................................................................................................. 62
Criteri di confronto e di validazione .............................................................................................................. 63
Risultati di validazione....................................................................................................................................... 63
Una previsione completa ............................................................................................................... 69
Le informazioni a disposizione ........................................................................................................................ 70
Le informazioni acquisite .................................................................................................................................. 74
Conclusioni .................................................................................................................................... 78
Bibliografia essenziale .................................................................................................................. 82

Analisi dei dati di guasto per la stima di affidabilità di componenti automobilistici
85
©
ISBN 978-88-906500-8-6 Copyright 2012
Alma Mater Studiorum Università di Bologna
Dipartimento di Ingegneria delle Costruzioni Meccaniche,
Nucleari, Aernonatuiche e di Metallurgia [DIEM]
Tutti i diritti sono riservati.
Nessuna parte di questo libro può
essere riprodotta senza il permesso
scritto con l’eccezione di brevi citazioni all’interno di articoli
scientifici e saggi
All rights reserved. No part of this
book may be reproduced in any
manner whatsoever without written
permission except in the case of
brief quotation embodied in scientific articles and reviews.
Stampato a
Bologna
Maggio 2010
100 copie
Related Documents