An Automatic Text Mining Framework for Knowledge Discovery on the Web Wingyan Chung The University of Arizona March 30, 2004

An Automatic Text Mining Framework for Knowledge Discovery on the Web Wingyan Chung The University of Arizona March 30, 2004.
Dec 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

An Automatic Text Mining Framework for Knowledge
Discovery on the Web
Wingyan ChungThe University of Arizona
March 30, 2004

2
Acknowledgments
• NSF and NIJ Grants• Dr. Hsinchun Chen, Dr. Jay F.
Nunamaker , Dr. J. Leon Zhao, Dr. Richard T. Snodgrass, Dr. D. Terence Langendoen, Dr. Olivia Sheng
• Dept. of MIS, U. of Arizona• Artificial Intelligence Lab, U. of
Arizona

3
Outline
• Introduction• Literature Review• Research Formulation and Approach• Empirical Studies on Business Intelligence
Applications– Previous Work
• Building a BI Search Portal for Integrated Analysis on Heterogeneous Information
• Using Visualization Techniques to Discover BI
– Automating Business Stakeholder Analysis
• Conclusions, Limitations and Future Directions

Introduction

5
The Internet
• Advances in electronic network and IT support ubiquitous access to and convenient storage of information– They have changed human lives
fundamentally (Negroponte, 2003)– The role of global electronic network– Facilitation in communication and transaction
• The Internet emerges as the largest global electronic network– Rapid growth (Lyman & Varian, 2000)– Advantages in information storage and retrieval,
but …

6
Convenient storage has made information exploration
difficult
Heterogeneity and unmonitored quality of information on the Web
Interconnected nature of the Web complicates
understanding of relationships
Problems of the InternetInformatio
n Overload
Information is
unreliable
Hard to know all
stakeholders
Challenges To effectively and efficiently discover knowledge (business intelligence) from vast amount of textual information on the Web
???

7
Research QuestionsHow can we develop an automatic text mining approach to address the problems of knowledge discovery on the Web?How effective and efficient does such an approach assist human beings in discovering knowledge on the Web?
What lessons can be learned from applying such an approach in the context of human-computer interaction (HCI)?

Literature Review
Knowledge and Knowledge Management
Human-Computer InteractionText Mining for Web Analysis

9
-Hierarchical view (Nunamaker et al., 2001)-Reversed hierarchy (Tuomi, 1999)-As a state of mind, an object, a process, access to information, and a capability (Alavi and Leidner, 2001)-Resource-based theory (Barney, 1991; Penrose, 1959; Wernerfelt, 1984; Drucker, 1995)
Views
-Tacit and explicit dimensions (Polanyi, 1965)-Individual vs. collective knowledge-Declarative vs. procedural knowledge-Causal, conditional, relational and pragmatic knowledge
Classifications
Knowledge
-Revealed underlying assumptions in KM-Implied different roles of knowledge in organizations-Textual knowledge - Most efficient way to store, retrieve, and transfer vast amount of information-Advanced processing needed to obtain knowledge
- Traditionally done by humans- It is useful to review the discipline of Human-Computer Interaction to understand human analysis needs
-Revealed underlying assumptions in KM-Implied different roles of knowledge in organizations-Textual knowledge - Most efficient way to store, retrieve, and transfer vast amount of information-Advanced processing needed to obtain knowledge
- Traditionally done by humans- It is useful to review the discipline of Human-Computer Interaction to understand human analysis needs

10

11
Human Analysis Needs
• Satisfied when the problemproblem in information seeking is solved (Kuhlthau, 1993; Kuhlthau, Spink and Cool 1992; Saracevic, Kantor, Chamis and Trivison, 1988; Choo et al., 2000)
• Involve value-adding processes:– Information seeking: locating useful
information from large amount of data– Intelligence generation: acquisition,
interpretation, collation, assessment, and exploitation of the information obtained (Davis, 2002)
– Relationship extraction: deriving patterns and relationships from data and information
Knowledge Discovery

12
Need Automating KD Processes
• Human beings can undertake KD processes by applying their experience and knowledge– But inefficient and not scalable
• Text mining has been identified as a set of technologies that can automate the knowledge discovery process (Trybula, 1999)– Stages: information acquisition, extraction,
mining, presentation• Need more preprocessing when considering KD on the
Web (more noisy, voluminous, heterogeneous sources): Collection building, conversion, extraction
– Evolved from work in automatic text processing

13

14
Text Mining Technologies
• For Web KD:– Web mining techniques: resource discovery on the
Web, information extraction from Web resources, and uncovering general patterns (Etzioni, 1996)
• Pattern extraction, meta searching, spidering– Web page summarization (Hearst, 1994; McDonald &
Chen, 2002)– Web page classification (Glover et al., 2002; Lee et
al., 2002; Kwon & Lee, 2003)– Web page clustering (Roussinov & Chen, 2001; Chen
et al., 1998; Jain & Dube, 1988)– Web page visualization (Yang et al., 2003; Spence,
2001; Shneiderman, 1996)• These techniques and approaches can be used to
automate important parts of human analyses

15
Summary
• Human analyses are precise but not efficient and not scalable to the growth of the Web
• A number of text mining techniques exist but there has not been a comprehensive approach to addressing problems of knowledge discovery on the Web, namely,– Information overload– Heterogeneity and unmonitored quality of
information– Difficulties of identifying relationships on the Web
• The HCI aspects of using a text mining approach to knowledge discovery on the Web have not been widely explored

Research Formulation and Approach

17

18

19
Methodology
• System Development (Nunamaker et al., 1991)– A Multi-methodological Approach– Conceptual frameworks, Mathematical models– Observation, Experimentation
• Validation– Effectiveness (accuracy, precision, recall),
efficiency (time)– Information quality (Wang & Strong, 1996)– User satisfaction (subjective ratings and
comments)

20
Domain of Study
• Business intelligence applications– BI is increasingly becoming an important practice in
today's organizations• More than 40% surveyed individuals by Fuld & Co. have
organized BI efforts (Fuld et al., 2002)– Collecting and analyzing BI have become a profession
• SCIP has over 50 chapters worldwide• A new journal called Journal of Competitive Intelligence and
Management was launched in 2003– Vibrant growth of e-commerce calls for better approaches
to knowledge discovery on the Web (Morgan-Stanley, 2003)
• Businesses use the Web to share and disseminate information
• Many companies are conducting business using the Internet platform (e.g., Amazon.com, EBay.com)
– Our focus is on the first category

Empirical Studies on Business Intelligence
Applications

22
Previous Work (1)
• Building a BI search portal for integrated analysis on heterogeneous information– The portal provides post-retrieval analysis
(summarization, categorization, meta-searching)– Conducted a systematic evaluation to test
CBizPort's ability to assist human analysis of Chinese BI
– Results:• Searching and browsing performance comparable to
regional Chinese SEs• CBizPort could significantly augment existing SEs• Subjects strongly favored analysis capability of CBizPort
summarizer and categorizer

23
Previous Work (2)
• Applying Web page visualization techniques to discovering BI– Two browsing methods (Web community and
Knowledge map) were developed to help visualize the landscape of search engine results
• WC uses a genetic algorithm; KM uses MDS
– The methods were empirically compared against a graphical search engine (Kartoo) and a textual result list (RL) display
– Results: KM > Kartoo (in terms of effectiveness, efficiency, and users' ratings on point placement); WC > RL (in terms of effectiveness, efficiency, and user satisfaction)

Using Web Page Classification Techniques
to Automate Business Stakeholder Analysis

25
Current Business Environment
• Networked business environment facilitates information sharing and collaboration (Applegate, 2003)
• Collaborative commerce: automating business processes by electronic sharing of information
• Knowledge sharing about stakeholder relationships through companies’ Web sites and pages– Textual content or annotated hyperlinks

26
Problems
• Knowledge hidden in interconnected Web resources– Posing challenges to identifying and
classifying various business stakeholders• e.g., A company’s manager may not know who
are using their company’s Web resources
• Need better approaches to uncovering such knowledge – Enhance understanding of business
stakeholders and competitive environments

27
Related Work
• Stakeholder theories have evolved over time while the view of firm changes– Production view (19th century): Suppliers and
Customers– Managerial view (20th century): + Owners,
Employees– Stakeholder view (1960-80s) (Freeman, 1984):
+ Competitors, Governments, News Media, Environmentalists, …
– E-commerce view (1990s - now): + International partners, Online communities, Multinational employees, …
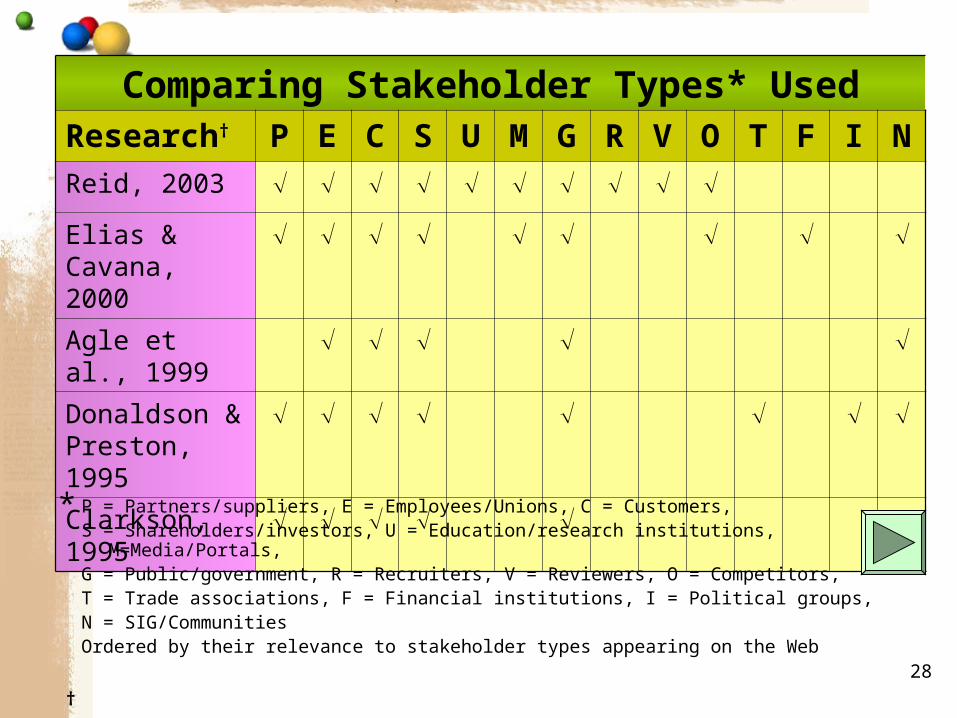
28
Comparing Stakeholder Types* UsedResearch† P E C S U M G R V O T F I NReid, 2003
Elias & Cavana, 2000
Agle et al., 1999
Donaldson & Preston, 1995
Clarkson, 1995
P = Partners/suppliers, E = Employees/Unions, C = Customers,S = Shareholders/investors, U = Education/research institutions,
M=Media/Portals,G = Public/government, R = Recruiters, V = Reviewers, O = Competitors,T = Trade associations, F = Financial institutions, I = Political groups,N = SIG/CommunitiesOrdered by their relevance to stakeholder types appearing on the Web
*
†

29
Stakeholder Research and BI
• Previous research rarely considers the many opportunities offered by the Web for stakeholder analysis, e.g.,– Business intelligence, obtained from the business
environment, is likely to help in stakeholder analysis
• Tools and techniques have been developed to exploit business intelligence on the Web– PageRank (Brin & Page 1998), HITS (Kleinberg 1999),
Web IF (Ingwersen 1998)• External links mirror social communication phenomena
(e.g., stakeholder relationships)– Ong et al. 2001; Tan et al. 2002; Reiterer et al. 2000;
Chung et al. 2003; Reid 2003; Byrne 2003• Lack stakeholder analysis capability

30
Existing BI Tools and Techniques
• Exploit structural and textual content• But commercial BI tools lack analysis
capability (Fuld et al. 2003)• Need to automate stakeholder
classification, a primary step in stakeholder analysis– Automatic classification of Web pages is a
promising way to alleviate the problem

31
Web Page Classification
• The process of assigning pages to predefined categories – Helps to classify business stakeholders’ Web pages
and enables companies to understand the competitive environment better
• Major approaches: k-nearest neighbor, neural network, Support Vector Machines, and Naïve Bayesian network (Chen & Chau 2004)
• Previous work– Kwon and Lee 2003; Mladenic 1998; Furnkranz
1999; Lee et al. 2002; Glover et al. 2002– NN and SVM achieved good performance

32
Feature selection in Web Page Classification
• Features considered– Page textual content: full text, page title, headings – Link related textual content: anchor text, extended
anchor text, URL strings – Page structural information: #words, #page out-
links, inbound outlinks (i.e., links that point to its own company), outbound outlinks (i.e., links that point to external Web sites)
• Methods for selection– Human judgment / Use of domain lexicon– Feature ratios and thresholding – Frequency counting / MI

33
Research Gaps
• Stakeholder research provides rich theoretical background but rarely considers the tremendous opportunities offered by the Web for stakeholder analysis– Conclusions drawn from old data may not reflect
rapid development in e-commerce
• Existing BI tools lack stakeholder analysis capability
• Automatic Web page classification techniques are well developed but have not yet been applied to business stakeholder classification

34
Research Questions
• How can we apply our automatic text mining approach to business stakeholder analysis on the Web?
• How can Web page textual content and structural information be used in such an approach?
• What are the effectiveness (measured by accuracy) and efficiency (measured by time requirement) of such an approach for business stakeholder classification on the Web?

35
Application of the Approach
• Purpose: To automatically identify and classify the stakeholders of businesses on the Web in order to facilitate stakeholder analysis
• Rationale– Business stakeholders’ Web pages should contain
identifiable clues that can be used to distinguish their types– Web textual and structural content information is important
for understanding the clues for stakeholder classification
• Two generic steps:– Creation of a domain lexicon that contains key textual
attributes for identifying stakeholders– Automatic classification of Web pages (stakeholders) linking
to selected companies based on textual and structural content of Web pages

36
Building a Research Testbed
• Business stakeholders of the KM World top 100 KM companies (McKellar 2003)
• Used backlink search function of the Google search engine to search for Web pages having hyperlinks pointing to the companies’ Web sites (e.g., “link:www.siebel.com”)
• For each host company, we considered only the first 100 results returned – Removed self links and extra links from same sites– After filtering, we obtained 3,713 results in total – Randomly selected the results of 9 companies as
training examples (414 283 pages stored in DB)

37
Creation of a Domain Lexicon
• Manually read through all the Web pages of the nine companies’ business stakeholders to identify one-, two-, and three-word terms that were indicative of business stakeholder types (Thanks to Edna Reid)
• Extracted a total of 329 terms (67 one-word terms, 84 two-word terms, and 178 three-word terms), e.g.,

38
Automatic Stakeholder Classification
• Three steps:
Manual Tagging
Feature selection
Automatic classificatio
n

39
Manual Tagging
• Manually classified each of the stakeholder pages of the nine selected companies into one of the 11 stakeholder types (based on our literature review) (thanks Edna again)
Manual taggin
g
Feature selectio
n
Automatic classificatio
n

40
Feature Selection
• Structural content features: binary variables indicating whether certain lexicon terms are present in the structural content– A term could be a one-, two-, or three-word long– Considered occurrences in title, extended anchor
text, and full text (Lee et al. 2002)• Textual content features: frequencies of
occurrences of the extracted features (see next slide)
– The first set of features was selected based on human knowledge, while the second was selected based on statistical aggregation (Glover et al. 2002), thereby combining both kinds of knowledge
Manual taggin
g
Feature selectio
n
Automatic classificatio
n

41
Feature Selection (Textual Content)
Manual taggin
g
Feature selectio
n
Automatic classificatio
n

42
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>David Schatsky: Search and Discovery in the Post-Cold War Era</title> ...
<p>I just saw a demo by <a href = "http://www.clearforest.com"> ClearForest, </a> a company that provides tools for analyzing unstructured textual information. It's truly amazing, and truly the search tool for the post-Cold War era. ... </p> ...
</body>
</html>
An Example(A media stakeholder type)
Link to the host company (ClearForest)
HTML hyperlink and extended anchor text

43
Automatic Classification
• A feedforward/backpropagation neural network (Lippman 1987) and SVM (Joachims, 1998) were used due to their robustness in automatic classification– Train the algorithms using the stakeholder
pages of the 9 training companies and obtain a model or sets of weights for classification
– Test the algorithms on sets of stakeholder pages of 10 companies different from training examples
Manual taggin
g
Automatic classificatio
n
Feature selectio
n

44
Evaluation Methodology • Motivation: to know effectiveness and
efficiency of the approach• Consisted of algorithm comparison, feature
comparison, and a user evaluation study– Compared the performance of neural network (NN),
SVM, baseline method (random classification), human judgment
– Compared structural content features, textual content features, and a combination of the two sets of features
– 36 Univ. of Arizona business school students performed manual stakeholder classification and provided comments on the approach

Performance Measures
• Effectiveness:
• Efficiency: time used (in minutes)• User subjective ratings and
comments

46
User Study
• Each subject was introduced to stakeholder analysis and was asked to use our system named “Business Stakeholder Analyzer (BSA)” to browse companies’ stakeholder lists
• We randomly selected three companies (Intelliseek, Siebel, and WebMethods) from testing companies to be the targets of analysis

47
Definitions of business stakeholders
Business stakeholders of Siebel

48
Hypotheses (1)
• H1: NN and SVM would achieve similar effectiveness when the same set of features was used – Both techniques were robust – Procedure: created 30 sets of
stakeholder pages by randomly selecting groups of 5 stakeholder pages of each of the 10 testing companies

49
Hypotheses (2)
• H2: NN and SVM would perform better than the baseline method – Incorporated human knowledge and machine
learning capability into the classification
• H3: Human judgment in stakeholder classification would achieve effectiveness similar to that of machine learning, but that the former is less efficient– They could make use of the Web page’s textual
and structural content in classifying stakeholders – Humans might spend more time on it

50
Hypotheses (3)
• H4 & H5 examined the use of different types of features in automatic stakeholder classification – H4: structural = textual– H5: combined > structural or textual
alone

51
Experimental Results
Algorithm Comparison • H1 not confirmed• NN performed significantly differently than
SVM when the same set of features was used – NN performed significantly better than SVM when
structural content features were used – SVM performed significantly better than NN when
textual content features or a combination of both feature sets were used
– More studies would be needed to identify optimal feature sets for each algorithm

52
Effectiveness of the Approach
• H2 confirmed• The use of any combination of features
and techniques in automatic stakeholder classification outperformed the baseline method significantly – Our approach has integrated human
knowledge with machine-learned information related to stakeholder types …
– and was significantly better than a random conjecture

53
Comparing with Human Judgment
• H3b and H3d (efficiency) confirmed– Human: 22 minutes (average), varied– Algorithms: 1 – 30 seconds (average)– Showing high efficiency of using the automatic
approach to facilitate stakeholder analysis
• H3a and H3c (effectiveness) not confirmed– Humans were significantly more effective than NN
or SVM – Could rely on more clues in performing
classification– Experience in Internet browsing and searching
helped narrow down choices

54
However, the algorithms achieved better within-class accuracies than humans in frequently occurring types …

55
Use of Features
• To our surprise, hypotheses H4a-b, H5a-b, and H5d were not confirmed – Different feature sets yielded different performances
of the algorithms • Structural features enabled NN to achieve better
effectiveness than textual ones• Textual and combined features enabled SVM to achieve
better effectiveness than structural ones
– Do not know exactly why– Future research: studying the effect of features and
the nature of algorithms
• H5c was confirmed: structural content feature did not add value to the performance of SVM

Subjects’ Comments
• Overwhelmingly positive
• “It would be very helpful!”• “That’s cool!” • “I want to use it.”

Conclusions, Limitations and Future Directions

58
Conclusions
• General conclusion: our approach helped alleviate information overload and enhance human analysis on the Web
• Conclusions related to this presentation:– Showed how our approach could be applied to
business stakeholder analysis on the Web • Integrated Human expert knowledge + machine-
learned knowledge• Promising in terms of effectiveness and efficiency
– Could potentially facilitate business analysts’ interaction with automated stakeholder analysis systems in today’s networked enterprises

59
Contributions
• Developing and validating a useful and comprehensive approach to knowledge discovery on the Web
• New integration and application of techniques together with appropriate human intervention
• Contributions related to this presentation:– Helps BI analysts to understand business
stakeholders more efficiently– The feature selection approach can be used as a
way of knowledge acquisition– Extends current stakeholder research by providing a
new perspective for automated analysis

60
Limitations
• Technical limitations (e.g., efficiency)• Lab experiment limits external validity• Limitations in the presented study:
– Limited data provided by Google– The use of business school students in our
study reduces external validity– Limitation in identifying stakeholder
relationships (only rely on hyperlinks)– Limited domain knowledge

61
Building a BI Search Portal
Using Web Page Classification for
Business Stakeholder Analysis
Applying Web Page Visualization to Exploring
BI
Contributions
Generic applicability
Enhance knowledge discovery on the
Web
Better understanding in
HCI
Problems
Information overload
Unreliable information
Complicated relationships

62
Future Directions
• Related to the presented study:– Automate next steps of business stakeholder
analysis• Type-specific stakeholder analysis • Strategic management
– Cross-regional issues
• Other domains (e.g., terrorism)• New text mining and visualization techniques,
and related HCI issues• Collaborative commerce topics
– Integration of the approach with business process logics, collaborative technologies
Related Documents











