1 個⼈的に Amazon EMR 5.0.0 で Spark 2.0 を使ってZeppelin で SQL集計 してみる 2016年8⽉ 篠原英治

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
個⼈的に Amazon EMR 5.0.0 で Spark 2.0 を使ってZeppelin で SQL集計 してみる
2016年8⽉ 篠原英治

2
Amazon EMR – 2016年のアップデート• 1⽉: EMR 4.3.0 – Spark, Presto, Ganglia • 3⽉: EMR 4.4.0 – Sqoop, HCatalog, Java 8, 他• 4⽉: EMR 4.5.0 – Hadoop, Presto, SparkとEMRFS追加• 4⽉: EMR 4.6.0 – 巨⼤データへのリアルタイムアクセス⽤
に、Hbase• 6⽉: EMR 4.7.0 – Apache Tez, Apache Phoenix, Presto,
HBase, Mahout• 8⽉: EMR 5.0.0 - メジャーアップデート!
https://aws.amazon.com/jp/blogs/news/amazon-emr-5-0-0-major-app-updates-ui-improvements-better-debugging-and-more/

3
Amazon EMR – 5.0.0• 16のオープンソースのHadoopエコシステムプロジェクトを
サポート• SparkとHiveのメジャーバージョンアップ• TezがHiveとPigのデフォルトに• HueとZeppelinのUI改善• デバッグ機能の改良
https://aws.amazon.com/jp/blogs/news/amazon-emr-5-0-0-major-app-updates-ui-improvements-better-debugging-and-more/

4
Amazon EMR – 5.0.0

5
Amazon EMR – 5.0.0 – Spark 2.0

6
Amazon EMR – 5.0.0 – Spark 2.0.0

7
Spark 2.0 – Machine Learning• Announcement: DataFrame-based API is primary API– DataFrame-basedのAPIがプライマリのAPIに
• The MLlib RDD-based API is now in maintenance mode– MLlib RDD-based APIはメンテナンスモードに
http://spark.apache.org/docs/latest/ml-guide.html

8
Spark 2.0 – Machine Learning• As of Spark 2.0, the RDD-based APIs in the spark.mllib
package have entered maintenance mode– Spark2.0からspark.mllibパッケージのRDD-based APIは
メンテナンスモードに• The primary Machine Learning API for Spark is now the
DataFrame-based API in the spark.ml package– Sparkにおけるプライマリな機械学習APIはspark.mlパッ
ケージのDataFrame-based APIに
http://spark.apache.org/docs/latest/ml-guide.html

9
Spark 2.0 – Machine Learning• RDD-based API ⇒ DataFrame-based APIへ– spark.mllib のサポートは基本的にはバグフィックス– RDD-based APIには新しい機能追加は⾏わない– Spark 2.xのリリースでMLlibはDataFrame-based APIに
機能追加を⾏い、RDD-based APIに追いつく– DataFrame-based APIがRDD-based APIに追いついたら
(おおよそSpark 2.2)、RDD-based APIはdeprecatedに– RDD-based APIはSpark 3.0で削除予定
http://spark.apache.org/docs/latest/ml-guide.html

10
Spark 2.0 – Machine Learning• なぜDataFrame-based APIか?
– DataFrameはRDDよりユーザーフレンドリーなAPIを提供• Spark Datasources• SQL/DataFrame queries• Tungsten and Catalyst optimizations• ⾔語によらない統合されたAPI
– DataFrame-based API for Mllibは機械学習アルゴリズム及び⾔語によらない統合されたAPIを提供する
– DataFrameは実践的なfeature transformations(tokenize, normalize, n-gram等)といった機械学習パイプラインを提供
http://spark.apache.org/docs/latest/ml-guide.html

11
Spark 2.0 – Getting Started• Zeppelinでアクセス
– Security Group で SSH の設定
– SSH で トンネル
12
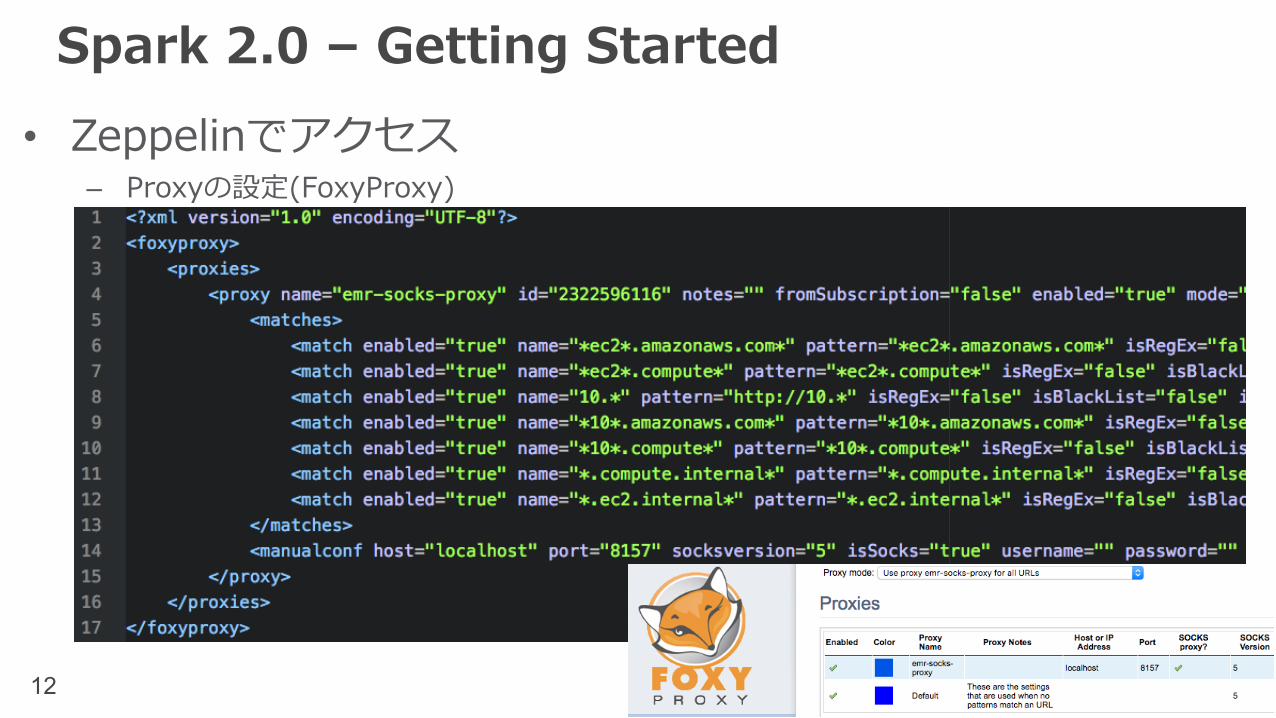
Spark 2.0 – Getting Started• Zeppelinでアクセス
– Proxyの設定(FoxyProxy)

13
Spark 2.0 – Getting Started• Welcome to Zeppelin

14
Spark 2.0 – Getting Started• Zeppelinでチュートリアルを実⾏

15
Spark 2.0 – Getting Started• “Spark DataframeのSample Code集”
– http://qiita.com/taka4sato/items/4ab2cf9e941599f1c0ca

16
Spark 2.0 – Getting Started• ZeppelinでNotebookを作成して実⾏
– とりあえずsc
– S3のデータを読み込んでメモリ上のテーブルへval wholeRawLog = sc.textFile("s3n://try-spark-eshinoha/click_data_sample.csv")val header = wholeRawLog.first()case class Click(clickAt: String, userId: String, campaignId: String)val click = wholeRawLog.map(s=>s.split(",")).filter(s=>s(0)!="\"click.at\"").map(
s=>Click(s(0).replaceAll("\"", ""),s(1).replaceAll("\"", ""),s(2).replaceAll("\"", "")
)).toDF()click.registerTempTable("click")Scalaに慣れてなくて⽇付型の扱いとかアレで全部Stringでスミマセン…汗

17
Spark 2.0 – Getting Started• ZeppelinでNotebookを作成して実⾏
– S3から取り込んだデータをSQLを使って集計
Related Documents











