In Search of a Missing Link in the Data Deluge vs. Data Scarcity Debate Amarnath Gupta Univ. of California San Diego If There is a Data Deluge, Where are the Data?

Amarnath Gupta Univ. of California San Diego If There is a Data Deluge, Where are the Data?
Dec 26, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

In Search of a Missing Link in the Data Deluge vs. Data
Scarcity Debate
Amarnath Gupta
Univ. of California San Diego
If There is a Data Deluge, Where are the Data?

The Neuroscience Information Framework (NIF)
Assembled the largest searchable collation of neuroscience data on the webThe largest catalog of biomedical resources (data, tools, materials, services) availableThe largest ontology for neuroscienceNIF search portal: simultaneous search over data, NIF catalog and biomedical literatureNeurolex Wiki: a community wiki serving neuroscience conceptsA unique technology platform Cross-neuroscience analyticsA reservoir of cross-disciplinary biomedical data expertise

Form
al K
now
ledge/O
nto
logie
s
Extr
act
ed/A
naly
zed F
act
Colle
ctio
ns
What do we mean by Data?
Least Shared
Most Shared
Useful for Deep (Re-) Analysis
Useful for Comprehension
, Discovery
Uneven distribution of data volume, velocity, variability, location and
availability
Raw Data (in files) and Data Sets (in directories)LOCAL OFFLINE/ONLINE STORAGE, IRs, PRs?
Data Collections and DatabasesSPECIALIZED & GENERAL PRs, DBs
Processed Data Products, Processes
DBs, WEB-PRs, PUBS
Papers w,w/o DataPUBs
Pub/
DB
Ann
otat
ions
Pub/DB C
ross-Links
Aggregates and Resource Hubs
NIF is aware of 761 repositories

Data Sharing:The “Reliable, Verifiable Science”
Perspective
Need Data, not just stories about them!47/50 major preclinical published cancer studies could not be replicated
“The scientific community assumes that the claims in a preclinical study can be taken at face value-that although there might be some errors in detail, the main message of the paper can be relied on and the data will, for the most part, stand the test of time. Unfortunately, this is not always the case.”
Getting data out sooner in a form where they can be exposed to many eyes and many analyses, and easily compared, may allow us to expose errors and develop better metrics to evaluate the validity of dataBegley and Ellis, 29 MARCH 2012 |
VOL 483 | NATURE | 531
“There are no guidelines that require all data sets to be reported in a paper; often, original data are removed during the peer review and publication process.”
“There must be more opportunities to present negative data.”
Significant cross-linking between original papers, supporting/refuting papers/data
Courtesy: Maryann Martone

And The Case AgainstHello All, Thank you for the people who are taking a look at the data in tera15 :-) There are a whole lot of data (about +8TB) that can be looked at and/or removed. If you had assistants, students, or volunteers who assisted you in processing data, please locate those folders and remove any duplicate or unused data. This will help EVERYONE have space to process new data. Any old data that has been sitting in tera15 untouched in more than 4 years will be removed to a different area for deletion. Please take a look carefully!

What the Requirement Asks - I
For every neuroscientist For every experiment he/she runs
For every data set that leads to positive or negative results Store the data in some shared or on-demand repository Annotate the data with experimental and other contextual
information Perform some analysis and contribute your analysis
method to the repository where the data is being stored For every analysis result
Keep the complete processing provenance of the result Point back to the data set or data element that contribute
to the analysis, specifically mark positively and negatively contributing data
If an error is pointed out in some result, Provide an explanation of the error Create a pointer back to the part of the publication and
to that part of the data set or data element that produced the error

What the Requirement Asks - II For every publication
For every result reported Create a pointer back to all data used in that section For every experimental object (e.g., reagents, or auxiliary data from
another group) used, Create an appropriate, if needed time-stamped, pointer to the correct
version of the dataFor every repository/database … that holds the data
Ensure rapid availability Allow scientists to download or perform in-place analyses Adhere to appropriate data standards Keep consistency of all data + references Should permit multiple simultaneous analsyses by different
users Should allow searching/browsing/querying all possible
metadataDiverse distributed infrastructures consisting of individual researchers in different institutions, institutional repositories, public data centers, publishers, annotators and aggregators, bioinformaticians …

What the Requirement Asks - III
Scalable, Elastic Storage and ComputationService Expectations
Scalable Search and Query across structured/semi-structured/unstructured data Facts – What neurons do Purkinje cells project to? Resources – What are recent data sets on biomarkers for SMA? Analytical Results -- What animal models have similar phenotypes
to Parkinson’s disease? Landscape Surveys – Who has what data holdings on
neurodegenerative diseases? Active Analyses
Combining these data and mine, compute how the connectivity of the human brain differ from non-human primates
Perform GO-enrichment analysis on all genes upregulated in Alzheimer’s on all available data and compare with my results
Tracebacks What data and processing have been used to reach this result in this
paper? Which publication refuted the claims in this paper and how?

Many Groups Working on Data Sharing

A Few QuestionsIf all neuroscientists want to comply with this data sharing today, will the current infrastructure be able to support it?Is enough attention being paid to an overarching architecture and interoperation protocol for data sharing?
Is today’s technology properly harnessed to create a holistic data sharing infrastructure?
What would motivate neuroscientists and other players to really play their parts in data sharing?Should there be a “monitoring scheme” to ensure proper data sharing practices are actually happening?

A Distributed Activity Model
The Data-Sharing Ecosystem is a distributed system that can be viewed as an operating system where
Each object has a set of unique structured ids (e.g., extended DOIs) that identify any data set, data object, or any interval of a data object The semantic category of the data element Any human/software agent Any parameter set of a software invocation
A log is maintained and transmitted for each activity by any agent on any data element Submission, transfer to repository, pickup by aggregator, creating
derived product, being crawled by search services, … These logs can be accessed by a central monitoring system
covering the ecosystem using a Twitter Storm-like infrastructureThink of Facebook maintaining a log of the different actions such as being present at the system, sending and accepting friend requests, posting comments and photos, starting and ending chat sessions, …
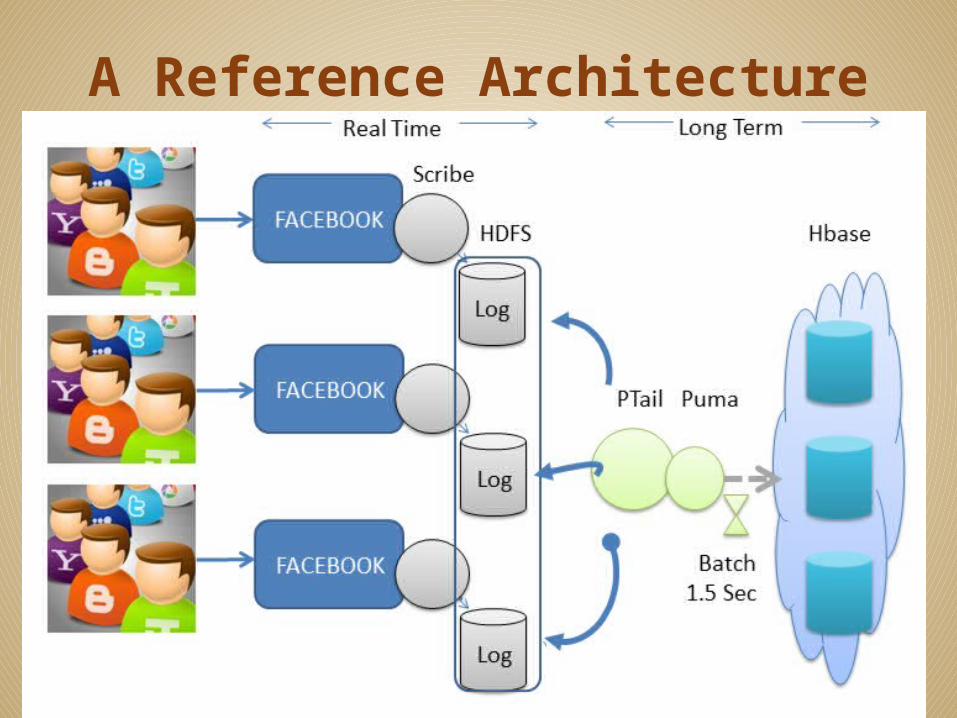
A Reference Architecture

Some Activities to LogUpdate activities on data elements from Data Centers and RepositoriesResource References from literature and web sites, including opinion cites like blogs and forumsCitation categories from automated/human-driven annotation systems like DataCite or DOMEOProvenance chains from workflow systems like KeplerData derivation changes from rule-based metadata management systems like iRODS

Counting: the Forte of Big DataFrequency and regularity of data creation vis-à-vis submission to the data-sharing ecosystemFrequency and regularity of data usage of various kinds
Viewing, downloading, replication, uptake by a software, …
Number of derived data products Compounding by cascades of derived data
Cross-referencing of data and resources in publications
Compounding by publication data citation cascadesHuman and programmatic access to data

From Counting to an Accountability Score
Accountability Score: a measure of “good data citizenship”
Of People Increases with contribution of data and analyses Decays (slowly) with time Increases with references and citations Increases with supporting work by others Decreases with refutation Decreases (rapidly) with paper retraction
Of Publications Increases with addition of reference-able data Increases with data access Increases with keeping updated with data updates
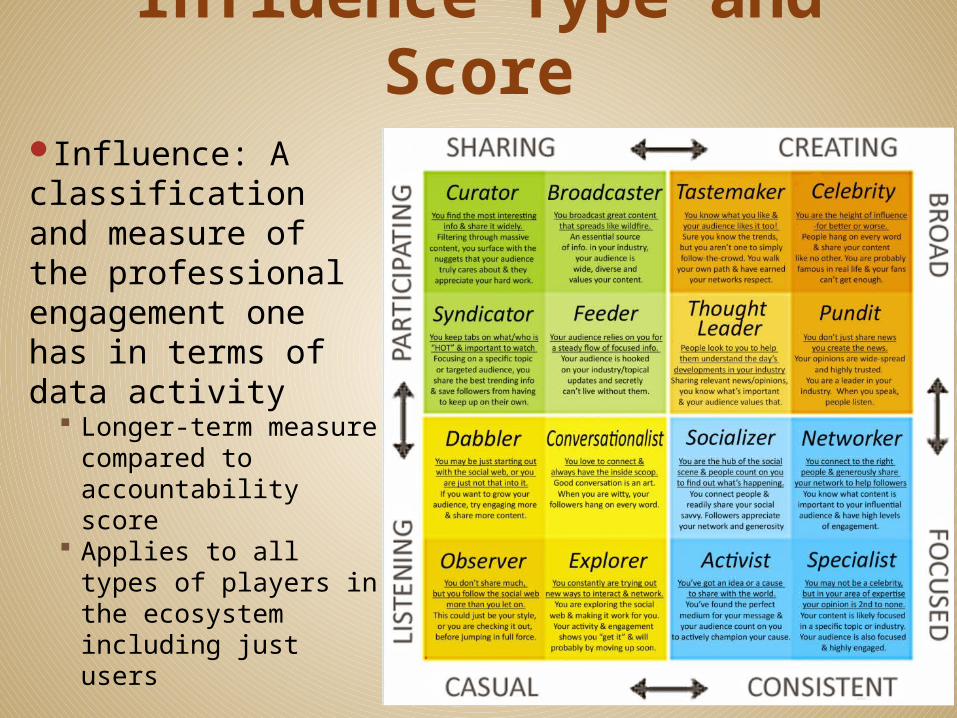
Influence Type and Score
Influence: A classification and measure of the professional engagement one has in terms of data activity
Longer-term measure compared to accountability score
Applies to all types of players in the ecosystem including just users

Influence Engines

AdaptationsThese measures do not hold for scientists who do not produce data The measures are mostly designed for online activities and must be modified to match the dynamics of different scientific communities
Parameters like decay constants Time-window for score revision
Global scores should be supplemented by community scores where a
community is defined by ontological regions where one’s research lies
per activity type rather than a single overall score

Objection, Your Honor!This is the Big Brother for scienceThis is going to create a bias against “non-performers”Scientific errors will be penalized more than necessaryThe algorithms can be manipulated to the advantage of some people over othersSmaller individuals/organizations will be penalized with respect to better-funded, higher-throughput organizationThis will be hard to implement due to oppositions from different groups and institutions

No One has a Crystal Ball
My speculations If the community decides that it needs data sharing, it will
naturally gravitate toward some degree of judgment of those who
don’t comply
Technology frameworks similar to what we discussed will be
adopted within individual e-infrastructures
As more data become available and data sharing efforts become
successful, third-party watchers like credit bureaus that monitor
scientist’s products with respect to data will emerge
Such scores would be used for community perception and in-
kind incentives earlier than their adoption for formal evaluations

ConclusionThe real question is “How do we promote data sharing?”Creating infrastructural elements and reusing today’s (tomorrow’s) technological capabilities is not enoughWe need a more holistic approach that factors in the human componentUsing social activity analysis as a starting point we should be able to build a monitoring-cum-incentivizing scheme for data sharing
Related Documents











