Advancing MPI Libraries to the Many-core Era: Designs and Evalua<ons with MVAPICH2 S. Chakraborty, M. Bayatpour, H. Subramoni and DK Panda The Ohio State University E-mail: {Chakraborty.52,Bayatpour.1,Subramoni.1,panda.2}@osu.edu IXPUG ’17 Presenta<on

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

AdvancingMPILibrariestotheMany-coreEra:DesignsandEvalua<onswithMVAPICH2
S.Chakraborty,M.Bayatpour,H.SubramoniandDKPandaTheOhioStateUniversity
E-mail:{Chakraborty.52,Bayatpour.1,Subramoni.1,panda.2}@osu.edu
IXPUG’17Presenta<on
IXPUG‘17 2NetworkBasedCompu<ngLaboratory
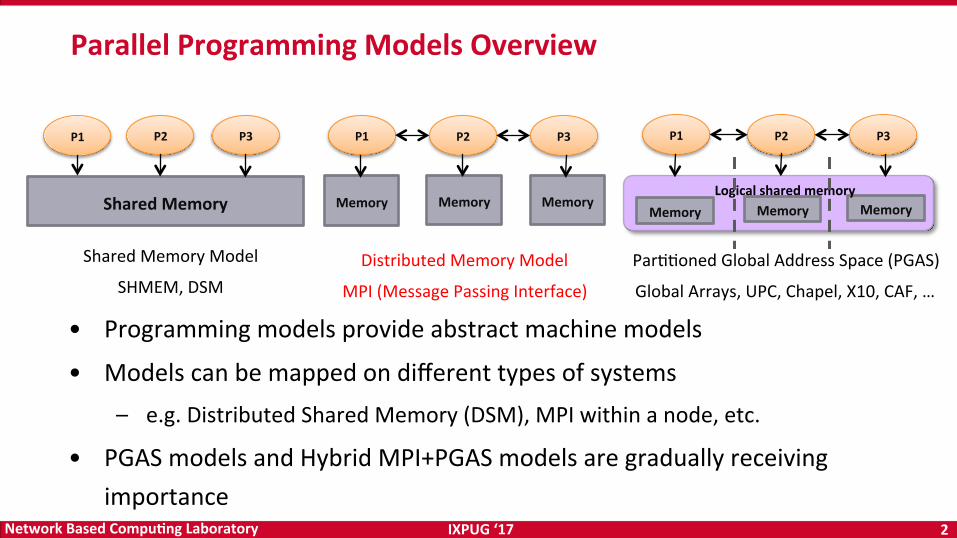
ParallelProgrammingModelsOverview
P1 P2 P3
SharedMemory
P1 P2 P3
Memory Memory Memory
P1 P2 P3
Memory Memory MemoryLogicalsharedmemory
SharedMemoryModel
SHMEM,DSMDistributedMemoryModel
MPI(MessagePassingInterface)
ParOOonedGlobalAddressSpace(PGAS)
GlobalArrays,UPC,Chapel,X10,CAF,…
• Programmingmodelsprovideabstractmachinemodels
• Modelscanbemappedondifferenttypesofsystems– e.g.DistributedSharedMemory(DSM),MPIwithinanode,etc.
• PGASmodelsandHybridMPI+PGASmodelsaregraduallyreceivingimportance

IXPUG‘17 3NetworkBasedCompu<ngLaboratory
Suppor<ngProgrammingModelsforMul<-PetaflopandExaflopSystems:Challenges
ProgrammingModelsMPI,PGAS(UPC,GlobalArrays,OpenSHMEM),CUDA,OpenMP,OpenACC,Cilk,Hadoop(MapReduce),Spark(RDD,DAG),etc.
Applica<onKernels/Applica<ons
NetworkingTechnologies(InfiniBand,40/100GigE,Aries,andOmni-Path)
Mul<-/Many-coreArchitectures
Accelerators(GPUandFPGA)
MiddlewareCo-Design
Opportuni<esand
ChallengesacrossVarious
Layers
PerformanceScalabilityResilience
Communica<onLibraryorRun<meforProgrammingModelsPoint-to-pointCommunica<on
Collec<veCommunica<on
Energy-Awareness
Synchroniza<onandLocks
I/OandFileSystems
FaultTolerance

IXPUG‘17 4NetworkBasedCompu<ngLaboratory
Designing(MPI+X)forExascale• Scalabilityformilliontobillionprocessors
– Supportforhighly-efficientinter-nodeandintra-nodecommunicaOon(bothtwo-sidedandone-sided)
• ScalableCollecOvecommunicaOon– Offloaded– Non-blocking– Topology-aware
• Balancingintra-nodeandinter-nodecommunicaOonfornextgeneraOonmulO-/many-core(128-1024cores/node)– MulOpleend-pointspernode
• SupportforefficientmulO-threading• IntegratedSupportforGPGPUsandFPGAs• Fault-tolerance/resiliency• QoSsupportforcommunicaOonandI/O• SupportforHybridMPI+PGASprogramming
• MPI+OpenMP,MPI+UPC,MPI+OpenSHMEM,CAF,MPI+UPC++…• VirtualizaOon• Energy-Awareness

IXPUG‘17 5NetworkBasedCompu<ngLaboratory
OverviewoftheMVAPICH2Project• HighPerformanceopen-sourceMPILibraryforInfiniBand,Omni-Path,Ethernet/iWARP,andRDMAoverConvergedEthernet(RoCE)
– MVAPICH(MPI-1),MVAPICH2(MPI-2.2andMPI-3.0),Startedin2001,Firstversionavailablein2002
– MVAPICH2-X(MPI+PGAS),Availablesince2011
– SupportforGPGPUs(MVAPICH2-GDR)andMIC(MVAPICH2-MIC),Availablesince2014
– SupportforVirtualizaOon(MVAPICH2-Virt),Availablesince2015
– SupportforEnergy-Awareness(MVAPICH2-EA),Availablesince2015
– SupportforInfiniBandNetworkAnalysisandMonitoring(OSUINAM)since2015
– Usedbymorethan2,825organiza<onsin85countries
– Morethan427,000(>0.4million)downloadsfromtheOSUsitedirectly– EmpoweringmanyTOP500clusters(June‘17ranking)
• 1st,10,649,600-core(SunwayTaihuLight)atNa<onalSupercompu<ngCenterinWuxi,China
• 15th,241,108-core(Pleiades)atNASA
• 20th,462,462-core(Stampede)atTACC
• 44th,74,520-core(Tsubame2.5)atTokyoInsOtuteofTechnology
– AvailablewithsonwarestacksofmanyvendorsandLinuxDistros(RedHatandSuSE)
– hip://mvapich.cse.ohio-state.edu• EmpoweringTop500systemsforoveradecade
– System-XfromVirginiaTech(3rdinNov2003,2,200processors,12.25TFlops)->
– SunwayTaihuLight(1stinJun’17,10Mcores,100PFlops)

IXPUG‘17 6NetworkBasedCompu<ngLaboratoryTimeline Ja
n-04
Jan-
10
Nov
-12
MVAPICH2-X
OMB
MVAPICH2
MVAPICH
Oct
-02
Nov
-04
Apr
-15
EOL
MVAPICH2-GDR
MVAPICH2-MIC
MVAPICHProjectTimeline
Jul-
15
MVAPICH2-Virt
Aug
-14
Aug
-15
Sep-
15
MVAPICH2-EA
OSU-INAM

IXPUG‘17 7NetworkBasedCompu<ngLaboratory
0
50000
100000
150000
200000
250000
300000
350000
400000
450000Sep-04
Feb-05
Jul-0
5
Dec-05
May-06
Oct-06
Mar-07
Aug-07
Jan-08
Jun-08
Nov-08
Apr-09
Sep-09
Feb-10
Jul-1
0
Dec-10
May-11
Oct-11
Mar-12
Aug-12
Jan-13
Jun-13
Nov-13
Apr-14
Sep-14
Feb-15
Jul-1
5
Dec-15
May-16
Oct-16
Mar-17
Aug-17
Num
bero
fDow
nloa
ds
Timeline
MV0.9.4
MV2
0.9.0
MV2
0.9.8
MV2
1.0
MV1.0
MV2
1.0.3
MV1.1
MV2
1.4
MV2
1.5
MV2
1.6
MV2
1.7
MV2
1.8
MV2
1.9 MV2
2.1
MV2
-GDR
2.0b
MV2
-MIC2.0
MV2
-Virt2.2
MV2
-GDR
2.2rc1
MV2
-X2.2
MV2
2.3b
MVAPICH2ReleaseTimelineandDownloads

IXPUG‘17 8NetworkBasedCompu<ngLaboratory
ArchitectureofMVAPICH2SojwareFamily
HighPerformanceParallelProgrammingModels
MessagePassingInterface(MPI)
PGAS(UPC,OpenSHMEM,CAF,UPC++)
Hybrid---MPI+X(MPI+PGAS+OpenMP/Cilk)
HighPerformanceandScalableCommunica<onRun<meDiverseAPIsandMechanisms
Point-to-point
Primi<ves
Collec<vesAlgorithms
Energy-Awareness
RemoteMemoryAccess
I/OandFileSystems
FaultTolerance
Virtualiza<on Ac<veMessagesJobStartup
Introspec<on&Analysis
SupportforModernNetworkingTechnology(InfiniBand,iWARP,RoCE,Omni-Path)
SupportforModernMul<-/Many-coreArchitectures(Intel-Xeon,OpenPower,Xeon-Phi(MIC,KNL),NVIDIAGPGPU)
TransportProtocols ModernFeatures
RC XRC UD DC UMR ODPSR-IOV
Mul<Rail
TransportMechanismsSharedMemory CMA IVSHMEM
ModernFeatures
MCDRAM* NVLink* CAPI*
*Upcoming
IXPUG‘17 9NetworkBasedCompu<ngLaboratory
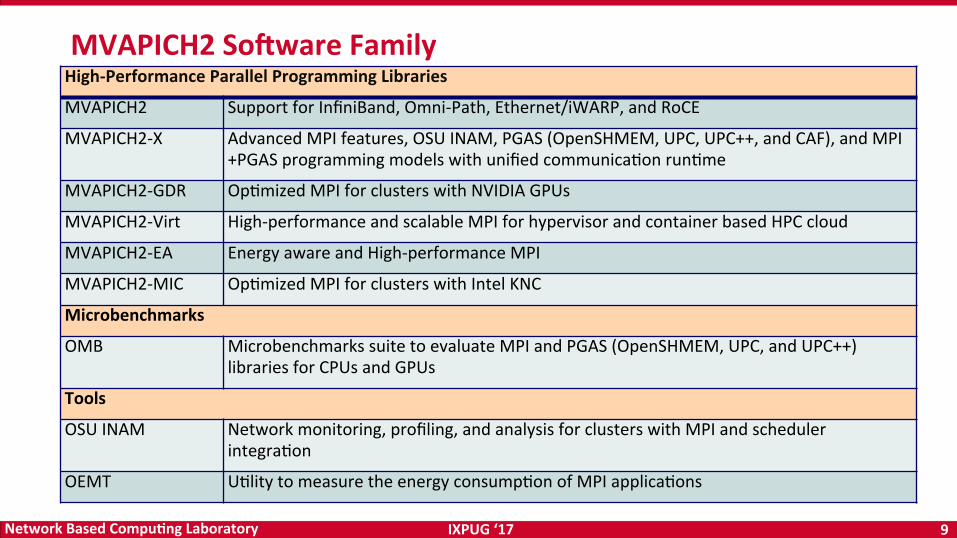
MVAPICH2SojwareFamilyHigh-PerformanceParallelProgrammingLibraries
MVAPICH2 SupportforInfiniBand,Omni-Path,Ethernet/iWARP,andRoCE
MVAPICH2-X AdvancedMPIfeatures,OSUINAM,PGAS(OpenSHMEM,UPC,UPC++,andCAF),andMPI+PGASprogrammingmodelswithunifiedcommunicaOonrunOme
MVAPICH2-GDR OpOmizedMPIforclusterswithNVIDIAGPUs
MVAPICH2-Virt High-performanceandscalableMPIforhypervisorandcontainerbasedHPCcloud
MVAPICH2-EA EnergyawareandHigh-performanceMPI
MVAPICH2-MIC OpOmizedMPIforclusterswithIntelKNC
Microbenchmarks
OMB MicrobenchmarkssuitetoevaluateMPIandPGAS(OpenSHMEM,UPC,andUPC++)librariesforCPUsandGPUs
Tools
OSUINAM Networkmonitoring,profiling,andanalysisforclusterswithMPIandschedulerintegraOon
OEMT UOlitytomeasuretheenergyconsumpOonofMPIapplicaOons

IXPUG‘17 10NetworkBasedCompu<ngLaboratory
• Releasedon08/10/2017
• MajorFeaturesandEnhancements– BasedonMPICH-3.2
– Enhanceperformanceofpoint-to-pointoperaOonsforCH3-Gen2(InfiniBand),CH3-PSM,andCH3-PSM2(Omni-Path)channels
– ImproveperformanceforMPI-3RMAoperaOons
– IntroducesupportforCaviumARM(ThunderX)systems
– Improvesupportforprocesstocoremappingonmany-coresystems
• NewenvironmentvariableMV2_THREADS_BINDING_POLICYformulO-threadedMPIandMPI+OpenMPapplicaOons
• Support`linear'and`compact'placementofthreads
• Warnuserifover-subscripOonofcoreisdetected
– ImprovelaunchOmeforlarge-scalejobswithmpirun_rsh
– Addsupportfornon-blockingAllreduceusingMellanoxSHARP
– EfficientsupportfordifferentIntelKnight'sLanding(KNL)models
– ImproveperformanceforIntra-andInter-nodecommunicaOonforOpenPOWERarchitecture
– ImprovesupportforlargeprocessespernodeandhugepagesonSMPsystems
– EnhancecollecOvetuningformanyarchitectures/systems
– EnhancesupportforMPI_TPVARsandCVARs
MVAPICH22.3b

IXPUG‘17 11NetworkBasedCompu<ngLaboratory
• FastandScalableJobStart-up• DynamicandAdapOveCommunicaOonProtocolsandTagMatching• ContenOon-awareDesignsforIntra-nodeCollecOves• ScalableMulO-leaderDesignsforCollecOves• Kernel-AssistedCommunicaOonDesignsforKNL• EfficientRMA-basedDesignsforGraph500onKNL
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforMany-coreEra
IXPUG‘17 12NetworkBasedCompu<ngLaboratory
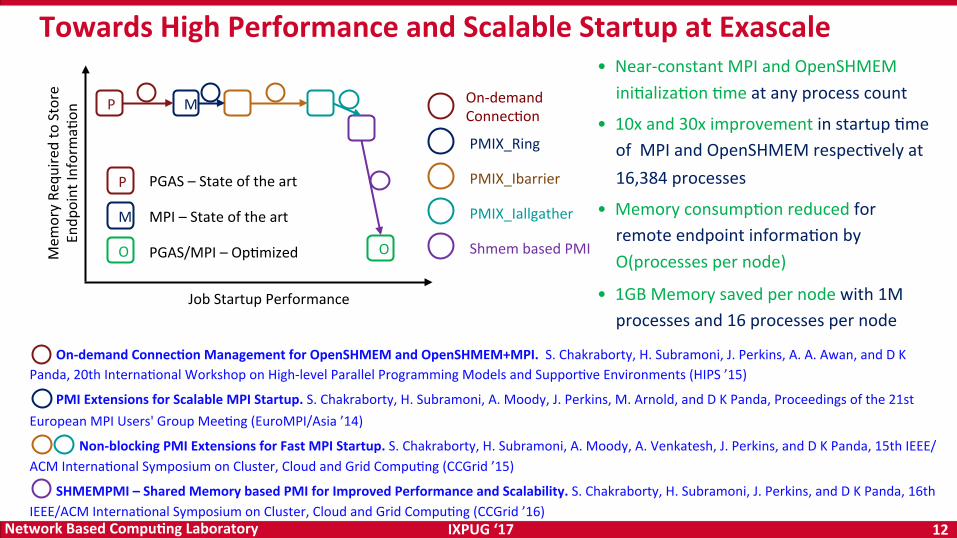
• Near-constantMPIandOpenSHMEMiniOalizaOonOmeatanyprocesscount
• 10xand30ximprovementinstartupOmeofMPIandOpenSHMEMrespecOvelyat16,384processes
• MemoryconsumpOonreducedforremoteendpointinformaOonbyO(processespernode)
• 1GBMemorysavedpernodewith1Mprocessesand16processespernode
TowardsHighPerformanceandScalableStartupatExascale
P M
O
JobStartupPerformance
Mem
oryRe
quire
dtoStore
Endp
ointInform
aOon
a b c d
eP
M
PGAS–Stateoftheart
MPI–Stateoftheart
O PGAS/MPI–OpOmized
PMIX_Ring
PMIX_Ibarrier
PMIX_Iallgather
ShmembasedPMI
b
c
d
e
aOn-demandConnecOon
On-demandConnec<onManagementforOpenSHMEMandOpenSHMEM+MPI.S.Chakraborty,H.Subramoni,J.Perkins,A.A.Awan,andDKPanda,20thInternaOonalWorkshoponHigh-levelParallelProgrammingModelsandSupporOveEnvironments(HIPS’15)
PMIExtensionsforScalableMPIStartup.S.Chakraborty,H.Subramoni,A.Moody,J.Perkins,M.Arnold,andDKPanda,Proceedingsofthe21stEuropeanMPIUsers'GroupMeeOng(EuroMPI/Asia’14)
Non-blockingPMIExtensionsforFastMPIStartup.S.Chakraborty,H.Subramoni,A.Moody,A.Venkatesh,J.Perkins,andDKPanda,15thIEEE/ACMInternaOonalSymposiumonCluster,CloudandGridCompuOng(CCGrid’15)
SHMEMPMI–SharedMemorybasedPMIforImprovedPerformanceandScalability.S.Chakraborty,H.Subramoni,J.Perkins,andDKPanda,16thIEEE/ACMInternaOonalSymposiumonCluster,CloudandGridCompuOng(CCGrid’16)
a
b
c d
e
IXPUG‘17 13NetworkBasedCompu<ngLaboratory
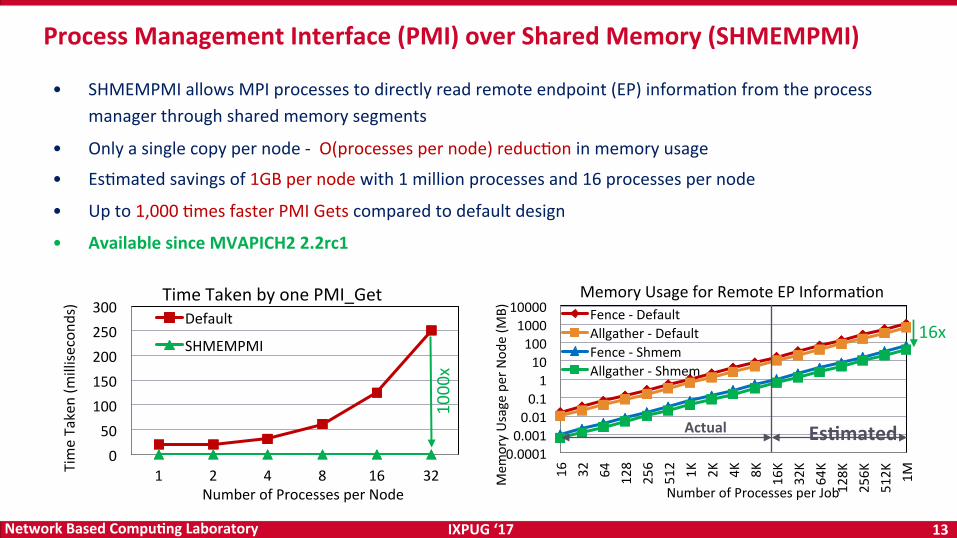
• SHMEMPMIallowsMPIprocessestodirectlyreadremoteendpoint(EP)informaOonfromtheprocessmanagerthroughsharedmemorysegments
• Onlyasinglecopypernode-O(processespernode)reducOoninmemoryusage
• EsOmatedsavingsof1GBpernodewith1millionprocessesand16processespernode
• Upto1,000OmesfasterPMIGetscomparedtodefaultdesign
• AvailablesinceMVAPICH22.2rc1
ProcessManagementInterface(PMI)overSharedMemory(SHMEMPMI)
050
100150200250300
1 2 4 8 16 32TimeTaken(m
illise
cond
s)
NumberofProcessesperNode
TimeTakenbyonePMI_GetDefault
SHMEMPMI
0.00010.0010.010.1110100100010000
16
32
64
128
256
512 1K
2K
4K
8K
16K
32K
64K
128K
256K
512K
1M
Mem
oryUsageperNod
e(M
B)
NumberofProcessesperJob
MemoryUsageforRemoteEPInformaOonFence-DefaultAllgather-DefaultFence-ShmemAllgather-Shmem
Es<mated1000x
Actual
16x
IXPUG‘17 14NetworkBasedCompu<ngLaboratory
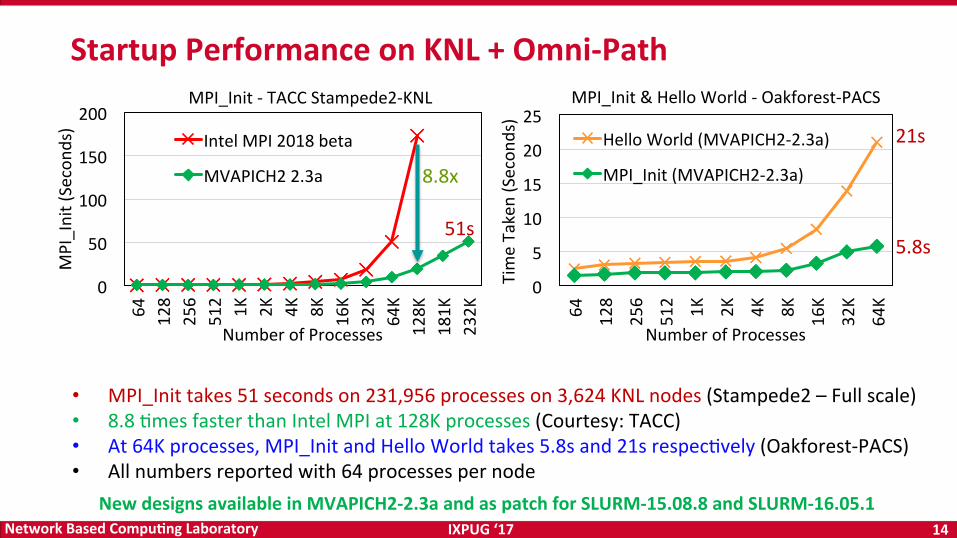
StartupPerformanceonKNL+Omni-Path
0
50
100
150
20064
128
256
512 1K
2K
4K
8K
16K
32K
64K
128K
181K
232K
MPI_Init(Second
s)
NumberofProcesses
MPI_Init-TACCStampede2-KNL
IntelMPI2018beta
MVAPICH22.3a
0
5
10
15
20
25
64
128
256
512 1K
2K
4K
8K
16K
32K
64K
TimeTaken(Secon
ds)
NumberofProcesses
MPI_Init&HelloWorld-Oakforest-PACS
HelloWorld(MVAPICH2-2.3a)
MPI_Init(MVAPICH2-2.3a)
• MPI_Inittakes51secondson231,956processeson3,624KNLnodes(Stampede2–Fullscale)• 8.8OmesfasterthanIntelMPIat128Kprocesses(Courtesy:TACC)• At64Kprocesses,MPI_InitandHelloWorldtakes5.8sand21srespecOvely(Oakforest-PACS)• Allnumbersreportedwith64processespernode
5.8s
21s
51s
8.8x
NewdesignsavailableinMVAPICH2-2.3aandaspatchforSLURM-15.08.8andSLURM-16.05.1

IXPUG‘17 15NetworkBasedCompu<ngLaboratory
• FastandScalableJobStart-up• DynamicandAdapOveCommunicaOonProtocolsandTagMatching• ContenOon-awareDesignsforIntra-nodeCollecOves• ScalableMulO-leaderDesignsforCollecOves• Kernel-AssistedCommunicaOonDesignsforKNL• EfficientRMA-basedDesignsforGraph500onKNL
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforMany-coreEra
IXPUG‘17 16NetworkBasedCompu<ngLaboratory
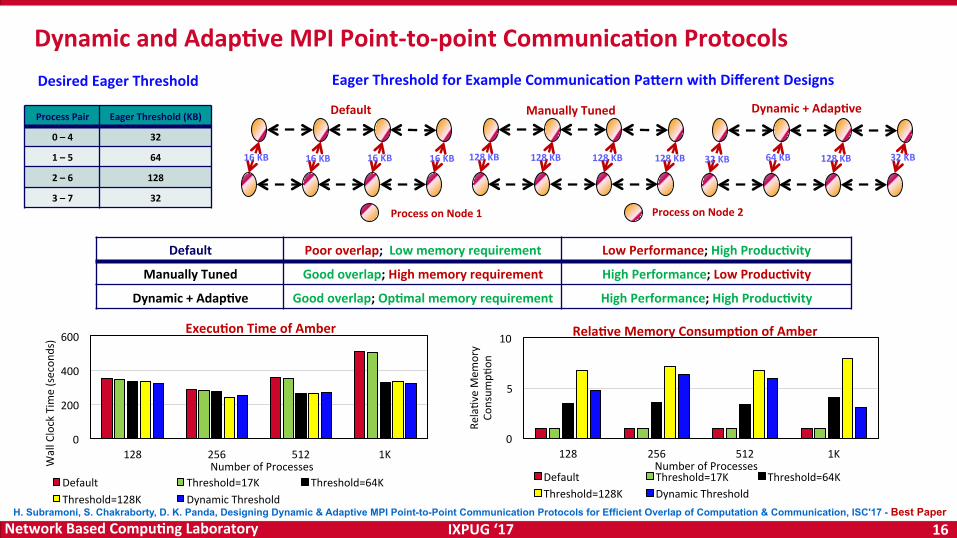
DynamicandAdap<veMPIPoint-to-pointCommunica<onProtocols
ProcessonNode1 ProcessonNode2
EagerThresholdforExampleCommunica<onPaiernwithDifferentDesigns
0 1 2 3
4 5 6 7
Default
16KB 16KB 16KB 16KB
0 1 2 3
4 5 6 7
ManuallyTuned
128KB 128KB 128KB 128KB
0 1 2 3
4 5 6 7
Dynamic+Adap<ve
32KB 64KB 128KB 32KB
H. Subramoni, S. Chakraborty, D. K. Panda, Designing Dynamic & Adaptive MPI Point-to-Point Communication Protocols for Efficient Overlap of Computation & Communication, ISC'17 - Best Paper
0
200
400
600
128 256 512 1K
WallClockTim
e(secon
ds)
NumberofProcesses
Execu<onTimeofAmber
Default Threshold=17K Threshold=64KThreshold=128K DynamicThreshold
0
5
10
128 256 512 1K
RelaOveMem
ory
Consum
pOon
NumberofProcesses
Rela<veMemoryConsump<onofAmber
Default Threshold=17K Threshold=64KThreshold=128K DynamicThreshold
Default Pooroverlap;Lowmemoryrequirement LowPerformance;HighProduc<vity
ManuallyTuned Goodoverlap;Highmemoryrequirement HighPerformance;LowProduc<vity
Dynamic+Adap<ve Goodoverlap;Op<malmemoryrequirement HighPerformance;HighProduc<vity
ProcessPair EagerThreshold(KB)
0–4 32
1–5 64
2–6 128
3–7 32
DesiredEagerThreshold
IXPUG‘17 17NetworkBasedCompu<ngLaboratory
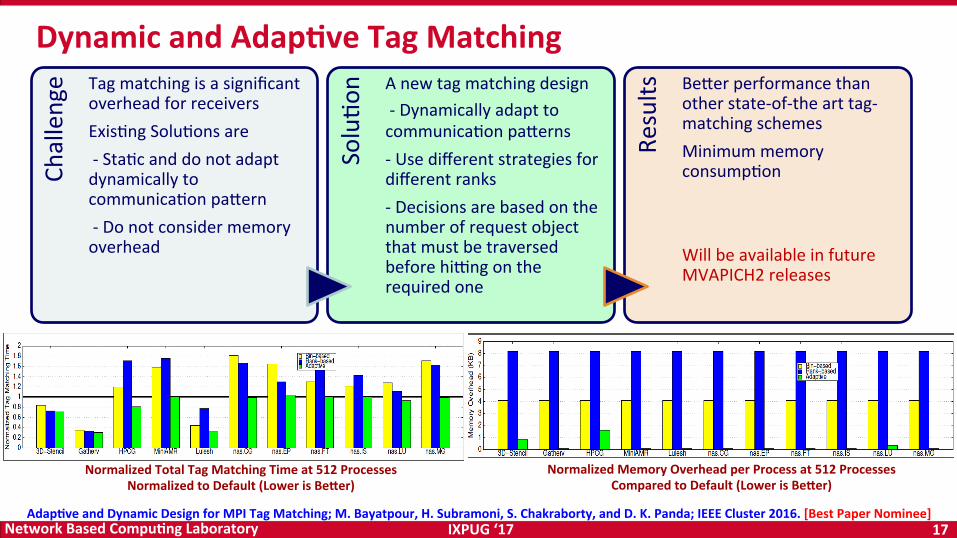
DynamicandAdap<veTagMatching
NormalizedTotalTagMatchingTimeat512ProcessesNormalizedtoDefault(LowerisBeier)
NormalizedMemoryOverheadperProcessat512ProcessesComparedtoDefault(LowerisBeier)
Adap<veandDynamicDesignforMPITagMatching;M.Bayatpour,H.Subramoni,S.Chakraborty,andD.K.Panda;IEEECluster2016.[BestPaperNominee]
Challenge Tagmatchingisasignificant
overheadforreceiversExisOngSoluOonsare-StaOcanddonotadaptdynamicallytocommunicaOonpa{ern-Donotconsidermemoryoverhead
SoluOo
n Anewtagmatchingdesign-DynamicallyadapttocommunicaOonpa{erns-Usedifferentstrategiesfordifferentranks-Decisionsarebasedonthenumberofrequestobjectthatmustbetraversedbeforehi|ngontherequiredone
Results
Be{erperformancethanotherstate-of-thearttag-matchingschemesMinimummemoryconsumpOonWillbeavailableinfutureMVAPICH2releases

IXPUG‘17 18NetworkBasedCompu<ngLaboratory
• FastandScalableJobStart-up• DynamicandAdapOveCommunicaOonProtocolsandTagMatching• ContenOon-awareDesignsforIntra-nodeCollecOves• ScalableMulO-leaderDesignsforCollecOves• Kernel-AssistedCommunicaOonDesignsforKNL• EfficientRMA-basedDesignsforGraph500onKNL
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforMany-coreEra

IXPUG‘17 19NetworkBasedCompu<ngLaboratory
DifferentKernel-AssistedSingleCopyMechanismsCMA KNEM LiMiC
Cookie/RegionCreaOon NotRequired Required Required
PermissionCheck Supported Supported NotSupported
Availability IncludedinLinux3.2+ KernelModule KernelModule
CMA KNEM LiMiC
MVAPICH2-2.3a √ x √
OpenMPI2.1.0 √ √ x
IntelMPI2017 √ x x
MPILibrarySupport
CMA(CrossMemoryA{ach)isthemostwidelysupportedkernel-assistedtransfermechanism

IXPUG‘17 20NetworkBasedCompu<ngLaboratory
ImpactofCommunica<onPaiernonCMAPerformance
1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K256K 1M 4MMessageSize
DifferentProcesses
PPN-2PPN-4PPN-8PPN-16
1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K 256K 1M 4MMessageSize
SameProcess,SameBuffer
1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K 256K 1M 4MMessageSize
SameProcess,DiffBuffers
Latency(us)
All-to-All–GoodScalability One-to-All-PoorScalability One-to-All–PoorScalability
>100xworse
>100xworse
NoincreasewithPPN
P0
P1
P3
P2
P0
P1 P3
P2
P0
P1 P3
P2
Conten<onisatProcesslevel

IXPUG‘17 21NetworkBasedCompu<ngLaboratory
One-to-allCommunica<onwithCMAonDifferentArchitectures
1
10
100
1000
10000
100000
1000000
1 2 4 8 16 32 64NumberofProcessesperNode
KNL,68PhysicalCores4K 16K64K 256K1M 4M
Latency(us)
1
10
100
1000
10000
100000
1000000
1 2 4 8 16 28NumberofProcessesperNode
Broadwell,2x14PhysicalCores4K 16K64K 256K1M 4M
1
10
100
1000
10000
100000
1000000
1 2 4 8 16 32 64 128NumberofProcessesperNode
Power8,2x10PhysicalCores4K 16K64K 256K1M 4M
• Super-lineardegradaOoninallthreearchitectures• MoreCores=>MoreContenOon=>MoreDegradaOon• ContenOonawaredesign:limitnumberofconcurrentreads/writes
• Hitthe“sweetspot”betweencontenOonandconcurrency
>250x >40x >150x
IXPUG‘17 22NetworkBasedCompu<ngLaboratory
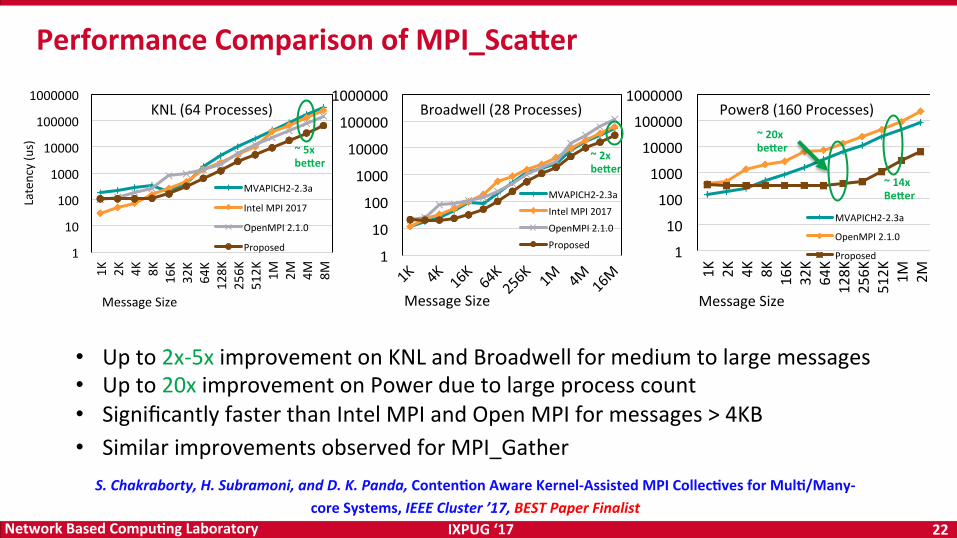
PerformanceComparisonofMPI_Scaier
1
10
100
1000
10000
100000
10000001K
2K
4K
8K
16K
32K
64K
128K
256K
512K
1M
2M
4M
8M
MessageSize
KNL(64Processes)
MVAPICH2-2.3a
IntelMPI2017
OpenMPI2.1.0
Proposed
Latency(us)
1
10
100
1000
10000
100000
1000000
MessageSize
Broadwell(28Processes)
MVAPICH2-2.3aIntelMPI2017OpenMPI2.1.0Proposed 1
10
100
1000
10000
100000
1000000
1K
2K
4K
8K
16K
32K
64K
128K
256K
512K
1M
2M
MessageSize
Power8(160Processes)
MVAPICH2-2.3a
OpenMPI2.1.0
Proposed
• Upto2x-5ximprovementonKNLandBroadwellformediumtolargemessages• Upto20ximprovementonPowerduetolargeprocesscount• SignificantlyfasterthanIntelMPIandOpenMPIformessages>4KB
~20xbeier
~14xBeier
~5xbeier ~2x
beier
• SimilarimprovementsobservedforMPI_GatherS.Chakraborty,H.Subramoni,andD.K.Panda,Conten<onAwareKernel-AssistedMPICollec<vesforMul</Many-
coreSystems,IEEECluster’17,BESTPaperFinalist

IXPUG‘17 23NetworkBasedCompu<ngLaboratory
PerformanceComparisonofMPI_Bcast
1
10
100
1000
10000
100000
1K 4K 16K 64K256K 1M 4MMessageSize
KNL(64Processes)
MVAPICH2-2.3a
IntelMPI2017
OpenMPI2.1.0
Proposed
Latency(us)
1
10
100
1000
10000
100000
MessageSize
Broadwell(28Processes)
MVAPICH2-2.3a
IntelMPI2017
OpenMPI2.1.0
Proposed1
10
100
1000
10000
100000
1K 4K 16K 64K256K 1M 4MMessageSize
Power8(160Processes)
MVAPICH2-2.3a
OpenMPI2.1.0
Proposed
• Upto2x-4ximprovementoverexisOngimplementaOonfor1MBmessages• Upto1.5x–2xfasterthanIntelMPIandOpenMPIfor1MBmessages
UseCMA
UseSHMEM
UseCMA
UseSHMEM
UseCMA
UseSHMEM
• Improvementsobtainedforlargemessagesonly• p-1copieswithCMA,pcopieswithSharedmemory• FallbacktoSHMEMforsmallmessages

IXPUG‘17 24NetworkBasedCompu<ngLaboratory
PerformanceComparisonofMPI_AlltoallLatency(us)
1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K 256K 1M 4MMessageSize
Broadwell(28Processes)
MVAPICH2-2.3a
IntelMPI2017
OpenMPI2.1.0
Proposed1101001000
10000100000100000010000000
1K 4K 16K 64K 256K 1MMessageSize
Power8(160Processes)
MVAPICH2-2.3a
OpenMPI2.1.0
Proposed
• Improvementfromavoidingexchangeofcontrolmessages• Improvementobservedevenfor1KBmessages
1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K 256K 1M 4MMessageSize
KNL(64Processes)
MVAPICH2-2.3a
IntelMPI2017
OpenMPI2.1.0
Proposed
>3xBeier
>5xBeier
>20%Beier
~5%Beier
• Upto3x-5ximprovementforsmallandmediummessages(comparedtodefault)• Largemessageperformanceboundbysystembandwidth(5-20%improvement)• SimilarimprovementsforMPI_Allgather

IXPUG‘17 25NetworkBasedCompu<ngLaboratory
• FastandScalableJobStart-up• DynamicandAdapOveCommunicaOonProtocolsandTagMatching• ContenOon-awareDesignsforIntra-nodeCollecOves• ScalableMulO-leaderDesignsforCollecOves• Kernel-AssistedCommunicaOonDesignsforKNL• EfficientRMA-basedDesignsforGraph500onKNL
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforMany-coreEra

IXPUG‘17 26NetworkBasedCompu<ngLaboratory
ScalableReduc<onCollec<veswithMul<-Leaders
• ExisOngdesignsforMPI_AllreducedonottakeadvantageofthevastparallelismavailableinmodernmulO-/many-coreprocessors
• ProposedanewsoluOonforMPI_Allreduce• DPMLTakeadvantageoftheparallelismofferedby
– MulO-/many-corearchitectures– Thehighthroughputandhigh-endfeaturesofferedbyInfiniBandand
Omni-Path
M.Bayatpour,S.Chakraborty,H.Subramoni,X.Lu,andD.K.Panda,ScalableReduc<onCollec<veswithDataPar<<oning-basedMul<-LeaderDesign,SuperCompu<ng'17.
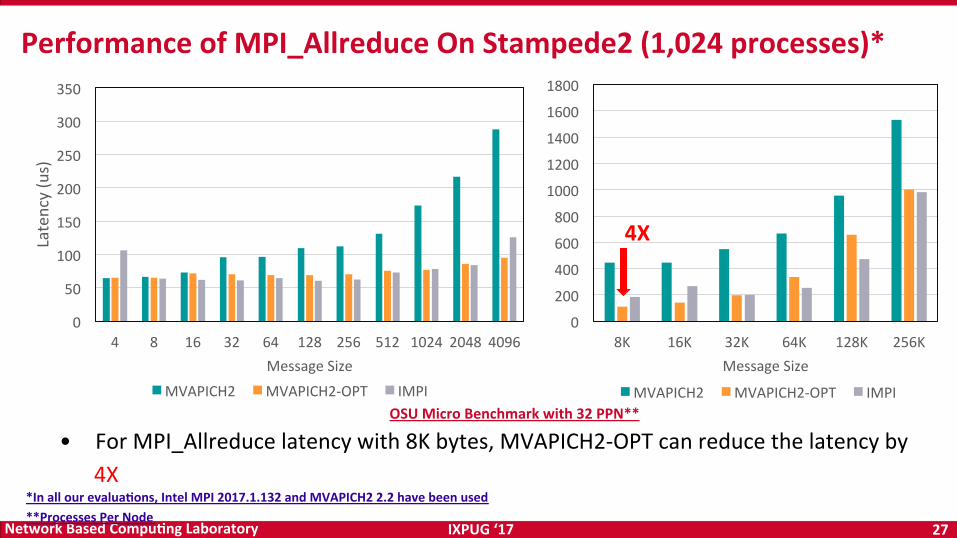
IXPUG‘17 27NetworkBasedCompu<ngLaboratory
PerformanceofMPI_AllreduceOnStampede2(1,024processes)*
0
50
100
150
200
250
300
350
4 8 16 32 64 128 256 512 1024 2048 4096
Latency(us)
MessageSize
MVAPICH2 MVAPICH2-OPT IMPI
0
200
400
600
800
1000
1200
1400
1600
1800
8K 16K 32K 64K 128K 256KMessageSize
MVAPICH2 MVAPICH2-OPT IMPIOSUMicroBenchmarkwith32PPN**
4X
• ForMPI_Allreducelatencywith8Kbytes,MVAPICH2-OPTcanreducethelatencyby4X
*Inallourevalua<ons,IntelMPI2017.1.132andMVAPICH22.2havebeenused**ProcessesPerNode
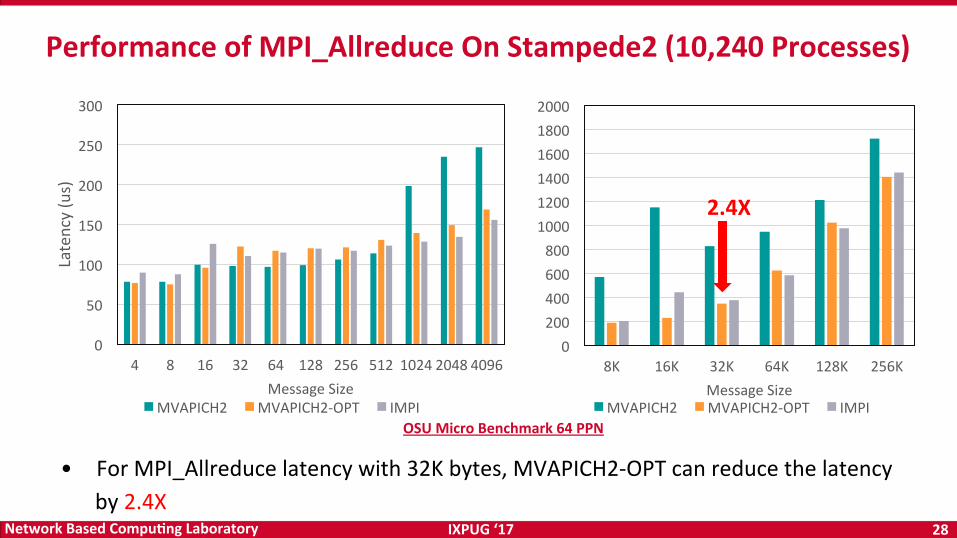
IXPUG‘17 28NetworkBasedCompu<ngLaboratory
PerformanceofMPI_AllreduceOnStampede2(10,240Processes)
0
50
100
150
200
250
300
4 8 16 32 64 128 256 512 102420484096
Latency(us)
MessageSizeMVAPICH2 MVAPICH2-OPT IMPI
0200400600800
100012001400160018002000
8K 16K 32K 64K 128K 256KMessageSize
MVAPICH2 MVAPICH2-OPT IMPIOSUMicroBenchmark64PPN
2.4X
• ForMPI_Allreducelatencywith32Kbytes,MVAPICH2-OPTcanreducethelatencyby2.4X

IXPUG‘17 29NetworkBasedCompu<ngLaboratory
PerformanceofMPI_AllreduceOnBridges(1,024Processes)
0
20
40
60
80
100
120
140
4 8 16 32 64 128 256 512 1024 2048 4096
Latency(us)
MessageSizeMVAPICH2 MVAPICH2-OPT IMPI
0
100
200
300
400
500
600
8K 16K 32K 64K 128K 256KMessageSize
MVAPICH2 MVAPICH2-OPT IMPIOSUMicroBenchmarkwith16PPN
• ForMPI_Allreducelatencywith2Kbytes,MVAPICH2-OPTcanreducethelatencyby2.6X
2.6X

IXPUG‘17 30NetworkBasedCompu<ngLaboratory
PerformanceofMPI_AllreduceOnBridges(1,792Processes)
0
20
40
60
80
100
120
140
4 8 16 32 64 128 256 512 1024 2048 4096
Latency(us)
MessageSizeMVAPICH2 MVAPICH2-OPT IMPI
0
200
400
600
800
1000
1200
1400
8K 16K 32K 64K 128K 256KMessageSize
MVAPICH2 MVAPICH2-OPT IMPIOSUMicroBenchmarkwith28PPN
• ForMPI_Allreducelatencywith4Kbytes,MVAPICH2-OPTcanreducethelatencyby1.5X
1.5X

IXPUG‘17 31NetworkBasedCompu<ngLaboratory
PerformanceofMiniAMRApplica<onOnStampede2andBridges
01020304050607080
448 896 1792NumberofProcesses
Bridges(28PPN)
MVAPICH2 MVAPICH2-OPT IMPI
0
10
20
30
40
50
60
70
512 1024 1280 2048
Latency(s)
NumberofProcesses
Stampede2(32PPN)
MVAPICH2 MVAPICH2-OPT IMPI
• ForMiniAMRApplicaOonlatencywith2,048processes,MVAPICH2-OPTcanreducethelatencyby2.6XonStampede2
• OnBridges,with1,792processes,MVAPICH2-OPTcanreducethelatencyby1.5X
2.6X 1.5X

IXPUG‘17 32NetworkBasedCompu<ngLaboratory
• FastandScalableJobStart-up• DynamicandAdapOveCommunicaOonProtocolsandTagMatching• ContenOon-awareDesignsforIntra-nodeCollecOves• ScalableMulO-leaderDesignsforCollecOves• Kernel-AssistedCommunicaOonDesignsforKNL• EfficientRMA-basedDesignsforGraph500onKNL
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforMany-coreEra

IXPUG‘17 33NetworkBasedCompu<ngLaboratory
Kernel-assistedCommunica<onDesignsforKNL• Proposedkernel-assistedon-loadingcommunicaOonengineformany-cores
withhighbandwidthmemories– ExploitshighconcurrencyandMCDRAMofferedbyKNL
• ImplementedasaLinuxKernelModulewithMPIasahigh-levelrunOme• ApplicabletootherprogrammingmodelssuchasPGAS,Task-basedetc.
• Providesportability,performance,andapplicabilitytorunOmeaswellasapplicaOonsinatransparentmanner
• Lowlatencyandhighthroughput– Mediumtolargemessages– OpOmizedforDeepLearningworkloads
J.Hashmi,K.Hamidouche,H.Subramoni,D.Panda,Kernel-assistedCommunicaFonEngineforMPIonEmergingMany-coreProcessors,Int’lConferenceonHigh-PerformanceCompuFng,Data,andAnalyFcs(HiPC),Dec2017.

IXPUG‘17 34NetworkBasedCompu<ngLaboratory
MicrobenchmarkEvalua<on
0
5000
10000
15000
20000
64K128K256K512K1M 2M 4M 8M16M32M64M
Latency(us)
MessageSize
MV2-CMAMV2-LiMICIMPI2007-KASSISTMV2-Proposed
33%
0
2000
4000
6000
8000
10000
64K128K256K512K 1M 2M 4M 8M 16M32M64M
Band
width(M
B/s)
MessageSize
MV2-CMA MV2-LiMICIMPI2007-KASSIST MV2-Proposed
30%
osu_latency osu_bw
• ProposeddesignexploitsKNLcoresandMCRAMtoacceleratelargemessagetransfers
• Twoprocesslatencyisimprovedbyupto33%andbandwidthby30%
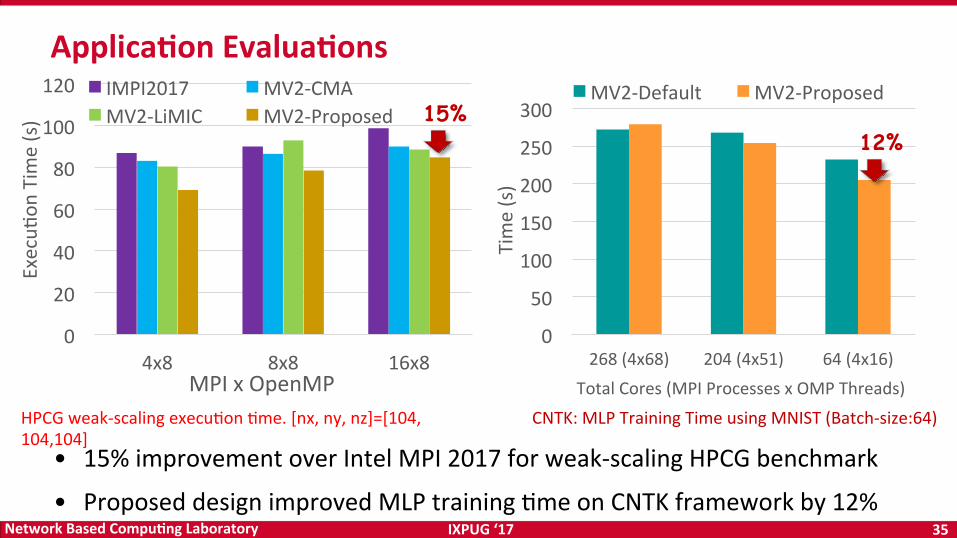
IXPUG‘17 35NetworkBasedCompu<ngLaboratory
0
20
40
60
80
100
120
4x8 8x8 16x8
ExecuO
onTim
e(s)
MPIxOpenMP
IMPI2017 MV2-CMAMV2-LiMIC MV2-Proposed
Applica<onEvalua<ons
HPCGweak-scalingexecuOonOme.[nx,ny,nz]=[104,104,104]
15%
• 15%improvementoverIntelMPI2017forweak-scalingHPCGbenchmark
• ProposeddesignimprovedMLPtrainingOmeonCNTKframeworkby12%
0
50
100
150
200
250
300
268(4x68) 204(4x51) 64(4x16)
Time(s)
TotalCores(MPIProcessesxOMPThreads)
MV2-Default MV2-Proposed
12%
CNTK:MLPTrainingTimeusingMNIST(Batch-size:64)

IXPUG‘17 36NetworkBasedCompu<ngLaboratory
• FastandScalableJobStart-up• DynamicandAdapOveCommunicaOonProtocolsandTagMatching• ContenOon-awareDesignsforIntra-nodeCollecOves• ScalableMulO-leaderDesignsforCollecOves• Kernel-AssistedCommunicaOonDesignsforKNL• EfficientRMA-basedDesignsforGraph500onKNL
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforMany-coreEra

IXPUG‘17 37NetworkBasedCompu<ngLaboratory
Mul<-threadingandLock-FreeMPIRMABasedGraph500onKNL
• ProposemulO-threadingandlock-freedesignsinMPIrunOmeaswellasGraph500totakeadvantageof– LargenumberofCPUhardwarethreads
– High-BandwidthMemory(HBM)

IXPUG‘17 38NetworkBasedCompu<ngLaboratory
MPILevelOne-sidedPutLatency&Bandwidth
0
200
400
600
800
1000
64K 128K 256K 512K 1M 2M 4M
Latency(us)
MessageSize(bytes)
PutLatencyIMPIMV2MV2-2TMV2-4T
0
5000
10000
15000
20000
64K 128K 256K 512K 1M 2M 4M
Band
width(M
B/s)
MessageSize(bytes)
PutBandwidth
IMPIMV2MV2-2TMV2-4T
• ForPutlatencywith4Mbytes,MV2-4Tcanreducethelatencyby3X
3X

IXPUG‘17 39NetworkBasedCompu<ngLaboratory
• WithFlat-Alltoallmode,G500-OPT-HBMschemecouldreducethekernelexecuOonOmeby27%comparedwiththeG500-OPT-DDR
Graph500BFSKernelPerformanceEvalua<on
110
1001000
10000
ExecuO
onTim
e(s)
ApplicaOons(64Processes)
Pin-down ODP-Enhanced ODP-OpOmal ODP-NaOve
110
1001000
10000
ExecuO
onTim
e(s)
ApplicaOons(64Processes)
Pin-down ODP-Enhanced ODP-OpOmal ODP-NaOve
110
1001000
10000
ExecuO
onTim
e(s)
ApplicaOons(64Processes)
Pin-down ODP-Enhanced ODP-OpOmal ODP-NaOve
110
1001000
10000
ExecuO
onTim
e(s)
ApplicaOons(64Processes)
Pin-down ODP-Enhanced ODP-OpOmal ODP-NaOve
0
5
10
15
IMPI MV2 IMPI MV2 IMPI MV2
Flat-Alltoall Flat-Quadrant Cache
Execu<
onTim
e(s)
Graph500BFSKernelExecuOonTimewith64ProcessesonKNLG500-S/R-DDRG500-RMA-DDRG500-Opt-DDRG500-S/R-HBMG500-RMA-HBMG500-Opt-HBM27%
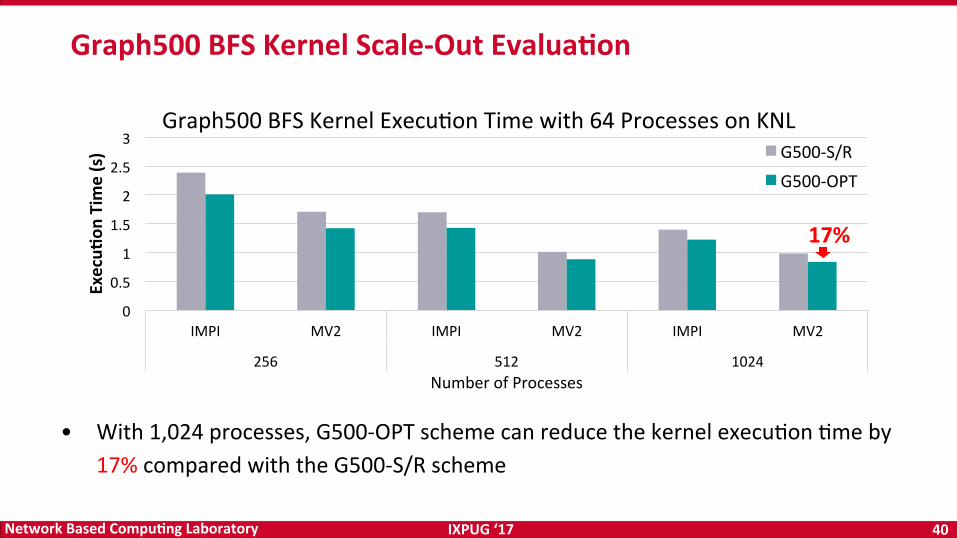
IXPUG‘17 40NetworkBasedCompu<ngLaboratory
Graph500BFSKernelScale-OutEvalua<on
0
0.5
1
1.5
2
2.5
3
IMPI MV2 IMPI MV2 IMPI MV2
256 512 1024
Execu<
onTim
e(s)
NumberofProcesses
Graph500BFSKernelExecuOonTimewith64ProcessesonKNLG500-S/RG500-OPT
• With1,024processes,G500-OPTschemecanreducethekernelexecuOonOmeby17%comparedwiththeG500-S/Rscheme
17%

IXPUG‘17 41NetworkBasedCompu<ngLaboratory
• Many-corenodeswillbethefoundaOonblocksforemergingExascalesystems
• CommunicaOonmechanismsandrunOmesneedtobere-designedtotakeadvantageoftheavailabilityoflargenumberofcores
• Presentedasetofnoveldesignsanddemonstratedtheperformancebenefits
• ThenewdesignswillbeavailableinupcomingMVAPICH2libraries
ConcludingRemarks

IXPUG‘17 42NetworkBasedCompu<ngLaboratory
FundingAcknowledgmentsFundingSupportby
EquipmentSupportby

IXPUG‘17 43NetworkBasedCompu<ngLaboratory
PersonnelAcknowledgmentsCurrentStudents
– A.Awan(Ph.D.)
– M.Bayatpour(Ph.D.)– S.Chakraborthy(Ph.D.)
– C.-H.Chu(Ph.D.)
PastStudents– A.AugusOne(M.S.)
– P.Balaji(Ph.D.)
– S.Bhagvat(M.S.)
– A.Bhat(M.S.)
– D.BunOnas(Ph.D.)
– L.Chai(Ph.D.)
– B.Chandrasekharan(M.S.)– N.Dandapanthula(M.S.)
– V.Dhanraj(M.S.)
– T.Gangadharappa(M.S.)
– K.Gopalakrishnan(M.S.)
– R.Rajachandrasekar(Ph.D.)
– G.Santhanaraman(Ph.D.)
– A.Singh(Ph.D.)– J.Sridhar(M.S.)
– S.Sur(Ph.D.)
– H.Subramoni(Ph.D.)
– K.Vaidyanathan(Ph.D.)
– A.Vishnu(Ph.D.)
– J.Wu(Ph.D.)
– W.Yu(Ph.D.)
PastResearchScienFst– K.Hamidouche
– S.Sur
PastPost-Docs– D.Banerjee
– X.Besseron
– H.-W.Jin
– W.Huang(Ph.D.)
– W.Jiang(M.S.)
– J.Jose(Ph.D.)
– S.Kini(M.S.)
– M.Koop(Ph.D.)
– K.Kulkarni(M.S.)
– R.Kumar(M.S.)
– S.Krishnamoorthy(M.S.)
– K.Kandalla(Ph.D.)
– P.Lai(M.S.)
– J.Liu(Ph.D.)
– M.Luo(Ph.D.)
– A.Mamidala(Ph.D.)
– G.Marsh(M.S.)
– V.Meshram(M.S.)
– A.Moody(M.S.)
– S.Naravula(Ph.D.)
– R.Noronha(Ph.D.)
– X.Ouyang(Ph.D.)
– S.Pai(M.S.)
– S.Potluri(Ph.D.)
– S.Guganani(Ph.D.)– J.Hashmi(Ph.D.)
– N.Islam(Ph.D.)– M.Li(Ph.D.)
– J.Lin
– M.Luo
– E.Mancini
CurrentResearchScienFsts– X.Lu
– H.Subramoni
PastProgrammers– D.Bureddy
– J.Perkins
CurrentResearchSpecialist– J.Smith
– M.Arnold
– M.Rahman(Ph.D.)– D.Shankar(Ph.D.)
– A.Venkatesh(Ph.D.)– J.Zhang(Ph.D.)
– S.Marcarelli
– J.Vienne
– H.Wang
CurrentPost-doc– A.Ruhela

IXPUG‘17 44NetworkBasedCompu<ngLaboratory
ThankYou!
Network-BasedCompuOngLaboratoryh{p://nowlab.cse.ohio-state.edu/
TheHigh-PerformanceMPI/PGASProjecth{p://mvapich.cse.ohio-state.edu/
TheHigh-PerformanceDeepLearningProjecth{p://hidl.cse.ohio-state.edu/
TheHigh-PerformanceBigDataProjecth{p://hibd.cse.ohio-state.edu/
Related Documents


![What is [Open] MPI?open]-mpi-1up.pdfMay 2008 Screencast: What is [Open] MPI? 3 MPI Forum • Published MPI-1 spec in 1994 • Published MPI-2 spec in 1996 Additions to MPI-1 • Recently](https://static.cupdf.com/doc/110x72/6143c7b66b2ee0265c024306/what-is-open-mpi-open-mpi-1uppdf-may-2008-screencast-what-is-open-mpi-3.jpg)








