Advanced MPI Programming Pavan Balaji Argonne National Laboratory Email: [email protected] Web: www.mcs.anl.gov/~balaji Torsten Hoefler ETH Zurich Email: [email protected] Web: http://htor.inf.ethz.ch/ Rajeev Thakur Argonne National Laboratory Email: [email protected] Web: www.mcs.anl.gov/~thakur William Gropp University of Illinois, Urbana-Champaign Email: [email protected] Web: www.cs.illinois.edu/~wgropp Latest slides and code examples are available at www.mcs.anl.gov/~thakur/sc17-mpi-tutorial Tutorial at SC17, November 2017

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Advanced MPI Programming
Pavan BalajiArgonneNationalLaboratory
Email:[email protected]:www.mcs.anl.gov/~balaji
Torsten HoeflerETHZurich
Email:[email protected]:http://htor.inf.ethz.ch/
RajeevThakurArgonneNationalLaboratory
Email:[email protected]:www.mcs.anl.gov/~thakur
WilliamGroppUniversityofIllinois,Urbana-Champaign
Email:[email protected]:www.cs.illinois.edu/~wgropp
Latestslidesandcodeexamplesareavailableat
www.mcs.anl.gov/~thakur/sc17-mpi-tutorial
TutorialatSC17,November2017

About the Speakers
§ Pavan Balaji:ComputerScientist,ArgonneNationalLaboratory
§ WilliamGropp:Director,NCSA;Professor,UniversityofIllinois,Urbana-Champaign
§ Torsten Hoefler:AssociateProfessor,ETHZurich
§ RajeevThakur:SeniorComputerScientist,ArgonneNationalLaboratory
§ AllfourofusaredeeplyinvolvedinMPIstandardization(intheMPIForum)andinMPIimplementation
AdvancedMPI,SC17(11/13/2017) 2

Outline
Morning
§ Introduction– MPI-1,MPI-2,MPI-3
§ Runningexample:2Dstencilcode– Simplepoint-to-pointversion
§ Derived datatypes– Usein2Dstencilcode
§ One-sidedcommunication– BasicsandnewfeaturesinMPI-3
– Usein2Dstencilcode
– Advancedtopics
• Globaladdressspacecommunication
Afternoon§ MPIandThreads
– ThreadsafetyspecificationinMPI– Howitenableshybridprogramming– Hybrid(MPI+sharedmemory)version
of2Dstencilcode– MPI+accelerators
§ Nonblocking collectives– ParallelFFTexample
§ Processtopologies– 2Dstencilexample
§ Neighborhoodcollectives– 2Dstencilexample
§ RecenteffortsoftheMPIForum§ Conclusions
33AdvancedMPI,SC17(11/13/2017)

MPI-1
§ MPIisamessage-passinglibraryinterfacestandard.– Specification,notimplementation– Library,notalanguage
§ MPI-1supportstheclassicalmessage-passingprogrammingmodel:basicpoint-to-pointcommunication,collectives,datatypes,etc
§ MPI-1wasdefined(1994)byabroadlybasedgroupofparallelcomputervendors,computerscientists,andapplicationsdevelopers.– 2-yearintensiveprocess
§ ImplementationsappearedquicklyandnowMPIistakenforgrantedasvendor-supportedsoftwareonanyparallelmachine.
§ Free,portableimplementationsexistforclustersandotherenvironments(MPICH,OpenMPI)
44AdvancedMPI,SC17(11/13/2017)

MPI-2
§ SameprocessofdefinitionbyMPIForum
§ MPI-2isanextensionofMPI– Extendsthemessage-passingmodel
• ParallelI/O
• Remotememoryoperations(one-sided)
• Dynamicprocessmanagement
– Addsotherfunctionality• C++andFortran90bindings
– similartooriginalCandFortran-77bindings
• Externalinterfaces
• Languageinteroperability
• MPIinteractionwiththreads
55AdvancedMPI,SC17(11/13/2017)

6
Timeline of the MPI Standard§ MPI-1(1994),presentedatSC’93
– Basicpoint-to-pointcommunication,collectives,datatypes,etc
§ MPI-2(1997)– AddedparallelI/O, RemoteMemoryAccess(one-sidedoperations),dynamicprocesses,
threadsupport,C++bindings,…
§ ---- Stablefor10years----
§ MPI-2.1(2008)– MinorclarificationsandbugfixestoMPI-2
§ MPI-2.2(2009)– SmallupdatesandadditionstoMPI2.1
§ MPI-3.0(2012)– Majornewfeaturesandadditionsto MPI
§ MPI-3.1(2015)– MinorupdatesandfixestoMPI3.0
AdvancedMPI,SC17(11/13/2017)

Overview of New Features in MPI-3§ Majornewfeatures
– Nonblocking collectives– Neighborhoodcollectives– Improvedone-sidedcommunicationinterface– Toolsinterface– Fortran2008bindings
§ Othernewfeatures– MatchingProbeandRecv forthread-safeprobeandreceive– Noncollective communicatorcreationfunction– “const”correctCbindings– Comm_split_type function– Nonblocking Comm_dup– Type_create_hindexed_block function
§ C++bindingsremoved§ Previouslydeprecatedfunctionsremoved§ MPI3.1addednonblocking collectiveI/Ofunctions
7AdvancedMPI,SC17(11/13/2017)
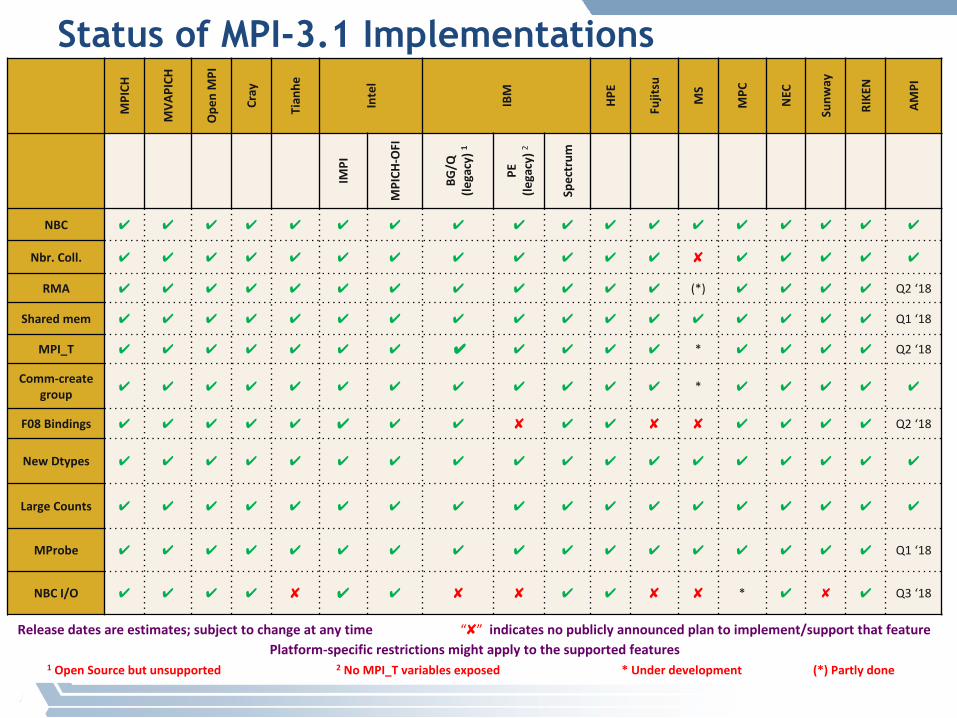
Status of MPI-3.1 Implementations
MPICH
MVA
PICH
Ope
nMPI
Cray
Tian
he
Intel
IBM
HPE
Fujitsu
MS
MPC
NEC
Sunw
ay
RIKE
N
AMPI
IMPI
MPICH
-OFI
BG/Q
(legacy)1
PE(le
gacy)2
Spectrum
NBC ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔
Nbr.Coll. ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✘ ✔ ✔ ✔ ✔ ✔
RMA ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ (*) ✔ ✔ ✔ ✔ Q2‘18
Sharedmem ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ Q1‘18
MPI_T ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ * ✔ ✔ ✔ ✔ Q2‘18
Comm-creategroup ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ * ✔ ✔ ✔ ✔ ✔
F08Bindings ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✘ ✔ ✔ ✘ ✘ ✔ ✔ ✔ ✔ Q2‘18
NewDtypes ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔
LargeCounts ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔
MProbe ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ Q1‘18
NBCI/O ✔ ✔ ✔ ✔ ✘ ✔ ✔ ✘ ✘ ✔ ✔ ✘ ✘ * ✔ ✘ ✔ Q3‘18
1 OpenSourcebutunsupported 2 NoMPI_Tvariablesexposed *Underdevelopment (*)Partlydone
Releasedatesareestimates;subjecttochangeatanytime “✘” indicatesnopubliclyannouncedplantoimplement/supportthatfeaturePlatform-specificrestrictionsmightapplytothesupportedfeatures

Important considerations while using MPI
§ Allparallelismisexplicit:theprogrammerisresponsibleforcorrectlyidentifyingparallelismandimplementingparallelalgorithmsusingMPIconstructs
9AdvancedMPI,SC17(11/13/2017)

Web Pointers
§ MPIstandard:http://www.mpi-forum.org/docs/docs.html
§ MPIForum:http://www.mpi-forum.org/
§ MPIimplementations:– MPICH:http://www.mpich.org
– MVAPICH:http://mvapich.cse.ohio-state.edu/
– IntelMPI:http://software.intel.com/en-us/intel-mpi-library/
– MicrosoftMPI:https://msdn.microsoft.com/en-us/library/bb524831%28v=vs.85%29.aspx
– OpenMPI:http://www.open-mpi.org/
– IBMMPI,CrayMPI,HPMPI,THMPI,…
§ SeveralMPItutorialscanbefoundontheweb
AdvancedMPI,SC17(11/13/2017) 10

New Tutorial Books on MPI
AdvancedMPI,SC17(11/13/2017) 11
§ ForbasicMPI– UsingMPI,3rd edition,2014,byWilliamGropp,EwingLusk,andAnthonySkjellum
– https://mitpress.mit.edu/using-MPI-3ed
§ ForadvancedMPI,includingMPI-3
– UsingAdvancedMPI,2014,byWilliamGropp,Torsten Hoefler,RajeevThakur,andEwingLusk
– https://mitpress.mit.edu/using-advanced-MPI

New Book on Parallel Programming ModelsEditedbyPavan Balaji• MPI:W.Gropp andR.Thakur• GASNet: P.Hargrove• OpenSHMEM: J.KuehnandS.Poole• UPC: K.Yelick andY.Zheng• GlobalArrays: S.Krishnamoorthy,J.Daily,A.Vishnu,
andB.Palmer• Chapel: B.Chamberlain• Charm++: L.Kale,N.Jain,andJ.Lifflander• ADLB: E.Lusk,R.Butler,andS.Pieper• Scioto: J.Dinan• SWIFT: T.Armstrong,J.M.Wozniak,M.Wilde,andI.
Foster• CnC: K.Knobe,M.Burke,andF.Schlimbach• OpenMP: B.Chapman,D.Eachempati,andS.
Chandrasekaran• Cilk Plus: A.RobisonandC.Leiserson• IntelTBB: A.Kukanov• CUDA:W.Hwu andD.Kirk• OpenCL: T.Mattson
https://mitpress.mit.edu/models
12AdvancedMPI,SC17(11/13/2017)

Our Approach in this Tutorial
§ Exampledriven– 2Dstencilcodeusedasarunningexamplethroughoutthetutorial
– Otherexamplesusedtoillustratespecificfeatures
§ Wewillwalkthroughactualcode
§ Weassumefamiliaritywith basicconceptsofMPI-1
1313AdvancedMPI,SC17(11/13/2017)

Regular Mesh Algorithms
§ Manyscientificapplicationsinvolvethesolutionofpartialdifferentialequations(PDEs)
§ ManyalgorithmsforapproximatingthesolutionofPDEsrelyonformingasetofdifferenceequations– Finitedifference,finiteelements,finitevolume
§ Theexactformofthedifferenceequationsdependsontheparticularmethod– Fromthepointofviewofparallelprogrammingforthese
algorithms,theoperationsarethesame
14AdvancedMPI,SC17(11/13/2017)

Poisson Problem
§ ToapproximatethesolutionofthePoissonProblemÑ2u=f ontheunitsquare,withu definedontheboundariesofthedomain(Dirichlet boundaryconditions),thissimple2ndorderdifferenceschemeisoftenused:– (U(x+h,y)- 2U(x,y)+U(x-h,y))/h2 +
(U(x,y+h)- 2U(x,y)+U(x,y-h))/h2 =f(x,y)• WherethesolutionUisapproximatedonadiscretegridofpointsx=0,h,2h,3h,…,(1/h)h=1,y=0,h,2h,3h,…1.
• Tosimplifythenotation,U(ih,jh)isdenotedUij
§ Thisisdefinedonadiscretemeshofpoints(x,y)=(ih,jh),forameshspacing“h”
15AdvancedMPI,SC17(11/13/2017)

The Global Data Structure
§ Eachcircleisameshpoint
§ Differenceequationevaluatedateachpointinvolvesthefourneighbors
§ Thered“plus”iscalledthemethod’sstencil
§ GoodnumericalalgorithmsformamatrixequationAu=f;solvingthisrequirescomputingBv,whereBisamatrixderivedfromA.Theseevaluationsinvolvecomputationswiththeneighborsonthemesh.
16AdvancedMPI,SC17(11/13/2017)
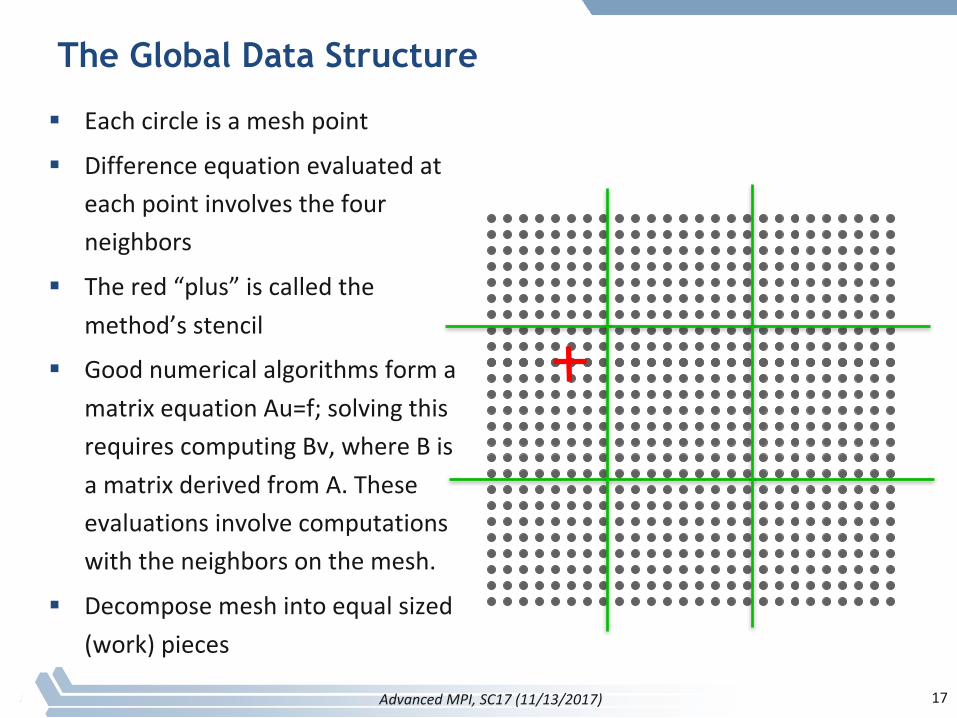
The Global Data Structure
§ Eachcircleisameshpoint
§ Differenceequationevaluatedateachpointinvolvesthefourneighbors
§ Thered“plus”iscalledthemethod’sstencil
§ GoodnumericalalgorithmsformamatrixequationAu=f;solvingthisrequirescomputingBv,whereBisamatrixderivedfromA.Theseevaluationsinvolvecomputationswiththeneighborsonthemesh.
§ Decomposemeshintoequalsized(work)pieces
17AdvancedMPI,SC17(11/13/2017)

Necessary Data Transfers
18AdvancedMPI,SC17(11/13/2017)
Necessary Data Transfers
19AdvancedMPI,SC17(11/13/2017)
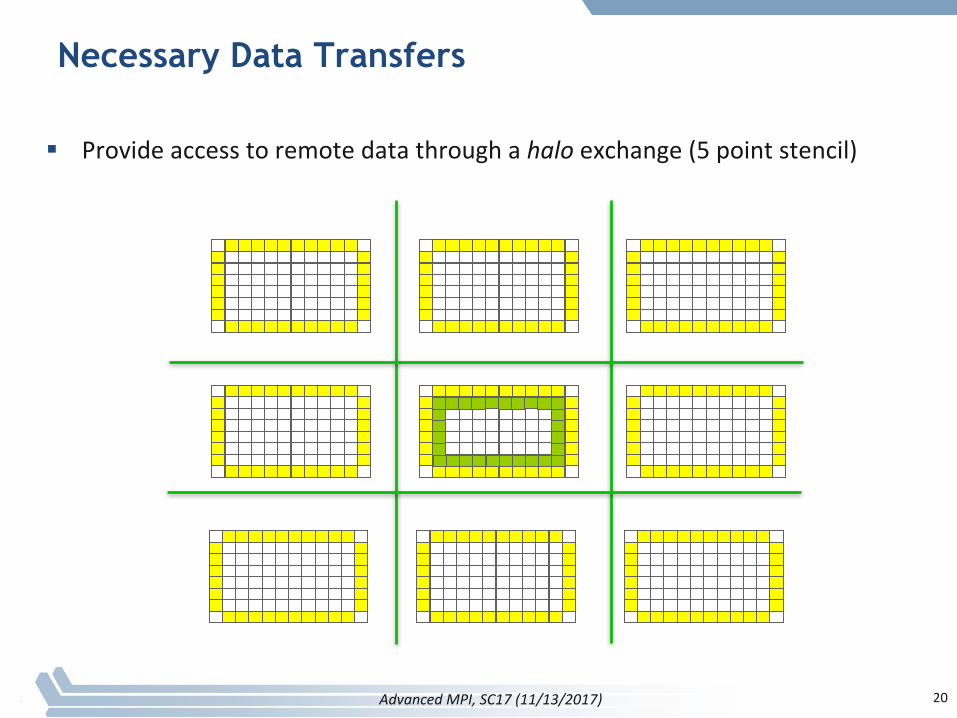
Necessary Data Transfers
§ Provideaccesstoremotedatathroughahalo exchange(5pointstencil)
20AdvancedMPI,SC17(11/13/2017)
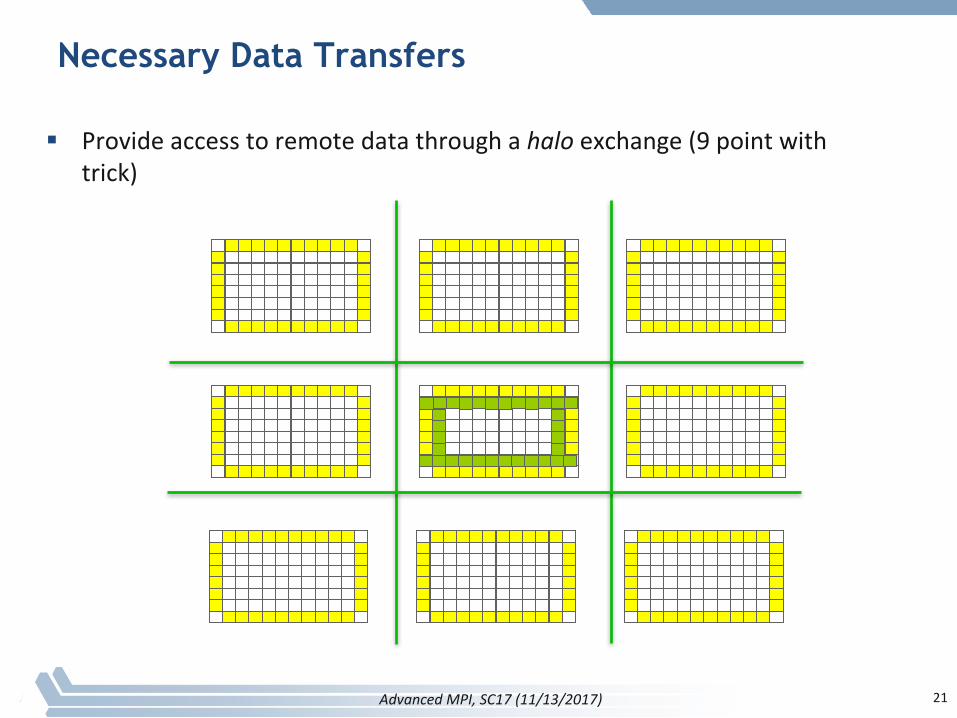
Necessary Data Transfers
§ Provideaccesstoremotedatathroughahalo exchange(9pointwithtrick)
21AdvancedMPI,SC17(11/13/2017)
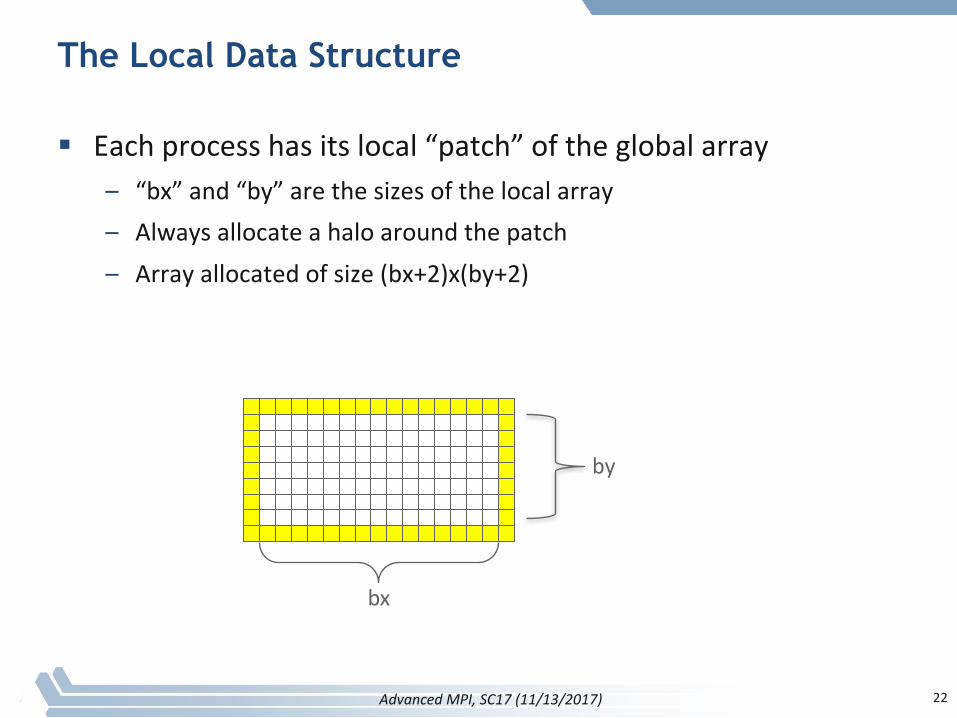
The Local Data Structure
§ Eachprocesshasitslocal“patch”oftheglobalarray– “bx”and“by”arethesizesofthelocalarray– Alwaysallocateahaloaroundthepatch– Arrayallocatedofsize(bx+2)x(by+2)
bx
by
22AdvancedMPI,SC17(11/13/2017)

2D Stencil Code Walkthrough
§ Codecanbedownloadedfromwww.mcs.anl.gov/~thakur/sc17-mpi-tutorial
AdvancedMPI,SC17(11/13/2017) 23

Datatypes
24AdvancedMPI,SC17(11/13/2017)

Introduction to Datatypes in MPI
§ Datatypes allowuserstoserializearbitrary datalayoutsintoamessagestream– Networksprovideserialchannels
– SameforblockdevicesandI/O
§ Severalconstructorsallowarbitrarylayouts– Recursivespecificationpossible
– Declarative specificationofdata-layout• “what”andnot“how”,leavesoptimizationtoimplementation(manyunexplored possibilities!)
– Choosingtherightconstructorsisnotalwayssimple
25AdvancedMPI,SC17(11/13/2017)
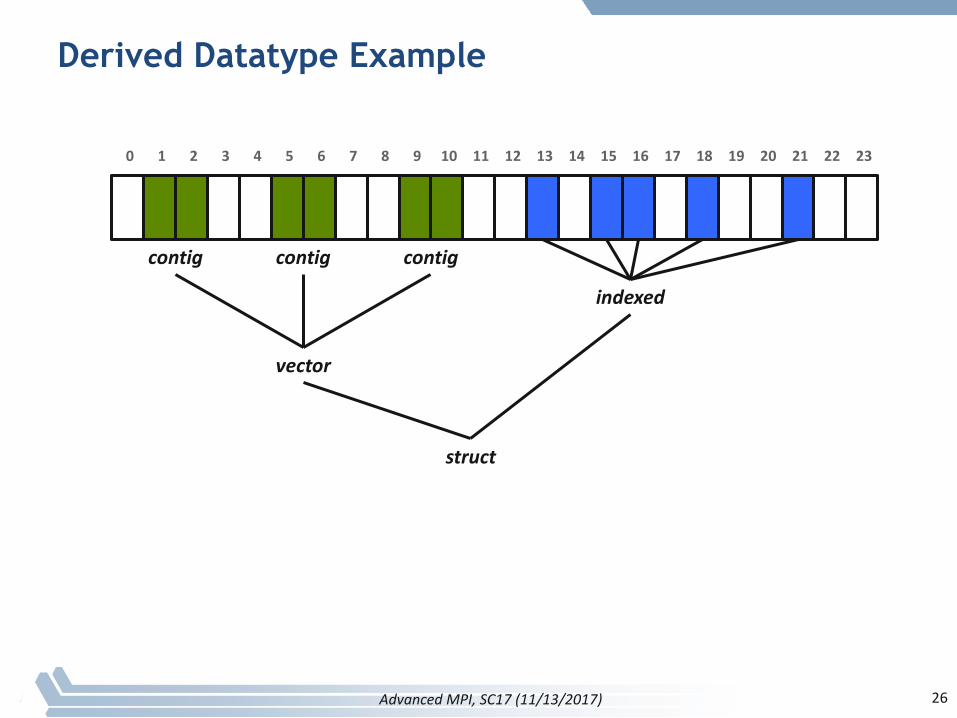
Derived Datatype Example
AdvancedMPI,SC17(11/13/2017) 26
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
contig contig contig
vector
indexed
struct

MPI’s Intrinsic Datatypes
§ Whyintrinsictypes?– Heterogeneity,nicetosendaBooleanfromCtoFortran
– Conversionrulesarecomplex,notdiscussedhere
– Lengthmatchestolanguagetypes• Nosizeof(int)mess
§ Usersshouldgenerallyuseintrinsictypesasbasictypesforcommunicationandtypeconstruction
§ MPI-2.2addedsomemissingCtypes– E.g.,unsignedlonglong
27AdvancedMPI,SC17(11/13/2017)

MPI_Type_contiguous
§ Contiguousarrayofoldtype
§ Shouldnotbeusedaslasttype(canbereplacedbycount)
AdvancedMPI,SC17(11/13/2017) 28
0 1 2 3 4 5 6 7 8 9 10 11
contig
1817150 1 2 3 4 5 6 7 8 9 10 11 12 14 16
struct struct struct
contig
13
MPI_Type_contiguous(int count, MPI_Datatype oldtype,MPI_Datatype *newtype)

MPI_Type_vector
§ Specifystrided blocksofdataofoldtype
§ VeryusefulforCartesianarrays
AdvancedMPI,SC17(11/13/2017) 29
vector 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
struct struct
vector
19 20
struct struct
0 1 2 3 4 5 6 7 8 9 10 11
MPI_Type_vector(int count, int blocklen, int stride,MPI_Datatype oldtype, MPI_Datatype *newtype)

Use Datatype in Halo Exchange
AdvancedMPI,SC17(11/13/2017) 30
bx
by
vector(count=by,blocklen=1,stride=bx+2,MPI_DOUBLE,…)
contig (count=bx,MPI_DOUBLE,…)orcountwithMPI_DOUBLE

2D Stencil Code with Datatypes Walkthrough
§ Codecanbedownloadedfromwww.mcs.anl.gov/~thakur/sc17-mpi-tutorial
AdvancedMPI,SC17(11/13/2017) 31

MPI_Type_create_hvector
§ Strideisspecifiedinbytesinsteadofsizeofoldtype
§ Usefulforcomposition,e.g.,vectorofstructs
AdvancedMPI,SC17(11/13/2017) 32
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
struct struct
hvector
19
struct struct
vector
stride=3oldtypes
stride=11bytes
MPI_Type_create_hvector(int count, int blocklen, MPI_Aint stride,MPI_Datatype oldtype, MPI_Datatype *newtype)

MPI_Type_create_indexed_block
§ Pullingirregularsubsetsofdatafromasinglearray– dynamiccodeswithindexlists,expensivethough!
– blen=2
– displs={0,5,8,13,18}
AdvancedMPI,SC17(11/13/2017) 33
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Indexed_block
MPI_Type_create_indexed_block(int count, int blocklen,int *array_of_displacements,MPI_Datatype oldtype, MPI_Datatype *newtype)

MPI_Type_indexed
§ Likeindexed_block,butcanhavedifferentblocklengths– blen={1,1,2,1,2,1}
– displs={0,3,5,9,13,17}
AdvancedMPI,SC17(11/13/2017) 34
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
indexed
MPI_Type_indexed(int count, int* array_of_blocklens,int *array_of_displacements,MPI_Datatype oldtype, MPI_Datatype *newtype)

MPI_Type_create_struct
§ Mostgeneralconstructor,allowsdifferenttypesandarbitraryarrays(alsomostcostly)
AdvancedMPI,SC17(11/13/2017) 35
0 1 2 3 4
struct
MPI_Type_create_struct(int count,int *array_of_blocklens,MPI_Aint *array_of_displacements,MPI_Datatype *array_of_types,MPI_Datatype *newtype)

MPI_Type_create_subarray
§ Conveniencefunctionforcreatingdatatypes forarraysegments
§ Specifysubarray ofn-dimensionalarray(sizes)bystart(starts)andsize(subsize)
AdvancedMPI,SC17(11/13/2017) 36
(0,0) (0,1) (0,2) (0,3)
(1,0) (1,1) (1,2) (1,3)
(2,0) (2,1) (2,2) (2,3)
(3,0) (3,1) (3,2) (3,3)
MPI_Type_create_subarray(int ndims, int* array_of_sizes,int *array_of_subsizes, int *array_of_starts,int order, MPI_Datatype oldtype, MPI_Datatype *newtype)
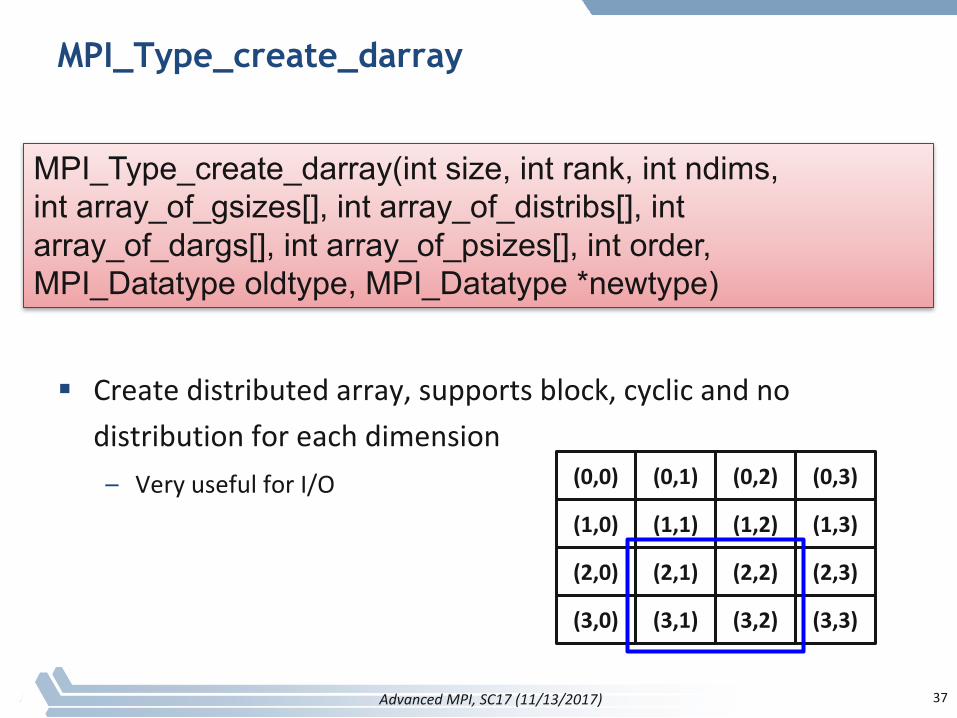
MPI_Type_create_darray
§ Createdistributedarray,supportsblock,cyclicandnodistributionforeachdimension– VeryusefulforI/O
MPI_Type_create_darray(int size, int rank, int ndims,int array_of_gsizes[], int array_of_distribs[], intarray_of_dargs[], int array_of_psizes[], int order,MPI_Datatype oldtype, MPI_Datatype *newtype)
37AdvancedMPI,SC17(11/13/2017)
(0,0) (0,1) (0,2) (0,3)
(1,0) (1,1) (1,2) (1,3)
(2,0) (2,1) (2,2) (2,3)
(3,0) (3,1) (3,2) (3,3)

MPI_BOTTOM and MPI_Get_address
§ MPI_BOTTOMistheabsolutezeroaddress– Portability(e.g.,maybenon-zeroingloballysharedmemory)
§ MPI_Get_address– ReturnsaddressrelativetoMPI_BOTTOM
– Portability(donotuse“&”operatorinC!)
§ Veryimportantto– buildstruct datatypes
– Ifdataspansmultiplearrays
AdvancedMPI,SC17(11/13/2017) 38
int a = 4;float b = 9.6;MPI_Datatype struct;
MPI_Get_address(&a, &disps[0]);MPI_Get_address(&b, &disps[1]);
MPI_Type_create_struct(count,blocklens[], disps,oldtypes[], &struct);

Commit, Free, and Dup
§ Typesmustbecommittedbeforeuse– Onlytheonesthatareused!
– MPI_Type_commit mayperformheavyoptimizations(andwillhopefully)
§ MPI_Type_free– FreeMPIresourcesofdatatypes
– Doesnotaffecttypesbuiltfromit
§ MPI_Type_dup– Duplicatesatype
– Libraryabstraction(composability)
39AdvancedMPI,SC17(11/13/2017)

Other Datatype Functions
§ Pack/Unpack– Mainlyforcompatibilitytolegacylibraries
– Avoidusingityourself
§ Get_envelope/contents– Onlyforexpertlibrarydevelopers
– LibrariessuchasMPITypes1 makethiseasier
§ MPI_Type_create_resized– Changeextentandsize(dangerousbutuseful)
1http://www.mcs.anl.gov/mpitypes/
40AdvancedMPI,SC17(11/13/2017)

Datatype Selection Order
§ Simpleandeffectiveperformancemodel:– Moreparameters==slower
§ predefined<contig <vector<index_block <index<struct
§ Some(most)MPIsareinconsistent– Butthisruleisportable
§ Advicetousers:– Constructdatatypes hierarchicallybottom-up
W.Gropp etal.:PerformanceExpectationsandGuidelinesforMPIDerivedDatatypes
AdvancedMPI,SC17(11/13/2017) 41

Advanced Topics: One-sided Communication

One-sided Communication
§ Thebasicideaofone-sidedcommunicationmodelsistodecoupledatamovementwithprocesssynchronization– Shouldbeabletomovedatawithoutrequiringthattheremote
processsynchronize
– Eachprocessexposesapartofitsmemorytootherprocesses
– Otherprocessescandirectlyreadfromorwritetothismemory
Process 1 Process 2 Process 3
PrivateMemory
PrivateMemory
PrivateMemory
Process 0
PrivateMemory
RemotelyAccessible
Memory
RemotelyAccessible
Memory
RemotelyAccessible
Memory
RemotelyAccessible
Memory
GlobalAddressSpace
PrivateMemory
PrivateMemory
PrivateMemory
PrivateMemory
43AdvancedMPI,SC17(11/13/2017)

Two-sided Communication Example
MPI implementation
Memory Memory
MPI implementation
Send Recv
MemorySegment
Processor Processor
Send Recv
MemorySegment
MemorySegment
MemorySegment
MemorySegment
44AdvancedMPI,SC17(11/13/2017)

One-sided Communication Example
MPI implementation
Memory Memory
MPI implementation
Send Recv
MemorySegment
Processor Processor
Send Recv
MemorySegment
MemorySegment
MemorySegment
45AdvancedMPI,SC17(11/13/2017)

Comparing One-sided and Two-sided Programming
Process0 Process1
SEND(data)
RECV(data)
DELAY
Eventhesendingprocessisdelayed
Process0 Process1
PUT(data) DELAY
Delayinprocess1doesnotaffect
process0
GET(data)
46AdvancedMPI,SC17(11/13/2017)

MPI RMA can be efficiently implemented
§ “EnablingHighly-ScalableRemoteMemoryAccessProgrammingwithMPI-3OneSided”byRobertGerstenberger,Maciej Besta,Torsten Hoefler (SC13BestPaperAward)
§ TheyimplementedcompleteMPI-3RMAforCrayGemini(XK5,XE6)andAries(XC30)systemsontopoflowest-levelCrayAPIs
§ Achievedbetterlatency,bandwidth,messagerate,andapplicationperformancethanCray’sMPIRMA,UPC,andCoarray Fortran
Lowerisbetter
Higherisbetter
AdvancedMPI,SC17(11/13/2017) 47
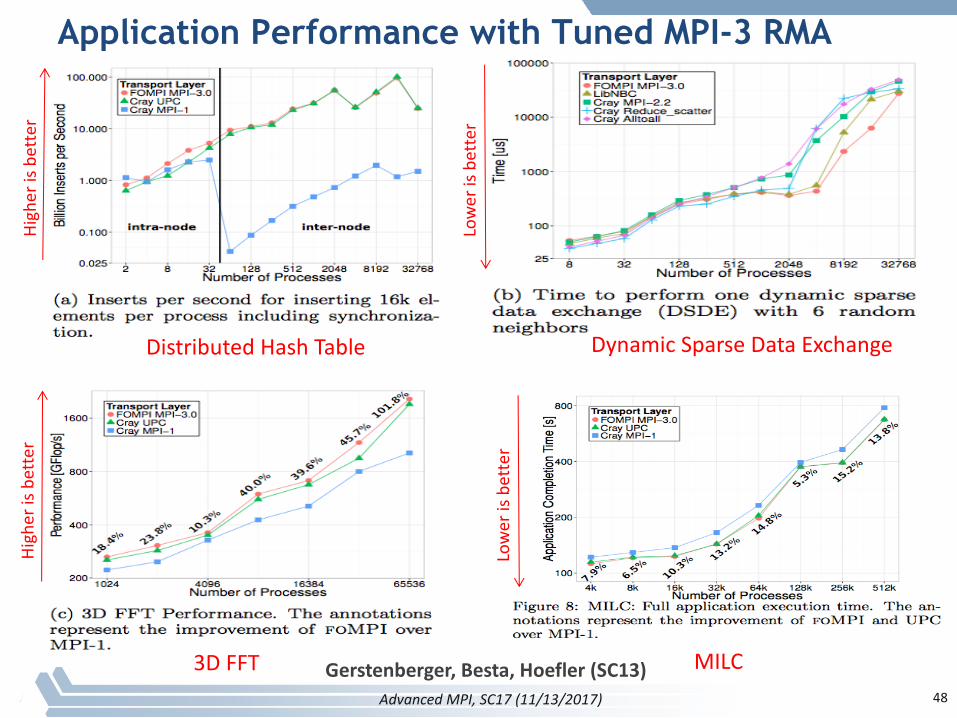
Application Performance with Tuned MPI-3 RMA
3DFFT MILC
DistributedHashTable DynamicSparseDataExchange
Higherisbetter
Higherisbetter
Lowerisbetter
Lowerisbetter
Gerstenberger,Besta,Hoefler (SC13)AdvancedMPI,SC17(11/13/2017) 48

MPI RMA is Carefully and Precisely Specified
§ Toworkonbothcache-coherentandnon-cache-coherentsystems– Eventhoughtherearen’tmanynon-cache-coherentsystems,itisdesigned
withthefutureinmind
§ ThereevenexistsaformalmodelforMPI-3RMAthatcanbeusedbytoolsandcompilersforoptimization,verification,etc.– See“RemoteMemoryAccessProgramminginMPI-3”byHoefler,Dinan,
Thakur,Barrett,Balaji,Gropp,Underwood.ACMTOPC,July2015.
– http://htor.inf.ethz.ch/publications/index.php?pub=201
AdvancedMPI,SC17(11/13/2017) 49

What we need to know in MPI RMA
§ Howtocreateremoteaccessiblememory?
§ Reading,WritingandUpdatingremotememory
§ DataSynchronization
§ MemoryModel
50AdvancedMPI,SC17(11/13/2017)

Creating Public Memory
§ Anymemoryusedbyaprocessis,bydefault,onlylocallyaccessible– X=malloc(100);
§ Oncethememoryisallocated,theuserhastomakeanexplicitMPIcalltodeclareamemoryregionasremotelyaccessible– MPIterminologyforremotelyaccessiblememoryisa“window”
– Agroupofprocessescollectivelycreatea“window”
§ Onceamemoryregionisdeclaredasremotelyaccessible,allprocessesinthewindowcanread/writedatatothismemorywithoutexplicitlysynchronizingwiththetargetprocess
51AdvancedMPI,SC17(11/13/2017)
Process 1 Process 2 Process 3
PrivateMemory
PrivateMemory
PrivateMemory
Process 0
PrivateMemoryPrivateMemory
PrivateMemory
PrivateMemory
PrivateMemory
window window window window

Window creation models
§ Fourmodelsexist– MPI_WIN_ALLOCATE
• Youwanttocreateabufferanddirectlymakeitremotelyaccessible
– MPI_WIN_CREATE• Youalreadyhaveanallocatedbufferthatyouwouldliketomakeremotelyaccessible
– MPI_WIN_CREATE_DYNAMIC• Youdon’thaveabufferyet,butwillhaveoneinthefuture
• Youmaywanttodynamicallyadd/removebuffersto/fromthewindow
– MPI_WIN_ALLOCATE_SHARED• Youwantmultipleprocessesonthesamenodeshareabuffer
52AdvancedMPI,SC17(11/13/2017)

MPI_WIN_ALLOCATE
§ CreatearemotelyaccessiblememoryregioninanRMAwindow– OnlydataexposedinawindowcanbeaccessedwithRMAops.
§ Arguments:– size - sizeoflocaldatainbytes(nonnegativeinteger)
– disp_unit - localunitsizefordisplacements,inbytes(positiveinteger)
– info - infoargument(handle)
– comm - communicator(handle)
– baseptr - pointertoexposedlocaldata
– win- window(handle)
53AdvancedMPI,SC17(11/13/2017)
MPI_Win_allocate(MPI_Aint size, int disp_unit,MPI_Info info, MPI_Comm comm, void *baseptr,MPI_Win *win)

Example with MPI_WIN_ALLOCATE
int main(int argc, char ** argv){
int *a; MPI_Win win;
MPI_Init(&argc, &argv);
/* collectively create remote accessible memory in a window */MPI_Win_allocate(1000*sizeof(int), sizeof(int), MPI_INFO_NULL,
MPI_COMM_WORLD, &a, &win);
/* Array ‘a’ is now accessible from all processes in* MPI_COMM_WORLD */
MPI_Win_free(&win);
MPI_Finalize(); return 0;}
54AdvancedMPI,SC17(11/13/2017)

MPI_WIN_CREATE
§ ExposearegionofmemoryinanRMAwindow– OnlydataexposedinawindowcanbeaccessedwithRMAops.
§ Arguments:– base - pointertolocaldatatoexpose– size - sizeoflocaldatainbytes(nonnegativeinteger)– disp_unit - localunitsizefordisplacements,inbytes(positiveinteger)– info - infoargument(handle)– comm - communicator(handle)– win- window(handle)
55AdvancedMPI,SC17(11/13/2017)
MPI_Win_create(void *base, MPI_Aint size, int disp_unit, MPI_Info info,MPI_Comm comm, MPI_Win *win)

Example with MPI_WIN_CREATEint main(int argc, char ** argv){
int *a; MPI_Win win;
MPI_Init(&argc, &argv);
/* create private memory */MPI_Alloc_mem(1000*sizeof(int), MPI_INFO_NULL, &a);/* use private memory like you normally would */a[0] = 1; a[1] = 2;
/* collectively declare memory as remotely accessible */MPI_Win_create(a, 1000*sizeof(int), sizeof(int),
MPI_INFO_NULL, MPI_COMM_WORLD, &win);
/* Array ‘a’ is now accessibly by all processes in* MPI_COMM_WORLD */
MPI_Win_free(&win);MPI_Free_mem(a);MPI_Finalize(); return 0;
}
56AdvancedMPI,SC17(11/13/2017)

MPI_WIN_CREATE_DYNAMIC
§ CreateanRMAwindow,towhichdatacanlaterbeattached– OnlydataexposedinawindowcanbeaccessedwithRMAops
§ Initially“empty”– Applicationcandynamicallyattach/detachmemorytothiswindowby
callingMPI_Win_attach/detach– Applicationcanaccessdataonthiswindowonlyafteramemory
regionhasbeenattached
§ WindoworiginisMPI_BOTTOM– DisplacementsaresegmentaddressesrelativetoMPI_BOTTOM– Musttellothersthedisplacementaftercallingattach
57AdvancedMPI,SC17(11/13/2017)
MPI_Win_create_dynamic(MPI_Info info, MPI_Comm comm,MPI_Win *win)

Example with MPI_WIN_CREATE_DYNAMICint main(int argc, char ** argv){
int *a; MPI_Win win;
MPI_Init(&argc, &argv);MPI_Win_create_dynamic(MPI_INFO_NULL, MPI_COMM_WORLD, &win);
/* create private memory */a = (int *) malloc(1000 * sizeof(int));/* use private memory like you normally would */a[0] = 1; a[1] = 2;
/* locally declare memory as remotely accessible */MPI_Win_attach(win, a, 1000*sizeof(int));
/* Array ‘a’ is now accessible from all processes */
/* undeclare remotely accessible memory */MPI_Win_detach(win, a); free(a);MPI_Win_free(&win);
MPI_Finalize(); return 0;}
58AdvancedMPI,SC17(11/13/2017)

Data movement
§ MPIprovidesabilitytoread,writeandatomicallymodifydatainremotelyaccessiblememoryregions– MPI_PUT
– MPI_GET
– MPI_ACCUMULATE(atomic)
– MPI_GET_ACCUMULATE(atomic)
– MPI_COMPARE_AND_SWAP(atomic)
– MPI_FETCH_AND_OP (atomic)
59AdvancedMPI,SC17(11/13/2017)

Data movement: Put
§ Movedatafrom origin,to target
§ Separatedatadescriptiontriplesfororigin andtarget
60
Origin
MPI_Put(void *origin_addr, int origin_count,MPI_Datatype origin_dtype, int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_dtype, MPI_Win win)
AdvancedMPI,SC17(11/13/2017)
Target
RemotelyAccessibleMemory
PrivateMemory

Data movement: Get
§ Movedatato origin,from target
§ Separatedatadescriptiontriplesfororigin andtarget
61
Origin
MPI_Get(const void *origin_addr, int origin_count,MPI_Datatype origin_dtype, int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_dtype, MPI_Win win)
AdvancedMPI,SC17(11/13/2017)
Target
RemotelyAccessibleMemory
PrivateMemory

Atomic Data Aggregation: Accumulate
§ Atomicupdateoperation,similartoaput– Reducesoriginandtargetdataintotargetbufferusingopargumentascombiner
– Op=MPI_SUM,MPI_PROD,MPI_OR,MPI_REPLACE,MPI_NO_OP,…
– Predefinedopsonly,nouser-definedoperations
§ Differentdatalayoutsbetweentarget/originOK– Basictypeelementsmustmatch
§ Op=MPI_REPLACE– Implementsf(a,b)=b
– AtomicPUT
62
MPI_Accumulate(const void *origin_addr, int origin_count,MPI_Datatype origin_dtype, int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_dtype, MPI_Op op, MPI_Win win)
AdvancedMPI,SC17(11/13/2017)
Origin Target
RemotelyAccessibleMemory
PrivateMemory
+=

Atomic Data Aggregation: Get Accumulate
§ Atomicread-modify-write– Op=MPI_SUM,MPI_PROD,MPI_OR,MPI_REPLACE,MPI_NO_OP,…– Predefinedopsonly
§ Resultstoredintargetbuffer§ Originaldatastoredinresultbuf§ Differentdatalayoutsbetween
target/originOK– Basictypeelementsmustmatch
§ AtomicgetwithMPI_NO_OP§ AtomicswapwithMPI_REPLACE
63
MPI_Get_accumulate(const void *origin_addr,int origin_count, MPI_Datatype origin_dtype, void *result_addr,int result_count,MPI_Datatype result_dtype, int target_rank, MPI_Aint target_disp,int target_count, MPI_Datatype target_dype, MPI_Op op, MPI_Win win)
AdvancedMPI,SC17(11/13/2017)
+=
Origin Target
RemotelyAccessibleMemory
PrivateMemory

Atomic Data Aggregation: CAS and FOP
§ FOP:SimplerversionofMPI_Get_accumulate– Allbuffersshareasinglepredefineddatatype
– Nocountargument(it’salways1)
– Simplerinterfaceallowshardwareoptimization
§ CAS:Atomicswapiftargetvalueisequaltocomparevalue
64
MPI_Compare_and_swap(void *origin_addr, void *compare_addr,void *result_addr, MPI_Datatype dtype, int target_rank,MPI_Aint target_disp, MPI_Win win)
MPI_Fetch_and_op(void *origin_addr, void *result_addr,MPI_Datatype dtype, int target_rank,MPI_Aint target_disp, MPI_Op op, MPI_Win win)
AdvancedMPI,SC17(11/13/2017)

Ordering of Operations in MPI RMA
§ NoguaranteedorderingforPut/Getoperations§ ResultofconcurrentPutstothesamelocation undefined§ ResultofGetconcurrentPut/Accumulateundefined
– Canbegarbageinbothcases
§ Resultofconcurrentaccumulateoperationstothesamelocationaredefinedaccordingtotheorderinwhichtheoccurred– Atomicput:Accumulatewithop=MPI_REPLACE– Atomicget:Get_accumulate withop=MPI_NO_OP
§ Accumulateoperationsfromagivenprocessareorderedbydefault– UsercantelltheMPIimplementationthat(s)hedoesnotrequireordering
asoptimizationhint– Youcanaskforonlytheneededorderings:RAW(read-after-write),WAR,
RAR,orWAW
65AdvancedMPI,SC17(11/13/2017)
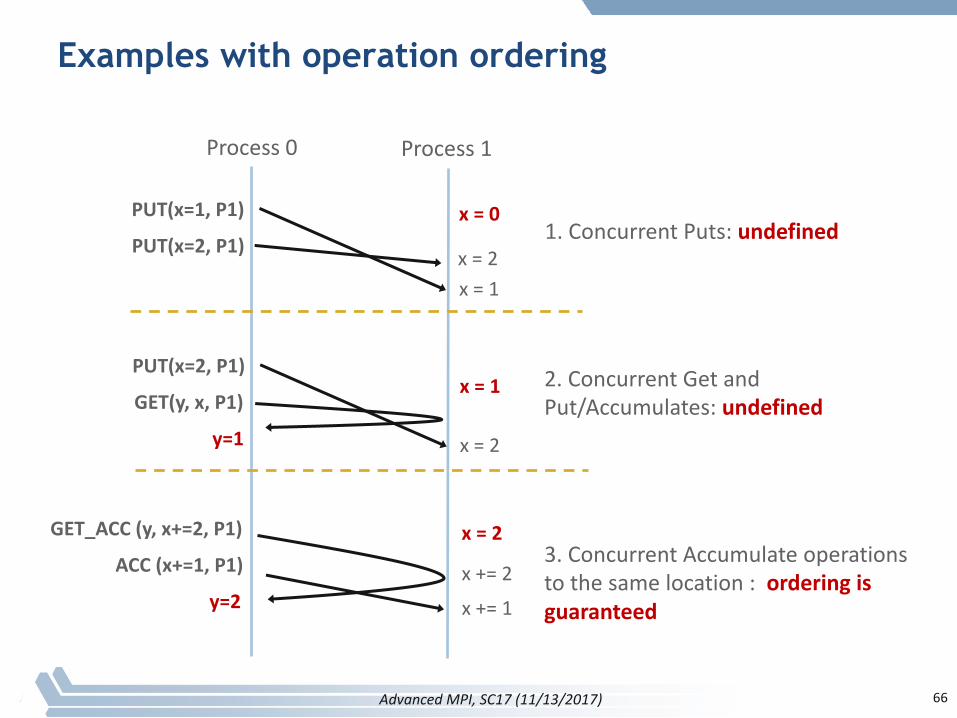
Examples with operation ordering
66
Process0 Process1
GET_ACC(y,x+=2,P1)
ACC(x+=1,P1) x +=2
x+=1y=2
x=2
PUT(x=2,P1)
GET(y,x,P1)
x=2y=1
x=1
PUT(x=1,P1)
PUT(x=2,P1)
x=1
x=0
x=21.ConcurrentPuts:undefined
2.ConcurrentGetandPut/Accumulates:undefined
3.ConcurrentAccumulateoperationstothesamelocation: orderingisguaranteed
AdvancedMPI,SC17(11/13/2017)

RMA Synchronization Models
§ RMAdataaccessmodel– Whenisaprocessallowedtoread/writeremotelyaccessiblememory?– WhenisdatawrittenbyprocessXisavailableforprocessYtoread?– RMAsynchronizationmodelsdefinethese semantics
§ ThreesynchronizationmodelsprovidedbyMPI:– Fence(activetarget)– Post-start-complete-wait(generalizedactivetarget)– Lock/Unlock(passivetarget)
§ Dataaccessesoccurwithin“epochs”– Accessepochs:containasetofoperationsissuedbyanoriginprocess– Exposureepochs:enableremoteprocessestoupdateatarget’swindow– Epochsdefineorderingandcompletionsemantics– Synchronizationmodelsprovidemechanismsforestablishingepochs
• E.g.,starting,ending,andsynchronizingepochs
67AdvancedMPI,SC17(11/13/2017)
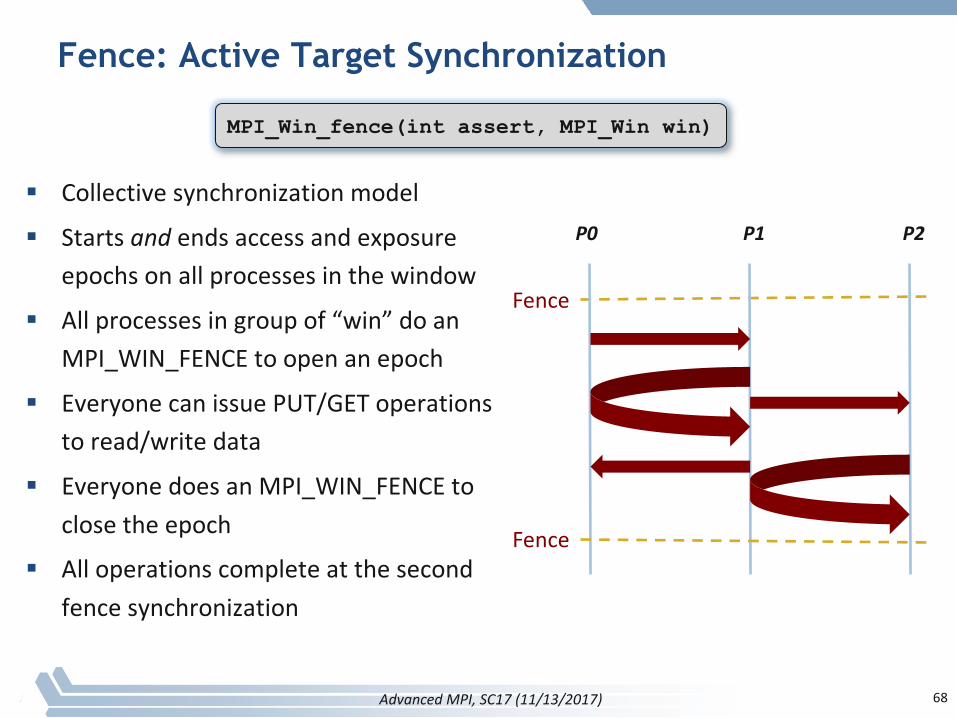
Fence: Active Target Synchronization
§ Collectivesynchronizationmodel
§ Startsand endsaccessandexposureepochsonallprocessesinthewindow
§ Allprocessesingroupof“win”doanMPI_WIN_FENCEtoopenanepoch
§ EveryonecanissuePUT/GEToperationstoread/writedata
§ EveryonedoesanMPI_WIN_FENCEtoclosetheepoch
§ Alloperationscompleteatthesecondfencesynchronization
68
Fence
Fence
MPI_Win_fence(int assert, MPI_Win win)
AdvancedMPI,SC17(11/13/2017)
P0 P1 P2
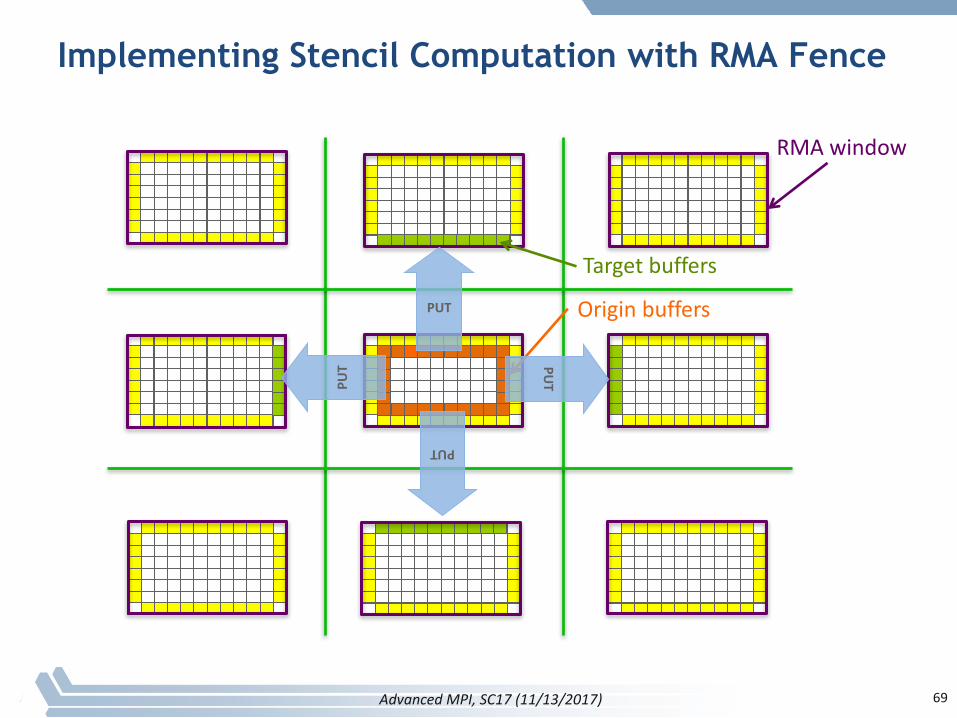
Implementing Stencil Computation with RMA Fence
69
Originbuffers
Targetbuffers
RMAwindow
PUT
PUT
PUT
PUT
AdvancedMPI,SC17(11/13/2017)

70
Code Example
§ stencil_mpi_ddt_rma.c
§ UseMPI_PUTstomovedata,explicitreceivesarenotneeded
§ DatalocationspecifiedbyMPIdatatypes
§ Manualpackingofdatanolongerrequired
AdvancedMPI,SC17(11/13/2017)

PSCW: Generalized Active Target Synchronization
§ LikeFENCE,butoriginandtargetspecifywhotheycommunicatewith
§ Target:Exposureepoch– OpenedwithMPI_Win_post
– ClosedbyMPI_Win_wait
§ Origin:Accessepoch– OpenedbyMPI_Win_start
– ClosedbyMPI_Win_complete
§ Allsynchronizationoperationsmayblock,toenforceP-S/C-Wordering– Processescanbebothoriginsandtargets
71
Start
Complete
Post
Wait
Target Origin
MPI_Win_post/start(MPI_Group grp, int assert, MPI_Win win)MPI_Win_complete/wait(MPI_Win win)
AdvancedMPI,SC17(11/13/2017)

Lock/Unlock: Passive Target Synchronization
§ Passivemode:One-sided,asynchronous communication
– Targetdoesnotparticipateincommunicationoperation
§ Sharedmemory-likemodel
72
ActiveTargetMode PassiveTargetMode
Lock
Unlock
Start
Complete
Post
Wait
AdvancedMPI,SC17(11/13/2017)

Passive Target Synchronization
§ Lock/Unlock:Begin/endpassivemodeepoch– TargetprocessdoesnotmakeacorrespondingMPIcall– Caninitiatemultiplepassivetargetepochstodifferentprocesses– Concurrentepochstosameprocessnotallowed(affectsthreads)
§ Locktype– SHARED:Otherprocessesusingsharedcanaccessconcurrently– EXCLUSIVE:Nootherprocessescanaccessconcurrently
§ Flush:RemotelycompleteRMAoperationstothetargetprocess– Aftercompletion,datacanbereadbytargetprocessoradifferentprocess
§ Flush_local:LocallycompleteRMAoperationstothetargetprocess
MPI_Win_lock(int locktype, int rank, int assert, MPI_Win win)
73AdvancedMPI,SC17(11/13/2017)
MPI_Win_unlock(int rank, MPI_Win win)
MPI_Win_flush/flush_local(int rank, MPI_Win win)

Advanced Passive Target Synchronization
§ Lock_all:Sharedlock,passivetargetepochtoallotherprocesses– Expectedusageislong-lived:lock_all,put/get,flush,…,unlock_all
§ Flush_all – remotelycompleteRMAoperationstoallprocesses
§ Flush_local_all – locallycompleteRMAoperationstoallprocesses
74
MPI_Win_lock_all(int assert, MPI_Win win)
AdvancedMPI,SC17(11/13/2017)
MPI_Win_unlock_all(MPI_Win win)
MPI_Win_flush_all/flush_local_all(MPI_Win win)

NWChem [1]
§ Highperformancecomputationalchemistryapplicationsuite
§ Quantumlevelsimulationofmolecularsystems– Veryexpensiveincomputationanddata
movement,soisusedforsmallsystems– Largersystemsusemolecularlevelsimulations
§ Composedofmanysimulationcapabilities– MolecularElectronicStructure– QuantumMechanics/MolecularMechanics– PseudopotentialPlane-WaveElectronicStructure– MolecularDynamics
§ Verylargecodebase– 4MLOC;Totalinvestmentof~200M$todate
[1]M.Valiev,E.J.Bylaska,N.Govind,K.Kowalski,T.P.Straatsma,H.J.J.vanDam,D.Wang,J.Nieplocha,E.Apra,T.L.Windus,W.A.deJong,"NWChem:acomprehensiveandscalableopen-sourcesolutionforlargescalemolecularsimulations"Comput.Phys.Commun.181,1477(2010)
Water(H2O)21
CarbonC20
AdvancedMPI,SC17(11/13/2017) 75
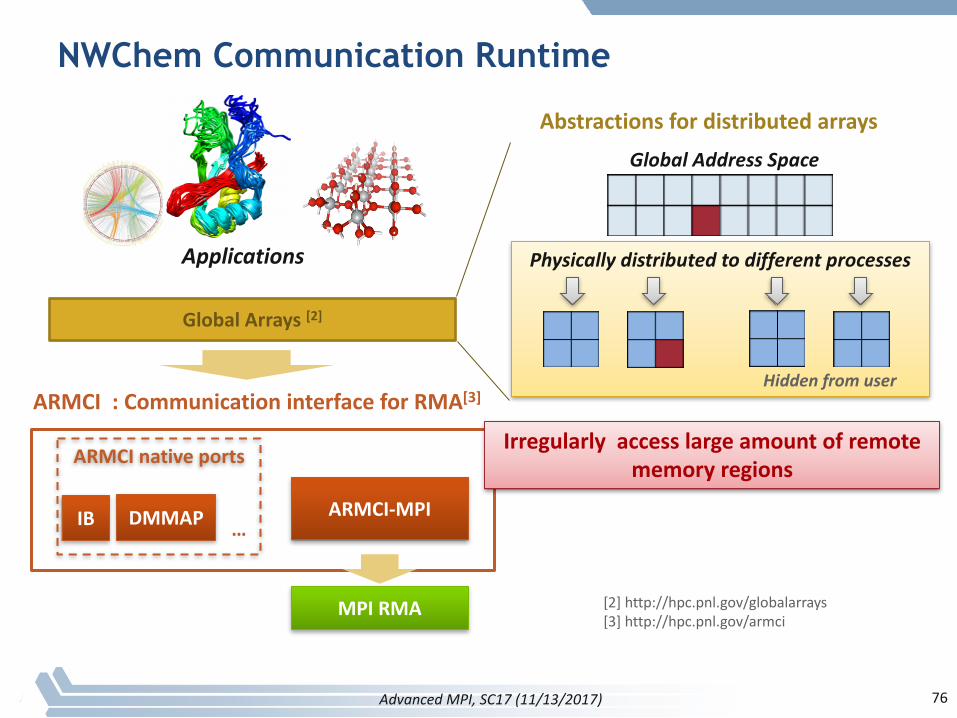
NWChem Communication Runtime
ARMCI:CommunicationinterfaceforRMA[3]
GlobalArrays[2]
[2]http://hpc.pnl.gov/globalarrays[3]http://hpc.pnl.gov/armci
ARMCInativeports
IB DMMAP …
MPI RMA
ARMCI-MPI
AbstractionsfordistributedarraysGlobalAddressSpace
Physicallydistributedtodifferentprocesses
Hiddenfromuser
Applications
Irregularlyaccesslargeamountofremotememoryregions
AdvancedMPI,SC17(11/13/2017) 76
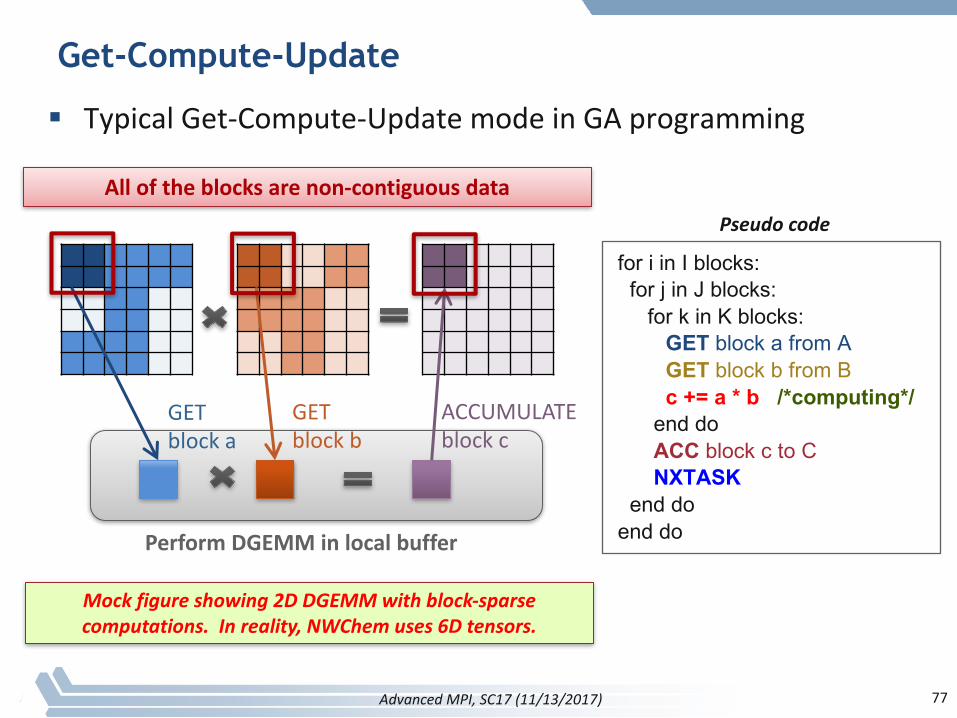
Get-Compute-Update
§ TypicalGet-Compute-UpdatemodeinGAprogramming
PerformDGEMMinlocalbuffer
for i in I blocks:for j in J blocks:
for k in K blocks:GET block a from AGET block b from Bc += a * b /*computing*/
end do ACC block c to CNXTASK
end doend do
Pseudocode
ACCUMULATEblockc
GETblockb
GETblocka
Alloftheblocksarenon-contiguousdata
Mockfigureshowing2DDGEMMwithblock-sparsecomputations.Inreality,NWChem uses6Dtensors.
AdvancedMPI,SC17(11/13/2017) 77

Code Example
§ ga_mpi_ddt_rma.c
§ Onlysynchronizationfromoriginprocesses,nosynchronizationfromtargetprocesses
78AdvancedMPI,SC17(11/13/2017)

Which synchronization mode should I use, when?
§ RMAcommunicationhaslowoverheadsversussend/recv– Two-sided:Matching,queuing,buffering,unexpectedreceives,etc…– One-sided:Nomatching,nobuffering,alwaysreadytoreceive– UtilizeRDMAprovidedbyhigh-speedinterconnects(e.g.InfiniBand)
§ Activemode:bulksynchronization– E.g.ghostcellexchange
§ Passivemode:asynchronousdatamovement– Usefulwhendatasetislarge,requiringmemoryofmultiplenodes– Also,whendataaccessandsynchronizationpatternisdynamic– Commonusecase:distributed,sharedarrays
§ Passivetargetlockingmode– Lock/unlock– Usefulwhenexclusiveepochsareneeded– Lock_all/unlock_all – Usefulwhenonlysharedepochsareneeded
79AdvancedMPI,SC17(11/13/2017)

MPI RMA Memory Model
§ MPI-3providestwomemorymodels:separateandunified
§ MPI-2:SeparateModel– Logicalpublicandprivatecopies– MPIprovidessoftwarecoherencebetween
windowcopies– Extremelyportable,tosystemsthatdon’t
providehardwarecoherence
§ MPI-3:NewUnifiedModel– Singlecopyofthewindow– Systemmustprovidecoherence– Supersetofseparatesemantics
• E.g.allowsconcurrentlocal/remoteaccess– Providesaccesstofullperformance
potentialofhardware
80
PublicCopy
PrivateCopy
UnifiedCopy
AdvancedMPI,SC17(11/13/2017)
Separate Unified
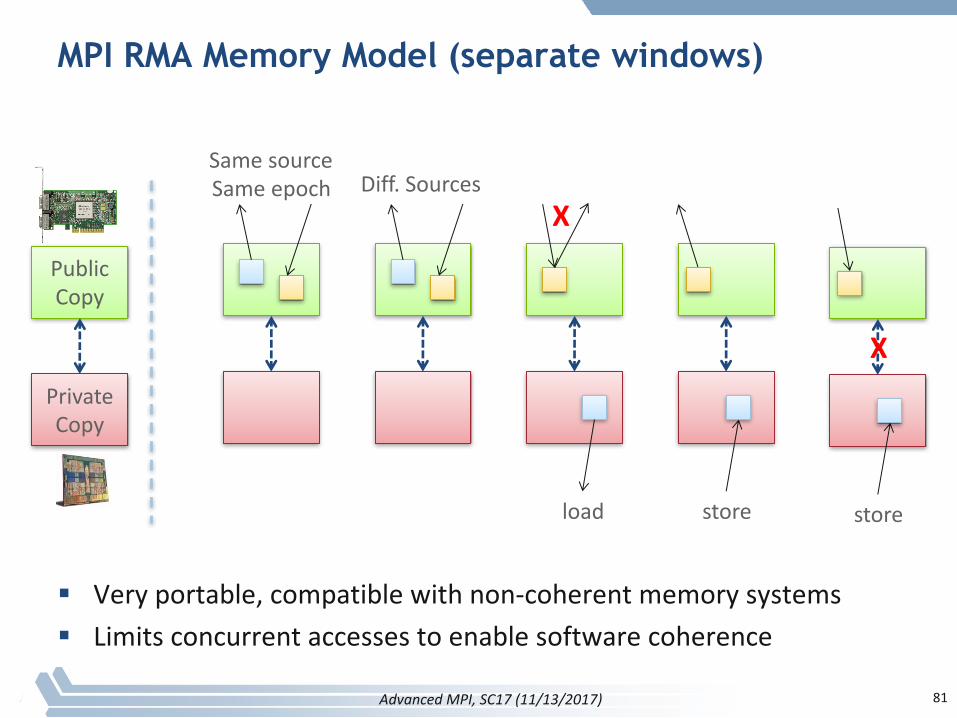
MPI RMA Memory Model (separate windows)
§ Veryportable,compatiblewithnon-coherentmemorysystems§ Limitsconcurrentaccessestoenablesoftwarecoherence
PublicCopy
PrivateCopy
SamesourceSameepoch Diff.Sources
load store store
X
81
X
AdvancedMPI,SC17(11/13/2017)

MPI RMA Memory Model (unified windows)
§ Allowsconcurrentlocal/remoteaccesses§ Concurrent,conflictingoperationsareallowed(notinvalid)
– OutcomeisnotdefinedbyMPI(definedbythehardware)
§ Canenablebetterperformancebyreducingsynchronization
82
UnifiedCopy
SamesourceSameepoch Diff.Sources
load store store
X
AdvancedMPI,SC17(11/13/2017)

MPI RMA Operation Compatibility (Separate)
Load Store Get Put Acc
Load OVL+NOVL OVL+NOVL OVL+NOVL NOVL NOVL
Store OVL+NOVL OVL+NOVL NOVL X X
Get OVL+NOVL NOVL OVL+NOVL NOVL NOVL
Put NOVL X NOVL NOVL NOVL
Acc NOVL X NOVL NOVL OVL+NOVL
ThismatrixshowsthecompatibilityofMPI-RMAoperationswhentwoormoreprocessesaccessawindowatthesametargetconcurrently.
OVL – OverlappingoperationspermittedNOVL – Nonoverlapping operationspermittedX – CombiningtheseoperationsisOK,butdatamightbegarbage
83AdvancedMPI,SC17(11/13/2017)
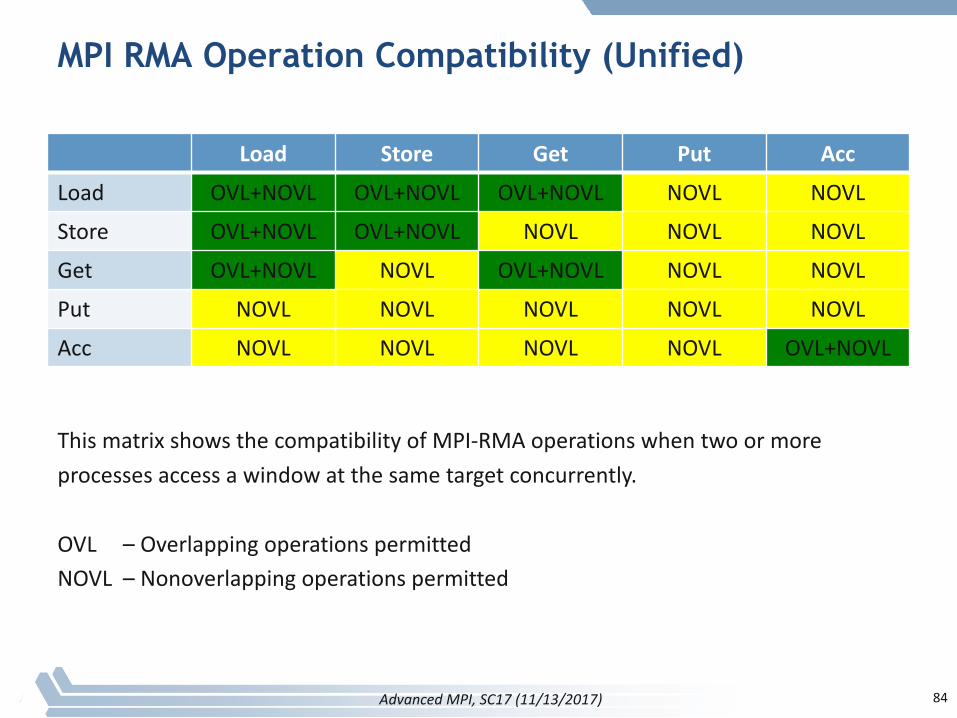
MPI RMA Operation Compatibility (Unified)
Load Store Get Put Acc
Load OVL+NOVL OVL+NOVL OVL+NOVL NOVL NOVL
Store OVL+NOVL OVL+NOVL NOVL NOVL NOVL
Get OVL+NOVL NOVL OVL+NOVL NOVL NOVL
Put NOVL NOVL NOVL NOVL NOVL
Acc NOVL NOVL NOVL NOVL OVL+NOVL
ThismatrixshowsthecompatibilityofMPI-RMAoperationswhentwoormoreprocessesaccessawindowatthesametargetconcurrently.
OVL – OverlappingoperationspermittedNOVL – Nonoverlapping operationspermitted
84AdvancedMPI,SC17(11/13/2017)

Hybrid Programming with Threads, Shared Memory, and GPUs

Why Hybrid MPI + X Programming?
Core
Core Core
Core Core
Core Core
Core
Core
Core Core
Core Core
Core Core
Core
GrowthofnoderesourcesintheTop500systems.PeterKogge:“ReadingtheTea-Leaves:HowArchitectureHasEvolvedattheHighEnd”.IPDPS2014Keynote
DomainDecomposition
§ Sharingpromotescooperation– Reducedmemoryconsumption– Efficientuseofsharedresources:
caches,TLBentries,networkendpoints,etc.
AdvancedMPI,SC17(11/13/2017) 86

MPI + Threads
87AdvancedMPI,SC17(11/13/2017)

MPI and Threads
§ MPIdescribesparallelismbetweenprocesses(withseparateaddressspaces)
§ Thread parallelismprovidesashared-memorymodelwithinaprocess
§ OpenMP andPthreads arecommonmodels– OpenMP providesconvenientfeaturesforloop-
levelparallelism.Threadsarecreatedandmanagedbythecompiler,basedonuserdirectives.
– Pthreads providemorecomplexanddynamicapproaches.Threadsarecreatedandmanagedexplicitlybytheuser.
AdvancedMPI,SC17(11/13/2017) 88
MPIProcess
COMP.
COMP.
MPICOMM.
MPIProcess
COMP.
COMP.
MPICOMM.

Hybrid Programming with MPI+Threads
§ InMPI-onlyprogramming,eachMPIprocesshasasinglethreadofexecution
§ InMPI+threads hybridprogramming,therecanbemultiplethreadsexecutingsimultaneously– AllthreadsshareallMPI
objects(communicators,requests)
– TheMPIimplementationmightneedtotakeprecautionstomakesurethestateoftheMPIstackisconsistent
AdvancedMPI,SC17(11/13/2017)
Rank0 Rank1
MPI-onlyProgramming
Rank0 Rank1
MPI+Threads HybridProgramming
89

MPI’s Four Levels of Thread Safety
§ MPIdefinesfourlevelsofthreadsafety-- thesearecommitmentstheapplicationmakestotheMPI– MPI_THREAD_SINGLE:onlyonethreadexistsintheapplication– MPI_THREAD_FUNNELED:multithreaded,butonlythemainthread
makesMPIcalls(theonethatcalledMPI_Init_thread)– MPI_THREAD_SERIALIZED:multithreaded,butonlyonethreadatatime
makesMPIcalls– MPI_THREAD_MULTIPLE:multithreadedandanythreadcanmakeMPI
callsatanytime(withsomerestrictionstoavoidraces– seenextslide)
§ Threadlevelsareinincreasingorder– IfanapplicationworksinFUNNELEDmode,itcanworkinSERIALIZED
§ MPIdefinesanalternativetoMPI_Init– MPI_Init_thread(requested,provided)
• Applicationspecifieslevelitneeds;MPIimplementationreturnslevelitsupports
AdvancedMPI,SC17(11/13/2017) 90

MPI_THREAD_SINGLE
§ Therearenoadditionaluserthreadsinthesystem– E.g.,therearenoOpenMP parallelregions
AdvancedMPI,SC17(11/13/2017)
int main(int argc, char ** argv){
int buf[100];
MPI_Init(&argc, &argv);MPI_Comm_rank(MPI_COMM_WORLD, &rank);
for (i = 0; i < 100; i++)compute(buf[i]);
/* Do MPI stuff */
MPI_Finalize();
return 0;}
91
MPIProcess
COMP.
COMP.
MPICOMM.

MPI_THREAD_FUNNELED
§ AllMPIcallsaremadebythemaster thread– OutsidetheOpenMP parallelregions– InOpenMP masterregions
AdvancedMPI,SC17(11/13/2017)
int main(int argc, char ** argv){
int buf[100], provided;
MPI_Init_thread(&argc, &argv, MPI_THREAD_FUNNELED, &provided);if (provided < MPI_THREAD_FUNNELED) MPI_Abort(MPI_COMM_WORLD,1);
#pragma omp parallel forfor (i = 0; i < 100; i++)
compute(buf[i]);
/* Do MPI stuff */
MPI_Finalize();return 0;
}
92
MPIProcess
COMP.
COMP.
MPICOMM.

MPI_THREAD_SERIALIZED
§ Onlyone threadcanmakeMPIcallsatatime– ProtectedbyOpenMP criticalregions
AdvancedMPI,SC17(11/13/2017)
int main(int argc, char ** argv){
int buf[100], provided;
MPI_Init_thread(&argc, &argv, MPI_THREAD_SERIALIZED, &provided);if (provided < MPI_THREAD_SERIALIZED) MPI_Abort(MPI_COMM_WORLD,1);
#pragma omp parallel forfor (i = 0; i < 100; i++) {
compute(buf[i]);#pragma omp critical
/* Do MPI stuff */}
MPI_Finalize();return 0;
}
93
MPIProcess
COMP.
COMP.
MPICOMM.

MPI_THREAD_MULTIPLE
§ Any threadcanmakeMPIcallsanytime(restrictionsapply)
AdvancedMPI,SC17(11/13/2017)
int main(int argc, char ** argv){
int buf[100], provided;
MPI_Init_thread(&argc, &argv, MPI_THREAD_MULTIPLE, &provided);if (provided < MPI_THREAD_MULTIPLE) MPI_Abort(MPI_COMM_WORLD,1);
#pragma omp parallel forfor (i = 0; i < 100; i++) {
compute(buf[i]);/* Do MPI stuff */
}
MPI_Finalize();return 0;
}
94
MPIProcess
COMP.
COMP.
MPICOMM.

Threads and MPI
§ AnimplementationisnotrequiredtosupportlevelshigherthanMPI_THREAD_SINGLE;thatis,animplementationisnotrequiredtobethreadsafe
§ Afullythread-safeimplementationwillsupportMPI_THREAD_MULTIPLE
§ AprogramthatcallsMPI_Init (insteadofMPI_Init_thread)shouldassumethatonlyMPI_THREAD_SINGLEissupported– MPIStandardmandatesMPI_THREAD_SINGLEforMPI_Init
§ AthreadedMPIprogramthatdoesnotcallMPI_Init_thread isanincorrectprogram(commonusererrorwesee)
AdvancedMPI,SC17(11/13/2017) 95
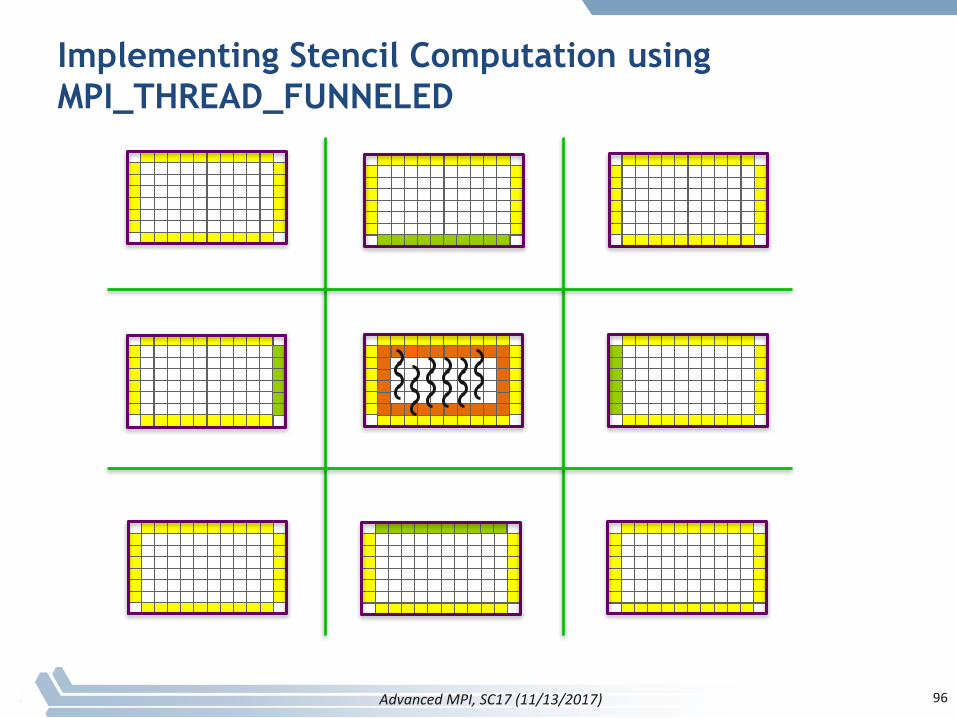
Implementing Stencil Computation using MPI_THREAD_FUNNELED
96AdvancedMPI,SC17(11/13/2017)

Code Examples
§ stencil_mpi_ddt_funneled.c
§ Parallelizecomputation(OpenMP parallelfor)
§ Mainthreaddoesallcommunication
97AdvancedMPI,SC17(11/13/2017)

MPI Semantics and MPI_THREAD_MULTIPLE
§ Ordering:WhenmultiplethreadsmakeMPIcallsconcurrently,theoutcomewillbeasifthecallsexecutedsequentiallyinsome(any)order– Orderingismaintainedwithineachthread– Usermustensurethatcollectiveoperationsonthesamecommunicator,
window,orfilehandlearecorrectlyorderedamongthreads• E.g.,cannotcallabroadcastononethreadandareduceonanotherthreadonthesamecommunicator
– Itistheuser'sresponsibilitytopreventraceswhenthreadsinthesameapplicationpostconflictingMPIcalls
• E.g.,accessinganinfoobjectfromonethreadandfreeingitfromanotherthread
§ Progress: BlockingMPIcallswillblockonlythecallingthreadandwillnotpreventotherthreadsfromrunningorexecutingMPIfunctions
AdvancedMPI,SC17(11/13/2017) 98

Ordering in MPI_THREAD_MULTIPLE: Incorrect Example with Collectives
Process 0
MPI_Bcast(comm)
MPI_Barrier(comm)
Process 1
MPI_Bcast(comm)
MPI_Barrier(comm)
AdvancedMPI,SC17(11/13/2017) 99
Thread0
Thread1

Ordering in MPI_THREAD_MULTIPLE: Incorrect Example with Collectives
§ P0andP1canhavedifferentorderingsofBcast andBarrier§ Heretheusermustusesomekindofsynchronizationto
ensurethateitherthread1orthread2getsscheduledfirstonbothprocesses
§ Otherwiseabroadcastmaygetmatchedwithabarrieronthesamecommunicator,whichisnotallowedinMPI
Process 0Thread 1 Thread 2
MPI_Bcast(comm)
MPI_Barrier(comm)
AdvancedMPI,SC17(11/13/2017) 100
Process 1Thread 1 Thread 2
MPI_Barrier(comm)
MPI_Bcast(comm)

Ordering in MPI_THREAD_MULTIPLE: Incorrect Example with RMA
AdvancedMPI,SC17(11/13/2017) 101
int main(int argc, char ** argv){
/* Initialize MPI and RMA window */
#pragma omp parallel forfor (i = 0; i < 100; i++) {
target = rand();MPI_Win_lock(MPI_LOCK_EXCLUSIVE, target, 0, win);MPI_Put(..., win);MPI_Win_unlock(target, win);
}
/* Free MPI and RMA window */
return 0;}
Differentthreadscanlockthesameprocesscausingmultiplelockstothesametargetbeforethefirstlockisunlocked

Ordering in MPI_THREAD_MULTIPLE: Incorrect Example with Object Management
§ Theuserhastomakesurethatonethreadisnotusinganobjectwhileanotherthreadisfreeingit– Thisisessentiallyanorderingissue;theobjectmightgetfreedbefore
itisused
AdvancedMPI,SC17(11/13/2017) 102
Process 0Thread 1 Thread 2
MPI_Comm_free(comm)
MPI_Bcast(comm)

Blocking Calls in MPI_THREAD_MULTIPLE: Correct Example
§ Animplementationmustensurethattheaboveexampleneverdeadlocksforanyorderingofthreadexecution
§ ThatmeanstheimplementationcannotsimplyacquireathreadlockandblockwithinanMPIfunction.Itmustreleasethelocktoallowotherthreadstomakeprogress.
Process 0
MPI_Recv(src=1)
MPI_Send(dst=1)
Process 1
MPI_Recv(src=0)
MPI_Send(dst=0)
Thread 1
Thread 2
AdvancedMPI,SC17(11/13/2017) 103

Implementing Stencil Computation using MPI_THREAD_MULTIPLE
104AdvancedMPI,SC17(11/13/2017)

Code Examples
§ stencil_mpi_ddt_multiple.c
§ DividetheprocessmemoryamongOpenMP threads
§ Eachthreadresponsibleforcommunicationandcomputation
105AdvancedMPI,SC17(11/13/2017)

The Current Situation
§ AllMPIimplementationssupportMPI_THREAD_SINGLE
§ TheyprobablysupportMPI_THREAD_FUNNELEDeveniftheydon’tadmitit.– Doesrequirethread-safetyforsomesystemroutines(e.g.malloc)
– Onmostsystems-pthread willguaranteeit(OpenMP implies
-pthread )
§ Many(butnotall)implementationssupportTHREAD_MULTIPLE– Hardtoimplementefficientlythough(threadsynchronizationissues)
§ Bulk-synchronousOpenMP programs(loopsparallelizedwithOpenMP,communicationbetweenloops)onlyneedFUNNELED– Sodon’tneed“thread-safe”MPIformanyhybridprograms
– ButwatchoutforAmdahl’sLaw!
AdvancedMPI,SC17(11/13/2017) 106

Performance with MPI_THREAD_MULTIPLE
§ Threadsafetydoesnotcomeforfree
§ Theimplementationmustaccess/modifyseveralsharedobjects(e.g.messagequeues)inaconsistentmanner
§ Tomeasuretheperformanceimpact,weranteststomeasurecommunicationperformancewhenusingmultiplethreadsversusmultipleprocesses– Forresults,seeThakur/Gropp paper:“TestSuiteforEvaluating
PerformanceofMultithreadedMPICommunication,”ParallelComputing,2009
AdvancedMPI,SC17(11/13/2017) 107

Message Rate Results on BG/P
MessageRateBenchmark
AdvancedMPI,SC17(11/13/2017) 108
“EnablingConcurrentMultithreadedMPICommunicationonMulticore PetascaleSystems”EuroMPI 2010

Why is it hard to optimize MPI_THREAD_MULTIPLE
§ MPIinternallymaintainsseveralresources
§ BecauseofMPIsemantics,itisrequiredthatallthreadshaveaccesstosomeofthedatastructures– E.g.,thread1canpostanIrecv,andthread2canwaitforitscompletion– thustherequestqueuehastobesharedbetweenboththreads
– Sincemultiplethreadsareaccessingthissharedqueue,thread-safetyisrequiredtoensureaconsistentstateofthequeue– addsalotofoverhead
AdvancedMPI,SC17(11/13/2017) 109

Hybrid Programming: Correctness Requirements
§ HybridprogrammingwithMPI+threads doesnotdomuchtoreducethecomplexityofthreadprogramming– Yourapplicationstillhastobeacorrectmulti-threadedapplication
– Ontopofthat,youalsoneedtomakesureyouarecorrectlyfollowingMPIsemantics
§ ManycommercialdebuggersoffersupportfordebugginghybridMPI+threads applications(mostlyforMPI+PthreadsandMPI+OpenMP)
AdvancedMPI,SC17(11/13/2017) 110

An Example we encountered
§ WereceivedabugreportaboutaverysimplemultithreadedMPIprogramthathangs
§ Runwith2processes
§ Eachprocesshas2threads
§ Boththreadscommunicatewiththreadsontheotherprocessasshowninthenextslide
§ WespentseveralhourstryingtodebugMPICHbeforediscoveringthatthebugisactuallyintheuser’sprogramL
AdvancedMPI,SC17(11/13/2017) 111

2 Proceses, 2 Threads, Each Thread Executes this Code
for(j=0;j<2;j++){
if(rank==1){
for(i=0;i<2;i++)
MPI_Send(NULL,0,MPI_CHAR,0,0,MPI_COMM_WORLD);
for(i=0;i<2;i++)
MPI_Recv(NULL,0,MPI_CHAR,0,0,MPI_COMM_WORLD,&stat);
}
else{/*rank==0*/
for(i=0;i<2;i++)
MPI_Recv(NULL,0,MPI_CHAR,1,0,MPI_COMM_WORLD,&stat);
for(i=0;i<2;i++)
MPI_Send(NULL,0,MPI_CHAR,1,0,MPI_COMM_WORLD);
}
}AdvancedMPI,SC17(11/13/2017) 112

Intended Ordering of Operations
§ Everysendmatchesareceiveontheotherrank
AdvancedMPI,SC17(11/13/2017)
2recvs (T2)2 sends(T2)2 recvs (T2)2 sends(T2)
2recvs (T1)2 sends(T1)2 recvs (T1)2 sends(T1)
Rank0
2sends(T2)2recvs (T2)2sends(T2)2recvs (T2)
2sends(T1)2recvs (T1)2sends(T1)2recvs (T1)
Rank1
113

Possible Ordering of Operations in Practice
§ BecausetheMPIoperationscanbeissuedinanarbitraryorderacrossthreads,allthreadscouldblockinaRECVcall
1 recv (T2)
1recv (T2)
2sends(T2)2 recvs (T2)2 sends(T2)
2recvs (T1)2 sends(T1)1 recv (T1)
1recv (T1)
2sends(T1)
Rank0
2sends(T2)1 recv (T2)
1recv (T2)
2sends(T2)2recvs (T2)
2sends(T1)1 recv (T1)
1recv (T1)
2sends(T1)2recvs (T1)
Rank1
114AdvancedMPI,SC17(11/13/2017)

Some Things to Watch for in OpenMP
§ Limitedthreadandnoexplicitmemoryaffinitycontrol(butseeOpenMP4.0and4.5)– “Firsttouch”(haveintended“owning”threadperformfirstaccess)
providesinitialstaticmappingofmemory• Nexttouch(moveownershiptomostrecentthread)couldhelp
– Noportablewaytoreassignmemoryaffinity– reducestheeffectivenessofOpenMPwhenusedtoimproveloadbalancing.
§ Memorymodelcanrequireexplicit“memoryflush”operations– Defaultsallowraceconditions
– Humansnotoriouslypooratrecognizingallraces• Itonlytakesonemistaketocreateahard-to-findbug
AdvancedMPI,SC17(11/13/2017) 115

Some Things to Watch for in MPI + OpenMP
§ NointerfaceforapportioningresourcesbetweenMPIandOpenMP– OnanSMPnode,howmanyMPIprocessesandhowmanyOpenMP
Threads?• Notethestaticnatureassumedbythisquestion
– Notethathavingmorethreadsthancorescanbeimportantforhidinglatency• Requiresverylightweightthreads
§ Competitionforresources– Particularlymemorybandwidthandnetworkaccess
– Apportionmentofnetworkaccessbetweenthreadsandprocessesisalsoaproblem,aswe’vealreadyseen.
AdvancedMPI,SC17(11/13/2017) 116

Where Does the MPI + OpenMP Hybrid Model Work Well?
§ Compute-boundloops– Manyoperationspermemoryload
§ Fine-grainparallelism– Algorithmsthatarelatency-sensitive
§ Loadbalancing– Similartofine-grainparallelism;easeof
§ Memoryboundloops
AdvancedMPI,SC17(11/13/2017) 117

Compute-Bound Loops
§ Loopsthatinvolvemanyoperationsperloadfrommemory– Thiscanhappeninsomekindsofmatrixassembly,forexample.
– Jacobiupdatenotcomputebound
AdvancedMPI,SC17(11/13/2017) 118

Fine-Grain Parallelism
§ Algorithmsthatrequirefrequentexchangesofsmallamountsofdata
§ E.g.,inblockedpreconditioners,wherefewer,largerblocks,eachmanagedwithOpenMP,asopposedtomore,smaller,single-threadedblocksintheall-MPIversion,givesyouanalgorithmicadvantage(e.g.,feweriterationsinapreconditionedlinearsolutionalgorithm).
§ Evenifmemorybound
AdvancedMPI,SC17(11/13/2017) 119

Load Balancing
§ Wherethecomputationalloadisn'texactlythesameinallthreads/processes;thiscanbeviewedasavariationonfine-grainedaccess.
§ OpenMPschedulescanhandlesomeofthis– Forveryfinegraincases,amixofstaticanddynamicschedulingmay
bemoreefficient
– Currentresearchlookingatmoreelaborateandefficientschedulesforthiscase
AdvancedMPI,SC17(11/13/2017) 120

Memory-Bound Loops
§ Wherereaddataisshared,sothatcachememorycanbeusedmoreefficiently.
§ Example:Tablelookupforevaluatingequationsofstate– Tablecanbeshared
– Iftableevaluatedasnecessary,evaluationscanbeshared
AdvancedMPI,SC17(11/13/2017) 121

Where is Pure MPI Better?
§ TryingtouseOpenMP+MPIonveryregular,memory-bandwidth-boundcomputationsislikelytolosebecauseofthebetter,programmer-enforcedmemorylocalitymanagementinthepureMPIversion.
§ AnotherreasontousemorethanoneMPIprocess- ifasingleprocess(orthread)can'tsaturatetheinterconnect- thenusemultiplecommunicatingprocessesorthreads.– Notethatthreadsandprocessesarenotequal
AdvancedMPI,SC17(11/13/2017) 122

MPI + Shared-Memory
123AdvancedMPI,SC17(11/13/2017)

Hybrid Programming with Shared Memory
§ MPI-3allowsdifferentprocessestoallocatesharedmemorythroughMPI– MPI_Win_allocate_shared
§ Usesmanyoftheconceptsofone-sidedcommunication
§ ApplicationscandohybridprogrammingusingMPIorload/storeaccessesonthesharedmemorywindow
§ OtherMPIfunctionscanbeusedtosynchronizeaccesstosharedmemoryregions
§ Canbesimplertoprogramthanthreads
AdvancedMPI,SC17(11/13/2017) 124
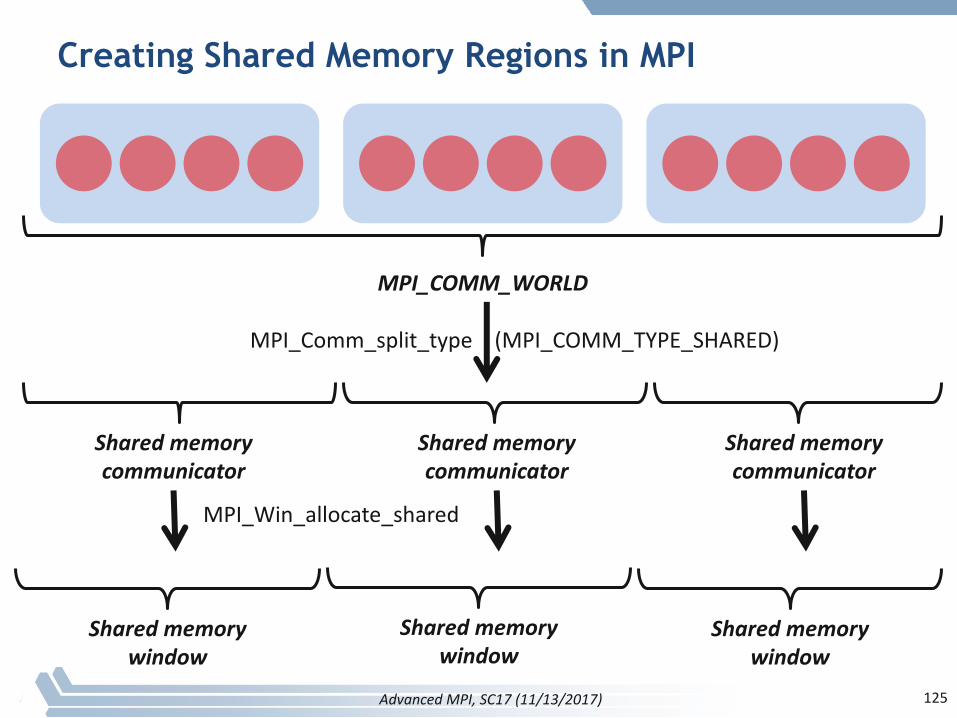
Creating Shared Memory Regions in MPI
AdvancedMPI,SC17(11/13/2017)
MPI_COMM_WORLD
MPI_Comm_split_type (MPI_COMM_TYPE_SHARED)
Sharedmemorycommunicator
MPI_Win_allocate_shared
Sharedmemorywindow
Sharedmemorywindow
Sharedmemorywindow
Sharedmemorycommunicator
Sharedmemorycommunicator
125

Load/store
Regular RMA windows vs. Shared memory windows
§ Sharedmemorywindowsallowapplicationprocessestodirectlyperformload/storeaccessesonallofthewindowmemory– E.g.,x[100]=10
§ AlloftheexistingRMAfunctionscanalsobeusedonsuchmemoryformoreadvancedsemanticssuchasatomicoperations
§ Canbeveryusefulwhenprocesseswanttousethreadsonlytogetaccesstoallofthememoryonthenode– Youcancreateasharedmemory
windowandputyourshareddata
AdvancedMPI,SC17(11/13/2017)
Localmemory
P0
Localmemory
P1
Load/storePUT/GET
TraditionalRMAwindows
Load/store
Localmemory
P0 P1
Load/store
Sharedmemorywindows
Load/store
126

MPI_COMM_SPLIT_TYPE
§ Createacommunicatorwhereprocesses“shareaproperty”– Propertiesaredefinedbythe“split_type”
§ Arguments:– comm - inputcommunicator(handle)
– Split_type - propertyofthepartitioning(integer)
– Key - Rankassignmentordering(nonnegativeinteger)
– info - infoargument(handle)
– newcomm- outputcommunicator(handle)
127AdvancedMPI,SC17(11/13/2017)
MPI_Comm_split_type(MPI_Comm comm, int split_type,int key, MPI_Info info, MPI_Comm *newcomm)

MPI_WIN_ALLOCATE_SHARED
§ CreatearemotelyaccessiblememoryregioninanRMAwindow– DataexposedinawindowcanbeaccessedwithRMAopsorload/store
§ Arguments:– size - sizeoflocaldatainbytes(nonnegativeinteger)
– disp_unit - localunitsizefordisplacements,inbytes(positiveinteger)
– info - infoargument(handle)
– comm - communicator(handle)
– baseptr - pointertoexposedlocaldata
– win- window(handle)
128AdvancedMPI,SC17(11/13/2017)
MPI_Win_allocate_shared(MPI_Aint size, int disp_unit,MPI_Info info, MPI_Comm comm, void *baseptr,MPI_Win *win)

Shared Arrays with Shared memory windows
AdvancedMPI,SC17(11/13/2017)
int main(int argc, char ** argv){
int buf[100];
MPI_Init(&argc, &argv);MPI_Comm_split_type(..., MPI_COMM_TYPE_SHARED, .., &comm);MPI_Win_allocate_shared(comm, ..., &win);
MPI_Win_lockall(win);
/* copy data to local part of shared memory */MPI_Win_sync(win);
/* use shared memory */
MPI_Win_unlock_all(win);
MPI_Win_free(&win);MPI_Finalize();return 0;
}
129

Memory allocation and placement
§ Sharedmemoryallocationdoesnotneedtobeuniformacrossprocesses– Processescanallocateadifferentamountofmemory(evenzero)
§ TheMPIstandarddoesnotspecifywherethememorywouldbeplaced(e.g.,whichphysicalmemoryitwillbepinnedto)– Implementationscanchoosetheirownstrategies,thoughitis
expectedthatanimplementationwilltrytoplacesharedmemoryallocatedbyaprocess“closetoit”
§ Thetotalallocatedsharedmemoryonacommunicatoriscontiguousbydefault– Userscanpassaninfohintcalled“noncontig”thatwillallowtheMPI
implementationtoalignmemoryallocationsfromeachprocesstoappropriateboundariestoassistwithplacement
AdvancedMPI,SC17(11/13/2017) 130
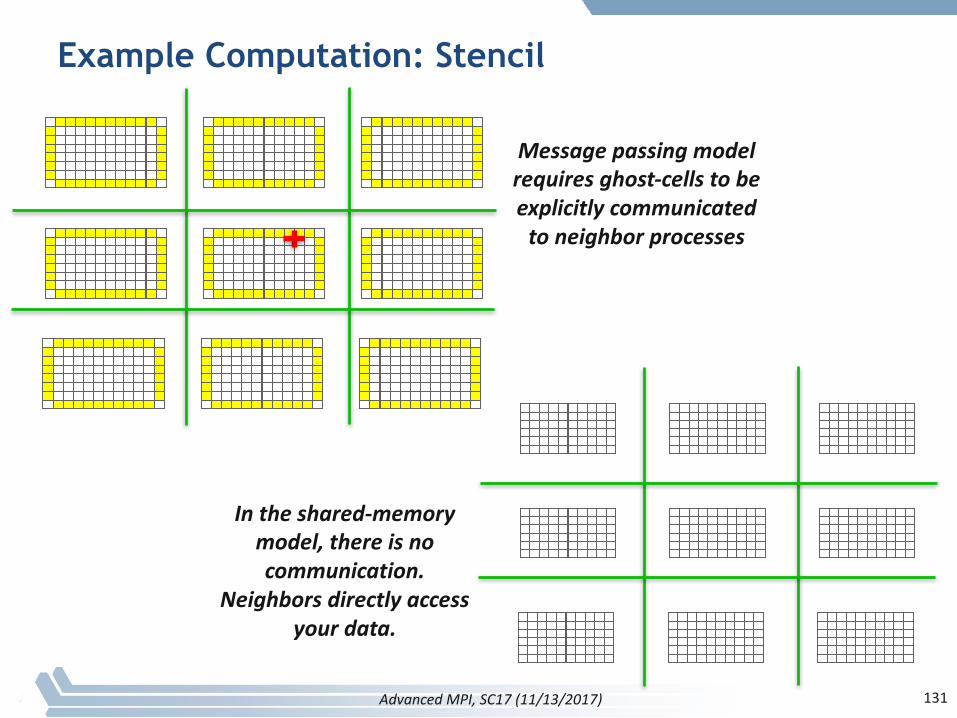
Example Computation: Stencil
AdvancedMPI,SC17(11/13/2017)
Messagepassingmodelrequiresghost-cellstobeexplicitlycommunicatedtoneighborprocesses
Intheshared-memorymodel,thereisnocommunication.
Neighborsdirectlyaccessyourdata.
131

Walkthrough of 2D Stencil Code with Shared Memory Windows
§ stencil_mpi_shmem.c
AdvancedMPI,SC17(11/13/2017) 132

Which Hybrid Programming Method to Adopt?
§ Itdependsontheapplication,targetmachine,andMPIimplementation
§ WhenshouldIuseprocesssharedmemory?– Theonlyresourcethatneedssharingismemory
– Fewallocatedobjectsneedsharing(easytoplacetheminapublicsharedregion)
§ WhenshouldIusethreads?– Morethanmemoryresourcesneedsharing(e.g.,TLB)
– Manyapplicationobjectsrequiresharing
– Applicationcomputationstructurecanbeeasilyparallelizedwithhigh-levelOpenMP loops
AdvancedMPI,SC17(11/13/2017) 133

Example: Quantum Monte Carlo
WWalkerdata
§ MemorycapacityboundwithMPI-only§ Hybridapproaches
– MPI+threads(e.g.X=OpenMP,Pthreads)– MPI+shared-memory(X=MPI)
§ Canusedirectload/storeoperationsinsteadofmessagepassing
LargeB-splinetable
W W W W
Thread0 Thread1
MPITask1
Core Core
MPI+Threads• Shareeverythingbydefault• Privatizedatawhennecessary
MPI+Shared-Memory(MPI3.0)• Everythingprivatebydefault• Exposeshareddataexplicitly
MPITask1MPITask0
LargeB-splinetableinaShare-MemoryWindow
W
Core
W
Core
WW
AdvancedMPI,SC17(11/13/2017) 134

MPI + Accelerators
135AdvancedMPI,SC17(11/13/2017)
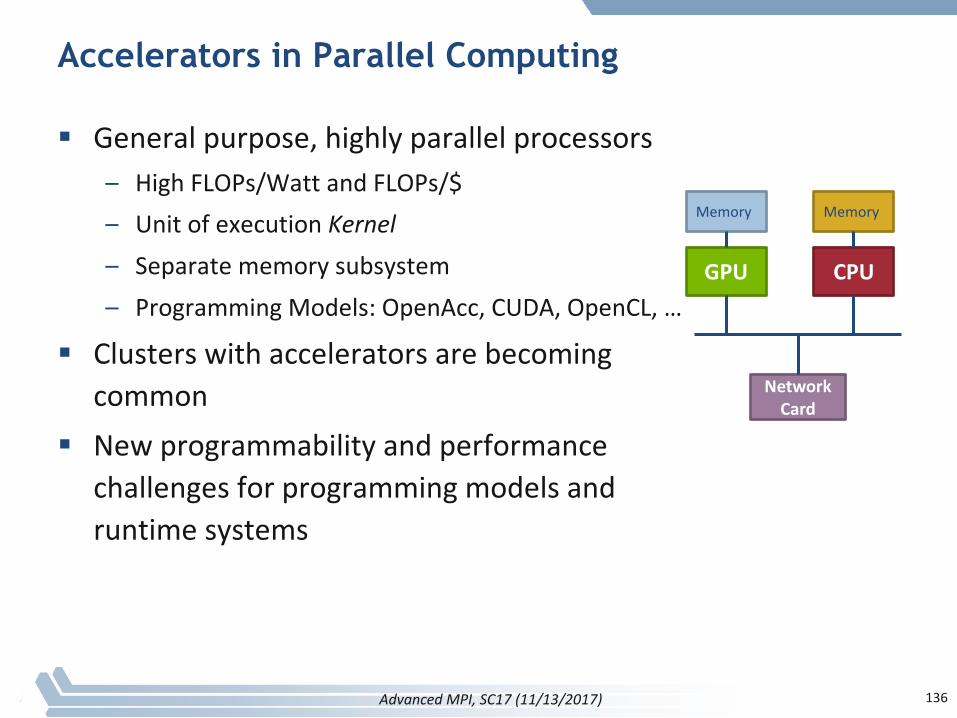
Accelerators in Parallel Computing
§ Generalpurpose,highlyparallelprocessors– HighFLOPs/WattandFLOPs/$– UnitofexecutionKernel– Separatememorysubsystem– ProgrammingModels:OpenAcc,CUDA,OpenCL,…
§ Clusterswithacceleratorsarebecomingcommon
§ Newprogrammabilityandperformancechallengesforprogrammingmodelsandruntimesystems
136
GPU
Memory
CPU
Memory
NetworkCard
AdvancedMPI,SC17(11/13/2017)

MPI + Accelerator Programming Examples (1/2)
137
GPU
Memory
CPU
Memory
NetworkCard
GPU
Memory
CPU
Memory
NetworkCard
FAQ:HowtomovedatabetweenGPUswithMPI?
AdvancedMPI,SC17(11/13/2017)

MPI + Accelerator Programming Examples (2/2)
138
double *dev_buf, *host_buf;cudaMalloc(&dev_buf, size);cudaMallocHost(&host_buf, size);
if(my_rank == sender) {computation_on_GPU(dev_buf);cudaMemcpy(host_buf, dev_buf, size, …);MPI_Isend(host_buf, size, …);
} else {MPI_Irecv(host_buf, size, …);cudaMemcpy(dev_buf, host_buf, size, …);computation_on_GPU(dev_buf);
}
CUDA
double *buf;buf = (double*)malloc(size * sizeof(double));#pragma acc enter data create(buf[0:size])
if(my_rank == sender) {computation_on_GPU(buf);#pragma acc update host (buf[0:size])MPI_Isend(buf, size, …);
} else {MPI_Irecv(buf, size, …);#pragma acc update device (buf[0:size])computation_on_GPU(buf);
}
Ope
nACC
AdvancedMPI,SC17(11/13/2017)
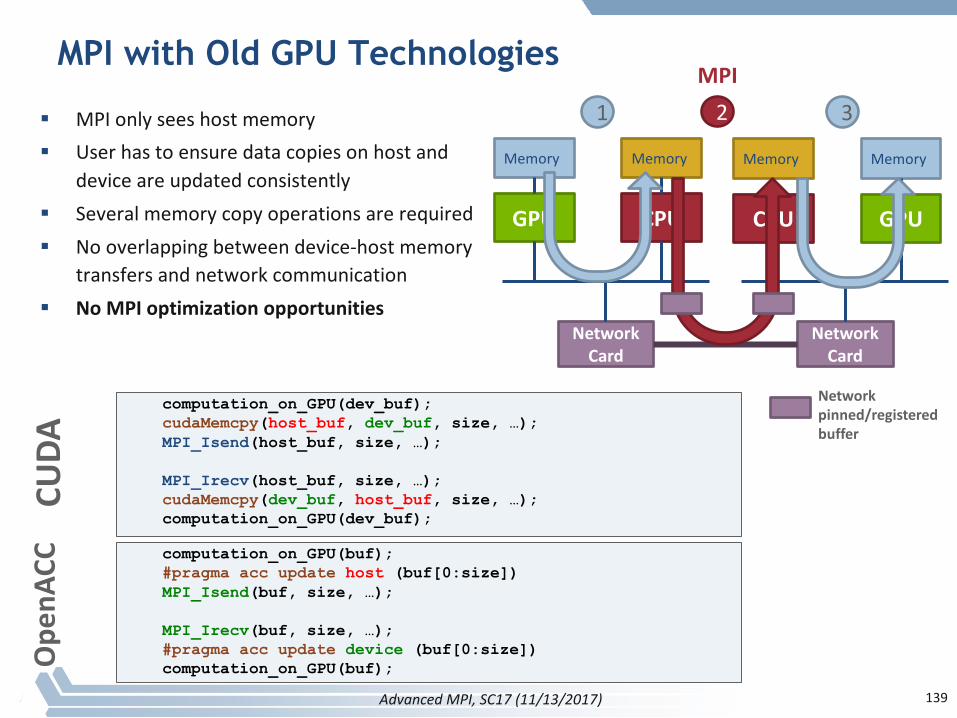
MPI with Old GPU Technologies
139
GPU
Memory
CPU
Memory
NetworkCard
GPU
Memory
CPU
Memory
NetworkCard
computation_on_GPU(dev_buf);cudaMemcpy(host_buf, dev_buf, size, …);MPI_Isend(host_buf, size, …);
MPI_Irecv(host_buf, size, …);cudaMemcpy(dev_buf, host_buf, size, …);computation_on_GPU(dev_buf);
CUDA
computation_on_GPU(buf);#pragma acc update host (buf[0:size])MPI_Isend(buf, size, …);
MPI_Irecv(buf, size, …);#pragma acc update device (buf[0:size])computation_on_GPU(buf);O
penA
CC
§ MPIonlyseeshostmemory§ Userhastoensuredatacopiesonhostand
deviceareupdatedconsistently§ Severalmemorycopyoperationsarerequired§ Nooverlappingbetweendevice-hostmemory
transfersandnetworkcommunication§ NoMPIoptimizationopportunities
1 32MPI
Networkpinned/registeredbuffer
AdvancedMPI,SC17(11/13/2017)
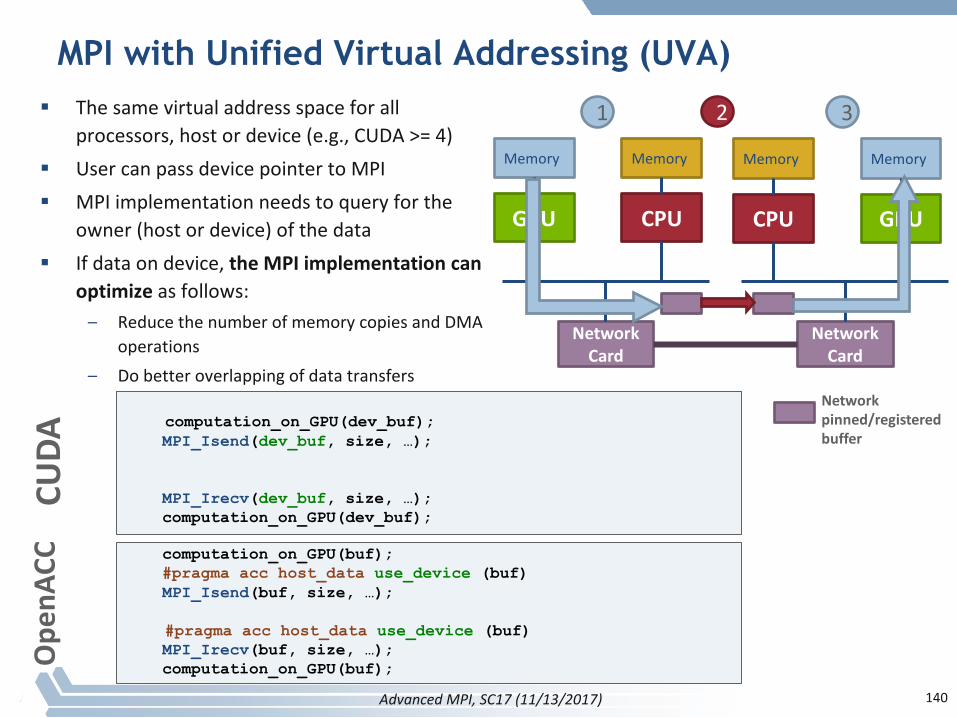
MPI with Unified Virtual Addressing (UVA)
140
GPU
Memory
CPU
Memory
NetworkCard
GPU
Memory
CPU
Memory
NetworkCard
CUDA
computation_on_GPU(buf);#pragma acc host_data use_device (buf)MPI_Isend(buf, size, …);
#pragma acc host_data use_device (buf)MPI_Irecv(buf, size, …);computation_on_GPU(buf);O
penA
CC
§ Thesamevirtualaddressspaceforallprocessors,hostordevice(e.g.,CUDA>=4)
§ UsercanpassdevicepointertoMPI§ MPIimplementationneedstoqueryforthe
owner(hostordevice)ofthedata§ Ifdataondevice,theMPIimplementationcan
optimize asfollows:– Reducethenumberofmemorycopiesand DMA
operations– Dobetteroverlappingofdatatransfers
1 32
Networkpinned/registeredbuffer
computation_on_GPU(dev_buf);MPI_Isend(dev_buf, size, …);
MPI_Irecv(dev_buf, size, …);computation_on_GPU(dev_buf);
AdvancedMPI,SC17(11/13/2017)

MPI with UVA + GPUDirect
141
GPU
Memory
CPU
Memory
NetworkCard
GPU
Memory
CPU
Memory
NetworkCard
CUDA
Ope
nACC
§ ThehardwaresupportsdirectGPU-to-GPUdatatransferswithinoracrossnodes
§ MPIimplementationsmayusethefollowingoptimizationstotransferdatabetweenGPUs– CanusedirectlyGPUmemoryforRDMA
communication– Peer-to-peerdatatransferswhenGPUsareonthe
samenode
computation_on_GPU(buf);#pragma acc host_data use_device (buf)MPI_Isend(buf, size, …);
#pragma acc host_data use_device (buf)MPI_Irecv(buf, size, …);computation_on_GPU(buf);
computation_on_GPU(dev_buf);MPI_Isend(dev_buf, size, …);
MPI_Irecv(dev_buf, size, …);computation_on_GPU(dev_buf);
AdvancedMPI,SC17(11/13/2017)

Advanced Topics: Nonblocking Collectives, Topologies, and Neighborhood Collectives

§ Nonblocking(send/recv)communication– Deadlockavoidance
– Overlappingcommunication/computation
§ Collectivecommunication– Collectionofpre-definedoptimizedroutines
§ à Nonblockingcollectivecommunication– Combinesbothtechniques(morethanthesumofthepartsJ)
– Systemnoise/imbalanceresiliency
– Semanticadvantages
143AdvancedMPI,SC17(11/13/2017)
Nonblocking Collective Communication

Nonblocking Collective Communication
§ Nonblockingvariantsofallcollectives– MPI_Ibcast(<bcast args>,MPI_Request *req);
§ Semantics– Functionreturnsnomatterwhat– Noguaranteedprogress(qualityofimplementation)– Usualcompletioncalls(wait,test)+mixing– Out-ofordercompletion
§ Restrictions– Notags,in-ordermatching– Sendandvectorbuffersmaynotbeupdatedduringoperation– MPI_Cancel notsupported– Nomatchingwithblockingcollectives
Hoefleretal.:ImplementationandPerformanceAnalysisofNon-BlockingCollectiveOperationsforMPI144AdvancedMPI,SC17(11/13/2017)

Nonblocking Collective Communication
§ Semanticadvantages– Enableasynchronousprogression(andmanual)
• Softwarepipelining
– Decoupledatatransferandsynchronization• Noiseresiliency!
– Allowoverlappingcommunicators• Seealsoneighborhoodcollectives
– Multipleoutstandingoperationsatanytime• Enablespipeliningwindow
Hoefleretal.:ImplementationandPerformanceAnalysisofNon-BlockingCollectiveOperationsforMPI145AdvancedMPI,SC17(11/13/2017)

Nonblocking Collectives Overlap
§ Softwarepipelining– Morecomplexparameters
– Progressionissues
– Notscale-invariant
Hoefler:LeveragingNon-blockingCollectiveCommunicationinHigh-performanceApplications146AdvancedMPI,SC17(11/13/2017)

A Non-Blocking Barrier?
§ Whatcanthatbegoodfor?Well,quiteabit!
§ Semantics:– MPI_Ibarrier()– callingprocessenteredthebarrier,no
synchronizationhappens
– Synchronizationmay happenasynchronously
– MPI_Test/Wait()– synchronizationhappens ifnecessary
§ Uses:– Overlapbarrierlatency(smallbenefit)
– Usethesplitsemantics!Processesnotify non-collectivelybutsynchronize collectively!
147AdvancedMPI,SC17(11/13/2017)
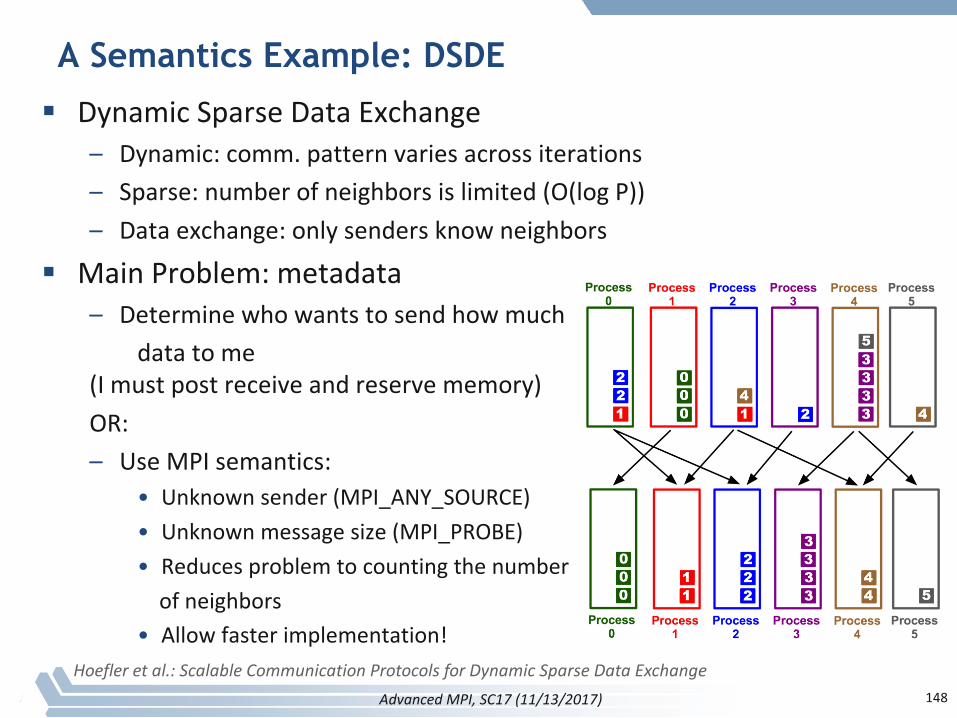
A Semantics Example: DSDE
§ DynamicSparseDataExchange– Dynamic:comm.patternvariesacrossiterations– Sparse:numberofneighborsislimited(O(logP))– Dataexchange:onlysendersknowneighbors
§ MainProblem:metadata– Determinewhowantstosendhowmuch
datatome(Imustpostreceiveandreservememory)OR:– UseMPIsemantics:
• Unknownsender(MPI_ANY_SOURCE)• Unknownmessagesize(MPI_PROBE)• Reducesproblemtocountingthenumberofneighbors
• Allowfasterimplementation!Hoefleretal.:ScalableCommunicationProtocolsforDynamicSparseDataExchange
148AdvancedMPI,SC17(11/13/2017)
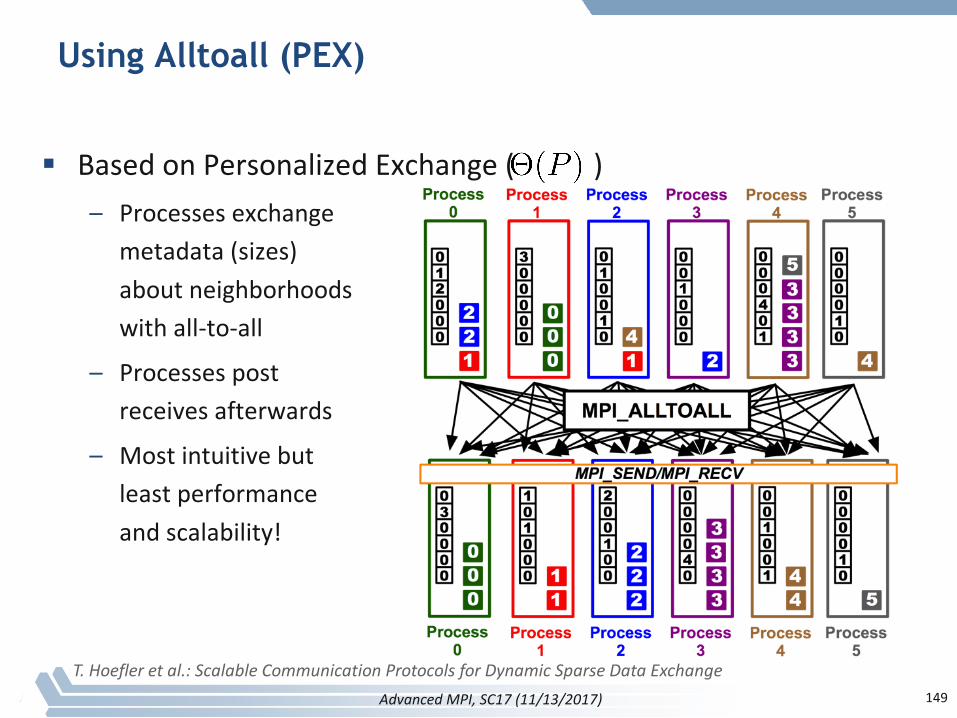
Using Alltoall (PEX)
§ BasedonPersonalizedExchange()– Processesexchange
metadata(sizes)aboutneighborhoodswithall-to-all
– Processespostreceivesafterwards
– Mostintuitivebutleastperformanceandscalability!
T.Hoefleretal.:ScalableCommunicationProtocolsforDynamicSparseDataExchange149AdvancedMPI,SC17(11/13/2017)

Reduce_scatter (PCX)
§ BasesonPersonalizedCensus()– Processesexchange
metadata(counts)aboutneighborhoodswithreduce_scatter
– ReceiverscheckswithwildcardMPI_IPROBEandreceivesmessages
– BetterthanPEXbutnon-deterministic!
T.Hoefleretal.:Scalable CommunicationProtocolsforDynamicSparseDataExchange150AdvancedMPI,SC17(11/13/2017)

MPI_Ibarrier (NBX)
§ Complexity- census(barrier):()– Combinesmetadatawithactualtransmission– Point-to-point
synchronization– Continuereceiving
untilbarriercompletes– Processesstartcoll.
synch.(barrier)whenp2pphaseended• barrier=distributed
marker!
– BetterthanAlltoall,reduce-scatter!
T.Hoefleretal.:ScalableCommunicationProtocolsforDynamicSparseDataExchange151AdvancedMPI,SC17(11/13/2017)

Parallel Breadth First Search
§ OnaclusteredErdős-Rényi graph,weakscaling– 6.75millionedgespernode(filled1GiB)
§ HWbarriersupportissignificantatlargescale!
BlueGene/P– withHWbarrier! Myrinet 2000withLibNBC
T.Hoefleretal.:ScalableCommunicationProtocolsforDynamicSparseDataExchange152AdvancedMPI,SC17(11/13/2017)

Parallel Fast Fourier Transform
§ 1DFFTsinallthreedimensions– Assume1Ddecomposition(eachprocessholdsasetofplanes)
– Bestway:calloptimized1DFFTsinparallelà alltoall
– Red/yellow/greenarethe(three)differentprocesses!
à Alltoall
153AdvancedMPI,SC17(11/13/2017)

A Complex Example: FFT
for(int x=0; x<n/p; ++x) 1d_fft(/* x-th stencil */);
// pack data for alltoallMPI_Alltoall(&in, n/p*n/p, cplx_t, &out, n/p*n/p, cplx_t, comm);// unpack data from alltoall and transpose
for(int y=0; y<n/p; ++y) 1d_fft(/* y-th stencil */);
// pack data for alltoallMPI_Alltoall(&in, n/p*n/p, cplx_t, &out, n/p*n/p, cplx_t, comm);// unpack data from alltoall and transpose
Hoefler:LeveragingNon-blockingCollectiveCommunicationinHigh-performanceApplications154AdvancedMPI,SC17(11/13/2017)

Parallel Fast Fourier Transform
§ Dataalreadytransformediny-direction
155AdvancedMPI,SC17(11/13/2017)

Parallel Fast Fourier Transform
§ Transformfirsty planeinz
156AdvancedMPI,SC17(11/13/2017)

Parallel Fast Fourier Transform
§ Startialltoall andtransformsecondplane
157AdvancedMPI,SC17(11/13/2017)
Parallel Fast Fourier Transform
§ Startialltoall (secondplane)andtransformthird
158AdvancedMPI,SC17(11/13/2017)
Parallel Fast Fourier Transform
§ Startialltoall ofthirdplaneand…
159AdvancedMPI,SC17(11/13/2017)

Parallel Fast Fourier Transform
§ Finishialltoall offirstplane,startx transform
160AdvancedMPI,SC17(11/13/2017)

Parallel Fast Fourier Transform
§ Finishsecondialltoall,transformsecondplane
161AdvancedMPI,SC17(11/13/2017)

Parallel Fast Fourier Transform
§ Transformlastplane→done
162AdvancedMPI,SC17(11/13/2017)

FFT Software Pipelining
AdvancedMPI,SC17(11/13/2017) 163
MPI_Request req[nb];for(int b=0; b<nb; ++b) { // loop over blocksfor(int x=b*n/p/nb; x<(b+1)n/p/nb; ++x) 1d_fft(/* x-th stencil*/);
// pack b-th block of data for alltoallMPI_Ialltoall(&in, n/p*n/p/bs, cplx_t, &out, n/p*n/p, cplx_t, comm, &req[b]);
}MPI_Waitall(nb, req, MPI_STATUSES_IGNORE);
// modified unpack data from alltoall and transposefor(int y=0; y<n/p; ++y) 1d_fft(/* y-th stencil */);// pack data for alltoallMPI_Alltoall(&in, n/p*n/p, cplx_t, &out, n/p*n/p, cplx_t, comm);// unpack data from alltoall and transpose
Hoefler:LeveragingNon-blockingCollectiveCommunicationinHigh-performanceApplications

Nonblocking Collectives Summary
§ Nonblocking communicationdoestwothings:– Overlapandrelaxsynchronization
§ Collectivecommunicationdoesonething– Specializedpre-optimizedroutines
– Performanceportability
– Hopefullytransparentperformance
§ Theycanbecomposed– E.g.,softwarepipelining
164AdvancedMPI,SC17(11/13/2017)

Topologies and Topology Mapping
AdvancedMPI,SC17(11/13/2017) 165

Topology Mapping and Neighborhood Collectives
§ Topologymappingbasics– Allocationmappingvs.rankreordering
– Ad-hocsolutionsvs.portability
§ MPItopologies– Cartesian
– Distributedgraph
§ Collectivesontopologies– neighborhoodcollectives– Usecases
166AdvancedMPI,SC17(11/13/2017)

Topology Mapping Basics
§ MPIsupportsrankreordering– Changenumberinginagivenallocationtoreducecongestionor
dilation
– Sometimesautomatic(earlyIBMSPmachines)
§ Properties– Alwayspossible,buteffectmaybelimited(e.g.,inabadallocation)
– Portableway:MPIprocesstopologies• Networktopologyisnotexposed
– Manualdatashufflingafterremappingstep
167AdvancedMPI,SC17(11/13/2017)

Example: On-Node Reordering
NaïveMapping OptimizedMapping
Topomap
Gottschling etal.:ProductiveParallelLinearAlgebraProgrammingwithUnstructuredTopologyAdaption168AdvancedMPI,SC17(11/13/2017)
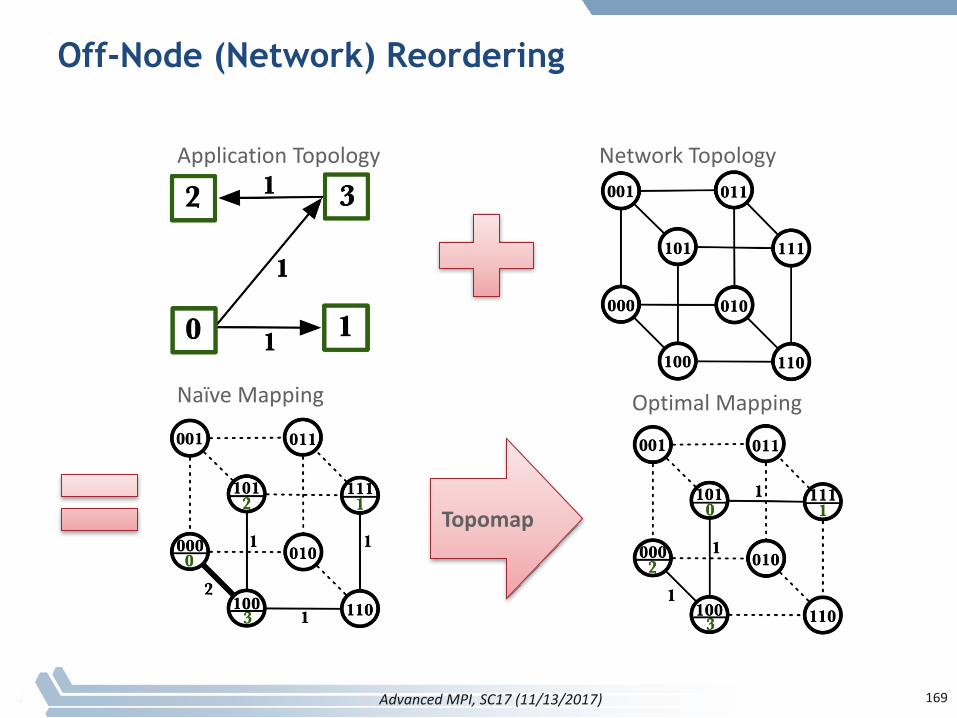
Off-Node (Network) Reordering
ApplicationTopology NetworkTopology
NaïveMapping OptimalMapping
Topomap
169AdvancedMPI,SC17(11/13/2017)

MPI Topology Intro
§ Conveniencefunctions(inMPI-1)– Createagraphandqueryit,nothingelse
– UsefulespeciallyforCartesiantopologies• Queryneighborsinn-dimensionalspace
– Graphtopology:eachrankspecifiesfullgraphL
§ ScalableGraphtopology(MPI-2.2)– Graphtopology:eachrankspecifiesitsneighborsor anarbitrary
subsetofthegraph
§ Neighborhoodcollectives(MPI-3.0)– Addingcommunicationfunctionsdefinedongraphtopologies
(neighborhoodofdistanceone)
170AdvancedMPI,SC17(11/13/2017)

MPI_Cart_create
§ Specifyndims-dimensionaltopology– Optionallyperiodicineachdimension(Torus)
§ SomeprocessesmayreturnMPI_COMM_NULL– Productsumofdimsmustbe<=P
§ Reorderargumentallowsfortopologymapping– Eachcallingprocessmayhaveanewrankinthecreatedcommunicator
– Datahastoberemappedmanually
171AdvancedMPI,SC17(11/13/2017)
MPI_Cart_create(MPI_Comm comm_old, int ndims, const int *dims,const int *periods, int reorder, MPI_Comm *comm_cart)

MPI_Cart_create Example
§ Createslogical3DTorusofsize5x5x5
§ Butwe’restartingMPIprocesseswithaone-dimensionalargument(-pX)– Userhastodeterminesizeofeachdimension
– Oftenas“square”aspossible,MPIcanhelp!
172AdvancedMPI,SC17(11/13/2017)
int dims[3] = {5,5,5};int periods[3] = {1,1,1};MPI_Comm topocomm;MPI_Cart_create(comm, 3, dims, periods, 0, &topocomm);

MPI_Dims_create
§ CreatedimsarrayforCart_create withnnodes andndims– Dimensionsareascloseaspossible(well,intheory)
§ Non-zeroentriesindimswillnotbechanged– nnodes mustbemultipleofallnon-zeroes
173AdvancedMPI,SC17(11/13/2017)
MPI_Dims_create(int nnodes, int ndims, int *dims)

MPI_Dims_create Example
§ Makeslifealittlebiteasier– Someproblemsmaybebetterwithanon-squarelayoutthough
174AdvancedMPI,SC17(11/13/2017)
int p;MPI_Comm_size(MPI_COMM_WORLD, &p);MPI_Dims_create(p, 3, dims);
int periods[3] = {1,1,1};MPI_Comm topocomm;MPI_Cart_create(comm, 3, dims, periods, 0, &topocomm);

Cartesian Query Functions
§ Librarysupportandconvenience!
§ MPI_Cartdim_get()– GetsdimensionsofaCartesiancommunicator
§ MPI_Cart_get()– Getssizeofdimensions
§ MPI_Cart_rank()– Translatecoordinatestorank
§ MPI_Cart_coords()– Translateranktocoordinates
175AdvancedMPI,SC17(11/13/2017)

Cartesian Communication Helpers
§ Shiftinonedimension– Dimensionsarenumberedfrom0tondims-1
– Displacementindicatesneighbordistance(-1,1,…)
– MayreturnMPI_PROC_NULL
§ Veryconvenient,allyouneedfornearestneighborcommunication– No“overtheedge”though
176AdvancedMPI,SC17(11/13/2017)
MPI_Cart_shift(MPI_Comm comm, int direction, int disp,int *rank_source, int *rank_dest)
Code Example
§ stencil-mpi-carttopo.c
§ Addscalculationofneighborswithtopology
AdvancedMPI,SC17(11/13/2017) 177
bx
by

MPI_Graph_create(MPI_Comm comm_old, int nnodes,const int *index, const int *edges, int reorder,MPI_Comm *comm_graph)
MPI_Graph_create
§ Don’tuse!!!!!
§ nnodes isthetotalnumberofnodes
§ indexi storesthetotalnumberofneighborsforthefirstinodes(sum)– Actsasoffsetintoedgesarray
§ edgesstorestheedgelistforallprocesses– Edgelistforprocessjstartsatindex[j]inedges
– Processjhasindex[j+1]-index[j]edges
178AdvancedMPI,SC17(11/13/2017)

Distributed graph constructor
§ MPI_Graph_create isdiscouraged– Notscalable
– Notdeprecatedyetbuthopefullysoon
§ Newdistributedinterface:– Scalable,allowsdistributedgraphspecification
• Eitherlocalneighborsor anyedgeinthegraph
– Specifyedgeweights• Meaningundefinedbutoptimizationopportunityforvendors!
– Infoarguments• CommunicateassertionsofsemanticstotheMPIlibrary
• E.g.,semanticsofedgeweights
Hoefleretal.:TheScalableProcessTopologyInterfaceofMPI2.2179AdvancedMPI,SC17(11/13/2017)

MPI_Dist_graph_create_adjacent
§ indegree,sources,~weights– sourceproc.Spec.§ outdegree,destinations,~weights– dest.proc.spec.§ info,reorder,comm_dist_graph – asusual§ directedgraph§ Eachedgeisspecifiedtwice,onceasout-edge(atthesource)
andonceasin-edge(atthedest)
Hoefleretal.:TheScalableProcessTopologyInterfaceofMPI2.2180AdvancedMPI,SC17(11/13/2017)
MPI_Dist_graph_create_adjacent(MPI_Comm comm_old,int indegree, const int sources[], const int sourceweights[],int outdegree, const int destinations[],const int destweights[], MPI_Info info, int reorder,MPI_Comm *comm_dist_graph)
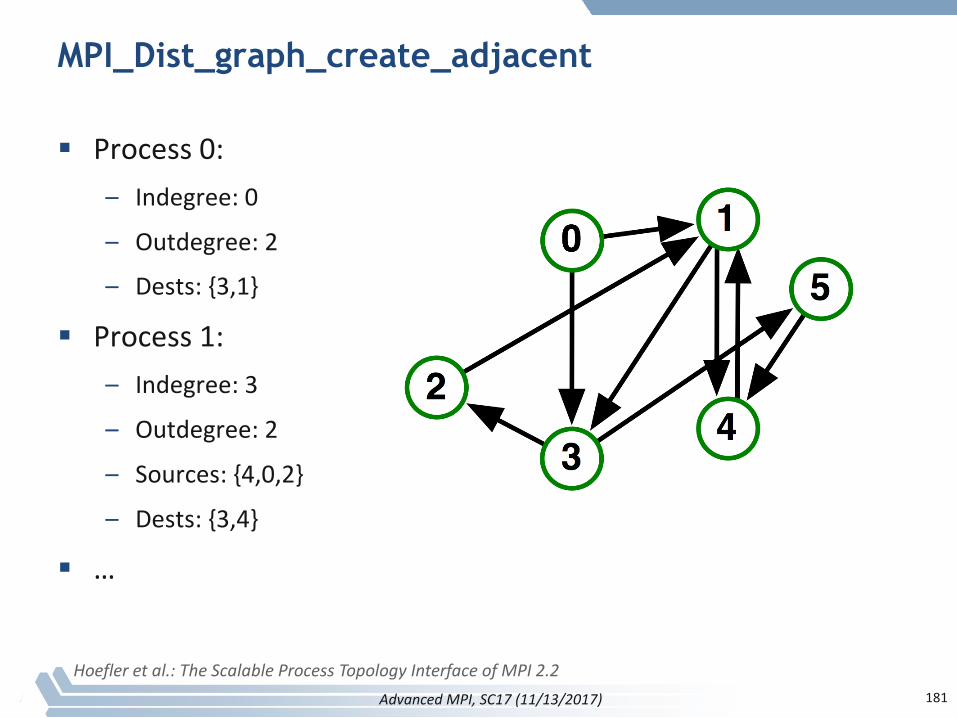
MPI_Dist_graph_create_adjacent
§ Process0:– Indegree:0
– Outdegree:2
– Dests:{3,1}
§ Process1:– Indegree:3
– Outdegree:2
– Sources:{4,0,2}
– Dests:{3,4}
§ …
Hoefleretal.:TheScalableProcessTopologyInterfaceofMPI2.2181AdvancedMPI,SC17(11/13/2017)

MPI_Dist_graph_create
§ n– numberofsourcenodes§ sources– nsourcenodes§ degrees– numberofedgesforeachsource§ destinations,weights– dest.processorspecification§ info,reorder– asusual§ Moreflexibleandconvenient
– Requiresglobalcommunication– Slightlymoreexpensivethanadjacentspecification
182AdvancedMPI,SC17(11/13/2017)
MPI_Dist_graph_create(MPI_Comm comm_old, int n,const int sources[], const int degrees[],const int destinations[], const int weights[], MPI_Info info,int reorder, MPI_Comm *comm_dist_graph)

MPI_Dist_graph_create
§ Process0:– N:2
– Sources:{0,1}
– Degrees:{2,1} *
– Dests:{3,1,4}
§ Process1:– N:2
– Sources:{2,3}
– Degrees:{1,1}
– Dests:{1,2}
§ …
Hoefleretal.:TheScalableProcessTopologyInterfaceofMPI2.2183
*Notethatinthisexample,process0specifiesonlyoneofthetwooutgoingedgesofprocess1;thesecondoutgoingedgeneedstobespecifiedbyanotherprocess
AdvancedMPI,SC17(11/13/2017)

Distributed Graph Neighbor Queries
§ Querythenumberofneighborsofcallingprocess§ Returnsindegree andoutdegree!§ Alsoinfoifweighted
Hoefleretal.:TheScalableProcessTopologyInterfaceofMPI2.2184AdvancedMPI,SC17(11/13/2017)
§ Querytheneighborlistofcallingprocess
§ Optionallyreturnweights
MPI_Dist_graph_neighbors_count(MPI_Comm comm,int *indegree,int *outdegree, int *weighted)
MPI_Dist_graph_neighbors(MPI_Comm comm, int maxindegree,int sources[], int sourceweights[], int maxoutdegree,int destinations[],int destweights[])

Further Graph Queries
§ Statusiseither:– MPI_GRAPH(ugs)
– MPI_CART
– MPI_DIST_GRAPH
– MPI_UNDEFINED(notopology)
§ EnablesustowritelibrariesontopofMPItopologies!
185AdvancedMPI,SC17(11/13/2017)
MPI_Topo_test(MPI_Comm comm, int *status)

Neighborhood Collectives
§ Topologiesimplementnocommunication!– Justhelperfunctions
§ Collectivecommunicationsonlycoversomepatterns– E.g.,nostencilpattern
§ Severalrequestsfor“buildyourowncollective”functionalityinMPI– Neighborhoodcollectivesareasimplifiedversion
– Cf.Datatypesforcommunicationpatterns!
186AdvancedMPI,SC17(11/13/2017)

Cartesian Neighborhood Collectives
§ CommunicatewithdirectneighborsinCartesiantopology– Correspondstocart_shift withdisp=1
– Collective(allprocessesincommmustcallit,includingprocesseswithoutneighbors)
– Buffersarelaidoutasneighborsequence:• Definedbyorderofdimensions,firstnegative,thenpositive
• 2*ndims sourcesanddestinations
• Processesatborders(MPI_PROC_NULL)leaveholesinbuffers(willnotbeupdatedorcommunicated)!
T.HoeflerandJ.L.Traeff:SparseCollectiveOperationsforMPI187AdvancedMPI,SC17(11/13/2017)
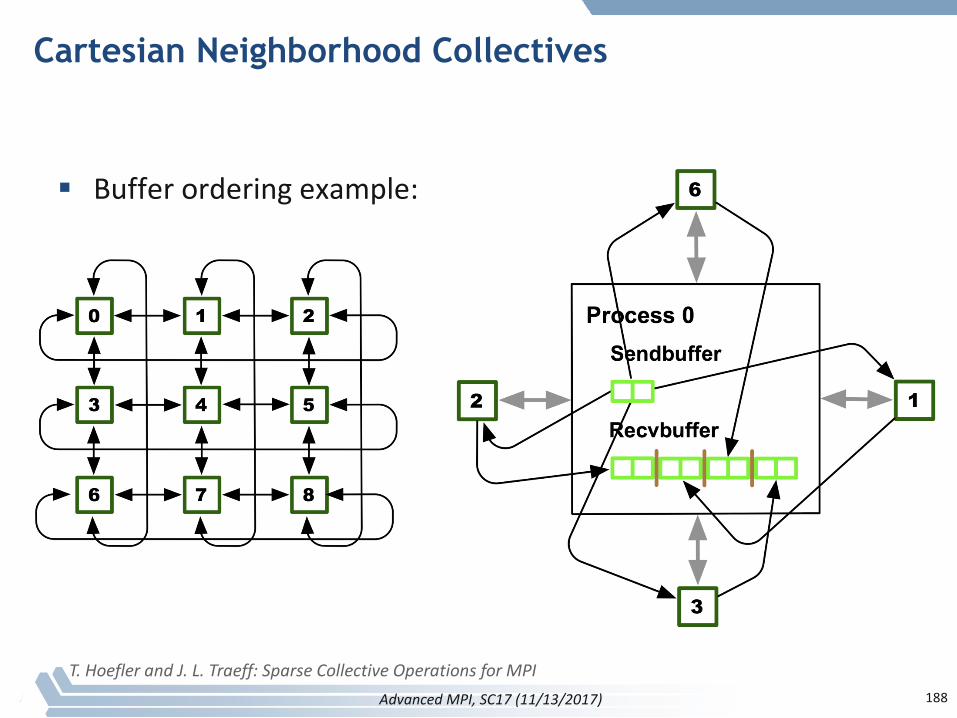
Cartesian Neighborhood Collectives
§ Bufferorderingexample:
T.HoeflerandJ.L.Traeff:SparseCollectiveOperationsforMPI188AdvancedMPI,SC17(11/13/2017)

Graph Neighborhood Collectives
§ CollectiveCommunicationalongarbitraryneighborhoods– Orderisdeterminedbyorderofneighborsasreturnedby
(dist_)graph_neighbors.
– Distributedgraphisdirected,mayhavedifferentnumbersofsend/recv neighbors
– CanexpressdensecollectiveoperationsJ
– Anypersistentcommunicationpattern!
T.HoeflerandJ.L.Traeff:SparseCollectiveOperationsforMPI189AdvancedMPI,SC17(11/13/2017)

MPI_Neighbor_allgather
§ Sendsthesamemessagetoallneighbors
§ Receivesindegree distinctmessages
§ SimilartoMPI_Gather– Theallprefixexpressesthateachprocessisa“root”ofhis
neighborhood
§ Vectorversionforfullflexibility
190AdvancedMPI,SC17(11/13/2017)
MPI_Neighbor_allgather(const void* sendbuf, int sendcount,MPI_Datatype sendtype, void* recvbuf, int recvcount,MPI_Datatype recvtype, MPI_Comm comm)

MPI_Neighbor_alltoall
§ Sendsoutdegree distinctmessages
§ Receivedindegree distinctmessages
§ SimilartoMPI_Alltoall– Neighborhoodspecifiesfullcommunicationrelationship
§ Vectorandwversionsforfullflexibility
191AdvancedMPI,SC17(11/13/2017)
MPI_Neighbor_alltoall(const void* sendbuf, int sendcount,MPI_Datatype sendtype, void* recvbuf, int recvcount,MPI_Datatype recvtype, MPI_Comm comm)

Nonblocking Neighborhood Collectives
§ Verysimilartononblockingcollectives
§ Collectiveinvocation
§ Matchingin-order(notags)– Nowildtrickswithneighborhoods!Inordermatchingper
communicator!
192AdvancedMPI,SC17(11/13/2017)
MPI_Ineighbor_allgather(…, MPI_Request *req);MPI_Ineighbor_alltoall(…, MPI_Request *req);

Code Example
§ stencil_mpi_carttopo_neighcolls.c
§ Addsneighborhoodcollectivestothetopology
AdvancedMPI,SC17(11/13/2017) 193

Why is Neighborhood Reduce Missing?
§ Wasoriginallyproposed(seeoriginalpaper)
§ Highoptimizationopportunities– Interestingtradeoffs!
– Researchtopic
§ Notstandardizedduetomissingusecases– Myteamisworkingonanimplementation
– Offeringtheobviousinterface
MPI_Ineighbor_allreducev(…);
T.HoeflerandJ.L.Traeff:SparseCollectiveOperationsforMPI194AdvancedMPI,SC17(11/13/2017)

Topology Summary
§ Topologyfunctionsallowuserstospecifyapplicationcommunicationpatterns/topology– Conveniencefunctions(e.g.,Cartesian)
– Storingneighborhoodrelations(Graph)
§ Enablestopologymapping(reorder=1)– Notwidelyimplementedyet
– Mayrequiresmanualdatare-distribution(accordingtonewrankorder)
§ MPIdoesnotexposeinformationaboutthenetworktopology(wouldbeverycomplex)
195AdvancedMPI,SC17(11/13/2017)

Neighborhood Collectives Summary
§ Neighborhoodcollectivesaddcommunicationfunctionstoprocesstopologies– Collectiveoptimizationpotential!
§ Allgather– Oneitemtoallneighbors
§ Alltoall– Personalizeditemtoeachneighbor
§ Highoptimizationpotential(similartocollectiveoperations)– Interfaceencouragesuseoftopologymapping!
196AdvancedMPI,SC17(11/13/2017)

Section Summary
§ Processtopologiesenable:– High-abstractiontospecifycommunicationpattern
– Hastoberelativelystatic(temporallocality)• Creationisexpensive(collective)
– Offersbasiccommunicationfunctions
§ Librarycanoptimize:– Communicationscheduleforneighborhoodcolls
– Topologymapping
197AdvancedMPI,SC17(11/13/2017)

Please submit a tutorial evaluation
§ Itisusefulinplanningnextyear’stutorialprogram
§ URL:http://bit.ly/sc17-eval
§ QRCode
AdvancedMPI,SC17(11/13/2017) 198

Recent Efforts of the MPI Forum for MPI-4 and Future MPI Standards

Introduction
§ TheMPIForumcontinuestomeetevery3monthstodefinefutureversionsoftheMPIStandard
§ WedescribesomeoftheproposalstheForumiscurrentlyconsidering
§ NoneofthesetopicsareguaranteedtobeinMPI-4– Thesearesimplyproposalsthatarebeingconsidered
AdvancedMPI,SC17(11/13/2017) 200

MPI Working Groups
§ Point-to-pointcommunication
§ Faulttolerance
§ Hybridprogramming
§ Persistence
§ Toolsinterfaces
§ Largecounts
§ Others:RMA,Collectives,I/O
§ http://mpi-forum.org/meetings/
AdvancedMPI,SC17(11/13/2017) 201

Point-to-Point Working Group
AdvancedMPI,SC17(11/13/2017) 202
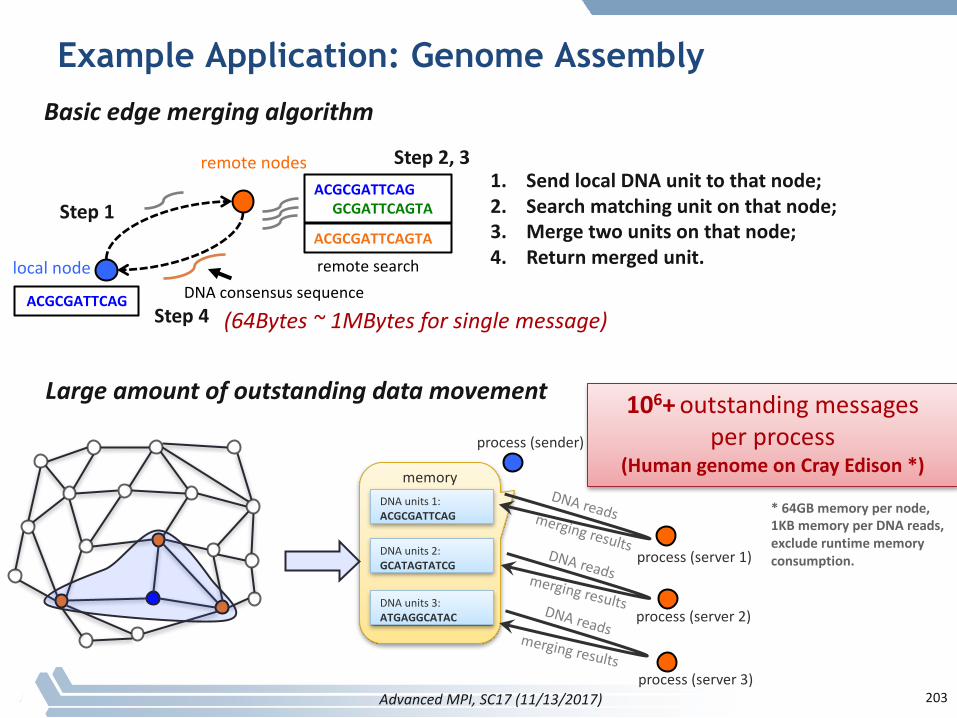
Example Application: Genome AssemblyBasicedgemergingalgorithm
106+outstandingmessagesperprocess
(HumangenomeonCrayEdison*)
remotesearchlocalnode
remotenodesACGCGATTCAG
GCGATTCAGTA
DNAconsensussequence
1. SendlocalDNAunittothatnode;2. Searchmatchingunitonthatnode;3. Mergetwounitsonthatnode;4. Returnmergedunit.
ACGCGATTCAG
ACGCGATTCAGTA
(64Bytes~1MBytesforsinglemessage)
Step1
Step2,3
Step4
process(server1)
process(server2)
process(server3)
DNAunits1:ACGCGATTCAG
DNAunits3:ATGAGGCATAC
DNAunits2:GCATAGTATCG
memory
process(sender)
*64GBmemorypernode,1KBmemoryperDNAreads,excluderuntimememoryconsumption.
Largeamountofoutstandingdatamovement
AdvancedMPI,SC17(11/13/2017) 203

Proposal 1: Batched Communication Operations
§ MPI-3.1semantics– Eachpoint-to-pointoperationcreatesanewrequestobject
– MPIlibrarymightrunoutofrequestobjectsafterafewthousandoperations
– Applicationcannotissuealotofmessagestofullyutilizethenetwork
§ Batchedoperations– RMA-likesemanticsforMPIsend/recv communication
• Applicationfreesrequestassoonastheoperationisissued
• Batchcompletionofalloperationsonacommunicator
– MPI_COMM_WAITALL
– Proportionallyreducednumberofrequests
– Canallowapplicationstoconsolidatemultiplecompletionsintoasinglerequest
AdvancedMPI,SC17(11/13/2017) 204

Proposal 2: Communication Relaxation Hints
§ mpi_assert_no_any_tag– TheprocesswillnotuseMPI_ANY_TAG
§ mpi_assert_no_any_source– TheprocesswillnotuseMPI_ANY_SOURCE
§ mpi_assert_exact_length– Receivebuffersmustbecorrectsizeformessages
§ mpi_assert_overtaking_allowed– Allmessagesarelogicallyconcurrent
AdvancedMPI,SC17(11/13/2017) 205

Fault Tolerance Working Group
AdvancedMPI,SC17(11/13/2017) 206

207
Improved Support for Fault Tolerance
§ MPIalwayshadsupportforerrorhandlersandallowsimplementationstoreturnanerrorcodeandremainalive
§ MPIForumworkingonadditionalsupportforMPI-4
§ Currentproposalhandlesfail-stopprocessfailures(notsilentdatacorruptionorByzantinefailures)§ Ifacommunicationoperationfailsbecausetheotherprocesshasfailed,thefunction
returnserrorcodeMPI_ERR_PROC_FAILED
§ UsercancallMPI_Comm_shrink tocreateanewcommunicatorthatexcludesfailedprocesses
§ Collectivecommunicationcanbeperformedonthenewcommunicator
AdvancedMPI,SC17(11/13/2017)

Proposal 1: Noncatastrophic Errors
§ CurrentlythestateofMPIisundefinedifanyerroroccurs§ Evensimpleerrors,suchasincorrectarguments,cancausethe
stateofMPItobeundefined§ Noncatastrophic errorsareanopportunityfortheMPI
implementationtodefinesomeerrorsas“ignorable”§ Foranerror,theusercanqueryifitiscatastrophicornot§ Iftheerrorisnotcatastrophic,theusercansimplypretendlike
(s)heneverissuedtheoperationandcontinue
208

Proposal 2: Error Handlers
§ Cleanersemanticsforerrorhandling§ EvenwithMPI-3.1,errorsarenotalwaysfatal
– Butsemanticsoferrorhandlingarecumbersometouse– Theirspecificationcanusemoreprecision
§ Howareerrorhandlersinherited?§ MovedefaulterrorhandlersfromMPI_COMM_WORLDto
MPI_COMM_SELF
209

Proposal 3: User Level Failure Mitigation
●Enableapplication-levelrecoverybyprovidingminimalFTAPItopreventdeadlockandenablerecovery
●Don’tdorecoveryfortheapplication,butlettheapplication(oralibrary)dowhatisbest.
●Currentlyfocusedonprocessfailure(notdataerrorsorprotection)
210

Hybrid Programming Working Group
AdvancedMPI,SC17(11/13/2017) 211

MPI-3.1 Performance/Interoperability Concerns
§ ResourcesharingbetweenMPIprocesses– Systemresourcesdonotscaleatthesamerateasprocessingcores
• Memory,networkendpoints,TLBentries,…• Sharingisnecessary
– MPI+threads givesamethodforsuchsharingofresources
§ PerformanceConcerns– MPI-3.1providesasingleviewoftheMPIstacktoallthreads
• RequiresallMPIobjects(requests,communicators)tobesharedbetweenallthreads
• Notscalabletolargenumberofthreads• Inefficientwhensharingofobjectsisnotrequiredbytheuser
– MPI-3.1doesnotallowahigh-levellanguagetointerchangeablyuseOSprocessesorthreads• Nonotionofaddressingasingleoracollectionofthreads• Needstobeemulatedwithtagsorcommunicators
AdvancedMPI,SC17(11/13/2017) 212

MPI Endpoints: Proposal for MPI-4
§ Havemultipleaddressablecommunicationentitieswithinasingleprocess– InstantiatedintheformofmultipleranksperMPIprocess
§ Eachrankcanbeassociatedwithoneormorethreads
§ Lessercontentionforcommunicationoneach“rank”
§ Intheextremecase,wecouldhaveonerankperthread(orsomeranksmightbeusedbyasinglethread)
AdvancedMPI,SC17(11/13/2017) 213
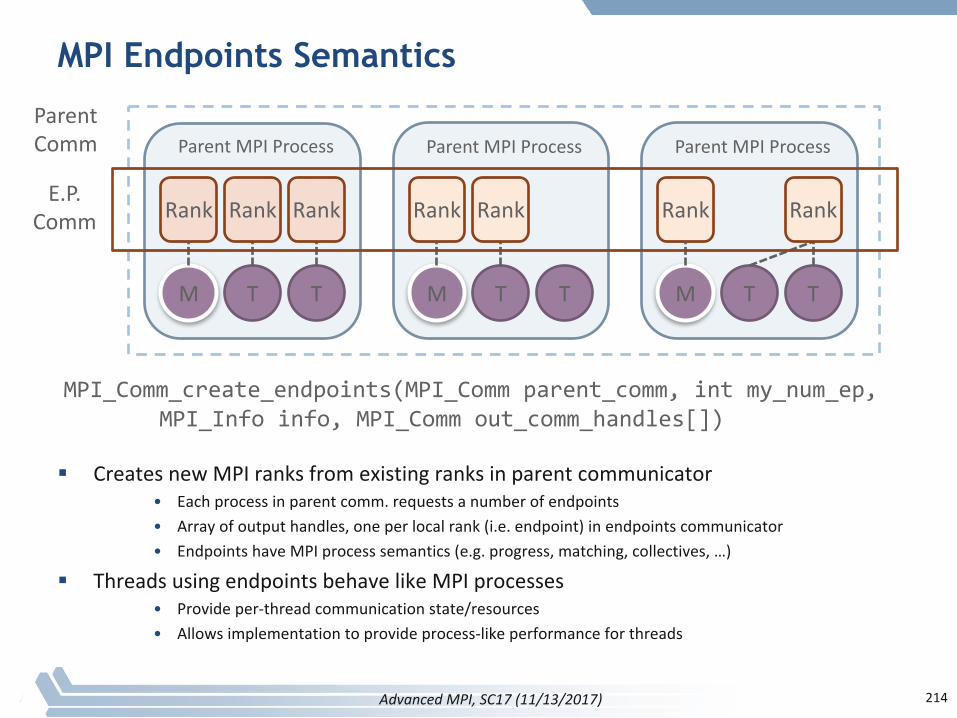
MPI Endpoints Semantics
§ CreatesnewMPIranksfromexistingranksinparentcommunicator• Eachprocessinparentcomm.requestsanumberofendpoints• Arrayofoutputhandles,oneperlocalrank(i.e.endpoint)inendpointscommunicator• EndpointshaveMPIprocesssemantics(e.g.progress,matching,collectives,…)
§ ThreadsusingendpointsbehavelikeMPIprocesses• Provideper-threadcommunicationstate/resources• Allowsimplementationtoprovideprocess-likeperformanceforthreads
ParentComm
Rank
M T T
ParentMPIProcess
RankRank Rank
M T T
ParentMPIProcess
Rank Rank
M T T
ParentMPIProcess
RankE.P.
Comm
MPI_Comm_create_endpoints(MPI_Comm parent_comm, int my_num_ep,MPI_Info info, MPI_Comm out_comm_handles[])
AdvancedMPI,SC17(11/13/2017) 214

Persistence Working Group
AdvancedMPI,SC17(11/13/2017) 215

Persistent Collective Operations
§ Anall-to-alltransferisdonemanytimesinanapplication
§ Thespecificsendsandreceivesrepresentedneverchange(size,type,lengths,transfers)
§ Anonblocking persistentcollectiveoperationcantakethetimetoapplyaheuristicandchooseafasterwaytomovethatdata
§ Fixedcostofmakingthosedecisionscouldbehigh(areamortizedoverallthetimesthefunctionisused
§ Staticresourceallocationcanbedone
§ Choosefast(er)algorithm,takeadvantageofspecialcases
§ Reducequeueingcosts
§ Speciallimitedhardwarecanbeallocatedifavailable
§ Choiceofmultipletransferpathscouldalsobeperformed
AdvancedMPI,SC17(11/13/2017) 216

Basics
§ Mirrorregularnonblocking collectiveoperations
§ Foreachnonblocking MPIcollective,addapersistentvariant
§ ForeveryMPI_I<coll>,addMPI_<coll>_init
§ Parametersareidenticaltothecorrespondingnonblockingvariant
§ Allarguments“fixed”forsubsequentuses
§ Persistentcollectiveoperationscannotbematchedwithblockingornonblocking collectivecalls
AdvancedMPI,SC17(11/13/2017) 217

Init/Start
§ Theinit functioncallsonlyperforminitialization;donotstarttheoperation
§ E.g.,MPI_Allreduce_init– Producesapersistentrequest(notdestroyedbycompletion)
§ WorkswithMPI_Start/MPI_Startall (cannothavemultipleoperationsonthesamecommunicatorinStartall)
§ Onlyinactiverequestscanbestarted
§ MPI_Request_free canfreeinactiverequests
AdvancedMPI,SC17(11/13/2017) 218

Ordering of Inits and Starts
§ Inits arenonblocking collectivecallsandmustbeordered
§ Persistentcollectiveoperationsmustbestartedinthesameorderatallprocesses
§ Startall cannotcontainmultipleoperationsonthesamecommunicatorduetoorderingambiguity
AdvancedMPI,SC17(11/13/2017) 219

Example
AdvancedMPI,SC17(11/13/2017) 220

Tools Working Group
AdvancedMPI,SC17(11/13/2017) 221

Active Proposals (1/2)
§ NewinterfacetoreplacePMPI– Known,longstandingproblemswiththecurrentprofilinginterface
PMPI• Onetoolatatimecanuseit
• Forcestoolstobemonolithic(asinglesharedlibrary)
• TheinterceptionmodelisOSdependent
– Newinterface• Callbackdesign
• Multipletoolscanpotentiallyattach
• Maintainalloldfunctionality
§ NewfeatureforeventnotificationinMPI_T– PERUSE
– Toolregistersforinterestingeventandgetscallbackwhenithappens
AdvancedMPI,SC17(11/13/2017) 222

Active Proposals (2/2)
§ Debuggersupport- MPIRinterface– Fixingsomebugsintheoriginal“blessed”document
• Missinglinenumbers!
– Supportnon-traditionalMPIimplementations• Ranksareimplementedasthreads
– Supportfordynamicapplications• Commercialapplications/Ensembleapplications
• Faulttolerance
– HandleIntrospectionInterface• SeeinsideMPItogetdetailsaboutMPIObjects
– Communicators,FileHandles,etc.
AdvancedMPI,SC17(11/13/2017) 223

Sessions Working Group
AdvancedMPI,SC17(11/13/2017) 224
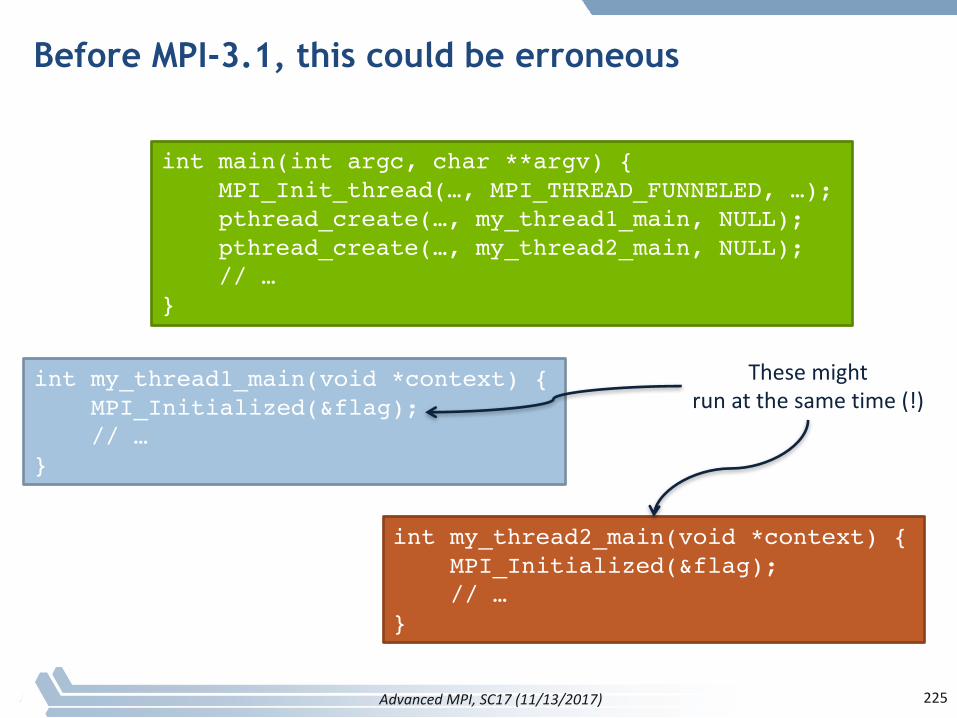
Before MPI-3.1, this could be erroneous
int my_thread1_main(void *context) {MPI_Initialized(&flag);// …
}
int my_thread2_main(void *context) {MPI_Initialized(&flag);// …
}
int main(int argc, char **argv) {MPI_Init_thread(…, MPI_THREAD_FUNNELED, …);pthread_create(…, my_thread1_main, NULL);pthread_create(…, my_thread2_main, NULL);// …
}
Thesemightrunatthesametime(!)
AdvancedMPI,SC17(11/13/2017) 225

What we want
§ Anythread(e.g.,library)canuseMPIanytimeitwants
§ ButstillbeabletototallycleanupMPIif/whendesired
§ NewparameterstoinitializetheMPIAPI
MPIProcess// Library 1MPI_Init(…);
// Library 2MPI_Init(…);
// Library 3MPI_Init(…);
// Library 4MPI_Init(…);
// Library 5MPI_Init(…);
// Library 6MPI_Init(…);// Library 7
MPI_Init(…);
// Library 8MPI_Init(…);
// Library 9MPI_Init(…);
// Library 10MPI_Init(…);
// Library 11MPI_Init(…);
// Library 12MPI_Init(…);
AdvancedMPI,SC17(11/13/2017) 226
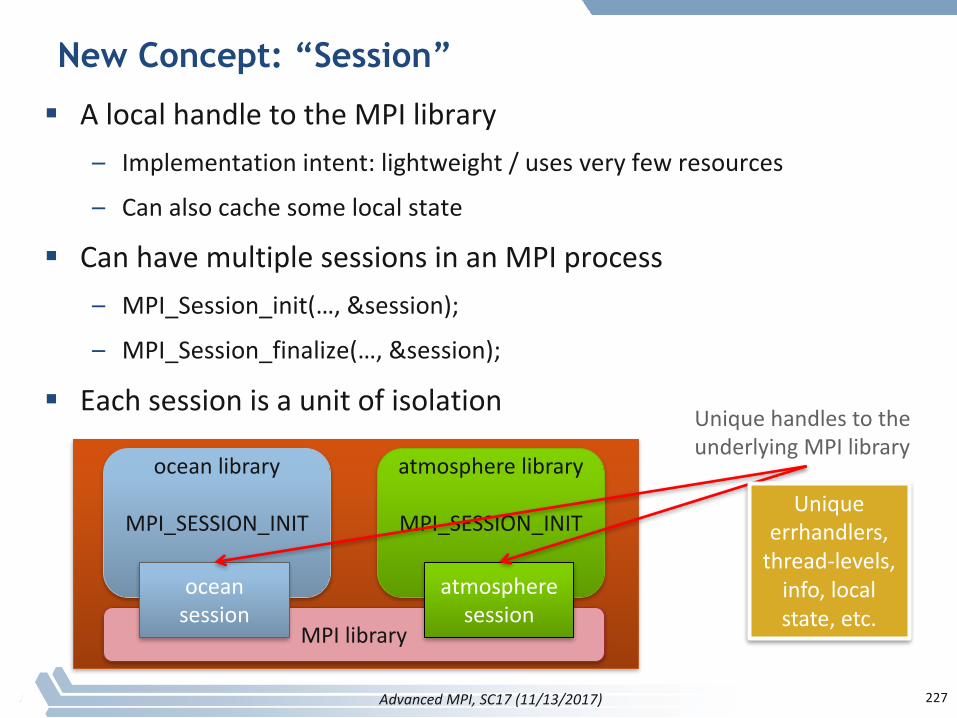
New Concept: “Session”
§ AlocalhandletotheMPIlibrary– Implementationintent:lightweight/usesveryfewresources
– Canalsocachesomelocalstate
§ CanhavemultiplesessionsinanMPIprocess– MPI_Session_init(…,&session);
– MPI_Session_finalize(…,&session);
§ Eachsessionisaunitofisolation
oceanlibrary
MPI_SESSION_INIT
atmospherelibrary
MPI_SESSION_INIT
MPIlibrary
oceansession
atmospheresession
UniquehandlestotheunderlyingMPIlibrary
Uniqueerrhandlers,thread-levels,info,localstate,etc.
AdvancedMPI,SC17(11/13/2017) 227
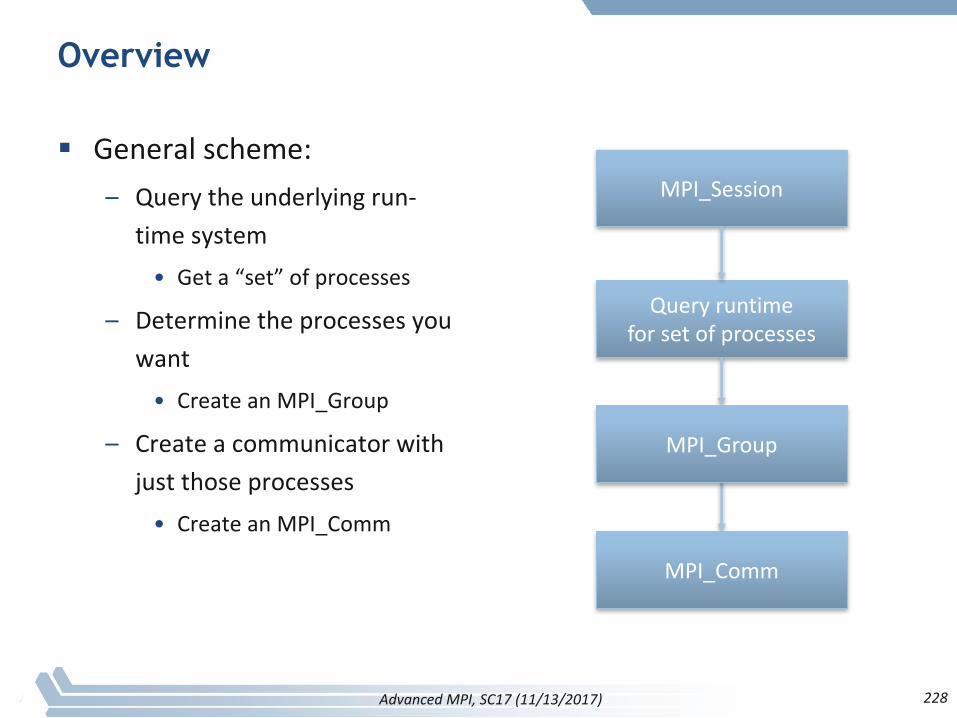
Overview
§ Generalscheme:– Querytheunderlyingrun-
timesystem• Geta“set”ofprocesses
– Determinetheprocessesyouwant• CreateanMPI_Group
– Createacommunicatorwithjustthoseprocesses• CreateanMPI_Comm
Queryruntimeforsetofprocesses
MPI_Group
MPI_Comm
MPI_Session
AdvancedMPI,SC17(11/13/2017) 228

Static sets of processes
§ Twosetsaremandatedtoexist1. AsetofprocesseseffectivelyequivalenttotheprocessesinMPI-
3.1’sMPI_COMM_WORLD
2. Asetcontainingonlyasingleprocess
§ Setsareidentifiedbystringname– “mpi://WORLD”:referstoset#1,above
– “mpi://SELF”:referstoset#2,above
§ Bydefinition,processeswillbeinmorethanoneset
AdvancedMPI,SC17(11/13/2017) 229

Large Counts Working Group
AdvancedMPI,SC17(11/13/2017) 230

Problem with Large Counts
§ MPI_Send/Recv andotherfunctionstake“int”asthecountfordata– Whathappensfordatalargerthan2GBxdatatype size?
– Youcreateanewlarge“contiguous”deriveddatatype andsendthat
– Possible,butclumsy
§ WhataboutduplicatingallMPIfunctionstochange“int”to“MPI_Count”(whichisalarge,typically64-bit,integer)– DoublesthenumberofMPIfunctions
– Possible,butclumsy
AdvancedMPI,SC17(11/13/2017) 231

New C11 Bindings
§ UseC11_Generictypetoprovidemultiplefunctionprototypes– LikeC++functionoverloading,butdonewithcompiletimemacro
replacement
§ MPI_Send willhavetwofunctionsignatures– Onefortraditional“int”arguments
– Onefornew“MPI_Count”arguments
§ Fullybackwardcompatibleforexistingapplications
§ Newapplicationscanpromotetheirdatalengthsto64-bitwithoutchangingfunctionseverywhere
AdvancedMPI,SC17(11/13/2017) 232

Concluding Remarks

Conclusions
§ Parallelismiscriticaltoday,giventhatitistheonlywaytoachieveperformanceimprovementwithmodernhardware
§ MPIisanindustrystandardmodelforparallelprogramming– AlargenumberofimplementationsofMPIexist(bothcommercialand
publicdomain)
– VirtuallyeverysystemintheworldsupportsMPI
§ Givesuserexplicitcontrolondatamanagement
§ Widelyusedbymanyscientificapplicationswithgreatsuccess
§ Yourapplicationcanbenext!
AdvancedMPI,SC17(11/13/2017) 234

Web Pointers
§ MPIstandard:http://www.mpi-forum.org/docs/docs.html
§ MPIForum:http://www.mpi-forum.org/
§ MPIimplementations:– MPICH:http://www.mpich.org
– MVAPICH:http://mvapich.cse.ohio-state.edu/
– IntelMPI:http://software.intel.com/en-us/intel-mpi-library/
– MicrosoftMPI:https://msdn.microsoft.com/en-us/library/bb524831%28v=vs.85%29.aspx
– OpenMPI:http://www.open-mpi.org/
– IBMMPI,CrayMPI,HPMPI,THMPI,…
§ SeveralMPItutorialscanbefoundontheweb
AdvancedMPI,SC17(11/13/2017) 235

New Tutorial Books on MPI
AdvancedMPI,SC17(11/13/2017) 236
§ ForbasicMPI– UsingMPI,3rd edition,2014,byWilliamGropp,EwingLusk,andAnthonySkjellum
– https://mitpress.mit.edu/using-MPI-3ed
§ ForadvancedMPI,includingMPI-3
– UsingAdvancedMPI,2014,byWilliamGropp,Torsten Hoefler,RajeevThakur,andEwingLusk
– https://mitpress.mit.edu/using-advanced-MPI

New Book on Parallel Programming ModelsEditedbyPavan Balaji• MPI:W.Gropp andR.Thakur• GASNet: P.Hargrove• OpenSHMEM: J.KuehnandS.Poole• UPC: K.Yelick andY.Zheng• GlobalArrays: S.Krishnamoorthy,J.Daily,A.Vishnu,
andB.Palmer• Chapel: B.Chamberlain• Charm++: L.Kale,N.Jain,andJ.Lifflander• ADLB: E.Lusk,R.Butler,andS.Pieper• Scioto: J.Dinan• SWIFT: T.Armstrong,J.M.Wozniak,M.Wilde,andI.
Foster• CnC: K.Knobe,M.Burke,andF.Schlimbach• OpenMP: B.Chapman,D.Eachempati,andS.
Chandrasekaran• Cilk Plus: A.RobisonandC.Leiserson• IntelTBB: A.Kukanov• CUDA:W.Hwu andD.Kirk• OpenCL: T.Mattson
https://mitpress.mit.edu/models
237AdvancedMPI,SC17(11/13/2017)

Please submit a tutorial evaluation
§ Itisusefulinplanningnextyear’stutorialprogram
§ URL:http://bit.ly/sc17-eval
§ QRCode
AdvancedMPI,SC17(11/13/2017) 238
Related Documents











