Advanced Hybrid MPI/OpenMP Advanced Hybrid MPI/OpenMP Parallelization Paradigms for Parallelization Paradigms for Nested Loop Algorithms onto Nested Loop Algorithms onto Clusters of SMPs Clusters of SMPs Nikolaos Drosinos and Nectarios Koziris National Technical University of Athens Computing Systems Laboratory {ndros,nkoziris}@cslab.ece.ntua.gr www.cslab.ece.ntua.gr

Advanced Hybrid MPI/OpenMP Parallelization Paradigms for Nested Loop Algorithms onto Clusters of SMPs Nikolaos Drosinos and Nectarios Koziris National.
Dec 24, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Advanced Hybrid MPI/OpenMP Advanced Hybrid MPI/OpenMP Parallelization Paradigms for Parallelization Paradigms for Nested Loop Algorithms onto Nested Loop Algorithms onto
Clusters of SMPsClusters of SMPs
Nikolaos Drosinos and Nectarios Koziris
National Technical University of Athens
Computing Systems Laboratory
{ndros,nkoziris}@cslab.ece.ntua.grwww.cslab.ece.ntua.gr

2/10/2003 EuroPVM/MPI 2003 2
OverviewOverview
Introduction Pure MPI Model Hybrid MPI-OpenMP Models
• Hyperplane Scheduling• Fine-grain Model• Coarse-grain Model
Experimental Results Conclusions – Future Work

2/10/2003 EuroPVM/MPI 2003 3
IntroductionIntroduction
Motivation:
• SMP clusters• Hybrid programming models
Mostly fine-grain MPI-OpenMP paradigms Mostly DOALL parallelization

2/10/2003 EuroPVM/MPI 2003 4
IntroductionIntroduction
Contribution:
• 3 programming models for the parallelization of nested loops algorithms
• pure MPI• fine-grain hybrid MPI-OpenMP• coarse-grain hybrid MPI-OpenMP
• Advanced hyperplane scheduling• minimize synchronization need• overlap computation with communication

2/10/2003 EuroPVM/MPI 2003 5
IntroductionIntroduction
Algorithmic Model:
FOR j0 = min0 TO max0 DO
…
FOR jn-1 = minn-1 TO maxn-1 DO
Computation(j0,…,jn-1);
ENDFOR
…
ENDFOR
Perfectly nested loops Constant flow data dependencies

2/10/2003 EuroPVM/MPI 2003 6
IntroductionIntroduction
Target Architecture: SMP clusters

2/10/2003 EuroPVM/MPI 2003 7
OverviewOverview
Introduction Pure MPI Model Hybrid MPI-OpenMP Models
• Hyperplane Scheduling• Fine-grain Model• Coarse-grain Model
Experimental Results Conclusions – Future Work

2/10/2003 EuroPVM/MPI 2003 8
Pure MPI ModelPure MPI Model
Tiling transformation groups iterations into atomic execution units (tiles) Pipelined execution Overlapping computation with communication Makes no distinction between inter-node and intra-node communication

2/10/2003 EuroPVM/MPI 2003 9
Pure MPI ModelPure MPI Model
Example:
FOR j1=0 TO 9 DO FOR j2=0 TO 7 DO A[j1,j2]:=A[j1-1,j2] + A[j1,j2-1]; ENDFORENDFOR
10
01D

2/10/2003 EuroPVM/MPI 2003 10
Pure MPI ModelPure MPI Model
j1
j2
CPU1
CPU0
CPU1
CPU0
NODE1
NODE0
4 MPI nodes

2/10/2003 EuroPVM/MPI 2003 11
Pure MPI ModelPure MPI Model
j1
j2
CPU1
CPU0
CPU1
CPU0
NODE1
NODE0
4 MPI nodes

2/10/2003 EuroPVM/MPI 2003 12
Pure MPI ModelPure MPI Model
tile0 = nod0;…tilen-2 = nodn-2;FOR tilen-1 = 0 TO DO
Pack(snd_buf, tilen-1 – 1, nod); MPI_Isend(snd_buf, dest(nod)); MPI_Irecv(recv_buf, src(nod)); Compute(tile); MPI_Waitall; Unpack(recv_buf, tilen-1 + 1, nod);END FOR
1
11 minmax
n
nn
x

2/10/2003 EuroPVM/MPI 2003 13
OverviewOverview
Introduction Pure MPI Model Hybrid MPI-OpenMP Models
• Hyperplane Scheduling• Fine-grain Model• Coarse-grain Model
Experimental Results Conclusions – Future Work

2/10/2003 EuroPVM/MPI 2003 14
Hyperplane SchedulingHyperplane Scheduling
Implements coarse-grain parallelism assuming inter-tile data dependencies Tiles are organized into data-independent subsets (groups) Tiles of the same group can be concurrently executed by multiple threads Barrier synchronization between threads

2/10/2003 EuroPVM/MPI 2003 15
Hyperplane SchedulingHyperplane Scheduling
j1
j2
CPU1
CPU0
CPU1
CPU0
NODE1
NODE0
2 MPI nodes
x
2 OpenMP threads

2/10/2003 EuroPVM/MPI 2003 16
j1
j2
Hyperplane SchedulingHyperplane Scheduling
CPU1
CPU0
CPU1
CPU0
NODE1
NODE0
2 MPI nodes
x
2 OpenMP threads

2/10/2003 EuroPVM/MPI 2003 17
Hyperplane SchedulingHyperplane Scheduling#pragma omp parallel{ group0 = nod0; … groupn-2 = nodn-2; tile0 = nod0 * m0 + th0; … tilen-2 = nodn-2 * mn-2 + thn-2; FOR(groupn-1){ tilen-1 = groupn-1 - ;
if(0 <= tilen-1 <= ) compute(tile); #pragma omp barrier }}
tnn 11 minmax
2
0
n
iitile

2/10/2003 EuroPVM/MPI 2003 18
OverviewOverview
Introduction Pure MPI Model Hybrid MPI-OpenMP Models
• Hyperplane Scheduling• Fine-grain Model• Coarse-grain Model
Experimental Results Conclusions – Future Work

2/10/2003 EuroPVM/MPI 2003 19
Fine-grain ModelFine-grain Model
Incremental parallelization of computationally intensive parts Relatively straightforward from pure MPI Threads (re)spawned at computation Inter-node communication outside of multi-threaded part Thread synchronization through implicit barrier of omp parallel directive

2/10/2003 EuroPVM/MPI 2003 20
Fine-grain ModelFine-grain Model
FOR(groupn-1){ Pack(snd_buf, tilen-1 – 1, nod); MPI_Isend(snd_buf, dest(nod)); MPI_Irecv(recv_buf, src(nod)); #pragma omp parallel { thread_id=omp_get_thread_num(); if(valid(tile,thread_id,groupn-1)) Compute(tile); } MPI_Waitall; Unpack(recv_buf, tilen-1 + 1, nod);}

2/10/2003 EuroPVM/MPI 2003 21
OverviewOverview
Introduction Pure MPI Model Hybrid MPI-OpenMP Models
• Hyperplane Scheduling• Fine-grain Model• Coarse-grain Model
Experimental Results Conclusions – Future Work

2/10/2003 EuroPVM/MPI 2003 22
Coarse-grain ModelCoarse-grain Model
SPMD paradigm Requires more programming effort Threads are only spawned once Inter-node communication inside multi-threaded part (requires MPI_THREAD_MULTIPLE) Thread synchronization through explicit barrier (omp barrier directive)

2/10/2003 EuroPVM/MPI 2003 23
Coarse-grain ModelCoarse-grain Model#pragma omp parallel{ thread_id=omp_get_thread_num(); FOR(groupn-1){ #pragma omp master{ Pack(snd_buf, tilen-1 – 1, nod); MPI_Isend(snd_buf, dest(nod)); MPI_Irecv(recv_buf, src(nod)); } if(valid(tile,thread_id,groupn-1)) Compute(tile); #pragma omp master{ MPI_Waitall; Unpack(recv_buf, tilen-1 + 1, nod); } #pragma omp barrier }}

2/10/2003 EuroPVM/MPI 2003 24
Summary: Fine-grain vs Summary: Fine-grain vs Coarse-grainCoarse-grain
Fine-grain Coarse-grainThreads re-spawning Threads are only
spawned onceInter-node MPI communication outside of multi-threaded region
Inter-node MPI communication inside multi-threaded region, assumed by master thread
Intra-node synchronization through implicit barrier (omp parallel)
Intra-node synchronization through explicit OpenMP barrier

2/10/2003 EuroPVM/MPI 2003 25
OverviewOverview
Introduction Pure MPI model Hybrid MPI-OpenMP models
• Hyperplane Scheduling• Fine-grain Model• Coarse-grain Model
Experimental Results Conclusions – Future Work

2/10/2003 EuroPVM/MPI 2003 26
Experimental ResultsExperimental Results
8-node SMP Linux Cluster (800 MHz PIII, 128 MB RAM, kernel 2.4.20) MPICH v.1.2.5 (--with-device=ch_p4, --with-comm=shared) Intel C++ compiler 7.0 (-O3 -mcpu=pentiumpro -static) FastEthernet interconnection ADI micro-kernel benchmark (3D)
2/10/2003 EuroPVM/MPI 2003 27
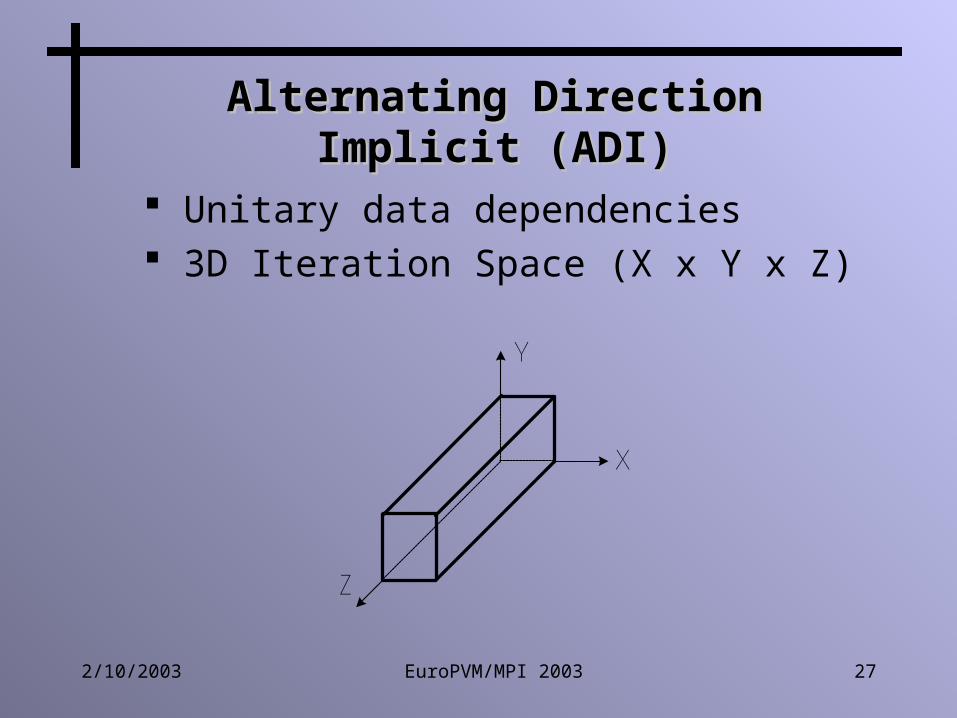
Alternating Direction Implicit Alternating Direction Implicit (ADI)(ADI)
Unitary data dependencies 3D Iteration Space (X x Y x Z)
X
Y
Z

2/10/2003 EuroPVM/MPI 2003 28
ADI – 4 nodesADI – 4 nodes
Pure MPI Hybrid
I: MPII: OpenMP
XX
Y Y

2/10/2003 EuroPVM/MPI 2003 29
ADI – 4 nodesADI – 4 nodes
X < Y
X > Y
Pure MPI HybridX
Y
X
Y
Pure MPI HybridXX
Y Y

2/10/2003 EuroPVM/MPI 2003 30
ADI X=512 Y=512 Z=8192 – 4 ADI X=512 Y=512 Z=8192 – 4 nodesnodes

2/10/2003 EuroPVM/MPI 2003 31
ADI X=128 Y=512 Z=8192 – 4 ADI X=128 Y=512 Z=8192 – 4 nodesnodes

2/10/2003 EuroPVM/MPI 2003 32
ADI X=512 Y=128 Z=8192 – 4 ADI X=512 Y=128 Z=8192 – 4 nodesnodes

2/10/2003 EuroPVM/MPI 2003 33
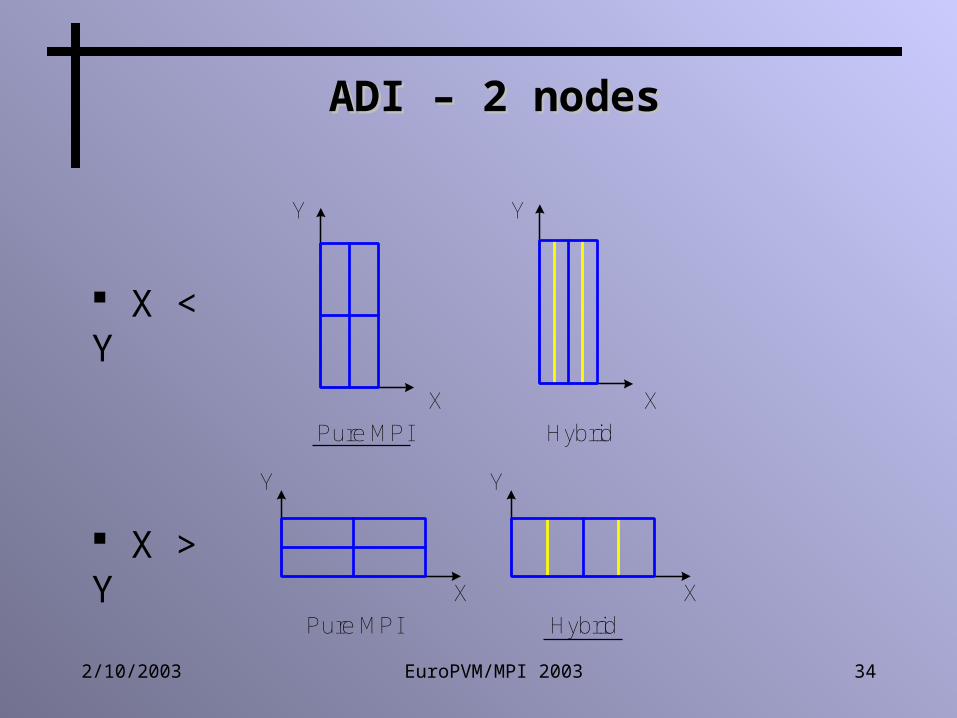
ADI – 2 nodesADI – 2 nodes
Pure MPI Hybrid
I: MPII: OpenMP
XX
Y Y
2/10/2003 EuroPVM/MPI 2003 34
ADI – 2 nodesADI – 2 nodes
X < Y
X > Y
Pure MPI HybridXX
Y Y
Pure MPI HybridXX
Y Y

2/10/2003 EuroPVM/MPI 2003 35
ADI X=128 Y=512 Z=8192 – 2 ADI X=128 Y=512 Z=8192 – 2 nodesnodes

2/10/2003 EuroPVM/MPI 2003 36
ADI X=256 Y=512 Z=8192 – 2 ADI X=256 Y=512 Z=8192 – 2 nodesnodes

2/10/2003 EuroPVM/MPI 2003 37
ADI X=512 Y=512 Z=8192 – 2 ADI X=512 Y=512 Z=8192 – 2 nodesnodes

2/10/2003 EuroPVM/MPI 2003 38
ADI X=512 Y=256 Z=8192 – 2 ADI X=512 Y=256 Z=8192 – 2 nodesnodes

2/10/2003 EuroPVM/MPI 2003 39
ADI X=512 Y=128 Z=8192 – 2 ADI X=512 Y=128 Z=8192 – 2 nodesnodes

2/10/2003 EuroPVM/MPI 2003 40
ADI X=128 Y=512 Z=8192 – 2 ADI X=128 Y=512 Z=8192 – 2 nodesnodes
Computation Communication

2/10/2003 EuroPVM/MPI 2003 41
ADI X=512 Y=128 Z=8192 – 2 ADI X=512 Y=128 Z=8192 – 2 nodesnodes
Computation Communication

2/10/2003 EuroPVM/MPI 2003 42
OverviewOverview
Introduction Pure MPI model Hybrid MPI-OpenMP models
• Hyperplane Scheduling• Fine-grain Model• Coarse-grain Model
Experimental Results Conclusions – Future Work

2/10/2003 EuroPVM/MPI 2003 43
ConclusionsConclusions
Nested loop algorithms with arbitrary data dependencies can be adapted to the hybrid parallel programming paradigm Hybrid models can be competitive to the pure MPI paradigm Coarse-grain hybrid model can be more efficient than fine-grain one, but also more complicated Programming efficiently in OpenMP not easier than programming efficiently in MPI

2/10/2003 EuroPVM/MPI 2003 44
Future WorkFuture Work
Application of methodology to real applications and benchmarks Work balancing for coarse-grain model Performance evaluation on advanced interconnection networks (SCI, Myrinet) Generalization as compiler technique

2/10/2003 EuroPVM/MPI 2003 45
Questions?Questions?
http://www.cslab.ece.ntua.gr/~ndros
Related Documents











