Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Spark Data Sources API + Spark-ElasticSearch Connector + Spark-ElasticSearch In Action Advanced Apache Spark Meetup Thanks Rackspace (Space) and Loggly (Food)!! Feb 15, 2016 Chris Fregly Principal Data Engineer @ IBM Spark Tech Center advancedspark.com + Costin Leau Engineer, Elastic Urvish Mahida Data Platform Engineer, Loggly

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Spark Data Sources API + Spark-ElasticSearch Connector + Spark-ElasticSearch In Action
Advanced Apache Spark Meetup Thanks Rackspace (Space) and Loggly (Food)!!
Feb 15, 2016
Chris Fregly Principal Data Engineer @ IBM Spark Tech Center
advancedspark.com!
+
Costin Leau Engineer, Elastic
Urvish Mahida Data Platform Engineer, Loggly

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Who Am I?
2
Streaming Data Engineer Open Source Committer
Data Solutions Engineer
Apache Contributor
Principal Data Solutions Engineer IBM Technology Center
Founder Advanced Apache Meetup
Author Advanced .
Due 2016

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Where Am I?
3
Summit East 2016
New York City
Spark-NYC (Co-presenting with Databricks)

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Advanced Apache Spark Meetup http://advancedspark.com Meetup Metrics Top 5 Most-active Spark Meetup! ~2600 Members in just 6 mos!! ~2600 Docker image downloads
Meetup Mission Deep-dive into Spark and related open source projects Surface key patterns and idioms Focus on distributed systems, scale, and performance
4

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline ① Partitions, Pruning, Pushdowns
② Spark Data Sources API ③ DataFrames and DataSets
④ Spark and ElasticSearch In Action 5

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Partitions Partition Based on Data Access Patterns /genders.parquet/gender=M/… /gender=F/… <-- Use Case: Access Users by Gender /gender=U/…
Dynamic Partition Creation (Write) Dynamically create partitions on write based on column (ie. Gender) SQL: INSERT TABLE genders PARTITION (gender) SELECT … DF: gendersDF.write.format("parquet").partitionBy("gender")
.save("/genders.parquet")
Partition Discovery (Read) Dynamically infer partitions on read based on paths (ie. /gender=F/…) SQL: SELECT id FROM genders WHERE gender=F DF: gendersDF.read.format("parquet").load("/genders.parquet/").select($"id"). .where("gender=F")
6

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Pruning Partition Pruning Filter out rows by partition
SELECT id, gender FROM genders WHERE gender = ‘F’
Column Pruning Filter out columns by column filter Extremely useful for columnar storage formats (ie. Parquet) Skip entire blocks of columns
SELECT id, gender FROM genders
7

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Pushdowns aka. Predicate or Filter Pushdowns Predicate returns true or false for given functionFilters rows deep into the data source Reduces number of rows returned Data Source must implement PrunedFilteredScan def buildScan(requiredColumns: Array[String],
filters: Array[Filter]): RDD[Row]
8

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Filter Collapse and Pushdown
9
Filter Collapse
Filter is Not Pushed Down
(JSON)
Filter is Pushed Down
(Parquet)

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Join Between Partitioned & Unpartitioned
10
Note: JSON supports partitioning, We’re not using it here.

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Join Between Partitioned & Partitioned
11
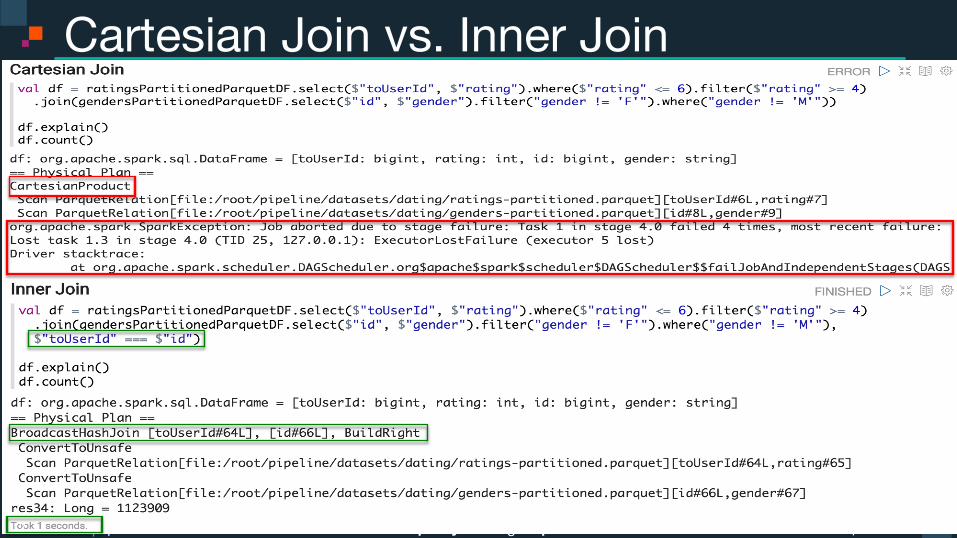
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Cartesian Join vs. Inner Join
12

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Broadcast Join vs. Normal Shuffle Join
13

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Visualizing the Query Plan
14
Effectiveness of Filter
Cost-based Join Optimization
Similar to MapReduce
Map-side Join & DistributedCache
Peak Memory for Joins and Aggs
UnsafeFixedWidthAggregationMapgetPeakMemoryUsedBytes()

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline ① Partitions, Pruning, Pushdowns
② Spark Data Sources API ③ DataFrames and DataSets
④ Spark and ElasticSearch In Action 15

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Spark Data Sources API Relations (o.a.s.sql.sources.interfaces.scala) BaseRelation (abstract class): Provides schema of data TableScan (impl): Read all data from source PrunedFilteredScan (impl): Column pruning & predicate pushdowns InsertableRelation (impl): Insert/overwrite data based on SaveMode RelationProvider (trait/interface): Handle options, BaseRelation factory
Filters (o.a.s.sql.sources.filters.scala) Filter (abstract class): Handles all filters supported by this source EqualTo (impl) GreaterThan (impl) StringStartsWith (impl)
16

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Native Spark SQL Data Sources
17

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
JSON Data Source DataFrame val ratingsDF = sqlContext.read.format("json")
.load("file:/root/pipeline/datasets/dating/ratings.json.bz2") -- or – val ratingsDF = sqlContext.read.json ("file:/root/pipeline/datasets/dating/ratings.json.bz2")
SQL Code CREATE TABLE genders USING json OPTIONS (path "file:/root/pipeline/datasets/dating/genders.json.bz2") 18
json() convenience method

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Parquet Data Source Configuration
spark.sql.parquet.filterPushdown=true spark.sql.parquet.mergeSchema=false (unless your schema is evolving) spark.sql.parquet.cacheMetadata=true (requires sqlContext.refreshTable()) spark.sql.parquet.compression.codec=[uncompressed,snappy,gzip,lzo]
DataFrames val gendersDF = sqlContext.read.format("parquet") .load("file:/root/pipeline/datasets/dating/genders.parquet") gendersDF.write.format("parquet").partitionBy("gender") .save("file:/root/pipeline/datasets/dating/genders.parquet")
SQL CREATE TABLE genders USING parquet OPTIONS (path "file:/root/pipeline/datasets/dating/genders.parquet")
19

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
ElasticSearch Data Source Github https://github.com/elastic/elasticsearch-hadoop
Maven org.elasticsearch:elasticsearch-spark_2.10:2.2.0
Code
val esConfig = Map("pushdown" -> "true", "es.nodes" -> "<hostname>", "es.port" -> "<port>") df.write.format("org.elasticsearch.spark.sql”).mode(SaveMode.Overwrite) .options(esConfig).save("<index>/<document-type>")
20

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Creating a Custom Data Source ① Study existing implementations o.a.s.sql.execution.datasources.jdbc.JDBCRelation ② Extend base traits & implement required methods o.a.s.sql.sources.{BaseRelation,PrunedFilterScan}
Examples Spark JDBC (o.a.s.sql.execution.datasources.jdbc) class JDBCRelation extends BaseRelation
with PrunedFilteredScan, InsertableRelation
DataStax Cassandra (o.a.s.sql.cassandra) class CassandraSourceRelation extends BaseRelation with PrunedFilteredScan, InsertableRelation!
21

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Demo! Create a Simple Integer Data Source
Predicate (Filter) Pushdowns
https://github.com/fluxcapacitor/pipeline/blob/master/myapps/sql/src/main/scala/com/advancedspark/sql/source/IntegerDataSource.scala
22

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline ① Partitions, Pruning, Pushdowns
② Spark Data Sources API ③ DataFrames and DataSets
④ Spark and ElasticSearch In Action 23

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
DataFrames and DataSets DataFrames Lost compile-time typing from RDD’s Favored untyped o.a.s.sql.Row Code could break at runtime
DataSets Re-introduce compile-time types Requires Custom Encoders/Serializers Tip: Use Kryo Serializer for custom Encoder Check out mapGroups() and flatMapGroups() methods Operate on grouped data
24

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline ① Partitions, Pruning, Pushdowns
② Spark Data Sources API ③ DataFrames and DataSets
④ Spark and ElasticSearch In Action 25

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
advancedspark.com (github and docker) End User ->
ElasticSearch ->
Spark ML ->
Data Scientist -> 26
<- Kafka <- Spark Streaming <- Cassandra, Redis <- Zeppelin, iPython

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Thank You!!! Chris Fregly IBM Spark Tech Center (http://spark.tc) San Francisco, California, USA advancedspark.com Sign up for the Meetup and Book Clone, Contribute, Commit on Github Run All Demos using Docker Image 2600 Docker Downloads!!
Find me on LinkedIn, Twitter, Github, Email, Fax 27
Image derived from http://www.duchess-france.org/

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Up Next… Costin Leau Developer @ Elastic (45 mins – 1 hour w/ Q & A) Urvish Mahida Data Platform Dev @ Loggly (30 – 45 mins w/ Q & A)
28
Related Documents











