Adaptive document clustering based on query-based similarity Seung-Hoon Na * , In-Su Kang, Jong-Hyeok Lee Division of Electrical and Computer Engineering, POSTECH (Pohang University of Science and Technology), San 31, Hyojadong, Namgu, Pohang 790-784, Republic of Korea Received 24 May 2006; received in revised form 7 August 2006; accepted 16 August 2006 Available online 14 November 2006 Abstract In information retrieval, cluster-based retrieval is a well-known attempt in resolving the problem of term mismatch. Clustering requires similarity information between the documents, which is difficult to calculate at a feasible time. The adaptive document clustering scheme has been investigated by researchers to resolve this problem. However, its theoretical viewpoint has not been fully discovered. In this regard, we provide a conceptual viewpoint of the adaptive document clus- tering based on query-based similarities, by regarding the user’s query as a concept. As a result, adaptive document clus- tering scheme can be viewed as an approximation of this similarity. Based on this idea, we derive three new query-based similarity measures in language modeling framework, and evaluate them in the context of cluster-based retrieval, compar- ing with K-means clustering and full document expansion. Evaluation result shows that retrievals based on query-based similarities significantly improve the baseline, while being comparable to other methods. This implies that the newly devel- oped query-based similarities become feasible criterions for adaptive document clustering. Ó 2006 Elsevier Ltd. All rights reserved. Keywords: Adaptive document clustering; Query-based similarity; Cluster-based retrieval; Language modeling approach 1. Introduction Most retrieval engines suffer from the term-mismatch problem because of insufficient information of the user’s query. This problem causes the retrieval system to provide non-relevant documents to the user, which forces the user to spend countless time on reformulating queries until the relevant documents are retrieved. To resolve this problem, IR researches have developed many techniques such as query expansion (Lafferty & Zhai, 2001; Lavrenko & Croft, 2001; Zhai & Lafferty, 2002), user profile analysis and cluster-based retrieval (Kurland & Lee, 2004, 2005; Liu, 2004). Among these techniques, cluster-based retrieval is an attempt to rank the documents by utilizing the scores of their clusters, and has been revisited recently in the language modeling framework. Although their retrieval on ad hoc retrieval shows high effectiveness, it is nontrivial to perform clustering in a large collection at a feasible time. First, the agglomerative clustering requires similarities between all pairs of documents, which 0306-4573/$ - see front matter Ó 2006 Elsevier Ltd. All rights reserved. doi:10.1016/j.ipm.2006.08.008 * Corresponding author. Tel.: +82 54 279 5656; fax: +82 54 279 5699. E-mail address: [email protected] (S.-H. Na). Information Processing and Management 43 (2007) 887–901 www.elsevier.com/locate/infoproman

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Information Processing and Management 43 (2007) 887–901
www.elsevier.com/locate/infoproman
Adaptive document clustering based on query-based similarity
Seung-Hoon Na *, In-Su Kang, Jong-Hyeok Lee
Division of Electrical and Computer Engineering, POSTECH (Pohang University of Science and Technology),
San 31, Hyojadong, Namgu, Pohang 790-784, Republic of Korea
Received 24 May 2006; received in revised form 7 August 2006; accepted 16 August 2006Available online 14 November 2006
Abstract
In information retrieval, cluster-based retrieval is a well-known attempt in resolving the problem of term mismatch.Clustering requires similarity information between the documents, which is difficult to calculate at a feasible time. Theadaptive document clustering scheme has been investigated by researchers to resolve this problem. However, its theoreticalviewpoint has not been fully discovered. In this regard, we provide a conceptual viewpoint of the adaptive document clus-tering based on query-based similarities, by regarding the user’s query as a concept. As a result, adaptive document clus-tering scheme can be viewed as an approximation of this similarity. Based on this idea, we derive three new query-basedsimilarity measures in language modeling framework, and evaluate them in the context of cluster-based retrieval, compar-ing with K-means clustering and full document expansion. Evaluation result shows that retrievals based on query-basedsimilarities significantly improve the baseline, while being comparable to other methods. This implies that the newly devel-oped query-based similarities become feasible criterions for adaptive document clustering.� 2006 Elsevier Ltd. All rights reserved.
Keywords: Adaptive document clustering; Query-based similarity; Cluster-based retrieval; Language modeling approach
1. Introduction
Most retrieval engines suffer from the term-mismatch problem because of insufficient information of theuser’s query. This problem causes the retrieval system to provide non-relevant documents to the user, whichforces the user to spend countless time on reformulating queries until the relevant documents are retrieved. Toresolve this problem, IR researches have developed many techniques such as query expansion (Lafferty &Zhai, 2001; Lavrenko & Croft, 2001; Zhai & Lafferty, 2002), user profile analysis and cluster-based retrieval(Kurland & Lee, 2004, 2005; Liu, 2004).
Among these techniques, cluster-based retrieval is an attempt to rank the documents by utilizing the scoresof their clusters, and has been revisited recently in the language modeling framework. Although their retrievalon ad hoc retrieval shows high effectiveness, it is nontrivial to perform clustering in a large collection at afeasible time. First, the agglomerative clustering requires similarities between all pairs of documents, which
0306-4573/$ - see front matter � 2006 Elsevier Ltd. All rights reserved.
doi:10.1016/j.ipm.2006.08.008
* Corresponding author. Tel.: +82 54 279 5656; fax: +82 54 279 5699.E-mail address: [email protected] (S.-H. Na).

888 S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901
are obtained by performing the retrieval, regarding each document as a query. In addition, there is an overheadfor merging clusters according to some criterions. Second, the partitional clustering (such as K-means cluster-ing) is relatively less-expensive than the agglomerative clustering. However, it is not effective because similaritiesbetween K centroids and all documents should be iteratively calculated until the centroid vectors are converged.Third, the document expansion is a method to cluster each document with the top nearest neighbors. Again, itstime complexity becomes the retrieval time thereby the agglomerative clustering is possible. Thus, effectivelycalculating the document similarities, which are necessary for clustering, is a critical issue.
The adaptive document clustering scheme has been investigated to effectively perform clustering of docu-ments from a set of past queries (Yu, Wang, & Chen, 1985). This scheme follows the cluster assumption thatrelevant documents tend to belong to the same cluster. Initially, a random position is assigned to each docu-ment on the real line, and for each query, the positions of relevant documents are shifted closer to each other.As the queries are continuously processed, the positions of the documents in the same cluster are closer whilethe positions of the documents in different clusters are far apart. Thus, the clusters of the documents can beeasily identified. However, several limitations have been noticed. First, Yu’s method lacks in theoretical argu-ment. In other words, Yu did not clearly identify an objective function which the updating algorithm finds.Thus, it is unclear whether the updating algorithm converges to a certain value or a state as the number ofqueries increases. Second, evaluations of the adaptive document clustering are highly restricted. They usedvery small collections, performed the updating algorithm for only about 200 queries and evaluated retrievalperformances using the same queries. Currently, we believe that there are no acceptable experimental resultsof the adaptive document clustering to information retrieval.
This paper provides a conceptual interpretation of the adaptive document clustering by regarding that itlearns a query-based similarities. This interpretation has several advantages for designing an adaptive cluster-ing scheme. First, it provides us a theoretical tool for answering a target value of similarities between the doc-uments when online learning is applied. Therefore, it is possible to consistently evaluate the convergence andverification of the updating algorithm by comparing several similarity measures.
Second, this interpretation clarifies the first priority of adaptive document clustering: First, a good query-based similarity measure should be examined. Developing approximation scheme is the next problem. In fact,given the objective function, the corresponding approximation algorithm can directly be derived by using theoptimization method. As shown in Appendix B, Yu’s approach is one of the methods to approximate the spe-cial similarity measure (or distance measure).
Third, the query-based similarity could be a more adequate measure than the original term-based similarity.A query is tightly coupled thematic unit rather than a simple term, since more complex terms such as nounphrase and collocation can be used as a query. Normally, such complex terms cannot be inferred by the simplecombination of their parts. Thus, the query-based similarity measure may be more elaborate if the estimationis successful.
At this point, this paper derives three query-based similarities measures based on the language modelingframework, and evaluates them on the context of cluster-based retrieval scheme, comparing K-mean clusteringand document expansion. These similarities are effective over the baseline, and comparative to other methodsbased on the traditional clustering algorithm.
From now on, we use the term of online learning of document similarities to clarify that similarities arelearned. Clustering is a by-product of these learned similarities.
The rest of the paper is organized as follows: Section 2 describes our online learning schemes and query-based similarities in the language modeling framework. Sections 3 and 4 describe conduced experiments onTREC data. Section 5 describes related works. Finally, Section 6 concludes and addresses some directionsfor future work.
2. Online learning framework of document similarities
Algorithm 1 describes the general template of an online learning framework of document similarity. Initial-
ization is performed before the retrieval system becomes online, which empties the similarity-database. Retrie-
val is performed to create the top retrieved documents R. In Update, similarities between two documents D
and D 0 in R are increased by f(D,D 0,Q). f(D,D 0,Q) is the amount of similarity increase which is derived from

S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901 889
similarity measure. If r is jRj, then the number of updates is r(r � 1)/2. In CheckQuery, whether the givenquery is previously processed or not is checked to avoid redundant updating. Without this control of redun-dant updating, the learned document similarities will be biased according to the frequency of query. To detectredundancy, data structure such as hash, B+ tree are useful. For a dynamic environment in which new doc-uments are inserted or old ones are deleted, redundant queries should be considered since the retrieval resultwill also change once the collection changes. However, this paper does not consider such dynamicenvironment.
Algorithm 1. Online learning framework of document similarities
Input: N documents in collection C
Initialization: For all D and D 0, Sim(D,D 0) = 0Retrieval: Create top retrieved documents R for given query Qif CheckQuery(Q) is true then
Update: For given Q and R
for each D,D 0in R do
sim(D,D 0) sim(D,D 0) + f(D,D 0,Q)end for
end if
The main advantages of online document clustering will be summarized in the following items:
� Collection adaptability: Even after the collection is changed, the system does not need to perform a separateprocess to reflect the change. It only needs to wait until the similarities are relearned.� User adaptability: This learning scheme provides useful bias. Some documents may not be an interest to
some users. Normally, documents have high utilities when the users are much interesting in them. For ahot topic, many users will provide similar queries. Then, the learnings are concentrated on related docu-ments, and the next user having a similar topic will obtain more accurate retrieval result since the systemhas more knowledge of such documents. Less interesting documents will be slowly learned. However, it isnot a disadvantage since the adaptability can be sufficiently controllable by extending the above framework.It is important to note that the framework is able to control the user adaptability.
In fact, Algorithm 1 contains a method of calculating traditional term-based document similarity. Considerthe vector space model, where similarity is represented by an inner-product (or cosine similarity) between thetwo document vectors.
simðDi;DjÞ ¼Xk2T
wikwjk ð1Þ
Di indicates ith document, wik is weight of kth term tk in ith document, and T is a set of all terms. Here, thenormalization factor is ignored. Algorithm 1 can exactly calculate Eq. (1), by setting query Q by the term tk, R
by the set of documents indexed with the term, and f(Di,Dj, tk) by wikwjk. After Update is performed for allterms, similarities of Eq. (1) are calculated on all pairs of documents.
Now, the query-based similarity is defined by taking query as a concept:
simðDi;DjÞ ¼XQ2T �
wiQwjQ ð2Þ
wiQ is the weight of the query Q in ith document, and T * is the set of queries. However, T * is a countableinfinite set, thus the similarity values (Eq. (2)) will be infinitely large. To avoid this problem, we regard thequery as the point of continuous vector space and refined similarity. For convenience, document vectorand query vector are restricted to 1 of p-norm:
simðDi;DjÞ ¼Z
q;jjqjj¼1
wiqwjq dq ð3Þ

890 S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901
where we use q as a query vector corresponding to query Q. Normally, Eq. (3) receives the finite value. Forexample, assume that the vector space, which consists of two terms, h and hi are angles between query vectorand ith document vector and wiq is the inner-product between query vector q and document vector di. Then, wecan easily show that Eq. (3) becomes a finite value. However, it is only a theoretical measure, since in practicalsituations, only the finite queries are processed. The discrete version such as
PqwiqwjqDq will be used in prac-
tice where Dq indicates a very small value.The critical problem is to define the query weight on each document, which is different from the retrieval
models. The goal of this paper is to define such similarity in the language modeling framework. In the nextsection, we define KL divergence-oriented similarity and derive inner-product-oriented similarity and aheuristic measure with their comparison.
2.1. Query-based KL divergence
Language modeling approach uses the negative KL divergence between the document models for measur-ing their similarity based on individual terms as follows (Lafferty & Zhai, 2001):
simðD;D0Þ ¼Xt2T
P ðtjhDÞ log P ðtjhD0 Þ
Our goal is to extend the term-based similarity to the query-based similarity. As in the vector space model, anaive extension is derived by regarding a sample unit as a concept instead of the term:
simðD;D0Þ ¼XQ2T �
P ðQjhDÞ log P ðQjhD0 Þ
where P(QjhD) is the generation probability of query Q = q1 . . .qk from the document model hD, which isthe multiplication of probabilities of each term:
QkP ðqkjhDÞ. However, P(QjhD) cannot be used as a proba-
bility defined on query space since the summation of P(QjhD) on the whole query space does not add up toone.
The proposed query-based similarity is defined on the continuous query space which consists of all possiblequery models. We denote P(hQjhD) by the probability of query model q for given document model hD, corre-sponding to P(QjhD):
P ðhQjhDÞ ¼1
ZD
Yt2Q
P ðtjhDÞP ðtjhCÞ
� �P ðtjhQÞ
ð4Þ
where ZD is the normalization factor and P(tjhC) is the probability of collection model. Based on this prob-ability, a new similarity measure is described as follows:
simðD;D0Þ ¼Z
hQ
PðhQjhDÞ log P ðhQjhD0 ÞdhQ ð5Þ
This measure is called the query-based KL divergence. Let V be the number of total terms. Normally, V is muchlarger than the number of terms in a document (the length of a document). In this case, ZD, which is almostthe same among the documents, exists. In other words:
Theorem 1. When V is much larger than the number of document terms, ZD is approximately the same for all
documents.
Proof. Detailed derivation is described in Appendix A. h
The similarity of Eq. (5) has several advantages as follows:
1. Equivalent to document ranking in language modeling approach: Since there is no difference between normal-ization factors among the documents, Eq. (4) is proportional to geometric (weighted) mean of query gen-eration probabilities, equivalent to the negative KL divergence.

S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901 891
2. Reflecting query importance: In term-based similarities, terms have different importance according to theirdocument frequencies (DF). Thus, a well-defined query-based similarity should reflect the query impor-tance. Fortunately, Eq. (4) implicitly reflects such importance using query clarity, by multiplyingQ
tð1=P ðtjhCÞÞPðtjhQÞ, which is proportional to query clarity (Cronen-Townsend, Zhou, & Croft, 2004).The only difference is the entropy of the query model.
Eq. (4) is simplified by using score(D;Q) which is the measure for ranking documents according to the givenquery Q:
scoreðD; QÞ ¼X
t
P ðtjhQÞ logkP ðtjhDÞ
ð1� kÞP ðtjhCÞþ 1
!ð6Þ
where hD is the MLE document model. Using score(D;Q), Eq. (5) is rewritten by ignoring ZD
simðD;D0Þ /Z
hQ
eð1�kÞscoreðD;QÞscoreðD0; QÞdhQ ð7Þ
Despite of its theoretical advantages, there is a critical problem. Consider the probability P(hDjhD) for givenhD, when hQ is hD. Since the query model is exactly the same as the given document model, the probabilitycould be the maximum value. However, P(hDjhD) is not a maximum. The maximum is obtained using hQ
by setting P(tjhQ) to 1, where t indicates a term that maximizes P(tjhD)/P(tjhC). Thus, the query-based KLdivergence does not reflect an the important and basic weighting characteristic well.
2.2. Query-based inner-product
Another query-based similarity can be derived from the vector space model, by using the negative KLdivergence between hQ and hD as a weight: �KL(hQihD). However, it is problematic to directly use the negativeKL divergence for query document weight wiQ since it is not a positive value. Thus, a mapping function eax isused where x is defined on [�1, 0] for transforming negative values into positive values on [0,1]. As a result,wiQ is defined as follows:
wiQ ¼ e�aKLðhQkhDÞ ð8Þ
where the positive parameter a determines the shape of exponential function. We call this measure the query-
based inner-product on language models.One advantage of query-based inner-product is that it has the intuitive weighting characteristic. The weight
is maximum when hQ is hD, which is not holed in query-based KL divergence. Unfortunately, Eq. (8) does notreflect the importance of query well. To demonstrate this, �KL(hQihD) is further derived as follows:
�KLðhQkhDÞ ¼X
t
P ðtjhQÞ logkP ðtjhDÞ
ð1� kÞP ðtjhCÞþ 1
!þX
t
P ðtjhQÞ logP ðtjhCÞPðtjhQÞ
þ logð1� kÞ ð9Þ
Moreover, we denote clarity(Q) as a measure for dissimilarity between the query model and the collectionmodel as follows (it has been proposed as an attempt to quantify query difficulty (Cronen-Townsend et al.,2004)):
clarityðQÞ ¼X
t
P ðtjhQÞ logP ðtjhQÞP ðtjhCÞ
ð10Þ
Since the first term and second terms in the right part of Eq. (9) are score(D;Q) (Eq. (6)) and �clarity(D;Q),respectively, Eq. (9) becomes
�KLðhQkhDÞ ¼ scoreðD; QÞ � clarityðQÞ þ logð1� kÞ ð11Þ
As the query clarity gets higher, �KL(hQihD) becomes smaller. It means that the query importance is not con-sidered well in the inner-product similarity scheme.
892 S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901
2.3. Query-based weighted inner-product
By adding related characteristics and redefining the inner-product, its measure is easily extended by explic-itly adding related characteristic into the measure and redefining inner-product. Instead of the query-basedinner-product, the query importance is reflected by introducing the new inner-product as follows:
TableA brie
KLInner-Weigh
KLInner-Weigh
SimðDi;DjÞ ¼X
Q
IðQÞwiQwjQDQ ð12Þ
where I(Q) measures the importance of query. This paper uses I(Q) as clarity(Q). We call this measure thequery-based weighted inner-product.
Unfortunately, the inner-product based measures are not consistent with the language modeling frame-work since they are not defined by the KL divergence or the likelihood-based scheme. Despite of it, inthe inner-product scheme, a new similarity measure containing several useful characteristics is defined moreeasily by simply redefining the inner-product. In comparison, the KL-divergence oriented measure is nottrivial to refine, where more sophisticated works should be investigated to reflect such useful features(characteristics).
Table 1 summarizes three similarity measures based on language models in three aspects. Here, f(D,D 0,Q)indicates the quantity of similarity to be updated between documents. Query importance signifies how queryimportance is reflected, and Query weighting signifies how document weight of query (wiQ) is assigned. In allmeasures, the query weights of all methods are equivalent to the ranking of documents in the language mod-eling approach.
2.4. Retrieval based on learned similarity
The cluster-based retrieval is one of the methods for improving retrieval performance by using a learnedsimilarity. We use one cluster per one document (Kurland & Lee, 2004). Each document has an individual clus-ter, which consists of the document and K-nearest neighbor documents for the document. For all clusters, thecluster langauge models are constructed in which the cluster score is calculated by applying the language mod-eling approach on these models. The final score of document is obtained by the linear interpolation of the ori-ginal document score with cluster score as follows:
scoreCRðD; QÞ ¼ cscoreðD; QÞ þ ð1� cÞscoreðcD; QÞ ð13Þ
where cD indicates a cluster to which document D belongs and c is used as an interpolation.score(cD,Q) is defined as the similarity between the cluster language model and the query model, which isproportional to the P(QjcD).
scoreðcD; QÞ ¼X
t
P ðtjhQÞ logbP ðtjhcDÞ
ð1� bÞP ðtjhCÞþ 1
� �ð14Þ
where b is the smoothing parameter of cluster-language model. Since a cluster contains larger terms than anormal document, it is reasonable to differentiate them by using b.
1f summary of three query-based similarity measures
f(D,D0,Q)
e(1�k) score(D; Q)score(D0;Q)product e�aðKLðhDkhQÞþKLðhD0 khQÞÞ
ted inner-product clarityðQÞe�aðKLðhDkhQÞþKLðhD0 khQÞÞ
Query weighting Query importance
Small weighting if hQ = hD Implicitly: �P
tPðtjhQÞ log P ðtjhCÞproduct Maximum weighting if hQ = hD Not reflected: Inversely-proportional to clarity(Q)ted inner-product Maximum weighting if hQ = hD Explicitly: clarity(Q)

S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901 893
Since the document similarity is partially learned, some documents do not have any nearest neighbors. Insuch documents, score(cD;Q) is exactly the same as score(D;Q) since cD consists of a single document D. Thus,scoreCR simply becomes score. This interpolation method is slightly different from aspect-x by Kurland andLee (2004) which is based on linear interpolation of probabilities for query generation from document modeland cluster model. In our terminology, it is rewritten by c0escoreðD;QÞ þ ð1� c0ÞescoreðcD;QÞ, where c 0 indicates thedegree of interpolation.
3. Experimental setting
3.1. Experimental setting
3.1.1. Test collectionsOur experimentation has two directions according to the size of the test collections. The first experiment is
to compare the three query-based similarity measures and to present their retrieval performances. This exper-iment only is performed in small test collections. In the second experiment, we test whether the use of the pro-posed query-based similarities are extended into more larger test collections or not.
In this regard, the experimental database is divided into two subsets according to their size. CISI and MEDare used for small collections, TREC4 is used for large collections. Among the 112 queries of CISI, 35 queriesare selected for only collecting title-like query. TREC4 data is divided into several sub-collections with Asso-ciated Press, San Jose Mercury News and Wall Street Journal. Since there are some researches performed onsuch divided collections (Gao, Nie, Wu, & Cao, 2004; Liu, 2004), external comparisons with our results arepossible. Table 2 summarizes the information of the three data collections. ‘Docs’ and ‘Topics’ indicate thenumber of documents and topics, respectively. All queries and documents are stemmed using the Porter stem-mer after stopping the use at about 400 stopwords.
For the baseline language modeling approach, Jelinek-Mercer smoothing is used where k is 0.25. For clus-ter-based retrieval, b and c are set collection-dependently. As for the evaluation measure of retrieval perfor-mance, mean average precision (MAP) is used.
3.1.2. Pseudo-query generation
Since no real user’s queries exist in any test collection, we randomly generate them according to the follow-ing steps:
1. Randomly select a document: Document is assumed to be uniformly distributed.2. Select a term according to the document language model, and add into the query: To contain many topical
terms in a query, we use parsimonious language model instead of MLE model (Hiemstra, Robertson, &Zaragoza, 2004), where only the document terms are selected when their summation is less than P. P isset to 0.4.
3. Determine whether the term generation process is continued or not: Probability to be continued is 1 � a. Ifcontinuing event arises, then go to the step 2, and do the next iteration. It causes the length of terms tofollow the geometric distribution with parameter a. Thus, the average length of query is 1/a. a is set to0.2. This generation process is iterated until the number of total queries is 1,000,000. The following showsexamples of randomly generated queries in AP test collections:
Table 2Overview of TREC collections and topics
Acronym Description of collection Size (MB) Docs Topics
CISI CISI collection 2.2 1463 35MED Medline collection 1.1 1033 30AP Associated Press 88, 89 484 158,240 49SJM San Jose Mercury News 91 291 90,257 44WSJ Wall St. Journal 90–92 248 74,250 43

894 S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901
(1) hostag hostag kauffmann.(2) problem meet reform parti confer elect said new.(3) govern angola angola.(4) pittsburgh.(5) western yugoslavia european east european east currenc east yugoslavia cross currenc currenc.(6) new new.
Since the generation process is based on unigram, pseudo-query has difficulty of understanding its meaning.Example 6 is also a bad query. Similar to ‘east’ in example 5, single high probable terms are frequently gen-
erated in one query. In fact, when the web-based retrieval service is online, many noisy queries occur fromworld wide users. Thus, all of the noisy queries are used without any filtering for evaluating how an updatingalgorithm of similarity is sensitive to noise. Surely, sampled queries could be more natural if we adopt thebigram or trigram in step 2.
3.1.3. Evaluation measure for learned similarity
To evaluate the learned similarity, we constructed top 100 nearest neighbor documents using term-basedsimilarity for each document. Negative KL divergence between documents in language modeling approachis used for term-based similarity (Lafferty & Zhai, 2001). These neighbor documents are compared to resultsof adaptive clustering on their similarity. We refer the neighbors based on term-based similarity by target
neighbors. To measure the similarity between two different neighbors, we introduce a new evaluation measure;AvgNS (average of neighbors similarity) where similarities of two different neighbors of each test documentare averaged on test documents. AvgNS is similar to 11pt recall–precision used in IR community (Baeza-Yates& Ribeiro-Neto, 1999). Regarding each document as a query, top 100 similar documents (neighbors) fromadaptively learned similarities are compared with target 100 neighbors by averaging precisions on 10 differentrecall level. ipt precision is calculated on top i * 10 neighbors from the adaptively learned similarities by check-ing how many documents appeared as one of top i * 10 target neighbors. Let T be a set of test documents. Forthe given test document D in T, let ADðrÞ and NDðrÞ be a set of top r neighbors of the learned similarities.Then, NS and AvgNS are defined as
NSðDÞ ¼X10
i¼1
jADði � 10Þ \NDði � 10Þji � 10
; AvgNS ¼ 1
jTjXD2T
NSðDÞ ð15Þ
4. Experimental results
4.1. Performance of online learned document similarities
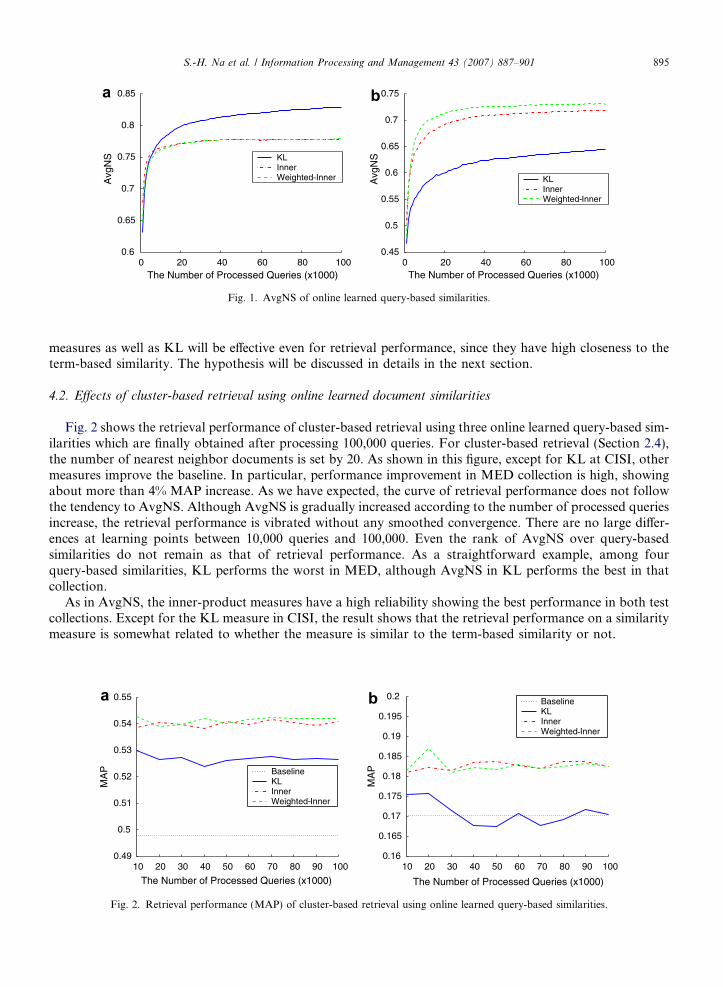
To evaluate three presented query-based similarity measures, we additionally evaluate three proposedquery-based similarities. Three proposed measures are annotated with: KL, Inner (Inner-product) andWeighted-Inner (Weighted inner-product). Fig. 1 shows AvgNS of online learned similarities using threequery-based similarities until 100,000 queries are processed. The number of top retrieved documents (R) isset by 20.
In terms of AvgNS, two different collections present different results. In MED test collection, KL shows thebest, inner-based methods such as Inner and Weighted-inner are ranked second. In CISI test collection, inner-based methods show the best, while KL is the worst in terms of AvgNS. From these two collections, inner-based methods seem to have a high reliability since they are performed relatively well in both collections.
Even if some measures are closer to the term-based similarity, retrieval performances can be different sincethe term-based similarity is not an ideal measure. Other measures can cover some real similarities which arenot represented in the term-based similarity. In such case, retrieval performance will be effective even in othermeasures. The important factor is that it is well-known that the term-based similarity is reliable for improvingretrieval performance. Thus, if a measure is closer to the term-based similarity, we can expect that the measurewill be effective for improving retrieval performance without additional experimentation. In this regard, all our
0 20 40 60 80 1000.6
0.65
0.7
0.75
0.8
0.85
The Number of Processed Queries (x1000)
Avg
NS KL
InnerWeighted-Inner
0 20 40 60 80 1000.45
0.5
0.55
0.6
0.65
0.7
0.75
The Number of Processed Queries (x1000)
Avg
NS
KLInnerWeighted-Inner
Fig. 1. AvgNS of online learned query-based similarities.
S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901 895
measures as well as KL will be effective even for retrieval performance, since they have high closeness to theterm-based similarity. The hypothesis will be discussed in details in the next section.
4.2. Effects of cluster-based retrieval using online learned document similarities
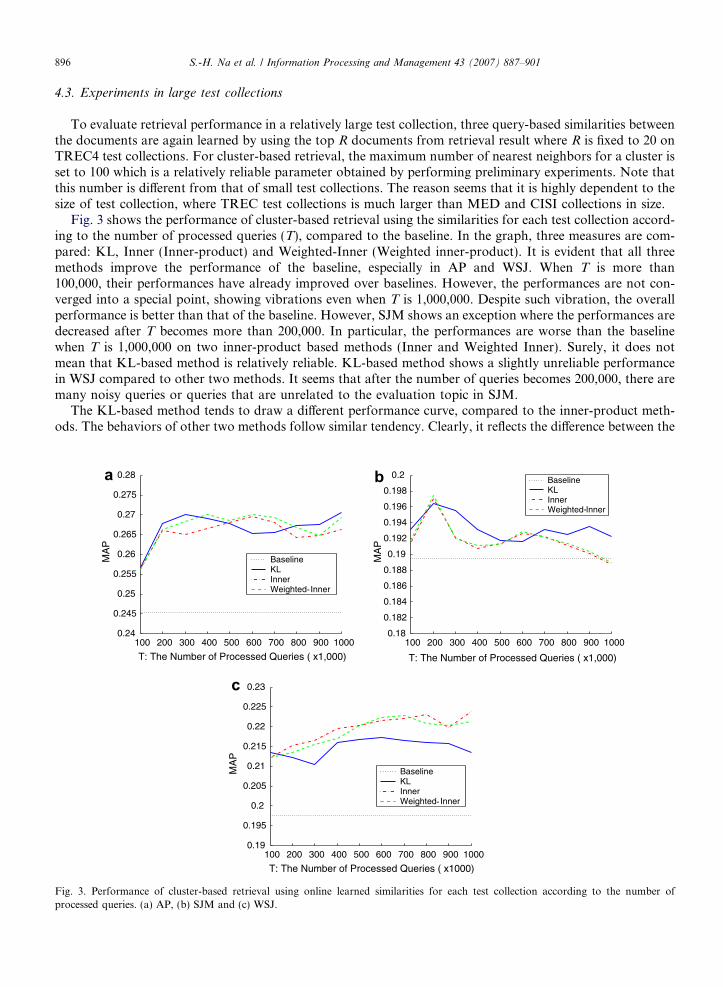
Fig. 2 shows the retrieval performance of cluster-based retrieval using three online learned query-based sim-ilarities which are finally obtained after processing 100,000 queries. For cluster-based retrieval (Section 2.4),the number of nearest neighbor documents is set by 20. As shown in this figure, except for KL at CISI, othermeasures improve the baseline. In particular, performance improvement in MED collection is high, showingabout more than 4% MAP increase. As we have expected, the curve of retrieval performance does not followthe tendency to AvgNS. Although AvgNS is gradually increased according to the number of processed queriesincrease, the retrieval performance is vibrated without any smoothed convergence. There are no large differ-ences at learning points between 10,000 queries and 100,000. Even the rank of AvgNS over query-basedsimilarities do not remain as that of retrieval performance. As a straightforward example, among fourquery-based similarities, KL performs the worst in MED, although AvgNS in KL performs the best in thatcollection.
As in AvgNS, the inner-product measures have a high reliability showing the best performance in both testcollections. Except for the KL measure in CISI, the result shows that the retrieval performance on a similaritymeasure is somewhat related to whether the measure is similar to the term-based similarity or not.
10 20 30 40 50 60 70 80 90 1000.49
0.5
0.51
0.52
0.53
0.54
0.55
The Number of Processed Queries (x1000)
MA
P BaselineKLInnerWeighted-Inner
10 20 30 40 50 60 70 80 90 1000.16
0.165
0.17
0.175
0.18
0.185
0.19
0.195
0.2
The Number of Processed Queries (x1000)
MA
P
BaselineKLInnerWeighted Inner-
Fig. 2. Retrieval performance (MAP) of cluster-based retrieval using online learned query-based similarities.
896 S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901
4.3. Experiments in large test collections
To evaluate retrieval performance in a relatively large test collection, three query-based similarities betweenthe documents are again learned by using the top R documents from retrieval result where R is fixed to 20 onTREC4 test collections. For cluster-based retrieval, the maximum number of nearest neighbors for a cluster isset to 100 which is a relatively reliable parameter obtained by performing preliminary experiments. Note thatthis number is different from that of small test collections. The reason seems that it is highly dependent to thesize of test collection, where TREC test collections is much larger than MED and CISI collections in size.
Fig. 3 shows the performance of cluster-based retrieval using the similarities for each test collection accord-ing to the number of processed queries (T), compared to the baseline. In the graph, three measures are com-pared: KL, Inner (Inner-product) and Weighted-Inner (Weighted inner-product). It is evident that all threemethods improve the performance of the baseline, especially in AP and WSJ. When T is more than100,000, their performances have already improved over baselines. However, the performances are not con-verged into a special point, showing vibrations even when T is 1,000,000. Despite such vibration, the overallperformance is better than that of the baseline. However, SJM shows an exception where the performances aredecreased after T becomes more than 200,000. In particular, the performances are worse than the baselinewhen T is 1,000,000 on two inner-product based methods (Inner and Weighted Inner). Surely, it does notmean that KL-based method is relatively reliable. KL-based method shows a slightly unreliable performancein WSJ compared to other two methods. It seems that after the number of queries becomes 200,000, there aremany noisy queries or queries that are unrelated to the evaluation topic in SJM.
The KL-based method tends to draw a different performance curve, compared to the inner-product meth-ods. The behaviors of other two methods follow similar tendency. Clearly, it reflects the difference between the
100 200 300 400 500 600 700 800 900 10000.24
0.245
0.25
0.255
0.26
0.265
0.27
0.275
0.28
T: The Number of Processed Queries ( x1,000)
MA
P
BaselineKLInnerWeighted Inner
100 200 300 400 500 600 700 800 900 10000.18
0.182
0.184
0.186
0.188
0.19
0.192
0.194
0.196
0.198
0.2
T: The Number of Processed Queries ( x1,000)
MA
P
BaselineKLInnerWeighted Inner
100 200 300 400 500 600 700 800 900 10000.19
0.195
0.2
0.205
0.21
0.215
0.22
0.225
0.23
T: The Number of Processed Queries ( x1000)
MA
P
BaselineKLInnerWeighted Inner
-
-
-
Fig. 3. Performance of cluster-based retrieval using online learned similarities for each test collection according to the number ofprocessed queries. (a) AP, (b) SJM and (c) WSJ.
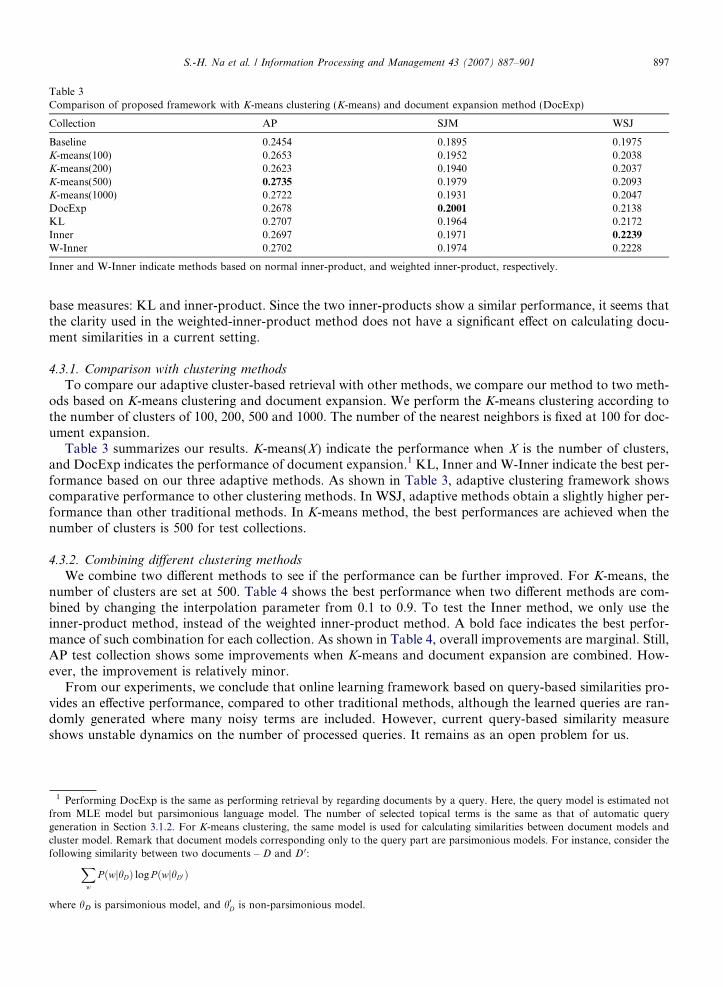
Table 3Comparison of proposed framework with K-means clustering (K-means) and document expansion method (DocExp)
Collection AP SJM WSJ
Baseline 0.2454 0.1895 0.1975K-means(100) 0.2653 0.1952 0.2038K-means(200) 0.2623 0.1940 0.2037K-means(500) 0.2735 0.1979 0.2093K-means(1000) 0.2722 0.1931 0.2047DocExp 0.2678 0.2001 0.2138KL 0.2707 0.1964 0.2172Inner 0.2697 0.1971 0.2239
W-Inner 0.2702 0.1974 0.2228
Inner and W-Inner indicate methods based on normal inner-product, and weighted inner-product, respectively.
S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901 897
base measures: KL and inner-product. Since the two inner-products show a similar performance, it seems thatthe clarity used in the weighted-inner-product method does not have a significant effect on calculating docu-ment similarities in a current setting.
4.3.1. Comparison with clustering methods
To compare our adaptive cluster-based retrieval with other methods, we compare our method to two meth-ods based on K-means clustering and document expansion. We perform the K-means clustering according tothe number of clusters of 100, 200, 500 and 1000. The number of the nearest neighbors is fixed at 100 for doc-ument expansion.
Table 3 summarizes our results. K-means(X) indicate the performance when X is the number of clusters,and DocExp indicates the performance of document expansion.1 KL, Inner and W-Inner indicate the best per-formance based on our three adaptive methods. As shown in Table 3, adaptive clustering framework showscomparative performance to other clustering methods. In WSJ, adaptive methods obtain a slightly higher per-formance than other traditional methods. In K-means method, the best performances are achieved when thenumber of clusters is 500 for test collections.
4.3.2. Combining different clustering methods
We combine two different methods to see if the performance can be further improved. For K-means, thenumber of clusters are set at 500. Table 4 shows the best performance when two different methods are com-bined by changing the interpolation parameter from 0.1 to 0.9. To test the Inner method, we only use theinner-product method, instead of the weighted inner-product method. A bold face indicates the best perfor-mance of such combination for each collection. As shown in Table 4, overall improvements are marginal. Still,AP test collection shows some improvements when K-means and document expansion are combined. How-ever, the improvement is relatively minor.
From our experiments, we conclude that online learning framework based on query-based similarities pro-vides an effective performance, compared to other traditional methods, although the learned queries are ran-domly generated where many noisy terms are included. However, current query-based similarity measureshows unstable dynamics on the number of processed queries. It remains as an open problem for us.
1 Performing DocExp is the same as performing retrieval by regarding documents by a query. Here, the query model is estimated notfrom MLE model but parsimonious language model. The number of selected topical terms is the same as that of automatic querygeneration in Section 3.1.2. For K-means clustering, the same model is used for calculating similarities between document models andcluster model. Remark that document models corresponding only to the query part are parsimonious models. For instance, consider thefollowing similarity between two documents – D and D 0:X
w
PðwjhDÞ log P ðwjhD0 Þ
where hD is parsimonious model, and h0D is non-parsimonious model.
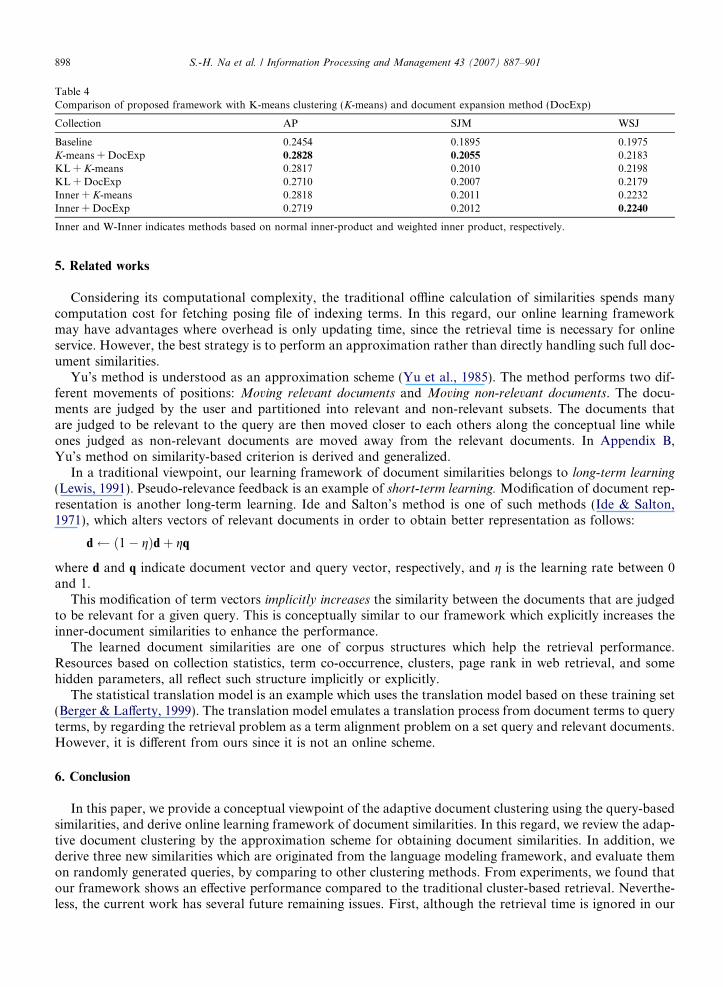
Table 4Comparison of proposed framework with K-means clustering (K-means) and document expansion method (DocExp)
Collection AP SJM WSJ
Baseline 0.2454 0.1895 0.1975K-means + DocExp 0.2828 0.2055 0.2183KL + K-means 0.2817 0.2010 0.2198KL + DocExp 0.2710 0.2007 0.2179Inner + K-means 0.2818 0.2011 0.2232Inner + DocExp 0.2719 0.2012 0.2240
Inner and W-Inner indicates methods based on normal inner-product and weighted inner product, respectively.
898 S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901
5. Related works
Considering its computational complexity, the traditional offline calculation of similarities spends manycomputation cost for fetching posing file of indexing terms. In this regard, our online learning frameworkmay have advantages where overhead is only updating time, since the retrieval time is necessary for onlineservice. However, the best strategy is to perform an approximation rather than directly handling such full doc-ument similarities.
Yu’s method is understood as an approximation scheme (Yu et al., 1985). The method performs two dif-ferent movements of positions: Moving relevant documents and Moving non-relevant documents. The docu-ments are judged by the user and partitioned into relevant and non-relevant subsets. The documents thatare judged to be relevant to the query are then moved closer to each others along the conceptual line whileones judged as non-relevant documents are moved away from the relevant documents. In Appendix B,Yu’s method on similarity-based criterion is derived and generalized.
In a traditional viewpoint, our learning framework of document similarities belongs to long-term learning
(Lewis, 1991). Pseudo-relevance feedback is an example of short-term learning. Modification of document rep-resentation is another long-term learning. Ide and Salton’s method is one of such methods (Ide & Salton,1971), which alters vectors of relevant documents in order to obtain better representation as follows:
d ð1� gÞdþ gq
where d and q indicate document vector and query vector, respectively, and g is the learning rate between 0and 1.
This modification of term vectors implicitly increases the similarity between the documents that are judgedto be relevant for a given query. This is conceptually similar to our framework which explicitly increases theinner-document similarities to enhance the performance.
The learned document similarities are one of corpus structures which help the retrieval performance.Resources based on collection statistics, term co-occurrence, clusters, page rank in web retrieval, and somehidden parameters, all reflect such structure implicitly or explicitly.
The statistical translation model is an example which uses the translation model based on these training set(Berger & Lafferty, 1999). The translation model emulates a translation process from document terms to queryterms, by regarding the retrieval problem as a term alignment problem on a set query and relevant documents.However, it is different from ours since it is not an online scheme.
6. Conclusion
In this paper, we provide a conceptual viewpoint of the adaptive document clustering using the query-basedsimilarities, and derive online learning framework of document similarities. In this regard, we review the adap-tive document clustering by the approximation scheme for obtaining document similarities. In addition, wederive three new similarities which are originated from the language modeling framework, and evaluate themon randomly generated queries, by comparing to other clustering methods. From experiments, we found thatour framework shows an effective performance compared to the traditional cluster-based retrieval. Neverthe-less, the current work has several future remaining issues. First, although the retrieval time is ignored in our

S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901 899
framework, fully updating such document similarities is not an ideal method due to its impracticality. We willdiscover an approximation scheme, which effectively creates clusters. Such approximation method may berelated to the modification of document representation. Second, it is a critical issue to develop a similarityupdating algorithm for dynamic environments in which documents are deleted or inserted. An interesting issueis to consider the framework on only inserting environments such as the retrieval of Electronic Journals.Third, we will examine features that the query-based similarities should satisfy, and develop a new similaritymeasure to contain all features. It will contain work on discovering why the online learning sometimes can beunstable.
Acknowledgement
This work was supported by the KOSEF through the Advanced Information Technology Research Center(AITrc) and by the BK21 project.
Appendix A. Approximation of normalization factor
According to our definition of query-based language model, the normalization factor ZD is defined as
ZD ¼Z
hQ
YVi¼1
P ðtijhDÞPðtijhCÞ
� �PðtijhQÞ
dhQ ðA:1Þ
where V is the number of possible terms, and ti indicates ith term. Reasonably we assume that the documentmodel hD is applied with smoothing by Jelinek-Mercer smoothing with collection model hC as follows:
P ðtjhDÞ ¼ kP ðtjhDÞ þ ð1� kÞP ðtjhCÞ
Then,
ZD ¼Z
hQ
YVi¼1
kP ðtijhDÞð1� kÞPðtijhCÞ
þ 1
!Pðti jhQÞ
dhQ ðA:2Þ
For simplification, we denote ai as (a P 1):
ai ¼ 1þ kP ðtijhDÞð1� kÞPðtijhCÞ
ðA:3Þ
Of total V terms, we select such terms where P(tijhD) is positive (>0) and assign indexes from 1 to jDj where jDjis the number of such selected terms ( the number of unique terms in document D). The remaining terms withthe number V � jDj, is assigned to index after jDj where ai is 1. By applying these indexes,
ZD ¼ ð1� kÞZ
hQ
YjDji¼1
aP ðti jhQÞi
YVi¼jDjþ1
1dhQ ðA:4Þ
Again, we write a query model hQ by V-dimensional vector x = Æx1, . . . ,xVæ where 1-norm of x is 1 (this spaceis (V � 1)-simplex)
ZD
ð1� kÞ ¼Z 1
0
Z 1�x1
0
� � �Z 1�
PjDj�1
i¼1
xi
0
YjDji¼1
axii dxjDj � � � dx1
0B@
1CA � Z 1�
PjDji¼1
xi
0
� � �Z 1�
PV�1
i¼1
xi
0
1dxV � � � dxjDjþ1
0B@
1CA ðA:5Þ
To derive further, we use the following formula:
Z A
0
Z A�x1
0
� � �Z A�
PK�1
K¼1
xK
0
1dx1 � � � dxK ¼AK
K!ðA:6Þ

900 S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901
which is the volume of K-simplex with edges of length of A. To substitute it into ZD, let A and K be 1�PjDj
k¼1xk
and V � jDj, respectively. Then, the Eq. (A.6) becomes
ð1�PjDj
k¼1xkÞV�jDj
ðV � jDjÞ! ðA:7Þ
The following lemma is the core of our approximation.
Lemma 1. If K is sufficiently large so that B lna� K, then the following approximation is reasonable:
Z B0
ax ðB� xÞK
K!dx � BKþ1
ðK þ 1Þ! ðA:8Þ
Proof. Let f(n) beR B
0ax ðB�xÞn
n!dx. By applying part integral, f(n) is recursively derived as follows:
f ðnÞ ¼ 1
ln a�Bn
n!þ f ðn� 1Þ
� �
Since f(0) is (aB � 1)/lna, f(n) is
f ðnÞ ¼ aB � 1
ðln aÞnþ1� Bn
n! ln aþ Bn�1
ðn� 1Þ!ðln aÞ2� � � B
1!ðln aÞn
!
¼ aB � 1
ðln aÞnþ1� 1
ðln aÞnþ1
Bnðln aÞn
n!þ � � �B ln a
� �
¼ 1
ðln aÞnþ1aB � 1� Bnðln aÞn
n!þ � � �B ln a
� �� �ðA:9Þ
Since polynomial expansion of ex is
ex ¼ 1þ x1!þ x2
2!þ � � �
aB is written by eBln a which is expanded with polynomial. By substituting polynomial expansion of eBln a intoEq. (A.9), f(n) becomes
f ðnÞ ¼ 1
ðln aÞnþ1
ðB ln aÞnþ1
ðnþ 1Þ! þðB ln aÞnþ2
ðnþ 2Þ! þ � � � !
The ratio of second term on the first term is (Blna)/(n + 2). If n is sufficiently large, then we can ignore theratio with a very small error. By dropping all terms after second term, f(n) is
f ðnÞ � 1
ðln aÞnþ1
ðB ln aÞnþ1
ðnþ 1Þ!
!¼ Bnþ1
ðnþ 1Þ! �
K corresponds to V � jDj which is very large. Thus, we can agree that this approximation is acceptable.Lemma 1 is consequently applied to further derive Eq. (A.5). After applying jDj � 1 times, ZD would beapproximated with
ZD � ð1� kÞZ 1
0
ax11
ð1� x1ÞV�1
ðV � 1Þ!
Finally, Lemma 1 is applied once more, ZD isZD � ð1� kÞ 1
V !
It is ‘approximately’ document-independent, which is the content of Theorem 1!

S.-H. Na et al. / Information Processing and Management 43 (2007) 887–901 901
Appendix B. Derivation of Yu’s method
In our viewpoint, Yu’s method is an approximation of the query-based similarity. To derive it, we introducethe dissimilarity function g(Di,Dj,Q). For given Q, g(Di,Dj,Q) is the dissimilarity amount to be updatedbetween ith and jth documents. Let zi be position of ith document assigned on a real line (�1,1).
First, the following criterion explains moving relevant documents:
J ¼ 0:5X
i;j2R;i6¼j
ðjzi � zjj � gijÞ2
where gij is g(Di,Dj,Q). The criterion defines the least square error between the target dissimilarities and theapproximated dissimilarities. For the given query Q, gij is assumed to be very small (close to zero). To find zi
and zj such that minimizes J, partial derivative of J on zi is
oJozi¼
Xi;j2R;i 6¼j
ðjzi � zjj þ gijð�1Þ�signðzi�zjÞÞ ðB:1Þ
where sign(x) is 1 if x is positive, 0 otherwise. By going gij to small value (gij! 0), Eq. (B.1) is zero when zi is
zi ¼1
jRjXj2R
zj
This will only be a solution for the single query Q. To integrate a solution for the previous queries, solutionsare interpolated to each other. Let c be 1
jRjP
j2Rzj. Thus, a reasonable movement of position is Dzi = gjzi � cj,where g is a learning rate (0 < g < 1). This is scheme of moving relevant documents.
Although Yu used an one-dimensional point to represent a position, a high-dimensional vector will providea better approximation. In this case, a database operation such as a spatial join is required to find the nearestneighbor documents in real time.
References
Baeza-Yates, R. A., & Ribeiro-Neto, B. A. (1999). Modern information retrieval. ACM Press/Addison-Wesley.Berger, A., & Lafferty, J. (1999). Information retrieval as statistical translation. In Proceedings of the 22nd annual international ACM
SIGIR conference on research and development in information retrieval, pp. 222–229.Cronen-Townsend, S., Zhou, Y., & Croft, W. (2004). A framework for selective query expansion. In Proceedings of CIKM’04, pp. 236–
237.Gao, J., Nie, J., Wu, G., & Cao, G. (2004). Dependence language model for information retrieval. In Proceedings of the 27th annual
international ACM SIGIR conference on research and development in information retrieval, pp. 170–177.Hiemstra, D., Robertson, S., & Zaragoza, H. (2004). Parsimonious language models for information retrieval. In Proceedings of the 27th
annual international ACM SIGIR conference on research and development in information retrieval, pp. 178–184.Ide, E., & Salton, G. (1971). Interactive search strategies and dynamic file organization in information retrieval. In G. Salton, editor. The
smart system – experiments in automatic document processing, pp. 373–393.Kurland, O., & Lee, L. (2004). Corpus structure, language models, and ad hoc information retrieval. In Proceedings of the 27th annual
international ACM SIGIR conference on research and development in information retrieval, pp. 194–201.Kurland, O., & Lee, L. (2005). Better than the real thing? iterative pseudo-query processing using cluster-based language models. In
Proceedings of the 28th annual international ACM SIGIR conference on research and development in information retrieval, pp. 19–26.Lafferty, J., & Zhai, C. (2001). Document language models, query models, and risk minimization for information retrieval. In Proceedings
of the 24th annual international ACM SIGIR conference on research and development in information retrieval, pp. 111–119.Lavrenko, V., & Croft, B. (2001). Relevance-based language models. In Proceedings of the 24th annual international ACM SIGIR
conference on research and development in information retrieval, pp. 120–127.Lewis, D. D. (1991). Learning in intelligent information retrieval. In Proceedings of the eighth international workshop on machine learning,
pp. 235–239.Liu, X. (2004). Cluster-based retrieval using language models. In Proceedings of the 27th annual international ACM SIGIR conference on
research and development in information retrieval, pp. 186–193.Yu, C., Wang, Y., & Chen, C. (1985). Adaptive document clustering. In Proceedings of the seventh annual international ACM SIGIR
conference on research and development in information retrieval, pp. 197–203.Zhai, C., & Lafferty, J. (2002). Model-based feedback in the language modeling approach to information retrieval. In Proceedings of
CIKM’02, pp. 403–410.
Related Documents











