Active object recognition based on Fourier descriptors clustering Elizabeth Gonza ´lez a, * , Antonio Ada ´n b , Vicente Feliu ´ a , Luis Sa ´nchez c a E.T.S. Ingenieros Industriales, University of Castilla La Mancha, Avda. Camilo Jose ´ Cela s/n, Ciudad Real 13071, Spain b E. Superior de Informa ´ tica, University of Castilla La Mancha, Ronda de Calatrava 5, Ciudad Real 13071, Spain c E.U. Ingenierı ´a Te ´cnica Industrial, University of Castilla La Mancha, Campus Tecnolo ´ gico Antigua Fa ´ brica de Armas, Toledo 45071, Spain Available online 17 July 2007 Abstract This paper presents a new 3D object recognition/pose strategy based on Fourier descriptors clustering for silhouettes. The method consists of two parts. Firstly, an off-line process calculates and stores a clustered Fourier descriptors database corresponding to the sil- houettes of the synthetic model of the object viewed from multiple viewpoints. Next, an on-line process solves the recognition/pose prob- lem for an object that is sensed by a camera placed at the end of a robotic arm. The method solves the ambiguity problem – due to object symmetries or similar projections belonging to different objects – by taking a minimum number of additional views of the scene which are selected through a heuristic next best view (NBV) algorithm. The method works in reduced computational time conditions and provides identification and pose of the object. A validation test of this method has been carried out in our lab yielding excellent results. Ó 2007 Elsevier B.V. All rights reserved. Keywords: Object recognition; Next best view; 3D pose; 3D ambiguity 1. Introduction 3D object recognition is a common task in industrial robotic applications like automatic assembly, inspection or object manipulation. Object recognition involves image data processing by comparing image-based features or image-computable representations with a stored represen- tation of the object. An active recognition system must control the positions and parameters of the vision sensor to make the recognition task more effective. Thus, due to the limited information contained in a 2D image, different objects may have the same appearance from different views. In such cases, a single view is insufficient to identify an object. A solution to this ambiguity problem consists of moving the sensor to different viewpoints and processing the new information until the uncertainty is resolved. Since the acquisition and processing of new images is an expensive task, it is desirable to take a minimal number of additional views (Deinzer et al., 2003). Therefore, in order to minimize the cost of the whole recognition process an efficient next best view (NBV) algorithm is mandatory. There are different cost functions to be minimized in a NBV algorithm. Most of them are related with the move- ment of the sensor (camera) to a new position. For instance, the distance between the initial and final camera positions and the joint angles of the device that supports the camera (usually a manipulator robot) are two typical cost measures. Classical active recognition systems have three main modules whose efficiency is decisive for the overall performance: • The object recognition system (identification and pose estimation). • The fusion task (combination of the hypotheses obtained from each sensor position). • The next best view planning (optimal sensor position to solve the ambiguity problem). All these modules can be implemented following differ- ent strategies but, in general, most research projects use stochastic or probabilistic models (Borotschnig et al., 0167-8655/$ - see front matter Ó 2007 Elsevier B.V. All rights reserved. doi:10.1016/j.patrec.2007.06.016 * Corresponding author. Fax: +34 926295361. E-mail address: [email protected] (E. Gonza ´lez). www.elsevier.com/locate/patrec Available online at www.sciencedirect.com Pattern Recognition Letters 29 (2008) 1060–1071

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Available online at www.sciencedirect.com
www.elsevier.com/locate/patrec
Pattern Recognition Letters 29 (2008) 1060–1071
Active object recognition based on Fourier descriptors clustering
Elizabeth Gonzalez a,*, Antonio Adan b, Vicente Feliu a, Luis Sanchez c
a E.T.S. Ingenieros Industriales, University of Castilla La Mancha, Avda. Camilo Jose Cela s/n, Ciudad Real 13071, Spainb E. Superior de Informatica, University of Castilla La Mancha, Ronda de Calatrava 5, Ciudad Real 13071, Spain
c E.U. Ingenierıa Tecnica Industrial, University of Castilla La Mancha, Campus Tecnologico Antigua Fabrica de Armas, Toledo 45071, Spain
Available online 17 July 2007
Abstract
This paper presents a new 3D object recognition/pose strategy based on Fourier descriptors clustering for silhouettes. The methodconsists of two parts. Firstly, an off-line process calculates and stores a clustered Fourier descriptors database corresponding to the sil-houettes of the synthetic model of the object viewed from multiple viewpoints. Next, an on-line process solves the recognition/pose prob-lem for an object that is sensed by a camera placed at the end of a robotic arm. The method solves the ambiguity problem – due to objectsymmetries or similar projections belonging to different objects – by taking a minimum number of additional views of the scene which areselected through a heuristic next best view (NBV) algorithm. The method works in reduced computational time conditions and providesidentification and pose of the object. A validation test of this method has been carried out in our lab yielding excellent results.� 2007 Elsevier B.V. All rights reserved.
Keywords: Object recognition; Next best view; 3D pose; 3D ambiguity
1. Introduction
3D object recognition is a common task in industrialrobotic applications like automatic assembly, inspectionor object manipulation. Object recognition involves imagedata processing by comparing image-based features orimage-computable representations with a stored represen-tation of the object. An active recognition system mustcontrol the positions and parameters of the vision sensorto make the recognition task more effective. Thus, due tothe limited information contained in a 2D image, differentobjects may have the same appearance from differentviews. In such cases, a single view is insufficient to identifyan object.
A solution to this ambiguity problem consists of movingthe sensor to different viewpoints and processing the newinformation until the uncertainty is resolved. Since theacquisition and processing of new images is an expensivetask, it is desirable to take a minimal number of additionalviews (Deinzer et al., 2003). Therefore, in order to minimize
0167-8655/$ - see front matter � 2007 Elsevier B.V. All rights reserved.
doi:10.1016/j.patrec.2007.06.016
* Corresponding author. Fax: +34 926295361.E-mail address: [email protected] (E. Gonzalez).
the cost of the whole recognition process an efficient nextbest view (NBV) algorithm is mandatory.
There are different cost functions to be minimized in aNBV algorithm. Most of them are related with the move-ment of the sensor (camera) to a new position. Forinstance, the distance between the initial and final camerapositions and the joint angles of the device that supportsthe camera (usually a manipulator robot) are two typicalcost measures.
Classical active recognition systems have three mainmodules whose efficiency is decisive for the overallperformance:
• The object recognition system (identification and poseestimation).
• The fusion task (combination of the hypothesesobtained from each sensor position).
• The next best view planning (optimal sensor position tosolve the ambiguity problem).
All these modules can be implemented following differ-ent strategies but, in general, most research projects usestochastic or probabilistic models (Borotschnig et al.,

E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071 1061
1999; Aksoy and Haralick, 2000; Deinzer et al., 2006). Var-ious factors affect the strategy used for recognition, such asthe sensor type, object type and object representationscheme.
The key of our active recognition system consists ofusing a reduced set of Fourier descriptors to connect anddevelop the recognition phases: object representation, clas-sification, identification, pose estimation, next best viewplanning and hypothesis fusion.
We focus the object representation on silhouettesbecause: they can be robustly extracted from images, theyare insensitive to surface feature variations – such as colorand texture – and, finally, they easily encode the shapeinformation (Poppe and Poel, 2005). The most popularmethods for 2D object recognition from silhouettes arebased on invariant moments or Fourier descriptors. Invari-ant moments exhibit the drawback that two completely dif-ferent silhouettes may have the same low order invariantmoments, which may lead to ambiguities in the recognitionprocess. Fourier descriptors yield much more informationabout the silhouette, and only similar silhouettes exhibitsimilar Fourier descriptors. Since we consider that theobjects to be non-occluded and that the background tobe uncluttered, we use a representation scheme in whichthe silhouettes from different viewpoints are representedby their Fourier descriptors.
This paper is organized as follows. Section 2 presents abrief state of the art on active recognition based on com-puter vision. Section 3 presents an overview of the method.Section 4 describes our object identification/pose estima-tion approach. Section 5 details the next best view method.Section 6 shows the performance of our method by carry-ing out experiments in a real platform and some conclu-sions are stated in Section 7.
2. Related research
Previous works on active recognition differ in the way ofrepresenting objects, the way they combine informationand the way they plan the next observation (Roy et al.,2004). Most 3D representation methods are model-based(CAD, solid geometry schemes and spatial-occupancy rep-resentations) and view-based (appearance-based paramet-ric eigenspaces, aspect graph and contours). Therepresentation schemes are characterized by a set of localor global features. The identification process matches fea-tures between the scene and the objects database estimatingthe matching uncertainty measure (ambiguity) (Bustoset al., 2005). Next we will refer to the most interestingworks related to ours.
Hutchinson and Kak (1992) use an aspect graph to rep-resent the objects and characterize the ambiguity by meansof the entropy measure (Dempster–Shafer theory). Theyevaluate the candidates through a set of hypotheses onidentity and position of the object which minimizes theambiguity. In their experiments they only use simpleobjects.
Kovacic et al. (1998) cluster similar views in the featurespace. The system learns the changes in this clustering foreach possible action and records the action which maxi-mally separates views originally belonging to the same clus-ter. By doing this for all obtained clusters they pre-compilea complete recognition–pose-identification plan, a three-like structure which encodes the next best view relative tothe current one and is traversed during object recognition.
Borotschnig et al. (2000) represent the objects throughthe appearance-based information, namely the parametriceigenspace, and augment it by probability distributions.This enables them to cope with possible variations in theinput images due to errors in the pre-processing chain orchanging imaging conditions. Furthermore, the use ofprobability distributions gives a gauge to perform viewplanning. Multiple observations lead up to a significantincrease in recognition rate. Action planning is shown tobe of great use in reducing the number of images necessaryto achieve a certain recognition performance when com-pared to a random strategy.
Sipe and Casasent (2002) use a probabilistic extension tothe feature space trajectory (FST) in a global eigenspace torepresent 3D views of an object. View planning is accom-plished by learning for each pair of objects the most dis-criminating viewpoint in an off-line training phase foeeach pair of objects. A viewpoint is highly discriminatingif the two FSTs of the inspected object pair are maximallyseparated. Their approach assumes that the cost of makingan error is much larger than the cost of moving the sensor.
Zhou et al. (2003) assume that, for an ambiguity case, allfeatures have different uncertainty degrees. Thus, a mea-sured feature, e.g., the visible patterns from the currentcamera angle, contains lower uncertainty, while a missingfeature, e.g., the unseen or self occluded parts of an object,has maximal uncertainty. They study the relative sensitivityfor all features in three treatment models and exploit thejoint power for dealing with complex feature interactionbut they do not include the measurement costs.
3. Overview of the method
In this method the scene silhouette (silhouette of the 3Dobject to be recognized) is recognized among a set of sil-houettes (in our case, 80 or 320 per object) of a group ofobjects through an algorithm based on Fourier descriptorsclustering. Therefore, the recognition of the silhouette ofthe scene involves both identification and pose of theobject. The method consists of off-line and on-line parts.
The off-line process consists of building a structureddatabase of silhouettes belonging to a generic set of objects.Firstly, a high precision three-dimensional model of eachobject is obtained in advance by means of a laser scannersensor. Next, this model is viewed from a set of homoge-neous viewpoints and the corresponding set of 2D silhou-ettes is obtained. The viewpoints correspond to thevertexes of a tessellated sphere with origin in the centreof mass of the object. Fig. 1 shows an object model inside

Fig. 1. (a) Object model put into a tessellated sphere, (b) view of the objectmodel from a specific viewpoint, (c) depth image obtained from the sameviewpoint and (d) silhouette obtained.
1062 E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071
the tessellated sphere, the projected image of the model andits silhouette from a viewpoint.
The database is structured in clusters using three Fou-rier descriptors. Clustering is the unsupervised classifica-tion of patterns (observations, data items, or featurevectors) into groups (clusters). This strategy allows us tosplit the silhouette space into zones where the silhouettesare coarsely similar. Consequently, the cost in the recogni-tion process is dramatically reduced. We have used the QTclustering method (Yuan and Nick Street (2007)) in whichthe number of clusters is not imposed a priori. The featurevector is composed by the second, third and penultimateFourier descriptors. Fig. 2a shows the most importantFourier descriptors modules for a couple of silhouettes,whereas Fig. 2b presents the reconstructed silhouettes tak-ing the three Fourier descriptors superimposed over the
Fig. 2. (a) Fourier descriptors modules for a couple of silhouettes (b)original silhouettes (dotted line) and recovered silhouettes using threeFourier descriptors (solid line).
original ones. Note that by selecting the most meaningfulFourier components it is possible to work with approxi-mate shapes.
The on-line process is devoted to solving the recogni-tion/pose problem of an object that is viewed by a camerain a real environment. The main stages are: Fourierdescriptor calculation, classification (discrimination) pro-cess, candidate selection, pose calculation and next bestview algorithm. Next a brief explanation of these phasesis given.
To calculate the Fourier descriptors a suitable imagepre-processing is carried out on the original image. Specif-ically, this process consists of filtering, thresholding andcontour extraction. Then, the points of the contour aretaken as a sequence of complex numbers and the Fourierdescriptors are finally computed.
In the discrimination phase we define a subset of clustersin which the silhouette of the scene is matched. Thus, theselected clusters constitute the work sub-space in the posephase. The selection is carried out as follows.
Let B = {O1,O2, . . .,Oh, . . .,OH} be a database of H
objects, sh,v the vth silhouette of the object Oh (we assumea number V of silhouettes per object), Sh,v the Fourierdescriptors of sh,v, Ck the kth cluster of silhouettes,k 2 [1, . . .,K], pk the kth cluster prototype, Pk its Fourierdescriptors, D the Euclidian distance, Rk the kth clusterradio defined as Rk ¼ maxðh;vÞ2Ck DðP k; Sh;vÞ, z the silhouetteof the scene to be classified and Z its Fourier descriptors.The subspace ssub of silhouettes that possibly match z isformed by the clusters which verify the conditionD(Pk,Z) < Rk + ek. Usually ek = 0, but if they were largeregions of the Fourier descriptors space not covered bythe clusters, it exists the possibility that a specific Z maynot be included in any cluster. In these cases that conditionmay be relaxed by using parameters ek P 0 which areempirically designed. Thus the discrimination process setsa work subspace ssub with a reduced database ofsilhouettes.
The candidate selection phase, which is carried out inssub, yields, in general, a reduced set of candidate silhou-ettes. The reason for taking only a few of the candidatesis as follows. Matching and alignment techniques basedon contour representations are usually effective in 2D envi-ronments. Nevertheless, in 3D environments these tech-niques have serious limitations in 3D environments. Themain problems with the contour-based techniques occurdue to the fact that the silhouette information may beinsufficient and ambiguous. Thus, similar silhouettes mightcorrespond to different objects from different viewpoints.Consequently, an object representation based on only onecontour may be ambiguous, especially when occlusion cir-cumstances occur.
In essence, the candidate selection phase compares thesilhouette from the scene with the silhouettes in the sub-space ssub by means of a quadratic error minimizationapplied on the modulus of the Fourier descriptors, whereasthe pose estimation phase is solved through the complex

E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071 1063
Fourier descriptors. Both procedures are presented inSection 4.
When there is more than one candidate silhouette thesolution is ambiguous and it is necessary to apply a nextbest view planning method (NBV). Section 5 shows theNBV strategy in detail. Fig. 3 shows a scheme of the wholeprocess.
4. Candidate selection and pose estimation
4.1. Statement of the problem
Let us assume a contour l(n) composed of N points onthe XY plane:
lðnÞ ¼ ½xðnÞ; yðnÞ�; n ¼ 0; . . . ;N � 1 ð1Þ
where the origin of the index n is an arbitrary point of thecurve, and n1 and n1 + 1 are consecutive points accordingto a given direction (for example, clockwise direction) overthe silhouette. Assume also that points over the curve havebeen regularized in the sense that two consecutive pointsare always at the same Euclidean distance. Let us definethe silhouette z by the complex sequence:
zðnÞ ¼ xðnÞ þ jyðnÞ ð2Þ
and its discrete Fourier transform Z(w) = F(z(n)) as:
ZðwÞ ¼XN�1
n¼0
zðnÞ expð�j2pwn=NÞ; 0 6 w 6 N � 1 ð3Þ
Assume also a database of HxV silhouettes sh,v(n),1 6 h 6 H, 1 6 v 6 V as stated in the previous section,where all the silhouettes are composed of N regularizedpoints (0 6 n 6 N � 1), and their respectives discrete Fou-rier transforms are Sh,v(w).
Fig. 3. Diagram of the active recognition system. In the off-line process the Focarried out. The on-line process is devoted to solving the recognition/pose pro
A critical aspect of our method is its computation speedbecause objects have to be recognized in real time. Then theFFT algorithm is used to obtain the Fourier descriptors.Then N must be power of 2 and both the scene silhouetteand the silhouettes from the data base must be regularizedto a number of N = 2N0 points.
The basic problem to be solved in our method is tomatch the scene silhouette z(n) to some silhouette sh0;v0
ðnÞof the database, under the assumptions that z(n) may bescaled (k), translated (c = cx + jcy) and rotated (u) withrespect to the best matching silhouette of the data base.Moreover the reference point on z(n) (the point labeledwith n = 0) may be different from the reference point ofthat database silhouette, and we denote that displacementwith d. The next subsection deals with selecting the silhou-ettes and obtaining c, d, u, k.
4.2. Candidate silhouette selection
Assume that z(n) is the silhouette of an object capturedby the camera. Assume also that it matches the silhouettesh0;v0ðnÞ of the silhouettes database. In general z coincides
with that database silhouette after modifying this last oneby some elemental operations: x–y displacement, rotationwith respect to the mass centre, scaling, and sequence ori-gin displacement. If we define these operations in the com-plex plane (x and y are the real and imaginary axes,respectively), the relationship between these two silhouettescan be expressed in a compact form as:
zðnÞ ¼ Dðsh0;v0ðnÞ; dÞk expðjuÞ þ c ð4Þ
where the operator D(sh,v(n),d) means the displacement ofthe origin of the sequence sh,v(n) in d elements, and theother parameters were introduced in Section 4.1. Taking
urier descriptors database is built and the silhouette clustering procedure isblem.

1064 E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071
the Fourier transform of the previous expression yields (seee.g. Brigham, 1988):
ZðwÞ ¼ k expðjuÞ expðj2pwd=NÞSh0;v0ðwÞ þ cN ð5Þ
Since all the silhouettes of the database are normalizedto have their coordinate origin at their centre of mass, wehave that Sh,v(0) = 0, "h, v. Then particularizing expression(5) to w = 0 yields that the translation can be calculatedfrom c = Z(0)/N.
If we define Z_
ðwÞ ¼ ZðwÞ � cN , the modulus of expres-sion (5) holds:
j Z_
ðwÞj ¼ kjSh0;v0ðwÞj ð6Þ
Now assume that we want to know if a generic silhouettesh,v(n) of the database matches z(n). In order to do thatwe propose a dissimilarity index between the scene andthe database silhouettes defined as
J 0h;v ¼ min
kfJ h;vðkÞg ð7Þ
where
J h;vðkÞ ¼ ðj Z_
j � kjSh;vjÞtðj Z_
j � kjSh;vjÞ=N ð8Þ
Z_
¼ ðbZð0Þ; ... ; bZðN � 1ÞÞt; Sh;v ¼ ðSh;vð0Þ; ... ; Sh;vðN � 1ÞÞt,|Æ| = absolute value. Notice that index (8) is the meansquared error between the modules of the Fourier descrip-tors of the scene silhouette and the silhouette of the data-base. Minimization of (7) allows obtaining the optimumscaling factor k0
h;v to be obtained making silhouettesk0
h;vsh;vðnÞ and z(n) � c the most similar.It is easy to derive analytical expressions to find that
optimum scaling factor and the minimum dissimilarityindex J 0
h;v between the scene silhouette and a given silhou-ette sh,v of the database:
k0h;v ¼
j Z_
jtjSh;vjjSh;vjtjSh;vj
; J 0h;v ¼ j Z
_
jtj Z_
j � ðj Z_
jtjSh;vjÞjSh;vjtjSh;vj
2
ð9Þ
Once we have defined the dissimilarity index, the matchingprocess consists of finding the silhouette sh0;v0
ðnÞ of thedatabase that minimize the index:
J 0 ¼ minh;vfJ 0
h;vg ð10Þ
If the matching were perfect then J0 = 0. Otherwise thisprocess would provide the silhouette sh0;v0
ðnÞ from the data-base that best fits z(n) in a least square error sense, accord-ing to Parseval’s Theorem applied to discrete signals (seee.g. Roberts, 2003). Notice that this matching process isindependent of silhouette translation, rotation, scalingand displacement operations.
In order to guarantee the robustness of the recognitionmethod – we previously mentioned that a single silhouettemay be insufficient to recognize an object – an ambiguitycriterion based on J 0
h;v is established. Thus, we take theset of the candidate silhouettes that verify:
J 0h;v � J 0
maxh;vfJ 0
h;vg � J 0< u ð11Þ
u being a predefined threshold. Then our matching processmay give us a set of database silhouettes that verify (11),which may be expressed by their indexes:L = {(h1,v1), (h2,v2), . . ., (hm,vm)}. Discrimination amongthem (silhouettes and their corresponding objects) mustbe done by moving the camera to another position and ori-entation, and repeating the matching process. This will al-low us to discard objects among the ones of the possible setL and, after repeating this process several times, discard allcandidate objects except for the one which is the bestmatch.
4.3. Pose calculation
In order to calculate the pose of z with respect to a gen-eric database silhouette sh,v, the complete complex Fourierdescriptors (not only the modules as in the previous pro-cess) are used. As a result of this process, a new similarityindex Fh,v is obtained and the pose parameters kh,v, uh,v, dh,v
are calculated.The cost function to be minimized is (see (4) and (5)):
F h;vðkh;v; hh;v; dh;vÞ ¼ ðZ � qh;vWh;vðdh;vÞÞt�ðZ � qh;vWh;vðdh;vÞÞ
ð12Þ
where Wh,v(dh,v) = (sh,v(0), sh,v(1) exp(j2pdh,v/N), . . ., sh,v-(N � 1)exp(j2pdh,v(N � 1)/N))t, qh,v = kh,v exp(juh,v), * de-notes conjugate, t* denotes transpose conjugate, and(h,v)�L (is now restricted to the set of candidates L).
If we minimize (12) with respect to the complex numberqh,v we get:
q0h;vðdh;vÞ ¼
bZ tW�h;vðdh;vÞSt�
h;vSh;v;
F 0h;vðdh;vÞ ¼ bZ t� Z � j
bZ t�Wh;vðdh;vÞj2
St�h;vSh;v
ð13Þ
where we have used Wt�h;vðdh;vÞWh;vðdh;vÞ ¼ St�
h;v � Sh;v.Taking into account that dh,v is an integer and
0 6 dh,v 6 N � 1, the right expression of (13) is calculatedfor all possible values of d, and we define F 0
h;v ¼mindfF 0
h;vðdÞg.Then F 0
h;v is the dissimilarity index of the silhouette sh,v
with respect to z in the fine matching process, d0h;v is its cor-
responding displacement and q0h;v is obtained from the left
equation of (13) particularized to that d0h;v. Rotation and
scaling are estimated from q0h;v:
k0h;v ¼ jq0
h;vj; u0h;v ¼ \q0
h;v ð14Þ

E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071 1065
5. Solving the ambiguity problem
5.1. Discriminant silhouettes
If only one silhouette (h1,v1) verifies expression (11)(L = {(h1,v1)}), then there is no ambiguity, the object isrecognized and its pose is calculated. If there were morethan one verified silhouette (11), then those silhouetteswould be similar and, in order to accomplish a reliable rec-ognition decision, more views of the scene must be taken.In this case, the next pose location of the camera is com-puted through the next best view algorithm (NBV) whichwill be presented in this section. Before presenting ourNBV algorithm, some concepts must be explained.
Let Oh be a generic object of the database B. As men-tioned in Section 3, the synthetic model of Oh is viewedfrom V viewpoints of the tessellated sphere T and a setof V corresponding silhouettes is obtained. The first ques-tion that we face is: what silhouette of Oh is the most differ-ent from the rest of the silhouettes of B? In other words:from which viewpoint does the object Oh seem to be moredifferent (less ambiguous matching) from the other objectsof B? The answer to this question is based on Fourierdescriptors clustering. Fig. 4a and b shows the clustersplotted in the 3D space and the silhouette cluster distribu-tion of our database. We define a normalized discrimina-tion measure of a cluster C as follows:
bðCÞ ¼ 1�# silouettes in C# silouettes in B
ð15Þ
Note that the less dense C is, the higher the value b is ex-pected to be and, consequently, the more discriminatorythe cluster is. Note that b 2 [0, 1]. Bearing in mind that eachsilhouette belongs to a specific cluster, we can sort the sil-houettes of Oh with respect to the normalized discrimination
Fig. 4. (a) Cluster plotted in the 3D space. (b) Cluster distribution of our sIllustration of discriminant silhouettes through the parameter b.
measure of the cluster they belong to. Thus, the setfsh;v1
; sh;v2; . . . ; sh;vV g represents the silhouettes of Oh sorted
from maximum to minimum b.We state that a silhouette sh,v is a discriminant silhouette
of the object Oh if it belongs to the most discriminatorycluster which has got silhouettes of Oh. Then if Ck1
is thecluster to which sh;v1
belongs, all the silhouettes of theobject Oh that belong to that cluster – DSh ¼ fsh;v1
;sh;v2
; . . . ; sh;vxhg with 1 6 xh 6 V – are discriminant. And
the best discriminant silhouette of Oh is defined as thesilhouette sh;v0
2 DSh that maximizes J ¼ maxs2DSh
fmins02DSh;s0 6¼sfDðs; s0Þgg. Maximization of this index givesthe silhouette sh;v0
belonging to DSh which is most isolatedfrom the others silhouettes of DSh in Ck, D being theEuclidean distance in the patterns space. Fig. 4c illustratesan example.
It is essential to bear in mind that, in our representationscheme we associate each stored silhouette in the databasewith a viewpoint of the tessellated sphere T. Therefore, thebest discriminant silhouette of an object has an associatedviewpoint with we denote as the best discriminant viewpoint
of the object. In the off-line process, the set of discriminantsilhouettes together with its corresponding set of discrimi-
nant viewpoints are stored for each one of the objects ofthe database B. As will be explained below, this informa-tion is capital in our next best view algorithm.
5.2. Next best view
Assume that after evaluating the cost function J 0h;v, a
sorted set of silhouettes of indexes L = {(h1,v1), (h2,v2), . . .,(hm,vm)} verify expression (11). Note that each of these sil-houettes belongs to the object: shi ;vi 2 Ohi . As commented inthe previous subsection, each one of these objects is associ-ated to a sorted set of discriminant silhouettes together with
ilhouette database. Note that very different cluster densities appear. (c)

1066 E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071
their discriminant viewpoints, which have been calculatedand stored in advance. From now on we will consider view-points instead of silhouettes. Thus, for instance, the objectOh has xhdiscriminant viewpoints: vðDShÞ ¼ v sh;v1
ð Þ;�
v sh;v2ð Þ; . . . ; v sh;vxh
� �g.
The search for of the NBV begins with the set of discrim-inant viewpoints corresponding to the first object Oh1
. If adiscriminant viewpoint of this object is rejected (the rejec-tion criterion is presented below), we try the next discrimi-
nant viewpoint from the list. If the list of viewpointscorresponding to object Oh1
is completed without success,the procedure continues by taking the list of discriminant
viewpoints corresponding to the next object Oh2and so on.
The rejection decision is taken by evaluating a NBV costfunction which is based on three key factors: the robotworkspace, the discrimination degree of the next viewpoint,and the movement that the robot must accomplish to gofrom the current position to the next one. If a discriminant
viewpoint does not pass the requirements imposed by theNBV cost function, the viewpoint will be rejected. Other-wise if it fulfils the requirements, then it will be selectedas the NBV. Next we will explain in detail the three factorswhich define the NBV cost function in detail.
Assume v be the current position of the camera and v 0 tobe a discriminant viewpoint which is going to be evaluatedas NBV, and that is associated to a generic discriminant sil-
houette sh0;v0 . With regards to the first factor, v 0 is directlyrejected if the next position of the camera is outside theworkspace of the robot. This factor can be modeled bymeans of a binary parameter a, that takes value 1 if thenext position of the camera is inside the robot workspaceand 0 otherwise. The second factor is the discrimination
RuðhÞ ¼uxuxð1� chÞ þ ch uxuyð1� chÞ � uzsh uxuzð1� chÞ þ uysh
uxuyð1� chÞ þ uzsh uyuyð1� chÞ þ ch uyuzð1� chÞ � uxsh
uxuzð1� chÞ � uysh uyuzð1� chÞ þ uxsh uzuzð1� chÞ þ ch
0B@
1CA ð18Þ
term, taken through the normalized discrimination mea-sure (b) corresponding to the cluster C 0 that containssh0 ;v0 . Finally, the third factor concerns the cost of robotmovement. This has been modeled by a parameter p thattakes into account the whole joint increments betweenthe current pose (/v,i, 1 6 i 6 nj) and the next robot poseð/v0 ;i; 1 6 i 6 njÞ where nj is the number of robot joints(see Niku, 2001). Formally:
RvðuÞ ¼vxvxð1� cuÞ þ cu vxvyð1� cuÞ � vzsu vxvzð1�
vxvyð1� cuÞ þ vzsu vyvyð1� cuÞ þ cu vyvzð1�vxvzð1� cuÞ � vysu vyvzð1� cuÞ þ vxsu vzvzð1�
0B@
pðv; v0Þ ¼ 1�P
ij/v;i � /v0 ;ijPiðUiÞ
ð16Þ
where p 2 [0, 1] and Ui is the ith robot joint range.Finally, the NBV cost function is defined as follows:
F NBVðv; v0Þ ¼ aðv0Þ � bðC0Þ � pðv; v0Þ ð17Þ
Note that the NBV cost function is a normalized func-tion. If FNBV(v,v 0) exceeds an empirically establishedthreshold l empirically established, v 0 is set as the NBV.Parameter l depends on the object database and the usedrobot.
Next we present in detail the movement of the camerafrom the current position to the NBV. This transforma-tion is explained in terms of rotations of the tesselatedsphere T on which the viewpoints v and v 0 are placed.Let Nv be a node of T which defines the current viewpointv, and N v0 be the node of T corresponding to the NBV v 0.In order to align v and v 0 (or Nv and N v0 ) the followingtransformation must be carried out (Adan et al., 2000):Let
~uðux; uy ; uzÞ ¼ON v��!� ON v0
��!ON v��!� ON
�!v0
��� ���be the normal vector to the plane defined by ON
�!v and ON
�!v0 ,
where ON�!
defines the vector that starts at the center of T
and ends in the node N. Let h be the angle between the lasttwo vectors. Then, a rotation h around the u axis can befirst applied to T. This spatial transformation is definedby the following rotation matrix Ru(h):
where ch = cosh and sh = sinh.Later, the swing angle u, which is computed in Eq. (13),
must be used for carrying out a complete pose of the cam-era. In order to do that, a second rotation u around the
axis ~vðvx; vy ; vzÞ ¼ON v0��!ON�!
v0
��� ��� is required. The rotation matrix
Rv(u) can be formally expressed as:
cuÞ þ vysu
cuÞ � vxsu
cuÞ þ cu
1CA ð19Þ
E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071 1067
Finally, the transformation between v and v 0, taking intoaccount the swing angle of the camera, is as follows:
Rðu; hÞ ¼ RvðuÞRuðhÞ ð20Þ
5.3. Multiview fusion and recognition
The NBV algorithm presented in the last section isrepeated until the ambiguity problem is solved. Assumethat we obtained from the first pose of the camera the set
of indexes of candidate silhouettes L1 ¼ h11; v
11
� �; h1
2; v12
� �;
�. . . ; h1
m1; v1
m1
� �g;m1 > 1, belonging to objects O1 ¼ Oh1
1;
nOh1
2; . . . ;Oh1
m1g. Since m1 > 1, there is ambiguity and a new
image of the scene from a new camera position must be
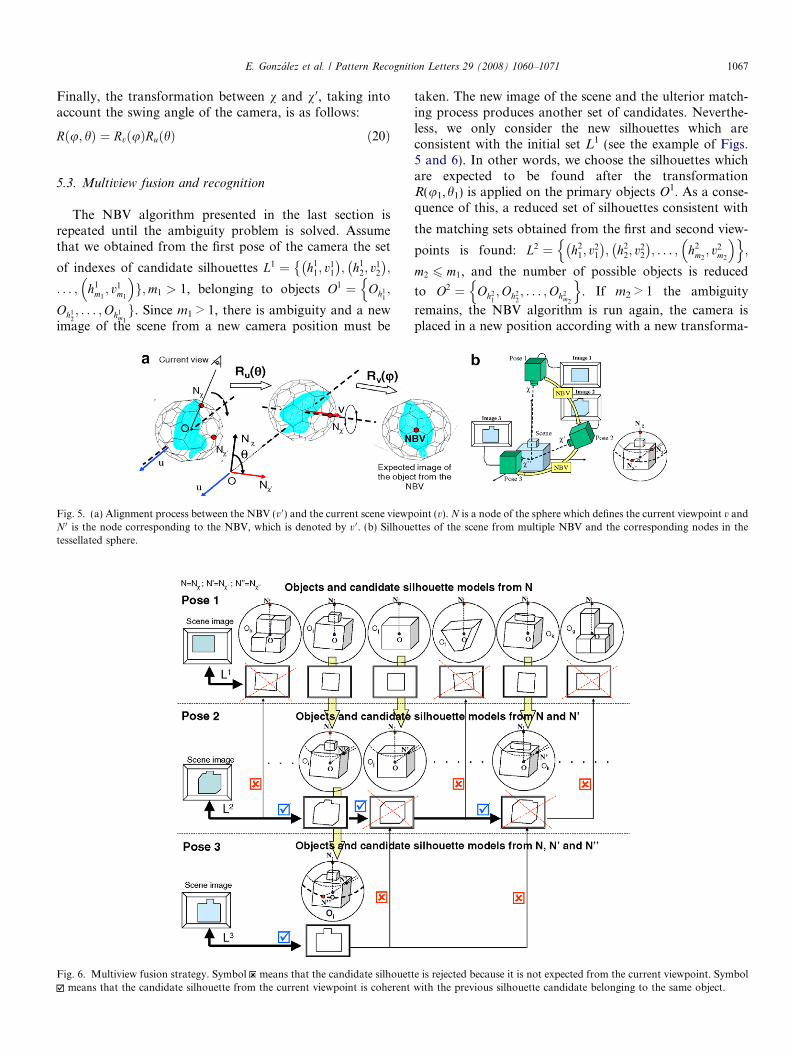
Fig. 5. (a) Alignment process between the NBV (v 0) and the current scene viewpN 0 is the node corresponding to the NBV, which is denoted by v 0. (b) Silhouetessellated sphere.
Fig. 6. Multiview fusion strategy. Symbol means that the candidate silhouettmeans that the candidate silhouette from the current viewpoint is coherent
taken. The new image of the scene and the ulterior match-ing process produces another set of candidates. Neverthe-less, we only consider the new silhouettes which areconsistent with the initial set L1 (see the example of Figs.5 and 6). In other words, we choose the silhouettes whichare expected to be found after the transformationR(u1,h1) is applied on the primary objects O1. As a conse-quence of this, a reduced set of silhouettes consistent with
the matching sets obtained from the first and second view-
points is found: L2 ¼ h21; v
21
� �; h2
2; v22
� �; . . . ; h2
m2; v2
m2
� �n o;
m2 6 m1, and the number of possible objects is reduced
to O2 ¼ Oh21;Oh2
2; . . . ;Oh2
m2
n o. If m2 > 1 the ambiguity
remains, the NBV algorithm is run again, the camera isplaced in a new position according with a new transforma-
oint (v). N is a node of the sphere which defines the current viewpoint v andttes of the scene from multiple NBV and the corresponding nodes in the
e is rejected because it is not expected from the current viewpoint. Symbolwith the previous silhouette candidate belonging to the same object.

1068 E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071
tion R(u2,h2), the object consistency procedure is repeatedfor the new matching set, and new sets L3 and O3 areobtained. Thus, as the number of iterations increases thenumber of candidate objects decreases until only one can-didate is finally found.
Fig. 6 illustrates an example of our multiview fusionstrategy. The first view of the scene (pose 1), yields six can-didate silhouettes belonging to six objects Oh, Oi, Oj, Of,Ok, Og. From the second pose of the camera, silhouettessi,a, sj,b, sk,c are selected because they are consistent withthe expected silhouettes of objects Oi, Oj, Ok seen fromthe NBV, N v0 . On the contrary, the silhouettes of objectsOh, Of, Og under the transformation R(u1,h1) do notbelong to L2 being labeled as inconsistent and rejected.Finally, only one consistent candidate is obtained fromthe third pose of the camera (node N v00 in T), and the objectOi of the scene is finally recognized.
Table 1
Number of silhouettes n tA qA tB qB
80 0.05 2.652 1.640 2.475 2.3820.5 2.047 1.653 1.863 2.4732.0 1.888 1.671 1.625 2.960
320 0.05 4.301 1.089 4.139 2.1070.5 3.336 1.339 3.096 2.2612.0 2.826 1.276 2.723 2.300
6. Experimentation
6.1. Recognition test without noise
A validation test of this method has been carried out inour lab. The experimental setup is composed of a StaubliRX 90 Robot with Jai-CVM1000 a microcamera at itsend. This system controls the position and vision directionof the camera, the object always being always centered inthe scene. Fig. 7 shows the experimental setup.
In the off-line process, the synthesized models (with80,000 polygons/object) are built through a VI-910 KonicaMinolta 3D Laser scanner. At the same time the silhouettedatabase with their respective Fourier descriptors areobtained and stored. Currently, we have used databaseswith 80 and 320 silhouettes/model.
In order to reduce redundant information and to opti-mize the recognition/pose time, a Fourier descriptorsreduction has been carried out on the silhouette models.Fig. 2a showed Fourier descriptors modulus of an example.It can be seen that the first and the last descriptors are themost meaningful. The reduction procedure consists of con-sidering the intervals [1, X(k)], [X(N � k),X(N)], k = 1,. . .,N, until the error/pixel between the original and
Fig. 7. (a) Experimental setup and (
reduced silhouettes is less than a threshold n. The smallernis, the more Fourier descriptors are taken.
The experimentation has been carried out with 28objects that have been previously modeled with 80 and320 views, considering descriptor reductions of n = 0.05,0.5 and 2.
In the clustering process we have used 50 clusters. Dur-ing this phase we used images with resolution 640 · 480.Each silhouette in the database was stored with a resolu-tion of 512 points and the database size was 12 MB (80views) and 42 MB (320 views).
Our active 3D recognition system worked in all testsachieving 96% of effectiveness. Table 1 shows the resultsobtained during the recognition process without (A) andwith (B) discrimination phase. The results are comparedtaking into account: number of silhouettes of the model,threshold for Fourier descriptors reduction (n), meansquare error between the silhouette of the scene and theestimated silhouette (q). Variable t is the computation time(s) on a Pentium III 800 Hz processor. In Table 2, we detailthe time percentage, with respect to the total time, neededby every one of the stages of the whole recognition proce-dure. We have also distinguished both with and without sil-houette clustering cases. Note that in the second case thediscrimination subprocess is included. Fig. 8 presents somematching and pose estimation results using the proposedalgorithm.
With regard to Tables 1 and 2 the following commentscan be made:
• Throughout the whole process, most of the time isdevoted to extracting the object’s silhouette (88, 6%and 94, 7%). Note that, this stage includes several image
b) examples of synthetic models.
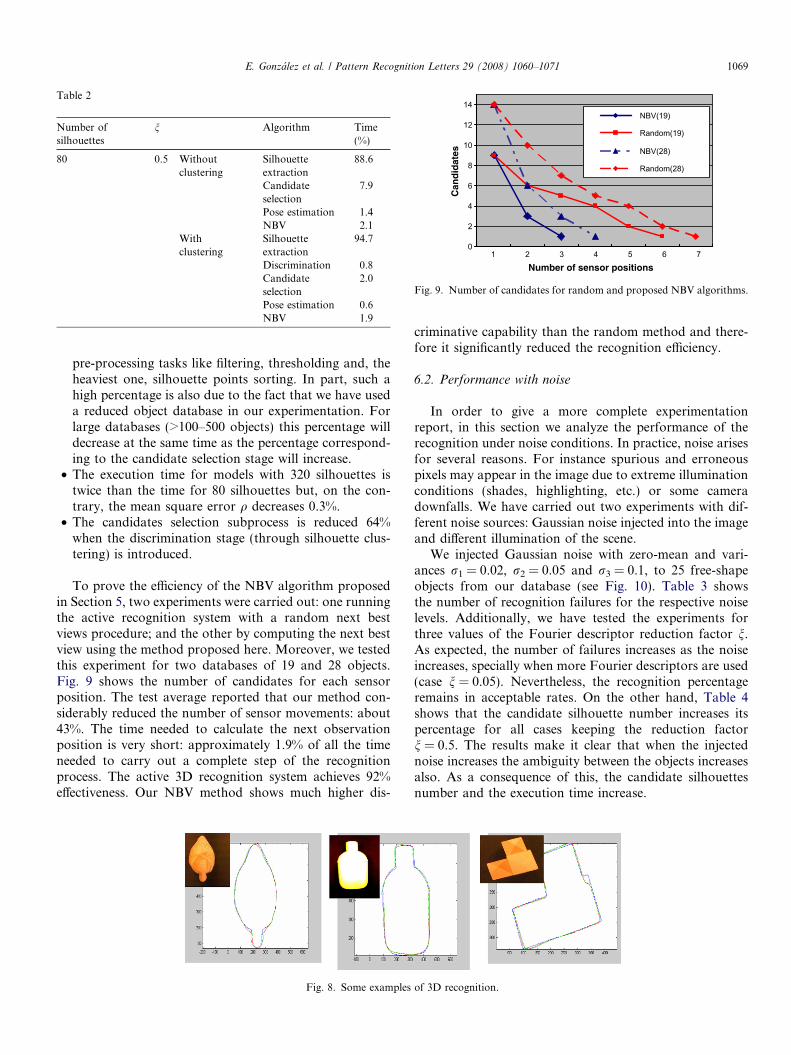
Table 2
Number ofsilhouettes
n Algorithm Time(%)
80 0.5 Withoutclustering
Silhouetteextraction
88.6
Candidateselection
7.9
Pose estimation 1.4NBV 2.1
Withclustering
Silhouetteextraction
94.7
Discrimination 0.8Candidateselection
2.0
Pose estimation 0.6NBV 1.9
0
2
4
6
8
10
12
14
1 2 3 4 5 6 7
Number of sensor positions
Can
did
ates
NBV(19)
Random(19)
NBV(28)
Random(28)
Fig. 9. Number of candidates for random and proposed NBV algorithms.
E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071 1069
pre-processing tasks like filtering, thresholding and, theheaviest one, silhouette points sorting. In part, such ahigh percentage is also due to the fact that we have useda reduced object database in our experimentation. Forlarge databases (>100–500 objects) this percentage willdecrease at the same time as the percentage correspond-ing to the candidate selection stage will increase.
• The execution time for models with 320 silhouettes istwice than the time for 80 silhouettes but, on the con-trary, the mean square error q decreases 0.3%.
• The candidates selection subprocess is reduced 64%when the discrimination stage (through silhouette clus-tering) is introduced.
To prove the efficiency of the NBV algorithm proposedin Section 5, two experiments were carried out: one runningthe active recognition system with a random next bestviews procedure; and the other by computing the next bestview using the method proposed here. Moreover, we testedthis experiment for two databases of 19 and 28 objects.Fig. 9 shows the number of candidates for each sensorposition. The test average reported that our method con-siderably reduced the number of sensor movements: about43%. The time needed to calculate the next observationposition is very short: approximately 1.9% of all the timeneeded to carry out a complete step of the recognitionprocess. The active 3D recognition system achieves 92%effectiveness. Our NBV method shows much higher dis-
Fig. 8. Some examples
criminative capability than the random method and there-fore it significantly reduced the recognition efficiency.
6.2. Performance with noise
In order to give a more complete experimentationreport, in this section we analyze the performance of therecognition under noise conditions. In practice, noise arisesfor several reasons. For instance spurious and erroneouspixels may appear in the image due to extreme illuminationconditions (shades, highlighting, etc.) or some cameradownfalls. We have carried out two experiments with dif-ferent noise sources: Gaussian noise injected into the imageand different illumination of the scene.
We injected Gaussian noise with zero-mean and vari-ances r1 = 0.02, r2 = 0.05 and r3 = 0.1, to 25 free-shapeobjects from our database (see Fig. 10). Table 3 showsthe number of recognition failures for the respective noiselevels. Additionally, we have tested the experiments forthree values of the Fourier descriptor reduction factor n.As expected, the number of failures increases as the noiseincreases, specially when more Fourier descriptors are used(case n = 0.05). Nevertheless, the recognition percentageremains in acceptable rates. On the other hand, Table 4shows that the candidate silhouette number increases itspercentage for all cases keeping the reduction factorn = 0.5. The results make it clear that when the injectednoise increases the ambiguity between the objects increasesalso. As a consequence of this, the candidate silhouettesnumber and the execution time increase.
of 3D recognition.

Fig. 10. Examples of images with Gaussian noise for different noise levels and the corresponding silhouettes.
Table 3Number of recognition failures
Number of silhouettes n r1 r2 r3
80 0.05 0 2 90.5 0 2 62.0 0 0 2
Fig. 11. Five different illumination conditions used in the ex
Table 4Candidate silhouette number increases its percentage
Number of silhouettes n r1 (%) r2 (%) r3 (%)
80 0.05 6.8 8.7 12.30.5 4.3 5.7 9.82.0 1.6 2.9 4.4
1070 E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071
Concerning experiences with different light conditions, atotal of 75 tests have been carried out. We tested ourmethod for five objects in three positions using five kindsof illumination. Fig. 11a presents the objects at the differentlight conditions: (I1) natural light, (I2) fluorescent light onthe lab ceiling, (I3) one lateral diffuse light 60 cm from thescene, (I4) fluorescent and lateral lights and (I5) three dif-fuse lights 60 cm around the scene. Table 5 shows the cor-responding recognition percentages for all cases. It can beseen that the method is quite robust achieving percentagesup to 90% is most cases. Fig. 11b shows some exampleswhere the method does not recognize the object. Whendark and highlighted zones appear together in the imagethe recognition procedure may fail due to the fact thatthe silhouette of the object is not well extracted.
periment and some cases where the silhouette is wrong.

Table 5Recognition percentage for different illumination conditions
n I1 I2 I3 I4 I5
0.05 92.0 96.0 89.3 93.3 88.00.5 93.3 97.3 90.7 96.0 92.02.0 94.7 98.7 90.7 97.3 93.3
E. Gonzalez et al. / Pattern Recognition Letters 29 (2008) 1060–1071 1071
7. Conclusion
This paper has presented a new active recognition sys-tem. The system turns a 3D object recognition problem intoa multiple silhouette recognition problem where images ofthe same object from multiple view points are considered.Fourier descriptors properties have been used to carry outthe silhouette clustering, matching and pose processes.
Our method implies the use of databases with a verylarge number of stored silhouettes but an efficient versionof the matching process with Fourier descriptors allowsus to solve the object recognition and pose estimationproblems in a reduced computation time.
On the other hand, the next best view (NBV) methodefficiently solves way the frequent ambiguity problem inrecognition systems. This method is very robust and fastbeing able to discriminate among very close silhouettes.
Acknowledgements
This work has been supported by the Spanish ProjectsPBI05-028 JCCM and DPI DPI2006-14794-C02-01.
References
Adan, A., Cerrada, C., Feliu, V., 2000. Modeling wave set: Definition andapplication of a new topological organization for 3D object modeling.Comput. Vis. Image Understand. 79, 281–307.
Aksoy, S., Haralick, R.M., 2000. Probabilistic vs. geometric similaritymeasures for image retrieval. In: Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, vol. 2. pp. 357–362.
Borotschnig, H., Paletta, L., Pranti, M., Pinz, A.H., 1999. A comparisonof probabilistic, possibilistic and evidence theoretic fusion schemes foractive object recognition. Computing 62, 293–319.
Borotschnig, H., Paletta, L., Pranti, M., Pinz, A., 2000. Appearance basedactive object recognition. Image Vis. Comput. 18, 715–727.
Brigham, E.O., 1988. The Fast Fourier Transform and Applications.Prentice-Hall, New York.
Bustos, B., Kein, D.A., Saupe, D., Schreck, T., Vranic, D., 2005.Feature-based similarity search in 3D object databases. ACMComput. Surv. (CSUR) 37 (4), 345–387 (Association For Comput-ing Machinery).
Deinzer, F., Denzler, J., Niemann, H., 2003. Viewpoint selection. Planningoptimal sequences of views for object recognition. Computer Analysisof Images and Patterns. Springer, Groningen, The Netherlands, pp.65–73.
Deinzer, F., Denzler, J., Derichs, C., Niemann, H., 2006. Integratedviewpoint fusion and viewpoint selection for optimal object recogni-tion. In: Chanteler, M.J., Trucco, E., Fisher, R.B., (Eds.), Proceedingsof the British Machine Vision Conference.
Hutchinson, S.A., Kak, A.C., 1992. Multisensor strategies using Demp-ster–Shafer belief accumulation. In: Abidi, M.A., Gonzalez, R.C.(Eds.), Data Fusion in Robotics and Machine Intelligence. AcademicPress, pp. 165–209 (Chapter 4).
Kovacic, S., Leonardis, A., Pernus, F., 1998. Planning sequences of viewsfor 3D object recognition and pose determination. Pattern Recogn. 31(10), 1407–1417.
Niku, S.B., 2001. Introduction to Robotics, Analysis, Systems, Applica-tions. Prentice Hall.
Poppe, R.W., Poel, M., 2005. Example-based pose estimation in monoc-ular images using compact fourier descriptors. CTIT Technical Reportseries TR-CTIT-05-49. Centre for Telematics and Information Tech-nology, University of Twente, Enschede. ISSN 1381-3625.
Roberts, M.J., 2003. Signals and Systems. McGraw-Hill.Roy, S.D., Chaudhury, S., Banerjee, S., 2004. Active recognition through
next view planning: A survey. Pattern Recogn. 37 (3), 429–446.Sipe, M., Casasent, D., 2002. Feature space trajectory methods for active
computer vision. IEEE Trans. PAMI 24, 1634–1643.Yuan, D., Nick Street, W., 2007. HACS: A heuristic algorithm for
clustering of subsets. In: Proceedings of the SIAM InternationalConference on Data Mining.
Zhou, X.S., Comaniciu, D., Krishnan A., 2003. Conditional featuresensitivity: A unifying view on active recognition and feature selection.Proceedings of the IEEE International Conference on ComputerVision (ICCV’03), Nice, France, October 13–16.
Related Documents










