Action and event recognition

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Action and event recognition

Bag-of-wordsSVM classifierrunningwalkingjogginghandwavinghandclappingboxing
Visual Dictionary
…
Bag-of-featuresInterest points extraction
• For the purpose of action recognition, we can follow the same three steps of the case of objectcategorization. After that descriptors of spatio-temporal features are obtained, we can define a spatio-temporal word dictionary and hence apply classification
Action recognition by bag of words classification

Clutter? Choreographed? Scale Rarity of actions Training/testin
g split
KTH No Yes 2391 videos Classification - one per video Defined – by actors
UCF Sports Yes No 150 videos Classification – one per video Undefined – LOO
UCF Youtube Yes No 1168 videos Classification – one per video Undefined – LOO
Hollywood2 Yes No 69 movies, ~1600instances
Detection,~xx actions/h
Defined – by videos
TRECVid Yes No ~100h Detection, ~20 actions/h
Defined – by time
• A “good” dataset should have the following characteristics:
− Scene and motion need to be cluttered.− People should not perform coreographed actions or gestures.− Need to define a consistent and reproducible performance measure.− Action should be rare (enforce detection w.r.t. classification)− Provide a large amount of annotated videos.
Summary of datasets:
Public datasets for action recognition

KTH-Actions dataset
• 6 action classes by 25 persons in 4 different scenarios
• Total of 2391 video samples
• Specified train, validation, test sets
• Performance measure: average accuracy over all classes
Schuldt, Laptev, Caputo ICPR 2004

UCF-Sports dataset
Diving Kicking Walking
Skateboarding High-Bar-Swinging Golf-Swinging
• 10 different action classes
• 150 video samples in total
• Evaluation method: leave-one-out
• Performance measure: average accuracy over all classes
Rodriguez, Ahmed, and Shah CVPR 2008

UCF - YouTube Action Dataset
• 11 categories, 1168 videos
• Evaluation method: leave-one-out
• Performance measure: average accuracy over all classes
Liu, Luo and Shah CVPR 2009

Hollywood2 dataset
• 12 action classes from 69 Hollywood movies
• 1707 video sequences in total
• Separate movies for training / testing
• Performance measure: mean average precision (mAP) over all classes
GetOutCar AnswerPhone Kiss
HandShake StandUp DriveCar
Marszałek, Laptev, Schmid CVPR 2009

TRECVid Surveillance Event Detection dataset
• 10 actions: person runs, take picture, cell to ear, …
• 5 cameras, ~100h video from LGW airport
• Detection (in time, not space); multiple detections count as false positives
• Evaluation method: specified training / test videos, evaluation at NIST
• Performance measure: statistics on DET curves
Smeaton, Over, Kraaij, TRECVid

Harris3D Dollar Hessian Dense
HOG3D 89.0% 90.0% 84.6% 85.3%
HOG/HOF 91.8% 88.7% 88.7% 86.1%
HOG 80.9% 82.3% 77.7% 79.0%
HOF 92.1% 88.2% 88.6% 88.0%
Dollar - 89.1% - -
E-SURF - - 81.4% -
Detectors
Des
crip
tors
• Best results for Sparse Harris3D + HOF• Dense features perform relatively poor compared to sparse features
Results: KTH actions
[Wang, Ullah, Kläser, Laptev, Schmid, BMVC 2009]

Harris3D Cuboids Hessian Dense
HOG3D 43.7% 45.7% 41.3% 45.3%
HOG/HOF 45.2% 46.2% 46.0% 47.4%
HOG 32.8% 39.4% 36.2% 39.4%
HOF 43.3% 42.9% 43.0% 45.5%
Cuboids - 45.0% - -
E-SURF - - 38.2% -
Detectors
Des
crip
tors
• Best results for Dense + HOG/HOF
• Good results for HOG/HOF
Results: Hollywood-2
[Wang, Ullah, Kläser, Laptev, Schmid, BMVC 2009]

− Early fusion: Multiple features are combined in a single representation which is fed to a learning algorithm that produces the decision. Example:
• Concatenate local features.• Concatenate bag of words.
− Late fusion: multiple representations of an instance are used in separate learning tasks so that the final decision is the combination of the single learning algorithm decisions. Examples:
• Represent an event with a vector of mid-level concept confidences (stack of classifiers or voting ensemble).
• Combine multiple kernels with a weighted sum to define another kernel.
Feature fusion
• Having multiple representations (e.g both holistic and local) can improve action classification. Fusion is necessary in this case. We consider two different approaches:

Visual Dictionaries
…
… …
Visual Dictionary
3DGrad + HoF BoW
3DGrad_HoF
3DGrad
HoF
BoW
ST Patch
ST Patch
Descriptor
Descriptors
Action Representation
Action Representation
Early fusion

Harris3D Cuboids Hessian Dense
HOG3D 43.7% 45.7% 41.3% 45.3%
HOG/HOF 45.2% 46.2% 46.0% 47.4%
HOG 32.8% 39.4% 36.2% 39.4%
HOF 43.3% 42.9% 43.0% 45.5%
Cuboids - 45.0% - -
E-SURF - - 38.2% -
Detectors
Des
crip
tors
Results: Hollywood-2
[Wang, Ullah, Kläser, Laptev, Schmid, BMVC 2009]
Early fusion of two descriptors HOG and HOF

Harris3D Dollar Hessian Dense
HOG3D 89.0% 90.0% 84.6% 85.3%
HOG/HOF 91.8% 88.7% 88.7% 86.1%
HOG 80.9% 82.3% 77.7% 79.0%
HOF 92.1% 88.2% 88.6% 88.0%
Dollar - 89.1% - -
E-SURF - - 81.4% -
Detectors
Des
crip
tors
Results: KTH actions
[Wang, Ullah, Kläser, Laptev, Schmid, BMVC 2009]
Early fusion of two descriptors HOG and HOFNot always effective!

……Hu moments of MHI HOF Bag of words HOG Bag of words
SVM+rbf kernel
SVM+Chi-square kernel
SVM+Chi-square kernel
SVM (trained on output of other classifiers)
Late fusion via stacking
decision

……Hu moments of MHI HOF Bag of words HOG Bag of words
RBF kernel Chi-Square kernel Chi-Square kernel
),(),( j
Ff
iffji xxkwxxK
SVM
Late fusion via kernel fusion (multiple kernel learning)
decision

• If the classifier is based on kernel defined as:
we can attempt to learn kernel parameters, weights w and classifier parameters in a single learning task performing multiple kernel learning.
• In general this approach is highly time consuming and often does not improve too much oversimple kernel averaging.
K(xi , x j ) w f k f (xi , x jf
)

• Event: something that happens at a certain moment in a certain place. [dictionary definition]
• An event is defined by the spatio-temporal evolution of the objects in a scene. Two cases: 1) Events of interest contain specific objects, activities, actions or take place in a given scene.
example query: “show me all videos with a person drinking in a street2) Events are are defined regardless of their specific content but just for their uniqueness:
example query: “ show me all videos containing unusual behaviors”
• Recognition of events according to Definition 1) requires strong supervision and the formulationof moding the event of interest vs rest (classification/retrieval). Events according to Definition 2) allows to treat problems with lower supervision and without a precise definition of the event to be recognized (one-class learning)
Event recognition
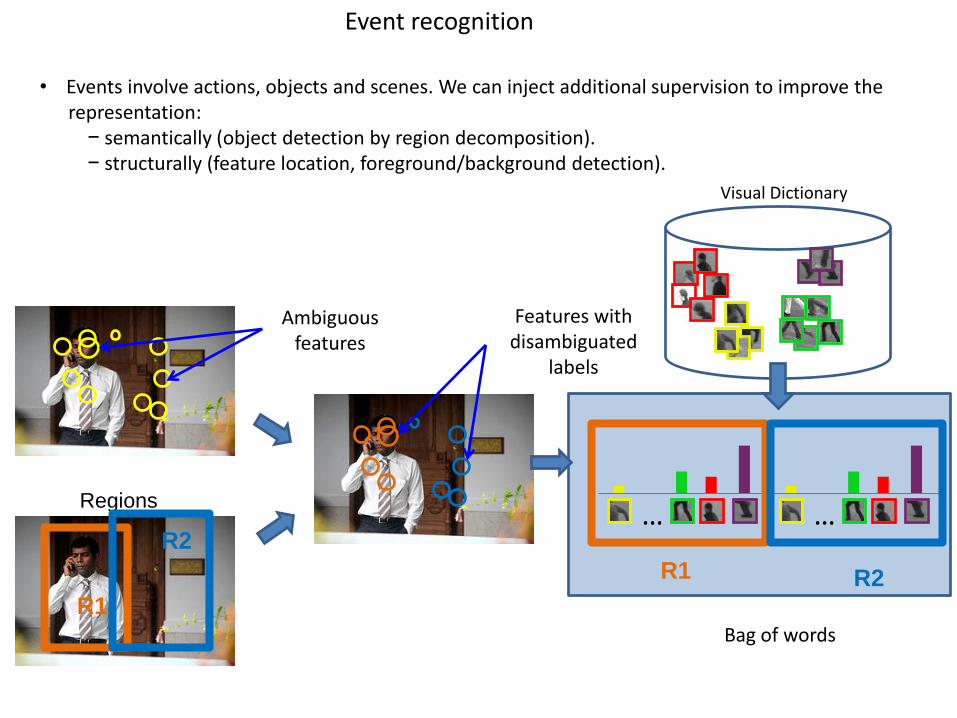
Regions
R1
R2
Ambiguous features
Features with disambiguated
labels
• Events involve actions, objects and scenes. We can inject additional supervision to improve the representation:
− semantically (object detection by region decomposition).− structurally (feature location, foreground/background detection).
Visual Dictionary
Bag of words
… …
R1 R2
Event recognition

• Use SVMs with a multi-channel chi-square kernel for classification
Chi-square is used since we are comparing BoW histograms.A channel c corresponds to the kernel computed on BoW of a particular segmented region.
Dc(Hi, Hj) is the chi-square distance between histograms.Ac is the mean value of the distances between all training samples (selected heuristically to reduce the number of parameters).
• The best set of channels C for a given training set is found based on a greedy approach, i.e. channels are a added/removed and performance is tested on a validation set. Top performing channel combination is then used on unseen videos.
Region decomposition

Structural video decompositions
• Spatio-temporal grids are inspired by spatial pyramids.The idea is to add the lacking structure tothe BoF representation: 6 spatial subdivision and 4 temporal subdivision defined for a total of
24 channels.
• Dominant motion estimation is used in order to extract regions subject to motion betweenconsecutive frames. 4 thresholds are used to separate FG from BG using dominant motion for a total of 8 channels

Semantic video decompositions
• Object detectors: HOG based object detectors
• Action detectors: HOG detector of still images actions.
• Person detectors: Viola Jones + HOG person detector

• Using 6 threshold for non-maximal suppression bounding boxes are extracted and define :− object/non-object regions− person/non-person regions− action/non-action regions
• Each region is further subdivided spatially with 2x2 grid. This setup generates 12 channels foreach detector.

Attributed feature Performance(meanAP)
BoF 48.55
Spatio-temporal grid 24 channels 51.83
Motion segmentation 50.39
Upper body 49.26
Object detectors 49.89
Action detectors 52.77
Spatio-temporal grid + Motion segmentation 53.20
Spatio-temporal grid + Upper body 53.18
Spatio-temporal grid + Object detectors 52.97
Spatio-temporal grid + Action detectors 55.72
Spatio-temporal grid + Motion segmentation + Upper body + Object detectors + Action detectors
55.33
Effect of feature fusion and context

• Feature disambiguation improves over completely unordered BoF. Feature disambiguationcombinations (feature fusion) improves over single feature disambiguation.
• Actions are not simply motion of humans but happen in a context and involve objects.
• Greedy search of best channel combination can be replaced with MKL.
Learn all Ac instead of using the heuristic of average intra-channel distance.

Abnormal event detection

What do we mean by anomaly?
• Given a learned statistics of an observed scene, an anomaly is an outlier to thatstatistical model.
• It is not possible to define a model for an anomaly but only for the normal data.• One-class learning or density estimation.• To test for abnormality we must compute the likelihood of the observed pattern with
respect to the previously seen data.

Trivial outlier example
Bivariate Gaussian observations
Outlier: not likely to be generated from the Gaussian !!

State of the art
• Existing approaches rely on: trajectories, optical flow, space-time descriptors.
− Trajectory based approaches only detect spatial anomalies and fail in crowded environments.[Ivanov AVSS 2009, Calderara ICDP 2009, Jiang TIP 2009]
− Optical flow approaches can cope with crowded scenes but discard appearance.[Kim CVPR 2009, Mehran CVPR2009]
− Spatio-temporal descriptors can model appearance and motion jointly.[Kratz CVPR 2009, Mahadevan CVPR 2010]
• Most existing systems do not have a real-time constraint [Mahadevan CVPR 2010 ]. They model the feature statistics with mixture models. [ Mahdevan CVPR 2010, Kim CVPR 2009]. Spatio-temporalfeatures allow joint appearance and motion modelling.

• A non-parametric approach eases the system deployment : − almost no training time.− easy system adaptation to different scenes.− straightforward model update over time.− testing time reduced via fast a-nn structures.
Non-parametric approach

• Video is dense sampled spatially and temporally.• We obtain a dense extraction of spatio-temporal patterns.
• Three different feature overlap are possible:
Feature extraction
spatial temporal spatio-temporal

Normal data Anomaly
Normal data
Anomaly
K-meanstree K-means
tree
K-meanstree
K-meanstree
Non-parametric modelling of a scene statistics
• Store “normal” samples in fast approximate NN structures.
• A pattern is anomalous if its “neighbourhood” is empty.
• Need to define a meaningful neighbourhood in feature space.

Optimal radius estimation
• An optimal radius for each location is estimated
• Compute CDF of distances from nearest neighbour.
• Probability of an anomalous event to happen (e.g. 10-4 )

Model update
• An anomaly list for each tree.
• Periodically estimate an intra-list optimal radius ra,i.• Test each pattern in list with ra,i.• Add it to the normal dataset if it has neighbours.• Re-estimate ri for each location.
K-meanstree K-means
tree
K-meanstree
K-meanstree
New regular patterns
Still anomalies

• ~30 minutes of videos from a fixed camera.• Normal frames contains pedestrian on a walk-way.• Abnormal frames contains bikers, skaters and carts.
• Ground truth provided at frame and pixel level (on a subset).
The dataset
Detection examples

• Qualitative comparison with other approaches
Social Force Model [Mehran 09]
Mixture of Dynamic Textures [Mahadevan 10]
Social Force + MPPCA [Mahadevan 10 (Kim 09 + Mehran09)]
Dense space-time features

• Varying the patch size.
60x60
20x20
40x40
10x10

• Non-parametric method outperforms other real-time approaches.
• The system is able to process 20fps (240x160) on a standard machine.
• The top performing method requires 25 s to process a frame.
System performance
Not realtime
Related Documents











