Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics Volume 1: Long Papers, pages 6675 - 6689 May 22-27, 2022 c 2022 Association for Computational Linguistics Accurate Online Posterior Alignments for Principled Lexically-Constrained Decoding Soumya Chatterjee IIT Bombay [email protected] Sunita Sarawagi IIT Bombay [email protected] Preethi Jyothi IIT Bombay [email protected] Abstract Online alignment in machine translation refers to the task of aligning a target word to a source word when the target sequence has only been partially decoded. Good online align- ments facilitate important applications such as lexically constrained translation where user- defined dictionaries are used to inject lexical constraints into the translation model. We propose a novel posterior alignment technique that is truly online in its execution and su- perior in terms of alignment error rates com- pared to existing methods. Our proposed in- ference technique jointly considers alignment and token probabilities in a principled man- ner and can be seamlessly integrated within existing constrained beam-search decoding al- gorithms. On five language pairs, including two distant language pairs, we achieve con- sistent drop in alignment error rates. When deployed on seven lexically constrained trans- lation tasks, we achieve significant improve- ments in BLEU specifically around the con- strained positions. 1 Introduction Online alignment seeks to align a target word to a source word at the decoding step when the word is output in an auto-regressive neural translation model (Kalchbrenner and Blunsom, 2013; Cho et al., 2014; Sutskever et al., 2014). This is un- like the more popular offline alignment task that uses the entire target sentence (Och and Ney, 2003). State of the art methods of offline alignment based on matching of whole source and target sentences (Jalili Sabet et al., 2020; Dou and Neubig, 2021) are not applicable for online alignment where we need to commit on the alignment of a target word based on only the generated prefix thus far. An important application of online alignment is lexically constrained translation which allows injection of domain-specific terminology and other phrasal constraints during decoding (Hasler et al., 2018; Hokamp and Liu, 2017; Alkhouli et al., 2018; Crego et al., 2016). Other applications include preservation of markups between the source and target (Müller, 2017), and supporting source word edits in summarization (Shen et al., 2019). These applications need to infer the specific source token which aligns with output token. Thus, alignment and translation is to be done simultaneously. Existing online alignment methods can be cate- gorized into Prior and Posterior alignment methods. Prior alignment methods (Garg et al., 2019; Song et al., 2020) extract alignment based on the atten- tion at time step t when outputting token y t . The at- tention probabilities at time-step t are conditioned on tokens output before time t. Thus, the alignment is estimated prior to observing y t . Naturally, the quality of alignment can be improved if we condi- tion on the target token y t (Shankar and Sarawagi, 2019). This motivated Chen et al. (2020) to propose a posterior alignment method where alignment is calculated from the attention probabilities at the next decoder step t +1. While alignment qual- ity improved as a result, their method is not truly online since it does not generate alignment syn- chronously with the token. The delay of one step makes it difficult and cumbersome to incorporate terminology constraints during beam decoding. We propose a truly online posterior alignment method that provides higher alignment accuracy than existing online methods, while also being syn- chronous. Because of that we can easily integrate posterior alignment to improve lexicon-constrained translation in state of the art constrained beam- search algorithms such as VDBA (Hu et al., 2019). Our method (Align-VDBA) presents a signifi- cant departure from existing papers on alignment- guided constrained translation (Chen et al., 2020; Song et al., 2020) that employ a greedy algorithm with poor constraint satisfaction rate (CSR). For example, on a ja→en their CSR is 20 points lower than ours. Moreover, the latter does not benefit 6675

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Proceedings of the 60th Annual Meeting of the Association for Computational LinguisticsVolume 1: Long Papers, pages 6675 - 6689
May 22-27, 2022 c©2022 Association for Computational Linguistics
Accurate Online Posterior Alignments for PrincipledLexically-Constrained Decoding
Soumya ChatterjeeIIT Bombay
Sunita SarawagiIIT Bombay
Preethi JyothiIIT Bombay
Abstract
Online alignment in machine translation refersto the task of aligning a target word to asource word when the target sequence has onlybeen partially decoded. Good online align-ments facilitate important applications such aslexically constrained translation where user-defined dictionaries are used to inject lexicalconstraints into the translation model. Wepropose a novel posterior alignment techniquethat is truly online in its execution and su-perior in terms of alignment error rates com-pared to existing methods. Our proposed in-ference technique jointly considers alignmentand token probabilities in a principled man-ner and can be seamlessly integrated withinexisting constrained beam-search decoding al-gorithms. On five language pairs, includingtwo distant language pairs, we achieve con-sistent drop in alignment error rates. Whendeployed on seven lexically constrained trans-lation tasks, we achieve significant improve-ments in BLEU specifically around the con-strained positions.
1 Introduction
Online alignment seeks to align a target word to asource word at the decoding step when the wordis output in an auto-regressive neural translationmodel (Kalchbrenner and Blunsom, 2013; Choet al., 2014; Sutskever et al., 2014). This is un-like the more popular offline alignment task thatuses the entire target sentence (Och and Ney, 2003).State of the art methods of offline alignment basedon matching of whole source and target sentences(Jalili Sabet et al., 2020; Dou and Neubig, 2021)are not applicable for online alignment where weneed to commit on the alignment of a target wordbased on only the generated prefix thus far.
An important application of online alignmentis lexically constrained translation which allowsinjection of domain-specific terminology and otherphrasal constraints during decoding (Hasler et al.,
2018; Hokamp and Liu, 2017; Alkhouli et al., 2018;Crego et al., 2016). Other applications includepreservation of markups between the source andtarget (Müller, 2017), and supporting source wordedits in summarization (Shen et al., 2019). Theseapplications need to infer the specific source tokenwhich aligns with output token. Thus, alignmentand translation is to be done simultaneously.
Existing online alignment methods can be cate-gorized into Prior and Posterior alignment methods.Prior alignment methods (Garg et al., 2019; Songet al., 2020) extract alignment based on the atten-tion at time step t when outputting token yt. The at-tention probabilities at time-step t are conditionedon tokens output before time t. Thus, the alignmentis estimated prior to observing yt. Naturally, thequality of alignment can be improved if we condi-tion on the target token yt (Shankar and Sarawagi,2019). This motivated Chen et al. (2020) to proposea posterior alignment method where alignment iscalculated from the attention probabilities at thenext decoder step t + 1. While alignment qual-ity improved as a result, their method is not trulyonline since it does not generate alignment syn-chronously with the token. The delay of one stepmakes it difficult and cumbersome to incorporateterminology constraints during beam decoding.
We propose a truly online posterior alignmentmethod that provides higher alignment accuracythan existing online methods, while also being syn-chronous. Because of that we can easily integrateposterior alignment to improve lexicon-constrainedtranslation in state of the art constrained beam-search algorithms such as VDBA (Hu et al., 2019).Our method (Align-VDBA) presents a signifi-cant departure from existing papers on alignment-guided constrained translation (Chen et al., 2020;Song et al., 2020) that employ a greedy algorithmwith poor constraint satisfaction rate (CSR). Forexample, on a ja→en their CSR is 20 points lowerthan ours. Moreover, the latter does not benefit
6675

from larger beam sizes unlike VDBA-based meth-ods that significantly improve with larger beamwidths. Compared to Chen et al. (2020), ourmethod improves average overall BLEU scores by1.2 points and average BLEU scores around theconstrained span by up to 9 points. In the evalua-tions performed in these earlier work, VDBA wasnot allocated the slightly higher beam size neededto pro-actively enforce constraints without com-promising BLEU. Compared to Hu et al. (2019)(VDBA), this paper’s contributions include onlinealignments and their use in more fluent constraintplacement and efficient allocation of beams.
Contributions• A truly online posterior alignment method that
integrates into existing NMT sytems via a train-able light-weight module.
• Higher online alignment accuracy on five lan-guage pairs including two distant language pairswhere we improve over the best existing methodin seven out of ten translation tasks.
• Principled method of modifying VDBA to in-corporate posterior alignment probabilities inlexically-constrained decoding. VDBA enforcesconstraints ignoring source alignments; ourchange (Align-VDBA) leads to more fluent con-straint placement and significant BLEU increaseparticularly for smaller beams.
• Establishing that VDBA-based pro-activeconstrained inference should be preferredover prevailing greedy alignment-guidedinference (Chen et al., 2021; Song et al., 2020).Further, VDBA and our Align-VDBA inferencewith beam size 10 provide 1.2 BLEU increaseover these methods with the same beam size.
2 Posterior Online Alignment
Given a sentence x = x1, . . . , xS in the source lan-guage and a sentence y = y1, . . . , yT in the targetlanguage, an alignmentA between the word stringsis a subset of the Cartesian product of the word po-sitions (Brown et al., 1993; Och and Ney, 2003):A ⊆ {(s, t) : s = 1, . . . , S; t = 1, . . . , T} suchthat the aligned words can be considered transla-tions of each other. An online alignment at time-step t commits on alignment of the tth output tokenconditioned only on x and y<t = y1, y2, . . . yt−1.Additionally, if token yt is also available we callit a posterior online alignment. We seek to embedonline alignment with existing NMT systems. Wewill first briefly describe the architecture of state
of the art NMT systems. We will then elaborateon how alignments are computed from attentiondistributions in prior work and highlight some limi-tations, before describing our proposed approach.
2.1 BackgroundTransformers (Vaswani et al., 2017) adopt the pop-ular encoder-decoder paradigm used for sequence-to-sequence modeling (Cho et al., 2014; Sutskeveret al., 2014; Bahdanau et al., 2015). The en-coder and decoder are both multi-layered networkswith each layer consisting of a multi-headed self-attention and a feedforward module. The decoderlayers additionally use multi-headed attention toencoder states. We elaborate on this mechanismnext since it plays an important role in alignments.
2.1.1 Decoder-Encoder Attention in NMTsThe encoder transforms the S input tokens intoa sequence of token representations H ∈ RS×d.Each decoder layer (indexed by ` ∈ {1, . . . , L})computes multi-head attention over H by aggregat-ing outputs from a set of η independent attentionheads. The attention output from a single headn ∈ {1, . . . , η} in decoder layer ` is computedas follows. Let the output of the self-attentionsub-layer in decoder layer ` at the tth target to-ken be denoted as g`t . Using three projection ma-trices W`,n
Q , W`,nV , W`,n
K ∈ Rd×dn , the query
vector q`,nt ∈ R1×dn and key and value matrices,K`,n ∈ RS×dn and V`,n ∈ RS×dn , are computedusing the following projections: q`,nt = g`tW
`,nQ ,
K`,n = HW`,nK , and V`,n = HW`,n
V .1 These areused to calculate the attention output from head n,Z`,nt = P (a`,nt |x,y<t)V`,n, where:
P (a`,nt |x,y<t) = softmax
(q`,nt (K`,n)ᵀ√
d
)(1)
For brevity, the conditioning on x,y<t is droppedand P (a`,nt ) is used to refer to P (a`,nt |x,y<t) inthe following sections.
Finally, the multi-head attention output is givenby [Z`,1t , . . . ,Z`,ηt ]WO where [ ] denotes thecolumn-wise concatenation of matrices and WO ∈Rd×d is an output projection matrix.
2.1.2 Alignments from AttentionSeveral prior work have proposed to extractword alignments from the above attention prob-
1dn is typically set to dη
so that a multi-head attention layerdoes not introduce more parameters compared to a single headattention layer.
6676

abilities. For example Garg et al. (2019) pro-pose a simple method called NAIVEATT thataligns a source word to the tth target token using
argmaxj1
η
η∑n=1
P (a`,nt,j |x,y<t) where j indexes
the source tokens. In NAIVEATT, we note that theattention probabilities P (a`,nt,j |x,y<t) at decodingstep t are not conditioned on the current output to-ken yt. Alignment quality would benefit from con-ditioning on yt as well. This observation promptedChen et al. (2020) to extract alignment of token ytusing attention P (a`,nt,j |x,y≤t) computed at timestep t+ 1. The asynchronicity inherent to this shift-by-one approach (SHIFTATT) makes it difficultand more computationally expensive to incorporatelexical constraints during beam decoding.
2.2 Our Proposed Method: POSTALN
We propose POSTALN that produces posterioralignments synchronously with the output tokens,while being more computationally efficient com-pared to previous approaches like SHIFTATT. Weincorporate a lightweight alignment module to con-vert prior attention to posterior alignments in thesame decoding step as the output. Figure 1 illus-trates how this alignment module fits within thestandard Transformer architecture.
The alignment module is placed at the penulti-mate decoder layer ` = L − 1 and takes as input(1) the encoder output H, (2) the output of theself-attention sub-layer of decoder layer `, g`t and,(3) the embedding of the decoded token e(yt). Likein standard attention it projects H to obtain a keymatrix, but to obtain the query matrix it uses bothdecoder state g`t (that summarizes y<t) and e(yt)to compute the posterior alignment P (a
postt ) as:
P (apostt ) =
1
η
η∑n=1
softmax
(qnt,post(K
npost)
ᵀ
√d
),
qnt,post = [g`t , e(yt)]WnQ,post, K
npost = HWn
K,post
Here WnQ,post ∈ R2d×dn and Wn
K,post ∈ Rd×dn .This computation is synchronous with produc-
ing the target token yt, thus making it compatiblewith beam search decoding (as elaborated furtherin Section 3). It also accrues minimal computa-tional overhead since P (a
postt ) is defined using H
and gL−1t , that are both already cached during a
standard decoding pass. Note that if the query vec-tor qnt,post is computed using only gL−1
t , withoutconcatenating e(yt), then we get prior alignments
Inputs x
Input Emb
PositionalEncoding
Layer 1
Layer 2
Layer L
H
Outputs y<t
Output Emb
PositionalEncoding
Layers 1 to `− 1
Self-Attention
Add and Norm
Cross-AttentionAlignmentModule
Add and Norm
Feed Forward
Add and Norm
Layers `+ 1 to L
Linear & Softmax
OutputProbabilities
AlignmentProbabilities
yt
g`t
Figure 1: Our alignment module is an encoder-decoder attention sub-layer, similar to the existingcross-attention sub-layer. It takes as inputs the encoderoutput H as the key, and the concatenation of the outputof the previous self-attention layer g`
t and the currentlydecoded token yt as the query, and outputs posterioralignment probabilities apost
t .
that we refer to as PRIORATT. In our experiments,we explicitly compare PRIORATT with POSTALN
to show the benefits of using yt in deriving align-ments while keeping the rest of the architectureintact.
Training Our posterior alignment sub-layer istrained using alignment supervision, while freez-ing the rest of the translation model parameters.Specifically, we train a total of 3d2 additional pa-rameters across the matrices Wn
K,post and WnQ,post.
Since gold alignments are very tedious and expen-sive to create for large training datasets, alignmentlabels are typically obtained using existing tech-niques. We use bidirectional symmetrized SHIF-TATT alignments, denoted by Si,j that refers to analignment between the ith target word and the jth
source word, as reference labels to train our align-ment sub-layer. Then the objective (following Garget al. (2019)) can be defined as:
maxWn
Q,post,WnK,post
1
T
T∑i=1
S∑j=1
Si,j log(P (aposti,j |x,y≤i))
Next, we demonstrate the role of posterior onlinealignments on an important downstream task.
6677

3 Lexicon Constrained Translation
In the lexicon constrained translation task, foreach to-be-translated sentence x, we are given aset of source text spans and the correspondingtarget tokens in the translation. A constraint Cjcomprises a pair (Cxj , Cyj ) where Cxj = (pj , pj +1 . . . , pj + `j) indicates input token positions, andCyj = (yj1, y
j2 . . . , y
jmj ) denote target tokens that
are translations of the input tokens xpj . . . xpj+`j .For the output tokens we do not know their po-sitions in the target sentence. The different con-straints are non-overlapping and each is expectedto be used exactly once. The goal is to translate thegiven sentence x and satisfy as many constraintsin C =
⋃j Cj as possible while ensuring fluent
and correct translations. Since the constraints donot specify target token position, it is natural touse online alignments to guide when a particularconstraint is to be enforced.
3.1 Background: Constrained DecodingExisting inference algorithms for incorporating lex-icon constraints differ in how pro-actively they en-force the constraints. A passive method is used inSong et al. (2020) where constraints are enforcedonly when the prior alignment is at a constrainedsource span. Specifically, if at decoding step t,i = argmaxi′ P (at,i′) is present in some constraintCxj , the output token is fixed to the first token yj1from Cyj . Otherwise, the decoding proceeds asusual. Also, if the translation of a constraint Cj hasstarted, the same is completed (yj2 through yjmj ) forthe next mj − 1 decoding steps before resumingunconstrained beam search. The pseudocode forthis method is provided in Appendix G.
For the posterior alignment methods of Chenet al. (2020) this leads to a rather cumbersome in-ference (Chen et al., 2021). First, at step t they pre-dict a token yt, then start decoding step t+ 1 withyt as input to compute the posterior alignment fromattention at step t+ 1. If the maximum alignmentis to the constrained source span Cxj they revise theoutput token to be yj1 from Cyj , but the output scorefor further beam-search continues to be of yt. Inthis process both the posterior alignment and tokenprobabilities are misrepresented since they are bothbased on yt instead of the finally output token yj1.The decoding step at t + 1 needs to be restartedafter the revision. The overall algorithm continuesto be normal beam-search, which implies that theconstraints are not enforced pro-actively.
Many prior methods have proposed more pro-active methods of enforcing constraints, includingthe Grid Beam Search (GBA, Hokamp and Liu(2017)), Dynamic Beam Allocation (DBA, Postand Vilar (2018)) and Vectorized Dynamic BeamAllocation (VDBA, Hu et al. (2019)). The latestof these, VDBA, is efficient and available in pub-lic NMT systems (Ott et al., 2019; Hieber et al.,2020). Here multiple banks, each corresponding toa particular number of completed constraints, aremaintained. At each decoding step, a hypothesiscan either start a new constraint and move to a newbank or continue in the same bank (either by notstarting a constraint or progressing on a constraintmid-completion). This allows them to achieve near100% enforcement. However, VDBA enforces theconstraints by considering only the target tokensof the lexicon and totally ignores the alignment ofthese tokens to the source span. This could leadto constraints being placed at unnatural locationsleading to loss of fluency. Examples appear in Ta-ble 4 where we find that VDBA just attaches theconstrained tokens at the end of the sentence.
3.2 Our Proposal: Align-VDBA
We modify VDBA with alignment probabilities tobetter guide constraint placement. The score of aconstrained token is now the joint probability ofthe token, and the probability of the token beingaligned with the corresponding constrained sourcespan. Formally, if the current token yt is a part ofthe jth constraint i.e. yt ∈ Cyj , the generation prob-ability of yt, P (yt|x,y<t) is scaled by multiplyingwith the alignment probabilities of yt with Cxj , thesource span for constraint i. Thus, the updatedprobability is given by:
P (yt, Cxj |x,y<t)︸ ︷︷ ︸Joint Prob
= P (yt|x,y<t)︸ ︷︷ ︸Token Prob
∑r∈Cxj
P (apostt,r |x,y≤t)
︸ ︷︷ ︸Src Align. Prob.
(2)
P (yt, Cxj |x,y<t) denotes the joint probability ofoutputting the constrained token and the align-ment being on the corresponding source span.Since the supervision for the alignment proba-bilities was noisy, we found it useful to recali-brate the alignment distribution using a temper-ature scale T , so that the recalibrated probability is∝ Pr(a
postt,r |x,y≤t)
1T . We used T = 2 i.e., square-
root of the alignment probability.Align-VDBA also uses posterior alignment prob-
abilities to also improve the efficiency of VDBA.
6678

Algorithm 1 Align-VDBA: Modifications to DBA shown in blue. (Adapted from Post and Vilar (2018))1: Inputs beam: K hypothesis in beam, scores: K × |VT | matrix of scores where scores[k, y] denotes the score of kth
hypothesis extended with token y at this step, constraints: {(Cxj , Cyj )}, threshold2: candidates← [(k, y, scores[k, y], beam[k].constraints.add(y)] for k, y in ARGMAX_K(scores)3: for 1 ≤ k ≤ K do . Go over current beam4: for all y ∈ VT that are unmet constraints for beam[k] do . Expand new constraints5: alignProb← Σconstraint_xs(y) POSTALN(k, y) . Modification in blue (Eqn (2))6: if alignProb > threshold then7: candidates.append( (k, y, scores[k, y] × alignProb), beam[k].constraints.add(y) ) )8: candidates.append( (k, y, scores[k, y], beam[k].constraints.add(y) ) ) . Original DBA Alg.9: w = ARGMAX(scores[k, :])
10: candidates.append( (k,w, scores[k,w], beam[k].constraints.add(w) ) ) . Best single word11: newBeam← ALLOCATE(candidates, K)
Currently, VDBA attempts beam allocation foreach unmet constraint since it has no way to dis-criminate. In Align-VDBA we allocate only whenthe alignment probability is greater than a thresh-old. When the beam size is small (say 5) this yieldshigher accuracy due to more efficient beam utiliza-tion. We used a threshold of 0.1 for all languagepairs other than ro→en for which a threshold of0.3 was used. Further, the thresholds were used forthe smaller beam size of 5 and not for larger beamsizes of 10 and 20.
We present the pseudocode of our modification(steps 5, 6 and 7, in blue) to DBA in Algorithm 1.Other details of the algorithm including the han-dling of constraints and the allocation steps (step11) are involved and we refer the reader to Postand Vilar (2018) and Hu et al. (2019) to understandthese details. The point of this code is to show thatour proposed posterior alignment method can beeasily incorporated into these algorithms so as toprovide a more principled scoring of constrainedhypothesis in a beam than the ad hoc revision-basedmethod of Chen et al. (2021). Additionally, pos-terior alignments lead to better placement of con-straints than in the original VDBA algorithm.
4 Experiments
We first compare our proposed posterior onlinealignment method on quality of alignment againstexisting methods in Section 4.2, and in Section 4.3,we demonstrate the impact of the improved align-ment on the lexicon-constrained translation task.
4.1 SetupWe deploy the fairseq toolkit (Ott et al., 2019)and use transformer_iwslt_de_en pre-configured model for all our experiments. Otherconfiguration parameters include: Adam optimizerwith β1 = 0.9, β2 = 0.98, a learning rate of 5e−4
de-en en-fr ro-en en-hi ja-enTraining 1.9M 1.1M 0.5M 1.6M 0.3MValidation 994 1000 999 25 1166Test 508 447 248 140 1235
Table 1: Number of sentence pairs for the five datasetsused. Note that gold alignments are available only forthe handful of sentence pairs in the test set.
with 4000 warm-up steps, an inverse square rootschedule, weight decay of 1e−4, label smoothingof 0.1, 0.3 probability dropout and a batch size of4500 tokens. The transformer models are trainedfor 50,000 iterations. Then, the alignment moduleis trained for 10,000 iterations, keeping the othermodel parameters fixed. A joint byte pair encoding(BPE) is learned for the source and the target lan-guages with 10k merge operation (Sennrich et al.,2016) using subword-nmt.
All experiments were done on a single 11GBNvidia GeForce RTX 2080 Ti GPU on a machinewith 64 core Intel Xeon CPU and 755 GB memory.The vanilla Transformer models take between 15to 20 hours to train for different datasets. Startingfrom the alignments extracted from these models,the POSTALN alignment module trains in about 3to 6 hours depending on the dataset.
4.2 Alignment Task
We evaluate online alignments on ten translationtasks spanning five language pairs. Three of theseare popular in alignment papers (Zenkel et al.,2019): German-English (de-en), English-French(en-fr), Romanian-English (ro-en). These are allEuropean languages that follow the same subject-verb-object (SVO) ordering. We also present re-sults on two distant language pairs, English-Hindi(en-hi) and English-Japanese (ja-en), that follow aSOV word order which is different from the SVO
6679
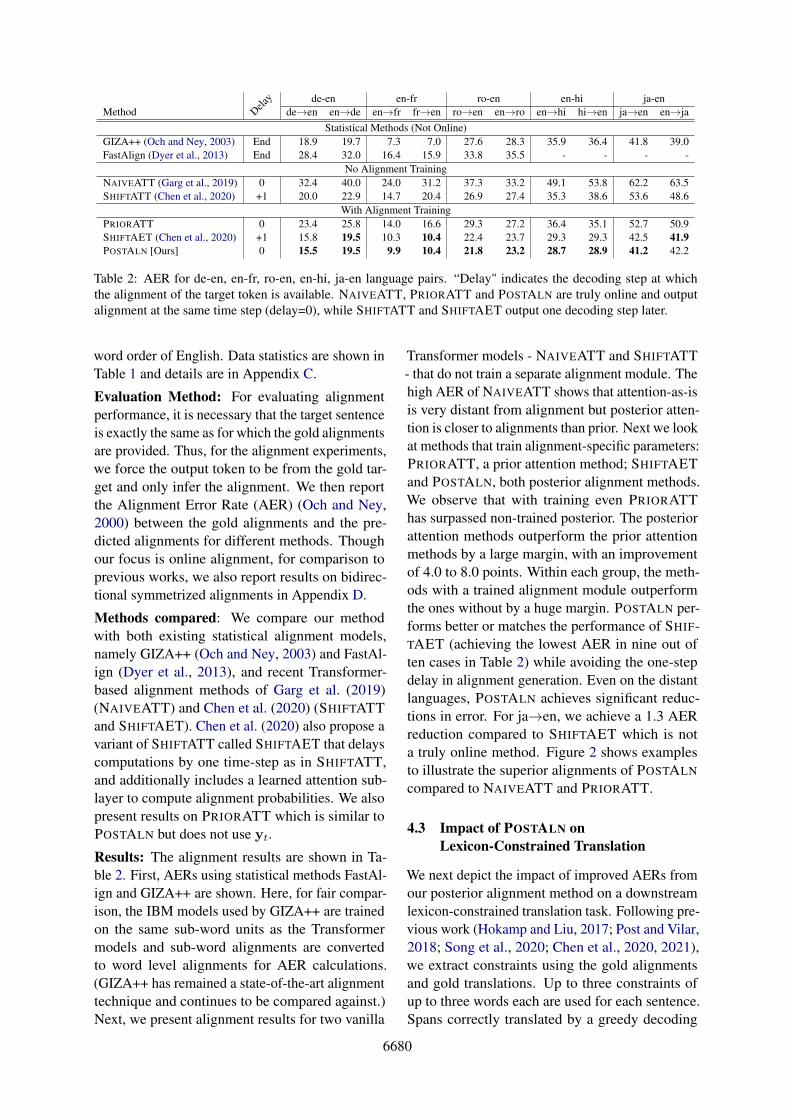
Delay de-en en-fr ro-en en-hi ja-en
Method de→en en→de en→fr fr→en ro→en en→ro en→hi hi→en ja→en en→jaStatistical Methods (Not Online)
GIZA++ (Och and Ney, 2003) End 18.9 19.7 7.3 7.0 27.6 28.3 35.9 36.4 41.8 39.0FastAlign (Dyer et al., 2013) End 28.4 32.0 16.4 15.9 33.8 35.5 - - - -
No Alignment TrainingNAIVEATT (Garg et al., 2019) 0 32.4 40.0 24.0 31.2 37.3 33.2 49.1 53.8 62.2 63.5SHIFTATT (Chen et al., 2020) +1 20.0 22.9 14.7 20.4 26.9 27.4 35.3 38.6 53.6 48.6
With Alignment TrainingPRIORATT 0 23.4 25.8 14.0 16.6 29.3 27.2 36.4 35.1 52.7 50.9SHIFTAET (Chen et al., 2020) +1 15.8 19.5 10.3 10.4 22.4 23.7 29.3 29.3 42.5 41.9POSTALN [Ours] 0 15.5 19.5 9.9 10.4 21.8 23.2 28.7 28.9 41.2 42.2
Table 2: AER for de-en, en-fr, ro-en, en-hi, ja-en language pairs. “Delay" indicates the decoding step at whichthe alignment of the target token is available. NAIVEATT, PRIORATT and POSTALN are truly online and outputalignment at the same time step (delay=0), while SHIFTATT and SHIFTAET output one decoding step later.
word order of English. Data statistics are shown inTable 1 and details are in Appendix C.
Evaluation Method: For evaluating alignmentperformance, it is necessary that the target sentenceis exactly the same as for which the gold alignmentsare provided. Thus, for the alignment experiments,we force the output token to be from the gold tar-get and only infer the alignment. We then reportthe Alignment Error Rate (AER) (Och and Ney,2000) between the gold alignments and the pre-dicted alignments for different methods. Thoughour focus is online alignment, for comparison toprevious works, we also report results on bidirec-tional symmetrized alignments in Appendix D.
Methods compared: We compare our methodwith both existing statistical alignment models,namely GIZA++ (Och and Ney, 2003) and FastAl-ign (Dyer et al., 2013), and recent Transformer-based alignment methods of Garg et al. (2019)(NAIVEATT) and Chen et al. (2020) (SHIFTATTand SHIFTAET). Chen et al. (2020) also propose avariant of SHIFTATT called SHIFTAET that delayscomputations by one time-step as in SHIFTATT,and additionally includes a learned attention sub-layer to compute alignment probabilities. We alsopresent results on PRIORATT which is similar toPOSTALN but does not use yt.
Results: The alignment results are shown in Ta-ble 2. First, AERs using statistical methods FastAl-ign and GIZA++ are shown. Here, for fair compar-ison, the IBM models used by GIZA++ are trainedon the same sub-word units as the Transformermodels and sub-word alignments are convertedto word level alignments for AER calculations.(GIZA++ has remained a state-of-the-art alignmenttechnique and continues to be compared against.)Next, we present alignment results for two vanilla
Transformer models - NAIVEATT and SHIFTATT- that do not train a separate alignment module. Thehigh AER of NAIVEATT shows that attention-as-isis very distant from alignment but posterior atten-tion is closer to alignments than prior. Next we lookat methods that train alignment-specific parameters:PRIORATT, a prior attention method; SHIFTAETand POSTALN, both posterior alignment methods.We observe that with training even PRIORATThas surpassed non-trained posterior. The posteriorattention methods outperform the prior attentionmethods by a large margin, with an improvementof 4.0 to 8.0 points. Within each group, the meth-ods with a trained alignment module outperformthe ones without by a huge margin. POSTALN per-forms better or matches the performance of SHIF-TAET (achieving the lowest AER in nine out often cases in Table 2) while avoiding the one-stepdelay in alignment generation. Even on the distantlanguages, POSTALN achieves significant reduc-tions in error. For ja→en, we achieve a 1.3 AERreduction compared to SHIFTAET which is nota truly online method. Figure 2 shows examplesto illustrate the superior alignments of POSTALN
compared to NAIVEATT and PRIORATT.
4.3 Impact of POSTALN onLexicon-Constrained Translation
We next depict the impact of improved AERs fromour posterior alignment method on a downstreamlexicon-constrained translation task. Following pre-vious work (Hokamp and Liu, 2017; Post and Vilar,2018; Song et al., 2020; Chen et al., 2020, 2021),we extract constraints using the gold alignmentsand gold translations. Up to three constraints ofup to three words each are used for each sentence.Spans correctly translated by a greedy decoding
6680

auch
könn
en dies die
zust
ändi
gen
inne
r@@
staa
tlich
enbe
hörd
enre
geln ,
sofe
rn sie es für
erfo
rder
lich
halte
n .
internalstate
authoritiescanalso
regul@@atethis
towhatever
extenttheythink
necessary.
NaiveATT
auch
könn
en dies die
zust
ändi
gen
inne
r@@
staa
tlich
enbe
hörd
enre
geln ,
sofe
rn sie es für
erfo
rder
lich
halte
n .
internalstate
authoritiescanalso
regul@@atethis
towhatever
extenttheythink
necessary.
PriorATT
auch
könn
en dies die
zust
ändi
gen
inne
r@@
staa
tlich
enbe
hörd
enre
geln ,
sofe
rn sie es für
erfo
rder
lich
halte
n .
internalstate
authoritiescanalso
regul@@atethis
towhatever
extenttheythink
necessary.
PostALN
auch
könn
en dies die
zust
ändi
gen
inne
r@@
staa
tlich
enbe
hörd
enre
geln ,
sofe
rn sie es für
erfo
rder
lich
halte
n .
internalstate
authoritiescanalso
regul@@atethis
towhatever
extenttheythink
necessary.
Gold
ital
sowa
nts to see
effe
ctiv
eco
nsum
erre
pres
@@
enta
tion .
@@
NaiveATT
ital
sowa
nts to see
effe
ctiv
eco
nsum
erre
pres
@@
enta
tion .
@@
PostALN
ital
sowa
nts to see
effe
ctiv
eco
nsum
erre
pres
@@
enta
tion .
@@
Gold
ital
sowa
nts to see
effe
ctiv
eco
nsum
erre
pres
@@
enta
tion .
@@
PriorATT
Figure 2: Alignments for de→en (top-row) and en→hi (bottom-row) by NAIVEATT, PRIORATT, and POSTALN.Note that POSTALN is most similar to Gold alignments in the last column.
de→en en→fr ro→en en→hi ja→enMethod BLEU-C CSR BLEU Time BLEU-C CSR BLEU Time BLEU-C CSR BLEU Time BLEU-C CSR BLEU Time BLEU-C CSR BLEU TimeNo constraints 0.0 4.6 32.9 87 0.0 8.7 34.8 64 0.0 8.8 33.4 47 0.0 6.3 19.7 21 0.0 8.8 18.9 237NAIVEATT 28.7 86.1 36.6 147 36.5 88.0 38.3 93 33.3 92.3 36.5 99 22.5 88.4 23.6 27 15.1 75.9 20.2 315PRIORATT 35.0 92.8 37.6 159 42.1 94.4 38.9 97 36.0 91.2 37.2 100 27.2 91.5 24.4 28 16.7 79.7 20.4 326SHIFTATT 41.0 96.6 38.7 443 45.0 93.5 38.7 239 39.2 94.2 37.4 241 23.2 78.7 21.9 58 15.2 72.7 19.3 567SHIFTAET 43.1 97.5 39.1 458 46.6 94.3 39.0 235 40.8 94.4 37.6 263 24.3 80.2 22.0 62 18.1 75.9 19.7 596POSTALN 42.7 97.2 39.0 399 46.3 94.1 38.7 218 40.0 93.5 37.4 226 23.8 79.0 22.0 47 18.2 75.7 19.7 460VDBA 44.5 98.9 38.5 293 51.9 98.5 39.5 160 43.1 99.1 37.9 165 29.8 92.3 24.5 49 24.3 95.6 21.6 494Align-VDBA 44.5 98.6 38.6 357 52.9 98.4 39.7 189 44.1 98.9 38.1 203 30.5 91.5 24.7 70 25.1 95.5 21.8 630
Table 3: Constrained translation results showing BLEU-C, CSR (Constraint Satisfaction Rate), BLEU scores andtotal decoding time (in seconds) for the test set. Align-VDBA has the highest BLEU-C on all datasets.
are not selected as constraints.Metrics: Following prior work (Song et al., 2020),we report BLEU (Papineni et al., 2002), time totranslate all test sentences, and Constraint Satisfac-tion Rate (CSR). However, since it is trivial to get100% CSR by always copying, we report anothermetric to evaluate the appropriateness of constraintplacement: We call this measure BLEU-C and com-pute it as the BLEU of the constraint (when satis-fied) and a window of three words around it. Allnumbers are averages over five different sets of ran-domly sampled constraint sets. The beam size isset to ten by default; results for other beam sizesappear in Appendix E.Methods Compared: First we compare all thealignment methods presented in Section 4.2 on theconstrained translation task using the alignmentbased token-replacement algorithm of Song et al.
(2020) described in Section 3.1. Next, we present acomparison between VBDA (Hu et al., 2019) andour modification Align-VDBA.
Results: Table 3 shows that VDBA and our Align-VDBA that pro-actively enforce constraints have amuch higher CSR and BLEU-C compared to theother lazy constraint enforcement methods. For ex-ample, for ja→en greedy methods can only achievea CSR of 76% compared to 96% of the VDBA-based methods. In terms of overall BLEU too, thesemethods provide an average increase in BLEU of1.2 and an average increase in BLEU-C of 5 points.On average, Align-VDBA has a 0.7 point greaterBLEU-C compared to VDBA. It also has a greaterBLEU than VDBA on all the five datasets. In Ta-ble 9 of Appendix we show that for smaller beam-size of 5, the gap between Align-VDBA and VDBAis even larger (2.1 points greater BLEU-C and 0.4
6681

Constraints (gesetz zur, law also), (dealer, pusher)Gold of course, if a drug addict becomes a pusher, then it is right and necessary that he should pay and answer before the law also.VDBA certainly, if a drug addict becomes a dealer, it is right and necessary that he should be brought to justice before the law also pusher.Align-VDBA certainly, if a drug addict becomes a pusher, then it is right and necessary that he should be brought to justice before the law also.Constraints (von mehrheitsverfahren, of qualified)Gold ... whether this is done on the basis of a vote or of consensus, and whether unanimity is required or some form of qualified majority.VDBA ... whether this is done by means of qualified votes or consensus, and whether unanimity or form of majority procedure apply.Align-VDBA ... whether this is done by voting or consensus, and whether unanimity or form of qualified majority voting are valid.Constraints (zustimmung der, strong backing of)Gold ... which were adopted with the strong backing of the ppe group and the support of the socialist members.VDBA ... which were then adopted with broad agreement from the ppe group and with the strong backing of the socialist members.Align-VDBA ... which were then adopted with strong backing of the ppe group and with the support of the socialist members.Constraints (den usa, the usa), (sicherheitssystems an, security system that), (entwicklung, development)Gold matters we regard as particularly important are improving the working conditions between the weu and the eu
and the development of a european security system that is not dependent on the usa .VDBA we consider the usa ’s european security system to be particularly important in improving working conditions
between the weu and the eu and developing a european security system that is independent of the united states development .Align-VDBA we consider the development of the security system that is independent of the usa to be particularly important
in improving working conditions between the weu and the eu .
Table 4: Anecdotes showing constrained translations produced by VDBA vs. Align-VDBA.
points greater BLEU). Table 4 lists some exampletranslations by VDBA vs. Align-VDBA. We ob-serve that VDBA places constraints at the end ofthe translated sentence (e.g., “pusher", “develop-ment") unlike Align-VDBA. In some cases whereconstraints contain frequent words (like of, the,etc.), VDBA picks the token in the wrong posi-tion to tack on the constraint (e.g., “strong backingof", “of qualified") while Align-VDBA places theconstraint correctly.
Dataset→ IATE.414 Wiktionary.727Method (Beam Size) ↓ BLEU (∆) CSR BLEU (∆) CSRBaseline (5) 25.8 76.3 26.0 76.9Train-by-app. (5) 26.0 (+0.2) 92.9 26.9 (+0.9) 90.7Train-by-rep. (5) 26.0 (+0.2) 94.5 26.3 (+0.3) 93.4No constraints (10) 29.7 77.0 29.9 72.4SHIFTAET (10) 29.9 95.9 30.4 97.2VDBA (10) 30.9 99.8 30.9 99.4Align-VDBA (10) 30.9 (+1.2) 99.8 31.1 (+1.2) 99.5
Table 5: Constrained translation results on the two realworld constraints from Dinu et al. (2019).
Real World Constraints: We also evaluate ourmethod using real world constraints extracted fromIATE and Wiktionary datasets by Dinu et al. (2019).Table 5 compares Align-VDBA with the soft-constraints method of Dinu et al. (2019) that re-quires special retraining to teach the model to copyconstraints. We reproduced the numbers from theirpaper in the first three rows. Their baseline is al-most 4 BLEU points worse than ours since theyused a smaller transformer NMT model, thus mak-ing running times incomparable. When we com-pare the increment ∆ in BLEU over the respectivebaselines, Align-VDBA shows much greater gainsof +1.2 vs. their +0.5. Also, Align-VDBA provides
a larger CSR of 99.6 compared to their 92. Resultsfor other beam sizes and other methods and metricsappear in Appendix F.
5 Related Work
Online Prior Alignment from NMTs: Zenkelet al. (2019) find alignments using a single-headattention submodule, optimized to predict the nexttoken. Garg et al. (2019) and Song et al. (2020)supervise a single alignment head from the penul-timate multi-head attention with prior alignmentsfrom GIZA++ alignments or FastAlign. Bahar et al.(2020) and Shankar et al. (2018) treat alignmentas a latent variable and impose a joint distributionover token and alignment while supervising on thetoken marginal of the joint distribution.Online Posterior Alignment from NMTs:Shankar and Sarawagi (2019) first identify the roleof posterior attention for more accurate alignment.However, their NMT was a single-headed RNN.Chen et al. (2020) implement posterior attention ina multi-headed Transformer but they incur a delayof one step between token output and alignment.We are not aware of any prior work that extractstruly online posterior alignment in modern NMTs.Offline Alignment Systems: Several recent meth-ods apply only in the offline setting: Zenkel et al.(2020) extend an NMT with an alignment module;Nagata et al. (2020) frame alignment as a questionanswering task; and Jalili Sabet et al. (2020); Douand Neubig (2021) leverage similarity between con-textual embeddings from pretrained multilingualmodels (Devlin et al., 2019).Lexicon Constrained Translation: Hokamp andLiu (2017) and Post and Vilar (2018); Hu et al.
6682

(2019) modify beam search to ensure that tar-get phrases from a given constrained lexicon arepresent in the translation. These methods ignorealignment with the source but ensure high successrate for appearance of the target phrases in the con-straint. Song et al. (2020) and Chen et al. (2021)do consider source alignment but they do not en-force constraints leading to lower CSR. Dinu et al.(2019) and Lee et al. (2021) propose alternativetraining strategies for constraints, whereas we fo-cus on working with existing models. Recently,non autoregressive methods have been proposedfor enforcing target constraints but they require thatthe constraints are given in the order they appear inthe target translation (Susanto et al., 2020).
6 Conclusion
In this paper we proposed a simple architecturalmodification to modern NMT systems to obtain ac-curate online alignments. The key idea that led tohigh alignment accuracy was conditioning on theoutput token. Further, our designed alignment mod-ule enables such conditioning to be performed syn-chronously with token generation. This propertyled us to Align-VDBA, a principled decoding algo-rithm for lexically constrained translation based onjoint distribution of target token and source align-ments. Future work includes increase efficiencyof constrained inference and harnessing such jointdistributions for other forms of constraints, for ex-ample, nested constraints.Limitations: All existing methods for hard con-strained inference, including ours, come with con-siderable runtime overheads. Soft constrainedmethods are not accurate enough.
Acknowledgements
We are grateful to the reviewers for their detailedanalysis, thoughtful comments and insightful ques-tions which have helped us improve the paper. Weare grateful to Priyesh Jain for providing alignmentannotations for 50 English-Hindi sentences.
ReferencesTamer Alkhouli, Gabriel Bretschner, and Hermann Ney.
2018. On the alignment problem in multi-headattention-based neural machine translation. In Pro-ceedings of the Third Conference on Machine Trans-lation: Research Papers, pages 177–185, Brussels,Belgium. Association for Computational Linguis-tics.
Parnia Bahar, Nikita Makarov, and Hermann Ney. 2020.Investigation of transformer-based latent attentionmodels for neural machine translation. In Proceed-ings of the 14th Conference of the Association forMachine Translation in the Americas (Volume 1: Re-search Track), pages 7–20, Virtual. Association forMachine Translation in the Americas.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-gio. 2015. Neural machine translation by jointlylearning to align and translate. In 3rd Inter-national Conference on Learning Representations,ICLR 2015, San Diego, CA, USA, May 7-9, 2015,Conference Track Proceedings.
Peter F. Brown, Stephen A. Della Pietra, Vincent J.Della Pietra, and Robert L. Mercer. 1993. The math-ematics of statistical machine translation: Parameterestimation. Computational Linguistics, 19(2):263–311.
Guanhua Chen, Yun Chen, and Victor O.K. Li. 2021.Lexically constrained neural machine translationwith explicit alignment guidance. Proceedingsof the AAAI Conference on Artificial Intelligence,35(14):12630–12638.
Yun Chen, Yang Liu, Guanhua Chen, Xin Jiang, andQun Liu. 2020. Accurate word alignment inductionfrom neural machine translation. In Proceedings ofthe 2020 Conference on Empirical Methods in Natu-ral Language Processing (EMNLP), pages 566–576,Online. Association for Computational Linguistics.
Kyunghyun Cho, Bart van Merriënboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014. On the propertiesof neural machine translation: Encoder–decoder ap-proaches. In Proceedings of SSST-8, Eighth Work-shop on Syntax, Semantics and Structure in Statisti-cal Translation, pages 103–111, Doha, Qatar. Asso-ciation for Computational Linguistics.
Josep Crego, Jungi Kim, Guillaume Klein, Anabel Re-bollo, Kathy Yang, Jean Senellart, Egor Akhanov,Patrice Brunelle, Aurelien Coquard, YongchaoDeng, Satoshi Enoue, Chiyo Geiss, Joshua Johan-son, Ardas Khalsa, Raoum Khiari, Byeongil Ko,Catherine Kobus, Jean Lorieux, Leidiana Martins,Dang-Chuan Nguyen, Alexandra Priori, ThomasRiccardi, Natalia Segal, Christophe Servan, Cyril Ti-quet, Bo Wang, Jin Yang, Dakun Zhang, Jing Zhou,and Peter Zoldan. 2016. Systran’s pure neural ma-chine translation systems.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2019. BERT: Pre-training ofdeep bidirectional transformers for language under-standing. In Proceedings of the 2019 Conferenceof the North American Chapter of the Associationfor Computational Linguistics: Human LanguageTechnologies, Volume 1 (Long and Short Papers),pages 4171–4186, Minneapolis, Minnesota. Associ-ation for Computational Linguistics.
Shuoyang Ding, Hainan Xu, and Philipp Koehn. 2019.Saliency-driven word alignment interpretation for
6683

neural machine translation. In Proceedings of theFourth Conference on Machine Translation (Volume1: Research Papers), pages 1–12, Florence, Italy. As-sociation for Computational Linguistics.
Georgiana Dinu, Prashant Mathur, Marcello Federico,and Yaser Al-Onaizan. 2019. Training neural ma-chine translation to apply terminology constraints.In Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics, pages3063–3068, Florence, Italy. Association for Compu-tational Linguistics.
Zi-Yi Dou and Graham Neubig. 2021. Word alignmentby fine-tuning embeddings on parallel corpora. InProceedings of the 16th Conference of the EuropeanChapter of the Association for Computational Lin-guistics: Main Volume, pages 2112–2128, Online.Association for Computational Linguistics.
Chris Dyer, Victor Chahuneau, and Noah A. Smith.2013. A simple, fast, and effective reparameter-ization of IBM model 2. In Proceedings of the2013 Conference of the North American Chapter ofthe Association for Computational Linguistics: Hu-man Language Technologies, pages 644–648, At-lanta, Georgia. Association for Computational Lin-guistics.
Sarthak Garg, Stephan Peitz, Udhyakumar Nallasamy,and Matthias Paulik. 2019. Jointly learning to alignand translate with transformer models. In Proceed-ings of the 2019 Conference on Empirical Methodsin Natural Language Processing and the 9th Inter-national Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP), pages 4453–4462, HongKong, China. Association for Computational Lin-guistics.
Eva Hasler, Adrià de Gispert, Gonzalo Iglesias, andBill Byrne. 2018. Neural machine translation decod-ing with terminology constraints. In Proceedings ofthe 2018 Conference of the North American Chap-ter of the Association for Computational Linguistics:Human Language Technologies, Volume 2 (Short Pa-pers), pages 506–512, New Orleans, Louisiana. As-sociation for Computational Linguistics.
Felix Hieber, Tobias Domhan, Michael Denkowski,and David Vilar. 2020. Sockeye 2: A toolkit for neu-ral machine translation. In Proceedings of the 22ndAnnual Conference of the European Association forMachine Translation, pages 457–458, Lisboa, Portu-gal. European Association for Machine Translation.
Chris Hokamp and Qun Liu. 2017. Lexically con-strained decoding for sequence generation using gridbeam search. In Proceedings of the 55th AnnualMeeting of the Association for Computational Lin-guistics (Volume 1: Long Papers), pages 1535–1546,Vancouver, Canada. Association for ComputationalLinguistics.
J. Edward Hu, Huda Khayrallah, Ryan Culkin, PatrickXia, Tongfei Chen, Matt Post, and Benjamin
Van Durme. 2019. Improved lexically constraineddecoding for translation and monolingual rewriting.In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics: Human Language Technologies,Volume 1 (Long and Short Papers), pages 839–850,Minneapolis, Minnesota. Association for Computa-tional Linguistics.
Masoud Jalili Sabet, Philipp Dufter, François Yvon,and Hinrich Schütze. 2020. SimAlign: High qual-ity word alignments without parallel training data us-ing static and contextualized embeddings. In Find-ings of the Association for Computational Linguis-tics: EMNLP 2020, pages 1627–1643, Online. As-sociation for Computational Linguistics.
Nal Kalchbrenner and Phil Blunsom. 2013. Recurrentcontinuous translation models. In Proceedings ofthe 2013 Conference on Empirical Methods in Natu-ral Language Processing, pages 1700–1709, Seattle,Washington, USA. Association for ComputationalLinguistics.
Philipp Koehn. 2004. Statistical significance testsfor machine translation evaluation. In Proceed-ings of the 2004 Conference on Empirical Meth-ods in Natural Language Processing, pages 388–395, Barcelona, Spain. Association for Computa-tional Linguistics.
Philipp Koehn, Amittai Axelrod, Alexandra BirchMayne, Chris Callison-Burch, Miles Osborne, andDavid Talbot. 2005. Edinburgh system descriptionfor the 2005 iwslt speech translation evaluation. InInternational Workshop on Spoken Language Trans-lation (IWSLT) 2005.
Anoop Kunchukuttan, Pratik Mehta, and Pushpak Bhat-tacharyya. 2018. The IIT Bombay English-Hindiparallel corpus. In Proceedings of the Eleventh In-ternational Conference on Language Resources andEvaluation (LREC 2018), Miyazaki, Japan. Euro-pean Language Resources Association (ELRA).
Gyubok Lee, Seongjun Yang, and Edward Choi.2021. Improving lexically constrained neural ma-chine translation with source-conditioned maskedspan prediction. In Proceedings of the 59th An-nual Meeting of the Association for ComputationalLinguistics and the 11th International Joint Confer-ence on Natural Language Processing (Volume 2:Short Papers), pages 743–753, Online. Associationfor Computational Linguistics.
Joel Martin, Rada Mihalcea, and Ted Pedersen. 2005.Word alignment for languages with scarce resources.In Proceedings of the ACL Workshop on Buildingand Using Parallel Texts, pages 65–74, Ann Arbor,Michigan. Association for Computational Linguis-tics.
Rada Mihalcea and Ted Pedersen. 2003. An evalua-tion exercise for word alignment. In Proceedingsof the HLT-NAACL 2003 Workshop on Building and
6684

Using Parallel Texts: Data Driven Machine Transla-tion and Beyond, pages 1–10.
Mathias Müller. 2017. Treatment of markup in sta-tistical machine translation. In Proceedings of theThird Workshop on Discourse in Machine Transla-tion, pages 36–46, Copenhagen, Denmark. Associa-tion for Computational Linguistics.
Masaaki Nagata, Katsuki Chousa, and MasaakiNishino. 2020. A supervised word alignmentmethod based on cross-language span prediction us-ing multilingual BERT. In Proceedings of the 2020Conference on Empirical Methods in Natural Lan-guage Processing (EMNLP), pages 555–565, Online.Association for Computational Linguistics.
Graham Neubig. 2011. The Kyoto free translation task.
Franz Josef Och and Hermann Ney. 2000. Improvedstatistical alignment models. In Proceedings of the38th Annual Meeting of the Association for Com-putational Linguistics, pages 440–447, Hong Kong.Association for Computational Linguistics.
Franz Josef Och and Hermann Ney. 2003. A systematiccomparison of various statistical alignment models.Computational Linguistics, 29(1):19–51.
Myle Ott, Sergey Edunov, Alexei Baevski, AngelaFan, Sam Gross, Nathan Ng, David Grangier, andMichael Auli. 2019. fairseq: A fast, extensibletoolkit for sequence modeling. In Proceedings ofthe 2019 Conference of the North American Chap-ter of the Association for Computational Linguistics(Demonstrations), pages 48–53, Minneapolis, Min-nesota. Association for Computational Linguistics.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic eval-uation of machine translation. In Proceedings ofthe 40th Annual Meeting of the Association for Com-putational Linguistics, pages 311–318, Philadelphia,Pennsylvania, USA. Association for ComputationalLinguistics.
Matt Post. 2018. A call for clarity in reporting BLEUscores. In Proceedings of the Third Conference onMachine Translation: Research Papers, pages 186–191, Brussels, Belgium. Association for Computa-tional Linguistics.
Matt Post and David Vilar. 2018. Fast lexically con-strained decoding with dynamic beam allocation forneural machine translation. In Proceedings of the2018 Conference of the North American Chapter ofthe Association for Computational Linguistics: Hu-man Language Technologies, Volume 1 (Long Pa-pers), pages 1314–1324, New Orleans, Louisiana.Association for Computational Linguistics.
Rico Sennrich, Barry Haddow, and Alexandra Birch.2016. Neural machine translation of rare wordswith subword units. In Proceedings of the 54th An-nual Meeting of the Association for Computational
Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computa-tional Linguistics.
Shiv Shankar, Siddhant Garg, and Sunita Sarawagi.2018. Surprisingly easy hard-attention for sequenceto sequence learning. In Proceedings of the 2018Conference on Empirical Methods in Natural Lan-guage Processing, pages 640–645, Brussels, Bel-gium. Association for Computational Linguistics.
Shiv Shankar and Sunita Sarawagi. 2019. Posterior at-tention models for sequence to sequence learning.In International Conference on Learning Represen-tations.
Xiaoyu Shen, Yang Zhao, Hui Su, and Dietrich Klakow.2019. Improving latent alignment in text summa-rization by generalizing the pointer generator. InProceedings of the 2019 Conference on EmpiricalMethods in Natural Language Processing and the9th International Joint Conference on Natural Lan-guage Processing (EMNLP-IJCNLP), pages 3762–3773, Hong Kong, China. Association for Computa-tional Linguistics.
Kai Song, Kun Wang, Heng Yu, Yue Zhang,Zhongqiang Huang, Weihua Luo, Xiangyu Duan,and Min Zhang. 2020. Alignment-enhanced trans-former for constraining nmt with pre-specified trans-lations. Proceedings of the AAAI Conference on Ar-tificial Intelligence, 34(05):8886–8893.
Raymond Hendy Susanto, Shamil Chollampatt, andLiling Tan. 2020. Lexically constrained neural ma-chine translation with Levenshtein transformer. InProceedings of the 58th Annual Meeting of the Asso-ciation for Computational Linguistics, pages 3536–3543, Online. Association for Computational Lin-guistics.
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014.Sequence to sequence learning with neural networks.In Advances in Neural Information Processing Sys-tems, volume 27. Curran Associates, Inc.
Ashish Vaswani, Noam Shazeer, Niki Parmar, JakobUszkoreit, Llion Jones, Aidan N Gomez, ŁukaszKaiser, and Illia Polosukhin. 2017. Attention is allyou need. In Advances in Neural Information Pro-cessing Systems, volume 30. Curran Associates, Inc.
David Vilar, Maja Popovic, and Hermann Ney. 2006.AER: Do we need to “improve” our alignments? InInternational Workshop on Spoken Language Trans-lation (IWSLT) 2006.
Thomas Zenkel, Joern Wuebker, and John DeNero.2019. Adding interpretable attention to neural trans-lation models improves word alignment.
Thomas Zenkel, Joern Wuebker, and John DeNero.2020. End-to-end neural word alignment outper-forms GIZA++. In Proceedings of the 58th AnnualMeeting of the Association for Computational Lin-guistics, pages 1605–1617, Online. Association forComputational Linguistics.
6685

A Alignment Error Rate
Given gold alignments consisting of sure align-ments S and possible alignments P , and the pre-dicted alignments A, the Alignment Error Rate(AER) is defined as (Och and Ney, 2000):
AER = 1− |A ∩ P|+ |A ∩ S||A|+ |S|Note that here S ⊆ P . Also note that since ourmodels are trained on sub-word units but gold align-ments are over words, we need to convert align-ments between word pieces to alignments betweenwords. A source word and a target word are said tobe aligned if there exists an alignment link betweenany of their respective word pieces.
B BLEU-C
Given a reference sentence, a predicted translationand a set of constraints, for each constraints, a seg-ment of the sentence is chosen which contains theconstraint and window size words (if available) sur-rounding the constraint words on either side. Suchsegments, called spans, are collected for the ref-erence and predicted sentences in the test set andBLEU is computed over these spans. If a constraintis not satisfied in the prediction, the correspondingspan is considered to be the empty string. An ex-ample is shown in Table 6. Table 7 shows howBLEU-C varies as a function of varying windowsize for a fixed English-French constraint set withbeam size set to 10.
Window Size→ 2 3 4 5 6 7 8No constraints 0.0 0.0 0.0 0.0 0.0 0.0 0.0NAIVEATT 34.4 32.0 30.4 29.5 29.4 29.5 29.7PRIORATT 41.5 38.7 36.4 35.1 34.9 35.0 35.2SHIFTATT 44.9 41.5 38.9 37.3 36.4 36.2 36.0SHIFTAET 47.0 43.2 40.4 38.7 38.0 37.6 37.4POSTALN 46.4 42.7 39.8 38.0 37.1 36.9 36.6VDBA 54.9 50.5 46.8 44.6 43.5 43.0 42.6Align-VDBA 56.4 51.7 47.9 45.6 44.4 43.7 43.3
Table 7: BLEU-C vs Window Size
C Description of the Datasets
The European languages consist of parallel sen-tences for three language pairs from the EuroparlCorpus and alignments from Mihalcea and Peder-sen (2003), Och and Ney (2000), Vilar et al. (2006).Following previous works (Ding et al., 2019; Chenet al., 2020), the last 1000 sentences of the trainingdata are used as validation data.
For English-Hindi, we use the dataset from Mar-tin et al. (2005) consisting of 3440 training sentence
pairs, 25 validation and 90 test sentences with goldalignments. Since training Transformers requiresmuch larger datasets, we augment the training setwith 1.6 million sentences from the IIT BombayParallel Corpus (Kunchukuttan et al., 2018). Wealso add the first 50 sentences from the dev set ofIIT Bombay Parallel Corpus with manually anno-tated alignments to the test set giving a total of 140test sentences.
For Japanese-English, we use The Kyoto FreeTranslation Task (Neubig, 2011). It comprisesroughly 330K training, 1166 validation and 1235test sentences. As with other datasets, gold align-ments are available only for the test sentences. TheJapanese text is already segmented and we use itwithout additional changes.
The real world constraints datasets of Dinu et al.(2019) are extracted from the German-EnglishWMT newstest 2017 task with the IATE datasetconsisting of 414 sentences (451 constraints) andthe Wiktionary 727 sentences (879 constraints).The constraints come from the IATE and Wik-tionary termninology databases.
All datasets were processed using the scriptsprovided by Zenkel et al. (2019) at https://github.com/lilt/alignment-scripts.Computation of BLEU and BLEU-C,and the paired test were performed usingsacrebleu (Post, 2018).
D Bidirectional Symmetrized Alignment
We report AERs using bidirectional symmetrizedalignments in Table 8 in order to provide fair com-parisons to results in prior literature. The sym-metrization is done using the grow-diagonal heuris-tic (Koehn et al., 2005; Och and Ney, 2000). Sincebidirectional alignments need the entire text in bothlanguages, these are not online alignments.
Method de-en en-fr ro-en en-hi ja-enStatistical Methods
GIZA++ 18.6 5.5 26.3 35.9 39.7FastAlign 27.0 10.5 32.1 - -
No Alignment TrainingNAIVEATT 29.2 16.9 31.4 43.8 57.1SHIFTATT 16.9 7.8 24.3 30.9 46.2
With Alignment TrainingPRIORATT 22.0 10.1 26.3 32.1 48.2SHIFTAET 15.4 5.6 21.0 26.7 40.1POSTALN 15.3 5.5 21.0 26.1 39.5
Table 8: AERs for bidirectional symmetrized align-ments. POSTALN consistently performs the best.
6686

Reference we consider the development of a robust security system that is independent of thePrediction we consider developing a robust security system which is independent of the
BLEU-C (Window Size = 2)Cons. No Reference Spans Predicted Spans1 consider the development of a (empty sentence)2 a robust security system that is a robust security system which isBLEU-C = BLEU(Reference Spans, Predicted Spans)
Table 6: An example BLEU-C computation
E Additional Lexicon-ConstrainedTranslation Results
Constrained translation results for beam sizes 5 and10 are shown in Table 9. We also present resultsfor Align-VDBA without the alignment probabilitybased beam allocation as Align-VDBA* in Table 9.We can see that our beam allocation technique re-sults in better beam utilization as evidenced by im-provements in BLEU and BLEU-C, and reductiontotal decoding time.
Paired bootstrap resampling test (Koehn, 2004)results with respect to Align-VDBA for beam size10 are shown in Table 10.
F Additional Real World ConstrainedTranslation Results
Results on the real world constrained translationdatasets of Dinu et al. (2019) for all the methodsin Table 3 with beam sizes 5, 10 and 20 are pre-sented in Table 11. Paired bootstrap resamplingtest (Koehn, 2004) results with respect to Align-VDBA for beam size 5 are shown in Table 12
G Alignment-based Token ReplacementAlgorithm
The pseudocode for the algorithm used in Songet al. (2020); Chen et al. (2021) and our non-VDBAbased methods in Section 4.3 is presented in Al-gorithm 2. As described in Section 3.1, at eachdecoding step, if the source token having the max-imum alignment at the current step lies in someconstraint span, the constraint in question is de-coded until completion before resuming normaldecoding.
Though different alignment methods are rep-resented using a call to the same ATTENTION
function in Algorithm 2, these methods incurvarying computational overheads. For instance,NAIVEATT incurs little additional cost, PRIO-RATT and POSTALN involve a multi-head atten-tion computation. For SHIFTATT and SHIFTAET,
an entire decoder pass is done when ATTENTION iscalled, thereby incurring a huge overhead as shownin Table 3.
H Layer Selection for AlignmentSupervision of Distant Language Pairs
For the alignment supervision, we used align-ments extracted from vanilla Transformers usingthe SHIFTATT method. To do so, however, weneed to choose the decoder layers from which toextract the alignments. The validation AERs canbe used for this purpose but since gold validationalignments are not available, Chen et al. (2020) sug-gest selecting the layers which have the best con-sistency between the alignment predictions fromthe two translation directions.
For the European language pairs, this turns out tobe layer 3 as suggested by Chen et al. (2020). How-ever, for the distant language pairs Hindi-Englishand Japanese-English, this is not the case and layerselection needs to be done. The AER between thetwo translation directions on the validation set, withalignments obtained from different decoder layers,are shown in Tables 13 and 14.
6687
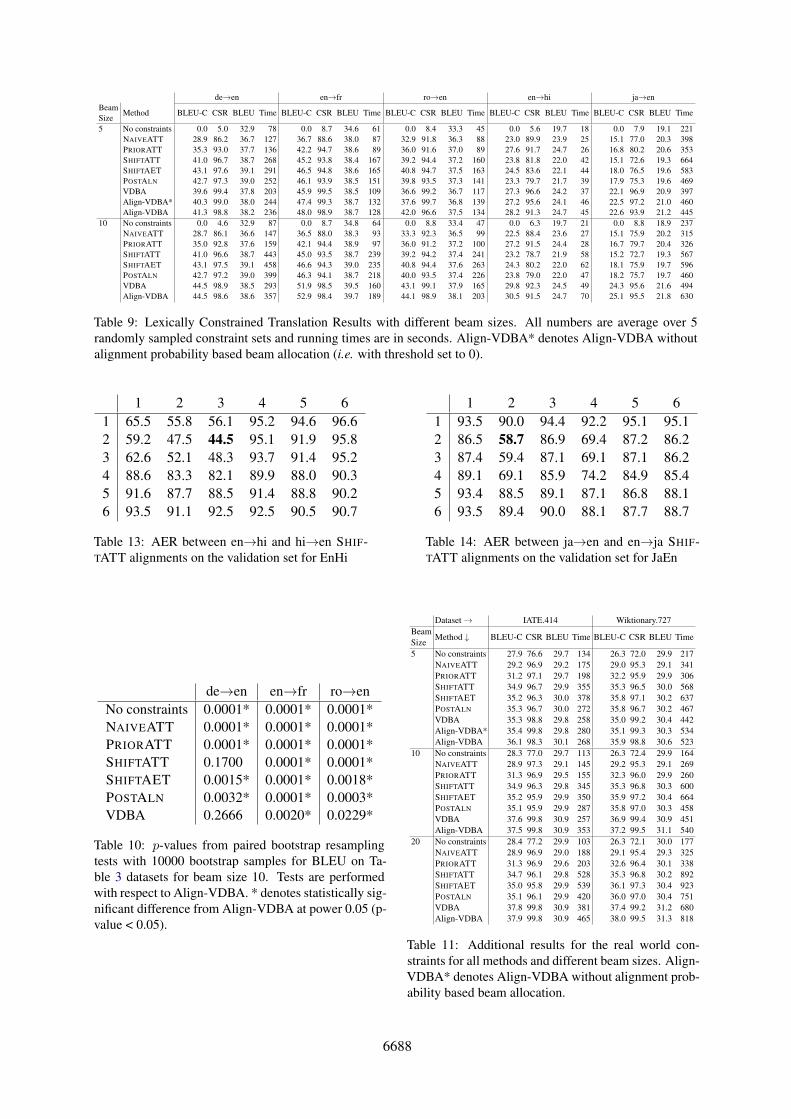
de→en en→fr ro→en en→hi ja→enBeamSize
Method BLEU-C CSR BLEU Time BLEU-C CSR BLEU Time BLEU-C CSR BLEU Time BLEU-C CSR BLEU Time BLEU-C CSR BLEU Time
5 No constraints 0.0 5.0 32.9 78 0.0 8.7 34.6 61 0.0 8.4 33.3 45 0.0 5.6 19.7 18 0.0 7.9 19.1 221NAIVEATT 28.9 86.2 36.7 127 36.7 88.6 38.0 87 32.9 91.8 36.3 88 23.0 89.9 23.9 25 15.1 77.0 20.3 398PRIORATT 35.3 93.0 37.7 136 42.2 94.7 38.6 89 36.0 91.6 37.0 89 27.6 91.7 24.7 26 16.8 80.2 20.6 353SHIFTATT 41.0 96.7 38.7 268 45.2 93.8 38.4 167 39.2 94.4 37.2 160 23.8 81.8 22.0 42 15.1 72.6 19.3 664SHIFTAET 43.1 97.6 39.1 291 46.5 94.8 38.6 165 40.8 94.7 37.5 163 24.5 83.6 22.1 44 18.0 76.5 19.6 583POSTALN 42.7 97.3 39.0 252 46.1 93.9 38.5 151 39.8 93.5 37.3 141 23.3 79.7 21.7 39 17.9 75.3 19.6 469VDBA 39.6 99.4 37.8 203 45.9 99.5 38.5 109 36.6 99.2 36.7 117 27.3 96.6 24.2 37 22.1 96.9 20.9 397Align-VDBA* 40.3 99.0 38.0 244 47.4 99.3 38.7 132 37.6 99.7 36.8 139 27.2 95.6 24.1 46 22.5 97.2 21.0 460Align-VDBA 41.3 98.8 38.2 236 48.0 98.9 38.7 128 42.0 96.6 37.5 134 28.2 91.3 24.7 45 22.6 93.9 21.2 445
10 No constraints 0.0 4.6 32.9 87 0.0 8.7 34.8 64 0.0 8.8 33.4 47 0.0 6.3 19.7 21 0.0 8.8 18.9 237NAIVEATT 28.7 86.1 36.6 147 36.5 88.0 38.3 93 33.3 92.3 36.5 99 22.5 88.4 23.6 27 15.1 75.9 20.2 315PRIORATT 35.0 92.8 37.6 159 42.1 94.4 38.9 97 36.0 91.2 37.2 100 27.2 91.5 24.4 28 16.7 79.7 20.4 326SHIFTATT 41.0 96.6 38.7 443 45.0 93.5 38.7 239 39.2 94.2 37.4 241 23.2 78.7 21.9 58 15.2 72.7 19.3 567SHIFTAET 43.1 97.5 39.1 458 46.6 94.3 39.0 235 40.8 94.4 37.6 263 24.3 80.2 22.0 62 18.1 75.9 19.7 596POSTALN 42.7 97.2 39.0 399 46.3 94.1 38.7 218 40.0 93.5 37.4 226 23.8 79.0 22.0 47 18.2 75.7 19.7 460VDBA 44.5 98.9 38.5 293 51.9 98.5 39.5 160 43.1 99.1 37.9 165 29.8 92.3 24.5 49 24.3 95.6 21.6 494Align-VDBA 44.5 98.6 38.6 357 52.9 98.4 39.7 189 44.1 98.9 38.1 203 30.5 91.5 24.7 70 25.1 95.5 21.8 630
Table 9: Lexically Constrained Translation Results with different beam sizes. All numbers are average over 5randomly sampled constraint sets and running times are in seconds. Align-VDBA* denotes Align-VDBA withoutalignment probability based beam allocation (i.e. with threshold set to 0).
1 2 3 4 5 61 65.5 55.8 56.1 95.2 94.6 96.62 59.2 47.5 44.5 95.1 91.9 95.83 62.6 52.1 48.3 93.7 91.4 95.24 88.6 83.3 82.1 89.9 88.0 90.35 91.6 87.7 88.5 91.4 88.8 90.26 93.5 91.1 92.5 92.5 90.5 90.7
Table 13: AER between en→hi and hi→en SHIF-TATT alignments on the validation set for EnHi
1 2 3 4 5 61 93.5 90.0 94.4 92.2 95.1 95.12 86.5 58.7 86.9 69.4 87.2 86.23 87.4 59.4 87.1 69.1 87.1 86.24 89.1 69.1 85.9 74.2 84.9 85.45 93.4 88.5 89.1 87.1 86.8 88.16 93.5 89.4 90.0 88.1 87.7 88.7
Table 14: AER between ja→en and en→ja SHIF-TATT alignments on the validation set for JaEn
de→en en→fr ro→enNo constraints 0.0001* 0.0001* 0.0001*NAIVEATT 0.0001* 0.0001* 0.0001*PRIORATT 0.0001* 0.0001* 0.0001*SHIFTATT 0.1700 0.0001* 0.0001*SHIFTAET 0.0015* 0.0001* 0.0018*POSTALN 0.0032* 0.0001* 0.0003*VDBA 0.2666 0.0020* 0.0229*
Table 10: p-values from paired bootstrap resamplingtests with 10000 bootstrap samples for BLEU on Ta-ble 3 datasets for beam size 10. Tests are performedwith respect to Align-VDBA. * denotes statistically sig-nificant difference from Align-VDBA at power 0.05 (p-value < 0.05).
Dataset→ IATE.414 Wiktionary.727BeamSize
Method ↓ BLEU-C CSR BLEU Time BLEU-C CSR BLEU Time
5 No constraints 27.9 76.6 29.7 134 26.3 72.0 29.9 217NAIVEATT 29.2 96.9 29.2 175 29.0 95.3 29.1 341PRIORATT 31.2 97.1 29.7 198 32.2 95.9 29.9 306SHIFTATT 34.9 96.7 29.9 355 35.3 96.5 30.0 568SHIFTAET 35.2 96.3 30.0 378 35.8 97.1 30.2 637POSTALN 35.3 96.7 30.0 272 35.8 96.7 30.2 467VDBA 35.3 98.8 29.8 258 35.0 99.2 30.4 442Align-VDBA* 35.4 99.8 29.8 280 35.1 99.3 30.3 534Align-VDBA 36.1 98.3 30.1 268 35.9 98.8 30.6 523
10 No constraints 28.3 77.0 29.7 113 26.3 72.4 29.9 164NAIVEATT 28.9 97.3 29.1 145 29.2 95.3 29.1 269PRIORATT 31.3 96.9 29.5 155 32.3 96.0 29.9 260SHIFTATT 34.9 96.3 29.8 345 35.3 96.8 30.3 600SHIFTAET 35.2 95.9 29.9 350 35.9 97.2 30.4 664POSTALN 35.1 95.9 29.9 287 35.8 97.0 30.3 458VDBA 37.6 99.8 30.9 257 36.9 99.4 30.9 451Align-VDBA 37.5 99.8 30.9 353 37.2 99.5 31.1 540
20 No constraints 28.4 77.2 29.9 103 26.3 72.1 30.0 177NAIVEATT 28.9 96.9 29.0 188 29.1 95.4 29.3 325PRIORATT 31.3 96.9 29.6 203 32.6 96.4 30.1 338SHIFTATT 34.7 96.1 29.8 528 35.3 96.8 30.2 892SHIFTAET 35.0 95.8 29.9 539 36.1 97.3 30.4 923POSTALN 35.1 96.1 29.9 420 36.0 97.0 30.4 751VDBA 37.8 99.8 30.9 381 37.4 99.2 31.2 680Align-VDBA 37.9 99.8 30.9 465 38.0 99.5 31.3 818
Table 11: Additional results for the real world con-straints for all methods and different beam sizes. Align-VDBA* denotes Align-VDBA without alignment prob-ability based beam allocation.
6688

Algorithm 2 k-best extraction with argmax replacement decoding.Inputs: A k × |VT | matrix of scores (for all tokens up to the currently decoded ones). k beam states.
1: function SEARCH_STEP(beam, scores)2: next_toks, next_scores← ARGMAX_K(scores, k=2, dim=1) . Best 2 tokens for each beam3: candidates← []4: for 0 ≤ h < 2 · k do5: candidate← beam[h//2]6: candidate.tokens.append(next_toks[h//2, h%2])7: candidate.scores← next_scores[h//2, h%2]8: candidates.append(candidate)9: attention← ATTENTION(candidates)
10: aligned_x← ARGMAX(attention, dim=1)11: for 0 ≤ h < 2 · k do12: if aligned_x[h] ∈ Cxi for some i and not candidates[h].inprogress then . Start constraint13: candidates[h].inprogress← True14: candidates[h].constraintNum← i15: candidates[h].tokenNum← 016: if candidates[h].inprogress then . Replace token with constraint tokens17: consNum← candidates[h].constraintNum18: candidates[h].tokens[-1]← constraints[consNum][candidates[h].tokenNum]19: candidates[h].tokenNum← candidates[h].tokenNum + 120: if constraints[consNum].length == candidates[h].tokenNum then21: candidates[h].inprogress← False . Finish current constraint22: candidates← REMOVE_DUPLICATES(candidates)23: newBeam← TOP_K(candidates)24: return newBeam
Dataset IATE.414 Wiktionary.727Method BLEU µ± 95% CI p-value BLEU µ± 95% CI p-valueAlign-VDBA 30.1 (30.0±1.7) 30.6 (30.6±1.2)No constraints 29.7 (29.7±1.7) 0.1059 29.9 (29.9±1.2) 0.0054*NAIVEATT 29.2 (29.2±1.7) 0.0121* 29.1 (29.1±1.2) 0.0001*PRIORATT 29.7 (29.6±1.6) 0.0829 29.9 (29.8±1.2) 0.0041*SHIFTATT 29.9 (29.8±1.6) 0.1827 30.0 (30.0±1.2) 0.0229*SHIFTAET 30.0 (29.9±1.6) 0.2824 30.2 (30.2±1.2) 0.0588POSTALN 30.0 (30.0±1.6) 0.3813 30.2 (30.2±1.2) 0.0646VDBA 29.8 (29.7±1.6) 0.0849 30.4 (30.4±1.2) 0.0960
Table 12: Paired bootstrap resampling tests with 10000bootstrap samples for BLEU on Dinu et al. (2019)datasets for beam size 5. * denotes statistically signif-icant difference from Align-VDBA at power 0.05 (p-value < 0.05).
6689
Related Documents











