Accelerating the Singular Value De composition of Rectangular Matrices with the C SX600 and the Integrable SVD September 7, 2007 PaCT-2007, Pereslavl-Zalessky Yusaku Yamamoto, Takeshi Fukaya, Takashi Uneyama, Masami Takata, Kinji Kimura, Masashi Iwas aki and Yoshimasa Nakamura

Accelerating the Singular Value Decomposition of Rectangular Matrices with the CSX600 and the Integrable SVD September 7, 2007 PaCT-2007, Pereslavl-Zalessky.
Jan 04, 2016
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Accelerating the Singular Value Decompositionof Rectangular Matrices with the CSX600 and t
he Integrable SVD
September 7, 2007
PaCT-2007, Pereslavl-Zalessky
Yusaku Yamamoto, Takeshi Fukaya, Takashi Uneyama,
Masami Takata, Kinji Kimura, Masashi Iwasaki
and Yoshimasa Nakamura

2
Outline
• Introduction• The CSX600 floating-point accelerator• Optimization of the rectangular SVD algorithm
for the CSX600• Performance evaluation• Conclusion

3
Introduction

4
• Image processing• Electronic structure calculation
– Filter Diagonalization Method
• Information retrieval– Latent Semantic Indexing
• Statistical computations– PCA, ICA and Least Squares
Singular value decomposition of rectangular matrices
=m
nn
n
: m n denseU : m n orthogonalV : n n orthogonal : n n diagonalwhere m >> n
ApplicationsExample
10 5
5000

5
• ClearSpeed CSX600– 1+96 processor cores
– 48GFLOPS (double precision)
Floating-point accelerators
• Cell– 1+8 processor cores
– 256GFLOPS (single precision)
• GRAPE-DR– 512 processor cores
– 512GFLOPS (single precision)
– 256GFLOPS (double precision)
•Very high GFLOPS value due to a large number of cores
•Performance is limited due to relatively low memory bandwidth.

6
• Matrix multiplication C:=C+AB
– The amount of data is O(1/N) of the computational work.– By using the cache memory effectively, the effect of low memory
bandwidth can be mitigated.
We can exploit the potential performance of the CSX600 by reorganizing the algorithm to use matrix multiplications efficiently.
Use of the Level-3 BLAS (matrix multiplication)
= +C A BCAmount of data : O(N 2)Computational work : O(N 3)
For matrix-vector multiplication (y := y + Ax), both the amount of data and computational work is O(N 2).

7
Objective of this study
• Accelerate the SVD of rectangular matrices using the CSX600 processor.
• To exploit the potential of the CSX600, we reorganize the existing algorithm so that matrix multiplications can be used efficiently.
• Evaluate the performance and clarify the technical problems for further improving the performance.

8
The CSX600 floating-point accelerator

9
Architecture and performance of the CSX600
• The CSX600 chip– One main processor– 96 floating-point processors
• 64 bits• 2 flops / cycle• 128B register files• 6KB SRAM
– Operates at 250MHz– Peak performance: 48GFLOPS
• ClearSpeed Advance board– Two CSX600 processors– 1GB DRAM– Connected to a host PC via the P
CI-X bus– Peak performance : 96GFLOPS

10
• Software Development Kit– Compiler: parallel programming with the Cn language– Debugger– Simulator
• CSXL library– Basic Linear Algebra Subprograms (BLAS) for the ClearSpeed A
dvance board– The library transfers the input data from the main memory to the
board, perform the computation and return the data to the main memory.
– Sustained performance: 50GFLOPS with the DGEMM (dense matrix-matrix multiplication)
• CSFFT library
Software environments for the CSX600
We use this in this study.
11
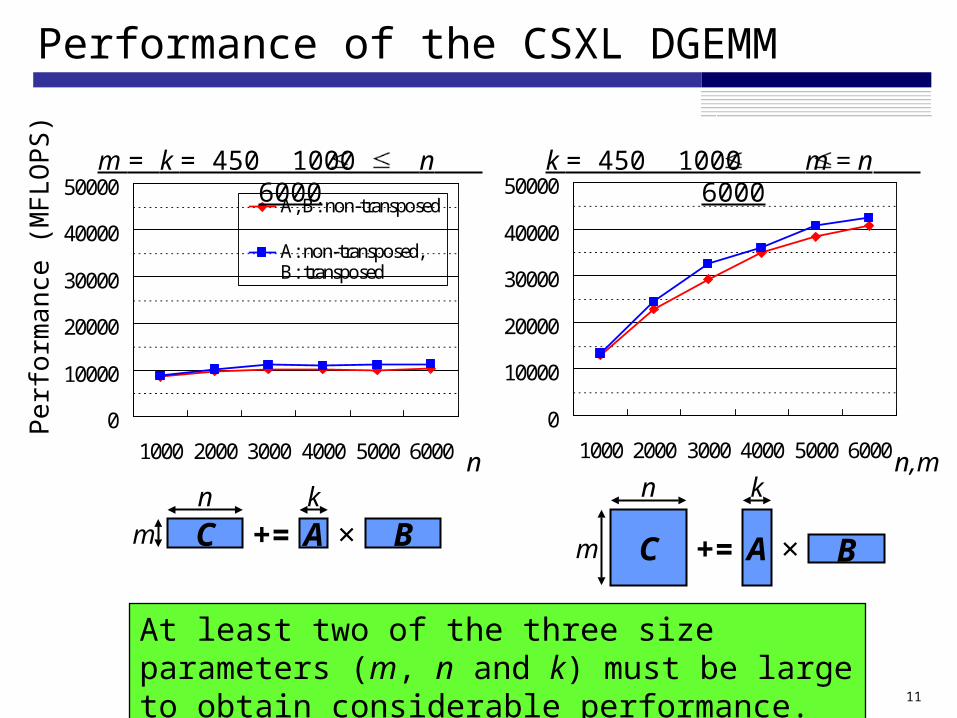
Performance of the CSXL DGEMM
0
10000
20000
30000
40000
50000
1000 2000 3000 4000 5000 6000
A, B: non-transposed
A: non-transposed, B: transposed
m = k = 450 1000 n 6000
0
10000
20000
30000
40000
50000
1000 2000 3000 4000 5000 6000
k = 450 1000 m = n 6000
Per
form
ance
(M
FL
OP
S)
A B×C +=
n k
m
kn
BA ×C +=m
At least two of the three size parameters (m, n and k) must be large to obtain considerable performance.
n n,m

12
Optimization of the rectangular SVD
algorithm for the CSX600

13
Algorithm for rectangular SVD
QR decomposition: A = QR
Bidiagonalization: R = U1 B V1T
SVD of thebidiagonal matrix:
B = U2 V2T
Inverse transformation:
R = U’ V T
V = V1 V2
U’= U1 U2
Multiplication by Q A = U V TU = QU’
Am
n
Qm
n
R
n
n
B
n
n

14
Computational work of each part
2mn2
(8/3)n3
O(n2) O(n3)
2n3 4n3
4mn2
When m >> n (e.g., m =100000, n =5000) Computational work
QR decomposition: A = QR
Bidiagonalization: R = U1 B V1T
SVD of thebidiagonal matrix:
B = U2 V2T
Inverse transformation:
R = U’ V T
V = V1 V2
U’= U1 U2
Multiplication by Q A = U V TU = QU’
Accounts for most of the computational work

15
QR decomposition: A = QR
Multiplication by Q A = U V TU = QU’
Optimization of each part
Parts accelerated with the CSX600
LAPACK DGEBRD
LAPACK DORMBR
Integrable SVD
Reorganize the algorithms to use matrix multiplications
Accelerate the matrix multiplication with the
CSXL BLASParts executed on the host only
Bidiagonalization: R = U1 B V1T
Inverse transformation:
V = V1 V2
U’= U1 U2
SVD of thebidiagonal matrix:
B = U2 V2T
R = U’ V T

16
QR decomposition of A
Upper triangularization by Householder transformations
A(1)A
Hn ・・・ H2 H1 A = A(n)
・・・
A(2) A(n) = R
A = H1 H2 ・・・ Hn A(n) = QR
where,
H1 A = ( I – t1 y1 y1T ) A
= A(1)
level-2 BLAS
CSXL cannot be used
17
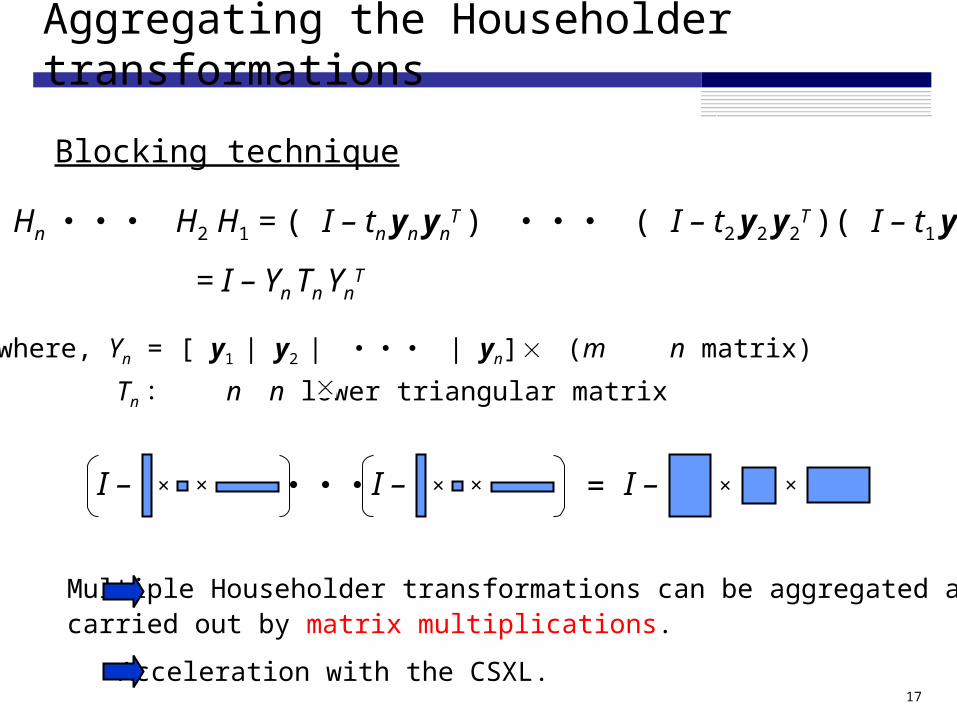
Aggregating the Householder transformations
Blocking technique
Hn ・・・ H2 H1 = ( I – tn yn ynT ) ・・・ ( I – t2 y2 y2
T )( I – t1 y1 y1T )
= I – Yn Tn YnT
where, Yn = [ y1 | y2 | ・・・ | yn] (m n matrix)
Tn : n n lower triangular matrix
× ×I – × ×I –・・・ × ×I –=
Multiple Householder transformations can be aggregated andcarried out by matrix multiplications.
Acceleration with the CSXL.

18
• Block QR requires the smallest amount of work, but some of the work is done with the level-2 BLAS. The size of matrix multiplication is rather small.
• Recursive QR requires the largest amount of work, but all in the level-3 BLAS. The size of matrix multiplication is large.
Blocking strategies for QR decomposition
Comparison of three blocking strategies
No.
Strategy QR decomposition Multiplication by Q
Level-2 work Level-3 work Size of matrix multiplication
Size of matrix multiplication
Non-blocked 2mn2 1 Block QR 2mnL 2mn(nL) L L
2 Recursive QR 3mn2 n/2 n
3 Extended recursive QR 2mn2 + mnL L L
L : blocking size. 1 L n/2.

19
Performance evaluation

20
Numerical experiments
• Xeon 3.2GHz, 8GB memory• Intel Fortran -O3 + Intel Math Kernel Library• ClearSpeed Advance board
Computational environments
• SVD of an m by n matrix whose elements are random numbers in [-0.5, 0.5]
• 10000 m 100000 , 1000 n 4000
Problem
• Performance comparison of the three QR decomposition algorithms on the ClearSpeed board
• Speedup effect of the whole SVD with the ClearSpeed board• Evaluation of accuracy
Experiments

21
Performance of three QR decomposition algorithms
0
200
400
600
800
1000
1200
1400
1600
1800
2000
500 1000 1500 2000
Multiplication by Q
QR decomposition
m =100000 n =4000
Com
puta
tion
al ti
me
(sec
)
Block QR Recursive QR Extended recursive QR

22
Performance of three QR decomposition algorithms
0
20
40
60
80
100
120
140
160
500 1000 1500 2000
Multiplication by Q
QR decomposition
m =10000 n =4000
Block QR Recursive QR Extended recursive QR
Com
puta
tion
al ti
me
(sec
)

23
0
5
10
15
20
25
PC PC+CSX PC PC+CSX
Totalmult. by QSVD of RQR decomp
0
500
1000
1500
2000
2500
3000
PC PC+CSX PC PC+CSX
LAPACK DGESDD
Our code LAPACK DGESDD
Our code
m = 10000 n=1000 (m:n = 10:1)
Speedup of the whole SVD with the CSX600
m = 100000 n=4000 (m:n = 25:1)
x 1.2
x 1.8
x 1.3
x 3.1
Com
puta
tion
al ti
me
(sec
) x 4

24
Speedup effect as a function of matrix size
0
1
2
3
4
5
4000 3000 2000 1000
10000
50000
100000
Spe
edup
m
n
Speedup = Time with the PC only / Time with the PC + CSX600
Our code with recursive QR

25
Evaluation of accuracy
1.00E-13
1.00E-12
1.00E-11
1.00E-10
10000 20000 30000 40000 10000 20000 30000 40000 10000 20000 30000
LAPACK
CS
||US
VT –
A|| F
||UTU
– I
||F
1.00E-13
1.00E-12
1.00E-11
1.00E-10
10000 20000 30000 40000 10000 20000 30000 40000 10000 20000 30000
Orthogonality of left singular vector Residual
m :n
:1000 2000 3000
m :n
:1000 2000 3000

26
Conclusion

27
Summary and future work
• We showed how to accelerate the rectangular SVD algorithm with the CSX600 floating-point accelerator.
• By modifying the algorithm to use large matrix multiplications, we obtained up to 4 times speedup over LAPACK code on the 3.2GHz Xeon.
• Further improve the performance by optimizing the bidiagonalization and inverse transformation parts.
• Performance evaluation on other accelerators such as the GRAPE-DR.
• Application to other matrix computations
Summary
Future work
Related Documents











