Gianmario Spacagna 14 th September, 2019 - Alluxio Meetup @ San Francisco, CA

Accelerating Machine Learning Pipelines with Alluxio at Alluxio Meetup 2016
Apr 16, 2017
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Gianmario Spacagna 14th September, 2019 - Alluxio Meetup @ San Francisco, CA

Takeaways
¨ What a logical data warehouse is ¨ How to handle governance issues ¨ An Agile workflow made of iterative exploratory
analysis and production-quality development ¨ A fully in-memory stack for fast computation on top
of Spark and Alluxio ¨ How to successfully do data science if your data
resides in a RDBMS and you don’t have a data lake

About me
¨ Engineering background in Distributed Systems ¤ (University of Cassino, Polytechnic of Turin, KTH of Stockholm)
¨ Data-relevant experience ¤ Predictive Marketing (AgilOne, StreamSend)
¤ Cyber Security (Cisco)
¤ Financial Services (Barclays)
¤ Automotive (Pirelli) ç

Areas of interest
¨ Functional Programming, Scala and Apache Spark
¨ Contributor of the Professional Data Science Manifesto
¨ Founder of Data Science Milan Meetup community (datasciencemilan.org)
¨ Co-authoring Python Deep Learning book, coming soon…
Building production-ready and scalable machine learning systems
(continue with list of principles...)

Data Science Agile cycle Get
access to data
Explore
Transform Train
Evaluate
Analyze results
Even dozens of iterations per
day!!!

Successful development of new data products
requires proper infrastructure and tools

Start by building a toy model with a small snapshot of data that can fit in your laptop
memory and eventually ask your organization for cluster resources

¨ You can’t solve problems with data science if data is not largely available
¨ Data processing should be fast and reactive to allow quick iterations
¨ The core team cannot depend on IT folks
Start by building a toy model with a small snapshot of data that can fit in your laptop
memory and eventually ask your organization for cluster resources

Data Lake in a legacy enterprise environment

Technical issues ¨ Engineering effort
¤ dedicated infrastructure team (expensive) ¨ Synchronization with new data from source
¤ Report what portion of data has been exported and what not
¨ Consistency / Data Versioning / Duplication ¤ ETL logic and requirements change very often ¤ Memory is cheap but when you have hundreds of sparse
copies of same data is confusing ¨ I/O cost
¤ Reading/writing is expensive for iterative and explorative jobs (machine learning)

Logical Data Warehouse
¨ View and access cleaned versions of data ¨ Always show latest version by default ¨ Apply transformations on-the-fly
(discovery-oriented analytics) ¨ Abstract data representation from rigid structures
of the DB’s persistence store ¨ Simply add new data sources using virtualization ¨ Flexible, fast time-to-market, lower costs

What about governance issues?
¨ Large corporations can’t move data before an approved governance plan
¨ Data can only be stored in a safe environment administered by only a few authorized people who don’t necessary understand data scientists needs
¨ Data leakage paranoia, cloud-phobia! ¨ As result, data cannot be easily/quickly pulled from the
central data warehouse and stored into an external infrastructure

Long time and large investment for setting up a new project
That’s not Agile!

Wait a moment, analysts don’t seem to have this problem…

From disk to volatile memory
Distribute and make data temporary available in-memory in an ad-hoc development cluster

¨ In-memory engine for distributed data processing ¨ JDBC drivers to connect to relational databases ¨ Structured data represented using DataFrame API ¨ Fully-functional data manipulation via RDD API ¨ Machine learning libraries (ML/MLllib) ¨ Interaction and visualization through
Spark Notebook or Zeppelin

In-memory workflow

Just Spark cache is not enough ¨ Data is dropped from memory
at each context restart due to ¤ Update dependency jar
(common for mixed IDE development / notebook analysis)
¤ Re-submit the job execution
¤ Kerberos ticket expires L
¨ Fetching 600M rows can take ~ 1 hour in a 5 nodes cluster
Dozens iterations per day => spending most of the time waiting for data to reload at each iteration!

Distribute and make data temporary persistently available in-memory in the development cluster and
shared among multiple concurrent applications
From volatile memory to persistent memory storage

¨ Formerly known as Tachyon ¨ In-memory distributed storage system ¨ Long-term caching of raw data and intermediate
results ¨ Spark can read/write in Alluxio seamlessly instead
of using HDFS ¨ 1-tier configuration safely leaves no traces to disk ¨ Data is loaded once and available for the whole
development period to multiple applications
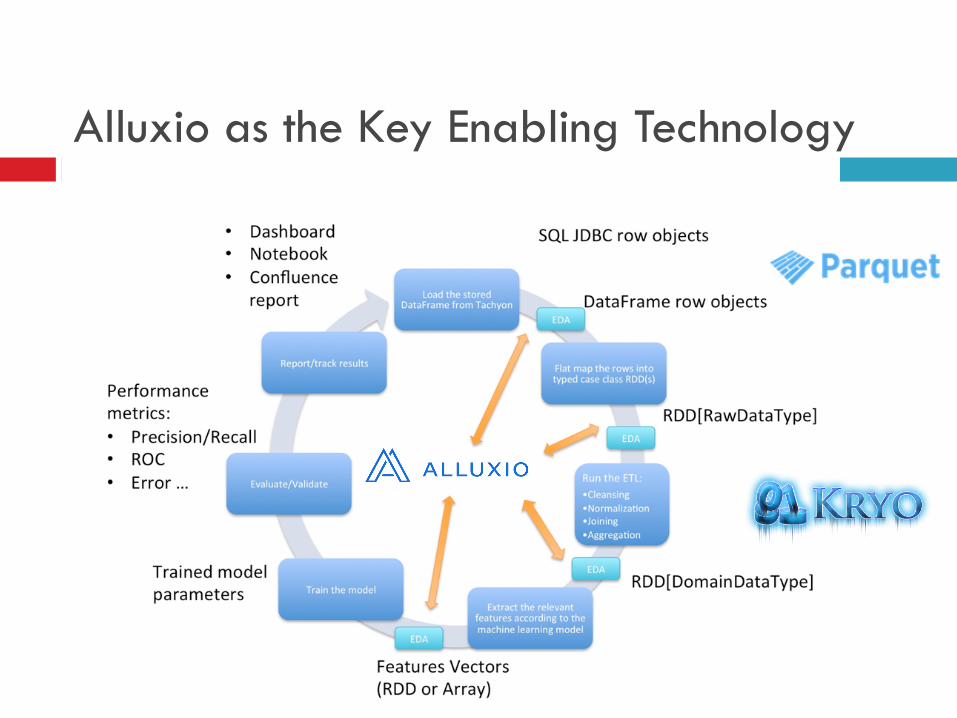
Alluxio as the Key Enabling Technology


1-tier configuration
¨ ALLUXIO_RAM_FOLDER=/dev/shm/ramdisk ¨ alluxio.worker.memory.size=24GB ¨ alluxio.worker.tieredstore
¤ levels=1 ¤ level0.alias=MEM ¤ level0.dirs.path=${ALLUXIO_RAM_FOLDER} ¤ level0.dirs.quota=24G
¨ We leave empty the under FS configuration ¨ Deploy without mount (no root access required)
¤ ./bin/alluxio-start.sh all NoMount

Spark read/write APIs
¨ DataFrame ¤ dataframe.write.save(”alluxio://master_ip:port/mydata/
mydataframe.parquet") ¤ val dataframe: DataFrame = sqlContext.read.load(”alluxio://
master_ip:port/mydata/mydataframe.parquet")
¨ RDD ¤ rdd.saveAsObjectFile(”alluxio://master_ip:port/mydata/myrdd.object")
¤ val rdd: RDD[MyCaseClass] = sc.objectFile[MyCaseClass] (”alluxio://master_ip:port/mydata/myrdd.object")

Making the impossible possible
¨ Agile workflow combining Spark, Scala, DataFrame, JDBC, Parquet, Kryo and Alluxio to create a scalable, in-memory, reactive stack to explore data directly from source and develop production-quality machine learning pipelines
¨ Data available since day 1 and at every iteration ¤ Alluxio decreased loading time from hours to seconds
¨ Avoid complicated and time-consuming Data Plumbing operations

Further developments 1. Memory size limitation
¤ Add external in-memory tiers? 2. Set-up overhead
¤ JDBC drivers, partitioning strategy and data frame from/to case class conversion (Spark 2 aims to solve this)
3. Shared memory resources between Spark and Alluxio ¤ Set Alluxio as OFF_HEAP memory as well and divide memory in
storage and cache 4. In-Memory replication for read availability
¤ If an Alluxio node fails, data is lost due the absence of an underlying file system
5. Would be nice if Alluxio could handle this and mount a relational table/view in the form of data files (csv, parquet…)

Follow-up links ¨ Original article on DZone:
¤ dzone.com/articles/Accelerate-In-Memory-Processing-with-Spark-from-Hours-to-Seconds-With-Tachyon
¨ Professional Data Science Manifesto: ¤ datasciencemanifesto.org
¨ Vademecum of Practical Data Science: ¤ datasciencevademecum.wordpress.com
¨ Sparkz ¤ github.com/gm-spacagna/sparkz
Related Documents











