Slide 1 A Problem from the Research Literature In this exercise, we will work an example of logistic regression as found in the literature: Sandra L. Hanson and Douglas M. Sloane, "Young Children and Job Satisfaction." Journal of Marriage and the Family, 54 (November, 1992), 799-811. The data for this problem is: YoungChildrenJobSatisfaction.Sav. Young Children and Job Satisfaction

A Problem from the Research Literature
Jan 04, 2016
A Problem from the Research Literature. In this exercise, we will work an example of logistic regression as found in the literature: Sandra L. Hanson and Douglas M. Sloane, "Young Children and Job Satisfaction." Journal of Marriage and the Family , 54 (November, 1992), 799-811. - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Slide 1
A Problem from the Research Literature
In this exercise, we will work an example of logistic regression as found in the literature: Sandra L. Hanson and Douglas M. Sloane, "Young Children and Job Satisfaction." Journal of Marriage and the Family, 54 (November, 1992), 799-811.
The data for this problem is: YoungChildrenJobSatisfaction.Sav.
Young Children and Job Satisfaction

Slide 2
Stage One: Define the Research Problem
In this stage, the following issues are addressed:
•Relationship to be analyzed•Specifying the dependent and independent variables•Method for including independent variables
Young Children and Job Satisfaction
Relationship to be analyzed
"We are interested in examining the effect of young children on the job satisfaction of men and women involved in a variety of work and family roles to see how the presence of family responsibilities affects their happiness at work. The research is comparative. It involves contrasts between men and women in different work and marital statuses as several points in time." (page 800)

Slide 3
Specifying the dependent and independent variables
The dependent variable is job satisfaction, measured on a four category Likert-scale: 1=Very Satisfied, 2=Moderately Satisfied, 3=A Little Dissatisfied, and 4=Very Dissatisfied. Because the data does not follow a normal distribution (See page 803-804), the authors’ recoded the variable to a dichotomous variable where 1 = Very Satisfied and 0 = Moderately Satisfied to Very Dissatisfied. The purpose of the analysis, then, is to determine what factors contribute to a high level of job satisfaction versus some other level of job satisfaction. With a dichotomous dependent variable, logistic regression becomes the analytic techniques of choice.
The independent variables are grouped into two categories:
1. Individual and family characteristics (age, race, education, spouse's work status, prestige of spouse's occupation, number of children, presence of young children, general happiness, and satisfaction with family)
2. Job characteristics (income, job prestige, job authority, job autonomy, convenience (number of hours worked per week), and past work experience).
The variable presence of young children is important to answering the main question of the article.
Other variables, which could have been included as independent variables, were used to divide the sample into subgroups which were compared with each other to answer the research questions. For example, Sex and Work Status were combined to form a composite variable WORK_SEX. We will use these variables with the SPSS "Select Cases” command to produce the results for different groups.
Young Children and Job Satisfaction

Slide 4
Method for including independent variables
With a dichotomous dependent variable and a variety of independent variables, the statistical technique to use is logistic regression. While we could structure the analysis to do hierarchical entry of variables (individual, family characteristics, and job characteristics in block 1 and the presence of young children in block 2), we will use direct entry of all variables on a single step to conform to the authors’ analysis.
Young Children and Job Satisfaction

Slide 5
Stage 2: Develop the Analysis Plan: Sample Size Issues
In this stage, the following issues are addressed:
•Missing data analysis•Minimum sample size requirement: 15-20 cases per independent variable
Young Children and Job Satisfaction

Slide 6
Missing data analysis
In the missing data analysis, we are looking for a pattern or process whereby the pattern of missing data could influence the results of the statistical analysis.
The data set for this problem is used for a large number of analyses in the article. Not all variables and cases are used in each analysis, so it makes sense to conduct the missing data analysis on the cases and variables to be included in the problem in this exercise.
We will compute the logistic regression model for 1976-77 married, full-time males as presented in table 2 on page 807. (Note: this analysis does not include the independent variables SPOCCUP 'Spouses Occupation' and EVWORK 'Ever Work as Long as One Year').
First, we will exclude the cases not used in this exercise and then we will examine missing data for the variables used in this exercise.
Young Children and Job Satisfaction

Slide 7
Specify the Cases to Include in this Analysis
Young Children and Job Satisfaction

Slide 8
Enter the Selection Criterion
Young Children and Job Satisfaction

Slide 9
Run the MissingDataCheck Script
Young Children and Job Satisfaction

Slide 10
Complete the 'Check for Missing Data' Dialog Box
Young Children and Job Satisfaction
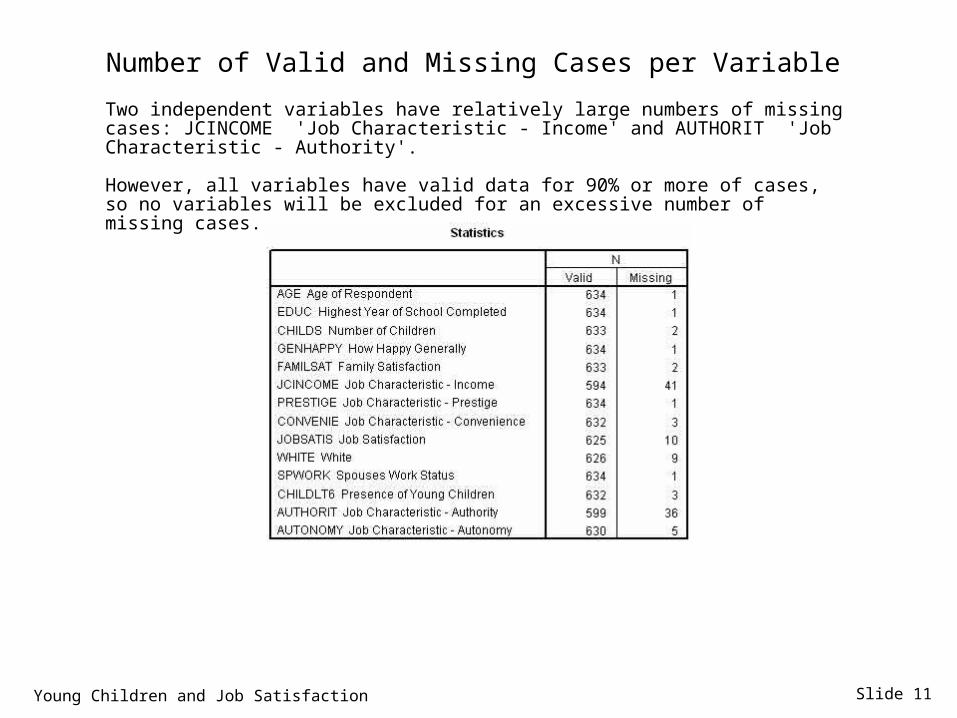
Slide 11
Number of Valid and Missing Cases per Variable
Two independent variables have relatively large numbers of missing cases: JCINCOME 'Job Characteristic - Income' and AUTHORIT 'Job Characteristic - Authority'.
However, all variables have valid data for 90% or more of cases, so no variables will be excluded for an excessive number of missing cases.
Young Children and Job Satisfaction

Slide 12
Frequency of Cases that are Missing Variables
Next, we examine the number of missing variables per case. Of the possible 14 variables in the analysis (13 independent variables and 1 dependent variable), one cases was missing half of the variables (7) and should be excluded from the remaining analyses.
Young Children and Job Satisfaction
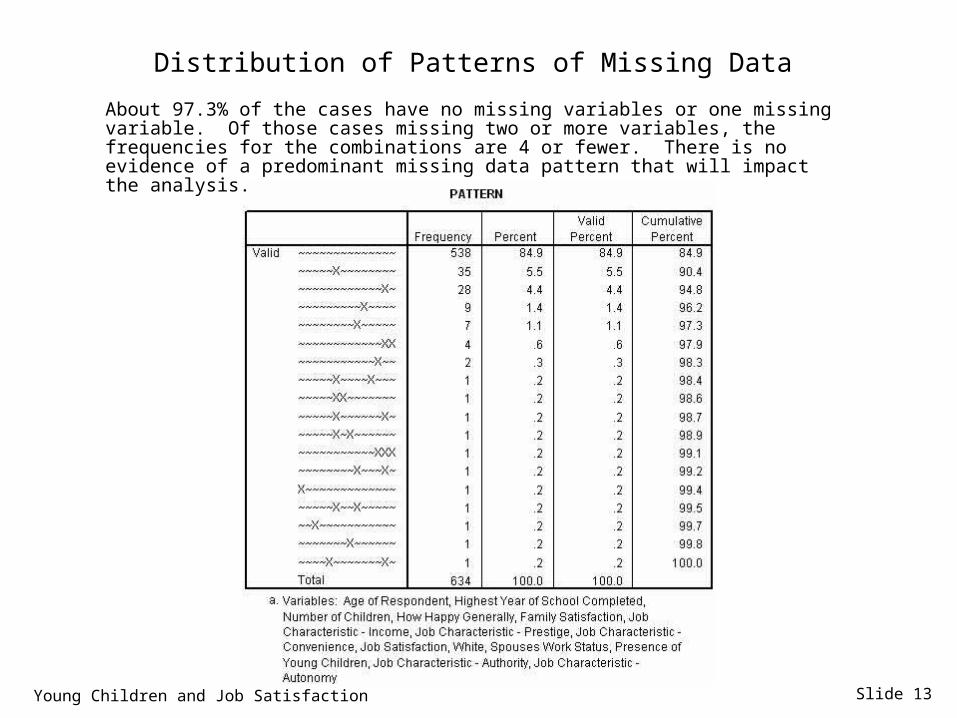
Slide 13
Distribution of Patterns of Missing Data
About 97.3% of the cases have no missing variables or one missing variable. Of those cases missing two or more variables, the frequencies for the combinations are 4 or fewer. There is no evidence of a predominant missing data pattern that will impact the analysis.
Young Children and Job Satisfaction

Slide 14
Correlation Matrix of Valid/Missing Dichotomous Variables
The largest correlation in the matrix of valid/missing data (not shown) is 0.363. None of the correlations for missing data values are above the weak level, so we can delete missing cases without fear that we are distorting the solution.
Young Children and Job Satisfaction

Slide 15
Minimum sample size requirement:15-20 cases per independent variable
If we accept the SPSS default of listwise deletion of missing data, we will have 538 cases in the analysis. The ratio of cases to independent variables is 538/13 or 41 to 1. We meet this requirement.
Young Children and Job Satisfaction

Slide 16
Stage 2: Develop the Analysis Plan: Measurement Issues:
In this stage, the following issues are addressed:
•Incorporating nonmetric data with dummy variables•Representing Curvilinear Effects with Polynomials•Representing Interaction or Moderator Effects
Young Children and Job Satisfaction
Incorporating Nonmetric Data with Dummy Variables
All of the nonmetric variables have recoded into dichotomous dummy-coded variables.
Representing Curvilinear Effects with Polynomials
We do not have any evidence of curvilinear effects at this point in the analysis.
Representing Interaction or Moderator Effects
We do not have any evidence at this point in the analysis that we should add interaction or moderator variables.

Slide 17
Stage 3: Evaluate Underlying Assumptions
In this stage, the following issues are addressed:
•Nonmetric dependent variable with two groups•Metric or dummy-coded independent variables
Young Children and Job Satisfaction
Nonmetric dependent variable having two groups
The dependent variable 'Job satisfaction' was recoded into dichotomous categories.
Metric or dummy-coded independent variables
Marital status, race, spouse's work status, presence of young children, job authority, job autonomy, and ever worked as long as one year are all coded as dichotomous variables.
Age of respondent, highest year of school completed, prestige of spouse's occupation, number or children, general happiness, satisfaction with family, income, job prestige, hours worked (convenience), and year of the survey can be treated as metric variables.

Slide 18
Stage 4: Estimation of Logistic Regression and Assessing Overall Fit: Model Estimation
In this stage, the following issues are addressed:
•Compute logistic regression model
Young Children and Job Satisfaction
Compute the logistic regression
The steps to obtain a logistic regression analysis are detailed on the following screens.
If the cases to be included in this analysis were not selected in the missing data analysis, the selection needs to be completed before proceeding.

Slide 19
Requesting a Logistic Regression
Young Children and Job Satisfaction

Slide 20
Specifying the Dependent Variable
Young Children and Job Satisfaction

Slide 21
Specifying the Independent Variables
Young Children and Job Satisfaction

Slide 22
Specify the method for entering variables
Young Children and Job Satisfaction

Slide 23
Specifying Options to Include in the Output
Young Children and Job Satisfaction

Slide 24
Specifying the New Variables to Save
Young Children and Job Satisfaction

Slide 25
Complete the Logistic Regression Request
Young Children and Job Satisfaction

Slide 26
Stage 4: Estimation of Logistic Regression and Assessing Overall Fit: Assessing Model Fit
In this stage, the following issues are addressed:
•Significance test of the model log likelihood (Change in -2LL)•Measures Analogous to R²: Cox and Snell R² and Nagelkerke R²•Hosmer-Lemeshow Goodness-of-fit•Classification matrices•Check for Numerical Problems•Presence of outliers
Young Children and Job Satisfaction

Slide 27
Initial statistics before independent variables are included
The Initial Log Likelihood Function, (-2 Log Likelihood or -2LL) is a statistical measure like total sums of squares in regression. If our independent variables have a relationship to the dependent variable, we will improve our ability to predict the dependent variable accurately, and the log likelihood value will decrease. The initial –2LL value is 742.850 on step 0, before any variables have been added to the model.
Young Children and Job Satisfaction

Slide 28
Significance test of the model log likelihood
The difference between these two measures is the model child-square value (57.153 = 742.850 – 685.697) that is tested for statistical significance. This test is analogous to the F-test for R² or change in R² value in multiple regression which tests whether or not the improvement in the model associated with the additional variables is statistically significant.
In this problem the model Chi-Square value of 57.153 has a significance of 0.000, less than 0.05, so we conclude that there is a significant relationship between the dependent variable and the set of independent variables.
Young Children and Job Satisfaction

Slide 29
Measures Analogous to R²
The next SPSS outputs indicate the strength of the relationship between the dependent variable and the independent variables, analogous to the R² measures in multiple regression.
The Cox and Snell R² measure operates like R², with higher values indicating greater model fit. However, this measure is limited in that it cannot reach the maximum value of 1, so Nagelkerke proposed a modification that had the range from 0 to 1. We will rely upon Nagelkerke's measure as indicating the strength of the relationship.
Based on the interpretive criteria, we would characterize this model as weak.
Young Children and Job Satisfaction

Slide 30
Correspondence of Actual and Predicted Values of the Dependent Variable
The final measure of model fit is the Hosmer and Lemeshow goodness-of-fit statistic, which measures the correspondence between the actual and predicted values of the dependent variable. In this case, better model fit is indicated by a smaller difference in the observed and predicted classification. A good model fit is indicated by a nonsignificant chi-square value.
The goodness-of-fit measure has a value of 5.678 which has the desirable outcome of nonsignificance.
Young Children and Job Satisfaction

Slide 31
The Classification Matrices
The classification matrices in logistic regression serve the same function as the classification matrices in Young Children and Job Satisfaction, i.e. evaluating the accuracy of the model.
To evaluate the accuracy of the model, we compute the proportional by chance accuracy rate and the maximum by chance accuracy rates, if appropriate. Since the sizes of the groups in this problem are equal to 46% and 54%, the proportional accuracy criterion is appropriate because we do not have a dominant group.
The proportional by chance accuracy rate is equal to 0.503 (0.463^2 + 0.537^2). A 25% increase over the by chance accuracy rate would equal 0.628.
Our model accuracy race of 63.2% meets this criterion.
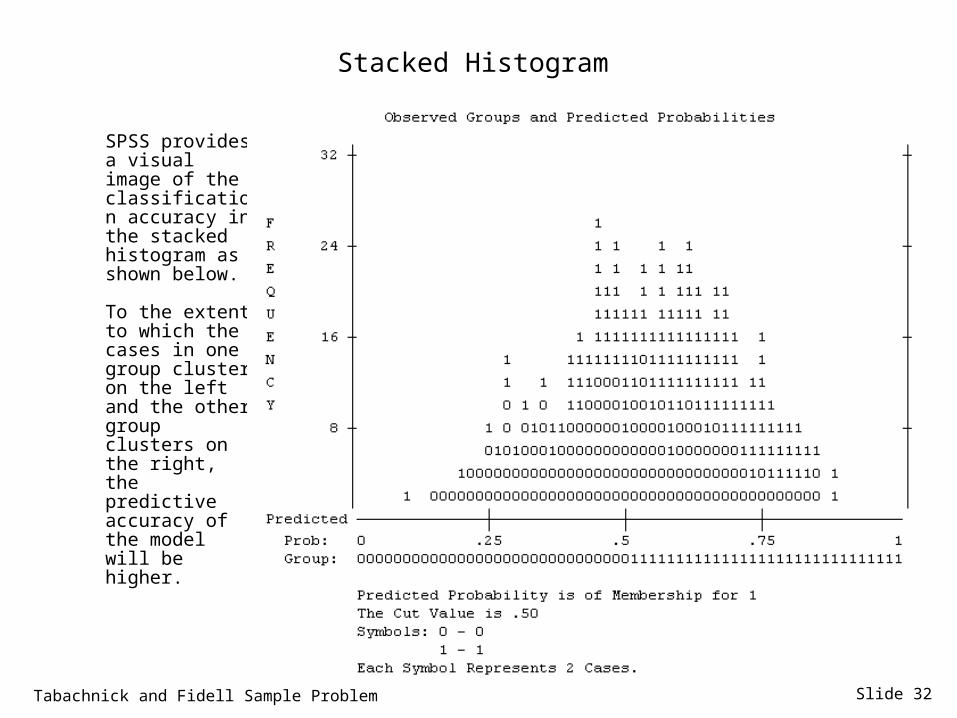
Slide 32
Stacked Histogram
SPSS provides a visual image of the classification accuracy in the stacked histogram as shown below.
To the extent to which the cases in one group cluster on the left and the other group clusters on the right, the predictive accuracy of the model will be higher.
Tabachnick and Fidell Sample Problem
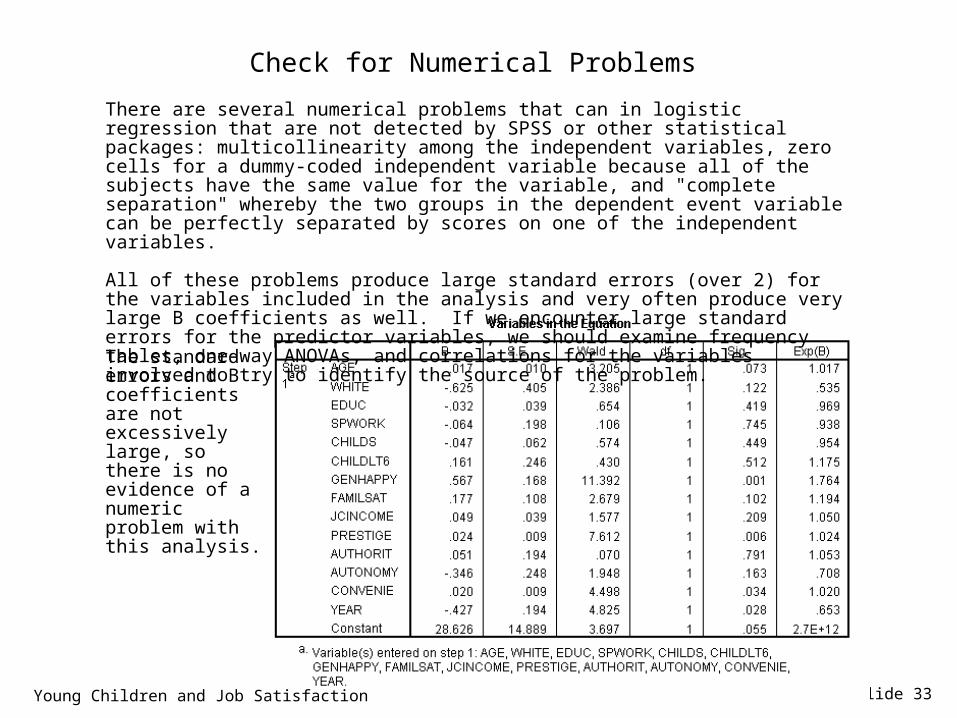
Slide 33
Check for Numerical Problems
There are several numerical problems that can in logistic regression that are not detected by SPSS or other statistical packages: multicollinearity among the independent variables, zero cells for a dummy-coded independent variable because all of the subjects have the same value for the variable, and "complete separation" whereby the two groups in the dependent event variable can be perfectly separated by scores on one of the independent variables.
All of these problems produce large standard errors (over 2) for the variables included in the analysis and very often produce very large B coefficients as well. If we encounter large standard errors for the predictor variables, we should examine frequency tables, one-way ANOVAs, and correlations for the variables involved to try to identify the source of the problem.The standard errors and B coefficients are not excessively large, so there is no evidence of a numeric problem with this analysis.
Young Children and Job Satisfaction

Slide 34
There are two outputs to alert us to outliers that we might consider excluding from the analysis: listing of residuals and saving Cook's distance scores to the data set.
SPSS provides a casewise list of residuals that identify cases whose residual is above or below a certain number of standard deviation units. Like multiple regression there are a variety of ways to compute the residual. In logistic regression, the residual is the difference between the observed probability of the dependent variable event and the predicted probability based on the model. The standardized residual is the residual divided by an estimate of its standard deviation. The deviance is calculated by taking the square root of -2 x the log of the predicted probability for the observed group and attaching a negative sign if the event did not occur for that case. Large values for deviance indicate that the model does not fit the case well. The studentized residual for a case is the change in the model deviance if the case is excluded. Discrepancies between the deviance and the studentized residual may identify unusual cases. (See the SPSS chapter on Logistic Regression Analysis for additional details).
In the output for our problem, SPSS listed one cases that have may be considered an outlier with a studentized residuals greater than 2:
Presence of outliers
Young Children and Job Satisfaction

Slide 35
Cook’s Distance
SPSS has an option to compute Cook's distance as a measure of influential cases and add the score to the data editor. I am not aware of a precise formula for determining what cutoff value should be used, so we will rely on the more traditional method for interpreting Cook's distance which is to identify cases that either have a score of 1.0 or higher, or cases which have a Cook's distance substantially different from the other. The prescribed method for detecting unusually large Cook's distance scores is to create a scatterplot of Cook's distance scores versus case id.
SPSS Sample Problem

Slide 36
Request the Scatterplot
Young Children and Job Satisfaction

Slide 37
Specifying the Variables for the Scatterplot
Young Children and Job Satisfaction

Slide 38
The Scatterplot of Cook's Distances
Horizontal gridlines were added to the scatterplot to aid interpretation. Based on the gridlines, we can identify four cases with Cook's distances about 0.175 as influential cases.
After sorting the data set by the Cook's distance variable, we identify the four cases as having id numbers: 99, 1807, 1833, and 1953. None of these cases were included on the casewise listing for large studentized residuals.
Based on these outputs, we identify five cases out of 538 that are potential outliers. Since the number of outliers represents less than 1% of the sample and none of the outliers are really extreme, I will opt to retain them in the analysis.
Young Children and Job Satisfaction

Slide 39
Stage 5: Interpret the Results
In this section, we address the following issues:
•Identifying the statistically significant predictor variables•Direction of relationship and contribution to dependent variable
Young Children and Job Satisfaction
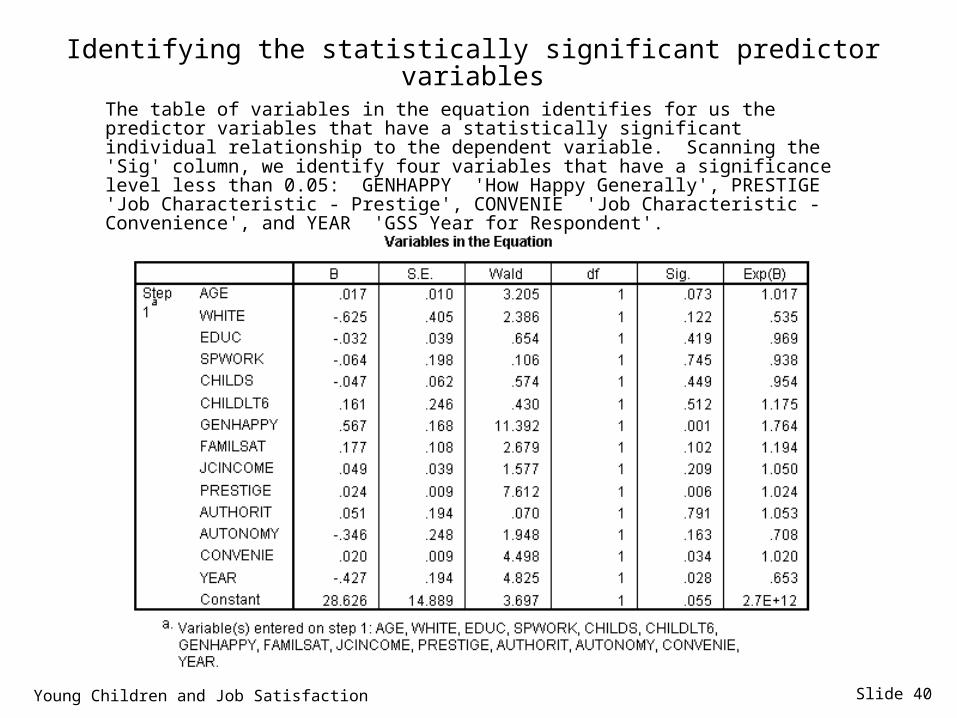
Slide 40
Identifying the statistically significant predictor variables
The table of variables in the equation identifies for us the predictor variables that have a statistically significant individual relationship to the dependent variable. Scanning the 'Sig' column, we identify four variables that have a significance level less than 0.05: GENHAPPY 'How Happy Generally', PRESTIGE 'Job Characteristic - Prestige', CONVENIE 'Job Characteristic - Convenience', and YEAR 'GSS Year for Respondent'.
Young Children and Job Satisfaction

Slide 41
Direction of relationship and contribution to dependent variable - 1
The sign of the B coefficients indicates whether the predictor variable increased or decreased the likelihood of belonging to the group of respondents who were very satisfied with their jobs.
Young Children and Job Satisfaction

Slide 42
Direction of relationship and contribution to dependent variable - 2
The coefficient signs for the variables GENHAPPY 'How Happy Generally', PRESTIGE 'Job Characteristic - Prestige', and CONVENIE 'Job Characteristic - Convenience' were all positive, indicating that a higher score on these variables enhanced the likelihood of belonging to the group that was very satisfied with their jobs. The coefficient for YEAR was negative, indicating that job satisfaction has been declining in later years of the survey.
The magnitude of change associated with each independent variable is given in the odds ratio column labeled 'Exp (B)'. This column indicates the increased or decreased odds of belonging to the group that was very satisfied with their jobs.
For each unit increment on the measure of overall happiness, a respondent was 1.76 times more likely to be very satisfied with his or her job. For each unit increment in job prestige, a subject was 1.02 times as likely to be very satisfied with his or her job. For each unit increment in job convenience (or hours worked), a subject was 1.02 times as likely to be very satisfied with his or her job. Finally, for each increase in year, a subject was 0.65 times as likely to be very satisfied with his or her job, i.e. was less likely to be satisfied.
Important to the research question raised by the authors is the finding that CHILDLT6 'Presence of Young Children' did not have a statistically significant impact on job satisfaction.
Young Children and Job Satisfaction

Slide 43
Stage 6: Validate The Model
In this stage, we are normally concerned with the following issues"
•Creating the Selection Variable•Computing the Split-half Analysis•The Output for the Validation Analysis
Young Children and Job Satisfaction
Conducting the Validation Analysis
To validate the logistic regression, we can randomly divide our sample into two groups, a screening sample and a validation sample. The analysis is computed for the screening sample and used to predict membership on the dependent variable in the validation sample. If the model in the screening sample is valid, we would expect that the accuracy rates for both samples to be about the same.
In the double cross- validation strategy, we reverse the designation of the screening and validation sample and re-run the analysis. We can then compare the significant independent variables found for both screening samples. If the two screening analyses contain a very different set of significant variables, it indicates that the variables might have achieved significance because of the sample size and not because of the strength of the relationship. Our findings about these individual variables would that the predictive utility of these variables is not generalizable.

Slide 44
Set the Starting Point for Random Number Generation
Young Children and Job Satisfaction

Slide 45
Compute the Variable to Randomly Split the Sample into Two Halves
Young Children and Job Satisfaction

Slide 46
Specify the Cases to Include in the First Screening Sample
Young Children and Job Satisfaction

Slide 47
Specify the Value of the Selection Variable for the First Validation Analysis
First, click on the 'Select>>" button to expose the 'Selection Variable:' text box.
Young Children and Job Satisfaction

Slide 48
Specify the Value of the Selection Variable for the Second Validation Analysis
Young Children and Job Satisfaction

Slide 49
Generalizability of the Logistic Regression Model
Only one predictor variable, CONVENIE 'Job Characteristic - Convenience, has a stable, statistically significant relationship to the dependent variable, Job Satisfaction. In addition, the accuracy that we should evaluate in assessing our model is in the 56% to 59% range rather than in the 63% to 72% range. At this accuracy rate, the model does not represent a 25% increase over the proportional by chance accuracy rate.
In sum, we do find a relationship between one of the independent variables and job satisfaction. Our findings should be regarded as tentative or exploratory rather than definitive because we would not meet the classification accuracy rate required for a usable model.
Tabachnick and Fidell Sample Problem
Full Model Split=0 Split=1
Model Chi-Square 57.153, p=.0000 54.386, p<.0001 28.867, p=.0109
Nagelkerke R2 .135 .246 .136
Accuracy Rate forLearning ample
63.20% 72.12% 65.80%
Accuracy Rate for Validation Sample
56.51% 59.85%
Significant Coefficients (p < 0.05)
GENHAPPY 'How Happy Generally'
PRESTIGE 'Job Characteristic - Prestige'
CONVENIE 'Job Characteristic - Convenience'
YEAR 'GSS Year for Respondent'
GENHAPPY 'How Happy Generally'
PRESTIGE 'Job Characteristic - Prestige'
CONVENIE 'Job Characteristic - Convenience'
FAMILSAT 'Family Satisfaction'
CONVENIE 'Job Characteristic - Convenience'
YEAR 'GSS Year for Respondent'
JCINCOME 'Job Characteristic - Income'
Related Documents











