A PRIVACY ENHANCED SITUATION-AWARE MIDDLEWARE FRAMEWORK FOR UBIQUITOUS COMPUTING ENVIRONMENTS by GAUTHAM V. PALLAPA Presented to the Faculty of the Graduate School of The University of Texas at Arlington in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY THE UNIVERSITY OF TEXAS AT ARLINGTON December 2009

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A PRIVACY ENHANCED SITUATION-AWARE MIDDLEWARE FRAMEWORK
FOR UBIQUITOUS COMPUTING ENVIRONMENTS
by
GAUTHAM V. PALLAPA
Presented to the Faculty of the Graduate School of
The University of Texas at Arlington in Partial Fulfillment
of the Requirements
for the Degree of
DOCTOR OF PHILOSOPHY
THE UNIVERSITY OF TEXAS AT ARLINGTON
December 2009

Copyright c© by GAUTHAM V. PALLAPA 2009
All Rights Reserved

Dedicated to my mother.
She was always supportive, loving, and a pillar of strength.

ACKNOWLEDGEMENTS
I am indebted to my advisor Prof. Sajal K. Das who has been amazingly
patient, helpful, and supportive during my research. He introduced me to the field
of Ubiquitous computing, guided me throughout my graduate work, and constantly
motivated and encouraged me to perform high quality research. I would also like to
thank Prof. Kalyan Basu, Prof. Yonghe Liu, Prof. Mohan Kumar, Prof. Gautam
Das and Prof. Nan Zhang, for their comments and suggestions regarding my work in
Ubiquitous computing.
I take this opportunity to thank all my friends and colleagues at the Center
for Research in Wireless Mobility and Networking (CReWMaN) for their valuable
discussions and support. I would like to acknowledge the Department of CSE, UT
Arlington, for providing me Teaching Assistantship, STEM Doctoral Fellowship, Her-
mann’s Fellowship, and an opportunity to teach undergraduate students during my
stay here. I would also like to acknowledge my previous institutions R. V. College of
Engineering (Bangalore), India, and Jawaharlal Nehru University, (New Delhi), India,
and offer my sincere regards to all my teachers and professors in these institutions.
I would like to thank my parents who have inspired and supported me through-
out my life. I am grateful to my father for his constant encouragement and support,
and for having ingrained a drive for research in me. Finally, I would like to thank my
wife Rama, who had to endure my long working hours, and has always supported me
emotionally throughout my doctoral studies.
December 3, 2009
iv

ABSTRACT
A PRIVACY ENHANCED SITUATION-AWARE MIDDLEWARE FRAMEWORK
FOR UBIQUITOUS COMPUTING ENVIRONMENTS
GAUTHAM V. PALLAPA, Ph.D.
The University of Texas at Arlington, 2009
Supervising Professor: Sajal K. Das
The Ubiquitous Computing paradigm integrates myriads of small, inexpensive,
heterogeneous networked devices, including sensors, distributed throughout the en-
vironment, with the intent of enabling context awareness in systems deployed to
monitor the environment. This is accomplished by monitoring events, such as ac-
cess, or utilization of resources, and obtaining knowledge about user activities, and
interactions with other entities in the environment. Existing context-aware systems
predominantly encapsulate the occurred activities either by using Event-Condition-
Action rules, where an instance of the event performs as a trigger, or by prediction
mechanisms, such as Dynamic Bayesian Networks, which compute decisions, based
on the information obtained. However, these approaches are constrained by compu-
tational overheads, rule complexities, and potential loss of information, introduced
by deconstructing activities. This emphasizes the need for a “natural interaction”
paradigm involving the input from the user and the environment in a cooperative
manner, making it imperative to understand the potential relationship between ac-
tivity and the embedded context information. In this dissertation, user activity is
v

described by a finite number of states called situations, characterized by interaction
with other entities or devices in the environment. The information perceived from
these situations enable systems deployed in the environment to monitor interactions,
and develop dynamic rules customized to the user. Deploying such systems on a sig-
nificant scale, however, introduces the additional challenge of protecting information
among users, thereby accentuating the need for robust privacy management.
This dissertation focuses on the challenges of situation perception, user privacy,
and human-computer interaction through ubiquitous middleware. We investigate the
limitations of deconstructing context to capture information required to describe sit-
uations. We discuss our approach to understand user interactions as situations, by
introducing the concept of situation trees, built by parsing the sequence of contexts
and device information obtained from the monitored environment. We then present
our scheme to build the vocabulary and situation grammar from the situation trees,
which facilitates behavior-specific dynamic rule generation, and demonstrate the po-
tential of our scheme for efficient decision making. This dissertation also looks at
the conundrum of privacy, and we have devised various approaches to quantify user
privacy in ubiquitous computing environment. We compare these approaches in var-
ious scenarios, and present our experimental results and findings. We finally present
the design of our ubiquitous middleware framework to support the perception, mod-
eling, rule generation, and privacy management of user interactions, and examine
the effectiveness of our framework in an assisted environment. The experimental re-
sults presented in this dissertation substantiate the effectiveness of our approach to
situation perception and privacy quantization.
vi

TABLE OF CONTENTS
ACKNOWLEDGEMENTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . iv
ABSTRACT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v
LIST OF FIGURES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xi
LIST OF TABLES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiii
Chapter Page
1. INTRODUCTION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Ubiquitous Computing . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Context Awareness and Situation Modeling . . . . . . . . . . . . . . 5
1.3 Challenges in Context-aware Computing . . . . . . . . . . . . . . . . 6
1.4 Ubiquitous Middleware . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.5 Contributions of the dissertation . . . . . . . . . . . . . . . . . . . . . 9
1.6 Organization of the dissertation . . . . . . . . . . . . . . . . . . . . . 13
2. BACKGROUND AND RELATED WORK . . . . . . . . . . . . . . . . . . 16
2.1 Ubiquitous Computing . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2 Context in Ubiquitous Computing . . . . . . . . . . . . . . . . . . . . 18
2.2.1 Context-aware Ubiquitous Computing . . . . . . . . . . . . . 18
2.2.2 Existing Ontological Approaches . . . . . . . . . . . . . . . . 20
2.2.3 Situation Grammar . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3 Privacy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3.1 User Privacy . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.4 Middleware frameworks for Ubiquitous environments . . . . . . . . . 24
2.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
vii

3. CONTEXT IN UBIQUITOUS COMPUTING . . . . . . . . . . . . . . . . 27
3.1 Perceiving Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2 Classification of Context . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2.1 Types of User Context . . . . . . . . . . . . . . . . . . . . . . 31
3.3 Capturing context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.3.1 Event - Condition - Action rules . . . . . . . . . . . . . . . . . 34
3.3.2 Limitations of ECA rules . . . . . . . . . . . . . . . . . . . . . 36
3.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4. PERCEPTION OF SITUATIONS . . . . . . . . . . . . . . . . . . . . . . 39
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.2 Motivating scenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.3 Perceiving Situation . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.3.1 Capturing action . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.3.2 Initial Configuration . . . . . . . . . . . . . . . . . . . . . . . 44
4.3.3 Building the Situation tree . . . . . . . . . . . . . . . . . . . . 46
4.3.4 Designing complex rules . . . . . . . . . . . . . . . . . . . . . 47
4.4 Generating Situation Grammar . . . . . . . . . . . . . . . . . . . . . 49
4.4.1 Formulating Initial Grammar . . . . . . . . . . . . . . . . . . 50
4.4.2 Specifying Detailed Grammar . . . . . . . . . . . . . . . . . . 51
4.4.3 Assigning probabilities . . . . . . . . . . . . . . . . . . . . . . 54
4.5 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.6 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5. USER PRIVACY . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.2 Motivating scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
viii

5.2.1 Scenario 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.2.2 Scenario 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.3 Our Approaches to Quantization of Privacy . . . . . . . . . . . . . . 70
5.3.1 Assignment of privacy weights . . . . . . . . . . . . . . . . . . 71
5.3.2 Context - Privacy Graph . . . . . . . . . . . . . . . . . . . . . 74
5.3.3 Incrementing and Decrementing Privacy . . . . . . . . . . . . 75
5.3.4 Hybrid Approach . . . . . . . . . . . . . . . . . . . . . . . . . 77
5.3.5 Privacy Quantization based on User Behavior . . . . . . . . . 79
5.4 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.4.1 System-centric approach . . . . . . . . . . . . . . . . . . . . . 82
5.4.2 Hybrid approach . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.4.3 Privacy Quantization based on User Behavior . . . . . . . . . 84
5.5 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
5.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6. SITUATION-AWARE MIDDLEWARE . . . . . . . . . . . . . . . . . . . . 93
6.1 Challenges of designing Ubiquitous middleware . . . . . . . . . . . . . 93
6.1.1 Inability to associate relevant information . . . . . . . . . . . 94
6.1.2 Lack of transparency in authentic information . . . . . . . . . 94
6.1.3 Configuration superseding action: . . . . . . . . . . . . . . . . 95
6.1.4 Granularity of the system incorporating social variations . . . 95
6.2 Motivating Scenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
6.3 Precision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
6.3.1 Device Abstraction Layer . . . . . . . . . . . . . . . . . . . . 98
6.3.2 Information Retrieval Layer . . . . . . . . . . . . . . . . . . . 101
6.3.3 Decision Layer . . . . . . . . . . . . . . . . . . . . . . . . . . 103
6.3.4 Application Layer . . . . . . . . . . . . . . . . . . . . . . . . . 104
ix

6.4 Results and analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.4.1 Case study 1: Information sharing between users . . . . . . . 105
6.4.2 Case Study 2: Patient monitoring in assisted environments . . 107
6.4.3 Motivating scenario . . . . . . . . . . . . . . . . . . . . . . . . 109
6.4.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
6.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
7. CONCLUSION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
REFERENCES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
BIOGRAPHICAL STATEMENT . . . . . . . . . . . . . . . . . . . . . . . . . 135
x

LIST OF FIGURES
Figure Page
1.1 Overview of Ubiquitous Computing . . . . . . . . . . . . . . . . . . . 3
3.1 Types of User Context . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.1 The environment in which the system is deployed . . . . . . . . . . . 42
4.2 Modifying a Situation Tree . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3 2-Level grammar hierarchy for the detection of therapy activity . . . . 52
4.4 Level-1 Parse Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.5 Level-2 Parse Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.6 Structure of S-Trees denoting cooking activity . . . . . . . . . . . . . 57
4.7 Effect of context elements and verbs over false positives/negatives . . 60
5.1 Structure of a context element . . . . . . . . . . . . . . . . . . . . . . 71
5.2 Transition of Context States in a k -privacy state system . . . . . . . . 74
5.3 A Context Privacy Graph . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.4 Decision Tree for the Hybrid approach . . . . . . . . . . . . . . . . . . 84
5.5 User interaction with peers . . . . . . . . . . . . . . . . . . . . . . . . 86
5.6 Graphical User Interfaces of the system . . . . . . . . . . . . . . . . . 86
5.7 Increment/Decrement operations with varying privacy states . . . . . 88
5.8 Comparison of our approaches over varying privacy levels . . . . . . . 91
6.1 Proposed middleware of Precision . . . . . . . . . . . . . . . . . . . . 98
6.2 Context Gatherer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
6.3 Situation Analyzer and Generator (SAGe) . . . . . . . . . . . . . . . 103
6.4 GUI for (a) Mobile phones (b) Desktops . . . . . . . . . . . . . . . . . 105
xi

6.5 Desktop frontend of the Chat application . . . . . . . . . . . . . . . . 106
6.6 Chat application sharing sensitive information . . . . . . . . . . . . . 106
6.7 Sample Patient Chart . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
6.8 Use case Diagram of a Smart Home for Assisted Healthcare . . . . . . 108
6.9 SmartBoard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
6.10 Challenges involved in development of SmartBoard . . . . . . . . . . . 111
6.11 Determination of optimal set of sensor size . . . . . . . . . . . . . . . 114
6.12 Performance Analysis: (a) Situation Prediction vs. Context Elements(b) Accuracy (c) Computational delay . . . . . . . . . . . . . . . . . . 115
6.13 Screenshot of the middleware in action . . . . . . . . . . . . . . . . . 117
6.14 Sunspot Readings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
6.15 Heart monitor output . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
xii

LIST OF TABLES
Table Page
3.1 Perspectives of context . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.1 Therapy Grammar Hierarchy . . . . . . . . . . . . . . . . . . . . . . . 53
4.2 Effect of the number of verbs on False Positives and Negatives . . . . 59
4.3 Performance of Activity Recognition . . . . . . . . . . . . . . . . . . . 62
4.4 Effect of increasing users . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.1 Different scenarios and user privacy preferences . . . . . . . . . . . . . 66
5.2 Hybrid Approach to Privacy Quantization . . . . . . . . . . . . . . . 85
5.3 Privacy Quantization based on User Behavior . . . . . . . . . . . . . . 85
5.4 Experimental results for Hybrid approach: 5 users, up to 50 sessions,variations in θ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
5.5 Experimental results for User Behavior approach . . . . . . . . . . . . 90
6.1 Multi Sensor Utility value with information acquisition cost . . . . . . 114
xiii

CHAPTER 1
INTRODUCTION
The most profound technologies are
those that disappear.
They weave themselves into the
fabric of everyday life until they are
indistinguishable from it.
Mark Weiser
Mark Weiser’s perception of Ubiquitous Computing [1] seems to be coming to
fruition as more computing devices are being embedded in our daily life and forming
an information lifeline to many users. Over the recent years there has been an im-
plosion of devices, mostly due to the constant push from the industry to handle the
insatiable need of the user to access information. Making the computer invisible is
not a matter of size or a challenge of seamless integration of hardware; it is about
how the human perceives the computer. To make the computer disappear (at least
in the user’s perception), the interaction has to be seamlessly integrated with the
primary task of the user. Users still interacts with the tools that help them to do a
certain job, but their focus is on the task itself. This is in contrast to typical usage of
a computer as a tool, where the focus usually ends on the computer not on the task.
Computers have advanced beyond the desktop into many parts of everyday life,
for e.g., smart phones, PDAs, touchscreen kiosks, tablet PCs, etc. Ubiquitous Com-
1

2
puting is inevitably computing in context: it takes place in situations in the real world.
So far most research, especially in mobile computing, has focused on enabling trans-
parent use of computers, independent of the environment. An orthogonal research
effort is to exploit context. The research presented in this dissertation investigates
how context can be acquired to enhance perception of the environment, effectively us-
ing this knowledge to understand user activity, and how it changes human computer
interaction in Ubiquitous Computing.
1.1 Ubiquitous Computing
After more than fifty years of designing computers that require users to adapt
to them, we now enter the epoch of human-centric computing, where computers are
designed to adapt to users. The objective here, is to create a total solution for the
perennial connection of the human with the environment, rather than focussing on
the devices, which are used for the sole purpose of obtaining input from the human.
Ubiquitous computing represents the concept of seamless “everywhere” com-
puting (Figure 1.1) and aims at making computing and communication essentially
transparent to the users. This constitutes a paradigm shift, and implies embedding
the technology unobtrusively within all types of everyday appliances/devices, which
can potentially transmit and receive information from the others. Ubiquitous com-
puting and Pervasive computing describe the same concept with a few subtleties.
Pervasive computing deals with acquiring context knowledge from the environment
and providing dynamic, proactive and context-aware services to the user. The fo-
cus of ubiquitous computing is on gleaning information from smart objects (active, or
passive), and performing user-centric tasks, with an attempt to improve the life of the
user, yet, remaining virtually hidden from the user. A ubiquitous computing environ-
ment is created by sharing knowledge and information between pervasive computing

3
environments. Ubiquitous computing can also be considered as roughly the opposite
of virtual reality. While virtual reality aims to integrate people inside a computer-
generated world, ubiquitous computing, on the other hand, forces computing devices
to exist in the world with people.
In expansive terms, ubiquitous computing is currently seen to comprise any
number of mobile, wearable, distributed and context-aware computing applications.
The core of ubiquitous or pervasive technologies is the ability of computers to be
perceptive, interpretive and reactive. In other words, information infrastructures
must be able to shift from sensors in the physical environment to decision making
systems and knowledge bases. The systems must be able to recognize and respond
to actual contexts of use. It is, therefore, imperative for ubiquitous technologies to
incorporate extensive data acquisition, storage, and delivery.
Figure 1.1. Overview of Ubiquitous Computing.

4
As a core paradigm, ubiquitous computing shares the vision of small, inexpen-
sive, heterogeneous networked devices, distributed throughout the environment, and
aimed to perform everyday tasks. For instance, lighting and environmental controls
might be interconnected in a ubiquitous computing environment, along with personal
biometric monitors, to maintain the ambient temperature and lighting according to
the user’s preferences and comfort levels. From a Human computer interaction (HCI)
viewpoint, ubiquitous computing describes the phenomenon of interacting with ob-
jects and environments that are interwoven with processing and communication capa-
bilities. Here the focus is on building a global computing environment where seamless
and invisible access to computing resources is provided to empower humans interact-
ing in such an environment and to enhance their interactive experience.
As an important consequence of integrating these myriad sensors and devices
of varying capabilities. ubiquitous computing present unique challenges in system
design, modeling, engineering, and user interface design. Contemporary human -
computer interaction models might tend to be inadequate to handle conditions and
events faced in a ubiquitous computing environment. This emphasizes the need for a
”natural interaction” paradigm involving the input from the user and the environment
in a cooperative manner, and a fully robust solution has yet to emerge, though there
are many examples of its application in the real world [39, 13, 20]. Ubiquitous comput-
ing, therefore, touches on a wide range of research topics, including distributed and
cooperative computing, sensor networks, human-computer interaction, mobile com-
puting, and machine learning. This list, however, is not exhaustive, and as a result,
ubiquitous computing can be considered as an umbrella of all forms of computations
which involve user interaction in any form.

5
1.2 Context Awareness and Situation Modeling
In recent years, the use of context information has attracted a lot of attention
from researchers and the industry community. Users and applications are often in-
terested in acquiring and utilizing widespread “context information” characterized
as an application’s environment or situation [37], and as a combination of features
of the execution environment, including computing, user and physical features [70].
Information about users (such as name, address, role, etc.), locations (coordinate,
rooms etc.), computational entities (device, network, application, etc.) and (sched-
uled) activities are some examples of context information.
Context may include information about the physical world (location, motion,
temperature, pressure, device characteristics, etc.) and about the logical world sur-
rounding the user. Context obtained from the physical world can be represented
as a function of some physical entity or entities. The logical world, on the other
hand includes identity, privacy, preferences, relationships, and interactions in differ-
ent domains, such as home, work, family, legal, community, etc. The definitions of
these parameters depend from person to person, and strongly depends on the domain
in which the logical parameters are used. Mapping these abstract notions and ideas
into quantifiable functions, implementing them in ubiquitous computing systems, and
predicting future interactions, still remains a monumental challenge.
As a result of this mapping, context cannot be considered as just a state, but
a part of a process. It is not sufficient for the system to behave correctly at a given
instant. it must behave correctly during the entire process in which users are involved.
Correctness must be defined with reference to the process, not simply the succession of
states constituting that process. In order for systems to be context-aware, they must
maintain a model describing the environment, its occupants, and their activities,
effectively describing the situation of the occupant in the environment. Situations

6
are therefore considered to be semantic abstractions from low-level contextual cues
that can be used for constructing such a model of the scene. Human behavior can be
described by a finite number of situations, characterized by entities playing particular
roles and being in relation within the environment. Perceptual information from
different sensors in the environment is associated to the situations, roles, and relations.
These different situations are connected within a network. A path in this network
describes behavior in the scene. As human behavior and needs evolve over time, a
context model representing behavior and needs of the users must also evolve.
1.3 Challenges in Context-aware Computing
A key to understanding Context-aware systems, and their use, is the obser-
vation that humans implicitly interact in context with their environments including
technology. The task of making this context information available to components in
computer systems has become a prerequisite to advancing human-computer interac-
tion processes in ubiquitous computing. Context awareness, or more specifically the
ability to create systems that are context-aware, is a key issue to ubiquitous comput-
ing research. Such research involves context acquisition, representation, distribution,
and abstraction, as well as programming paradigms, framework development, and
implications on human-computer interaction.
A major challenge in context-aware computing is physical integration and em-
bedding of computing and communication technology into environments. In a ubiq-
uitous computing paradigm, tools are enhanced with processing and communication
capabilities to help with achieving the task, and not drawing focus away from it. Em-
bedding interaction into tasks seems to be the obvious approach to take. However,
when it comes to modeling and implementing this vision, many unresolved issues
appear. Using explicit interaction, as in conversational computer systems, there is

7
provision for a choice of varying modalities. The interaction designer can chose from
command line user interfaces, graphical user interfaces, and speech and gesture in-
terfaces. Independent of the modality, the user still is required to interact with
a computer. Another issue that makes conversional interaction methods difficult is
that interface components can be physically distributed and dependent on each other.
On the other hand as there is also the potential for many applications to run at the
same time, requiring inputs to be directed to respective applications. Using solely
this approach would inevitably result in a complex interface and require a great deal
of the users attention, which is regarded as one of the most precious resources because
it is limited.
The following issues are some key research challenges in context-awareness:
• Understanding the concept of context, acquiring the context information and
connecting it to context use.
• Fusing heterogeneous context data to generate information about the environ-
ment and using this fused data to improve the perception of the current state
in the environment, and taking required actions.
• Understanding the influence on human computer interaction and activity his-
tory, and predicting user actions, based on these observations.
• Support for building context-aware Ubiquitous computing systems which per-
ceive human interaction and adapt to uncertainty in information.
Many of these research issues are highly interconnected. Nevertheless some of
the issues can be tackled fairly independently of others. In the approach pursued in
the course of research underlying this dissertation, context-awareness is approached
from a bottom-up perspective. In our approach, context acquisition and context use is
related to the influence on human computer interaction. Perception of user behavior
and activity is strengthened based on this interaction, and the system can efficiently

8
adapt to the user’s individual needs and behavioral patterns. This approach cuts
across several of the challenges above.
1.4 Ubiquitous Middleware
In ubiquitous computing environments, where the real world becomes a part of
the computer and of the user interface, users’ expectations towards the system are also
widely based on the experience of interaction in the real world. The designer, however,
has a great freedom of how to design interaction processes in such systems. Many
limitations inherent in conventional engineering are no longer an issue in ubiquitous
computing. in fact a networked switch could operate anything else that is networked.
To make a system useful and give the user the feeling of being in charge of the system
a switch should operate what the user anticipates in a particular situation.
Some of the ubiquitous computing systems have no mechanism for people to
reflect upon the system, to see how they and their information affect, contribute,
interact, or participate in the system [77]. It is also imperative that users are made
aware of the limitations and constraints of the system. For example, a kitchen system
that helps a person maintain groceries in the house will have sensing limitations, which
may be dynamic, based on sensors and situations. Effective use of this tool requires
understanding what the sensing system missed so that a person can compensate. As
ubiquitous computing systems rely on implicit sensing that is naturally ambiguous or
error-prone, designers must help users comprehend the limitations of the system [34].
Designers face many challenges while building a framework for a ubiquitous
computing environment. The key challenge is to engineer a framework capable of
adapting to such a highly chaotic environment and seamlessly integrate itself with
the existing legacy systems. One problem area to be tackled is that of sharing and
distributing information between users, i.e., not only between all participants in a

9
single application such as a conference, but also across different applications, for e.g.,
information retrieval. These conundrums that are constantly faced while developing
middleware frameworks for ubiquitous computing environments form the motivation
for privacy management in this dissertation. Security and privacy have an implicit re-
lationship. An elementary level of security is imperative while helping people manage
their personal privacy. Since, in many scenarios of a ubiquitous computing envi-
ronment, the users are not necessarily adversaries, and usually know each other’s
identities, the uncertainty would be less and hence we adapt a privacy risk model
rather than a threat model. Social and organizational context should also be taken
into consideration while developing a framework for the environment.
1.5 Contributions of the dissertation
The objective of the research presented is to assess ways in which situation-
awareness and privacy management can be integrated with ubiquitous computing
systems. In particular the focus is on using low-end, low-price computing and com-
munication technology in order to identify solutions that could be economically de-
ployed in ubiquitous computing environments in the near future. In this dissertation,
we have developed systemic approaches to user-centered perception of context and
situations, and present a situation-aware middleware framework for ubiquitous com-
puting environments.
The prime interest is on context acquisition using a variety of sensors and actu-
ators, and obtaining inherent context from the human computer interactions which
we consider as situations in the environment. The aim is to provide an effective
methodology for perceiving situations, and modeling dynamic rules using the knowl-
edge of user activity and behavior. A further goal is to develop architectures, and
methods that help to understand user interactions, and facilitate the development

10
process of adaptive ubiquitous middleware frameworks. The methods used include
systematically surveying literature and available information, designing and imple-
menting prototypes to prove the feasibility of the proposed ideas, creating models
and concepts that generalize what was learned from the prototypes, and evaluation
of the proposed solutions.
The main area of work is on perception of context, situation awareness, context
privacy, and human computer interaction through ubiquitous middleware. The major
contributions of this dissertation are:
• Extending the current scope and understanding of context.
Context in ubiquitous computing has been defined in different ways, depend-
ing on the kinds of frameworks and their core competencies. However, many
of the definitions are constrained by the emphasis on certain types of contexts
(location, event triggers, etc.), and as a result, are limited to the actions and
events triggered by these contexts. A weighted approach to context could po-
tentially result in discarded information, more often than not inadvertently, and
deprives proper understanding of future actions or events, that might require
the discarded context. A balanced approach to context evaluation and acqui-
sition is essential for a proper perception of the current state of the system
or the user in the environment, complemented with the concept of bottom-up
context-awareness, where generic intrinsic properties of context are taken as
the starting point to model context, is imperative for effective understanding of
the interactions in the environment. We have formulated a broader and more
encompassing definition, according to which, context is defined as a collection
of measured and inferred information of a state or environment in which the
entity has interacted, either passively or actively, to enable perception of the
current state of the entity from obtained knowledge, which influences inference

11
of the future states. Our definition stresses upon collecting knowledge about
the entity, and we use this knowledge to perceive the state of the entity. We
consider decision making as a function of the prior context, thereby allowing us
to predict future states and interactions.
• Understanding user interactions and activities as situations and using this knowl-
edge to perform situation modeling.
At present, most of the commonly deployed ubiquitous computing systems de-
construct an event or activity into context, and then attempt to reconstruct
them again. A potential problem with this kind of approach is loss of informa-
tion. The systems might discard information or context that are not currently
relevant to the context awareness of the current state of the system or the user
in the environment. However, the relationship of the user and the system with
the logical environment is translucent at best, and discarded information might
tend to be relevant in other scenarios, which in turn results in loss of infor-
mation, ambiguity in context awareness, or improper actions taken as a result
of lacking context information. It is therefore, essential to develop approaches
for ubiquitous computing systems which try to perceive the state of the system
or the user interaction with the environment as a whole, and take necessary
actions accordingly.
• Developing the vocabulary and situation grammar to generate user-specific dy-
namic rules.
A serious problem faced by designers and developers of ubiquitous computing
systems is developing mechanisms to adapt to the user. It is an immense task
to be able to predict and foresee all possible interactions of the user, and de-
veloping rules to handle such activities would reduce the performance of the
system overall. It is necessary, therefore, to develop an approach which would

12
seamlessly adapt to the various users and their behavior. We have developed
an approach which would cater to this need of the designers, and demonstrate
the feasibility of such an approach.
• Quantizing user privacy in ubiquitous computing environments.
Privacy is the ability of an individual or group to keep related information, their
social and behavioral patterns out of public view, or to control the flow of in-
formation about themselves. Traditionally, privacy enhancing techniques have
been thought as tools for hiding, obfuscating, and controlling disclosure. But in
terms of an overall approach to privacy management, it is necessary think about
how technology can be used to create visibility and awareness of information
security practices. The real privacy concerns people have today revolves around
who has access to what information rather than what information is collected.
A major portion of previous work on privacy has focused on anonymizing user
information or on preventing adversaries from obtaining personal information
and messages. Though anonymity and security are a priority, they focus on
some issues of privacy and do not completely handle many situations where
the users choose to share information with others. Existing approaches to sup-
porting user privacy focus largely on conventional data management schemes.
We have proposed a scheme for quantizing privacy based on user interactions
with the environment and have developed user-centric approaches which aim to
resolve some of the problems of user privacy, by introducing both user-centric
and system-centric privacy management schemes to handle granularity of user
privacy.
• Designing a ubiquitous middleware framework to support the perception, mod-
eling, rule generation, and privacy management of user interactions in the en-
vironment.

13
Traditionally, designers have adapted two approaches to introduce user prefer-
ences and privacy into systems: user-centric and system-centric approaches. In
the user-centric approach, the user chooses the rules and settings for the be-
havior of information contained in the system. In the system-centric approach,
rulesets and policies ordain the privacy settings. The user-centric approach is
more flexible and transparent, allowing the user to possess knowledge of the
information and their privacy levels. However, the privacy setting in such an
approach is based primarily on the user’s inference of the information stored
in the system and understanding of the repercussions of making information
transparent to others. In cases of healthcare and other sensitive data, the user
might not be aware of the standards and practices involved in disclosure of
information, and the privacy settings primarily depend on the awareness and
preference of the user. On the other hand, the system-centric approach, poli-
cies are generated, based on standards and privacy is set based on the rulesets
pertaining to different situations. This approach, however, proves to be rigid in
nature, and the user seldom has the option of altering the privacy setting. We
have developed a middleware framework that perceives the current user inter-
action with the environment as situations, and take necessary actions based on
prior user behavior and activities.
1.6 Organization of the dissertation
The dissertation is structured in the following way. In Chapter 2, the terms
of Ubiquitous Computing, Context awareness, Situation prediction, Context Privacy,
and ubiquitous middleware are assessed. We also present the related work of Context-
aware middleware frameworks in Ubiquitous computing.

14
In chapter 3, we discuss the perception of context in Ubiquitous Computing and
discuss our understanding of context. The different perspectives of context are dis-
cussed, along with our classification of context. We also look into the perception and
cognition of context in nature and how we can fuse context together to obtain rele-
vant information about the user in the environment. We investigate Event-Condition-
Action rules and discuss their limitations in ubiquitous computing environments.
Chapter 4 follows the basic question of how to acquire context information from
the environment using sensors, and other devices, and how this context can be con-
verted into viable information to the system. In particular the relationship between
situation, context and sensor data is examined. We present our methodology for
understanding situations by extracting actions and knowledge from the environment
and extract user actions by situation parsing. We show how dynamic vocabulary
needed for situation perception is generated by user activity and present our scheme
of formulating situation grammar to facilitate dynamic rule generation.
We investigate various problems of implementing user privacy in Chapter 5,
and present various approaches through which we optimally quantize the abstract
notion of privacy into parameters transparent to the user, yet allowing flexibility for
the system to monitor and vary privacy based on user interaction and changes in the
environment.
We present our middleware framework in Chapter 6. We discuss the archi-
tecture and functioning of our framework in ubiquitous environments. We present
two case studies and present the overall performance of our system in assisted envi-
ronments. Evaluation methods related to the middleware framework are introduced
and the objectives of the middleware are assessed and evaluated, and we present our
observations and results.

15
The conclusion in Chapter 7 summarises the contributions made in the thesis,
but also critically assesses the shortcomings and limitations detected in the course of
the research. Furthermore new issues that have been surfacing while working on the
thesis are addressed in this chapter.

CHAPTER 2
BACKGROUND AND RELATED WORK
Research in ubiquitous computing originates from many different areas such
as mobile computing, distributed systems, human computer interaction, AI, design,
embedded systems, processor design and computer architecture, material science,
civil engineering and architecture. This very broad view on ubiquitous computing
research is however not commonly shared. Ubiquitous computing it is not just about
technology and the deployment of technology in everyday environments; the human
perception of technologies and the interaction with technology is the crucial test. The
concept of “Ubiquitous Computing” goes beyond having computers that can be taken
everywhere and used independent of where the user is.
2.1 Ubiquitous Computing
In expansive terms, ubiquitous computing is currently seen to comprise any
number of mobile, wearable, distributed and context-aware computing applications.
The core of ubiquitous or pervasive technologies is the ability of computers to be
perceptive, interpretive and reactive. In other words, information infrastructures
must be able to shift from sensors in the physical environment to decision making
systems and knowledge bases. The systems must be able to recognize and respond
to actual contexts of use. It is, therefore, imperative for ubiquitous technologies to
incorporate extensive data acquisition, storage, and delivery. We need to develop a
system which can correctly assess the dynamic environment, systematically handle
uncertain sensory data of different modalities, and reason over time. The first step
16

17
involved in a highly dynamic environment is to discover the resources and services
available in the environment.
Resource discovery is the ability to locate resources that adhere to a set of re-
quirements pertaining to a query that invoked the discovery mechanism. [81] provides
a taxonomy for resource discovery systems by defining their design aspects. To sup-
port a large amount of resources, defining and grouping services in scopes facilitates
resource search. Location awareness is a key feature in ubiquitous computing [27] and
location information is helpful in many resource discovery cases. In Matchmaking,
a classified advertisement matchmaking framework, client requests are matched to
resources and one of the matched resources is selected for the user [30].
Ubiquitous computing is a challenge for the design of a middleware framework.
A modern smart home or hospital is an environment in which the users exhibit a
large degree of spatial mobility, owing to the nature of their work. Often the tasks
performed require contrasting yet exigent communication requirements [10, 59]. Re-
source constraints, mobility, heterogeneity, scalability are just a few issues that have
to be addressed [76, 47]. Such a middleware has to be tailored to the application sce-
nario as well as the target platform. It is therefore effectual that the framework has
to be built from minimal fine-grained components. A general framework for discov-
ery, composition and substitution was introduced in [69] and [9], in which knowledge
representation techniques and approaches were exploited and adapted to the highly
flexible and variable ubiquitous environments, not only from a software point of view,
but also by the user’s perspective.
One problem area to be tackled is that of sharing and distributing informa-
tion between users [53], i.e., not only between all participants in a single application,
but also across different applications, making the need of information brokers im-
perative. Traditional middleware like CORBA [23] and Jini [74] provide the basic

18
mechanisms for different objects (or agents) to communicate with each other, but
unfortunately, they fail to provide ways for agents to be context aware. Agent-based
resource discovery was presented by Ding et al. in [19], in which a distributed dis-
covery method, allowing individual nodes to gather information about resources in a
wide-area distributed system, was discussed. [67] proposes a middleware that facili-
tates the development of context-aware agents by using ontologies to define different
types of contextual information. A solution for context-aware privacy protection for
any type of fine-grained user sensitive data with profiles of the user, context, scenario
and service was also discussed in [60].
2.2 Context in Ubiquitous Computing
Context is the circumstance under which a device is being used, e.g. the current
occupation of the user. Toivonen et al [80] discuss methods for evaluating context-
aware trust for dynamic reconfigurable systems. In information systems, context
information is metadata stored in the system about entities (e.g. resources, events,
etc) that are related to, but not intrinsically about the entity itself. The line between
ordinary metadata and contextual metadata is a blurred one, and often depends on
individual perspectives about what counts as intrinsic information.
2.2.1 Context-aware Ubiquitous Computing
Heterogeneous sensors, devices and actuators exist in a ubiquitous computing
(ubicomp) environment, making context-aware systems one of the important services
for applications. System designers face many challenges while building a framework
for a ubicomp environment. The key challenge is to engineer a framework capable of
adapting to such a highly chaotic environment and seamlessly integrate itself with the
existing legacy systems. Many of the middleware are designed as an Event-Condition-

19
Action (ECA) approach [12, 52, 48]. Importance has to be given to the relevance of
data pertaining to a session. It would be more advantageous taking a user’s behavior
as an entity and deriving work flows from it, rather than considering events as a basal
unit [71]. The middleware should be able to predict the information required for a
particular service.
Many context-aware applications acquire and utilize context information not
only from one particular domain, but also from different domains over a wide-area
network. A critical issue here is to provide an efficient context data storage and
delivery mechanism to support such applications. It is important to allow context
information to be shared and delivered in a semantic way for heterogeneous applica-
tions (known as semantic-based context delivery). As context information exhibits
dynamic, temporal characteristics [4], the design of the underlying mechanism for
context delivery can be quite challenging as well. We believe semantic-based context
delivery is one of the key enablers for the building of more sophisticated, distributed
context-aware applications.
One problem area to be tackled is that of sharing and distributing informa-
tion between users, i.e., not only between all participants in a single application such
as a conference, but also across different applications, for e.g., information retrieval.
This makes the need of information brokers imperative. CORBA Component Model
(CCM), an extension of “language independent Enterprise Java Beans (EJB)” [17],
is a broker oriented architecture. By moving the implementation of these services
from the software components to a component container, the complexity of the com-
ponents is dramatically reduced [24]. One drawback of CCM is the lack of provision
for tackling the issue of disconnected processes, which is rampant in a ubiquitous
computing environment [83].

20
Designers constantly include huge configuration steps for incorporating privacy
into the model. This would be necessary for making the system robust, but deters
the user from using the system effectively. Web services [14, 33] aims at promoting a
modular, interoperable service layer on top of the existing Internet software [11], but
lacks consistent management and are tightly bound to the simple object access proto-
col (SOAP) which constrains compliance to various ubiquitous computing protocols.
Jini [74], is a service oriented architecture that defines a programming model which
both exploits and extends Java technology to build adaptive network systems that are
scalable, evolvable and flexible as typically required in dynamic computing environ-
ments. Jini, however, assumes that mobile devices are only service customers which
is not the case. We aim at reducing the task of user configuration by introducing
classification of information based on privacy levels.
2.2.2 Existing Ontological Approaches
An ontology is a formal representation of a set of concepts within a domain
and the relationships between those concepts. It is used to reason about the prop-
erties of that domain. [26] defines an ontology as a “formal, explicit specification
of a shared conceptualization.” An ontology, therefore, defines the vocabulary with
which queries and assertions are exchanged. Ontologies are used in various fields as a
form of knowledge representation about the world or a part of it. Contemporary on-
tologies share structural similarities, as they describe individuals (instances), classes
(concepts), attributes and relations.
An ontology language is a formal language used to encode the ontology. Some of
the popular ontology languages are KIF [26], RIF [44], RDF [88], and OWL [75]. The
Knowledge Interchange Format (KIF) has syntax for first-order logic. It has declar-
ative semantics, i.e.,meaning of expressions in the representation do not require an

21
interpreter for manipulating those expressions. The Rule Interchange Format (RIF)
is aimed at developing a web standard for exchanging rules, and is an extensible
framework for rule-based languages, and include formal specification of the syntax,
semantics, and XML serialization. Resource Description Framework (RDF) has come
to be used as a general method for conceptual description or modeling of informa-
tion using a variety of syntax formats. It is similar to classic conceptual modeling
approaches such as Entity-Relationship or Class diagrams, and is based upon mak-
ing statements about resources in the form of subject-predicate-object expressions,
known as triples. The Web Ontology Language (OWL) is a family of knowledge
representation languages for authoring ontologies, and is based on description logic
or RDF Schema. OWL ontologies are usually serialized using RDF/XML syntax
and therefore, OWL is considered one of the fundamental technologies of the Seman-
tic Web [55]. OWl provides the capability of creating classes, properties, defining
instances and operations, such as union, intersection, and complement, along with
enumeration, cardinality, and disjointedness.
2.2.3 Situation Grammar
There had been significant amount of work in the area of recognition of daily
life activities. Recognizing activities of daily life is challenging, especially in a home
or assisted environment. This is due to the fact that the user can perform activities
in several way, This would also imply that the underlying sensors must report the
features required of them robustly across various sensing contexts [20]. A popular
technique for detecting features of such activities is known as “dense sensing” [65],
in which a a wide range of sensor data is collected instead of relying on visual based
systems. Another technique has been to use wearable sensors such as accelerometers
and audio sensors which aim to provide data about body motion and the surroundings

22
where the data has been collected from [62]. It has been shown in [49] that a variety
of activities can be determined using this technique. Wang et. al [82] made use of
this technique to determine fine-grained arm actions.
Human activity recognition in the context of assisted environments using RFID
tags has been investigated in [65, 50, 78].Though this approach involves extensive
tagging of objects and users, it demonstrates that hierarchical organization of prob-
abilistic grammars provides sufficient inference power for recognizing human activity
patterns from low level sensor measurements. A sensing toolkit for pervasive activity
detection and recognition has been discussed in [86].
In our framework, similar functionality could be achieved using Hidden Markov
Models (HMMs) instead of probabilistic context free grammars (PCFGs) [85]. How-
ever, PCFGs are more general and more expressive and can be used to describe a
large family of HMMs. Using a small set of simple grammar rules, we can define fam-
ilies of HMMs, Grammar hierarchies provide a structured bottom-up processing of
sensor data for generating higher level semantics similar to streams. Additionally, the
semantics can be efficiently converted as the basic processing elements for top-level
queries. But, in order to fully appreciate human activity recognition, we would need
to incorporate context-aware production rules for the grammar hierarchies.
2.3 Privacy
One of the challenges in deploying ubiquitous computing services on a signif-
icant scale is making adequate provision for handling personal privacy in context-
aware ubiquitous frameworks. In this section, we examine privacy and context-aware
systems in ubiquitous computing environments.

23
2.3.1 User Privacy
User privacy is the ability of an individual or group to keep related information,
their social and behavioral patterns out of public view, or to control the flow of infor-
mation about themselves. The perception of privacy in the aspects of the information
receiver, user and sensitivity in terms of design was investigated in [7]. Traditionally,
privacy enhancing technologies [2] have been thought as tools for hiding, obfuscating,
and controlling disclosure. But in terms of an overall approach to privacy manage-
ment, it is necessary think about how technology can be used to create visibility and
awareness of information security practices. Tentori et al. [79], introduced the con-
cept of Quality of Privacy to address the tradeoff between the services provided by a
ubiquitous environment and the cost that the users might need to pay in regard to
privacy. Though this scheme incorporated context-aware communication, the system
was not suggestive and depended on the user’s knowledge of information sharing.
Confab [31] offers a framework where personal information is captured, stored and
processed on the end-user’s computer as much has possible. Though this addresses
the high-level requirements of decentralized architecture and plausible deniability, and
offers a larger amount of choice and control than previous systems, the system is not
obtrusive in nature. A scheme that alleviates loss of privacy without forbidding the
use of trust is described in [73]. A study of the relationship between context and pri-
vacy was made in [29]. [32] presented an architecture for privacy-sensitive ubiquitous
computing, where the authors claim that the large majority of work on privacy has
tended to focus on providing anonymity rather than considering the many scenarios
in everyday life, where people want to share information. Owing to the nature of
privacy, it is difficult to design privacy-sensitive ubiquitous applications. The pitfalls
that a designer faces while incorporating personal privacy in a ubiquitous computing
environment are discussed in [47]. In human-computer interaction, computer trans-

24
parency is an aspect of user friendliness which relieves the user of the need to worry
about technical details. When there is a large gap between user perception and actual
authentic information, the system is failing in representation of information. Infor-
mation transparency changes behavior [25], and there have been some efforts to in the
field of privacy enhancing technologies that help create transparency of information
security practices.
2.4 Middleware frameworks for Ubiquitous environments
Ubiquitous computing is a challenge for the design of a middleware framework.
An agent-based middleware architecture was presented in [72], in which an automatic
knowledge acquisition and processing mechanism, acts as the foundations of a semi-
autonomous multi-agent system for highly dynamic environments. A smart home is
an environment in which the users exhibit a large degree of spatial mobility, owing to
the nature of their work. Often the tasks performed require contrasting yet exigent
communication requirements [10], [59]. Resource constraints, mobility, heterogeneity,
scalability are just a few issues that have to be addressed [76], [47]. Such a middleware
has to be tailored to the application scenario as well as the target platform. It
is therefore effectual that the framework has to be built from minimal fine-grained
components, and the system structure should also be highly configurable [79], [32].
The problems of physical integration and spontaneous interoperation and their effect
on the design of ubiquitous system software was investigated by [45]
A general framework for discovery, composition and substitution was introduced
in [69], in which knowledge representation techniques and approaches were exploited
and adapted to the highly flexible and variable ubiquitous environments. [21] pro-
poses a dynamic architecture for resource constrained devices based on JXTA [43],
which enables peer to peer concept independently of the underlying technology. Mid-

25
dleware services predominantly deal with resource constraints of sensor networks, but
it is also critical to consider the requirements of information fusion from an applica-
tions perspective [3]. DFuse [46] is a data fusion framework that facilitates transfer of
different areas of application level information fusion into the network to save power.
DFuse does this transfer dynamically by determining the cost of using the network
using cost functions. Adaptive middleware [35] has been proposed for context-aware
applications in smart-home setups.
In dynamic and pervasive computing environments, the number and types of
sensors available to the applications may vary. Therefore, it is impractical to include
knowledge about all the different sensor nodes that an application can potentially
make use of. In addition, all these sensors come at various levels of cost and benefit
to the application [22]. Our approach discovers and selects the best set of sensors
on behalf of applications. The proposed probabilistic sensor fusion scheme is based
on Bayesian networks [73] which provides a powerful mechanism for measuring the
effectiveness of derivation of higher level of context information from multi-modal data
sources. Our framework supports the application developer in the following key ways:
(i) It provides abstractions for sensors and actuators, thus relieving the developer of
the burden of low level interaction with various hardware devices. (ii) It provides a
probabilistic mechanism for fusing multimodal fragments of sensor data together in
order to derive higher-level context information. (iii) It provides an efficient approach
to intelligent reasoning based on a hierarchy of contexts. (iv) It provides a layered and
modularized system design using Dynamic Bayesian networks for interaction between
sensors, mediators and actuators.
A number of other middleware proposals address the challenges of effectively
developing context-aware applications. Seminal work by Dey [18] provided a toolkit
which enabled the integration of context data into applications, but did not provide

26
mechanisms for performing sensor fusion, reasoning about context, or dealing with
mobility. Other work provided mechanisms for reasoning about context [16] but
still did not provide a well defined context fusion model and did not address the
challenges of mobility and situation prediction. Recent and ongoing work [68] provides
programmer support for the development of context-aware applications, but does
not provide the ability to systematically specify and manage situation modeling,
privacy quantization, and rule-based inference in a ubiquitous environment, which
our framework aims to achieve.
2.5 Summary
In this section, we have discussed the background of ubiquitous computing. We
have presented the related works for context-awareness and grammar generation in
ubiquitous computing. We have discussed the conundrum of privacy, and its impli-
cations to the user in a ubiquitous computing environment, and also some of the
problems faced by developers of privacy management schemes. We have also pre-
sented related works for ubiquitous middleware and the different ways in which the
problems faced by designers have been tackled.

CHAPTER 3
CONTEXT IN UBIQUITOUS COMPUTING
The ultimate goal of computing research is to have computer-controlled systems
behave like smart human assistants by making the computers and systems understand
the real world so that human-computer interactions can happen at a much higher
abstraction level [61], hence making the interactions more pleasant or transparent
to human users. In order to achieve this objective, it is essential for the systems to
understand the context in which the interactions occur.
The perception of “context” has been adapted to the computing domain from its
original application to linguistics. Winograd [87] points that this notion is reflected
in the structure of the word. Composed of “con” (with) and “text”, the meaning
of context implies “inferring from the adjacent text”. If we translate this to the
computing domain, context is the representation of the machine or the system along
with the larger world in which the user is present and the presence or absence of
entities in the world. This implies that context refers to the conditions in which
something exists or occurs (situation). Formally, situation can be defined as an
expression on prior {device, action} pairs over a period of time and context is any
relevant attribute of a device which provides information about its interaction with
other devices and/or its surrounding environment at any instant of time [89].
Dey [18] defines context as “any information relevant to an interaction that can
be used to characterize the situation of an entity. An entity is a person, place, or
object that is considered relevant to the interaction between a user and an application,
including the user and application themselves”. While we concur with this rationale
27

28
for [18]’s definition, we observe some significant shortcomings when the definition
is applied to ubiquitous healthcare. Context is more than just data or information
- it is knowledge. We define the three terms in the following way: Data is just
an informal piece of information without explicit structure or format. Information
is interpretation of informal pieces of data which are associated with a particular
context. When contextual information is interpreted and understood, we then have
knowledge.
According to Dey’s definition, context only exists if there is an interaction
between the user and the application. This limits the definition of context to an
occurrence of an event and does not encompass the other contexts, especially in
assisted healthcare. If the user is sleeping, and does not interact with any application,
we would lose precious information of the context (sleeping). In a pressure sensitive
floor, when no one walks or sits, we still have information about the absence of a user,
and that would also correspond to context. Context therefore, should not be just an
interaction between the user and application, but any information obtained from the
user actions (or inactions) with respect to an application.
Another problem with the definition is the characterization of the situation
of an entity. It is not necessary that an entity should be in a situation to define
context. Situation implies “ relation to its surroundings”, which connotes that context
is focused on location. In ubiquitous computing environments, location is just one of
the characteristics of context and we have to develop an extensible model of context,
where the specific aspects of knowledge about the user and the environment are
aggregated and context-aware policies are applied.
We define Context of an entity [63] as “a collection of measured and inferred
information of a state or environment in which the entity has had an interaction,
either passive or active, to enable perception of the current state of the entity from the

29
obtained knowledge, which influences inference of the future states”. Our definition
stresses upon information collected from various sensors, and inherent information
obtained from reasoning about the state or environment, which form knowledge. We
use this knowledge to perceive the state of the entity and consider decision making
as a function of the prior context about an entity, allowing us to predict future states
of the entity.
3.1 Perceiving Context
The trend of context-aware computing development is to integrate more context
information to enable reliable situation prediction. We encounter two problems while
sensing context: proper representation of context, and mapping sensor outputs into
this context representation. A taxonomy of context information needs to be devel-
oped to accurately perceive and delineate the context elements and their uncertainty
management.
For effective perception, context has to be classified into two general categories
– user environment, which consists of the information on the user, information on the
user’s social environment, and information on the user’s activities, and physical en-
vironment, which encompasses location information, infrastructure information and
information of the physical conditions. Intuitively, a systematic method of classifying
the user’s context information would involve exploration of the context in physical
and temporal dimensions, and an attempt to classify the context in terms of user
interactions and social nuances. A user-centered approach is preferred in ubiquitous
computing, where context is grouped into four categories: (1) the physical environ-
ment around the user; (2) the user’s activity (3) the history of prior activities (4)
the user’s physiological state. The perspective of these categories and their interpre-
tations of various context parameters is depicted in Table 3.1. Since context-aware
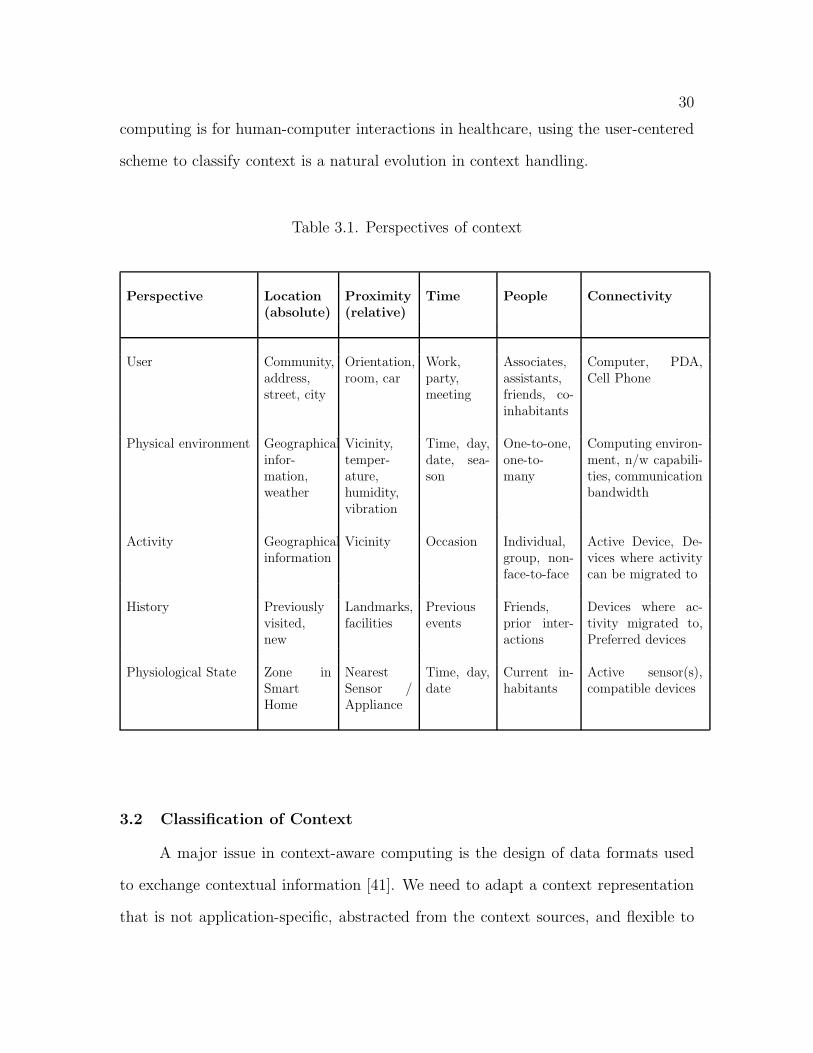
30
computing is for human-computer interactions in healthcare, using the user-centered
scheme to classify context is a natural evolution in context handling.
Table 3.1. Perspectives of context
Perspective Location(absolute)
Proximity(relative)
Time People Connectivity
User Community,address,street, city
Orientation,room, car
Work,party,meeting
Associates,assistants,friends, co-inhabitants
Computer, PDA,Cell Phone
Physical environment Geographicalinfor-mation,weather
Vicinity,temper-ature,humidity,vibration
Time, day,date, sea-son
One-to-one,one-to-many
Computing environ-ment, n/w capabili-ties, communicationbandwidth
Activity Geographicalinformation
Vicinity Occasion Individual,group, non-face-to-face
Active Device, De-vices where activitycan be migrated to
History Previouslyvisited,new
Landmarks,facilities
Previousevents
Friends,prior inter-actions
Devices where ac-tivity migrated to,Preferred devices
Physiological State Zone inSmartHome
NearestSensor /Appliance
Time, day,date
Current in-habitants
Active sensor(s),compatible devices
3.2 Classification of Context
A major issue in context-aware computing is the design of data formats used
to exchange contextual information [41]. We need to adapt a context representation
that is not application-specific, abstracted from the context sources, and flexible to

31
accommodate system enhancements, which tends to be challenging in a ubiquitous
environment, owing to the diversity of devices deployed. In order to effectively rep-
resent the context elements obtained from our user-centered approach, we have to
consider the following properties of context:
1. Dynamic nature of context:
The context of a user (or the physical environment) is dynamic in nature as
the attributes can vary with time. The values of the context elements are also
time-variant.
2. Accumulation of Knowledge:
User history and interactions with the physical environment and other users
has to be accumulated over large periods of time to encompass past experiences
and situations. An effective retrieval mechanism is also necessary to enable the
context-aware system to learn from the experiences.
3. Fusion of related context:
Since a situation can be analyzed as an sequence of context attributes, we
need to be capable of fusing related context attributes together and passing the
aggregated context to the context-aware system to perform situation prediction
3.2.1 Types of User Context
Based on the interaction of the user, we can classify context into physical context
and logical context
1. Physical Context:
Physical context is obtained from various sensors, devices, actuators, and other
smart objects that are distributed in the environment. When a user interacts
with the environment, context is generated which indicates the interaction with
a particular smart object. Some examples of physical context are location,

32
Figure 3.1. Types of User Context.
motion, access, etc. This type of context usually enables the system to identify
the presence of the user in the environment, along with inferring the intent of
the user based on the type of object accessed, the location, and other details.
In other words, physical context captures the user activity in the environment.
2. Logical Context:
Logical context describes the relationship that the user has with the environ-
ment and other entities. This kind of context is used to capture user behavior
and interaction. An example of logical context is the way in which the user
demarcates environments, such as home, work, communities, etc. Another ex-
ample is the relationship of an entity with the user, such as peer, friend, relative,
etc. The aim of logical context, therefore, is to observe the social nuances, and
relationship of the user with other entities in the environment, and effectively
capture the user behavior and interaction history.

33
3.3 Capturing context
Context information about the physical world can be gathered in real time
from sensors embedded in the environment. However, a concerted effort is required
to obtain context from the logical world, obtained by gathering information directly
from the user, or deducing from interactions the user has made with other entities
over time. Whatever the nature of this information, context may come from disparate
sources and has a relatively transient lifetime.
Building a general context information model to capture all aspects of the
user’s information is a difficult task. However, the key is to make the information
representation consistent over different applications, thereby, making the information
generalizable. The context representation must, therefore, be modular, distinct, and
should have a set of well-defined interfaces by which heterogeneous devices can access
and manipulate the context representation.
In a ubiquitous computing environment, the underlying assumption is that the
user and some of the devices are mobile, and activities performed in such an environ-
ment often include mobility. As a result, location information usually is considered
more valuable than others. However, we consider context gathering to be analogous
to the function in humans. Perception and cognition are the foundation of intelligent
behavior of sentient beings, and the incorporating a method to effectively capture an
overall understanding of the environment would facilitate better perception. However,
the information sensed from the environment has to be first translated into patterns,
and these patterns are then associated with meaning. This therefore, implies that
perception requires some form of memory or history, and patterns with history are
translated to knowledge or experience.

34
3.3.1 Event - Condition - Action rules
Event - Condition - Action (ECA) rules are an intuitive and powerful method
of implementing reactive systems, and are applied in many areas such as distributed
systems, real time systems, agent based systems, and context-aware systems. The
basic construct of an ECA rule is of the form:
On Event If Condition Do Action (3.1)
which translates to: when Event occurs, if Condition is true, then execute
Action. Systems programmed with ECA rules receive input from the environment
in the form of events, and react by performing actions that change the state of the
system or of the environment. The event part specifies when a rule is triggered, the
condition part is considered as a query on the state of the system or the environment,
and the action part states the actions to be performed if the condition is verified.
Executing the rule’s actions may in turn trigger further ECA rules, and execution
proceeds until no more rules are triggered.
An ECA rule has to satisfy several properties for implementation in a wide range
of applications. Firstly, complex events occurring in a reactive rule are considered to
be a composition of several basic rules. Similarly, complex actions that are triggered
are decomposed into several actions that have to be performed concurrently or in a
given order. The ECA rules should, in general, be coupled with a knowledge base,
which contains all the rules that specify information about the environment, along
with the ECA rules that specify reaction to events. Thus, ECA rules are developed
to deal with systems that evolve. However, the evolution is limited to the knowledge
base in most of the applications. In a truly evolving system, not only the knowledge

35
base, but also the reactive rules themselves change over time to handle unambiguous
and ambiguous context information.
Unambiguous context refers to context that can be definitely depicted by events
and conditions of an ECA rule. This kind of context usually includes quantifiable data
obtained from the environment. For instance,
On < location == bedroom > (3.2)
If < Time ≥ 6 : 00PM >
Do < Switch on bedroom light >
represents an ECA rule where the bedroom light is switched on after 6:00 PM if
the user is in the bedroom. This rule is triggered on the event of the user entering the
bedroom, and the system then checks the time to see if the condition is valid. If true,
then the system executes the action, i.e., Switch on the bedroom light. In this rule,
both the location and the time are quantifiable, as sensors have the ability to detect
the person’s mobility as they pass from one room to another, and also harbor limited
capability to record the interaction of the person with the surrounding environment.
Thus discrepancies about the rule do not occur.
On the other hand, consider the following rule:
On < location == bedroom > (3.3)
If < user state == sleeping >
Do < Switch off bedroom light >
In this rule, the event can be quantified with location as the context. However,
determining the current user state proves to be a harder task. If the bed contains

36
pressure sensors, then, the system can detect the presence of the user. But the user
states could be standing, sitting, lying down and reading, or sleeping. This form of
multiple states over a single event introduces ambiguity in capturing context.
The situations or activities in a real world are often dynamic and unfold over
time. The sensory observations also evolve over time to reflect changes in the envi-
ronment. As a consequence, the dynamic aspect of ubiquitous computing requires a
monitoring system to be a time-varying dynamic model that not only captures the the
current events, but handles the evolution of different scenarios as well. The inability
of current sensory systems to correlate and reason about a vast amount of information
over time is an impediment to providing a coherent overview of the unfolding events
since it is often the temporal changes that provide critical information about inferring
the current situation [90]. To correctly assess and interpret the situation, an adaptive
approach is therefore needed that can systematically handle corrupted sensory data
of different modalities and, at the same time, can reason over time as well to reduce
context ambiguity.
3.3.2 Limitations of ECA rules
While ECA rules provide an intuitive technique to model reactive systems,
their power is limited by their implementation. Complex events or actions have to
be broken down into simpler blocks (primitives), and this could potentially lead to
multiple ECA rules being executed over a single trigger. For illustration, consider
the following rules that can be used to actively monitor a patient in an assisted
environment:

37
On < location == bedroom > (3.4)
& < body temperature > Threshold >
& < Respiratory rate > Threshold >
If < userstate == sleeping >
Do < Report condition to physician >
In this rule, we have a complex event, which fuses the context of location and
health monitoring context. The condition, on the other hand, is of the user state, and
queries if the user is sleeping, which is an ambiguous context. Even if we were able
to resolve the ambiguity with the help of other sensors, such as a video camera which
captures the position of the user, or a pressure pad, which captures the surface area
over which pressure is applied over the bed, there still exists uncertainty about the
situation, The patient could have performed some physical activity, prior to sleeping
on the bed, which could push the body temperature and respiratory rate above the
threshold. Flagging this situation as a sickness of the patient would generate a false
positive in the detection. This example, therefore, emphasizes the need for analyzing
the state of the user or an entity in the environment not just as a set of complex
events or conditions. On the other hand, prior activities usually build up to an
event occurrence, and monitoring a ubiquitous environment should be considered
as a continuous process, rather than a discrete set of events. Designers developing
systems deployed in ubiquitous environments should consider the history of activities
in the environment, and model situations based on the knowledge obtained.

38
3.4 Summary
In this chapter, we have discussed various interpretations of context, and their
limitations. In order to improve upon the understanding of context, we have presented
our definition of context which aims at extending the functionality of context with
respect to perception of user activity. We have discussed the various perspectives of
context and presented the various ways in which context can be classified. We have
investigated methods to capture context, and develop rules. We have also discussed
the limitations of such rules, and this forms the motivation for our work in situation
awareness.

CHAPTER 4
PERCEPTION OF SITUATIONS
4.1 Introduction
With the rising popularity of ubiquitous computing, the focus of developing
systems has shifted from generic to user-centric solutions. This paradigm shift in-
volves seamless integration of heterogeneous devices and sensors in the environment
to constantly monitor and perform tasks traditionally performed by the user. There
is a considerable push, therefore, to develop systems which can perceive user behav-
ior, and adapt to their idiosyncrasies. In this chapter, we discuss some limitations of
the interpretations of context, and aim to extend them, to facilitate improved con-
text awareness, and aim to perceive the situation of an entity in the environment
using context as building blocks of information. We discuss a user-centric approach
to perception of user activity in the environment, and use the knowledge obtained,
to understand user activities. We present a system for perceiving situations in the
environment, and discuss an approach to empower the user to develop complex, yet
intuitive, rules. We then present our scheme for dynamic generation of situation
grammar. We evaluate the system with two scenarios and present the performance
of the system in a dynamic ubiquitous environment.
4.2 Motivating scenario
Human behavior is described by a finite number of states called situations,
These situations are characterized by entities playing particular roles and being in
relation within the environment. Perceptual information from different sensors in
39

40
the environment is associated to the situations, roles, and relations. These different
situations are connected within a network. A path in this network describes behavior
in the scene. Human behavior and needs evolve over time. Hence, a context model
representing behavior and needs of the users must also evolve.
Consider the following real life scenario: John is a patient in an assisted en-
vironment, and his physician would like to monitor his progress remotely. John’s
physician uploads the regimen onto the system, and John is reminded to take his
medicine at the right time. Based on his recovery, John’s physician might want to
change his regimen or medication, and John is informed of the same. The system
now adjusts to the new regimen and alerts John of any new medication needed. The
system also registers the number of usages of the medication, and informs John to fill
his prescription well in advance. This scenario incorporates the concepts of remote
and local monitoring of the patient, access to sensitive information, and predictive
actions performed proactively by the system.
Consider another scenario. Mary has obtained a recipe and wants to try it out.
She accesses the ingredients from the refrigerator and pantry, and prepares the recipe.
Some of the items called for in the recipe are depleted in the preparation and Mary
wants to add them to the grocery list. After cooking, she finds that she wants to
store the recipe for future reference. Normally, Mary would file the recipe for future
reference, and add the depleted items to the grocery list. At a future date, she would
have to manually look through the recipe and check that the necessary ingredients are
available for the preparation. If would benefit the user if the system could take care
of all these tasks with a minimal amount of work. The system would file the recipe,
and check if the required ingredients are available. Also, to reduce the number of
tasks to the user, the system could automatically generate a grocery list and transfer
it to Mary’s cell phone.

41
Both these scenarios mentioned above would require the system to understand
the situation in which the user are currently in, and perform most of the tasks, and
at the same time, reducing the interaction with the user. There had been significant
amount of work in the area of recognition of daily life activities. Recognizing activities
of daily life is challenging, especially in a home or assisted environment. This is due
to the fact that the user can perform activities in several way, This would also imply
that the underlying sensors must report the features required of them robustly across
various sensing contexts [20]. A popular technique for detecting features of such
activities is known as “dense sensing” [65], in which a a wide range of sensor data is
collected instead of relying on visual based systems. Another technique has been to
use wearable sensors such as accelerometers and audio sensors which aim to provide
data about body motion and the surroundings where the data has been collected
from [62]. It has been shown in [82] that a variety of activities can be determined
using this technique.
Human activity recognition in the context of assisted environments using RFID
tags has been investigated in [65, 78].Though this approach involves extensive tagging
of objects and users, it demonstrates that hierarchical organization of probabilistic
grammars provides sufficient inference power for recognizing human activity patterns
from low level sensor measurements. A sensing toolkit for pervasive activity de-
tection and recognition has been discussed in [86]. Systems deployed in ubiquitous
environments are characterized by multiple smart cooperating entities and will have
to perform high-level inferencing from low-level sensor data reporting [8, 6]. The
presence of such heterogeneous sensors, coupled with myriad devices, drives the need
for appropriate perception of situations in the environment.

42
4.3 Perceiving Situation
(a) (b)
Figure 4.1. The environment of the system showing (a) Floor plan and distributionof nodes, (b) Minimum Spanning Tree and calculation of a zone.
Consider an ubiquitous environment shown in Figure 4.1(a). Let S = {s1, s2, . . . , sm}
sensors be distributed in this environment. Each sensor monitors a zone around it.
The zone of a sensor is calculated in the following manner: Draw a straight line con-
necting a sensor and its neighbor. The perpendicular bisector of this line forms the
edge demarcating the zones of these adjacent sensors. If a wall is encountered within
the zone, then that wall forms the edge of the zone for the sensor. We next define a
context element:
Definition 1 Context Element
A context element ci contains the information from sensor si. Therefore, C =
{c1, c2, . . . , cm} contains the data from m sensors distributed in the environment.

43
Let D = {d1, d2, . . . , dk} be k devices that are present in the environment. We
define a device as a part of the environment which the user accesses or interacts
with. In other words, we consider a device to be an object in the environment. We
collectively call the sensors and devices as nodes, and assume that there are n nodes
in the environment, where n = m + k.
During the initial discovery phase, the location of all the nodes is obtained and
a minimum spanning tree is calculated, to enable tracking of the user activity, shown
in Figure 4.1(b).
If a user enters a zone at any point and leaves the zone from any point, we
represent that using the edge present in the minimum spanning tree. If an edge is not
found, then we log the activity, and upon repeated usage of that path, we include it
into the spanning tree and remove the existing path between the two nodes. When a
user enters a node’s zone, we assume that the node generates a context element and
transmits it to the system. We define a situation in the following way:
Definition 2 Situation
A situation γ(t) is a sequence of context elements c1, c2, . . ., terminated by a device
at time t. In other words,
γ(t) = c1c2 . . . , cidj, where i ∈ {1, . . . , n}, j ∈ {1, . . . , k} represents a situation at
time t, γ(t) ∈ Γ.
According to our definition of situation, context elements correspond to non-
terminal, and devices correspond to terminal symbols respectively. As the user moves
in the environment, the context elements corresponding to the zones in which the user
traverses are obtained, and we process the elements in an online manner.

44
4.3.1 Capturing action
In order to capture activity, we associate action words or “verbs′′ to each node.
Let vi be the verb associated with the node i. Additionally, since we are capturing
user activity, we would need to analyze the motion of the user. Each type of node
is assigned verbs according to their capability. For instance, a sensor which captures
user motion would be assigned the verbs “walk”, “stand”, and “sit”. If we assume that
a normal person walks 1 m/s, and the average house size is 200 m2, the user would
enter an exit a zone once per second on an average. This would imply that we would
want our nodes to report with a very low frequency (about 1 Hz). When the user is
within the zone of the node i, we assign vi to it, where the verb would correspond to
“walk”. If the user is still in the same zone after 2 reporting cycle, we upgrade the
verb as v′
i = “stand′′. Some verbs associated with devices are “switch on”, “switch
off”, “access”, “replace”, etc. In order to differentiate between the verb of the context
element and the verb of the device, let V = {v1, v2, . . . , vp}, p ≤ m correspond to the
verbs associated with the context elements and A = {a1, a2, . . . , ap}, q ≤ k correspond
to the set of verbs associated with devices. A situation in our approach is interpreted
as an activity in the environment, and therefore, we can represent a situation as
user (subject)→ verb (action)→ environment (devices, context elements).
4.3.2 Initial Configuration
Initially, the system has to be trained to the various activities of the user and
we perform it in the following manner. Consider an arbitrary activity pattern of the
user. Let us assume that the system informs the user to take the medication. The
user, who is in the living room, gets up and moves to the bathroom, via the bedroom,
and accesses the medicine cabinet (d5). We can represent this activity by the sequence
c2v1c5v1c9v1c10v1c11v1d5v2, with the initial position of the user being a location in the

45
zone of c2. The system obtains the first (context, verb) pair and compares it with
the next (context, verb) pair in the sequence. Since the verbs in both the pairs are
similar, it uses the following rule:
Rule 1 A sequence xvyv, x, y ∈ N can be represented as (x, y)v
This rule is called the Rule of Simple Contraction. This is commutative in nature,
i.e., sequence vxvy, x, y ∈ N can be represented as v(x, y)
The system then contracts the first two (context, verb) pairs. It then compares
this with the next (context, value) pair that arrives and uses Rule 2.
Rule 2 A sequence (c1, c2)vc3v, {c1, c2, c3 ∈ C} can be contracted to (c1, c3)v
This rule is called the Rule of Compound Contraction. As in Rule 1, this rule is also
commutative, i.e., v(c1, c2)vc3, {c1, c2, c3 ∈ C} can be contracted to v(c1, c3). This rule
is helpful in eliminating redundant context information when the action performed is
the same over multiple context elements.
Rule 3 A sequence v(d1, d2)vd3, {d1, d2, d3 ∈ D} can be contracted to v(d1, d2, d3)
This rule is called the Rule of Device Listing, and is different from Rule 2, since we
would like to capture a list of all the devices that the user has interacted with.
The system continues contracting the sequence till we obtain (c2, c11)v. When
it encounters d5, it realizes that a terminal symbol has been encountered. It then
constructs the situation tree. Figure 4.2(a) describes Rule 2, and Figure 4.2(b) shows
the sequence after encountering a device.
Definition 3 An activity is considered complete when any situation si, terminating
at device di with verb v is immediately followed by a situation si+1 terminating at the
same device, but with verb v′
To implement Definition 3, we introduce the following rule:
Rule 4 A sequence terminating with v(d1, d2, . . . , di), {di ∈ D}, is constructed until
we encounter the complement

46
v′
(d1, d2, . . . , di), {di ∈ D}
This rule is called the Complement Rule, and ensures that any device accessed/switched-
on is replaced/switched-off.
Specifically, when dealing with usage of a particular device, we have the follow-
ing rule:
Rule 5 An activity is considered a usage of a device di if situation γi, terminating
at device di with verb v = “access/switch on′′ is immediately followed by a situation
γi+1 terminating at the same device, but with verb v′
= “replace/switch off ′′
In some situations, there could be a large amount of activity between accessing
a device and replacing it, for instance, talking on a phone while cooking. In such
circumstances, the sequence should be decomposed into activity performed up to
device access, intermediate activity, and activity for device release.
Rule 6 If a sequence terminates with a device or a set of devices, and the subsequent
verb obtained is not a complement of the prior verb, construct a new sequence for the
current activity, until the complement is encountered.
Using these rules, we can now represent the sequence(s) obtained as a structure.
4.3.3 Building the Situation tree
The Situation Tree structure is a binary tree constructed bottom-up, from the
sequence of context elements, verbs and devices obtained from the environment. The
Situation Tree (S − Tree) contains the following properties:
Property 1 The root of any subtree of a S-Tree is always a verb.
Property 2 The left child of any verb is a non-terminal symbol (i.e., context element
or verb).

47
Property 3 The right child of the root is either a terminal symbol (device) or a
subtree of terminals.
Property 4 The right child of any intermediate verb, whose parent is not its com-
plement, is a context element.
Property 5 The right child of any intermediate verb, whose parent is its comple-
ment, is a terminal or a subtree of terminals.
Property 6 The left subtree of any intermediate verb represents the prior activity of
the user.
Another interesting property of an S-Tree is that the post-order traversal of any
left sub-tree generates the prior user activity.
(a) (b)
Figure 4.2. Situation Tree (S-Tree) after (a) Compound Contraction, (b) Encounter-ing a terminal symbol.
4.3.4 Designing complex rules
One of the complexities of context-aware computing that developers face is to
perceive the current state of user activity. In order to resolve this, many systems
incorporate a form of “Event − Condition − Action′′(ECA) rules in order to
perform actions based on event triggers. An example of an ECA rule is given below:

48
rule: "Cooking_Rule":
Event: (location == "Kitchen")
Condition
(device == "Oven") &&
(status == "On")
Action:
assign activity == "Cooking"
A problem with ECA rules is that it tends to become complex and requires
chaining of logical operations to encompass multiple events. Additionally, since events
trigger an action, the prior activity (history) of the user might not be taken into
consideration in the condition. For instance, in the activity discussed in Section 4.3.2,
the developers might choose to discard the context information of user movement
from c2 to c10, and focus on information obtained from c11 onwards, resulting in loss
of information about the user behavior, which might be beneficial in understanding
user behavior for situation prediction. ECA rules are also not very user-friendly,
and require the user to manually decompose a complex action into various steps,
and integrate them using logical operations, which could potentially result in loss of
information.
We believe that our system improves the user interaction and allows the user to
specify custom rules naturally. Let us assume that the user would like to create a rule
which turns on the television when she walks from the bedroom to the living room.
Using ECA mechanism would involve initial location as “Bedroom”, final location
as “Living room”, and a series of operations to include the activity of walking. Our
system handles this in a graceful manner. The user would enter the rule without
decomposition as “If user walks from Bedroom to Living room, turn on the television
”. The system perceives that the subject is the user and the rest of the rule, “walks

49
from Bedroom to Living Room, turn on the television” is the activity. It then parses
the rule sequentially. The first word is a verb “walk” v1 followed by the keyword
“from”. From Rule 2, it obtains the next two elements c12, and c3, and constructs the
sequence (c12, c3)v1. It then looks up the minimum spanning tree (Figure 4.1(b)) and
expands the sequence to c12c10c9c7c5c2c3v1. The part “turn on (v2) the television” is
then translated to v2d9 and appended to the initial sequence. After parsing the rule,
therefore, we obtain the situation γ(t) = c12c10c9c7c5c2c3v1v2d9.
Suppose the user now moves from the bedroom to the living room along a
different path c12c10c9c5c3. The sequence obtained would be c12v1c10v1c9v1c5v1c3v1.
Using Rules 1 and 2, the sequence still reduces to (c12, c3)v1, and the system turns
on the television. It also registers the new path taken by the user, and upon frequent
usage of this path by the user, the system perceives that this is a preferred path, and
updates its spanning tree. The system could also observe the behavior of the user,
and develop dynamic rules based on user history. The advantages of this approach
are two-fold: (1) The system allows the user to create user-friendly rules (2) The
system can be dynamically customized to the user behavior and idiosyncrasies.
4.4 Generating Situation Grammar
From the properties of an S-Tree, we observe that we can generate different
levels of grammar by observing the elements of the tree at that level. For instance,
since all the leaves of the S-Tree are either terminals or non-terminals, we obtain
the phonemes of the situation grammar. An In-order traversal at any left child will
generate the sequence of symbols required to generate higher Level grammar. To
demonstrate the versatility of our scheme, let us consider heat therapy as an activity,
in which the user uses a heat pad to obtain muscular relief.

50
Our objective is to recognize, with a predefined confidence, if the patient has
undertaken heat therapy, by monitoring the person’s activity in the assisted envi-
ronment. However, it is not enough to recognize individual instances of “Therapy
activity”. For efficient performance of the automated system:
1. “Therapy activity” should be properly identifies and differentiated from other
similar activities, such as “cooking” or “sleeping”, that might involve accessing
common items or being in similar locations.
2. “Therapy activity” recognition should also be person-specific. This implies that
we should correctly analyze the monitored activity and differentiate it with
respect to different users.
3. In a case where the “Therapy activity” cannot be detected, the system has
to predict the most probable activity similar to it, and take necessary actions
based on pre-determined rules.
4.4.1 Formulating Initial Grammar
Our description of the “therapy activity” is based on the floor plan of the
assisted environment shown in Figure 4.1(a). We considered the approach discussed
in [54] and simulated a similar approach using S-Trees. To specify a sensory grammar
that recognizes heat therapy, we decomposed the therapy activity into a sequence of
primitive actions as:
1. Get required items from the medicine cabinet or the closet.
2. Heat the heating pad by spending time at the microwave oven.
3. Apply the heat pad on the bed or in the living room.
4. Replace the heating pad in the medicine cabinet or closet.
By decomposing the activity in this way, we can describe the process as an
ordered sequence of actions 1, 2, 3, and 4. Though this simplistic approach can ade-

51
quately capture the actions, there could be ambiguous activities when users deviate
from the normal actions. For instance, if the user forgets to replace the heat pad, or
misplaces it in a different location, the activity could be considered incomplete. Our
approach of S-Tree construction takes care of this problem and we have addressed it
in the analysis of our scheme. Another cause for ambiguity is the tendency of people
to multitask, and S-Trees resolve this problem gracefully. For example, while the heat
pad is in the microwave oven, the user might move to the living room to watch tele-
vision, or rest in the bedroom. It, therefore, becomes evident that the system would
have to handle these realistic events, and we feel that the approach of S-Trees would
resolve the ambiguity introduced by such activities. The grammar derived from these
trees would be robust to recognize as many of these instances as possible, and at the
same time, differentiate from similar activities, thereby, reducing the occurrence of
false positives, and false negatives.
4.4.2 Specifying Detailed Grammar
Figure 4.3 shows the structure of a 2-Level grammar hierarchy for recognizing
therapy activity based on the our decomposition of the activity, using the method
discussed in [54]. At the lowest level, sensors correlate the user’s identity and location
with areas and provides a string of symbols, where each symbol coincides with an
area in the assisted environment (e.g., d6, d4, etc.). This string of symbols is fed as
input to the first level grammar which translates it and encapsulates it to a new
string of higher level semantics related to the detection of the therapy activity (e.g.,
AccessPad, HeatPad, etc). The second level grammar uses the high-level semantics
identified at the immediate previous level to describe and identify a typical therapy
activity. Similarly, the output of the second level grammar can be fed to any other
higher level grammar for the detection of even higher level semantics.

52
Figure 4.3. 2-Level grammar hierarchy for the detection of therapy activity.
The detailed implementation of the proposed grammar hierarchy is shown in
Table 4.4.2. Level 1 grammar identifies the four therapy activity components (PadAc-
tion). We assume that the underlying sensors provide a sequence of the activity
regions., which are the phonemes of this language. The terminal symbols are fed
as input to the grammar and represent the different activity regions. We have also
aimed to make the grammar more powerful by adding the user as a terminal symbol.
This would help us to predict and log situations specific to a user. The non-terminal
symbols include the four heat therapy components, and a set of standard symbols
including the Start, P, and M symbols. The Start symbol is a standard symbol used
in grammar descriptions to represent the starting point of the grammar. We use the
P symbol to factor in the user, and the M symbol for recursion. The non-terminal
symbols represent the semantics into which the input of the grammar is mapped. In
our case, the output of the Level 1 grammar is any sequence of the following seman-

53
Table 4.1. Therapy Grammar Hierarchy
Level 1 Grammar
Input: A sequence of any of the terminal symbols (devices)Output: A sequence of any of the following non-terminal symbols:{ AccessPad, HeatPad, ApplyPad, ReplacePad }1. VN = { Start, M, User, Action, PadAction, ApplyPad, HeatPad,
ReplacePad, AccessPad }2. VT = { d1, d2, . . . }3. Start → P (1.0)
4. P → User M (0.5)|M (0.5)
5. M → M PadAction(0.5)|PadAction(0.5)
6. PadAction → AccessPad(0.25)|HeatPad(0.25)|ApplyPad(0.25)|ReplacePad(0.25)
7. AccessPad → MC AccessPad(0.16)|C AccessPad(0.16)|MC K(0.16)|C K(0.16) |MC O(0.16)|C O(0.16)
8. HeatPad → O HeatPad(0.5)|O(0.5)
9. ApplyPad → B ApplyPad(0.25)|ApplyPad L(0.25)|B(0.25)|L(0.25)
10. ReplacePad → ReplacePad B MC(0.125)|ReplacePad B C(0.125) |ReplacePad L MC(0.125) |ReplacePad L C(0.125)|B MC(0.125)|B C(0.125)|L MC(0.125)|L C(0.125)
Level 2 Grammar
Input: A sequence of any of the terminal symbols: { AccessPad, HeatPad, ApplyPad, ReplacePad }Output: A sequence of any of the non-terminal symbols: { HeatTherapy }1. VN = { Start, M, User, Therapy, Process, Heat }2. VT = { AccessPad, HeatPad, ApplyPad, ReplacePad }3. Start → P (1.0)
4. P → User M (0.5)|M (0.5)
5. M → M Therapy(0.5)|Therapy(0.5)
6. Therapy → Process Therapy(0.2)|HeatPad Therapy(0.2)|Heat Therapy(0.2)|Process HeatPad Process(0.2)|Heat Therapy Process(0.2)
7. Heat → AccessPad Heat(0.25)|HeatPad Heat(0.25)|AccessPad(0.25)|HeatPad(0.25)
8. Process → ReplacePad Process(0.25)|Heat Process(0.25)|ReplacePad Heat(0.25)|ReplacePad(0.25)
tics: AccessPad, HeatPad, ApplyPad, ReplacePad. When we apply this approach to
S-Trees, we obtain the Level-1 grammar from the root and the right child of each
S-Tree, and can develop the vocabulary in constant time. We then obtain the Level-2
grammar from the production rules. The rest of the lines in Table 4.4.2 describe the
production rules of the Level 1 grammar.

54
4.4.3 Assigning probabilities
Let Σ be a dictionary of the non-terminal symbols. When a user performs an
activity, the sequence vd is constructed as a non-terminal symbol and is added to
Σ. If the symbol is already present in the dictionary, then, the value of the symbol
is incremented to denote the frequency at which the symbol was generated. The
probability that a symbol is generated is therefore, a function of the symbol’s value
and the frequency of occurrence of the activity.
Figure 4.4. Level-1 Parse Tree.
The Level 2 grammar takes the activity components identified at level 1 as input.
The vocabulary of the second level grammar in Line 2 is composed by the output
semantics of Level 1 grammar. As the grammar is probabilistic, each production rule
is associated with a probability denoted as a superscript at the end of each production
rule in Table 4.4.2. It is important to note that the sum of the production probabilities
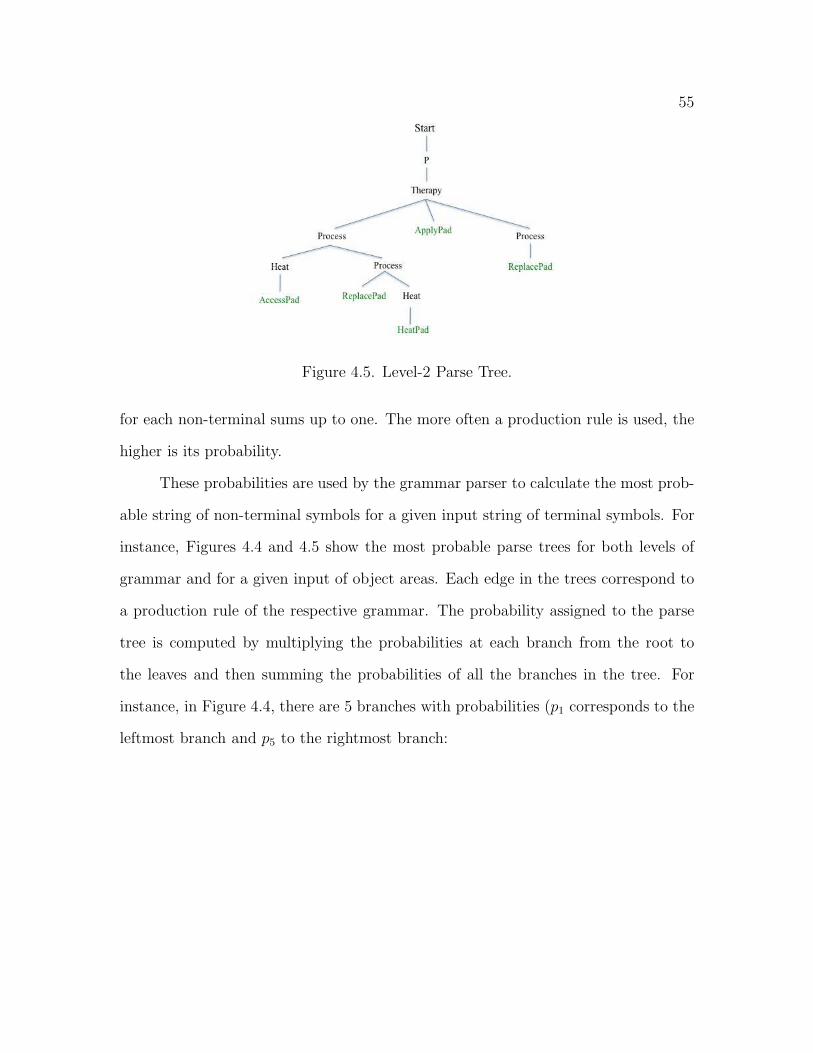
55
Figure 4.5. Level-2 Parse Tree.
for each non-terminal sums up to one. The more often a production rule is used, the
higher is its probability.
These probabilities are used by the grammar parser to calculate the most prob-
able string of non-terminal symbols for a given input string of terminal symbols. For
instance, Figures 4.4 and 4.5 show the most probable parse trees for both levels of
grammar and for a given input of object areas. Each edge in the trees correspond to
a production rule of the respective grammar. The probability assigned to the parse
tree is computed by multiplying the probabilities at each branch from the root to
the leaves and then summing the probabilities of all the branches in the tree. For
instance, in Figure 4.4, there are 5 branches with probabilities (p1 corresponds to the
leftmost branch and p5 to the rightmost branch:

56
p1 = (0.5)4 × 0.5× 0.5× 0.25× (0.16)2 = 0.0001
p2 = (0.5)4 × 0.5× 0.25× 0.125 = 0.000977
p3 = (0.5)3 × 0.5× 0.25× 0.5 = 0.0078125
p4 = (0.5)2 × 0.5× 0.25× 0.5 = 0.015625
p5 = 0.5× 0.5× 0.25× 0.125 = 0.0078125
The probability of the tree is given by
5∑
i=1
pi = 0.032327
The probability for the tree shown in Figure 4.5 can be calculated in a similar
way using the probabilities assigned to the production rules in Table 4.4.2.
4.5 Analysis
In this section, we analyze the performance of our approach with respect to
the cooking scenario, described in Section 4.2. Mary has customized a rule in the
system as “Store a new recipe”. We can make the system understand the meaning of
“recipe” by defining a recipe with the following steps:
1. Access ingredients from the refrigerator and/or pantry.
2. Spend time at the kitchen counter preparing the ingredients for cooking
3. Cook the ingredients by spending time at the stove with the stove on
4. Switch off the stove and move dish to the dining table
In our approach, we have considered that all users are honest. A honest user is
one who accesses any device or item with the intent of using the device or the item.
A single usage is equal to one unit of the item consumed or one instance of the device
being used. We have also limited the recipe generation to entering the sequence of

57
steps observed by the system, and additional nuances such as stirring, sauteing, etc.,
along with quantities of the ingredients are to be entered by the user.
(a)
(b)
Figure 4.6. Structure of S-Trees (a) After accessing ingredients, (b)(i) After switchingoff the stove, (b)(ii) When d4−2 is misplaced.
Let us assume that Mary was initially in the zone of c6 (Figure 4.1(a)), moves
to the kitchen, and accesses the ingredients in the refrigerator and the pantry. Let
us assume that d2 and d3 correspond to the refrigerator and pantry respectively,
Let {d2−1, d2−2, d2−3, d2−4} and {d4−1, d4−2, d4−3} be the ingredients accessed, and

58
verbs v1 = “walk′′, v2 = “access′′. Initially, the system monitors Mary’s activity and
observes her movement from c6 to c8, and terminates the situation when she accesses
d2−1. The initial sequence is therefore, represented as
γ1 = c6v1c7v1c8v1c8v2d2−1 (4.1)
Since the situation terminated with a device, the system, now observes the
next (context, verb) pair, to satisfy the Complement Rule (Rule 4). Instead, when it
encounters another device (d2−2), it perceives that multiple devices are being accessed,
and therefore, follows Rule 3. It simultaneously continues monitoring for a (context,
verb) pair satisfying Rule 4, until the following sequence of devices is obtained:
γ2 = c8v2d2−1c8v2d2−2c8v2d2−3c8v2d2−4c8v2d4−1c8v2d4−2c8v2d4−3c8v3d3 (4.2)
The situation at this stage is given by γ(t) = γ1 + γ2. When the system
encounters c8v3d3, it perceives that the user has started a different activity. Therefore,
from Rule 6, it creates a new S-Tree, and continues monitoring. The S-Tree for γ(t)
is constructed after applying Rules 1, 2, 3 is represented in Figure 4.6(a).
When Mary finishes cooking and switches off the oven, the sequence c8v′
3d3 is
encountered. The system then uses Rules 4, and 5 to ascertain that the activity of
cooking has been completed (Figure 4.6(b)(i)). When Mary places the dish on the
dining table, the sequence c8v1c7v1c6d8 signals the system that the recipe is complete
and can be filed in the system. When Mary starts replacing the ingredients, the
system deletes the corresponding node in the S-Tree until no right child exists, and
the S-Tree is cleared, as the system perceived that all tasks are completed.
Occasionally, the user might misplace an ingredient, and the system would have
to inform the user accordingly. Let us assume that Mary misplaced ingredient d4−2 in

59
the closet(c15) instead of the pantry. The system now has a situation where “access”
of d4−2 was at c8 but “replace” was at c15, as depicted in Figure 4.6(b)(ii). The system
would then generate the complement of the expected replace as c8v′
2d4−2, and prompts
Mary to “replace d4−2 in d4”. Mary then accesses d4−2, thereby deleting c15v2d4−2
(using Rule 4), and when the ingredient is replaced in the pantry, all S-Trees related
to the activity are cleared.
4.6 Evaluation
We simulated the environment shown in Figure 4.1(a) with up to 100 sensors
and 200 devices. We initially trained the system with 10 scenarios, to correspond to
the average daily activity of a user in the environment. We considered a total of 25
verbs, over 10 types of sensors to describe the possible actions in the environment.
We then simulated the movement of the user, changing the path at random intervals
to introduce perturbations in the sequences generated. We also altered the user path
after every 100 runs, in order to observe the adaptation of the system to new user
behavior. We conducted 1000 runs of the simulation and present an average of the
results obtained.
Table 4.2. Effect of the number of verbs on False Positives and Negatives
Runs = 500 Runs = 1000Number of False False False False
verbs Positives Negatives Positives Negatives
5 1 2 1 110 1 4 2 915 2 11 3 2820 4 26 7 6825 7 47 11 122

60
The effect of the number of verbs on false positives and false negatives is shown
in Table 4.2. We observed that the system is not affected by false positives, though
there is a significant increase in the number of false negatives, as the number of verbs
increase. This could be attributed to the number of verbs assigned to the types of
sensors. For instance, it is difficult for the system to differentiate between a user
standing, or sitting in a location. In order to resolve these, the system requires input
from surrounding sensors to resolve the ambiguity of the situation.
Figure 4.7. Effect of context elements and verbs over false positives/negatives.
We then measured the effect of varying the number of context elements over the
occurrences of false positive and negatives, with a fixed set of 10 verbs. Figure 4.7
depicts the average of 1000 test runs. We observed that though the number of false
positives and negatives were near each other, when we increased the verbs to 25,
the number of false negatives increased significantly over the number of context ele-

61
ments. This affirms the requirement of surrounding context information to alleviate
the ambiguity of the system.
In order to challenge the capabilities of the proposed scheme, we also recorded
a set of activities other than therapy in the same assisted environment. 40 traces of
such activities was collected. These activities include complex activities which could
generate sequences similar to the therapy sequence, such as getting a sweater from
the closet, then moving to the kitchen to heat coffee in the microwave oven, go to
the living room, and then move back to the bedroom to replace the sweater in the
closet. Out of these 40 traces, 30 were considered with a slight deviation from the
actual heat therapy movement, such as taking the heating pad to the dining room
and moving to the living room without replacing the pad. 10 traces of other activities
with similar sequences were also considered.
For each activity trace, we generated a simulated dataset by manually calcu-
lating the path required to be followed to perform the activity. Variations in the
paths were introduced to represent deviation from the activity into a different case.
This information was used to calculate false positives and negatives of our framework.
Table 4.3 shows the recognition results of the proposed grammar hierarchy for all the
recorded activities and the actual data. We considered heat therapy (HT ) and a
slight deviation (TD) for the activity. We also included some other activity in the
same assisted environment to test if our grammar hierarchy could properly classify
the activity as Other.
We then increased the number of users in the assisted environment to study
the effects of multiple user tracking. The results of this experiment are shown in
Table 5.3. Each user was equipped with RFID tags for differentiation. Due to the
low reliability of the tags, we saw number of false positives and negatives.

62
Table 4.3. Performance of Activity Recognition
Activity Number of Trials Correctly Classified
Simulation Experiment
HT 60 60 60
TD 30 29 28
Other 10 10 10
Table 4.4. Effect of increasing users
Activity Number of Users
2 3 4
HT 57 53 47
TD 51 48 43
Other 8 6 3
As expected, the performance degraded as the number of users increased. From
these experiments, we can infer that RF IDs are not efficient in tagging multiple users
in an assisted environment as they are prone to interference. We also surmise that,
in order to test the strength of our grammar hierarchies, varied activities with more
robust sensors have to be incorporated. For our next set of experiments, we intend to
replace the RFID tags with more reliable sensors in order to increase the reliability of
inference, thereby reducing false positives and false negatives. We are also curious to
investigate the behavior of our grammar framework in the presence of multiple users
performing different tasks.
4.7 Summary
In this chapter, we have presented a user-centric approach for capturing user
behavior and activity in a ubiquitous computing environment. We discussed some

63
limitations of the current definitions of context, and proposed a definition, focussed
on activity, rather than location. We developed a structure called a Situation Tree (S-
Tree) to represent the context elements, devices, and actions performed by the user
in the environment (verbs). We discussed the various rules required for analyzing
activity, and discussed the functionality of our system with two regular scenarios. We
simulated the environment and evaluated the system over varying context elements,
and verbs. We also discussed ways of improving the efficiency of the system by
integrating surrounding sensors.
Our approach has been designed to enable the system to dynamically adapt to
user behavior, and to empower the user to customize the system according to their
requirements, intuitively, yet efficiently. We envision that the S-Trees constructed
by the system, will enable us to develop dynamic situation grammar, customized to
user behavior, and history of user activity. An advantage of this approach is that the
loss of information during deconstruction and reconstruction of activities is minimal,
facilitating the developers, and users to create complex and varied rules to handle
scenarios in a ubiquitous environment.
We have used the heat therapy grammar as an example to demonstrate how
situational grammars can be used to detect complex patterns and situations from
simple measurements in assisted environments. From this experiment, we inferred
that there is a learning curve associated with writing good grammars. One advantage
of the grammar hierarchies is that it considerably reduces the effort in programming
the assisted environment to convert the data obtained at the sensor level, into high
level information, thus shifting focus to sophisticated pattern searching. We have
shown how reasoning with locations and a map can be performed in an assisted
environment. We are confident that this could be scaled to a much larger environment

64
with sensor networks. and also, utilize the same framework to other patterns in
different domains.

CHAPTER 5
USER PRIVACY
5.1 Introduction
Ubiquitous computing represents the concept of seamless “everywhere” com-
puting and aims at making computing and communication essentially transparent
to the users. It usually implies embedding the technology unobtrusively within all
manner of everyday computers/appliances which can potentially transmit and receive
information from the others [1]. In light of these developments, it is dangerously com-
placent to assume that social and organizational controls over accessibility of personal
information are sufficient [66], or that intrusions into privacy will ultimately become
acceptable when traded against potential benefits [8, 51]. Such a position could leave
individual users with a heavy burden of responsibility to ensure that they do not,
even inadvertently, intrude on others. It also leaves them with limited control over
their own privacy.
A frequent definition of information privacy is “the claim of individuals, groups,
or institutions to determine for themselves when, how, and to what extent informa-
tion about them is communicated to others” [84]. Despite this definition, “not sharing
information” is a fundamental aspect of privacy. The real privacy concerns people
have today revolves around who has access to what information rather than what
information is collected. A major portion of previous work on privacy has focused on
anonymizing user information or on preventing adversaries from obtaining personal
information and messages [5, 38, 36]. Though anonymity and security are a priority,
they focus on some issues of privacy and do not completely handle many situations
65

66
Table 5.1. Different scenarios and user privacy preferences
Scenarios
Activities Campus Work Home Accident
Contact Details√ √ √
Current Location√
Current Activity√ √
Context-aware remindersand notifications
√ √ √
Current Status√ √
Data Transfer/Sharing√ √ √ √
Buddy List (Chat)√ √
Identify People withsimilar needs/interests
√
Special permissions forEmergency Services
√ √ √
Number of Privacy States 3 2 2 3
where the users choose to share information with others. For example, sharing ac-
tivities or resources with friends and co-workers might be essential for a user since it
portrays a sense of virtual presence. Similarly, sharing blood type and allergies might
be essential for prompt treatment from emergency medical technicians. Existing ap-
proaches to supporting user privacy focus largely on conventional data management
schemes. However, due to the highly dynamic nature of user data, Context awareness
is a key issue in ubiquitous computing environments and has to be addressed in a
user-centric manner [36]. This implies that privacy depends not only on sets of rules
to resolve situations, but also on the granularity of user-specific privacy levels.
We conducted a survey in which we asked the students in a university cam-
pus to indicate their preference of privacy states for various context elements in a

67
campus setting, work place, home environment and in an accident scenario. Each
scenario was defined to explore both the benefit of using an application supporting
context-awareness and its impacts for privacy of those using it. One hundred subjects
were considered and we discussed our system for privacy management using privacy
states, to gauge whether they found the proposed context-aware system capable of
handling their privacy concerns. Our observations from the survey enabled us to iden-
tify users’ behavioral preferences and social interactions in these environments, and
identify contextual information needed to manage user privacy. Table 5.1 indicates
the different activities that were included in each of the four scenarios we selected
and the user preferences for privacy. These observations gave us insight to developing
context-aware rulesets for our system.
In this chapter, we present various approaches for quantizing privacy and in-
corporating it in a context-aware ubiquitous computing system. We provide a formal
representation of our scheme in the presence of context states and generate a Context-
Privacy Graph based on the rulesets and privacy settings of context elements in the
system. We also present a hybrid approach, along with an approach incorporating
user behavior in the environment. Our approaches aim to configure and monitor the
privacy of the overall system (1) based on the overall privacy set by the user (2) prior
user interactions with peers, and (3) dynamically, based on the context rulesets and
policies. At the same time, we strive to reduce the number of interactions of the
system with the user, in order to make the system more user-centric.
5.2 Motivating scenarios
A key concept of ubiquitous computing is empowering technology to create a
convenient environment surrounding the user which merges physical and computa-
tional infrastructures into an integrated information oriented habitat. One of the

68
challenges in deploying ubiquitous computing services on a significant scale is making
adequate provision for handling personal privacy.
Consider a highly dynamic ubiquitous environment such as a university campus
with complete wireless coverage. The diversity of heterogeneous devices and the
volume of users of the infrastructure causes implementation of privacy policies a
daunting tasks. It is difficult for designers of ubiquitous middleware to encompass
the myriad information flows into rulesets and incorporate them. The key challenge
is to engineer a framework capable of adapting to such a highly chaotic environment
and seamlessly integrate itself with the existing legacy systems. To illustrate this
point, we present the following scenario:
5.2.1 Scenario 1
Bob logs into an instant messenger service on campus using his PDA. He would
like to be visible to his friends on his messenger list and sets his status to ”available”.
He also wants his friends to know his location on campus but does not want to reveal
his current activity. Bob has also stored his address, and contact details and would
like to make them private to others. Alice is his partner on a project and would like
to make changes to the project report. Bob shares the file with Alice and they update
the new file on both their devices.
In the scenario described above, it is necessary for the user to interact with
the system to perform all the tasks, since most of the actions needed are based on
the social and behavioral nature of the user. Increased queries to the user or limited
flexibility of the system would defeat the purpose of a ubiquitous computing system.
In is for this reason that designers constantly include huge configuration steps for
incorporating privacy into the system. This would be necessary for making the system

69
robust, but deters the user for using the system efficiently. A case in point would be
the User Account Protection feature of MicrosoftR Windows Vista [57].
A user profile is another method of setting the required privacy levels to infor-
mation and also generating rulesets for the system. In this approach, a preference
pane is included in the settings of the system, in which the user chooses the privacy of
various elements of information. These in turn translate into rules and are referred to
upon occurrence of an event. One problem area to be tackled is that of sharing and
distributing information between users, i.e., not only between participants in a sin-
gle application such as a conference, but also across difference applications, without
querying the user for authentication. Scenario 2 describes such an event
5.2.2 Scenario 2
John stores his emergency information, medical and auto insurance, blood type,
allergies, and a couple of work-related files on his smartphone. In the eventuality of
an accident, the Emergency Medical Technicians (EMTs) arrive at the scene of the
accident and issue a request to all the devices in the vicinity for information. When
John’s smartphone receives the request, it checks the user profile of John and shares
only the emergency information. medical insurance, blood type, and allergies with
the EMTs, and hide the other information from them. The system queries John for
approval of the new rules. Upon receiving no user input, the system predicts that John
has been incapacitated and enforces the new rules.
This scenario involves modification to the system based upon various context
elements such as location, device properties, type of user, etc., and also on the social
interaction of the users. The ubiquitous system should be able to predict the pri-
vacy level of the interaction or the session based on peer bonding and organizational

70
hierarchy. At the same time, it should allow the user to set privacy levels to other
individuals based on their social interaction.
These problems that are constantly faced while developing systems for ubiqui-
tous computing environments form the motivation for our work. In this paper, we
present a scheme for quantizing privacy in context-aware systems, and aim to resolve
some of the challenges of infusing privacy into such systems.
Designers constantly include huge configuration steps for incorporating privacy
into the model. This would be necessary for making the system robust, but deters
the user from using the system effectively. Web services [14, 33] aims at promoting a
modular, interoperable service layer on top of the existing Internet software [11], but
lacks consistent management and are tightly bound to the simple object access proto-
col (SOAP) which constrains compliance to various ubiquitous computing protocols.
Jini [74], is a service oriented architecture that defines a programming model which
both exploits and extends Java technology to build adaptive network systems that are
scalable, evolvable and flexible as typically required in dynamic computing environ-
ments. Jini, however, assumes that mobile devices are only service customers which
is not the case. We aim at reducing the task of user configuration by introducing
classification of information based on privacy levels.
5.3 Our Approaches to Quantization of Privacy
Consider a ubiquitous computing environment U in which n heterogeneous sen-
sors have been deployed. Let S = {s1, s2, . . . , sn} denote the set of all sensors in U ,
which collect data about U and report them periodically. The data from each sensor
is collected and stored in a structure called a context element.
Figure 5.1 shows the structure of a context element. It consists of a SensorID
which indicates the sensor si from which the context element was created, data

71
Figure 5.1. Structure of a context element.
from si, a T imeStamp to denote the time of creation of the context element, and
a Privacysetting which indicates the privacy level assigned to the context element.
If a context element is created at time t, it is said to be active. Related active context
elements merge together to form a context state
Definition 4 Context State
A context state I(t) describes the current state of the application (or system) at time
t, and is derived from the active context elements at that time. It is a collection of r
context elements that are used to represent a particular state of the system at that time.
A context state Ij(t) at time t is defined as Ij(t) = {c1(t), c2(t), . . . , cr(t)}(r ≤ m)
Definition 5 Privacy State
A privacy state P (t) represents the amount of privacy assigned to the various con-
text states. it is a collection of various context states and is given by Pk(t) =
{I1(t), I2(t), . . . , Iq(t)} for q context states present at time t.
5.3.1 Assignment of privacy weights
We consider a weighted approach to assignment of privacy in our scheme. Let
l be the number of privacy levels allowed. Let L = {1
l, 2
l, 3
l, . . . , a
l, . . . , 1}, (a < l)
be the permissible privacy levels in our scheme. Privacy weights are assigned to the

72
actice context elements, and these weights are used to compute the weights of the
context states and privacy states. These weights are then stored in a transaction
log. There are two approaches of assigning privacy weights to the context elements -
User − centric and System− centric.
5.3.1.1 User-centric approach
In the user-centric approach, the frontend of the system contains a privacy
slider which ranges from 1
lto 1. This enables the user to adjust the privacy setting
of the overall system in a simple way, and also allows the user to understand the
amount of privacy set. This is similar to the security level slider in the internet
explorer browser of MicrosoftR Windows. The privacy slider introduces familiarity
to the assignment of privacy and also makes the setting intuitive to the user. The
frontend also contains simple methods to generate user-specified rule sets to handle
various context elements. The system obtains the active context elements and creates
context states from the rule set present in the system. The various context states
formed from the active context elements are then assigned to privacy states and a
Context − Privacy Graph is generated. In this approach, we set the number of
privacy states to three for ease of computation and for easy interpretation by the
user.
5.3.1.2 System-centric approach
In this approach, the system sets a privacy setting for the context elements by
assigning weights to the active context elements and computing the weights of the
context states. These context states are then assigned to privacy states depending on
the weights.

73
Let wt(ci) be the privacy weight of context element ci at t. The system first
searches the transaction log for any prior existence of the context element and assigns
that weight to wt(ci(t)) if obtained. In the absence of any record of the context
element in the transaction log, the system sets a default weight of w0(ci(0)) = 1
lto
the context element, where w0(ci) represents the initial privacy weight of the context
element ci. wt(ci(t)). If weights have been specified for context elements in the rule
set, the corresponding weight is set as the initial weight for ci(t).
Based on the rule set present in the system, different context states are created
based on the active context elements at time t. Since wt(ci(t)) represents the un-
certainty of privacy in ci(t), the privacy weights of the context state wt(Ij(t)) is the
entropy contained by Ij(t) and is calculated by
wt(Ij(t)) = −r
∑
i=1
wt(ci(t)) log wt(ci(t)), (5.1)
where, Ij(t) = {c1(t), c2(t), . . . , cr(t)}.
The number of privacy states (k) is then obtained by the ratio of the total
number of context elements to the number of active elements present in the system
at time t.
k =m
r(5.2)
If the ratio results in a fraction, it is rounded up to the next nearest integer.
Thresholds are set for assignment of context states to the various privacy states in
increments of 1
k. If rules have been specified in the rule set for assigning context
spaces (or elements) to particular privacy states, the weights of the context states
are increased (or decreased) accordingly using increment (or decrement) functions.

74
Figure 5.2. Transition of Context States in a k -privacy state system.
Figure 5.2 describes the transition of context states from one privacy state to another
based on their privacy weight. The weight of each privacy state then is calculated by
wt(Pk(t)) =
q∑
j=1
Ij(t) (5.3)
where, Pk(t) = {I1(t), I2(t), . . . , Iq(t)}.
The overall privacy setting of the system (θ) is now obtained by
θ =
k∑
i=1
Pi(t) (5.4)
5.3.2 Context - Privacy Graph
The Context - Privacy Graph (CPG) is a Directed Acyclic Graph (DAG) created
with the privacy setting of the system (θ) as the root and the context elements at
the lowest level. Figure 5.3 describes a Context - Privacy Graph with three privacy
states. Multiple context elements form a context state based on the existing rules in
the rule set, and based on the privacy of each context element, the weights of the
context states and the privacy states are calculated.

75
Figure 5.3. A Context Privacy Graph.
5.3.3 Incrementing and Decrementing Privacy
Context states are allocated to Privacy states based on their weights and can be
moved from one privacy state to another based on their weights as shown in Figure 5.2.
To achieve this, we define two functions Incδ(w) and Decδ(w) which increment or
decrement the value of w by δ. These two functions are of type [0, 1]→ [0, 1] such that
given a weight w, they return an incremented or decremented weight, w′
, respectively.
We assume that these functions [80] satisfy the following two properties:
• Incδ(Decδ(w)) = w and Decδ(Incδ(w)) = w, i.e., they are mutually commuta-
tive.
• The two functions are order-independent with regard to the context elements,
i.e., fδ(gδ′ (w)) = gδ1(fδ(w)) where f, gǫ{Inc, Dec}
We choose the following functions, which satisfy the above properties, to calcu-
late the adjustments:

76
Incδ(w) = wδ (5.5)
Decδ(w) = δ√
w (5.6)
Incδ(w) and Decδ(w) can be used in either user-centric or system-centric ap-
proaches. In a user-centric approach, the overall privacy setting of the system (θ) and
the assignment of context elements to one of the three privacy settings are performed
by the user. The privacy weights of the context states are then incremented and
decremented using the Equations 5.5 and 5.6 such that Equations 5.3 and 5.4 are
satisfied. In the user-centric approach, δ is set to 1
3.
In the system-centric approach, the CPG of the system at time t is created with
the weights of the context elements, context states, and privacy states at t. Based
on the rule set, the allocation of context states to privacy states might need to be
altered. In such a situation, we set δ as the ratio of the number of context elements
in context state Ij(t) to the number of active context elements at t. Therefore,
δ =r
m, (r < m) (5.7)
Let Ij(t) be the context state to be incremented. Applying Equation 5.5, we
obtain wt(Ij(t)) as the new weight of Ij(t).
wt(Ij(t)) = Inc rm
(wt(Ij(t)) (5.8)
= (wt(Ij(t))rm
wt(Ij(t)) is rounded off to the nearest lth privacy level and the privacy weights
of the context elements in Ij(t) are increased by multiples of 1
lto satisfy Equation 5.1.
Algorithm 1 describes Privacy Tuning using Incδ(w) and Decδ(w).

77
Algorithm 1 Privacy Tuning1: /* Construct CPG with ci(t), Ij(t), and Pk(t) */
2: Compare CPG with rulesets
3: if Ij(t)) is allocated to different Pk(t) in ruleset then
4: Obtain weight thresholds wmin and wmax for proper privacy state
5: if wt(Ij(t)) < wmin then
6: Incδ(wt(Ij(t))
7: Increment wt(ci(t)) by 1l
until
wt(Ij(t)) = −∑r
i=1 wt(ci(t)) log wt(ci(t))
8: Calculate wt(Pk(t)) and θ
9: Incδ(wt(Ij(t)) until θ =
∑ki=1 Pi(t)
10: end if
11: if wt(Ij(t)) > wmin then
12: Decδ(wt(Ij(t))
13: Decrement wt(ci(t)) by 1l
until
wt(Ij(t)) = −∑r
i=1 wt(ci(t)) log wt(ci(t))
14: Calculate wt(Pk(t)) and θ
15: Decδ(wt(Ij(t)) until θ =
∑k
i=1 Pi(t)
16: end if
17: end if
5.3.4 Hybrid Approach
A problem observed in the system-centric approach to quantization of privacy
elements is the time taken to obtain a steady-state solution. As the number of con-
text elements and privacy levels increase, the delay involved in computation of the
weights becomes observable. This problem is further magnified by the choice of the
incrementing and decrementing functions. In this regard, we have designed a hybrid
approach to reduce the computational delay.

78
Consider a session in which user B requests context elements Creq =
{c1(t), c2(t), c3(t), . . . , cs(t)}. Let us assume that the user A has set the privacy values
for context elements, and a value for the total privacy of the system (θ). In the user-
centric approach, we would query the user regarding permission for satisfying the
request from B. In the hybrid approach, we calculate the total privacy weight of all
the elements in Creq(t) and compare with θ. Formally, we check if
s∑
j=1
Pj(t) ≤ θ (5.9)
where s is the number of elements in Creq(t). If Eq. 5.9 is satisfied, we then
inform A of the requested elements, and await approval. If not satisfied, we then
calculate the maximum number of elements which can satisfy Eq. 5.9. This can be
achieved using dynamic programming, by mapping it to a 0-1 knapsack problem. The
aim is to
maximize C′
req(t) =s
∑
j=1
cj subject tos
∑
j=1
Pj(t) ≤ θ, cj(t) ∈ {0, 1} (5.10)
We then inform A of the session, C1req(t), and query the user for permission to
share 1 − C′
req(t) context elements. This approach is advantageous in the following
ways: (1) If Eq. 5.9 is satisfied, we only have to inform the user of the session and the
information that has been allowed for sharing, thereby eliminating multiple queries.
(2) We calculate the elements that can be shared using Eq. 5.10, and then appraise
the user of the session, context elements that are currently allowed, and permission to
share the remaining context elements. This approach enables the user to know at a
glance, the context elements that have been shared, and also modify privacy levels of
context elements without additional interactions. The Hybrid Approach is depicted
in Algorithm 2.

79
Algorithm 2 The Hybrid Approach1: Obtain request Creq = {c1(t), c2(t), c3(t), . . . , cs(t)}
2: if∑s
j=1 Pj(t) ≤ θ, cj(t) then
3: Inform user of session request; Obtain permission to share.
4: else
5: Construct Decision Tree
6: Maximize C′
req(t) =∑s
j=1 cj subject to∑s
j=1 Pj(t) ≤ θ, cj(t) ∈ {0, 1}
7: Inform user of session request
8: Obtain approval for C′
req(t); Query permissions for 1− C′
req(t)
9: end if
5.3.5 Privacy Quantization based on User Behavior
The hybrid approach reduces the number of queries prompted to the user to
resolve sharing permissions. Indeed, this significantly decreases the number of inter-
actions that the user has with the system. However, this approach is on a per-session
basis, and it is advantageous to implement a generic solution. One shortcoming of
the hybrid approach is the inability to factor session history in order to obtain a
better understanding of privacy levels. This problem can be resolved in the following
approach.
Let D be a dictionary of the interactions, and context elements shared by user A
(Source) with other users. Let us set the key for this dictionary as a tuple (uj, cs(t)) for
a session in which user uj requests context element cs at time t. The value for this key
would be the number of times that cs has been shared with uj, and will be incremented
for consequent sharing. Initially, we start with an empty dictionary, and then train
the system based on the history of interaction of A with various users, by querying A
for permission. When we receive a request Creq = {c1(t), c2(t), c3(t), . . . , cs(t)} from
uj, for every element in Creq, we check if the key (uj, cs) is present in D. If the key is

80
Algorithm 3 Privacy Quantization based on User Behavior1: /* Construct a Dictionary D */
2: for every element in Creq = {c1(t), c2(t), c3(t), . . . , cs(t)} from uj do
3: if (uj , cs) has no key in D then
4: p(cs|uj)← 1P
Nuj
5: else
6: p(cs|uj)← value(uj ,cs)P
Nuj
7: end if
8: end for
9: Display Creq with corresponding p(cs|uj) for permission from user
10: C′
req ← updated Creq
11: for every element in C′
req do
12: if (uj , cs) has no key in D then
13: Insert (uj , cs) in D
14: value(uj, cs)← 1
15: else
16: value(uj, cs)← value(uj, cs) + 1
17: end if
18: end for
not present, insert the key with a value of 1, indicating that this is the first time cs is
being shared with uj. If the key is already present, we then calculate the probability
that context element cs is shared with user uj as
p(cs|uj) =value(uj, cs)
∑
Nuj
(5.11)
where, Nujrepresents the number of sessions between A and uj. If
p(cs|uj) ≥∑s p(cs|uj)
s(5.12)

81
we add that element to the session list and continue with the next element.
Finally, we display the proposed session list C′
req to A, along with the request for
confirmation, and based on permission, increment the value of the corresponding key.
We describe this in Algorithm 3.
5.4 Analysis
In this section, we consider the two scenarios presented in Section 5.2 and
demonstrate the working of our scheme presented in the previous section. Consider
Scenario 1 presented in 5.2.1. The user Bob logs into his instant messenger (im)
client and sets his status as “available”. He has also created rules to set his loca-
tion transparent and his current activity, address, and contact details (name, phone
number, email address, etc.) private. He also intends to share a file with Alice, and
allow read/write permissions to her for that file. In this scenario, let us assume that
there are 10 privacy levels (l) and P1, P2, and P3 correspond to the privacy states
Transparent, Protected, and Private respectively. The active context elements and
context states are
C =
im status, activity, first name, last name
location, address, email, phone, file, buddy
I =
{
active application, contact, shared resource
}
The context states are assigned the privacy states based on the rule sets in the
system. An example of a rule set is given below:
rule: "rule_A"
when
(active_application == "im") &&

82
(location == "campus")
then
assign active_application to Transparent
5.4.1 System-centric approach
We now assign weights to the active context elements. The context state
contact information (I1(t)) consists of the active context elements {first name, last name,
address, email, phone} and the context state should be private. The context state
active application (I2(t)) consists of the context elements im status and location and
has been set Transparent. Also, the context state shared resource (I3(t)) consists
of the file to be shared and the buddy to share the file with and is assigned a privacy
state of Protected. Each context element is assigned a privacy level of 1
l= 0.1. Then
wt(I1(t) = −∑5
i=1wt(ci(t) log wt(ci(t) which gives a privacy level of 0.5. Since I1(t)
is private, wt(P3) = 0.5. Similarly, we calculate the weights of the other privacy
states and obtain wt(I2(t)) = 0.2 (with context elements {imstatus, location}) and
wt(I3(t)) = 0.2 (with context elements {file, buddy}). The overall privacy setting of
the system θ is obtained from Equation 5.4.
θ =3
∑
i=1
wt(Pi(t))
= 0.2 + 0.2 + 0.5
Therefore, the overall privacy setting for Scenario 1 is 0.9. Let us now consider
Scenario 2 described in 5.2.2. Let us assume that there are 100 privacy levels (l = 100),
10 active context elements (m) and I1, I2, . . . , I5 correspond to the context states for
emergency information, auto and medical insurance, blood type, allergies, and work-
related files respectively. Let wt(P1(t)) = 0.1, wt(P2(t)) = 0.2, and wt(P3(t)) = 0.4.
John then modifies his preferences and sets I1, I2, . . . , I5 to Protected and the overall

83
privacy setting θ to 0.8. The privacy weight of P2(t) has to be increased to 0.3,
and the system achieves this by incrementing the weights of the context states under
P2(t) using Equation 5.8. Let us assume that I3 has 4 context elements (r) and initial
privacy weight of 0.02. We first calculate δ = 4
10which comes up to 0.4. We then
apply Equation 5.8 to get
wt(I3(t)) = Inc0.4(0.02)
= 0.21
The context elements of I3(t) are increased by 0.01 until they satisfy Equation 5.1.
The other context states are also incremented until wt(P2(t)) = 0.3. If the user
modifies the rulesets by assigning context elements to different privacy states, the
context states containing those elements are assigned to the new privacy states in the
CPG and the weights are updated.
5.4.2 Hybrid approach
Let us assume that a request Creq = {c1, c2, c3} was sent by user B to user A.
Let us assume that the privacy levels for c1, c2, c3 are 0.5, 0.3 and 0.2 respectively. Let
us assume that θ = 0.6. We can calculate
3∑
j=1
Pj(t) = 0.4 + 0.3 + 0.2
= 0.9
Since this does not satisfy Eq. 5.9, we then develop the decision tree, as shown in
Figure 5.4, and try to maximize

84
Figure 5.4. Decision Tree for the Hybrid approach.
C′
req(t) =
s∑
j=1
cj
subject tos
∑
j=1
Pj(t) ≤ θ, cj(t) ∈ {0, 1}
The decision tree is a greedy algorithm and therefore chooses C′
req = {c1, c3}.
We display these elements as shareable, and query the user regarding permission for
c2. Table ?? shows the working of the algorithm with one user, over various privacy
levels.
5.4.3 Privacy Quantization based on User Behavior
We considered a dynamic environment, in which each user interacts with a
number of peers, and numerous sessions of information exchange occur. We defined
each session as any established connection between two users. Figure 5.5 depicts
a typical user’s interaction with his/her peers in an environment. Let us consider
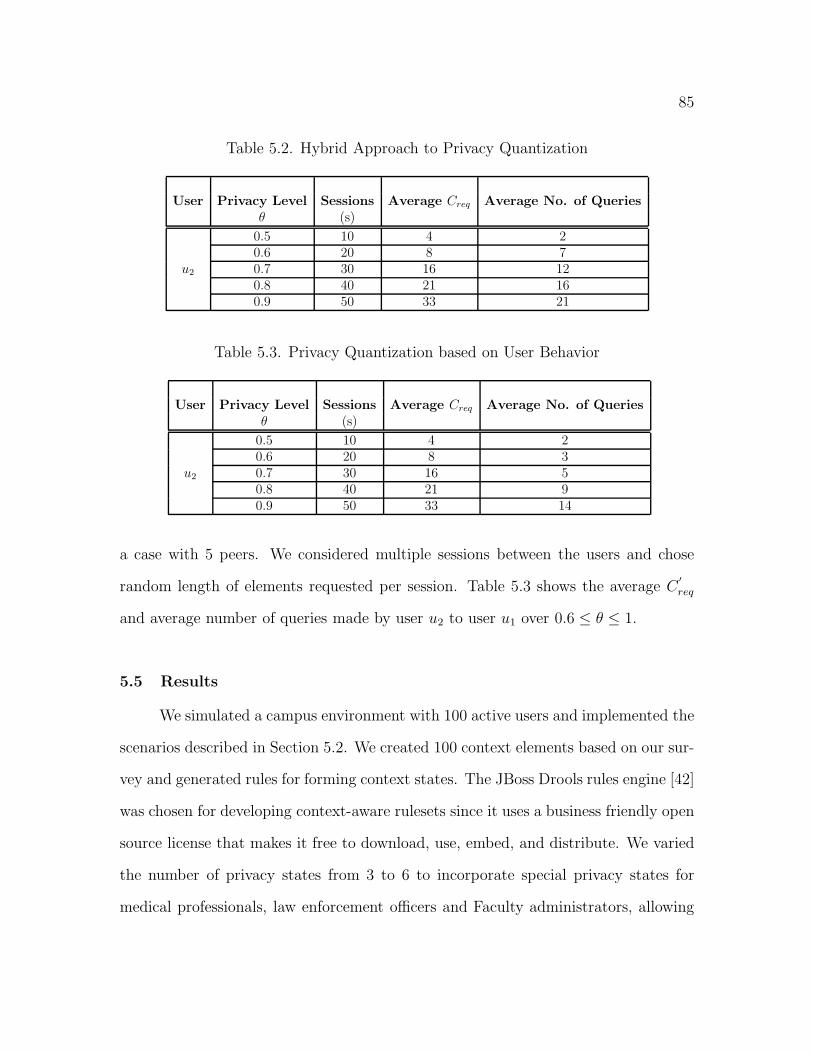
85
Table 5.2. Hybrid Approach to Privacy Quantization
User Privacy Level Sessions Average Creq Average No. of Queriesθ (s)
u2
0.5 10 4 20.6 20 8 70.7 30 16 120.8 40 21 160.9 50 33 21
Table 5.3. Privacy Quantization based on User Behavior
User Privacy Level Sessions Average Creq Average No. of Queriesθ (s)
u2
0.5 10 4 20.6 20 8 30.7 30 16 50.8 40 21 90.9 50 33 14
a case with 5 peers. We considered multiple sessions between the users and chose
random length of elements requested per session. Table 5.3 shows the average C′
req
and average number of queries made by user u2 to user u1 over 0.6 ≤ θ ≤ 1.
5.5 Results
We simulated a campus environment with 100 active users and implemented the
scenarios described in Section 5.2. We created 100 context elements based on our sur-
vey and generated rules for forming context states. The JBoss Drools rules engine [42]
was chosen for developing context-aware rulesets since it uses a business friendly open
source license that makes it free to download, use, embed, and distribute. We varied
the number of privacy states from 3 to 6 to incorporate special privacy states for
medical professionals, law enforcement officers and Faculty administrators, allowing

86
Figure 5.5. User interaction with peers.
us to assign pertinent context elements directly to those states. Different users were
created using various J2METM Mobile Information Device Profiles (MIDP) [58]. We
implemented an instant messaging (IM) client on all the active user devices and built
buddy lists based on the sharing rules created.
(a) (b)
Figure 5.6. Graphical User Interfaces (GUIs) of the system showing (a) User prefer-ences (b) User Query.

87
Figure 5.6(a) shown the GUI of the system, where the user can set privacy
levels for different context elements. Since we observed in our survey that users have
a better perception of data, we have represented the context elements as data in order
to bring transparency into the system. A privacy slider is also included to enable the
user to set the overall privacy setting of the system, and based on the ruleset, the
context elements are assigned to the different privacy states. The range of the privacy
slider has been set as 1 – 10 for the user to intuitively understand the functioning
of the slider. The user can view his/her prior sessions, and also view the context
elements stored in different categories based on his/her social interactions with other
users.
Figure 5.7(a) shows the behavior of Incδ(w) and Decδ(w) with various ranges
of δ. We then varied the number of privacy states from 2 – 6 to find its effect on the
number of incremental or decremental operations. We considered 5 variations in θ over
varying privacy weights and Figure 5.7(b) represents an average of 100 test runs. We
found that the number of operations increase drastically when we add extra privacy
states beyond 4. We then decided to vary the Increasing and decreasing functions to
find their impact on the number of operations. We considered the alternate functions:
Incδ(w) =(w + wδ)
2(5.13)
Decδ(w) =(w + δ
√w)
2(5.14)
We observed that these functions incremented and decremented slower than
Equations 5.5 and 5.6 in the presence of privacy states more than 3. Figure 5.7(d)
shows the number of operations with the new function. It is therefore advantageous
to use Equations 5.5 and 5.6 for up to 4 privacy states.

88
(a) (b)
(c) (d)
Figure 5.7. (a) Incδ(w)/Decδ(w) with various ranges of δ (b) Number of Incre-ment/Decrement operations with varying privacy states (c) Equations 5.13 and 5.14for ranges of δ (d) Number of Increment/Decrement operations using Equations 5.13and 5.14.
We then simulated a dynamic environment with up to 100 users and ran an
average of 50 sessions between them. The results of this simulation for 5 random
users are shown in Table 5.4. We set the number of privacy states to 3 (Transparent,
Private, and Protected), and varied the privacy setting of the system from 0.5 to 0.9,

89
Table 5.4. Hybrid Approach: 5 users, up to 50 sessions, variations in θ
User Privacy Levels Sessions Average Creq Average No. of Queriesθ (s)
u2
0.5 10 4 20.6 20 8 30.7 30 16 50.8 40 21 90.9 50 33 15
u3
0.5 10 4 60.6 20 7 90.7 30 12 130.8 40 19 170.9 50 23 21
u4
0.5 10 5 30.6 20 11 40.7 30 18 90.8 40 22 110.9 50 37 23
u5
0.5 10 6 10.6 20 14 60.7 30 23 110.8 40 31 180.9 50 39 27
with a random size of Creq for each session. We observed that when we increased the
privacy setting, the average number of queries made to the user for sharing permissions
reduced. This implies that the decision tree generated a maximized solution for C′
req,
reducing the effective number of queries to the user. We then reduced the privacy
setting up to 0.1, but observed that the Hybrid approach presented the optimal
solution only when the decision tree could be populated with a few marked context
elements, and a privacy setting < 0.5, tended to increase the number of queries to
the user.
We then repeated the same experiment for privacy quantization using user be-
havior, and the results are presented in Table 5.5. We observed that this approach
drastically reduced the number of queries for sharing permissions. In our experiment,

90
Table 5.5. Privacy Quantization based on User Behavior: 5 users and up to 50 sessionswith variations in θ
User Privacy Level Sessions Average Creq Average No. of Queriesθ (s)
u2
0.5 10 4 10.6 20 8 20.7 30 16 40.8 40 21 60.9 50 33 8
u3
0.5 10 4 30.6 20 11 30.7 30 15 40.8 40 18 50.9 50 23 7
u4
0.5 10 4 10.6 20 8 10.7 30 12 40.8 40 17 70.9 50 23 11
u5
0.5 10 5 20.6 20 7 30.7 30 14 40.8 40 26 60.9 50 33 8
we observed that if the user has sessions which involved smaller size of Creq, it took a
longer time to populate the dictionary with (user, element) pairs, and therefore, the
number of queries for the initial sessions was pretty high. However, as the number
of elements were shared with a user, the system reduced significantly, as can be seen
in Table 5.5. We also observed that for a large size of Creq, the system outperformed
both the System-centric and the Hybrid approaches. As a case study, we increased
the number of sessions to 100 and the number of context elements to 100. We varied
the privacy setting from 0.5 to 0.9 as before. We observed that the System-centric
approach spent considerable amount of time in balancing the weights, while the Hy-
brid approach eliminated this problem. However, the number of queries to the user
were large, since the decision tree could not mark a majority of context elements, and

91
therefore, had to rely on the user feedback. On the other hand, the approach with
user behavior improved over time, due to a rich population of the dictionary, and the
average number of queries was still considerably small.
(a) (b)
(c) (d)
Figure 5.8. (a) System-centric approach with varying privacy levels (b) Hybrid Ap-proach with varying privacy settings (c) Privacy quantization using user behaviorover varying privacy settings (d) Comparison of the three approaches with respect tothe number of operations/queries.

92
The averaged results of our simulation are presented in Figures 5.8(a) - 5.8(d).
We considered 2 - 10 privacy levels for the system-centric approach and ran a sim-
ulation with up to 25 sessions, as shown in Figure 5.8(a). We then increased the
number of sessions to 50, and observed that it took a considerable amount of time
for the system to attain a steady state. We then tested the hybrid approach and
the approach with user behavior, for up to 50 sessions, and presented the results in
Figures 5.8(b) and 5.8(c) respectively. Figure 5.8(d) describes our comparison of the
three approaches with respect to the number of context elements and average number
of operations (or queries).
5.6 Summary
In this chapter, we have presented user-centric approaches for introducing gran-
ularity of user privacy in context-aware systems deployed in ubiquitous computing
environments. We have described our proposed approaches and analyzed them in
various scenarios. The approaches are highly scalable and can be extended to include
input from sensors monitoring the physical environment, or new devices entering the
ubiquitous computing environment. We have developed a GUI to make perception
of privacy intuitive for the user, yet allowing the scheme to be adept in resolving
context.

CHAPTER 6
SITUATION-AWARE MIDDLEWARE
As applications and systems are rapidly becoming more networked, there is a
constant need for an approach to manage the complexity and heterogeneity inherent
in such distributed systems. Middleware performs this task of connecting parts of the
distributed application, and is traditionally a layer between the network and appli-
cation layers. A common definition of middleware is software that connects different
parts of an application or a series of application. In other words, it can be considered
as software that functions as a conversion or translation layer, a consolidator, and an
integrator. Many middleware solutions have been developed to enable applications
running on different platforms, or developed by different vendors, to communicate
with each other. Every type of middleware, however, has the same general purpose
of extending the scope of an application or applications over a network. Ubiquitous
middleware, on the other hand, are constrained in development by unique challenges
owing to the nature of the environment in which they are deployed.
6.1 Challenges of designing Ubiquitous middleware
Conventional middleware include five pitfalls that a designer faces while imple-
menting middleware in a ubiquitous computing environment in [47]. The common
vulnerabilities encountered while developing such a ubiquitous computing system can
be categorized into flow-based, or process-based. The former is the inability to asso-
ciate relevant information and lack of transparency, and the latter deals with issues
such as configuration being given importance over action, and the granularity of the
93

94
system incorporating social variations. These two categories are interwoven, but de-
marcating them can help designers in analyzing them. Some of the current problems
involved in developing a privacy-sensitive ubiquitous computing framework are:
6.1.1 Inability to associate relevant information
A ubiquitous computing environment is a challenge to designers of middleware.
It is difficult to encompass the myriad information flows that exist in such a chaotic
environment. Many of the middleware are designed as an Event-Condition-Action
(ECA) approach [12, 52, 48]. Importance has to be given to the relevance of data
pertaining to a session. It would be more advantageous taking a user’s behavior as
an entity and deriving work flows from it, rather than considering events as a basal
unit [71]. The middleware should be able to predict the information required for a
particular service. For example, a request for a user’s contact details should include
email address, address, and phone number. It is redundant to have multiple requests
for each piece of information.
6.1.2 Lack of transparency in authentic information
In human-computer interaction, computer transparency is an aspect of user
friendliness which relieves the user of the need to worry about technical details. When
there is a large gap between user perception and actual authentic information, the
system is failing in representation of information. Information transparency changes
behavior [25], and there have been some efforts in the field of privacy enhancing
technologies that help create transparency of information security practices.
One problem area to be tackled is that of sharing and distributing informa-
tion between users, i.e., not only between all participants in a single application such
as a conference, but also across different applications, for e.g., information retrieval.

95
This makes the need of information brokers imperative. CORBA Component Model
(CCM), an extension of “language independent Enterprise Java Beans (EJB)” [17],
is a broker oriented architecture. By moving the implementation of these services
from the software components to a component container, the complexity of the com-
ponents is dramatically reduced [24]. One drawback of CCM is the lack of provision
for tackling the issue of disconnected processes, which is rampant in a ubiquitous
computing environment [83].
6.1.3 Configuration superseding action:
Designers constantly include huge configuration steps for incorporating privacy
into the model. This would be necessary for making the system robust, but deters
the user from using the system effectively. Web services [14, 33] aims at promoting a
modular, interoperable service layer on top of the existing Internet software [11], but
lacks consistent management and are tightly bound to the simple object access proto-
col (SOAP) which constrains compliance to various ubiquitous computing protocols.
Jini [74, ?], is a service oriented architecture that defines a programming model which
both exploits and extends Java technology to build adaptive network systems that are
scalable, evolvable and flexible as typically required in dynamic computing environ-
ments. Jini, however, assumes that mobile devices are only service customers which
is not the case. We aim at reducing the task of user configuration by introducing
classification of information based on privacy levels.
6.1.4 Granularity of the system incorporating social variations
The ubiquitous framework should be able to predict the privacy level of the
session based of peer bonding and organizational hierarchy. At the same time, it
should allow the user to set privacy levels to other individuals based on their social

96
interaction. Since it is difficult to define privacy, we considered it beneficial to incor-
porate a privacy slider to effectively depict the granularity of user interpretation. In
a social environment, maladroit situations, such as denial of a service or a request for
information, have to be handled gracefully.
These conundrums that are constantly faced while developing middleware frame-
works for ubiquitous computing environments form the motivation for this work. Se-
curity and privacy have an implicit relationship. An elementary level of security is
imperative while helping people manage their personal privacy. Since, in many scenar-
ios of a ubiquitous computing environment, the users are not necessarily adversaries,
and usually know each other’s identities, the uncertainty would be less and hence we
adapt a privacy risk model rather than a threat model. Social and organizational
context should also be taken into consideration while developing a framework for the
environment [40].
6.2 Motivating Scenario
Consider a scenario in a ubiquitous health care environment, where Dr. Alice,
who is in charge of a recent patient, intends to discuss the medical condition with
one of her colleagues, Dr. Bob. Since the patient recently entered the hospital, there
could arise a situation where the central database is not updated, and the results of
the various tests conducted and procedures administered, are still in the respective
departmental servers. When Dr. Alice issues a request to send the patient’s chart to
Dr. Bob, the system, upon finding that the central database has not been updated,
searches for the various bits of information distributed in the hospital and aggregates
all the data and sends it to Dr. Bob.
John stores his emergency information, auto insurance, and medical records on
his PDA. If the PDA detects an accident, it sends a dialog box, requesting John if

97
he needs medical assistance. Upon receiving no response, the PDA places a call to
the Emergency Medical Services (EMS), giving the location of the user. When the
Emergency Medical Technicians (EMTs) arrive, they request all the devices of the
user to transmit data about the user. When the PDA checks that the request was
issued by an Emergency Medical Technician, it transmits the personal and medical
details, which the EMT aggregates with the vital signs and health monitoring data
and transmits it to the Emergency Room prior to arrival, facilitating the doctors in
the ER to prepare for the victim. A case sheet is generated with the patient details
and the doctor on call, Dr. Alice is informed of the status of the new case. Suppose,
Dr. Alice wishes to discuss John’s case with Dr. Bob, she messages him and asks if
he is free to discuss the case. On receiving Dr. Bob’s response, Dr. Alice’s laptop
decreases the privacy level of the session since the data is being sent to a peer (doctor).
It then collects all the related patient information, checks the target device and makes
necessary changes to match Dr. Bob’s device and his privacy settings. Concurrently,
a video conference session is set up between the doctors. When the session ends, Dr.
Alice’s privacy level is set back to the default setting.
The scenario described, though common in real life, involves modifications to
the system based upon various context elements such as location, device properties,
etc., and also on the social interactions of the users. In this chapter, we focus on
patterns of personal information disclosure and privacy implications associated with
user interactions in a ubiquitous computing environment. In the next section, we
present our middleware framework, and discuss its architecture and functioning. We
also demonstrate the working of our middleware in assisted environments, and present
experimental results, and our findings.

98
6.3 Precision
Currently, computing devices have penetrated the hospital environment, but
inter-networking is not yet seamless. Many procedures are still manually entered
into the system, and there is no end-to-end transparency in the process. Due to the
diversity in ubiquitous computing devices, incompatibility and reliability issues are
predominant. Data takes a long time to migrate and availability issues constantly
plague the staff and the doctors. We have developed a Privacy enhanced Context-
aware Information Fusion framework for ubiquitous computing environments called
Precision to handle personal privacy of a user in highly dynamic environments. Figure
6.1 shows the architecture of Precision.
Figure 6.1. Proposed middleware of Precision.
6.3.1 Device Abstraction Layer
Since Ubiquitous computing environments contain myriads of heterogeneous de-
vices, middleware developed for a ubiquitous computing system requires an abstrac-

99
tion layer to hide the hardware and implementation details from the upper layers. The
device abstraction layer is responsible for obtaining data from the various devices, and
translating this into context attributes. Each type of device contains an abstraction
module and an adaptor to connect to the various devices. The abstraction module
contains application programming interfaces which obtain the information from the
device, aggregate data obtained from similar sensors, if possible, and pass the ob-
tained data as an XML formatted context attribute to the Context gatherer in the
Information retrieval layer.
Currently, inter-networking among the heterogeneous devices is not inherently
seamless. Due to the diversity in ubiquitous computing devices, incompatibility and
reliability issues are predominant. Data takes a long time to migrate and availability
issues constantly plague the ubiquitous computing environment. To resolve this issue,
we have implemented an intelligent mobile agent-based resource discovery scheme. We
assume that several devices are distributed in the ubiquitous computing environment
and nodes capable of routing context information regarding usage of devices in their
zone1 are strategically identified as Resource Index nodes (RIns). RIns maintain
routing and resource indexing information. Any device that has had an interaction
with the user dispatches a message to its nearest RIn with resource update information
and this mobile agent is then sent with the resource information to the abstraction
module. Upon successful delivery, the mobile agent retracts to the originating RIn
and is destroyed.
Resource discovery is the ability to locate resources that adhere to a set of re-
quirements pertaining to a query that invoked the discovery mechanism. [81] provides
a taxonomy for resource discovery systems by defining their design aspects. To sup-
port a large amount of resources, defining and grouping services in scopes facilitates
1Zone creation is discussed in Chapter 4.3

100
resource search. Location awareness is a key feature in ubiquitous computing [27] and
location information is helpful in many resource discovery cases. In Matchmaking,
a classified advertisement matchmaking framework, client requests are matched to
resources and one of the matched resources is selected for the user [30].
The RIn is equipped with superior processing power, more than average nor-
malized link capacity, and reliability, as compared to other nodes. These nodes are
responsible for indexing all the local and some of the remote services and resources
and contain logic to create intelligent mobile agents that serve to explore the ubiq-
uitous computing environment and index resources and services available therein in
the dispatching RIn. The RIns are chosen by an election procedure and are assumed
to be present all the time in a locality. The election procedure is started as soon as
a RIn is not reachable.
RIns are placed such that each node is connected to at least one RIn within two
hops. Reliability of a node depends on past performance of the node, like number of
packets dropped at that node, connected links failure, and node failure. The average
normalized link capacity is the average of capacities of all adjacent links to of a node.
The RIn placement algorithm [64] is distributed. Initially each node sends its
information packet to neighbor nodes. The information packet contains the node
id and the weight of the node. A node calculates its weight using the equation
Wi = (∑N
j=1
1
dj) + Pi + Ri + Lavg where N is total number of neighbor nodes of ith
node, dj is the degree of jth neighbor node, Pi is processing power of ith node, Ri is
reliability of ith node, Lavg is average normalized link capacity at ith node, given by
Lavg = C1+C2+C3
3where C1, C2, C3 are adjacent link capacities.
On receiving weight packets from all the neighboring nodes, a node compares
its weight with its neighbor nodes. A RIn vote is sent back to the node with the
highest weight. A node receiving MaxVotes number of votes will announce itself as

101
the RIn. Nodes in the neighborhood of the RIn note down their local RIn. MaxVotes
can be chosen depending on the density of the nodes and requirement of RIns. The
RIn selection procedure might also be started when a node detects that its local RIn
is not responding.
6.3.2 Information Retrieval Layer
The Information Retrieval Layer retrieves information from the Device abstrac-
tion layer, and generates situations based on the gathered information. This layer
is tightly coupled with the Decision layer, and consists of a Context Gatherer and a
Situation Analyzer and Generator (SAGe).
6.3.2.1 Context Gatherer
The Context Gatherer manages the underlying context information. The archi-
tecture of the Context Information Management Unit is illustrated in Figure 6.2.
The XML formatted context information obtained from the Device Abstraction
layer is fed as input to the Context Acquirer, which parses the XML and encapsulates
the data, along with the type of device or node to the Context Identifier. The Context
Identifier identifies the verbs related to the type of device and attaches this informa-
tion to the Context Information Aggregator. The Aggregator continues to buffer
context information until a device is encountered, and then generates the activity
sequence of the situation, and passes it to the Situation Analyzer and Generator.
Input: XML formatted Context Information
Output:
Output from the Context Gatherer
< Activity Sequence >
consisting of context attributes, verbs, and a terminal device

102
Figure 6.2. Context Gatherer.
6.3.2.2 Situation Analyzer and Generator (SAGe)
SAGe consists of a Situation Tree constructor and a Rules Engine. The sequence
of context obtained from the Context Gatherer is parsed with the help of the Rules
engine, and situation trees are constructed. Depending on the nature of the context
sequence, multiple situation trees could be generated and these are stored in a cache.
Level-1 and Level-2 grammar are generated by the Rules Engine using rules and the
vocabulary generated, and the situation in constructed and passed to the Decision
Layer. The architecture of Sage is shown in Figure 6.3
Input: Activity Sequence describing the situation
Output:

103
Figure 6.3. Situation Analyzer and Generator (SAGe).
Output from the SAGe
Level − 2 Grammar and Parse Tree
describing the situation
6.3.3 Decision Layer
The Decision Layer consists of a Decision Engine and a Policy engine, a knowl-
edge base for storing dynamic rules generated, and a policy database with stores all
the policies related to privacy.
6.3.3.1 Decision Engine
Decision making is crucial in any middleware for ubiquitous computing. The
property of Event-Condition-Actions (ECA) often becomes inadequate in these appli-
cations, where combinations of multiple contexts and user actions need to be analyzed
over a period of time. Based on the situation trees obtained from the SAGe, actions
can be performed based on the situation’s presence in the knowledge base. If the
situation is not present, then the situation is broken down into simpler units, until

104
the units can be mapped to situations in the knowledge base, and the corresponding
actions are sent to the application layer. Based on the actions approved by the user,
the knowledge base is updated with the new situation, enabling the system to improve
its knowledge, and accuracy in decision making.
6.3.3.2 Policy Engine
The policy engine consists of our developed schemes in user privacy (discussed in
Chapter 5. Guidelines for privacy of sensitive information (such as HIPAA directives),
and user settings are stored, and the policy engine generates privacy levels for the
context attributes, based on these policies. The proper set of context attributes that
can be shared are sent to the decision engine to calculate the required actions for the
situation.
6.3.4 Application Layer
The user interface consists of an application manager and a message center.
The application manager coordinates the various messages on the device. In the
event of a request for information, a query is generated and sent to the Decision
Layer. The message center is connected to the application manager and is similar to
an instant messaging client. This also acts as a conduit to the information that is
received for a request issued by the user or by a message that is sent to the user. Our
proposed scheme is implemented beneath the user interface layer and on top of the
existing middleware. We chose JavaTM technology in order to incorporate seamless
migration of agents over cross-platform technologies.

105
6.4 Results and analysis
6.4.1 Case study 1: Information sharing between users
In this case study, we considered two types of interactions. We initially con-
sidered a Instant Messaging (IM) application in which users could chat in real time
and share files. We developed privacy levels to the files based on prior interactions
with the users. We then simulated exchange of information, and validated our privacy
management with varying levels of privacy. Figure 6.4(a) shows the GUI of our appli-
cation on a mobile phone, through which the user can enter contact information, and
set privacy levels. The desktop version of the GUI is shown in Figure 6.4(b). This is
a more comprehensive user interface, and the user is capable of obtaining information
about the privacy settings, social and organizational information, privacy level, and
prior sessions, within one click.
(a) (b)
Figure 6.4. GUI for (a) Mobile phones (b) Desktops.

106
The desktop version of the chat application is shown in Figure 6.5. The chat
application enables the users to share a file, create permissions for multiple users, and
allow collaboration between users, based on the permissions set by the owner of the
file. This enables easy migration of information within a team or between project
members, and all members share the same resource concurrently.
Figure 6.5. Desktop frontend of the Chat application.
Figure 6.6. Chat application sharing sensitive information.
Figure 6.6 describes a scenario in which two doctors are discussing a patient’s
case. Here, the electronic patient chart, shown in Figure 6.7, is shared between the
doctors. Based on the privacy settings of the doctors, and the HIPAA guidelines, the

107
authorized information is displayed, and other information is obscured, and the tem-
porary patient chart is shared between the doctors. After the session is terminated,
the temporary patient chart is destroyed.
Figure 6.7. Sample Patient Chart.
6.4.2 Case Study 2: Patient monitoring in assisted environments
Figure 6.8 describes the use case diagram of a smart home environment for
assisted healthcare. A smart home consists of multiple inhabitants with heterogeneous
sensors and health monitors deployed in a home to capture the various contexts of
the inhabitants and monitor their health. One or more inhabitants could be patients
and an external actor could be included for assisting the patients. A physician would
be able to monitor, remotely, the physiological state of the patient and make changes
to the regimen/diet of the patient. The smart home intimates the necessary persons
about the change in the regimen/diet. Owing to the myriad sensors deployed in a

108
Inhabitant
Patient’s Assistant
Patient
Physician
View/Query Smart Home
Set/Update Smart Home
View/Query patient’s regime
Set/Update Regimen
View/Query patient’s Health Condition
Authentication
Set/Update Smart Homesettings based on userpreferences and rules
Healthcare related rulesmight affect Smart Home’sfeatures such as suggesteddiet/regimen for the patient
There can be severalinstances of each actor
<<include>>
<<include>>
<<include>>
<<include>>
<<include>>
<<include>>
<<include>>
<<include>>
Patient’s Assistant is more thana simple housemate and canview patient’s regimen
Figure 6.8. Use case Diagram of a Smart Home for Assisted Healthcare.
smart home environment, a proper understanding of context is crucial for efficient
smart home monitoring.
Current smart home [15] technology offers a viable solution to the increasing
needs of the elderly in home based healthcare applications. The objective here, is
to create a total solution for the perennial connection of the human with the envi-
ronment, rather than focusing on the devices, which are used for the sole purpose of
obtaining input from the human. This form of computing is revolutionizing many
areas and processes and is becoming ubiquitous in health care and nursing environ-
ments, transforming patients from passive to active consumers of healthcare [28].
The research to date has largely focused on the development of communication tech-
nologies and intelligent user interfaces. In order to reduce obtrusiveness of patient
monitoring systems in smart homes, it is essential for an integration of these two
systems in an efficient manner.

109
Figure 6.9. SmartBoard.
6.4.3 Motivating scenario
Our motivation in developing SmartBoard stems from the concept of user in-
sulation. We intend to develop a patient monitoring system which predominantly
monitors the user in a passive mode, and which switches to active mode based on
the context in which the user currently is. In order to emphasize the functionality
of the patient monitoring system, we aim to incorporate actions which increase user
comfort. A motivating scenario of unobtrusive patient monitoring is given below:
”John recently had a myocardial infarction and his physician put him on a
new regimen of drugs. The dosage and the frequency of the drugs is stored on his
health monitor which constantly monitors his blood pressure. When he arrives at his
home, the health monitor transfers the new regimen to SmartBoard. A list of the new
medications is stored in the SmartBoard database along with the prescribed dosage.
John is then intimated at the necessary intervals to take his medication. A constant
log of his blood pressure is stored (Passive Mode), and is reported to John’s physician,

110
if requested. If the medication is about to be depleted, John is reminded by SmartBoard
to refill his prescription. If a study of John’s health monitoring log reveals that the new
dosage is not working efficiently, the physician could inform SmartBoard to change
the medication, upon which John is informed of the change. John can go about with
his daily life and a continuous log of his health status is monitored and logged by
SmartBoard.
In the eventuality of another episode of myocardial infarction (event), Smart-
Board switches to Active mode and searches for the relevant guidelines in the Knowl-
edge Base. If the guideline states that John has to take medication, he is informed
by SmartBoard to do so. Also, SmartBoard requests John if he requires medical as-
sistance. If no response is obtained, SmartBoard assumes that John is incapacitated
in some way, and places a call to the Emergency Medical Services (EMS). John’s
physician is also informed of the medical status and a recent log of John’s health mon-
itoring is sent to his physician. The physician is also informed of the call placed to
the EMS.”
6.4.4 Results
Building a general context information model to capture all aspects of the
user’s information is a difficult task. However, the key is to make the information
representation consistent over different applications, thereby, making the information
generalizable. The context representation must, therefore, be modular, distinct, and
should have a set of well-defined interfaces by which heterogeneous devices can access
and manipulate the context representation.
In our analysis of a patient monitoring system, we have narrowed our challenges
to five main components as described in Figure 6.10. Modularizing our approach
helps in ease of update and implementation of new functionalities. In the remainder

111
Figure 6.10. Challenges involved in development of SmartBoard.
of this subsection, we give a brief overview of each component and their functions as
envisioned in our design of SmartBoard.
6.4.4.1 Authentication
Authentication of the user is imperative in a patient monitoring system to
incorporate the guidelines of the HIPAA act [56]. We are currently investigating
biometric scans of the user such as a fingerprint or handscan in order to authenticate
the user. This technique is viable for a single user and we are looking into methods
for multiple user authentications for deployment of SmartBoard is a real-life scenario.
We envision that fingerprint scanner are placed on user devices such as a telephone
receiver, TV remote, refrigerator handle, cabinet handle, etc.
6.4.4.2 Unobtrusive Monitoring
Unobtrusive monitoring of the patient for the various vital signs such as heart
rate, blood pressure, blood sugar level, respiratory rate, temperature, etc., is preferred
in a patient monitoring system. The monitoring sensors are usually integrated on a

112
device which the user wears constantly, such as a watch or an armband and the sensors
transmit the collected data periodically using either wireless or BlueTooth technol-
ogy. In order to increase user comfort, SmartBoard also monitors various devices in
the smart home. We are currently considering television, telephone, refrigerator, mi-
crowave, medicine cabinet, pantry, and a personal computer as the monitored devices.
RfID tags are placed on all the items present in the refrigerator, medicine cabinet and
the pantry. An RfID reader is placed in each of these to enable SmartBoard to recog-
nize the items accessed. Depending on the context, a grocery list, a prescription refill
request, or a recipe could be generated and displayed by SmartBoard. For instance,
suppose the user accesses a box of pasta in the pantry. SmartBoard would then query
the user if s/he requires a recipe for preparing the pasta. Upon acknowledgment, a
search is initiated on the personal computer and the recipe is retrieved and displayed
on Smart Board along with the other ingredients required for the recipe. If, the carton
of milk in the refrigerated has been depleted, that item would be automatically added
to the grocery list. SmartBoard stores the favorite television programs of the user in
the knowledge base. The telephone is also monitored by SmartBoard and the address
book is stored in the knowledge base. in the event of a telephone call, the caller ID
is displayed if the user is in the visual vicinity of SmartBoard. Else, an audio alert is
issued and the event is logged.
6.4.4.3 Decision Making
Decision making is crucial in any patient monitoring system. SmartBoard incor-
porates a Decision engine and a Rules engine which access a Knowledge Base housing
the various rules and guidelines related to the user’s health condition. The physician
could also set thresholds to the various vital signs making SmartBoard programmable
to the user’s body condition. This is essential in a patient monitoring system as indi-

113
vidual body metabolisms and vital signs differ, and a generic threshold or guideline
would not suffice as an indicator. An explanation function would be incorporated in
SmartBoard to explain the rationale behind tagging a certain event as necessitating
attention. The physician could look at the explanation and make necessary changes
to the function, thereby refining the guidelines stored in the Knowledge Base. This
enables SmartBoard to improve its accuracy of monitoring.
6.4.4.4 Actuation
Owing to the heterogeneity of devices accessed by SmartBoard, and also due
to the various tasks incorporated to maximize user comfort, the challenge involved in
actuation is primarily one of translation and presentation. The action to be performed
by SmartBoard has to be properly translated into a command that can be successfully
interpreted by the device which has to perform the action. We are currently looking
into JXTATMtechnology, which is a set of open, generalized peer-to-peer protocols
that allows any connected device (cell phone to PDA, PC to server) on the network
to communicate and collaborate [43].
6.4.4.5 Active logging
SmartBoard is envisioned to contain two databases for logging events. A trans-
action database is required to log all the events monitored by SmartBoard. A re-
lational database is also implemented to enrich the user preferences stored in the
various devices with the context and environment. This enables SmartBoard to cross-
reference an event with the relational database in order to increase the information
content of an event, thereby arriving at a context-aware decision.
We used simulations to evaluate the performance of SmartBoard and present
our results in this section. We have divided our implementation of SmartBoard into

114
Table 6.1. Multi Sensor Utility value with information acquisition cost
Time Selected Sensor Utility Utility UtilityStamp Position Temp ECG
1 Temp− Position 0.1723 0.2393 0.12132 Position−ECG 0.2421 0.1987 0.21933 Temp− Position 0.2187 0.2267 0.21054 Position−ECG 0.2378 0.2198 0.22375 Temp−ECG 0.2303 0.2498 0.23786 Temp− Position 0.2421 0.2590 0.23767 Temp−ECG 0.2204 0.2653 0.23938 Temp− Position 0.2535 0.2843 0.24879 ECG− Position 0.2810 0.2703 0.290610 Position− Temp 0.3034 0.2979 0.2852
two phases. In the first phase, we have deployed various sensors to monitor the health
of the user and the physical environment in the monitored environment. The sensors
used for our application are classified according to their numbers such as Sensor-1,
Sensor-2, Sensor-3, Sensor-4, and Sensor-5. We have calculated the expected profit
utility value for different combination of sensors with varying set size.
1 2 3 4 5 60
50
100
150
200
250
300
350
Sensor Set Size
Util
ity V
aria
tion
in %
Figure 6.11. Determination of optimal set of sensor size.

115
From Fig. 6.11, it is observed that utility increases as the number of selected
sensors increases, for different states of the application. But increase in utility achieves
a steady state after a certain sensor set size.
(a)
(b) (c)
Figure 6.12. Performance Analysis: (a) Situation Prediction vs. Context Elements(b) Accuracy (c) Computational delay.
We then compared the performance of the three approaches (ECA rules, Con-
text Fusion, and S-Trees). Figure 6.12(a) shows the performance of the approaches
with varying number of context elements. We observe that even in complex situa-

116
tions with as many as 50 context elements, S-Trees perform better than the other two
approaches due to intermediate resolution and fusion of information using the rules
and properties of the S-Trees. We then calculated the accuracy of the approaches,
shown in Figure 6.12(b), and found that our approach using S-Trees far exceeds con-
ventional ECA rules. One reason for the lower accuracy in ECA rules is the necessity
to deconstruct compound activities into simpler blocks, resulting in potential loss of
information about the situation. This also accounts for the reduced effectiveness of
ECA rules in resolving complex actions, which are formed by integrating individual
actions. Context Fusion performs better in these activities. However, ambiguity in
the actions result in reduced accuracy of Context Fusion. S-Trees overcome these lim-
itations by assuming that an activity is complete only when a device is encountered,
and the constructed S-Tree capture all the prior user activity, enabling increased ac-
curacy in situation prediction. Figure 6.12(c) shows the amount of time taken by
each approach to arrive at a confident prediction of the situation. For this study, we
assumed that a situation is predicted when the system can predict the activity with a
confidence of at least 90%. As the number of context elements increase, the complex-
ity of the activity increases, and this results in multiple ECA rules being triggered
and evaluated. Context Fusion does not suffer from this problem, however, as the
number of context elements increase, the number of computations to evaluate utility
and fuse the information increases and this results in computational delay. In S-Trees,
the root and the right child always denote the device and the action performed, and
therefore, the action of the user can be retrieved in constant time. Since the context
elements leading to the activity are fused during construction of the tree, and the
trees are pruned when a new device is encountered, the amount of computational
delay is significantly reduced even in complex activities. The number of S-Trees in

117
the cache correspond to the number of devices encountered, and this contributes to
the delay.
Figure 6.13. Screenshot of the middleware in action.
Figure 6.13 shows the various devices integrated with SmartBoard. In this
figure, contents of the medicine cabinet, and the refrigerator are displayed. The
TV guide is obtained from the television, and the grocery list is displayed. The
medicines in the medicine cabinet, and items in the refrigerator are equipped with
RF id tags, and we mounted an RF id reader on the door of the medicine cabinet
and the refrigerator to capture the access and replacement of an item. We assumed
that when an item is accessed and replaced,one unit of the item is consumed. If the
item is removed and is not replaced, the system understands that the item has been
depleted and adds it to the grocery or prescription list. We have also set thresholds

118
on the level of items, and when the quantity of the items falls below the threshold,
the item is automatically added to the grocery list. When the system detects that the
user is leaving the assisted environment, the grocery list is transmitted to the mobile
phone for procurement.
Figure 6.14. Sunspot Readings.
To simulate various activities, we have also integrated Sun SPOTs with Smart-
Board, and Figure 6.14 shows the GUI corresponding to the Sun SPOT monitor for
light and acceleration. We used the photosensitivity readings to simulate conditions
of the weather (cloudy, bright, fog, night) and use the information obtained from the
Sun SPOTs to automate and control the lighting and shades of the window in the as-
sisted environment. We set a default light setting in the bedroom which corresponds

119
to a bright day, and adjust the bedroom light intensity and the angle of shade opening
to constantly maintain the specified light setting in the room.
Figure 6.15. Heart monitor output.
We have also integrated a heart monitor with SmartBoard, and the GUI with
anonymized data is displayed in Figure 6.15.The anonymized data is securely stored
in the database, and a log of the readings is reported to the remote physician. We
inserted certain levels to indicate critical conditions (low Systole, low diastole, high
systole, high diastole, high pulse) and enabled the system to inform the physician
when the readings crossed the thresholds. We envision that this approach will enable
us to integrate other health monitors, allowing us to study the effects of a prescribed
regimen. This would also enable the physicians and pharmaceutical companies to
study the effectiveness of the drugs administered, and also reaction time of medica-
tions.

120
6.5 Summary
In this chapter, we have presented our middleware framework for ubiquitous
computing environments. we have considered two case studies and have discussed the
performance of the framework in those scenarios. We have compared the performance
of our scheme with a context fusion mechanism using dynamic bayesian network, and
have presented our observations and experimental results. We have also discussed
scenarios in which our middleware framework has been deployed, and have presented
the GUIs of the system, along with our measured observations.

CHAPTER 7
CONCLUSION
In this dissertation, we have presented a privacy enhanced situation-aware mid-
dleware framework for ubiquitous computing environments. We have discussed the
current perceptions of context and have extended its scope to include capture of user
activity in an environment with heterogeneous sensors and devices. We have also
discussed the limitations of Event-Condition-Action rules with respect to capturing
unambiguous and ambiguous context, and their constraints of analyzing activities as
discrete events. We have proposed a scheme to capture user activity as a continu-
ous process using situation trees, and have effectively shown how situation grammar
can be constructed from our scheme to enable user-specific rule generation. We have
also presented user-centric and system-centric approaches to quantize and handle
granularity of user privacy. We have designed a middleware framework to support
perception and modeling of situation, dynamic rule generation, and privacy manage-
ment of user interactions in a ubiquitous computing environment. We have considered
two case studies and have presented our observations, results, and the performance
of our middleware framework. While the middleware framework presented here can
approximately capture most of the activities and manage user privacy, other modules
are required to realize our endeavor of a complete ubiquitous middleware. Some of
these are as follows:
• Integration of gestures and motion detection: In this dissertation, we have
considered various sensors and devices to improve the user interaction with the
middleware framework. This work can be extended to include motion sensing
121

122
and capturing gestures to make the system more user friendly and interactive.
This would also increase the situations of the user and we believe that our
system can be scaled accordingly to incorporate these functionalities.
• Integration of various health monitors: In our dissertation, we have incorpo-
rated a few health monitors to capture the user’s vital signs. Additional health
monitors would enhance the functionality of our framework, resulting in a pow-
erful patient monitoring system, and enables patients suffering from various
conditions to be monitored.
• Security and Authentication: Though our work is predominantly focused on
user privacy, security and authentication are necessary modules which have to
be incorporated in the middleware. These functionalities are of prime impor-
tance when deploying our system in environments with sensitive information.
We have used simple application programming interfaces and protocols to en-
crypt and anonymize health data in accordance with the HIPAA guidelines for
remote telemedicine. However, industry standards of these functionalities would
generate a higher trust and confidence in the middleware framework.
• Incorporation of the entire HIPAA guidelines. In our dissertation, we have
implemented the HIPAA guidelines as policies, focusing on the requirements
of an assisted environment. Though this contributes as a proof of concept,
a thorough implementation of the entire HIPAA guidelines would make the
system robust, and include additional constraints, such as quality of privacy,
and resolution of shared information in the presence of entities with varied
privacy authorizations.
• Decision Making: Our approaches to decision making in our middleware frame-
work were driven by the requirement of scalability and portability among hetero-
geneous devices. Though our approaches work seamlessly, additional decision

123
making schemes would allow resolution of complex situations, and enable the
system to predict actions. An explanation function could also be included in
the framework to enable designers debug the decision making process, and fine
tune the necessary parameters to perform enhanced decision making.
The approaches presented in this dissertation can also be improved in terms of
accuracy and computational speed. Our goal, however, was to present approaches
which could be seamlessly ported onto devices with limited resources, and to develop
a generic framework for ubiquitous computing environments, where scalability and
portability were the prime focus. Our privacy management approaches presented
were developed with focus on user friendliness, and abstraction, enabling designers
to change the mechanism of privacy quantization to more robust schemes without
affecting the user’s familiarity or perception of privacy. Further work is required
to develop an end to end solution which integrates all the modules into a single
deployable package.

REFERENCES
[1] M. Weiser, “The computer for the twenty-first century,” Scientific American, pp.
94 – 100, September 1991.
[2] R. Agrawal, A. Evfimievski, and R. Srikant, “Information sharing across private
databases,” in Proc. 2003 ACM SIGMOD International Conf. on Management
of Data, 2003.
[3] H. Alex, M. Kumar, and B. Shirazi, “Midfusion: An adaptive middleware for
information fusion in sensor network applications,” Elsevier Journal of Informa-
tion Fusion, 2005.
[4] J. C. Augusto, C. D. Nugent, and N. D. Black, “Management and analysis of
time-related data in smart home environments,” in in Proceedings of Mediter-
ranean Conference on Medical and Biological Engineering (Medicon’04), 2004.
[5] R. Babbitt, J. Wong, and C. Chang, “Towards the modeling of personal pri-
vacy in ubiquitous computing environments,” in Proc. 31st Annual International
Computer Software and Applications Conf., 2007.
[6] M. Balazinska, H. Balakrishnan, and D. Karger, “Ins/twine: A scalable peer-
to-peer architecture for intentional resource discovery,” in In Proceedings of the
First International Conference on Pervasive Computing, Springer-Verlag, Ed.,
2002, pp. 195–210.
[7] R. Beckwith, “Designing for ubiquity: the perception of privacy,” IEEE Perva-
sive Computing, 2003.
[8] G. Bell, “Auspicious computing?” IEEE Journal of Internet Computing, 2004.
124

125
[9] M. Beyer, K. A. Kuhn, C. Meiler, S. Jablonski, and R. Lenz, “Towards a flex-
ible, process-oriented it architecture for an integrated healthcare network,” in
in Proceedings of the 2004 ACM symposium on Applied computing (SAC ’04),
2004, pp. 264–271.
[10] D. Bottazzi, A. Corradi, and R. Montanari, “Context-aware middleware solu-
tions for anytime and anywhere emergency assistance to elderly people,” IEEE
Communications Magazine, vol. 44, no. 4, pp. 82–90, 2006.
[11] P. Cauldwell, “Professional xml web services,” Wrox Press Ltd., 2001.
[12] O.-H. Choi, J.-E. Lim, H.-S. Na, and D.-K. Baik, “Modeling of situation-
middleware for tpo metadata based on event-condition-action rule,” in Fourth
International Conference on Software Engineering Research, Management and
Applications, 2006, pp. 423–427.
[13] M. Coen, “The future of human-computer interaction or how i learnt to stop
worrying and love my intelligent room,” IEEE Intelligent systems, vol. 14, no. 2,
pp. 8–10, 1999.
[14] F. P. Coyle, “Xml, web services, and the data revolution,” Addison Wesley Pro-
fessional, March 2002.
[15] S. K. Das, N. Roy, and A. Roy, “Context-aware resource management in multi-
inhabitant smart homes: A framework based on nash h-learning,” Pervasive and
Mobile Computing (PMC) Journal, vol. 2, no. 4, pp. 372–404, November 2006.
[16] D. L. de Ipina, “An eca rule-matching service for simpler development of reactive
applications,” IEEE Middleware, vol. 2, no. 7, November 2001.
[17] L. DeMichiel, “Enterprise java beans specification version 2.1,” Sun Microsys-
tems Inc., 2002.
[18] A. K. Dey, “Providing architectural support for building context aware applica-
tions,” Ph.D. dissertation, 2000.

126
[19] S.-L. Ding, J.-B. Yuan, and J.-B. Ju, “n algorithm for agent-based task schedul-
ing in grid environments,” in in Proceedings of 2004 International Conference on
Machine Learning and Cybernetics, vol. 5, August 2004, pp. 2809–2814.
[20] M. Ermes, J. Parkka, J. Mantyjarvi, and I. Korhonen, “Detection of daily activi-
ties and sports with wearable sensors in controlled and uncontrolled conditions,”
In IEEE Transactions on Information Technology in Biomedicine,, vol. 12, no. 1,
pp. 20–26, Jan 2006.
[21] A. Frei and G. Alonso, “A dynamic lightweight architecture,” in Proceedings of
the 3rd International Conference on Pervasive Computing and Communications
(PerCom 2005), March 2005.
[22] H. Gellersen, A. Schmidt, and M. Beigl, “Multi-sensor context-awareness in mo-
bile devices and smart artifacts,” Mobile Networks and Applications (MONET),
October 2002.
[23] O. M. Group, CORBA Component Model Specification, v4.0, April 2006.
[24] O. M. Group, “CCM specification,” v4.0, April, 2006.
[25] R. Gross, A. Acquisti, and H. Heinz, “Information revelation and privacy in on-
line social networks,” in Proc. ACM CCS Workshop on Privacy in the Electronic
Society, 2005.
[26] T. Gruber, “Toward principles for the design of ontologies used for knowledge
sharing,” in International Journal Human-Computer Studies, vol. 43, no. 5–6,
1995, pp. 907–928.
[27] E. Guttman, “Vendor extensions for service location protocol, ver-
sion 2,” Network Working Group, Request for Comments: 3224.
http://www.ietf.org/rfc/rfc3224.txt, 2002. [Online]. Available: Network Working
Group, Request for Comments: 3224. http://www.ietf.org/rfc/rfc3224.txt

127
[28] H. D. M. Report, “Datamonitor: The changing role of consumers in healthcare,”
August 2006.
[29] T. Heiber and P. J. Marron, “Exploring the relationship between context and pri-
vacy,” Privacy, Security and Trust within the Context of Pervasive Computing,
Kluwer International Series in Engineering and Computer Science, 2005.
[30] S. Helal, N. Desai, V. Verma, and C. Lee, “Konark: A service discovery and
delivery protocol for ad-hoc networks,” in In Proc. of the Third IEEE Conference
on Wireless Communication Networks (WCNC), New Orleans, 2003.
[31] J. I. Hong and J. A. Landay, “An architecture for privacy-sensitive ubiquitous
computing,” in Proc. 2nd International Conf. on Mobile systems, applications,
and services (MobiSys ’04), 2004.
[32] J. I. Hong, J. D. Ng, S. Lederer, and J. A. Landay, “Privacy risk models for
designing privacy-sensitive ubiquitous computing systems,” in Proc. 2004 Conf.
on Designing interactive systems, 2004.
[33] W. Hoschek, “The web service discovery architecture,” in Proc. 2002 ACM/IEEE
Conf. on Supercomputing, 2002.
[34] E. M. Huang, E. D. Mynatt, D. M. Russell, and A. E. Sue, “Secrets to success and
fatal flaws: the design of large-display groupware,” IEEE Journal of Computer
Graphics and Applications, vol. 26, no. 3, pp. 37–45, Jan–Feb 2006.
[35] M. C. Huebscher and J. McCann, “Adaptive middleware for context-aware ap-
plications in smart homes,” in Proc. of the 2nd Workshop on Middleware for
Pervasive and Ad-hoc Computing, October 2004, pp. 111–116.
[36] R. Hull, B. Kumar, D. Lieuwen, P. F. Patel-Schneider, A. Sahuguet, S. Varadara-
jan, and A. Vyas, “Enabling context-aware and privacy-conscious user data shar-
ing,” in Proc. 2004 IEEE International Conf. on Mobile Data Management, 2004.

128
[37] R. Hull, P. Neaves, and J. Bedford-Roberts, “Towards situated computing,”
in In Proceedings of the 1st International Symposium on Wearable Computers,
Cambridge, October 1997.
[38] G. Iachello, K. N. Truong, G. D. Abowd, G. R. Hayes, and M. Stevens, “Proto-
typing and sampling experience to evaluate ubiquitous computing privacy in the
real world,” in Proc. SIGCHI Conf. on Human Factors in computing systems,
2006.
[39] S. Intille, “The goal: smart people, not smart homes,” in in Proceedings of the
International Conference on Smart Homes and Health Telematics. IOS Press,
2006.
[40] X. Jiang, J. I. Hong, and J. A. Landay, “Approximate information flows: Socially-
based modeling of privacy in ubiquitous computing,” in In Proceedings of Ubi-
comp 2002, 2002, pp. 176–193.
[41] G. Jodd and P. Steenkiste, “Providing contextual information to pervasive com-
puting applications,” in in Proceedings of First IEEE International Conference
on Pervasive Computing and Communications (PerCom’03), 2003, pp. 133–142.
[42] T. J. Rules, “http://labs.jboss.com/drools/,” The Drools Project, 2008.
[43] “Jxta project.” [Online]. Available: http://www.jxta.org
[44] M. Kifer, “Rule interchange format: The framework,” in In Proceedings of the
Second International Conference on Web Reasoning and Rule Systems, RR 2008,
ser. Lecture Notes in Computer Science, Springer-Verlag, Ed., vol. 5341, 2008,
pp. 1–11.
[45] T. Kindberg and A. Fox, “System software for ubiquitous computing,” in IEEE
Pervasive Computing, vol. January–March, 2002, pp. 70–81.
[46] R. Kumar, M. Wolenetz, B. Agarwalla, J. Shin, P. Hutto, A. Paul, and U. Ra-
machandran, “Dfuse: a framework for distributed data fusion,” in Proc. of the

129
1st International Conference on Embedded Networked Sensor Systems, November
2003, pp. 114–125.
[47] S. Lederer, J. Hong, A. Dey, and J. Landay, “Personal privacy through un-
derstanding and action: Five pitfalls for designers,” Personal and Ubiquitous
Computing, 2004.
[48] K.-W. Lee, E.-S. Cho, and H. Kim, “An eca rule-based task programming lan-
guage for ubiquitous environments,” in Proceedings of the 8th International Con-
ference of Advanced Communication Technology, ICACT 2006, vol. 1, 2006.
[49] J. Lester, T. Choudhury, N. Kern, G. Borriello, and B. Hannaford, “A hybrid
discriminative/generative approach for modeling human activities,” in Proceed-
ings of the 19th International Joint Conference on Artificial Intelligence, 2005,
pp. 766–772.
[50] L. Liao, D. Fox, and H. Kautz, “Location-based activity recognition using rela-
tional markov models,” in In International Joint Conference on Artificial Intel-
ligence, 2005.
[51] Y. Liu and K. Connelly, “Smartcontacts: a large scale social context service
discovery system,” in Proc. 4th Annual IEEE International Conf. on Pervasive
Computing and Communications Workshops, 2006.
[52] E. Loureiro, F. Bublitz, N. Barbosa, A. Perkusich, H. Almeida, and G. Fer-
reira, “A flexible middleware for service provision over heterogeneous pervasive
networks,” in Proceedings of the 2006 International Symposium on on World of
Wireless, Mobile and Multimedia Networks WOWMOM ’06, 2006, pp. 609–614.
[53] P. Louvieris, N. Mashanovich, S. Henderson, G. White, M. Petrou, and
R. O’Keefe, “Smart decision support system using parsimonious information fu-
sion,” in in Proceedings of 8th International Conference on Information Fusion,
vol. 2, July 2005, pp. 25–28.

130
[54] D. Lymberopoulos, T. Teixeira, and A. Savvides, “Detecting Patterns for As-
sisted Living Using Sensor Networks: A Case Study,” In Proceedings of the 2007
international Conference on Sensor Technologies and Applications, pp. 590–596,
2007.
[55] A. Maedche, E. Maedche, and S. Staab, “Learning ontologies for the semantic
web,” in In Proceedings of the Second International Workshop on the Semantic
Web, 2001, pp. 200–1.
[56] “Medical privacy - national standards to protect the privacy of personal health
information.” [Online]. Available: http://www.hhs.gov/ocr/hipaa/
[57] Microsoft, “Windows vista security and data protection improve-
ments,” 2008. [Online]. Available: http://technet.microsoft.com/en-
us/windowsvista/aa905073.aspx
[58] M. I. D. Profile, “http://java.sun.com/products/midp/overview.html,” MIDP:
JSR 37, JSR 118 Overview, 2008.
[59] S. Mitchell, M. D. Spiteri, J. Bates, and G. Coulouris, “Context-aware multime-
dia computing in the intelligent hospital,” in Proc. SIGOPS EW2000, the Ninth
ACM SIGOPS European Workshop, Kolding, Denmark, September 2000.
[60] A. Mitseva, M. Imine, and N. R. Prasad, “Context-aware privacy protection
with profile management,” in in Proceedings of the 4th international Workshop
on Wireless Mobile Applications and Services on WLAN Hotspots, WMASH ’06,
2006, pp. 53–62.
[61] M. A. Munoz, M. Rodriguez, J. Favela, A. I. Martinez-Garcia, and V. M. Gon-
zalez, “Context-aware mobile communication in hospitals,” IEEE Computer,
vol. 36, no. 9, pp. 38 – 46, September 2003.

131
[62] U. Naeem and J. Bigham, “Activity recognition using a hierarchical framework,”
in Second International Conference on Pervasive Computing Technologies for
Healthcare (PervasiveHealth 2008), Jan 30–Feb 1 2008, pp. 24–27.
[63] G. Pallapa and S. K. Das, “Challenges of designing privacy enhanced context-
aware middleware for assisted healthcare,” in ICOST ’08: Proceedings of the
6th international conference on Smart Homes and Health Telematics. Berlin,
Heidelberg: Springer-Verlag, 2008, pp. 200–207.
[64] G. Pallapa, and S. Das, “Resource Discovery in Ubiquitous Health Care,” In
Proceedings of the 21st International Conference on Advanced Information Net-
working and Applications (AINA 2007), Vol. 2, pp. 1–6, 2007.
[65] M. Philipose, K. P. Fishkin, M. Perkowitz, D. J. Patterson, D. Fox, H. Kautz,
and D. Hahnel, “Inferring activities from interactions with objects,” In IEEE
Pervasive Computing, vol. 3, no. 4, pp. 50–57, Oct–Dec 2004.
[66] M. Radenkovic and T. Lodge, “Engaging the public through mass-scale multi-
media networks,” IEEE Journal of Multimedia, 2006.
[67] A. Ranganathan and R. H. Campbell, “A middleware for context-aware agents in
ubiquitous computing environments,” in in ACM/IFIP/USENIX International
Middleware Conference, 2003.
[68] M. Roman, Christopher K. Hess, C. K. Hess, R. Cerqueira, A. Ranganathan,
R. H. Campbell, and K. Nahrstedt, “Gaia: A middleware infrastructure to enable
active spaces,” in IEEE Pervasive Computing, Oct–Dec 2002, pp. 74–83.
[69] M. Ruta, T. D. Noia, E. D. Sciascio, and F. Donini, “Semantic enabled resource
discovery, and substitution in pervasive environments,” in EEE Mediterranean
Electrotechnical Conference, MELECON 2006, May 2006, pp. 754–760.
[70] B. N. Schilit and M. M. Theimer, “Disseminating active map information to
mobile hosts,” IEEE Network, vol. 8, no. 5, pp. 22–32, 1994.

132
[71] A. Shchzad, H. Q. Ngo, S. Y. Lee, and Y.-K. Lee, “A comprehensive middleware
architecture for context-aware ubiquitous computing systems,” in Fourth Annual
ACIS International Conference on Computer and Information Science, 2005, pp.
251–256.
[72] M. A. A. Seleznyov and S. Hailes, “Adam: An agent-based adam: An agent-
based middleware architecture for distributed access control,” in Twenty-Second
International Multi-Conference on Applied Informatics: Artificial Intelligence
and Applications, 2004, pp. 200–205.
[73] J.-M. Seigneur and C. D. Jensen, “Trust enhanced ubiquitous payment without
too much privacy loss,” in Proc. 2004 ACM symposium on Applied computing,
2004.
[74] L. Smith, C. Roe, and K. Knudsen, “A jiniTM lookup service for resource-
constrained devices.”
[75] M. K. Smith, C. Welty, and D. L. McGuinness, “Owl web ontology language,”
http://www.w3.org/TR/owl-guide/, February 2004.
[76] G. Stevenson, P. Nixon, and R. I. Ferguson, “A general purpose program-
ming framework for ubiquitous computing environments,” in Proceedings of the
First System Support for Ubiquitous Computing Workshop, UbiSys’03, UbiComp,
2003.
[77] O. Storz, A. Friday, N. Davies, J. Finney, C. Sas, and J. Sheridan, “Public
ubiquitous computing systems: Lessons from the e-campus display deployments,”
IEEE Journal of Pervasive Computing,, vol. 5, no. 3, pp. 40–47, July–September
2006.
[78] E. Tapia, S. Intille, and K. Larson, “Activity recognition in the home setting
using simple and ubiquitous sensors,” in In Proceedings of PERVASIVE 2004,

133
A. Ferscha and F. Mattern, Eds., vol. LNCS 3001. Berlin Heidelberg: Springer-
Verlag, 2004, pp. 158–175.
[79] M. Tentori, J. Favela, and V. Gonzalez, “Quality of privacy (qop) for the design
of ubiquitous healthcare applications,” Journal of Universal Computer Science,
2006.
[80] S. Toivonen, G. Lenzini, and I. Uusitalo, “Context-aware trust evaluation func-
tions for dynamic reconfigurable systems,” in In Proceedings of Models of Trust
for the Web workshop, May 2006.
[81] K. Vanthournout, G. Deconinck, and R. Belmans, “A taxonomy for resource
discovery,” Personal Ubiquitous Computing, vol. 5, no. 2, pp. 81–89, 2005.
[82] S. Wang, W. Pentney, A. Popescu, T. Choudhury, and M. Philipose,
“Commonsense-based joint training of human activity recognizers,” in Proceed-
ings of the 21st International Joint Conference on Artificial Intelligence, January
2007.
[83] M. Weiser, “Hot topics: Ubiquitous computing,” IEEE Computer, October 1993.
[84] A. Westin, “Privacy and freedom,” Atheneum, New York, 1967.
[85] D. Wilson, D. Wyaat, and M. Philipose, “Using context history for data col-
lection in the home,” in In Proceedings of PERVASIVE 2005, H.-W. Gellersen,
R. Want, and A. Schmidt, Eds., vol. LNCS 3468, 2005.
[86] R. Wimmer, M. Kranz, S. Boring, and A. Schmidt, “A capacitive sensing toolkit
for pervasive activity detection and recognition,” in Fifth Annual IEEE Interna-
tional Conference on Pervasive Computing and Communications (PerCom ’07),
March 2007, pp. 171–180.
[87] T. Winograd, “Architectures for context,” Human-Computer Interaction, vol. 16,
no. 2–4, pp. 401–419, 2001.

134
[88] World Wide Web Consortium (W3C), “Resource description framework (rdf)
model and syntax specification,” http://www.w3.org/TR/PR-rdf-syntax/.
[89] S. S. Yau and F. Karim, “Reconfigurable context-sensitive middleware for ads
applications in mobile ad hoc network environments,” in Proceedings of the 5th
International Symposium on Autonomous Decentralized Systems (ISADS 2001),
March 2001, pp. 319–326.
[90] Y. Zhang, Q. Ji, and C. G. Looney, “Active information fusion for decision mak-
ing under uncertainty,” in in Proceedings of the Fifth International Conference
on Information Fusion, vol. 1, 2002, pp. 643–650.

BIOGRAPHICAL STATEMENT
Gautham V. Pallapa was born in Bangalore, India, in 1979. He received his
Bachelors in Electrical Engineering and Electronics from Bangalore University, India,
in 2000, his Master of Technology in Computer Science and Engineering from Jawa-
harlal Nehru University, New Delhi, India, in 2003, and Ph.D. in Computer Science
from the University of Texas at Arlington in 2009.
From 2003 to 2004, he was a lecturer in Computer Science at M. S. Ramaiah
Institute of Technology, Bangalore, India, and an Assistant Professor with the De-
partment of Information Technology, Padre Conceicao College of Engineering, Goa,
India. From 2006 - 2007, he was a lab coordinator, and from 2007 to 2008, he was an
instructor and web master at the Department of Computer Science and Engineering.
He was also a researcher, webmaster and network administrator for the Center for
Research in Wireless Mobility and Networking (CReWMaN), University of Texas at
Arlington, from 2004–2009. His current research interests are Context and Situation
awareness, privacy management, and predictive middleware for Ubiquitous Comput-
ing. He is a member of several IEEE and ACM societies.
135
Related Documents











