J. Kolodziej et al. (Eds.): ICA3PP 2013, Part I, LNCS 8285, pp. 176–185, 2013. © Springer International Publishing Switzerland 2013 A Parallel Distributed System for Gene Expression Profiling Based on Clustering Ensemble and Distributed Optimization Zakaria Benmounah and Mohamed Batouche Computer Science Department, College of NTIC, Constantine University 2, 25000 Constantine, Algeria {zbenmounah,mcbatouche}@gmail.com Abstract. With the development of microarray technology, it is possible now to study and measure the expression profiles of thousands of genes simultaneously which can lead to identify subgroup of specific disease or extract hidden relationships between genes. One computational method often used to this end is clustering. In this paper, we propose a parallel distributed system for gene expression profiling (PDS-GEF) which provides a useful basis for individualized treatment of a certain disease such as Cancer. The proposed approach is based on two major techniques: the GIM (Generalized Island Model) and clustering ensemble. GIMs are used to generate good quality clusterings which are refined by a consensus function to get a high quality clustering. PDS-GEF system is implemented using Matlab®’s PCT (Parallel Computing Toolbox™) which runs on a desktop computer, and tested on 34 different publicly available gene expression data sets. The obtained results compete with and even outperform existing methods. 1 Introduction During the last decade, biomedical research has undergone changes which have transformed the development towards automation and at the same time the treatment has led to an increase in speed and high throughput [1]. One of the emergent technologies following this development which is considered as a platform for various applications is Microarrays technology. The latter assesses the expression patterns of thousands of genes at one time, and helps to identify appropriate targets for therapeutic intervention and discovery of new disease subclasses. Microarray has three major classes [2]: class comparison, class prediction and class discovery. The first involves finding differences in expression levels between predefined groups of samples. The second class involves identifying the class membership of a sample based on its gene expression profile. The third class involves analyzing a given set of gene expression profiles with the goal to understand the mechanisms underlying a disease by discovering subgroups of genes that share common features. A computational method often used for class discovery is clustering which aims at dividing the data points (genes) into groups (clusters) using similarity measures, such

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

J. Kołodziej et al. (Eds.): ICA3PP 2013, Part I, LNCS 8285, pp. 176–185, 2013. © Springer International Publishing Switzerland 2013
A Parallel Distributed System for Gene Expression Profiling Based on Clustering Ensemble and Distributed
Optimization
Zakaria Benmounah and Mohamed Batouche
Computer Science Department, College of NTIC, Constantine University 2, 25000 Constantine, Algeria
{zbenmounah,mcbatouche}@gmail.com
Abstract. With the development of microarray technology, it is possible now to study and measure the expression profiles of thousands of genes simultaneously which can lead to identify subgroup of specific disease or extract hidden relationships between genes. One computational method often used to this end is clustering. In this paper, we propose a parallel distributed system for gene expression profiling (PDS-GEF) which provides a useful basis for individualized treatment of a certain disease such as Cancer. The proposed approach is based on two major techniques: the GIM (Generalized Island Model) and clustering ensemble. GIMs are used to generate good quality clusterings which are refined by a consensus function to get a high quality clustering. PDS-GEF system is implemented using Matlab®’s PCT (Parallel Computing Toolbox™) which runs on a desktop computer, and tested on 34 different publicly available gene expression data sets. The obtained results compete with and even outperform existing methods.
1 Introduction
During the last decade, biomedical research has undergone changes which have transformed the development towards automation and at the same time the treatment has led to an increase in speed and high throughput [1]. One of the emergent technologies following this development which is considered as a platform for various applications is Microarrays technology. The latter assesses the expression patterns of thousands of genes at one time, and helps to identify appropriate targets for therapeutic intervention and discovery of new disease subclasses. Microarray has three major classes [2]: class comparison, class prediction and class discovery. The first involves finding differences in expression levels between predefined groups of samples. The second class involves identifying the class membership of a sample based on its gene expression profile. The third class involves analyzing a given set of gene expression profiles with the goal to understand the mechanisms underlying a disease by discovering subgroups of genes that share common features. A computational method often used for class discovery is clustering which aims at dividing the data points (genes) into groups (clusters) using similarity measures, such

A Parallel Distributed System for Gene Expression Profiling 177
as Correlation or Euclidean distance [3, 4]. The notion of "cluster" cannot be precisely defined [5] which is one of the reasons that explains the wide range of clustering algorithms proposed in the literature to solve the problem of gene expression profiling [6, 7, 8].
When facing clustering algorithm for gene expression, selecting the best clustering method with the correct parameter values is not an easy task in most cases. Users may not be capable of introducing the precise parameter value. Therefore a small change on the input parameter may impact the output result. Also if not properly handled, noisy genes data may degrade significantly the quality of the results. The frequently used method to overcome these limitations is clustering ensemble. It takes as an input a set of clusterings generated by different algorithms [9], or by the same algorithm using different parameters [10], and provides as an output a better quality final clustering [11, 12].
In this paper, we propose a parallel distributed system for gene expression profiling (PDS-GEF) dedicated for class discovery which provides a useful basis for individualized treatment of a certain disease such as Cancer. The proposed approach is based on two major techniques: the GIM (Generalized Island Model) and clustering ensemble. GIMs are composed of many metaheuristics (particle swarm optimization, ant colony optimization, artificial bee colony, genetic algorithm …) performing in parallel and cooperating by using a migration operator. They are used to generate good quality clusterings which are refined by a consensus function to get a high quality clustering. PDS-GEF system is implemented using Matlab’s PCT (Parallel Computing Toolbox) which runs on a desktop computer, and is tested on 34 different publicly available gene expression data sets.
The rest of the paper is organized as follows. In section 2, we present the background and related works. Sections 3 and 4 are dedicated to the description and the implementation of the proposed approach for gene expression profiling. In section 5, we present the experimental results obtained by using publicly available data sets. Finally, conclusions and future work are drawn.
2 Background and Related Work
Before a formal description of our approach, we briefly introduce the principle of the two used methods namely generalized island model and clustering ensemble.
2.1 Generalized Island Model
The Generalized Island Model (GIM) [13] is as an approach that can be applied to a broad class of optimization algorithms. The study of the effect of this generalized model distribution was performed on several well-known population based clustering metaheuristics which include: the differential evolution (DE) [14], Genetic Algorithms (GA) [15], search for harmony (HS) [16], artificial bees’ colony (ABC) [17], particle swarm optimization (PSO) [18], ant colony optimization (ACO) [19]. The GIM has been proposed in order to improve the diversity of solutions. It enables

178 Z. Benmounah and M. Batouche
to efficiently distribute algorithms across multiple processors. A new operator called the migration operator can improve the overall performance of algorithms. Informally, this operator has both the role to select individuals in the current island to be sent to other islands, as well as to potentially introduce individuals outside the local population.
2.2 Clustering Ensemble
Cluster ensemble is made up of two steps: Generation and Consensus Function [20] (see figure 1). In the following, we describe these two steps.
Generation Step. Is the first step of the cluster ensemble. Given a data set, it generates a collection of clustering solutions. For best performance, it is necessary to apply the most appropriate method so that the combined result will bring considerable changes in the outcome of the second step.
Consensus Function. Is the main step of the clustering ensemble. It combines the clustering solutions of the ensemble and produces a best clustering as the final output. There are two main consensus function approaches: objects co-occurrence and median partition. Ensemble clustering has been shown to be NP-complete [21].
Many algorithms have been developed in this field [20]. COMUSA finds the true number of final clusters but it requires an exact parameter [22]. EAC, COMUSA, and CSPA may not reveal the relationship between clusters [23]. Although HGPA is very fast, however cannot handle large data with noise [9]. LCE needs a lot of computation [24]. GCC Genetic methods suffer from long execution times [25]. In the domain of clustering ensemble, determining crossover, chromosome encoding, mutation, and the fitness function are not immediate. DICLEANS outperforms all algorithms cited above in time execution and clusters quality, it uses minimum spanning tree as the input where each vertex represents an input cluster and each vertex represents the intercluster similarity [26].
Dataset
Generation step
Clustering m
Final Clustering
Clustering 2
Clustering 1
Concensus step
Fig. 1. Diagram of the general process of cluster ensemble [20]
A Parallel Distributed System for Gene Expression Profiling 179
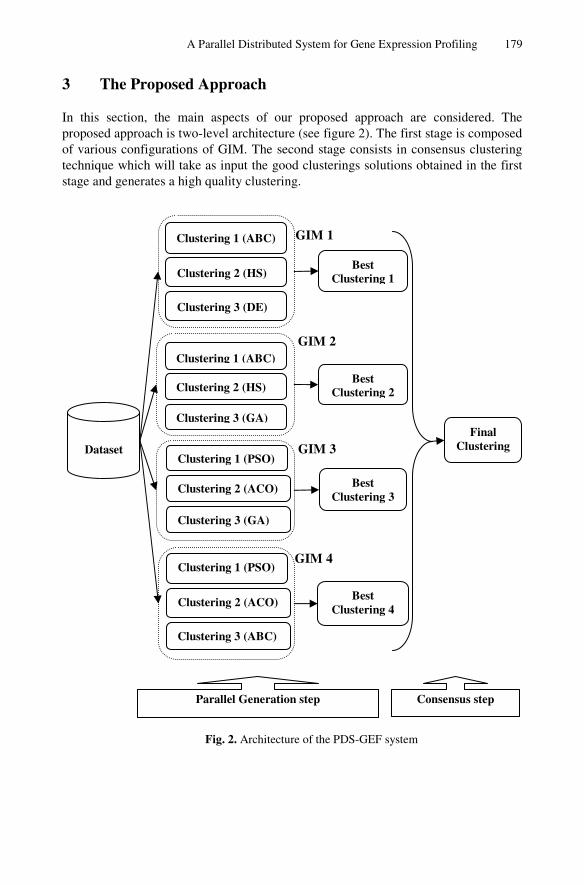
3 The Proposed Approach
In this section, the main aspects of our proposed approach are considered. The proposed approach is two-level architecture (see figure 2). The first stage is composed of various configurations of GIM. The second stage consists in consensus clustering technique which will take as input the good clusterings solutions obtained in the first stage and generates a high quality clustering.
Dataset
Parallel Generation step
Clustering 1 (ABC)
Final Clustering
Consensus step
Fig. 2. Architecture of the PDS-GEF system
Clustering 3 (DE)
Clustering 1 (ABC)
Clustering 2 (HS)
Clustering 3 (GA)
Clustering 1 (PSO)
Clustering 2 (ACO)
Clustering 3 (GA)
Clustering 1 (PSO)
Clustering 2 (ACO)
Clustering 3 (ABC)
GIM 1
GIM 2
GIM 3
GIM 4
Best Clustering 1
Best Clustering 2
Best Clustering 3
Best Clustering 4
Clustering 2 (HS)

180 Z. Benmounah and M. Batouche
3.1 First Level (Parallel Generation Step)
In our system, we use four GIMs including each three islands representing instances of existing clustering algorithms based optimization selected among the following list: DE (Differential Evolution), PSO (Particle Swarm Optimization), HS (Harmony Search), GA (Genetic Algorithm), and ABC (Artificial Bee Colony). All the selected algorithms are population based.
Inside one GIM, optimization algorithms (Metaheuristics) work in parallel and cooperate by using the migration operator which consists in the exchange of a subset of solutions each a preset number of iterations. It should be noted that there is no communication between two different GIMs. However, communication is performed between two islands in the same GIM. The communication flow can circulates between any two islands (in the same GIM) and toward any direction (bi-direction). Our approach follows an asynchronous communication initiated by the source to boost the speed and scalability of the system.
The whole process can be described as follows. Both of GIMs and islands are executed in parallel in order to accelerate generation and allow population migration. The migration topology of different islands in the same GIM is fully connected.
3.2 Second Step (Consensus Function Step)
Once good quality clustering solutions are generated by the different GIMs, the cluster ensemble process is launched in order to get high quality clustering by using a clustering consensus technique. The latter combines, in a smart way, a set of clustering solutions in order to obtain at the end one high quality clustering.
The use of cluster ensemble can be justified by the fact that weak clustering solutions when combined using a consensus clustering technique will give rise to high quality clustering solutions [26]. Therefore, there is no constraint regarding the way the partitions must be obtained. Each GIM has to generate a good enough clustering solution which is not necessarily the best. It is the consensus function which is in charge of generating the high quality clustering solution.
In our approach, we used an objects co-occurrence approach (EAC: Evidence ACcumulation) [23] which consists in accumulating the evidence in each cluster to form a coassociation matrix. Each entry in this matrix is the number of times that objects a and b are assigned to the same clusters. If a and b are often together they must belong to the same cluster in the final clustering.
4 Parallel Implementation of the Proposed Approach
In the following, we explain the way we implement our approach using MATLAB’s Parallel Computing Toolbox (PCT). The pseudo code in Matlab regarding our approach can be summarized as follows:

A Parallel Distributed System for Gene Expression Profiling 181
Program: PDS-GEF input: gene expression data sets Matlabpool(12); spmd switch labindex % the identifier of each Island case 1: apply Island (1) algorithm; case 2: apply Island (2) algorithm; % GIM 1 case 3: apply Island (3) algorithm; case 4: apply Island (4) algorithm; case 5: apply Island (5) algorithm; % GIM 2 case 6: apply Island (6) algorithm; case 7: apply Island (7) algorithm; case 8: apply Island (8) algorithm; % GIM 3 case 9: apply Island (9) algorithm; case 10: apply Island (10) algorithm; case 11: apply Island (11) algorithm; % GIM 4 case 12: apply Island (12) algorithm; end % switch end % spmd BestClustering ← EAC (BestClusterings); % consensus Matlabpool close; output: BestClustering; % final result end.
Our proposed system is composed of 12 parallel cooperating islands algorithms.
The pseudo code of the Island algorithm: algorithm: Island(id) input: id % identification number P % initial population S % selection strategy R % recombination policy Ai % optimization algorithm Ui % number of iteration in Ai initalize P; % initialize population while !stop_ criterion P'← Ai(P, Ui); % new population M ← S(P'); % selection policy labSend M; ← % send selected solutions M'←labReceive; % receive migrant solutions P''← R(P', M'); % recombination policy P ← P''; % update current population end % while end.
182 Z. Benmounah and M. Batouche
In each island, a metaheuristic (GA, PSO, ACO, HS, DE, ABC) is deployed to carry out the clustering generation process. Its dynamic can be described as follows. Initially, the metaheuristic is launched with randomly generated population P. After ui iterations, a set M of solutions, chosen using a selection policy S to undergo migration, is broadcasted to all neighboring islands. Once all selected solutions sent by neighboring islands are received, a recombination policy R is used to form the new population. This process is repeated until a stopping criterion is reached. labSend and labReceive are two functions in Matlab’s parallel computing toolbox used for communication purposes.
5 Experimental Results
To assess the performance of our system, we tested our approach on 34 different publicly available gene expression data sets having the proprieties shown in table 1.
Table 1. Description of used gene expression datasets [27]
Dataset Name Array Type Tissue Total Num Total Selected # samples classes Genes of Genes
Bladder carcinoma Affymetrix Bladder 40 3 7129 1203 Breast Cancer Affymetrix Breast 49 2 7129 1198
Breast-Colon tumors Affymetrix Breast, Colon 104 2 22283 182 Carcinomas Affymetrix Multi-tissue 174 10 12533 1571
Central nervous system-1 Affymetrix Brain 34 2 7129 857 Central nervous system-2 Affymetrix Brain 42 5 7129 1379
Endometrial cancer D-Channel Endometrium 42 4 8872 1771 Glioblastoma multiforme D-Channel Brain 37 3 24192 1411
Gliomagenesis D-Channel Brain 50 3 41472 1739 Gliomas-1 Affymetrix Brain 50 4 12625 1377 Gliomas-2 Affymetrix Brain 28 2 12625 1070 Gliomas-3 Affymetrix Brain 22 2 12625 1152
Hepatocellular carcinoma D-Channel Liver 178 2 22699 85 Leukemia-1 Affymetrix Bone Marrow 248 2 12625 2526 Leukemia-2 Affymetrix Bone Marrow 248 6 12625 2526 Leukemia-3 Affymetrix Blood 72 2 12582 1081 Leukemia-4 Affymetrix Blood 72 3 12582 2194 Leukemia-5 Affymetrix Bone Marrow 72 2 7129 1877 Leukemia-6 Affymetrix Bone Marrow 72 3 7129 1877
Lung tumor-1 Affymetrix Lung 203 5 12600 1543 Lung tumor-2 D-Channel Lung 66 4 24192 4553 Lymphoma-1 D-Channel Blood 42 2 4022 1095 Lymphoma-2 D-Channel Blood 62 3 4022 2093 Lymphoma-3 Affymetrix Blood 77 2 7129 798
Melanoma D-Channel Skin 38 2 8067 2201 Mesothelioma Affymetrix Lung 181 2 12533 1626 Multi-tissue Affymetrix Multi-tissue 190 14 16063 1363
Prostate cancer-1 D-Channel Prostate 104 5 20000 2315 Prostate cancer-2 D-Channel Prostate 92 4 20000 1288 Prostate cancer-3 D-Channel Prostate 69 3 42640 1625 Prostate cancer-4 D-Channel Prostate 110 4 42640 2496 Prostate cancer-5 Affymetrix Prostate 102 2 12600 339
Round blue-cell tumor D-Channel Multi-tissue 83 4 6567 1069 Serrated carcinomas Affymetrix Colon 37 2 22883 2202
A Parallel Distributed System for Gene Expression Profiling 183
Array Type refers to the type of microarray used in the experiment. There are two types namely Affymetrix and Double Channel. Tissue indicates the tissue from where the samples were taken. Total samples is the number of conditions used in the experiment and it represents the dimensional of data. Num of Classes is the optimal number of groups (clusters) expected after the data has been clustered. Total genes is the number of genes present in the experiment. Selected # of Genes is the data set is large and a lot of information corresponds to genes not showing any interesting changes during the experiment. Filtering allows to find the interesting genes and passes over genes with expression profiles that do not show anything of interest.
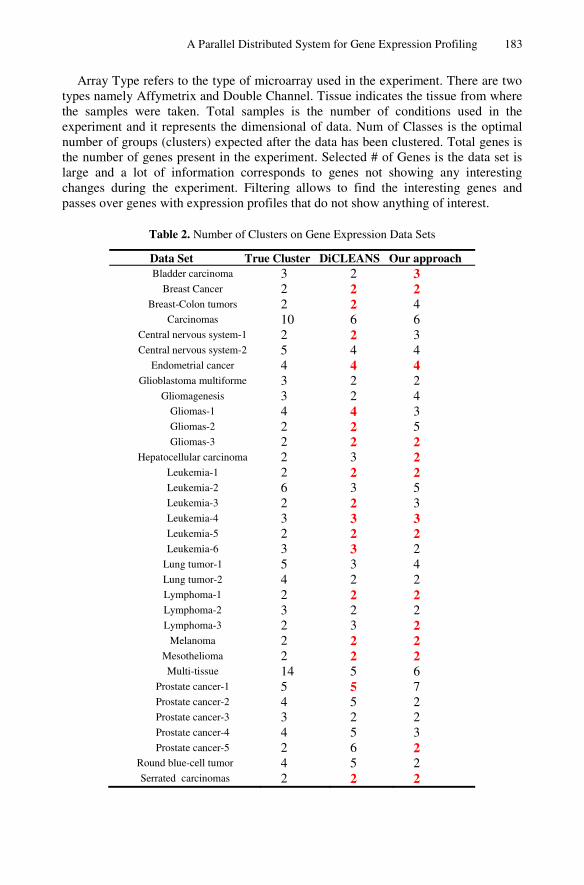
Table 2. Number of Clusters on Gene Expression Data Sets
Data Set True Cluster DiCLEANS Our approach Bladder carcinoma 3 2 3
Breast Cancer 2 2 2 Breast-Colon tumors 2 2 4
Carcinomas 10 6 6 Central nervous system-1 2 2 3 Central nervous system-2 5 4 4
Endometrial cancer 4 4 4 Glioblastoma multiforme 3 2 2
Gliomagenesis 3 2 4 Gliomas-1 4 4 3 Gliomas-2 2 2 5 Gliomas-3 2 2 2
Hepatocellular carcinoma 2 3 2 Leukemia-1 2 2 2 Leukemia-2 6 3 5 Leukemia-3 2 2 3 Leukemia-4 3 3 3 Leukemia-5 2 2 2 Leukemia-6 3 3 2
Lung tumor-1 5 3 4 Lung tumor-2 4 2 2 Lymphoma-1 2 2 2 Lymphoma-2 3 2 2 Lymphoma-3 2 3 2
Melanoma 2 2 2 Mesothelioma 2 2 2 Multi-tissue 14 5 6
Prostate cancer-1 5 5 7 Prostate cancer-2 4 5 2 Prostate cancer-3 3 2 2 Prostate cancer-4 4 5 3 Prostate cancer-5 2 6 2
Round blue-cell tumor 4 5 2 Serrated carcinomas 2 2 2

184 Z. Benmounah and M. Batouche
The data sets used in our approach are filtered from non significant genes. We compared our results with the expected optimal number of classes and also with a recent developed consensus function called DiCLEANS (Divisive Clustering Ensemble with Automatic Cluster Number) [26]. The experimental results show that our approach competes with and even outperforms DiCLEANS in some cases as shown in table 2.
6 Conclusion and Future Work
In this work, we proposed a parallel distributed system for gene expression profiling PDS-GEF dedicated to class discovery using microarrays technology. It combines mainly two major techniques namely distributed optimization and clustering ensemble. The parallel distributed optimization techniques are used for generating good quality cluster solutions which are combined to get high quality clustering by exploiting a consensus function namely EAC technique. The proposed approach is implemented using Matlab’s PCT (Parallel Computing Toolbox) which runs on a desktop machine. The parallelism allows dealing with the huge amount of data inherent to bioinformatics. The conducted experiments on real data sets have led to very encouraging results.
There are many ways to improve the performance of the system and the quality of the resulting clustering. The use of MATLAB Distributed Computing Server, GPU and cluster of GPUs will certainly improve the performance of the system. The application of other consensus functions like DiCLEANS or those based on median partition would also enhance the quality of the resulting clustering yielding to a better diagnosis.
References
1. Jens, S., Kerstin, B., Anette, J., Jvrg, D.H., Philipp, A.: Microarray Technology as a Universal Tool for High-Throughput Analysis of Biological Systems. Combinatorial Chemistry & High Throughput Screening 9, 365–380 (2006)
2. Tarca, A.L., Roberto, R., Sorin, D.: Analysis of microarray experiments of gene expression profiling. American Journal of Obstetrics and Gynecology 195, 373–388 (2006)
3. Aach, J., Rindone, W., George, M.S.: Systematic management and analysis of yeast gene expression data. Genome Research 10, 431–445 (2000)
4. Bethin, K.E., Nagai, Y., Sladek, R., Asada, M., Sadovsky, Y., Hudson, T.J., et al.: Microarray analysis of uterine gene expression in mouse and human pregnancy. Mol. Endocrinol. 17, 1454–1469 (2003)
5. Vladimir, E.C.: Why so many clustering algorithms. Sigkdd Explorations 4, 65–75 (2002) 6. Daxin, J., Chun, T., Aidong, Z.: Cluster Analysis for Gene Expression Data: A Survey.
IEEE Transaction on Knowledge And Data Engineering 16, 1370–1386 (2004) 7. Kerr, G., Ruskin, H.J., Crane, M., Doolan, P.: Techniques for clustering gene expression
data. Computer in Biology and Medecine 38, 283–293 (2008) 8. Harun, P., Burak, E., Andy, D.P., Çertin, Y.: Clustering of high throughput gene
expression data. Computer & Operation Research 39, 3046–3061 (2012)

A Parallel Distributed System for Gene Expression Profiling 185
9. Strehl, A., Ghost, J.: Cluster A Knowledge Reuse Framework for combining Mutiple Partitions. J. Machine Learning Research 3, 583–617 (2002)
10. Fred, A., Jain, A.: Combining Multiple Clusterings Using Evidence Accumulation. IEEE Transaction Pattern Analysis and Machine Intelligence 27, 835–850 (2005)
11. Strehl, A., Ghosh, J.: Cluster: Cluster Ensembles - A Knowledge Reuse Framework for Combining Multiple Partitions. J. Machine Learning Research. 3, 583–617 (2002)
12. Mimaroglu, S., Erdil, E.: Obtaining Better Quality Final Clustering by Merging a Collection of Clusterings. Bioinformatics 26, 2645–2646 (2010)
13. Izzo, D., Ruciński, M., Biscani, F.: The Generalized Island Model. In: Fernandez de Vega, F., Hidalgo Pérez, J.I., Lanchares, J. (eds.) Parallel Architectures & Bioinspired Algorithms. SCI, vol. 415, pp. 151–170. Springer, Heidelberg (2012)
14. Ravi, V., Aggarwal, N., Chauhan, N.: Differential Evolution Based Fuzzy Clustering. In: Panigrahi, B.K., Das, S., Suganthan, P.N., Dash, S.S. (eds.) SEMCCO 2010. LNCS, vol. 6466, pp. 38–45. Springer, Heidelberg (2010)
15. Sheikh, R.H., Raghuwanshi, M.M., Jaiswal, A.N.: Genetic Algorithm Based Clustering: A Survey. Emerging Trends in Engineering and Technology 8, 314–319 (2008)
16. Alia, O.M., Al-Betar, M.A., Mandava, R., Khader, A.T.: Data Clustering Using Harmony Search Algorithm. In: Panigrahi, B.K., Suganthan, P.N., Das, S., Satapathy, S.C. (eds.) SEMCCO 2011, Part II. LNCS, vol. 7077, pp. 79–88. Springer, Heidelberg (2011)
17. Changsheng, Z., Dantong, O., Jiaxu, N.: An artificial bee colony approach for clustering. Expert Systems with Applications 37, 4761–4767 (2010)
18. Yau, K.L., Tsang, P.W.M., Leung, C.S.: PSO-based K-means clustering with enhanced cluster matching for gene expression data. Neural Computing and Application 22, 1349–1355 (2013)
19. Kao, Y., Cheng, K.: An ACO-Based Clustering Algorithm. In: Dorigo, M., Gambardella, L.M., Birattari, M., Martinoli, A., Poli, R., Stützle, T. (eds.) ANTS 2006. LNCS, vol. 4150, pp. 340–347. Springer, Heidelberg (2006)
20. Sandro, V.P., José, R.S.: A Survey of Clustering Ensemble Algorithms. International Journal of Pattern Recognition and Artificial Intelligence 25, 337–372 (2011)
21. Filkov, V.: Integrating microarray data by consensus clustering. IEEE International Conference on Tools with Artificial Intelligence 15, 418–426 (2003)
22. Mimaroglu, S., Erdil, E.: Obtaining Better quality final clustering by Merging a Collection of Clusterings. Bioinformatics 26, 2645–2646 (2010)
23. Fred, A., Jain, A.: Combining Multiple Clusterings Using Evidence Accumulation. IEEE Tran. Pattern Analysis and Machine Intelligence 27, 835–850 (2005)
24. Natthakan, I.O., Tossapon, B., Simon, G.: LCE: A Link-Based Cluster Ensemble Method for Improved Gene Expression Data Analysis. Bioinformatics 26, 1513–1519 (2010)
25. Yu, Z., Wong, H., Wang, H.: Graph-Based Consensus Clustering for Class Discovery from Gene Expression Data. Bioinformatics 33, 2888–2896 (2007)
26. Selim, M., Emin, A.: DICLEANS: Divisive Clustering Ensemble With Automatic Cluster Number. IEEE/ACM Tran. Computational Biology and Bioinformatics 9, 408–420 (2012)
27. Souto, M., Costa, I., de Araujo, D., Ludermir, T., Schliep, A.: Clustering Cancer Gene Expression Data: A Comparative Study. BMC Bioinformatics 9, 497 (2008)
Related Documents











