InL J. Man-Machine Studies (1985) 23, 335-367 A natural language information retrieval system with extentions towards fuzzy reasoning LEONARD BOLC Institute for lnformatics, Warsaw University, PKiN, pok. 850, 00-901 Warszawa, Poland ADAM KOWALSKI Institute of Computer Science, Polish Academy of Sciences, 00-901 Warszawa, P.O. Box 22, Poland MALGORZATA KOZLOWSKA Institute for Informatics, Warsaw University, PKiN, pok. 850, 00-901 Warszawa, Poland TOMASZ STRZALKOWSKI Department of Computing Science, Simon Fraser University, Burnaby, B.C. Canada, V5A IS6 (Received 19 February 1984, and in revised form 16 February 1985) For the last few years we have observed a growing interest among reseachers about how to make computers behave "intelligently". The field of computer science has gained a substantial level of development especially in the field of so-called expert systems. This particular area has also obtained relatively wide approval and applicabil- ity. This paper describes an experimental version of the conversational natural language information retrieval system which is currently under investigation at the Institute for Informatics of Warsaw University. This system deals with gastroenterology, a branch of internal medicine. The system's purpose is to provide physicians and hospital personnel with information which may be consulted during the diagnostic process. The system first acquires a base knowledge in the field which is presented to it in the form of a comprehensive natural language text. From this point on knowledge can be retrieved and/or updated in conversational manner. The system has a modular structure and its most important parts are the natural language processor and the reasoning module based on procedural deduction. The deduction process is realized through the mechan- isms known as fuzzy logic incorporated in the FUZZY programming language. The system has been designed in close co-operation with specialists in medical science, and implemented on an IBM 370/148 at Warsaw University. 1. Introduction In the last few years we have observed a growing interest among reseachers in computer science about how to make computers behave "intelligently". The field has gained a substantial level of development especially in the field of constructing expert systems (Feigenbaum, 1980; Michie, 1979; Raulefs, 1981), the task-oriented information retrieval systems. A particularly important role in the construction of expert systems is played by knowledge representation (McCalla & Cercone, 1983; McDermott, 1978; Mylopoulos, 335 0020-7373/85/040335+33503.00/0 1985 AcademicPress Inc. (London) Limited

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

InL J. Man-Machine Studies (1985) 23, 335-367
A natural language information retrieval system with extentions towards fuzzy reasoning
LEONARD BOLC
Institute for lnformatics, Warsaw University, PKiN, pok. 850, 00-901 Warszawa, Poland
ADAM KOWALSKI
Institute of Computer Science, Polish Academy of Sciences, 00-901 Warszawa, P.O. Box 22, Poland
MALGORZATA KOZLOWSKA
Institute for Informatics, Warsaw University, PKiN, pok. 850, 00-901 Warszawa, Poland
TOMASZ STRZALKOWSKI
Department of Computing Science, Simon Fraser University, Burnaby, B.C. Canada, V5A IS6
(Received 19 February 1984, and in revised form 16 February 1985)
For the last few years we have observed a growing interest among reseachers about how to make computers behave "intelligently". The field of computer science has gained a substantial level of development especially in the field of so-called expert systems. This particular area has also obtained relatively wide approval and applicabil- ity. This paper describes an experimental version of the conversational natural language information retrieval system which is currently under investigation at the Institute for Informatics of Warsaw University. This system deals with gastroenterology, a branch of internal medicine. The system's purpose is to provide physicians and hospital personnel with information which may be consulted during the diagnostic process. The system first acquires a base knowledge in the field which is presented to it in the form of a comprehensive natural language text. From this point on knowledge can be retrieved and/or updated in conversational manner. The system has a modular structure and its most important parts are the natural language processor and the reasoning module based on procedural deduction. The deduction process is realized through the mechan- isms known as fuzzy logic incorporated in the FUZZY programming language. The system has been designed in close co-operation with specialists in medical science, and implemented on an IBM 370/148 at Warsaw University.
1. Introduction
In the last few years we have observed a growing interest among reseachers in computer science about how to make computers behave "intelligently". The field has gained a substantial level of development especially in the field of constructing expert systems (Feigenbaum, 1980; Michie, 1979; Raulefs, 1981), the task-oriented information retrieval systems.
A particularly important role in the construction of expert systems is played by knowledge representation (McCalla & Cercone, 1983; McDermott, 1978; Mylopoulos,
335
0020-7373/85/040335+33503.00/0 �9 1985 Academic Press Inc. (London) Limited

336 L. BOLC E T AL.
1981 ; Wahlster, 1977). The complex knowledge available to the expert system is defined as a knowledge database. The expert systems are therefore defined as systems with a knowledge database. A number of methods of representing semantic knowledge have been developed which are defined as knowledge representation languages (Brachman & Levesque, 1983).
Many expert systems are known at present which assist the work of chemists (DENDRAL, Buchanan & Feigenbaum, 1977), geologists (PROSPECTOR, Hart & Duda, 1977), bridge construction engineers (SACON, Bennet et aL, 1978), lawyers (TAXMAN, McCarthy et al., 1979) and electrotechnicians (EL, Stallman & Sussman, 1977).
Medical science is interested in using the possibilities of expert systems in particular ways, mainly for such purposes as:
(1) Raising the standard of medical diagnosis (2) Relieving the physician from arduous calculation connected with drug dosage (3) The use by the physician of the latest results in medical science in widely
understood medical practice (4) Shortening the medical diagnosis process (5) Avoiding wrong medical diagnosis (6) The possibility of consultation in conditions of difficult access to a specialist,
e.g. during the night or in a place situated far from a diagnostic specialist centre.
The architecture of expert systems developed for medical science has been quite well described. Therefore, in Table I we present only a number of, as we believe, representative systems (Wahlster, 1983).
Table 1 shows that the spectrum of expert system usage in medicine is very wide; from the large systems for internal medicine (INTERNIST, EXPERT/PI) to highly specialized systems focused on closely defined diseases, e.g. cholestasis (DOX). The size of the knowledge base is designed adequately for the size of a given expert system. The INTERNIST system, therefore, possessing 24,000 inferential rules, belongs to systems with the largest knowledge base, while the PUFF system, with only 250 inferential rules, belongs to systems with the smallest knowledge base. One of the presently best known expert systems, MYCIN, is a system with a medium-sized knowledge base (1000 inferential rules).
The implementation of expert systems orientated towards their practical use in medicine requires the usage of computers with large internal and external memories, and with fast access to data. Until now, most of the expert systems have been developed on DECsystem I0 and DECsystem 20 computers. It should be assumed though that at present most of the expert systems in medicine will be designed for LISP-Machine computers (Weinreb & Moon, 1981). Due to the technical qualities of these computers and their exceptionally low price nowadays, expert systems can be installed today in medical institutes and even smaller hospitals.
The fast development of expert systems throughout the world has encouraged us to design and implement our own expert system, with the possibility of its future applica- tion in clinical practice in an experimental form. This work presents the state of development of the system. Its working definition is: A Natural Language Information Retrieval System with Extensions towards Fuzzy Reasoning. The aim of the system is to provide an automatic extraction of facts from the system data base. The base system

A NATURAL LANGUAGE INFORMATION RETRIEVAL SYSTEM 337
TABLE 1 Brief characteristics o f selected medical expert systems. For more information the reader
is referred to original works
Knowledge System Field of medicine representation
Glaucoma Inference net CASNET (Weinreb & Moon, 1981) CENTAUR (Atkins, 1979) Digitalis Advisor (Skala, 1978) EMYCIN-HEADMED (Heiser & Brooks, 1978) EMYCIN-PUFF (Nilsson, 1982) EXPERT-PI (Goldberg et al. 1980) EXPERT-THYROID (Goldberg & Weiss, 1980) EXPERT-General Reumatology (Goldberg & Weiss, 1980) EXPERT-Connective Tissue Diseases (Goldberg & Weiss, 1980) INTERNIST I-II (Pople, 1977) IRIS (Szolovits & Pauker, 1978) MOX (Chandrasekaran et al., 1979) MYCIN (Shortliffe, 1976) PIP (Swartout, 1977) VM (Fagan et al., 1979)
Pulmonary diseases
Digitalis dosage control Drug dosage control in psychofarmacology Pulmonary diseases
Internal diseases
Schilddmsenerkran- kungen (German) Reumatology
Frames and production Systems OWL procedures
Production systems
Production systems
Production systems
Production systems
Production systems
Erkrankungen des Bindegewebes (German) Internal diseases
Ophalmology
Cholestasis
Bacterial infectious diseases diagnosis and therapy Kidney diseases
Emergency system data processing
Production systems
Production systems
Semantic nets and inference procedures Actor-system
Production systems
Frames
Production systems
knowledge has been acquired from an extensive medical text giving a complex descrip- tion of the present state of knowledge in gastroenterology. From this point on, the data base can be questioned and /o r updated in the conversational manner with Polish as the query language.
Our system has a modular structure which is presented in Fig. 1 in a simplified form. In the development of our system we have paid particular attention to two of its modules: the natural language analysis module and the reasoning module based on procedural deduction. The language analysis module has been particularly widely developed and it constitutes a sort of subsystem in the general system framework. This subsystem has been called TESS (Transformation Expert SyStem). TESS's aim is to secure the transition of specialistic medical text inputs from their natural form, i.e.

338 L. BOLC E T AL .
|
~ - - N L sentence
onalyser I FOL formula
t DedJction module Certainty calculation
I FOLF with modifiers
JAnswer generation ~-
E NL answer
User's Iquery
FIG. 1. The diagram of the Natural Language Information Retrieval System with Extensions towards Fuzzy Reasoning.
sentences formed by specialists, into a formal logical notation. The medical text possesses all the features of a typical medical jargon making its processing more difficult. It is characterized by the ambiguity of words and entire language phrases. The most characteristic feature of the majority of medical texts though is their so-called "blurring", defined in computing science literature as the information of fuzzy-type, and considered in information systems within the theory of incomplete information.
The program for language analysis has been written using Cascaded ATN methods (CATN), where the syntactic and semantic components constitute separate cascade layers. The logical formulae obtained as a result of the language analysis is quite universal. This means that TESS output can be easily adapted to various methods of reasoning and knowledge representation.
The second module to which special attention has been paid, is the reasoning module based on natural deduction realized through mechanisms provided by the FUZZY programming language. We have used the concepts of linguistic variables and language modifiers to cope with the vagueness of certain expressions. This is directly connected with the style of knowledge representation and question formulation in medical science. The language modifiers have been ordered according to the increasing degree of certainty they convey and the number of cases defined in which they are comparable. A definition of language modifier operations constitutes a separate problem. Most of these problems have also been solved successfully due to flexibility of the FUZZY language.
The present version of the system was implemented on an IBM 370/148 computer under the VM 370 operating system. Below we present the state of research on our

A N A T U R A L L A N G U A G E I N F O R M A T I O N R E T R I E V A L S Y S T E M 339
system: the state of the theoretical issues as well as a description of the practical experiments. The remainder of the paper is organized as follows. Section 2 gives a description of the natural language analyser TESS. Section 3 briefly introduces the theoretical background of fuzzy-type resolution as well as the concepts of language modifiers and linguistic variables. Then, some experimental results of automatic reason- ing from a medical database are presented. Section 4 notes some preliminary results of work on natural language answer generators from the system.
2. Translating natural language into logical form: TESS
2.1. I N T R O D U C T I O N
The TESS system (Transformation Expert SyStem) translates written Polish sentences into a formal representation which expresses their meanings in the context of a dialogue subject. The system is mainly designed for the processing of professional texts such as medical descriptions and diagnosis, juridical documents, agricultural reports, and so on. The present version of the system is adapted to the processing of highly specialized medical descriptions.
TESS is intended to be used as a natural language processing component in a variety of information systems: natural language question-answering systems, expert systems, or story-understanding systems. The design of TESS was influenced by the goal of using it as a transferable compact subsystem of large-scale artificial intelligence projects. The system was thoroughly tested as a component of the natural language information retrieval system for physicians which is being developed at Warsaw University.
TESS has been equipped with numerous linguistic instruments which are simul- taneously or successively applied to a given natural language text. In the theoretical approach these mechanisms are called lexis, syntax, semantics and pragmatics. In practice no sharp boundaries exist between them. Often we cannot indicate where syntax ends and semantics begins.
TESS is divided into two main components. The first of them, called the analytical stage (AS), is generally domain independent. Though syntax plays the most important role in AS, the component has been enriched by selected elements of semantics, providing that the domain-independence requirement is preserved. AS also maintains a lexicon which contains information of the syntactical properties of words used in dialogue. Since Polish belongs to the highly inflexional family of languages, the lexicon must provide enough information concerning different word forms since the lexical description of words found in a Polish sentence have, in general, far greater influence on the sentence reading than other features of the sentence surface form (as word order, phrase order etc.).
The second component, called the interpretational stage (IS), assigns meanings to sentences. The process is strongly dependent on the conversation subject so that IS could be considered as an exchangeable part of the system. Nevertheless, since the interpretation process is based on a universal algorithm of pattern matching, the only actually domain-dependent elements of IS are so-called experts and a special semantic dictionary. Experts keep elementary knowledge on the subject of conversation. These facts together with the semantic dictionary enable TESS to bridge numerous prag- matical gaps which may occur in highly specialized descriptions. IS must act as a

340 L. BOLC E T AL.
qualified specialist in the subject otherwise TESS will miss its goal. These aforemen- tioned IS experts guarantee the desired system behaviour.
A no less important problem was the selection of a suitable representation to express meanings of sentences. The representation must be a formal language such as first-order logic, frames or semantic nets. The representation has to be "unders tandable" for co-operating shell system components, especially for a reasoning module. On the other hand, the representation should be clear and readable, and should provide the possibil- ity of reproducing the original sentence at least in a rough form. This feature seems to be desirable in automatic response generation.
In its present implementation, TESS transforms natural language medical descrip- tions into first-order logic formulae. This fact, however, should not suggest that the logical form is the only kind of representation which can be produced by the system. An alteration of the representation form can be made by changing some of the system's built-in primitives. The version of TESS presented here has been adapted to co-operate with the fuzzy-type reasoning module described in the next section.
The following paragraphs give a more detailed view of both system components. First, however, let us look briefly at TESS's overall organization.
2.2. THE ORGANIZATION OF THE SYSTEM
The core of the TESS system is constructed as a Cascaded Augmented Transition Network (CATN) net. A CATN net consists of two or more transition grammars which successively process the same information (Woods, 1980). Each g rammar is an ordinary ATN (Bates, 1978), which has, in addition, a new action called TRANSMIT. The T R A N S M I T action can be set on any arc and causes a piece of information to be sent from the current cascade level to the immediately lower one. Whenever a TRANSMIT
Info of failure
L Sema
User ]
I % l Syntax ,.
I o-form
Dictionary T [
Dictionary 11" J
Context [
FOL formulae ]
FIG. 2. The overall structure of the language processor TESS.

A NATURAL L A N G U A G E INFORMATION RETRIEVAL SYSTEM 341
occurs the level issuing it is suspended while the system operates on the lower level. The former will be eventually reactivated from its latest configuration when the information sent with TRANSMIT has been processed. In practice there exists a special intermediate buffer between each two cascade levels where the TRANSMITed informa- tion is stored. Therefore, the buffer is written by one ATN (the higher) and read by the other (the lower).
Each of the two TESS stages (AS and IS) creates the separate level in the two-layered CATN. AS produces syntactical parse structures and TRANSMITs them to IS. IS, in turn, tries to assign an appropriate semantic interpretation to the syntactic structures. In the case that no reasonable semantic interpretation can be found, AS is asked to derive another syntactically correct parsing for the sentence fragment. This may also involve a retreat from already committed results, thus causing backtracking at both cascade levels. Should AS eventually fail after perhaps numerous attempts, the sentence will be announced as meaningless and returned to the user for a reformulation. The schematic structure of TESS is presented in Fig. 2.
A limited-range spelling corrector has been appended to TESS which examines each sentence entering the analytical stage. The user is advised of every misspelled or unknown word. It is possible then to correct a mistake, add a new word to the lexicon, or even retype the entire sentence in another way.
The cross-textual context reference problem has been partially solved with a special context register globally available from any state of IS. The context register keeps information of the recently transformed sentence which, in the majority of cases, suffices to solve pronominal reference problems.
2.3. THE ANALYTICAL STAGE (AS)
The analytical component of TESS I~ ~ocesses an input sentence to uncover its syntactical structure. The sentence elements: subject, verb group, direct object, indirect object, prepositional phrases and the like, are distinguished and bounded. All constituents found in the original sentence are then moved into their underlying positions in the Canonical Polish Sentence Scheme (CPS) (roughly based on ideas discussed by Szober, 1967). CPS's of original sentences are represented in the system as o-forms: output forms from AS. Before we go into more detail about how AS works, let us first review (very briefly) some aspects of written Polish.
The syntactic analysis comprises a wide subset of contemporary Polish. AS can recognize declaratives and interrogatives, complement clauses, relative clauses, and certain types of co-ordinations. It can account for NP-movement, constituent- constituent agreement (like subject-verb agreement, subject-object agreement, noun- adjective agreement, and other similar phenomena common in Polish), passivations, word-order changes and the like. In the context of the shell system database, a number of specific properties of"medica l slang" have been taken into account. AS can recognize most of "medical Polish" which often appears to be quite different from ordinary Polish. If we think of a transportable NL processor, however, the parser must be able to cope with the ordinary language, before it is adapted to particular narrow purposes. The grammar underlying AS has been made as feasible and universal as possible to fulfil the transportability requirements. Much of this work is done by the lexicon and the proper partition of the "word space" into syntactical categories and subcategories. The lexicon releases the AS grammar from any domain dependency.

342 L. BOLC E T AL.
Polish is very different from English mainly due to inflexion which allows for free (but, of course, not casual) word-order in sentences. However sentences exist where any permutation of words creates a correct Polish sentence. This would not be so surprising, as in English you can also permute sentence words yielding syntactically well-formed strings (even if not all permutations are acceptable), without losing the following property. These word-order changing operations generally preserve the sen- tence meaning, even if the operation objectives are such sensitive sentence components as subject, direct object or indirect object.t The following example sheds some light on the problem range. Let us take a Polish sentence:
Jan dal Marii ksiazke (Jan gave Maria a book) (1)
All 4! = 24 possible permutations of the sentence words yield the correct Polish sentence preserving the original meaning. If we ignore some very subtle semantic deviations, to utter (1) in Polish you can say:
Ksiazke Marii dal Jan Marii Jan ksiazke dal Dal Marii ksiazke Jan etc.
As the reader has probably already guessed, the key to analysing Polish sentences is in a proper recognition and classification of inflexional forms of nouns, adjectives, adverbs and even prepositions. These forms are determined by four main lexical parameters: case, number, gender and person. The parameters propagate from words up to components and lay strong presuppositions on the role each component plays in the higher level constituent, and finally under the outermost S node. Also, the inflexional form of the verb group (main verb with auxiliaries) influences the goodness of formation of the sentence. This time, however, we face far greater syntactical requirements than in English. In addition to expected transitivity constraints and, in a limited range, person-number subject-verb agreement, in analysing Polish we have a collection of stronger or weaker phrase-phrase agreement constraints which can appear in almost every position, making the parsing process fairly complicated. On the other hand, in flexion often helps in reaching the constantly pursued best parsing, and in many cases narrows the decision choices concerning which path to proceed on next. This fact, contrary to previous statements, can speed up the parsing process remarkably. We will not go into details of Polish grammar as it would probably take twice as much space as this paper. Instead we will focus on some aspects of how one can cope with the aforementioned problems.
The TESS grammar differs slightly from the classical Polish grammar described by Szober (1967). A new categorization of the selected subset of Polish has been made according to the requirements of various kinds of professional texts. TESS recognizes 11 different syntactic categories (parts of speech) which can be listed informally as: nouns, adjectives, adverbs, numbers, quantifiers, verbs, auxiliary verbs, conjunctions,
t There exist, as everywhere, some limitation and exception to above statement. One can argue against the meaning preserving rule as almost every syntactical operation does not leave the sentence meaning without even a very subtle change. But, as in Polish, we can very often say of such subtle (and therefore discussable and dependent on a dialogue subject) sentence meaning changes, the corresponding operation on an English sentence normally completly changes its meaning (for example, if one changes subject and direct object phrase roles).

A NATURAL LANGUAGE INFORMATION RETRIEVAL SYSTEM 343
prepositions, question words and remaining words used in communicat ion which create the last category of undefined words. Almost all of them are, in turn, divided into not necessarily disjoint subcategories. Inside the category of nouns, for example, we distinguish proper names, nominal pronouns, and gerundives and object-taking nouns grouped under the common subcategory G E R U N D . Among verbs we have intransitive, unitransitive and bitransitive verbs, active and passive participles, reflexive verbs, perfect and imperfect forms, and modal verbs. Adjectives and adverbs are classified into different subcategories depending on lexical degree. Even the category of preposi- tions has been divided into subclasses grouping prepositions which can precede nominal phrases appearing in a specific lexical case. The subcategories are assigned by the fixed grammatical properties of the words. In other words, the subcategories are closed under four lexical operations on words, t i.e. changing case and /o r number and /o r person and /o r gender. So these are categories as well. The ranges of the lexical operations are much wider than in English. The case operation yields 12 different forms of noun* while gender offers nine values (we have five different genders for masculine). We cannot give any detailed example which would support the importance of the above issue without extensive reference to principles of Polish inflexion. Instead, let us look at the following problem. Suppose we have an adjective (an element of the syntactic category of adjectives), and a noun (an element of the syntactic category of nouns). Suppose further, they are compatible in some (semantic) sense. We want to compose a nominal expression from these words by writing them down one after the other. What seems to be so straightforward in English (e.g. having " g o o d " and " b o y " one can create "good boy") , requires much more attention when performed in Polish. We must select appropriate inflexional forms for both words to make a well-formed Polish expression. Moreover, from numerous inflexional forms for the adjective and the noun only one combination suits (assuming the intended meaning). When we add that adjectives are inflexionally sensitive on both case and gender changes, and that nouns inflect with case changes, we should have to select one out o f up to 648 (theoretically) possible combinations. Fortunately, in practice we do not have to operate such an enormous number of forms. The lexical operations are not one-to-one functions, and they allow a several times less number of morphologically distinct word forms. This last point raises a problem typical to parsing English. Different lexical parameters can yield the same inflexional word forms. In such cases the methods developed in parsing English have been found helpful. For more details concerning language categorization and lexical operation ranges the reader is refered to Bolc & Strzalkowski (1982, 1984).
The analytical stage transforms a Polish sentence into the ordered and inflexion-free form: the o-form. The o-form gives a first approximat ion of the sentence deep structure. It expresses the underlying construction of the sentence where each constituent has sharp boundaries. The necessity of such an intermediate parsing structure is initiated by the flexibility of Polish syntax as outlined above. This is also an occasion to emphasize as much as possible information on the sentence structure which may help the semantic process to behave more confidently. Two levels of the analytical process
t We are generalizing this idea here since lexical operations of number, gender, case and person are not equally applicable to all categories, or even subcategories such as common nouns and gerundives.
~: Classical Polish grammar states six cases for singular and six for plural (e.g. nominative, genitive, dative, accusative, instrumental and locative), but we found it more convenient to treat them as 12 different cases.

344 L. BOLC E T A L
are reflected in an o-form. First, each sentence is divided into a collection of clauses some of which can be embedded in others. Each clause expresses a propositional constituent of the sentence, those at the bottom of the syntactic hierarchy being the elementary events. It is worth noting that the clauses in an o-form are yielded not only by the strict clausal sentence subcomponents like relative or gerundive clauses, or complements. Also, the ordinary noun groups built up around common nouns can do that. We have found that insertion of limited conversation domain-related information concerning the semantic-pragmatic usage of common nouns into the syntactic diction- ary helps significantly. The information is essentially limited to a notification about whether a common noun can be treated as an object-taking noun or not, even if such a statement appears to be contrary to purely syntactical judgement. The idea can be developed further to the concept of parsing with a knowledge base, which on the one hand influences the parsing process, and on the other hand, can be updated as the parser acquires experience.
The construction of an o-form clause contains all the elements necessary in a syntactically well-formed clause. It has a subject, main predicate and perhaps other constituents such as objects and /o r preposition phrases. Every well-formed sentence contains at least one clause - itself, and some elements of a clause can be clauses as well. The top-level o-form clause is always built up around the main verb of the sentence.
The o-form has a linear structure where each constituent occupies a fixed position. Schematically, it can be illustrated as (2):
(o-form)::= (S (question?) ] (negation?) ] (time) [ (modality) [
(predicate) I (weight) [ (subject) [ (object) I (ind. object) [ {(preposition ph) l} + {CAUSE/RESULT (o-form)}* END) (2)
The S and END delimiters signal single clause boundaries. They play the role of parentheses as some clause constituents may be clauses as well. The (subject), (object) and (ind. object) are the most often among them. Vertical bars (I) divide clauses into constituents. When a phrase is missing in the original sentence the corresponding place between two such bars is left empty. For some of these "slots", however, specific default "fillers" are assumed. For example, if the (question?) slot is empty in the top-level clause of an o-form, the semantic interpretation process will assume the interrogative without question words (most often called a yes-no-question). Elsewhere, the empty (question?) slot will be equivalent to DCL (declarative), unless the clause in question inherits the filler from another clause. The CAUSE and RESULT keywords begin conditional clauses (if any). This part of the o-form is apparently optional, and will be included in the output from AS only if the original input sentence can be treated as a denotation of some causal relation. This particular sentence type has been distinguished because, as the reader probably agrees, the causal relations play very important and specific roles in medical descriptions.
Two examples of the o-forms generated by AS are shown below. Notice the use of the MODIFIERS keyword to separate the head noun phrase from its qualifier phrase (if any) in the (object) slot. It has been done to facilitate the access of the semantic interpreter to this very fragment of a clause which, as we have discovered, can sometimes

A N A T U R A L L A N G U A G E I N F O R M A T I O N R E T R I E V A L S Y S T E M 345
bear the actual clause predicate. Note also that the TRACE filler used in the first example in the place of subject of embedded clause is the "trace" of the subject phrase from the outer clause (ALKOHOL), as the inner clause modifies this phrase. The same rule is adapted everywhere the TRACE is used.
Original sentence Alkohol podany doustnie powoduje wzmozone uwalnianie gastryny. [Alcohol ingested orally causes increased release of gastrin]
o-form (s OCL I I I I POWODOWAC I I ALKOHOL s l I I I PODAC I D O U S T N I I T R A C E I I I E N D I S I I I U W A L N I A N I E I WZMOZON I I GASTRYNA MODIFIERS I I I END I I I END)
o-form translation (s DEE I I I I CAUSE I I ALCOHOL S IIII INGEST I ORALLY I I TRACE I I I END I S I I I RELEASE t INCREASED I I GASTRIN "MODIFIERS" I I I END I I I END)
Original sentence Co moze byc przyczyna ostrego zapalenia trzustki? [What may be a cause of acute pancreatitis?]
o-form (s c o IIII MOC I BYE III PRZYCZYNA MODIFIERS OSTR ZAPALENIE TRZUSTICA I I I END)
o-form translation (s WHAT I t I I MAY I BE I I I A CAUSE "MODIFIERS" ACUTE PANCREATITIS [ I I END)
Both sentences have been selected to have a one-to-one Polish-English translation. The translation of the above o-forms into English can be regarded as the o-forms of the English translation of the original Polish sentences. For more details concerning the AS parsing scheme and the discussion of its output form the reader is referred to Bolc & Strzalkowski (1984).
The analytical stage consists of five ATN nets. The most important of them, called SENTENCE, is presented (in somewhat simplified form) in Fig. 3. This net plays at least two different roles in parsing. It initiates and supervizes the parsing process, recognizes the sentence's outermost structure, and eventually returns the sentence's o-form. SENTENCE can also be called recursively by itself and with the NOUN- PHRASE net, whenever a new clause start-point is discovered. The latter net analyses the noun-phrase structures, and returns its description along with values of lexical indicators calculated as functions of lexical parameters of words building up the phrase.
The remaining three nets: ADJ-PHRASE, ADV-PHRASE, and Q-EXPR are inten- ded to recognize different types of non-cyclic syntactical constructions, that is, adjectival phrases, adverbial phrases and question expressions, respectively. These nets, although fairly well developed (especially ADJ-PHRASE), have a much simpler control structure

3 4 6 L. BOLC E T AL.
~ ~/.
e~
Z [ -
Z m
r
~L

A NATURAL LANGUAGE INFORMATION RETRIEVAL SYSTEM 347
than the two mentioned above. They cannot initiate deeply embedded recursive PUSH calls, as they never PUSH to either SENTENCE or NOUN-PHRASE nets.t
AS maintains the syntactic dictionary that keeps all the discourse vocabulary. Figure 4 presents some selected dictionary entries.
(JEST AUX BYC PERSON 3 NUMBER SG TNS PRES) (PRZEWODOW N PRZEWOD
CASES (GENPL) NUMBER PL GENDER M3PL) (TRZUSTKOWYCH ADJ TRZUSKOW*
CASES (GEN GENPL) GENDER (M1 M2PL M3PL FPL NEPL) FEATURES (POSIT))
(BYC AUX *) (ALKOHOL N * CASES (NOM ACC) NUMBER SG GENDER M3) (PODANY V PODAC
CASES (NOM ACC) NUMBER SG GENDER (M1 M2 M3) FEATURES (TRANS PASSPART) CPBJ (ACC ACCPL))
(DOUSTNIE ADV DOUSTN* FEATURES (POSIT)) (WZMOZONE ADJ WZMOZON*
CASES (NOM ACC NOMPL ACCPL) NUMBER (SG PL) GENDER (NEUT NEPL FPL M2PL M3PL) FEATURES (POSIT))
(UWALNIANIE N * CASES (NOM ACC) NUMBER SG GENDER NEUT FEATURES (GERUND TRANS) COBJ (GEN GENPL))
(W PREP *) (MOGA V MOC PERSON 3
NUMBER SG FEATURES (MODAL)) (CZY QWRD *)
F1G 4. A fragment of the syntactic dictionary. The first item of each entry is the word being defined. It is followed by the category name the word belongs to and its root form in this category. The * is used when both these words are the same. FEATURES indicates subcategories of the word, COBJ the case(s) of direct
object phrase for transitive verbs.
2.4. THE INTERPRETATIONAL STAGE (IS)
When the syntactical analysis is completed the o-form generated by the first stage becomes a subject of the semantic interpretation in the second stage. Each clause in the o-form is interpreted as a description of an elementary event in the world of gastroenterology. The meaning of the whole utterance combines meanings of all its clauses.
The semantic component maintains a collection of frameworks which serve as pattern-concept pairs (Wilensky & Arens, 1980). These frameworks, which are actually nothing other than semantic rules, have been designed as shown in Fig. 5. The pattern determines which phrases may be expected around the predicate and which of them must be specified (explicitly or in context). Each pattern slot consists of the name determining its semantic role and a description of syntaco-semantic conditions which must hold true during the matching process. The interpretation of a clause is driven by such a pattern so it may be called expectation and/or structure driven. The concept is a notion that represents the meaning of the clause. Together these pairs associate different forms of utterances with their meanings.
t An alternative version of ADJ-PHRASE net had been investigated, where the net can call NOUN- PHRASE for resolving comparative or superlative adjective clauses. Recent observations have brought us to the conclusion that the adjectival construction mentioned belongs to the noun phrase structure rather than creates a specific adjective phrase.

348 L. BOLC E T AL.
(APPLY TYPE TREATMENT AGT ( 0 HUMAN OPT) OBJ ( 0 MEDICAMENT OBL) MANNER ( 0 MOA OPT) CONCEPT (BUILDQ (( CA APPLY 3) + + + ) AGT OBJ MANNER ))
(IMPLY1 TYPE ETIO CAUSE ( 0 ETIO OBL) DEST ( (DO) SICKNESS OBL) CONCEPT (BUILDQ (( CA IMPLY 2) + + ) CAUSE DEST ))
(LEAKAGE TYPE SYMPTOM OBJ ( 0 LIQUID OBL) DEST ( (DO KU) ORGAN OPT) CONCEPT (BUILDQ ((CA LEAKAGE 3) (SYMPTOM +) + + ) VAR OBJ DEST ))
FIG. 5. Examples of semantic rules used by the parser.
The main predicative element of each clause activates one or more instances of such frameworks. The sentence consisting of a number of clauses then creates a kind of cluster of rules which are applied to the o-form segments in a mixed top-down/bottom- up manner. The bindings between clause predicates found in the syntactic stage and rule patterns strongly depend on the field of the man-machine dialogue. The meanings of verbs, nouns and adjectives have been limited to the restricted closed domain of gastroenterology. Some words have received quite new, not used in the common sense, meanings, while others have been simplified. This caused the effect that some subtle differences between commonly used words have disappeared and the words could be used further as synonyms. For example, the following verbs and verb expressions: "powodowac" (to induce), "stymulowac" (to stimulate), "prowadzic do" (to conduct), "byc przyczyna" (to be a cause), "byc skutkiem" (to be a result), and the like refer to the IMPLY conceptualization, while "podac" (to give), "stosowac" (to apply) and the like to the APPLY rule.
We will now devote some discussion to explaining the rule construction details (see Fig. 5). In the first rule called APPLY, TYPE is an indicator which points out that the event being described is a TREATMENT. The slots: AGT, OBJ and MANNER determine that the three phrases may be expected round the predicate APPLY. The only phrase which must be provided to keep the entire construction meaningful is the OBJ. The OBL option stands for "obligatory parameter", while the OPT one stands for "optional parameter". Fillers for these slots can be any syntactic constructions but prepositional phrases. It is indicated by the "empty" pair of brackets at the beginning of each slot. Below on the same Fig. 5 the DEST slot in the IMPLY1 rule must be filled by a phrase preceded by the preposition "do". The medical parameter specified in each slot determines the semantic requirements of the matching with this slot. Let us return to the APPLY rule. The AGT phrase (agent who applies something) must be a human. The OBJ phrase (object which is being applied) must be a medicament. The MANNER slot may be filled when a manner of medicament application (MOA) is found in the sentence. The CONCEPT part of the rule describes the way an atomic formula has to be built. In this case we should receive the three-ary predicate called

A N A T U R A L L A N G U A G E I N F O R M A T I O N R E T R I E V A L S Y S T E M 349
# APPLY. I f all obligatory, and as many as possible, optional slots are successfully matched against the o-form clause tied with this rule, the atomic formula of ( # APPLY x y z) is generated as the result. The arguments have a special form which is constructed during the matching process. The BUILDQ function is an ATN form allowing it to BUILD any Quoted expressions.
The filling of the frame slots is done after all the syntactical and semantic requirements have been satisfied. When the whole pattern is completed, an atomic formula is generated. Therefore, the interpretation process is an attempt to squeeze the syntactical structure of a sentence into one or more instances of frameworks described above. More than one semantic rule can be involved in the interpretation of a simple clause when its predicative element refers to more than one pattern. In the restricted world of gastroenterology we can often avoid such situations by the careful description of the database.
Apart from the central clause information expressed it. the atomic formula, a number of additional facts concerning the environment of the event in the light o f our limited world are generated by the semantic stage. These facts, usually not included explicitly in the text, guarantee the continuity of the world model kept in the database. They are stored partly in the semantic dictionary and in expert nets of the interpreter. They create a system base knowledge which must be provided before any contact with the system is started. This is absolutely fundamental know-how in the specified domain without which no advanced dialogue is possible. On the other hand, it is hard to expect the professional texts to specify in too much detail the levels o f the problems they describe. The semantic component must possess a quantity of such fundamental medical knowledge to make sure that every user's utterance really be understood.
IS has been equipped with a limited capability for resolving cross-textual context references like pronominal references or ellipsis unfolding. As the o-form clause is the basic unit in the interpretation process, the context references actually have a cross- clausal character. Thus, when a clause is processed by IS, reference can be made to the clause immediately containing the processed one. IS can examine the partial logical structure constructed so far for the outer clause and perhaps inherit some of its elements to present an interpretation. I f the analysed clause is the top-level o-form clause then the last processed sentence top-level clause becomes available for reference. Reference is made via the special context stack, where the two top elements are accessible at any time (and only they): the one at the very tip, where IS deposits fragments of currently processed clause to be used by a possibly embedded clause, and the second immediately under the tip, which the current process can refer to. This reference passing process has all the features of a transitive operation, so reference can actually be made through several clauses, providing each subsequent clause inherits the fragment in question from the clause where it was originally specified. Both pronominal references and ellipsis unfolding are made on the mixed syntactic/semantic basis. The reason for involving syntax at this stage is that inflexional forms of pronouns are extremely helpful in finding the proper denotations for them. This makes sense especially when the pronominal reference is semantically ambiguous, or more than one pronoun has been found in a sentence.
The second stage consists of a collection of ATN nets. The supervizing network called FORMULA guides the interpretation process and controls the semantic correct- ness of clauses. The F OR MULA net starts with the top-level o-form clause and then

350 L. BOLC E T AL.
recursively attends embedded clauses (if any). First, the predicative element of the clause is determined, and then the suitable semantic rule is selected from these provided by the dictionary. The FORMULA net successively calls the CASES network to fill the rule pattern slots. The latter serves as a communicational level between the supervizing net and experts. It can also handle the nominal phrase structures in order to determine pronominal references and numerous syntactic influences on the phrase meanings. The CASES net can eventually call the FORMULA net to interpret relative clauses modifying the noun phrase. The most important task of the CASES net is, however, the activation of expert nets which can account for the phrase meanings. The expert net is chosen according to the semantic constraints specified in the rule pattern.
There are seven expert nets in the semantic interpreter. They can recognize special medical expressions such as names of disease, symptoms, organs, treatments, sub- stances, physical objects considered in our limited world, and even a class of animate objects. The experts can be regarded as the compact, portable "knowledge cassettes" or submodulcs, which are prepared almost independently of the rest of IS. You can remove an expert, modify its contents, and install it again. You can also add new experts, for example, specializing in a very narrow subject, which can help the existing ones or extend the IS capabilities. There are no (theoretical) limitations on the number of experts IS is able to maintain. Some work is needed, however, when one wants to add a new expert or remove another one permanently. The communication level of IS (the CASES net) must be told of any changes in the collection of experts it serves. We are working currently on how to make the expert update process fully independent of the rest of the system.
Experts generate the additional information, mentioned above, to fulfill the numerous pragmatic gaps appearing in professional texts. They express the system knowledge about the selected limited domain of conversation. Experts match professional terms against their knowledge. This knowledge is specified on different levels of detail, and we cannot explain now (except by intuition), why some concepts are coded only as schematic patterns, while others are stated literally. In the former case, the semantic dictionary maintained by IS appears very helpful. The use of a semantic dictionary allows us to generalize the expert knowledge whenever possible, leaving the construc- tion of specific cases for the expert itself. As the experts are supposed to be prepared by human specialists in the fields of interest, it will be convenient to think in general concepts (if possible), instead of specifying hundreds of specific cases. Therefore, experts match professional terms against their knowledge, perhaps using the informa- tion stored in a semantic dictionary. Sometimes, when a term is more complex, the help of other experts may be required. In medical descriptions we often face such complex terms; the names of diseases or symptoms often require the DISEASE expert to consult the ORGAN or SUBSTANCE experts to recognize a term. Examples of such terms are: chronic subcapsular inflammation, coma hypoglycaemicum, cirrhosis hepatis. Thus experts support each other, and the final "expertize" is provided for the expert which was originally called on to recognize the term in question. The expert passes this result to the IS communication level, which in turn returns it to the supervizing FORMULA net where the recognized term is put into the currently open semantic rule pattern. Occasionally, a quantity of extra information is generated by experts involved in a recognition process, regarding the term in question. The informa- tion provides the desired continuity of the descriptions generated by IS, i.e. the

A N A T U R A L L A N G U A G E I N F O R M A T I O N R E T R I E V A L S Y S T E M 351
f
�9 , ~, .~" _
a
O .o
t~
.o
N
u;
o e~
8
O to
8 o
o
o ~ uJ tt~ < m ttJ
<
,6
rE

352 L. BOLC E T AL.
continuity of knowledge at a particular level of detail, even if the original text does not have this property (to some degree, of course). A fragment of the DISEASE expert is presented in Fig. 6.
The second stage produces a formula of first-order logic corresponding to the input sentence. The formula has an implicative form. The conclusion is created by the central predicate derived from the clause, while the additional generated facts are presump- tions. As each simple o-form clause is transformed onto such a form the implications can be embedded. Two generated formulae are presented in Figs. 7 and 8: the first
input sentence:
Alkohol zwieksza wydzielanie soku trzustkowego. (Alcohol increases pancreatic juice secretion.)
the formula:
(IMPLSYM (KONJSYM 3 ((# BADMEDIC 1) (MEDIC X85)) (( # MEDICAMENT 2) (MEDIC X85) (MNAME X86 ALKOHOL)) (IMPLSYM (KONJSYM 4 ((# ORGAN 2) (ORGAN X89) (ONAME X90 TRZUSTKA))
( (# WYDZIELNICZ-NARZAD 1) (ORGAN X89)) (#JUICE 1) (LUQUID X88)) (# SUBSTANCE 3) (LIQUID X88) (LNAME X91) (ORGAN X89)))
( (# SYMPTOM 3) (SYMPTOM X87) (SNAME X92) (BODY X88)))) ( (# INCREASE 2) (ETIO X85) (SYMPTOM X87)))
FIG. 7. The output formula.
input sentence:
Co powoduje alkohol podany doustnie? (What damages are caused by alcohol drinking?)
the formula:
((X39) (IMPLSYM (KONJSYM 3 ( (# BADMEDIC 1) (MEDIC X30)) ( (# MEDICAMENT 2) (MEDIC X30) (MNAME X31 ALKOHOL)) ( (# APPLY 3) (ANIM X38) (MEDIC X30) (MANNER X33 DOUSTN*)))
( (# IMPLY 2) (ETIO X30) (SYMPTOM X39))))
FIG. 8. The output formula
received from an indicative sentence and the second which denotes a question. Both have been rewritten in the original LISP notation, and some words of clarification are needed. The IMPLSYM and KONJSYM symbols are the logical operators IMPLY ( 3 ) and AND (&), respectively. The integer following after the KONJSYM symbol indicates how many factors have been joined. Each predicate name is preceded by the hash character ( # ) and followed by an integer to indicate a number of arguments involved. Parameters of predicates have forms of pairs or triples which determine a type, a name and a constant (if any). It is supposed that all unbound variables are quantified universally.
Formulae presented here can be used by a classical inference process or certain modifications of such one. They may also serve to build advanced knowledge rep- resentations as multilayered semantic nets.

A N A T U R A L L A N G U A G E I N F O R M A T I O N R E T R I E V A L S Y S T E M 353
The semantic dictionary is an integral part of the second stage. It keeps all the semantic rules described above as well as some special entries for indicating the references between verbs and patterns, elementary constants and higher concepts etc. The latter have been classified in several "semantic categories". Motivation of distin- guishing such "categories" parallels the syntactic categorization of the language subset described in Section 2.3. Another reason is to allow the experts to use CAT arcs to create paths expressing non-terminal patterns.
2.5. CONCLUSION
The natural language processing component for the question-answering system for physicians has been presented here. The authors believe that the approach is applicable to the wide spectrum of so-called professional descriptions and texts. The parsing system can be used as an interface for various types of retrieval systems such as natural language information systems, question-answering systems, expert systems or auto- matic understanding of texts. The parser itself should be regarded as an "expert system" which is able to recognize specific professional terminology. This is provided by expert nets of the semantic interpreter module. Although the subdomain of medicine is the subject we have chosen for this research, any change in the conversation field is allowed without violation of the system principles. The authors subscribe to the fashionable thesis that the syntactical and semantic components should act simultaneously, but with a domination of the syntax over the semantics. This is especially important for languages like Polish where syntax structures of phrases and sentences can mirror much more semantics than in other fixed word-order languages (like English). This approach, however, provides no less efficiency of the parsing process than in semantic- dominated systems (Carbonell, 1981; Gershman, 1979; Wilensky & Arens, 1980), but certainly increases the greater universality of the system.
The system is still in the experimental phase. All modules will be thoroughly tested to improve the system efficiency. We are also trying to combine the parser with different database management programs. The present system version has been implemented on an IBM 370/148 at Warsaw University. Most of the system modules as well as the parser reported here have been written in UWLISP - a dialect of the LISP 1.5 programming language.
3. Deduction module
3.1. THEORETICAL BACKGROUND
Unlike the majority of today's retrieval systems, the system presented by us has not been restricted to storing, processing and measuring information. Our design includes the extensive interpretation of processed information, i.e. every natural language sentence or text fragment has a meaning assigned to it in the current dialogue context. This provides a more "meaningful" man-machine conversation, which becomes cruc- cial when, like in a medical expert system, it is not only quantitive information which counts. Thus, an approach quite different from that offered by classical extentional 0/1 logic or statistical inference is required. The need to create new mechanisms of reasoning admitting uncertainty has been signaled for a long time. The Fuzzy Sets

354 L. BOLC E T A L
Theory of Zadeh (1975), preceded by the many valued logics of Lukaszewicz, con- stituted the first stage in that direction. The theory enables storage and manipulation of non-precise information which cannot be definitely described as being true or false. However, in order to simulate human reasoning one has to reflect semantic information in the best possible way: numerical modifiers like numerical weights, fuzzy z-values etc. should somehow be eliminated from its description.
In medical documents we can find many sentences which contain at least one word which is susceptible to various interpretations. Those words may be names of fuzzy sets: "high", "young", "old", "few", "many", etc. Moreover, the sentences may contain doubts expressed by wording: "perhaps", "probably", "practically certain", "surely smaller", etc. Obviously, medical knowledge also consists of sentences commonly admitted as true, nevertheless, the majority of them are not of a strictly deterministic character. They pronounce that some phenomena happen in parallel, influence each other, or cause one another, not necessarily always, but rather "often", "very often", "sometimes", etc. Qualitative estimations of concominant phenomena (or probabilities) are often presented in a descriptive form.
Example 3.1.1 From among diseases A, B and C, A happens predominatingly, B rarely, and C exceptionally. Symptom S1 occurs often in disease A, quite often in B, unusually in C, and symptom $2 occurs several times more often in A than in B (Doroszewski, 1972).
Example 3.1.2 Alcohol increasing a discharge of pancreatic liquid and causing an increase of pressure in pancreatic canals may be the reason for acute pancreatitis.
Changes in ultrastructure of the pancreas may perhaps lead to acute pancreatitis. Acute pancreatitis may probably be caused by distempers of the ultrastructure of
pancreas.
The description can be even more complicated when it takes into account the facts concerning the situation of a particular patient.
Example 3.1.3 The pancreatitis is widespread, the concomitant symptoms are becoming more intense (. . .) The examined organ is in a typical condition.
For diagnostic purposes, however, it is crucial to define the above "hard to scale" descriptions more precisely. We need a clear, and for all cases universal, scale of such medical concepts as abnormality, intensivity, and so on. As in natural language descriptions the scaling is provided by the lexical modifiers shown in italics in the above examples; we must assign the desired precise meanings with these words or phrases. Natural language understanding is meant here not only as a capability to assign literal meaning structures to sentences, but also as an ability to operate linguistic modifiers interpreted in an uniform way as values of appropriate linguistic variables. The latter is the domain of Theory of Possibility (Zadeh, 1976, 1980) based on Fuzzy Set Theory.
First, all the adverbs expressing different levels of certainty have been extracted. Examples of such words are: rarely, often, predominatingly, perhaps, probably, and so forth. Following the Linguistic Variable Theory, two distinct linguistic variables

A N A T U R A L L A N G U A G E I N F O R M A T I O N R E T R I E V A L S Y S T E M 355
have been created:
XI = "frequency",
T(X1) = {often, rarely, predominatingly}, and
X2 = "possibility",
T(X2) = {perhaps, probably}.
Intuitively, both the variables correspond to the notion of the base variable (Zadeh, 1976) that takes its values from the real number interval of [0, 1]. Some questions arise naturally concerning a more accurate definition of the above terms and their influence on sentence meaning.
(1) Which subsets of the [0, 1] interval correspond to which variable? (2) Which numerical values correspond to the meanings of such words as "perhaps",
"rarely", etc?
Only after exhaustive consultations with medical experts have we eventually come to some conclusion. We present the issues below.
The following classification has been suggested by physicians. If no less than half of observed patients are affected by some disease A, we shall assume that A appears "of ten", otherwise "rarely". Hence
"of ten" ~ [0.5, 1] (3.1)
"rarely" ~ [0, 0.5]
The word "probably" expresses a bit greater "degree of certainty" than the word "perhaps". Moreover, both are understood as medial between "rarely" and "often". The corresponding subsets are [0.5, 0.85] and [0.3, 0.7], respectively.
Thus, the ordered set W of the union T ( X 1 ) u T(X2) is obtained as: W = {rarely, perhaps, probably, often, predominatingly} The possibility distribution for the values from T(X1) and T(X2) is presented on Fig. 9. Notice that some pairs of SUPPORT IIx = {u I I Ix(u) > 0} in the distribution are mutually disjoint. (Which is more significant than a mere disjoinment of CORE IIx = {u [ I Ix (u )= 1} sets). This fact has resulted in the idea of some differently defined sums of elements from W, namely, defined in terms of intersection of common (non-fuzzy) subsets.
wl[]w2 = SUPPORT I lwl c~ SUPPORT IIw2; (3.2)
where
SUPPORT IIwi={ulIIwi(u)>O}, i=1,2
It may be of some interest to pay attention to the case of wlfl]w2 = 0. Although it is possible to leave it unchanged, some convenient extensions of the above definition can be suggested.
For instance, in the experiment discussed, there is only one such pair of disjoint SUPPORTs. These are
SUPPORT IIpredominatingly n SUPPORT IIrarely = 0 (3.3)

356 L. BOLC ET AL.
E E IS
Often
E E E
[ ~ Perhops
IS
E E
~ Probobly FIG, 9. Possibility distribution in the set W..
We define a new operation O on elements of W:
[ wl[]w2 if wl~qw2 # 0
wl@ w2= [.Ilperhaps otherwise
Some results of using @ on W can be seen in Tables 2a and b.
(3,4)
TABLE 2a Possibility distribution for the operation ~ over the set W
Rarely Often Predominatingly Perhaps Probably
Rarely Often Predominatingly Perhaps Probably
[0, 0-51 {0-5} [0.3, 0.7] [0-3, 0.5] {0.5} {0.5} [0.5, 1] [0.6, 1] [0.5,0.7] [0.5,0.85]
[0.3, 0.7] [0.6, 1] [0.6, 1] [0.6, 0.7] [0.6, 0.85] [0.3, 0.7] [0.5, 0.7] [0.6, 0.7] [0.3, 0-7] [0.5, 0.7]
{0-5} [0.5,0.85] [0-6,0.85] [0-5,0.7] [0.5,0.85]
TABLE 2b
~) Rarely Often Predominatingly Perhaps Probably
Rarely Often Predominatingly Perhaps Probably
Rarely Perhaps Perhaps P e r h a p s Perhaps Perhaps Often Predominatingly Perhaps Probably Perhaps Predominatingly Predominatingly Probably Probably Perhaps Perhaps Probably P e r h a p s Perhaps Perhaps Probably Probably Perhaps Probably

A N A T U R A L L A N G U A G E I N F O R M A T I O N R E T R I E V A L S Y S T E M 357
The next step was to define linguistic equivalents for the above defined intervals. To assure the closeness of e in W the following strategy has been chosen. Let us call the property P = SUPPORT IIw, where P is an element of Table 2a, the (x)-property of w; the property p c SUPPORT I/w, where P is an element of Table 2a, the (xx)-property of w, and P c CORE Hw the (xxx)-property of w. Table 2b has been derived from Table 2a using the following four "translation" rules.
(1) If there exists a w from W which has (x)-property, P in Table 2a is replaced by w in Table 2b.
(2) Otherwise, if there is a unique w from W with (xx)-property, then P replaced by this w.
(3) Otherwise, if there can be found several elements in W with (xx)-property, and one of them has also (xxx)-property (this is normally the smallest one), then P is replaced by the latter.
(4) In the case when none of above holds, P is replaced by a w from W such that there exist P1 c p, and P1 c CORE IIw.
The above construction is somehow analogous to that of Freksa (1981). However, our strategy is more generalized because it is applicable to natural language texts, and not restricted to object descriptions only.
3.2. PROGRAMMING LANGUAGE
The deduction module has been implemented with the FUZZY programming language. The language belongs to the family of AI languages with mechanisms enabling rep- resentation and processing of fuzzy knowledge. The FUZZY language was designed by LeFaivre (1974) from Rutgers University, New Jersey. The fact followed the Theory of Fuzzy Sets and the works of McKling. In some sense FUZZY can be considered as an extension of PLANNER.
FUZZY was thought out in a close dependence on another AI language LISP, in which the former is always embedded. As FUZZY normally cannot exist outside the LISP environment, it possesses a number of specific properties not found in ordinary LISP systems. One of the key differences between LISP and FUZZY is its MULTI- VALUENESS.
3.3. IMPLEMENTATION
The deduction module gives answers to the following three types of questions:
(1) For confirmation of a specified concordance, Does A cause B? (2) About reason of a symptom, What is the reason of B? (3) About effects of an observed disorder, What causes A?
One of the important features of the module is its ability to define the certainty factor for every issued answer:
Example 3.3. I Q: Does alcohol cause damages in pancreas? A: Yes, perhaps. Q: Does alcoholism cause acute pancreatitis? A: Yes, often.

358 L. BOLC E T A L .
Another property worth noting is the ability of the module to order a set of answers on their certainity factors:
Example 3.3.2 Q: What is the reason of acute pancreatitis? A: The predominant reason of acute pancreatitis is cholelithiasis.
Alcoholism is often a reason of acute pancreatitis. Hypertension in pancreatic ducts perhaps causes acute pancreatitis.
The above results became possible thanks to the application of the fuzzy information processing techniques such as operations on linguistic variables, possibility distribution, etc. (see also Section 3.1).
The information processing scheme of the system (with some control parameters included) is shown in Fig. 10.
I Alcohol ]
A n s w e r ~ Answer 2 ond 3
I oo. ,.ns 'oo,.~ I [ Gas"in r'le~ I
Answer 2 ond 3
I Answer 2
Secritine releose" ]
FIG. 10.
Once the system knowledge base is established, all communication with the database proceeds in natural language via a natural language processor. Both assertions and queries are posed as Polish sentences. They are then translated into the form of first-order predicate calculus formulae (see Section 2.4 for details).
As suggested in Fig. 11, there are several options for dealing with formulae coming to the database. Using an option depends, roughly speaking, on the level of information details contained in the formula in question. We distinguished three stages in query processing by the deduction module. They provide maximum computational efficiency, yet allow optionally more expensive deduction schemes for extracting information hidden from the straightforward resolution model. After a new formula has passed

A N A T U R A L L A N G U A G E I N F O R M A T I O N R E T R I E V A L S Y S T E M 359
NLP ]
I FOL query
I ~176 1 IFF, SURE= DONE
I . r ,o , . . I I
FOL for morion with rnodificotions
1
c I IFF~ SURE= FAIL
l
FIG. 11. The information processing in the system. C, control flow; remaining arcs, information flow.
from the natural language processor, the deduction module attempts deductions until success or complete failure occurs:
(1) To find an assertion (in the database) which has precisely the same form as the query (in the case of confirmation query), or contains precisely the same phenomenon description (in the case of reason or effect query), using the IFF procedure;
(2) To find an assertion which has a slightly different form than a query formula, using for instance the SURE procedure;
(3) When both the above options fail, deduction through procedures IFD and WHAT take place. WHAT finds answers to reason and effect queries tracing and displaying the whole chain of formulae from reason to effect.
When (3) fails to find an answer the database is assumed to be lacking suitable information for answering the question. As the deduction module works on formulae delivered by TESS, it should never be the case that a user's question recognized as valid by the language processor remains unprocessed by the deduction module. This calls for a high level of compatibili ty and "mutual understanding" between modules. Queries that cannot be safely forwarded to the deduction module are normally returned to user's console for reformulation.
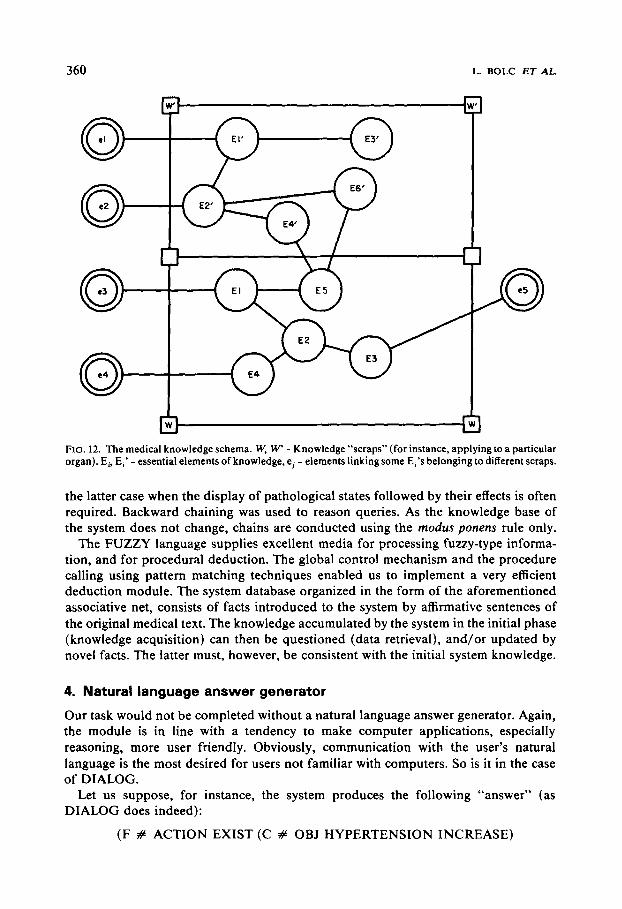
Let us now turn to knowledge structure in the system. The structure can be illustrated schematically as Fig. 12 shows.
The interpretation of Fig. 12 may be somehow messy. We hope the following example (see Fig. 13) extracted from the system medical database will be more informative. The facts are expressed in a way that, we hope, preserve the initial intentions of the medical experts who prepared the domain description. The use of natural deduction in our system appears to be the simplest, and the most appropriate. Forward chaining was applied to confirmation and effect queries. It appeared especially convenient in
360
Q L. BOLC E T A L
T
Fro. 12. The medical knowledge schema. W, W' - Knowledge "'scraps" (for instance, applying to a particular organ). Ei, E~' - essential elements of knowledge, ej - elements linking some E~'s belonging to different scraps.
the latter case when the display of pathological states followed by their effects is often required. Backward chaining was used to reason queries. As the knowledge base of the system does not change, chains are conducted using the modus ponens rule only.
The FUZZY language supplies excellent media for processing fuzzy-type informa- tion, and for procedural deduction. The global control mechanism and the procedure calling using pattern matching techniques enabled us to implement a very efficient deduction module. The system database organized in the form of the aforementioned associative net, consists of facts introduced to the system by affirmative sentences of the original medical text. The knowledge accumulated by the system in the initial phase (knowledge acquisition) can then be questioned (data retrieval), and/or updated by novel facts. The latter must, however, be consistent with the initial system knowledge.
4. Natural language answer generator
Our task would not be completed without a natural language answer generator. Again, the module is in line with a tendency to make computer applications, especially reasoning, more user friendly. Obviously, communication with the user's natural language is the most desired for users not familiar with computers. So is it in the case of DIALOG.
Let us suppose, for instance, the system produces the following "answer" (as DIALOG does indeed):
(F # ACTION EXIST (C # OBJ HYPERTENSION INCREASE)

A N A T U R A L L A N G U A G E I N F O R M A T I O N R E T R I E V A L S Y S T E M 361
/
1 ~.~
0 o 0
~ . ~
~.~ ~.~ ~
o 0
0

362 L. BOLC E T AL.
(F # PARTOFORGAN DUCT) (C # ORGLIQ PANCREAS)))
It is unreasonable to expect an inexperienced user to understand the latter as "Hyper- tension increase in pancreatic ducts".
The natural language (Polish) answer generator has been situated within the system configuration as Fig. 14 suggests. Figure 15 shows the organization of the language generation module.
Linguistic problems connected with construction of an acceptable natural language generator are more or less common for the Indo-European family of languages, Although in some languages inflexion is more used than in others, the structure of the problems remains the same. Basically, there are different registers and vocabularies of endings for different parts of speech. For instance, for adjectives to define a proper ending unmistakably, it is sufficient to check the contents of three registers: NUMBER, CASES and GENDER. In some languages, however, registers of the strict grammatical type do not define endings unequivocally. That is the case with Polish verbs which have to be split into several groups. To be more precise, let us consider two Polish verbs in the infinitive, and in their corresponding forms of second person plural.
inf: rysowac, 2nd plural: rysujecie
inf: patrzec, 2nd plural: patrzycie.
I . L . . . - , . - ~ I 'E'' I
Y Deduction answer LoQical form
I , Deduction I
\ h FIG. 14. The natural language answer generator in the system configuration.

A NATURAL LANGUAGE INFORMATION RETRIEVAL SYSTEM 363
Confirmotion query
Parsing I tree
deduction Orgonizing L
query type
" ~ 1 User's query I
Answer l generator I Dictionary I
~ NL answer I FIG. 15. The natural language answer generator.
Finally, the last problem which had to be solved is connected with so-called two-fold forms, i.e. exchanged, fallen out, or supervened letters in various inflexional forms of some words. The problem has been solved either by providing a distinct vocabulary for two-fold form exchanges (as in English: ladY - ladiES, flY - fliES, etc., i.e. Y always turns into IES in the plural form of a certain class of nouns), or by making guesses with some help from the vocabulary (for irregular forms). Routinely, the first hypothesis appears to be true; however, some additional work will be needed to raise the efficiency of existing rules.
5. Conclusion
The present state-of-the-art in the development of the natural language question- answering system DIALOG has been described here. The system consists of a natural language (Polish) understanding subsystem TESS providing the logical representation of input for the database system. The database is organized in the form of "logical" associative net, and served by the deduction module based on fuzzy-type logic. Some work has also been done to provide system users with the natural language form of system answers. DIALOG is designed to be used by medical personnel. The present, yet experimental version has been thoroughly tested on an extensive medical text from gastroenterology which has created the system knowledge base. The results obtained encourage us to continue the work in this chosen direction. Our further work will concentrate on the constant improvement of the existing modules, especially language analysis and reasoning. At the same time we plan to pursue other current trends in the subject, and design concurrent versions of the natural language processor as well as work on database organization and management.
The authors are indebted to Dr Nick Cercone and Dr Bob Hadley for their valuable comments and criticism to earlier drafts of this paper. We also would like to thank Dr Bozena Strzalkowska for her help in translation of the medical terminology. Any remaining mistakes are, of course, our fault.

364 L. BOLC ET AL
References
ADAMO, J. M. (1980). LPL a fuzzy programming language. Fuzzy Sets and Systems, 3. ATKINS, J. (1979). Prototype and production rules: an approach to knowledge representation
for hypoteses formation. Proceedings of the 6th IJCAI, pp. 1-3, Tokyo. BALDWIN, J. F. (1979). A new approach to approximate reasoning using a fuzzy logic. Fuzzy
Sets and Systems, 2. BATES, M. (1978). The theory and practice of augmented transition network grammars. In
BOLE, L. ed. Natural Communication with Computers. Berlin: Springer. BENNET, J., CREARY, L., ENGELMORE, R. S. & MELOSH, R. (1978). SACON knowledge-based
consultant for structural analysis. Department of Computer Science, Stanford University, Memo HPP-78-28.
BERRY-ROGGHE, G. L. & WULZ, H. (1978). An overview of PLIDIS a problem solving information system with German as query language. In BOLE, L. ed. Natural Communication with Computers. Berlin: Springer.
BEZDEK, J. (guest ed.) (1983). Special issue on advances in fuzzy information processing. International Journal of Man-Machine Studies, 19.
BOBROW, D. & COLLINS, D. A. (eds.) (1975). Representation and understanding: Studies in Cognitive Science. London, New York: Academic Press.
BODEN, M. A. (1977). Artificial Intelligence and Natural Man. Brighton: Harvester. BOLE, L. (ed.) (1978). Natural Language Communication with Computers. Lecture Notes in
Computer Science, vol. 63. Berlin: Springer. BOLE, L. (ed.) (1980a). Natural Language Based Computer Systems. Hanser. BOLE, L. (ed.) (1980b). Natural Language Question-Answering Systems. Hanser. BOLE, L. (ed.) (1980c). Representation and Processing of Natural Language, Hanser. BOLE, L. (ed.) (1983). The Design of Interpreters, Compilers, and Editors for Augmented Transition
Networks, Symbolic Computation. Berlin: Springer. BOLE, L. & STRZALKOWSKI, T. (1982). Transformation of natural language into logical formulas.
Proceedings of the 9th International Conference on Computational Lingaistics COLING. Amsterdam: North-Holland.
BOLE, L. & STRZALKOWSKI, T. (1984). Natural language interface to the question-answering system for physicians. Computers and Artificial Intelligence, 3, 31-46.
BOLE, L. (ed.) (1983). Przetwarzanie informacji reprezentowanej w postaci naturalnej (Processing of Information Posed in Natural Form) (in Polish). Warsaw University, Warszawa.
BOLE, L., FRIES, B. & OKSENIUK, A. (1983). Wprowadzenie dojezyka programowania FUZZY (Introduction to the FUZZY Programming Language) (in Polish). Warsaw University, War- szawa.
BOLE, L., KOCHUT, K. RYCHLIK, P. & STRZALKOWSKI, T. (1984). Deductive question- answering system DIALOG. In PLANDER, I. Artificial Intelligence and Information-Control Systems of Robots. Amsterdam: Elsevier, pp. 17-24.
BOLE, L., KOCHUT, K., KOWALSKI, A. & KOZLOWSKA, M. (1984). Natural language informa- tion retrieval system with extensions towards fuzzy reasoning in medicine. Proceedings of the ECAI-84, Pisa, Italy.
BOLE, L. & RYCHLIK, P. (1984). The use of modal default reasoning in a medical diagnostic system with natural language interface. Proceedings of the ECAI.84, Pisa, Italy.
BRACHMAN, R. J. & LEVESQUE, H. J. (1983). Knowledge representation. In Tutorial on Artificial Intelligence. Proceedings of IJCAI-83, Karlsruhe.
BUCHANAN, B. G. & FEIGENBAUM, E. A. (1977). DENDRAL and META-DENDRAL: their application dimensions. Artificial Intelligence, 11, 5-24.
BURTON, R. & BROWN, J. S. (1977). Semantic Grammars: A Technique of Constructing Natural Language Interfaces to Industrial Systems. BBN Report no. 3587, Cambridge, MA.
CARBONELL, J. G. (1981). Multi-Strategy Parsing. Department of Computer Science, Carnegie- Mellon University, Pittsburgh, PA.
CHANDRASEKARAN, B., GOMEZ, F., MITTAL, S. & SMITH, J. (1979). An approach to medical diagnosis based on conceptual structures. Proceedings of the 6th IJCAI, Tokyo, pp. 134-142.
CHANG, C. L. & LEE, F. C. (1973). Symbolic Logic and Mechanical Theorem Proving. New York: Academic Press.

A NATURAL LANGUAGE INFORMATION RETRIEVAL SYSTEM 365
CODD, F. C., ARNOLD, R. S., CADIOU, J-M., CHANG, C. L. & ROUSSOPOULOS, N. (1978). RENDEZ-VOUS Version 1, An Experimental English Language Query Formulation System for Casual Users of Relational Data Base. RJ 2144, IB Research Laboratory, San Jose.
DAHL, V. (1981). Translating Spanish into logic through logic. AJCL, 7 DOROSZEWSKI, J. (1972). Ewaluacja prawdopodobienstwa w sprawdzaniu hipotez diagnostycznych
(Probability Evaluation in Diagnostic Hypothesis Examination). Studia Filozoficzne, nr 10 (in Polish).
DOROSZEWSKI, J. (1980a). O rozwiazywaniu problemow diagnostycznych, ( On diagnostic problem solving). Materialy szkoleniowe, Warszawa.
DOROSZEWSKI, J. (1980b). Struktura diagnozy (Diagnosis structure (in Polish)). Materialy szkoleniowe, Warszawa.
DOROSZEWSKI, J. (1980c). Hypothetico-Nomological Aspects of Medical Diagnosis Part L Report, Warszawa (in Polish).
FAGAN, L. M., KUNZ, J. C., FEIGENBAUM, E. A. & OSBORN, J. J. (1979). Representation of dynamic clinical knowledge: measurement interpretation in the intensive care unit. Proceed- ings of the 6th IJCAL Tokyo, pp. 260-262.
FEIGENBAUM, E. A. (1980). Expert systems: looking back and looking ahead. In WILHELM, R. ed. GI-10, Jahrestagung, Saarbruecken, Informatik-Fachberichte no. 35, Heidelberg. Berlin: Springer, pp. 1-14.
FINDLER, N. V. (ed.) (1979). Associative Networks: Representation and Use of Knowledge by Computers. London, New York: Academic Press.
FREKSA, Ch. (1981). Linguistic pattern characterisation and analysis. PhD Dissertation, Univer- sity of California, Berkeley.
GILES, R. (1980). A computer program for fuzzy reasoning. Fuzzy Sets and Systems, 4. GERSHMAN, A. V. (1979). Knowledge-Based Parsing. Research Report no. 156, Department of
Computer Science, Yale University. GROSZ, B., HAAS, N., HENDRIX, G., HOBBS, J., MARTIN, P., MOORE, R., ROBINSON, J. &
ROSENSCHEIN, S. (1982). DIALOGIC: a core natural language processing system. Proceed- ings of the 9th International Conference on Computational Linguistic COLING. Amsterdam: North-Holland.
GROSZ, B. (1977). The representation and use of focus in a system for understanding dialogues. Proceedings of the 5th IJCAI. Cambridge: Cambridge University Press, pp. 67-76.
GOLDBERG, R. N. & WEISS, S. M. (1980). An Experimental Translation of a Large Expert Knowledge-Base. Technical Report CBM-TR-110, Department of Computer Science, Rutgers University.
HART, P. & DUDA, R. (1977). PROSPECTOR-Computer-Based Consultation System for Mineral Exploration. Note no. 155, AI CenterTech, SRI Int., Menlo Park, CA.
HEISER, J. F. & BROOKS, R. E. (1978). A computerized psychofarmacology advisor. Proceedings of the 4th Annual Workshop on Artificial Intelligence in Medicine. Rutgers University, pp. 68-69.
KAUFMAN, A. (1975). Introduction to the Theory of Fuzzy Subsets, Vol. 1, London: New York: Academic Press.
KLEIN, N. (1978). Implementierung eines Frage-Antwort-Systems auf der Basis der Praedikaten- logik H Stufe. Berlin: TUB.
KONRAD, E. (1976). Formale Semantik yon Datrabanksprachen, Doktor Ingenieur genehmighte Dissertation. Berlin: TUB.
LEFAIVRE, R. (1977). Fuzzy Representation and Approximate Reasoning Laboratory for Computer Science Research. Rutgers University, New Brunswick.
MARCUS, M. P. (1980). A Theory of Syntactic Recognition for Natural Language. Cambridge, Mass: MIT Press.
MARTIN, W. A., CHURCH, K. N. & PATIL, R. S. (1981). Preliminary Analysis of a Breadth-First Parsing Method. MIT Laboratory of Computer Science.
MOORE, R. C. (1981). Problems in logical form. Proceedings of the 19th Annual Meeting of the ACL, Stanford.
MADALINSKA, E. (1979). Klasyfikacja metod dedukcfi w systemach wyszukiwania informacji (Classification of the Deduction Methods in Information Retrieval Systems). Sprawozdania IIUW, Wydawnictwa Uniwersytetu Warszawskiego (in Polish).

366 L. BOLC ~ r AL.
MCCALLA, G. & CERCONE, N. (guest eds.) (1983). IEEE Computer, Special Issue on Knowledge Representation, 16.
MCCARTHY, L. T., SRIDHARAN, N. S. & SANGSTER, B. C. (1979). The Implementation of TAXMAN H: An Experiment in AI and Legal Reasoning. Department of Computer Science, Rutgers University, Technical Report LRP-TR-2.
MCDERMOTt', D. (1978). The last survey of representation of knowledge. Proceedings of the AISB/ GI Conference on Artificial Intelligence, Hamburg, pp. 206-221.
MICHIE, D. (ed.) (1979). Expert Systems in the Micro.ElectronicAge. Edinburgh: University Press. MYLOPOULOS, J. (1981). An overview of knowledge representation. SIGART Newsletter, 74,
pp. 5-12. NEGOITA, C. V. & RALESCU, D. A. (1975). Applications of Fuzzy Sets to System Analysis. Basel:
Birkhaeuser Verlag. NICOLAS, J. H. & GALLAIRE, H. (1978). Data Base: Theory vs Interpretation in Logic and Data
Base. Plenum Press. NILSSON, N. J. (1982). Principles of Artificial Intelligence. Berlin: Springer. OSBORN, J., FAGAN, L., FALLAT, R., McCLUNG, D. & MITCHELL, R. (1979). Managing data
from respiratory measurement. Medical Instrumentation, 13, 6. OSTASIEWICZ, W. (1980). O zbiorach rozmytych (On Fuzzy Sets). Matematyka Stosowana, seria
III, PWN, Warszawa (in Polish). POPLE, H. (1977). The formation of composite hypotheses in Diagnostic Problem Solving. Proceedings
of the 5th IJCAI, Cambridge, MA, pp. 1030-1037. RAULEFS, P. (1981). Expert systems: state of art and future prospects. In SlEKMANN, J. ed.
Proceedings of the 5th German Workshop on AI, Bad Honnef, Informatik-Fachberichte. Berlin: Springer.
ROBINSON, J. J. (1982). DIAGRAM: a grammar for dialogues. Communications of the ACM, 25. ROSENSCHEIN, S. J. d~ SHIEBER, S. M. (1982). Translating English into logical form. Proceedings
of the 20th Annual Meeting of the ACL, Toronto. SHORTLIFFE, E. H. (1976). Computer-Based Medical Consultations: MYCIN. Amsterdam:
Elsevier. SKALA, H. J. (1978). On many-valued logics, fuzzy sets, fuzzy logics, and their applications.
Fuzzy Sets and Systems, 2. STALLMAN, R. M. & SUSSMAN, G. J. (1977). Forward reasoning and dependency-directed
backtracking in a system for computer-aided circuit analysis. Artificial Intelligence, 9, 135-196.
SWARTOUT, W. R. (1977). A Digitalis Therapy Advisor with Explanations, MIT Laboratory for Computer Science, Report TR-176.
SZOBER, S. (1967). Gramatyka jezyka polskiego. Warszawa. SZOLIVlTS, P. & PAUKER, S. G. (1978). Categorial and probabilistic reasoning in medical
diagnosis. Artificial Intelligence, 11, 115-144. TRIGOBOFF, M. & KULIKOWSKI, C. A. (1977). IRIS: a system for the propagation of inferences
in a semantic net. Proceedings of the 5th IJCAI, pp. 274-280. ULLMAN, J. D. (1980). Principles of Data Base Systems. Maryland: Computer Science Press,
Potomac. WAHLSTER, W. (1977). Die Representation yon vagen Wissen in taruerlichsprachlichen Systemen
der Kuenstlichen InteUigenz. FB Informatik der Universitaet Hamburg, Bericht IfI HH-B- 38/77.
WAHLSTER, W. (1981). Natuerlichsprachliche KI-Systeme: Entwicklungsstand und Forschung- sperpektive. In SIEKMANN, J., ed. Proceedings of the 5th German Workshop on AI, Bad Honnef, Informatik-Fachberichte. Berlin: Springer.
WAHLSTER, W. (1983). KI-Verfahren zur Unterstuetzung der aertzlichen Urteilsbildung, Univer- sitaet Hamburg, Forschungsstelle fuer Informationswissenschaft und Kuenstliche Intel- ligenz, Bericht GEN-I.
WALTZ, D. L., FININ, T. W., GREEN, F., CONRAD, E., GOODMAN, B. & HADDEN, G. (1976). The PLANES System: Natural Language Access to a Large Data Base. Technical Report "I"-34, Coordinated Science Laboratory, University of Illinois.
WEINREB, D. & MOON, D. (1981). The Lisp Machine Manual, 4th edn. Woodland Hills: Symbolic Inc.

A NATURAL LANGUAGE INFORMATION RETRIEVAL SYSTEM 367
WEISS, S., KULIKOWSKI, C., AMAREL, S. • SAFIR, A. (1978). A model-based method for computer-aided medical decision-making. Artificial Intelligence, 11, 145-172.
WILENSKY, R. & ARENS, Y. (1980). PHRAN: A Knowledge-Based Approach to Natural Language Analysis. Electronics Research Laboratory, University of California, Berkeley.
WINSTON, P. H. (1977). Artificial Intelligence. London: Addison-Wesley. WOODS, W. A. (1970). Transition network grammars for natural language analysis. Communica-
tions of the ACM, 13. WOODS, W. A., KAPLAN, R. i . & NASH-WEBBER, B. (1972). The Lunar Science Natural
Language Information System: Final Report. BBN Report no. 2378, Bolt Beranek and Newman Inc, Cambridge MA.
WOODS, W. A. (1980). Cascaded ATN grammars. American Journal of Computational Linguistics, 6.
ZADEH, L. A. (1975). Fuzzy Sets and Their Application to Cognitive Reasoning and Decision Processes. London, New York: Academic Press.
ZADEH, L. A. (1976). The Concept of Linguistic Variable and Its Application to Approximate Reasoning. Moscow: MIR.
ZADEH, L. A. (1977). PRUF: A Meaning Representation Language for Natural Languages. Electronic Research Laboratory, University of California, Berkeley.
ZADEH, L. A. (1980). Fuzzy sets as a basis for a theory of possibility. Fuzzy Sets and Systems, 1.
ZADEH, L. A. (1983). A computational approach to fuzzy quantifiers in natural languages. Computers and Mathematics with Applications, 9, 140-184.
ZADEH, L. A. (1983). A Fuzzy-Set-Theoretic Approach to the Compositionality of Meaning: Propositions, Dispositions, and Canonical Forms. Memo UCB/BRL M83/24, College of Engineering, University of California, Berkeley.
Related Documents











