IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012 1809 A Multiple Insertion/Deletion Correcting Code for Run-Length Limited Sequences Filip Palunˇ cic ´, Khaled A. S. Abdel-Ghaffar, Hendrik C. Ferreira, and Willem A. Clarke Abstract—A code construction is proposed to add a multiple insertion/deletion error correcting capability to a run-length limited sequence. The codewords of this code are themselves run-length limited. The insertion/deletion correcting capability is achieved by requiring several weighted sums of run-lengths in the codewords to satisfy certain congruences modulo primes. The construction is similar to the number-theoretic code proposed by Dolecek and Anantharam, which can correct multiple repetition errors or, equivalently, multiple insertions of zeros. It is shown that if the codewords in this code are run-length limited, then the code is capable of correcting both insertions and deletions of zeros and ones. An algorithm is proposed for decoding over a multiple insertion/deletion channel. Following the work of Dolecek and Anantharam, a systematic encoding method is also proposed for the codes. Furthermore, it is shown that the proposed construction has a higher rate asymptotically than the Helberg code, which is unconstrained in terms of run-lengths, even though our con- struction has the additional run-length constraints. The need for run-length limited codes that can correct insertion/deletion errors is motivated by bit-patterned media for magnetic recording. Index Terms—Helberg code, insertion/deletion error, magnetic recording media, run-length limited sequence. I. INTRODUCTION T HE performance of bit-patterned media for magnetic recording systems is to a large extent determined by insertion/deletion errors. It is because insertion/deletion errors, if not detected or corrected, will lead to catastrophic error prop- agation. Because of this, recently, there have been a number of publications dealing with insertion/deletion errors with regard to bit-patterned media [1]–[3]. Unlike with conventional mag- netic recording systems, in bit-patterned media, perfect write synchronization is required because bit islands have predefined locations [4]. For possible causes of insertion/deletion errors in bit-patterned media recording, see [5]. The correction of insertion/deletion errors occurring in -constrained codes has been the subject of a number of papers [6]–[10]. The constructions in [7] and [8] use the single insertion/deletion correcting Levenshtein code as their Manuscript received November 15, 2010; revised June 07, 2011; accepted October 10, 2011. Date of publication January 9, 2012; date of current version October 10, 2011. F. Palunˇ cic ´, H. C. Ferreira, and W. A. Clarke are with the Department of Elec- trical and Electronic Engineering Science, University of Johannesburg, Auck- land Park 2006, South Africa (e-mail: [email protected]; [email protected]; [email protected]). K. A. S. Abdel-Ghaffar is with the Department of Electrical and Com- puter Engineering, University of California, Davis, CA 95616 USA (e-mail: [email protected]). Communicated by N. Kashyap, Associate Editor for Coding Techniques. Digital Object Identifier 10.1109/TIT.2011.2172725 basis. This code, which is binary, is based on a construction originally developed by Varshamov and Tenengol’ts [11] to correct a single asymmetric error. However, in the context of correcting insertions and deletions, the code is referred to as the Levenshtein code. (See also [12] and [13] for constructions of nonbinary asymmetric error correcting codes.) These construc- tions create a systematic form of the Levenshtein code in such a way that with the addition of the systematic bits, the required -constraint is maintained. (The construction in [8] super- sedes the one in [7]). The constructions by Roth and Siegel [10] and Bours [6] can correct multiple insertion/deletion errors, but only insertions and deletions of zeros. The methods proposed by Blaum et al. [9] can detect insertion/deletion errors in order to limit the error propagation and use burst error correcting codes to correct the resulting substitution errors. In this paper, instead of using -constrained sequences, we consider the equivalent run-length limited sequences [14]. The code construction presented here is inspired by the number-theoretic code presented by Dolecek and Anantharam [15] which can correct multiple repetition errors. In fact, the code is designed to correct multiple insertions of zeros. But, by a simple transform, any repetition error can be transformed into an insertion of zero error. Our construction is intended for arbitrary multiple insertion/deletion errors. There are a few number-theoretic codes used for the correc- tion of insertion/deletion-type errors, such as the Levenshtein code [16], the Helberg code [17], and the repetition error cor- recting code [15]. All these codes restrict the codewords such the weighted sums of their symbols, as in the case of the Lev- enshtein code and the Helberg code, or the weighted sums of the lengths of the runs of zeros, as in the case of the repeti- tion error correcting code, satisfy certain congruences. These weighted sums are called moments. In this paper, we show that the construction method of the repetition error correcting code of Dolecek and Anantharam [15] can be applied to run-length limited sequences resulting in a run-length limited code which is capable of correcting, not only repetition errors, but also multiple insertions and dele- tions. We also present an algorithm to decode the code over a multiple insertion/deletion channel. For a given run-length lim- ited sequence, redundancy bits can be added in such a manner that both the constraints of the multiple insertion/deletion cor- recting code and of the run-lengths are met simultaneously. This is achieved by using a modified version of the prefixing algo- rithm developed by Dolecek and Anantharam [15] for the repe- tition correcting code. The prefixing method is the generalized form of the moment balancing scheme developed in [7], ap- plied to multiple congruency equations. This approach leads to 0018-9448/$31.00 © 2012 IEEE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012 1809
A Multiple Insertion/Deletion Correcting Code forRun-Length Limited Sequences
Filip Paluncic, Khaled A. S. Abdel-Ghaffar, Hendrik C. Ferreira, and Willem A. Clarke
Abstract—A code construction is proposed to add a multipleinsertion/deletion error correcting capability to a run-lengthlimited sequence. The codewords of this code are themselvesrun-length limited. The insertion/deletion correcting capabilityis achieved by requiring several weighted sums of run-lengths inthe codewords to satisfy certain congruences modulo primes. Theconstruction is similar to the number-theoretic code proposed byDolecek and Anantharam, which can correct multiple repetitionerrors or, equivalently, multiple insertions of zeros. It is shownthat if the codewords in this code are run-length limited, then thecode is capable of correcting both insertions and deletions of zerosand ones. An algorithm is proposed for decoding over a multipleinsertion/deletion channel. Following the work of Dolecek andAnantharam, a systematic encoding method is also proposed forthe codes. Furthermore, it is shown that the proposed constructionhas a higher rate asymptotically than the Helberg code, whichis unconstrained in terms of run-lengths, even though our con-struction has the additional run-length constraints. The need forrun-length limited codes that can correct insertion/deletion errorsis motivated by bit-patterned media for magnetic recording.
Index Terms—Helberg code, insertion/deletion error, magneticrecording media, run-length limited sequence.
I. INTRODUCTION
T HE performance of bit-patterned media for magneticrecording systems is to a large extent determined by
insertion/deletion errors. It is because insertion/deletion errors,if not detected or corrected, will lead to catastrophic error prop-agation. Because of this, recently, there have been a number ofpublications dealing with insertion/deletion errors with regardto bit-patterned media [1]–[3]. Unlike with conventional mag-netic recording systems, in bit-patterned media, perfect writesynchronization is required because bit islands have predefinedlocations [4]. For possible causes of insertion/deletion errors inbit-patterned media recording, see [5].
The correction of insertion/deletion errors occurring in-constrained codes has been the subject of a number
of papers [6]–[10]. The constructions in [7] and [8] use thesingle insertion/deletion correcting Levenshtein code as their
Manuscript received November 15, 2010; revised June 07, 2011; acceptedOctober 10, 2011. Date of publication January 9, 2012; date of current versionOctober 10, 2011.
F. Paluncic, H. C. Ferreira, and W. A. Clarke are with the Department of Elec-trical and Electronic Engineering Science, University of Johannesburg, Auck-land Park 2006, South Africa (e-mail: [email protected]; [email protected];[email protected]).
K. A. S. Abdel-Ghaffar is with the Department of Electrical and Com-puter Engineering, University of California, Davis, CA 95616 USA (e-mail:[email protected]).
Communicated by N. Kashyap, Associate Editor for Coding Techniques.Digital Object Identifier 10.1109/TIT.2011.2172725
basis. This code, which is binary, is based on a constructionoriginally developed by Varshamov and Tenengol’ts [11] tocorrect a single asymmetric error. However, in the context ofcorrecting insertions and deletions, the code is referred to as theLevenshtein code. (See also [12] and [13] for constructions ofnonbinary asymmetric error correcting codes.) These construc-tions create a systematic form of the Levenshtein code in sucha way that with the addition of the systematic bits, the required
-constraint is maintained. (The construction in [8] super-sedes the one in [7]). The constructions by Roth and Siegel [10]and Bours [6] can correct multiple insertion/deletion errors, butonly insertions and deletions of zeros. The methods proposedby Blaum et al. [9] can detect insertion/deletion errors in orderto limit the error propagation and use burst error correctingcodes to correct the resulting substitution errors. In this paper,instead of using -constrained sequences, we consider theequivalent run-length limited sequences [14].
The code construction presented here is inspired by thenumber-theoretic code presented by Dolecek and Anantharam[15] which can correct multiple repetition errors. In fact, thecode is designed to correct multiple insertions of zeros. But,by a simple transform, any repetition error can be transformedinto an insertion of zero error. Our construction is intended forarbitrary multiple insertion/deletion errors.
There are a few number-theoretic codes used for the correc-tion of insertion/deletion-type errors, such as the Levenshteincode [16], the Helberg code [17], and the repetition error cor-recting code [15]. All these codes restrict the codewords suchthe weighted sums of their symbols, as in the case of the Lev-enshtein code and the Helberg code, or the weighted sums ofthe lengths of the runs of zeros, as in the case of the repeti-tion error correcting code, satisfy certain congruences. Theseweighted sums are called moments.
In this paper, we show that the construction method of therepetition error correcting code of Dolecek and Anantharam[15] can be applied to run-length limited sequences resultingin a run-length limited code which is capable of correcting,not only repetition errors, but also multiple insertions and dele-tions. We also present an algorithm to decode the code over amultiple insertion/deletion channel. For a given run-length lim-ited sequence, redundancy bits can be added in such a mannerthat both the constraints of the multiple insertion/deletion cor-recting code and of the run-lengths are met simultaneously. Thisis achieved by using a modified version of the prefixing algo-rithm developed by Dolecek and Anantharam [15] for the repe-tition correcting code. The prefixing method is the generalizedform of the moment balancing scheme developed in [7], ap-plied to multiple congruency equations. This approach leads to
0018-9448/$31.00 © 2012 IEEE

1810 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012
an asymptotically optimal code. Furthermore, we compare thecode construction with the only other known number-theoreticmultiple insertion/deletion correcting code, the Helberg code.Even though the proposed code construction is intended forrun-length limited sequences, it is still worth comparing thesetwo constructions. We will show that, even despite the additionalrun-length constraints, for a sufficiently large codeword length,the rate of the new construction is better than that of the Helbergcode.
This paper is organized as follows. In Section II, we presentbasic definitions and notation used in the paper and considerthe effect of insertions and deletions on run-length limitedsequences. In Section III, we describe our construction andprove its multiple insertion/deletion correcting capability.Decoding and encoding for the proposed codes are discussedin Sections IV and V, respectively. In Section VI, we compareour construction to the Helberg code. Finally, we conclude thepaper in Section VII.
II. INSERTIONS/DELETIONS AND RUN-LENGTH
LIMITED SEQUENCES
Let be a binary sequence of length. (Throughout this paper, a sequence is represented by
a bold lowercase letter, which, for the reader’s convenience, isoften assigned a subscript denoting its length. The elements ofthe sequence are denoted by roman lowercase letters with in-dices ranging from 1 up to the length of the sequence. In casethe sequence has more than one subscript, it is the last one whichequals its length.) Assume that is transmitted over a channelcausing bits to be inserted and bits to be deleted. Then, thereceived sequence has length and is denoted by
.A code is a set of sequences called codewords. Here, we
consider codes where all codewords are binary sequences ofthe same length, denoted by . A code is -insertion/deletioncorrecting if every binary sequence can be obtained from at mostone codeword in the code by inserting bits and deletingbits for any pair of nonnegative integers and such that
. The code is -deletion correcting code if every binarysequence can be obtained from at most one codeword in thecode by deleting at most bits. Clearly, an -insertion/deletioncorrecting code is an -deletion correcting code. Levenshtein[16] has shown that the converse of this statement also holds.Indeed, suppose that a sequence can be obtained from twodistinct codewords and in the code by subjecting the firstto insertions and deletions and the second to insertionsand deletions, where and . Since thetwo codewords have the same length, then ,which implies that . Furthermore, as
and , we have whichensures that . Deleting all bits inthat have to be inserted in either or , or both, to obtainresults in a sequence that can be obtained from by at most
deletions with no insertions, and from by atmost deletions with no insertions. The existence ofthis sequence proves that the code is not an -deletion correctingcode.
A run in is a maximal substring con-sisting of identical symbols. More precisely, if
, whereand and are defined by and, then we say that is a run of length
. Let denote the number of runs of . To the binarysequence , we assign the positive integer-valued sequence
, where is the lengthof the th run in . This sequence is called the run-lengthrepresentation of . Clearly, , the lengthof . As an example, the run-length representation of
is (2, 1, 3, 1), which is also the run-length repre-sentation of the sequence (0010001). In general, any positiveinteger-valued sequence that sums to is the run-length rep-resentation of two complementary sequences of length . Wesay that is a run-length limited sequence if all its runshave lengths at least equal to and at most equal to , i.e.,
for . Clearly, if is arun-length limited sequence, then
(1)
A code is run-length limited if every codeword in the codeis run-length limited.
In Section III, we present a construction of a run-lengthlimited code that is capable of correcting insertions/deletionswhere . Here, we would like to consider the effectsof deletions and insertions caused by a channel on the runs of atransmitted and, more generally, run-length lim-ited sequence. From the physical point of view, the channel actson the transmitted sequence bit by bit by possibly inserting anddeleting bits. Mathematically, a more convenient, but exactlyequivalent, way to view the action of the channel is to considerthe channel as a concatenation of a channel causing only dele-tions and insertions that do not create new runs followed by achannel causing insertions that create new runs. An inserted bitdoes not create a new run if, and only if, it is inserted adjacentto at least one bit of the same value. If the channel causes atmost insertions/deletions and each run in the transmitted se-quence is of length , then no run can be deleted. Insertionsand deletions that do not create or delete a run are called simpleinsertions and deletions. Notice that all deletions are simple if
. Nonsimple insertions create new runs of length atmost which we call inserted runs. More generally, runs in thereceived sequence of length at most equal to will be called in-valid runs as they do not form valid runs in the run-lengthlimited transmitted sequence. Clearly, all inserted runs are in-valid runs, but the converse is not true. Indeed an invalid runmay also be caused by deletions of bits from a run in the trans-mitted sequence so that the resulting run has length at most equalto or it may be caused by splitting a run in the transmitted se-quence by an inserted run to two runs, one or both of them havelengths at most . Hence, the number of runs in the received se-quence may be greater, but not less, than the number of runs inthe transmitted sequence. In spite of this, we have the followinglemma.

PALUNCIC et al.: A MULTIPLE INSERTION/DELETION CORRECTING CODE FOR RUN-LENGTH LIMITED SEQUENCES 1811
Lemma 1: No two run-length limited sequences ofthe same length, with different number of runs, can lead to thesame sequence by applying at most insertions/deletions, where
, to each of the two sequences.Proof: Let and be two run-length limited
sequences of the same length but with different number ofruns. To get a contradiction, assume that the same sequenceis obtained by applying at most insertions/deletions to each ofthe sequences and . Then, by applying no more thandeletions/insertions to one of them, it is possible to obtain theother. Since and have different number of runs, we mayassume that has more runs than . We will lower boundthe numbers of deletions and of insertions needed to transform
to . Clearly, the number of deletions is at least since atleast one run in has to be deleted. As both sequences have thesame length , then an equal number of bits has to be inserted. Inparticular, no less than insertions and deletions are needed totransform one sequence to the other, contradicting the statementthat no more than insertions and deletions areneeded.
The strength of Lemma 1 is that it does not assume that thetwo run-length limited sequences are codewords in an-insertion/deletion correcting code and does not put an upper
limit on the maximum run-length. Hence, provided that the de-coder knows that the transmitted codeword is a run-length limited sequence of length and the channel caused atmost insertions/deletions, where , it can correctlydetermine the number of runs in the transmitted codeword byobserving the received sequence without knowing the structureof the code as explained next. This can be accomplished if thedecoder knows the inserted runs. Deleting them results in a se-quence that differs from the transmitted sequence in simple in-sertions/deletions and, therefore, has the same number of runsas the transmitted sequence. However, the decoder only knowsthat the inserted runs are invalid and it can identify all invalidruns, i.e., of length at most equal to , in the received sequence.By using trial and error, it can be attempted to exhaustively ex-amine all subsets of invalid runs since one of these subsets isthe set of inserted runs. However, a criterion is needed to deter-mine if the assumed inserted runs are indeed so. The followingtheorem gives a criterion that can be applied by the decoder todetermine the number of runs in the transmitted codeword andto give a list of candidate sets of inserted runs. The fact that thetheorem does not unambiguously specify the inserted runs is notdue to a weakness in the result, but rather to the generality of thesetting since we are not assuming that the transmitted sequencebelongs to a code that can correct insertions/deletions. (Sucha code is constructed in Section III.)
Let be a received sequence obtained from a run-length limited sequence of length by at most inser-tions/deletions. Let be the run-length rep-resentation of . Define tobe the set of indices of invalid runs in the received sequence .For a subset , let be the sequence obtainedfrom after deleting the runs with indices in , where
is the number of bits in the deleted runs. Let be thenumber of runs and be the run-lengthrepresentation of . Let be the sequence obtainedfrom by increasing the length of every run of lengthless than to be of length . Then, is a run-length
limited sequence that has runs with run-length representa-tion , where . Thenumber of bits that need to be inserted in to obtain
is . In particular, the length ofis . Now define to be the set of
run-length limited sequences of length that differ fromin at most simple insertions/deletions. Then,
the following theorem holds.Theorem 1: Let be a sequence that differs from a
run-length limited sequence of length in at mostinsertions/deletions.
1) The set is nonempty if and only if
(2)Furthermore, all sequences in have the samenumber of runs as .
2) There is at least one choice of for whichsuch that .
Proof: Since the inserted runs are invalid, for some subset,, is precisely the set of indices of the inserted runs.
By deleting the bits in the inserted runs from , the re-sulting sequence has the same number of runs as thetransmitted sequence and differs from it in at most simpleinsertions/deletions. By inserting bits in the runs of sothat each run has length at least , we obtain the sequencewhich differs from the transmitted sequence in at most
simple insertions/deletions, where .Hence, , which proves the second statement inthe theorem. To prove the first statement, notice that every se-quence in differs from in at mostinsertions/deletions and differs from in in-sertions/deletions. Hence, every sequence in differsfrom in at most insertions/deletions. Since all sequencesin , as well as which also differs from in at most
insertions/deletions, are run-length limited, we con-clude, from Lemma 1, that all the sequences in havethe same number of runs as . Next, we show that (2) holds ifand only if is nonempty, i.e., by at mostsimple insertions/deletions applied to , a run-lengthlimited sequence of length can be obtained. Notice that isitself a run-length limited sequence but has length
. Therefore, the question is whether or not it is pos-sible to obtain from this sequence a run-length limitedsequence of length by no more than simple in-sertions/deletions. If , then simple insertions areneeded to increase the length of to . Hence, this numberis at most equal to , i.e., ,if, and only if, is nonempty. Finally, if , thenat least deletions are needed to decrease the length of
to . Since, after these deletions, each run in the sequenceshould have length at least , this is possible if and only if thereare at least bits that can be deleted from withoutreducing the length of any run below . The number of such bitsis

1812 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012
Hence, a sequence of length can be obtained fromby at most simple insertions/deletions, i.e.,is nonempty, if and only if and .
Let be the set of all sequences for whichis nonempty. The first part of Theorem 1 characterizes all se-quences in and the second part tells us that at least one ofthese sequences differs from the transmitted sequence in nomore than a well defined number of simple insertions and dele-tions which is at most equal to . We would like to see how thedecoder can determine the set . Notice that every sequence inthis set corresponds to a candidate set of inserted runs. Basedon the first part of Theorem 1, a simple algorithm to determinethe sequences in can be developed. For efficiency, the al-gorithm can be applied to the run-length representation
of the received sequence . Then,is the set of indices of the invalid
runs in the received sequence. Next, subsets of are con-sidered. Let be such a subset. To obtain the run-length rep-resentation of , we have to delete the runs indexed by
and we may need to combine runs adjacent to the deletedruns if the bits in these runs have the same value. For this pur-pose, we first list the indices of the set in in-creasing order as and form the aux-iliary sequence .Then, all consecutive numbers having the same sign are com-bined into a single number which equals the absolute value oftheir sum. The resulting sequence is the run-length represen-tation of . From , the run-length representation
of can be obtained and can be determined. We thencheck whether or not (2) holds. If it does, then is a candidateset of indices of inserted runs and is placed in . It suf-fices to consider subsets of for which which isa necessary condition for (2) to hold.
Example 1: Suppose that a run-length limitedsequence, , of length is transmitted over a channelcausing at most insertions/deletions. Suppose that therun-length representation of the received sequence, , is
. It follows that the received sequence is of length. Among the six runs in
the received sequence, there are three invalid runs, i.e., runs oflength at most . The indices of the invalid runs form theset . Let us consider the subsetof . For this subset, the number of bits in runs with in-dices in is and , , , .These are the indices of runs in the received sequence whichare not indexed by . The auxiliary sequence isand the run-length representation of the sequence oflength is . The sequence
has run-length representation obtained from the run-lengthrepresentation of by increasing the length of each runof length less than to be of length . Hence,
has run-length representation and length, and is obtained by inserting
to . Notice that ,, and (2) does not hold. Hence,
is not a candidate set for the indices of the insertedruns. Suppose next we choose the subset .For this subset, the number of bits in runs with indices in is
TABLE IDETERMINING THE CANDIDATE SETS OF INSERTED RUNS IN EXAMPLE 1
and , , , , . Theseare the indices of runs in the received sequence which arenot indexed by . The auxiliary sequence isand the run-length representation of the sequence oflength is (6, 5, 8, 8). The sequence
has run-length representation obtained from the run-lengthrepresentation of by increasing the length of each runof length less than to be of length . Hence,
has run-length representation and length, and is obtained by inserting
to . Notice that ,, and (2) holds. Hence,
is a candidate set for the indices of the inserted runs, i.e., it ispossible to obtain a run-length limited sequence oflength from by at mostsimple insertions/deletions. This is equivalent to stating that theset is nonempty. Actually, for , con-sists of run-length limited sequences of length
with run-length representations given by
Notice that is not the only candidate set for the indices ofthe inserted runs. The set is also a candidate set with
, , and has run-length representationand length . For
, consists of run-length limitedsequences of length with run-length representationsgiven by
Other than and , there are no candidate sets for the in-dices of inserted runs. In particular, consists of two sequenceswith run-length representations and . Theresults are summarized in Table I where only subsets offor which are considered since subsets for whichthis bound does not hold are definitely not candidate sets forthe indices of the inserted runs. From Theorem 1, we know thatthe transmitted sequence is in the unionwhich contains 22 sequences. In order to be able to identify thetransmitted sequence, we need to restrict it to be a codeword ina 5-insertion/deletion correcting run-length limited code. Theconstruction of such code is the focus of the Section III.

PALUNCIC et al.: A MULTIPLE INSERTION/DELETION CORRECTING CODE FOR RUN-LENGTH LIMITED SEQUENCES 1813
III. MULTIPLE INSERTION/DELETION CORRECTING
RUN-LENGTH LIMITED CODE
In this section, we give a construction of a run-lengthlimited code of length that is capable of correcting inser-tions/deletions where . The construction is actuallybased on the one proposed by Dolecek and Anantharam [15] tocorrect insertions of zeros. We show that by applying this con-struction to run-length limited sequences, the code cancorrect insertions and deletions of zeros and ones. The code,which is denoted by , will be defined in termsof a union of subsets where each subset consists of codewordsthat have the same number of runs. From (1), the number ofsuch subsets is . Let be an integer suchthat . The subset of codewords that haveruns is characterized by a prime number , a se-quence of distinct nonnegative in-tegers less than , and a sequenceof nonnegative integers less than . The subset characterizedby such , , , and is given by
(3)
where and are the number of runs and the lengthof the th run, respectively, in .
The code , which is a run-length limitedcode of length , is defined as
(4)
It should be noted that the code depends not onlyon , , , and , but also on , , and for
. However, to simplify notation, these parameters aresuppressed.
We will show that the code is an -insertion/deletion correcting code if . Before proving this, wegive an example to illustrate the code construction.
Example 2: We construct a run-length lim-ited code, , of length which is doubleinsertion/deletion correcting, i.e., . From (4), it followsthat is a union of two sets:and . To define the first set, we may choose
, , and . Codewords in this sethave run. The only two sequences of length six composedof a single run are (000000) and (111111) and each has a run oflength . Since
and
both sequences are codewords and
To define the second set, we may choose , ,and . Codewords in this set have runs, eachof length not less than . The only two sequences of lengthsix composed of two runs each of length not less than three are(000111) and (111000) and each has a run-length representation
. Since
and
both sequences are codewords and
It should be obvious that
is indeed a double insertion/deletion error correcting code.Theorem 2: The code is an -insertion/dele-
tion correcting code if .Proof: Based on Levenshtein’s result [16] stated in
Section II that an -deletion correcting code is also an -in-sertion/deletion correcting code, it suffices to show that
is an -deletion correcting code. Suppose thata codeword is transmitted over a channelcausing deletions. Let be the received sequence. Wehave to show that from , we can uniquely determine .Since every codeword has length , the decoder can determinethe number of deletions . Second, notice that since
is strictly less than the minimum run-length, , no run isentirely deleted by the channel, i.e., the number of runs in ,which we denote by , equals the number of runs in . Hence,we know that belongs to the set . Itremains to identify within this set. Letand be the run-length representations of
and , respectively. Clearly, for ,since we are assuming that the channel causes deletions only.We define for . To complete theproof, it suffices to show that the numbers canbe uniquely determined from or, equivalently, from . Forthis purpose, let and for
, which can be determined, modulo , by thedecoder. Since , for , whichis a sum of at most nonzero terms, the decoder can uniquelydetermine the polynomial
(5)

1814 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012
and which can be written as . This isachieved by using Newton’s identities (see [18, Lemma 10.2])which state that
(6)
for where the computations are done over theprime field in which the inverses of are well definedas . From (6) and noticing that , the decodercan determine recursively in this order. Sincethese are the coefficients of , this polynomial is uniquelydetermined by the decoder. The decoder can then factor[see (5)] and, as the ’s are distinct for distinct values of
, this factorization uniquely determines for everyfor which . There is at most one value
of , which we denote by , for which . Then, canbe determined from
In any case, can be determined for all . Since, the run-length representation of the codeword
and, therefore itself, can be determined.From the proof, an algorithm to correct deletions can be im-
mediately deduced. However, we postpone the discussion of thedecoder till Section IV where an algorithm to correct insertionsand deletions is presented.
Next, we show that the code construction given in (4) isasymptotically optimal in terms of rate for any given .The rate of the code is defined by
(7)
First, let denote the total number of run-length limited sequences of length . The capacity of run-length limited sequences is defined by
(8)
and this limit does exist. By relating run-length limitedsequences to -constrained sequences, which arebinary sequences in which any two consecutive 1’s are separatedby at least zeros and no run of zeros has length greater than
[14], it follows that is the logarithm to basetwo of the largest magnitude of a root of the polynomial
(9)
Theorem 3: There exists a sequence of codesfor of increasing length for which the asymptotic rate
(10)
On the other hand, the limit superior of the rate of any sequenceof run-length limited codes of increasing length is upperbounded by .
Proof: We first prove the second statement. Consideran infinite sequence of run-length limited codes,
, of increasing lengths . Since every codewordin is run-length limited, it follows that
. Let denote the rate of. Then
From (8), we have
(11)
This proves the second statement. To prove the first statement,we will show that for some choices of and in (3)
(12)
For each subset in as givenin (4), we have . From BertrandPostulate [19], we know that there exists a prime greater than
but at most equal to for .Let be such a prime. Notice that for large , .Let be the number of all run-length limitedsequences of length that have runs. Then, from (1), we have
(13)
The union
which runs over all sequences of nonnegative integersless than , is the set of all run-length limited sequencesof length that have runs. Hence, for each ,
, there exists a choice of such that
(14)
From (4), (13), and (14), we conclude that
Therefore, from (7), we have
which, together with (8), proves (12). Combined with (11),which holds for any sequence of run-length limited codeswhich are not necessarily insertion/deletion correcting, weconclude that the limit in (10) exists and equals .

PALUNCIC et al.: A MULTIPLE INSERTION/DELETION CORRECTING CODE FOR RUN-LENGTH LIMITED SEQUENCES 1815
In words, the asymptotic rate of the proposed codes equalsthe capacity of the run-length limited sequences and thecorrection of at most insertions/deletions, for a fixed value of, does not cause any loss in the asymptotic rate.
IV. DECODING ALGORITHM
Let be a transmitted codeword whichis subjected to at most insertions/deletions, where ,to yield the received sequence . Our goal is to uniquely de-termine by observing . We propose a decoding techniquethat consists of two stages. In the first stage, a set of sequencesof the same number of runs as the transmitted codeword is pro-duced as explained in Section II. Each sequence isassociated with a candidate set of the indices of inserted runsand the numbers and that determine the number of dele-tions and insertions, respectively, performed on the received se-quence to obtain . From Theorem 1, we know that forsome set , the associated sequence differs from the trans-mitted sequence in at most simple insertions/dele-tions. Hence, once the set is identified, then the second stageis performed in which every sequence is decoded tofind a codeword that differs from it in atmost simple insertions/deletions. Since this code-word differs from in insertions/deletions and
differs from the received sequence in inser-tions/deletions, it follows that the codeword differs from inat most insertions/deletions. From Theorem 2, we know thatthere is a unique codeword that can be obtained in this way andthis codeword is actually the transmitted sequence.
The first stage of the algorithm is covered in Section II. To getan upper bound on the number of decoding trials in the secondstage, which is the size of , notice that an insertion causes nomore than three invalid runs since, in the worst case, in additionto forming an invalid run, it may split a run into two invalidruns while a deletion causes at most one invalid run. Hence, thenumber of invalid runs in the received sequence if the channelcauses at most insertions/deletions is no more than . Thesize of equals at most the number of subsets of invalid runscontaining no more than bits. This number is at most equal to
. We should also point out that the set contains allsequences that differ from at least one run-length limitedsequence of length by simple insertions/deletions. Since thecodeword is run-length limited, sequences that do notdiffer from at least one run-length limited sequence oflength by simple insertions/deletions can be removed fromsince decoding them does not yield the transmitted codeword.Removing such sequences from requires strengthening thecriterion in (2) by incorporating the maximum run-length .
In the following, we present an efficient algebraic algorithmto implement the second stage, i.e., to determine a codeword
that differs in at mostsimple insertions/deletions from a given sequence if sucha codeword exists. From Theorem 2, there is at most one suchcodeword. Clearly, if such a codeword exists, then the number ofruns in is the same as the number of runs in , which we de-note by . Based on the definition of given in (4)as a union of subsets of codewords having the same number ofruns, the codeword we are looking for, if it exists, resides in the
set defined in (3). Letand be the run-length representations of
and , respectively. We define
(15)
for . For decoding, it suffices to show that thenumbers can be uniquely determined from or,equivalently, from . For this purpose, we define
(16)
for , reduced modulo . These numbers can becomputed by the decoder.
Next, we define
(17)
Then, and are polynomials,, and . In
the following, we show how the decoder can determine thesetwo polynomials. This is achieved in two steps. In the first step,the decoder computes the polynomial
where is considered as a power series in . Wewrite . In the second step, the decoder deter-mines the two polynomials and from . Thefirst step can be achieved using the generalized Newton’s iden-tities (see [18, Lemma 10.3]) which state that
(18)
for where the computations are done over theprime field in which the inverses of are well definedas . From (18) and noticing that , the de-coder can determine recursively in this order.For the second step, we notice that and satisfythe congruence
Since and have no common factors, it followsfrom (see [18, Lemma 10.6 and Proposition 10.7]), that by ap-plying Euclid’s algorithm to the polynomials and ,the polynomials and , which are restricted to haveconstant terms of one, can be determined. The algorithm is firstinitialized by setting
Starting with , it iteratively computes the quotient polyno-mial obtained by dividing by , and sets

1816 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012
If , the value of is in-cremented by 1 and and are computed. Once
, then the algorithm stopsand sets and to be multiples of and ,respectively, with constant terms equal to 1. The decoder canthen factor and (see (17)) and, as the ’s aredistinct for distinct values of , these factoriza-tions uniquely determine for every for which
. There is at most one value of , denoted by , forwhich . Then, can be determined from
(19)
In any case, can be determined for all , asfor all . Since , the run-length
representation of the codeword and, therefore itself, canbe determined. Notice that all computations are performed overthe prime field .
It should be stated that the previous algorithm is similar, butnot identical, to the one developed in [18] to decode Lee-metricalternant and GRS codes.
Example 3: We continue with Example 1 and assume thatthe transmitted sequence is a codeword in arun-length limited code of length givenby (4) with . Since consists of two sequences withrun-length representations and , these arethe only two run-length limited sequences thatneed to be decoded for simple insertions/deletions to recover thetransmitted codeword. In particular, the transmitted codewordhas runs as each sequence in has four runs. Hence, thetransmitted codeword belongs to the set with
. We define this set by setting , ,and . We attempt to decode each sequencein .
1) with run-length representation : For this se-quence, , , , and , seeTable I. Hence, we seek to determine a codeword in the set
that differs from in at mostsimple insertions/dele-
tions. From (16), we have , 6, 5, and , 6, 1, for, 2, 3, respectively. Using the expression in (18), we
have . Applying Euclid’s algorithm,we obtain and .We stop here since
. As both polynomials have constant termsequal to 1, we have and
. To find the roots of these polynomials, we writeand . (Notice that
the polynomials are considered over .) Comparingwith (17), it follows that , , ,
. Hence, for ,respectively. From (15) and the run-length representation
of , we determine the run-length representa-tion of the transmitted codeword to be . Com-paring with the run-length representationof the received sequence, we deduce that it may be obtainedfrom the transmitted sequence by deleting three bits from
the second run, inserting a run of length one in the thirdrun, and inserting a bit in the last run of value equal to thatof the bits in the run.
2) with run-length representation : For this se-quence, , , , and , seeTable I. Hence, we seek to determine a codeword in the set
that differs from in at mostsimple insertions/dele-
tions. From (16), we have , 4, and , 1, for, 2, respectively. Using the expression in (18), we
have . Applying Euclid’s algorithm, weobtain and . We stop heresince .Since both polynomials have constant terms equal to 1, wehave and . However,
has no roots in . Hence, decoding of withrun-length representation fails.
From Theorem 2, we know that only one sequence in canbe successfully decoded. Hence, we did not need to decodewith run-length representation once the sequencewith run-length representation was successfullydecoded.
Finally, we consider the computational complexity of the pre-viously described decoding algorithm. Notice that this com-plexity is dominated by the computations needed to apply thesecond stage to the sequences in . For each sequence in , wewill show that this complexity is polynomial in , the maximumnumber of insertions/deletions that can be corrected. The secondstage of the decoding algorithm consists of four computationallyintensive steps. In the first step, for a given , op-erations are required to determine and for .Similarly, in the second step, operations are required todetermine , and hence . In the third step,
and are computed using the (extended) Euclid’salgorithm. This can be achieved in([20], Theorem 3.11), which is polynomial in . And, in thefourth step, the computed polynomials and needto be factorized over . As shown by Berlekamp [21], apolynomial of degree can be factorized in polynomial time in
and , where is the size of the finite field over whichthe polynomial is factorized. Since or is of degreeat most , it follows that they can be factorized in polynomialtime in and . Hence, since , the overall computa-tional complexity of the second stage of the decoding algorithmis polynomial in .
The second stage needs to be repeated for each ,where was determined during the first stage. As shown earlier,the size of is at most , which is exponential in. However, this bound does not take Theorem 1 into account.
Furthermore, the worst case scenario would occur only rarely.
V. SYSTEMATIC FORM OF THE CODE
Dolecek and Anantharam [15] presented a technique tosystematically encode their multiple repetition error correctingcode. With a simple modification of this technique, we candevelop a systematic encoder for the code, ora slight modification of this code, for selected values of , ,

PALUNCIC et al.: A MULTIPLE INSERTION/DELETION CORRECTING CODE FOR RUN-LENGTH LIMITED SEQUENCES 1817
, and appearing in (3) and (4). The modifications arenecessary to guarantee that the code is run-length limited.
Provided that is a sufficiently large prime and dividesfor all , Dolecek and Anantharam [15] gave
an explicit construction of disjoint subsets of, such that for each , every integer can
be written modulo as a sum of elements in raised to the thpower such that, instead of raising the elements to the th power,if they are raised to a positive power less than , the sum is zeromodulo . More precisely, for every integer , , thereis a subset such that and
for all . Let
(20)
Example 4: For , we can haveand . Notice thatand are disjoint. Table II shows the sets and forevery integer , . From (20),
. For example, from the table we haveas . We also have
as
and
Assume we are given a run-length limited sequencewith run-length representation , whereis the number of runs in . Let and let thesequence of length be chosen as follows. The num-bers are selected to be the elements inthe union of . We also set and , for
, to be distinct elements in thatdo not appear in any of the sets . Let be anygiven sequence of nonnegative numbers less than .
We will show that the sequence can be encoded into acodeword in an -insertion/deletion correcting code of length
(21)
where
(22)
This is achieved by prepending with a prefix of length
(23)
This prefix is a concatenation of two strings, i.e.,. The second string, , has runs as given
in (20). Let be the run-length representa-tion of . Then, has length . Thefirst string, , in the prefix has length and
runs.
TABLE IISETS � AND � FOR � � � � � WHERE � � �� IN EXAMPLE 4
The prefix is selected such that theresulting codeword
(24)
is run-length limited of length such that
(25)for all . Before showing how this can be achieved,let us first argue that the collection of such codewords for allpossible sequences of length forms an -insertion/dele-tion correcting code. The only difference between the congru-ences in (25) and the congruences in (3), is that in (25), it is thelength of which is multiplied by positive powers of
while in (3), it is the length of the first run in which ismultiplied by these powers. Decoding can then be performed asin Section IV with the minor modification where and arereplaced by the total length of the first runs, rather than thefirst run, in and respectively. Indeed from Theorem 1, thefirst runs in correspond to the first runs in as
and differ only by simple insertions and deletions. Notice

1818 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012
that the number of runs as given in (22) is determined by ,, and , which are assumed to be known to the
decoder. In particular, is the same for all codewords and doesnot depend on the message sequence . This slight modifica-tion in code construction is needed to guarantee that the string
is run-length limited. Actually, if , thenand there is no need for this modification.
Since , the string does not play a role in (25).Its function is to guarantee that the length of the codeword is .Let us focus first on the string . To obtain this string whichsatisfies the congruences in (25), we will iteratively constructa sequence of strings, , each consisting of runs with
run-length representation , such that
(26)
for all . The length of is .
Thus, satisfies the first congruences in (25). We in-
crease the value of until in which case satis-
fies the congruences in (25) and we set . We
will guarantee that is run-length limited for all
. Actually, we will keep it run-length lim-ited.
First, let be a sequence of runs with run-length
representation
(27)
Now, suppose that , for , is such that
(26) holds for . Let
(28)Then, from the way is constructed, there is a subset
such that and
for all . The subset
defines the lengths of the runs of as follows
(29)
for . Then, (26) holds for . Since none ofthe first congruences are affected, as
for all , (26) holds for . Thisprocedure can be performed for . Then, we set
. Notice that since the sets are
disjoint, then each for appears at most inone of the sets . If appears in one of
these sets, then the th run in is of length , otherwise itis of length . In particular, the length satisfies
(30)
We finally consider the string . This string has lengthand number of runs given by as stated in
(22). From (23) and (30), we have
(31)
We want to show that this string can be constructed suchthat it is run-length limited. We write
where is the remainder obtained from dividing by , i.e.,. Then, the string is constructed such that
its first runs are of length and its last runsare of length . Clearly, has length . From(31), we have and, hence, every run in is oflength at least equal to . To show that every run is of length atmost equal to , we consider two cases. In the first case, isdivisible by , i.e., . Then, every run is of lengthand from (31) and (22), we have
In the second case, is not divisible by , i.e., . Then,the maximum length of a run is . Again from (31)and (22), we have
Since is an integer, then it is at most equal to .We conclude that can be selected to be run-lengthlimited.
From the above, it follows that a string of lengthand a string with run-length representation
can be constructed such that (25) holds forall . Both strings are run-length limited. Toensure that the sequence given in (24) is run-length lim-ited, the boundary between and and the boundarybetween and should be run boundaries. To achievethis, recall, from Section II, that there are two complementarysequences that share the same run-length representation. Hence,we select from the two possibilities sharing the samerun-length representation such that its last bit is different fromthe first bit in and we select from the two possibilitiessharing the same run-length representation such that its last bitis different from the first bit in .
In summary, suppose that is aprime for which the sets are disjoint where
. Let ,be a sequence of distinct non-negative integers less than forwhich and are the elements inthe union of , and bea sequence of nonnegative integers less than . Then, any

PALUNCIC et al.: A MULTIPLE INSERTION/DELETION CORRECTING CODE FOR RUN-LENGTH LIMITED SEQUENCES 1819
run-length limited sequence of length that has runs canbe systematically encoded by prepending it by a prefix to forma codeword in the form of (24) of length as given in (21) andsatisfying (25) for . Let be thecollection of such codewords for a given . As has length ,it follows that
(32)
Hence, for to hold for all sequencesof length , it suffices to have
(33)
Let
where . Then, is an -inser-tion/deletion correcting code which is run-length limited.Note that the primes in andare used to differentiate them from and
in (3) and (4) since, as explained before, in thefirst two, the first runs are weighted by which is zerowhile in the last two, it is the first run which is weighted by .
Example 5: Suppose that we want to systematically en-code run-length limited sequence of length
into a double insertion/deletion correcting codewhich is run-length limited. From Example4, we can use and the setsand since
and (33) holds with . For eachsatisfying (32), let . We choose
,
(34)
for , respectively, and , for, to be the consecutive positive integers less than in
increasing order that are different from for .We also choose to be all zero sequence. Now suppose thatwe want to encode the message sequence of lengthand with run-length representation
(35)
This sequence has runs. Then
(36)
for , respectively. Wefirst determine the string that has runs. For thispurpose, we start with a string of runs with
run-length representation given in (27) as
(37)
Clearly, has length . From (28),
(34), (35), (36), and (37) with , we obtain . From
Table II, , see Example 4. Hence, we form astring with run-length representation given by (29) as
(38)Clearly, has length . This string
satisfies (26) for . From (28), (34)–(36), and
(38) with , we obtain . From Table II,, see Example 4. Hence, we form a string
with run-length representation given by (29) as
(39)Clearly, has length . This string
satisfies (26) for and . Since , we
take , which is a sequence of length .
Then, (25) holds for .Next, we consider the string . From (22), this string
has runs and lengthas is given in (23). A
run-length limited string can be constructedof length that has runs based on the run-lengthrepresentation
(40)
In conclusion, from (40), and (39), (35), the sequence is sys-tematically encoded as the codeword in (24) with run-lengthrepresentation
of length as given in (21).From Example 5, notice that the message sequence of
length 40 is encoded into a codeword of length 131. This isclearly not efficient. However, using sophisticated arguments,Dolecek and Anantharam [15] have shown that there is an in-finite sequence of primes and sets such that
is logarithmic in . Corresponding to this se-quence of ’s, one can come up with a sequence of ’s satisfying(33) for which is also logarithmic in . From (22) and (23), itfollows that the length, , of the prefix, ,is also logarithmic in . Hence, as the length, , of the mes-sage sequence increases, the ratio of the length, , of the prefix
to the length of the message sequences decreases to zero. Inconclusion, systematic encoding can be achieved without anyasymptotic loss in rate.
VI. COMPARISON WITH THE HELBERG CODE
The only known multiple insertion/deletion correcting code isthe Helberg code [17]. The Helberg code of length is definedas [17]
(41)
1820 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012
TABLE IIIMAXIMUM CARDINALITY COMPARISON BETWEEN � AND �
FOR SMALL VALUES OF � AND �
where
(42)
, and is an integer,. It can be proved that the Helberg code given in (41) is an-insertion/deletion error correcting code [22]. However, this
code suffers from a low rate. Because of this, the Helberg codeis of a more theoretical interest, rather than practical interest.
In this section, we would like to compare the cardinalities andrates of the run-length limited code, , con-structed in this paper and the Helberg code, . Sincethe Helberg code is, in general, not run-length limited, we relaxthe run-length constraints of to the minimumpossible that still allow for the correction of insertions/dele-tions, i.e., we set and . In the following, wedenote and simply by and
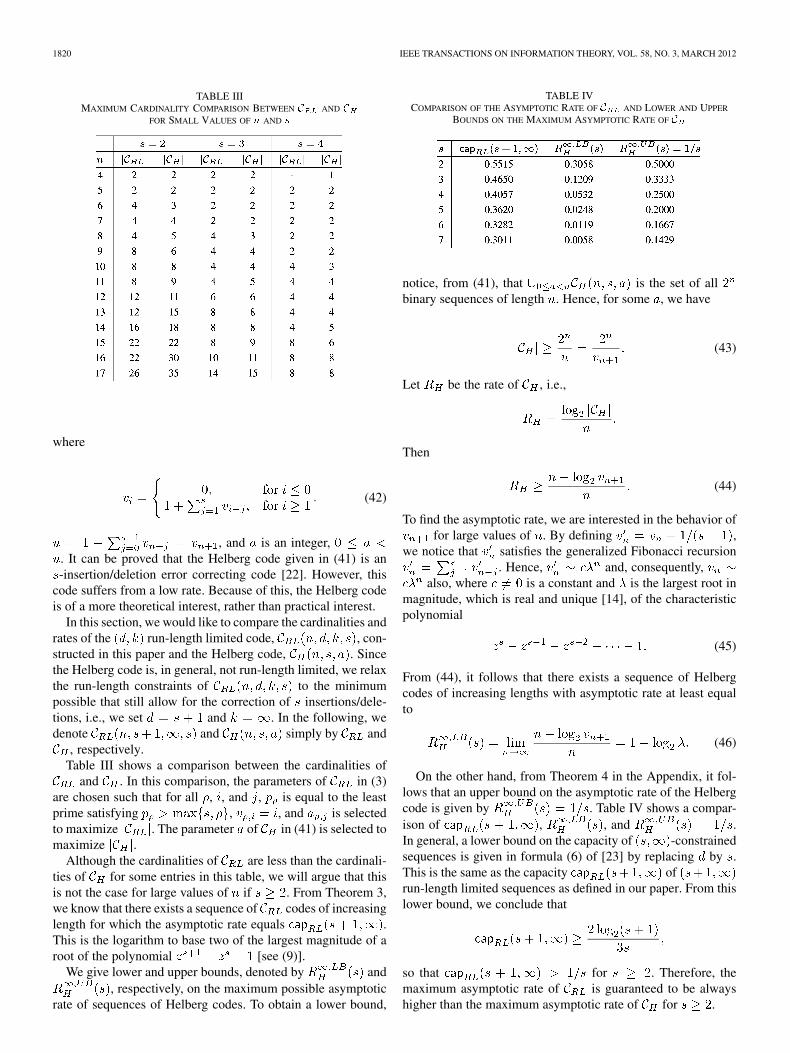
, respectively.Table III shows a comparison between the cardinalities of
and . In this comparison, the parameters of in (3)are chosen such that for all , , and , is equal to the leastprime satisfying , , and is selectedto maximize . The parameter of in (41) is selected tomaximize .
Although the cardinalities of are less than the cardinali-ties of for some entries in this table, we will argue that thisis not the case for large values of if . From Theorem 3,we know that there exists a sequence of codes of increasinglength for which the asymptotic rate equals .This is the logarithm to base two of the largest magnitude of aroot of the polynomial [see (9)].
We give lower and upper bounds, denoted by and, respectively, on the maximum possible asymptotic
rate of sequences of Helberg codes. To obtain a lower bound,
TABLE IVCOMPARISON OF THE ASYMPTOTIC RATE OF � AND LOWER AND UPPER
BOUNDS ON THE MAXIMUM ASYMPTOTIC RATE OF �
notice, from (41), that is the set of allbinary sequences of length . Hence, for some , we have
(43)
Let be the rate of , i.e.,
Then
(44)
To find the asymptotic rate, we are interested in the behavior offor large values of . By defining ,
we notice that satisfies the generalized Fibonacci recursion. Hence, and, consequently,
also, where is a constant and is the largest root inmagnitude, which is real and unique [14], of the characteristicpolynomial
(45)
From (44), it follows that there exists a sequence of Helbergcodes of increasing lengths with asymptotic rate at least equalto
(46)
On the other hand, from Theorem 4 in the Appendix, it fol-lows that an upper bound on the asymptotic rate of the Helbergcode is given by . Table IV shows a compar-ison of , , and .In general, a lower bound on the capacity of -constrainedsequences is given in formula (6) of [23] by replacing by .This is the same as the capacity ofrun-length limited sequences as defined in our paper. From thislower bound, we conclude that
so that for . Therefore, themaximum asymptotic rate of is guaranteed to be alwayshigher than the maximum asymptotic rate of for .

PALUNCIC et al.: A MULTIPLE INSERTION/DELETION CORRECTING CODE FOR RUN-LENGTH LIMITED SEQUENCES 1821
Thus, the code , even despite the run-length constraints,has a better asymptotic rate than the Helberg code. There-fore, our construction is an improvement, in a certain sense,over the Helberg code. However, this is not to imply that ourconstruction is a practical multiple insertion/deletion code forunconstrained data. Indeed, optimal multiple insertion/deletionerror correcting codes for unconstrained data still have to beinvestigated.
VII. CONCLUSION
We presented an asymptotically optimal code constructionthat can add a multiple insertion/deletion correcting capabilityto a run-length limited sequence, provided that ,where is the number of insertion/deletion errors that can becorrected. We developed a decoding algorithm for the code tocorrect multiple insertions and deletions. We also presented asystematic form of the code. The use of the systematic form ofthe code incurs a greater redundancy, but is nevertheless asymp-totically optimal.
The use of such a construction for run-length limited codesfor magnetic or optical recording media can be motivated by,for example, bit-patterned media where insertion/deletion er-rors can greatly degrade the performance of the system. Further-more, it should be noted that the presented code construction haslimited substitution error correcting capability.
Despite being intended for run-length limited codes, thisnumber-theoretic construction is also of importance for generalmultiple insertion/deletion correcting codes without any im-posed run-length constraints. The only other known multipleinsertion/deletion correcting code, the Helberg code, lacks adecoding algorithm (apart from trial-and-error decoding) andsuffers from a low rate. It is shown that the proposed construc-tion is guaranteed to have a better asymptotic rate than theHelberg code for .
APPENDIX
In this appendix, we aim to show that is upper boundedasymptotically by .
Lemma 2: For
Proof: We will use induction to prove this result. Considerthe case . Since for all , we have
and the statement holds for . Assume that it holds for ,i.e.,
Then, for , we have
Lemma 3: For
Proof: From Lemma 2, we have
Next, we prove a system of inequalities for :
where . For example, if , this system hasone inequality . If , the system hastwo inequalities and
.
Lemma 4: For , we have

1822 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012
Proof: From Lemma 2, we have
(47)
On the other hand
(48)
The lemma follows from (47) and (48).
We define to be the set of all binary sequencessatisfying . Clearly,
and
(49)
Let be a subset of . We say that is aset of distinct sums if for any distinct subsets
and of .For example, let and . Then, , 2, 4, 7, 12,
20, 33 for , 2, 3, 4, 5, 6, 7, respectively. It is straightfor-ward to show that is a set of distinct sums but
is not as .
Lemma 5: Let be a set of distinct sums. Then
Proof: Let and .Then, for any given values , , there arebinary sequences obtained by choosing
, . Let . Clearly, different choicesof ’s, yield different sets ’s. For each choice
The last sum is a sum of ’s in a subset of . Since is a setof distinct sums, the sums are different for differentchoices of ’s, . In particular, different choices of ’s,
give sequences ’s that belong to subsetswith different values of . Now we consider a fixed value .For each , by running over all possiblechoices of ’s, , one obtains a set of distinctbinary sequences of length and only one of them belongs to
, which is . Hence, is a dis-joint union of subsets each one containing exactly one sequencein . Therefore
and the result follows.
Lemma 6: Let be a set of distinct sums. Then, for
Proof: Notice that ranges from 0 to .Hence, there are at most values
such that for any integer. Since , from Lemma 3, it follows that
for . Combining this with Lemma 5 and (49), we obtainthe result.
In particular, to bound the size of the Helberg code, it sufficesto construct a large set of distinct sums. In the following, weconstruct such a set using a greedy approach. We use todenote the constructed set of distinct sums which is a subset of
. The set is constructed recursively as follows.Let . Suppose is constructed for some ,
. Then, is constructed as follows:
(50)
For example, let and . Then, , 2, 4, 7, 12,20, 33 and , , , , ,
, for , 2, 3, 4, 5, 6, 7,respectively.
Lemma 7: The set is a set of distinct sums.
Proof: The proof is by induction on . Clearlythe lemma holds for . Suppose it holds for . If
for some distinct subsets andof , then by the induction hypothesis, belongs
to exactly one of these two subsets. Suppose, without loss

PALUNCIC et al.: A MULTIPLE INSERTION/DELETION CORRECTING CODE FOR RUN-LENGTH LIMITED SEQUENCES 1823
of generality, that . Then, butas and
. This yields a contradiction which proves that is aset of distinct sums.
Lemma 8: For
Proof: Notice that is either 0 or 1. Formthe sequence with and for
,
Then, . Suppose . Then,, , and . Set-
ting , Lemma 4, with , implies that
, respectively. In particular, in thesequence , any two zeros are separated by at least ones.We conclude that the number of zeros in does not exceed
. Hence, .Theorem 4: For
Proof: The bound follows from Lemmas 6, 7, and 8.
From Theorem 4, it follows that the rate of Helberg code,given by , is upper bounded asymptoti-cally by .
ACKNOWLEDGMENT
We wish to thank an anonymous reviewer for pointing out therelationship between and as used in Section VI.
REFERENCES
[1] Y. Ng, B. V. K. V. Kumar, K. Cai, S. Nabavi, and T. C. Chong, “Picket-shift codes for bit-patterned media recording with insertion/deletionerrors,” IEEE Trans. Magn., vol. 46, no. 6, pp. 2268–2271, Jun. 2010.
[2] J. Hu, T. M. Duman, M. F. Erden, and A. Kavcic, “Achievable infor-mation rates for channels with insertions, deletions, and intersymbolinterference with i.i.d. inputs,” IEEE Trans. Commun., vol. 58, no. 4,pp. 1102–1111, Apr. 2010.
[3] A. R. Iyengar, P. H. Siegel, and J. K. Wolf, “Data-dependent writechannel model for magnetic recording,” in Proc. IEEE Int. Symp. Inf.Theory, Austin, TX, Jun. 13–18, 2010, pp. 958–962.
[4] H. J. Richter, A. Y. Dobin, O. Heinonen, K. Z. Gao, R. J. M. van deVeerdonk, R. T. Lynch, J. Xue, D. Weller, P. Asselen, M. F. Erden,and R. M. Brockie, “Recording on bit-patterned media at densitiesof � ����� and beyond,” IEEE Trans. Magn., vol. 42, no. 10, pp.2255–2260, Oct. 2006.
[5] Y. Tang, K. Moon, and H. J. Lee, “Write synchronization in bit-pat-terned media,” IEEE Trans. Magn., vol. 42, no. 2, pp. 822–827, Feb.2009.
[6] P. A. H. Bours, “Construction of fixed-length insertion/deletion cor-recting runlength-limited codes,” IEEE Trans. Inf. Theory, vol. 40, no.6, pp. 1841–1856, Nov. 1994.
[7] H. C. Ferreira, K. A. S. Abdel-Ghaffar, L. Cheng, T. G. Swart, andK. Ouahada, “Moment balancing templates: Constructions to add in-sertion/deletion correction capability to error correcting or constrainedcodes,” IEEE Trans. Inf. Theory, vol. 55, no. 8, pp. 3494–3500, Aug.2009.
[8] L. Cheng, H. C. Ferreira, and I. Broere, “Moment balancing templatesfor ��� �� constrained code,” in Proc. IEEE Int. Symp. Inf. Theory,Austin, TX, Jun. 13–18, 2010, pp. 1218–1222.
[9] M. Blaum, J. Bruck, C. M. Melas, and H. C. A. van Tilborg, “Methodsfor synchronizing ��� ��-constrained sequences,” in Proc. 1994 IEEEInt. Conf. Commun., New Orleans, LA, May 1–5, 1994, vol. 3, pp.1800–1808.
[10] R. M. Roth and P. H. Siegel, “Lee-metric BCH codes and their appli-cation to constrained and partial-response channels,” IEEE Trans. Inf.Theory, vol. 40, no. 4, pp. 1083–1096, Jul. 1994.
[11] R. R. Varshamov and G. M. Tenengol’ts, “Codes which correctsingle asymmetric errors,” Autom. Remote Control, vol. 26, no. 2, pp.286–290, 1965.
[12] R. R. Varshamov, “A class of codes for asymmetric channels and aproblem from the additive theory of numbers,” IEEE Trans. Inf. Theory,vol. 19, no. 1, pp. 92–95, Jan. 1973.
[13] P. Delsarte and P. Piret, “Spectral enumerators for certain additive-error-correcting codes over integer alphabets,” Inf. Control, vol. 48, pp.193–210, 1981.
[14] K. A. S. Immink, Codes for Mass Data Storage Systems, 2nd ed.Eindhoven, The Netherlands: Shannon Foundation Publishers, 2004.
[15] L. Dolecek and V. Anantharam, “Repetition error correcting sets: Ex-plicit constructions and prefixing methods,” SIAM J. Discrete Math.,vol. 23, no. 4, pp. 2120–2146, Jan. 2010.
[16] V. I. Levenshtein, “Binary codes capable of correcting deletions, in-sertions, and reversals,” Soviet Physics-Doklady, vol. 10, no. 8, pp.707–710, Feb. 1966.
[17] A. S. J. Helberg and H. C. Ferreira, “On multiple insertion/deletioncorrecting codes,” IEEE Trans. Inf. Theory, vol. 48, no. 1, pp. 305–308,Jan. 2002.
[18] R. M. Roth, Introduction to Coding Theory. Cambridge, U.K.: Cam-bridge Univ. Press, 2006.
[19] G. H. Hardy and E. M. Wright, An Introduction to The Theory of Num-bers, 5th ed. London, U.K.: Oxford Univ. Press, 1979.
[20] J. von zur Gathen and J. Gerhard, Modern Computer Algebra, 2nded. Cambridge, U.K.: Cambridge Univ. Press, 2003.
[21] E. R. Berlekamp, “Factoring polynomials over large finite fields,”Math. Comput., vol. 24, no. 111, pp. 713–735, Jul. 1970.
[22] K. A. S. Abdel-Ghaffar, F. Paluncic, H. C. Ferreira, and W. A.Clarke, “On Helberg’s generalization of the Levenshtein code formultiple deletion/insertion error correction,” IEEE Trans. Inf. Theory,submitted for publication.
[23] E. Zehavi and J. K. Wolf, “On runlength codes,” IEEE Trans. Inf.Theory, vol. 34, no. 1, pp. 45–54, Jan. 1988.
Filip Paluncic was born in Belgrade, Serbia. He received the B.Ing. and B.Sc.degrees in 2006 and the M.Ing. degree in 2008 from the University of Johan-nesburg, South Africa, where he is currently pursuing the D.Ing. degree underthe supervision of Prof. H. C. Ferreira and Prof. W. A. Clarke.
His research interests include various topics on insertion/deletion correctingcodes and coding for magnetic recording media.
Khaled A. S. Abdel-Ghaffar received the B.Sc. degree from Alexandria Uni-versity, Alexandria, Egypt, in 1980, and the M.S. and Ph.D. degrees from theCalifornia Institute of Technology, Pasadena, CA, in 1983 and 1986, respec-tively, all in electrical engineering.
In 1988, he joined the University of California, Davis, where he is now aProfessor of electrical and computer engineering. He did research at the IBMAlmaden Research Center, San Jose, CA, Delft University of Technology, TheNetherlands, University of Bergen, Norway, and Alexandria University, Egypt.His main interest is coding theory.
Dr. Abdel-Ghaffar served as an Associate Editor for Coding Theory for theIEEE Transactions on Information Theory from 2002 to 2005. He is a co-recip-ient of the IEEE Communications Society 2007 Stephen O. Rice Prize paperaward.

1824 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 58, NO. 3, MARCH 2012
Hendrik C. Ferreira was born and educated in South Africa where he receivedthe D.Sc. (Eng.) degree from the University of Pretoria in 1980.
From 1980 to 1981, he was a post doctoral researcher at the Linkabit Corpora-tion in San Diego, CA, USA. In 1983, he joined the Rand Afrikaans University,Johannesburg, South Africa where he was promoted to professor in 1989 andserved two terms as Chairman of the Department of Electrical and ElectronicEngineering, from 1994 to 1999. He is currently a research professor at the Uni-versity of Johannesburg. His research interests are in Digital Communicationsand Information Theory, especially Coding Techniques, as well as in Power LineCommunications.
Dr. Ferreira is a past chairman of the Communications and Signal ProcessingChapter and founding chairman of the Information Theory Society Chapterof the IEEE South Africa section. From 1997 to 2006 he was Editor-in-Chiefof the Transactions of the South African Institute of Electrical Engineers. Hehas served as chairman of several international conferences, including the1999 IEEE Information Theory Workshop in the Kruger National Park, SouthAfrica, the 2010 IEEE African Winter School on Information Theory andCommunications, and the 2013 IEEE International Symposium on Power LineCommunications.
Willem A. Clarke was born in Sweden and educated in South Africa. He re-ceived the D.Ing. (Elec.) degree from the Rand Afrikaans University (now theUniversity of Johannesburg), South Africa.
He started his career as an engineer in 1995 at Eskom Telecoms (telecommu-nications network management). In 1998, he joined BSW Telecoms (as productmanager) and in 1999, he joined the Rand Afrikaans University (now the Uni-versity of Johannesburg) as a Senior Lecturer in telecommunications and lateras an Associate Professor. He is currently the Head of the School of ElectricalEngineering in the Faculty of Engineering and the Built Environment. His re-search interests mainly include applied Image Processing and Telecommunica-tions (network management and error correction coding). He has been principleadviser to more than 25 students (past and present) and together with his stu-dents he has published more than 60 papers in journals and conferences.
Related Documents











