A Markov Process Based Approach to Effective Attacking JPEG Steganography Yun Q. Shi, Chunhua Chen, Wen Chen New Jersey Institute of Technology Newark, NJ USA 07102 {shi,cc86}@njit.edu Abstract. In this paper, a new steganalysis scheme is presented to effectively detect the advanced JPEG steganography. For this purpose, we first choose to work on JPEG 2-D arrays formed from the magnitudes of JPEG quantized block DCT coefficients. Difference JPEG 2-D arrays along horizontal, vertical and diagonal directions are then used to enhance changes caused by JPEG steg- anography. Markov process is applied to modeling these difference JPEG 2-D arrays so as to utilize the second order statistics for steganalysis. In addition to the utilization of difference JPEG 2-D arrays, a thresholding technique is de- veloped to greatly reduce the dimensionality of transition probability matrices, i.e., the dimensionality of feature vectors, thus making the computational com- plexity of the proposed scheme manageable. The experimental works are pre- sented to demonstrate that the proposed scheme has outperformed the existing steganalyzers in attacking OutGuess, F5, and MB1. 1 Introduction Internet has become an important communication channel since the 90’s of the last century, through which emails, speeches, images and videos are easily transmitted and shared. With image steganography, covert communication through the Internet can al- so be conducted. Steganography is the art and science of “invisible” communication, which is to conceal the very existence of hidden messages. Images have many attributes, which make it suitable for steganography. Images can convey a large size of message. For in- stance, some steganographic method can accomplish a steganographic proportion that exceeds 13% of the image file size [1]. Because the non-stationarity of images, the image steganography is hard to attack. Especially, as the interchange of digital images is frequently used nowadays, image steganography becomes promising. Recently, research in the field of JPEG (Joint Photographic Experts Group) steg- anography has become active as JPEG images are used popularly. Many steg- anographic techniques operating on JPEG images have been published and become publicly available. Most of the techniques in this category modify the LSB (least sig- nificant bit) of the block discrete cosine transform (BDCT) coefficients, which are the

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A Markov Process Based Approach
to Effective Attacking JPEG Steganography
Yun Q. Shi, Chunhua Chen, Wen Chen
New Jersey Institute of Technology
Newark, NJ USA 07102 {shi,cc86}@njit.edu
Abstract. In this paper, a new steganalysis scheme is presented to effectively
detect the advanced JPEG steganography. For this purpose, we first choose to
work on JPEG 2-D arrays formed from the magnitudes of JPEG quantized
block DCT coefficients. Difference JPEG 2-D arrays along horizontal, vertical
and diagonal directions are then used to enhance changes caused by JPEG steg-
anography. Markov process is applied to modeling these difference JPEG 2-D
arrays so as to utilize the second order statistics for steganalysis. In addition to
the utilization of difference JPEG 2-D arrays, a thresholding technique is de-
veloped to greatly reduce the dimensionality of transition probability matrices,
i.e., the dimensionality of feature vectors, thus making the computational com-
plexity of the proposed scheme manageable. The experimental works are pre-
sented to demonstrate that the proposed scheme has outperformed the existing
steganalyzers in attacking OutGuess, F5, and MB1.
1 Introduction
Internet has become an important communication channel since the 90’s of the last
century, through which emails, speeches, images and videos are easily transmitted and
shared. With image steganography, covert communication through the Internet can al-
so be conducted.
Steganography is the art and science of “invisible” communication, which is to
conceal the very existence of hidden messages. Images have many attributes, which
make it suitable for steganography. Images can convey a large size of message. For in-
stance, some steganographic method can accomplish a steganographic proportion that
exceeds 13% of the image file size [1]. Because the non-stationarity of images, the
image steganography is hard to attack. Especially, as the interchange of digital images
is frequently used nowadays, image steganography becomes promising.
Recently, research in the field of JPEG (Joint Photographic Experts Group) steg-
anography has become active as JPEG images are used popularly. Many steg-
anographic techniques operating on JPEG images have been published and become
publicly available. Most of the techniques in this category modify the LSB (least sig-
nificant bit) of the block discrete cosine transform (BDCT) coefficients, which are the

outcomes of block-wise two-dimensional (2-D) DCT followed by quantization using
JPEG quantization table.
In this paper we look at three recent published and most advanced steganographic
methods, i.e., Outguess [2], F5 [1], and the model-based steganography (MB) [3].
OutGuess constructs a universal steganographic framework, which embeds hidden
data using the redundancy of a cover image. For JPEG images, OutGuess preserves
statistics of the BDCT coefficient histogram. Two measures are taken to reduce the
change on the cover image introduced by data embedding. Before embedding, Out-
Guess identifies the redundant BDCT coefficients which have least effect on the cover
image and will be modified if necessary during the data embedding. It also adjusts the
untouched coefficients during the embedding procedure to preserve the original histo-
gram of the BDCT coefficients after embedding.
F5 was developed from Jsteg, F3, and F4. JPEG is the only image format that F5
works with. F5 takes two main actions to increase the security against steganalysis at-
tacks: straddling and matrix coding. Straddling scatters the message as uniformly as
possible over the cover image to equalize the change density. With matrix embedding,
F5 improves the embedding efficiency that is defined as the number of bits embedded
per change of BDCT coefficient. Generally speaking, the smaller the embedding mes-
sage size is, the larger the embedding efficiency of F5 is.
In general, the hidden data may be uncorrelated to the cover image, which is util-
ized by many steganalysis algorithms to attack the data hiding algorithms. MB em-
bedding tries to make the embedded data correlated to the cover image. This is real-
ized by splitting the cover image into two parts, modeling the parameter of the
distribution of the second part given the first part, encoding the second part using the
model and to-be-embedded message, and then combining the two parts to form the
stego image. In embedding method MB1 ([3]), which operates on JPEG images, a
Cauchy distribution is used to model the JPEG BDCT mode histogram. The embed-
ding procedure keeps the lower precision version of the BDCT mode histogram un-
changed.
To attack steganography, some steganalysis schemes have been proposed. There
are two categories, i.e., specific steganalysis and universal steganalysis [4]. Specific
steganalysis concentrates on detecting some particular steganographic tool and has
good performance on this steganographic tool if well designed. Universal steganalysis
yet tries to steganalyze any steganographic tool, known or unknown in advance.
Farid proposed a universal steganalyzer based on image’s high order statistics [5].
Quadrature mirror filters are used to decompose the image into wavelet subbands and
then the high order statistics are calculated for each high frequency subband. The sec-
ond set of statistics is calculated for the errors in an optimal linear predictor of the co-
efficient magnitude. Both sets of statistical moments are used as features for stegana-
lysis. It can achieve generally better detection rate than random guess for universal
steganographic methods.
In [6], Shi et al presented a universal steganalysis system. The statistical moments
of characteristic functions of the image, its prediction-error image, and their discrete
wavelet transform (DWT) subbands are selected as features. All of the low-low wave-
let subbands are also used in their system. This steganalyzer can provide a better per-
formance than [5] in general.

In [7], Fridrich has proposed a set of distinguishing features from the BDCT do-
main and spatial domain aiming at detecting information embedded in JPEG images.
The statistics of the original image are estimated by decompressing the JPEG image
followed by cropping the four rows and four columns on the boundary, and then re-
compressing the cropped image to JPEG format using the original quantization table.
The author claimed that the obtained image has statistical properties very much simi-
lar to that of the cover image. Features for steganalysis are generated from the statis-
tics of the JPEG image and its estimated version. Designed specifically for detecting
JPEG steganography, this scheme performs better than [5, 6] in attacking JPEG steg-
anography [1, 2, 3].
Recently, a specific steganalysis scheme detecting data hidden with spread spec-
trum method is proposed, in which the inter-pixel dependencies are used and a Mark-
ov chain model is adopted [8]. The empirical transition matrix of a given test image is
formed. This matrix has a dimensionality of 256×256 for a grayscale image with a bit
depth of 8. That is, this matrix has 65,536 elements. Obviously, these elements cannot
be straightforwardly used as features. The authors select several largest probabilities
along the main diagonal together with their neighbors, and some randomly selected
probabilities along the main diagonal as features. As a result, some information loss is
inevitable due to the random fashion of feature selection. Furthermore, this method
uses Markov chain only along horizontal direction, which cannot reflect the 2-D na-
ture of digital image.
In this paper, a new steganalysis scheme is presented to effectively detect the ad-
vanced JPEG steganography. First, we choose to work on JPEG 2-D arrays to formu-
late features for steganalysis. Difference JPEG 2-D arrays along horizontal, vertical
and diagonal directions are then used to generally enhance changes caused by JPEG
steganography. Markov process is applied to modeling these difference JPEG 2-D ar-
rays so as to utilize the second order statistics for steganalysis. In addition to the utili-
zation of difference JPEG 2-D arrays, a thresholding technique is developed to greatly
reduce the dimensionality of transition probability matrixes, i.e., the dimensionality of
feature vectors, thus making the computational complexity of the proposed scheme
manageable. The experimental works are presented to demonstrate that the proposed
scheme has outperformed the state-of-the-arts in attacking OutGuess, F5, and MB1.
The rest of this paper is organized as follows. The feature construction procedure is
described in Section 2. In Section 3, support vector machine, the classifier used in our
investigation, is introduced. Experimental results are given in Section 4. Next, some
discussion is made in Section 5. Finally, conclusion is drawn in Section 6.
2 Feature Construction
In this paper, steganalysis is considered as a task of two-class pattern recognition.
That is, a given test image needs to be classified as either a stego image (with hidden
data) or a non-stego image (without hidden data). Therefore, feature construction is a
key step in the steganalysis.

As mentioned in Section 1, modern steganorgraphic methods such as OutGuess and
MB have made great efforts to keep the changes of BDCT coefficients caused by data
hiding as less as possible. In particular, they attempt to keep the changes on the histo-
gram of JPEG coefficients as less as possible. Under these circumstances, we propose
to use the second order statistics as features for steganalysis to detect these JPEG
steganographic methods.
In this section, we first define the JPEG 2-D array, followed by introducing the dif-
ference JPEG 2-D array along different directions. We then propose to model the dif-
ference JPEG 2-D array using Markov random process. According to the theory of
random process, the transition probability matrix can be used to characterize the
Markov process. Our proposed features are derived from the transition probability ma-
trix. In order to achieve an appropriate balance between steganalysis capability and
computational complexity, we use the so-called one-step transition probability matrix
in this work. In order to further reduce computational cost by reducing the dimension-
ality of feature vectors, we resort to a thresholding technique.
2.1 JPEG 2-D Array
Generating features from the exact 8×8 block discrete cosine transform (BDCT) do-
main to attack the steganographic algorithms operating on JPEG images is natural and
reasonable. For this purpose, it is necessary to first study the property of JPEG BDCT
coefficients. Su
Sv
Fig. 1. A sketch of JPEG coefficient 2-D array
For a given image, consider a 2-D array consisting of all of the 8×8 block DCT co-
efficients which have been quantizated with a JPEG quantization table and have not
been zig-zag scanned, run-length coded and Huffman coded. That is, this 2-D array
has the same size as the given image with each 8×8 block filled up with the corre-
sponding JPEG quantized 8×8 block DCT coefficients. Furthermore, we take absolute
value for each DCT coefficient, resulting in a 2-D array as shown in Figure 1. We call
this resultant 2-D array as JPEG 2-D array in this paper. The features proposed in this
scheme are formed from the JPEG 2-D array.

The reason for taking absolute values is discussed below. Note that these JPEG
BDCT quantized coefficients can be either positive, or negative, or zero. It is known
that the BDCT coefficients have been decorrelated effectively. Since the BDCT coef-
ficients in general do not obey Gaussian distribution, however, these coefficients are
not statistically independent of each other. It is also well-known that the power of an
8×8 block of DCT coefficients is highly concentrated in the DC (direct current) and
low-frequency AC (alternative current) coefficients. The JPEG quantization, after
which the majority of high-frequency BDCT AC coefficients may become zero, fur-
ther enhances this disparity in power distribution among quantized BDCT coefficients.
The general trend in power distribution of the BDCT coefficients in each block is non-
increasing along the zig-zag scan order of all of the DCT coefficients in the block if
we ignore some up-and-down of small magnitudes. This is consistent with the fact that
the zig-zag scanning makes the use of run-length coding efficient [9]. Combining the-
se observations, we can state that the magnitude of the non-zero BDCT coefficients is
somehow correlated each other along the zig-zag scan order. Hence, there exists the
correlation among the absolute values of the BDCT coefficients along horizontal, ver-
tical and diagonal directions. This observation can be further justified by observing
Figure 3 shown below. That is, the difference of the absolute values of two immedi-
ately (horizontally in Figure 3) neighboring BDCT coefficients are highly concen-
trated around 0, having a Laplacian-like distribution. The same is true along the verti-
cal and diagonal directions.
In addition, the steganographic methods operating on the JPEG images do not
touch the DCT DC coefficients nor change the sign of the DCT AC coefficients dur-
ing data embedding [2, 3] (note that a DCT coefficient with a non-zero magnitude
changing to zero is not a sign change). Further discussion in this regard is made in
Section 5.1, which shows that taking absolute value results in higher detection rates in
general and lower computational complexity.
2.2 Difference JPEG 2-D Array
According to [6], the disturbance caused by the data embedding manifests itself more
obviously in the prediction-error image than in the original test image. Hence, it is ex-
pected that the disturbance caused by the steganographic methods in JPEG images can
be enlarged by observing the difference between an element and one of its neighbors
in the JPEG 2-D array. For this purpose, we consider the following four difference
JPEG 2-D arrays.
Denote the JPEG 2-D array generated from a given test image by ( , )F u v
( [1, ], [1, ])u vu S v S∈ ∈ , where uS is the size of the JPEG 2-D array in horizontal direc-
tion and vS in vertical direction. Then as shown in Figure 2, the difference arrays are
generated by the following formulae:
( , ) ( , ) ( 1, )hF u v F u v F u v= − + , (1)
( , ) ( , ) ( , 1)vF u v F u v F u v= − + , (2)
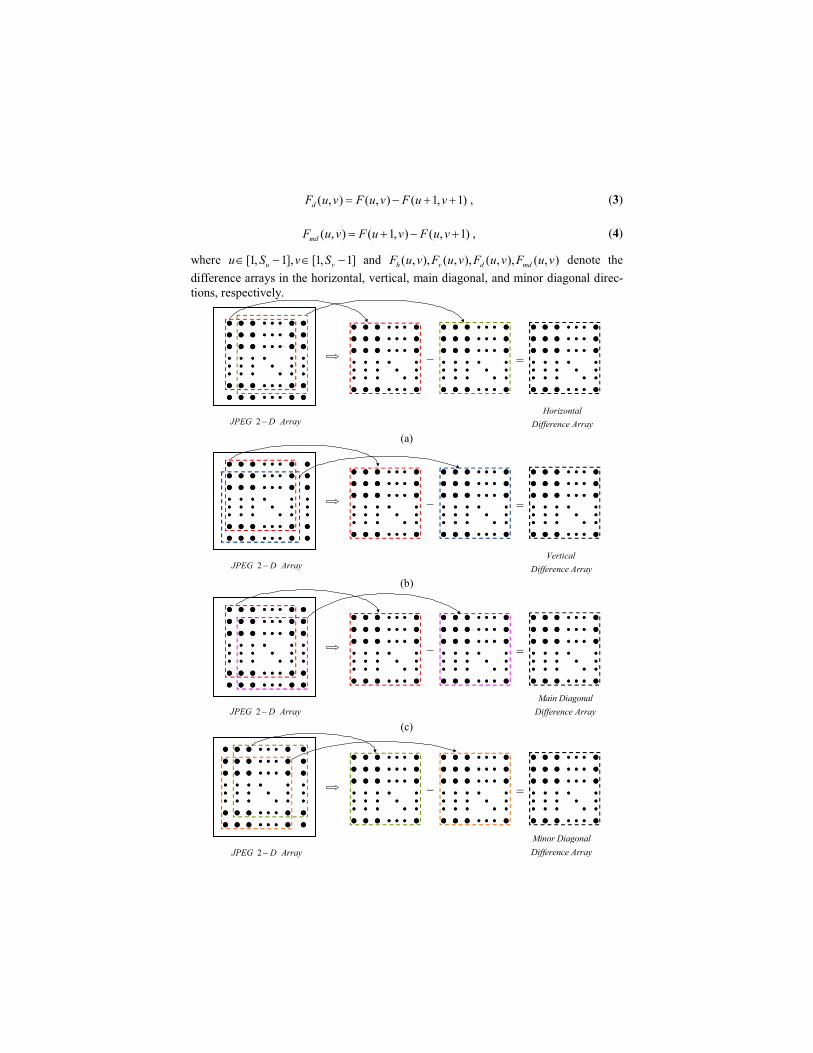
( , ) ( , ) ( 1, 1)dF u v F u v F u v= − + + , (3)
( , ) ( 1, ) ( , 1)mdF u v F u v F u v= + − + , (4)
where [1, 1], [1, 1]u vu S v S∈ − ∈ − and ( , ), ( , ), ( , ), ( , )h v d mdF u v F u v F u v F u v denote the
difference arrays in the horizontal, vertical, main diagonal, and minor diagonal direc-
tions, respectively.
_=
2JPEG D Array−
Horizontal
Difference Array (a)
2JPEG D Array− Vertical
Difference Array
_=
(b)
_=
2JPEG D Array−
Main Diagonal
Difference Array
(c)
_=
2JPEG D Array−
Minor Diagonal
Difference Array
(d)
Fig. 2. The generation of four difference JPEG 2-D arrays. Parts (a), (b), (c), and (d) corre-
spond to horizontal, vertical, main diagonal, and minor diagonal difference JPEG 2-D arrays,
respectively
It is observed that the distribution of the elements of the above-described difference
arrays is Laplacian-like. Most of the difference values are close to zero. In our ex-
perimental works reported in this paper, an image set consisting of 7560 JPEG images
with quality factors ranging from 70 to 90 is used. The arithmetic average of the his-
tograms of the horizontal difference JPEG 2-D arrays generated from this JPEG image
set and the histogram of the horizontal difference JPEG 2-D array generated from a
randomly selected image from the set are shown in Figure 3 (a) and (b), respectively.
It is observed that most elements in the horizontal difference JPEG 2-D arrays fall into
the interval [-T, T] as long as T is large enough. The values of mean and standard de-
viation of percentage number of elements of horizontal difference JPEG 2-D arrays
for the image set falling into [-T, T] when T = {1, 2, 3, 4, 5, 6, 7} are shown in Table
1. Both Figure 3 and Table 1 support the claim of Laplacian-like distribution of the
elements of the horizontal difference JPEG 2-D arrays. The same is true for the differ-
ence JPEG 2-D array along other three directions.
Table 1. Mean and standard deviation of percentage numbers of elements of horizontal
difference JPEG 2-D arrays falling within [-T, T] for T = 1, 2, 3, 4, 5, 6, 7
[-1, 1] [-2, 2] [-3, 3] [-4, 4] (*) [-5, 5] [-6, 6] [-7, 7]
Mean 84.72 88.58 90.66 91.99 92.92 93.60 94.12
Standard deviation 5.657 4.243 3.464 2.836 2.421 2.104 1.850
* 91.99% is the mean, meaning that on statistic average 91.99% of all elements of
horizontal difference arrays generated from the image set fall into the range [-4, 4].
The standard deviation is 2.836%.
(a) (b)

Fig. 3. Histogram plots. Part (a) displays the statistical average of histograms of horizontal dif-
ference arrays generated from the image set consisting of 7560 JPEG images with quality fac-
tors ranging from 70 to 90. Part (b) corresponds to the histogram of horizontal difference array
of a randomly selected image in the set
2.3 Transition Probability Matrix
As mentioned before, the modern steganographic methods such as OutGuess and MB
have made great efforts to keep the changes on the histogram of JPEG BDCT coeffi-
cients as less as possible during data embedding. Therefore, we propose to use higher
order statistics for steganalyzing the JPEG steganography. In this work the second or-
der statistics are used in order not to increase the computational complexity dramati-
cally.
We propose to model the above-defined difference JPEG 2-D arrays by using
Markov random process. According to the theory of random process, the transition
probability matrix can be used to characterize the Markov process. There are so-called
one-step transition probability matrix and n-step transition probability matrix [10].
Roughly speaking, the former refers to the transition probabilities between two imme-
diately neighboring elements in the difference JPEG 2-D array while the latter refers
to the transition probabilities between two elements separated by (n-1) elements. In
order to have a suitable balance between high steganalysis capability and manageable
computational complexity, we only use the one-step transition probability matrix in
this work, as shown in Figure 4.
Fig. 4. The formation of the transition probability matrices
In order to further reduce computational complexity, we resort to a thresholding
technique. That is, we select a threshold value T, meaning that we only consider those
elements in the difference JPEG 2-D arrays whose value falls into {-T, -T+1, …, -1, 0,
1, …, T-1, T}. If an element whose value is either larger than T or smaller than –T, it
will be represented by T or –T correspondingly. This procedure results in a transition
probability matrix of dimensionality (2T+1)×(2T+1). The elements of these four ma-
trices associated with the horizontal, vertical, main diagonal and minor diagonal dif-
ference JPEG 2-D arrays are given by

1 1
1 1
1 1
1 1
( ( , ) , ( 1, ) )
{ ( 1, ) | ( , ) }
( ( , ) )
v u
v u
S S
v u
S S
v u
F u v m F u v n
p F u v n F u v m
F u v m
δ
δ
− −
= =− −
= =
= + =
+ = = =
=
∑∑
∑∑, (5)
1 1
1 1
1 1
1 1
( ( , ) , ( , 1) )
{ ( , 1) | ( , ) }
( ( , ) )
v u
v u
S S
v u
S S
v u
F u v m F u v n
p F u v n F u v m
F u v m
δ
δ
− −
= =− −
= =
= + =
+ = = =
=
∑∑
∑∑, (6)
1 1
1 1
1 1
1 1
( ( , ) , ( 1, 1) )
{ ( 1, 1) | ( , ) }
( ( , ) )
v u
v u
S S
v u
S S
v u
F u v m F u v n
p F u v n F u v m
F u v m
δ
δ
− −
= =− −
= =
= + + =
+ + = = =
=
∑∑
∑∑, (7)
1 1
1 1
1 1
1 1
( ( 1, ) , ( , 1) )
{ ( , 1) | ( 1, ) }
( ( 1, ) )
v u
v u
S S
v u
S S
v u
F u v m F u v n
p F u v n F u v m
F u v m
δ
δ
− −
= =− −
= =
+ = + =
+ = + = =
+ =
∑∑
∑∑, (8)
where { , 1, ,0, , }, { , 1, ,0, , }m T T T n T T T∈ − − + ∈ − − +� � � � , and
1, ( , ) , ( , 1)( ( , ) , ( , 1) )
0,
if F u v m F u v nF u v m F u v n
Otherwiseδ
= + == + = =
. (9)
In summary, we have (2T+1)×(2T+1) elements for each of these four transition
probability matrices. In total, we have 4×(2T+1)×(2T+1) elements. All of them are
serving as features for steganalysis. In other words, we have 4×(2T+1)×(2T+1)-D
feature vectors for steganaysis. It is clear that we should choose a proper T value for
good steganalysis capability with manageable computational complexity.
For this reason, in our experimental works, we set the threshold, T, equal to 4 ac-
cording to our statistical study shown in Figure 3 and Table 1. Hence, if an element
has an absolute value larger than 4, this element is reassigned a new absolute value 4
without sign change. The resultant transition probability matrix is of 9×9 for each of
the four difference JPEG 2-D arrays. That is, 9×9 = 81 elements in each of these four
transition probability matrices, or equivalently, we have 81×4 = 324 elements in total.
The feature construction procedure is summarized in Figure 5.

JPEG
Coefficient
Array
Given
Image
Horizontal
Difference
Array
Vertical
Difference
Array
Main
Diagonal
Difference
Array
(2T+1)×(2T+1)
Feature Components
Transition
Probability
Matrix
| |
Minor
Diagonal
Difference
Array
Transition
Probability
Matrix
Transition
Probability
Matrix
Transition
Probability
Matrix
(2T+1)×(2T+1)
Feature Components
(2T+1)×(2T+1)
Feature Components
(2T+1)×(2T+1)
Feature Components
(2T+1)×(2T+1)×4-D
Feature Vector
Fig. 5. The block diagram of the feature formation procedure
3 Support Vector Machine
The support vector machine (SVM) is a kind of popularly used classifiers for pattern
recognition. It is easier to use than neural network (NN) while its performance is com-
parable to the NN.
SVM is based on the idea of hyperplane classifier. It uses Lagrangian multipliers to
find the optimal separation hyperplane which distinguishes the positive pattern from
the negative pattern. If the feature vectors are one-dimensional (1-D), the separation
hyperplane reduces to a point on the number axis.
SVM can handle both linear separable and no-linear separable cases. Denote the
training data pairs by { , }, 1, ,i i i lω =y … , where N
i R∈y is the feature vector, N is the
dimensionality of the feature vectors, and 1iω =± for positive/negative pattern class.
In the steganalysis context, an image with hidden data (stego-image) is considered as a
positive pattern while an image without hidden data is considered as a negative pattern.
The linear support vector algorithm looks for a hyperplane : 0TH b+ =w y and two
hyperplanes 1 : 1TH b+ = −w y and 2 : 1TH b+ =w y parallel to and with equal dis-
tances to H with the condition that there are no data points between 1H and
2H and
the distance between 1H and 2H is maximized, where w and b are the parameters
to be optimized. Once the SVM has been trained, the novel exemplar z from the test-
ing data can be classified using w and b .
For non-linearly case, the learning machine maps the input feature vectors to a
higher dimensional space where a linear hyperplane is located by using kernel func-
tion. There are three basic kernels: polynomial, radial basis function and sigmoid. For

more detailed information about SVM, readers please refer to [11]. In our investiga-
tion, the polynomial kernel is used [12].
4 Experiments and Results
4.1 Image set
As mentioned in Section 2, an image set consisting of 7560 JPEG images with quality
factors ranging from 70 to 90 is used in our experimental work. Among these 7560
images, 2500 images were taken by members of our research group in different places
at different time with different digital cameras; the other 5060 images were download-
ed from the Internet. Each image was cropped (central portion) to the dimension of ei-
ther 768×512 or 512×768. Some sample images are given in Figure 6.
The images shown in Figure 6 are color images. In our experiments, the chromi-
nance components are set to be zero while the luminance coefficients are untouched
before data embedding.
Fig. 6. Some sample images used in this experimental work
4.2 Stego images generation
Our experiments focus on attacking the Outguess, F5, and MB1 steganographic meth-
ods. The codes for these algorithms are publicly available [13, 14, 15].
As mentioned before, there are quite a few zero coefficients in the JPEG 2-D array.
Also, the amount of zero coefficients per image varies from image to image. Therefore,
the absolute embedding rate of each image also varies. A reasonable way to define
embedding rate is to consider a ratio between message length to non-zero elements in
the JPEG 2-D array. The ratio is often measured in the unit of bpc, i.e., bits per non-
zero BDCT AC coefficients (after quantization). In our experimental works, the con-
sidered embedding rates for OutGuess are 0.05, 0.1, and 0.2 bpc, respectively. The
numbers of stego image generated are 7498, 7452, and 7215, respectively. For F5 and
MB1, we consider four embedding rates, 0.05, 0.1, 0.2, and 0.4 bpc. For each rate, we
have 7560 stego images. Note that we set step size equal to two when implementing
MB1.
4.3 Experimental results obtained by using SVM with polynomial kernel
We randomly select 1/2 of the non-stego and stego image pairs to train the SVM clas-
sifier and the remaining 1/2 pairs to test the trained classifier. We use Farid’s [4], Shi
et al.’s [5], and Fridrich’s [6], and our proposed steganalyzers’s features to detect
OutGess, F5 and MB schemes. The test results shown in Table 2 are the arithmetic
average of 20 random experiments with polynomial kernel.
Table 2. Performance comparison using polynomial kernel (in the unit of %; TN stands for true
negative rate, TP stands for true positive rate, and AR stands for accuracy)
bpc Farid’s Shi et al.’s Fridrich’s Our Proposed
TN TP AR TN TP AR TN TP AR TN TP AR
OutGuess 0.05 59.0 57.6 58.3 55.6 58.5 57.0 49.8 75.4 62.6 87.6 90.1 88.9 OutGuess 0.1 70.0 63.5 66.8 61.4 66.3 63.9 68.9 83.3 76.1 94.6 96.5 95.5 OutGuess 0.2 81.9 75.3 78.6 72.4 77.5 75.0 90.0 93.6 91.8 97.2 98.3 97.8
F5 0.05 55.6 45.9 50.8 57.9 45.0 51.5 46.1 61.0 53.6 58.6 57.0 57.8 F5 0.1 55.5 48.4 52.0 54.6 54.6 54.6 58.4 63.3 60.8 68.1 70.2 69.1 F5 0.2 55.7 55.3 55.5 59.5 63.3 61.4 77.4 77.2 77.3 85.8 88.3 87.0

F5 0.4 62.7 65.0 63.9 71.5 77.1 74.3 92.6 93.0 92.8 95.9 97.6 96.8
MB1 0.05 48.5 53.2 50.8 57.0 49.2 53.1 39.7 66.9 53.3 79.4 82.0 80.7 MB1 0.1 51.9 52.3 52.1 57.6 56.6 57.1 45.6 70.1 57.9 91.2 93.3 92.3 MB1 0.2 52.3 56.7 54.5 63.2 66.7 65.0 58.3 77.5 67.9 96.7 97.8 97.3 MB1 0.4 55.3 63.6 59.4 74.2 80.0 77.1 82.9 86.8 84.8 98.8 99.4 99.1
It is observed that our proposed steganalyzer outperforms the prior-arts by a sig-
nificant margin. The detection rate for F5 at the same embedding rate is lower than
that of MB1. This will be discussed in the next section.
4.4 Experimental results with features from one direction at a time
We also implement experiment with reduced dimensionality of feature vectors in or-
der to examine the contributions made by features along different directions. Hence,
we use features from only one direction at a time. The results shown in Table 3 are the
arithmetic average of 20 random experiments with polynomial kernel.
It is observed that the contributions made from the horizontal and vertical direc-
tions are more than that from the main diagonal and minor diagonal directions. Fur-
thermore, the contribution made from the main diagonal is larger than that from the
minor diagonal direction. Comparing Table 2 and Table 3, we can observe that com-
bining four directions has enhanced the detection rate in attacking JPEG steganogra-
phy.
Table 3. Detection rate with reduced feature space (in the unit of %)
bpc Horizontal Vertical Main Diagonal Minor Diagonal
TN TP AR TN TP AR TN TP AR TN TP AR
OutGuess 0.05 77.7 82.6 80.1 78.9 83.1 81.0 75.9 79.0 77.5 73.8 77.4 75.6
OutGuess 0.1 89.1 95.0 92.0 90.5 95.4 93.0 88.8 93.1 90.9 86.6 92.3 89.4
OutGuess 0.2 95.4 98.3 96.8 95.8 98.2 97.0 95.3 97.9 96.6 93.8 97.5 95.6
F5 0.05 55.8 53.7 54.7 56.7 52.4 54.6 51.6 56.3 54.0 51.3 52.9 52.1
F5 0.1 61.6 62.3 62.0 61.7 62.3 62.0 57.4 62.8 60.1 54.2 56.9 55.5
F5 0.2 75.0 79.8 77.4 75.8 80.2 78.0 71.8 76.2 74.0 61.4 65.7 63.6
F5 0.4 91.5 95.6 93.5 91.3 95.7 93.5 89.1 92.5 90.8 77.4 82.7 80.1
MB1 0.05 69.9 72.4 71.1 70.6 72.8 71.7 67.6 69.6 68.6 66.1 67.4 66.7
MB1 0.1 82.5 87.9 85.2 83.7 87.7 85.7 81.2 84.4 82.8 78.1 82.5 80.3
MB1 0.2 92.5 96.4 94.4 94.1 96.8 95.5 92.8 95.6 94.2 90.1 93.9 92.0
MB1 0.4 97.6 98.9 98.2 98.2 99.4 98.8 97.9 99.1 98.5 96.5 98.7 97.6

5 Discussion
Some further discussions are made in this section.
5.1 Taking absolute values in JPEG 2-D array: advantages
In Section 2, we have indicated that the magnitude (i.e., absolute values) of the neigh-
boring BDCT coefficients are correlated to each other and the known JPEG steg-
anographic algorithms do not change the signs of coefficients. These motivated us to
take absolute values of the JPEG coefficients in forming JPEG 2-D array. Now we
continue this discussion.
We shall show that if we do not take absolute values, the performance of the stega-
nalysis will go down and the computational complexity will increase.
Let’s consider the formulation of JPEG 2-D array without taking absolute value.
While forming difference 2-D array, the dynamic range will obviously increase. Hence,
a larger threshold value T has to be used to build four Markov transition probability
matrices. Assume that we set up a new threshold ' 8T = , thus resulting in four transi-
tion probability matrices of 17×17 each. The resultant feature dimensionality will in-
crease to 17×17×4 = 1156, which raises the computation cost significantly. Table 4
provides a performance comparison between using 324-D feature vectors (T=4) and
using 1156-D feature vectors (T’=8) for attacking the MB1 with an embedding rate
0.2 bpc. Our experiments indicate that this trend of performance reduction also holds
for other embedding rates, and for OutGuess and F5 as well. Obviously, taking abso-
lute value provides higher detection rates and lower computational complexity.
Table 4. Performance comparison: with and without taking absolute value (in the unit of %)
bpc with without
TN TP AR TN TP AR
MB1 0.2 96.7 97.8 97.3 93.9 94.2 94.1
5.2 Detection rates for F5
Taking a close look at Table 2, one can observe that the detection rates achieved by
our proposed steganalyzer for MB1 are higher than that for F5 at the same embedding
rates. It appears contradicting to what reported in [7, 16]. In what follows we discuss
this issue from two angles.
One is from a theoretical analysis. We can show that a steganographic method,
which always reduces the magnitude of a non-zero DCT AC coefficients by one in or-
der to embed a bit (F5 belongs to this category), will have a relatively larger probabil-
ity to keep the elements in the difference JPEG 2-D array unchanged after the data
embedding than another steganographic method, which has equal probability to in-
crease the magnitude of a non-zero DCT AC coefficient by one or decrease the magni-
tude by one in order to embed one bit.

Another angle is from an experimental investigation, which is based on the image
set used in our experimental works, i.e., 7560 JPEG images with quality factors rang-
ing from 70 to 90. In the experimental study, the mean values of embedding efficiency
(defined in Section 1) of MB1 and F5 at four different data embedding rates, i.e., 0.05
bpc, 0.1 bpc, 0.2 bpc and 0.4 bpc are obtained and listed in Table 5. From these statis-
tical means, one can observe that at the low rates such as 0.05 bpc and 0.1 bpc, F5
changes fewer DCT coefficients than MB1 does. The opposite is true at the high rates
such as 0.2 bpc and 0.4 bpc. This statistics reveals some inside information, which can
partially explain the phenomenon. Obviously, further investigation in this regard is
needed, which is our future work.
Table 5. The mean value of embedding efficiency
bpc
0.05 0.1 0.2 0.4
F5 2.8695 2.4586 2.0606 1.7484
MB1 2.1141 2.1139 2.1142 2.1141
6 Conclusion
We have presented an effective steganalysis scheme in this paper, which outperforms
the state-of-the-arts in detecting the modern steganographic methods for JPEG images:
OutGuess, F5, and MB1. The success can be attributed to the following measures
taken in this new scheme.
(1) Taking absolute values in forming JPEG 2-D arrays not only helps raise stega-
nalysis capability but also helps reduce computational complexity.
(2) Difference JPEG 2-D arrays along horizontal, vertical, diagonal and minor di-
agonal directions have enlarged changes caused by steganographic methods.
(3) Thresholding technique applied to handle transition probability matrices has
greatly reduced dimensionality of feature vectors to a manageable extent.
(4) Through using Markov process to model difference JPEG 2-D arrays and using
all of elements of transition probability matrices as features the second order statistics
have been used in this proposed steganalyzer.
References
1. A. Westfeld, “F5 a steganographic algorithm: High capacity despite better steganalysis,” 4th
International Workshop on Information Hiding, Pittsburgh, PA, USA, 2001
2. N. Provos, “Defending against statistical steganalysis,” 10th USENIX Security Symposium,
Washington DC, USA, 2001
3. P. Sallee, “Model-based methods for steganography and steganalysis,” International Journal
of Image and Graphics, 5(1): 167-190, 2005

4. M. Kharrazi, H. T. Sencar, and N. Memon, “Image Steganography: Concepts and Practice”,
Lecture Note Series, Institute f or Mathematical Sciences, National University of Singapore,
2004
5. H. Farid, “Detecting hidden messages using higher-order statistical models”, International
Conference on Image Processing, Rochester, NY, USA, 2002
6. Y. Q. Shi, G. Xuan, D. Zou, J. Gao, C. Yang, Z. Zhang, P. Chai, W. Chen, and C. Chen,
“Steganalysis based on moments of characteristic functions using wavelet decomposition,
prediction-error image, and neural network,” International Conference on Multimedia and
Expo, Amsterdam, Netherlands, 2005
7. J. Fridrich, “Feature-based steganalysis for JPEG images and its implications for future de-
sign of steganographic schemes,” 6th Information Hiding Workshop, Toronto, ON, Canada,
2004
8. K. Sullivan, U. Madhow, S. Chandrasekaran, and B. S. Manjunath, “Steganalysis of Spread
Spectrum Data Hiding Exploiting Cover Memory”, the International Society for Optical En-
gineering, Electronic Imaging, San Jose, CA, USA, 2005
9. Y. Q. Shi and H. Sun, “Image and Video Compression for Multimedia Engineering: Funda-
mentals, Algorithms and Standards”, CRC press, 1999
10. A. Leon-Garcia, “Probability and Random Processes for Electrical Engineering”, 2nd Edi-
tion, Addison-Wesley Publishing Company, 1994
11. C. J. C. Burges. “A tutorial on support vector machines for pattern recognition”, Data Min-
ing and Knowledge Discovery, 2(2):121-167, 1998
12. C. C. Chang and C. J. Lin, “LIBSVM: a library for support vector machines”, 2001.
http://www.csie.ntu.edu.tw/~cjlin/libsvm
13. http://www.outguess.org/
14. http://wwwrn.inf.tu-dresden.de/~westfeld/f5.html
15. http://redwood.ucdavis.edu/phil/papers/iwdw03.htm
16. M. Kharrazi, H. T. Sencar, N. D. Memon, “Benchmarking steganographic and steganalysis
techniques”, Security, Steganography, and Watermarking of Multimedia Contents 2005, San
Jose, CA, USA, 2005
Related Documents











