Int J Digit Libr (2015) 15:153–167 DOI 10.1007/s00799-015-0147-1 A linked open data architecture for the historical archives of the Getulio Vargas Foundation Alexandre Rademaker · Dário Augusto Borges Oliveira · Valeria de Paiva · Suemi Higuchi · Asla Medeiros e Sá · Moacyr Alvim Received: 30 December 2013 / Revised: 3 March 2015 / Accepted: 3 March 2015 / Published online: 19 March 2015 © Springer-Verlag Berlin Heidelberg 2015 Abstract This paper presents an architecture for histori- cal archives maintenance based on Open Linked Data tech- nologies and open source distributed development model and tools. The proposed architecture is being implemented for the archives of the Centro de Pesquisa e Documentação de História Contemporânea do Brasil (Center for Research and Documentation of Brazilian Contemporary History) of the Fundação Getulio Vargas (Getulio Vargas Foundation). We discuss the benefits of this initiative and suggest ways of implementing it, as well as describing the preliminary mile- stones already achieved. We also present some of the pos- sibilities for extending the accessibility and usefulness of the data archives information using semantic web technolo- gies, natural language processing, image analysis tools, and audio–textual alignment, both in progress and planned. A. Rademaker (B ) IBM Research and FGV/EMAp, Rio de Janeiro, Brazil e-mail: [email protected] D. A. B. Oliveira · S. Higuchi FGV/CPDOC, Rio de Janeiro, Brazil e-mail: [email protected] S. Higuchi e-mail: [email protected] V. de Paiva Nuance Communications, Sunnyvale, USA e-mail: [email protected] A. Medeiros e Sá · M. Alvim FGV/EMAp, Rio de Janeiro, Brazil e-mail: [email protected] M. Alvim e-mail: [email protected] Keywords Historical archives · Digital humanities · Semantic Web · NLP · Image processing · Audio processing · Open data 1 Introduction The paradigm of linked open data has changed significantly the way knowledge and information are made available over the Internet. Information portals are facing the challenge of enhancing semantically their information so as to provide richer and interlinked content, which ultimately allows users to access data more efficiently for their specific applications. Institutions that provide content with recognized quality, such as universities and museums, are specially interested in having their rich data accessed and referenced by a broader audience. In the field of collections, heritage and cultural assets, we can identify many efforts to publish existing metadata as linked open data. The BiographyNet [21] is extremely sim- ilar to our project. It is a multi-disciplinary project bringing together history, Linked Data and tools that aims at enhancing the research potential of the Biography Portal of the Nether- lands 1 , a heterogenous collection made up out of 23 sources which provides access to over 125,000 entries describ- ing 76,000 people considered prominent figures of Dutch history. Other similar projects are: the Europeana project [25, 39] which mapped and published data from more than 2000 insti- tutions across Europe; the Smithsonian project [43] which published data from a collection of 41,000 objects from the Smithsonian American Art Museum; and the Finnish Muse- ums project [26] which published data concerning some 260 1 http://www.biografischportaal.nl/en. 123

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Int J Digit Libr (2015) 15:153–167DOI 10.1007/s00799-015-0147-1
A linked open data architecture for the historical archives of theGetulio Vargas Foundation
Alexandre Rademaker · Dário Augusto Borges Oliveira ·Valeria de Paiva · Suemi Higuchi · Asla Medeiros e Sá · Moacyr Alvim
Received: 30 December 2013 / Revised: 3 March 2015 / Accepted: 3 March 2015 / Published online: 19 March 2015© Springer-Verlag Berlin Heidelberg 2015
Abstract This paper presents an architecture for histori-cal archives maintenance based on Open Linked Data tech-nologies and open source distributed development model andtools. The proposed architecture is being implemented forthe archives of the Centro de Pesquisa e Documentação deHistória Contemporânea do Brasil (Center for Research andDocumentation of Brazilian Contemporary History) of theFundação Getulio Vargas (Getulio Vargas Foundation). Wediscuss the benefits of this initiative and suggest ways ofimplementing it, as well as describing the preliminary mile-stones already achieved. We also present some of the pos-sibilities for extending the accessibility and usefulness ofthe data archives information using semantic web technolo-gies, natural language processing, image analysis tools, andaudio–textual alignment, both in progress and planned.
A. Rademaker (B)IBM Research and FGV/EMAp, Rio de Janeiro, Brazile-mail: [email protected]
D. A. B. Oliveira · S. HiguchiFGV/CPDOC, Rio de Janeiro, Brazile-mail: [email protected]
S. Higuchie-mail: [email protected]
V. de PaivaNuance Communications, Sunnyvale, USAe-mail: [email protected]
A. Medeiros e Sá · M. AlvimFGV/EMAp, Rio de Janeiro, Brazile-mail: [email protected]
M. Alvime-mail: [email protected]
Keywords Historical archives · Digital humanities ·Semantic Web · NLP · Image processing · Audio processing ·Open data
1 Introduction
The paradigm of linked open data has changed significantlythe way knowledge and information are made available overthe Internet. Information portals are facing the challenge ofenhancing semantically their information so as to providericher and interlinked content, which ultimately allows usersto access data more efficiently for their specific applications.
Institutions that provide content with recognized quality,such as universities and museums, are specially interested inhaving their rich data accessed and referenced by a broaderaudience.
In the field of collections, heritage and cultural assets,we can identify many efforts to publish existing metadata aslinked open data. The BiographyNet [21] is extremely sim-ilar to our project. It is a multi-disciplinary project bringingtogether history, Linked Data and tools that aims at enhancingthe research potential of the Biography Portal of the Nether-lands1, a heterogenous collection made up out of 23 sourceswhich provides access to over 125,000 entries describ-ing 76,000 people considered prominent figures of Dutchhistory.
Other similar projects are: the Europeana project [25,39]which mapped and published data from more than 2000 insti-tutions across Europe; the Smithsonian project [43] whichpublished data from a collection of 41,000 objects from theSmithsonian American Art Museum; and the Finnish Muse-ums project [26] which published data concerning some 260
1 http://www.biografischportaal.nl/en.
123

154 A. Rademaker et al.
historical sites in Finland. These initiatives aim at promotingthe integration of digital collections of cultural heritage basedon the use of archival metadata, cross-domain ontologies andopen data technologies [22].
Even though much public data are available freely onlinein Brazil, only few repositories use open data standards.Examples in this direction are the Federal Government OpenData [19], the LeXML [31] and the SNIIC [13] projects.Despite being a reference in the field of organizing andpreserving historical collections, CPDOC (the Center forResearch and Documentation of Brazilian ContemporaryHistory of the Getulio Vargas Foundation) currently doesnot adopt any metadata standards nor does it use any opendata model for its collections.
Given the trends for data sharing and interoperability ofdigital collections, it is a challenge to keep CPDOC inno-vative in its mission of efficiently making available histor-ical data. In this article, we present CPDOC’s collectionsand discuss our approach for delivering its content usingsemantics technologies. We also present some audiovisualsignal and natural language processing tools that we areusing to enrich the metadata of the documents, to allow bet-ter search and browsing experience on the collections. Ourproposal introduces changes in the way CPDOC deals withits archives maintenance and accessibility, building a modelfor data organization and storage that ensures easy access,interoperability and reuse by service providers. The goal isto deliver an open and flexible framework, that uses seman-tically interconnected data about images, audio and textualcontent, to provide knowledge in a smart, collaborative andefficient environment.
Concerning automatic extraction of semantics from thecollections, three major applications are being currentlyexplored and will be described in the next sections: (1) naturallanguage processing for enriching the metadata and extract-ing knowledge currently embedded into the historical dic-tionary’s textual entries; (2) voice recognition and transcrip-tion alignment from the audiovisual archives of oral historyinterviews; and (3) face detection and identification of impor-tant characters in historical photographs [44]. Among otherdetails, this paper complements [40] with the description ofthese techniques and how we use them to expand the meta-data from knowledge extraction from raw data in images,sound and text files.
Amongst our main objectives are the construction of aRDF [34] data store from data originally stored in a relationaldatabase and the construction of an OWL [16] ontology toproperly represent the CPDOC domain, using Open LinkedData Initiative principles [28]. The project also aims to makethe RDF data freely available for downloading, similarly towhat DBpedia [6] does. We believe that these efforts willmotivate the interoperability of CPDOC’s collections withother open data projects.
The paper is organized as follows: Sect. 2 presentsCPDOC’s current database and information systems’ archi-tecture. The shortcomings of this architecture are describedin Sect. 3 and the requirements for a new one in Sect. 4. Thenew architecture proposed in this work is presented in Sect. 5,and in Sect. 6 we exploit the possibilities of enhancing thedata in the archives using complementary technologies. InSect. 7, we present some plans for evaluating our proposaland the results obtained. Finally, conclusions are summarizedin Sect. 8.
2 Current database and information systemsarchitecture
CPDOC was created in 1973 and became an important his-torical research institute in Brazil, housing a major collectionof personal archives, oral history interviews and audiovisualsources. Since its foundation, the center has received thedonation of personal archives of prominent Brazilian figuresfrom the 1930s onward, starting with President Getulio Var-gas himself. In 1975, the institute launched its Oral HistoryProgram (PHO), which involved the recording and archivingof interviews with major players in events in Brazilian his-tory. In 1984, the center published the Brazilian Historical-Biographical Dictionary [1] (DHBB), a regularly updatedreference resource that documents the contemporary historyof the country.
More recently the center has placed an increasing empha-sis on applied research, working in collaborative projects thatextend the availability and scope of the valuable historicalrecords it holds.
The current CPDOC database architecture is presented inFig. 1. The data are stored in three different information sys-tems that share a common relational database. Each of thesystems is maintained separately and adopts idiosyncraticcriteria concerning the organization and indexing of its infor-mation, which vary depending on the specifications of thecontent it hosts: personal archives documents, oral historyinterviews and the Brazilian Historical Biographic Dictio-nary entries. CPDOC’s website provides a query interface tothese data. In the following subsections, we briefly describeeach of the systems.
2.1 Personal archives (Accessus)
This system contains information from personal files of peo-ple who influenced onwards scene in Brazil from the early20th century. These historical documents, in textual or audio-visual sources, represent more than private memories, theyare registries of a collective memory.
123

A linked open data architecture 155
Fig. 1 CPDOC’s currentarchitecture: Accessus, DHBBand PHO information systems(intranet) feed a database serverwith metadata. The files arestored in file servers (highresolution in a storage andlow-resolution images anddocuments in a file serveraccessible by a web server(CPDOC’s website)
Currently, more than 200 personal archives from pres-idents, ministers, military personal and others constitutethe Accessus collections. The organization structure of thecollections follows the guidelines established for archiv-ing and comprehends: funds (or archives), series, sub-series, document units, documents and pages. For instance,there is the archive “Azeredo da Silveira” where one ofthe series is called “Ministry of Foreign Affairs” whichin turn has the subserie “Inter-American Affairs”. Oneof the document units of this subseries deals with thetheme “Environment”, containing various documents suchas telegrams, reports and speeches. Another document unitin this subseries covers the subject “Nuclear Agreement”, forinstance.
Together, they comprise nearly 1.8 million documents or5 million pages. From this, nearly 900 thousand pages are indigital format and it is expected that they will be all digitizedin the next few years. The collection entries metadata arestored in the database. It can be accessed through the insti-tution’s intranet for data maintenance or via the CPDOC’swebsite for simple data queries. Currently, the queries arerestricted to keyword searches linked to specific databasefields defined in an ad hoc manner. For those documents thatare already digitized, two digital file versions were gener-ated: one in high resolution aiming at long-term preserva-tion and another in low resolution for web delivery. High-resolution files are stored in a system with disk redundancyand restricted access, while low-resolution files are stored infile servers (Fig. 1).
2.2 Oral history interviews (PHO)
CPDOC’s collection of Oral History entries hosts currentlymore than 6000 h of recording, corresponding to about 2000interviews. More than 90 % of those, video or audio, arein digital format. For the time being, two kinds of queriesare available for the database: query by subject and queryby interviewee. Each interview record holds brief technicalinformation and a textual summary with descriptions of theinterview themes in the order they appear in the recording.Almost 80 % of the interviews are transcribed, but to accessthe audio and video content the user needs to come in personto the CPDOC. Currently, the institution is analyzing differ-ent aspects such as the best format, use policies, access con-trol and copyright issues for making this data available online.As in the case of Accessus, the database actually stores onlythe interviews’ metadata, while the digitized recorded audiosand videos are stored as digital files in the file servers (storagesystem).
The PHO data comprises a set of interviews whose inter-viewees are chosen according to the project funding the initia-tive for collecting the data. These projects are usually linkedto political events, and therefore the persons interviewed aremainly the ones who took part in them.
2.3 Brazilian Historical-Biographic Dictionary (DHBB)
The Brazilian Historical-Biographic Dictionary (DHBB)is widely considered one of the main research sources
123

156 A. Rademaker et al.
for information on contemporary Brazilian politicians andthemes. It contains about 7500 entries of biographic andthematic nature, i.e., people, institutions, organizations andevents’ records carefully selected using criteria that mea-sure the relevance of those to the political history ofthe given period. The entries are written objectively, try-ing to avoid, as much as possible ideological or per-sonal judgments. CPDOC researchers carefully revise allentries to ensure accuracy of the information and uniformstyle.
The DHBB relational model can be summarized as onemain table that contains a text field with the dictionary entriestext encoded in HTML [41] with a set of auxiliary tablesthat provide keys for metadata values such as: professions,governments, and places. The current dictionary entries arecreated and revised in text editors outside the system andare imported into the database. DHBB’s database stores notmany metadata concerning each entry, moreover the amountof metadata differs between recent entries and old ones. Theavailable queries are limited to keyword searches of the titleor the text of the entries.
3 Issues and opportunities
CPDOC’s archives are maintained by three different infor-mation systems based on traditional relational data mod-els. This infrastructure is hard to maintain, improve andrefine, and the information they contain is not found by stan-dard search engines for two main reasons: (1) the CPDOCwebsite HTML pages are created dynamically only after aspecific query is issued; (2) users are required to login tothe CPDOC’s website to issue queries or access the dig-ital files. Service providers do not reach the data directlyand therefore cannot provide specialized applications usingit. Users themselves are not able to expand the queriesover the collections, being limited to the available searchinterface. In summary, data in CPDOC’s collections can beconsidered to be currently limited to the so-called “DeepWeb” [3].
CPDOC’s systems maintenance is difficult and improve-ments are hard to implement and therefore innovative initia-tives are hardly ever adopted. A relational database modelis not easily modified since it is supposed to be defined apriori, i.e., before data acquisition. Moreover, changes in thedatabase usually require changes in system interfaces andreports. The whole workflow is expensive, time consumingand demands professionals with different skills from inter-face developers to database administrators. For instance, inthe current data model, any enrichment of DHBB entrieswith metadata extracted from natural language processing ofthe entries texts would require a complete adaptation of therelational model, new tables and columns would need to be
added and the current SCRUD2 interfaces would need to beadapted.
CPDOC’s collections do not follow any metadata stan-dards, which hinders considerably the interoperability withother digital sources. Besides, the available queries usuallyface idiosyncratic indexing problems with low rates of recalland precision. These problems are basically linked to the adhoc indexing strategy adopted earlier to define the databasetables and fields.
Finally, data storage is also an issue. Digitized Acces-sus documents and Oral History interviews are not stored ina single place, but scattered into different file systems andservers. The database only stores the metadata and file pathsto the file servers, making it very difficult to ensure consis-tency between files, metadata information and access controlpolicies.
4 Requirements
The requirements for the migration of this whole frame-work have different perspectives: the users, scholars, stu-dents and researchers within the FGV or other institutions;developers and IT specialists; curators and administratorsof CPDOC collections. In this section, we list the ones weidentified.
From the users’ perspective, more flexible ways to interactwith the data are needed. Non-technical users may want touse web query interfaces complemented with faceted results,but more advanced users expect to be able to make more flex-ible queries, possibly exploring relations to entities in otherdatasets. Another class of users that we aim to support are ser-vice providers. That is, developers or companies interested inusing CPDOC datasets for novel applications such as the cre-ation of learning objects3 or systems for online courses likeMOOC courses4. Such advanced users or developers need tohave direct access to the data.
Internal developers, that is, the technical staff workingfor CPDOC, need to answer the demands of new require-ments made by the historians and CPDOC researchers. Forthese goals, the reuse of tools and modeling decisions madeby the community of historians and archives’ curators playan important role. The adoption of standard vocabulariesand open source systems for digital content management,version control, website generators and search engines canimprove considerably their response time of new features andinterfaces.
2 This is an acronym for specifying information systems that usuallyimplement the search, create, read, update and delete operations, http://goo.gl/33piYJ.3 http://en.wikipedia.org/wiki/Learning_object.4 http://en.wikipedia.org/wiki/Massive_open_online_course.
123

A linked open data architecture 157
Researchers and historians of CPDOC, the data curators,need an agile and flexible workflow for adoption of inno-vations. This means that new features should be easier tobe tested and implemented. Improving the data model withnew properties or entry types should be as painless as possi-ble. It should not demand too much effort for the adaptationof the existing systems and transformation of the alreadyavailable data. The curators also desire more interoperabilitywith other well-known datasets, ontologies and vocabular-ies such as DBPedia [6], GeoNames [45], YAGO [42], andSUMO [37]. Such interoperability can, promote and improvethe publication of the CPDOC archives. Contributions fromthe community in the improvement of the quality and volumeof the collections are also desired. In this sense, interoper-ability can help in the engagement of the community oncethey perceive the value, transparency and availability of thedata. However, these contributions should be curated and ver-sioned since the trust and quality of the collections and theirmetadata is an important asset of CPDOC.
5 The suggested architecture
Relational databases are often hard to maintain and share.Moreover, the idea of having in-house developed informa-tion systems is being increasingly replaced by the concept ofopen source systems. In such systems the updating and cre-ating of new features are not sustained by a single institutionbut usually by a whole community that shares knowledgeand interests with associates. In this way, the system is keptup-to-date, accessible and improving much faster due to theincreased number of contributors. Such systems are also usu-ally compatible with standards so as to ensure they can bewidely used.
The intention is to equip CPDOC with modern open datatools so that the way data are maintained, stored and sharedcan be improved. The proposal focuses on open source sys-tems as a lightweight and shared way of dealing with data.More concretely, it is proposed the replacement of the threeCPDOC information systems by the technologies describedin the following paragraphs.
Concerning PHO and Accessus data managementdemands, we believe that a digital repository managementsystem (DRMS for short) would be suitable for the taskat hand. DRMSs have all desirable features that are notfound in Accessus or PHO, such as: (1) flexible data modelbased on standard vocabularies such as Dublin Core [27]and SKOS [29]; (2) long-term data preservation functionali-ties such as tracking and notifications of changes in files; (3)fine-grained access control policies; (4) flexible user interfacefor basic and advanced queries; (5) compliance with standardprotocols for repository synchronization and interoperability(e.g., OAI-PMH [30]); (6) import and export functionalities
using standard file formats and protocols. In our proposal,the metadata and files from Accessus and PHO systems areto be stored in Dspace,5 but any other popular open sourceinstitutional repository software such as Fedora CommonsFramework6 would be equally suitable.
With respect to the DHBB, the nature of its data suggeststhat its entries could be easily maintained as text files using alightweight human-readable markup syntax. The files can beorganized in an intuitive directory structure and kept underversion control for structured and collaborative maintenance.The use of text files can be justified by: (1) easiness of main-tenance using any text editor (tool independence); (2) confor-mity to long-term standards by being software and platformindependent; (3) easiness to be kept under version control byany modern version control system7 since they are textuallycomparable; and (4) efficiency of information storage.8
The adoption of a version control system will improveconsiderably the current workflow of DHBB reviewers andcoordinators. Today the workflow is basically composedof the creation of entries using Microsoft Word and theexchange of emails. The adoption of the new tool will allowfile changes to be tracked, implementing a process of col-laborative creation without the need of sophisticated work-flow systems. This follows the methodology developed byopen sources’ communities for open source software main-tenance. Git9 is specially suited since it ensures data consis-tency and keeps track of changes and authorship in a collab-orative development environment.
5.1 Migration schema
Many of the described proposals are already implementedas a proof of concept prototype to evaluate the viability ofthis environment in CPDOC. Figure 2 illustrates the neces-sary steps to fully implement the project. In the followingparagraphs, we briefly describe these steps.
Step (1) is already implemented: the relational databasewas exported to RDF [34] using the open source D2RQ [5]tool. The D2RQ mapping language [14] allows the definitionof a detailed mapping that implements the migration of agiven relational model to a graph model based on RDF, assketched out in [4]. The mapping created so far defers anymodel improvement to step (2) described below.
Step (2) represents a refinement of the graph data modelproduced in step (1). The idea is to create a data model basedon standard vocabularies like Dublin Core [27], SKOS [29],
5 http://www.dspace.org/.6 http://www.fedora-commons.org.7 https://en.wikipedia.org/wiki/Revision_control.8 In text files, all DHBB entries uses less than 50 % of the current spaceused by the entries saved as HTML in the database.9 http://git-scm.com.
123

158 A. Rademaker et al.
Fig. 2 Migration schema fromcurrent relational databasesmodel to the proposed model.Accessus and PHO files are tobe stored in a digital repository,while DHBB files are versioncontrolled using a web hostingservice. The metadata isconverted from relationaldatabases to a RDF database
PROV [23] and FOAF [8] using well-known conceptual mod-els like [12]. The adoption of standard vocabularies makesthe data interchangeable with other collections and facilitatesits use by service providers and other users. In Sect. 6, wedescribe a refinement proposal to also complete and extendthe available metadata using tools to process the raw dataavailable in different file formats such as images, sound andtext.
In Step (3), which is also implemented, we deploy a textfile for each DHBB entry. The files use YAML [2] and Mark-down [24] markup languages to describe the metadata and theentry content. YAML and Markdown were chosen becausethey are both text-based, human-readable and are supportedby nearly all static website generators.
In the planned step (4), digital files and their metadatawill be stored in a DRMS. This step is more easily imple-mented using the RDF produced in step (2) than having toaccess the original database for two main reasons: SPARQLCONSTRUCT queries allow the extraction of graph patternsfrom RDF into RDF subgraphs; and most of DRMS systemsmaintain metadata of items already in RDF format.
Considering that all DRMS have detailed control accessmechanisms, both high- and low-resolution files can beimported to the same digital repository making only thelow resolution open for public access. This is necessarymainly to preserve bandwidth and because in general, thelow-resolution files also contain some watermark and embed-ded metadata.
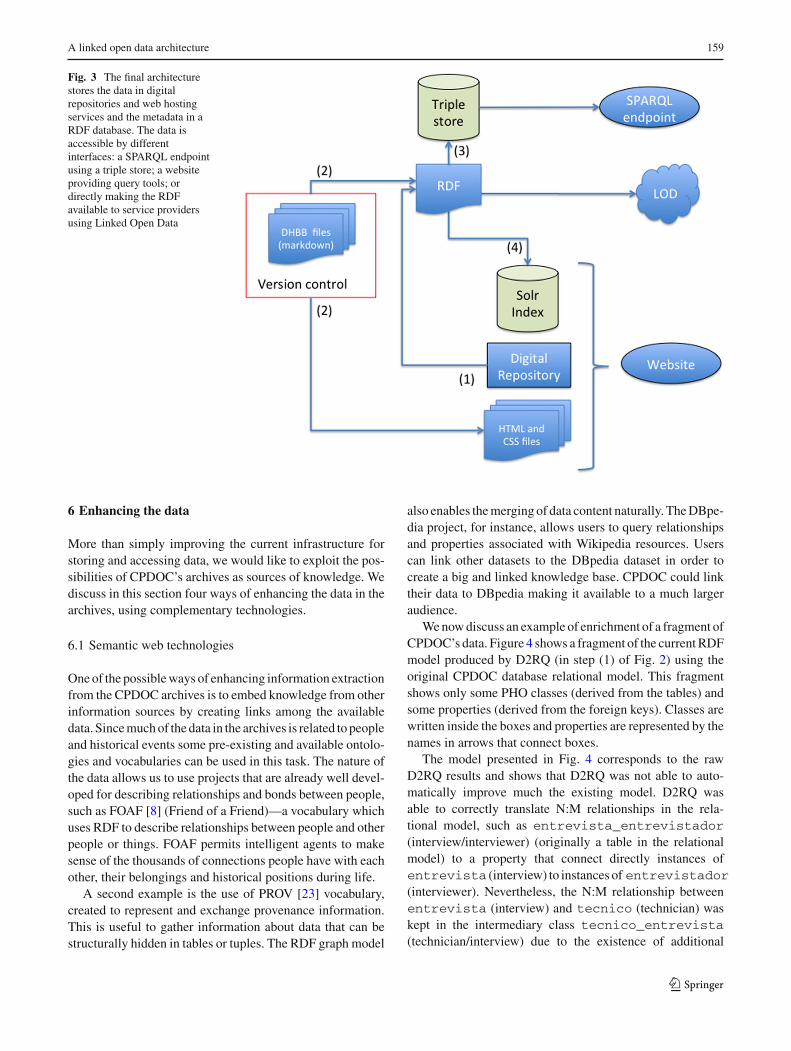
The proposed architecture for CPDOC’s archives main-tenance is presented in Fig. 3. We emphasize that one ofour main goals is to make the collections available as openlinked data. This can be accomplished by releasing dataas RDF and OWL files for download or by providing a
SPARQL Endpoint [10] for queries. Since data evolve con-stantly, the team of CPDOC would deliver periodical datareleases and updates. Apart from the RDF and OWL filesand the SPARQL Endpoint, it is also important to providea lightweight and flexible web interface for final users tobrowse and query data. This can be done using a static web-site generator and Apache Solr10 for advanced queries. Asa modern index solution, Solr can provide more powerfuland fast queries’ support when compared to traditional rela-tional database systems. The use of a static site generator11
allows the maintainers to have full control over the release ofnew data on the web. It is interesting to notice that CPDOC’smaintenance workflow fits well the static website genera-tor approach, since the generated website only needs to beupdated, manually, when a new collection is scheduled to bepublished.
In addition, this approach allows the generation of sta-ble URLs for each relevant entry. For instance, each DHBBentry can have a stable URL that can be indexed by stan-dard search engines. In this way different and complemen-tary outputs are delivered for different purposes and users: awebsite for browsing, RDF and OWL files for downloadingand SPARQL Endpoints for queries.
The results obtained so far encouraged us to propose acomplete data model aligned with open linked data vocab-ularies and enhanced by pattern recognition techniques, aspresented in detail in next section.
10 http://lucene.apache.org/solr/.11 In this application we used Jekyll, http://jekyllrb.com, but any otherstatic site generator could be used.
123
A linked open data architecture 159
Fig. 3 The final architecturestores the data in digitalrepositories and web hostingservices and the metadata in aRDF database. The data isaccessible by differentinterfaces: a SPARQL endpointusing a triple store; a websiteproviding query tools; ordirectly making the RDFavailable to service providersusing Linked Open Data
6 Enhancing the data
More than simply improving the current infrastructure forstoring and accessing data, we would like to exploit the pos-sibilities of CPDOC’s archives as sources of knowledge. Wediscuss in this section four ways of enhancing the data in thearchives, using complementary technologies.
6.1 Semantic web technologies
One of the possible ways of enhancing information extractionfrom the CPDOC archives is to embed knowledge from otherinformation sources by creating links among the availabledata. Since much of the data in the archives is related to peopleand historical events some pre-existing and available ontolo-gies and vocabularies can be used in this task. The nature ofthe data allows us to use projects that are already well devel-oped for describing relationships and bonds between people,such as FOAF [8] (Friend of a Friend)—a vocabulary whichuses RDF to describe relationships between people and otherpeople or things. FOAF permits intelligent agents to makesense of the thousands of connections people have with eachother, their belongings and historical positions during life.
A second example is the use of PROV [23] vocabulary,created to represent and exchange provenance information.This is useful to gather information about data that can bestructurally hidden in tables or tuples. The RDF graph model
also enables the merging of data content naturally. The DBpe-dia project, for instance, allows users to query relationshipsand properties associated with Wikipedia resources. Userscan link other datasets to the DBpedia dataset in order tocreate a big and linked knowledge base. CPDOC could linktheir data to DBpedia making it available to a much largeraudience.
We now discuss an example of enrichment of a fragment ofCPDOC’s data. Figure 4 shows a fragment of the current RDFmodel produced by D2RQ (in step (1) of Fig. 2) using theoriginal CPDOC database relational model. This fragmentshows only some PHO classes (derived from the tables) andsome properties (derived from the foreign keys). Classes arewritten inside the boxes and properties are represented by thenames in arrows that connect boxes.
The model presented in Fig. 4 corresponds to the rawD2RQ results and shows that D2RQ was not able to auto-matically improve much the existing model. D2RQ wasable to correctly translate N:M relationships in the rela-tional model, such as entrevista_entrevistador(interview/interviewer) (originally a table in the relationalmodel) to a property that connect directly instances ofentrevista (interview) to instances of entrevistador(interviewer). Nevertheless, the N:M relationship betweenentrevista (interview) and tecnico (technician) waskept in the intermediary class tecnico_entrevista(technician/interview) due to the existence of additional
123

160 A. Rademaker et al.
Fig. 4 RDF model example from PHO using the D2RQ conversion tool. This result is to be refined
information: the role of the interview technician (classfuncao). The relational model also seems to have someinconsistencies.
For instance, although the connection between technicianand interview is parametrized by different roles, the donor,interviewer and interviewee of a given interview are repre-sented each one in a specific table. Moreover, interviewee,interviewer, donor and technician are all people, and as sothey share common properties such as name and address,and therefore could be modeled using a person class (morespecifically, the foaf:Person from FOAF vocabulary),for instance.
Figure 5 shows how the PHO model can be refined inour approach. The new model uses standard vocabulariesand ontologies, making the whole model much more under-standable and interoperable. The activity box describingprovenance prov:Activity was duplicated just for eas-iness of presentation. The prefixes in the names indicate thevocabularies and ontologies used: prov [23], skos [29],dcterms and dc [27], geo [46], and bio [15]. We alsodefined a CPDOC ontology that declares its own classes andspecific ontology links, such as the one that states that afoaf:Agent is also a prov:Agent. In Fig. 5, we seethat some classes can be subclasses of standard classes (e.g.,Interview is a prov:Activity), while some otherscan be replaced by standard classes (e.g., LOCALIDADE(location) by geo:Place).
The main advantage of adopting well-known vocabular-ies is that users and researchers from other institutions areable to understand and use CPDOC data. Moreover, by usingvocabularies like FOAF and PROV, adopted by many otherdata providers, we improve accessibility, that is, the possibil-ity of links between entities from CPDOC’s data and entitiesresidents in data from other data providers. This network ofinterlinked entities ultimately will generate more knowledgefrom the available data.
6.2 Lexical resources and natural language processing
Another way of enhancing data from historical archives is bymeans of natural language processing (NLP) methods suchas question answering. We would like, for instance, to be ableto answer generic questions about the entries in the DHBBdatabase, such as “to which top 5 schools most of the Brazil-ian leaders of the beginning of the 20th century went to?”
To answer generic questions as well as for many otherknowledge-intensive tasks, the use of lexical resources suchas WordNet [20] is indispensable. It is well-known that Word-Net is an extremely valuable resource for research in Com-putational Linguistics and NLP in general. WordNet hasbeen used for a number of different purposes in informationsystems, including word sense disambiguation, informationretrieval, text classification and summarization, and dozensof other tasks.
123

A linked open data architecture 161
Fig. 5 PHO revised RDF model. Using some of the commonly used standards for Linked Open Data it is possible to make the data more accessibleand semantically meaningful
Given that the texts in CPDOC’s archives are written inBrazilian Portuguese, it is convenient to be able to use aBrazilian version of Wordnet, such as the OpenWordnet-PT [17], developed by some of the authors, to address NLPtasks. OpenWordnet-PT is being developed with the supportof FGV. The goal of that project, in the long run, is to useformal logic tools to reason about knowledge obtained fromtexts in Portuguese. OpenWordnet-PT is available for down-load12 and query13 in the Open Multilingual Wordnet web-site [7].
OpenWordnet-PT is being improved by drawing on atwo-tiered methodology that offers high precision for themore salient and frequent words of the language, butalso high recall to cover a wide range of words in thedesired corpora. We combined manual base concepts’ anno-tation with statistical cross-lingual projection techniques toobtain the first version of the resource. Recently, we com-bined OpenWordnet-PT with NomLex-PT [11]. We startedNomlex-PT with a manual translation of the original Eng-lish NOMLEX [33] to Brazilian Portuguese. Incorporating
12 https://github.com/arademaker/openWordnet-PT.13 http://logics.emap.fgv.br/wn/.
NomLex-PT data into OpenWordnet-PT has shown itselfuseful in pinpointing some issues with the coherence andrichness of OpenWordnet-PT.
For the time being, we have mainly used the DHBB dataas a way of checking the coverage of nominalizations inNomLex-PT and OpenWordnet-PT. The DHBB corpus isvery well suited to observe nominalizations in Portuguese,since it is somewhat erudite, written in higher register thannewswire, but meant to be accessible to students, and domainspecific: historical data lends itself to conceptualizations thatare usually expressed via nominalizations. In one small,but telling experiment, we used Freeling [38] to automat-ically process the entry data of the DHBB by performingtokenization, sentence splitting, part-of-speech tagging, andword sense disambiguation with respect to OpenWordnet-PT. Then we manually checked the nouns (over a certainthreshold) that were nominalizations and verified how manyof these were already included in both resources: NomLex-PT and OpenWordnet-PT. This gave us confidence that thecoverage of OpenWordnet-PT is reasonably good for nouns(specifically for nominalizations), as well as providing a col-lection of “concepts” that should be the seed for a DHBB-History Ontology, which we hope to develop next. Named
123

162 A. Rademaker et al.
entities recognition and other NLP tasks can automaticallycreate connections that improve dramatically the usabilityof the content of the DHBB. Resources such as YAGO [42]and BabelNet [35] link Wikipedia to WordNet. The resultis an “encyclopedic dictionary” that provides concepts andnamed entities lexicalized in many languages and connectedwith large amounts of semantic relations. The SUMO Ontol-ogy [37] could also be used to provide a complete formaldefinition of terms linked to WordNet, over which we cando automated inference, using theorem provers and proofassistants.
Until now, DHBB entries have been used as a clean andhigh-quality corpus that is helping us to improve the lexiconin OpenWordnet-PT. Much more needs to be implemented,such as, the similar work done by [21] for informationextraction.
6.3 Audio alignment technologies
Another very promising approach for enriching CPDOC’sdata is to exploit the audio and video interviews stored byPHO (Sect. 2).
Currently about 75 % of PHO interviews are transcribed.The transcription process is manual and provides a fluid andcorrect text, often omitting disfluencies, irrelevant grammat-ical errors or hesitations. The NLP techniques and resourcesfrom Sect. 6.2 are clearly suited for handling transcriptions,but the alignment of audio and the corresponding transcrip-tion plays an important role to make audio data availablewithin the semantic structure hereby proposed.
The manual alignment of audio and transcription istedious, very time consuming and therefore virtually unman-ageable even for a small amount of data. We propose theuse of a couple of open source tools to automatically alignPHO audio and transcription files. The first one is the HiddenMarkov Model Toolkit (HTK) developed by the Universityof Cambridge [47]. This tool is specially suitable for speechrecognition tasks based on Markov models. We also usethe collection of tools provided by the FalaBrasil ResearchGroup at the Federal University of Pará (UFPA): Portugueseacoustic model, Portuguese language model, phonetic dic-tionary and grapheme–phoneme converter [36].
To compare words in text and audio, we identify thephonemes present in a given transcription, but the sequence ofcharacters that compose words hardly ever has a straightfor-ward phonetical translation. The same character correspondsto different sounds (phonemes) depending on the word inwhich it is included (e.g., the character “u” in the words “fun”and “full”). Therefore, a new text file is generated from thetranscription containing the words expressed by means oftheir phonemes, to allow the comparison between text andaudio. The “UFPAdic3.0” phonetical dictionary is used tocreate this text file of phonemes, and contains about 64,800
words in Portuguese and the corresponding phonemes. Thephonemes of words not present in the dictionary are esti-mated using the “Conversor Grafema-fone 1.6” grapheme–phoneme converter, also provided by the group FalaBrasil.
The most computationally intensive step of the alignmentprocedure is the matching between the phonemes from thetranscription and the audio file. For this alignment, we usean acoustic model (LapSAM v1.5) for Portuguese based onMarkov chains provided by the FalaBrasil group with 16hours of recording, in a format compatible with HTK. Thismodel allows the estimation of the phonemes more likely tohave been pronounced at a given audio snippet. The processconsists of maximizing the global likelihood of matchingthe phonemes estimated from the transcription and the onespresent in the audio sequence.
To perform this optimization, we used the Viterbi algo-rithm, also available in HTK. Instead of using the algorithmfor the whole audio content, we decided to split the audiointo smaller snippets and process them sequentially. Thiswas done after we had problems to processing the wholedata at once, which delivered inaccurate results for audioover 10 minutes long. This is probably due to the very natureof Viterbi algorithm, which performs a global optimization,and therefore might deliver inaccurate and computationaltime demanding results for long audio snippets. To tacklethis problem, we split the audio in overlapping snippets of5 minutes, processing the snippets and taking only the firstminute of each snippet in the final result. This simple proce-dure provides a more accurate alignment within the snippet,speeds up the process, and guarantees that long interviewscan be handled properly.
The alignment procedure outcome is a file with timestampsfor each word in the audio within the given transcription.These words are grouped to create timestamps for sentenceswith 30–45 characters long and ultimately organized as asubtitles file. Using this file we are able to construct an userinterface that allows users to query for a given word in thetranscription text and be automatically redirected to the timein the audio when the queried word is spoken.
The alignment of audio and transcription allows thesemantic linking of the audio data in the interviews to othertextual and audiovisual data, from Wikipedia or DHBB, forinstance. This improves not only the data present in the audiofiles, but also the external data that can be linked to them,integrating CPDOC archives in their different supports.
6.4 Image processing technologies
Historical images play an important role in CPDOC collec-tions. They hold much information and usually represent achallenge to extract semantically the information for con-necting visual with textual data. The Accessus system storeshistorical photos and their metadata, which is expected to
123

A linked open data architecture 163
explain part of the information the image holds. Still, imageprocessing techniques can help to extract unknown informa-tion from images, or tagging information graphically into thephotos themselves.
Over the last decade several photographic collections havebeen digitized and many of them have been made avail-able for public access through web portals, for instance seethe Library of Congress’ photo-stream on Flickr [32]. Eachimage may potentially have captions and/or texts that havebeen produced by experts to describe its content, which isusually stored as free text within a data basis. Captions mayrefer to the picture as a whole and/or describe a specificimportant feature that occurs in a particular subregion of theimage. In order to specify the referred subregion with naturallanguage, sentences such as: on top of, on the right of, in thefirst plane, from right to left, dressed in white, using a red hatare used frequently. All of these sentences suffer from lackof precision, from ambiguity, and their automatic processingcan be difficult. Nowadays, the information retrieval of struc-tured information is appealing and the migration of naturallanguage captions to structured information is desirable in avariety of photographic collections.
The CPDOC photographic archive has been arranged andhandled manually in its organizational phase. In 2008, anextensive digitization project began, where the images andthe results of the intellectual process of character identifica-tion and captioning were made available for public accessthrough a web information portal. However, with the evolu-tion of multimedia collection retrieval resources introducedby the use of semantic standards, the need to convert thecollection to semantic standards arose.
The CPDOC’s photographic collection has important idio-syncrasies for image processing: (1) Non-frontal faces appearvery frequently (non-trivial for detection and recognition);(2) typically characters that are important within a singlephoto are just a few when compared to the number of facesthat actually appear in the image; and (3) many of the imagespresent some characteristic that makes the automatic imageprocessing pipeline harder than usual; more specifically, theymay be monochromatic, contain different types of noise andmay present the characters in very low resolution. These char-acteristics lead us to discard the use of off-the-shelf characterannotation tools and libraries, such as Google’s Picasa photoorganizer and editing software14. Of course, one additionalreason to discard the adoption of any off-the-shelf tool is theneed of a integrated system in the CPDOC’s workflow ofimage annotation and archiving. But the most evident limi-tation of the majority of the available photo annotation toolsand libraries is that they were not designed to process infor-mation available in captions or texts produced by experts that
14 http://picasa.google.com.
describe the content of previously organized photographiccollections.
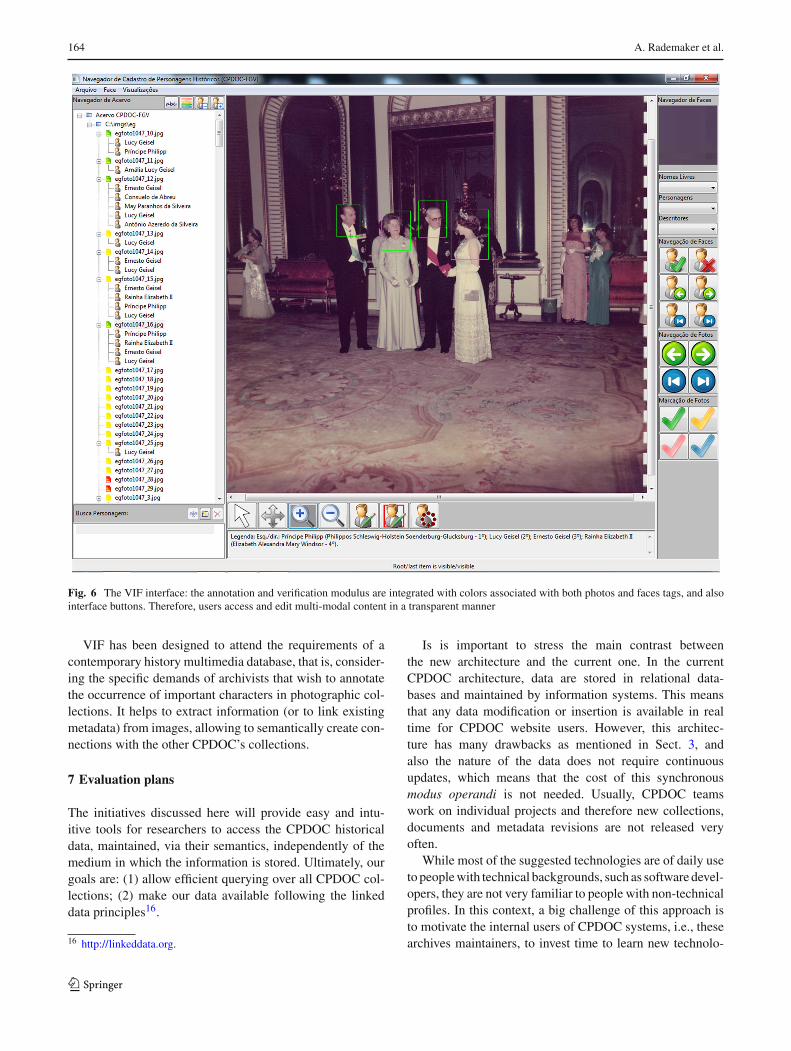
To address our specific problems, we developed the VIF(Very Important Faces) software [44] as an environment fordescribing image contents throughout analysis, annotationand verification of multi-modal metadata (see Fig. 6). TheVIF combines face detection techniques and basic regularexpressions15 to help the user in the association of namesthat occur in the legend to faces that occur within an image.
In order to achieve the desired result, faces of importanthistorical figures need to be detected within the images. Theface detection task consists of identifying subregions withinan image where a human face occurs. Face detection is awell-developed research subject and is already an off-the-shelf technique for the frontal face case. However, its generalform is still a challenging computer vision problem due tovariations in head pose orientation, facial expression, occlu-sions, variation in lighting and imaging conditions and thepresence of non-uniform backgrounds.
Concerning the textual information present in the cap-tions, an automatic proper name extraction task was imple-mented in order to ease face tagging. We took advantage ofthe description dictionary provided by Accessus to simplifythe proper name extraction task using regular expressions.
The expected outcome consists of descriptions of thefaces’ spatial positions within the images, followed by thename matched to the face. We call attention to the fact thatthe face’s spatial position annotation is more precise than thenatural language annotation and can potentially solve someof the ambiguities present in captions; the drawback is thatspatial descriptors are easily readable by machines, but not bypeople. Thus we generate the demand of a layer of processingbetween the information and the user.
In order to support the experts to efficiently review theannotation produced within VIF, which aims to avoid errorinclusion in the database re-annotated by non-experts or byautomatic processing, we proposed the adoption of a setof annotation maturity levels to tag annotation provenance.Image embedded metadata seems to be the natural tendencyfor dealing with questions related to association of prove-nance of the image content description. The role of an expertis to guarantee a high level of confidence in the informa-tion associated with the photo, but experts can be expensive.Therefore, it is desirable to use this resource efficiently. Con-sidering databases that have been previously annotated byexperts, the migration of this information to structured stan-dards would become infeasible if experts were required toredo the annotation task. Thus, less costly solutions shouldbe proposed, that is, the task has to be performed by non-experts, crowd-sourcing or automated means, leaving to theexpert the task of verifying the annotation.
15 http://en.wikipedia.org/wiki/Regular_expression.
123
164 A. Rademaker et al.
Fig. 6 The VIF interface: the annotation and verification modulus are integrated with colors associated with both photos and faces tags, and alsointerface buttons. Therefore, users access and edit multi-modal content in a transparent manner
VIF has been designed to attend the requirements of acontemporary history multimedia database, that is, consider-ing the specific demands of archivists that wish to annotatethe occurrence of important characters in photographic col-lections. It helps to extract information (or to link existingmetadata) from images, allowing to semantically create con-nections with the other CPDOC’s collections.
7 Evaluation plans
The initiatives discussed here will provide easy and intu-itive tools for researchers to access the CPDOC historicaldata, maintained, via their semantics, independently of themedium in which the information is stored. Ultimately, ourgoals are: (1) allow efficient querying over all CPDOC col-lections; (2) make our data available following the linkeddata principles16.
16 http://linkeddata.org.
Is is important to stress the main contrast betweenthe new architecture and the current one. In the currentCPDOC architecture, data are stored in relational data-bases and maintained by information systems. This meansthat any data modification or insertion is available in realtime for CPDOC website users. However, this architec-ture has many drawbacks as mentioned in Sect. 3, andalso the nature of the data does not require continuousupdates, which means that the cost of this synchronousmodus operandi is not needed. Usually, CPDOC teamswork on individual projects and therefore new collections,documents and metadata revisions are not released veryoften.
While most of the suggested technologies are of daily useto people with technical backgrounds, such as software devel-opers, they are not very familiar to people with non-technicalprofiles. In this context, a big challenge of this approach isto motivate the internal users of CPDOC systems, i.e., thesearchives maintainers, to invest time to learn new technolo-
123

A linked open data architecture 165
gies, instead of keeping their inefficient but well-known wayof dealing with data.
Our evaluation plans for the new architecture are manifoldand will generate, once implemented, qualitative and quan-titative insights of the quality leap we expect to see. First,we plan to do surveys to evaluate the user experience whenusing the new tools proposed in this paper. This survey willgive us inputs to statistically quantify how users are affectedby the solutions we propose. These statistics will be sharedwith the community.
Another simple but powerful metric that is going to beanalyzed is the evolution of the number of visitors in the querytools and data dumps. We expect that easier and more efficienttools will increase substantially the number of visitors to theCPDOC archives. Since the archives will be made availableas RDF following linked data principals, we can quantify thenumber of dereferences of URIs of our datasets made to ourserver.
We also expect a growth in the involvement of researchersof CPDOC in feeding, analyzing and using the data hostedby CPDOC, in their own individual research agendas. Thisgrowth can be verified by the publications and citations madeabout CPDOC’s data and hopefully will indicate an improve-ment of accessibility and availability of the CPDOC archivesfor its researchers. We also expect that CPDOC researcherscontribute with more insights and ideas for data enrichmentgiven the more flexible architecture.
However, how to evaluate the results of our efforts for dataenrichment? In Sect. 6, we presented some techniques thatwe are exploring. At the end of each subsection, we providedsome discussion of the expected benefits of each approach. Inthe next paragraphs, we highlight some aspects of evaluation.
Regarding the image processing for faces detection andannotation, a tricky discussion arose when we proposed to thedata curators a semi-automatic annotation approach. Cura-tors considered the automatic annotation, as well as the non-expert annotators, as potentially inserting errors in an infor-mation data, which were originally produced by experts.Even if our semi-automatic name to face matching werecapable of 95 % of correct assignments, that would meanthe potential insertions of information with at least 5 % oferror, which is usually unacceptable. For this reason, it is cru-cial to keep track of all data produced in automatic or semi-automatic manner. We plan to provide provenance annota-tions for all automatic or semi-automatic generated data, fol-lowing the same directions of [21].
When dealing with cultural heritage database annotation,it is crucial to define a maturity level related to the pro-duced annotation. The annotation maturity level is to beused, for instance, to decide if a document is ready or notto be published. From this discussion, we conceived theVIF annotation verification module. The aim is to supportan authorized expert with tools for efficient review of the
annotation produced by non-experts, which includes bothmanual and semi-automatic. We have already made somepreliminary evaluation of the VIF usability. The CPDOC’steam approved the tool interface and the features. Naturally,the assessment of such tool is not quantitative but qualitative.We are not focused on reducing time spent with annotationsnor improving the automatic face recognition or face identi-fication. Our goal is to lessen the necessity of experts for theminimal necessary intervention in the archiving workflow.This kind of evaluation will only be possible with the use ofthe tool by the CPDOC team for a while.
In order to enhance efficiency in the verification work,VIF offers querying and sorting over both the captions andthe annotations. The interface based on fast informationvisualization allows an expert to navigate through quicklyand review a summary of the annotation produced by non-experts. In the preliminary experiments that we conducted,we had positive feedbacks by non-experts and experts fromCPDOC.
Nevertheless, we can evaluate the identification of impor-tant people in historical images in a quantitative manner ifnecessary. This evaluation can be done by sampling andmanually inspecting and using semi-automatic methods topresent results for verification. Some findings on this direc-tion were already published [44] concerning this ongoingtask.
In [18], we presented the evaluation of natural languageprocessing outcomes on the historical dictionary. The nextstep regarding NLP for DHBB entries is to experiment withdifferent techniques for information extraction. In the firstinstance, we are interested in extracting life events (i.e., birth,death, marriage) and professional activities mentioned in thedictionaries entries. We can take advantage of the fact thatsome entries have already metadata about professional activ-ities to compare the facts extracted from the text with the factspresented in the metadata available.
For evaluating the alignment and automatic transcriptionof interviews, we plan to sample, and manually inspect theresults. Given our limit resources, we also believe that makingthe data available as soon as possible will allow visitors toprovide feedbacks for data improvements.
8 Conclusion
We presented a new architecture for CPDOC’s archives cre-ation and maintenance, based on open linked data conceptsand on open source methodologies and tools. This effort isexpected to have a great impact on the way data are accessedand made available. The identification of entities in histor-ical images, interviews and textual data can make explicitthe semantics of these entries and therefore provide inter-connections within the archives and with the outside com-
123

166 A. Rademaker et al.
munity. This represents a leap of quality of the experiencewe expect to provide for researchers when consulting thearchives. The goal is to provide a smart, multimedia andsemantically rich environment, a large knowledge database,accessible using modern standards of semantics.
Among the advantages of the architecture proposed, wehighlight that it ensures more control and easiness of datamaintenance. It allows easy integration of changes in the datamodel, without the need for database refactoring. This ulti-mately means less dependency of the CPDOC’s team on theFGV’s Information Technology department. We are awarethat the migration process of CPDOC’s archives from rela-tional database to RDF bases is not a trivial task: we foundseveral sources of data inconsistency and noise, as the datawere maintained by many different individuals over a longspan of time, using poorly documented protocols. We expectthat the staff involved will need to be trained to use the pro-posed new tools (text editors, version control software sys-tems and command line scripts etc), but this seems worth thetrouble, given the benefits outlined.
With regard to automated analysis of the content of thearchives, many research opportunities for the open linkeduse of CPDOC collections were proposed in Sect. 6. The useof lexical resources in Portuguese is being carried out so asto improve the structure and quality of the DHBB entriesand the automatic extension of their mapping can be definedfollowing ideas of [9]. The alignment of audio and transcrip-tions implemented a way of embedding semantics into audiofiles of the interviews hosted by PHO; while the CPDOChistorical imagery team is benefiting from image processingtechniques to automatically extract useful information thatcan be linked to other collections and accessed more effi-ciently.
The technologies proposed in this paper for migratingCPDOC’s archives to a model with the open linked data per-spective can be applied to other digital libraries and archives.Actually they are already being used in many projects citedin the introduction, and can be combined to solve differentchallenges. In this paper, we proposed models for archivesusing audio, images and textual support. Even though thismedia are very common, different archives, with differentsupport, probably will have idiosyncrasies that will requirespecific tools related to the kind of data hosted.
The possibilities offered by the paradigm of open linkeddata that we intend to bring to CPDOC directly affect theway people collaborate for the construction of knowledge.The knowledge about something is not simply about cap-turing data. People combine cognitive and perceptual facul-ties as they interact with the resources that surround them,which means that they create new forms of participating inthe construction of knowledge. This paper aligns the CPDOCarchives with modern concepts of linked open data, hoping toprovide efficient dissemination and creation of knowledge.
References
1. Abreu, A.A., Lattman-Weltman, F., de Paula, C.J.: DicionárioHistórico–Biográfico Brasileiro pós-1930, 3 edn. CPDOC/FGV,Rio de Janeiro (2010)
2. Ben-Kiki, O., Evans, C., dot Net, I.: Yaml: Yaml ain’t markuplanguage. http://www.yaml.org/spec/1.2/spec.html
3. Bergman, M.K.: White paper: the deep web: surfacing hiddenvalue. J. Electron. Publ. 7(1) (2001). http://quod.lib.umich.edu/j/jep/3336451.0007.104?view=text;rgn=main
4. Berners-Lee, T.: Relational databases on the semantic web. Tech.rep., W3C (1998). http://www.w3.org/DesignIssues/RDB-RDF.html
5. Bizer, C., Cyganiak, R.: D2R server-publishing relational databaseson the semantic web. In: 5th International Semantic Web Confer-ence, p. 26 (2006). http://d2rq.org
6. Bizer, C., Lehmann, J., Kobilarov, G., Auer, S., Becker, C., Cyga-niak, R., Hellmann, S.: Dbpedia—a crystallization point for theweb of data. Web Semant. 7(3), 154–165 (2009). doi:10.1016/j.websem.2009.07.002
7. Bond, F., Paik, K.: A survey of wordnets and their licenses. In:Proceedings of the 6th Global WordNet Conference (GWC 2012),pp. 64–71. Matsue (2012). http://bit.ly/1aN0Xxd
8. Brickley, D., Miller, L.: FOAF vocabulary specification (2010).http://xmlns.com/foaf/spec/
9. Cafezeiro, I., Haeusler, E.H., Rademaker, A.: Ontology and con-text. In: IEEE International Conference on Pervasive Comput-ing and Communications. IEEE Computer Society, Los Alamitos(2008). doi:10.1109/PERCOM.2008.21
10. Clark, K.G., Feigenbaum, L., Torres, E.: SPARQL protocol forRDF. Tech. rep., W3C (2008)
11. Coelho, L.M.R., Rademaker, A., de Paiva, V., de Melo, G.:Embedding NomLex-BR nominalizations into OpenWordnet-PTIn: Orav, H., Fellbaum, C., Vossen, P. (eds.) Proceedings of the 7thglobal WordNet conference, Tartu, Estonia, pp. 378–382. http://globalwordnet.org/global-wordnetconferences-2/ (2014)
12. Crofts, N., Doerr, M., Gill, T., Stead, S., Stiff, M.: Definition ofthe CIDOC conceptual reference model. Tech. Rep. 5.0.4, CIDOCCRM Special Interest Group (SIG) (2011). http://www.cidoc-crm.org/index.html
13. da Cultura, M.: Registro aberto da cultura (r.a.c): manual do usuário(2013). http://sniic.cultura.gov.br
14. Cyganiak, R., Bizer, C., Garbers, J., Maresch, O., Becker, C.: TheD2RQ mapping language. http://d2rq.org/d2rq-language
15. Davis, I., Galbraith, D.: BIO: a vocabulary for biographical infor-mation (2011). http://vocab.org/bio/0.1/.html
16. Deborah L., McGuinness, F.v.H. (ed.): OWL 2 Web Ontology Lan-guage Document Overview, 2 edn. W3C Recommendation. WorldWide Web Consortium (2012)
17. de Paiva, V., Rademaker, A., de Melo, G.: Openwordnet-pt: an openbrazilian wordnet for reasoning. In: Proceedings of the 24th Inter-national Conference on Computational Linguistics (2012). http://hdl.handle.net/10438/10274
18. de Paiva, V., Oliveira, D.A.B., Higuchi, S., Rademaker, A., de Melo,G.: Exploratory information extraction from a historical dictio-nary. In: Proceedings of IEEE 10th International Conference one-Science (e-Science), Sao Paulo, 20-24 Oct 2014, vol. 2, pp. 11–18 (2014)
19. Federal, G.: Governo federal dados abertos (2013). http://dados.gov.br/
20. Fellbaum, C. (ed.): WordNet: An Electronic Lexical Database. MITPress, Cambridge (1998)
21. Fokkens, A., ter Braake, S., Ockeloen, N., Vossen, P., Legêne, S.,Schreiber, G.: Biographynet: methodological issues when nlp sup-ports historical research. In: Proceedings of the 9th Edition of the
123

A linked open data architecture 167
Language Resources and Evaluation Conference (LREC). Reyk-javik, Iceland (2014)
22. Friesen, N., Hill, H.J., Wegener, D., Doerr, M., Stalmann,K.: Semantic-based retrieval of cultural heritage multimediaobjects. Int. J. Semantic Comput. 06(03), 315–327 (2012). doi:10.1142/S1793351X12400107. http://www.worldscientific.com/doi/abs/10.1142/S1793351X12400107
23. Gil, Y., Miles, S.: PROV model primer. Tech. rep., W3C (2013).http://www.w3.org/TR/prov-primer/
24. Gruber, J.: Markdown language. http://daringfireball.net/projects/markdown/
25. Haslhofer, B., Isaac, A.: data.europeana.eu—the europeana linkedopen data pilot. In: DCMI International Conference on Dublin Coreand Metadata Applications. The Hague, The Netherlands (2011).http://eprints.cs.univie.ac.at/2919/
26. Hyvönen, E., Mäkelä, E., Salminen, M., Valo, A., Viljanen, K.,Saarela, S., Junnila, M., Kettula, S.: Finnish museums on thesemantic web. J. Web Semant. 3, 25 (2005)
27. Initiative, D.C.: Dublin core metadata element set (2012). http://dublincore.org/documents/dces/
28. Initiative, O.D.: Open data initiative (2013). http://www.opendatainitiative.org
29. Isaac, A., Summers, E.: SKOS simple knowledge organizationsystem prime. Tech. Rep., W3C (2009). http://www.w3.org/TR/skos-primer/
30. Lagoze, C., de Sompel, H.V., Nelson, M., Warner, S.: The openarchives initiative protocol for metadata harvesting (2008). http://www.openarchives.org/OAI/openarchivesprotocol.html
31. LexML: Rede de informação informativa e jurídica (2013). http://www.lexml.gov.br
32. Library of Congress: The library of congress’ photostream on flickr.http://www.flickr.com/photos/library_of_congress/
33. Macleod, C., Grishman, R., Meyers, A., Barret, L., Reeves, R.:Nomlex: A lexicon of nominalizations. In: Proceedings of Euralex1998, pp. 187–193. Liege, Belgium (1998)
34. Manola, F., Miller, E. (eds.): RDF Primer. W3C Recommenda-tion. World Wide Web Consortium (2004). http://www.w3.org/TR/rdf-primer/
35. Navigli, R., Ponzetto, S.P.: BabelNet: the automatic construction,evaluation and application of a wide-coverage multilingual seman-tic network. Artif. Intell. 193, 217–250 (2012)
36. Neto, N., Patrick, C., Klautau, A., Trancoso, I.: Free tools andresources for Brazilian Portuguese speech recognition. J. Braz.Comput. Soc. 17, 53–68 (2011)
37. Niles, I., Pease, A.: Towards a standard upper ontology. In: Pro-ceedings of the International Conference on Formal Ontology inInformation Systems, vol. 2001, pp. 2–9. ACM, New York (2001)
38. Padró, L., Stanilovsky, E.: Freeling 3.0: towards wider multilin-guality. In: Calzolari, N., Choukri, K., Declerck, T., Dogan, M.U.,Maegaard, B., Mariani, J., Odijk, J., Piperidis, S. (eds.) Proceedingsof the Eight International Conference on Language Resources andEvaluation (LREC’12), pp. 23–25. European Language ResourcesAssociation (ELRA), Istanbul, Turkey (2012)
39. Purday, J.: Think culture: Europeana.eu from concept to construc-tion. Electron. Libr. 27, 919–937 (2009)
40. Rademaker, A., Higuchi, S., Oliveira, D.A.B.: A linked opendata architecture for contemporary historical archives. In: Pre-doiu, L., Mitschick, A., Nurnberger, A., Risse, T., Ross, S. (eds.)Proceedings of 3rd Edition of the Semantic Digital ArchivesWorkshop. Valetta, Malta (2013). Workshop website at http://mt.inf.tu-dresden.de/sda2013/. Proceedings at http://ceur-ws.org/Vol-1091/
41. Raggett, D., Hors, A.L., Jacobs, I.: Html 4.01 specification. Tech.Rep. REC-html401-19991224, W3C (1999). http://www.w3.org/TR/html401/
42. Suchanek, F.M., Kasneci, G., Weikum, G.: Yago: a core of semanticknowledge. In: 16th International World Wide Web Conference(WWW 2007). ACM Press, New York (2007)
43. Szekely, P., Knoblock, C., Yang, F., Zhu, X., Fink, E., Allen, R.,Goodlander, G.: Connecting the smithsonian american art museumto the linked data cloud. In: Cimiano, P., Corcho, O., Presutti, V.,Hollink, L., Rudolph, S. (eds.) The Semantic Web: Semantics andBig Data, Lecture Notes in Computer Science, vol. 7882, pp. 593–607. Springer, Berlin (2013). doi:10.1007/978-3-642-38288-8_40
44. Vasconcelos, C.N., Sa, A.M., Carvalho, P.C., Sa, M.I.: Structuringand embedding image captions: the v.i.f. multi-modal system. In:VAST: International Symposium on Virtual Reality. Archaeologyand Intelligent Cultural Heritage, pp. 25–32. Eurographics Asso-ciation, Brighton (2012)
45. Vatant, B., Wick, M.: Geonames Ontology (2012). http://www.geonames.org/ontology/documentation.html
46. Wick, M., Vatant, B.: Geonames Ontology (2011). http://www.geonames.org/ontology
47. Young, S.J., Evermann, G., Gales, M., Kershaw, D., Moore, G.,Odell, J., Ollason, D., Povey, D., Valtchev, V., Woodland, P.:The HTK Book Version 3.4. Cambridge University EngineeringDepartment, Cambridge (2006)
123
Related Documents











