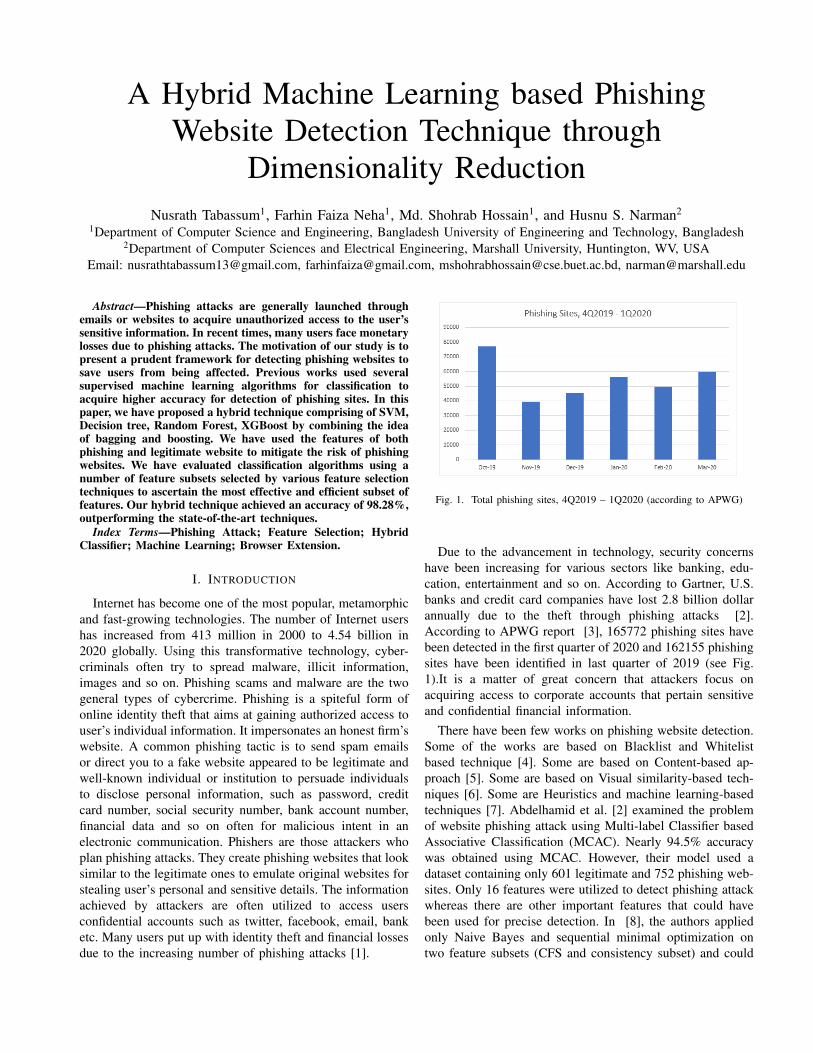
A Hybrid Machine Learning based Phishing Website Detection Technique through Dimensionality Reduction Nusrath Tabassum 1 , Farhin Faiza Neha 1 , Md. Shohrab Hossain 1 , and Husnu S. Narman 2 1 Department of Computer Science and Engineering, Bangladesh University of Engineering and Technology, Bangladesh 2 Department of Computer Sciences and Electrical Engineering, Marshall University, Huntington, WV, USA Email: [email protected], [email protected], [email protected], [email protected] Abstract—Phishing attacks are generally launched through emails or websites to acquire unauthorized access to the user’s sensitive information. In recent times, many users face monetary losses due to phishing attacks. The motivation of our study is to present a prudent framework for detecting phishing websites to save users from being affected. Previous works used several supervised machine learning algorithms for classification to acquire higher accuracy for detection of phishing sites. In this paper, we have proposed a hybrid technique comprising of SVM, Decision tree, Random Forest, XGBoost by combining the idea of bagging and boosting. We have used the features of both phishing and legitimate website to mitigate the risk of phishing websites. We have evaluated classification algorithms using a number of feature subsets selected by various feature selection techniques to ascertain the most effective and efficient subset of features. Our hybrid technique achieved an accuracy of 98.28%, outperforming the state-of-the-art techniques. Index Terms—Phishing Attack; Feature Selection; Hybrid Classifier; Machine Learning; Browser Extension. I. I NTRODUCTION Internet has become one of the most popular, metamorphic and fast-growing technologies. The number of Internet users has increased from 413 million in 2000 to 4.54 billion in 2020 globally. Using this transformative technology, cyber- criminals often try to spread malware, illicit information, images and so on. Phishing scams and malware are the two general types of cybercrime. Phishing is a spiteful form of online identity theft that aims at gaining authorized access to user’s individual information. It impersonates an honest firm’s website. A common phishing tactic is to send spam emails or direct you to a fake website appeared to be legitimate and well-known individual or institution to persuade individuals to disclose personal information, such as password, credit card number, social security number, bank account number, financial data and so on often for malicious intent in an electronic communication. Phishers are those attackers who plan phishing attacks. They create phishing websites that look similar to the legitimate ones to emulate original websites for stealing user’s personal and sensitive details. The information achieved by attackers are often utilized to access users confidential accounts such as twitter, facebook, email, bank etc. Many users put up with identity theft and financial losses due to the increasing number of phishing attacks [1]. Fig. 1. Total phishing sites, 4Q2019 – 1Q2020 (according to APWG) Due to the advancement in technology, security concerns have been increasing for various sectors like banking, edu- cation, entertainment and so on. According to Gartner, U.S. banks and credit card companies have lost 2.8 billion dollar annually due to the theft through phishing attacks [2]. According to APWG report [3], 165772 phishing sites have been detected in the first quarter of 2020 and 162155 phishing sites have been identified in last quarter of 2019 (see Fig. 1).It is a matter of great concern that attackers focus on acquiring access to corporate accounts that pertain sensitive and confidential financial information. There have been few works on phishing website detection. Some of the works are based on Blacklist and Whitelist based technique [4]. Some are based on Content-based ap- proach [5]. Some are based on Visual similarity-based tech- niques [6]. Some are Heuristics and machine learning-based techniques [7]. Abdelhamid et al. [2] examined the problem of website phishing attack using Multi-label Classifier based Associative Classification (MCAC). Nearly 94.5% accuracy was obtained using MCAC. However, their model used a dataset containing only 601 legitimate and 752 phishing web- sites. Only 16 features were utilized to detect phishing attack whereas there are other important features that could have been used for precise detection. In [8], the authors applied only Naive Bayes and sequential minimal optimization on two feature subsets (CFS and consistency subset) and could

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript
A Hybrid Machine Learning based PhishingWebsite Detection Technique through
Dimensionality ReductionNusrath Tabassum1, Farhin Faiza Neha1, Md. Shohrab Hossain1, and Husnu S. Narman2
1Department of Computer Science and Engineering, Bangladesh University of Engineering and Technology, Bangladesh2Department of Computer Sciences and Electrical Engineering, Marshall University, Huntington, WV, USA
Email: [email protected], [email protected], [email protected], [email protected]
Abstract—Phishing attacks are generally launched throughemails or websites to acquire unauthorized access to the user’ssensitive information. In recent times, many users face monetarylosses due to phishing attacks. The motivation of our study is topresent a prudent framework for detecting phishing websites tosave users from being affected. Previous works used severalsupervised machine learning algorithms for classification toacquire higher accuracy for detection of phishing sites. In thispaper, we have proposed a hybrid technique comprising of SVM,Decision tree, Random Forest, XGBoost by combining the ideaof bagging and boosting. We have used the features of bothphishing and legitimate website to mitigate the risk of phishingwebsites. We have evaluated classification algorithms using anumber of feature subsets selected by various feature selectiontechniques to ascertain the most effective and efficient subset offeatures. Our hybrid technique achieved an accuracy of 98.28%,outperforming the state-of-the-art techniques.
Index Terms—Phishing Attack; Feature Selection; HybridClassifier; Machine Learning; Browser Extension.
I. INTRODUCTION
Internet has become one of the most popular, metamorphicand fast-growing technologies. The number of Internet usershas increased from 413 million in 2000 to 4.54 billion in2020 globally. Using this transformative technology, cyber-criminals often try to spread malware, illicit information,images and so on. Phishing scams and malware are the twogeneral types of cybercrime. Phishing is a spiteful form ofonline identity theft that aims at gaining authorized access touser’s individual information. It impersonates an honest firm’swebsite. A common phishing tactic is to send spam emailsor direct you to a fake website appeared to be legitimate andwell-known individual or institution to persuade individualsto disclose personal information, such as password, creditcard number, social security number, bank account number,financial data and so on often for malicious intent in anelectronic communication. Phishers are those attackers whoplan phishing attacks. They create phishing websites that looksimilar to the legitimate ones to emulate original websites forstealing user’s personal and sensitive details. The informationachieved by attackers are often utilized to access usersconfidential accounts such as twitter, facebook, email, banketc. Many users put up with identity theft and financial lossesdue to the increasing number of phishing attacks [1].
Fig. 1. Total phishing sites, 4Q2019 – 1Q2020 (according to APWG)
Due to the advancement in technology, security concernshave been increasing for various sectors like banking, edu-cation, entertainment and so on. According to Gartner, U.S.banks and credit card companies have lost 2.8 billion dollarannually due to the theft through phishing attacks [2].According to APWG report [3], 165772 phishing sites havebeen detected in the first quarter of 2020 and 162155 phishingsites have been identified in last quarter of 2019 (see Fig.1).It is a matter of great concern that attackers focus onacquiring access to corporate accounts that pertain sensitiveand confidential financial information.
There have been few works on phishing website detection.Some of the works are based on Blacklist and Whitelistbased technique [4]. Some are based on Content-based ap-proach [5]. Some are based on Visual similarity-based tech-niques [6]. Some are Heuristics and machine learning-basedtechniques [7]. Abdelhamid et al. [2] examined the problemof website phishing attack using Multi-label Classifier basedAssociative Classification (MCAC). Nearly 94.5% accuracywas obtained using MCAC. However, their model used adataset containing only 601 legitimate and 752 phishing web-sites. Only 16 features were utilized to detect phishing attackwhereas there are other important features that could havebeen used for precise detection. In [8], the authors appliedonly Naive Bayes and sequential minimal optimization ontwo feature subsets (CFS and consistency subset) and could

achieve an accuracy of 88.17% and 94.6% for CFS subsetand 83.69% and 95.39% for consistency subset respectively.
The main objective of this research work is detecting bestsubset of features by combining and assessing the perfor-mance of various classification algorithms for identifyingphishing attack.
The main contributions of this work are as follows:• We have derived best possible features and reduced the
dimensionality of feature subset that can be used forphishing detection through the feature ranking usingthe combination of Random Forest algorithm, XGBoostalgorithm and correlation matrix with heatmap.
• We have evaluated performance of the implemented clas-sifiers and among them we have proposed the best hybridclassifier consisting of SVM, Decision Tree, RandomForest and XGBoost to attain higher accuracy.
Our proposed hybrid classifier will help the Internet usersverify authentic websites, thereby mitigating the risk ofphishing websites and ensuing secure online usage.
The rest of the paper is organized as follows. In Sec-tion II, few existing works in phishing website detectionare explained. In Section III, all the features are explainedbriefly that we have used in our study. In Section IV, wehave explained the system architecture. Feature selectiontechniques are explained in Section IV. In Section V, wehave presented our results by combining and assessing theperformance of several classifiers. Based on the evaluation,we presented our best classifier for detecting phishing attacks.Finally, we conclude the paper in Section VI.
II. LITERATURE REVIEW
1) Blacklisting & Whitelisting based techniques: Inblacklist-based approach, the requisitioned URL is contrastedwith a pre-established phishing URLs. Whitelisting approachis completely opposite to the blacklist approach. In thewhitelisting approach, the requested URL is compared with apreset authentic URLs. The drawback of these two approachesis that the blacklist or whitelist usually cannot cover everyphishing or legitimate websites since a newly created websitetakes a significant time before being appended to the list.
Li et al. [4] made an assumption that a blacklist based anti-phishing toolbar is more accurate than a whitelist based onefor identifying more phishing websites. authors used Anti-phishing IEPlug and Google Safe Browsing as whitelist andblacklist based anti-phishing toolbar. They found accuracy forboth approach and suggested that both blacklist or whitelistcan be used since they did not find any difference in toolbar.
2) Heuristics and Machine learning-based techniques:There are several techniques for machine learning like Sup-port Vector Machine(SVM), Decision Tree, Random Forest,XGBoost, Artificial Neural Network and so on. Alswailem etal. [7] studied 36 features. Authors ignored irrelevant featuresand selected relevant 26 features. Random Forest classifierwas chosen for classification to pursue high performance.Aminu et al. [9] worked on improving the existing methods by
proposing a hybrid technique (Random Forest and XGBoost)algorithms. For ranking and selecting most relevant features,Random Forest was used. And XGBoost was utilized build-ing the model. They collected dataset from UCI repositorycomprising of 11055 phishing websites. 97.2% accuracy wasobtained using hybrid technique.
3) Content-based approach: Text-based contents are anal-ysed to identify whether the website is phishing or legitimate.There are several techniques such as Deep MD5 Matching,phishDiff, TF-IDF etc. In [5], the authors proposed high-performance content-based phishing attack detection wherefor detecting malicious websites, a file matching algorithmsis executed. Syntactical Fingerprinting algorithm comparestructural components within files. This new algorithm gavelow false positive rate.
4) Visual similarity-based techniques: In these techniquesvisual similarities between web pages are detected by ex-tracting visual features. Chiew et al. [6] proposed a methodwhere logo images were extracted to identify consistencybetween authentic and phishing websites via machine learningtechnique. SVM was used to classify logo and non-logoimages.
III. FEATURE SET
We are determining whether a website is malicious or notbased on its features. So we need to know clearly about thosefeatures. Basically there are four main features:
• Address bar based features (see Table I)• Abnormal based features (see Table II)• HTML and JavaScript based features (see Table III)• Domain based features (see Table IV)Address bar based feature has 12 sub-features, abnormal
based features has 6 sub-features. HTML and JavaScriptbased feature has 5 sub-features and domain based feature has7 sub-features. In Table I, II, III and IV, feature explanationsare given [10]. In this section, we have consolidated total 30features. After that, 23 best features are selected thoroughranking procedure.
IV. PROPOSED APPROACH
Our proposed methodology is shown in Fig. 2. By in-vestigating existing works, we collected our dataset with 30features. After finding out a valid dataset, it is pre-processedusing sampling for splitting the dataset into training and testdataset. Then, the dimensionality of feature subset is reducedand a new feature subset using vedis derifeature rankingprocedure. After that, a hybrid classification algorithm isproposed by combining the concept of bagging and boost-ing.A chrome browser extension is also created for detectingphishing websites.
A. Data collection
We collected our dataset from UCI machine learning repos-itory [11]. This dataset was also used by other works [11],[12]. The dataset comprises of 11055 phishing URLs with 30features where 4898 URLs are legitimate and the remaining’s
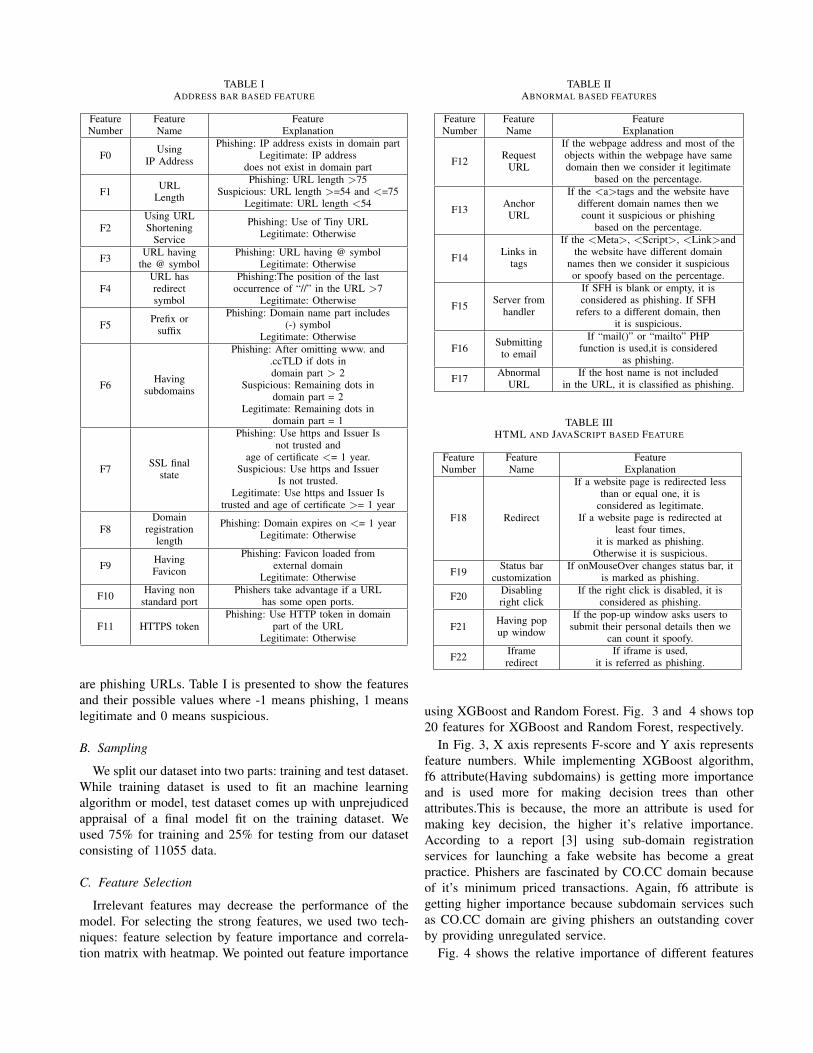
TABLE IADDRESS BAR BASED FEATURE
FeatureNumber
FeatureName
FeatureExplanation
F0 UsingIP Address
Phishing: IP address exists in domain partLegitimate: IP address
does not exist in domain part
F1 URLLength
Phishing: URL length >75Suspicious: URL length >=54 and <=75
Legitimate: URL length <54
F2Using URLShortening
Service
Phishing: Use of Tiny URLLegitimate: Otherwise
F3 URL havingthe @ symbol
Phishing: URL having @ symbolLegitimate: Otherwise
F4URL hasredirectsymbol
Phishing:The position of the lastoccurrence of “//” in the URL >7
Legitimate: Otherwise
F5 Prefix orsuffix
Phishing: Domain name part includes(-) symbol
Legitimate: Otherwise
F6 Havingsubdomains
Phishing: After omitting www. and.ccTLD if dots indomain part > 2
Suspicious: Remaining dots indomain part = 2
Legitimate: Remaining dots indomain part = 1
F7 SSL finalstate
Phishing: Use https and Issuer Isnot trusted and
age of certificate <= 1 year.Suspicious: Use https and Issuer
Is not trusted.Legitimate: Use https and Issuer Is
trusted and age of certificate >= 1 year
F8Domain
registrationlength
Phishing: Domain expires on <= 1 yearLegitimate: Otherwise
F9 HavingFavicon
Phishing: Favicon loaded fromexternal domain
Legitimate: Otherwise
F10 Having nonstandard port
Phishers take advantage if a URLhas some open ports.
F11 HTTPS tokenPhishing: Use HTTP token in domain
part of the URLLegitimate: Otherwise
are phishing URLs. Table I is presented to show the featuresand their possible values where -1 means phishing, 1 meanslegitimate and 0 means suspicious.
B. Sampling
We split our dataset into two parts: training and test dataset.While training dataset is used to fit an machine learningalgorithm or model, test dataset comes up with unprejudicedappraisal of a final model fit on the training dataset. Weused 75% for training and 25% for testing from our datasetconsisting of 11055 data.
C. Feature Selection
Irrelevant features may decrease the performance of themodel. For selecting the strong features, we used two tech-niques: feature selection by feature importance and correla-tion matrix with heatmap. We pointed out feature importance
TABLE IIABNORMAL BASED FEATURES
FeatureNumber
FeatureName
FeatureExplanation
F12 RequestURL
If the webpage address and most of theobjects within the webpage have samedomain then we consider it legitimate
based on the percentage.
F13 AnchorURL
If the <a>tags and the website havedifferent domain names then wecount it suspicious or phishing
based on the percentage.
F14 Links intags
If the <Meta>, <Script>, <Link>andthe website have different domain
names then we consider it suspiciousor spoofy based on the percentage.
F15 Server fromhandler
If SFH is blank or empty, it isconsidered as phishing. If SFH
refers to a different domain, thenit is suspicious.
F16 Submittingto email
If “mail()” or “mailto” PHPfunction is used,it is considered
as phishing.
F17 AbnormalURL
If the host name is not includedin the URL, it is classified as phishing.
TABLE IIIHTML AND JAVASCRIPT BASED FEATURE
FeatureNumber
FeatureName
FeatureExplanation
F18 Redirect
If a website page is redirected lessthan or equal one, it is
considered as legitimate.If a website page is redirected at
least four times,it is marked as phishing.
Otherwise it is suspicious.
F19 Status barcustomization
If onMouseOver changes status bar, itis marked as phishing.
F20 Disablingright click
If the right click is disabled, it isconsidered as phishing.
F21 Having popup window
If the pop-up window asks users tosubmit their personal details then we
can count it spoofy.
F22 Iframeredirect
If iframe is used,it is referred as phishing.
using XGBoost and Random Forest. Fig. 3 and 4 shows top20 features for XGBoost and Random Forest, respectively.
In Fig. 3, X axis represents F-score and Y axis representsfeature numbers. While implementing XGBoost algorithm,f6 attribute(Having subdomains) is getting more importanceand is used more for making decision trees than otherattributes.This is because, the more an attribute is used formaking key decision, the higher it’s relative importance.According to a report [3] using sub-domain registrationservices for launching a fake website has become a greatpractice. Phishers are fascinated by CO.CC domain becauseof it’s minimum priced transactions. Again, f6 attribute isgetting higher importance because subdomain services suchas CO.CC domain are giving phishers an outstanding coverby providing unregulated service.
Fig. 4 shows the relative importance of different features

TABLE IVDOMAIN BASED FEATURE
FeatureNumber
FeatureName
FeatureExplanation
F23 Age ofdomain
If the age of domain isgreater than or equal 6
months, it is classified as legitimate.
F24 DNSrecord
If the DNS record for thedomain is not found,
it is marked as phishing website.
F25 Webtraffic
A higher ranked website hasless chance of being spoofy.If the domain has no traffic
or is not recognized by Alexa database,it is considered as phishing.
F26 Pagerank
If the page rank is less than 0.2,it is marked as phishing.
F27 Googleindexed
If the website is in Google’s index,it is classified as legitimate.
F28Links
pointingto page
If number of links pointing tothe website is zero,
it is considered as phishing.Because phishing websites
have short life span.
F29 Statisticalreport
If the host of the website belongs toany top phishing domains,it is classified as phishing.
Fig. 2. Proposed system
where feature f7 (SSL final state) is the top feature. Thisis because if anyone enter his personal credentials withoutchecking whether a website is authentic or not, it might be in-cepted by adversaries. So, before entering credentials, an usermust check whether the website has encrypted connectionor not. Most of the phishing websites do not use encrypted
Fig. 3. Top 20 features using XGBoost
Fig. 4. Top 20 features for random forest
connection.We also find out correlation matrix with heatmap. By using
correlation matrix, we can find out highly correlated variables.Perfect negative correlation is indicated by -1, whereas +1denotes perfect positive correlation between two variables.And 0 means no association between two variables. Whenthe result becomes negative for some features then we haveomitted those features because those features have a negativeimpact on the result.
Using these techniques, we created several subsets. Amongthem, we have proposed the best feature subset consisting of23 features F0, F1, F3, F5, F6, F7, F8, F10, F11, F12, F13,F14, F15, F16, F20, F21, F23, F24, F25, F26, F27, F28, F29.Because other subsets do not provide better accuracy than thisone. In this way, we reduced the dimensionality of featuresubset. Table V represents accuracy for several feature subsetsincluding our proposed feature subset also. In table V, firstsubset represents top 6 features using Random Forest featureselection technique. Second subset represents top 9 featuresusing XGBoost feature selection technique.Third subset ischosen using correlation matrix with heatmap. We selectedthreshold value +0.1. In subset 4, we have added three more

TABLE VACCURACY FOR SEVERAL FEATURE SUBSETS USING PROPOSED HYBRID
CLASSIFIER
SL. Feature Subsets Accuracy1 F5, F6, F7, F13, F14, F25 93.60%2 F6, F7, F8, F12, F13, F14, F23, F25, F28 94.21%
3 F5, F6, F7, F12, F13, F14,F15, F23, F25, F26, F27 94.46%
4 F0, F5, F6, F7, F12, F13,F14, F15, F23, F24, F25, F26, F27, F29 96.24%
5F0, F1, F3, F5, F6, F7, F10, F11,F12, F13, F14, F15, F16, F20, F21,F23, F24, F25, F26, F27, F29
95.93%
6F0, F1, F3, F5, F6, F7, F8, F10, F11,F12, F13,F14, F15, F16, F20, F21, F23, F24,F25, F26, F27, F28, F29
98.28%
features (F0, F24, F29) contrasted with subset 3 since allpositive result for corresponding features have a positiveimpact in correlation matrix. Here, our selected thresholdvalue is +0.076. We have chosen F11 in subset 5 thoughthe result becomes negative for this feature. Because F11 isranked 17 when we use Random Forest and 18 for XGBoostfeature selection technique. Last subset is our proposed one.we have added two more features (F8 and F28) in subset6 than previous subset 5 as F8 and F28 are also importantaccording to XGBoost and Random Forest feature selectiontechnique.
D. Classification Algorithms
We have applied several classifiers for training, testingand evaluating the performance. Naive Bayes (NB), LogisticRegression (LR), Support Vector Machine (SVM), DecisionTree (DT), Random Forest (RF), XGBoost and several hybridclassifiers such as RF + XGBoost, DT + XGBoost, DT + RF,DT + RF + XGBoost, SVM + DT + XGBoost,SVM + DT+ RF, LR + DT + RF + XGBoost and SVM + DT + RF +XGBoost were applied.
E. Browser Extension
We have also created a browser extension. When the userenters a URL, the extension accepts the URL using the GETmethod and passes the same to the python code using the Javascript of the extension. The python code forms an array bypulling out all the features from the URL. We then test this onthe trained hybrid classifier consisting of SVM, DT, RF andXGBoost. We have tested our proposed system against somephishing urls for example [email protected]/secure-environment and also against some legitimate urls for exam-ple https://www.phishing.org/ etc.
The screenshots of browser extension for detecting safe andphishing website are shown in Fig. 5 and Fig. 6, respectively.
V. PERFORMANCE EVALUATION
We have measured the effectiveness of our proposed sys-tem by the various performance metrics, such as Accuracy,Precision, Recall and F1-score which can be calculated using
Fig. 5. Result for a safe website
Fig. 6. Result for a phishing website
four terms: True Positive (TP), True Negative (TN), FalsePositive (FP), False Negative (FN) as follows:
Accuracy =TP + TN
TP + FP + TN + FN(1)
Precision =TP
TP + FP(2)
Recall =TP
TP + FN(3)
F1− score =2 ∗ Precision ∗Recall
Precision+Recall(4)
Table VI summarizes the results (accuracy, precision, re-call, F1-score) for the phishing detection data set for allclassifiers: Naive Bayes, LR, SVM, Decision Tree, RandomForest, XGBoost and combination of these classifiers for all30 features. Our proposed hybrid classifier outperforms otherclassifiers by 36.69%, 5.18%, 5.11%, 1.59%, 0.63%, 0.89%,0.34%, 1.44%, 1.23%, 0.29%, 0.37%, 0.34% and 0.14%respectively, for all 30 features. This is because we havemerged the concept of bagging and boosting for classifierswhich provides stability and fault-tolerance in contrast totraditional classification methods.
We have selected significant 23 features among 30 fea-tures. Various classifiers were applied on these 23 features.Such dimensionality reduction of the dataset has resulted insignificant reduction in classification delay and improved theaccuracy of the detection system. Table VII shows perfor-mance results such as accuracy, precision, recall, F1-score of
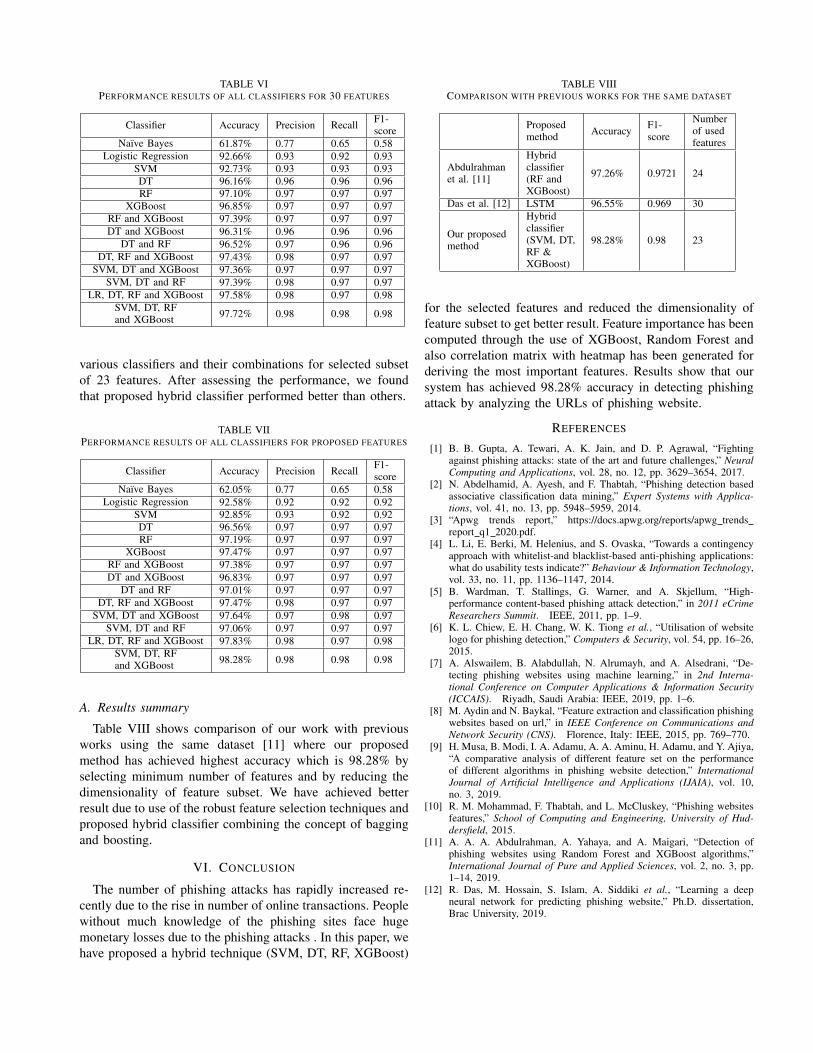
TABLE VIPERFORMANCE RESULTS OF ALL CLASSIFIERS FOR 30 FEATURES
Classifier Accuracy Precision Recall F1-score
Naı̈ve Bayes 61.87% 0.77 0.65 0.58Logistic Regression 92.66% 0.93 0.92 0.93
SVM 92.73% 0.93 0.93 0.93DT 96.16% 0.96 0.96 0.96RF 97.10% 0.97 0.97 0.97
XGBoost 96.85% 0.97 0.97 0.97RF and XGBoost 97.39% 0.97 0.97 0.97DT and XGBoost 96.31% 0.96 0.96 0.96
DT and RF 96.52% 0.97 0.96 0.96DT, RF and XGBoost 97.43% 0.98 0.97 0.97
SVM, DT and XGBoost 97.36% 0.97 0.97 0.97SVM, DT and RF 97.39% 0.98 0.97 0.97
LR, DT, RF and XGBoost 97.58% 0.98 0.97 0.98SVM, DT, RFand XGBoost 97.72% 0.98 0.98 0.98
various classifiers and their combinations for selected subsetof 23 features. After assessing the performance, we foundthat proposed hybrid classifier performed better than others.
TABLE VIIPERFORMANCE RESULTS OF ALL CLASSIFIERS FOR PROPOSED FEATURES
Classifier Accuracy Precision Recall F1-score
Naı̈ve Bayes 62.05% 0.77 0.65 0.58Logistic Regression 92.58% 0.92 0.92 0.92
SVM 92.85% 0.93 0.92 0.92DT 96.56% 0.97 0.97 0.97RF 97.19% 0.97 0.97 0.97
XGBoost 97.47% 0.97 0.97 0.97RF and XGBoost 97.38% 0.97 0.97 0.97DT and XGBoost 96.83% 0.97 0.97 0.97
DT and RF 97.01% 0.97 0.97 0.97DT, RF and XGBoost 97.47% 0.98 0.97 0.97
SVM, DT and XGBoost 97.64% 0.97 0.98 0.97SVM, DT and RF 97.06% 0.97 0.97 0.97
LR, DT, RF and XGBoost 97.83% 0.98 0.97 0.98SVM, DT, RFand XGBoost 98.28% 0.98 0.98 0.98
A. Results summary
Table VIII shows comparison of our work with previousworks using the same dataset [11] where our proposedmethod has achieved highest accuracy which is 98.28% byselecting minimum number of features and by reducing thedimensionality of feature subset. We have achieved betterresult due to use of the robust feature selection techniques andproposed hybrid classifier combining the concept of baggingand boosting.
VI. CONCLUSION
The number of phishing attacks has rapidly increased re-cently due to the rise in number of online transactions. Peoplewithout much knowledge of the phishing sites face hugemonetary losses due to the phishing attacks . In this paper, wehave proposed a hybrid technique (SVM, DT, RF, XGBoost)
TABLE VIIICOMPARISON WITH PREVIOUS WORKS FOR THE SAME DATASET
Proposedmethod Accuracy F1-
score
Numberof usedfeatures
Abdulrahmanet al. [11]
Hybridclassifier(RF andXGBoost)
97.26% 0.9721 24
Das et al. [12] LSTM 96.55% 0.969 30
Our proposedmethod
Hybridclassifier(SVM, DT,RF &XGBoost)
98.28% 0.98 23
for the selected features and reduced the dimensionality offeature subset to get better result. Feature importance has beencomputed through the use of XGBoost, Random Forest andalso correlation matrix with heatmap has been generated forderiving the most important features. Results show that oursystem has achieved 98.28% accuracy in detecting phishingattack by analyzing the URLs of phishing website.
REFERENCES
[1] B. B. Gupta, A. Tewari, A. K. Jain, and D. P. Agrawal, “Fightingagainst phishing attacks: state of the art and future challenges,” NeuralComputing and Applications, vol. 28, no. 12, pp. 3629–3654, 2017.
[2] N. Abdelhamid, A. Ayesh, and F. Thabtah, “Phishing detection basedassociative classification data mining,” Expert Systems with Applica-tions, vol. 41, no. 13, pp. 5948–5959, 2014.
[3] “Apwg trends report,” https://docs.apwg.org/reports/apwg trendsreport q1 2020.pdf.
[4] L. Li, E. Berki, M. Helenius, and S. Ovaska, “Towards a contingencyapproach with whitelist-and blacklist-based anti-phishing applications:what do usability tests indicate?” Behaviour & Information Technology,vol. 33, no. 11, pp. 1136–1147, 2014.
[5] B. Wardman, T. Stallings, G. Warner, and A. Skjellum, “High-performance content-based phishing attack detection,” in 2011 eCrimeResearchers Summit. IEEE, 2011, pp. 1–9.
[6] K. L. Chiew, E. H. Chang, W. K. Tiong et al., “Utilisation of websitelogo for phishing detection,” Computers & Security, vol. 54, pp. 16–26,2015.
[7] A. Alswailem, B. Alabdullah, N. Alrumayh, and A. Alsedrani, “De-tecting phishing websites using machine learning,” in 2nd Interna-tional Conference on Computer Applications & Information Security(ICCAIS). Riyadh, Saudi Arabia: IEEE, 2019, pp. 1–6.
[8] M. Aydin and N. Baykal, “Feature extraction and classification phishingwebsites based on url,” in IEEE Conference on Communications andNetwork Security (CNS). Florence, Italy: IEEE, 2015, pp. 769–770.
[9] H. Musa, B. Modi, I. A. Adamu, A. A. Aminu, H. Adamu, and Y. Ajiya,“A comparative analysis of different feature set on the performanceof different algorithms in phishing website detection,” InternationalJournal of Artificial Intelligence and Applications (IJAIA), vol. 10,no. 3, 2019.
[10] R. M. Mohammad, F. Thabtah, and L. McCluskey, “Phishing websitesfeatures,” School of Computing and Engineering, University of Hud-dersfield, 2015.
[11] A. A. A. Abdulrahman, A. Yahaya, and A. Maigari, “Detection ofphishing websites using Random Forest and XGBoost algorithms,”International Journal of Pure and Applied Sciences, vol. 2, no. 3, pp.1–14, 2019.
[12] R. Das, M. Hossain, S. Islam, A. Siddiki et al., “Learning a deepneural network for predicting phishing website,” Ph.D. dissertation,Brac University, 2019.
Related Documents











