A Discriminative Framework A Discriminative Framework for Clustering via Similarity for Clustering via Similarity Functions Functions Maria-Florina Balcan Carnegie Mellon University Joint with Avrim Blum and Santosh Vempala

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A Discriminative Framework for A Discriminative Framework for
Clustering via Similarity FunctionsClustering via Similarity Functions
Maria-Florina BalcanCarnegie Mellon University
Joint with Avrim Blum and Santosh Vempala

2
Brief Overview of the Talk
Vague, difficult to reason
about
at a general technical level.
Supervised
Learning
Good theoretical
models:
Clustering
Lack of good unified
models.
Learning from labeled
data. Learning from unlabeled data.
• PAC, SLT
• Kernels & Similarity fns
A PAC-style
framework
Our work: fix the problem

3
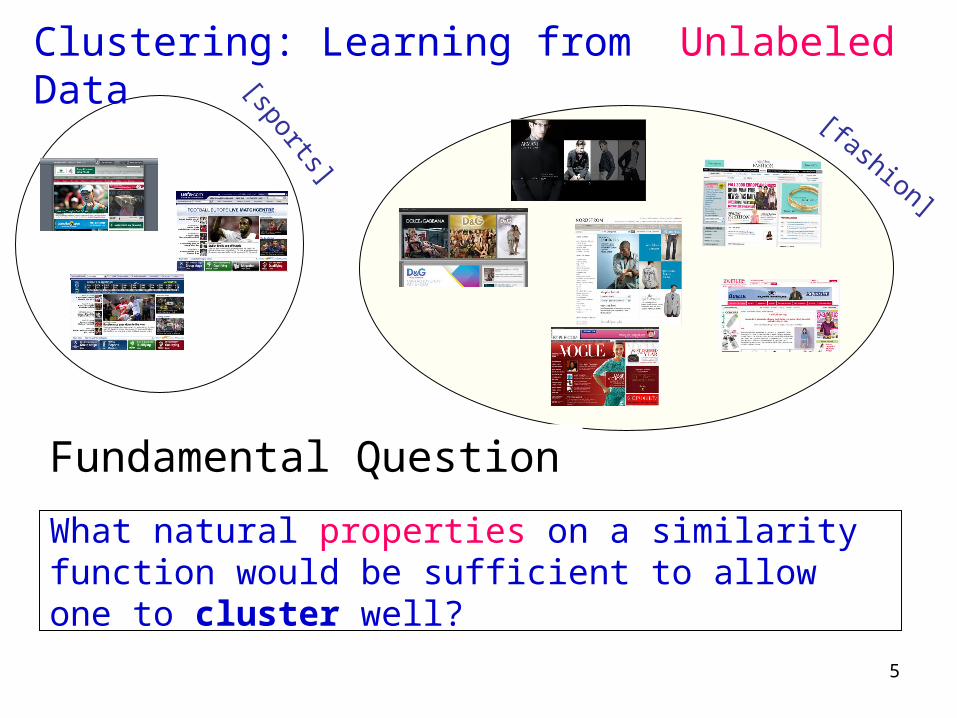
Clustering: Learning from Unlabeled Data
[documents]
[topic]
S set of n objects.
9 ground truth clustering.
Goal: h of low error where
x, l(x) in {1,…,t}.
err(h) = minPrx~S[(h(x)) l(x)]
Problem: unlabeled data only!
But have a Similarity Function!
[sports]
[fashion]

4
Clustering: Learning from Unlabeled Data
[sports]
[fashion]
9 ground truth clustering for S
i.e., each x in S has l(x) in {1,…,t}. The similarity function K has to be related to the ground-truth.
Input S, a similarity function K.
Output Clustering of small error.
Protocol
5
Clustering: Learning from Unlabeled Data
[sports]
[fashion]
What natural properties on a similarity function would be sufficient to allow one to cluster well?
Fundamental Question
6
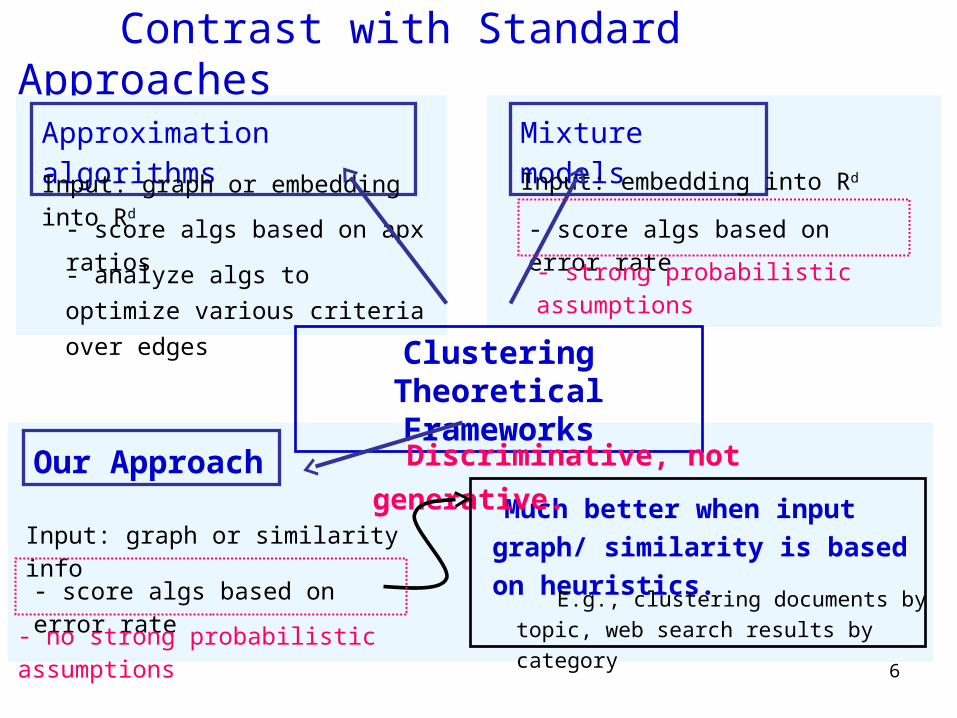
Contrast with Standard Approaches
Approximation algorithms
- analyze algs to optimize
various criteria over edges
- score algs based on apx ratios
Input: graph or embedding into Rd
Much better when input graph/ similarity is based on heuristics.
Mixture models
Clustering Theoretical Frameworks
Our Approach
Discriminative, not
generative.
Input: embedding into Rd
- score algs based on error rate
- strong probabilistic assumptions
Input: graph or similarity info
- score algs based on error rate
- no strong probabilistic assumptions
E.g., clustering documents by topic, web search results by category

7
[sports][fashion]
Condition that trivially works.
K(x,y) > 0 for all x,y, K(x,y) > 0 for all x,y, ll(x) = (x) = ll(y).(y).
K(x,y) < 0 for all x,y, K(x,y) < 0 for all x,y, ll(x) (x) ll(y).(y).
C C’
A A’
What natural properties on a similarity function would be sufficient to allow one to cluster well?

8
Problem: same K can satisfy it for two very different, equally natural clusterings of the same data!
All x more similar to all y in own cluster than any z in any other cluster
sports fashion
soccer
tennis
Lacoste
Gucci
sports fashion
soccer
tennis
Lacoste
Gucci
K(x,x’)=1
K(x,x’)=0.5K(x,x’)=0
What natural properties on a similarity function would be sufficient to allow one to cluster well?

9
Relax Our Goals
1. Produce a hierarchical clustering s.t. correct answer is approximately some pruning of it.

10
Relax Our Goals
soccer
tennis
Lacoste
Gucci
1. Produce a hierarchical clustering s.t. correct answer is approximately some pruning of it.
soccer
sports fashion
Guccitennis Lacoste
All topics
2. List of clusterings s.t. at least one has low error.
Tradeoff strength of assumption with size of list.Obtain a rich, general model.

11
Strict Separation Property
Single-Linkage.
• merge “parts” whose max similarity is highest.
Sufficient for hierarchical clustering
(If K is symmetric)
soccer
sports fashion
Guccitennis Lacoste
All topics
All x more similar to all y in own cluster than any z in any other cluster
sports fashion
soccer
tennis
Lacoste
1
0.5 0
Gucci
Algorithm

12
Strict Separation Property
Use Single-Linkage, construct a tree s.t. ground-truth clustering is a pruning of the tree.
Theorem
All x more similar to all y in own cluster than any z in any other cluster
If use c-approx. alg. to objective f (e.g, k-median) to minimize error rate, then implicit assumption:
Most points (1-O() fraction) satisfy Strict Separation.
Clusterings within factor c of optimal are Clusterings within factor c of optimal are -close to the target.-close to the target.
Incorporate Approximation Assumptions in Our Model
Can still cluster well in the tree model.
k-median,
k-means

13
Stability Property
Sufficient for hierarchical clustering
Merge “parts” whose average similarity is highest.
Single linkage fails, but average linkage works.
Neither A or A’ more attracted to the other one than to the rest of its own cluster.
For all C, C’, all A ½ C, A’ µ C’, K(A,C-A) > K(A,A’)(K(A,A’) - average attraction between A and A’)
AA’
C C’

14
Stability Property
K(P1,P3) ¸ K(P1,C-P1) and
K(P1,C-P1) > K(P1,P2).
All “parts” laminar wrt target clustering.
Contradiction.
Analysis:
Use Average Linkage, construct a tree s.t. the ground-truth clustering is a pruning of the tree.
Theorem
• Failure iff merge P1, P2 s.t. P1½ C, P2Å C =.
• But must exist P3 ½ C s.t.
P1
P2P3C
(K(A,A’) - average attraction between A and A’)
AA’
C C’
For all C, C’, all A ½ C, A’ µ C’, K(A,C-A) > K(A,A’)

15
Stability Property
(K(A,A’) - average attraction between A and A’)
AA’
C C’
Average Linkage breaks down if K is not symmetric. 0.5
0.25
Instead, run “Boruvka-inspired” algorithm:
– Each current cluster Ci points to argmaxCjK(Ci,Cj)
– Merge directed cycles.
For all C, C’, all A ½ C, A’ µ C’, K(A,C-A) > K(A,A’)
16
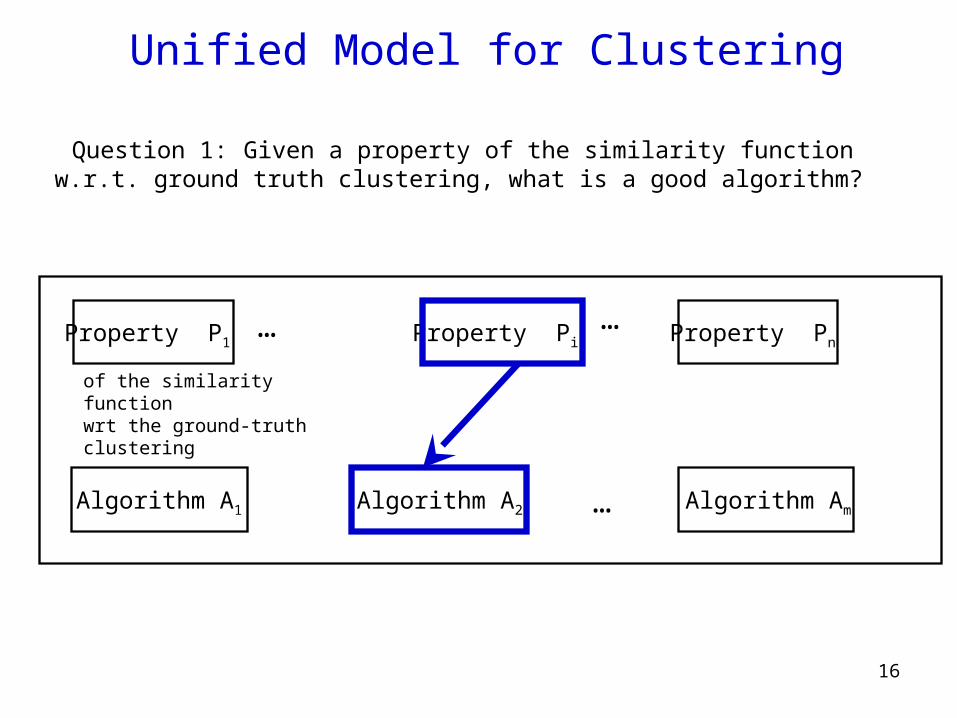
Unified Model for Clustering
Algorithm A1
…
…
…Property P1 Property Pi Property Pn
Algorithm A2 Algorithm Am
of the similarity functionwrt the ground-truth clustering
Question 1: Given a property of the similarity function w.r.t. ground truth clustering, what is a good algorithm?
17
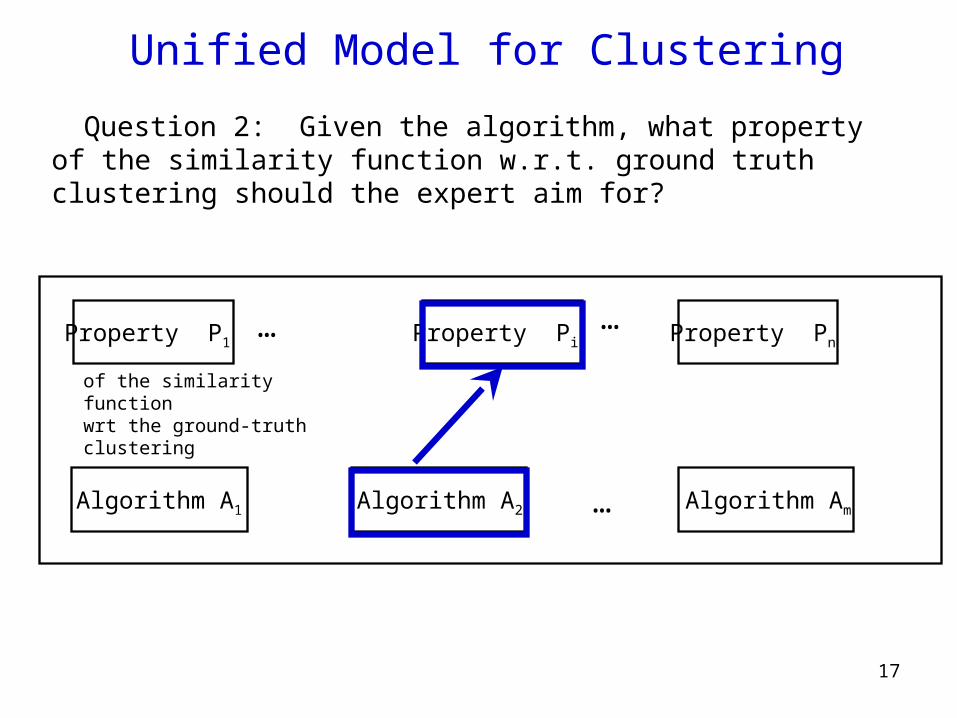
Unified Model for Clustering
Algorithm A1
…
…
…Property P1 Property Pi Property Pn
Algorithm A2 Algorithm Am
of the similarity functionwrt the ground-truth clustering
Question 2: Given the algorithm, what property of the similarity function w.r.t. ground truth clustering should the expert aim for?

18
Other Examples of Properties and Algorithms
AA’
C C’
Sufficient for hierarchical clustering
Find hierarchy using a multi-stage learning-based algorithm.
Average Attraction Property
Not sufficient for hierarchical clustering
Can produce a small list of clusterings.(sampling based algorithm)
Stability of Large Subsets Property
Upper bound:tO(t/2 log t/) Lower bound:tO(1/)
EEx’ x’ 22 C(x) C(x)[K(x,x’)] > E[K(x,x’)] > Ex’ x’ 22 C’ C’ [K(x,x’)]+[K(x,x’)]+ (8 C’C(x))
For all clusters C, C’, for all Aµ C, A’ µ C, |A|+|A’|¸ sn, neither A nor A’ more attracted to the other one than to the rest of its own cluster.

19
1) Generate list L of candidate clusters (average attraction alg.)
2) For every (C, C0) in L s.t. all three parts are large:
3) Clean and hook up the surviving clusters into a tree.
If K(C Å C0, C \ C0) ¸ K(C Å C0, C0 \ C),
then throw out C0
C
C0
C Å C0
Ensure that any ground-truth cluster is f-close to one in L.
Else throw out C.
ClusteringClustering
AA’
Algorithm
C C’For all C, C’, all A ½ C, A’ µ C’, K(A,C-A) > K(A,A’)
|A|+|A’| ¸ sn
Stability of Large Subsets Property

20
Stability of Large Subsets
A
For all C, C’, all A½C, A’µC’, |A|+|A’| ¸ sn
K(A,C-A) > K(A,A’)+
ClusteringClustering
A’
C C’
If s=O(2/k2), f=O(2 /k2), then produce a tree s.t. the ground-truth is -close to a pruning.
Theorem

21
The Inductive Setting
Insert new points as they arrive.
Draw sample S, cluster S (in the list or tree model).
Inductive Setting
Many of our algorithms extend naturally to this setting.
instance space XSample S
xxxx
To get poly time for stab of all subsets, need to argue that sampling preserves stability. [AFKK]

22
Similarity Functions for Clustering, Summary
• Natural conditions on K to be useful for clustering.
• For robust theory, relax objective: hierarchy, list.
• Algos for stability of large subsets; -strict separation.
• Algos and analysis for the inductive setting.
Main Conceptual Contributions
Technically Most Difficult Aspects
• A general model that parallels PAC, SLT, Learning with
Kernels and Similarity Functions in Supervised Classification.

23
Related Documents











