A COMPUTATIONAL LINGUISTIC APPROACH FOR METADATA GENERATION FOR HINDI POETRY A Ph.D. Synopsis submitted to GUJARAT TECHNOLOGICAL UNIVERSITY, AHMEDABAD for the Award of Doctor of Philosophy in Computer Science By MILIND KUMAR AUDICHYA 159997431001 Under the Supervision of DR. JATINDERKUMAR RAMDASS SAINI Professor and Director, Symbiosis Institute of Computer Studies and Research, Symbiosis International (Deemed University), Pune, India. DPC Member 1 DR. RAVI M. GULATI Associate Professor, Veer Narmad South Gujarat University, Surat, India. DPC Member 2 DR. RUSTOM D. MORENA Professor, Veer Narmad South Gujarat University, Surat, India.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A COMPUTATIONAL LINGUISTIC APPROACH FOR
METADATA GENERATION FOR HINDI POETRY
A Ph.D. Synopsis submitted to
GUJARAT TECHNOLOGICAL UNIVERSITY,
AHMEDABAD
for the Award of
Doctor of Philosophy
in
Computer Science
By
MILIND KUMAR AUDICHYA
159997431001
Under the Supervision of
DR. JATINDERKUMAR RAMDASS SAINI
Professor and Director, Symbiosis Institute of Computer Studies and Research,
Symbiosis International (Deemed University), Pune, India.
DPC Member 1
DR. RAVI M. GULATI
Associate Professor,Veer Narmad South Gujarat University,
Surat, India.
DPC Member 2
DR. RUSTOM D. MORENA
Professor,Veer Narmad South Gujarat University,
Surat, India.

2
Table of Contents
A. Title of the thesis and abstract .......................................................................................... 3
a. Title ........................................................................................................................................... 3
b. Abstract ..................................................................................................................................... 3
B. A brief description of the state of the art of the research topic ....................................... 5
C. Motivation.......................................................................................................................... 7
D. Definition of the Problem ................................................................................................. 7
E. Objective and Scope of work ............................................................................................. 8
F. Original contribution by the thesis. .................................................................................. 8
G. The methodology of Research, Results / Comparisons ................................................... 9
H. Achievements concerning objectives .............................................................................. 16
I. Conclusion ....................................................................................................................... 17
J. Copies of papers published and a list of all publications arising from the thesis ........ 17
K. Patents (if any) ................................................................................................................ 18
L. References ....................................................................................................................... 18

3
A. Title of the thesis and abstract
a. Title
A Computational Linguistic Approach For Metadata Generation For Hindi Poetry
b. Abstract
Poems are an unbreakable part of literature. Many poems have been written and
are being written in Hindi literature as well. Hindi poems are mainly based on verses
(‘Chhand’), the figure of speech (‘Alankar’), and emotions (‘Ras’). This trio itself is a
research series in terms of research. This research work focuses explicitly on the verses.
The composition of verses in Hindi literature requires the knowledge of special rules.
These rules of verses are gradually becoming extinct. People who know the
composition of the verses are gradually becoming extinct, and there is no official
standard of the rules of the verses except the well-known verses. How much better will
it be if a poem inputted to a computer and the computer identifies that this poem is
written using this verse? It sounds great, isn’t it? Well, this research work is trying to
do something beyond that.
In various research of languages by natural language processing (NLP), Hindi
has an important place. However, the verses are still untouched in this context. From
the point of view of computational linguistics (CL), knowledge of the extinct verses
can be saved. This research is the best combination of the NLP and CL, wherein NLP
one can do wonders using human language, and in CL, computers are used to
understand the languages. Here both are performing their duties very well to establish
an automatic metadata generator of poetries based on the different rules of Hindi verses.
As the research work is an initial one and unique in this segment, it opens a new wing
in the research domain for upcoming researchers.
The research proposes a systematic hierarchical structure of Hindi verses and
the proper management of the different composition rules of verses after identifying
and validating the rules. This research work mainly revolves around the rule-based
modeling of an automatic metadata generator based on the well-managed verse rules.
Apart from that, the proposed metadata generator is robust and sufficient to handle both
old and new poems. From the implementation and application perspective, for a better

4
understanding of poem words, meaning and examples are suggested with the existing
wordnet integration. Stop word filtering, symbolic representation, and numerical
sequence with verse identification make this research work more innovatively
beautiful. A similar example suggestion for the detected verse is the cherry on the
writers’ community’s cake feature. With this all, the primary and regular metadata is
essential, including Character Count, Word Count, Diacritic Count, Total Laghu Matra,
Total Guru Matra, Total Half Characters, Line Count, Charan Count, Matra Count,
Varna Count, Charan Matra Count, Charan Matra Sum, Charna Varna, Charan Varna
Sum. One can now imagine this research work’s beauty and its value for the research
fraternity.
This research work is not associated with the development of an algorithm to
understand or interpret Hindi poems. However, it gives a mechanism for distinguishing
between the different kinds of Hindi verses by identifying them through the rule-based
modeled automatic metadata generator. As a perk, this study provided meanings and
examples of the words used in the poem with the help of Wordnet but also irrespective
of context.
The purpose of the research is to open a new research wing, emphasizing the
significance of verses identification in Hindi poetry. Moreover, one might find this a
meaningful application for learning about the different Hindi verses. Apart from that,
if anyone wants to search any Hindi verse-based poetry in a database or a search engine,
the results are generally delivered through keyword matching; with this traditional
approach, a user might not always get the correct result. Instead, suppose the metadata
generated by this automatic metadata generator gets stored while storing the poems. In
that case, it will help populate the exact results by using that metadata to the users, and
it will also provide users their specific interest-based result filtering features. It is just
one of the applications of this research. Additionally, research in this segment may
improve our existing knowledge by bringing out the high intellect hidden behind the
Hindi verses’ composition rules.

B. A brief description of the state of the art of the research topic
Hindi is one of the constitutionally accepted official languages of the Republic
of India. Devanagari script is used to write the Hindi language and is also used for over
120 languages[1]. The Devanagari Unicode range for Hindi is 0900–097F [2]. To know
state of the art with an aspect to Hindi verses based researches, an extensive literature
review was carried out.
Since the 1950s, Natural Language Processing (NLP) and Computational
Linguistics (CL) researches are going parallelly to deliver and serve society something
extraordinary[3]. Usually, both are often considered a grouped bundled part of artificial
intelligence (AI), but both were present even before artificial intelligence came into the
picture[4]. In this combination of NLP and CL, both computers and human languages
are equally important.
Poems, written in any language, give a different experience in itself. Many
Writers follow specific predefined rules for writing poems so that the joy of those
poems is increased. Many poems have been written in the Hindi language for centuries.
A literature review is a fundamental part of any research work. For the same, best efforts
had been given to find out the relevant research works. Research work directly related
to the metadata generation, related to the Hindi Prosody, and precisely based on the
Computation Linguistics not found.
Some nearby research work related to computational linguistics or metadata
generation was seen, which is enlightening here. Only two slightly nearby research
works were found in the recent literature review. Joshi and Kushwah[5] did research
emphasizing the detection of “Chaupai Chhand” in Hindi Poems and achieved 95.03%
accuracy using an automatic Chaupai detection algorithm developed in Java (JDK 8.1).
In another research, Kushwah and Joshi[6] researched “Rola: An Equi-Matrik Chhand
of Hindi Poems” and achieved 89.83% accuracy through their algorithm.
In some other poetry classification-related works Bafna and Saini[7-9] classify
Hindi verses such as Bal geet, Bhajan, Desh Bhakti, and Updesh Geet using different
machine learning algorithms. Kaur and Saini[10] researched Punjabi poetry
classification tests on the ten machine learning algorithms on 240 poetries. They
achieved respective accuracy of 50.63% (Hyperpipes), 52.92% (K- nearest neighbor),
52.75% (Naive Bayes), and 58.79% (Support Vector Machine). In another research
work, Kaur and Saini[11] worked for poetry classification using machine learning

6
algorithms with the reduced feature set and found that with 60% accuracy Naive Bayes
performed the best.
Kaur and Saini[12] worked for automatic Punjabi poetry classification using
poetic features on 2034 poetries and achieved 71.98% accuracy with the Support Vector
Machine (SVM) algorithm. Kaur and Saini[13-14] also attempted to develop a Punjabi
poetry classifier using logistics features and weighting in different research works and
tested using different algorithms with different textual features.
Some ‘Ras’ related works were also seen. Kaur and Saini[12] worked for
automatic Punjabi poetry classification using poetic features on 2034 poetries and
achieved 71.98% accuracy with the Support Vector Machine (SVM) algorithm. Kaur
and Saini[13-14] also attempted to develop a Punjabi poetry classifier using logistics
features and weighting in different research works and tested using different algorithms
with different textual features.
Bafna and Saini[17] also worked for Hindi and Marathi poems and stories token
extraction applications using Zipf’s law to count and compression extracted tokens.
They used 820 poems, 710 stories for Hindi and 505 poems, and 610 stories for Marathi.
Bafna and Saini[18] worked for a technique, “BaSa” to identify context-based common
tokens for Hindi verses and prose. Total 820 proses and 710 verses were processed.
In other works of other related languages, Sanskrit Computational Linguistics
related work by Kulkarni and Huet[19] were seen and observed. They worked on
Panini’s Astadhyayi structure and parsing related issues and machine translation. Han
et al.[20] researched the rule-based metadata extraction from documents. Different
research works related to computational linguistics based metadata generation were
explored [21-23]. Ghneim et al.[24] did extensive research work for Arabic poetry
based on gender, dialect, and age. Hamidi et al.[25] worked for the automatic meter
classification in Persian poetries. He et al.[26] worked with SVM based classification
methods for poetry styles. Abbasi et al.[27] did sentiment analysis in multiple
languages. Kaur and Saini[28] also studied opinion mining in Indo-Aryan, Dravidian,
and Tibeto-Burman language families.
After research-level articles, efforts were made to find the facts and information
in old ancient books also. Some ancient books published almost before 50 years were
found in the archive of the web in which we found some information regarding
Chhands, And we found that all the books were coming from a base book named
‘Chhand Prabhakar’ written by Jagannath Prasad[29-31].

7
‘Chhands’ are one of the six Vedangs, which are auxiliary disciplines
associated with Vedas’ study in Vedic culture, developed in ancient times. We also
found the presence of information related to Chhands in Agni Purana[32], one of the
eighteen Puranas. The core information related to Chhands and other writing arts can
be seen in Agni Purana from Chapter 328 to 347. All this information is in Sanskrit,
which is an old Indo-Aryan language. Chhandsharstra, which provides knowledge of
creating Chhands, which is discussed and referenced in Vedas and Puranas, was created
by a saint and great old mathematician named Pingal is also known as Pingalacharya
and Sheshavtar.
Apart from the research kind of publication, some findings from the ancient
books and some information related to the ‘Chhands’ only can be obtained from the
various books, blogs, and experts contributions (Dr. G. Wankhede, Maharashtra and
Dr. G. R. Dudwe, Madhya Pradesh) [33-35]. The information found from these sources
vary, or we can say they are contradictory [36-37].
Despite all the research efforts so far, the authors could not discover any
research related to the verses identification in Hindi poetry. From the aspect of
computational linguistics, this lack of research motivated us to initialize this research
work.
C. Motivation
After a thorough literature review, it was observed that Hindi has a rich heritage
of poetry. Many verses are written in the Hindi language. This composition of verses
in Hindi has been from ancient times. The knowledge hidden behind the rules of the
creation of verses is genuinely inspiring. The metadata generation based on Hindi
Poetry can improve the current search engine results based on metadata information
based filtered search queries. Also, it can be used for the advancement of digital
libraries. However, not much research work was seen in this area, and this research gap
inspired us to do this research work.
D. Definition of the Problem
The official languages used by the Central Government of India are Hindi and
English. Hindi is one of the 23 constitutionally recognized official languages in India.
The Hindi language is having a vast heritage of poetry. A significant portion of poetry
is available in the form of physical books, magazines, and papers. Physical Hindi poetry

8
will be digitized today or tomorrow as research works to digitize the offline physical
data at a good pace using Optical Character Recognition (OCR), which helps store data
through the higher quality of document imaging. Some advanced OCR based research
works even claim to extract text out of it. Here comes the need for the hour; there is a
need for a particular automatic system to generate the metadata about these poems
individually to manage and digitize the Hindi poetry systematically.
In this aspect, the problem is developing a strong rule-based automatic metadata
generator that can identify the poetry based on the existing rules and capable enough to
incorporate the new practices in upcoming times with no or minimal efforts.
E. Objective and Scope of work
● To come out with a systematic hierarchical structure of Hindi verses.
● To model the metadata generator through computational linguistics perspective
rule-based modeling of Hindi verses construction rules for Hindi poetry.
● To develop a corpus for Hindi poetry
F. Original contribution by the thesis.
The entire work mentioned in this synopsis is innovative and novel work, with
the research papers as evidence. The proposed automatic metadata generator has been
visualized as a collection of various functionalities with the relevant publications. The
details of the associated research papers are as follow:
Papers Presented and Published:
1. Computational linguistic prosody rule-based unified technique for automatic
metadata generation for Hindi poetry, IEEE - 2019 1st International Conference
on Advances in Information Technology (ICAIT), Chikmagalur, India, 2019
2. Stanza Type Identification using Systematization of Versification System of
Hindi Poetry, International Journal of Advanced Computer Science and
Applications (IJACSA), 2021
3. Towards Natural Language Processing with Figures of Speech in Hindi Poetry.
International Journal of Advanced Computer Science and Applications
(IJACSA), 2021

9
G. The methodology of Research, Results / Comparisons
a. ‘Chhand’ Introduction
The research work is majorly based on the Hindi verses, and there are plenty of
rules for the construction of verse associated with the different Hindi verses. Each verse
is having its own unique rule of formation. Hindi verses are based on plenty of rules. It
is not possible to include all the rules in the synopsis hence just focusing on the Part of
Verse, Types of Verse, and Classification and Identification related parts only.
Character, No. of Characters and their sequence, diacritics count, and quantity
and pause-speed related rules create a Verse which is known as ‘Chhand’. There are six
major parts of ‘Chhand’, which are: 1. Stanza, 2. Characters and Quantity, 3. Flow, 4.
Pause, 5. End of Stanza, 6. Predefined Sequence of Characters.
There are two types of ‘Chhands’ which are widely known as 1. ‘Vedic Chhand’
and 2. ‘Laukik Chhand’. This research work is dealing with the second type, ‘Laukik
Chhand’. Classification of verses for this research is based on the Hindi’ Laukik
Chhand’, There are three main streams of this type, which are known as: 1. ‘Matrik
Chhand’, 2. ‘Varnik Chhand’, 3. ‘Mukt’ or ‘Muktak Chhand’. Chhands in which Matra
(Quantity) Count is fixed are called Matrik Chhand. In Varnik Chhand, all stanza will
be having the same number of characters, along with the sequence for the characters
based on the different rules. ‘Mukt Chhand’ doesn’t have any specific rule like ‘Varnik’
or ‘Matrik’. This type was introduced later and can be said to be free-form. Including
these mainstream class types, In this research work, 111 different Chhand classes were
included, which are having specific appropriate rules. These three stream classes are
further divided into several classes and subclasses, which are denoted as subtypes and
subtypes of subtypes. Although not each subtype is having further subtypes or ‘Chhand’
but this research is structured in such a way that in case if in any class any new kind of
‘Chhand’ is found or will be found, then it will not require much effort to integrate with
the system.
Based on the systemized rules, the best attempts were made to provide the best
possible concrete concept for the automatic metadata generation for Hindi poetries by
incorporating the rules-based unified modeling. Based on the systemized rules, the
best attempts were made to provide the best possible concrete concept for the
automatic metadata generation for Hindi poetries by incorporating the rules-based
unified modeling.

10
b. Data Preprocessing
UTF-8 standard encoded data for Devanagari was chosen to work with as input
for automatic metadata generator to use and integrate with the latest technologies and
will be more comfortable in the future. The automatic metadata generator expects the
information in the form of the UTF-8 based complete poems or a few lines or part of
poems. These lines are further processed for the pre-processing of the input for passing
it for further calculations after some necessary trimming and cleaning operations. Once
the pre-processed data is ready after the trimming operation, the cleaned data can be
passed for the next separation-related operations. Multiple levels of the separations
take place as per the demand of this research work. Initially, the separation of data is
for the line-level break based on the new line character (‘\n’) as the standard delimiter
for separating the lines.
After the separation of lines, the lines need to be further split into the parts known as
stanzas or ‘Charans’ of the verse. Separation uses a few delimiters (‘,’,’ || ‘, ‘| ‘). Any
other delimiter can also be used with a few minor changes. Once ‘Charan’ gets
separated, the separate stanzas are further chopped into the words by performing word-
level separation. Separated words further get divided into the characters and diacritics.
c. Identification and Detection of ‘Chhand’ based on the classification
Let us understand the concept of identification and detection with an example for in-
depth conceptual clarity. Here is an example of a Hindi verse named ‘Doha’ from
‘Hanuman Chalisa’ written by Saint Tulsidas.
पवनतनय संकट हरन, मंगल मरूित �प ।
राम लखन सीता सिहत, �दय बसह� सुर भपू ।।
These lines are inputted into the metadata generator, and the lines will go through the
trimming operation before the separation operation takes place.
Line Separation: (2 Lines)
Line 1: 'पवनतनय संकट हरन, मंगल मरूित �प',
Line 2: 'राम लखन सीता सिहत, �दय बसह� सुर भपू’
Stanza / ‘Charan’ Separation: (4 Stanzas)
Stanza 1: 'पवनतनय संकट हरन'
Stanza 2: 'मंगल मरूित �प'
Stanza 3: 'राम लखन सीता सिहत'
Stanza 4: '�दय बसह� सुर भपू'

11
Words Separation: (14 Words)
1. 'पवनतनय', 2. 'संकट', 3. 'हरन', 4. 'मंगल', 5. 'मरूित', 6. '�प', 7. 'राम',
8. 'लखन', 9. 'सीता', 10. 'सिहत', 11. '�दय', 12. 'बसह�', 13. 'सुर', 14. 'भपू'
Stanza Wise Words Separation:
1. i.'पवनतनय', ii.'संकट', iii.'हरन'
2. i.'मंगल', ii.'मरूित', iii.'�प',
3. i.'राम', ii.'लखन', iii.'सीता', iv.'सिहत'
4. i.'�दय', ii.'बसह�', iii.'सुर', iv'भपू'
Character Wise Separation: (53 Characters) :
'प','व','न','त','न','य','स','◌'ं,'क','ट','ह','र','न','म','◌ं','ग','ल','म','◌'ू,'र','त','ि◌','र','◌'ू,'प','र','◌ा,'म','ल','ख','न','स',
'◌ी','त','◌ा','स','ह','ि◌','त','ह','◌'ृ,'द','य','ब','स','ह','◌'ु,'स','◌'ु,'र','भ','◌'ू,'प'
After the separation, the Matra Allocation takes place based on the predefined
rule, including some special and exceptional rules which may vary as per the provided
input’s characters and related to different possibilities.
The ‘Matra’ allocation and the ‘Matra’ Count will be used further to detect verse
after the rule-based modeling of verse rules automatically. The ‘Matra’ allocation is
also used after a few modifications and merging for character sequence mapping,
specifically for ‘Varnik’ verses. After this allocation and ‘Matra’ counting, the input
passes through the different set of rule-based methods specifically designed for the
specific verse-based rules. Each verse follows its own unique set of rules. In the
discussed Example of ‘Doha’ the rule for the formation of ‘Doha’ is getting fulfilled
as the combination of the odd-even stanza matra count is 13-11,13-11. Similarly, other
‘Chhands’ have different rules based on those rules’ Chhands’ are classified and
detected. The fig.1 showing the core idea of the whole process of detection and
identification of the classified ‘Chhands’.
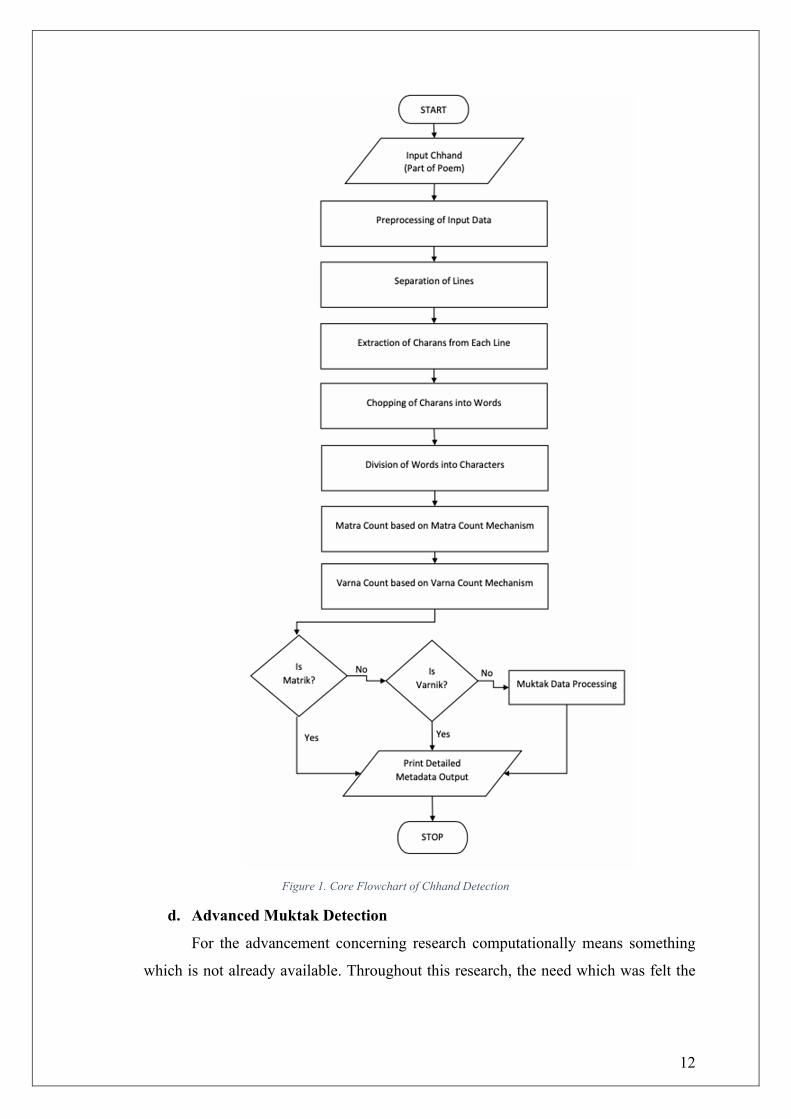
12
Figure 1. Core Flowchart of Chhand Detection
d. Advanced Muktak Detection
For the advancement concerning research computationally means something
which is not already available. Throughout this research, the need which was felt the

13
most is that usually, when the ‘Chhand’ detection takes place, the input gets detected
as ‘Muktak’.
In that case, the input gets separated into several parts again until it is possible to till
‘Charan’ level separation. Those separated parts are processed again from scratch as
separate input and from which the results get recorded. At last, the Metadata Generator
can recognize that in ‘Muktak’ verses, also it tries to find out if any part of the ‘Muktak’
verses is using any ‘Matrik’ or ‘Varnik’ verse rules or not. If any rules were used, then
that ‘Chhand’ will also be detected. That can be one or more than one ‘Chhand’ rules
combination also.
e. Stopwords Filtering
In this research work, stop words filtering is also managed very well using the
existing list of Hindi stopwords from a hybrid research work [38], specifically on the
Hindi’s stop words. Filtering stop words helps reduce the processing and save time
when in further stages of wordnet integration.
f. Meanings and Example of words using wordnet integration
With the use of the best available Hindi Wordnet named ‘pyiwn’ the meaning of the
words and examples of those particular words are populated as a part of the metadata
while generating metadata [39]. The benefit of this integration is to make people
understand the words better with the other Example of the uses of the words. Even
though the meaning of the word is not as per the context of the use of the word but it
will still help users understand the meaning of the word. Apart from this, the integration
is helpful for the betterment of this Wordnet as it also generates the list of words that
are not found in Wordnet while searching for the meaning of the words.
g. Example Suggestion of the detected Chhand
In this part of the metadata generator, a mechanism using JavaScript Object
Notation (JSON) file is implemented. In the JSON file, the examples are stored in the
form of Key-Value pairs, and whenever any type of ‘Chhand’ is detected, the same key
is used to access the Example of that type of ‘Chhand’ example. It will be very helpful
for those who are interested in that type of ‘Chhand’ and want to explore more about
the same.
h. Alankar Detection Integration
‘Alankars’ were also identified and structured. Total 58 classification types of
Alankars were found, out of which 3 classes can be identified using this metadata
generator which are (‘Shabdalankar’, ‘Anupras’, ‘Punrukti’).

14
Apart from these efforts were made to classify 4 more classes named
(‘Arthalankar’, ‘Yamak’, ‘Utpeksha’, ‘Upma’). All 4 were also implemented but as
context based meaning of word is required and that’s still a challenge in Hindi NLP,
these classes can't be said or claimed to be truly classified with this automatic metadata
generator.
i. Several Additional Helpful Utilities
As a part of the research, while carrying out this research, the needs of the
common utilities were felt, which did not exist but were required. Data collection utility
was created for the collection of the data to create a systematic data corpus. Later on, a
bulk collection utility for the data collection was also developed through which bulk
data can be processed and stored via text and comma-separated value (CSV) files. To
the research progress status, a utility for the research stats generation was also designed.
j. Results / Comparisons
The results are always the crucial part of any research study. Before proceeding
with the results, one thing to enlighten here is as not much-existing work was found in
this area, so comparing research work and the results is not possible. Any exactly
similar work related to the classification and identification of Hindi verses was not
found, and that only makes this work unique and novel.
Only two nearby research works were found. The first one was based on
identifying ‘Chaupai’ with 95.03% accuracy, while this research assures 97.09%
accuracy. Similarly, the second research work was based on ‘Rola’ with 89.83%
accuracy, where this research is providing 95.24% accuracy.
The automatic metadata generator is modeled based on the different rules of the
111 ‘Chhands’ classification types, subtypes, and subtypes of subtypes. The 53
different types of ‘Chhands’ data were collected for testing and validation. Each class
was having at least 20 and a maximum of 310 records based on the data’s availability.
From various sources Total of 3330 records were found and tested, out of which 3195
records were detected successfully.
The final accuracy rate on the basis of the results is 94.98%, and the failure rate
is 05.02%. Fig 2. Graph of the ‘Chhand’ data found, detected, and not found along with
the individual accuracy and failure rates of different ‘Chhands’ showing that the various
‘Chhands’ accuracy rate range is between 84% to 100%, and the failure rate is between
0% to 16%.

15
Out of all the 53 different types of ‘Chhands’ data, only 5 ‘Chhands’
(‘Chhappay’, ‘Chopaiya’, ‘Shankar’, ‘Sar’, ‘Tantak’) were having an accuracy rate
below 90%, and the rest (48) all were between 90-100%, and in that also 29
(‘Roopmala’, ‘Rola’, ‘Panchchamar’, ‘Doha’, ‘Dodhak’, ‘Manoram’, ‘Nidhi’,
‘Harigitika’, ‘Durmil Savaiya’, ‘Ullala (Sam Matrik)’, ‘Chandrika’, ‘Dhar’, ‘Barvai’,
‘Sur Dhanakshari’, ‘Pramanika’, ‘Chaupai’, ‘Piyushvarsh’, ‘Sortha’, ‘Trotak’,
‘Malini’, ‘Bhujangi’, ‘Vanshasth’, ‘Drutvilambit’, ‘Mandakranta’, ‘Bhujangprayag’,
‘Aansu’, ‘Janak’, ‘Tilka’, ‘Muktak’) were having 95 or more than 95-100% accuracy
rate. The lowest accuracy percentage, 84% was detected for ‘Chhapay Chhand’, which
is made up of a combination of two different ‘Chhands’, that makes its formation and
identification complex, and due to that, only the problems occur more. The best
performing ‘Chhands’ with 100% accuracy rate was ‘Aansu’, ‘Bhujangprayag’,
‘Janak’, ‘Mandakranta’, ‘Muktak’ and ‘Tilka’.
The research is not limited to the already mentioned 'Chhands'; 227 records of
50 more 'Chhand' types were modeled and tested based on these records, for which the
data for the same were between 1 to 15 records of each. Out of 50 'Chhands', 34
'Chhands' ('Gitika / Chanchri / Charchari','Sundari / Madhavi Savaiya', 'Chakor
Savaiya', 'Sukhi Savaiya', 'Arsat Savaiya', 'Lavanglata Savaiya', 'Mukthara Savaiya',
'Vam Savaiya', 'Mod Savaiya', 'Shuddh Gita', 'Gaganangana', 'Lavni', 'Madhumalti',
'Vijat', 'Janharan Dhanakshari', 'Dev Dhanakshari', 'Vijya Dhanakshari / Kamini',
Figure 2. Chhand Detection Results

16
'Jalharan Dhanakshari', 'Kanak Manjari', 'Giridhari', 'Panktika', 'Mattgayand Savaiya',
'Sumukhi Savaiya', 'Bihari', 'Nil', 'Ullala (Ardh Sam Matrik)', 'Shikhrini', 'Arvind
Savaiya', 'Muktamani', 'Indira', 'Gath', 'Damru Dhanakshari', 'Asabandha',
'Padhyamala') were having 1 to 5 examples for each, 9 'Chhands'
('Kusumasamudita','Dhuni','Pavan','Chanchala','Udiyana','Kaamrup','Chanchrik/Haripr
iya', 'Kanthi', 'Veer / Aalha / Matrik Savaiya') were having 6 to 10 examples each, the
remaining seven ('Shalini','Kirit Savaiya','Shakti', 'Indravajra', 'Ghanshyam',
'Upendravajra', 'Pavan') were having 11-15 records for each type. All the records were
detected successfully to their associated 'Chhand' types.
The primary three classes('Matrik Chhand', 'Varnik Chhand', 'Muktak / Mukt
Chhand') were incorporated, along with their associative further six subclasses ('Sam
Matrik', 'Ardh-Sam Matrik', 'Visham Matrik', 'Sam Varnik', 'Ardh Sam Varnik',
'Visham Varnik') were also included. However, any 'Chhand' type rules or examples
under two of the subclasses ('Ardh Sam Varnik', 'Visham Varnik') were not found, to
maintain the hierarchical structure and with a vision of upcoming times, these two were
also added so in upcoming times if any 'Chhand' is found in these subclasses than that
can be included quickly.
After analyzing all the results, it was found out that the lengthy data inputs took
more time. ‘Chhands’, which have a few numbers of lines, words, or characters, gets
detected faster than the ‘Chhands’, which have a more number of lines, words, and
characters.
H. Achievements concerning objectives
● A hierarchical structure of Hindi verses constructed.
● The construction rules of Hindi verses were identified and validated manually.
● An automatic metadata generator based on Hindi verse’s rule-based modelling
with a computational linguistics perspective is developed.
● A Hindi poetry corpus based on the Hindi verses is ready, and utility to collect
data systematically for corpus creation for Hindi Poetry is developed.
● Apart from the core objectives, To explore the ‘Alankar’ detection, a separate
module for ‘Alankar’ detection was also developed. Similar to ‘Chhands’, the
hierarchical structure was constructed.

17
I. Conclusion
To conclude, the Hindi verse hierarchy was taxonomically structured initially
to begin the research. Furthermore, ‘Chhand’ rules were identified, verified, and
appropriately structured with the aspect of the computational linguistics based research
works, which are managed very well by this research work. ‘Chhands’ were classified
in the standard classes for better and smooth hierarchical management in this research
work. It was experienced that ‘Chhand’ detection based on the rules is a complex
process. ‘Chhands’ made up of complicated rules, takes more time to detect.
Special exception rules slow down the execution time as it takes more time to
process and check the data. ‘Chhands’ made up of the combination of the one or more
‘Chhand’ rules, also takes more time as they need to be gone through more than once
while detection and metadata generation processing for the detection.
Additionally, this research can extract stop words by filtering from the existing
list of stop words. The meaning and example uses of the words can be suggested with
Wordnet integration, which helps understand the poems better. The words which were
still not included in the Wordnet are also filtered. After carrying out this much research
work, it can be powerfully conveyed that systematized Hindi Prosody Rules and the
concept of automatic metadata generation for Hindi poetry are capable enough to
generate meaningful metadata automatically.
The research work done so far is sufficient to open a new path for upcoming
researchers to think of some other relevant aspects and further contribute to Natural
Language Processing and Computational linguistics research domain.
J. List of all publications arising from the thesis
1. M. K. Audichya and J. R. Saini, “Computational linguistic prosody rule-based unified technique for automatic metadata generation for Hindi poetry,” 2019 1st International Conference on Advances in Information Technology (ICAIT), Jul. 2019, doi: 10.1109/icait47043.2019.8987239.
2. M. K. Audichya and J. R. Saini, “Stanza Type Identification using Systematization of Versification System of Hindi Poetry,” International Journal of Advanced Computer Science and Applications, vol. 12, no. 1, 2021, doi: 10.14569/ijacsa.2021.0120117.
3. M. K. Audichya and J. R. Saini, “Towards Natural Language Processing with Figures of Speech in Hindi Poetry,” International Journal of Advanced Computer Science and Applications, vol. 12, no. 3, 2021, doi: 10.14569/ijacsa.2021.0120316.

18
K. Patents (if any)
Nil
L. References
[1] Wikipedia Contributors, “Hindi,” Wikipedia, 04-May-2019. [Online]. Available:
https://en.wikipedia.org/wiki/Hindi
[2] “Unicode 13.0.0,” Unicode Inc, 22-Jan-2021. [Online]. Available:
https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf. [Accessed: 22-Jan-2021]
[3] Wikipedia Contributors, “Natural language processing,” Wikipedia, 28-Jun-2019. [Online]. Available:
https://en.wikipedia.org/wiki/Natural_language_processing
[4] Wikipedia Contributors, “Computational linguistics,” Wikipedia, 27-Oct-2019. [Online]. Available:
https://en.wikipedia.org/wiki/Computational_linguistics
[5] B. K. Joshi and K. K. Kushwah, “A Novel Approach to Automatic Detection of Chaupai Chhand in Hindi
Poems,” IEEE Xplore, 01-Sep-2018. [Online]. Available: https://ieeexplore.ieee.org/document/8675052
[6] K. K. Kushwah and B. K. Joshi, “Rola: An Equi-Matrik Chhand of Hindi Poems,” Journal of Computer Science
and Information Security (IJCSIS), vol. 15, no. 3, Mar. 2017 [Online]. Available:
https://www.academia.edu/32482898/Rola_An_Equi_Matrik_Chhand_of_Hindi_Poems. [Accessed: 22-Jan-2021]
[7] P. B. Bafna and J. R. Saini, “On Exhaustive Evaluation of Eager Machine Learning Algorithms for Classification
of Hindi Verses,” International Journal of Advanced Computer Science and Applications, vol. 11, no. 2, 2020, doi:
10.14569/ijacsa.2020.0110224.
[8] P. Bafna and J. R. Saini, “Hindi Poetry Classification using Eager Supervised Machine Learning Algorithms,”
IEEE Xplore, 01-Mar-2020. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9167632
[9] P. B. Bafna and J. R. Saini, “Hindi Verse Class Predictor using Concept Learning Algorithms,” IEEE Xplore,
01-Mar-2020. [Online]. Available: https://ieeexplore.ieee.org/document/9074850
[10] J. Kaur and J. R. Saini, “Punjabi Poetry Classification,” Proceedings of the 9th International Conference on
Machine Learning and Computing - ICMLC 2017, pp. 1–5, 2017, doi: 10.1145/3055635.3056589.
[11] J. Kaur and J. R. Saini, “Automatic Punjabi poetry classification using machine learning algorithms with
reduced feature set,” International Journal of Artificial Intelligence and Soft Computing, vol. 5, no. 4, p. 311, 2016,
doi: 10.1504/ijaisc.2016.081353.
[12] J. Kaur and J. R. Saini, “Automatic classification of Punjabi poetries using poetic features,” International
Journal of Computational Intelligence Studies, vol. 7, no. 2, p. 124, 2018, doi: 10.1504/ijcistudies.2018.094901.
[13] J. Kaur and J. R. Saini, “PuPoCl: Development of Punjabi Poetry Classifier Using Linguistic Features and
Weighting,” INFOCOMP Journal of Computer Science, vol. 16, no. 1–2, pp. 1–7, Dec. 2017 [Online]. Available:
https://infocomp.dcc.ufla.br/index.php/infocomp/article/view/546
[14] J. Kaur and J. R. Saini, “Designing Punjabi Poetry Classifiers Using Machine Learning and Different Textual
Features,” The International Arab Journal of Information Technology, pp. 38–44, Jan. 2019, doi:
10.34028/iajit/17/1/5.
[15] K. Pal and B. V. Patel, “Model for Classification of Poems in Hindi Language Based on Ras,” Smart Systems
and IoT: Innovations in Computing, pp. 655–661, Oct. 2019, doi: 10.1007/978-981-13-8406-6_62.
[16] J. R. Saini and J. Kaur, “Kāvi: An Annotated Corpus of Punjabi Poetry with Emotion Detection Based on
‘Navrasa,’” Procedia Computer Science, vol. 167, pp. 1220–1229, Jan. 2020, doi: 10.1016/j.procs.2020.03.436.
[Online]. Available: https://www.sciencedirect.com/science/article/pii/S1877050920309030
[17] P. B. Bafna and J. R., “An Application of Zipf’s Law for Prose and Verse Corpora Neutrality for Hindi and
Marathi Languages,” International Journal of Advanced Computer Science and Applications, vol. 11, no. 3, 2020,
doi: 10.14569/ijacsa.2020.0110331.
[18] P. B. Bafna and J. R. Saini, “BaSa: A Technique to Identify Context based Common Tokens for Hindi Verses
and Proses,” 2020 International Conference for Emerging Technology (INCET), Jun. 2020, doi:
10.1109/incet49848.2020.9154124.
[19] A. Kulkarni and G. Huet, Eds., Sanskrit Computational Linguistics: Third International Symposium,
Hyderabad, India, January 15-17, 2009. Proceedings. Berlin Heidelberg: Springer-Verlag, 2009 [Online].
Available: https://www.springer.com/gp/book/9783540938842
[20] H. Han, E. Manavoglu, H. Zha, K. Tsioutsiouliklis, C. L. Giles, and X. Zhang, “Rule-based word clustering for
document metadata extraction,” Proceedings of the 2005 ACM symposium on Applied computing - SAC ’05, 2005,
doi: 10.1145/1066677.1066917.
[21] X. Yu et al., “Using Automatic Metadata Extraction to Build a Structured Syllabus Repository,” Asian Digital
Libraries. Looking Back 10 Years and Forging New Frontiers, pp. 337–346, doi: 10.1007/978-3-540-77094-7_43.

19
[22] M.-T. . Sagri and D. Tiscornia, “Metadata for content description in legal information,” IEEE Xplore, 01-Sep-
2003. [Online]. Available: http://ieeexplore.ieee.org/document/1232110. [Accessed: 18-Sep-2020]
[23] J. L. Klavans et al., “Computational linguistics for metadata building (CLiMB): using text mining for the
automatic identification, categorization, and disambiguation of subject terms for image metadata,” Multimedia Tools
and Applications, vol. 42, no. 1, pp. 115–138, Nov. 2008, doi: 10.1007/s11042-008-0253-9.
[24] N. Ghneim, O. Alsharif, and D. Alshamaa, “Emotion Classification in Arabic Poetry using Machine Learning,”
International Journal of Computer Applications, vol. 65, no. 16, pp. 10–15, 2013 [Online]. Available:
https://www.ijcaonline.org/archives/volume65/number16/11006-6300. [Accessed: 23-Jan-2021]
[25] S. Hamidi, F. Razzazi, and M. P. Ghaemmaghami, “Automatic meter classification in Persian poetries using
support vector machines,” IEEE Xplore, 01-Dec-2009. [Online]. Available:
https://ieeexplore.ieee.org/document/5407514
[26] Z.-S. He, W.-T. Liang, L.-Y. Li, and Y.-F. Tian, “SVM-Based Classification Method for Poetry Style,” IEEE
Xplore, 01-Aug-2007. [Online]. Available: https://ieeexplore.ieee.org/document/4370650
[27] A. Abbasi, H. Chen, and A. Salem, “Sentiment analysis in multiple languages,” ACM Transactions on
Information Systems, vol. 26, no. 3, pp. 1–34, Jun. 2008, doi: 10.1145/1361684.1361685.
[28] J. Kaur and J. R. Saini, “A Study and Analysis of Opinion Mining Research in Indo-Aryan, Dravidian and
Tibeto-Burman Language Families,” Indian Journals, vol. 4, no. 2, 2014 [Online]. Available:
http://www.indianjournals.com/ijor.aspx?target=ijor:ijdmet&volume=4&issue=2&article=002. [Accessed: 23-Jan-
2021]
[29] Jagarnath Prasad, Chhand Sarawali. Jagarnath Press Bilaspur, 1917 [Online]. Available:
https://archive.org/details/in.ernet.dli.2015.478241. [Accessed: 25-Jan-2021]
[30] J. Prasad, Chhand Prabhakar. Jagarnath Press Bilaspur, 1935 [Online]. Available:
https://archive.org/details/in.ernet.dli.2015.322488/. [Accessed: 25-Jan-2021]
[31] N. Dass, Hindi Chhandolakshan, 2nd ed. Vani Prakashan Publisher, 2005.
[32] “स.ंअि�न पुराण | गीता�ेस, गोरखपुर.” [Online]. Available: https://book.gitapress.org/product-style-5/gita-press-570/
[33] “भारतीय छंद िवधान,” www.openbooksonline.com. [Online]. Available:
http://www.openbooksonline.com/groups/group/show?groupUrl=chhand. [Accessed: 25-Jan-2021]
[34] “छ�द - भारतकोश, �ान का िह�दी महासागर,” Bharatdiscovery.org, 2021. [Online]. Available:
https://bharatdiscovery.org/india/%E0%A4%9B%E0%A4%A8%E0%A5%8D%E0%A4%A6#gsc.tab=0.
[Accessed: 25-Jan-2021]
[35] “िह�दी सािह�य का�य संकलन – िह�दी क� किवता, लघुगीत, बालगीत, िफ�म गीत, गजल, शायरी, धािम�क लोकगीत का िवशाल संकलन.” [Online]. Available:
https://www.hindisahitya.org/. [Accessed: 25-Jan-2021]
[36] “Chhand In Hindi-छंद क� प�रभाषा, भेद और उदाहरण,” hindimeaning.com, 06-Feb-2018. [Online]. Available:
https://www.hindimeaning.com/2018/02/chhand-in-hindi.html
[37] “�व�थ िह�दी समाज: भुजंगी छंद (सािहल),” �व�थ िह�दी समाज, 13-May-2018. [Online]. Available:
http://hhindisamaj.blogspot.com/2018/05/blog-post_13.html
[38] V. Jha, M. N, P. D. Shenoy, and V. K R, “Hindi Language Stop Words List,” data.mendeley.com, vol. 1, Apr.
2018, doi: 10.17632/bsr3frvvjc.1. [Online]. Available: https://data.mendeley.com/datasets/bsr3frvvjc/1. [Accessed:
18-Sep-2020]
[39] P. Ritesh, K. Diptesh, and B. Pushpak, “pyiwn: A Python-based API to access Indian Language WordNets,”
Proceedings of the Global WordNet Conference, vol. 2018, 2018.
Related Documents











