A Bird’s-Eye View of Pig and Scalding with hRaven a tale by @gario and @joep Hadoop Summit 2013 v1.2 Friday, June 28, 13

A Bird's-Eye View of Pig and Scalding with hRaven
Aug 29, 2014
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A Bird’s-Eye View of Pig and Scalding
with hRavena tale by @gario and @joep
Hadoop Summit 2013
v1.2
Friday, June 28, 13
@Twitter#HadoopSummit2013 2
• Apache HBase PMC member and Committer
• Software Engineer @ Twitter• Core Storage Team - Hadoop/HBase
About the authors
• Software Engineer @ Twitter• Engineering Manager Hadoop/HBase team
Friday, June 28, 13

@Twitter#HadoopSummit2013 3
Chapter 1: The ProblemChapter 2: Why hRaven?Chapter 3: How Does it Work?
• 3a: Loading• 3b: Table structure / queryingChapter 4: Current UsesAppendix: Future Work
Table of Contents
Friday, June 28, 13

Chapter 1: The Problem
Illustration by Sirxlem (CC BY-NC-ND 3.0)
Friday, June 28, 13

@Twitter#HadoopSummit2013 5
Most users run Pig and Scalding scripts, not straight map reduceJobTracker UI shows jobs, not DAGs of jobs generated by Pig and Scalding
Chapter 1: Mismatched Abstractions
Friday, June 28, 13

@Twitter#HadoopSummit2013
Chapter 1: A Problem of Scale
6
Friday, June 28, 13

@Twitter#HadoopSummit2013 7
How many Pig versus Scalding jobs do we run ?What cluster capacity do jobs in my pool take ?How many jobs do we run each day ?What % of jobs have > 30k tasks ?Why do I need to hand-tune these (hundreds) of jobs, can’t the cluster learn ?
Chapter 1: Questions
Friday, June 28, 13

@Twitter#HadoopSummit2013 8
How many Pig versus Scalding jobs do we run ?What cluster capacity do jobs in my pool take ?How many jobs do we run each day ?What % of jobs have > 30k tasks ?Why do I need to hand-tune these (hundreds) of jobs, can’t the cluster learn ?
Chapter 1: Questions
#Nevermore
Friday, June 28, 13

Chapter 2: Why hRaven?
Photo by DAVID ILIFF. License: CC-BY-SA 3.0
Friday, June 28, 13

@Twitter#HadoopSummit2013 10
Stores stats, configuration and timing for every map reduce job on every clusterStructured around the full DAG of jobs from a Pig or Scalding applicationEasily queryable for historical trendingAllows for Pig reducer optimization based on historical run statsKeep data online forever (12.6M jobs, 4.5B tasks + attempts)
Chapter 2: Why hRaven?
Friday, June 28, 13

@Twitter#HadoopSummit2013 11
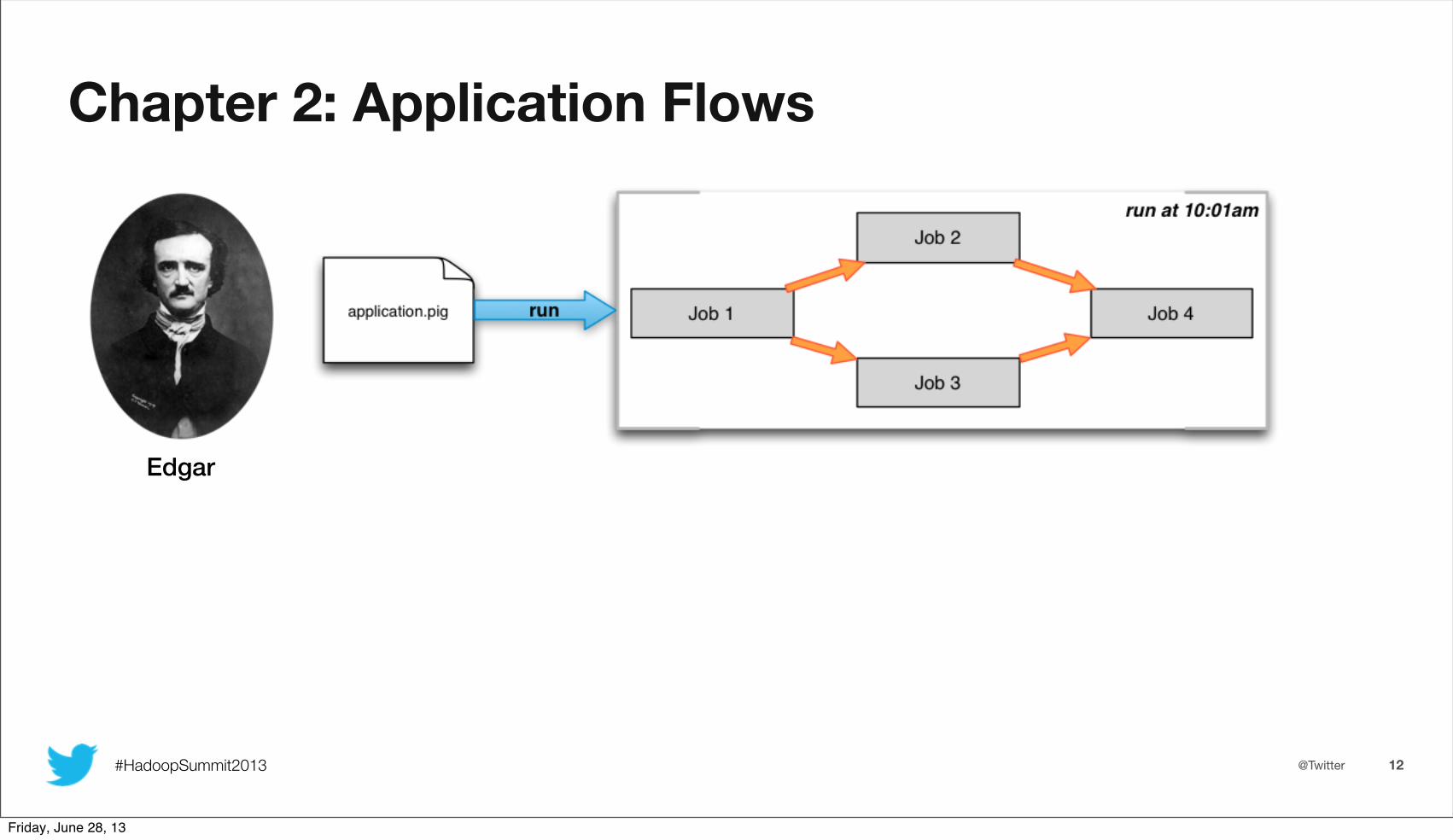
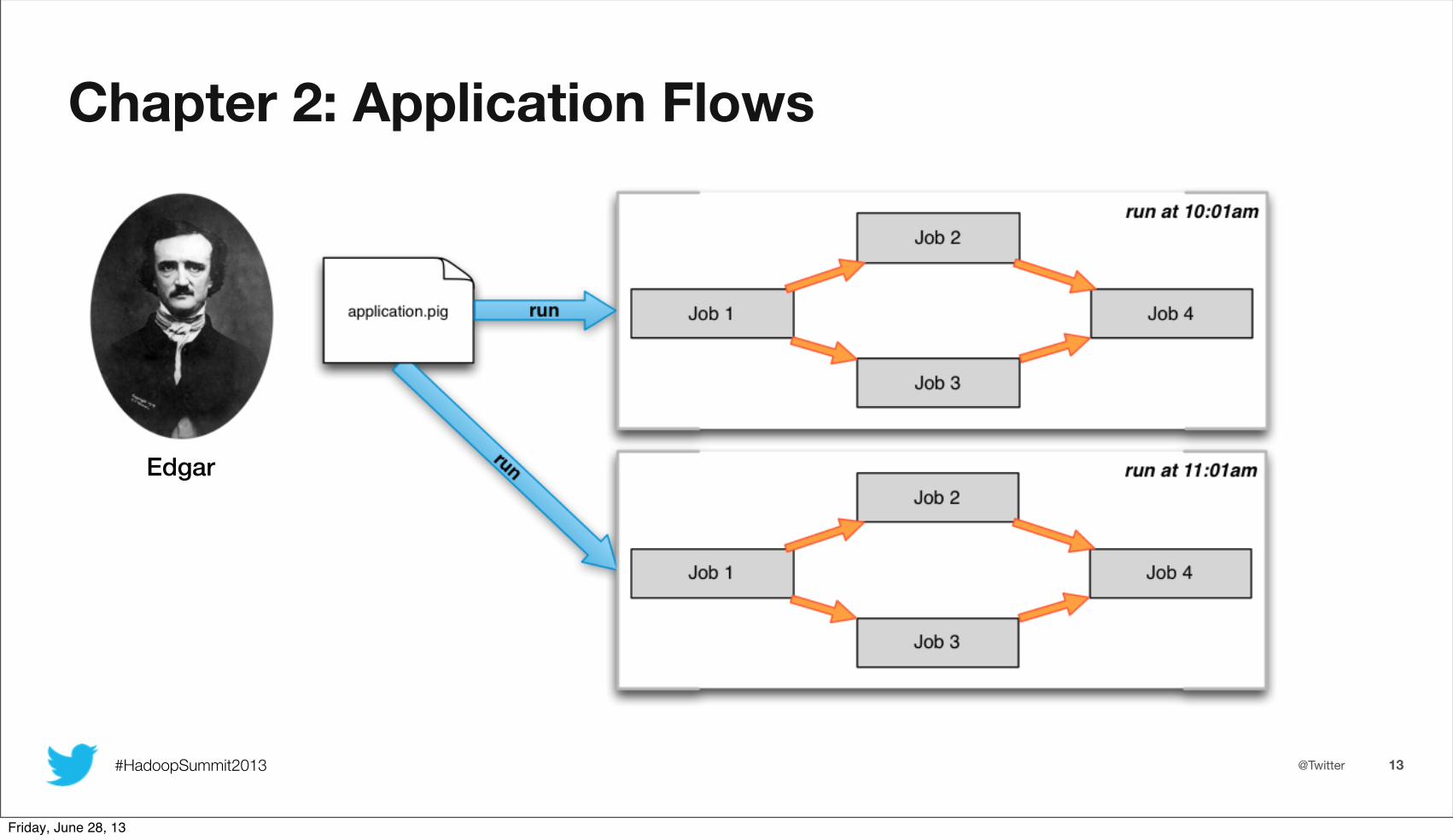
cluster - each cluster has a unique name mapping to the Job Trackeruser - map reduce jobs are run as a given userapplication - a Pig or Scalding script (or plain map reduce job)flow - the combined DAG of jobs executed from a single run of an applicationversion - changes impacting the DAG are recorded as a new version of the same application
Chapter 2: Key Concepts
Friday, June 28, 13
@Twitter#HadoopSummit2013 12
Chapter 2: Application Flows
Edgar
Friday, June 28, 13
@Twitter#HadoopSummit2013 13
Chapter 2: Application Flows
Edgar
Friday, June 28, 13
@Twitter#HadoopSummit2013 14
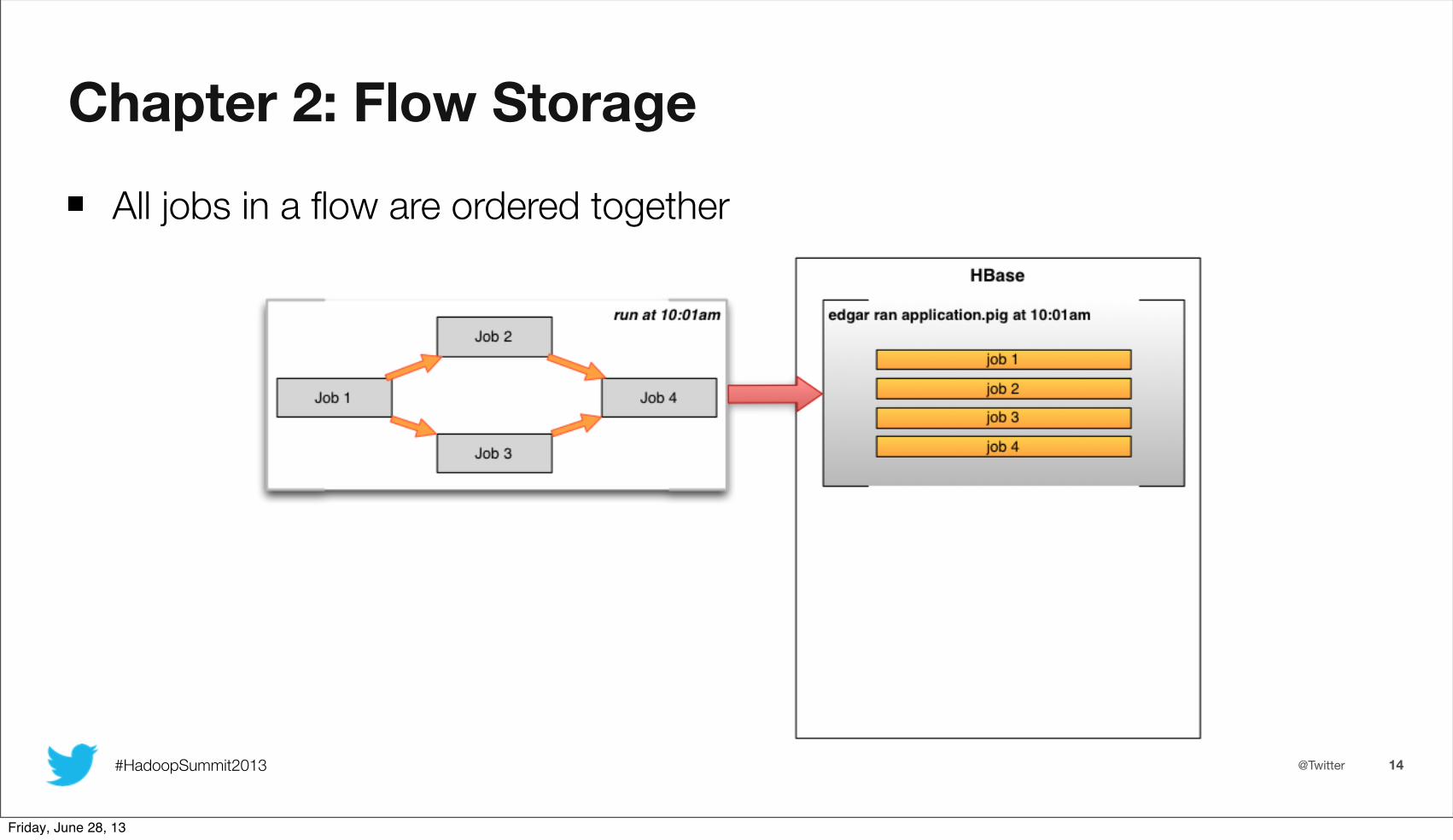
All jobs in a flow are ordered together
Chapter 2: Flow Storage
Friday, June 28, 13

@Twitter#HadoopSummit2013 15
Most recent flow is ordered first
Chapter 2: Flow Storage
Friday, June 28, 13

@Twitter#HadoopSummit2013 16
All jobs in a flow are ordered togetherPer-job metrics stored
• Total map and reduce tasks• HDFS bytes read / written• File bytes read / written• Total map and reduce slot millisecondsEasy to aggregate stats for an entire flowEasy to scan the timeseries of each application’s flows
Chapter 2: Key Features
Friday, June 28, 13

Chapter 3: How Does it Work?
Friday, June 28, 13
@Twitter#HadoopSummit2013 18
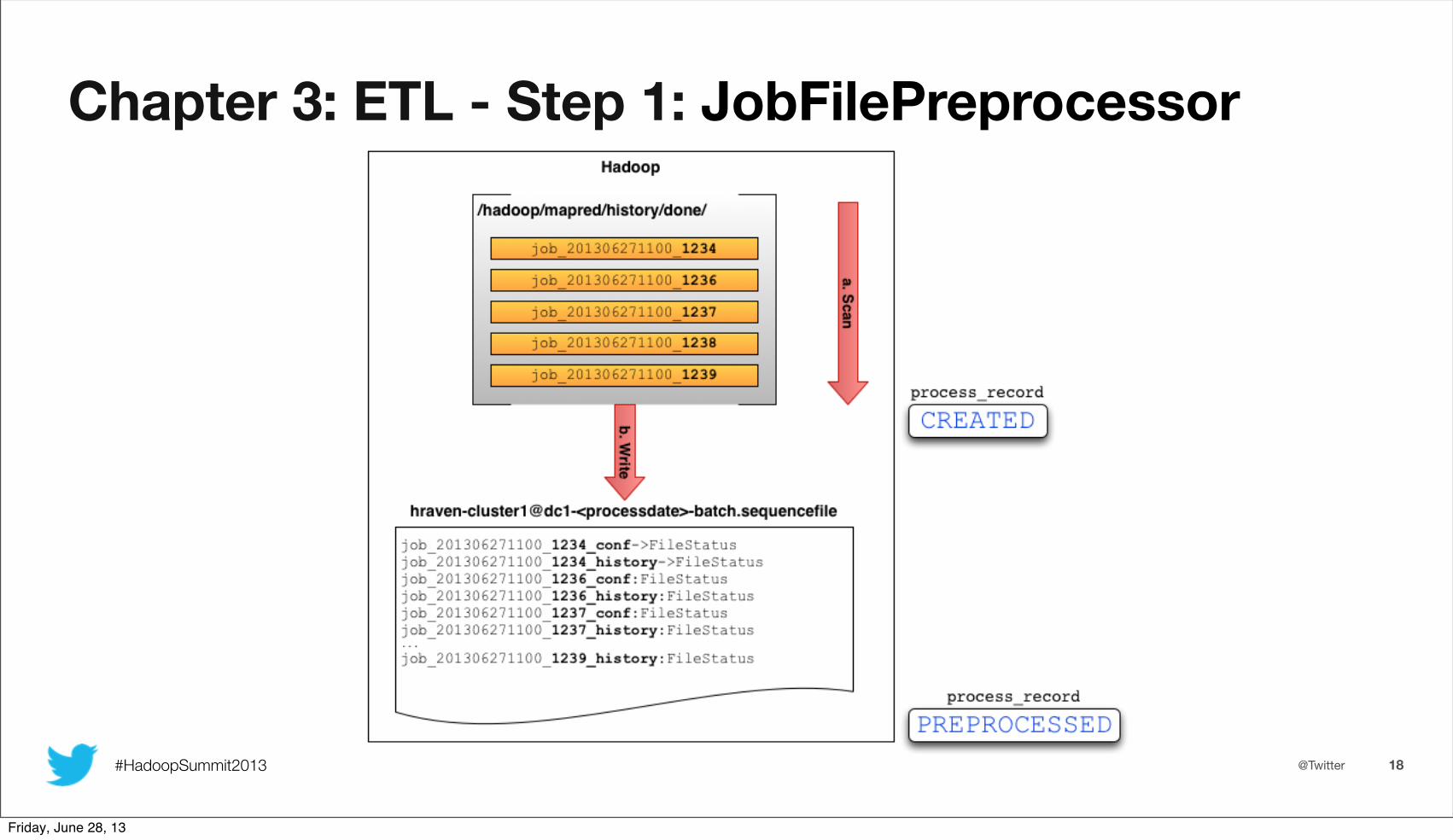
Chapter 3: ETL - Step 1: JobFilePreprocessor
Friday, June 28, 13
@Twitter#HadoopSummit2013 19
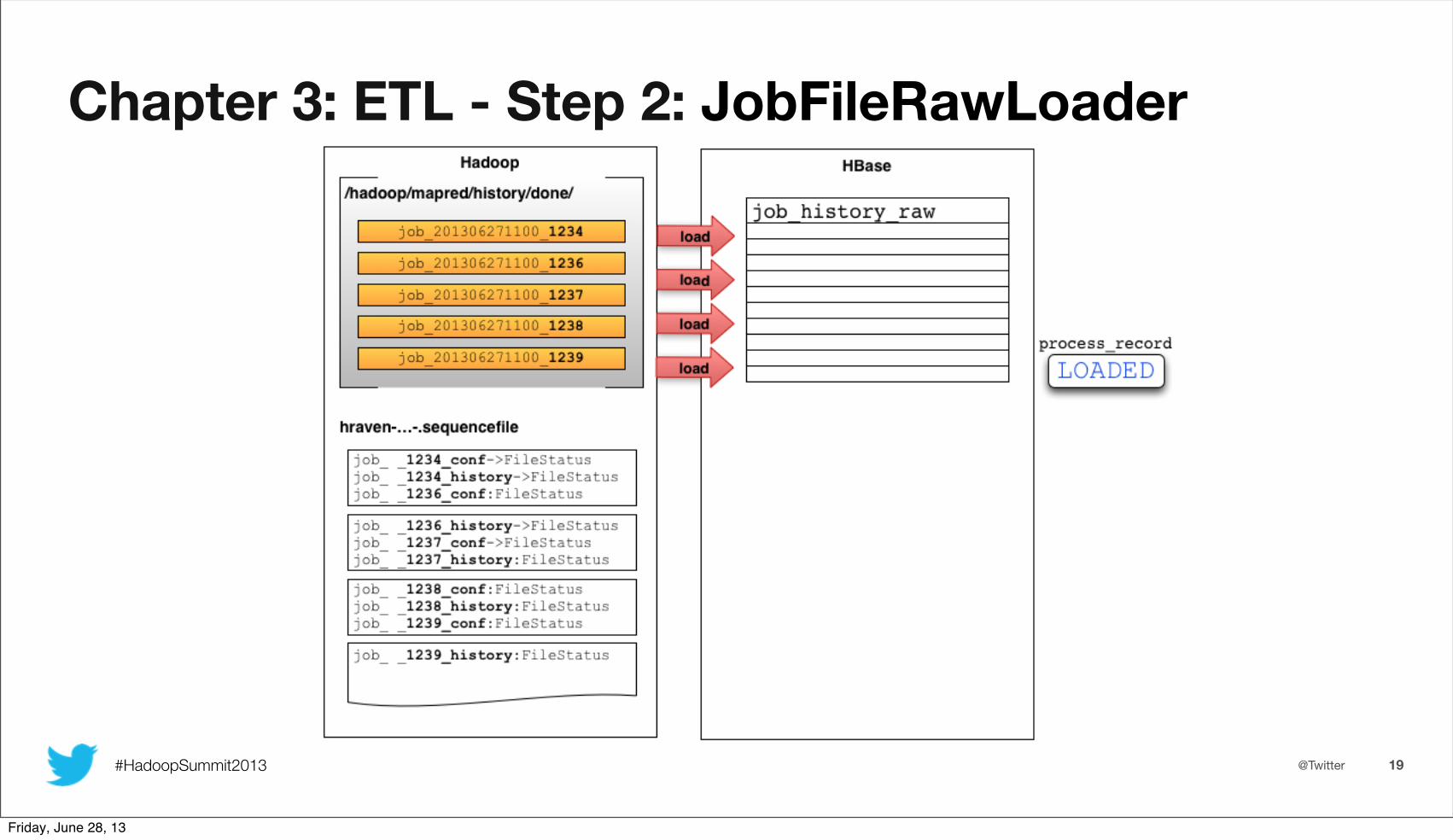
Chapter 3: ETL - Step 2: JobFileRawLoader
Friday, June 28, 13

@Twitter#HadoopSummit2013 20
Chapter 3: ETL - Step 3: JobFileProcessor
Friday, June 28, 13

@Twitter#HadoopSummit2013 21
Chapter 3: ETL - Step 3: JobFileProcessor
Jobs finish out of order with respect to job_id
Friday, June 28, 13

@Twitter#HadoopSummit2013 22
job_history_raw job_historyjob_history_taskjob_history_app_version
Chapter 3: Tables
Friday, June 28, 13
@Twitter#HadoopSummit2013 23
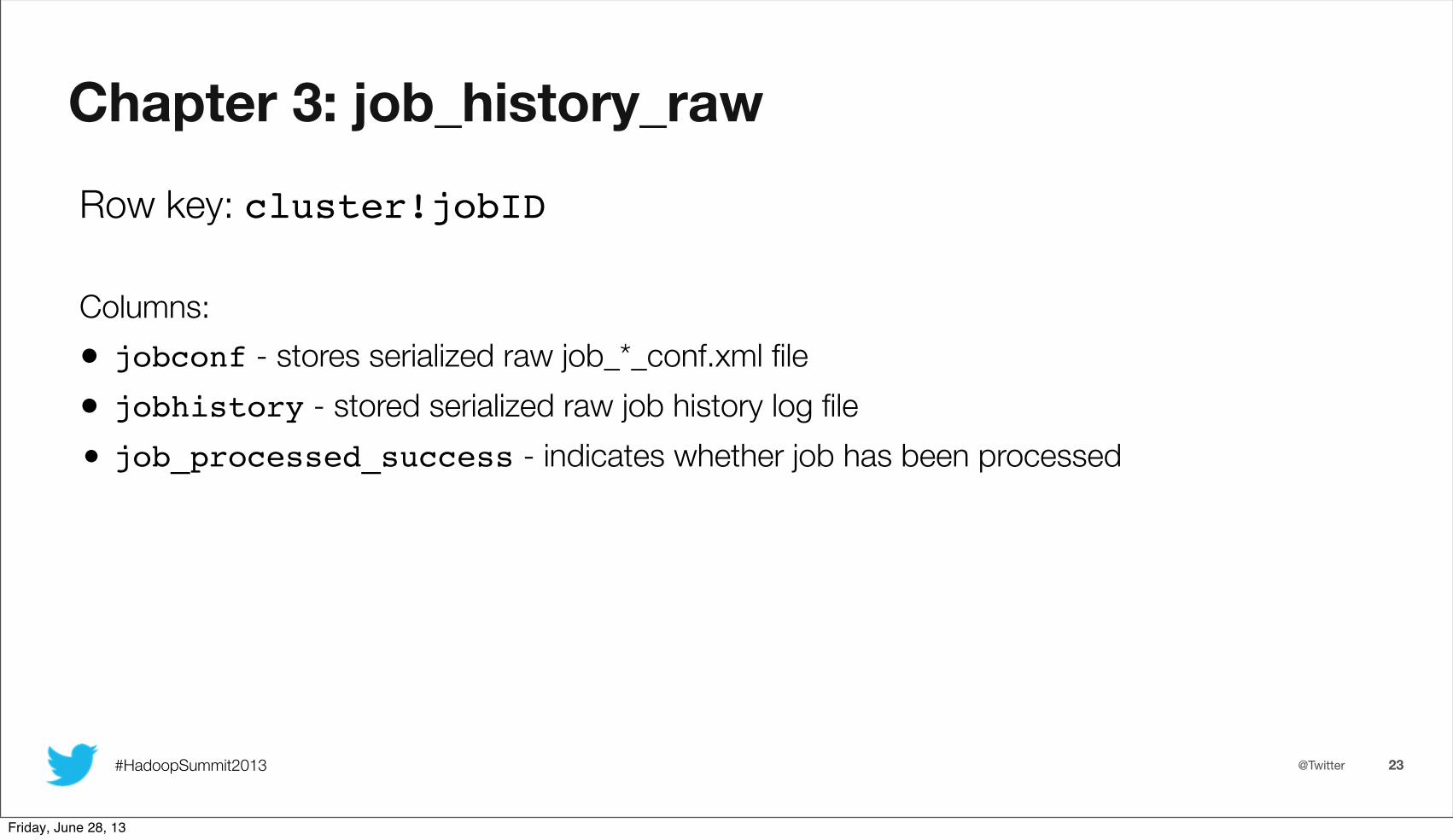
Row key: cluster!jobID
Columns:• jobconf - stores serialized raw job_*_conf.xml file• jobhistory - stored serialized raw job history log file• job_processed_success - indicates whether job has been processed
Chapter 3: job_history_raw
Friday, June 28, 13

@Twitter#HadoopSummit2013 24
Row key: cluster!user!application!timestamp!jobID• cluster - unique cluster name (ie. “cluster1@dc1”)• user - user running the application (“edgar”)• application - application ID derived from job configuration:
• uses “batch.desc” property if set• otherwise parses a consistent ID from “mapred.job.name”
• timestamp - inverted (Long.MAX_VALUE - value) value of submission time• jobID - stored as Job Tracker start time (long), concatenated with job sequence number
•job_201306271100_0001 -> [1372352073732L][1L]
Chapter 3: job_history
Friday, June 28, 13

@Twitter#HadoopSummit2013 25
Row key: cluster!user!application!timestamp!jobID!taskID• same components as job_history key (same ordering)• taskID - (ie. “m_00001”) uniquely identifies individual task/attempt in job
Two row types:• Task - “meta” rowcluster1@dc1!edgar!wordcount!9654...!...[00001]!m_00001
• Task Attempt - individual execution on a Task Trackercluster1@dc1!edgar!wordcount!9654...!...[00001]!m_00001_1
Chapter 3: job_history_task
Friday, June 28, 13
@Twitter#HadoopSummit2013 26
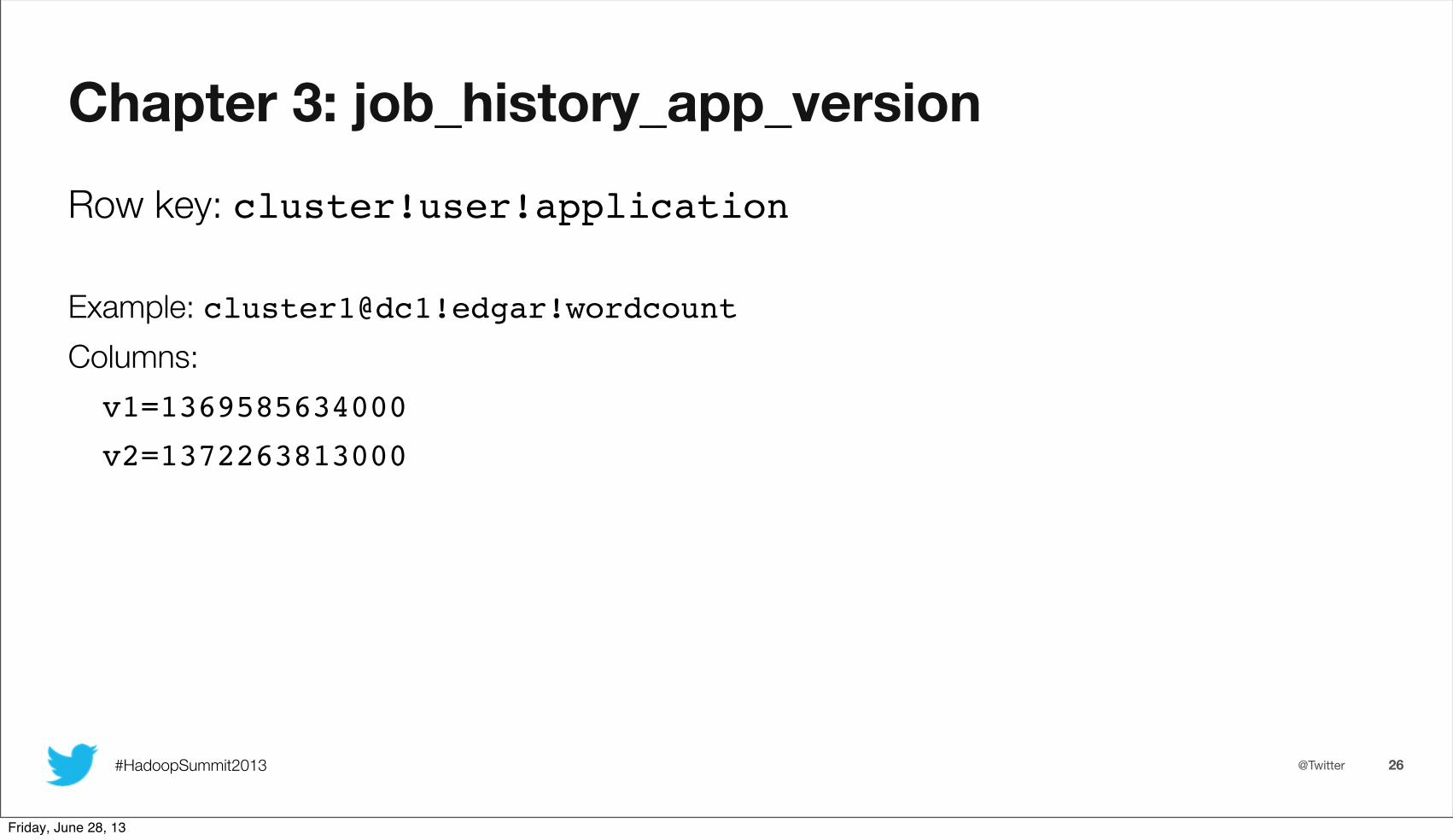
Row key: cluster!user!application
Example: cluster1@dc1!edgar!wordcountColumns:v1=1369585634000
v2=1372263813000
Chapter 3: job_history_app_version
Friday, June 28, 13

@Twitter#HadoopSummit2013 27
Using Pig’s HBaseStorage (or direct HBase APIs)Through Client APIThrough REST API
Chapter 3: Querying hRaven
Friday, June 28, 13

Chapter 4: Current Uses
Friday, June 28, 13

@Twitter#HadoopSummit2013 29
Pig reducer optimizationsCluster utilization / capacity planningApplication performance trending over timeIdentifying common job anti-patternsAd-hoc analysis troubleshooting cluster problems
Chapter 4: Current Uses
Friday, June 28, 13
@Twitter#HadoopSummit2013 30
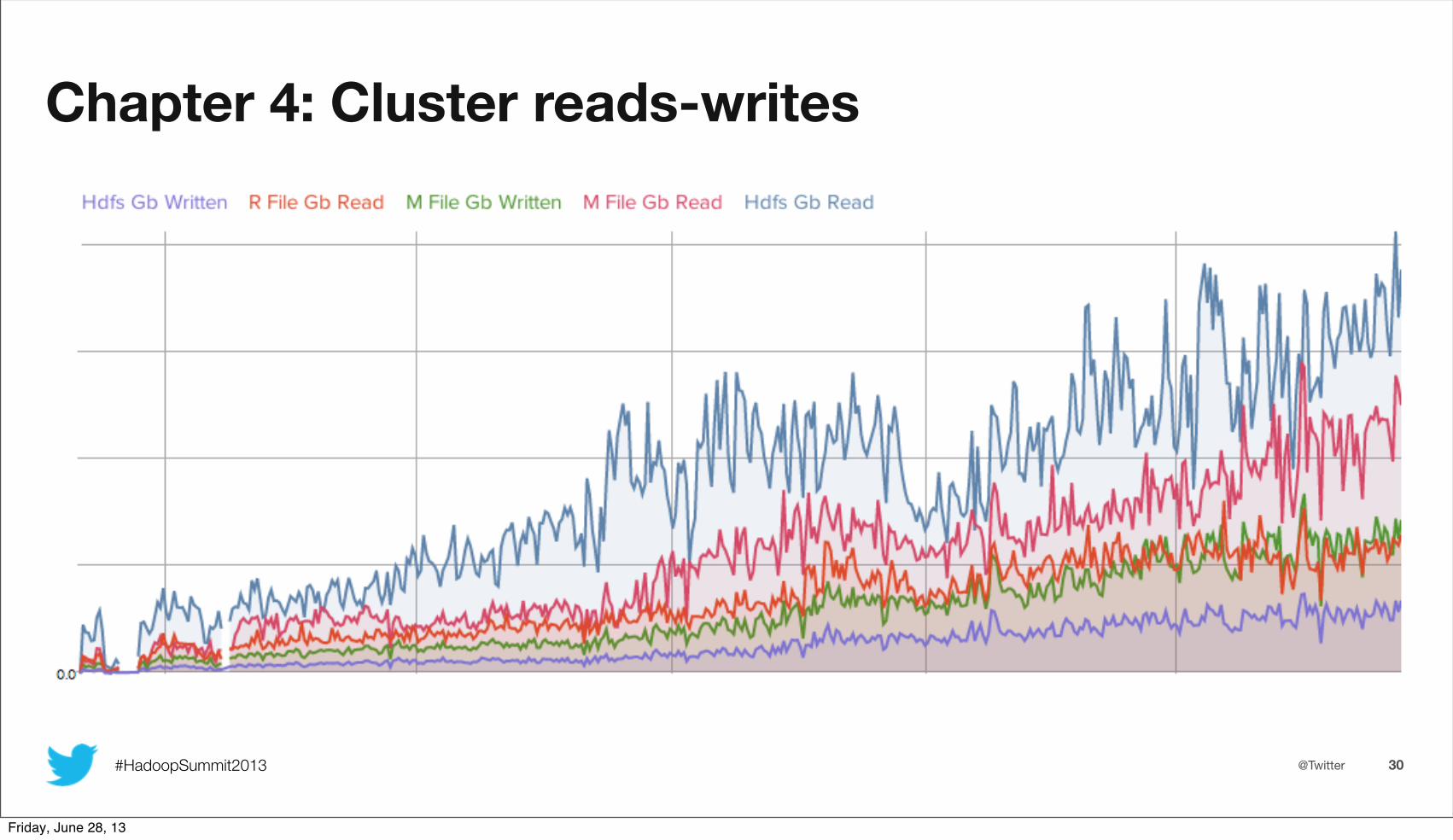
Chapter 4: Cluster reads-writes
Friday, June 28, 13

@Twitter#HadoopSummit2013
Chapter 4: Pool / Application reads/writes
31
Pool view• Spike in File size read• Indicates jobs spilling
Application view• Spike in HDFS size read• Indicates spiking input
Friday, June 28, 13

@Twitter#HadoopSummit2013
Chapter 4: Pool usage: Used vs. Allocated
32
Friday, June 28, 13

@Twitter#HadoopSummit2013 33
Chapter 4: Compute cost
Friday, June 28, 13

Appendix: Future Work
Friday, June 28, 13

@Twitter#HadoopSummit2013 35
Real-time data loading from Job Tracker / Application MasterFull flow-centric UI (Job Tracker UI replacement)Hadoop 2.0 compatibility (in-progress)Ambrose integration
Appendix: Future Work
Friday, June 28, 13

@Twitter#HadoopSummit2013 36
hRaven on Github• https://github.com/twitter/hraven
hRaven Mailing Lists• [email protected]• [email protected]
Additional Resources
Friday, June 28, 13

@Twitter#HadoopSummit2013
Afterword
37
Now will thou drop your job data on the floor ?Quoth the hRaven, 'Nevermore.'
Friday, June 28, 13

#TheEnd@gario and @joep
Come visit us at booth #26 to continue the story
Friday, June 28, 13

@Twitter#HadoopSummit2013 39
Desired orderjob_201306271100_9999
job_201306271100_10000
...
job_201306271100_99999
job_201306271100_100000
...
job_201306271100_999999
job_201306271100_1000000
Sort order Variable length job_idLexical order
job_201306271100_10000
job_201306271100_100000
job_201306271100_1000000
job_201306271100_9999
job_201306271100_99999
job_201306271100_999999
Friday, June 28, 13
Related Documents











