A benchmark for sparse matrix-vector multiplication ● Hormozd Gahvari and Mark Hoemmen {hormozd|mhoemmen}@eecs ● http://mhoemmen.arete.cc/Report/ ● Research made possible by: NSF, Argonne National Lab, a gift from Intel, National Energy Research Scientific Computing Center, and Tyler Berry [email protected]

A benchmark for sparse matrix- vector multiplication ● Hormozd Gahvari and Mark Hoemmen {hormozd|mhoemmen}@eecs {hormozd|mhoemmen}@eecs ●
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A benchmark for sparse matrix-vector multiplication
● Hormozd Gahvari and Mark Hoemmen {hormozd|mhoemmen}@eecs
● http://mhoemmen.arete.cc/Report/● Research made possible by: NSF,
Argonne National Lab, a gift from Intel, National Energy Research Scientific Computing Center, and Tyler Berry [email protected]

Topcs for today:
● Sparse matrix-vector multiplication (SMVM) and the Sparsity optimization
● Preexisting SMVM benchmarks vs. ours
● Results: Performance predictors● Test case: Desktop SIMD

Sparse matrix-vector multiplication
● Sparse vs. dense matrix * vector– Dense: Can take advantage of temporal,
spatial locality (BLAS level 2,3)– Sparse: “Stream through” matrix one
value at a time– Index arrays: Lose locality
● Compressed sparse row (CSR) format

Register block optimization
● Many matrices have small blocks– FEM matrices especially– 2x2, 3x3, 6x6 common
● Register blocking: Like unrolling a loop (circumvent latencies)
● Sparsity:– Automatic heuristic optimal block size
selection

SMVM benchmarks: Three strategies
1) Actually do SMVM with test cases
2) Simpler ops “simulating” SMVM
3) Analytical / heuristic model

1) Actually do SMVM
● SparseBench: Iterative Krylov solvers– Tests other things besides SMVM!
● SciMark 2.0:– Fixed problem size– Uses unoptimized CSR (no reg. blocks)
● Doesn't capture potential performance with many types of matrices
● Register blocking: Large impact (will see)

2) Microbenchmarks “simulating” SMVM
● Goal: capture SMVM behavior with simple set of operations
● STREAM http://www.streambench.org/– “Sustained memory bandwidth”– Copy, Scale, Add, Triad– Triad: like dense level-1 BLAS DAXPY
● Rich Vuduc's indirect indexed variants– Resemble sparse matrix addressing– Still not predictive

3) Analytical models of SMVM performance
● Account for miss rates, latencies and bandwidths
● Sparsity: bounds as heuristic to predict best block dimensions for a machine
● Upper and lower bounds not tight, so difficult to use for performance prediction
● Sparsity's goal: optimization, not performance prediction

Our SMVM benchmark
● Do SMVM with BSR matrix: randomly scattered blocks– BSR format: Typically less structured
matrices anyway● “Best” block size, 1x1
– Characterize different matrix types– Take advantage of potential optimizations
(unlike current benchmarks), but in a general way

Dense matrix in sparse format
● Test this with optimal block size:– To show that fill doesn't affect
performance much– Fill: affects locality of accesses to source
vector

Data set sizing
● Size vectors to fit in largest cache, matrix out of cache– Tests “streaming in” of matrix values– Natural scaling to machine parameters!
● “Inspiration” SPECfp92 (small enough so manufacturers could size cache to fit all data) vs. SPECfp95 (data sizes increased)
– Fill now machine-dependent:● Tests show fill (locality of source vector
accesses) has little effect

Results: “Best” block size
● Highest Mflops/s value for the block sizes tested, for:– Sparse matrix (fill chosen as above)– Dense matrix in sparse format (4096 x
4096)● Compare with Mflops/s for STREAM
Triad (a[i] = b[i] + s * c[i])




Rank processors acc. to benchmarks:
● For optimized (best block size) SMVM:– Peak mem bandwidth good predictor for
Itanium 2, P4, PM relationship– STREAM mispredicts these
● STREAM:– Better predicts unoptimized (1 x 1) SMVM– Peak bandwidth no longer helpful
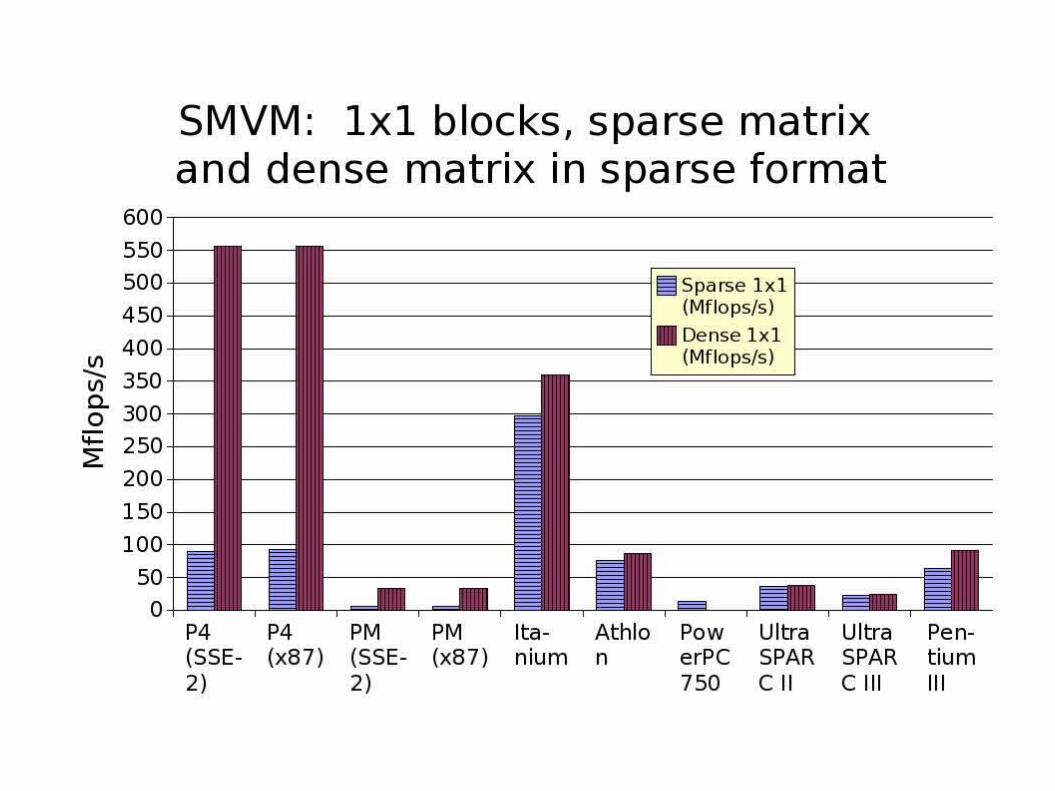

Our benchmark: Useful performance indicator
● Comparison with results for “real-life” matrices: – Works well for FEM matrices– Not always as well for non-FEM matrices– More wasted space in block data
structure: directly proportional to slowdown

Comparison of Benchmark with Real Matrices
● Following two graphs show MFLOP rate of matrices generated by our benchmark vs. matrices from BeBOP group and a dense matrix in sparse format
● Plots compare by block size; matrix “number” is given in parentheses. Matrices 2-9 are FEM matrices.
● A comprehensive list of the BeBOP test suite matrices can be found in Vuduc, et. al., “Performance Optimizations and Bounds for Sparse Matrix-Vector Multiply,” 2002.
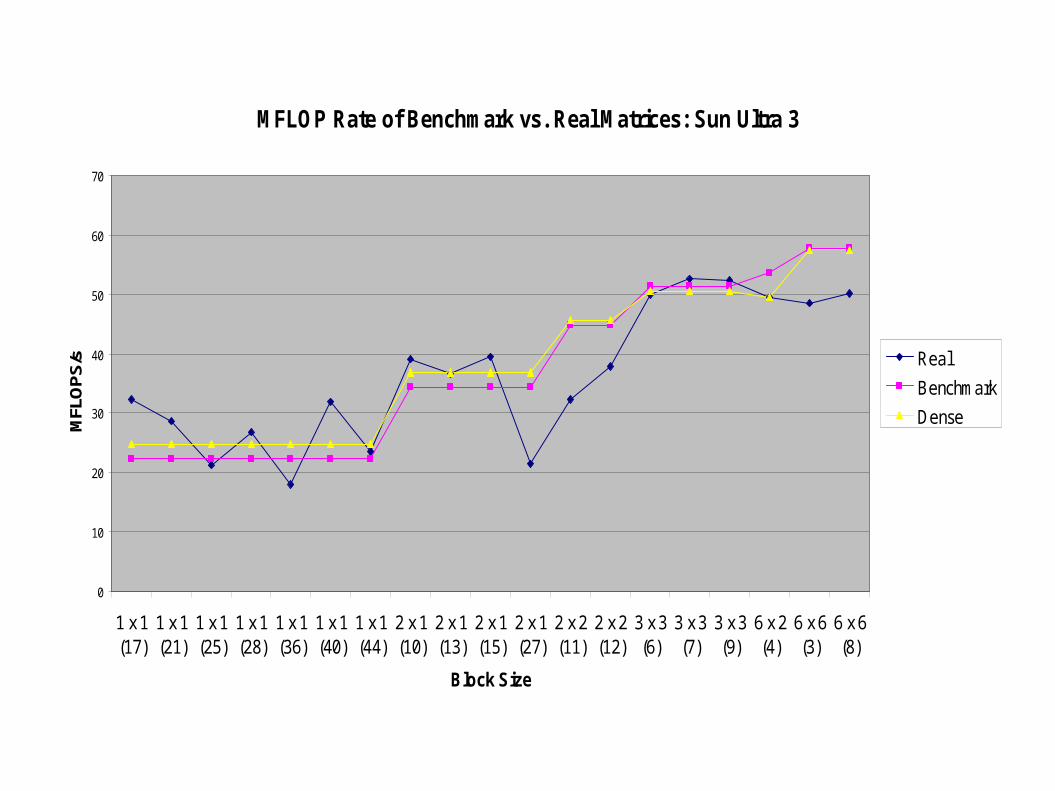
MFLOP Rate of Benchmark vs. Real Matrices: Sun Ultra 3
0
10
20
30
40
50
60
70
1 x 1(17)
1 x 1(21)
1 x 1(25)
1 x 1(28)
1 x 1(36)
1 x 1(40)
1 x 1(44)
2 x 1(10)
2 x 1(13)
2 x 1(15)
2 x 1(27)
2 x 2(11)
2 x 2(12)
3 x 3(6)
3 x 3(7)
3 x 3(9)
6 x 2(4)
6 x 6(3)
6 x 6(8)
Block Size
MFL
OP
S/s Real
Benchmark
Dense
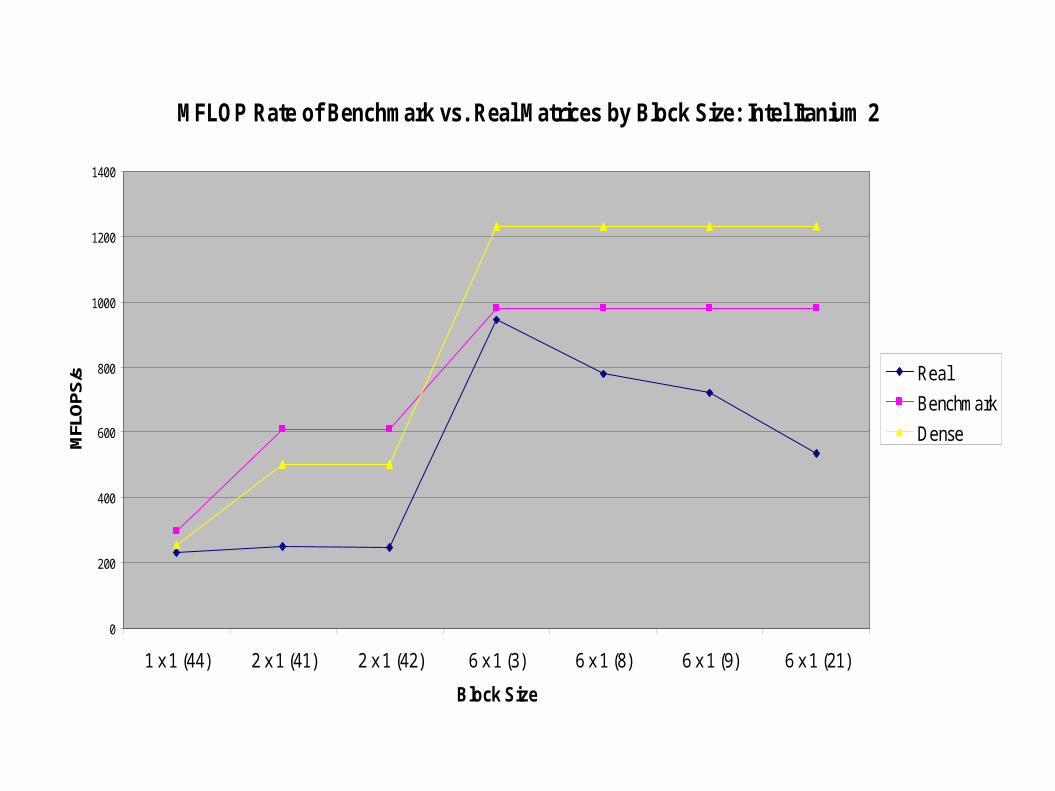
MFLOP Rate of Benchmark vs. Real Matrices by Block Size: Intel Itanium 2
0
200
400
600
800
1000
1200
1400
1 x 1 (44) 2 x 1 (41) 2 x 1 (42) 6 x 1 (3) 6 x 1 (8) 6 x 1 (9) 6 x 1 (21)
Block Size
MFL
OPS
/s Real
Benchmark
Dense

Comparison Conclusions
● Our benchmark does a good job modeling real data
● Dense matrix in sparse format looks good on Ultra 3, but is noticeably inferior to our benchmark for large block sizes on Itanium 2

Evaluating SIMD instructions
● SMVM benchmark: – Tool to evaluate arch. features
● e.g.: Desktop SIMD floating-point● SSE-2 ISA:
– Pentium 4, M; AMD Opteron– Parallel ops on 2 floating-point doubles
● {ADD|MUL|DIV}PD: arithmetic● MOVAPD: load aligned pair

Vectorizing DAXPY
● Register block: small dense Matrix * vector
● Dep. on matrix data ordering:– Column-major (Fortran-style):
● Need scalar * vector operation– Row-major (C-style):
● Need “reduce” (dot product)

Sparsity register block layout
● Row-major order within block– Vs. Sparse BLAS proposal (col-major)!– Vector reductions change associativity
(results may differ from scalar version, due to roundoff)
● We chose to keep it for now– Can't just switch algorithm: orientation
affects stride of vector loads– Need a good vector reduction

Vector reduce
● e.g. C. Kozyrakis' recent UC Berkeley Ph.D. thesis on multimedia vector ops
● “vhalf” instruction:– Copy lower half of src vector reg. -->
upper half of dest.● Iterate (vhalf, vector add) to reduce.

SSE-2 has “vhalf”!
# Sum the 2 elements of %xmm1:
# --------------------------------
# Low 8B %xmm1 --> high 8B %xmm0
SHUFPD %xmm0, %xmm1
# High 8B of %xmm0 gets sum
ADDPD %xmm0, %xmm1

One possible SSE-2 6x6 A*x
● %xmm0 <- (dest(0), 0) ● 6 MOVAPD: interleave matrix row pairs
and src vector pairs● Update indices● 3x (MULPD, then ADDPD to %xmm0)● Sum elems of %xmm0
– (SHUFPD and ADDPD)● Extract and store sum

SSE-2: gcc and Intel C compilers won't vectorize!
● Use SIMD registers for scalar math!– SSE-2 latency: 1 cycle less than x87– x87 uses same fn unit as SIMD anyway
● Vector reduce sub-optimal?– Fewer ops: less latency-hiding potential– Only 8 XMM regs: Can't unroll
● Col-major suboptimal– No scalar * vector instruction!
● Or the alignment issue...

“Small matrix library”
● From Intel: Matrix * vector● Optimized for 6x6 or less● Idea:
– Replace Sparsity's explicit (BLAS-1-like) register block multiplication...
– ...with optimized function (BLAS-2-like)● We're working on this● Needed to say if SIMD valuable

SIMD load: alignment
● Possible reason for no automatic vectorization– Load pair needs alignm. on 16B bdys– Non-aligned load: slower– Compiler can't guarantee alignment
● Itanium 2: Same issue reappears...

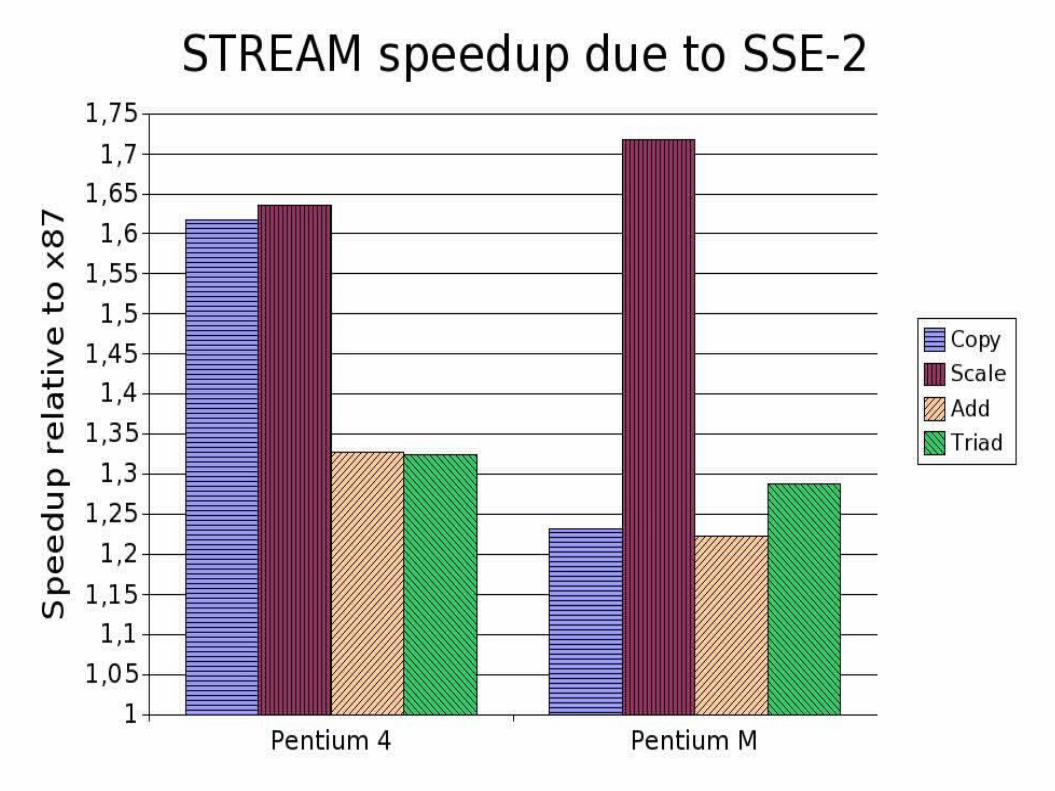
SSE-2 results: Disappointing
● Pentium M: gains nothing● Pentium 4: actually gains a little
– SSE-2 1 cycle lower latency than x87– Small blocks: latency dominates– x87 ISA harder to schedule
● AMD Opteron not available for testing– 16 XMM regs (vs. 8): better unrolling
capability?

How SSE-2 should look: STREAM Scale
b[0:N-1] = scalar * c[0:N-1](speedup 1.72)
Loop: movapd c(%eax), %xmm4 mulpd %xmm0, %xmm4 movntpd %xmm4, b(%eax) addl $16, %eax cmpl $16000000, %eax jl Loop
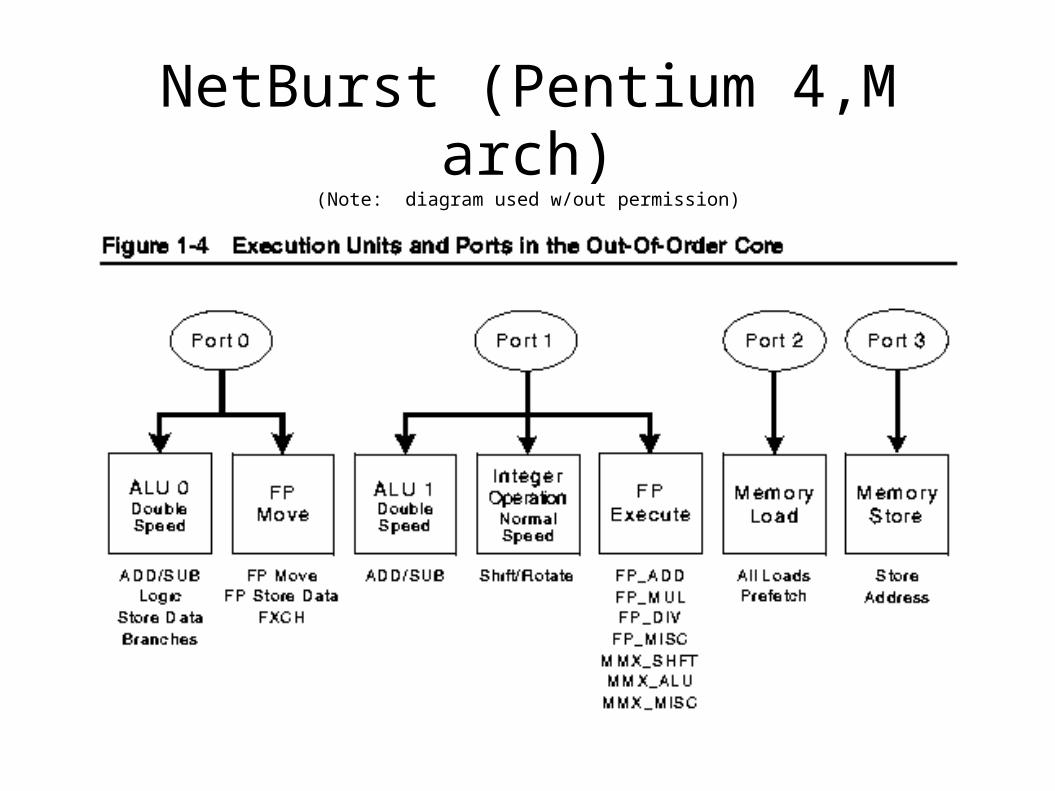
NetBurst (Pentium 4,M arch)(Note: diagram used w/out permission)

Can NetBurst keep up with DAXPY?
● One cycle: – 1 load aligned pair, 1 store aligned pair, 1
SIMD flop (alternate ADDPD/MULPD)● DAXPY (in row-major): Triad - like
– y(i) = y(i) + A(i,j) * x(j)– If y(i) loaded: 2 lds, 1 mul, 1 add, 1 store
● Ratio of loads to stores inadequate?– Itanium 2 changes this...

Itanium 2: Streaming fl-pt
● NO SSE-2 support!!!● BUT: In 1 cycle: 2 MMF bundles:
– 2 load pair (4 loads), 2 stores– 2 FMACs (a + s * b)
● (Or MFI: Load pair, FMAC, update idx)● 1 cycle: theoretically 2x DAXPY!

Itanium 2: Alignment strikes again!
● Intel C Compiler won't generate “load pair” instructions!!!
● Why?– ldfpd (“load pair”) needs aligned data– Compiler doesn't see underlying dense
BLAS 2 structure?– Register pressure?

SIMD conclusions:
● STREAM Triad suggests modest potential speedup
● Multiple scalar functional units: – More flexible than SIMD: Speedup
independent of orientation● Code scheduling difficult
– Pragmas to tell compiler data is aligned– Encapsulate block A*x in hand-coded
routine

Conclusions:
● Our benchmark: – Good SMVM performance prediction– Scales for any typical uniprocessor
● With “optimal” block sizes:– Performance tied to memory bandwidth
● With 1x1 blocks:– Performance related more to latency

Conclusions (2):
● SIMD: Need to test custom mini dense matrix * vector routines
● Development will continue after this semester:– More testing– Parallelization
Related Documents











