A 60Gbps DPI Prototype based on Memory-Centric FPGA Jinshu Su †‡ , Shuhui Chen † , Biao Han † , Chengcheng Xu † , Xin Wang † † College of Computer, National University of Defense Technology, Changsha, 410073, China ‡ National Key Laboratory of Parallel and Distributed Processing, Changsha, 410073, China {sjs, shchen, nudtbill, xuchengcheng, wangxin}@nudt.edu.cn ABSTRACT Deep packet inspection (DPI) is widely used in content- aware network applications to detect string features. It is of vital importance to improve the DPI performance due to the ever-increasing link speed. In this demo, we propose a novel DPI architecture with a hierarchy memory structure and parallel matching engines based on memory-centric FPGA. The implemented DPI pro- totype is able to provide up to 60Gbps full-text string matching throughput and fast rules update speed. CCS Concepts •Networks → Deep packet inspection; •Theory of computation → Pattern matching; Keywords DPI; string matching; hierarchical memory 1. INTRODUCTION DPI is a hardware and software solution that moni- tors a network’s data stream by looking deep into data packets. It provides important security and translation functions in many network applications, such as net- work intrusion detection system (NIDS), anti-virus pro- tection, Internet content filtering, etc. Until recently, most DPI systems are not able to keep up with mod- ern, 40Gbps+ network speed. String pattern matching (SPM) is one of the most widely used DPI mechanisms, in which the payload byte sequence is matched against a dictionary of strings. As the SPM methodology has to inspect the payload char- acters byte by byte, it is usually regarded as the bottle- neck of DPI. Most SPM solutions employ the classical Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is per- mitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected]. SIGCOMM ’16, August 22-26, 2016, Florianopolis , Brazil c 2016 ACM. ISBN 978-1-4503-4193-6/16/08. . . $15.00 DOI: http://dx.doi.org/10.1145/2934872.2959079 Figure 1: The DPI system architecture Aho-Corasick algorithm [5] to generate a time-efficient deterministic finite automaton (DFA) for fast process- ing. However, the throughputs of existing DPI systems are greatly limited by high memory access latency dur- ing the SPM procedure [6]. In order to break through the above limitations, we propose a novel DPI architecture with a hierarchy mem- ory structure and parallel matching engines based on memory-centric FPGA. Then, we implement a DPI pro- totype which is able to provide up to 60Gbps full-text string matching speed. We will demonstrate the high performance of the prototype with various rule sets and traffics in a well-deployed network environment. 2. SYSTEM ARCHITECTURE Fig.1 depicts the overview of our implemented DPI system architecture. The core components of the memory- centric FPGA in the DPI prototype are 48 parallel match- ing engines combined with a two-level hierarchy mem- ory architecture. An auxiliary multi-core processor is employed to compile the string dictionary to a DFA, which is deployed to memory through PCIe. Firstly, based on the observation that very few states are frequently accessed during the matching process, we combine the on-chip RAM banks with off-chip DRAM to build a two-level hierarchy memory architecture, where the large DRAM is used to store the whole state tran- sition table (STT) of DFA and the fast on-chip RAM is employed to store the frequently accessed parts of the STT. Thus, an optimized storage mechanism for DFA is able to store only a tiny part of the STT on FPGA while guaranteeing a relatively low cache miss rate. In 627

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A 60Gbps DPI Prototype based onMemory-Centric FPGA
Jinshu Su† ‡, Shuhui Chen†, Biao Han†, Chengcheng Xu†, Xin Wang††College of Computer, National University of Defense Technology, Changsha, 410073, China‡National Key Laboratory of Parallel and Distributed Processing, Changsha, 410073, China
{sjs, shchen, nudtbill, xuchengcheng, wangxin}@nudt.edu.cn
ABSTRACTDeep packet inspection (DPI) is widely used in content-aware network applications to detect string features. Itis of vital importance to improve the DPI performancedue to the ever-increasing link speed. In this demo,we propose a novel DPI architecture with a hierarchymemory structure and parallel matching engines basedon memory-centric FPGA. The implemented DPI pro-totype is able to provide up to 60Gbps full-text stringmatching throughput and fast rules update speed.
CCS Concepts•Networks → Deep packet inspection; •Theoryof computation → Pattern matching;
KeywordsDPI; string matching; hierarchical memory
1. INTRODUCTIONDPI is a hardware and software solution that moni-
tors a network’s data stream by looking deep into datapackets. It provides important security and translationfunctions in many network applications, such as net-work intrusion detection system (NIDS), anti-virus pro-tection, Internet content filtering, etc. Until recently,most DPI systems are not able to keep up with mod-ern, 40Gbps+ network speed.
String pattern matching (SPM) is one of the mostwidely used DPI mechanisms, in which the payload bytesequence is matched against a dictionary of strings. Asthe SPM methodology has to inspect the payload char-acters byte by byte, it is usually regarded as the bottle-neck of DPI. Most SPM solutions employ the classical
Permission to make digital or hard copies of all or part of this work for personalor classroom use is granted without fee provided that copies are not made ordistributed for profit or commercial advantage and that copies bear this noticeand the full citation on the first page. Copyrights for components of this workowned by others than ACM must be honored. Abstracting with credit is per-mitted. To copy otherwise, or republish, to post on servers or to redistribute tolists, requires prior specific permission and/or a fee. Request permissions [email protected].
SIGCOMM ’16, August 22-26, 2016, Florianopolis , Brazilc© 2016 ACM. ISBN 978-1-4503-4193-6/16/08. . . $15.00
DOI: http://dx.doi.org/10.1145/2934872.2959079
Figure 1: The DPI system architecture
Aho-Corasick algorithm [5] to generate a time-efficientdeterministic finite automaton (DFA) for fast process-ing. However, the throughputs of existing DPI systemsare greatly limited by high memory access latency dur-ing the SPM procedure [6].
In order to break through the above limitations, wepropose a novel DPI architecture with a hierarchy mem-ory structure and parallel matching engines based onmemory-centric FPGA. Then, we implement a DPI pro-totype which is able to provide up to 60Gbps full-textstring matching speed. We will demonstrate the highperformance of the prototype with various rule sets andtraffics in a well-deployed network environment.
2. SYSTEM ARCHITECTUREFig.1 depicts the overview of our implemented DPI
system architecture. The core components of the memory-centric FPGA in the DPI prototype are 48 parallel match-ing engines combined with a two-level hierarchy mem-ory architecture. An auxiliary multi-core processor isemployed to compile the string dictionary to a DFA,which is deployed to memory through PCIe.
Firstly, based on the observation that very few statesare frequently accessed during the matching process, wecombine the on-chip RAM banks with off-chip DRAMto build a two-level hierarchy memory architecture, wherethe large DRAM is used to store the whole state tran-sition table (STT) of DFA and the fast on-chip RAM isemployed to store the frequently accessed parts of theSTT. Thus, an optimized storage mechanism for DFAis able to store only a tiny part of the STT on FPGAwhile guaranteeing a relatively low cache miss rate. In
627
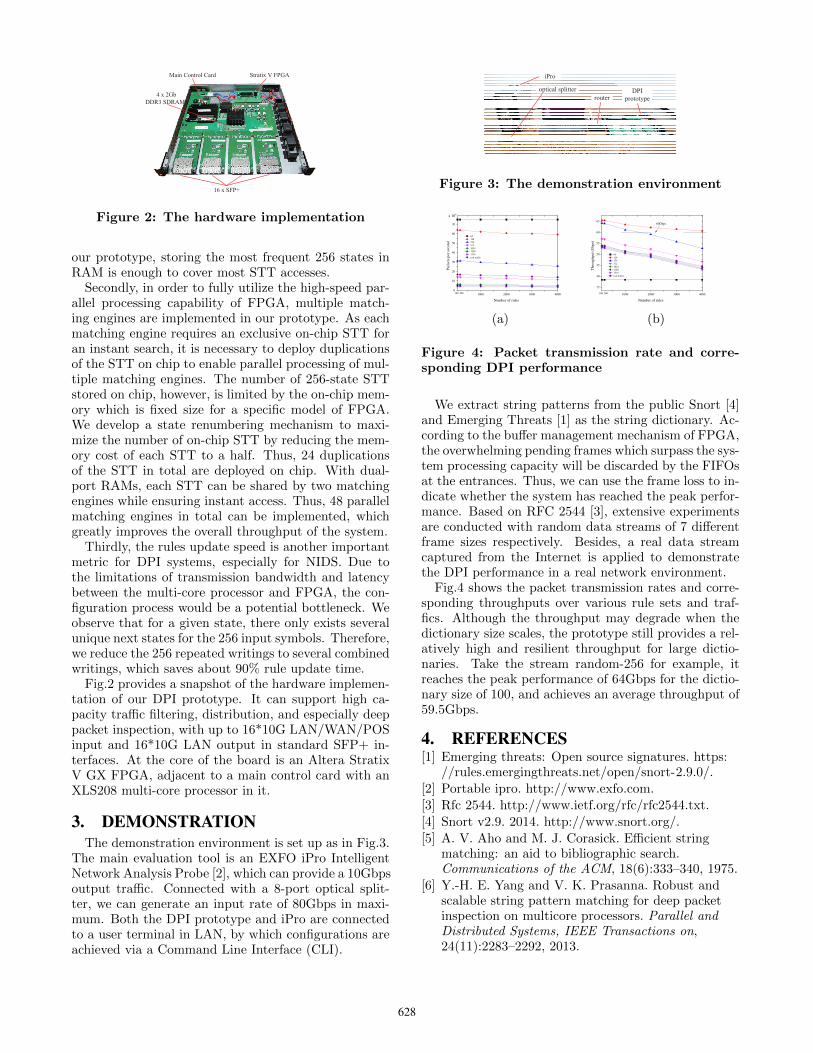
Figure 2: The hardware implementation
our prototype, storing the most frequent 256 states inRAM is enough to cover most STT accesses.
Secondly, in order to fully utilize the high-speed par-allel processing capability of FPGA, multiple match-ing engines are implemented in our prototype. As eachmatching engine requires an exclusive on-chip STT foran instant search, it is necessary to deploy duplicationsof the STT on chip to enable parallel processing of mul-tiple matching engines. The number of 256-state STTstored on chip, however, is limited by the on-chip mem-ory which is fixed size for a specific model of FPGA.We develop a state renumbering mechanism to maxi-mize the number of on-chip STT by reducing the mem-ory cost of each STT to a half. Thus, 24 duplicationsof the STT in total are deployed on chip. With dual-port RAMs, each STT can be shared by two matchingengines while ensuring instant access. Thus, 48 parallelmatching engines in total can be implemented, whichgreatly improves the overall throughput of the system.
Thirdly, the rules update speed is another importantmetric for DPI systems, especially for NIDS. Due tothe limitations of transmission bandwidth and latencybetween the multi-core processor and FPGA, the con-figuration process would be a potential bottleneck. Weobserve that for a given state, there only exists severalunique next states for the 256 input symbols. Therefore,we reduce the 256 repeated writings to several combinedwritings, which saves about 90% rule update time.
Fig.2 provides a snapshot of the hardware implemen-tation of our DPI prototype. It can support high ca-pacity traffic filtering, distribution, and especially deeppacket inspection, with up to 16*10G LAN/WAN/POSinput and 16*10G LAN output in standard SFP+ in-terfaces. At the core of the board is an Altera StratixV GX FPGA, adjacent to a main control card with anXLS208 multi-core processor in it.
3. DEMONSTRATIONThe demonstration environment is set up as in Fig.3.
The main evaluation tool is an EXFO iPro IntelligentNetwork Analysis Probe [2], which can provide a 10Gbpsoutput traffic. Connected with a 8-port optical split-ter, we can generate an input rate of 80Gbps in maxi-mum. Both the DPI prototype and iPro are connectedto a user terminal in LAN, by which configurations areachieved via a Command Line Interface (CLI).
Figure 3: The demonstration environment
64
128
256
512
1024
1280
1518
real traffic
1000 2000 3000 4000
0
10
20
30
40
50
60
70
x 106
Pac
ket
s p
er s
eco
nd
Number of rules
| |
200100
(a)
64
128
256
512
1024
1280
1518
real traffic
1000 2000 3000 4000
35
40
45
50
55
60
65
| |
200100
60Gbps
Th
rou
gh
pu
t (G
bp
s)
Number of rules
(b)
Figure 4: Packet transmission rate and corre-sponding DPI performance
We extract string patterns from the public Snort [4]and Emerging Threats [1] as the string dictionary. Ac-cording to the buffer management mechanism of FPGA,the overwhelming pending frames which surpass the sys-tem processing capacity will be discarded by the FIFOsat the entrances. Thus, we can use the frame loss to in-dicate whether the system has reached the peak perfor-mance. Based on RFC 2544 [3], extensive experimentsare conducted with random data streams of 7 differentframe sizes respectively. Besides, a real data streamcaptured from the Internet is applied to demonstratethe DPI performance in a real network environment.
Fig.4 shows the packet transmission rates and corre-sponding throughputs over various rule sets and traf-fics. Although the throughput may degrade when thedictionary size scales, the prototype still provides a rel-atively high and resilient throughput for large dictio-naries. Take the stream random-256 for example, itreaches the peak performance of 64Gbps for the dictio-nary size of 100, and achieves an average throughput of59.5Gbps.
4. REFERENCES[1] Emerging threats: Open source signatures. https:
//rules.emergingthreats.net/open/snort-2.9.0/.
[2] Portable ipro. http://www.exfo.com.
[3] Rfc 2544. http://www.ietf.org/rfc/rfc2544.txt.
[4] Snort v2.9. 2014. http://www.snort.org/.
[5] A. V. Aho and M. J. Corasick. Efficient stringmatching: an aid to bibliographic search.Communications of the ACM, 18(6):333–340, 1975.
[6] Y.-H. E. Yang and V. K. Prasanna. Robust andscalable string pattern matching for deep packetinspection on multicore processors. Parallel andDistributed Systems, IEEE Transactions on,24(11):2283–2292, 2013.
628
Related Documents











