Università degli Studi di Milano Bicocca Dipartimento di Informatica, Sistemistica e Comunicazione Corso di Strumenti e applicazioni del Web 9. Ricercare nel Web (Parte I) Roberto Polillo Edizione 2014-15

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Università degli Studi di Milano BicoccaDipartimento di Informatica, Sistemistica e Comunicazione
Corso di Strumenti e applicazioni del Web
9. Ricercare nel Web (Parte I)
Roberto Polillo
Edizione 2014-15

2
Queste slides fanno parte del corso “Strumenti e applicazioni del Web”. Ilsito del corso, con il materiale completo, si trova inwww.corsow.wordpress.com . Data la rapida evoluzione della rete, il corsoviene aggiornato ogni anno.
Il presente materiale è pubblicato con licenza Creative Commons“Attribuzione - Non commerciale - Condividi allo stesso modo – 3.0”(http://creativecommons.org/licenses/by-nc-sa/3.0/it/deed.it ):
La licenza non si estende alle immagini provenienti da altre fonti ealle screen shots, i cui diritti restano in capo ai rispettivi proprietari,che, ove possibile, sono stati indicati. L'autore si scusa per eventualiomissioni, e resta a disposizione per correggerle.
R.Polillo - Marzo 2015
Queste slides

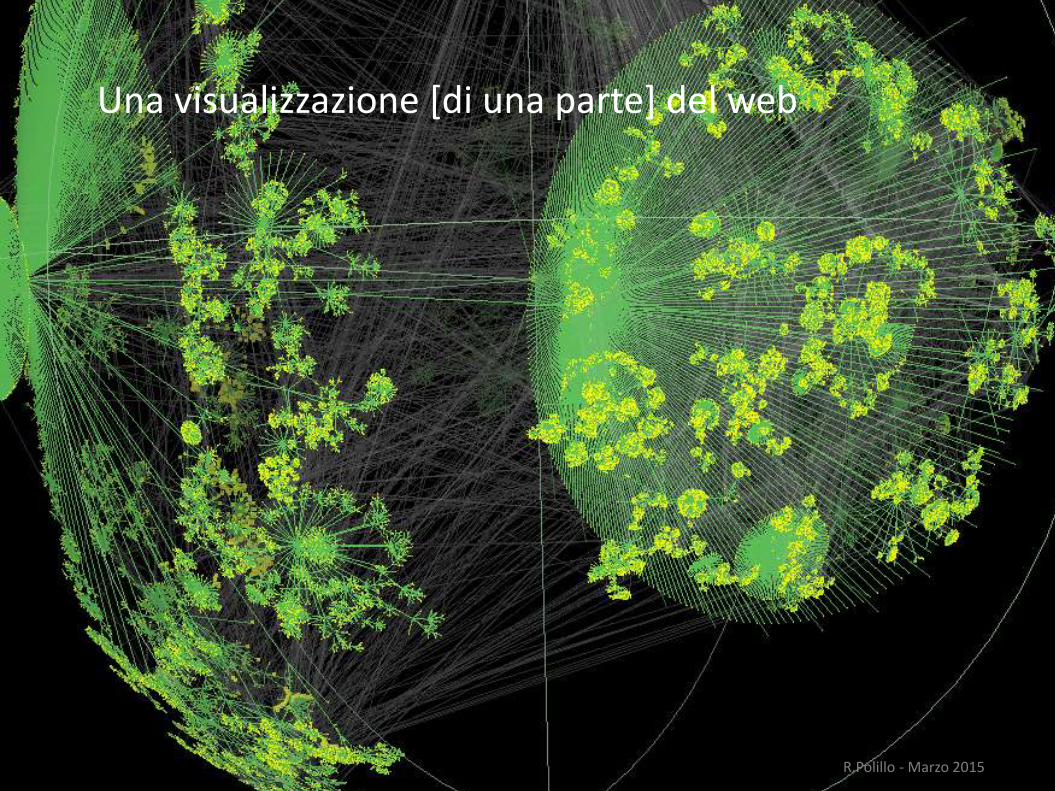
Una visualizzazione [di una parte] del web
La immagine mostra una porzione di Internet costituita da 535.000 nodi e più di 600.000 links
WALRUS Visualization tool, 2001 http://www.caida.org/tools/visualization/walrus/R.Polillo - Marzo 2015
3
4
R.Polillo - Marzo 2015
Una visualizzazione [di una parte] del web

R.Polillo - Marzo 2015
5
Una visualizzazione [di una parte] del web

Come trovare l'informazione in rete
DirectoriesIndici strutturati di argomenti (gestiti da una redazione)
WikipediaEnciclopedia collaborativa
Motori di ricercaQuery Risultati
Motori semanticiwww.wolframalpha.com, …
Sistemi di Q&A socialeYahoo! Answer, …
EsplorazioneBrowsing, serendipity
R.Polillo - Marzo 2015
6

Web directories7
Storicamente, il primo strumento di ausilio alle ricerche nel Web
Classificazione gerarchica dei siti (e non delle pagine) in categorie e sottocategorie, a più livelli, effettuata "a mano" -> varie "tassonomie"
Directories “generaliste” e directories verticali o di nicchia, anche prodotte in modo collaborativo
http://en.wikipedia.org/wiki/Web_directory
R.Polillo - Marzo 2015

Tassonomia8
Emporio celeste dei riconoscimenti benevoli(Enciclopedia cinese, J.L.Borges, 1973)
Gli animali si dividono in:a) Appartenenti all’imperatoreb) Imbalsamatic) Ammaestratid) Lattonzolie) Sirenef) Favolosig) Cani randagih) Inclusi in questa classificazionei) Che si agitano come pazzij) Innumerevolik) Disegnati con un pennello finissimo di peli di
cammellol) Ecceteram) Che hanno ritto il vason) Che da lontano sembrano mosche.
R.Polillo - Marzo 2015
Raggruppamento di
oggetti in classi,
secondo qualche
criterio
taxis=ordine
nomos=regola
Ogni tassonomia è
arbitraria, e dipende
dagli obiettivi
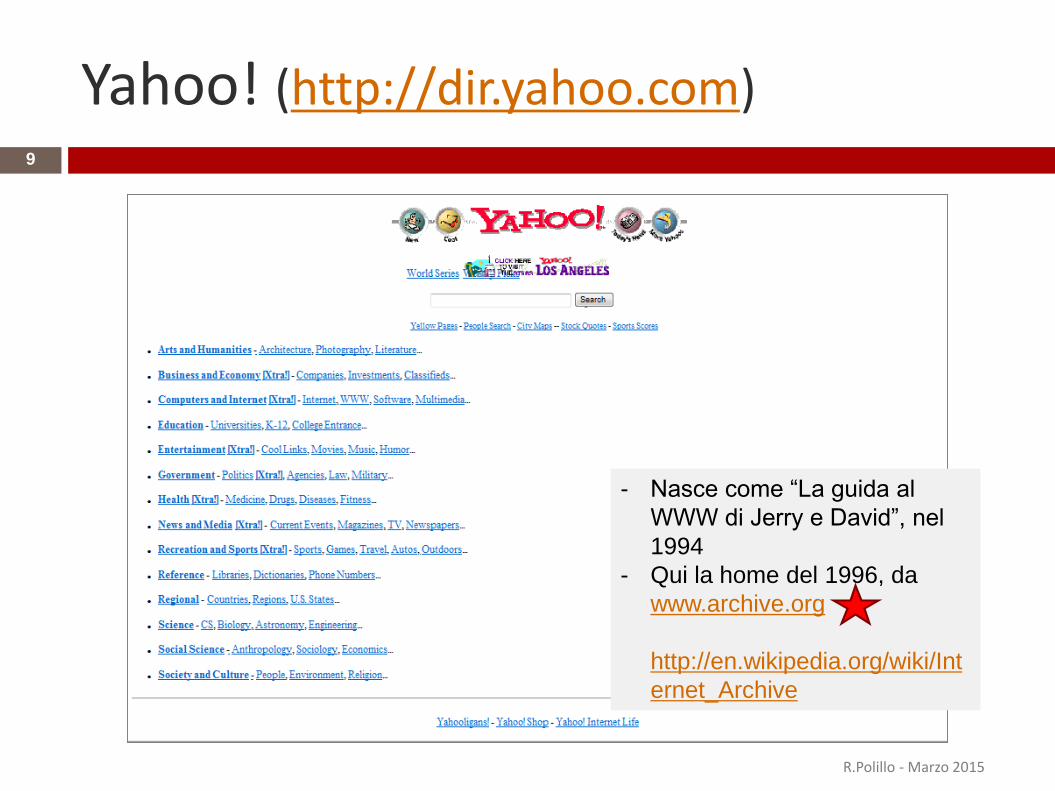
Yahoo! (http://dir.yahoo.com)9
R.Polillo - Marzo 2015
- Nasce come “La guida al
WWW di Jerry e David”, nel
1994
- Qui la home del 1996, da
www.archive.org
http://en.wikipedia.org/wiki/Int
ernet_Archive

The Open Directory Project (ODP)10
Nota anche come DMOZ (Directory Mozilla http://www.dmoz.org/
Directory gratuita, aperta e multilingua
Fondata nel 1998, poi acquisita da Netscape (1998), poi AOL, e manutenuta da una comunità di editor volontari
http://en.wikipedia.org/wiki/Open_Directory_Project
R.Polillo - Marzo 2015
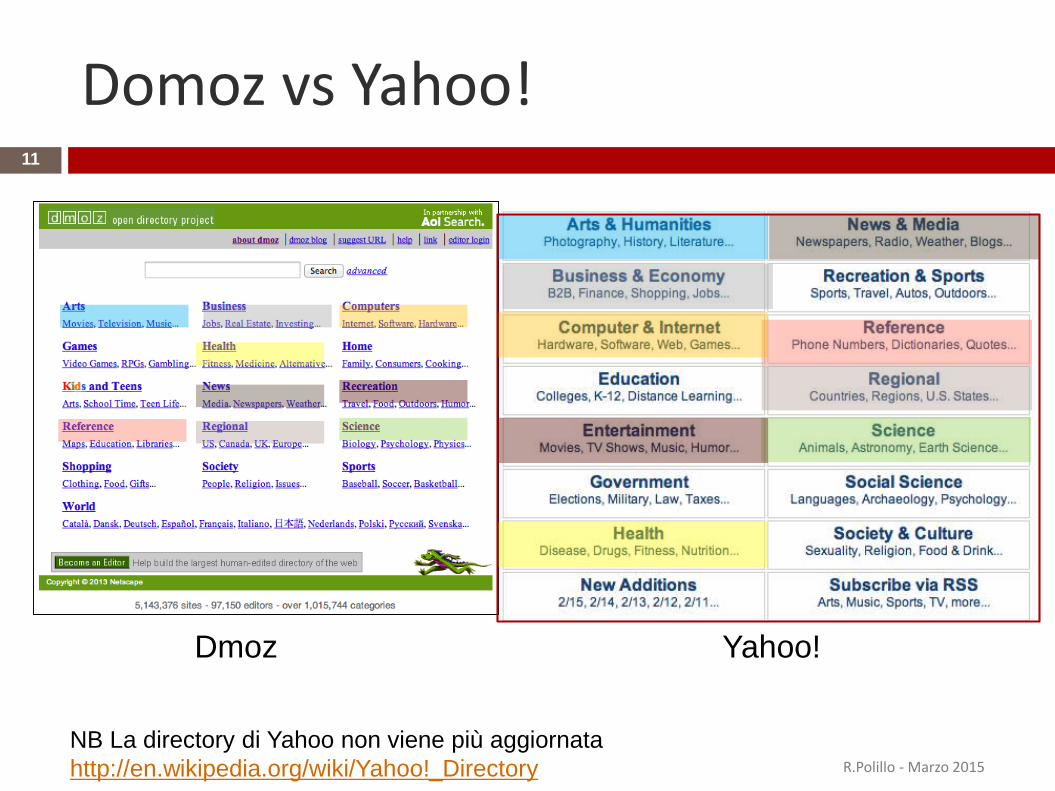
Domoz vs Yahoo!
R.Polillo - Marzo 2015
11
Dmoz Yahoo!
NB La directory di Yahoo non viene più aggiornata
http://en.wikipedia.org/wiki/Yahoo!_Directory

Wikipedia come strumento di ricerca12
Wikipedia è un formidabile strumento di ricerca e accesso al web
Ogni voce di Wikipedia è corredata da numerosi link interni ed esterni, che spesso permettono di raggiungere i siti più significativi correlati all’argomento esaminato
Inoltre Wikipedia contiene numerosi indici e directories, fra cui anche veri e propri portali tematici
(http://en.wikipedia.org/wiki/Portal:Contents/Portals)
R.Polillo - Marzo 2015

Serendipità13
Cerco una cosa e ne trovo un'altra
Nome coniato da Horace Walpole, tratto dalla fiaba “I tre principi di Serendip” (Serendip è l'antico nome di Sri Lanka)
Serve fortuna (“il caso”) e un atteggiamento di apertura: per cogliere l'indizio che porterà alla scoperta occorre essere aperti alla ricerca e riconoscere il valore di esperienze che non corrispondono alle originarie aspettative
http://en.wikipedia.org/wiki/Serendipity
http://serendip.brynmawr.edu/serendip/about.html
R.Polillo - Marzo 2015

14 R.Polillo - Marzo 2015

www.stumbleupon.com16
to stumble: inciampare, scoprire per caso
È una discovery engine di pagine web, fondato in Canada nel 2001
Premendo il bottone STUMBLE! installato sul browser, viene proposto un sito, un’immagine o un video scelti sulla base delle preferenze dell’utente, o delle raccomandazioni dei suoi amici o da altri utenti che hanno interessi simili
Il processo di selezione si affina sulla base del gradimento espresso (opzionalmente) dall’utente:
R.Polillo - Marzo 2015

Motori di ricerca per il Web
Componente software (utilizzabile come servizio online) progettato per ricercare informazioni sul World Wide Web
Le informazioni (di solito nella forma di link) sono presentate in una serie di Search Engine Results Page (SERP)
La qualità di un motore si valuta sulla base della pertinenza e rilevanza dei risultati
R.Polillo - Marzo 2015
17

Motori di ricerca
Una storia complessa, iniziata negli anni '90. Oggi, i primi:
Google- Dal 1998
Baidu- dal 2000, cinese
Yahoo!- Con motori esterni (dal 2009 "Powered by Bing")
Bing- Dal 2009 (prima: MSN Search, Windows Live Search, Live Search)
R.Polillo - Marzo 2015
18
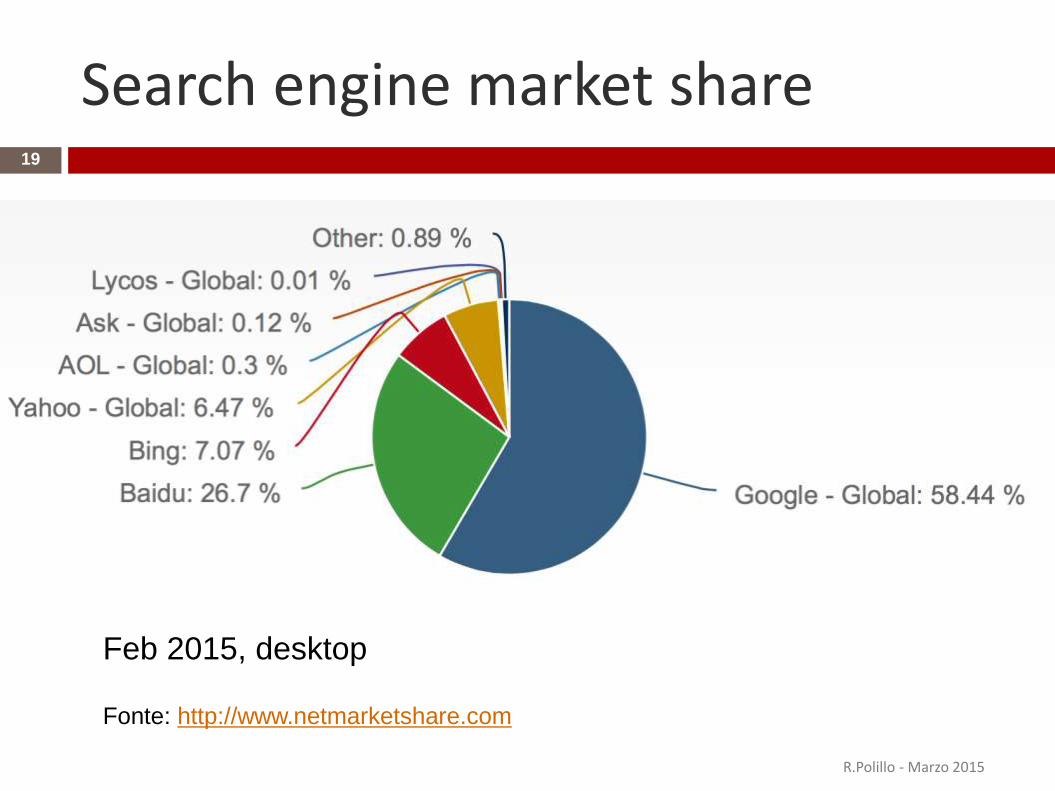
Search engine market share
R.Polillo - Marzo 2015
19
Fonte: http://www.netmarketshare.com
Feb 2015, desktop
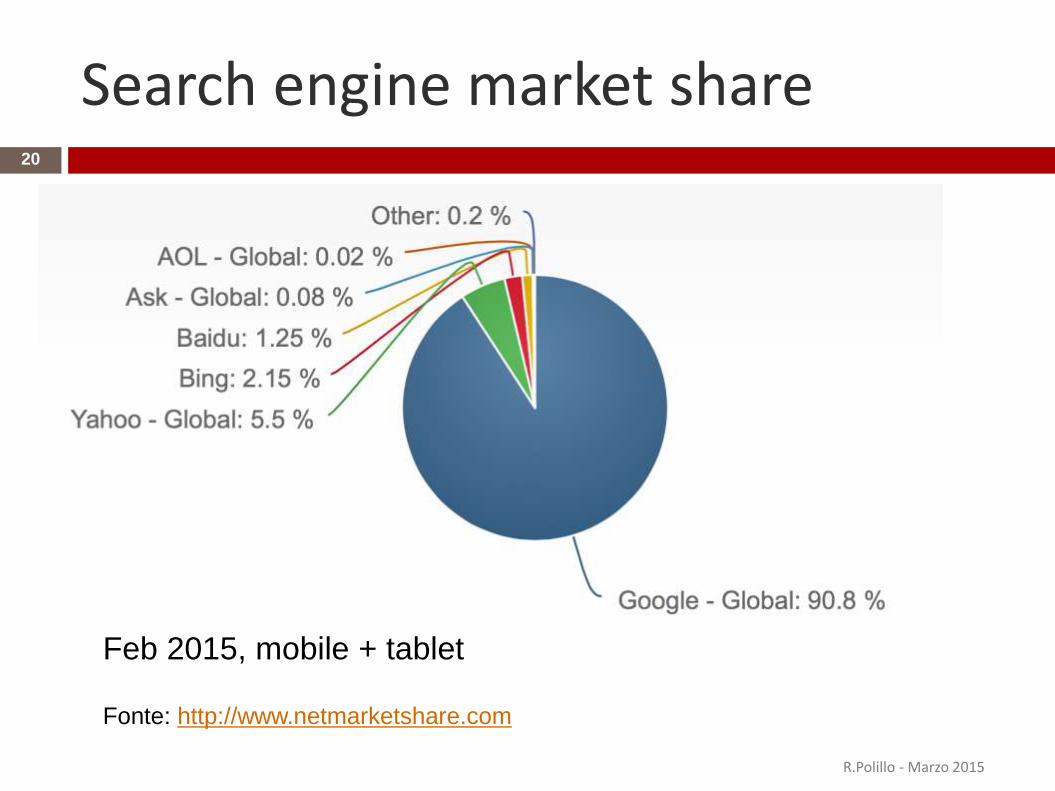
Search engine market share
R.Polillo - Marzo 2015
20
Fonte: http://www.netmarketshare.com
Feb 2015, mobile + tablet
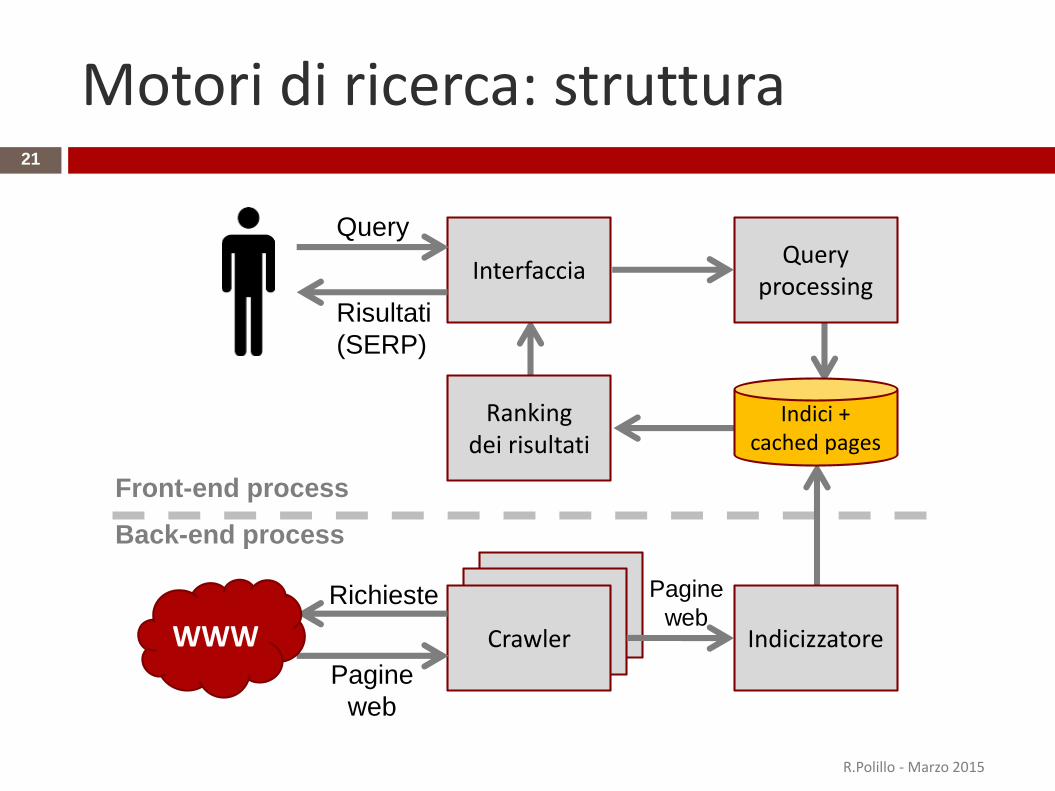
Motori di ricerca: struttura
R.Polillo - Marzo 2015
21
InterfacciaQuery
processing
Rankingdei risultati
Query
Risultati
(SERP)
Front-end process
Indici + cached pages
CrawlerCrawler
IndicizzatoreCrawler
Richieste
Pagine
web
Pagine
webWWW
Back-end process

Motori di ricerca: struttura22
Ogni motore di ricerca è composto da cinque componenti fondamentali:crawler, indice, interfaccia, query processor e il sistema di ranking
Il crawler è un software specializzato che naviga la rete e porta lepagine nell'indice. Il crawler tiene anche nota dei link che trova e li usaper raggiungere via via nuove pagine con nuovi link ...
L'indice è un enorme database dove le pagine vengono memorizzatecon tutti i metadati e dove tutte le parole vengono “invertite” creandoindici/chiavi per ognuna di esse
L'interfaccia interpreta la richiesta dell'utente, tenta di interpretarla epassa la richiesta al query processor che agisce sull'indice
Il sistema di ranking ordina i risultati della query in funzione della loro"rilevanza" (eventualmente filtrando risultati non pertinenti)
R.Polillo - Marzo 2015

Web crawling
I crawler (robot, spider, bot) sono programmi che navigano il Web, esaminando le diverse pagine e seguendo i link in esse presenti
Seguono opportune politiche di navigazione (per es. per decidere quando riesaminare una pagina già vista)
L'interazione con i Web server segue specifici protocolli (per es. robot exclusion protocol, o robot.txt)
Non tutto il Web è accessibile ai crawlerR.Polillo - Marzo 2015
23

robots.txt: esempio
www.domain.com
R.Polillo - Marzo 2015
24
/
robots.txt
utenti
foto
aboutUser-agent: Google
Disallow /utenti/foto
Allow: *
Crawl-delay: 20 sec

Deep vs surface Web
Non tutto il Web è accessibile ai motori di ricerca
Il Web invisibile ("deep Web") è parecchi ordini di grandezza più vasto del Web visibile ("surface Web")
Deep Web, esempi: Pagine "vietate" dai Web server (robots.txt)
Pagine generate dinamicamente a fronte di query o di input forniti attraverso form
Pagine senza link entranti
Pagine accessibili tramite registrazione e login
Ecc.
R.Polillo - Marzo 2015
25
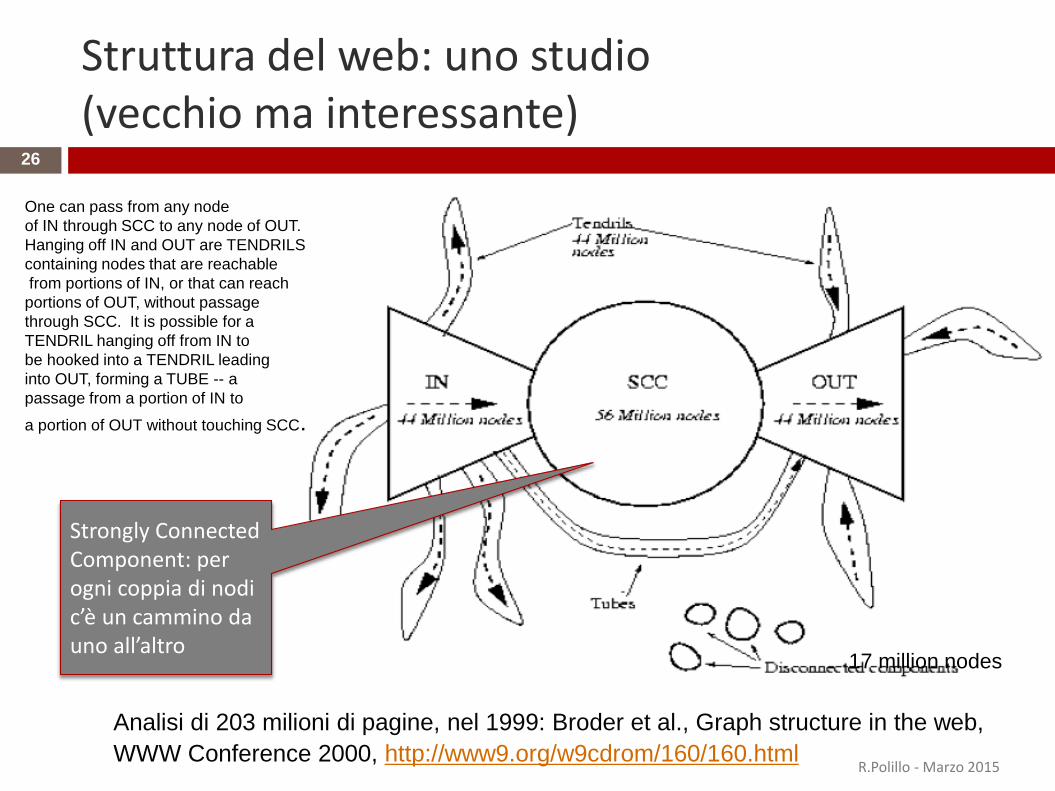
Struttura del web: uno studio (vecchio ma interessante)
Analisi di 203 milioni di pagine, nel 1999: Broder et al., Graph structure in the web,
WWW Conference 2000, http://www9.org/w9cdrom/160/160.html
17 million nodes
26
R.Polillo - Marzo 2015
Strongly Connected Component: per ogni coppia di nodi c’è un cammino da uno all’altro
One can pass from any node
of IN through SCC to any node of OUT.
Hanging off IN and OUT are TENDRILS
containing nodes that are reachable
from portions of IN, or that can reach
portions of OUT, without passage
through SCC. It is possible for a
TENDRIL hanging off from IN to
be hooked into a TENDRIL leading
into OUT, forming a TUBE -- a
passage from a portion of IN to
a portion of OUT without touching SCC.

Tipi di query
InformativaObiettivo: trovare un'informazione
NavigazionaleObiettivo: trovare una pagina web, che conosco già
RisorsaObiettivo: trovare una risorsa (non informativa) disponibile sul web
Il risultato è di solito (ma non sempre!) una lista di link a pagine web
Evoluzione: dal contenitore (anche) al contenuto
R.Polillo - Marzo 2015
27
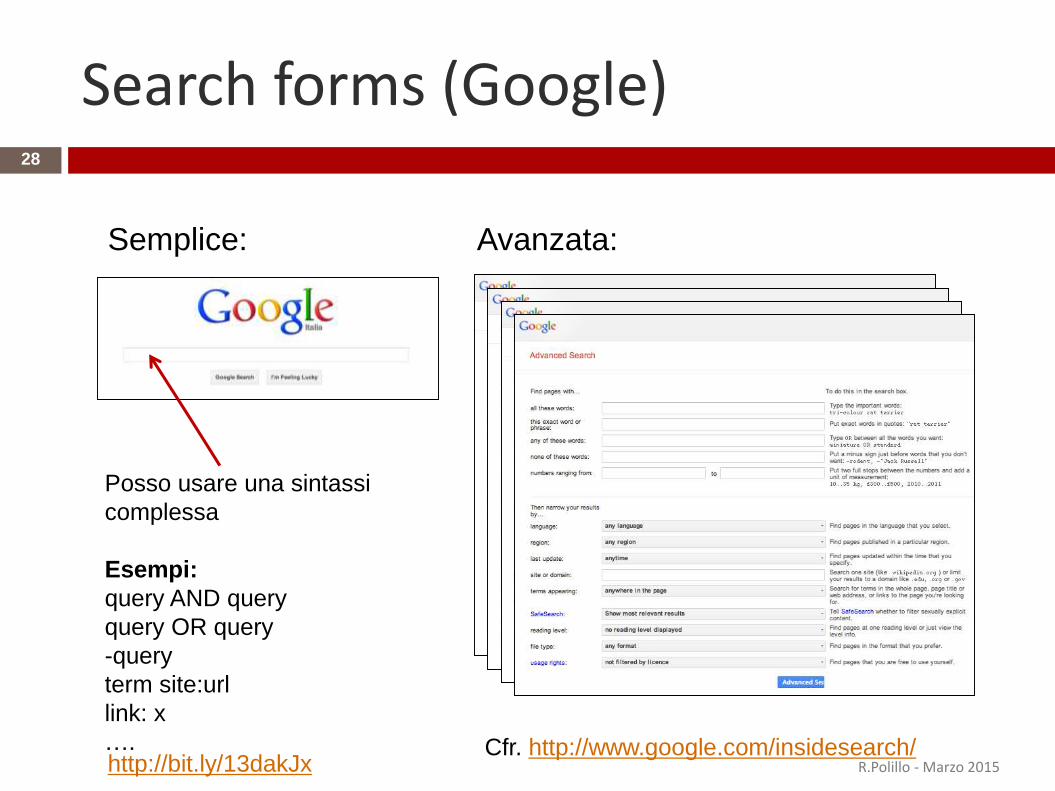
Search forms (Google)
R.Polillo - Marzo 2015
28
Semplice: Avanzata:
Posso usare una sintassi
complessa
Esempi:
query AND query
query OR query
-query
term site:url
link: x
…. Cfr. http://www.google.com/insidesearch/http://bit.ly/13dakJx
Google: evoluzione della home page
Video sulla evoluzione di www.google.com dal 1998 al 2007
http://www.youtube.com/watch?v=1vgprty39og
R.Polillo - Marzo 2015
29

SERP: struttura tipica
R.Polillo - Marzo 2015
30
Search box
Risultati sponsorizzati
Opzioni per la ricerca
Risultati "organici"
(non influenzati dalle
sponsorizzazioni)
Google:AdWords
Related Documents











