03/21/22 EECS 584, Fall 2011 1 Bigtable: A Distributed Storage System for Structured Data Jing Zhang Reference: Handling Large Datasets at Google: Current System and Future Directions, Jeff Dean

7/2/2015EECS 584, Fall 20111 Bigtable: A Distributed Storage System for Structured Data Jing Zhang Reference: Handling Large Datasets at Google: Current.
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

04/19/23 EECS 584, Fall 2011 1
Bigtable: A Distributed Storage System for Structured Data
Jing Zhang
Reference: Handling Large Datasets at Google: Current System and Future Directions, Jeff Dean

04/19/23 EECS 584, Fall 2011 2
Outline
Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation

04/19/23 EECS 584, Fall 2011 3
Outline
Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation

Google’s Motivation – Scale! Scale Problem
– Lots of data– Millions of machines– Different project/applications– Hundreds of millions of users
Storage for (semi-)structured data No commercial system big enough
– Couldn’t afford if there was one
Low-level storage optimization help performance significantly Much harder to do when running on top of a database layer
04/19/23 EECS 584, Fall 2011 4

Bigtable
Distributed multi-level map Fault-tolerant, persistent Scalable
– Thousands of servers– Terabytes of in-memory data– Petabyte of disk-based data– Millions of reads/writes per second, efficient scans
Self-managing– Servers can be added/removed dynamically– Servers adjust to load imbalance
04/19/23 EECS 584, Fall 2011 5
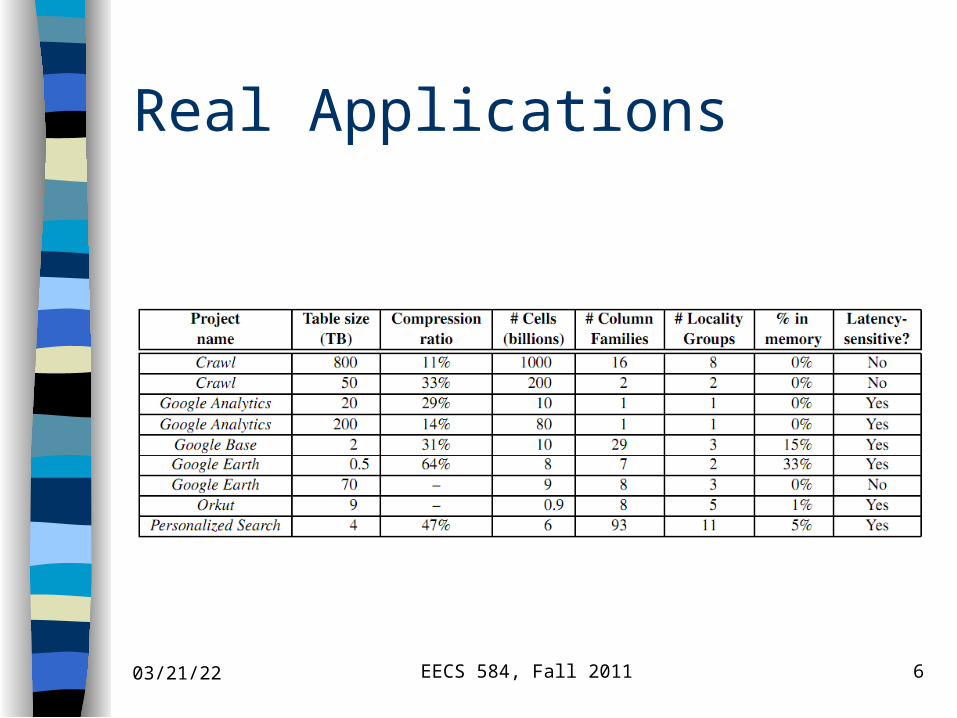
Real Applications
04/19/23 EECS 584, Fall 2011 6

04/19/23 EECS 584, Fall 2011 7
Outline
Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation

Data Model a sparse, distributed persistent multi-
dimensional sorted map
(row, column, timestamp) -> cell contents
04/19/23 EECS 584, Fall 2011 8

Data Model Rows
– Arbitrary string– Access to data in a row is atomic– Ordered lexicographically
04/19/23 EECS 584, Fall 2011 9
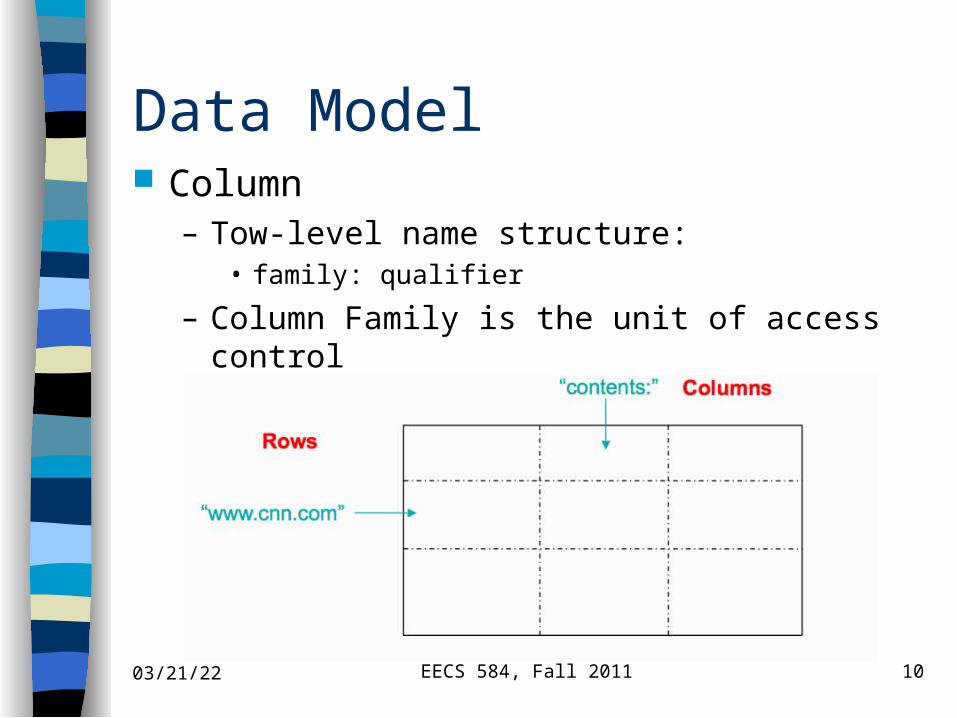
Data Model Column
– Tow-level name structure:• family: qualifier
– Column Family is the unit of access control
04/19/23 EECS 584, Fall 2011 10

Data Model Timestamps
– Store different versions of data in a cell– Lookup options
• Return most recent K values• Return all values
04/19/23 EECS 584, Fall 2011 11

Data Model The row range for a table is dynamically partitioned Each row range is called a tablet Tablet is the unit for distribution and load balancing
04/19/23 EECS 584, Fall 2011 12

04/19/23 EECS 584, Fall 2011 13
Outline
Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation

APIs Metadata operations
– Create/delete tables, column families, change metadata
Writes– Set(): write cells in a row– DeleteCells(): delete cells in a row– DeleteRow(): delete all cells in a row
Reads– Scanner: read arbitrary cells in a bigtable
• Each row read is atomic• Can restrict returned rows to a particular range• Can ask for just data from 1 row, all rows, etc.• Can ask for all columns, just certain column families, or specific
columns
04/19/23 EECS 584, Fall 2011 14
04/19/23 EECS 584, Fall 2011 15
Outline
Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation
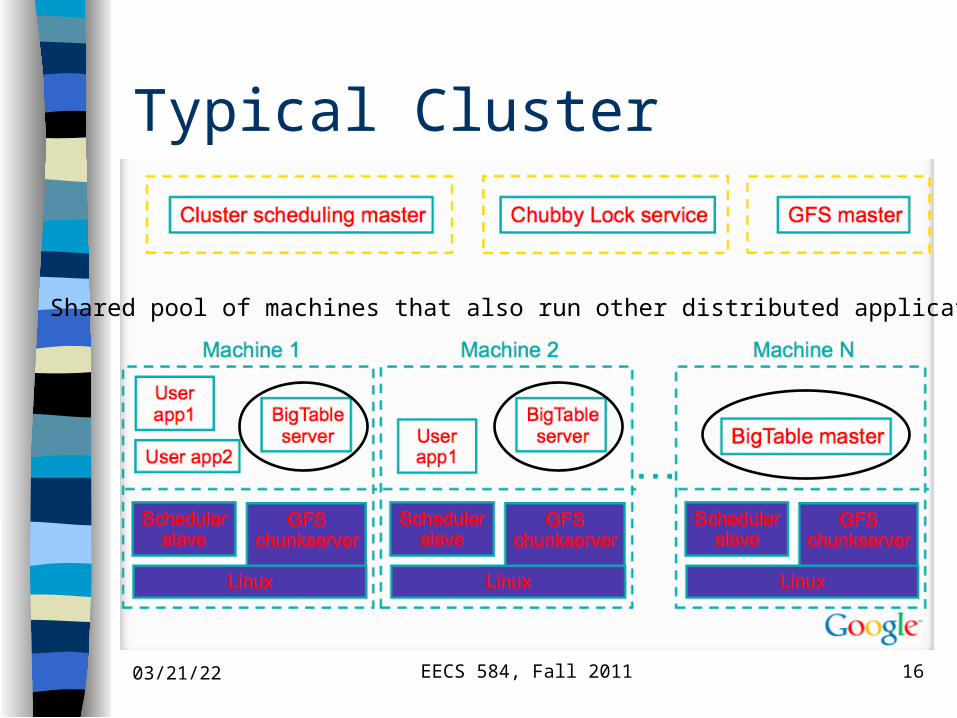
Typical Cluster
04/19/23 EECS 584, Fall 2011 16
Shared pool of machines that also run other distributed applications

Building Blocks Google File System (GFS)
– stores persistent data (SSTable file format) Scheduler
– schedules jobs onto machines Chubby
– Lock service: distributed lock manager– master election, location bootstrapping
MapReduce (optional)– Data processing– Read/write Bigtable data
04/19/23 EECS 584, Fall 2011 17

Chubby
{lock/file/name} service Coarse-grained locks Each clients has a session with Chubby.
– The session expires if it is unable to renew its session lease within the lease expiration time.
5 replicas, need a majority vote to be active Also an OSDI ’06 Paper
04/19/23 EECS 584, Fall 2011 18

04/19/23 EECS 584, Fall 2011 19
Outline
Motivation Overall Architecture & Building Blocks Data Model APIs Implementation Refinement Evaluation

Implementation Single-master distributed system Three major components
– Library that linked into every client– One master server
• Assigning tablets to tablet servers• Detecting addition and expiration of tablet servers• Balancing tablet-server load• Garbage collection• Metadata Operations
– Many tablet servers• Tablet servers handle read and write requests to its table• Splits tablets that have grown too large
04/19/23 EECS 584, Fall 2011 20

Implementation
04/19/23 EECS 584, Fall 2011 21

Tablets Each Tablets is assigned to one tablet server.
– Tablet holds contiguous range of rows• Clients can often choose row keys to achieve locality
– Aim for ~100MB to 200MB of data per tablet Tablet server is responsible for ~100 tablets
– Fast recovery:• 100 machines each pick up 1 tablet for failed machine
– Fine-grained load balancing:• Migrate tablets away from overloaded machine• Master makes load-balancing decisions
04/19/23 EECS 584, Fall 2011 22
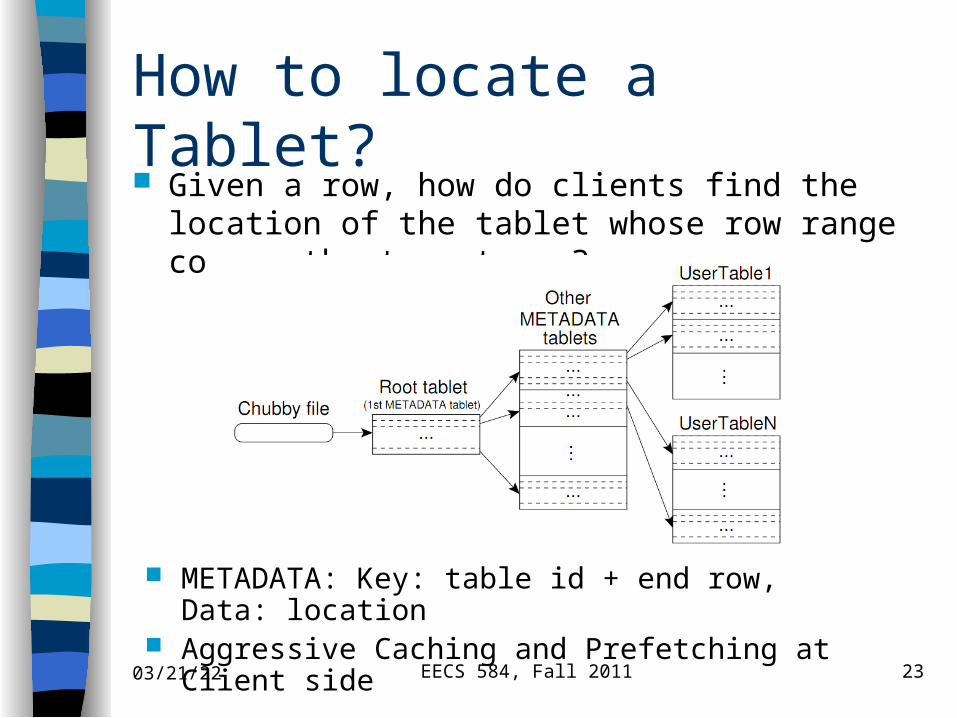
How to locate a Tablet? Given a row, how do clients find the location of the
tablet whose row range covers the target row?
04/19/23 EECS 584, Fall 2011 23
METADATA: Key: table id + end row, Data: location Aggressive Caching and Prefetching at Client side

Tablet Assignment
Each tablet is assigned to one tablet server at a time. Master server keeps track of the set of live tablet
servers and current assignments of tablets to servers.
When a tablet is unassigned, master assigns the tablet to an tablet server with sufficient room.
It uses Chubby to monitor health of tablet servers, and restart/replace failed servers.
04/19/23 EECS 584, Fall 2011 24

Tablet Assignment Chubby
– Tablet server registers itself by getting a lock in a specific directory chubby
• Chubby gives “lease” on lock, must be renewed periodically• Server loses lock if it gets disconnected
– Master monitors this directory to find which servers exist/are alive
• If server not contactable/has lost lock, master grabs lock and reassigns tablets
• GFS replicates data. Prefer to start tablet server on same machine that the data is already at
04/19/23 EECS 584, Fall 2011 25

04/19/23 EECS 584, Fall 2011 26
Outline
Motivation Overall Architecture & Building Blocks Data Model APIs Implementation Refinement Evaluation

Refinement – Locality groups & Compression Locality Groups
– Can group multiple column families into a locality group• Separate SSTable is created for each locality group in each
tablet.– Segregating columns families that are not typically accessed
together enables more efficient reads.• In WebTable, page metadata can be in one group and
contents of the page in another group.
Compression– Many opportunities for compression
• Similar values in the cell at different timestamps• Similar values in different columns• Similar values across adjacent rows
04/19/23 EECS 584, Fall 2011 27

04/19/23 EECS 584, Fall 2011 28
Outline
Motivation Overall Architecture & Building Blocks Data Model APIs Implementation Refinement Evaluation
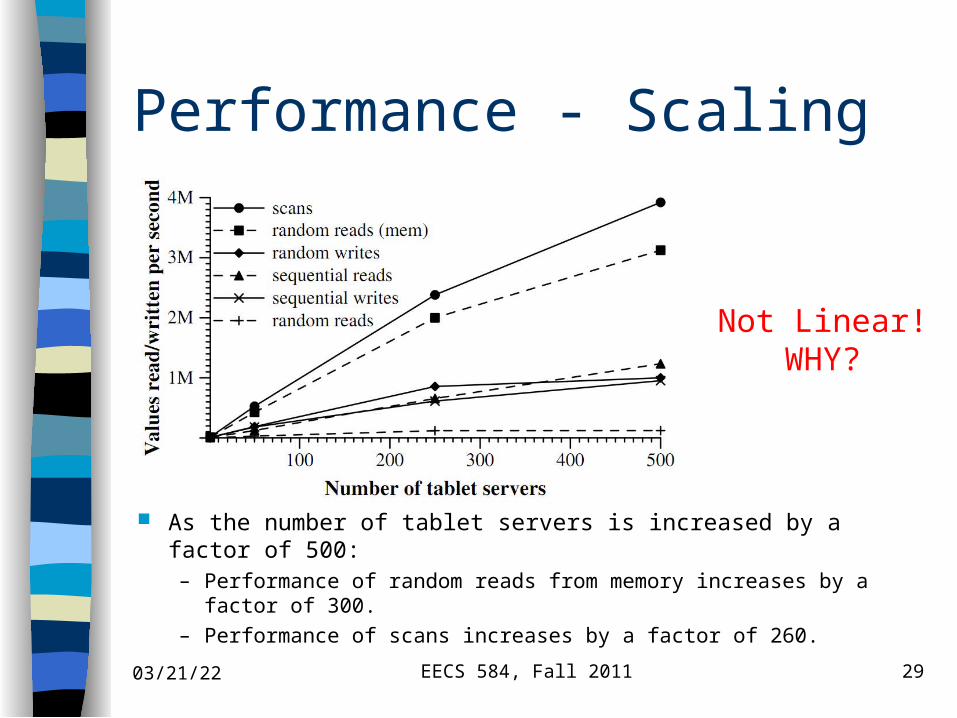
Performance - Scaling
04/19/23 EECS 584, Fall 2011 29
As the number of tablet servers is increased by a factor of 500:– Performance of random reads from memory increases by a factor
of 300.
– Performance of scans increases by a factor of 260.
Not Linear!WHY?

Not linearly?
Load Imbalance– Competitions with other processes
• Network• CPU
– Rebalancing algorithm does not work perfectly• Reduce the number of tablet movement• Load shifted around as the benchmark progresses
04/19/23 EECS 584, Fall 2011 30
Related Documents











