Copyright©2016 NTT corp. All Rights Reserved. トトトトトトトトトトトトトト トトトトトトトトトトトトトトトト NTT トトトト

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Copyright©2016 NTT corp. All Rights Reserved.
トランザクションの設計と進化
NTT ソフトウェアイノベーションセンタ熊崎宏樹

Copyright©2016 NTT corp. All Rights Reserved.
このスライドについて話すこと• 昔の DBの話• トランザクションの基本• 近代の DB界隈の潮流• トランザクション技術の変遷話さないこと• 特定の商用 DBの宣伝や F.U.D.• OSS DBの実装の詳細• 分散トランザクション

Copyright©2016 NTT corp. All Rights Reserved.
トランザクションの基本トランザクションとは: データに対する一連の操作を一つにまとめた単位の事トランザクションマネージャとは: 複数のトランザクションが ACIDを守って走るように管理する機構
A: Atomicity 結果が All-or-Nothingとなる事C: Consistency 一貫性を守る事I: Isolation 過程が他の処理から見えない事D: Durability 結果が永続化される事
Consistentな状態空間Inconsistentな状態空間
Diskが取りうる全ての状態の空間Atomicな遷移

Copyright©2016 NTT corp. All Rights Reserved.
何らかの実行順 (スケジュール空間 )
直列に実行した場合の結果
ACIDの実現手法• トランザクションが書く値はその前に Readした値に基づいていると仮定する
• つまり同じ値を読んだトランザクションは同じ値を書き込むはず• 読む際はその前に書かれた値を読むはず
• 何らかの直列な順序でトランザクションを一つずつ処理した場合と同じ結果が生成できればそれで良いんじゃなかろうか?• これを Historyの直列等価と言う
r r w r w w cT1:
r w r w cT2:
r r w r w w cSa: r w r w c
r r w r w w cSb: r w r w c
r r w r w w cr w r w c
トランザクション→ResultA
→ResultB
←たまたま ResultAと同じ結果になったr r w r w w cr w r w c ←ResultAとも Bとも違う結果になった…(無数にある) ResultAか Bと同じ結果になる順序を作りたい

Copyright©2016 NTT corp. All Rights Reserved.
スケジュールの空間• 例えばこんな感じ(W,X,Y,Zはそれぞれ DB上の変数)
r r w r w w cT1:
r w r w cT2:
r
r
w
r
w
w
W:
X:
Y:
Z: r w
r w
T2の後に T1が走ったと見做して OK!Serializableと呼ぶ
r
r
w
r
w
w
W:
X:
Y:
Z: r w
r w
どっちが先に走ったとも言えなくてダメ

Copyright©2016 NTT corp. All Rights Reserved.
スケジュールの空間• 長いので端折ると、 VSR以上でリカバリとバランスの取れたスケジュールを効率よく切り出すスケジューラが求められている
• 結論から言うと 2Phase LockとかMVCCとか全てのスケジュール直列に実行した場合と最終状態が同じになるスケジュール( FSR)直列に実行した場合とビュー等価なスケジュール( VSR)直列に実行した場合と競合等価なスケジュール( CSR)
2PLが作るスケジュール

Copyright©2016 NTT corp. All Rights Reserved.
リカバリ• 障害時でもトランザクションの Durabilityを維持するための機能• 大きく 3つのシナリオが定義される
• トランザクション障害• ユーザタイムアウトとかデッドロックとか自主的アボートとか…
• システム障害• DBプロセスが突然殺されたとか OS落ちたとか電源抜けたとか…
• メディア障害• ディスクが消し飛んだ。ログアーカイブから全部作り直すしかない
• これらの障害に耐えるようにディスク書き込みプロトコルを設計する• 難しい事で有名だが、大量に研究が積まれている
• これからその詳細について

Copyright©2016 NTT corp. All Rights Reserved.
DB 基本構造• データを保持するディスクと、ログを保持するディスクがある
• 物理的に同一でも一応構わない(メディア障害に脆弱になるが)• メモリにある B+ treeは飽くまでキャッシュに過ぎない
• どこかのタイミングでWrite Backする必要がある
Log DiskData Disk
B+ tree
B+ treelog buffer
log
flushevict

Copyright©2016 NTT corp. All Rights Reserved.
システム障害からのリカバリ• システムリスタート時にも DBには ACIDを守っていて欲しい。
• 走りかけのトランザクションは全てキャンセル• クライアントにコミットが済んだと応答したトランザクションは全て実行済み• 途中経過は他のトランザクションから見えない
T1:
T2:
T3:
T4:
Crash
RestartT1: cancel
T2:
T3:
T4: cancel
コミットされていないトランザクションを完全に抹消しコミットされたトランザクションは全て復活する

Copyright©2016 NTT corp. All Rights Reserved.
バッファマネージャー• ディスク上のデータをページ単位でメモリにキャッシュする機構• ディスクよりメモリの方が小さい前提で設計されている• 単純な LRUより賢いマネジメント技法が求められている
• select count(*) しただけでバッファが全部初期化されても困る• 割と Patentも取られていて危険( O 社と I 社が目立つ)
hash
12
213
1 01
1
page
page
page
page
page
page
PostgreSQL8.1から入った Clocksweep

Copyright©2016 NTT corp. All Rights Reserved.
バッファマネージャー (Steal)
• 任意のページをバッファに入れたい• select * from Table; は普通に実行できないと困る
• 使っていないバッファはディスクに書き出して evictしてでも再利用したい• えっコミットされていなくても?→はい(コミット済みか安価に確認する手段はない)
• この仕組みを Stealと呼ぶ• 多分トランザクションマネージャが知らない所で勝手にバッファを盗むから• Atomicityを守る工夫が別途必要になる
トランザクションの途中の値が読める (Atomictity違反 )T1:
T2:
T3:
T4:
Crash
RestartT1:
T2:
T3:
T4: cancel
evict

Copyright©2016 NTT corp. All Rights Reserved.
バッファマネージャー (Force)
• コミットされたデータの更新内容はディスクに書き戻したい• コミット完了時の操作として Dirtyなページをすべて書き戻せばよいのでは• この仕組みを Forceと呼ぶ
• たぶんトランザクションマネージャがディスク書き出しを強いるから• 一般にランダム IOは HDDで非常に遅いのでこれを選ばない事が多い
Log DiskData Disk
B+ tree
B+ treelog buffer
log
flushcommit

Copyright©2016 NTT corp. All Rights Reserved.
バッファマネージャー (No-Force)
• トランザクションがコミットする際に、ログさえ書いたら実際のページを書き換えなくても良いとするログプロトコル• コミットしてもディスク上に反映されているとは限らないので永続性を守る工夫が別途必要になる
T1:
T2:
T3:
T4:
Crash
RestartT1: cancel
T2: cancel
T3:
T4: cancel
書いた値が消えたDurability違反
evict
たまたま書き戻していれば無事

Copyright©2016 NTT corp. All Rights Reserved.
Stealと Forceの直交関係• Force, Stealの関係を整理すると以下• 有名そうなのを太字に
Force
No Force
No Steal Steal
PostgreSQLMySQL
OracleDBDB2UDSIMS
TOSPTWIST
IMS/FP
実例なし?

Copyright©2016 NTT corp. All Rights Reserved.
バッファマネージャー (Atomic)
• 複数のページを (論理的に )Atomicに書き出す技術はいくつか提案されている• 一番有名なのはシャドウページング(下図)
• 一般に遅くなりがちなので近代の DBでは好まれない• PostgreSQLの追記 &VACUMMな仕組みはこれの仲間と呼べるかも
A
B
C
D
E
A'
B'
C'
D'
E'
A
B
C
D
E
A'
B'
C'
D'
E'
Atomic書き換えシャドウページングの図
シャドウページ

Copyright©2016 NTT corp. All Rights Reserved.
チェックポイント• No-forceな DBはジャーナルに Redoログが溜まっていくので、そのログの長さがクラッシュ後の再起動時間に大きく響いてしまう
• あまりに参照され続ける為一度も evictされないページが有ったらそこに影響を与えるうるログの長さは DBの全ログにもなる• 定期的に Dirtyなページをディスクに書き出す事をチェックポイントと呼ぶ
• TOC: Transaction Oriented Checkpoint • 常に Forceしてればそもそもチェックポイント要らないよね(だが遅い)
• TCC: Transaction Consistent Checkpoint• 定期的にチェックポイントシグナル発行して新規トランザクションの受付をしばらく止めて全部のトランザクション終わるの待ってからディスクに全部書き出そうか(間欠停止)
• ACC: Action Consistent Checkpoint• 定期的にチェックポイントシグナルしたらその瞬間の Dirtyなページも含めて全部書きだしちゃえばいいよね ( 未コミットなデータも書き込むので Stealの一種だが無駄が多い )
• Fuzzy• 定期的なチェックポイント時に Dirtyになってるページ一覧のみを書き出せば充分リカバリコストを減らせるよね• 亜種が多すぎるので詳細はまた今度…

Copyright©2016 NTT corp. All Rights Reserved.
リカバリ技法生態図• Principles of Transaction-Oriented Database Recovery[1983 Theo et al.]が良くまとまってる• Force/Stealの他に「複数のページ書き込みを Atomicにやるか?」と「どうやってチェックポイントするか?」の観点で分類するとこうなる
• ¬ Atomic/Steal/ ¬ Force/fuzzyの組み合わせがのちの ARIES
ARIESはここからの発展形
Copyright©2016 NTT corp. All Rights Reserved.
ログの種類と用法• ログに含まれる情報は実装依存だが、その中でも着目すべき性質を持つログの種類は「 Undo 」「 Redo 」の情報を含んでいるか否か。
• Undoログ:更新前のデータを保持するログ• Redoログ:更新後のデータを保持するログ• Undo-Redoログ:更新前と後両方のデータを保持するログ
• Stealの起きるデータベースでは必ず Undoログが必要となる• ディスクに未コミットのデータが永続化されうるので、復旧時にそれを消去しないといけない
• 複数ページを Atomicに書けないデータベースで Forceする際も Undoログが必要となる• Force 途中で落ちたら復旧しないといけないから
• Forceしないデータベースでは必ず Redoログが必要となる• Atomicに複数ページを更新しない方式で行くなら、 Steal時も Force時もページを evictする前に必ずログを書かないといけない
• これがいわゆるWrite Ahead Logging(WAL)の事。 Stealより優先されるルール

Copyright©2016 NTT corp. All Rights Reserved.
リカバリ技法生態図もう一度• Undo/Redo 情報の必要性を図に直すと以下。
• 青い楕円は Undoログが必要となる方式• 黄色い楕円は Redoログが必要となる方式• 両方の楕円に入っている場合、 Undo/Redoの両方が必要

Copyright©2016 NTT corp. All Rights Reserved.
リカバリの手順 (Steal/No-Forceを例に )
• Redoログを全部実行してからUndo対象を決定し、Undoを行う• Undo時に Compensation Log Record(CLR)という Redoログを書けば復旧中に再度システム障害が起きた際に CLRまで RedoすればUndoのコストが減るよねと言うのが ARIES
T1:
T2:
T3:
T4:
Crash
evict
evict
RestartT1:
T2: 消失 T3:
T4: cancel
T1:
T2: T3:
T4:
Redo
Undo T1:
T2: T3:
T4:
完了 T1: cancel
T2: T3:
T4: cancel

Copyright©2016 NTT corp. All Rights Reserved.
リカバリつらい…• だいたい Stealと Non-atomic Updateのせい
• でも Stealを禁じるとページを evictする為にトランザクションを待たないといけない• しかもメモリ量を超えるページにいっぺんに触るトランザクションは実行不能になる
• 複数ページの Updateを Atomicに行おうとすると無駄が多くて辛い• PostgreSQLの追記 &VACUMMはかなり上手くやっている例• 「追記型 DBだからシンプルな構造が実現されている」は PostgreSQLの常套句
• そもそもなんで Stealが要るんだっけ?• メモリ容量<<<<ディスク容量という前提があるから

Copyright©2016 NTT corp. All Rights Reserved.
サーバの進化OracleDBの最初のバージョン (V2)が発売されたのは 1977 年
• 当時はミニコン後期、 AppleⅡ 発売の年• ミニコン・ VAX-11/780がDECから発売
• メインメモリは 2MB、最大 8MB– 当時メガバイト単価は 100 万円以上
• ディスクはハイエンドで 100MB 程度• メモリ容量<< (10 倍以上 ) <<ディスク容量の時代
2016 年現在• Broadwell-EPならメモリは最大 24TB
• ギガバイト単価が 500 円切ってる• ディスクは単発だと 10TBがやっと(ヘリウム充填 ?)• メモリ容量>ディスク容量の時代

Copyright©2016 NTT corp. All Rights Reserved.
In-Memory DBの登場市中でよく見かける「インメモリ技術」は大きく2種類① 「ディスクに書き込まないから高速です」
• 嘘をついてはいないが、本命ではない• tmpfsに書き込んでるから高速ですとか言うのは置いといて
② 「大容量になったメモリを活用しています」• ディスクにはちゃんと書き込んで永続化する• 現代のサーバの進化に合わせて再設計された DBの事この資料の主題

Copyright©2016 NTT corp. All Rights Reserved.
アーキテクチャの変遷:伝統的 DB
• ディスクが中心• メモリはキャッシュ及びバッファとして使う
• mmap/read等でディスクのページをメモリに写しとり書き戻す• 容量単価が貴重なメモリを大事に使う
• HDDのランダムアクセスの遅さがネックになりがち• シーケンシャルアクセスでパフォーマンスを上げるテクの研究が進んだ• WAL、グループコミット、ログ構造化、 ARIESなどなど
• CPUネックになるまで頑張る

Copyright©2016 NTT corp. All Rights Reserved.
DB 基本構造(再掲)• データを保持するディスクと、ログを保持するディスクがある
• 物理的に同一でも構わない• メモリにある B+ treeは飽くまでキャッシュに過ぎない
• どこかのタイミングでWrite Backする必要がある
Log DiskData Disk
B+ tree
B+ treelog buffer
log

Copyright©2016 NTT corp. All Rights Reserved.
DB 基本構造• トランザクションの進捗と同時にログを書き出し続けるのが一般的
• いつバッファがディスクに書き戻される (Steal)かトランザクション側は制御できない• Stealより先にログを書かないといけないので必然的に完了前にログを書く事になる
• 途中でクラッシュしたりアボートしたら Undoしないといけない。• ログが書き終わったらトランザクション完了と見做すのが一般的
• データディスクへの反映は後回し (no-force)でもよい
Log DiskData Disk
B+ tree
B+ treelog buffer
log
ログバッファのデータはトランザクションの完了を待たずに書き出し続ける(WAL)
いつキャッシュをディスクに書き戻すかは LRUやチェックポイント次第

Copyright©2016 NTT corp. All Rights Reserved.
In-Memory DB 基本構造• メインメモリがプライマリなストレージなので、メインメモリに載るデータしか使えない (例外はある )• メモリ上のデータとディスク上のデータに対応関係があるとは限らない
• いつの間にかバッファマネージャがページをディスクに書き出す (Steal)事はない• コミット時に DBがページをディスクに強制的に書き出す (Force)事もない
Log DiskData Disk
B+ treelog buffer
log
現在主流なのはコミットが完了したときに Redoログだけを書き出すタイプ
Snapshot
ディスクに B+treeを作るのは最適化の為であり、必須ではない

Copyright©2016 NTT corp. All Rights Reserved.
アーキテクチャの変遷: In-Memory DB
• メモリがメインのデータ置き場であり作業場• メモリに入りきらないデータはそもそも入らない
• ディスクは永続化を担当• ログとスナップショットの保存
• In-MemoryDBはそもそも HDDからのキャッシュではないので stealという概念が必要ない• ディスクのキャッシュではないのでページという概念も存在しない
• 永続性とリカバリについてはこれまでと同等にしっかりサポート

Copyright©2016 NTT corp. All Rights Reserved.
In-Memory DB 基本構造• Force, Stealの関係を整理すると以下
Force
No Force
No Steal Steal
In-DiskDBのほとんどはここ
In-Memory DBはここ

Copyright©2016 NTT corp. All Rights Reserved.
In-Memory DB リカバリアーキテクチャ• Stealも Forceも概念からして存在しない• ディスクのキャッシュという意味でのページと言う概念も存在しない• チェックポイントは依然として存在しうる• リカバリ戦略が圧倒的に楽になる (後述 )

Copyright©2016 NTT corp. All Rights Reserved.
In-Memory DBのアドバンテージ• メモリ上のデータレイアウトは必ずしもディスク上のものと対応しなくてもよくなった→ MassTree等の新しいデータ構造• Stealが無くなったので、実行中のトランザクションがコミットまでログを書く必要が無くなった(コミット時に Logを Forceすればよい)
• 個々のログエントリの為に LSN(ログシーケンスナンバー )というユニークな IDを発行するコストが要らなくなった• 単一の単調増加する値をロックで守っていたのでボトルネックになりがちだった
• 従って、 1トランザクション毎に 1つ IDがあればログが事足りるようになった• Redoログにトランザクションの順序を表す IDが付いていればそれでよい
• 更にその IDの発行も高速化したい → Silo• ログの書き出しも並列化したい → Silo

Copyright©2016 NTT corp. All Rights Reserved.
MassTree[Yandong Maoら eurosys2012]
• 複数階層の B+treeで木の部分集合を保持する事で木を辿る際の比較演算が cmp 命令一個で済む木構造• ReaderとWriterが物理衝突してもロック不要• 従来の B+treeと比べて 30% 程高速に読み書きができる
• レンジスキャンはその代わり遅いが ...• 近年のトランザクション論文で引っ張りだこ
1 ~8byte
9 ~16byte
17 ~24byte

Copyright©2016 NTT corp. All Rights Reserved.
• uint64_t を keyとした B+treeを複数階層作る• 1 層目はキーの 1 ~ 8byte 目に対応• 2 層目はキーの 9 ~ 16byte 目に対応• 中途半端な長さの keyは 0でパディングする
• leaf nodeは、次の層へのポインタとその長さの keyまでの値に対応するvalueの unionを持つ。• ほら、 trieに見えてきただろう?
1 ~8byte
9 ~16byte
17 ~24byte
MassTree[Yandong Maoら eurosys2012]

Copyright©2016 NTT corp. All Rights Reserved.
• 2 層目で同じ B+treeに入るデータは 1 層目の 1 ~ 8バイトが完全一致しているデータのみ• 例えば 72byteのキーが挿入されたら 9 階立ての Trie of B+treeができる
• 厳密には 65byte 目以降が異なる 2つ目の keyが挿入された瞬間に生成されるが詳細は論文を参照
1 ~8byte
9 ~16byte
17 ~24byte
MassTree[Yandong Maoら eurosys2012]

Copyright©2016 NTT corp. All Rights Reserved.
Silo[Stephenら SOSP’13]
• 高速なトランザクション処理アルゴリズム• データ構造はMassTreeの拡張• IDを専用スレッドが単調増加させながら払い出して (論文中では 40msに 1 回 ) IDの上 32bitデータとして使う (Epoch)• 各ワーカーはその Epochと同一 Epoch 内の依存順序を統合してユニークな 64bitの IDを作り出せる
• In-Memory DBなので Redoログだけで良い
次の Epochは 13だよー

Copyright©2016 NTT corp. All Rights Reserved.
• MassTreeが Optimisticな一貫性制御をしているので、それを拡張する形で Optimisticなトランザクションを設計• Optimistic Concurrency Control(OCC)自体は [1981 Kung, H.T. ら On Optimistic
Methods for Concurrency Control]まで遡る• …もっと昔からあったような気がする
• トランザクション実行中は共有データを一切汚さずに実行し最後に 5ステップの処理をする(詳細は次のページ以降)1. Write Lock
• 書き込み対象をロックしてここで TIDを生成2. Read Validation
• バージョン番号を ReadSetと比較する3. Write
• メモリに書き込みを行う。書いたデータは即 Unlockして良い。4. Durable Write
• ログに書き込みを行う。 Epoch 内の全データが書かれるまで待つ。5. Return
• ユーザに完了を報告する
Silo[Stephenら SOSP’13]

Copyright©2016 NTT corp. All Rights Reserved.
• CPUの上にトランザクション処理を行うWorkerと、ログを書き込むLoggerがそれぞれ存在する(それぞれの数は環境に合わせて増減して良い)
• Workerはログを生成し、 Loggerはそれらのログを集約して書き込む• 下の図は 2ソケットの 8コア CPU上でのイメージ図
worker
worker
worker
worker
worker
worker
worker
Logger
worker
worker
worker
worker
worker
worker
worker
Logger
Disk Disk
Silo[Stephenら SOSP’13]

Copyright©2016 NTT corp. All Rights Reserved.
キャッシュを汚す事はギルティ
http://www.1024cores.net/home/lock-free-algorithms/first-things-first から
共有データにWriteした場合の速度
localデータにWriteした場合の速度
共有 /localデータから Readした場合の速度

Copyright©2016 NTT corp. All Rights Reserved.http://www.1024cores.net/home/lock-free-algorithms/first-things-first から
まったくスケールしない!!!!

Copyright©2016 NTT corp. All Rights Reserved.
Siloトランザクション (Running)
• トランザクション実行中は共有データに対して書き換えは一切行わない• 全部の書き込みはローカルのWrite-Setに行う• Readしたデータは Validation用にバージョン番号と共にローカルの
Read-Setに保管
Read-Setname version value
x 34 9
y 22 45
Write-Setname version value
k 34 81
v 24 59

Copyright©2016 NTT corp. All Rights Reserved.
Siloトランザクション (Write Lock)
• WriteSetにあるデータを全部ロックする• なお、デッドロック回避の為、ロック順は何らかのユニークな順序で行う(ポインタの大きさ順とか)
• ロックし終わったら TIDを生成する• IDはmax( 参照したバージョン , 同一 Epoch 内の自スレッドの過去の最大 TID) + 1• Statusは論文参照
• この TIDが生成された瞬間がこのトランザクションの Serialization Pointになる• その恩恵は後述
Read-Setname version value
x 34 9
y 22 45
Write-Setname version value
k 34 81
v 24 59
epoch id statusTID:

Copyright©2016 NTT corp. All Rights Reserved.
Siloトランザクション (Read Validation)
Read-Setname version value
x 34 9
y 22 45
Write-Setname version value
k 34 81
v 24 59
• 読み出したデータとバージョンが一致しているか再度確認する• Write Lock後にやるのと同様な効果が得られる• 理論上これは Strong 2 Phase Lockと同一の保証が得られる
• SS2PLよりは弱いが問題ない

Copyright©2016 NTT corp. All Rights Reserved.
Siloトランザクション (Write)
Redo Logname version value
k 35 81
v 35 59
• 書き込みながら逐次アンロックしていく• バージョン番号はその際に更新する
• このタイミングでアンロックしても 2Phase Lockのルール内• ロガーのバッファに渡す前に Unlockするのでよく言う Early Lock
Releaseよりワンテンポ早い• ロック期間が短くなって並列度が上がる
• この瞬間にWriteが終わった値は Redo Logとなり、最寄りの Loggerに送られる

Copyright©2016 NTT corp. All Rights Reserved.
Silo[Stephenら SOSP’13]
• データ構造はMassTreeの拡張の形で使う• IDをバルクで払い出して (40msに 1 回 ) IDの上 32bitデータとして使う (Epoch)• 各スレッドはその Epochと、同一 Epoch 内の依存順序を統合して半順序な
64bitの IDを作り出す• In-Memory DBなので Redoログだけで良い
次の Epochは 13だよー12a
12b
12c
12d11d10d9d8d
11c
7d
11b10b9b8b7b
11a10a9a8a7a
10c9c8c7c
ログ(ロガーの数だけ用意する)

Copyright©2016 NTT corp. All Rights Reserved.
• 同一 epochのログが全部揃わない限りリカバリされない &クライアントに ackも返却しない• 全部のコアが緩やかに協調するのでキャッシュ競合が減る• トランザクションのセマンティクスはちゃんと守っている
同 Epoch 内全ログが残っている場合に限り Redoできる
Silo[Stephenら SOSP’13]
12a
12b
12c
12d11d10d9d8d
11c
7d
11b10b9b8b7b
11a10a9a8a7a
10c9c8c7c
Epoch11までのログが永続化できたからそこまでの完了をユーザに報告できる

Copyright©2016 NTT corp. All Rights Reserved.
Siloトランザクション (Return)
• 全 Loggerが同一 Epochのログを全部書き終えた時にユーザに報告する• こうする事で、トランザクションとしてのセマンティクスは守られる
終わったよー

Copyright©2016 NTT corp. All Rights Reserved.
Siloリカバリ• トランザクションの完了は同一の epochログが全て書かれるまで待たされる• 完了していないトランザクションが全て消失しても何の矛盾もない
• Stealとか実装するより遥かに楽
T1: T2: T3: T4:
Crash
T5: T6: T7: T8:
Restart
T1: T2: T3: T4: T5: T6: T7: T8:
epoch epoch epoch

Copyright©2016 NTT corp. All Rights Reserved.
In-Memory DB と Hybrid In-Memory DB
• Siloは Pureな In-Memory DB• 再起動時は Redoログから完全なMassTree構造が復旧できるから永続化はできている• ログをまとめて木構造を作ってスナップショットにすれば高速になると論文中では言っているが具体的な方法は未言及
• 商用 DBとして Pureな In-Memory DBは、どうやら SAP HANA?• 永続性はもちろんちゃんと作り込んである様子• メモリ内で圧縮する事で大きなデータも入る• 最近の実装でどうなっているかは知らない…
• でもやっぱりディスクにも DB本体を入れたいという要望は根強い

Copyright©2016 NTT corp. All Rights Reserved.
Hybrid In-Memory DB
• Hekaton(SQL Server)• ページという単位にデータ構造が縛られなくなったのでアグレッシブな最適化がいくつも搭載されている• 厳密には Diskも併用しているが、どう併用しているかは未調査
• Anti-Caching(H-store)• Stonebraker先生の研究室で作られた OLTP用ストレージエンジン• Indexとキーだけをすべて memoryに持ち、残りは Diskに書き出す• テーブルを各コアに割り当てるためにテーブルを水平に切り分割統治• Index数がそもそも巨大なデータに対してどうするつもりなのか…?
• Siberia• Hekatonの改良の一つ。使われていない行をまるっとディスクに書き出してブルームフィルタで存在を管理する• ディスクに書き出したデータだけ列指向型に書き換える等ができる
• OLTPと OLAP 両方に速いと主張• ブルームフィルタ含むメタデータが巨大になるのでは…?

Copyright©2016 NTT corp. All Rights Reserved.
FOEDUS[H. Kimuraら SIGMOD 2015]
• レイテンシが低くてスループットが高い NVRAM向けに最適化• Siloをベースにした楽観的並行制御• Siloをベースにした並列ログとリカバリプロトコル
• グローバルカウンタが排除されてスケーラビリティ向上• Log Gleanerによるスナップショットの並列作成• Dual PageによるMemoryと NVMの連携
• NVMのデータが常にどこかの瞬間のフルスナップショットになる• Snapshot Isolation レベルで良いトランザクションは NVMを読めば良い
• Split時の Retryコストを下げるMasterTreeと新しいコミットプロトコルによる低い Abort率

Copyright©2016 NTT corp. All Rights Reserved.
FOEDUS Dual Page
• 基本はMassTreeだけど、ポインタが 2つある( Dual Page)• 1つめは DRAM上の次のノードを指すポインタ• 2つめは NVM上の次のノードを指すポインタ
• どちらのポインタが Nullであることもありうる• NVM上のページは少し古い場合があるので DRAM 側のポインタを辿る• DRAM 側のポインタが Nullで NVM上のポインタが存在する場合、 NVM上のデータが最新なのでキャッシュする• NVM 側が Nullで Dram 側のポインタが存在する場合、 NVMデータがまだ存在しない
普通のMassTree FOEDUS
DRAMNVM
DRAM

Copyright©2016 NTT corp. All Rights Reserved.
FOEDUS Dual Page
• ボトルネックになりがちなバッファプール構造が、MassTree上のポインタという形で分割統治されているとも言える• 単一のバッファプールをみんなで共有して競合ロックに悩まなくても、そのページが必要になった人がその場でアクセスできる
• ツリーの外にメタデータを持たなくなるのでメタデータ競合が起きなくなる• memory上のデータは最小の場合木の root への NVM ポインタ 1つで済む
普通のMassTree FOEDUS
DRAMNVM
DRAM

Copyright©2016 NTT corp. All Rights Reserved.
Log Gleaner
• 貯まった Redo-LogからMap-Reduce的に NVM用のツリー構造を作成する• 通常のトランザクション実行時でも 10分に 1 度ほど起動する• ツリー構造が作れたら、今度は DRAM上のページと対応が取れる所のポインタを繋ぎ替え、 DRAM 側のデータと木が一致するなら DRAM 側を解放する
図は論文から抜粋

Copyright©2016 NTT corp. All Rights Reserved.
Log Gleaner
• ある意味で Siloのログ &リカバリ投げっぱなしに対する答え• FOEDUSの Log Gleanerはログの塊から Snapshotな Treeを生成して既存の Snapshot Treeと繋ぎ合わせ、 DRAM上のツリーから繋ぐ• リカバリをするときはリスタート時に Log Gleanerを一度走らせ、 rootポインタが最新の Snapshot Pageの rootを指すように繋ぎかえれば完了
• 超簡単!• No-Steal/No-Force + Atomicバンザイ!

Copyright©2016 NTT corp. All Rights Reserved.
ベンチマーク• TPC-Cで Siloをも超える圧倒的パフォーマンス• 1389 万トランザクション /秒出ている (ネットワーク通信無し )
• TPC-Cで登録されている世界記録は約 50 万トランザクション /秒
図は論文から抜粋

Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential開示先: 株式会社○○○○
予備スライド

Copyright©2016 NTT corp. All Rights Reserved.
In-Memory DBの世間的な需要• 想定質問「そんな高性能で誰が欲しがるの?」• サービスの高度化に伴い ExaData等の高速 DBの需要は伸びている• NTTドコモ「ピーク時には 300 万 SQL/秒捌かないといけない」
• NTTドコモの 6600 万顧客のリアルタイムビリング基盤「 MoBills 」を支えるデータベース基盤とは• http://www.atmarkit.co.jp/ait/articles/1601/20/news013_3.html
• 現状でも Cassandra等の分散 NoSQL エンジンの採用事例が増加している事からも「性能が出る永続 DB 」への需要は常にある

Copyright©2016 NTT corp. All Rights Reserved.
MassTree 中間ノード構造体
• B+ treeの繋ぎを為すデータ構造
struct interior_node { uint32_t version; uint8_t nkeys; uint64_t keyslice[15]; node* child[16]; node* parent;};
入っているキーの総数キーの値、 nkeysだけ使われている次のノードへのポインタ、 nkeys+1使う
親ノードへのポインタsizeof(interior_node) == 261 およそキャッシュライン 4本分、実測上一番パフォーマンスが出た、とのこと

Copyright©2016 NTT corp. All Rights Reserved.
MassTreeリーフノード構造体
• B+ treeの値を保持する構造体struct border_node { uint32_t version; uint8_t nremoved; uint8_t keylen[15]; uint64_t permutation; uint64_t keyslice[15]; link_or_value lv[15]; border_node* next; border_node* prev; node* parent; keysuffix_t suffix;};
消されたキーの数n 番目のキーの長さ
複雑なので次のページで話す
次の B+tree へのポインタ、もしくは値へのポインタ。どちらを意味しているかは keylen[n]の最上位ビットでスイッチ
keysuffixのサイズは adaptivelyに決定するらしいのでそれを除くと残りのサイズは 286byte、こちらもおよそキャッシュ 4本分
n 番目のキー
左右及び親へのポインタ

Copyright©2016 NTT corp. All Rights Reserved.
permutation
• readと insertが衝突しても動く鍵となる機構• 実体はノード当たり 1つの uint64_t
uint64_t
4bit が 16 個、と見做す、 0 ~ 15まで数えられる intが 16 個nkeyskey[0]の順位
key[1]の順位
key[14]の順位
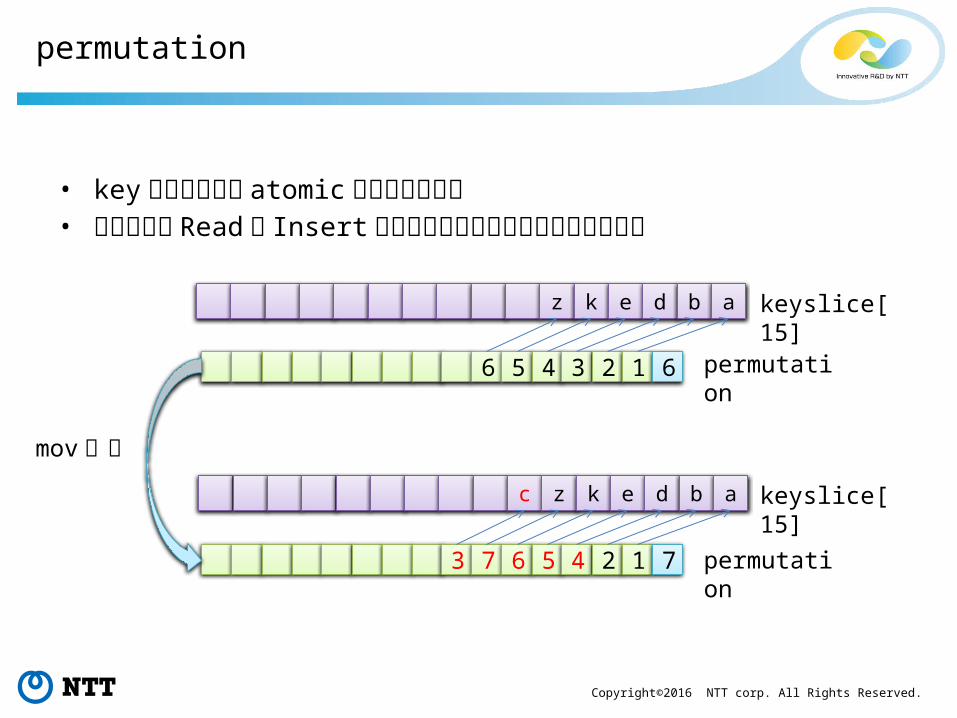
Copyright©2016 NTT corp. All Rights Reserved.
permutation
• key配列の順位を atomicに書き換えれる• これにより Readと Insertが衝突してもロック無しで調停できる
z k e d b a keyslice[15]
6 5 4 3 2 1 6 permutation
keyslice[15]
3 7 6 5 4 2 1 7 permutation
c z k e d b a
mov一発
Related Documents











