341: Introduction to Bioinformatics Dr. Nataša Pržulj Department of Computing Imperial College London [email protected] Winter 2011

341: Introduction to Bioinformatics Dr. Nataša Pržulj Department of Computing Imperial College London [email protected] Winter 2011.
Dec 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

341: Introduction to Bioinformatics
Dr. Nataša PržuljDepartment of ComputingImperial College [email protected]
Winter 2011

22
Topics
Introduction to biology (cell, DNA, RNA, genes, proteins) Sequencing and genomics (sequencing technology, sequence
alignment algorithms) Functional genomics and microarray analysis (array technology,
statistics, clustering and classification) Introduction to biological networks Introduction to graph theory Network properties
Global: network/node centralities Local: network motifs and graphlets
Network models Network/node clustering Network comparison/alignment Software tools for network analysis Interplay between topology and biology 2

33
Topics
Introduction to biology (cell, DNA, RNA, genes, proteins) Sequencing and genomics (sequencing technology, sequence
alignment algorithms) Functional genomics and microarray analysis (array technology,
statistics, clustering and classification) Introduction to biological networks Introduction to graph theory Network properties
Global: network/node centralities Local: network motifs and graphlets
Network models Network/node clustering Network comparison/alignment Software tools for network analysis Interplay between topology and biology 3

Network properties: summary of last class
Network Comparisons: Large network comparison is computationally hard due to NP-completeness of the underlying subgraph isomorphism problem:
• Given 2 graphs G and H as input, determine whether G contains a subgraph that is isomorphic to H.
Thus, network comparisons rely on easily computable heuristics (approximate solutions), called “network properties”
Network properties can roughly & historically be divided in two categories:
1.Global network properties: give an overall view of the network, but might not be detailed enough to capture complex topological characteristics of large networks.
2.Local network properties: more detailed network descriptors which usually encompass larger number of constraints, thus reducing degrees of freedom in which the networks being compared can vary.
4

Network properties: summary of last class
1. Global Network Properties
Readings: Chapter 3 of “Analysis of biological networks” by Junker and Schreiber.
Global Network Properties:1) Degree distribution2) Average clustering coefficient3) Clustering spectrum4) Average Diameter5) Spectrum of shortest path lengths6) Centralities
5

6
2. Local Network PropertiesReadings: Chapter 5 of “Analysis of Biological Networks” by Junker and Schreiber.
1) Network motifs
2) GraphletsTwo network comparison measures based on graphlets:
2.1) Relative Graphlet Frequency Distance between two networks 2.2) Graphlet Degree Distribution Agreement between two networks
Network properties: summary of last class

7
1) Network motifs (Uri Alon’s group, ’02-’04)
http://www.weizmann.ac.il/mcb/UriAlon/
Also, see Pajek, MAVisto, and FANMOD

N. Przulj, D. G. Corneil, and I. Jurisica, “Modeling Interactome: Scale Free
or Geometric?,” Bioinformatics, vol. 20, num. 18, pg. 3508-3515, 2004.
2) Graphlets2.1) Reltive graphlet frequency distance between two networks

2) Graphlets2.1) Graphlet degree distribution agreement between two networks
N. Przulj, “Biological Network Comparison Using Graphlet Degree Distribution,” ECCB, Bioinformatics, vol. 23, pg. e177-e183, 2007.

T. Milenkovic and N. Przulj, “Uncovering Biological Network Function via Graphlet Degree Signatures”, Cancer Informatics, vol. 4, pg. 257-273, 2008.
Graphlet Degree (GD) vectors, or “node signatures”
2) Graphlets2.1) Graphlet degree distribution agreement between two networks

T. Milenkovic and N. Przulj, “Uncovering Biological Network Function via Graphlet Degree Signatures”, Cancer Informatics, vol. 4, pg. 257-273, 2008.
Signature Similarity Measure between nodes u and v
2) Graphlets2.1) Graphlet degree distribution agreement between two networks

Software that implements many of these networkproperties and compares networks with respect to them: GraphCrunchhttp://bio-nets.doc.ic.ac.uk/graphcrunch/

Software that implements many of these networkproperties and compares networks with respect to them: GraphCrunchhttp://bio-nets.doc.ic.ac.uk/graphcrunch2/

Software that implements many of these networkproperties and compares networks with respect to them: GraphCrunchhttp://bio-nets.doc.ic.ac.uk/graphcrunch2/

Another Software: Cytoscapehttp://www.cytoscape.org/

T. Milenković and N. Pržulj, “Uncovering Biological Network Function via Graphlet Degree Signatures,” Cancer Informatics, 2008:6 257-273, 2008 (Highly Visible).
Examples of signatures and signature similarities:

40%SMD1
PMA1
YBR095C
T. Milenković and N. Pržulj, “Uncovering Biological Network Function via Graphlet Degree Signatures,” Cancer Informatics, 2008:6 257-273, 2008 (Highly Visible).
Examples of signatures and signature similarities:

T. Milenković and N. Pržulj, “Uncovering Biological Network Function via Graphlet Degree Signatures,” Cancer Informatics, 2008:6 257-273, 2008 (Highly Visible).
Examples of signatures and signature similarities:

90%*
SMD1
SMB1RPO26
T. Milenković and N. Pržulj, “Uncovering Biological Network Function via Graphlet Degree Signatures,” Cancer Informatics, 2008:6 257-273, 2008 (Highly Visible).
*Statistically significant threshold at ~85%
Examples of signatures and signature similarities:

Later we will see how to use this and other techniquesto link network structure with biological function

N. Przulj, “Biological Network Comparison Using Graphlet Degree Distribution,” Bioinformatics, vol. 23, pg. e177-e183, 2007.
Generalize Degree Distribution of a network
The degree distribution measures:• the number of nodes “touching” k edges for each value of k

N. Przulj, “Biological Network Comparison Using Graphlet Degree Distribution,” Bioinformatics, vol. 23, pg. e177-e183, 2007.

N. Przulj, “Biological Network Comparison Using Graphlet Degree Distribution,” Bioinformatics, vol. 23, pg. e177-e183, 2007.

/ sqrt(2) ( to make it between 0 and 1)
This is called Graphlet Degree Distribution (GDD) Agreement between networks G and H.

Software that implements many of these networkproperties and compares networks with respect to them: GraphCrunchhttp://bio-nets.doc.ic.ac.uk/graphcrunch/

Software that implements many of these networkproperties and compares networks with respect to them: GraphCrunchhttp://bio-nets.doc.ic.ac.uk/graphcrunch2/

2727
Topics
Introduction to biology (cell, DNA, RNA, genes, proteins) Sequencing and genomics (sequencing technology, sequence
alignment algorithms) Functional genomics and microarray analysis (array technology,
statistics, clustering and classification) Introduction to biological networks Introduction to graph theory Network properties
Network/node centralities Network motifs
Network models Network/node clustering Network comparison/alignment Software tools for network analysis Interplay between topology and biology 27

What is a network (graph) model?

Does the model network fit the data?
Use network properties:LocalGlobal
Why? “Hardness” of graph theoretic problems
E.g. NP-completeness of subgraph isomorphism Cannot exactly compare/align networks
• Use heuristics (approximate solutions)
Exact comparison inappropriate in biology• Due to biological variation
Noise revise models as data sets evolve

Why model networks?
Understand laws reproduction/predictions
Network models have already been used in biological applications:Network motifs
(Shen-Orr et al., Nature Genetics 2002, Milo et al., Science 2002)
De-noising of PPI network data (Kuchaiev et al., PLoS Comp. Biology, 2009)
Guiding biological experiments (Lappe and Holm, Nature Biotechnology, 2004)
Development of computationally easy algorithms for PPI nets that are computationally intensive on graphs in general (Przulj et al., Bioinformatics, 2006)

Network models
We will cover the following network models:
I. Erdos–Renyi random graphs
II. Generalized random graphs (with the same degree distribution as the data networks)
III. Small-world networks
IV. Scale-free networks
V. Hierarchical model
VI. Geometric random graphs
VII. Stickiness index-based network model

Erdos–Renyi random graphs (ER)
Model a data network G(V,E) with |V|=n and |E|=m An ER graph that models G is constructed as follows:
It has n nodes Edges are added between pairs of nodes uniformly at
random with the same probability p Two (equivalent) methods for constructing ER graphs:
Gn,p: pick p so that the resulting model network has m edges
Gn,m: pick randomly m pairs of nodes and add edges between them with probability 1

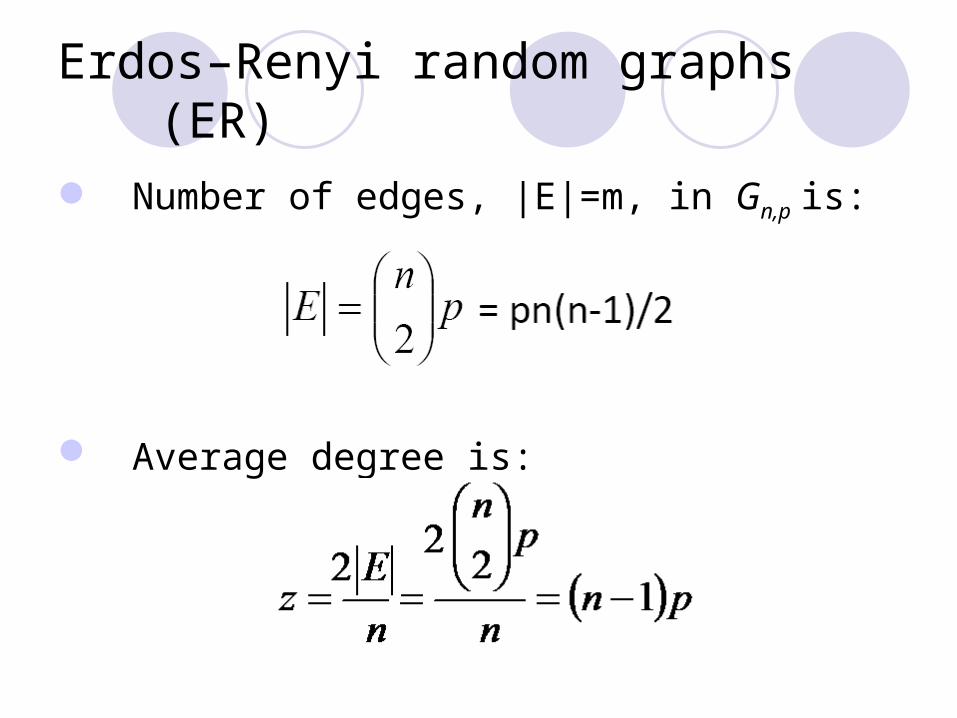
Erdos–Renyi random graphs (ER)
Number of edges, |E|=m, in Gn,p is:
Average degree is:

Erdos–Renyi random graphs (ER)
Many properties of ER can be proven theoretically (See: Bollobas, "Random Graphs," 2002)
Example: When m=n/2,suddenly the giant component
emerges, i.e.:• One connected component of the network has
O(n) nodes• The next largest connected component has
O(log(n)) nodes

Erdos–Renyi random graphs (ER)
The degree distribution is binomial:
For large n, this can be approximated with Poisson distribution:
where z is the average degree However, currently available biological
networks have power-law degree distribution

Erdos–Renyi random graphs (ER)
Clustering coefficient, C, of ER is low (for low p)
C=p, since probability p of connecting any two nodes in an ER graph is the same, regardless of whether the nodes are neighbors
However, biological networks have high clustering coefficients

Erdos–Renyi random graphs (ER)
Average diameter of ER graphs is small It is equal to
Biological networks also have small average diameters
Summary

Generalized random graphs (ER-DD)
Preserve the degree distribution of data
(“ER-DD”)
Constructed as follows: An ER-DD network has n nodes
(so does the data) Edges are added between pairs of nodes using
the “stubs method”

Generalized random graphs (ER-DD)
The “stubs method” for constructing ER-DD graphs: The number of “stubs” (to be filled by edges) is
assigned to each node in the model network according to the degree distribution of the real network to be modeled
Edges are created between pairs of nodes with
“available” stubs picked at random After an edge is created, the number of stubs left
available at the corresponding “end nodes” of the edges is decreased by one
Multiple edges between the same pair of nodes are not allowed

Generalized random graphs (ER-DD)
Summary
2 global network properties are matched by ER-DD How about local network properties (graphlet frequencies)?
Low-density graphlets are over-represented in ER and ER-DD However, data have lots of dense graphlets, since they have
high clustering coefficients

Small-world networks (SW)
Watts and Strogatz, 1998 Created from regular ring lattices by random
rewiring of a small percentage of their edges E.g.

Small-world networks (SW)
SW networks have: High clustering coefficients – introduced by “ring
regularity” Large average diameters of regular lattices – fixed
by randomly re-wiring a small percentage of edges
Summary

Scale-free networks (SF)
Power-law degree distributions: P(k) = k−γ
γ > 0; 2 < γ < 3

Scale-free networks (SF)
Power-law degree distributions: P(k) = k−γ
γ > 0; 2 < γ < 3

Scale-free networks (SF)
Different models exist, e.g.:
Preferential Attachment Model (SF-BA)(Barabasi-Albert, 1999)
Gene Duplication and Mutation Model (SF-GD)(Vazquez et al., 2003)

Scale-free networks (SF)
Preferential Attachment Model (SF-BA) “Growth” model: nodes are added to an existing network New nodes preferentially attach to existing nodes with
probability proportional to the degrees of the existing nodes; e.g.:
This is repeated until the size of SF network matches
the size of the data “Rich getting richer” The starting network strongly influences the properties
of the resulting network (F. Hormozdiari, et al., PLoS Computational Biology, 3(7):e118, July 2007. )
SF-BA: particularly effective at describing Internet

Scale-free networks (SF)
Gene Duplication and Mutation Model (SF-GD)
Biologically motivated
Attempts to mimic gene duplication and mutation processes

Scale-free networks (SF)
Gene Duplication and Mutation Model (SF-GD) At each time step, a node is added to the network as follows:

Scale-free networks (SF)
Summary

Hierarchical model
Preserves network “modularity” via a fractal-like generation of the network

Hierarchical model
These graphs do not match any biological data and are highly unlikely to be found in data sets

Geometric random graphs
“Uniform” geometric random graphs (GEO)N. Przulj lab, 2004-2010
Geometric gene duplication and mutation model (GEO-GD)
N. Przulj et al., PSB 2010

Geometric random graphs
“Uniform” geometric random graphs (GEO) Take any metric space and, using a uniform random
distribution, place nodes within the space If any nodes are within radius r (calculated via any
chosen distance norm for the space), they will be connected
Choose r so that the size of the GEO network matches that of the data
There are many possible metric spaces (e.g., Euclidean space)
There are many possible distance norms (e.g. the Euclidean distance, the Chessboard distance, and the Manhattan/Taxi Driver distance)










Geometric random graphs
“Uniform” geometric random graphs (GEO)
Summary

Geometric random graphs
Geometric gene duplication and mutation model (GEO-GD)
Gene duplications and mutations can be used to guide the growth process in geometric graph

Geometric random graphs
Geometric gene duplication and mutation model (GEO-GD)
Gene duplications and mutations can be used to guide the growth process in geometric graph

Geometric random graphs
Geometric gene duplication and mutation model (GEO-GD)
Gene duplications and mutations can be used to guide the growth process in geometric graph

Geometric random graphs
Geometric gene duplication and mutation model (GEO-GD)
Gene duplications and mutations can be used to guide the growth process in geometric graph

Geometric random graphs
Geometric gene duplication and mutation model (GEO-GD)
Gene duplications and mutations can be used to guide the growth process in geometric graph

Geometric random graphs
Geometric gene duplication and mutation model (GEO-GD)
This variant also reproduces graphlet properties of the empirical dataset
Also, these networks have power-law degree distributions
-GD

Stickiness index-based network model(N. Przulj and D. Higham, Journal of the Royal Society Interface, vol 3, num 10, pp 711 - 716, 2006.)
Based on the stickiness index: A number based on the a protein’s normalized degree in a PPI
network Used to summarize the abundance and popularity of binding
domains of a protein
Assumption: a high degree protein has many binding domains
However, remember “date” vs. “party” hubs
A pair of proteins is more likely to interact under this model if both proteins have high stickiness indices
The probability of an edge between two nodes is the product of their stickiness indices

Stickiness index-based network model
“Sticky networks” have the expected degree distribution of the data
Also, they mimic well the clustering coefficients and the diameters of real-world networks
Summary

Software that implements many of these network models and evaluates their fit to data networks with respect to a variety of network properties (but there are others): GraphCrunch: http://bio-nets.doc.ic.ac.uk/graphcrunch/

Software that implements many of these network models and evaluates their fit to data networks with respect to a variety of network properties (but there are others): GraphCrunch: http://bio-nets.doc.ic.ac.uk/graphcrunch2/

7676
Topics
Introduction to biology (cell, DNA, RNA, genes, proteins) Sequencing and genomics (sequencing technology, sequence
alignment algorithms) Functional genomics and microarray analysis (array technology,
statistics, clustering and classification) Introduction to biological networks Introduction to graph theory Network properties
Global: network/node centralities Local: network motifs and graphlets
Network models Network/node clustering Network comparison/alignment Software tools for network analysis Interplay between topology and biology 76
Related Documents











