Course Calendar Class DATE Contents 1 Sep. 26 Course information & Course overview 2 Oct. 4 Bayes Estimation 3 〃 11 Classical Bayes Estimation - Kalman Filter - 4 〃 18 Simulation-based Bayesian Methods 5 〃 25 Modern Bayesian Estimation :Particle Filter 6 Nov. 1 HMM(Hidden Markov Model) Nov. 8 No Class 7 〃 15 Bayesian Decision 8 〃 29 Non parametric Approaches 9 Dec. 6 PCA(Principal Component Analysis) 10 〃 13 ICA(Independent Component Analysis) 11 〃 20 Applications of PCA and ICA 12 〃 27 Clustering, k-means et al. 13 Jan. 17 Other Topics 1 Kernel machine. 14 〃 22(Tue) Other Topics 2

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

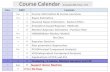
Course Calendar Class DATE Contents
1 Sep. 26 Course information & Course overview
2 Oct. 4 Bayes Estimation
3 〃 11 Classical Bayes Estimation - Kalman Filter -
4 〃 18 Simulation-based Bayesian Methods
5 〃 25 Modern Bayesian Estimation :Particle Filter
6 Nov. 1 HMM(Hidden Markov Model)
Nov. 8 No Class
7 〃 15 Bayesian Decision
8 〃 29 Non parametric Approaches
9 Dec. 6 PCA(Principal Component Analysis)
10 〃 13 ICA(Independent Component Analysis)
11 〃 20 Applications of PCA and ICA
12 〃 27 Clustering, k-means et al.
13 Jan. 17 Other Topics 1 Kernel machine.
14 〃 22(Tue) Other Topics 2

Lecture Plan
Nonparametric Approaches
1. Introduction
1.1 An Example
1.2 Nonparametric Density Estimation Problems
1.3 Histogram density estimation
2. Kernel Density Estimation
3. K-Nearest Neighbor Density Estimation
4. Cross-validation

1. Introduction
3
Automatic Fish-Sorting Process
action 1
belt conveyer
Classification/ Decision Theory
p ," sea bass" ,
p ," salmon"
x
x
x1
x2
Decision Boundary
R2 R1
(Duda, Hart, & Stork 2004)
Training phase
Test phase

1.1 An Example -Fish sorting problem-
4
The first step -Training process- The first task is a supervised learning process, thus each observed
sample has its own label either states of nature 𝜔1 𝑜𝑟 𝜔2.
Training(Learning) data
For a given set of N data samples, suppose the following labeled data
(the lightness of a fish) are observed.
1 21 2 1 2
1 2
( ) ( )
1
2
( ) ( )
: , , , , : , , ,
where , are the lightness of i-th samples of (sea bass)
and j-th sample of (salmon) respectively.
We assume , are discrete data as illustrated in Fig.1
N N
i j
i j
x x x y y y
x y
x y
(a)
This joint probability distribution gives the histograms of other
probabilities and densities as shown in Fig.1.

5 These histograms can be used for Bayes decision classification.
(a) Samples drawn from a joint probability over x and ω
Fig.1
iN
N
p x
1P
2P
1p x 2p x
x
x
x x
(b)
(c)
(d) (e)
1
2

6
Density Estimation The approach attempts to estimate the density directly from the
observed data.
The Bayes decision rules discussed in the last lecture have been
developed on the assumption that the relevant probability density
functions and prior probabilities are known. But this is not the case in
practice, we need to estimate the PDFs from a given se of observed data.
given data density distribution
Modeling of density
http://www.unt.edu/benchmarks/archives/2003/february03/rss.htm

7
1.2 Nonparametric approaches
Two approaches for density estimation
Parametric approach :
Assume that the forms of the density functions are known, and the
parameters of its are to be estimated.
Non-parametric approach:
This can be used with arbitrary distributions, and does not assume the
form of density function.
Why nonparametric?*
/ Classical parametric densities are unimodal ones whereas practical
problems involve multimodal densities. Non parametric approaches are
applicable to arbitrary density with few assumptions
*Another idea: a mixed (hybrid) with parametric and non-parametric densities.

8
1.3 Histogram density estimation A single variable (x) case
into distinct intervals (called ) of width (often chosen as
uniform bins ), and the number of data falling in -th bin.
For turning to a normalized probability density w
i
i
i
x
n i
n
Partition bins
count
e put
= at over i-th bin
The density ( ) is approximated by a stepwise function like bar graph.
In multi-dimensional case,
=
where V is
ii
i
i
np x
N
p x
np x
NV
the volume of the bin.
Fig. 2 (RIGHT) Histogram density estimation (from Bishop [3] web site) 50 data points are generated from the distribution shown by the green curve
(1)

9
The feature of the histogram estimation depends on the width (Δi
) of bins as shown in Fig.2.
Small Δ → density tends to have many spikes
Large Δ → density tends to be over-smoothed
Merit: Convenient visualization tool
Problems:
Discontinuities at the bin’s edges
Computational burden in high dimensional space (MD)

2. Kernel Density Estimation
10
-Basic idea of density estimation-
Unknown Density
D
p x
x R
1 2
A set of observations
, , N
N
x x x
p xEstimate
Consider a small regiron surrounding ( ) and define a probability
which means the probability of falling into
The number falling within of overall observe
x x
P p d
x
K N
R
R R
R
R.
d data would be
Suppose can be approximated by a constant over we have
K PN
p x R
generates
(2)
(3)

11
where means the volume of .
Eqs. (2) (3) give the following density estimation form.
Two wayes of exploitation of this:
1) Fix then estimate
P p x V
V
Kp x
NV
V K
R
Kernel Density Estimation
2) Fix then estimate k-Nearest Neighbor Estimation K V
(4)
(5)

12
Kernel Density Estimation
A point : wish to determine the density at this point
Region : small hypercube centered on
the volume of
Find the number of samples K that fall within the region .
For
x
x
V
R
R
R
counting we introduce the kernek function.
[one dimensional kernel function]
11
20
K
uK u
elsewhere
For a given observation , consider
n
n
x
x xK
h
(6)
(7)

13
1
1 2
0
where is called the bandwidth or smoothing parameter.
For a set of observations : 1, ,
gives the number of data which are located
nn
n
Nn
n
hx xx x
Kh
elsewhere
h
x n N
x xK K
h
1
within ,2 2
Substituting (9) into (5)
1
An example graph of is illustrated in Fig.3
Nn
n
h hx x
x xp x K
Nh h
p x
(8)
(9)
(10)

14
Example : Data set {xn} n=1~4
x x1 x2 x3 x4
x x1 x2 x3 x4
11 x xK
h h
41 x xK
h h
4
1
1 i
i
x xK
h h
1
4p x
x1
x2
x3
x4
Fig. 3

15
Discontinuity and Smooth Kernel Function
Kernel Density Estimator will suffer from discontinuities in
estimated density. Smooth kernel function such as Gaussian is used.
This general method is referred to as the kernel density estimator or
Parzen estimator.
Example: Gaussian and 1-D case,
where h is the standard deviation.
Determination of bandwidth h
Small h → spiky p(x)
Large h → over-smoothed p(x)
Defects:
High computational cost
Because of fixed V there may be too few samples in some regions.
2
21
( )1 1exp
22
Nn
n
x xp x
N hh
(11)

16

17
Example: Bayesian decision by the Parzen kernel estimation
Example: Kernel density estimation
Fig 4. Kernel density estimation (from Bishop [3] web site) Apply KDE method to the same 50 data used in Fig. 2
Fig. 5 The decision
boundaries
LEFT : small h
RIGHT: large h
Duda et al [1]

3. K-Nearest Neighbors density estimation
18
KDE approaches use fixed h throughout the data space. But we want
to apply small h for highly dense data region, on the other hand, to set
a larger h for sparse data region.
We come up with the idea of K-Nearest Neighbor (K-NN) approaches.
Expand the region (radius) surrounding the estimation point x until it
encloses K data points.
K
p xNV
Fixed
Determine the minimum
volume V containing K
points in R
Volume of hypersphere with radius ( )
D
D
r x
K Kp x
N V N c r x
(12)

19
x
K-th closest neighbor point
1 2 3
4( 2, , , )
3Dc c c c
Fig. 7 K-nearest neighbor density estimation (from Bishop [3] web site) Apply to the same 50 data points used in Fig. 2 K is the free parameter in K-NN method
r(x)
Problems: 1) integration of p(x) is not bounded, 2) discontinuities, 3)huge computation time and storage
Fig. 6 K-NN algorithm

20
K-NN estimation as a Bayesian classifier
A method to generate decision boundary directly based on a set of
data.
− N training data with class labels (ω1 ~ ωc)
Nl points for l-th class, such that
− Classify a test sample x
− Get a sphere with minimum radius r(x) which encircles K samples.
− The volume of the sphere:
− Kl points for l-th class (ωl)
− Class-conditioned density at x:
− Evidence:
− Prior probabilities:
− Posterior Probabilities (Bayes’ theorem)
1
c
l
l
N N
D
DV c r x
ll
l
Kp x
N V
ll
Np
N
K
p xNV
l l l
l
p x P KP x
p x K
(14)

21
K-NN classifier
− Find the class maximizing the posterior probability (Bayes decision)
− The point x is classified into 𝜔𝑙0
Summary: (Fig.8)
1) Select K data surrounding the estimation point x
2) The point x is assigned the major class of K points in the neighbor.
0 : arg max arg max ll
l l
Kl P x
K
Nearest Neighbor classifier
Let consider K=1 for K-NN classification.
The point x is classified into the class of the nearest point to x.
→ Nearest Neighbor Classifier
Classification boundary of the K-NN with respect to K
small K → tends to make many small class regions (Fig. 9 (b))
large K → few class regions (Fig.9(a))
(14)

22
K-Nearest Neighbor classifier algorithm (K=3)
Nearest Neighbor Classifier algorithm (K=1)
Fig. 9 K-Nearest Neighbor Classifiers (K=3, 1, 31) Bishop [3]
Fig. 8 (Bishop [3])
x
(a) (b) (c)

23
4. Cross-Validation Parameter determination problem:
- Since the classifier have free parameters such as K in K-NN
classifier and h in Kernel density based classifiers, we need to
select the optimal parameters by evaluating the classification
performances.
- Over-fitting problem
- The classifier’s parameter (decision boundary) obtained from
using overall training data will overfit to them
→ Need an appropriate new test data
Cross-Validation
- Given data are split into S parts.
S=4
- Fig. 10
- Use (S-1) parts for training and a rest part is used for testing
- Apply all different parts for the test as shown in Fig. 11 (S=4)
total data

24
training data test data
Experiment 1
Experiment 2
Experiment 3
Experiment 4
Score * 1
Score 2
Score 3
Score 4
×(1/4)=Averaged score
If we want to determine the best K for K-NN classifier, we
choose the K providing the highest averaged score by the
cross-validation procedure.
*Score= error rate or conditioned risk et al.
Fig. 11
+)

25
References: [1] R.O. Duda, P.E. Hart, and D. G. Stork, “Pattern Classification”, John Wiley & Sons, 2nd edition, 2004 [2] C. M. Bishop, “Pattern Recognition and Machine Learning”, Springer, 2006 [3] All data files of Bishop’s book are available at the “http://research.microsoft.com/~cmbishop/PRML”
Related Documents